1. Introduction
Machine learning (ML) models have exploded in complexity in recent years at the expense of high computational costs [
1]. ML is actually the calculation process of learning data through a certain algorithm. Parameters that can be updated during the training process are called model parameters. There is another kind of parameter, hyperparameter, which should be defined before training and cannot be learned from the normal training process. For instance, the kernel, regularization parameter, and kernel coefficient of a support vector machine (SVM), and the hidden state size and learning rate of a deep learning (DL) model are all hyperparameters. The process of finding the optimal hyperparameters is inevitable since hyperparameters have a remarkable effect on the performance in terms of time or accuracy of the model. In many cases, engineers rely on the trial-and-error method to manually tune hyperparameters. Even experienced engineers will try multiple times in a certain range to find the optimal combination of hyperparameters, not to mention that for non-experts in ML and DL, finding the best hyperparameters is time consuming and difficult.
To solve this issue, automated ML (AutoML) has been proposed, which can build ML pipelines on a limited computational budget automatically, without human interference. The overall process of AutoML consists of four phases: data preparation, feature engineering, model generation, and model evaluation [
2]. The optimization method is a part of model generation, which can be further divided into architecture optimization (AO) and hyperparameter optimization (HPO). Thornton et al. [
3] defined the automatic selection of learning algorithms and the setting of hyperparameters to optimize empirical performance as a combined algorithm selection and hyperparameter optimization (CASH) problem. In this work, we focus on the HPO task.
In practice, HPO is confronted with many challenges, which make it a difficult problem. First, the hyperparameter tuning of ML models is generally considered a black-box optimization problem, that is, we can only observe the inputs and outputs of the model during the tuning process. We usually cannot obtain the gradient of the cost function with respect to the hyperparameters. Second, when facing large models, large datasets, the target model needs to be trained with selected hyperparameters to obtain the loss value, so the process of evaluation is very expensive. Finally, the configuration space is very complex and high dimensional. For a given algorithm, there are multiple hyperparameters correspondingly, and each hyperparameter has its own range of values.
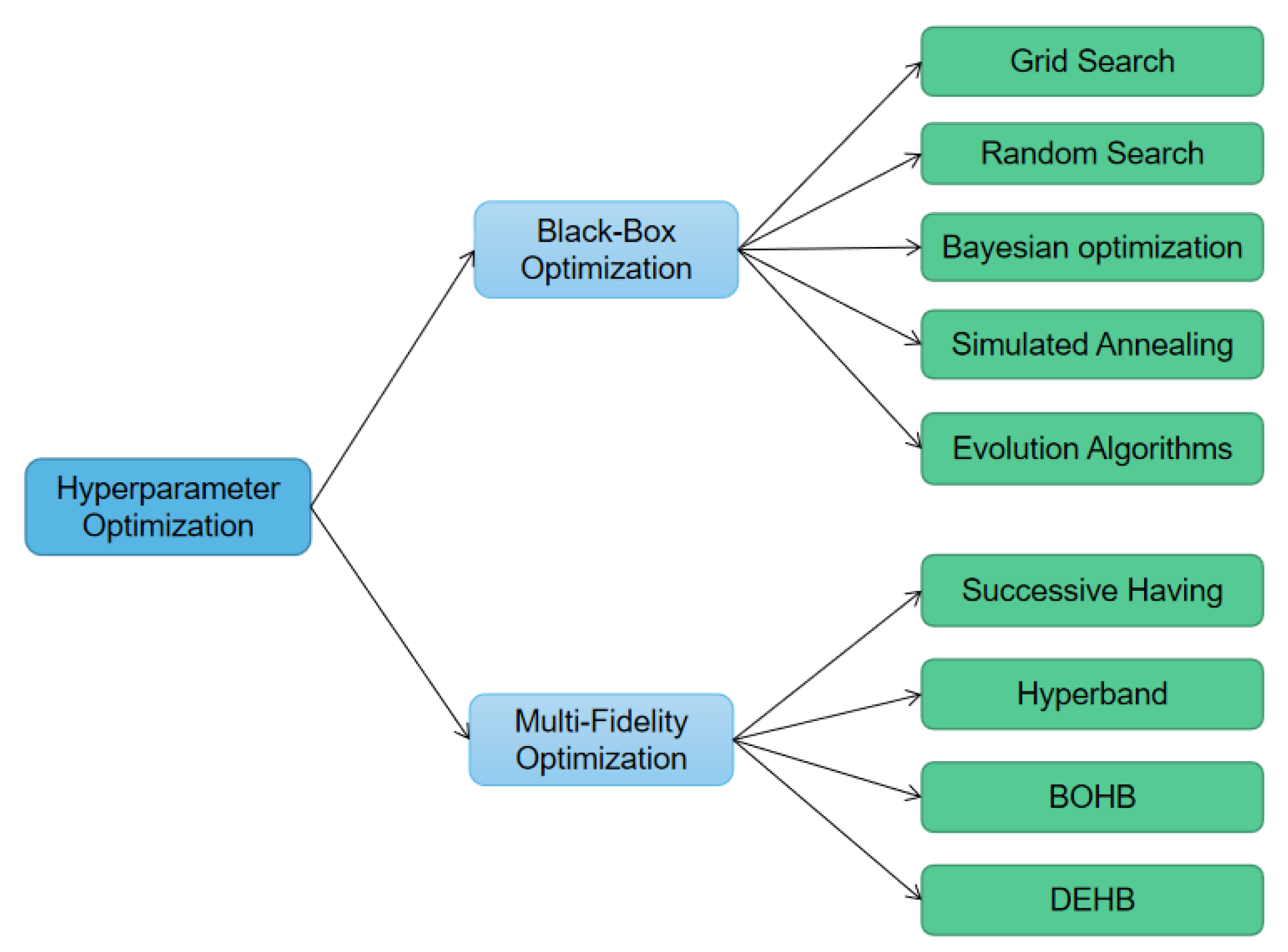
Recently, many methods are used to solve HPO problem, and several libraries have implemented these methods to allow researchers to conveniently work with them, such as Hyperopt (
https://github.com/hyperopt/hyperopt, accessed on 16 May 2022), HpBandSter (
https://github.com/automl/HpBandSter, accessed on 16 May 2022), SMAC (
https://github.com/automl/SMAC3, accessed on 16 May 2022), Sherpa [
4], etc. The methods shown in
Figure 1 are mainly classified into two categories:
Black-box optimization, e.g., grid search (GS) [
5], random search (RS) [
6], Bayesian optimization (BO) [
7,
8], simulated annealing (SA) [
9], and evolution algorithm (EA) [
10].
Multi-fidelity optimization, e.g., successive having (SH) [
11], hyperband [
1], Bayesian optimization hyperband (BOHB) [
12], and differential evolution hyperband (DEHB) [
13].
GS is very simple and can be executed in parallel; however, the number of trials increases exponentially with the number of hyperparameters. Compared to GS, RS is more efficient, but it does not guarantee finding the global optimum in the limit, whereas GS never will. A typical BO method is to adopt a Gaussian process (GP) as the surrogate model; however, GP is cubically related to the number of data sizes. Hyperband dynamically allocates resources to each set of configurations and uses SH to stop underperforming configurations. However, it randomly samples new configurations at each step. In order to learn the previously sampled configurations, BOHB combines BO with hyperband, and DEHB combines the evolutionary optimization method of differential evolution (DE [
14]) with hyperband. However, these hyperband-based methods tend to choose the hyperparameter settings that enable the model to converge quickly in the early stages of training. Wu et al. [
15] used the reinforcement learning (RL) method and treated HPO as a sequential decision process. In addition, to speed up training, they used MLP as a surrogate model to predict accuracy and dynamically train the agent with true accuracy and predicted accuracy. This approach reduces the number of trials and does not tend to choose a hyperparameter setting that converges quickly in the early stages of training. However, due to the sequential selection of hyperparameters, the reward is obtained only when the last hyperparameter is selected, and the rewards of previous steps are all 0, which causes the problem of sparse reward. Moreover, the MLP model needs to be carefully designed and requires a large sample size to prevent overfitting. Inspired by [
15], we adopt random forest (RF) as a surrogate model and use part of the real rewards and part of the predicted rewards from the surrogate model when updating the agent. Moreover, in order to solve the problem of sparse reward, we add the curiosity to provide intrinsic reward.
