
The Recommendation of the Rural Ecological Civilization Pattern Based on Geographic Data Argumentation


 ,
, 
Abstract
:1. Introduction
2. Related Work
2.1. The Recommendation of the Rural Ecological Civilization Pattern
2.2. The Data Argumentation Based on the GAN
2.3. Third Law of Geography
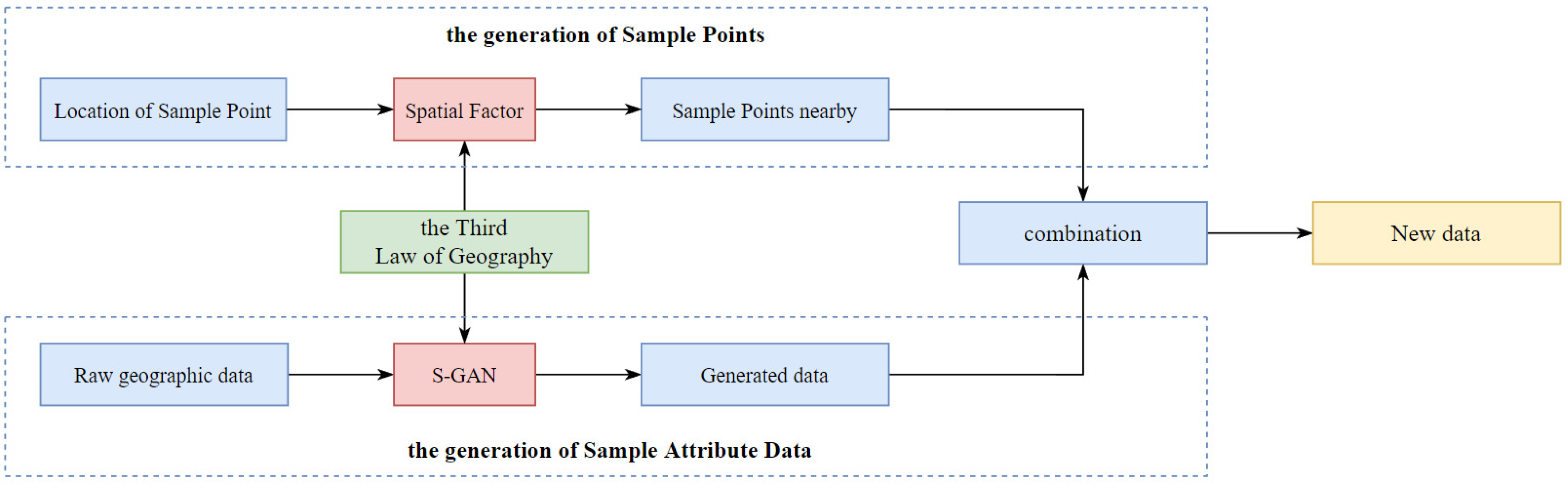
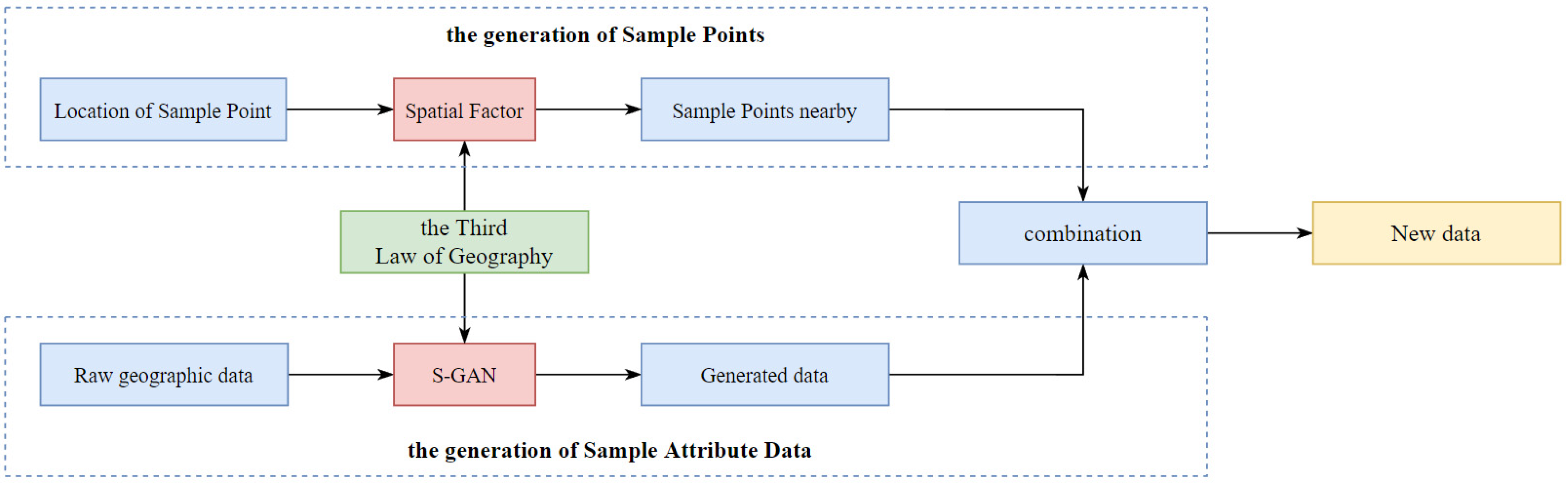
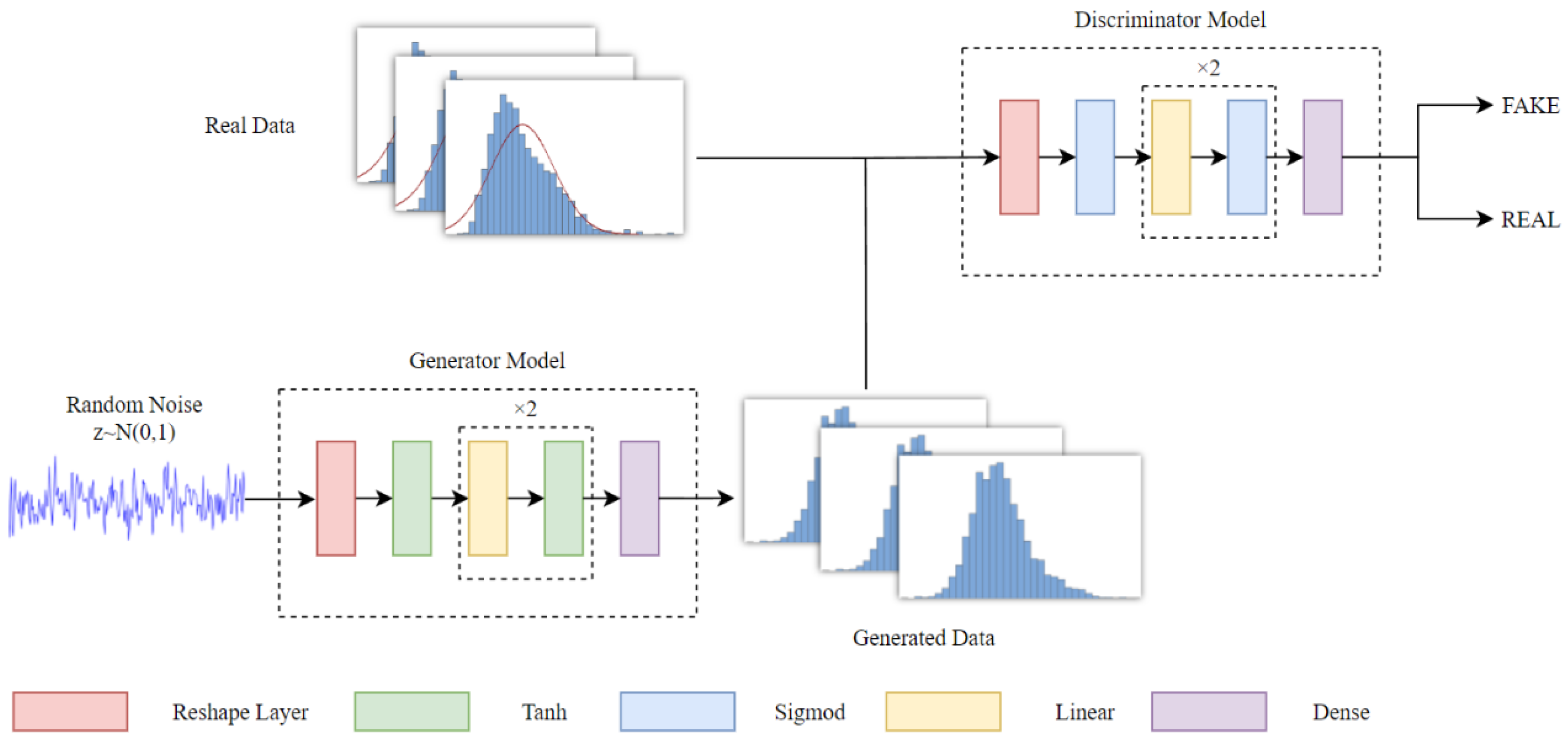
3. Data Augmentation Method Based on the GAN
3.1. The Data Structure of the S-GAN
3.2. The Generation of Geographic Data
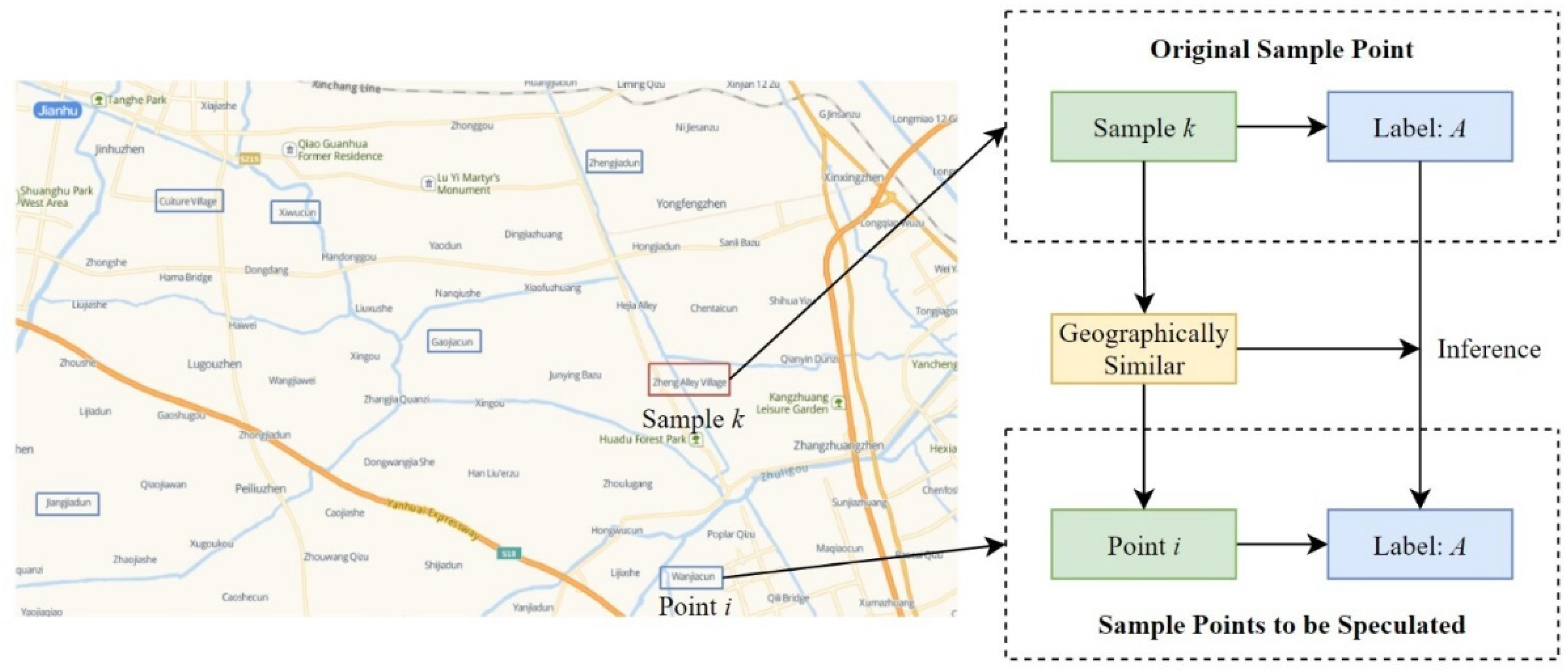
3.2.1. The Generation of Sample Points
3.2.2. The Generation of Sample Attribute Data
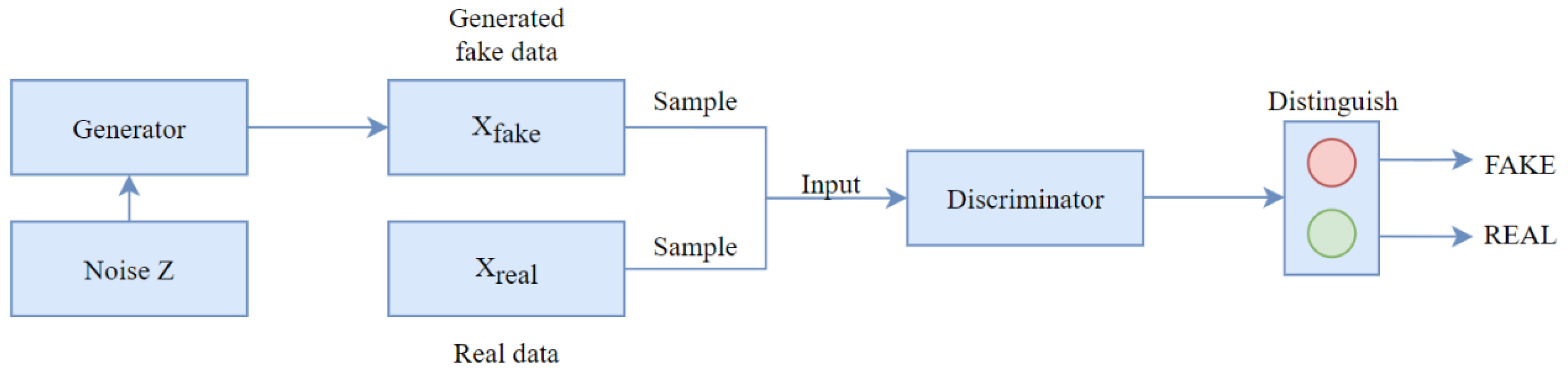
3.3. S-GAN Model
3.3.1. Generator
3.3.2. Discriminator
3.3.3. Objective Function
3.3.4. Training the Model
- (1)
- Fix the generator G, train the discriminator D, and update its parameters.
- (2)
- Fix the discriminator D, train the generator G, and update its parameters.
3.4. S-GAN Algorithm
| Algorithm 1 S-GAN algorithm |
| input: |
| (1) Z: random noise, which satisfies Z~N(0,1) |
| (2) X: real samples |
| output: |
| (1) G(Z): fake data generated by learning the distribution of the dataset |
| (2) D(G(z)): a score that represents the probability that the data is fake data |
| 1. for number of training iterations do |
| 2. for 1~ K do |
| 3. Sample m examples {x1, x2, …, xm} from X, which satisfies X~Pg(x). |
| 4. Sample m noise examples {z1, z2, …, zm} from Z. |
| 5. Train and update the Discriminator by ascending its stochastic gradient: |
| 6. end for |
| 7. Sample m noise examples {z1, z2, …, zm} from Z. |
| 8. Train and update the Generator by descending its stochastic gradient: |
| 9. end for |
4. Experiment
4.1. Experiment Environment
4.2. Dataset
4.2.1. Dataset Overview
4.2.2. Preprocessing
