Abstract
In multi-agent domains, dealing with non-stationary opponents that change behaviors (policies) consistently over time is still a challenging problem, where an agent usually requires the ability to detect the opponent’s policy accurately and adopt the optimal response policy accordingly. Previous works commonly assume that the opponent’s observations and actions during online interactions are known, which can significantly limit their applications, especially in partially observable environments. This paper focuses on efficient policy detecting and reusing techniques against non-stationary opponents without their local information. We propose an algorithm called Bayesian policy reuse with LocAl oBservations (Bayes-Lab) by incorporating variational autoencoders (VAE) into the Bayesian policy reuse (BPR) framework. Following the centralized training with decentralized execution (CTDE) paradigm, we train VAE as an opponent model during the offline phase to extract the latent relationship between the agent’s local observations and the opponent’s local observations. During online execution, the trained opponent models are used to reconstruct the opponent’s local observations, which can be combined with episodic rewards to update the belief about the opponent’s policy. Finally, the agent reuses the best response policy based on the updated belief to improve online performance. We demonstrate that Bayes-Lab outperforms existing state-of-the-art methods in terms of detection accuracy, accumulative rewards, and episodic rewards in a predator–prey scenario. In this experimental environment, Bayes-Lab can achieve about 80% detection accuracy and the highest accumulative rewards, and its performance is less affected by the opponent policy switching interval. When the switching interval is less than 10, its detection accuracy is at least 10% higher than other algorithms.
1. Introduction
Recently, deep neural networks have provided excellent performance in image recognition [1], pattern recognition [2], and security [3,4,5]. They are usually combined with reinforcement learning (RL) and have achieved great success [6,7,8,9]. Many advanced deep RL algorithms have been proposed and used to solve complex decision-making problems such as game playing [9,10], robotics [11,12,13,14], and autonomous driving [15,16,17,18]. In multi-agent systems [19,20], if an opponent’s policy is fixed, the agent can treat it as part of the stationary environment and learn the response policy using single-agent RL algorithms [21,22,23]. However, in many cases, the opponent’s behaviors may change over time and affect the objectives of the others, which implies a non-stationary environment [24]. As a result, it is essential for the agent to adapt its policy by taking into account the non-stationary opponent [25,26,27,28], which is regarded as the second sophisticated challenge categorized in [26]. In this paper, we focus on dealing with the non-stationary opponents in a partially observable environment, where we control an agent with a limited horizon and the other agents (opponents) select their fixed policies from a policy library. In our setting, the controlled agent is required to reason about the opponent’s policy and adjust its policy to achieve optimal rewards. One effective way to address the non-stationarity is opponent modeling [22,27,29,30]. According to [30], the opponent modeling methods can be divided into implicit modeling and explicit modeling.
A natural idea for implicit modeling is to use deep neural networks to encode the opponent’s policy features [27,29,31,32]. Specifically, such models usually consist of two networks [33]: one is to extract the latent policy features from supervision signals such as the opponent’s actions [31], goals [34], and beliefs [27], and the other learns the response policy by taking into account these policy features. The deep reinforcement opponent network (DRON) [29] uses an additional network to extract the opponent’s policy features, and it incorporates a mixed-of-expert structure with a deep Q-network (DQN) [35] to handle different opponent policies. However, it cannot guarantee optimality against each particular opponent’s policy and assumes that the agent can observe the opponent’s actions. Deep policy inference Q-network (DPIQN) [36] learns policy features directly from the opponent’s raw observations. These features are learned by auxiliary tasks that provide additional supervision signals, such as the opponent’s actions. Self-other modeling (SOM) [34] proposes using the agent’s policy to predict the opponent’s goal. Despite its simplicity, it takes longer to train, as an additional optimization step is required to consider the opponent’s actions. Most studies reviewed here assume that the opponent’s observations and actions can be accessed during online interactions. However, this assumption is unlikely to hold in practical scenarios. To address this problem, local information agent modeling (LIAM) [37] first proposed the use of a variational autoencoders (VAE) [38] model to learn the opponent’s policy features in RL. This method can extract the hidden opponent features during training conditioned only on the agent’s local observations. In other words, it does not require the opponent’s local information during execution. A mutual limitation of the above studies is that they cannot reuse the existing offline response policies to accelerate online decisions for lacking explicit opponent categorization. When the opponent switches between several known policies, the agent has to learn new response policies from scratch, which is inefficient [30].
The above problem is motivated by many application domains where the agent requires fast online decision making [39]. For example, a service robot has to interact with people with different policies (behaviors). For each of these policies, the robot needs to use an appropriate response policy to achieve optimal performance on the task [40]. It is very inefficient if the robot has to learn new coping strategies from scratch during online interactions. More commonly, the robot maintains an offline response policy library and reuses the response policies directly based on human online behaviors. Compared with the implicit modeling methods that can only learn the response policy from scratch during online interactions, our algorithm can reuse the offline learned policy to accelerate online decisions using explicit modeling methods.
One feasible direction for implementing explicit modeling is to exploit offline knowledge to improve online performance [39]. Type-based reasoning methods [30,41] assume that the opponent switches between several known types and the agent maintains a prior belief about the probability distribution of the opponent’s types. During online interactions, the belief is updated based on any task-related signals, and then the agent can reuse the existing response policy based on the updated belief. Bayesian policy reuse (BPR) [39] is an explicit opponent modeling framework based on type-based reasoning. It was initially applied to single-agent domains, where the agent can detect task types and reuse the learned best response policies when faced with multiple tasks. Regarding different opponent’s policies as different task types in BPR, BPR+ [40] first extended BPR to multi-agent scenarios to detect dynamic changes in the opponent’s policies. In addition, Bayes-Pepper [25] combines BPR with Pepper [42] to improve detection accuracy by using the opponent’s state–action pairs as an additional signal during belief updating. However, as table-based algorithms, BPR+ and Bayes-Pepper are spatially inefficient and even infeasible when dealing with complex scenarios. To overcome this problem, Deep BPR+ [43] proposes using a deep neural network as a value function approximator and an opponent model, which can be used to rectify the belief model in BPR+ to improve the detection accuracy. However, Bayes-Pepper and Deep BPR+ may suffer from incomplete opponent information. The above algorithms [22,23,40,43] assume that the opponent switches randomly among a class of stationary policies, but the opponent may be equally capable of reasoning, and thus adopts a more complex policy-switching approach. To address this issue, Bayesian theory of mind on policy (Bayes-ToMop) [44] assumes that the opponent also uses BPR. However, Bayes-ToMop needs to detect whether the opponent is using BPR through additional interactions when the opponent switches strategies randomly, which can be extremely time-consuming. Most BPR-based algorithms reviewed here assume that the agent can observe the opponent’s local information during online interactions, including its observations and actions. In practice, many tasks are characterized by partial observability, in which the agent can only obtain incomplete and uncertain observations about the opponent, making accurate policy detection more challenging.