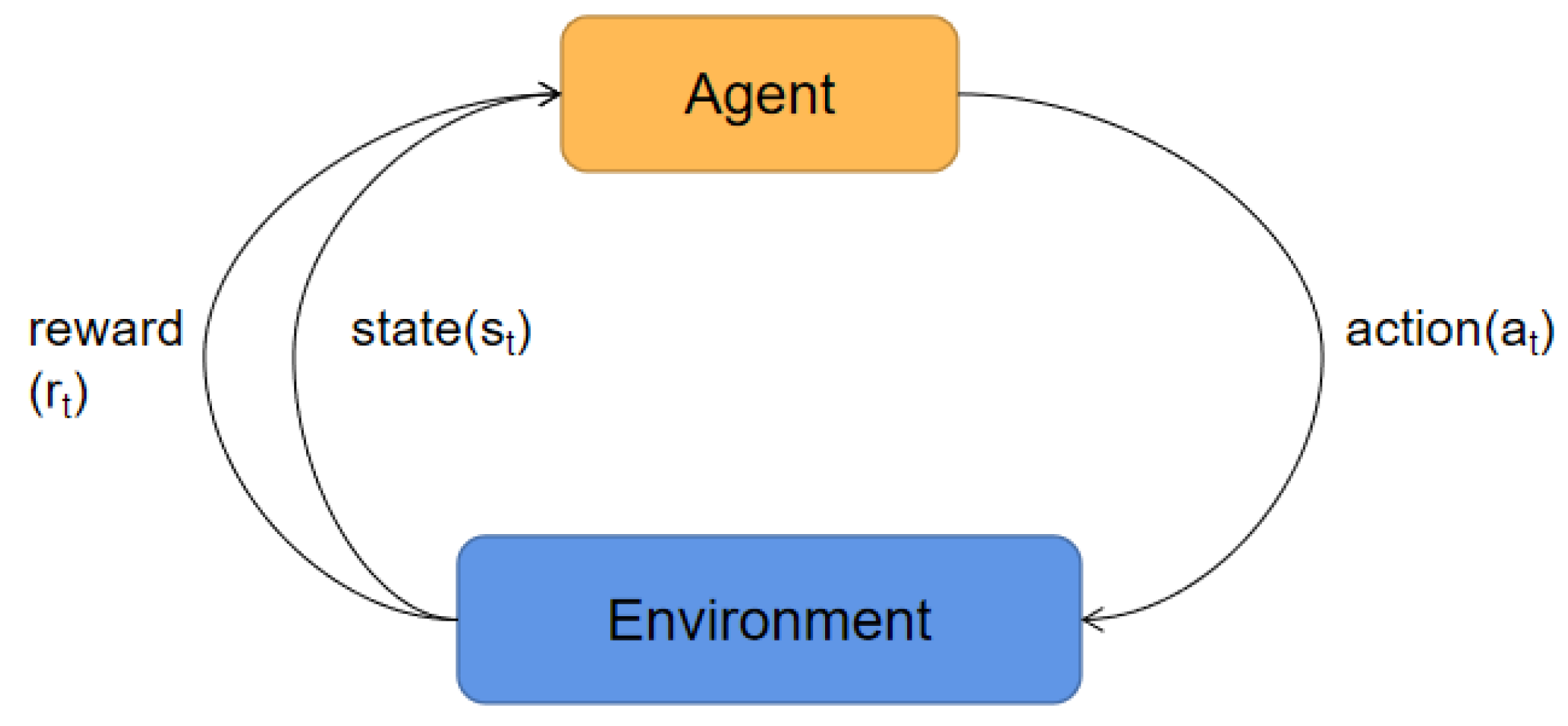
The basic process of RL-based HPO is shown in
Figure 2. The agent observes state
in the environment at time step
t and then executes action
according to the policy. Consequently, the environment returns a reward
to the agent, and the state is transferred from
to
. For the environment, state, action and reward of this paper, we introduce them in detail in
Section 3.
In this work, we use the proposed method to optimize the hyperparameters of extreme gradient boosting (XGBoost) [
16] on nine tabular datasets and convolutional neural network (CNN) on two image datasets. The main contributions of this paper are as follows:
We use the RF algorithm as a surrogate model which can predict rewards and then reduce the consumption of resources.
For the sparse reward problem of HPO, we use curiosity to provide an intrinsic reward that speeds up the convergence and finds better hyperparameter configuration faster.
We use the proposed method to tune the hyperparameters of the XGBoost on nine tabular datasets and CNN models on two image datasets. The experimental results show that our method has higher accuracy and faster convergence compared to other optimization algorithms.
The remainder of this paper is organized into four sections.
Section 2 introduces the hyperparameter optimization methods and the optimization objective of RL. In
Section 3, we describe our proposed method.
Section 4 displays and discusses the experiment results. Finally, we draw conclusions in
Section 5.
3. Methodology
In this section, we first transform the HPO task into an MDP task for RL. Second, we introduce the agent and training algorithm of RL that we use in this task. Finally, we describe our enhanced part.
3.1. MDP Formulation
MDP is a mathematical model for the sequential decision problem. It is often used to model the stochastic policies and rewards achievable by an agent in an environment that has Markovian properties. HPO can also be formulated as a MDP. Assume that we have n hyperparameters that need to be optimized, since the agent selects hyperparameters sequentially, each episode has n steps. According to our task, since the probability of transition is unknown, we define HPO as a MDP with a four-tuple , which is represented as follows:
S is the state space. As mentioned above, the agent selects hyperparameters sequentially, and the state at time t is the output of the agent at time , i.e, .
A is the action space. This task treats the hyperparameter selected at time t as an action . The hyperparameter is sampled from the distribution , which is the output of the agent.
R is the reward function. We need to obtain the metrics result as the reward signal on the validation set after selecting all hyperparameters. The reward is only available when the last hyperparameter is selected, and the rest of the time steps use the prediction error as intrinsic reward . The agent is updated once at the end of each episode.
is the discount factor.
