
Resolving Data Sparsity via Aggregating Graph-Based User–App–Location Association for Location Recommendations



Abstract
:1. Introduction
2. Related Work
2.1. Personalized Location Recommendations
2.2. Data Sparsity Solutions
3. Datasets and Analyses
3.1. Datasets
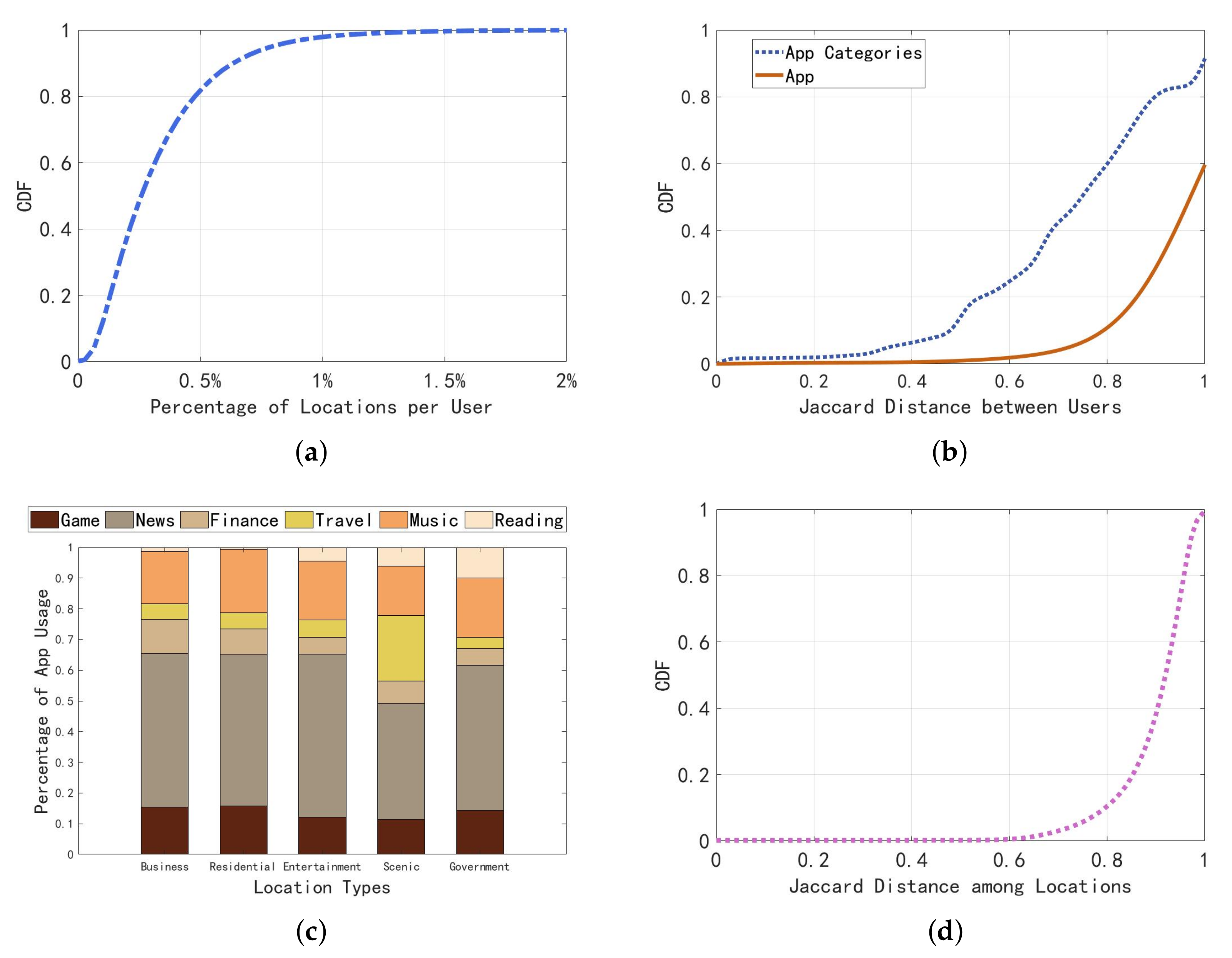
3.2. Analyses of User–Location–App Associations
4. Methodology
4.1. Problem Preliminaries
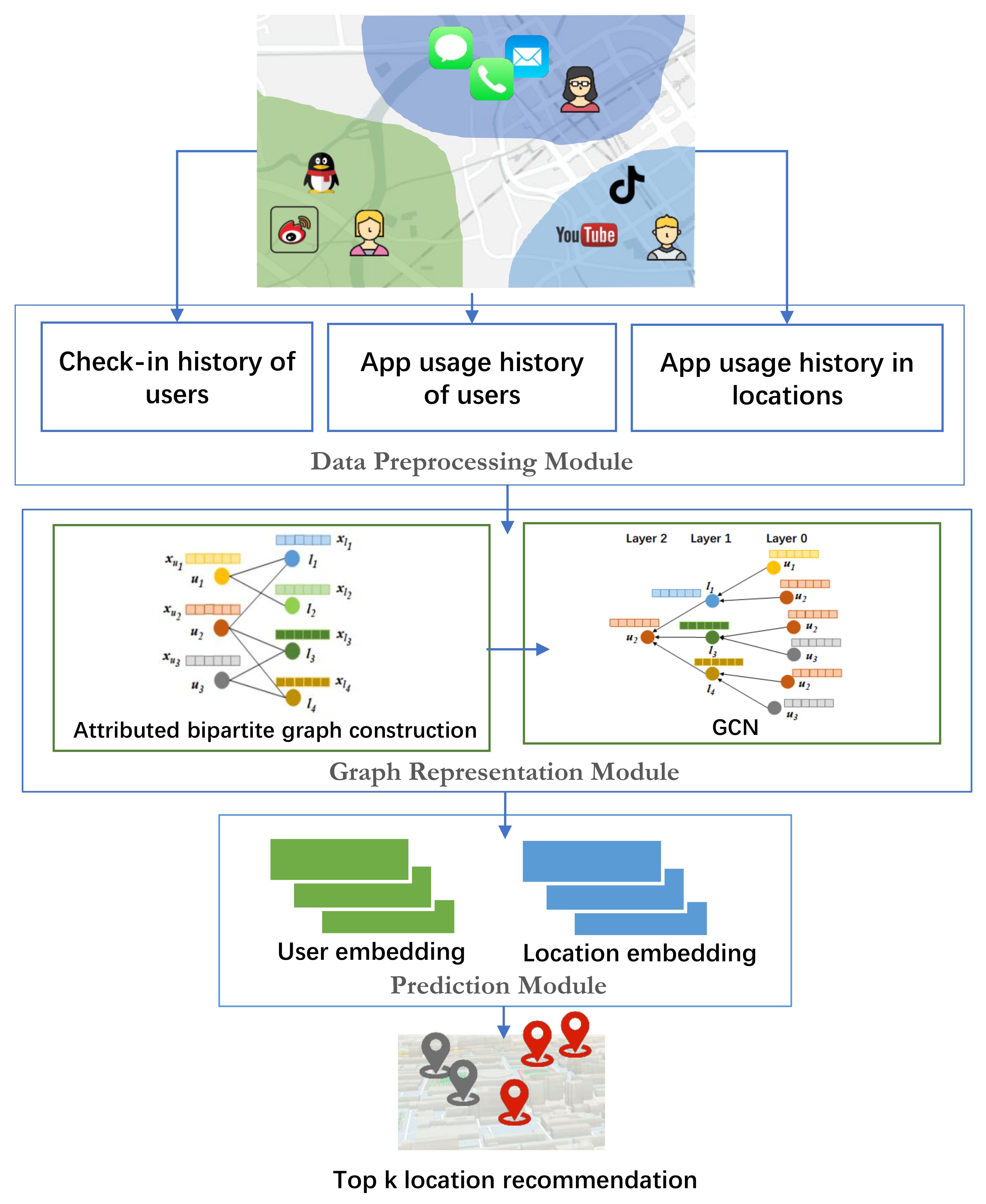
4.2. Framework of Proposed Recommendation Model
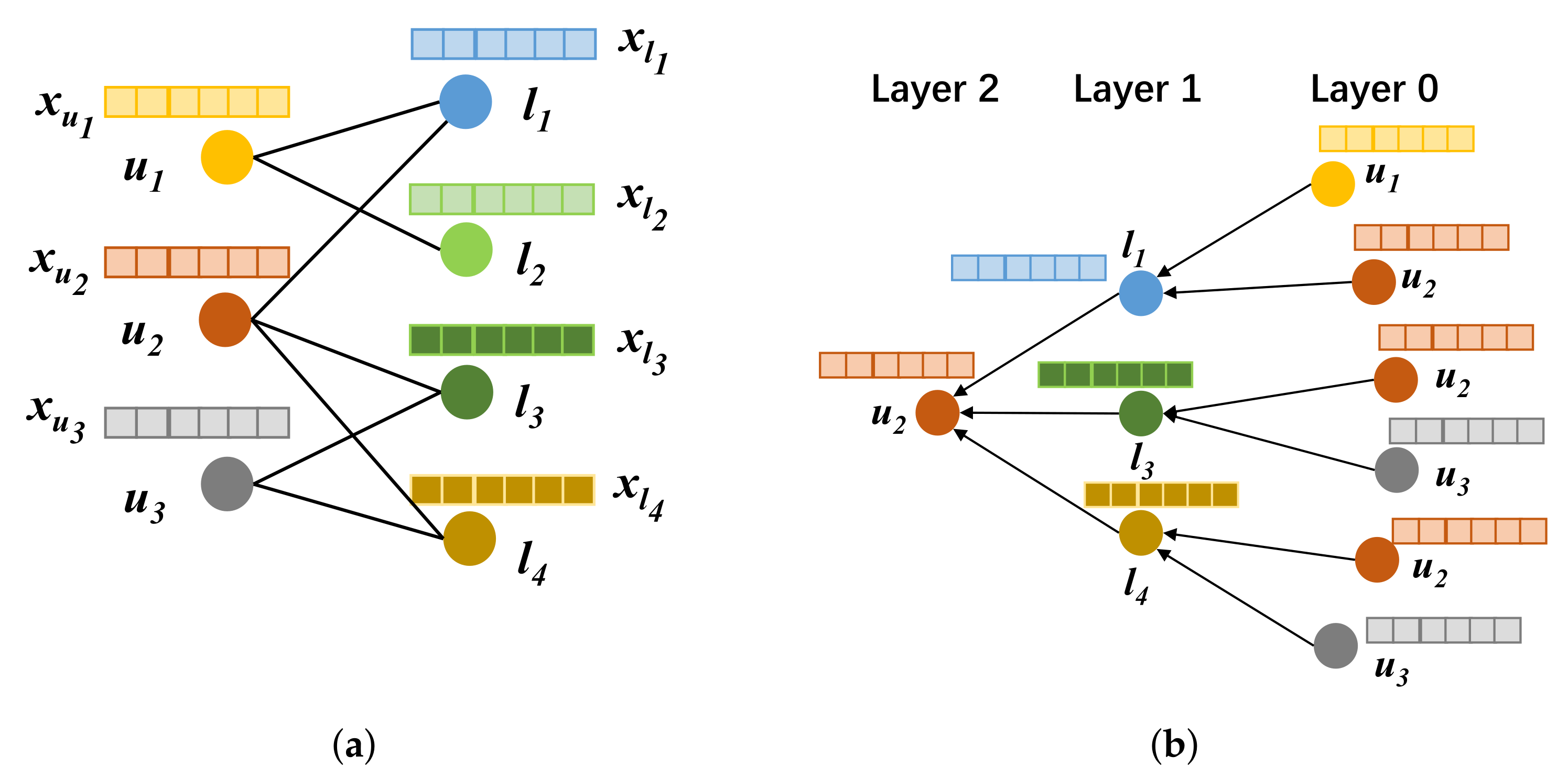
4.3. Generation of Attributed Bipartite Graph
4.4. Representation Model Construction
4.5. Graph Generation and Location Recommendation Algorithms
| Algorithm 1: Constructing attributed bipartite graph |
 |
| Algorithm 2: Training process of our model |
 |
5. Experiments and Evaluation
5.1. Experimental Setting
5.1.1. Metrics
5.1.2. Baselines
5.1.3. Parameter Setting
5.2. Model Performance Evaluation
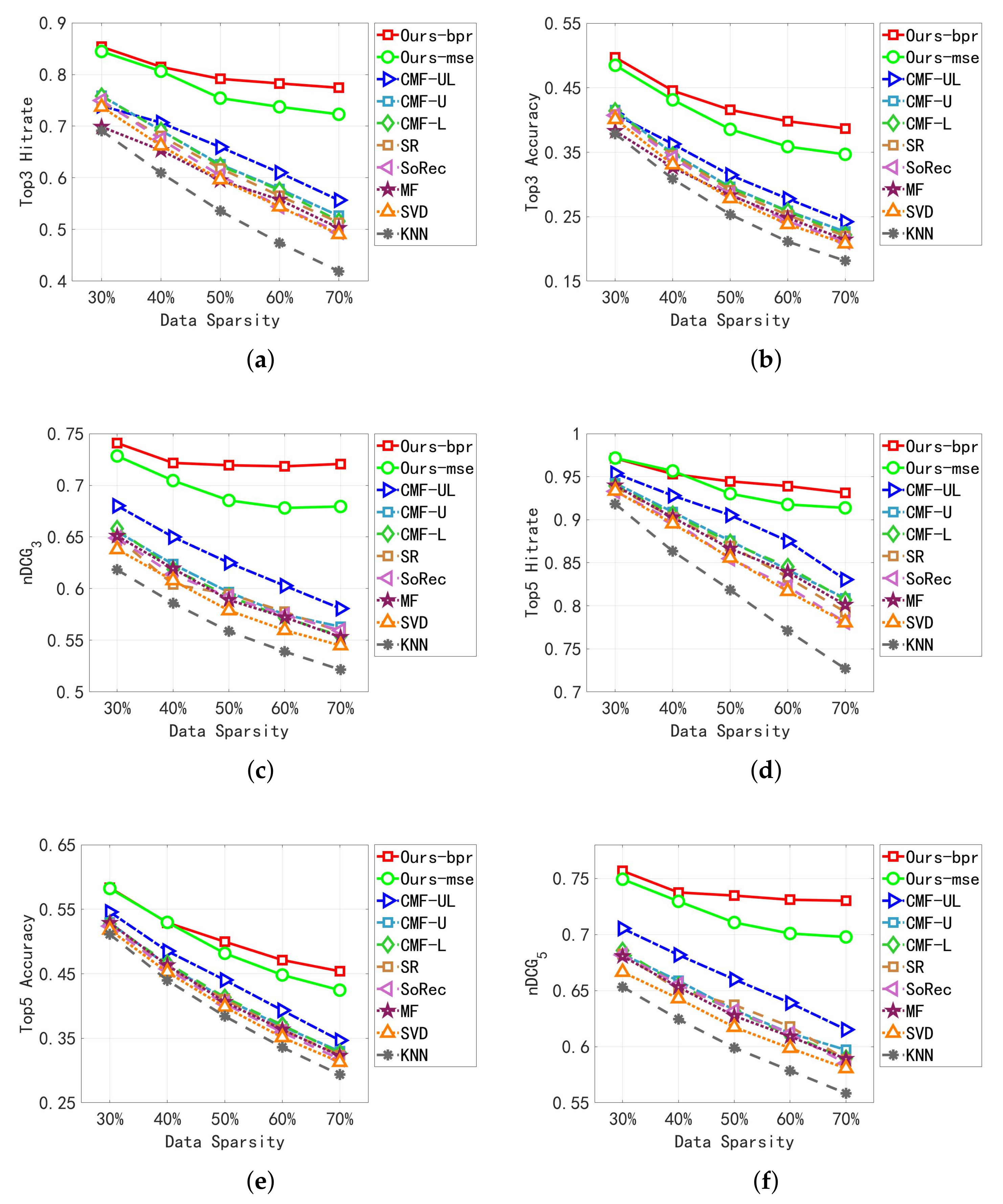
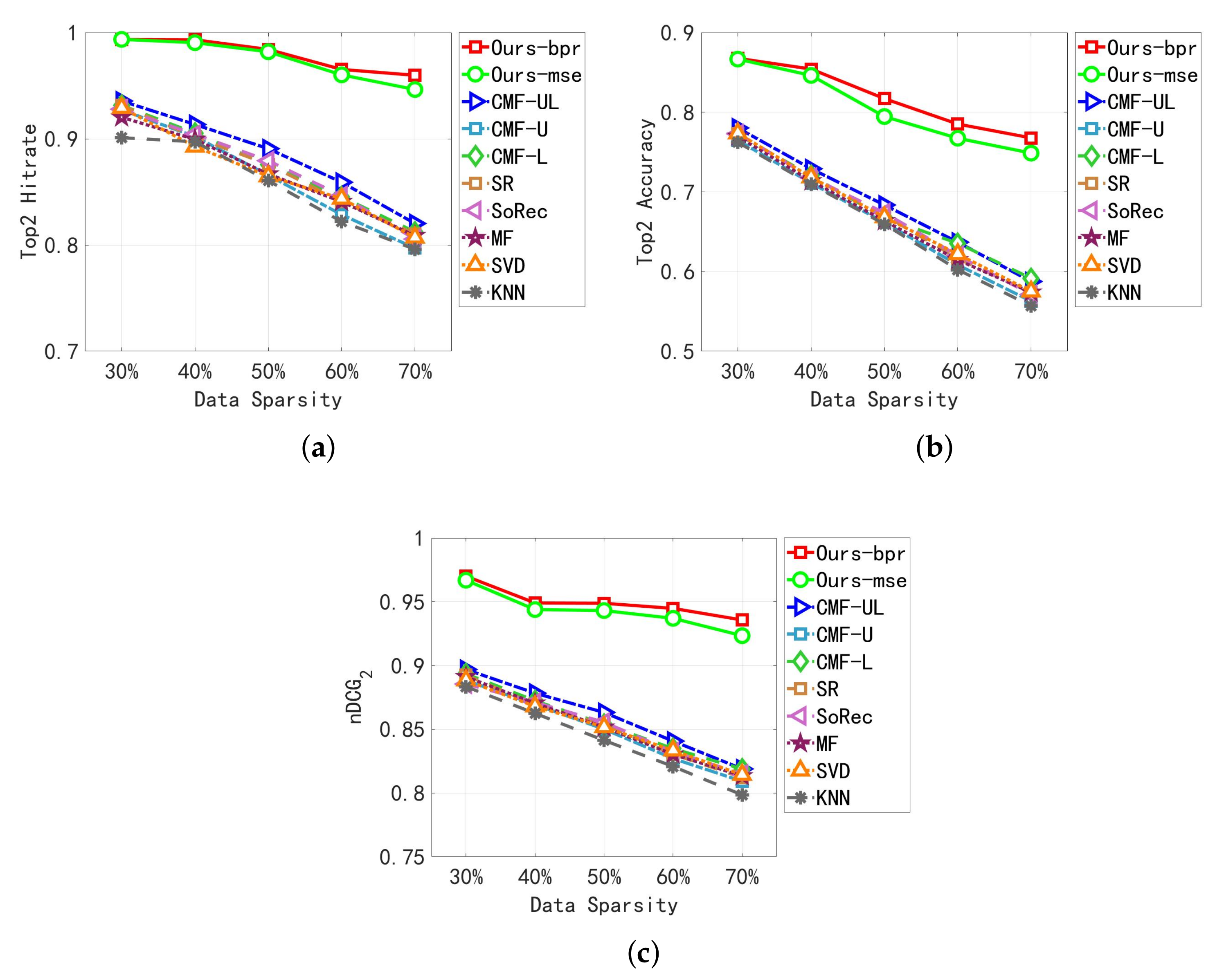
5.2.1. Results Analyses
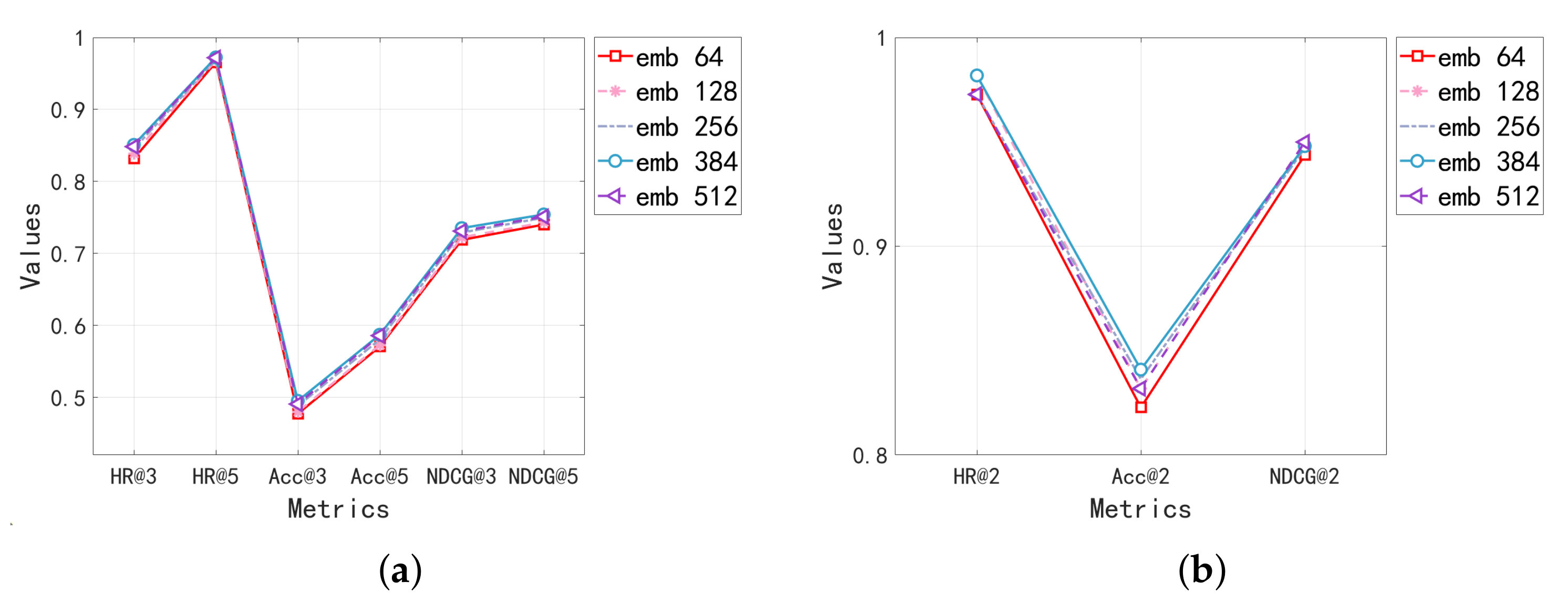
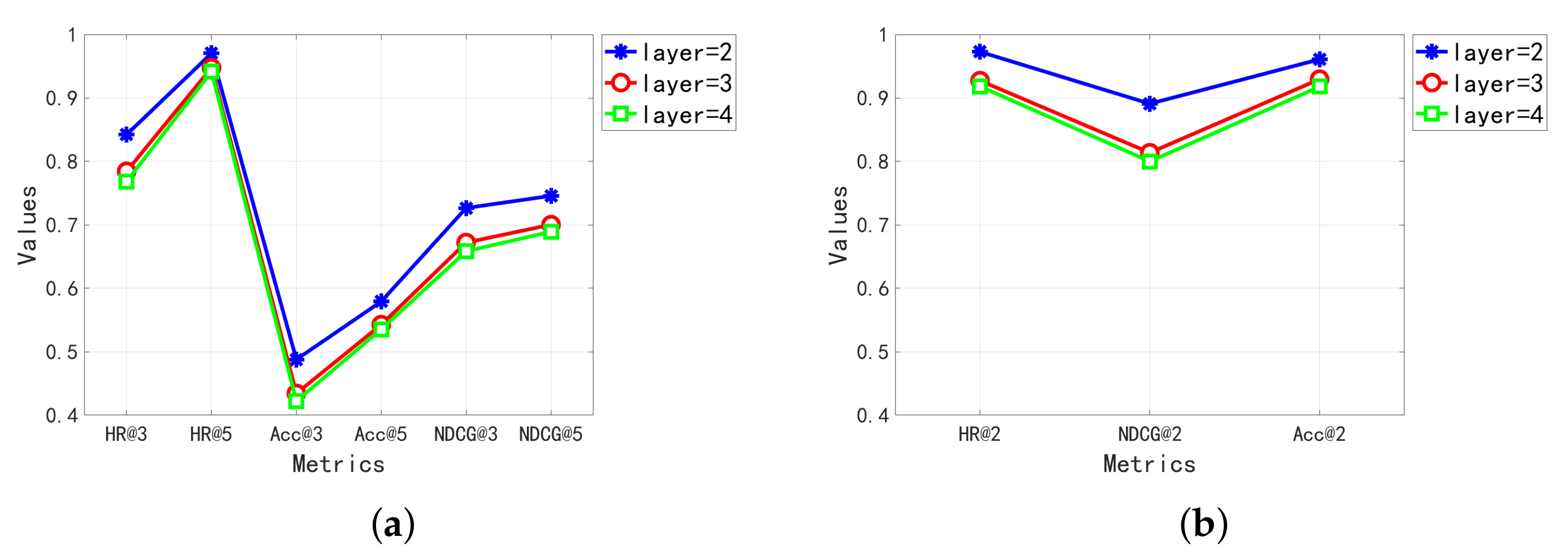
5.2.2. Parameter Study
6. Conclusions
- 1.
- To the best of our knowledge, it is the first to solve the data sparsity problem in location recommendations by aggregating user–app–location associations, which can also inspire the research works about users’ app usage behavior. We innovatively introduce app usage records as complementary information, in which both users’ habits and location features are revealed. This method effectively alleviates the data sparsity problem and greatly improves the recommendation performances.
- 2.
- A graph-based representation model is proposed to learn both users’ and locations’ latent representations from an attributed bipartite graph. Our model explicitly uses associations of user-app-location, and captures various high-order features due to the information propagation and aggregation in graph structure. Therefore, it can significantly improve location recommendations, even under the circumstances of severe data sparsity.