In this work, we consider how to act optimally against non-stationary opponents that switch among several stationary strategies under partial observability. According to [45], a strength of VAE is that it can reason about the opponent’s policies without the opponent’s local observations. However, this method cannot reuse the learned response policies during online interactions for lacking explicit classification of the opponent’s policies. On the contrary, the BPR-based methods explicitly classify the opponent’s policies, and the optimal learned response policies can be reused during online interactions. However, most BPR-based methods require the opponent’s local observations to accurately identify the opponent’s policies. We consider that it is possible to combine these two forms of modeling to improve online performance under partial observability. Specifically, we perform an explicit opponent categorization and reuse the learned response policies without the opponent’s local information. We follow the centralized training with decentralized execution (CTDE) paradigm and propose an algorithm called Bayesian policy reuse with LocAl oBservations (Bayes-Lab), which incorporates VAE into BPR. Specifically, we train VAE during the offline phase to extract the latent opponent’s policy features only based on the agent’s local observations, and then use VAE to reconstruct the opponent’s actions during online interactions. In addition, we collect the reconstructed actions and episodic rewards to fit the reconstruction accuracy model, planning similarity model, and performance model, which are defined as Gaussian distributions. Using the generated models, we update the agent’s belief about the opponent’s types during the online phase. Finally, we reuse the best response policy based on the updated belief. Compared with most BPR-based algorithms [22,23,40,43,44] that infer the opponent’s policy from their behaviors, Bayes-Lab can track the opponent’s policy only conditioned on the agent’s local observations.
The most significant contribution of Bayes-Lab is that it can efficiently detect the non-stationary opponents under partial observability and accurately reuse the offline response policies to improve the online performance. The main novelty of this paper is as follows: (1) An opponent model is introduced to reconstruct the opponent’s local observations only based on the agent’s local observations. Bayes-Lab uses VAE as an opponent model to learn the relationship between the agent’s local observations and the opponent’s local observations. Then, the learned opponent model can be used to reconstruct the opponent’s actions under partial observability. (2) An offline learning architecture is introduced to simultaneously learn the response policy and the opponent model. Bayes-Lab uses VAE to extract the opponent’s policy features which are integrated with the agent’s observations to learn the response policy. The advantage of this architecture is that each opponent’s policy can correspond to an optimal response policy and a specific opponent model, which is essential for detecting the opponent’s type and reusing the response policy. (3) Bayes-Lab is the first to propose integrating VAE as an opponent model into BPR. Specifically, it combines the ability of BPR to improve online performance by using offline knowledge with the capability of VAE to reason about the opponent’s behaviors under partial observability. It can continuously infer the opponent’s policies during online interactions without the opponent’s local observations. Compared with other BPR-based methods that can only be used in the globally observable environment, Bayes-Lab can effectively apply BPR in the partially observable environment. (4) The reconstruction accuracy model and planning similarity model are introduced to improve the detection accuracy during online interactions. Bayes-Lab can use these models to detect the opponent’s policy and whether or not the opponent’s actions can be observed.
The rest of the paper is organized as follows: Section 2 presents the formal model of RL, BPR, and VAE. Section 3 introduces the proposed Bayes-Lab algorithm. Section 4 presents a validation environment, experimental settings, and corresponding experimental results. Section 5 concludes our contributions and problems that need to be solved.
2. Preliminaries
2.1. Reinforcement Learning
An RL task can be modeled as an MDP [24,46], which consists of a 4-tuple , where is a finite set of states, is a finite set of actions, is a transition function which describes the probability of the next state , after taking action in state , and is a reward function which returns a scalar value conditioned on two consecutive states and the intermediate action. A policy function describes the probability distribution of choosing a in state s. An optimal policy can be learned by maximizing the state-value function or the action-value function. The state-value function is usually defined as , which represents the expected rewards for visiting state and following policy thereafter. Similarly, the action-value function is defined as , which describes the expected rewards for taking action a when visiting state s and keeping policy throughout, where is a discount factor, and H is the finite horizon of the episode.
In this paper, we use advantage actor–critic (A2C) [7] to learn the response policy. The opponent’s policy will remain fixed until the agent learns the optimal response policy. Suppose there is a policy network with parameter and a value network with parameter . A2C updates the network parameters as follows:
where is the batch of transitions, and is the basic advantage term.
2.2. Bayesian Policy Reuse
BPR [39] was originally proposed as a framework for an agent to determine the best response policy to execute when facing an unknown task in Markov Decision Process (MDP) [46,47]. Given a set of previously solved tasks and current task , the agent is expected to detect the type of task efficiently and reuse the optimal response policy from the policy library accordingly based on the observation signal within a small number of interactions. The signal can be any information related to the performance of a policy (e.g., episodic rewards, encountered state–action–state tuples). In addition, a performance model is a probability distribution over the utility U generated by applying a policy to a previously solved task . BPR uses the concept of belief , which is a probability distribution over the tasks , to estimate the matching degree between and the known tasks based on the signal . After each trial episode, is updated using a Bayes’ rule as follows:
where is the belief after episode . In addition, belief updating can be regarded as identifying task types. For example, suppose the agent’s policy library includes two learned response policies, and , which are used to handle tasks and , respectively. If the agent uses to interact with an unknown task which is one of or , the agent will receive a signal that can be combined with the performance model P to detect the task type. Specifically, reflects the possibility that the unknown task is . Similarly, reflects the possibility that the unknown task is . By comparing and , the agent can identify the unknown task type. Moreover, the received signal will be different if the task switches from one to another, resulting in changes in the performance model. As a result, the agent’s belief can be rectified based on Equation (2), leading the agent to reselect its response policy.
Several variants of BPR with exploration heuristics are available to choose the optimal response policy, among which BPR using an expected improvement (BPR-EI) presents the best performance. Assume that is the optimal estimated utility following the existing belief. BPR-EI selects the policy most likely to lead to any utility improvement as follows:
2.3. Variational Autoencoders
In recent years, variational autoencoders (VAE) [38] have become one of the most popular methods for unsupervised learning of complex distributions [48]. The VAE model uses deep neural networks [49] as standard function approximators and can be trained using stochastic gradient descent [50]. In image generation [48,51], the VAE model has been proven to be effective in generating wide varieties of complex data. In RL [24], many works use VAE to learn low-dimensional representations of the environment, leading to significant improvements [52,53].