4.3. The Data Argumentation Experiment
4.3.1. Generate New Sample Points
4.3.2. Generate New Sample Attribute Data
4.4. The Recommendation System Experiment
4.4.1. Different Recommendation Methods
4.4.2. Parameters and Evaluation Metrics of the Experiment
4.4.3. The Results and Analysis of Experiments
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Yang, D.; Wang, Z.; Jiang, J.; Xiao, Y. Knowledge embedding towards the recommendation with sparse user-item interactions. In Proceedings of the 2019 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining, Vancouver, BC, Canada, 27–30 August 2019; pp. 325–332. [Google Scholar]
- Kawtar, N.; El, H.B.; Nawal, S.; Ahmed, Z. Collaborative Filtering Approach: A Review of Recent Research. In Proceedings of the 3rd International Conference on Advanced Intelligent Systems for Sustainable Development (AI2SD), Tangier, Morocco, 21–26 December 2020; pp. 151–163. [Google Scholar]
- Ye, Z.; Zhao, H.; Zhang, K.; Zhu, Y.; Xiao, Y.; Wang, Z. Improved DeepWalk Algorithm Based on Preference Random Walk. In Proceedings of the International Conference Natural Language Processing, Sanya, China, 20–22 December 2019; pp. 265–276. [Google Scholar]
- Wang, H.; Zhao, M.; Xie, X.; Li, W.; Guo, M. Knowledge graph convolutional networks for recommender systems. In Proceedings of the International Conference on World Wide Web, San Francisco, CA, USA, 13–17 May 2019; pp. 3307–3313. [Google Scholar]
- Guo, Q.; Zhuang, F.; Qin, C.; Zhu, H.; Xie, X.; Xiong, H.; He, Q. A survey on knowledge graph-based recommender systems. IEEE Trans. Knowl. Data Eng. 2020, 34, 3549–3568. [Google Scholar] [CrossRef]
- Chen, X.L.; Xie, H.R.; Li, Z.X.; Cheng, G. Topic analysis and development in knowledge graph research: A bibliometric review on three decades. Neurocomputing 2021, 461, 497–515. [Google Scholar] [CrossRef]
