
Extraction of Joint Entity and Relationships with Soft Pruning and GlobalPointer

Abstract
:1. Introduction
- (1)
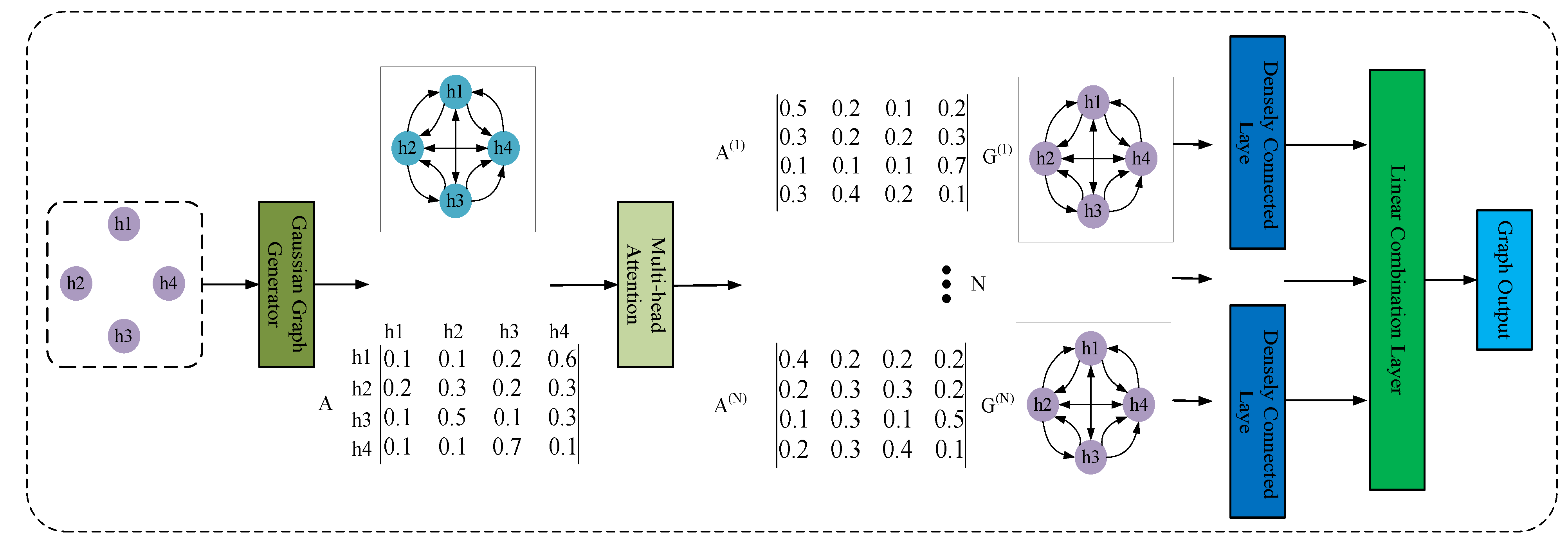
- We employ a Gaussian Graph Generator to initialize the text graph to avoid the problem of missing information caused by pruning. Each word in the sentence is a node in the graph. Edges are obtained by computing the distribution difference between two nodes by KL divergence to encourage information propagation between nodes with high distribution differences.
- (2)
- We decompose the quintuple extraction problem into scoring the four token pairs after transforming the triple extraction into a quintuple extraction task. Constructing (sh, st) matrices and (oh, ot) matrices using GlobalPointer, as well as (sh, oh|p) matrices and (st, ot|p) matrices under certain relations, allows for joint entity–relational extraction.
- (3)
- We conduct experiments to evaluate our model on the two NYT and WebNLG public datasets. The experimental results show that our model outperforms the baseline model in extracting both overlapping and non-overlapping triples, demonstrating the effectiveness of the graph module and joint decoding module.