- 3.
- Adequate experiments are conducted on two real-life datasets to show the superior and stable performance of our proposed model. Our model achieves the best performance compared with the state-of-art methods. It also works well under severe data sparsity, which has a higher increase in recommending performances when facing higher sparsity. For example, in Telecom dataset, when the data sparsity is 30%, , , and of our model are 11.42%, 8.19%, and 6.07% higher than the best baseline model, respectively. While data sparsity is 70%, , , and of our model achieve performances at least 21.76%, 14.47%, and 14.00% higher than the best baseline model, respectively.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| RNN | Recurrent Neural Network |
| GCN | Graph Convolutional Network |
| CNN | Convolutional Neural Network |
| LSTM | Long Short-Term Memory |
| POI | Point of Interest |
| GRU | Gated Recurrent Unit |
| SVD-MFN | Singular Value Decomposition with Multi-Factor Neighborhood |
| KNN | K-Nearest Neighbor |
References
- Werneck, H.; Silva, N.; Viana, M.C.; Mourão, F.; Pereira, A.C.M.; Rocha, L. A Survey on Point-of-Interest Recommendation in Location-Based Social Networks. In Proceedings of the Brazilian Symposium on Multimedia and the Web, São Luís, Brazil, 30 November–4 December 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 185–192. [Google Scholar] [CrossRef]
- Zhu, D.H.; Chang, Y.P.; Luo, J.J.; Li, X. Understanding the adoption of location-based recommendation agents among active users of social networking sites. Inf. Process. Manag. 2014, 50, 675–682. [Google Scholar] [CrossRef]
- Wu, C.; Kao, S.C.; Wu, C.C.; Huang, S. Location-aware service applied to mobile short message advertising: Design, development, and evaluation. Inf. Process. Manag. 2015, 51, 625–642. [Google Scholar] [CrossRef]
- Bao, J.; Zheng, Y.; Wilkie, D.; Mokbel, M.F. Recommendations in location-based social networks: A survey. GeoInformatica 2015, 19, 525–565. [Google Scholar] [CrossRef]
