1. Introduction
As the Internet becomes widely available and accessible, the ways that consumers purchase goods have changed rapidly from offline to online. For offline purchases, it is possible for consumers to have an opportunity to select, touch, and test the goods directly. On the other hand, for online purchases, it is common that consumers do not have an opportunity to directly touch and test the goods. Accordingly, in the case of an online purchase, consumers tend to depend heavily on the reviews given by other consumers. Such reviews provide potential customers and companies with necessary and meaningful information [
1,
2].
In the digital game market of Korea, mobile RPGs (role-playing games) have recently become mass-produced and they include similar content, sensational advertisements, low quality, and excessive charging induction. These have negatively affected the game market and users’ satisfactory game experiences. In this regard, we conduct a big data analysis on the users’ reviews to find out what will be needed to have a positive gaming experience for mobile RPGs.
This study deals with the analysis of user reviews on the Google Play Store to find ways to improve the mobile RPGs. This is acheived through crawling the online user reviews, collecting meaningful text data through tokenization, and extracting meaningful information. The results are visualized through LDA (latent Dirichlet allocation) and topic modeling algorithms, and are analyzed and interpreted based on the results of visualization.
2. Relevant Studies
Big data analysis aims to get meaningful information through performing an algorithm and mathematical process based on the purposes of the analysis. As part of data mining, text mining refers to the discovery of meaningful patterns based on massive amounts of text data [
3]. The unprocessed crawling text data include lots of meaningless words, and thus, it is not easy to find the main topics from a set of such words. In this regard, topic modeling algorithms are one of the data mining techniques and is a statistical method that aims to find topics by analyzing the words used in a vast amount of texts and analyzing how topics are correlated and how they have changed over time.
There is much research to analyze and evaluate the playability of video games by using heuristics [
4,
5], MDA (mechanics, dynamics, aesthetics) framework [
6], A.G.E. (actions, gameplay, experience) framework [
7], etc.; however, such methods fall short in directly reflecting the players’ opinions and their overall gameplay satisfaction. Thus, a data-driven approach has recently been used to analyze the playability of video games by mining a large number of player’s opinions from their reviews [
8]. In a similar line, this study proposes a text-mining approach to analyze a specific genre of RPGs for the purpose of their better game design. The most objective way of evaluating games is to figure out the sentiments of users and the text mining technique enables us to collect, draw, and analyze users’ thoughts and requests.
This study selects the RPG genre because mobile RPGs occupy higher ranks in market sales that many users play, and the games with high sales are also high in daily active users (DAU). Again, in order to effectively collect users’ opinions, mobile RPGs is a practical choice to collect and analyze users’ thoughts and requests through text mining techniques to propose a game design improvement.
3. RPG (Role-Playing Game)
RPGs are among the most played major game genres across platforms. Among the mobile games registered in the Google Play Store as of June 2020, the RPG genre accounted for 56 out of the top 100 sales [
9].
The advantages and characteristics of RPGs are as follows:
RPGs give users the role of characters and determine the identity of users and the direction of games through a sense of unity between game characters and users. RPGs exercise a direct influence on performing roles in games [
10].
Users play the roles they are assigned in in the game, which makes them deeply immersed. For such sense of immersion, game worlds should be alive and dynamic [
11].
Various forms of content that users should perform in playing a role in games exist [
12].
Along with long play time, outstanding extensibility, and strong game addiction, the identified advantages and characteristics make RPGs suitable for online platforms thatmatch the interests of game developers that should make profits continuous.
4. Problems by Recent Excessive RPG Supply
“Game developers” expectations for high sales and continuous profit-making has led them to supply various RPGs to market and accordingly, the number of users who enjoy RPGs has increased. Recently-produced RPGs have shown problems of dramatic advertising, low quality gameplays, excessive charging, and similar content, which are significantly different from various characteristics of RPGs created at their beginning [
13]. Several studies have shown that such games created in mass production negatively affect the game industry, market, and also the users’ gameplay experiences.