2. Related Work
3. Methodology
3.1. BERT Model
3.2. Graph Model
3.2.1. Gaussian Graph Generator
3.2.2. KL Divergence
3.3. GlobalPointer Joint Decoder
3.4. Training and Prediction
4. Experiment
4.1. Datasets
4.2. Evaluation Metrics
4.3. Implementation Details
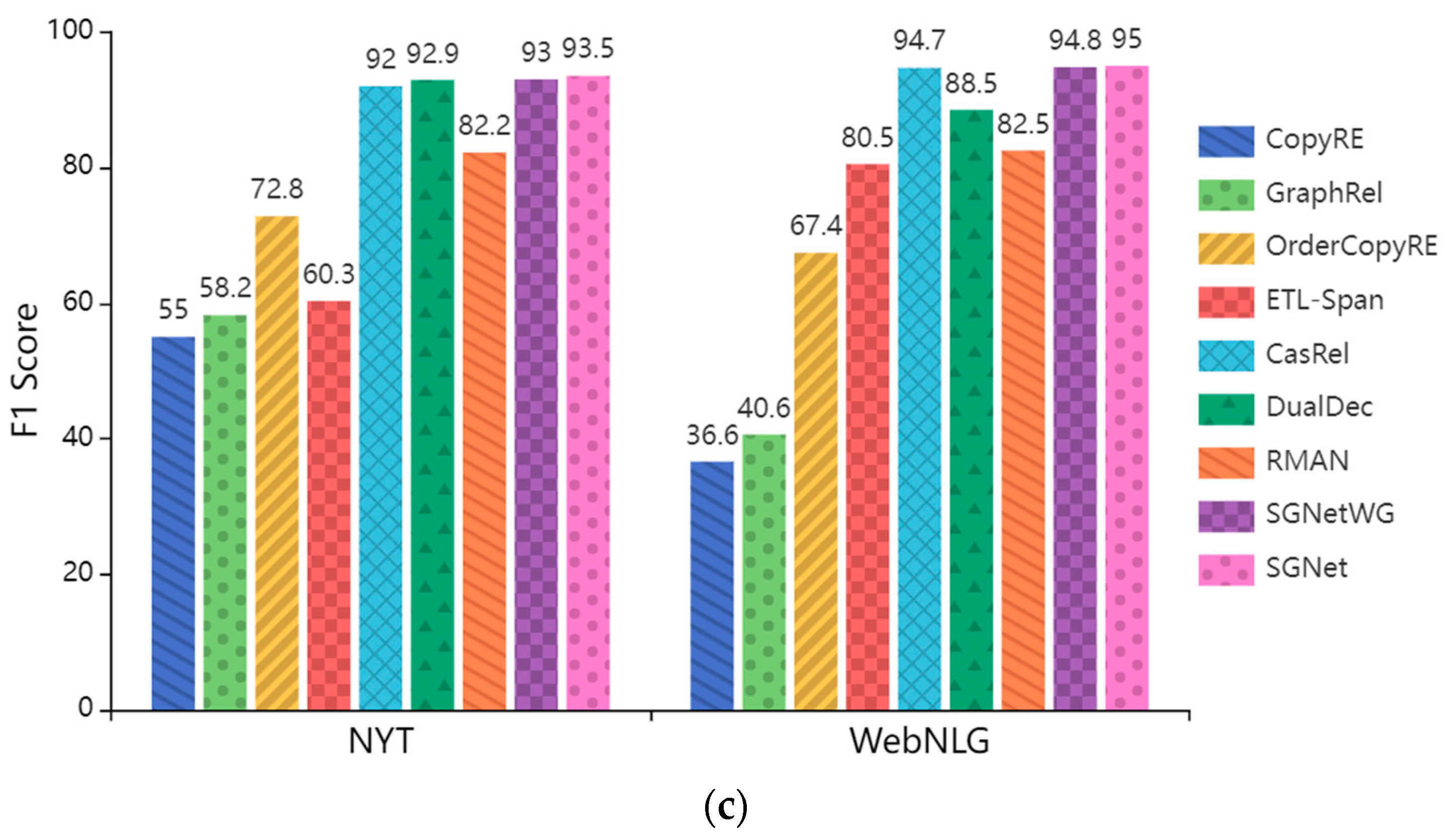
4.4. Result and Analysis
4.4.1. Main Results
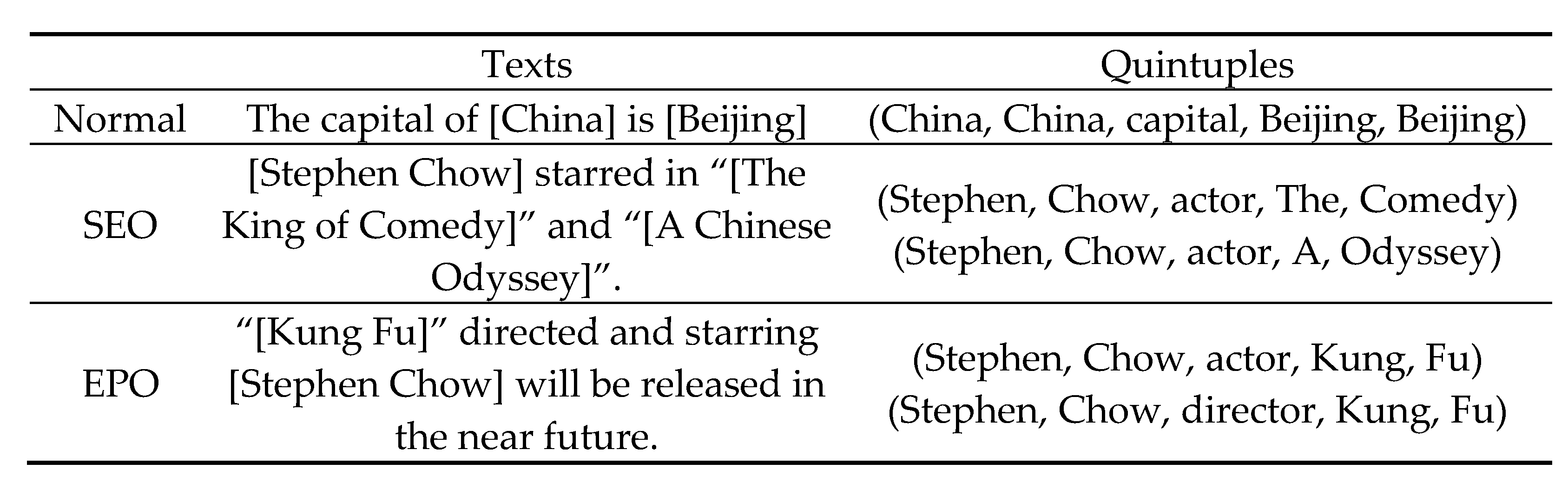
- NovelTagging [35] applies a novel tagging method to transform the joint extraction of entities and relations into a sequence tagging problem, but it cannot tackle the overlap problem.
- CopyRE [32] uses seq2seq to generate all triples to solve the overlap problem for a sentence, but such an approach only considers a single token and not multiple tokens.
- GraphRel [24]: A model that generates a weighted relation graph for each relation type, and applies a GCN to predict relations between all entity pairs.
- OrderCopyRE [23]: An improved model of CopyRE that uses reinforcement learning to generate multiple triples.
- ETL-Span [36] decomposes the joint extraction task into two subtasks. The first subtask is to distinguish all head entities that may be related to the target relation, and the second subtask is to determine the corresponding tail entity and relation for each extracted head entity.
- WDec [48]: An improved model of CopyRE, which solves the problem that CopyRE misses multiple tokens.
- CasRel [26] identifies the head entity first and then the tail entity under a particular relationship.
- DualDec [49] designs an efficient cascaded dual-decoder approach to address the extraction of overlapping relation triplets, which consists of a text-specific relation decoder and a relation-corresponding entity decoder.
- RMAN [50] not only considers the semantic features in the sentence but also leverages the relation type to label the entities to obtain a complete triple.