- Lian, D.; Zhao, C.; Xie, X.; Sun, G.; Chen, E.; Rui, Y. GeoMF: Joint geographical modeling and matrix factorization for point-of-interest recommendation. In Proceedings of the The 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD’14, New York, NY, USA, 24–27 August 2014; ACM: New York, NY, USA, 2014; pp. 831–840. [Google Scholar] [CrossRef]
- Lian, D.; Zheng, K.; Ge, Y.; Cao, L.; Chen, E.; Xie, X. GeoMF++: Scalable Location Recommendation via Joint Geographical Modeling and Matrix Factorization. ACM Trans. Inf. Syst. 2018, 36, 33:1–33:29. [Google Scholar] [CrossRef]
- Zhong, C.; Zhu, J.; Xi, H. PS-LSTM: Popularity Analysis And Social Network For Point-Of-Interest Recommendation In Previously Unvisited Locations. In Proceedings of the CNIOT 2021: 2nd International Conference on Computing, Networks and Internet of Things, Beijing, China, 20–22 May 2021; ACM: New York, NY, USA, 2021; pp. 28:1–28:6. [Google Scholar] [CrossRef]
- Luo, Y.; Liu, Q.; Liu, Z. STAN: Spatio-Temporal Attention Network for Next Location Recommendation. In Proceedings of the WWW’21: The Web Conference 2021, Ljubljana, Slovenia, 19–23 April 2021; ACM/IW3C2: New York, NY, USA, 2021; pp. 2177–2185. [Google Scholar] [CrossRef]
- Ameen, T.; Chen, L.; Xu, Z.; Lyu, D.; Shi, H. A Convolutional Neural Network and Matrix Factorization-Based Travel Location Recommendation Method Using Community-Contributed Geotagged Photos. ISPRS Int. J. Geo Inf. 2020, 9, 464. [Google Scholar] [CrossRef]
- Xu, H.; Wang, J.; Wei, J. Recommending irregular regions using graph attentive networks. Ad Hoc Networks 2021, 113, 102383. [Google Scholar] [CrossRef]
- Guo, Z.; Wang, H. A Deep Graph Neural Network-Based Mechanism for Social Recommendations. IEEE Trans. Ind. Inform. 2021, 17, 2776–2783. [Google Scholar] [CrossRef]
- Liu, X.; Song, R.; Wang, Y.; Xu, H. A Multi-Granular Aggregation-Enhanced Knowledge Graph Representation for Recommendation. Information 2022, 13, 229. [Google Scholar] [CrossRef]
- Hu, B.; Ye, Y.; Zhong, Y.; Pan, J.; Hu, M. TransMKR: Translation-based knowledge graph enhanced multi-task point-of-interest recommendation. Neurocomputing 2022, 474, 107–114. [Google Scholar] [CrossRef]