Assume that samples from a data set are generated from some hidden (latent) random variables z based on a generative distribution with unknown parameters . The prior distribution over the latent variables z is a Gaussian distribution with mean and unit variance . The VAE model learns a variational parametric distribution to approximate the true posterior probability . In addition, the approximation of the true posterior starts with the computation of the KL divergence . Moreover, the lower bound of evidence (ELBO) is derived as follows:
A VAE model is composed of an encoder and a decoder. Specifically, the encoder receives samples and generates a Gaussian variational distribution . The decoder accepts the samples generated by the Gaussian variational distribution and reconstructs the original input x. In addition, the VAE model is usually trained by a parameterization trick [38]. -VAE [54] proposes taking advantage of the parameter which is positive to control the balance between the KL divergence and the reconstruction loss:
3. Bayes-Lab
An overview of Bayes-Lab is shown in Figure 1. It consists of two stages: (1) an offline stage used to learn the response policies and generate the corresponding models and (2) an online stage for opponent’s policy detection and optimal response policy reuse. The left part presents the process of learning a new response policy and the corresponding opponent model and generating the performance model , the reconstruction accuracy model , and the planning similarity model . The right part describes the process of belief update and policy reuse during online interactions. The episodic belief is used for opponent policy detection and optimal response policy reuse, and it is updated based on episodic returns and the agent’s local observations. In addition, each model generated in the offline process remains fixed in the online process, and the agent can constantly update the episodic belief through these models. With the change of the online signals, such as the episodic rewards and the agent’s local observations, the episodic belief calculated by offline models will be different, which can be used to track the change in the opponent’s behaviors.
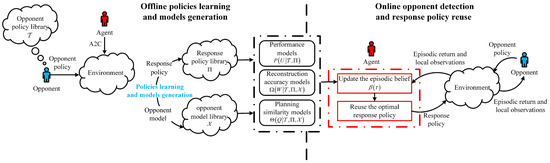
Figure 1.
An overview of Bayes-Lab.
During the offline stage, the agent interacts with each opponent’s policy to learn the corresponding response policy and the opponent model. In addition, the agent is also required to fit the performance models, reconstruction accuracy models, and planning similarity models, which are defined as Gaussian distributions. During the online stage, the agent incorporates the generated models to update the belief about the opponent’s types at the end of each episode, and then reuses the best response policies with the updated belief.
In the following sections, we denote the agent’s local observations within an episode by , where and are the agent’s observations and actions, respectively, and H is the finite horizon of the episode. Similarly, the opponent’s local information within an episode can be defined as . Moreover, the opponent’s actions reconstructed by the opponent model within an episode can be referred to as .
3.1. Offline Policy Learning and Model Generation
During the offline stage, Bayes-Lab first needs to learn the response policy and the opponent model x and then use them to constitute the response policy library and the opponent model library , respectively. In addition, we use the VAE networks to represent the opponent model. As shown in Figure 2, Bayes-Lab updates the A2C networks and the VAE networks simultaneously, and the VAE networks consist of an encoder and a decoder. The encoder learns a variational Gaussian distribution with parameters and is denoted as , which is used to approximate the true posterior distribution . The approximate posterior distribution can map the agent’s local observations to a hidden variable space from which the hidden variable z is sampled as the representation of the current opponent policy. In addition, the KL divergence is used to measure the similarity between the approximate posterior distribution and the real posterior distribution.
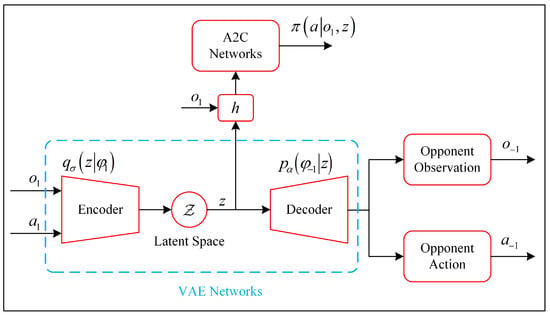
Figure 2.
Diagram of offline learning architecture.
The decoder learns a generative distribution with parameters that maps the hidden variable z to the opponent’s local information , which is used as a supervision signal to update the encoder–decoder networks. As a result, the opponent model can reconstruct conditioned only on . Moreover, we use the distance [55,56] for regularization. The loss of the encoder–decoder networks is formulated as follows:
where is a scaling parameter.
In the original A2C algorithm, the input of the policy networks is only the agent’s observations, and the obtained policy can be expressed by . Obviously, it cannot be directly applied in a multi-agent environment for not considering the impact of the opponent’s policy on its policy. To explicitly consider the coexisting opponents in the environment, we propose using the latent variable z, which is sampled as the low-level feature of the current opponent policy. Specifically, the agent’s observation augmented with z can be used as input signals to update the A2C networks, and the learned policy can be expressed by . We emphasize that the VAE networks are updated by supervised learning, while the A2C networks are updated by reinforcement learning. Therefore, A2C is a separate network, not another decoder. One advantage of this architecture is that each opponent’s policy can correspond to an optimal response policy and a specific opponent model , which is essential for reusing the response policies based on the opponent types. Although A2C and VAE are updated simultaneously, they use different optimizers and learning rates. As a result, the loss generated by A2C will not affect the parameters of VAE through back-propagating the gradient. Given a batch of the agent’s behaviors data, the objective of A2C is:
where B is the batch of transitions, and is the basic advantage term.
Furthermore, the offline learning mechanism of Bayes-Lab is relatively similar to LIAM [37], but there are significant differences: LIAM combines multiple opponent policies randomly and uses VAE to learn the general features of the combined policies. As a result, it only trains a single VAE model to deal with different opponent policies. The drawback of LIAM is that the agent can only learn from scratch and cannot reuse the existing policies during online interactions. In contrast, Bayes-Lab trains several VAE models, and each VAE model corresponds to a particular opponent type. Therefore, it can reuse the learned policies based on the detection results.
After learning the response policies and the opponent models, we formulate the corresponding performance model, the reconstruction accuracy model, and the planning similarity model, which are defined as Gaussian distributions. Algorithm 1 outlines the above process.
| Algorithm 1 Offline models’ generation |
|
For all policies in and , we simulate them playing against each other for multiple episodes. Moreover, the generated episodic rewards are modeled as the performance model . In addition, the agent’s local observations , the opponent’s real actions , and the reconstructed actions are also collected for further calculations.
We propose two generating modes to fit different models, where the opponent’s observations cannot be obtained by the agent. Specifically, when the opponent’s actions are available, we compute the reconstruction accuracy w by comparing with , and then use w to generate the reconstruction accuracy model (line 9 in Algorithm 1). Otherwise, we propose a planning method when the opponent’s actions are unavailable. In detail, we create a basic environment and a parallel environment , in which the initial states are identical and known. In , the opponent follows policy , while in , the agent assumes that the opponent chooses the reconstructed actions , which is used to infer its own observations . By comparing and , the planning similarity q can be calculated to build the planning similarity model (line 17 in Algorithm 1). In addition, we use the mean square error to measure the similarity. The larger the mean squared error, the lower the similarity.
3.2. Online Opponent Detection and Policy Reuse
During the online stage, the agent needs to accurately detect unknown opponent types and reuse the optimal response policies accordingly. Algorithm 2 outlines the above process.
| Algorithm 2 Online opponent detection and policy reuse |
|
Before starting the interaction, the belief is initialized with a uniform distribution. Based on the current belief , the agent selects an optimal response policy by using BPR-EI as follows (line 3 in Algorithm 2):
where the optimal estimated utility , and is adopted until the end of episode k. In addition, the agent uses a corresponding opponent model to reconstruct the opponent’s actions only based on its local observations (line 7 in Algorithm 2).