4.4.2. Result Analysis on Different Sentence Types
4.4.3. Case Study
4.4.4. Model Efficiency
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Liu, Q.; Li, Y.; Duan, H.; Liu, Y.; Qin, Z.G. Knowledge Graph Construction Techniques. J. Comput. Res. Dev. 2016, 53, 582–600. [Google Scholar] [CrossRef]
- Auer, S.; Bizer, C.; Kobilarov, G.; Lehmann, J.; Cyganiak, R.; Ives, Z. DBpedia: A nucleus for a Web of open data. In Proceedings of the 6th International Semantic Web Conference, ISWC 2007 and 2nd Asian Semantic Web Conference, ASWC 2007, Busan, Korea, 11–15 November 2007; pp. 722–735. [Google Scholar] [CrossRef] [Green Version]
- Bollacker, K.; Evans, C.; Paritosh, P.; Sturge, T.; Taylor, J. Freebase: A collaboratively created graph database for structuring human knowledge. In Proceedings of the 2008 ACM SIGMOD International Conference on Management of Data 2008, SIGMOD’08, Vancouver, BC, Canada, 9–12 June 2008; pp. 1247–1249. [Google Scholar] [CrossRef]
- Carlson, A.; Betteridge, J.; Kisiel, B.; Settles, B.; Hruschka, E.R., Jr.; Mitchell, T.M. Toward an architecture for never-ending language learning. In Proceedings of the AAAI-10/IAAI-10-Proceedings of the 24th AAAI Conference on Artificial Intelligence and the 22nd Innovative Applications of Artificial Intelligence Conference, Atlanta, GA, USA, 11–15 July 2010; pp. 1306–1313. Available online: https://ojs.aaai.org/index.php/AAAI/article/view/7519 (accessed on 5 January 2010).
- Wu, W.; Li, H.; Wang, H.; Zhu, K.Q. Probase: A probabilistic taxonomy for text understanding. In Proceedings of the 2012 ACM SIGMOD International Conference on Management of Data, SIGMOD ‘12, Scottsdale, AZ, USA, 21–24 May 2012; pp. 481–492. [Google Scholar] [CrossRef]
- Vrandei, D.; Krotzsch, M. Wikidata: A free collaborative knowledgebase. Commun. ACM 2014, 57, 78–85. [Google Scholar] [CrossRef]
- Han, X.; Liu, Z.; Sun, M. Neural knowledge acquisition via mutual attention between knowledge graph and text. In Proceedings of the 32nd AAAI Conference on Artificial Intelligence, AAAI 2018, New Orleans, LA, USA, 2–7 February 2018; pp. 4832–4839. Available online: https://ojs.aaai.org/index.php/AAAI/article/view/11927 (accessed on 26 April 2018).
- Luan, Y.; He, L.; Ostendorf, M.; Hajishirzi, H. Multi-task identification of entities, relations, and coreference for scientific knowledge graph construction. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 Octomber–4 November 2018; pp. 3219–3232. [Google Scholar] [CrossRef] [Green Version]
- Qian, L.; Zhou, G.; Kong, F.; Zhu, Q.; Qian, P. Exploiting constituent dependencies for tree kernel-based semantic relation extraction. In Proceedings of the 22nd International Conference on Computational Linguistics, Manchester, UK, 18–22 August 2008; Volume 1, pp. 697–704. [Google Scholar] [CrossRef] [Green Version]
- Zelenko, D.; Aone, C.; Richardella, A. Kernel Methods for Relation Extraction. J. Mach. Learn. Res. 2003, 3, 1083–1106. [Google Scholar] [CrossRef] [Green Version]
- Nadeau, D.; Sekine, S. A Survey of Named Entity Recognition and Classification. Lingvisticae Investig. 2007, 30, 3–26. [Google Scholar] [CrossRef]
- Li, J.; Sun, A.; Han, J.; Li, C. A Survey on Deep Learning for Named Entity Recognition. IEEE Trans. Knowl. Data Eng. 2022, 34, 50–70. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.; Lu, Z. Exploring semi-supervised variational autoencoders for biomedical relation extraction. Methods 2019, 166, 112–119. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.; Qi, P.; Manning, C.D. Graph Convolution over Pruned Dependency Trees Improves Relation Extraction. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 2205–2215. [Google Scholar] [CrossRef] [Green Version]