- Cai, X.; Xie, L.; Tian, R.; Cui, Z. Explicable recommendation based on knowledge graph. Expert Syst. Appl. 2022, 200, 117035. [Google Scholar] [CrossRef]
- Singh, M. Scalability and sparsity issues in recommender datasets: A survey. Knowl. Inf. Syst. 2020, 62, 1–43. [Google Scholar] [CrossRef]
- Zheng, L.; Li, C.; Lu, C.; Zhang, J.; Yu, P.S. Deep Distribution Network: Addressing the Data Sparsity Issue for Top-N Recommendation. In Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, Paris, France, 21–25 July 2019; ACM: Paris, France, 2019; pp. 1081–1084. [Google Scholar]
- Liu, Y.; Pham, T.; Cong, G.; Yuan, Q. An Experimental Evaluation of Point-of-interest Recommendation in Location-based Social Networks. Proc. VLDB Endow. 2017, 10, 1010–1021. [Google Scholar] [CrossRef]
- Long, X.; Joshi, J. A HITS-based POI recommendation algorithm for location-based social networks. In Proceedings of the Advances in Social Networks Analysis and Mining, Niagara, ON, Canada, 25–28 August 2013; ACM: Niagara, ON, Canada, 2013; pp. 642–647. [Google Scholar]
- Gao, H.; Tang, J.; Liu, H. Addressing the cold-start problem in location recommendation using geo-social correlations. Data Min. Knowl. Discov. 2015, 29, 299–323. [Google Scholar] [CrossRef] [Green Version]
- Yu, F.; Cui, L.; Guo, W.; Lu, X.; Li, Q.; Lu, H. A Category-Aware Deep Model for Successive POI Recommendation on Sparse Check-in Data. In Proceedings of the Web Conference 2020, Taipei, Taiwan, 20–24 April 2020; ACM/IW3C2: Taipei, Taiwan, 2020; pp. 1264–1274. [Google Scholar]
- Guo, H.; Li, X.; He, M.; Zhao, X.; Liu, G.; Xu, G. CoSoLoRec: Joint Factor Model with Content, Social, Location for Heterogeneous Point-of-Interest Recommendation. In Proceedings of the Knowledge Science, Engineering and Management—9th International Conference, KSEM 2016, Passau, Germany, 5–7 October 2016; Lecture Notes in Computer Science. Volume 9983, pp. 613–627. [Google Scholar] [CrossRef] [Green Version]
