
Enhanced Seagull Optimization with Natural Language Processing Based Hate Speech Detection and Classification

 , , and
, , and
Abstract
:1. Introduction
2. Related Works
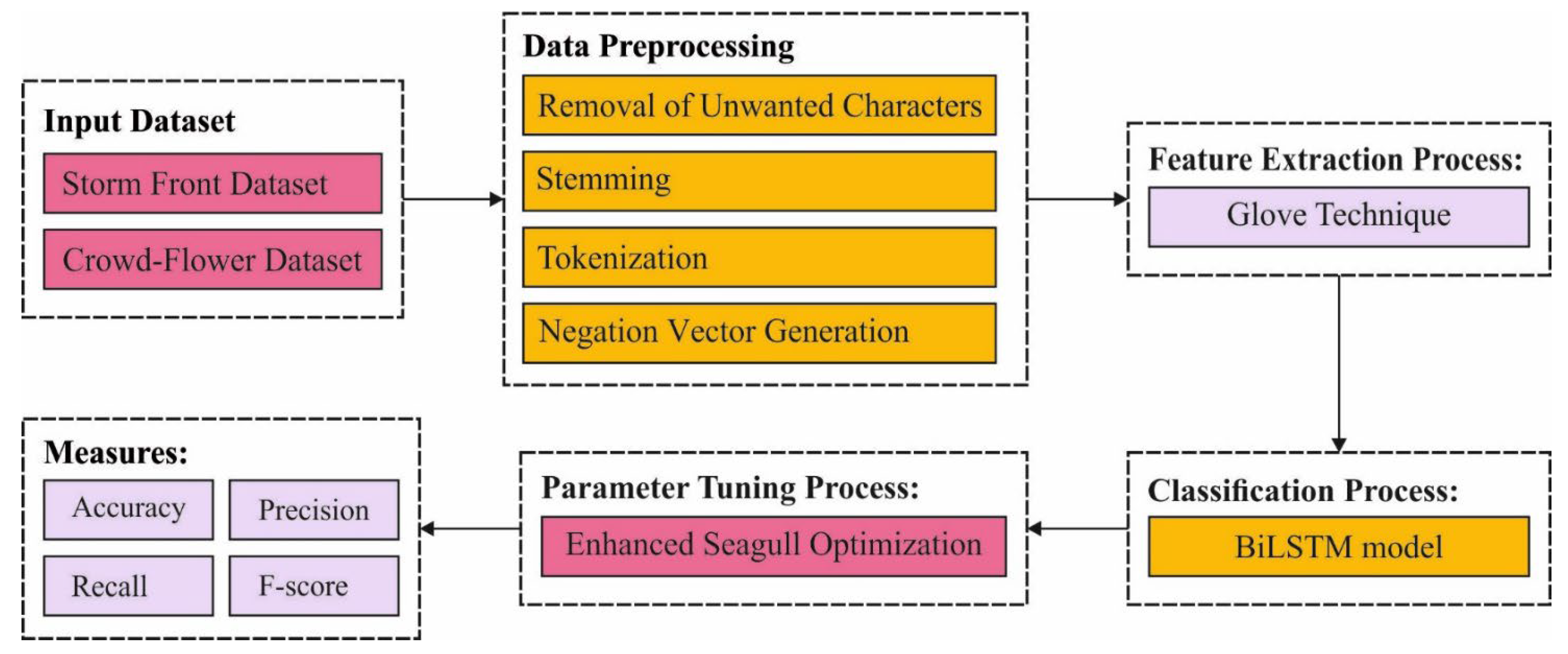
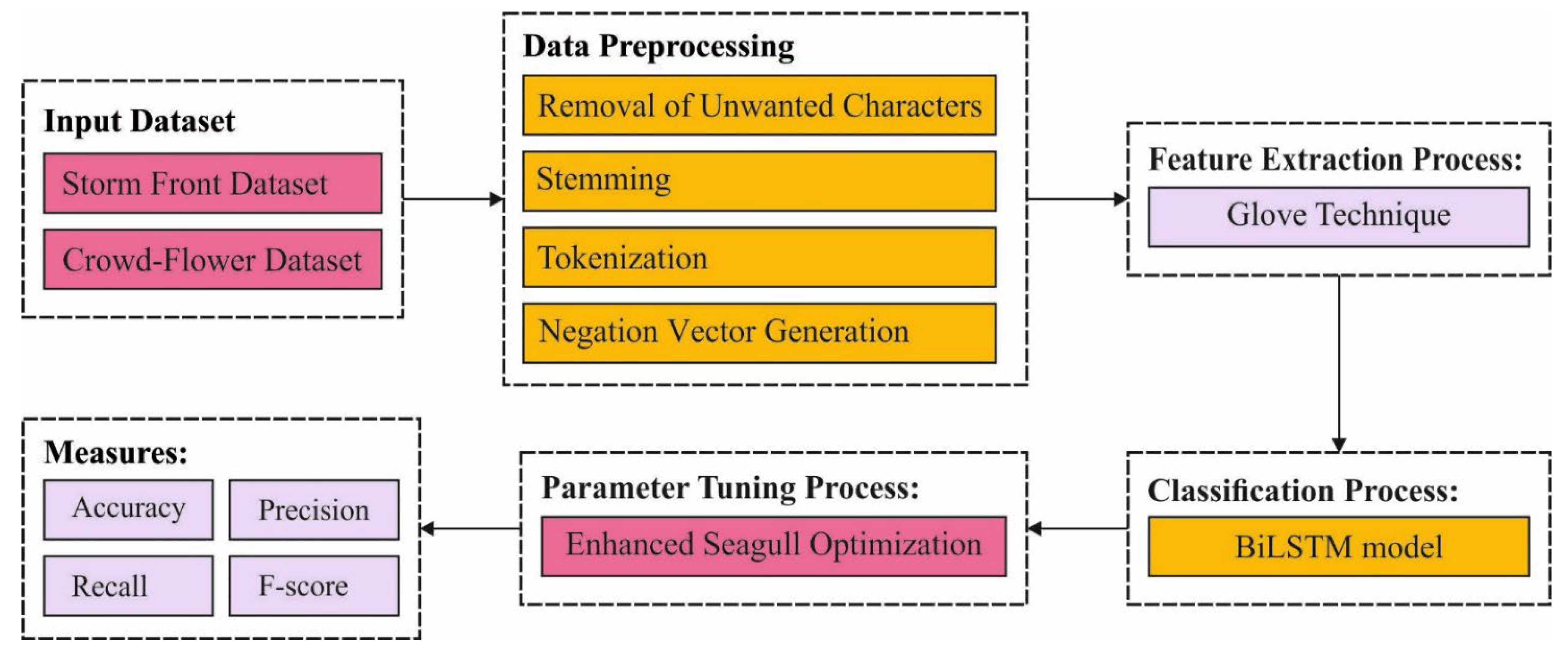
3. The Proposed ESGONLP-HSC Model
- Data Preprocessing
- Feature Extraction
- Data Classification
- Hyperparameter Tuning
3.1. Data Pre-Processing
- Unnecessary characters such as ‘\’, ‘/’, ‘#’, ‘@’, etc. were eliminated from Twitter data.
- Once unwanted characters are removed, the stemming process takes place, which derives the root words in the tweet. It is an effective NLP model due to the fact that it effectively processes words by the identification of the root or origin. At this stage, a lookup table is used for managing the incoming words related root words. It determines origin words using a suffix stripping process.
- NLP tokenization was the following step, where tweets were examined with the help of the OpenNLP tool. It uses sentDetect() function for identifying the start and end boundaries of all sentences. Once each sentence is recognized, the tokenization splits the sentence into smaller sentences.
- At last, a negation vector was produced with the help of the lookup table. The table encompasses root words and mixed stemmed words. Then, negative words are examined and a few of them are allocated a −1 value. The rest of the words are allocated a +1 value.