In their study on collective emotions and mobile game user experience, Cheon and Kwak stated that provides feedback on the quality of content was not fully reviewed on the platform, which generated a serious problem that may worsen the reliability of the service [
14]. Ki and Park argued in their study on the interaction between social network services and social network game users that the keyword of “mass production of low-quality plagiarism games” may bring a negative view of platforms that serve games [
15]. Jeong et al. stated that mass-produced games without improvements prevent domestic games from growing and lead to service failure [
16].
DAU (daily active user) and ARPU (average revenue per user) are very important indicators for game developers that place profits before anything else. The number of users indicates immediate profit and the game content is reflected in the game development based on such profit, which can create a virtuous cycle. Developing a mass-produced type of game has been characterized by similar contents and gameplay that guarantee high sales, eventually leading to the lack of diversity in games and users’ distrust. Thus, presenting a direction that can satisfy both game developers and users is needed.
5. Using Big Data Text Mining
5.1. Text Mining
This study proposes a method to collect game reviews from various users and analyze them through text mining techniques. Most reviews can be collected from the internet; in other words, a set of data with atypical text form, and thus, a text mining technique is used as a way to extract information from such atypical data [
2]. Text mining is a part of data mining that finds a meaningful patterns based on huge text data [
3].
Each human language has unique characteristics in terms of vocabulary and grammar. Forms of expression are so diverse and complex that it is difficult to find regularity. Human languages continue to change according to the language-use environment. In this respect, “natural language processing” is necessary to analyze and process languages that are expressed as characters and to understand their structure and meaning. Natural language processing allows us to convert documents to a form that can be analyzed by passing through the collection and preprocessing [
17].
5.2. Topic Modeling
Topic modeling finds main topics by analyzing words used in an enormous amount of text collected according to the association between subjects and time [
18].
Topic modeling is a methodology that is usefully covered in the field of text mining and LDA (latent Dirichlet allocation).
5.3. LDA (Latent Dirichlet Allocation)
LDA is one of the most used techniques in topic modeling for natural language processing. LDA is an algorithm proposed by Blei and is known as a standard tool in the study of topic modeling [
19]. LDA shows the topics through topic probability. Words with the highest probability in each topic provide a good idea of the topics [
20]. LDA algorithm finds topics hidden in documents as a production model. LDA algorithms can figure out topics in the entire document set, topic percent by documents, and the probability that each word is included in each topic and infers posterior probabilities based on conditions that words are produced under the assumption that words are not independent [
21].
Figure 1 shows the LDA algorithm as a stochastic graph model.
The topic is
β1:
K and each
βk is a distribution of words. The topic proportion of
dth document is
θd.
θd,k is the topic proportion of document d for topic
k.
Zd is the topic designation of document d.
Zd,n which is
nth topic allocation of d can be obtained from fixed words [
22]. Tian et al. used LDA in their study to sort out software automatically [
23]. Tirunillai and Gerard have used LDA to study online chatters’ mining marketing by analyzing strategic brands of big data [
24]. Bolelli et al. used LDA to study topics and trends in text collection [
25]. On the other hand, Somasundaran and Gail used LDA to automatically sort out bug reports [
26].
5.4. Visualization of Data
Results of text mining through LDA are provided as a raw number and it is very difficult to analyze them, thus, visualizing data is needed to make it easy to analyze [
27].
6. Mobile RPG Data Analysis
Meaningful topics should be extracted from mobile RPG users’ reviews for this study. To this end, data are extracted through several processing steps, as shown in
Figure 2.
First, collect the users’ reviews using the web crawling method.
Then, the text data collected through web crawling are converted to numerical data that can be analyzed by the computers. Preprocessing is performed to filter unnecessary words for converting text data to figure data. Preprocessing allows only meaningful letters to remain in the text data.
Next, configure the topic models by using the LDA algorithm and find the optimum topic models by conducting a performance evaluation.
Finally, visualize the result of topic models so that it can be interpreted easily and seek the direction of improvement of games by the reasoning interests of users.
For this study, we used Python.