3.2. Agent Architecture
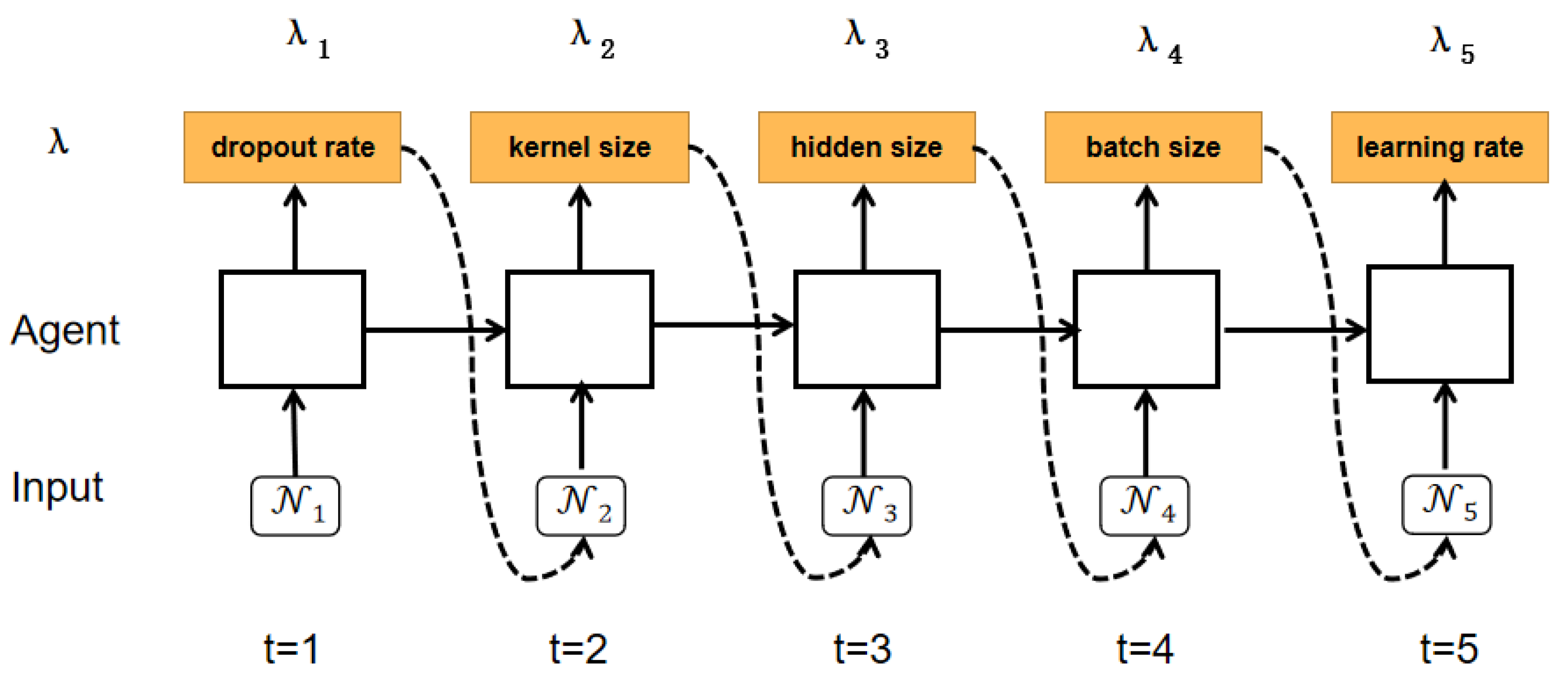
Figure 3 shows an example of the selection process for the five hyperparameters of a CNN with an agent. The initial state is randomly initialized, and then the action distribution output at each time step is used as the input for the next time step. As depicted in
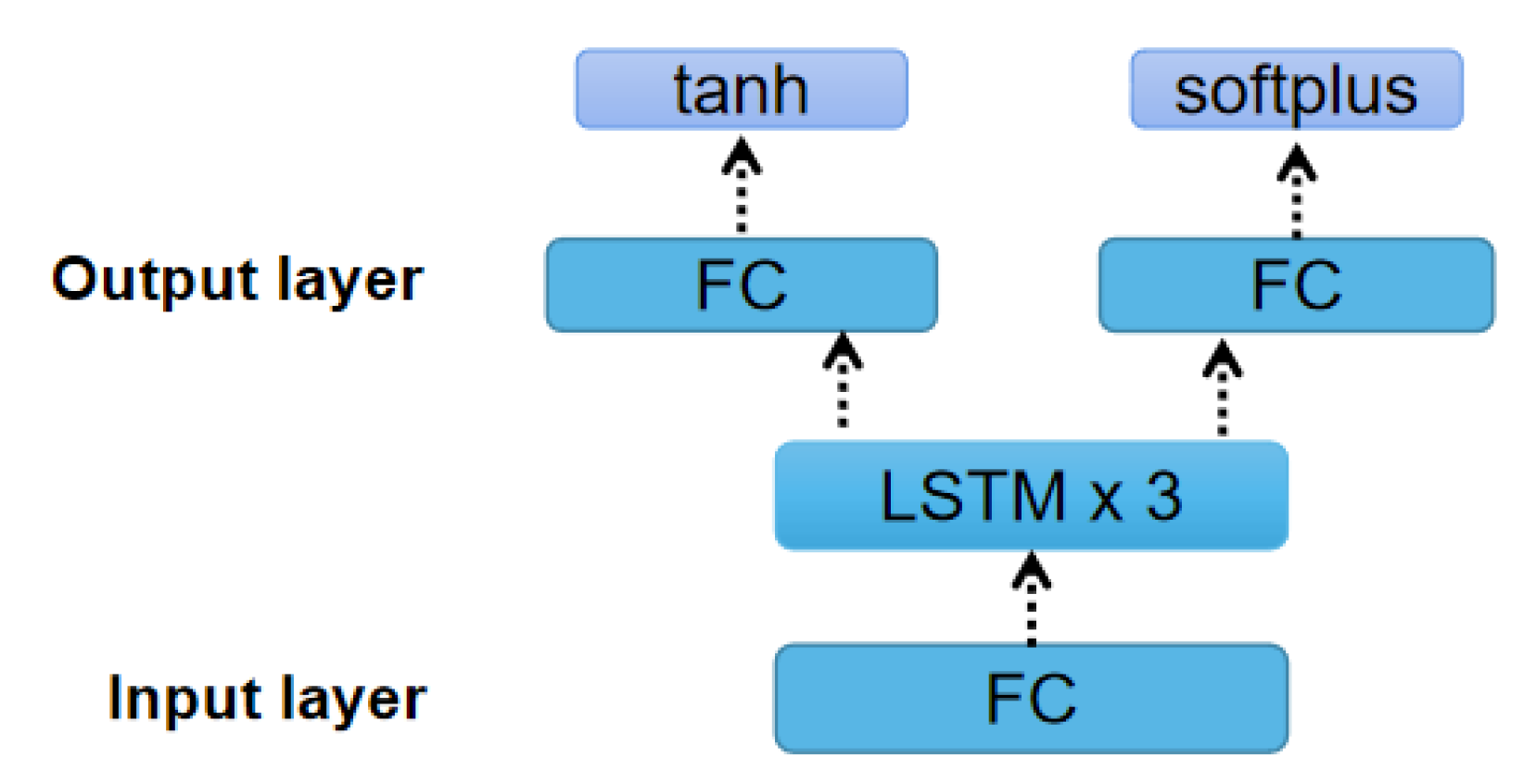
Figure 4, the agent consists of an input fully connected (FC) layer, three LSTM layers, and an output FC layer.
LSTM is a variant of the recurrent neural network (RNN) that solved the long-term dependency problem of vanilla RNN by using a gating system. There is a cell state
and three gates in the LSTM cell: input gate
, output gate
, and forget gate
. The input gate
determines how much new information is allowed to be added to the cell state; the forget gate
determines what information is discarded from the cell state
; and the output gate
determines what values are output. The following formulas denote the forward process of the LSTM cell:
where
,
,
,
are weight matrices and
,
,
,
are bias vectors need to be learned.
and ⊙ are the sigmoid function and Hadamard product, respectively. Furthermore,
is the hidden state and
is the input at step
t. This structure can also be extended into a multi-layer structure by leveraging the output of the last layer as the input to the next layer.
Following [
15], we represent the distribution of each hyperparameter as a Gaussian distribution. Then, both the input and output of our agent are vectors containing two values: the mean
and standard deviation
of the Gaussian distribution, respectively. The output at step
t will be sent to the agent to obtain the result at step
. The initial input we set to the standard normal distribution. The input FC layer is used to expand the input into the same dimensions as the LSTM layer, with the aim of learning more patterns. The LSTM layer is applied to learn the temporal dependency between the steps. The output layer consists of two FC layers. After receiving the output of the LSTM layer, one of the FC layers uses the tanh function to output a value as
, while the other uses the softplus function to output
.