3.2. Glove-Based Feature Extraction
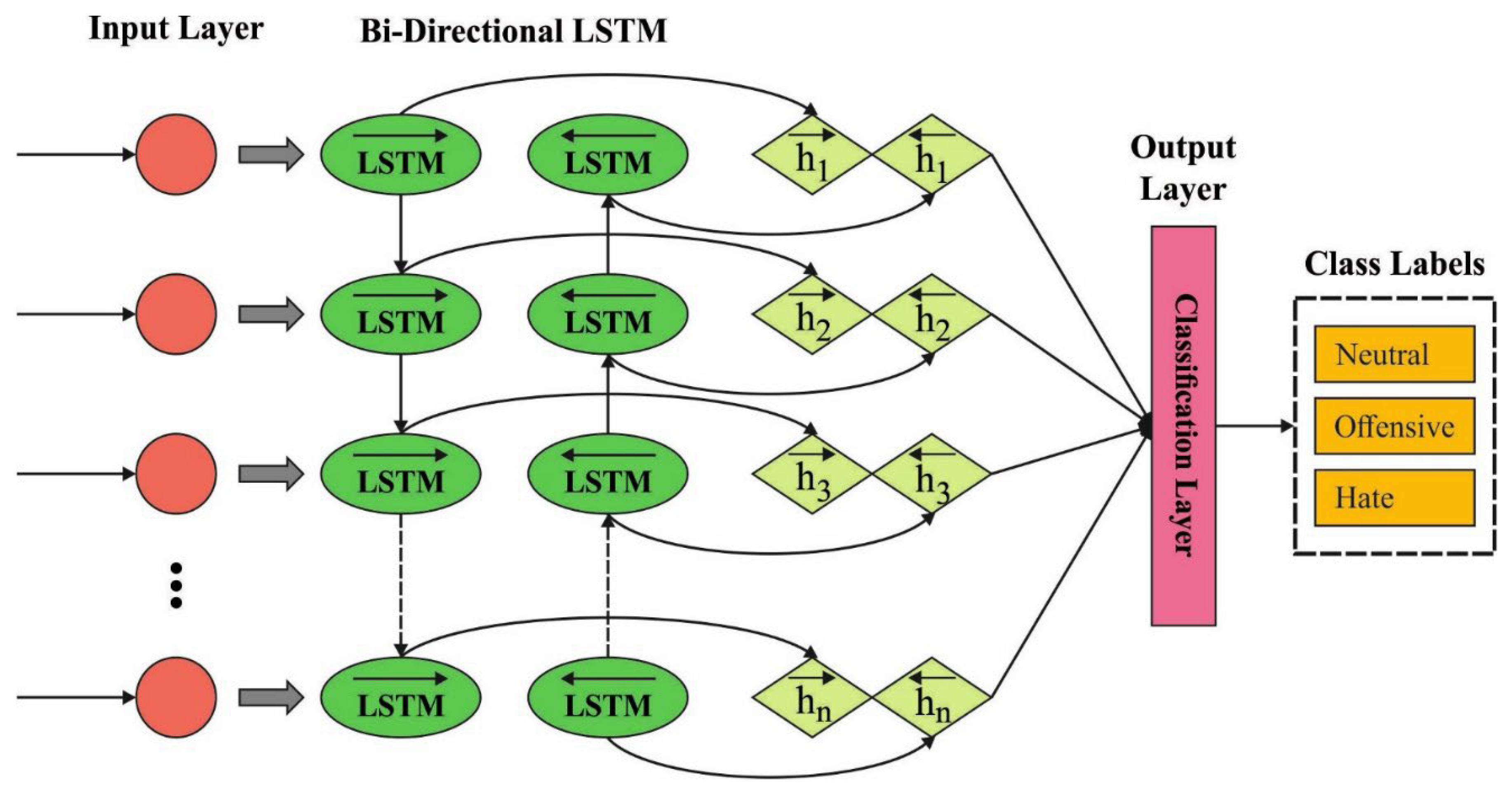
3.3. Hate Speech Classification
3.4. Hyperparameter Optimization
| Algorithm 1: Pseudocode of ESGO Algorithm |
| Input: Seagull population Output: Optimum searching agent Parameter initialization: and Assume Assume Assume while do determine fitness values of seagulls for to (every dimension), do Fitness_Function end for elect optimal fitness value* for to do if then end if end for elect fitness value for searching agent/ Carry out OBL process Elect and via greedy selection end while return |
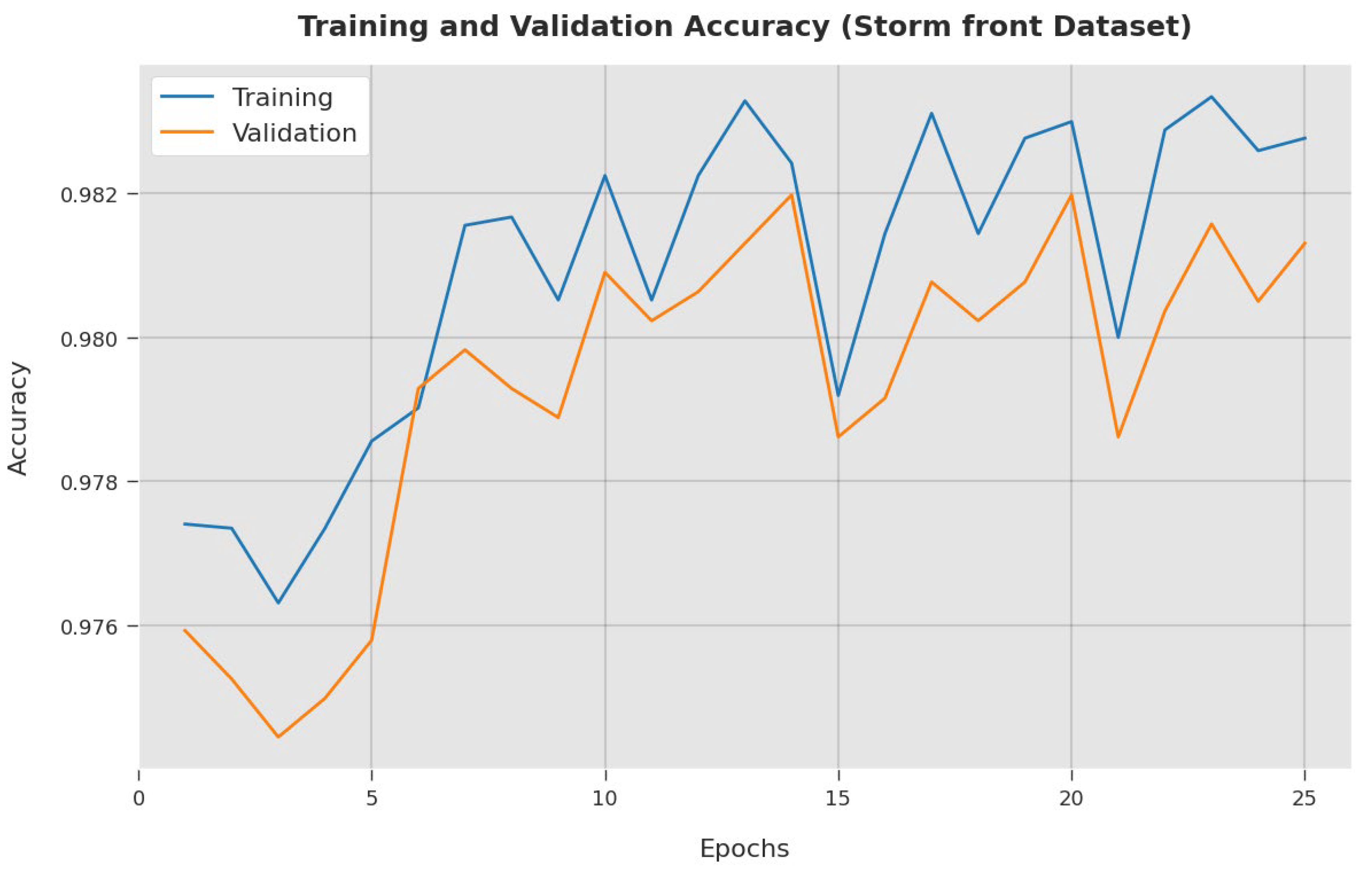
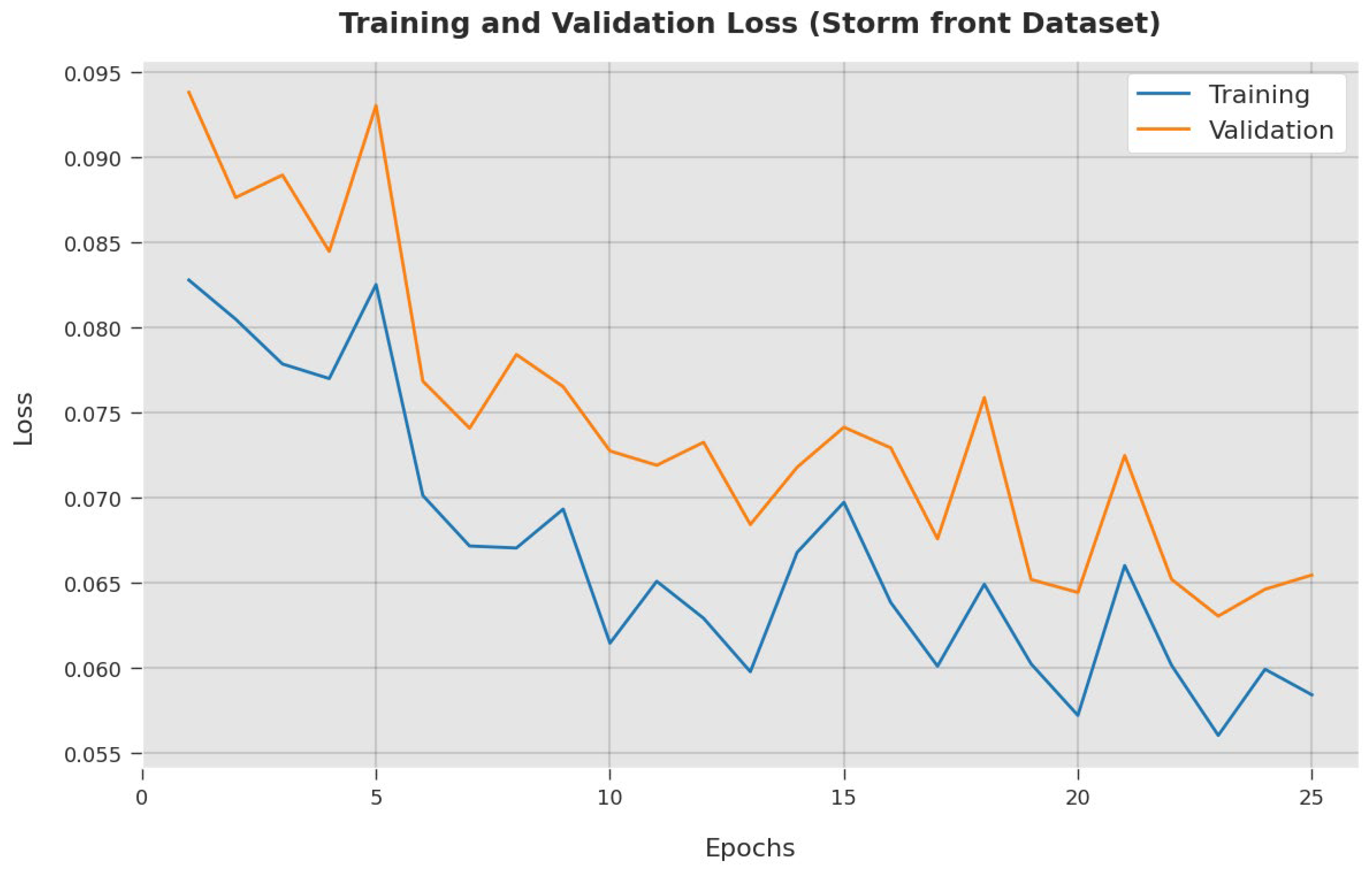
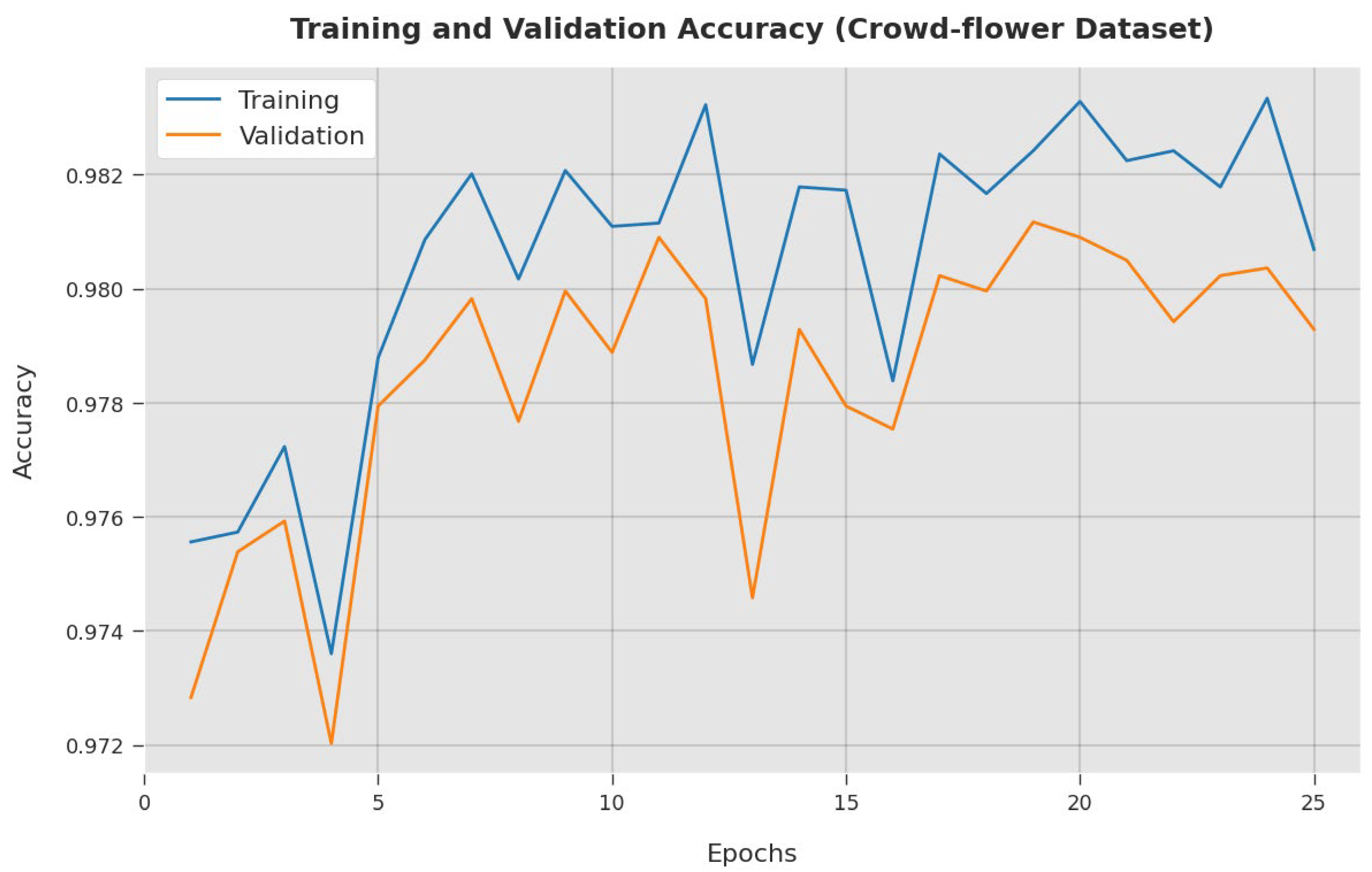
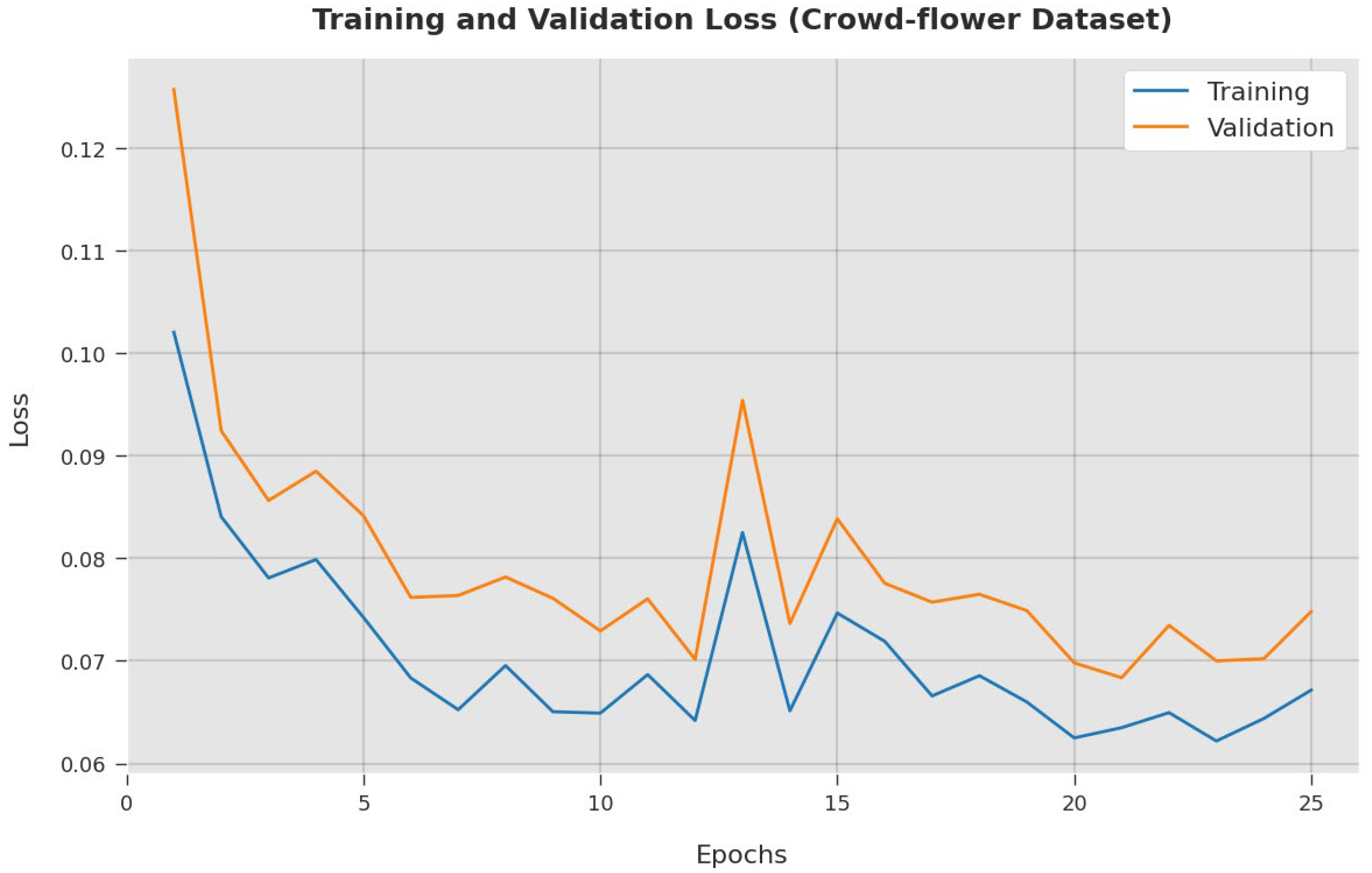
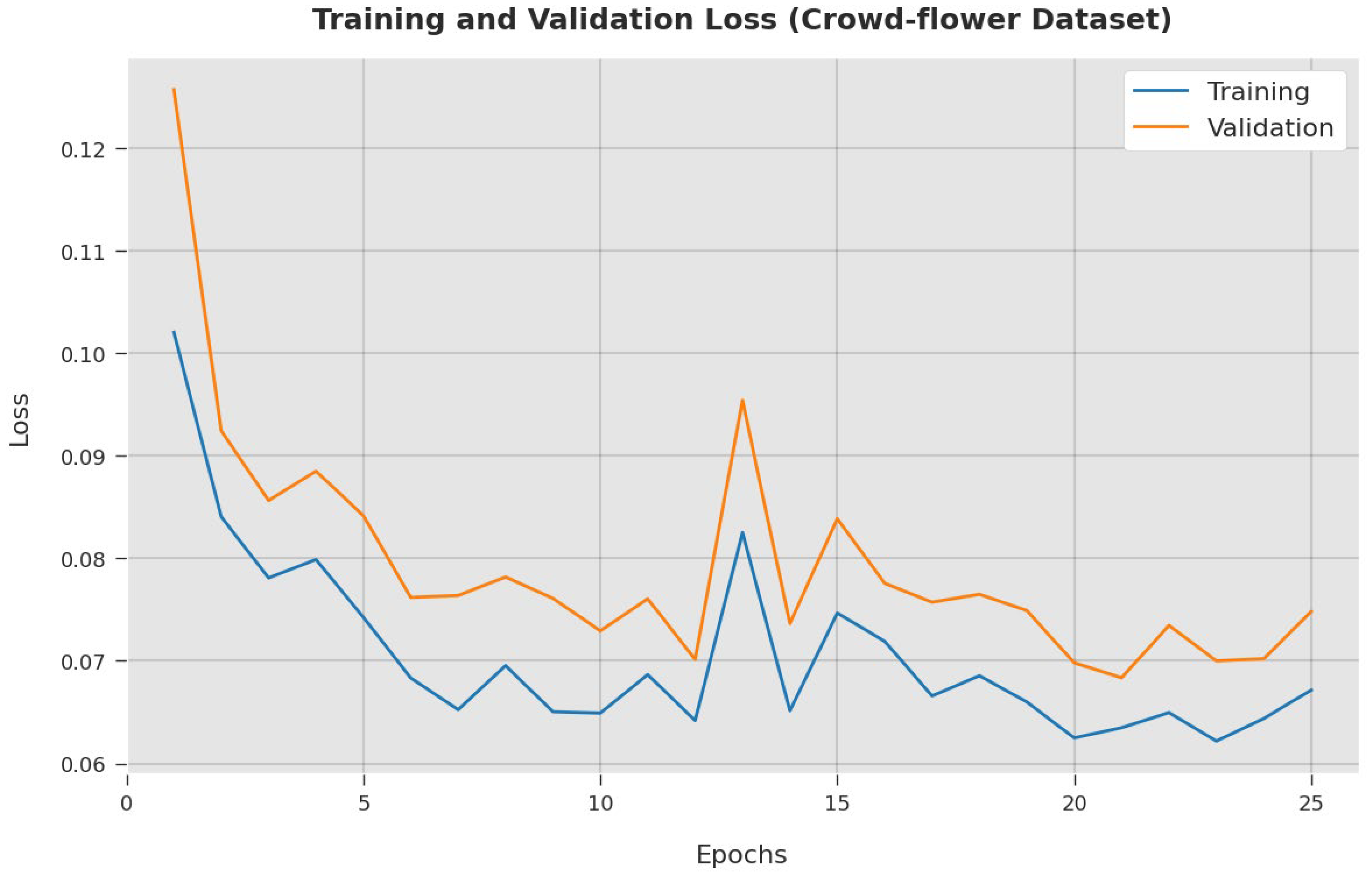
4. Results and Discussion
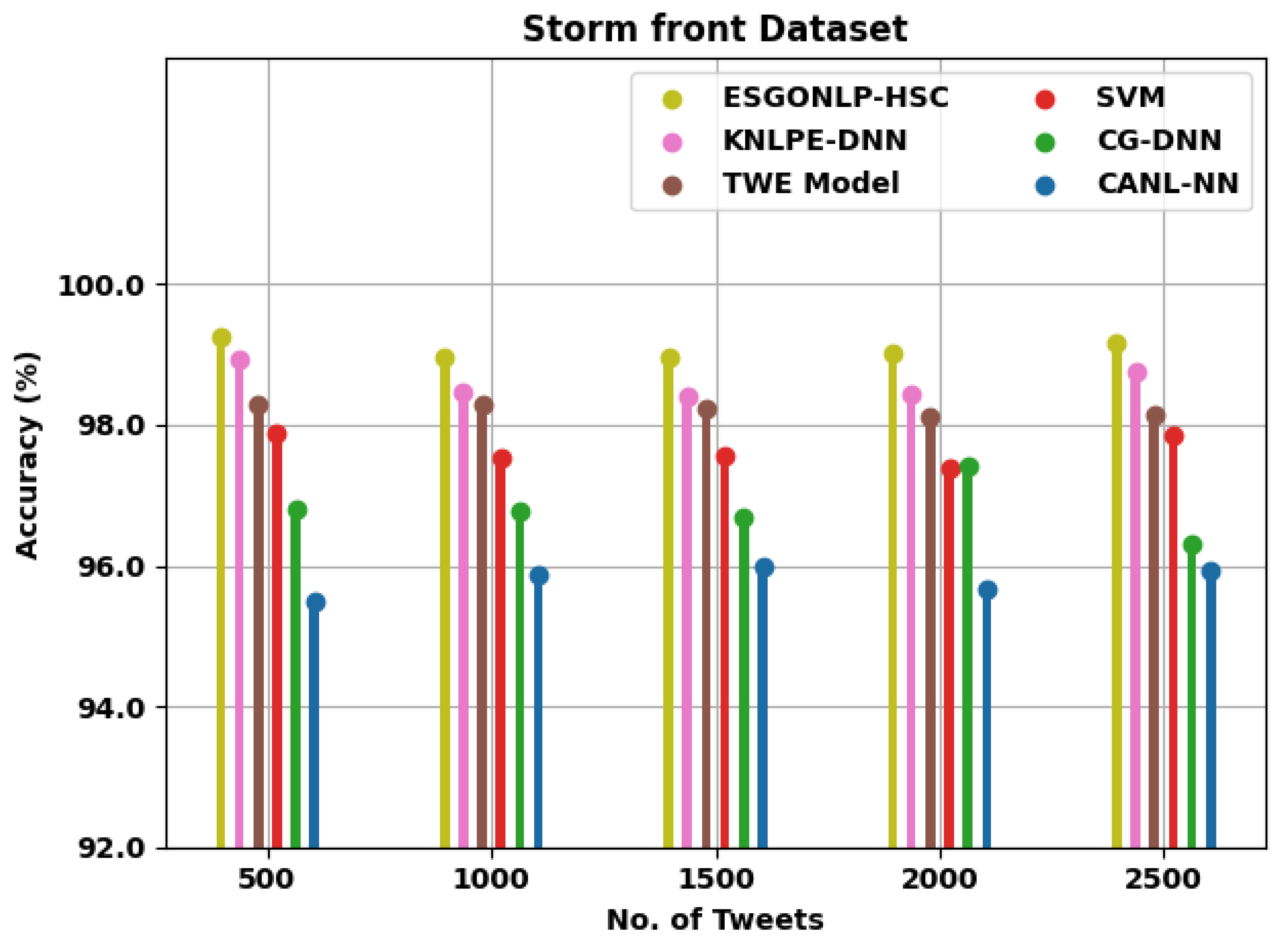
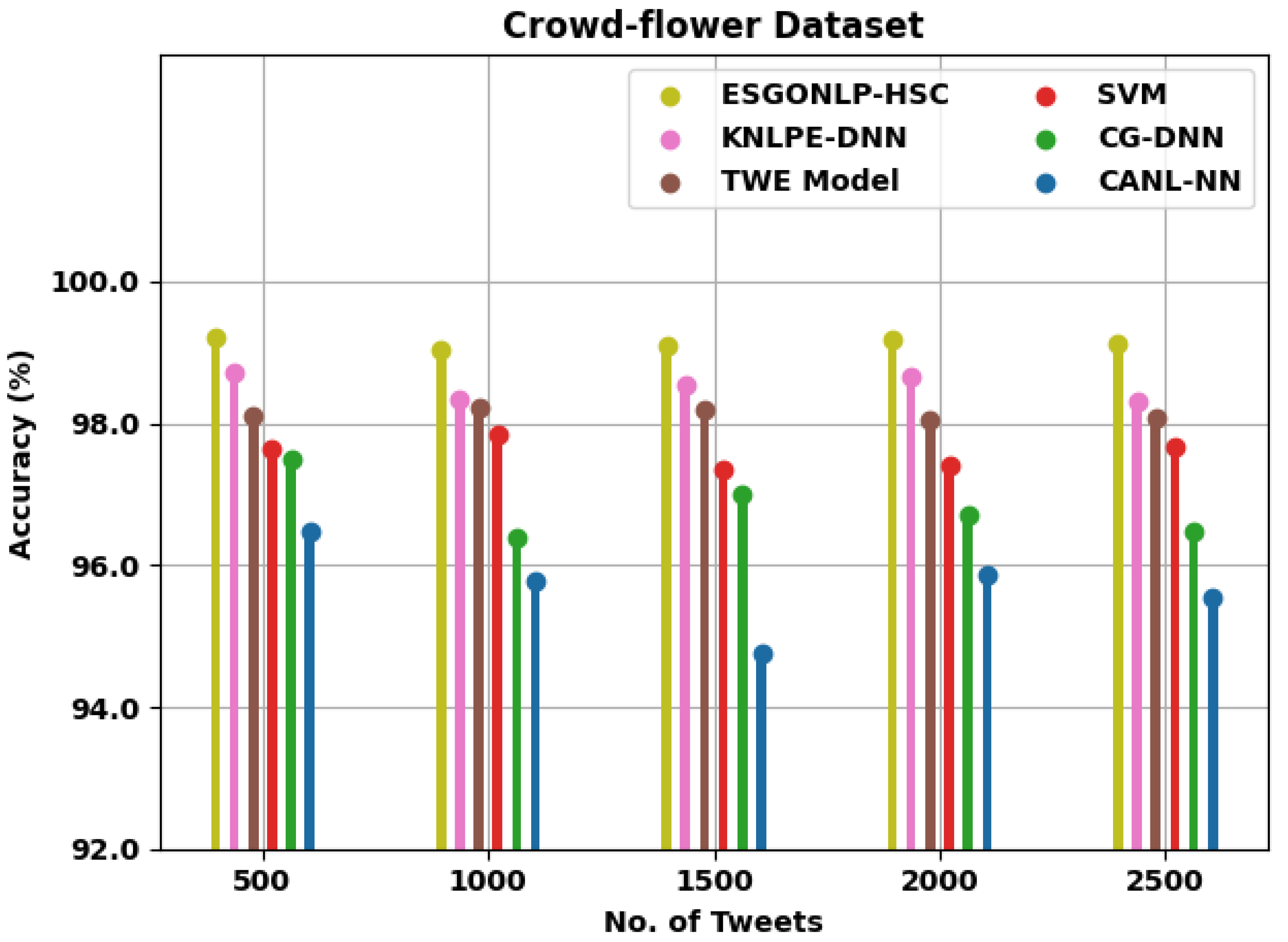
4.1. Dataset Details
4.2. Result Analysis
5. Conclusions
6. Theoretical and Practical Implications
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- García-Díaz, J.A.; Jiménez-Zafra, S.M.; García-Cumbreras, M.A.; Valencia-García, R. Evaluating feature combination strategies for hate-speech detection in spanish using linguistic features and transformers. Complex Intell. Syst. 2022, 1–22. [Google Scholar] [CrossRef]
- Kovács, G.; Alonso, P.; Saini, R. Challenges of hate speech detection in social media. SN Comput. Sci. 2021, 2, 95. [Google Scholar] [CrossRef]
- Jahan, M.S.; Oussalah, M. A systematic review of Hate Speech automatic detection using Natural Language Processing. arXiv 2021, arXiv:2106.00742. [Google Scholar]
- Alkomah, F.; Ma, X. A Literature Review of Textual Hate Speech Detection Methods and Datasets. Information 2022, 13, 273. [Google Scholar] [CrossRef]