- Wang, H.; Zhang, F.; Xie, X.; Guo, M. DKN: Deep knowledge-aware network for news recommendation. In Proceedings of the 2018 World Wide Web Conference, Lyon, France, 23–27 April 2018; pp. 1835–1844. [Google Scholar]
- Wang, X.; He, X.; Cao, Y.; Liu, M.; Chua, T.S. KGAT: Knowledge Graph Attention Network for Recommendation. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 950–958. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the 27th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Choi, S.H.; Shin, J.M.; Liu, P.; Choi, Y.H. ARGAN: Adversarially Robust Generative Adversarial Networks for Deep Neural Networks against Adversarial Examples. IEEE Access 2022, 10, 33602–33615. [Google Scholar] [CrossRef]
- Souibgui, M.A.; Kessentini, Y. DE-GAN: A Conditional Generative Adversarial Network for Document Enhancement. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 1180–1191. [Google Scholar] [CrossRef] [PubMed]
- Toshpulatov, M.; Lee, W.; Lee, S. Generative adversarial networks and their application to 3D face generation: A survey. Image Vis. Comput. 2021, 108, 104–119. [Google Scholar] [CrossRef]
- Zhu, A.X.; Lu, G.; Liu, J.; Qin, C.Z.; Zhou, C. Spatial prediction based on Third Law of Geography. Ann. GIS 2018, 24, 225–240. [Google Scholar] [CrossRef]
- Shen, S. Ecological Civilization and Its Theoretical and Practical Basis. J. Peking Univ. Philos. Soc. Sci. 1994, 3, 31–37. [Google Scholar]
- Yu, K. Scientific Outlook on Development and Ecological Civilization. Marx. Real. 2005, 4, 4–5. [Google Scholar]
- Zhou, S.X. Actively Build Ecological Civilization. Environ. Sustain. Dev. 2010, 1, 1–3. [Google Scholar]
- Ko, H.; Lee, S.; Park, Y.; Choi, A. A Survey of Recommendation Systems: Recommendation Models, Techniques, and Application Fields. Electronics 2022, 11, 141. [Google Scholar] [CrossRef]