3.3. Proximal Policy Optimization with Curiosity
Let
denote the parameters of the agent, and we use the PPO-clip algorithm to update the
in this work. As mentioned in
Section 2.2, the policy gradient algorithm is difficult to select an appropriate step size. Too much difference between older and newer policies during the training process is not helpful for learning. PPO is a novel policy gradient algorithm, which can solve the issue of difficulty in determining the step length in the policy gradient algorithm. PPO algorithm introduces a new objective function that can achieve small batch update in multiple training steps. PPO-clip updates the policy with the following objective function:
where
L is given by
where
is a hyperparameter of PPO and we set
= 0.2, according to the authors’ recommendations. Let
; the PPO approach is summarized by controlling the ratio
of the old and new policies to prevent the change of update magnitude from affecting the agent’s learning. Clip operation will limit the value of
to
. Furthermore,
A is the advantage function.
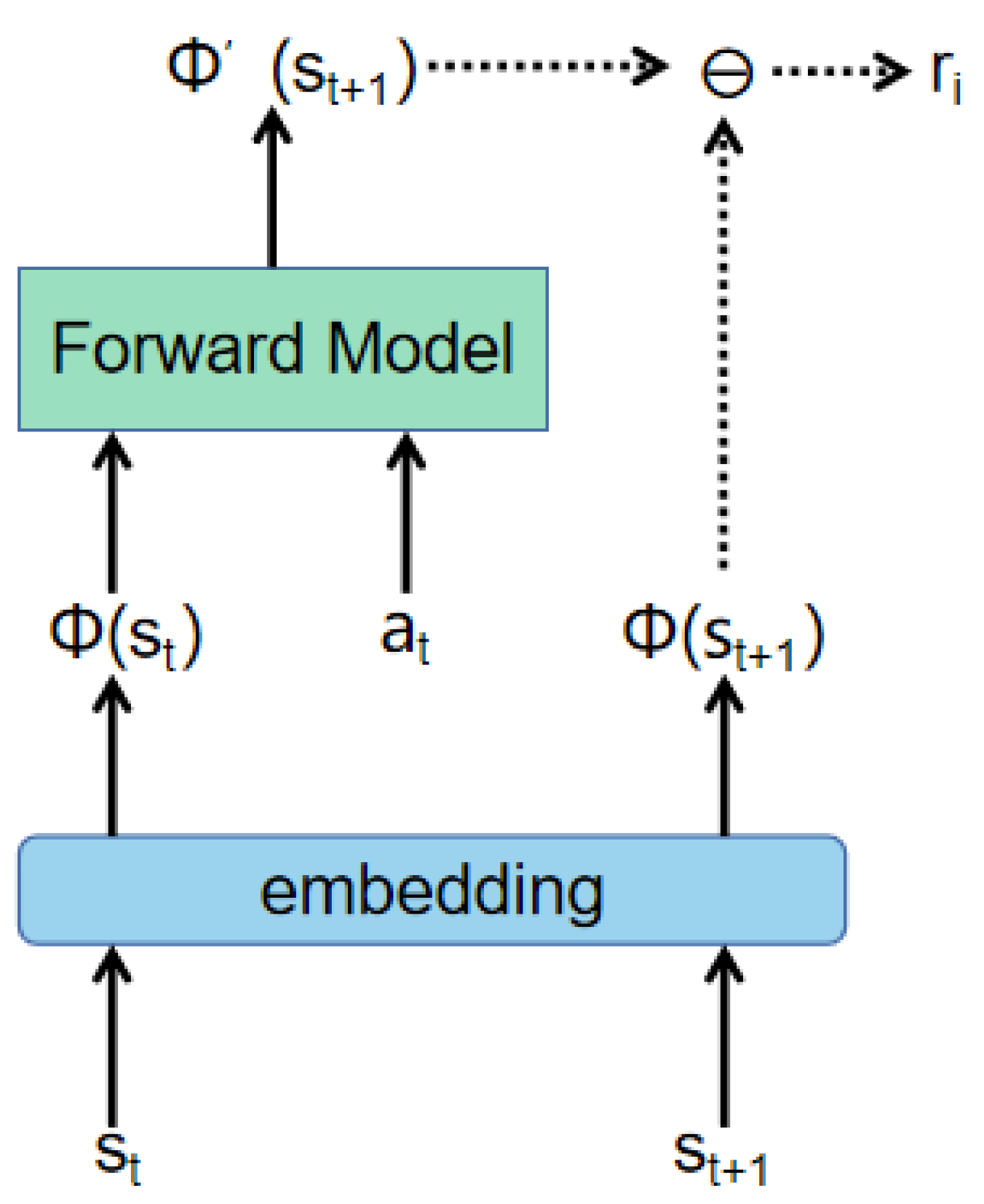
To solve the sparse reward problem, we use the curiosity-based prediction error method to obtain an intrinsic reward. We construct a model that receives the state
and action
of the current time step
t and predicts the state
of the next time step
. Then, the difference between the predicted state and the true next state is used as the intrinsic reward. The agent obtains a reward
after executing action
at each time step. The reward
is composed of
and
, where
is the intrinsic reward and
is the environment reward. Assuming that each episode has
T time steps, the
of time steps 1 to
is 0, while the
of time step
T is the validation set accuracy. The
is related to the state
, the action
of the current time step
t, and the state
of the next time step
.
Figure 5 shows how the intrinsic reward is calculated. Since each state is composed of
and
, we need to extend the state to a certain dimension. First, we convert
and
to
and
with an embedding layer. Then we concatenate the
and
, and then feed them to the forward network to predict the
. The mean squared error (MSE) between the predicted state
and the true next state
is used as the intrinsic reward
for the current time step
t.
3.4. Random Forest Surrogate Model
To speed up training the agent, we use the surrogate model to establish the mapping of hyperparameter settings to the corresponding rewards. We adopt the RF algorithm to predict rewards in this work. RF belongs to the bagging algorithm in ensemble learning (EL) and has many advantages, such as determining the importance of features, determining the interaction between different features, being relatively simple to implement, etc.
Although RF can speed up the search for hyperparameters, using the surrogate model for a long time can make the agent unstable since the predicted reward is not the true accuracy after all and will produce a certain degree of bias. Therefore, we follow the works of [
15] to control the adoption of the surrogate model dynamically. In the initial stage of searching, we use real rewards to update the agent. Then, we use all the obtained hyperparameter combinations and corresponding rewards as samples to train the RF algorithm and save the policy at this episode, defined as
. The KL distance of the before-and-after policy is used to control the utilization of the surrogate model dynamically. When the KL distance is less than the threshold, the surrogate model is used to predict the evaluation results of validation data set to avoid training the model. When the distance exceeds the threshold, indicating that the policy changes too much, the agent is updated by real rewards. The threshold is set to
in this work. In this way, we can utilize surrogate models to make the search process more efficient.