We propose two detecting modes to handle different opponent information, and we assume that the opponent’s observations are always unavailable. Specifically, when the opponent’s actions are observable, the agent calculates the reconstruction accuracy by comparing and , and then jointly uses the episodic reward and to update the episodic belief as follows (line 10 in Algorithm 2):
Otherwise, a planning method is proposed to infer the opponent’s type if the opponent’s actions cannot be observed. In detail, the opponent executes the real action in , while in , the opponent executes the reconstructed actions . The agent starts planning with a known initial state, and then reasons about its observations in . Sampling the real observations from , the planning similarity can be measured by calculating the mean squared error between and . Finally, we incorporate and the episodic reward to update the prior belief as follows: (line 17 in Algorithm 2)
When the agent detects a poor execution of the current policy, it can improve the performance by updating the belief and reselecting the response policy according to the updated belief. For example, suppose the agent’s policy library includes two response policies and , which are used to handle the opponent’s policies and , respectively. The belief is initialized with a uniform distribution , which can be used to select the response policy based on Equation (8). If the agent selects to deal with , which is unknown to the agent, it will result in a poor performance, including low episodic rewards u, low reconstruction accuracy w, and low planning similarity q. Using these signals, the belief will be updated based on Equations (9) and (10). For example, the belief may change from to , and the agent will select based on the updated belief. As a result, the execution performance can be improved by selecting the corresponding policy to interact with . Moreover, if the opponent’s policy changes, the agent will receive different signals, and the belief will be updated accordingly, as mentioned above.
We note that both Bayes-Lab and Deep-BPR+ [43] use the episodic rewards and the opponent’s behaviors in belief update. However, Deep-BPR+ infers the opponent’s type based on the opponent’s local information. In contrast, our model can track the opponent’s type based solely on the agent’s local observations.
4. Experiments and Results
4.1. Experimental Setup
In this section, we use a predator–prey environment, which is a well-known multi-agent scenario used in many studies [37,57,58,59,60]. As shown in Figure 3, the environment consists of one prey, three predators, and two immovable obstacles. The predators try to collide with the prey, while the prey must avoid collisions. All players choose actions from the action set , and any action that tries to move the players out of the environment is ignored. At each time step, if the prey avoids collisions with the predators, it will receive a reward of 0.1. As the number of collisions increases to 1, 2, and 3, the reward will become −1, −5, and −10, respectively. In this environment, we control the prey, and the predators sample their policies from several fixed policies. This environment is partially observable, where the prey can only see the predators and obstacles within a limited range of vision, while the predators can see all players and obstacles without limitations. The state observations are represented as a fourteen-dimensional vector which consists of the position of all players and obstacles and the speed of the prey. Each episode terminates after 100 time steps, and the position of all players and obstacles will be regenerated randomly.
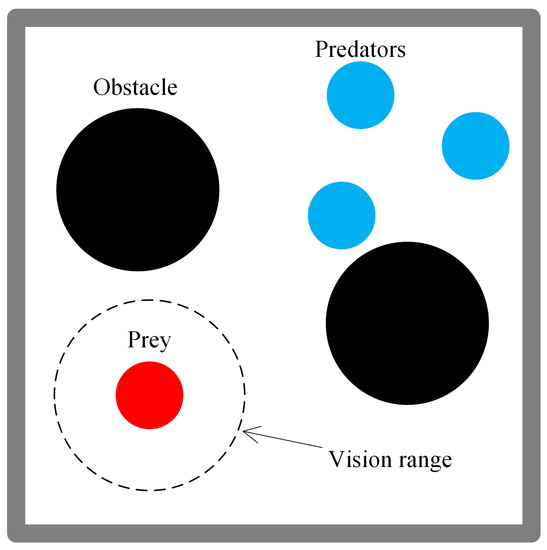
Figure 3.
Predator–Prey: an adversarial multi-agent environment used in our evaluation.
We design four fixed policies for the predators. (1) Vertical priority pursuit (): the predators first reduce the vertical distance to the prey by moving up or down, and then move left or right when the vertical distance is small enough. (2) Horizontal priority pursuit (): the predators first take a left or right movement to reduce the horizontal distance to the prey, and then take an up or down movement when the horizontal distance is small enough. (3) Clockwise pursuit (): the predators pursue the prey in an action sequence of right, down, left, and up. (4) Counterclockwise pursuit (): the predators pursue the prey in a left, down, right, and up action sequence. These four policies constitute the opponent policy library . Then, the prey uses A2C to learn the optimal response policy for each opponent’s policy and construct the optimal response policy library .
By designing the opponent’s fixed policy and learning the optimal response policy in the offline stage, both the agent and the opponent will directly choose the corresponding actions according to the existing policies during online interactions. Specifically, the opponent randomly selects a fixed policy in and executes the corresponding action. The agent needs to identify which fixed policy the opponent has chosen and select the corresponding response policy from , which is used to select the optimal action. In addition, when identifying the opponent’s fixed policy, the agent needs to reconstruct the opponent’s actions, which are used in two ways: First, they are used to compare with the real opponent’s actions to calculate the reconstruction accuracy. Second, the agent will estimate the opponent’s position by assuming that the opponent uses these reconstructed actions in a parallel environment, and then calculate the planning similarity. In other words, in the online stage, the reconstructed actions are only used as additional information to assist the agent in identifying the opponent’s policy, and then the agent reuses the optimal response policy to execute the optimal actions.
There are significant differences between Bayes-Lab and Deep-BPR+ [43] in the experimental environment. Deep-BPR+ uses the grid-world environments, which have the following characteristics: (1) Both the observations and actions are discrete. (2) The opponent does not consider the agent’s behaviors, and it can only act according to a fixed trajectory. (3) They are globally observable: the controlled agent has access to the opponent’s observations and actions. (4) There is only a single opponent in the environment. In the predator–prey scenario, the players have continuous observations, and the opponents take into account the effects of the agent’s behaviors rather than only following a fixed trajectory. In addition, the agent cannot observe the opponents’ local information during online interactions due to the environment being partially observable. Therefore, detecting the opponent’s policies and reusing the response policies in our setting is more challenging.
4.2. Results in the Offline Stage
In this section, we will evaluate the reconstruction accuracy of the opponent model and the distributions in the generated models. In the following experiments, we assume that the agent adopts the optimal response policy to play against the opponent policy and uses the opponent model to reconstruct the opponent’s actions.
Figure 4 illustrates the accuracy of the opponent model in reconstructing the opponent’s actions. We observe that both and can achieve an accuracy of approximately 80%, while and can only reach 44% and 52%. This is because and have fewer random actions to pursue the prey. In contrast, and have greater randomness, and they take all possible actions with a slight frequency difference, making VAE inaccurate in reconstructing the predators’ actions.