- Ma, Y.; Mao, J.; Ba, Z.; Li, G. Location recommendation by combining geographical, categorical, and social preferences with location popularity. Inf. Process. Manag. 2020, 57, 102251. [Google Scholar] [CrossRef]
- Tu, Z.; Fan, Y.; Li, Y.; Chen, X.; Su, L.; Jin, D. From Fingerprint to Footprint: Cold-start Location Recommendation by Learning User Interest from App Data. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2019, 3, 26:1–26:22. [Google Scholar] [CrossRef]
- Su, Y.; Li, X.; Zha, D.; Tang, W.; Jiang, Y.; Xiang, J.; Gao, N. HRec: Heterogeneous Graph Embedding-Based Personalized Point-of-Interest Recommendation. In Proceedings of the ICONIP, Bangkok, Thailand, 8–12 December 2019; Lecture Notes in Computer Science. Volume 11955, pp. 37–49. [Google Scholar]
- Hu, X.; Xu, J.; Wang, W.; Li, Z.; Liu, A. A graph embedding based model for fine-grained POI recommendation. Neurocomputing 2021, 428, 376–384. [Google Scholar] [CrossRef]
- Huang, Z.; Chen, H.; Zeng, D.D. Applying associative retrieval techniques to alleviate the sparsity problem in collaborative filtering. ACM Trans. Inf. Syst. 2004, 22, 116–142. [Google Scholar] [CrossRef] [Green Version]
- Xie, H.; Fan, Q.; Xiao, Q. A Social Collaborative Filtering Method to Alleviate Data Sparsity Based on Graph Convolutional Networks. IEICE Trans. Inf. Syst. 2020, 103-D, 2611–2619. [Google Scholar] [CrossRef]
- Natarajan, N.; Shin, D.; Dhillon, I.S. Which app will you use next? Collaborative filtering with interactional context. In Proceedings of the the 7th ACM Conference on Recommender Systems, Hong Kong, China, 12–16 October 2013; ACM: Hong Kong, China, 2013; pp. 201–208. [Google Scholar]
- Zou, X.; Zhang, W.; Li, S.; Pan, G. Prophet: What app you wish to use next. In Proceedings of the The 2013 ACM International Joint Conference on Pervasive and Ubiquitous Computing, Zurich, Switzerland, 8–12 September 2013; ACM: Zurich, Switzerland, 2013; pp. 167–170. [Google Scholar]