3.5. Overall Framework
Algorithm 1 describes the entire process. For a given task, the agent selects hyperparameters sequentially in each episode in order, then we use the selected hyperparameters to obtain the evaluation results of the
as a reward, and finally use the PPO algorithm to update the parameters
of the agent.
| Algorithm 1 RFEPPO |
Input:n: Number of hyperparameters; : Randomly generated distributions; : Data set = ⌀;
Output: top-1 hyperparameter configuration;
- 1:
while not done do - 2:
for to do - 3:
= [] - 4:
agent selects and obtains on - 5:
= [] - 6:
use to update agent according to Equation ( 8) - 7:
add to - 8:
end for - 9:
Use to train random forest - 10:
Save the current policy - 11:
for to do - 12:
= [] - 13:
agent selects - 14:
if then - 15:
use random forest to predict - 16:
= [] - 17:
use to update agent according to Equation ( 8) - 18:
add to - 19:
else - 20:
obtain real on - 21:
= [] - 22:
use to update agent according to Equation ( 8) - 23:
add to - 24:
end if - 25:
end for - 26:
end while
|
At the beginning of the search process, we first collect some samples of the real hyperparameter combinations and their corresponding validation accuracy . After each episode, the combination of hyperparameters and corresponding accuracy are collected for training the surrogate model. The agent is updated at the end of each episode using the trajectory , where in the trajectory is . After the initial phase, the surrogate model is trained with the collected samples, and the policy is recorded at this time. In the subsequent search process, the policy of each episode is compared with the , and the RL agent is updated by the intrinsic reward and real accuracy if it is greater than ; otherwise, the agent is learned by the intrinsic reward and the predicted accuracy is made by the surrogate model. Episodes is the total number of times to search for hyperparameters.
The time complexity of searching for hyperparameters is , where E is the number of episodes in the whole process, and t is the time required for each episode. It is worth noting that , t is divided into and , where is the number of episodes with real rewards, and is the time required for various operations in each episode at this time; is the number of episodes with rewards predicted by the surrogate model; and is the time required for various operations in each episode at this time. The time required to train the RF is , where m is the number of samples, n is the number of hyperparameters, and k is the number of decision trees. Therefore, the time complexity of the whole process is .
4. Experiments
In this section, to evaluate our proposed RFEPPO method, we use it to optimize the hyperparameters of XGBoost and CNN. Among them, XGBoost is a common algorithm for handling tabular data, while CNN is a typical model for processing image data. We first introduce the experimental setup, present the datasets, the conventional approaches, and the evaluation method. Then we conduct comparison experiments on tabular and image datasets to compare our method with conventional methods. Finally, to verify the effect of the components in our method on the HPO results, we perform ablation experiments.
For fairness, all search algorithms ran on Intel Core i9-11900K CPU. The XGBoost algorithm also ran on the CPU. To save time, we used a single NVIDIA GeForce RTX 3090 GPU when training the CNN model.
4.1. Experimental Setup
Datasets: We validated our method on 11 datasets, 9 of which are tabular data to verify the performance of RFEPPO tuning the hyperparameters of XGBoost, and the remaining two image datasets to verify the performance tuning the hyperparameters of CNN.
Table 1 shows the details of the datasets.
The tabular datasets are from the UCI Machine Learning Repository [
31] and openML [
32]. These datasets come from different fields, including computer, medicine, education, life, and physics. The MNIST dataset [
33] and Fashion MNIST dataset [
34] are classic image classification datasets in the field of ML. Both of them consist of 60,000 training samples and 10,000 test samples, each of which is a
pixel grayscale image. Fashion MNIST is identical to the original MNIST in training set/test set division, size and format.
For the tabular datasets, we divide each dataset into training, validation and test set by a ratio of ; for the image datasets, we follow the original split ratio and then use the last 5000 samples of the training set as the validation set.
Comparison Methods: In this paper, we compared our approach with the following optimization algorithms: RS [
6], TPE [
5], hyperband [
1], BOHB [
12], and the default configuration of XGBoost (baseline). In this paper, we implemented these algorithms with the Hyperopt and HpBandSter Libraries. In addition, we also compared our method with the MBRL-SDP model proposed in the [
15]. RS randomly selects samples within the search range. By random sampling, the global optimum or its approximation can also be searched with high probability if the set of samples is sufficiently large.TPE is a sequential model-based optimization (SMBO) method that tries to build a probabilistic model of the function at each step and selects the most promising parameters for the next step. Hyperband attempts to explore as many configurations as possible with limited resources and returns the most probable configuration as a final result. The weakness of hyperband is generating new configurations randomly without leveraging finished trials. BOHB is a follow-up work to hyperband, which generates a certain percentage of new configurations by constructing multiple TPE models to take advantage of the finished trials.
Evaluation metrics: The performance of HPO methods are evaluated using the following metrics:
Details: As presented in
Section 3.2, the agent consists of an input FC layer, three LSTM layers with hidden state size of 128, and an output FC layer. The learning rate of the agent is set to
. The rest of the settings are configured using the default configuration of the PPO algorithm. Before using the surrogate model RF, we adopted grid search to find the best hyperparameters for RF. The accuracy of the validation set is collected for the first 100 episodes, and then the combination of hyperparameters and accuracy from these 100 episodes are used as samples to train the RF. The KL distance threshold between policies is set to
. For the curiosity model, the embedding layer captures state information and extends the state to 32 dimensions. The input of the forward network is the action and the state after embedding, and the middle layer is a fully connected layer with hidden_size of 64. Since the prediction error is calculated with the next true state, the output layer size of the forward network is also 32.
In this experiment, we ran each method five times and the budget for each run was training 200 episodes. For the five best configurations output from five trials, the average of the corresponding test set accuracy is compared.
4.2. Performance Evaluation
4.2.1. HPO for XGBoost
XGBoost is derived from the gradient boosting framework. It is more efficient because of the algorithm’s parallel computation, approximate tree building, efficient handling of sparse data, and memory usage optimization, which make it at least 10 times faster than the existing gradient boosting implementations. XGBoost can handle many tasks, such as regression, classification, and sorting.
Search Space: We consider the 10 hyperparameters of XGBoost as shown in
Table 2. We ran experiments with XGBoost on nine classification datasets, and
Table 3 shows the performance.
Results: We ran each method five times, and the average search time and accuracy on the test set are tabulated in
Table 3. It can be seen that RFEPPO outperforms other optimization methods and baseline in terms of accuracy. The accuracy of our method is substantially higher than the baseline, which indicates the importance of HPO. For the search time, hyperband and BOHB spend the least time on all datasets due to the fact that the bandit-based approach would use a very small budget in the initial stage and would quickly discard the poorly performing hyperparameter configurations. However, for the accuracy, both BOHB and hyperband are lower than our method. We believe that BOHB and hyperband may throw away the hyperparameter configurations that really perform well in the initial stage. Compared to RS and TPE, our method can reduce the time by about 27% to 40% on winequality_white, optdigits and Turkiye_Student_Evalution datasets, and reduce the time by about 4% on the Cardiotocography dataset. For other datasets, the search time of our method is a little slower. However, the accuracy on test set of our method is better than all other methods. This shows that our method has a clear advantage for datasets with a large sample size and a large number of features. Although the search time of our method is slower for small datasets, the accuracy is higher than other methods. In addition, compared to MBRL-SDP, our method has higher accuracy in the test set. This demonstrates that intrinsic reward can encourage the exploration of novel states and thus quickly find well-performing hyperparameter configurations.