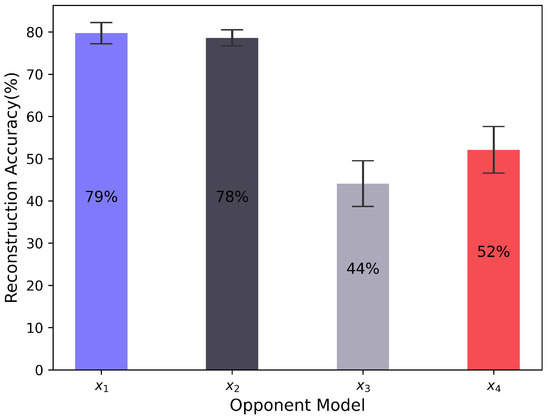
Figure 4.
The accuracy of the opponent model in reconstructing the opponent’s actions.
Figure 5 illustrates the performance model (line 5 in Algorithm 1). Four opponent policies and four response policies play against each other to fit sixteen Gaussian distributions. Each distribution reflects the corresponding episodic reward information. We observe that the optimal response policy receives the highest average episodic reward, all-around 10, with minor variance. In addition, the distribution is likely to be very similar to each other. For example, when the agent uses , the distributions of interacting with and are almost the same. When the agent only uses the performance model to detect the opponent’s policy, such as BPR [39] and BPR+ [40], the high similarity of distributions may cause low detection accuracy.
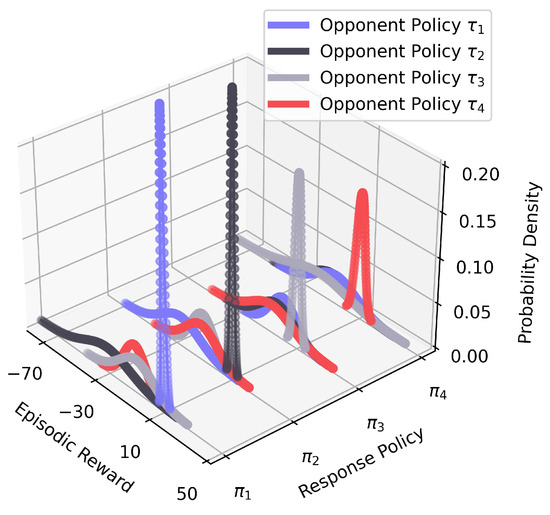
Figure 5.
The performance model P.
Figure 6 illustrates the reconstruction accuracy model (line 9 in Algorithm 1). It also consists of sixteen Gaussian distributions, like in the performance model P. Each distribution describes how accurately the corresponding opponent model x reconstructs the opponent’s actions. We observe that the optimal response policy has the highest accuracy, with and achieving an accuracy of around 80%, while and only reach approximately 50%. The difference between distributions in is more significant than that in P. For example, when the agent adopts to play against and , the distributions in P are very similar, but they are much more different in . In addition, is more suitable for situations where the opponent’s actions are available, and it can be jointly used with P during online detection.
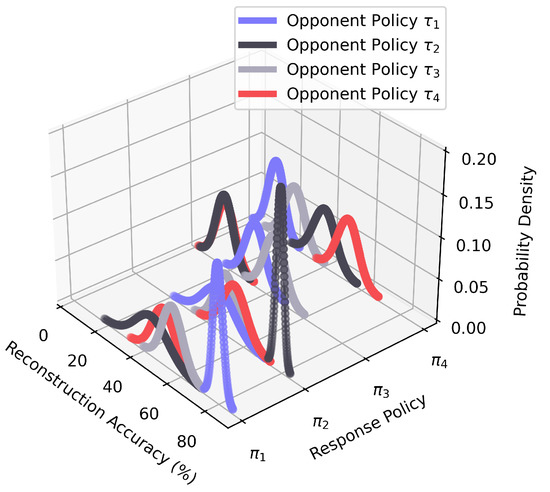
Figure 6.
The reconstruction accuracy model .
Figure 7 shows the planning similarity model (line 17 in Algorithm 1). We measure the similarity in terms of the mean square error between continuous observations. The smaller the error, the greater the similarity. We observe that the optimal response policy has the minimum mean squared error, with and reaching around 0. However, the minimum mean squared error for and is around 200 due to the lower accuracy of action reconstruction. In addition, is more suitable for situations where neither the opponent’s observations nor the actions are available, and it can also be used in combination with P during the online phase.
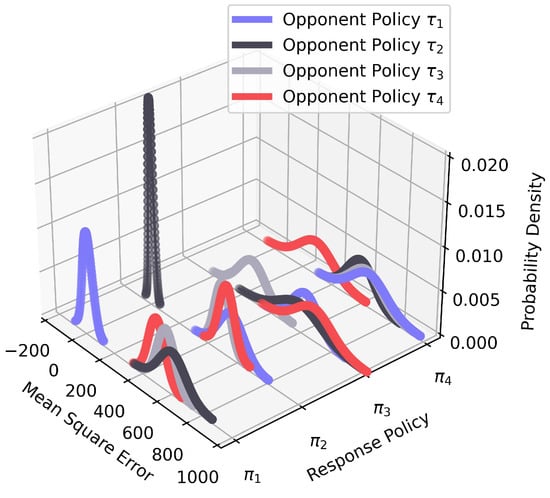
Figure 7.
The planning similarity model .
4.3. Results in Online Stage
In this section, we will evaluate the performance of Bayes-Lab by comparing it with the state-of-the-art algorithms, including BPR+ [40], Deep BPR+ [43], and Bayes-Tomop [44]. In the following experiments, we use Bayes-Lab(A) to represent the first detecting mode (line 10 in Algorithm 2), which combines with P to update , while using Bayes-Lab to define the second detecting mode (line 17 in Algorithm 2), which incorporates with P to detect the opponent’s type. In addition, we assume that the agent cannot obtain the opponent’s observations. We evaluated the performance of the proposed algorithm comprehensively through indicators such as episodic rewards, accumulated rewards, and detection accuracy. The following results were averaged over 500 runs to enable statistical analysis. There are 100 episodes in each run, and the opponents switch policies every 10 episodes. The order of policy switching is (, , , , , , , , , ). Each episode terminates after 100 time steps.
Figure 8 illustrates the episodic rewards for 100 episodes of interactions. The optimal reward will be around 10 within 100 time steps, as the agent receives a reward of 0.1 for each step without colliding with the opponents. We observe that the policy switch will lead to a rapid decrease in the reward, and the performance of the algorithms can be evaluated by observing how quickly the episodic rewards recover to 10. Bayes-Lab (A) recaptures the optimal reward most quickly during each policy switch. Bayes-Lab has a similar performance to Bayes-Lab (A) for the most part, but it has significantly lower rewards in episodes 50–60 and 70–80, where the policy switches from to . By observing (Figure 6) and (Figure 7), we notice that the difference in the distributions in is more significant when the response policy is . Therefore, is better suited to cope with the situation where the switches to .
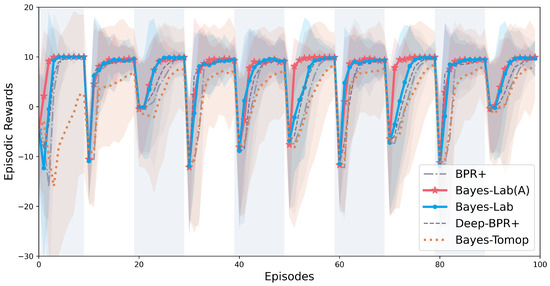
Figure 8.