- Dai, D.; Xiao, X.Y.; Lyu, Y.J.; Dou, S.; She, Q.Q.; Wang, H.F. Joint Extraction of Entities and Overlapping Relations Using Position-Attentive Sequence Labeling. In Proceedings of the 33rd AAAI Conference on Artificial Intelligence/31st Innovative Applications of Artificial Intelligence Conference/9th AAAI Symposium on Educational Advances in Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 6300–6308. [Google Scholar] [CrossRef] [Green Version]
- Ren, X.; Wu, Z.; He, W.; Qu, M.; Voss, C.R.; Ji, H.; Abdelzaher, T.F.; Han, J. CoType: Joint Extraction of Typed Entities and Relations with Knowledge Bases. In Proceedings of the 26th International Conference on World Wide Web (WWW), Perth, Australia, 3–7 May 2017; pp. 1015–1024. [Google Scholar] [CrossRef]
- Li, Q.; Ji, H. Incremental Joint Extraction of Entity Mentions and Relations. In Proceedings of the 52nd Annual Meeting of the Association-for-Computational-Linguistics (ACL), Baltimore, MD, USA, 22–27 June 2014; pp. 402–412. [Google Scholar]
- Yu, X.; Lam, W. Jointly identifying entities and extracting relations in encyclopedia text via a graphical model approach. In Proceedings of the 23rd International Conference on Computational Linguistics: Posters, Beijing, China, 23–27 August 2010; pp. 1399–1407. [Google Scholar]
- Miwa, M.; Sasaki, Y. Modeling Joint Entity and Relation Extraction with Table Representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1858–1869. [Google Scholar] [CrossRef]
- Zheng, S.C.; Hao, Y.X.; Lu, D.Y.; Bao, H.Y.; Xu, J.M.; Hao, H.W.; Xu, B. Joint entity and relation extraction based on a hybrid neural network. Neurocomputing 2017, 257, 59–66. [Google Scholar] [CrossRef]
- Gupta, P.; Schütze, H.; Andrassy, B. Table Filling Multi-Task Recurrent Neural Network for Joint Entity and Relation Extraction. In Proceedings of the COLING 2016, the 26th International Conference on Computational Linguistics: Technical Papers, Osaka, Japan, 11–16 December 2016; pp. 2537–2547. Available online: https://aclanthology.org/C16-1239 (accessed on 11 December 2016).
- Tan, Z.; Zhao, X.; Wang, W.; Xiao, W.D. Jointly Extracting Multiple Triplets with Multilayer Translation Constraints. In Proceedings of the 33rd AAAI Conference on Artificial Intelligence/31st Innovative Applications of Artificial Intelligence Conference/9th AAAI Symposium on Educational Advances in Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 7080–7087. [Google Scholar] [CrossRef]
- Zeng, X.; He, S.; Zeng, D.; Liu, K.; Zhao, J. Learning the extraction order of multiple relational facts in a sentence with reinforcement learning. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and 9th International Joint Conference on Natural Language Processing, Hong Kong, China, 3–7 November 2019; pp. 367–377. [Google Scholar] [CrossRef]
- Fu, T.J.; Li, P.H.; Ma, W.Y. GraphRel: Modeling Text as Relational Graphs for Joint Entity and Relation Extraction. In Proceedings of the 57th Annual Meeting of the Association-for-Computational-Linguistics (ACL), Florence, Italy, 28 July–2 August 2019; pp. 1409–1418. [Google Scholar] [CrossRef] [Green Version]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. In Proceedings of the 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, 24–26 April 2017. [Google Scholar]
- Wei, Z.P.; Su, J.L.; Wang, Y.; Tian, Y.; Chang, Y.; Assoc Computat, L. A Novel Cascade Binary Tagging Framework for Relational Triple Extraction. In Proceedings of the 58th Annual Meeting of the Association-for-Computational-Linguistics (ACL), Electr Network, 5–10 July 2020; pp. 1476–1488. [Google Scholar] [CrossRef]
- Chan, Y.S.; Roth, D. Exploiting syntactico-semantic structures for relation extraction. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Portland, OR, USA, 19–24 June 2011; Volume 1, pp. 551–560. Available online: https://aclanthology.org/P11-1056 (accessed on 1 January 2011).