- Zhang, S.C. Research on Recommendation Algorithm Based on Collaborative Filtering. In Proceedings of the 2021 2nd International Conference on Artificial Intelligence and Information Systems, Chongqing, China, 28–30 May 2021; pp. 1–4. [Google Scholar]
- Natthawut, K.; Rungsiman, N.; Ryutaro, I. UWKGM: A Modular Platform for Knowledge Graph Management. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management, Virtual Event, Ireland, 19–23 October 2020; pp. 3421–3424. [Google Scholar]
- Jalota, R.; Vollmers, D.; Moussallem, D.; Ngomo, A.C.N. LAUREN—Knowledge Graph Summarization for Question Answering. In Proceedings of the 15th IEEE International Conference on Semantic Computing(ICSC), Elector Network, Laguna Hills, CA, USA, 27–29 January 2021; pp. 221–226. [Google Scholar]
- Ji, S.X.; Pan, S.R.; Cambria, E.; Marttinen, P.; Yu, P.S. A Survey on Knowledge Graphs: Representation, Acquisition, and Applications. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 494–514. [Google Scholar] [CrossRef] [PubMed]
- Tang, X.; Wang, T.; Yang, H.; Song, H. Akupm: Attention-enhanced knowledge-aware user preference model for recommendation. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 1891–1899. [Google Scholar]
- Wang, H.; Zhang, F.; Wang, J.; Zhao, M.; Li, W.; Xie, X.; Guo, M. Ripplenet: Propagating user preferences on the knowledge graph for recommender systems. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management, Torino, Italy, 22–26 October 2018; pp. 417–426. [Google Scholar]
- Wang, H.; Zhang, F.; Zhao, M.; Li, W.; Xie, X.; Guo, M. Multi-task feature learning for knowledge graph enhanced recommendation. In Proceedings of the International Conference on World Wide Web, San Francisco, CA, USA, 13–17 May 2019; pp. 2000–2010. [Google Scholar]