- Al-Makhadmeh, Z.; Tolba, A. Automatic hate speech detection using killer natural language processing optimizing ensemble deep learning approach. Computing 2020, 102, 501–522. [Google Scholar] [CrossRef]
- Pariyani, B.; Shah, K.; Shah, M.; Vyas, T.; Degadwala, S. February. Hate speech detection in twitter using natural language processing. In Proceedings of the 2021 Third International Conference on Intelligent Communication Technologies and Virtual Mobile Networks (ICICV), Tirunelveli, India, 4–6 February 2021; pp. 1146–1152. [Google Scholar]
- Perifanos, K.; Goutsos, D. Multimodal Hate Speech Detection in Greek Social Media. Multimodal Technol. Interact. 2021, 5, 34. [Google Scholar] [CrossRef]
- Plaza-del-Arco, F.M.; Molina-González, M.D.; Urena-López, L.A.; Martín-Valdivia, M.T. Comparing pre-trained language models for Spanish hate speech detection. Expert Syst. Appl. 2021, 166, 114120. [Google Scholar] [CrossRef]
- Khan, S.; Kamal, A.; Fazil, M.; Alshara, M.A.; Sejwal, V.K.; Alotaibi, R.M.; Baig, A.R.; Alqahtani, S. HCovBi-caps: Hate speech detection using convolutional and Bi-directional gated recurrent unit with Capsule network. IEEE Access 2022, 10, 7881–7894. [Google Scholar] [CrossRef]
- Khan, S.; Fazil, M.; Sejwal, V.K.; Alshara, M.A.; Alotaibi, R.M.; Kamal, A.; Baig, A.R. BiCHAT: BiLSTM with deep CNN and hierarchical attention for hate speech detection. J. King Saud Univ.-Comput. Inf. Sci. 2022, 34, 4335–4344. [Google Scholar] [CrossRef]
- Husain, F.; Uzuner, O. Investigating the Effect of Preprocessing Arabic Text on Offensive Language and Hate Speech Detection. Trans. Asian Low-Resour. Lang. Inf. Process. 2022, 21, 73. [Google Scholar] [CrossRef]