- GuoDong, Z.; Jian, S.; Jie, Z.; Min, Z. Exploring various knowledge in relation extraction. In Proceedings of the 43rd Annual Meeting on Association for Computational Linguistics, Ann Arbor, MI, USA, 25–30 June 2005; pp. 427–434. [Google Scholar] [CrossRef] [Green Version]
- Wang, S.; Zhang, Y.; Che, W.; Liu, T. Joint extraction of entities and relations based on a novel graph scheme. In Proceedings of the 27th International Joint Conference on Artificial Intelligence, IJCAI 2018, Stockholm, Sweden, 13–19 July 2018; pp. 4461–4467. [Google Scholar] [CrossRef] [Green Version]
- Miwa, M.; Bansal, M. End-to-End Relation Extraction using LSTMs on Sequences and Tree Structures. In Proceedings of the 54th Annual Meeting of the Association-for-Computational-Linguistics (ACL), Berlin, Germany, 7–12 August 2016; pp. 1105–1116. [Google Scholar] [CrossRef] [Green Version]
- Katiyar, A.; Cardie, C. Going out on a limb: Joint Extraction of Entity Mentions and Relations without Dependency Trees. In Proceedings of the 55th Annual Meeting of the Association-for-Computational-Linguistics (ACL), Vancouver, BC, Canada, 30 July–4 August 2017; pp. 917–928. [Google Scholar] [CrossRef] [Green Version]
- Zeng, X.R.; Zeng, D.J.; He, S.Z.; Liu, K.; Zhao, J. Extracting Relational Facts by an End-to-End Neural Model with Copy Mechanism. In Proceedings of the 56th Annual Meeting of the Association-for-Computational-Linguistics (ACL), Melbourne, Australia, 15–20 July 2018; pp. 506–514. [Google Scholar] [CrossRef] [Green Version]
- Katiyar, A.; Cardie, C. Investigating LSTMs for joint extraction of opinion entities and relations. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, ACL 2016, Berlin, Germany, 7–12 August 2016; pp. 919–929. [Google Scholar] [CrossRef] [Green Version]
- Zhang, M.; Zhang, Y.; Fu, G. End-to-end neural relation extraction with global optimization. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, EMNLP 2017, Copenhagen, Denmark, 9–11 September 2017; pp. 1730–1740. [Google Scholar] [CrossRef]
- Zheng, S.C.; Wang, F.; Bao, H.Y.; Hao, Y.X.; Zhou, P.; Xu, B. Joint Extraction of Entities and Relations Based on a Novel Tagging Scheme. In Proceedings of the 55th Annual Meeting of the Association-for-Computational-Linguistics (ACL), Vancouver, BC, Canada, 30 July–4 August 2017; pp. 1227–1236. [Google Scholar] [CrossRef] [Green Version]
- Yu, B.W.; Zhang, Z.Y.; Shu, X.B.; Liu, T.W.; Wang, Y.B.; Wang, B.; Li, S.J. Joint Extraction of Entities and Relations Based on a Novel Decomposition Strategy. In Proceedings of the 24th European Conference on Artificial Intelligence (ECAI), European Assoc Artificial Intelligence, Electr Network, 29 August–8 September 2020; pp. 2282–2289. [Google Scholar] [CrossRef]
- Wang, Y.; Yu, B.; Zhang, Y.; Liu, T.; Zhu, H.; Sun, L. TPLinker: Single-stage Joint Extraction of Entities and Relations through Token Pair Linking. In Proceedings of the 28th International Conference on Computational Linguistics, Barcelona, Spain (Online), 13–18 September 2020; pp. 1572–1582. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. In Proceedings of the 31st Annual Conference on Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL HLT 2019, Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Xue, F.Z.; Sun, A.X.; Zhang, H.; Chng, E.S. GDPNet: Refining Latent Multi-View Graph for Relation Extraction. In Proceedings of the 35th AAAI Conference on Artificial Intelligence/33rd Conference on Innovative Applications of Artificial Intelligence/11th Symposium on Educational Advances in Artificial Intelligence, Electr Network, 2–9 February 2021; pp. 14194–14202. [Google Scholar]
- Lee, Y.; Lee, Y. Toward scalable internet traffic measurement and analysis with Hadoop. SIGCOMM Comput. Commun. Rev. 2012, 43, 5–13. [Google Scholar] [CrossRef]
- Guo, Z.J.; Zhang, Y.; Lu, W. Attention Guided Graph Convolutional Networks for Relation Extraction. In Proceedings of the 57th Annual Meeting of the Association-for-Computational-Linguistics (ACL), Florence, Italy, 28 July–2 August 2019; pp. 241–251. [Google Scholar] [CrossRef] [Green Version]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the 30th IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar] [CrossRef] [Green Version]
- Su, J.L. GlobalPointer: Deal with Nested and Non-Nested NER in a Unified Way. 2021. Available online: https://spaces.ac.cn/archives/8373 (accessed on 1 May 2021).