6.1. Collecting Data by Using Python
The web is basically expressed as HTML and it is managed in a typical form within HTML. The technique that brings typical data on the internet, parses, and extracts only the needed data is called crawling [
28], which is conducted by using Python.
6.2. Preprocessing by Using Python
Corpus data obtained from crawling is preprocessed through tokenization, clearing, and normalization to one’s needs. Tokenization [
29] refers to a process that classifies and sorts out a series of input text sections and separates language that cannot be divided anymore in terms of grammar, in other words, as tokens [
30]. Clearing means removing unnecessary data during the process of tokenization. Special symbols are representative data that should be removed. Normalization means binding words that are different but have the same meaning together (
Table 1).
6.3. Encoding
Encoding is performed through the one-hot encoding process while a computer converts the characters into numbers to process the letters [
31]. In the case of one-hot encoding, which is a collection of words that do not allow duplication when making a word set, it has a weakness that, as the number of words increases, storage space increases, and thus, data are digitized by focusing on word appearance frequency without considering BoW (bag of words) model-order of words.
6.4. Natural Language Processing
Natural language processing is a series of technical sets that analyze, extract, and understands meaningful information from text. This study used the Twitter package among Python packages for processing Korean information [
32].
7. Topic Modeling by Using Python
7.1. Marking Word Dictionary