- Pham, Q.H.; Nguyen, V.A.; Doan, L.B.; Tran, N.N.; Thanh, T.M. November. From universal language model to downstream task: Improving RoBERTa-based Vietnamese hate speech detection. In Proceedings of the 2020 12th International Conference on Knowledge and Systems Engineering (KSE), Can Tho, Vietnam, 12–14 November 2020; pp. 37–42. [Google Scholar]
- Robinson, D.; Zhang, Z.; Tepper, J. Hate speech detection on twitter: Feature engineering vs feature selection. In Proceedings of the European Semantic Web Conference, Crete, Greece, 3–7 June 2018; Springer: Cham, Switzerland, 2018; pp. 46–49. [Google Scholar]
- Awal, M.R.; Cao, R.; Lee, R.K.W.; Mitrović, S. Angrybert: Joint learning target and emotion for hate speech detection. In Proceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining, Virtual Event, 11–14 May 2021; Springer: Cham, Switzerland, 2021; pp. 701–713. [Google Scholar]
- Qureshi, K.A.; Sabih, M. Un-compromised credibility: Social media based multi-class hate speech classification for text. IEEE Access 2021, 9, 109465–109477. [Google Scholar] [CrossRef]
- Mohtaj, S.; Schmitt, V.; Möller, S. A Feature Extraction based Model for Hate Speech Identification. arXiv 2022, arXiv:2201.04227. [Google Scholar]
- Kumar, D.; Kumar, N.; Mishra, S. QUARC: Quaternion multi-modal fusion architecture for hate speech classification. In Proceedings of the 2021 IEEE International Conference on Big Data and Smart Computing (BigComp), Jeju Island, Korea, 17–20 January 2021; pp. 346–349. [Google Scholar]
- Araque, O.; Iglesias, C.A. An ensemble method for radicalization and hate speech detection online empowered by sentic computing. Cogn. Comput. 2022, 14, 48–61. [Google Scholar] [CrossRef]
- Miok, K.; Škrlj, B.; Zaharie, D.; Robnik-Šikonja, M. To BAN or not to BAN: Bayesian attention networks for reliable hate speech detection. Cogn. Comput. 2022, 14, 353–371. [Google Scholar] [CrossRef]