- Riedel, S.; Yao, L.; McCallum, A. Modeling relations and their mentions without labeled text. In Machine Learning and Knowledge Discovery in Databases, Proceedings of the European Conference, ECML PKDD 2010, Barcelona, Spain, 19–23 September 2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 148–163. [Google Scholar] [CrossRef] [Green Version]
- Gardent, C.; Shimorina, A.; Narayan, S.; Perez-Beltrachini, L. Creating Training Corpora for NLG Micro-Planning. In Proceedings of the 55th Annual Meeting of the Association-for-Computational-Linguistics (ACL), Vancouver, BC, Canada, 30 July–4 August 2017; pp. 179–188. [Google Scholar] [CrossRef]
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. arXiv 2019, arXiv:1711.05101. [Google Scholar]
- Nayak, T.; Ng, H.T. Effective Modeling of Encoder-Decoder Architecture for Joint Entity and Relation Extraction. In Proceedings of the 34th AAAI Conference on Artificial Intelligence/32nd Innovative Applications of Artificial Intelligence Conference/10th AAAI Symposium on Educational Advances in Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 8528–8535. [Google Scholar] [CrossRef]
- Ma, L.; Ren, H.; Zhang, X. Effective Cascade Dual-Decoder Model for Joint Entity and Relation Extraction. arXiv 2021, arXiv:2106.14163. [Google Scholar]
- Lai, T.; Cheng, L.; Wang, D.; Ye, H.; Zhang, W. RMAN: Relational multi-head attention neural network for joint extraction of entities and relations. Appl. Intell. 2022, 52, 3132–3142. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | NYT | WebNLG | ||
|---|---|---|---|---|
| Train | Test | Train | Test | |
| Normal | 37,013 | 3266 | 1596 | 246 |
| EPO | 9782 | 978 | 227 | 26 |
| SEO | 14,735 | 1297 | 3406 | 457 |
| ALL | 56,195 | 5000 | 5019 | 703 |
| Model | NYT | WebNLG | ||||
|---|---|---|---|---|---|---|
| Prec. | Rec. | F1 | Prec. | Rec. | F1 | |
| NovelTagging | 62.4 | 31.7 | 42.0 | 52.5 | 19.3 | 28.3 |
| CopyREOneDecoder | 61.0 | 56.6 | 58.7 | 37.7 | 36.4 | 37.1 |
| CopyREMultiDecoder | 61.0 | 56.6 | 58.7 | 37.7 | 36.4 | 37.1 |
| GraphRel1p | 62.9 | 57.3 | 60.0 | 42.3 | 39.4 | 37.1 |
| GraphRel2p | 63.9 | 60.0 | 61.9 | 44.7 | 41.1 | 42.9 |
| OrderCopyRE | 77.9 | 67.2 | 72.1 | 63.3 | 59.9 | 61.6 |
| ETL-Span | 84.9 | 72.3 | 78.1 | 84.0 | 91.5 | 87.6 |
| WDec | 94.5 | 76.2 | 84.4 | - | - | - |
| CasRel | 89.7 | 89.5 | 89.6 | 93.4 | 90.1 | 91.8 |
| DualDec | 90.2 | 90.9 | 90.5 | 90.3 | 91.5 | 90.9 |
| RMAN | 87.1 | 83.8 | 85.4 | 83.6 | 85.3 | 84.5 |
| SGNetWG | 90.5 | 89.8 | 90.2 | 90.6 | 90.0 | 90.2 |
| SGNet | 91.2 | 91.4 | 91.3 | 91.8 | 91.9 | 91.9 |