Gensim, a library for topic modeling implemented as Python provides the LDA algorithm.
7.2. LDA Model Training
The following parameters were necessarily important to make the LDA model in Gensim.
The two parameters are adjusted and measured in their confusion and consistency scores. The parameter with the best evaluation is determined to complete the final LDA model.
7.3. Finding Optimum Passes
Testing passes with steps classified from 1 to 50 by multiples of 5 assuming that num_topics is 10 among LDA model parameters and the measurements for the confusion and consistency scores allows us to get the graphs in
Figure 3. Passes with the best score by analyzing the graphs are designated as final LDA model parameter values.
Perplexity is a standard way of showing that one model has an advantage over an-other. Coherence shows that topics are consistent with each other in different data sets. They are used to evaluate how well a particular probabilistic model predicts the actually observed values. Passes are the appropriate number of tests for the LDA model.
7.4. Finding Num_Topocs (Number of Topics)
The value of passes obtained in
Section 7.3 is applied and num_topics can be found among the LDA model parameters. Testing the num_topics with steps classified from 2 to 20 by multiples of 2 and the measurements for the confusion and consistency scores allows us to get the graphs in
Figure 4.
The num_topics with best scores by analyzing the graphs are designated as final LDA model parameter values.
In the case that the number of topics is twenty or fewer, the confusion and consistency scores continue to worsen, and thus, inspecting topics of twenty or more can be meaningless.
8. Visualization by Using Python