- Nascimento, F.R.; Cavalcanti, G.D.; Da Costa-Abreu, M. Unintended bias evaluation: An analysis of hate speech detection and gender bias mitigation on social media using ensemble learning. Expert Syst. Appl. 2022, 201, 117032. [Google Scholar] [CrossRef]
- Cruz, R.M.; de Sousa, W.V.; Cavalcanti, G.D. Selecting and combining complementary feature representations and classifiers for hate speech detection. arXiv 2022, arXiv:2201.06721. [Google Scholar] [CrossRef]
- Yao, Z.; Sun, Y.; Ding, W.; Rao, N.; Xiong, H. Dynamic word embeddings for evolving semantic discovery. In Proceedings of the Eleventh ACM International Conference on Web Search and Data Mining, Marina Del Rey, CA, USA; 2018; pp. 673–681. [Google Scholar]
- Hong, G. Relation extraction using support vector machine. In Proceedings of the International Conference on Nat-Ural Language Processing, Jeju Island, Korea, 11-13 October 2005; Springer: Berlin, Germany, 2005; pp. 366–377. [Google Scholar]
- Zhang, Z.; Robinson, D.; Tepper, J. Detecting hate speech on Twitter using a convolutionGRU based deep neural network. In Proceedings of the European Semantic Web Conference, Crete, Greece, 3–7 June 2018; Springer: Cham, Switzerland, 2018; pp. 745–760. [Google Scholar]
- Kim, Y.; Jernite, Y.; Sontag, D.; Rush, A.M. Character-aware neural language models. In Proceedings of the Thirtieth AAAI Conference on Artifcial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; pp. 1–9. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Liu, G.; Guo, J. Bidirectional LSTM with attention mechanism and convolutional layer for text classification. Neurocomputing 2019, 337, 325–338. [Google Scholar] [CrossRef]
- Dhiman, G.; Kumar, V. Seagull optimization algorithm: Theory and its applications for large-scale industrial engineering problems. Knowl.-Based Syst. 2019, 165, 169–196. [Google Scholar] [CrossRef]