The episodic rewards for 100 episodes of interactions.
Moreover, Deep-BPR+ performs worse than Bayes-Lab (A) and Bayes-Lab because it overly depends on the opponent’s information and can only obtain the opponent’s behavior data within the agent’s vision range in our setting. BPR+ is slower to respond than Deep BPR+ because it detects the opponent based only on P (Figure 5). In other words, the distributions in P are relatively similar, resulting in poor performance for BPR+. Bayes-Tomop has the bottom performance of all algorithms as it takes additional steps to determine whether the opponent is using BPR, which is time-consuming.
Figure 9 illustrates the accumulative rewards for 100 episodes of interactions. We observe that the rewards decrease with each policy switch but increase again when detection and reuse are completed. Bayes-Lab (A) achieves the highest accumulative rewards because it detects and reuses the most quickly. Bayes-Lab has a lower performance than Bayes-Lab (A), but it is still better than the other algorithms because can compensate for the effects of the incomplete opponent information. Deep-BPR+ archives significantly higher rewards than BPR+, proving that detecting the opponent’s type by using its behaviors is more effective. Bayes-Tomop has the lowest rewards, demonstrating that it is inefficient in identifying whether the opponent is using BPR. Moreover, it assumes that the optimal rewards are consistent, but the agent may receive different optimal rewards in our setting, making detection more difficult.
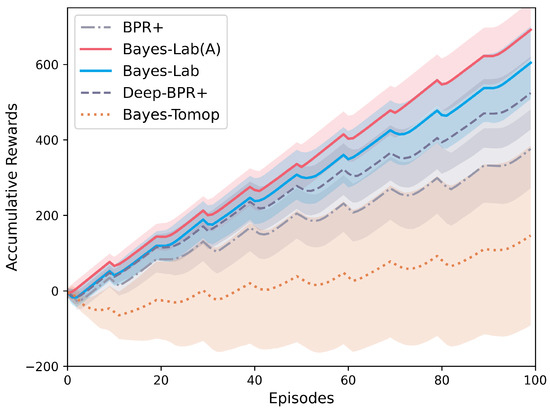
Figure 9.
The accumulative rewards for 100 episodes of interactions.
Figure 10 shows the detection accuracy against non-stationary opponents. We observe that Bayes-Lab (A) and Bayes-Lab achieve relatively higher detection accuracies than other algorithms. We note that Bayes-Lab (A) and Bayes-Lab detect the opponent’s type only based on the agent’s observations. In contrast, Deep-BPR+ requires the opponent’s local information to achieve a high detection accuracy of 72%. BPR+ only achieves 65% detection accuracy by relying solely on reward signals. Bayes-Tomop has the lowest detection accuracy as it is hard to deal with opponents using random policies.
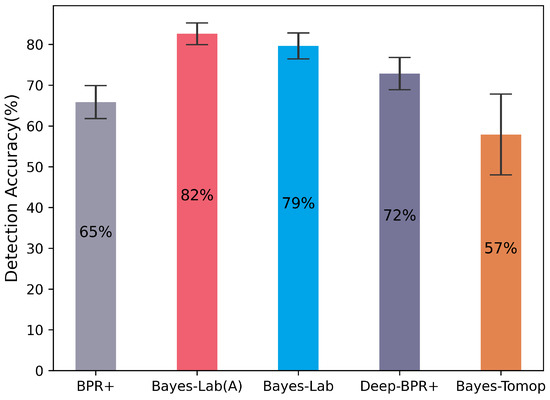
Figure 10.
The detection accuracy against non-stationary opponents.
Figure 11 shows the switching interval’s effect on the algorithms’ performance. We design four switching intervals of 4, 8, 10, and 12, and we observe that the larger the switching interval, the higher the detection accuracy, with Bayes-Lab (A) and Bayes-Lab outperforming the other algorithms at all switching intervals. Specifically, when the switching interval is 12, the detection accuracy of all algorithms is relatively high, with Deep-BPR+ and BPR+ exceeding 70% and Bayes-Tomop exceeding 60%. When the switching interval changes from 12 to 8, there is a slight decrease in performance for all algorithms, and the degradation is relatively small for Bayes-Lab (A) and Bayes-Lab because they detect the opponent’s type most quickly. Most algorithms suffer a dramatic drop in performance when the switching interval changes from 8 to 4 because the opponent’s behaviors change rapidly. In this case, the gap between Bayes-Lab (A) and other algorithms increases obviously. In summary, the switching interval of the opponent policy has a crucial influence on detection accuracy. In other words, frequent switching strategies by opponents will lead to significant challenges to detection, while Bayes-Lab and Bayes-Lab (A) exhibit better performance in dealing with this problem due to and .
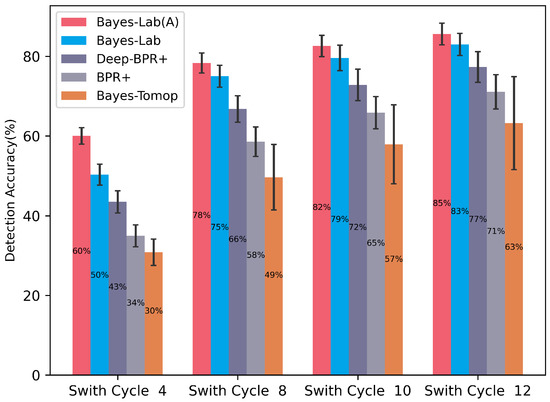
Figure 11.
The effect of the switching interval on the detection accuracy.
Table 1 shows the effect of the switching interval on the accumulative rewards. We observe that only Bayes-Lab (A) and Bayes-Lab have positive rewards when the switching interval is 4, and the other algorithms all have negative rewards, demonstrating that and effectively improve the performance against the opponent who switches policies frequently. Deep-BPR+ performs better than BPR+ and Bayes-Tomop, proving that it is essential for the agent to consider the opponent’s behaviors. The rewards improve significantly as the switching interval increases, showing that the longer the opponent’s policy remains fixed, the more accessible the agent can track the opponent. Bayes-Lab (A) and Bayes-Lab have similar performance, and their rewards far exceed that of BPR+ and Bayes-Tomop when the switching interval becomes 12. In summary, Bayes-Lab (A) and Bayes-Lab can adapt to a wide range of policy switching intervals without the opponent’s information.

Table 1.
The effect of the switching interval on the accumulative rewards.