| Method | NYT | WebNLG | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| N = 1 | N = 2 | N = 3 | N = 4 | N ≥ 5 | N = 1 | N = 2 | N = 3 | N = 4 | N ≥ 5 | |
| CopyREOneDecoder | 66.6 | 52.6 | 49.7 | 48.7 | 20.3 | 65.2 | 33.0 | 22.2 | 14.2 | 13.2 |
| CopyREMultiDecoder | 67.1 | 58.6 | 52.0 | 53.6 | 30.0 | 59.2 | 42.5 | 31.7 | 24.2 | 30.0 |
| GraphRel1p | 69.1 | 59.5 | 54.4 | 53.9 | 37.5 | 63.8 | 46.3 | 34.7 | 30.8 | 29.4 |
| GraphRel2p | 71.0 | 61.5 | 57.4 | 55.1 | 41.1 | 66.0 | 48.3 | 37.0 | 32.1 | 32.1 |
| OrderCopyRE | 71.7 | 72.6 | 72.5 | 77.9 | 45.9 | 63.4 | 62.2 | 64.4 | 57.2 | 55.7 |
| ETL-Span | 85.5 | 82.1 | 74.7 | 75.6 | 76.9 | 82.1 | 86.5 | 91.4 | 89.5 | 91.1 |
| CasRel | 88.2 | 90.3 | 91.9 | 94.2 | 83.7 | 89.3 | 90.8 | 94.2 | 92.4 | 90.9 |
| DualDec | 88.5 | 90.8 | 92.4 | 95.5 | 90.1 | 85.8 | 90.5 | 88.9 | 89.9 | 85.4 |
| RMAN | 84.3 | 86.0 | 86.6 | 92.5 | 76.1 | - | - | - | - | - |
| SGNet | 89.2 | 91.6 | 92.7 | 95.9 | 90.6 | 89.4 | 91.1 | 93.7 | 93.4 | 91.7 |
| Sentence | SGNet |
|---|---|
| Barcelona will discharge Ronaldinho to Brazil, Deco to Portugal and the young star Lionel Messi to Argentina. | (Ronaldinho, person, Brazil) (Messi, person, Argentina) |
| Ms. Rice met with China’s leaders in Beijing in March specifically to ask them to pressure North Korea. | (Beijing, administrative_division, China) (China, location, Beijing) (China, country, Beijing) |
| Dataset | Model | Training Time | Inference Time | F1 |
|---|---|---|---|---|
| NYT | TPLinker * | 1592 | 46.2 | 90.6 |
| SGNetWG | 1390 | 43.2 | 90.2 | |
| SGNet | 2165 | 69.6 | 91.3 | |
| WebNLG | TPLinker * | 599 | 40.1 | 90.9 |
| SGNetWG | 142 | 37.4 | 90.2 | |
| SGNet | 631 | 63.4 | 91.9 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liang, J.; He, Q.; Zhang, D.; Fan, S. Extraction of Joint Entity and Relationships with Soft Pruning and GlobalPointer. Appl. Sci. 2022, 12, 6361. https://doi.org/10.3390/app12136361
Liang J, He Q, Zhang D, Fan S. Extraction of Joint Entity and Relationships with Soft Pruning and GlobalPointer. Applied Sciences. 2022; 12(13):6361. https://doi.org/10.3390/app12136361
Chicago/Turabian StyleLiang, Jianming, Qing He, Damin Zhang, and Shuangshuang Fan. 2022. "Extraction of Joint Entity and Relationships with Soft Pruning and GlobalPointer" Applied Sciences 12, no. 13: 6361. https://doi.org/10.3390/app12136361
APA StyleLiang, J., He, Q., Zhang, D., & Fan, S. (2022). Extraction of Joint Entity and Relationships with Soft Pruning and GlobalPointer. Applied Sciences, 12(13), 6361. https://doi.org/10.3390/app12136361