- Caren, T.N.; Jowers, K.; Gaby, S. A social movement online community: Stormfront and the white nationalist movement. In Media, Movements, and Political Change (Research in Social Movements, Conficts and Change, Volume 33); Earl, J., Rohlinger, D.A., Eds.; Emerald Group Publishing Limited: Bingley, UK, 2012; pp. 163–193. [Google Scholar]
- Davidson, T.; Warmsley, D.; Macy, M.; Weber, I. Automated Hate Speech Detection and the Problem of Offensive Language. In Proceedings of the 11th International Conference on Web and Social Media (ICWSM), Montreal, QC, Canada, 15–18 May 2017. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameter | Value |
|---|---|
| Learning rate | 0.01 |
| Dropout | 0.5 |
| Batch size | 5 |
| Number of epochs | 50 |
| Activation function | ReLU |
| Accuracy (%) | ||||||
|---|---|---|---|---|---|---|
| No. of Tweets | ESGONLP-HSC | KNLPE-DNN | TWE Model | SVM | CG-DNN | CANL-NN |
| Storm front Dataset | ||||||
| 500 | 99.24 | 98.92 | 98.29 | 97.88 | 96.81 | 95.50 |
| 1000 | 98.95 | 98.48 | 98.29 | 97.54 | 96.78 | 95.87 |
| 1500 | 98.97 | 98.41 | 98.23 | 97.55 | 96.68 | 96.00 |
| 2000 | 99.01 | 98.43 | 98.11 | 97.38 | 97.43 | 95.67 |
| 2500 | 99.17 | 98.75 | 98.14 | 97.85 | 96.31 | 95.92 |
| Crowd-flower Dataset | ||||||
| 500 | 99.22 | 98.71 | 98.11 | 97.65 | 97.50 | 96.46 |
| 1000 | 99.04 | 98.35 | 98.22 | 97.83 | 96.38 | 95.77 |
| 1500 | 99.08 | 98.55 | 98.18 | 97.34 | 97.00 | 94.76 |
| 2000 | 99.18 | 98.65 | 98.04 | 97.42 | 96.70 | 95.86 |
| 2500 | 99.12 | 98.31 | 98.07 | 97.66 | 96.48 | 95.54 |
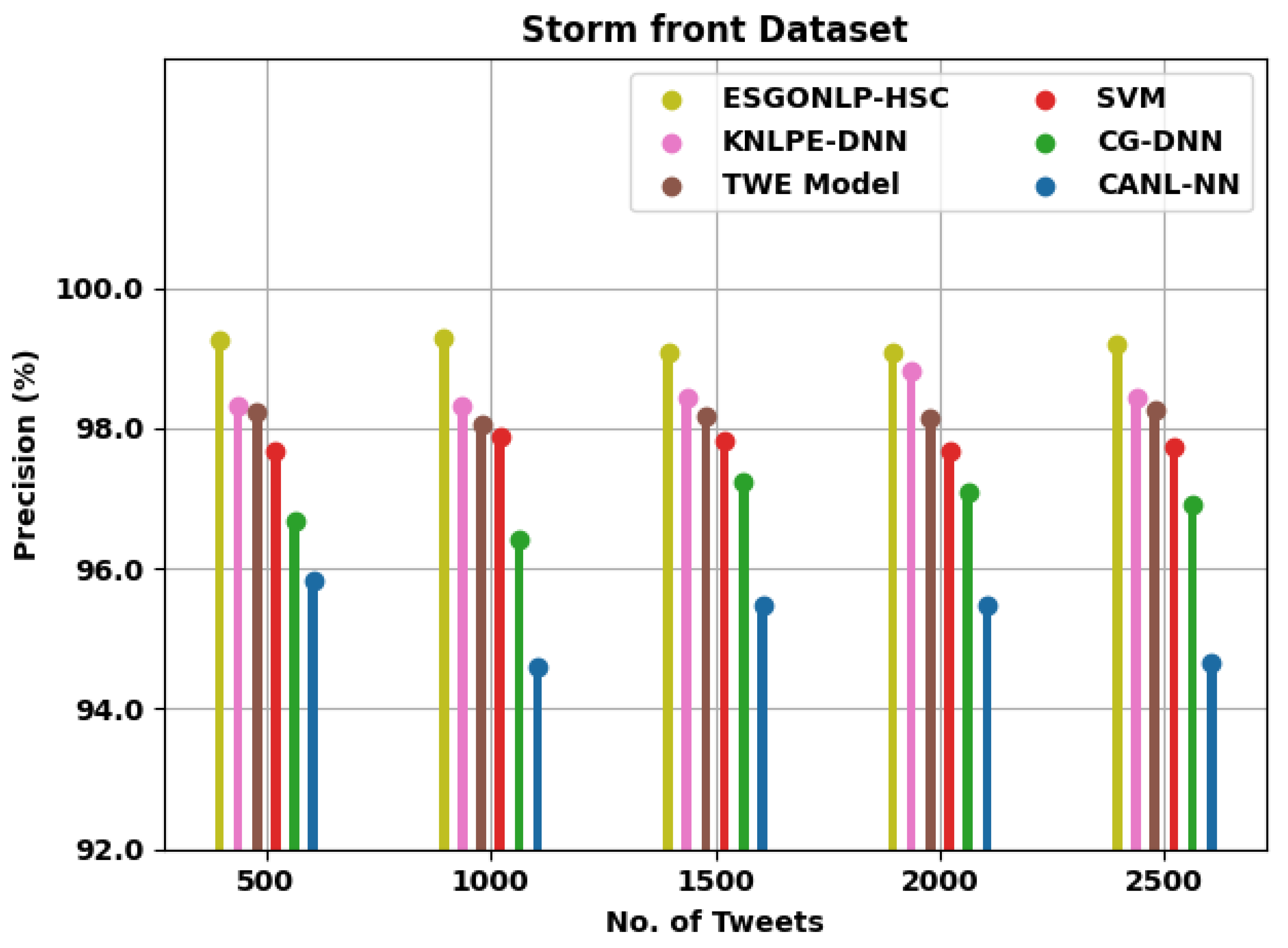
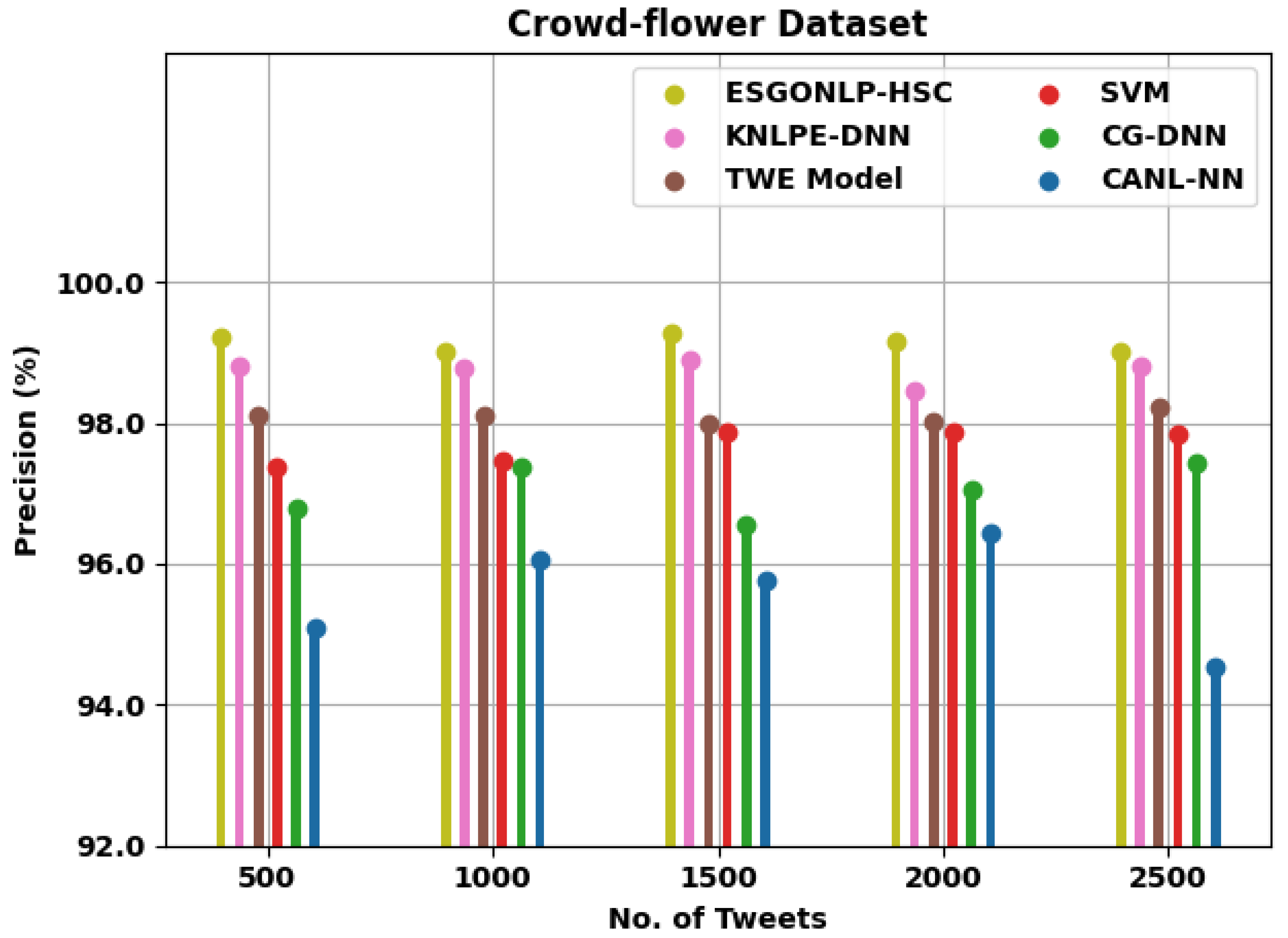
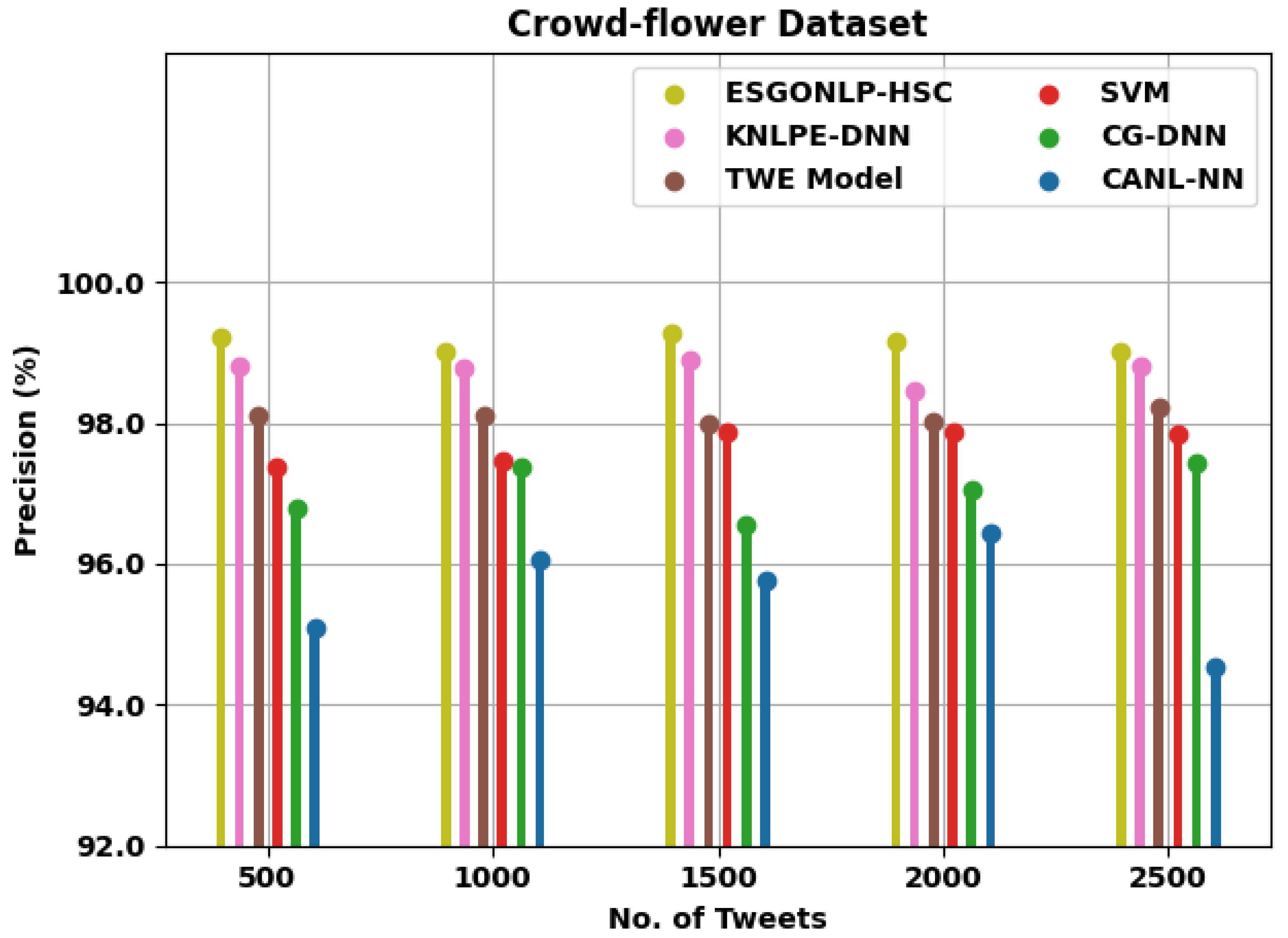
| Precision (%) | ||||||
|---|---|---|---|---|---|---|