- Baeza-Yates, R.; Jiang, D.; Silvestri, F.; Harrison, B. Predicting The Next App That You Are Going To Use. In Proceedings of the Eighth ACM International Conference on Web Search and Data Mining, Shanghai, China, 2–6 February 2015; ACM: Shanghai, China, 2015; pp. 285–294. [Google Scholar]
- Xia, B.; Ni, Z.; Li, T.; Li, Q.; Zhou, Q. VRer: Context-Based Venue Recommendation using embedded space ranking SVM in location-based social network. Expert Syst. Appl. 2017, 83, 18–29. [Google Scholar] [CrossRef]
- Lyu, D.; Chen, L.; Xu, Z.; Yu, S. Weighted multi-information constrained matrix factorization for personalized travel location recommendation based on geo-tagged photos. Appl. Intell. 2020, 50, 924–938. [Google Scholar] [CrossRef]
- Yin, Y.; Chen, L.; Xu, Y.; Wan, J. Location-Aware Service Recommendation With Enhanced Probabilistic Matrix Factorization. IEEE Access 2018, 6, 62815–62825. [Google Scholar] [CrossRef]
- Yang, D.; Zhang, D.; Yu, Z.; Wang, Z. A sentiment-enhanced personalized location recommendation system. In Proceedings of the 24th ACM Conference on Hypertext and Social Media (Part of ECRC), Paris, France, 1–3 May 2013; ACM: Paris, France, 2013; pp. 119–128. [Google Scholar]
- Qi, M.; Ma, W.; Shan, R. Design and Implementation of Tourist Location Recommendation System Based on Recurrent Neural Network. Electron. Technol. Softw. Eng. 2020, 1, 184–185. [Google Scholar]
- Zhao, P.; Zhu, H.; Liu, Y.; Xu, J.; Zhou, X. Where to Go Next: A Spatio-Temporal Gated Network for Next POI Recommendation. Proc. AAAI Conf. Artif. Intell. 2019, 33, 5877–5884. [Google Scholar] [CrossRef]
- Zhou, F.; Yin, R.; Zhang, K.; Trajcevski, G.; Zhong, T.; Wu, J. Adversarial Point-of-Interest Recommendation. In Proceedings of the The World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; ACM: San Francisco, CA, USA, 2019; pp. 3462–34618. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. In Proceedings of the The 5th International Conference on Learning Representations, Toulon, France, 24–26 April 2017; OpenReview.net: Toulon, France, 2017. [Google Scholar]