5. Conclusions and Future Works
This paper focuses on accurate opponent policy detection and optimal response policy reuse in partially observable settings. The most significant contribution of the proposed algorithms, which include Bayes-Lab and Bayes-Lab (A), is that they can efficiently track the non-stationary opponents without their local information. Our model incorporates VAE into the BPR framework and follows the CTDE paradigm. It can reconstruct the opponent’s actions only based on its own local observations. Moreover, the reconstructed actions and episodic rewards are jointly used to update the belief about the opponent’s types. As a result, the agent can reuse the best response policies accurately. Extensive simulations in a predator–prey scenario with continuous observations and multiple opponents demonstrate that Bayes-Lab and Bayes-Lab (A) can adapt to a wide range of different policy switching intervals and achieve higher detection accuracy and accumulative rewards than other state-of-the-art algorithms. Many end applications that require quick online decisions may benefit from the proposed networks, such as human–computer interaction and service robots.
The main limitations of Bayes-Lab and Bayes-Lab (A) are as follows: First, we assume that the opponent’s behaviors significantly affect the agent’s local observations. However, the opponent’s behaviors may have little correlation to the agent’s local observations. In this case, it is difficult for the opponent model to learn the policy features of the opponent from the local observations. Second, we only consider the opponent switching policies at the end of an episode. However, the opponent may change more frequently, such as switching policies within an episode. Third, we assume that the opponent adopts its policy from a library that is fully known to the agent. However, the opponent may use a new strategy unknown to the agent. In future work, we would like to investigate how to build the model from different supervision signals rather than just depending on the opponent’s local information, and how to deal with opponents with abrupt policy changes, such as switching policies within an episode, is also worth investigating. Furthermore, we are also interested in accurately detecting the unknown opponent’s policy and learning a new optimal response policy by efficiently extracting available knowledge from the learned policies.
Author Contributions
Conceptualization, Y.W.; software, Y.W. and K.F.; validation, H.C. and K.F.; writing—original draft preparation, Y.W.; writing—review and editing, H.C. and Z.Z.; visualization, Q.L.; supervision, J.H. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Natural Science Foundation of China, grant number No. 61906202.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Acknowledgments
The authors thank the support from the National University of Defense Technology.
Conflicts of Interest
The authors declare no conflict of interest.
References
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Wang, J.; Chen, Y.; Hao, S.; Peng, X.; Hu, L. Deep learning for sensor-based activity recognition: A survey. Pattern Recognit. Lett. 2019, 119, 3–11. [Google Scholar] [CrossRef] [Green Version]
- Kwon, H.; Lee, S. Ensemble transfer attack targeting text classification systems. Comput. Secur. 2022, 117, 102695. [Google Scholar] [CrossRef]
- Kwon, H.; Lee, S. Textual Adversarial Training of Machine Learning Model for Resistance to Adversarial Examples. Secur. Commun. Netw. 2022, 2022, 4511510. [Google Scholar] [CrossRef]
- Kwon, H.; Kim, Y. BlindNet backdoor: Attack on deep neural network using blind watermark. Multimed. Tools Appl. 2022, 81, 6217–6234. [Google Scholar] [CrossRef]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. arXiv 2015, arXiv:1509.02971. [Google Scholar]
- Mnih, V.; Badia, A.P.; Mirza, M.; Graves, A.; Lillicrap, T.; Harley, T.; Silver, D.; Kavukcuoglu, K. Asynchronous methods for deep reinforcement learning. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 20–22 June 2016; pp. 1928–1937. [Google Scholar]
- Van Hasselt, H.; Guez, A.; Silver, D. Deep reinforcement learning with double q-learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; Volume 30. [Google Scholar]
- Silver, D.; Huang, A.; Maddison, C.J.; Guez, A.; Sifre, L.; Van Den Driessche, G.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Lanctot, M.; et al. Mastering the game of Go with deep neural networks and tree search. Nature 2016, 529, 484–489. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef]
- Gu, S.; Holly, E.; Lillicrap, T.; Levine, S. Deep reinforcement learning for robotic manipulation with asynchronous off-policy updates. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 3389–3396. [Google Scholar]
- Tai, L.; Paolo, G.; Liu, M. Virtual-to-real deep reinforcement learning: Continuous control of mobile robots for mapless navigation. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 31–36. [Google Scholar]
- Zhang, F.; Leitner, J.; Milford, M.; Upcroft, B.; Corke, P. Towards vision-based deep reinforcement learning for robotic motion control. arXiv 2015, arXiv:1511.03791. [Google Scholar]
- Barzegar, A.; Lee, D.J. Deep Reinforcement Learning-Based Adaptive Controller for Trajectory Tracking and Altitude Control of an Aerial Robot. Appl. Sci. 2022, 12, 4764. [Google Scholar] [CrossRef]
- Sallab, A.E.; Abdou, M.; Perot, E.; Yogamani, S. Deep reinforcement learning framework for autonomous driving. Electron. Imaging 2017, 2017, 70–76. [Google Scholar] [CrossRef] [Green Version]
- Kiran, B.R.; Sobh, I.; Talpaert, V.; Mannion, P.; Al Sallab, A.A.; Yogamani, S.; Pérez, P. Deep reinforcement learning for autonomous driving: A survey. IEEE Trans. Intell. Transp. Syst. 2021, 23, 4909–4926. [Google Scholar] [CrossRef]
- Chang, C.C.; Tsai, J.; Lin, J.H.; Ooi, Y.M. Autonomous Driving Control Using the DDPG and RDPG Algorithms. Appl. Sci. 2021, 11, 10659. [Google Scholar] [CrossRef]
- Zhao, W.; Meng, Z.; Wang, K.; Zhang, J.; Lu, S. Hierarchical Active Tracking Control for UAVs via Deep Reinforcement Learning. Appl. Sci. 2021, 11, 10595. [Google Scholar] [CrossRef]
- Wooldridge, M. An Introduction to Multiagent Systems; John Wiley & Sons: Hoboken, NJ, USA, 2009. [Google Scholar]
- Nguyen, T.T.; Nguyen, N.D.; Nahavandi, S. Deep reinforcement learning for multiagent systems: A review of challenges, solutions, and applications. IEEE Trans. Cybern. 2020, 50, 3826–3839. [Google Scholar] [CrossRef] [Green Version]
- Conitzer, V.; Sandholm, T. AWESOME: A general multiagent learning algorithm that converges in self-play and learns a best response against stationary opponents. Mach. Learn. 2007, 67, 23–43. [Google Scholar] [CrossRef] [Green Version]
- Chen, H.; Liu, Q.; Huang, J.; Fu, K. Efficiently tracking multi-strategic opponents: A context-aware Bayesian policy reuse approach. Appl. Soft Comput. 2022, 121, 108715. [Google Scholar] [CrossRef]