| No. of Tweets | ESGONLP-HSC | KNLPE-DNN | TWE Model | SVM | CG-DNN | CANL-NN |
| Storm front Dataset | ||||||
| 500 | 99.26 | 98.32 | 98.22 | 97.67 | 96.69 | 95.82 |
| 1000 | 99.29 | 98.31 | 98.06 | 97.89 | 96.41 | 94.59 |
| 1500 | 99.07 | 98.45 | 98.16 | 97.82 | 97.25 | 95.47 |
| 2000 | 99.07 | 98.82 | 98.15 | 97.69 | 97.08 | 95.49 |
| 2500 | 99.20 | 98.43 | 98.26 | 97.73 | 96.92 | 94.66 |
| Crowd-flower Dataset | ||||||
| 500 | 99.22 | 98.80 | 98.11 | 97.38 | 96.78 | 95.09 |
| 1000 | 99.02 | 98.77 | 98.10 | 97.46 | 97.37 | 96.05 |
| 1500 | 99.27 | 98.90 | 97.98 | 97.88 | 96.56 | 95.76 |
| 2000 | 99.15 | 98.46 | 98.02 | 97.86 | 97.04 | 96.43 |
| 2500 | 99.00 | 98.82 | 98.23 | 97.83 | 97.44 | 94.55 |
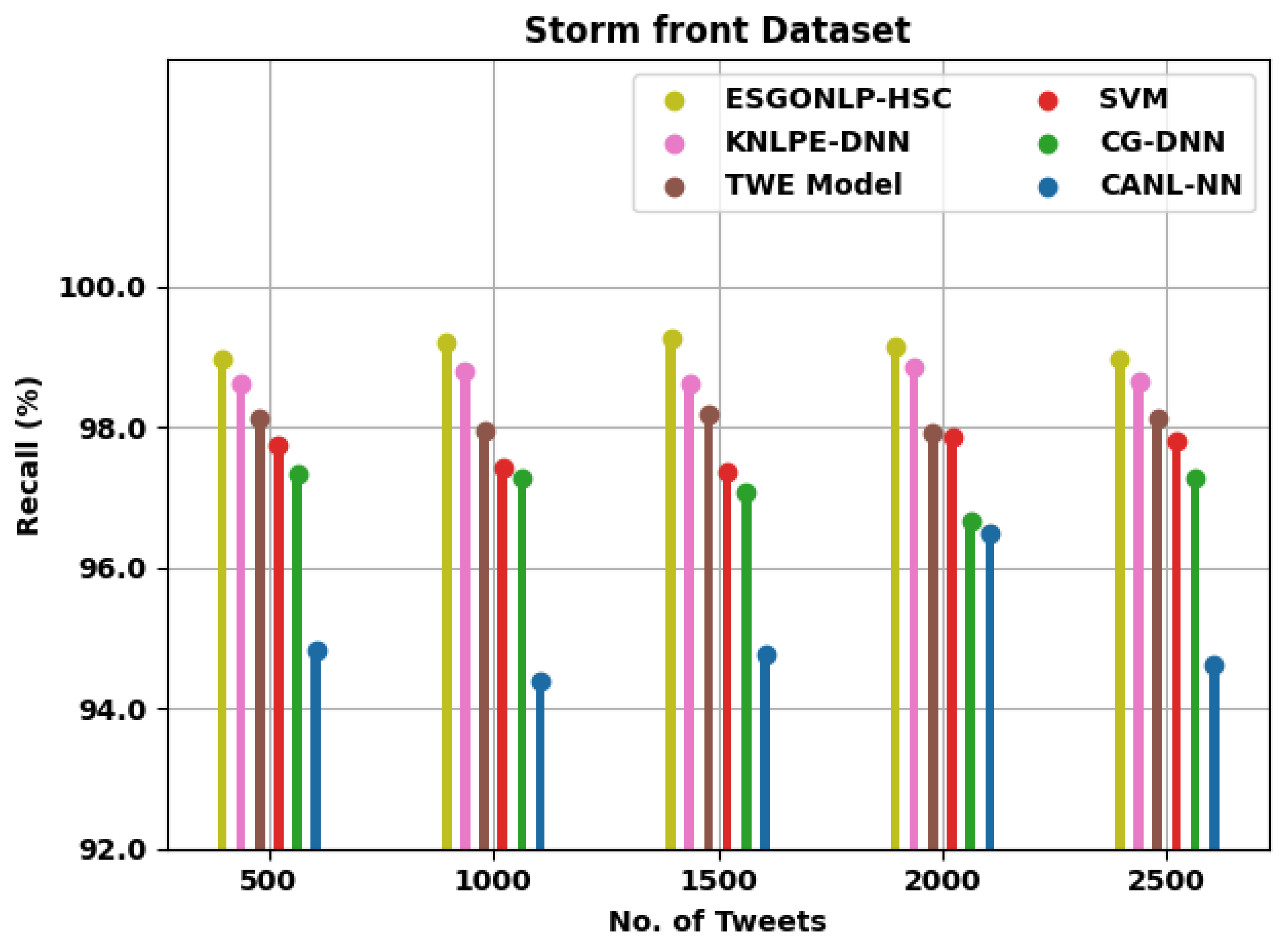
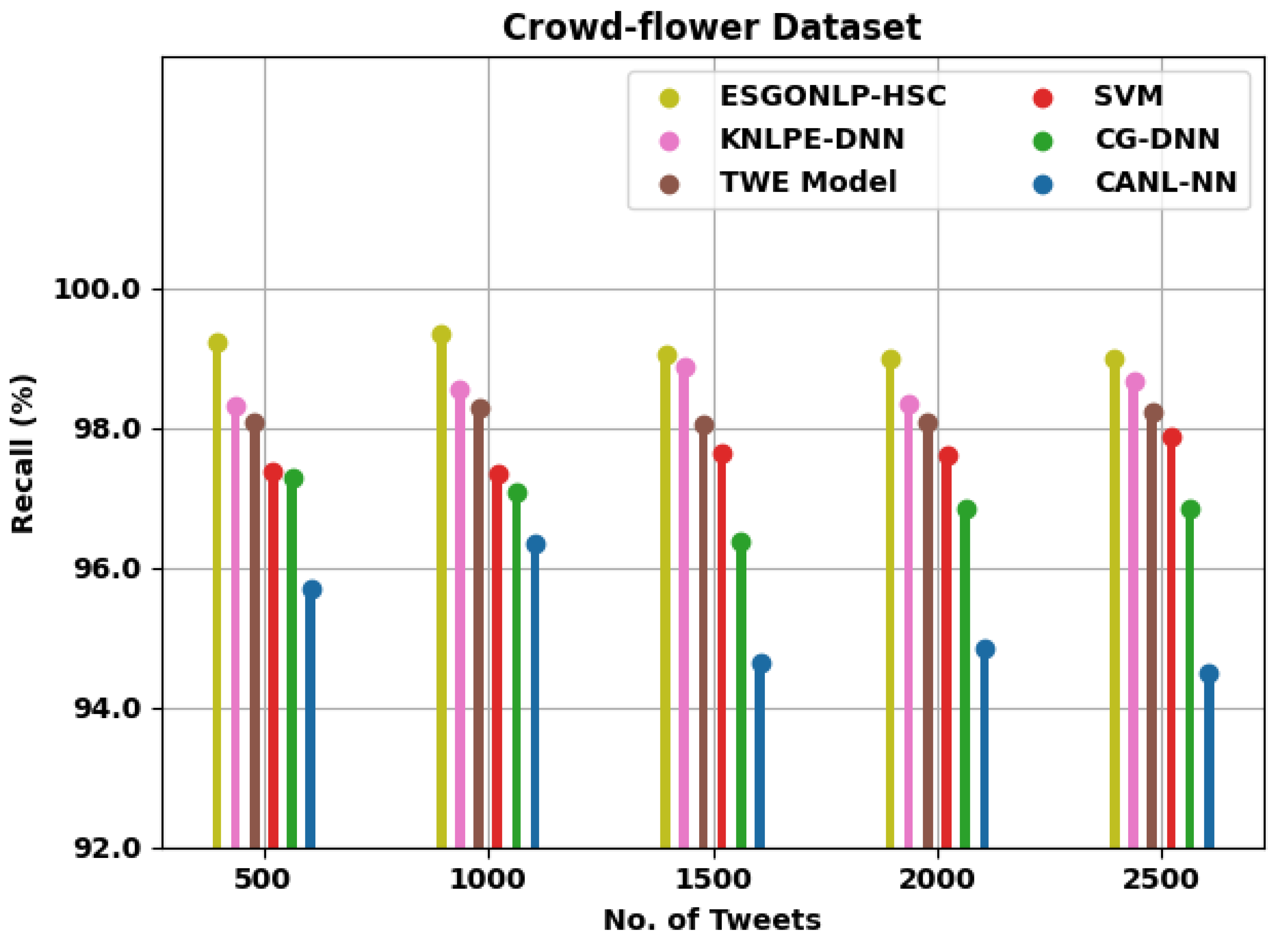
| Recall (%) | ||||||
|---|---|---|---|---|---|---|
| No. of Tweets | ESGONLP-HSC | KNLPE-DNN | TWE Model | SVM | CG-DNN | CANL-NN |
| Storm front Dataset | ||||||
| 500 | 98.96 | 98.63 | 98.14 | 97.76 | 97.33 | 94.84 |
| 1000 | 99.20 | 98.79 | 97.94 | 97.44 | 97.27 | 94.40 |
| 1500 | 99.26 | 98.63 | 98.18 | 97.37 | 97.09 | 94.78 |
| 2000 | 99.16 | 98.86 | 97.91 | 97.85 | 96.67 | 96.50 |
| 2500 | 98.98 | 98.64 | 98.14 | 97.80 | 97.27 | 94.62 |
| Crowd-flower Dataset | ||||||
| 500 | 99.23 | 98.32 | 98.09 | 97.36 | 97.29 | 95.71 |
| 1000 | 99.33 | 98.55 | 98.28 | 97.33 | 97.09 | 96.35 |
| 1500 | 99.04 | 98.88 | 98.05 | 97.65 | 96.38 | 94.64 |
| 2000 | 98.98 | 98.34 | 98.08 | 97.60 | 96.85 | 94.83 |
| 2500 | 99.00 | 98.66 | 98.22 | 97.88 | 96.84 | 94.49 |
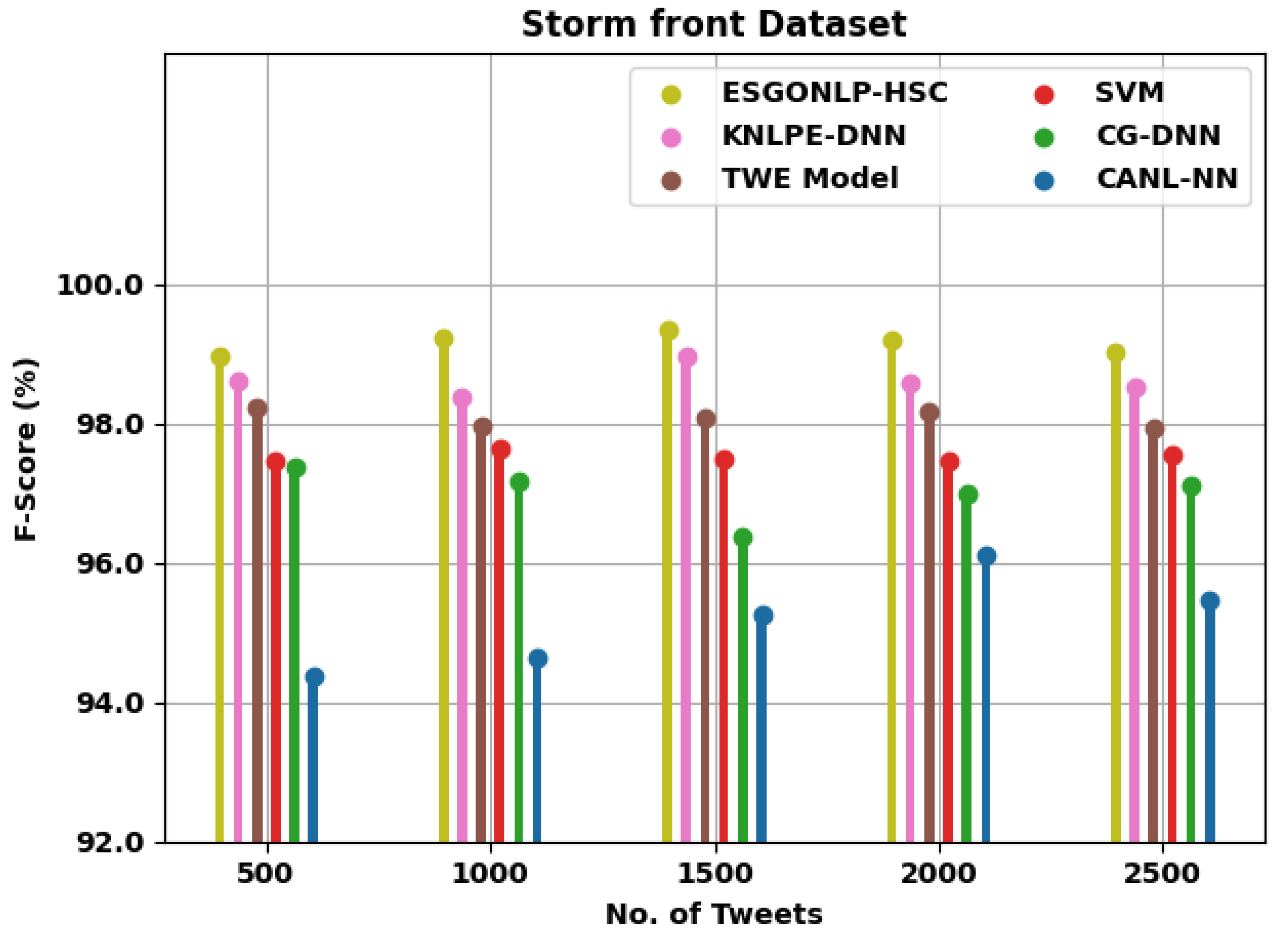
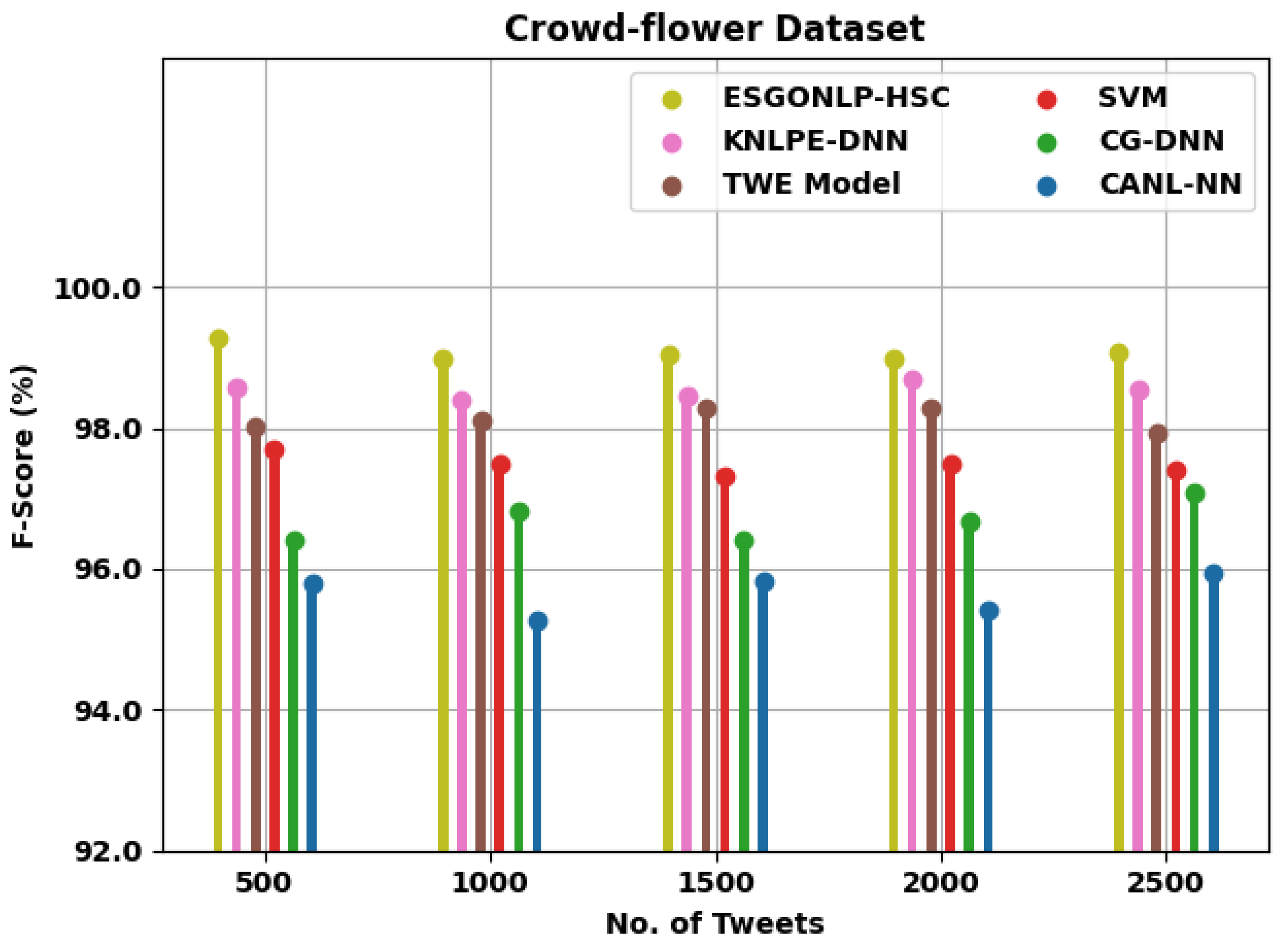
| F-Score (%) | ||||||
|---|---|---|---|---|---|---|
| No. of Tweets | ESGONLP-HSC | KNLPE-DNN | TWE Model | SVM | CG-DNN | CANL-NN |
| Storm front Dataset | ||||||