- Wang, X.; He, X.; Wang, M.; Feng, F.; Chua, T. Neural Graph Collaborative Filtering. In Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR 2019, Paris, France, 21–25 July 2019; Piwowarski, B., Chevalier, M., Gaussier, É., Maarek, Y., Nie, J., Scholer, F., Eds.; ACM: New York, NY, USA, 2019; pp. 165–174. [Google Scholar] [CrossRef] [Green Version]
- Canturk, D.; Karagoz, P. SgWalk: Location Recommendation by User Subgraph-Based Graph Embedding. IEEE Access 2021, 9, 134858–134873. [Google Scholar] [CrossRef]
- Xu, S.; Cao, J.; Legg, P.; Liu, B.; Li, S. Venue2Vec: An Efficient Embedding Model for Fine-Grained User Location Prediction in Geo-Social Networks. IEEE Syst. J. 2020, 14, 1740–1751. [Google Scholar] [CrossRef] [Green Version]
- Zhong, T.; Zhang, S.; Zhou, F.; Zhang, K.; Trajcevski, G.; Wu, J. Hybrid graph convolutional networks with multi-head attention for location recommendation. World Wide Web 2020, 23, 3125–3151. [Google Scholar] [CrossRef]
- Huang, D.; Chen, G.; Haibing Li et, a. Spark personalized location recommendation system. J. Liaoning Tech. Univ. Nat. Sci. Ed. 2020, 39, 533–540. [Google Scholar]
- Xia, T.; Li, Y.; Feng, J.; Jin, D.; Zhang, Q.; Luo, H.; Liao, Q. DeepApp: Predicting Personalized Smartphone App Usage via Context-Aware Multi-Task Learning. Trans. Interact. Intell. Syst. 2020, 11, 64:1–64:12. [Google Scholar] [CrossRef]
- Lee, Y.; Park, I.; Cho, S.; Choi, J. Smartphone user segmentation based on app usage sequence with neural networks. Telemat. Inform. 2018, 35, 329–339. [Google Scholar] [CrossRef]
- Xia, T.; Li, Y. Revealing Urban Dynamics by Learning Online and Offline Behaviours Together. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2019, 3, 30:1–30:25. [Google Scholar] [CrossRef]
- Yu, D.; Li, Y.; Xu, F.; Zhang, P.; Kostakos, V. Smartphone App Usage Prediction Using Points of Interest. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2017, 1, 174:1–174:21. [Google Scholar] [CrossRef] [Green Version]
- 2018, K. TalkingData Mobile User Demographics. Available online: https://www.kaggle.com/c/talkingdata-mobile-user-demographics (accessed on 11 October 2018).