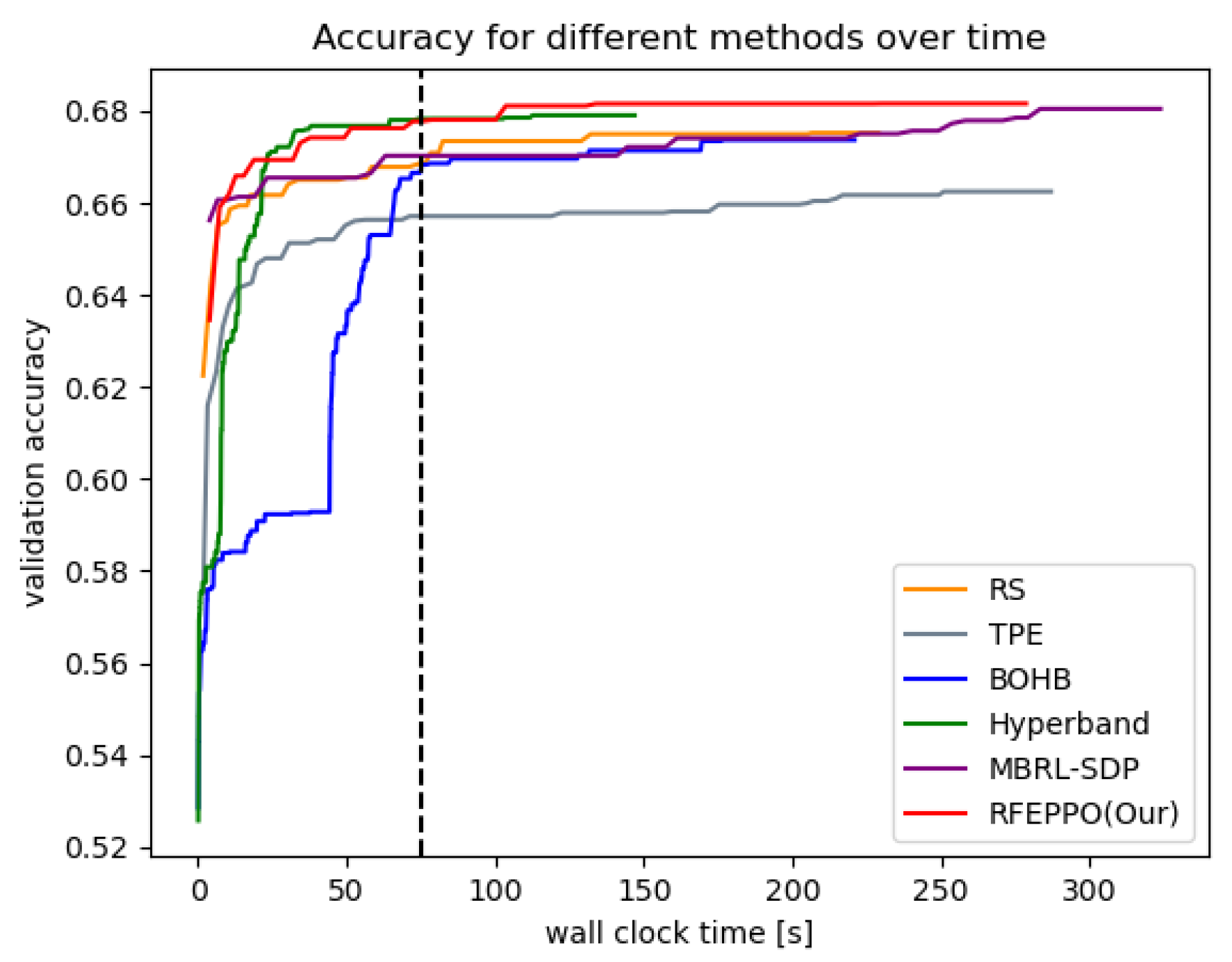
To verify the effectiveness of RFEPPO, we visualize the performance curve as the validation accuracy of all methods over a period of wall clock time.
Figure 6 compares RFEPPO with all methods on the winequality_white dataset. From the figure, we can see that our method can find good hyperparameter configurations faster and performs better overall compared to MBRL-SDP and RS. As can be seen by the left part of the black line, our method can achieve similar performance to hyperband, and is initially slightly faster than it. Although TPE also converges quickly in the initial stage, the final performance is worse than RFEPPO. This experiment demonstrates that our method not only shortens the search time on large datasets, but also improves the accuracy and reliability of the tasks.
4.2.2. HPO for CNN
In this experiment, we try to optimize the hyperparameters of the LeNet [
35] automatically. The LeNet-5 designed for handwritten font recognition is one of the most popular CNN models. LeNet-5 saves a lot of computational cost by cleverly designing the network to extract features using convolution operation, parameter sharing, and pooling, then using an FC layer for classification recognition. Moreover, many recent novel CNN models are inspired by this network structure.
Search Space: We consider the five hyperparameters of LeNet as shown in
Table 4. Experiments were carried with LeNet on MNIST and Fashion MNIST datasets, which are commonly used to test the performance of ML and DL models.
Results: The results for average accuracy and search time of our method and other conventional methods are tabulated in
Table 5. As can be seen in this table, our method outperforms other methods in terms of accuracy and time. The search time is greatly reduced since utilizing the surrogate model. Among RS, TPE, hyperband and BOHB, for MNIST and Fashion MNIST datasets, BOHB takes the shortest time, and TPE has the highest accuracy. Compared to BOHB, our method can reduce the time by about 15% to 20%, demonstrating that the surrogate model can reduce the search time. For MBRL-SDP, although its time is similar to our method on these two datasets, it does not perform well on the test set. This also illustrates the effectiveness of intrinsic reward. This experiment demonstrates that our method not only achieves high accuracy on large datasets, but also requires much less time.
Figure 7 shows the best validation set accuracy over time for all methods on the MNIST dataset. Each method was run five times and the average of the five accuracy was calculated. By observing the black line, we can see that our method can find a good hyperparameter configuration much faster compared to MBRL-SDP. Since hyperband and BOHB use a small budget (e.g., epoch) in the initial stage, these two methods will run multiple sets of hyperparameter configurations initially, and it is possible to find hyperparameter configurations that perform well. Therefore the speed of finding good configurations is faster than our method. Although TPE and our method will find good configurations simultaneously, our method converges faster in the initial stage. Moreover, our method has significant advantages over RS and MBRL-SDP. This experiment demonstrates that RFEPPO not only achieves high accuracy on large datasets, but also requires much less time.
4.3. Ablation Experiments
In this section, first we compare the performance with and without the curiosity-driven method, then compare the performance with different RL algorithms, and next we compare the performance with and without the surrogate model. Finally, we replace RF with other conventional regression models and compare the performance of these different algorithms.
4.3.1. Performance Comparison with and without Curiosity-Driven Method
To demonstrate that the addition of intrinsic reward has a better effect and can improve accuracy in the test set, we removed the curiosity mechanism and only used the validation set accuracy as reward. We conducted comparison experiments on the balance_scale data set.