| 500 | 98.97 | 98.60 | 98.24 | 97.47 | 97.36 | 94.36 |
| 1000 | 99.24 | 98.36 | 97.96 | 97.65 | 97.18 | 94.64 |
| 1500 | 99.33 | 98.95 | 98.07 | 97.50 | 96.38 | 95.26 |
| 2000 | 99.19 | 98.58 | 98.18 | 97.45 | 96.99 | 96.11 |
| 2500 | 99.02 | 98.53 | 97.92 | 97.56 | 97.11 | 95.47 |
| Crowd-flower Dataset | ||||||
| 500 | 99.27 | 98.58 | 98.03 | 97.69 | 96.41 | 95.78 |
| 1000 | 98.98 | 98.41 | 98.09 | 97.50 | 96.81 | 95.26 |
| 1500 | 99.04 | 98.45 | 98.29 | 97.32 | 96.42 | 95.81 |
| 2000 | 98.97 | 98.68 | 98.27 | 97.50 | 96.66 | 95.42 |
| 2500 | 99.06 | 98.53 | 97.92 | 97.40 | 97.09 | 95.93 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Asiri, Y.; Halawani, H.T.; Alghamdi, H.M.; Abdalaha Hamza, S.H.; Abdel-Khalek, S.; Mansour, R.F. Enhanced Seagull Optimization with Natural Language Processing Based Hate Speech Detection and Classification. Appl. Sci. 2022, 12, 8000. https://doi.org/10.3390/app12168000
Asiri Y, Halawani HT, Alghamdi HM, Abdalaha Hamza SH, Abdel-Khalek S, Mansour RF. Enhanced Seagull Optimization with Natural Language Processing Based Hate Speech Detection and Classification. Applied Sciences. 2022; 12(16):8000. https://doi.org/10.3390/app12168000
Chicago/Turabian StyleAsiri, Yousef, Hanan T. Halawani, Hanan M. Alghamdi, Saadia Hassan Abdalaha Hamza, Sayed Abdel-Khalek, and Romany F. Mansour. 2022. "Enhanced Seagull Optimization with Natural Language Processing Based Hate Speech Detection and Classification" Applied Sciences 12, no. 16: 8000. https://doi.org/10.3390/app12168000
APA StyleAsiri, Y., Halawani, H. T., Alghamdi, H. M., Abdalaha Hamza, S. H., Abdel-Khalek, S., & Mansour, R. F. (2022). Enhanced Seagull Optimization with Natural Language Processing Based Hate Speech Detection and Classification. Applied Sciences, 12(16), 8000. https://doi.org/10.3390/app12168000