- He, X.; Deng, K.; Wang, X.; Li, Y.; Zhang, Y.; Wang, M. LightGCN: Simplifying and Powering Graph Convolution Network for Recommendation. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual, 11–15 July 2020; ACM: New York, NY, USA, 2020; pp. 639–648. [Google Scholar]
- Rendle, S.; Freudenthaler, C.; Gantner, Z.; Schmidt-Thieme, L. BPR: Bayesian Personalized Ranking from Implicit Feedback. In Proceedings of the Twenty-Fifth Conference on Uncertainty in Artificial Intelligence, Montreal, QC, Canada, 18–21 June 2009; pp. 452–461. [Google Scholar]
- Rong, D.; Yu, Z.; Tao, M.; Wang, Z.; Guo, B. Predicting activity attendance in event-based social networks: Content, context and social influence. In Proceedings of the ACM International Joint Conference on Pervasive and Ubiquitous Computing, Seattle, WA, USA, 13–17 September 2014; ACM: Seattle, WA, USA, 2014; pp. 425–434. [Google Scholar]
- Hao, M.; Yang, H.; Lyu, M.R.; King, I. SoRec: Social recommendation using probabilistic matrix factorization. In Proceedings of the 17th ACM Conference on Information and Knowledge Management, Napa Valley, CA, USA, 26–30 October 2008; ACM: Napa Valley, CA, USA, 2008; pp. 931–940. [Google Scholar]
- Ma, H.; Zhou, D.; Liu, C.; Lyu, M.R.; King, I. Recommender systems with social regularization. In Proceedings of the Forth International Conference on Web Search and Web Data Mining, Hong Kong, China, 21–25 February 2011; pp. 287–296. [Google Scholar]
- Elinas, P.; Bonilla, E.V. Addressing Over-Smoothing in Graph Neural Networks via Deep Supervision. arXiv 2022, arXiv:2202.12508. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Telecom Dataset | TalkingData | |
|---|---|---|
| Data Sources | Cellular network | Mobile application |
| City | Shanghai, China | Guangzhou, China |
| Time Duration | 20–26 April 2016 | 1–7 May 2016 |
| Records | 40,470,865 | 180,106 |
| Users | 10,000 | 256 |
| Locations | 11,584 | 439 |
| Apps | 1327 | 689 |
| Dataset | Telecom Dataset | TalkingData | |||||||
|---|---|---|---|---|---|---|---|---|---|
| HR@3 | ACC@3 | nDCG@3 | HR@5 | ACC@5 | nDCG@5 | HR@2 | ACC@2 | nDCG@2 | |
| KNN | 0.5359 | 0.2534 | 0.5586 | 0.8185 | 0.3841 | 0.5990 | 0.8606 | 0.6596 | 0.8413 |
| SVD | 0.5968 | 0.2784 | 0.5788 | 0.8557 | 0.3985 | 0.6174 | 0.8648 | 0.6683 | 0.8517 |
| MF | 0.5968 | 0.2831 | 0.5890 | 0.8664 | 0.4062 | 0.6274 | 0.8668 | 0.6636 | 0.8516 |
| SoRec | 0.6045 | 0.2849 | 0.5919 | 0.8548 | 0.4035 | 0.6318 | 0.8794 | 0.6738 | 0.8555 |
| SR | 0.6184 | 0.2911 | 0.5949 | 0.8697 | 0.4103 | 0.6372 | 0.8759 | 0.6708 | 0.8538 |
| CMF-L | 0.6233 | 0.2945 | 0.5926 | 0.8736 | 0.4135 | 0.6317 | 0.8756 | 0.6675 | 0.8540 |
| CMF-U | 0.6258 | 0.2961 | 0.5965 | 0.8754 | 0.4114 | 0.6327 | 0.8657 | 0.6617 | 0.8501 |
| CMF-UL | 0.6596 | 0.3146 | 0.6250 | 0.9053 | 0.4403 | 0.6600 | 0.8907 | 0.6836 | 0.8632 |
| Ours-mse | 0.7543 | 0.3855 | 0.6854 | 0.9303 | 0.4817 | 0.7107 | 0.9819 | 0.7946 | 0.9431 |
| Ours-bpr | 0.7916 | 0.4156 | 0.7194 | 0.9446 | 0.4997 | 0.7347 | 0.9841 | 0.8171 | 0.9488 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, X.; Chen, J.; Lian, X.; Mai, W. Resolving Data Sparsity via Aggregating Graph-Based User–App–Location Association for Location Recommendations. Appl. Sci. 2022, 12, 6882. https://doi.org/10.3390/app12146882
Chen X, Chen J, Lian X, Mai W. Resolving Data Sparsity via Aggregating Graph-Based User–App–Location Association for Location Recommendations. Applied Sciences. 2022; 12(14):6882. https://doi.org/10.3390/app12146882
Chicago/Turabian StyleChen, Xiang, Junxin Chen, Xiaoqin Lian, and Weimin Mai. 2022. "Resolving Data Sparsity via Aggregating Graph-Based User–App–Location Association for Location Recommendations" Applied Sciences 12, no. 14: 6882. https://doi.org/10.3390/app12146882
APA StyleChen, X., Chen, J., Lian, X., & Mai, W. (2022). Resolving Data Sparsity via Aggregating Graph-Based User–App–Location Association for Location Recommendations. Applied Sciences, 12(14), 6882. https://doi.org/10.3390/app12146882