- Cao, Y.; Wang, X.; He, X.; Hu, Z.; Chua, T.S. Unifying knowledge graph learning and recommendation: Towards a better understanding of user preferences. In Proceedings of the International Conference on World Wide Web, San Francisco, CA, USA, 13–17 May 2019; pp. 151–161. [Google Scholar]
- Raghuwanshi, B.S.; Shukla, S. Classifying imbalanced data using SMOTE based class-specific kernelized ELM. Int. J. Mach. Learn. Cybern. 2021, 12, 1255–1280. [Google Scholar] [CrossRef]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. mixup: Beyond Empirical Risk Minimization. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Cheng, J.R.; Yang, Y.; Tang, X.Y.; Xiong, N.X.; Zhang, Y.; Lei, F.F. Generative Adversarial Networks: A Literature Review. KSII Trans. Internet Inf. Syst. 2020, 14, 4625–4647. [Google Scholar]
- Zhang, A.; Lipton, Z.C.; Li, M.; Smola, A.J. Dive into Deep Learning; People Post Press: Beijing, China, 2019; pp. 128–133. [Google Scholar]
- Wang, H.; Zhang, F.; Zhang, M.; Jure Leskovec Zhao, M.; Li, W.; Wang, Z. Knowledge-aware Graph Neural Networks with Label Smoothness Regularization for Recommender Systems. In Proceedings of the 25th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 968–977. [Google Scholar]
- Fawcett, T. An introduction to ROC analysis. Pattern Recogn. Lett. 2006, 27, 861–874. [Google Scholar] [CrossRef]
- Bradley, A.P. The use of the area under the ROC curve in the evaluation of machine learning algorithms. Pattern Recogn. 1997, 30, 1145–1159. [Google Scholar] [CrossRef] [Green Version]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sample Point | Value: attribute 1 | Value: attribute 2 | …… | Value: attribute N |
| Title | Version |
|---|---|
| OS | Windows 11 64 bit |
| RAM | 16 GB |
| CPU | Intel(R) Core(TM) i7-8750H @ 2.20 GHz |