- Chen, H.; Liu, Q.; Fu, K.; Huang, J.; Wang, C.; Gong, J. Accurate policy detection and efficient knowledge reuse against multi-strategic opponents. Knowl.-Based Syst. 2022, 242, 108404. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Hernandez-Leal, P.; Kaisers, M. Towards a fast detection of opponents in repeated stochastic games. In International Conference on Autonomous Agents and Multiagent Systems; Springer: Berlin/Heidelberg, Germany, 2017; pp. 239–257. [Google Scholar]
- Hernandez-Leal, P.; Kaisers, M.; Baarslag, T.; de Cote, E.M. A survey of learning in multiagent environments: Dealing with non-stationarity. arXiv 2017, arXiv:1707.09183. [Google Scholar]
- Rabinowitz, N.; Perbet, F.; Song, F.; Zhang, C.; Eslami, S.A.; Botvinick, M. Machine theory of mind. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 4218–4227. [Google Scholar]
- Papoudakis, G.; Christianos, F.; Rahman, A.; Albrecht, S.V. Dealing with non-stationarity in multi-agent deep reinforcement learning. arXiv 2019, arXiv:1906.04737. [Google Scholar]
- He, H.; Boyd-Graber, J.; Kwok, K.; Daumé, H., III. Opponent modeling in deep reinforcement learning. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 20–22 June 2016; pp. 1804–1813. [Google Scholar]
- Albrecht, S.V.; Stone, P. Autonomous agents modelling other agents: A comprehensive survey and open problems. Artif. Intell. 2018, 258, 66–95. [Google Scholar] [CrossRef] [Green Version]
- Grover, A.; Al-Shedivat, M.; Gupta, J.; Burda, Y.; Edwards, H. Learning policy representations in multiagent systems. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 1802–1811. [Google Scholar]
- Tacchetti, A.; Song, H.F.; Mediano, P.A.; Zambaldi, V.; Rabinowitz, N.C.; Graepel, T.; Botvinick, M.; Battaglia, P.W. Relational forward models for multi-agent learning. arXiv 2018, arXiv:1809.11044. [Google Scholar]
- Hernandez-Leal, P.; Kartal, B.; Taylor, M.E. A survey and critique of multiagent deep reinforcement learning. Auton. Agents Multi-Agent Syst. 2019, 33, 750–797. [Google Scholar] [CrossRef] [Green Version]
- Raileanu, R.; Denton, E.; Szlam, A.; Fergus, R. Modeling others using oneself in multi-agent reinforcement learning. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 4257–4266. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing atari with deep reinforcement learning. arXiv 2013, arXiv:1312.5602. [Google Scholar]
- Hong, Z.W.; Su, S.Y.; Shann, T.Y.; Chang, Y.H.; Lee, C.Y. A deep policy inference q-network for multi-agent systems. arXiv 2017, arXiv:1712.07893. [Google Scholar]
- Papoudakis, G.; Christianos, F.; Albrecht, S. Agent Modelling under Partial Observability for Deep Reinforcement Learning. Adv. Neural Inf. Process. Syst. 2021, 34, 19210–19222. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Rosman, B.; Hawasly, M.; Ramamoorthy, S. Bayesian policy reuse. Mach. Learn. 2016, 104, 99–127. [Google Scholar] [CrossRef] [Green Version]
- Hernandez-Leal, P.; Taylor, M.E.; Rosman, B.; Sucar, L.E.; De Cote, E.M. Identifying and tracking switching, non-stationary opponents: A Bayesian approach. In Proceedings of the Workshops at the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–13 February 2016. [Google Scholar]
- Harsanyi, J.C. Games with incomplete information played by “Bayesian” players, I–III Part I. The basic model. Manag. Sci. 1967, 14, 159–182. [Google Scholar] [CrossRef]
- Crandall, J.W. Just add Pepper: Extending learning algorithms for repeated matrix games to repeated markov games. In Proceedings of the 11th International Conference on Autonomous Agents and Multiagent Systems, Valencia, Spain, 4–8 June 2012; Volume 1, pp. 399–406. [Google Scholar]
- Zheng, Y.; Meng, Z.; Hao, J.; Zhang, Z.; Yang, T.; Fan, C. A deep bayesian policy reuse approach against non-stationary agents. Adv. Neural Inf. Process. Syst. 2018, 31, 962–972. [Google Scholar]
- Yang, T.; Meng, Z.; Hao, J.; Zhang, C.; Zheng, Y.; Zheng, Z. Towards efficient detection and optimal response against sophisticated opponents. arXiv 2018, arXiv:1809.04240. [Google Scholar]
- Papoudakis, G.; Christianos, F.; Albrecht, S.V. Local Information Opponent Modelling Using Variational Autoencoders. arXiv 2020, arXiv:2006.09447. [Google Scholar]
- Bellman, R. A Markovian decision process. J. Math. Mech. 1957, 6, 679–684. [Google Scholar] [CrossRef]
- Zacharaki, A.; Kostavelis, I.; Dokas, I. Decision Making with STPA through Markov Decision Process, a Theoretic Framework for Safe Human-Robot Collaboration. Appl. Sci. 2021, 11, 5212. [Google Scholar] [CrossRef]
- Doersch, C. Tutorial on variational autoencoders. arXiv 2016, arXiv:1606.05908. [Google Scholar]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bottou, L. Stochastic gradient descent tricks. In Neural Networks: Tricks of the Trade; Springer: Berlin/Heidelberg, Germany, 2012; pp. 421–436. [Google Scholar]
- Yan, X.; Yang, J.; Sohn, K.; Lee, H. Attribute2image: Conditional image generation from visual attributes. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2016; pp. 776–791. [Google Scholar]
- Ha, D.; Schmidhuber, J. Recurrent world models facilitate policy evolution. In Proceedings of the Advances in Neural Information Processing Systems 31, Montréal, QC, Canada, 3–8 December 2018. [Google Scholar]
- Igl, M.; Zintgraf, L.; Le, T.A.; Wood, F.; Whiteson, S. Deep variational reinforcement learning for POMDPs. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 2117–2126. [Google Scholar]
- Higgins, I.; Matthey, L.; Pal, A.; Burgess, C.; Glorot, X.; Botvinick, M.; Mohamed, S.; Lerchner, A. Beta-vae: Learning basic visual concepts with a constrained variational framework. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Gretton, A.; Borgwardt, K.; Rasch, M.; Schölkopf, B.; Smola, A. A kernel method for the two-sample-problem. arXiv 2006, arXiv:0805.2368. [Google Scholar]
- Zhao, S.; Song, J.; Ermon, S. Infovae: Information maximizing variational autoencoders. arXiv 2017, arXiv:1706.02262. [Google Scholar]
- Stone, P.; Veloso, M. Multiagent systems: A survey from a machine learning perspective. Auton. Robot. 2000, 8, 345–383. [Google Scholar] [CrossRef]
- Böhmer, W.; Kurin, V.; Whiteson, S. Deep coordination graphs. In Proceedings of the International Conference on Machine Learning, Virtual, 13–18 July 2020; pp. 980–991. [Google Scholar]
- Lowe, R.; Wu, Y.I.; Tamar, A.; Harb, J.; Abbeel, O.P.; Mordatch, I. Multi-agent actor-critic for mixed cooperative-competitive environments. arXiv 2017, arXiv:1706.0227530. [Google Scholar]
- Son, K.; Kim, D.; Kang, W.J.; Hostallero, D.E.; Yi, Y. Qtran: Learning to factorize with transformation for cooperative multi-agent reinforcement learning. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 5887–5896. [Google Scholar]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).