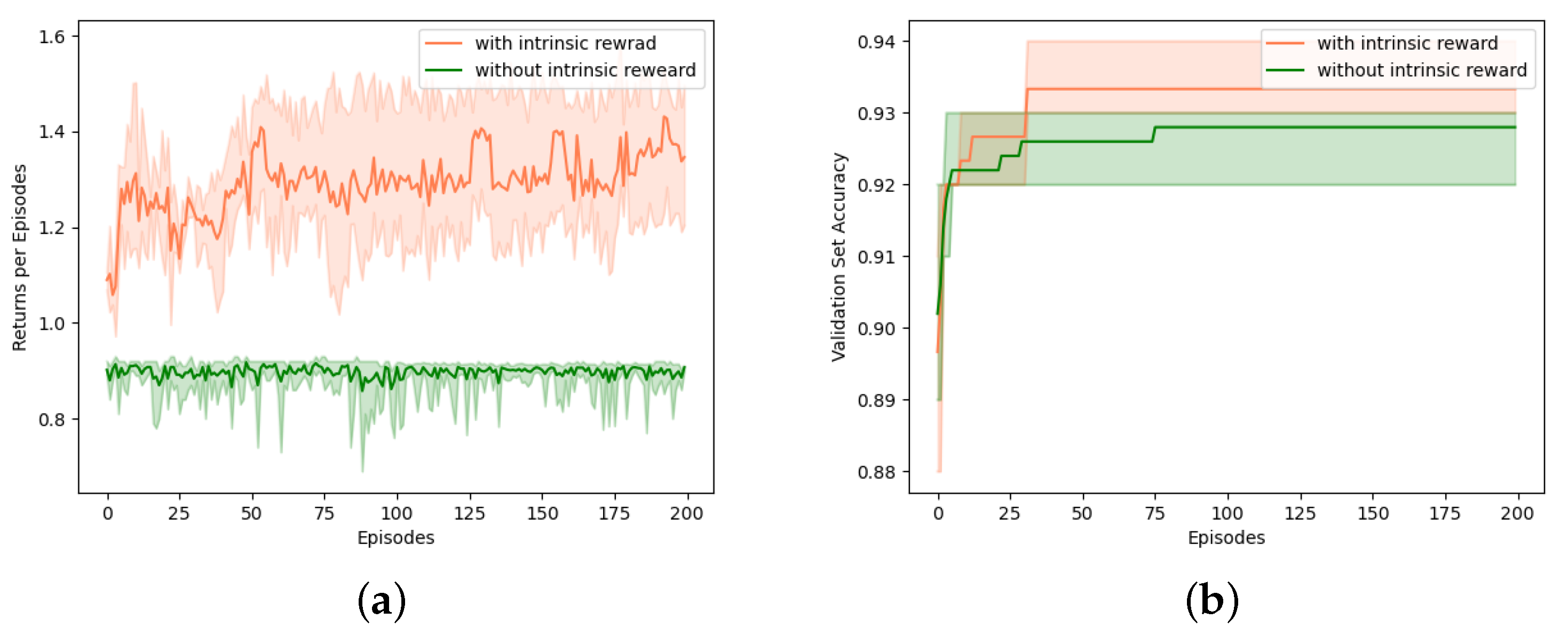
Figure 8 shows the effect of intrinsic reward on the overall search process. In
Figure 8a, the green line refers to the reward return for each episode using only the accuracy of the validation set as the reward. We can find that the agent’s reward has no obvious upward trend with the growth of episodes. We believe that the reason for this phenomenon is that the agent is updated slowly due to too many sparse rewards and little sample utilization. Moreover, better validation set accuracy is obtained at the initial stage of the search process, which we believe is caused by the suitability of the initial state of this dataset. The coral line refers to the reward return for each episode when using the intrinsic reward. We can find an overall upward trend in the reward return for the whole search process. This is because the curiosity-driven method encourages the agent to explore more unfamiliar states, and the more novel the state, the higher the intrinsic reward. The use of intrinsic reward improves the utilization of the sample, which allows the agent to learn more about the environment.
Figure 8b shows the accuracy of the validation set corresponding to the best hyperparameter configuration searched in the current episode. We can see that compared to the non-intrinsic reward approach, the use of the intrinsic reward approach can find high-performance hyperparameter configuration quickly and with higher accuracy. Therefore, we believe that intrinsic reward can solve the problem of sparse reward in HPO. The curiosity-driven method encourages the agent to keep exploring unfamiliar states, and finds better hyperparameter configurations faster.
4.3.2. Performance Comparison with Different RL Algorithms
To verify the effectiveness of PPO used in this experiment, we replaced PPO with other RL algorithms. In this experiment, we did not use the intrinsic reward and surrogate model, and performed comparisons on nine tabular datasets by replacing PPO with advantage actor–critic (A2C), deep deterministic policy gradient (DDPG) [
36], soft actor–critic (SAC) [
37], and twin delayed DDPG (TD3) [
38]. For A2C, DDPG and SAC, we set the hidden size to a range of
. For TD3, we set the exploration noise scale to a range of
and the delay update frequency to a range of
. The hyperparameters of these RL algorithms were determined by the grid search within their respective ranges, ensuring the final model performance.
Table 6 shows the accuracy and search time of the five sets of experiments. We ran each method five times, and trained 200 episodes each time.
As can be seen from
Table 6, the highest accuracy is achieved on most of the datasets using the PPO algorithm, while other algorithms can only achieve the highest accuracy on one data set. DDPG has the lowest accuracy on all datasets. However, in terms of search time, PPO is slower than other algorithms. A2C has a relatively fast search time on small datasets, DDPG and TD3 have a relatively fast search time on large datasets, but none of the corresponding accuracies is the highest. Therefore, for the task of HPO, we believe that PPO is more effective than other RL algorithms.
4.3.3. Performance Comparison with Surrogate Model and without Surrogate Model
To verify the effectiveness of the surrogate model, we removed the RF surrogate model in RFEPPO and compared it with our method. In this experiment, we performed comparisons on nine tabular datasets.
Table 7 shows the accuracy and search time of the two sets of experiments. Each method was run five times and trained 200 episodes each time.
As can be seen from
Table 7, the time spent is reduced after adding the surrogate model. This indicates that the predicted accuracy of the surrogate model is used to update the agent during the search, making part of the process without actually training XGBoost, which ultimately reduced the time. Additionally, seven of the nine datasets also show an increase in accuracy after adding the surrogate model. Thus, this demonstrates that the inclusion of the surrogate model speeds up the search without affecting the accuracy of the test set.
4.3.4. Performance Comparison with Different Surrogate Models
To verify the effectiveness of RF in our approach, we replaced RF in RFEPPO with other common ML methods and compared them. Since the surrogate model in our method can be replaced with other regression models arbitrarily, we compared our method with LREPPO, KNNEPPO, SVRPPO, REPPO, BAGEPPO, XGBEPPO, ABEPPO, and GBEPPO, which replace RF in RFEPPO with linear regression, KNN, SVR, Ridge, Bagging, XGBoost, AdaBoost, and gradient boost, respectively. For KNN, we set the number of neighbors and the power parameter to a range of
and
respectively. For SVR, we used the radial basis function (RBF) kernel. For ridge, we set regularization strength among
. For bagging, XGBoost, AdaBoost, gradient boost and RF, we set the number of decision trees among
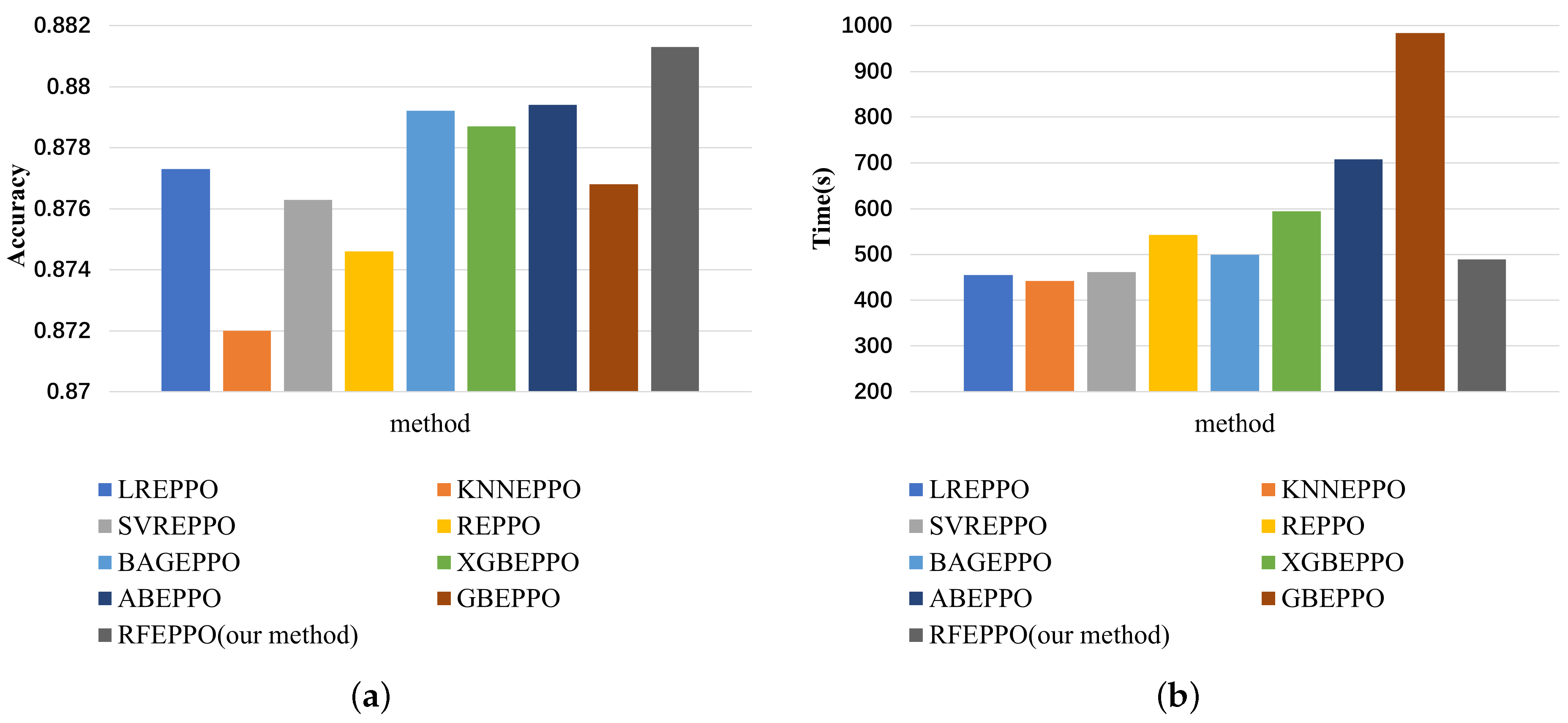
. The hyperparameters of these methods were determined by the grid search within their respective ranges, ensuring the final model performance. In this experiment, we chose the Turkiye Student Evaluation dataset for validation. As in previous experiments, we ran each method five times and trained 200 episodes each time. The accuracy and time for each method are shown in
Figure 9. From this figure, it can be seen that RF has better final accuracy than other models. Although LREPPO, KNNEPPO, and SVRPPO take less time than RFEPPO, the cost of using them is reduced accuracy. Other methods are worse than RF in terms of both time and accuracy. Therefore, we believe that RF is the most suitable surrogate model in our method.