| GPU | NIVIDA GeForce GTX1060 6 GB |
| Anaconda3 | 4.10.3 64 bit |
| TensorFlow | 1.4.0 |
| Classification | Attributes | Description |
|---|---|---|
| Basic | Village | The name of the village |
| LongitudeLatitude | Latitude and longitude | |
| GeographicalPosition | Geographical location | |
| District | District/County | |
| Province | Province | |
| Humanities and Economics | Road | The total length of roads |
| Area | Regional area | |
| RoadDensity | Road network density | |
| GDP | Region GDP | |
| GDPPer | GDP per capita | |
| First | GDP of the primary industry | |
| Second | GDP of the secondary industry | |
| Third | GDP of the tertiary industry | |
| Nature and Ecology | Climate | Climate |
| Farm | Cultivated area | |
| Grass | Grass area | |
| Frost | Forest area | |
| Water | Water area | |
| WaterDensityIndex | Water network density index | |
| BioabundanceIndex | Bioabundance index | |
| VegetationCoverIndex | Vegetation cover index | |
| ForestCoverIndex | Forest cover index | |
| DroughtIndex | Drought index |
| Ecological Civilization Pattern | The Number of Sample Points |
|---|---|
| Grassland Pasture Pattern | 2 |
| Industrial Development Pattern | 22 |
| Suburban Intensive Pattern | 4 |
| High-efficiency Agricultural Pattern | 1 |
| Environmental Remediation Pattern | 1 |
| Social Comprehensive Treatment Pattern | 9 |
| Ecological Protection Pattern | 6 |
| Cultural Heritage Pattern | 14 |
| Leisure Travel Pattern | 42 |
| Pattern | Before | After |
|---|---|---|
| Industrial Development Pattern | 22 | 210 |
| Social Comprehensive Treatment Pattern | 9 | 90 |
| Ecological Protection Pattern | 6 | 61 |
| Cultural Heritage Pattern | 14 | 117 |
| Leisure Travel Pattern | 42 | 387 |
| The Name of the Village | Village Nearby |
|---|---|
| Tiantaishan Village | Daxihan Village |