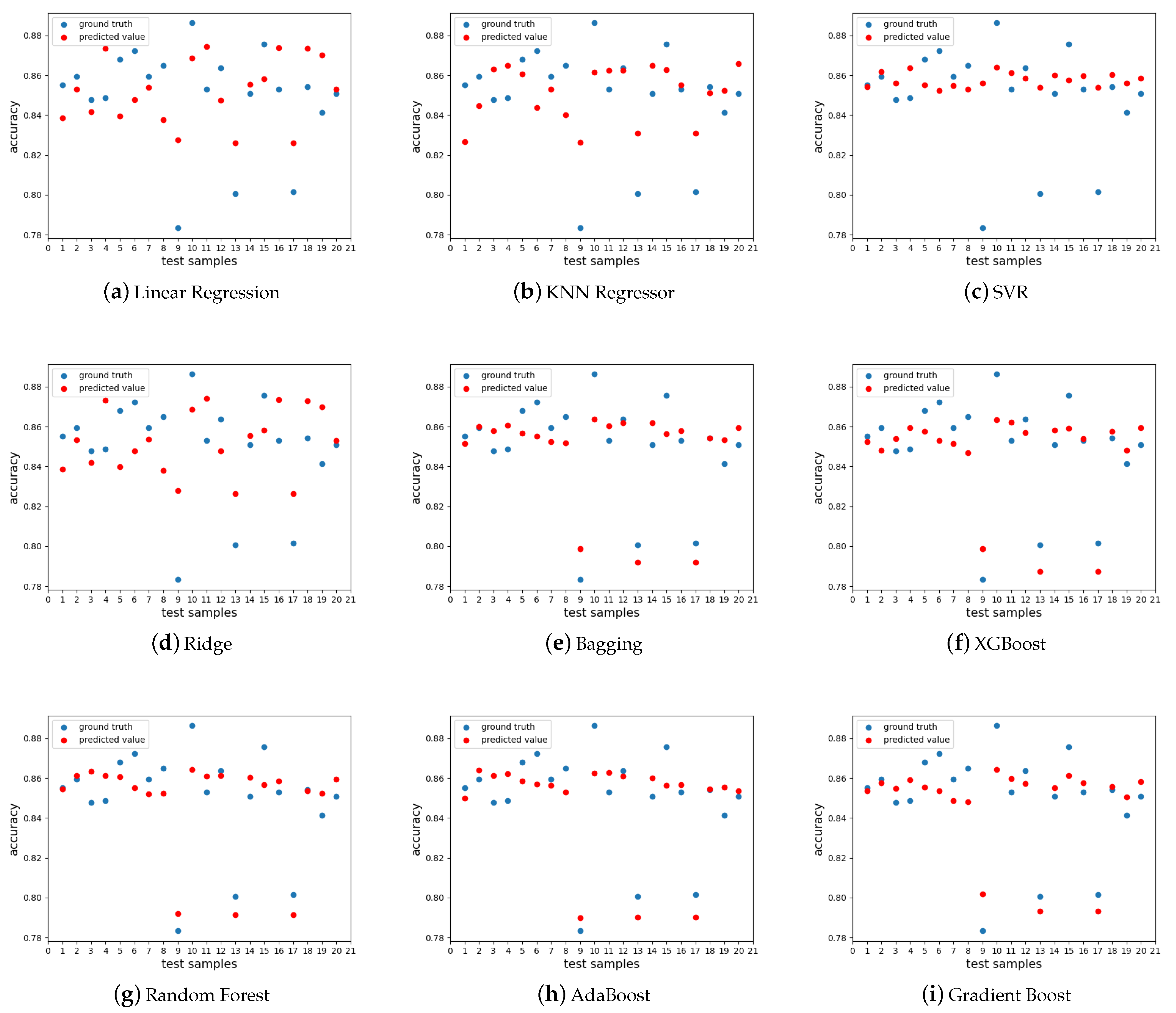
In order to further analyze the RF surrogate model, we need to know its predictive performance, thus we collected 100 samples from the first 100 episodes. Each sample was a combination of hyperparameters and the corresponding accuracy of validation set. To compare the performance of these surrogate models, the 100 samples were divided into training and testing samples in the ratio of 8:2. The RMSE results of the test samples are tabulated in
Table 8, and the ground truth of the test samples and the predicted results of each model are presented in the
Figure 10. It is obvious from
Table 8 that RF performs the best. In
Figure 10, the blue points represent the true values and the red points represent the predicted results. Moreover, we can see that the ensemble methods, bagging, RF, XGBoost, Adaboost, and gradient boost, perform better than the remaining methods.
4.4. Discussion
This paper focuses on the HPO problem and proposes an RL-based approach. First, we treated the HPO problem as a sequential decision process and model it as MDP. Then, we designed an agent to select the hyperparameters sequentially and be updated by PPO. In order to mitigate sparse rewards problem, the curiosity-driven approach was used to provide intrinsic rewards. Additionally, we adopted RF as a surrogate model to reduce the search time. We validated our method on multi-classification, binary classification and image datasets. The accuracy of our method is better than other methods on all datasets. Our proposed method does not take less time than bandit-based methods when processing tabular data, but we have a significant improvement in search efficiency when processing image data. We believe that our approach is more efficient than bandit-based methods in the case of relatively large dataset sizes and long model training times. The reason is that bandit-based methods have to train the model with all candidate hyperparameter combinations for at least one epoch in the initial stage, while our method avoids the process of training the model many times by using the surrogate model.
In our future work, we will focus on two research directions. First, we will study how to optimize the hyperparameters of models that accomplish more complex tasks, such as object detection and sentiment analysis, which have been widely studied recently. Second, we will study how to accomplish model generation and HPO simultaneously, and eventually develop a complete automatic ML framework.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}