| Panzhai Village | |
| Zhangda Village | |
| Nanzhongbao Village | |
| Gaozhuang Village | |
| Dasishang Village | |
| Shizhuang Village | |
| Dongbeizhuang Village | |
| Xinanzhuang Village | |
| Xiyaobao Village |
| Rural Knowledge Graph (Before) | Rural Knowledge Graph (After) | |
|---|---|---|
| Users | 101 | 873 |
| Items | 101 | 873 |
| Number of entities | 441 | 1684 |
| Number of relations | 22 | 23 |
| Recommendation System | Evaluation Metrics | Rural Knowledge Graph (Before) | Rural Knowledge Graph (After) |
|---|---|---|---|
| RippleNet | AUC | 0.5933 | 0.8653 |
| ACC | 0.5806 | 0.9028 | |
| F1 | 0.6027 | 0.8439 | |
| KGCN | AUC | 0.6237 | 0.8779 |
| ACC | 0.6094 | 0.7625 | |
| F1 | 0.6379 | 0.7895 | |
| KGNN-LS | AUC | 0.6521 | 0.9097 |
| ACC | 0.6250 | 0.7946 | |
| F1 | 0.6333 | 0.8185 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, M.; Wang, S.; Song, C.; Zhu, A.; Zhu, Y.; Zou, Z. The Recommendation of the Rural Ecological Civilization Pattern Based on Geographic Data Argumentation. Appl. Sci. 2022, 12, 8024. https://doi.org/10.3390/app12168024
Xu M, Wang S, Song C, Zhu A, Zhu Y, Zou Z. The Recommendation of the Rural Ecological Civilization Pattern Based on Geographic Data Argumentation. Applied Sciences. 2022; 12(16):8024. https://doi.org/10.3390/app12168024
Chicago/Turabian StyleXu, Mengfei, Shu Wang, Chenlong Song, Anqi Zhu, Yunqiang Zhu, and Zhiqiang Zou. 2022. "The Recommendation of the Rural Ecological Civilization Pattern Based on Geographic Data Argumentation" Applied Sciences 12, no. 16: 8024. https://doi.org/10.3390/app12168024
APA StyleXu, M., Wang, S., Song, C., Zhu, A., Zhu, Y., & Zou, Z. (2022). The Recommendation of the Rural Ecological Civilization Pattern Based on Geographic Data Argumentation. Applied Sciences, 12(16), 8024. https://doi.org/10.3390/app12168024