After generating the LDA, it is visualized by pyLDAvis [
33], as shown in
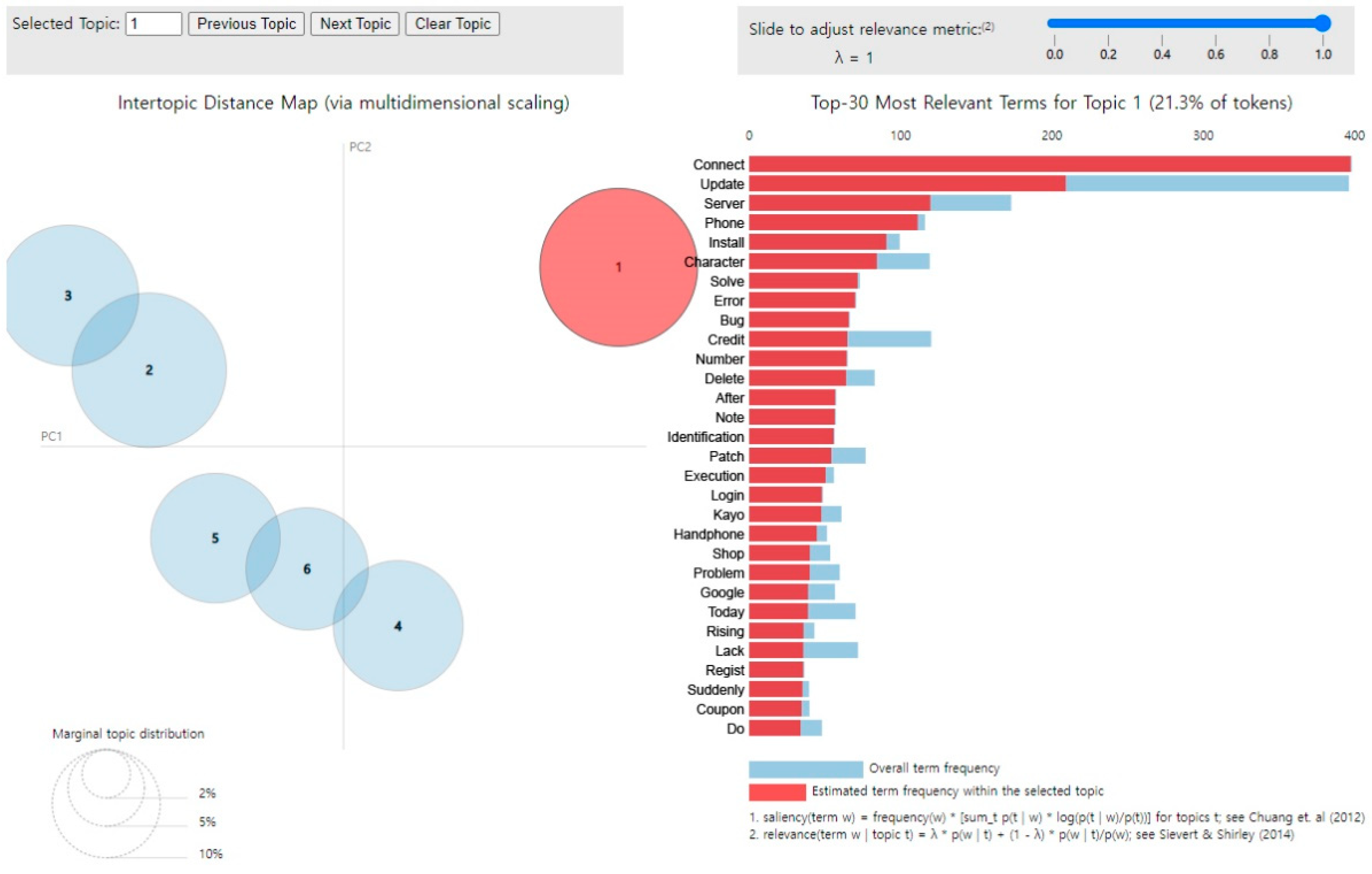
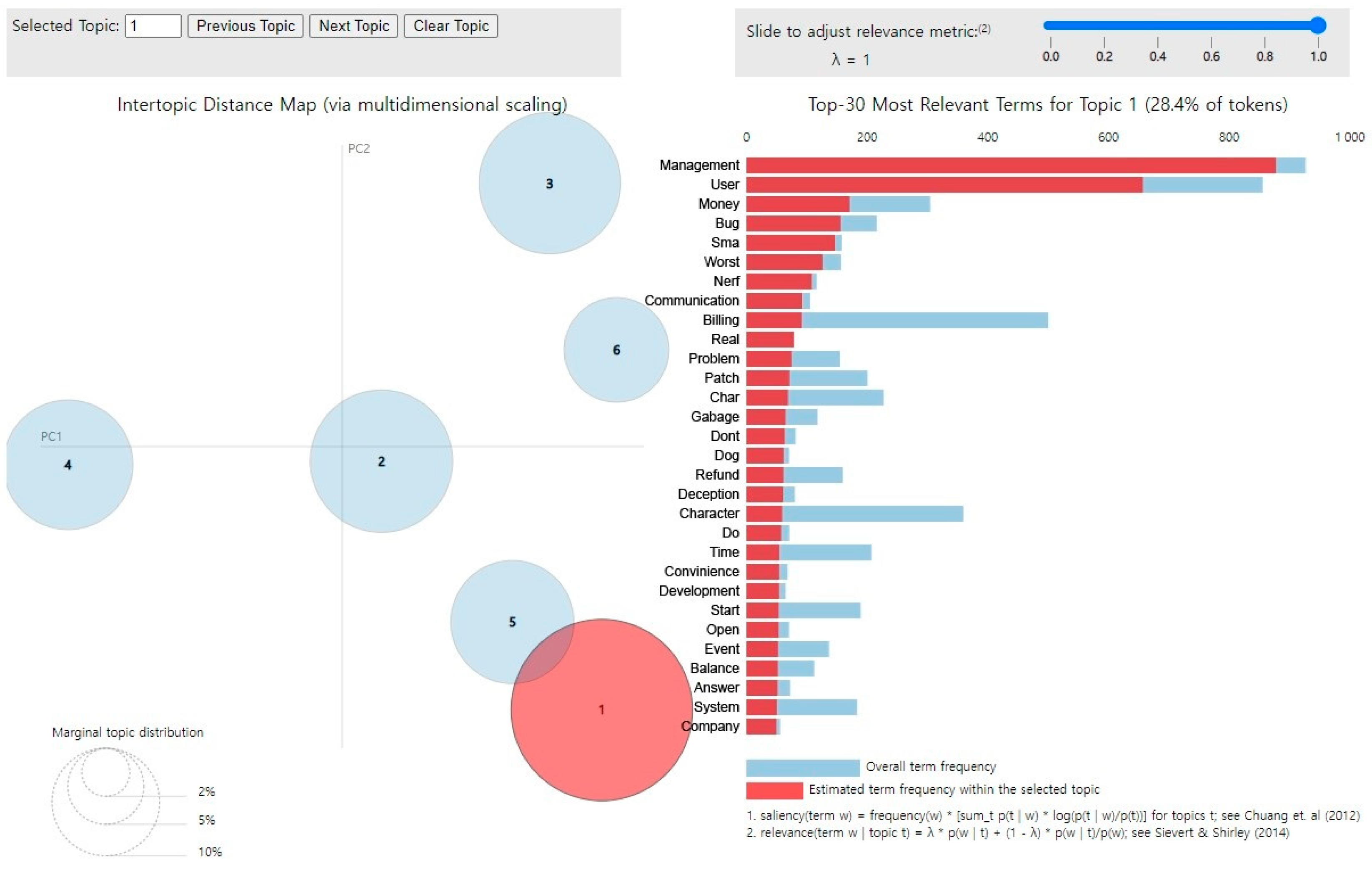
Figure 5.
The pie chart shows the association between the two topics. If the distance is closer, the two topics are dealing with similar content, and if the distance is far, it means that the two topics are dealing with different content. The more keywords are mentioned, the longer the bar graph will be. Through this, it is possible to extract the keywords that are mentioned a lot and to infer what topic they are talking about.
9. Topic Analysis
For this study, three mobile RPGs of Google Play in Korea were analyzed. Game A is a Korean mobile game playing an eight-heads-high character with high degree of graphic reality. Game B is a Korean mobile game with a three-heads-high character and Game C is a Chinese RPG game with high performance graphics. For the analysis of Game A, 5240 reviews were collected, and both Game B and C have each collected 5200 reviews.
For Game A, we found that there were relative more reviews related to “system error” and as for Game B, mostly mentioned reviews are about “graphic quality” and for Game C, they are about “character growth” and their “item enhancement”. For detail information, the LDA results for Game C was analyzed by pyLDAvis, as shown in
Figure 6, even though we should keep its dataset private for commercial reasons. Finding topics based on LDA model schematization was carried out by combining and inferring words with high salient values in case there was no knowledge of documents and where it may be difficult to find topics. There was a considerable concern that the analyzer’s subjective thoughts were involved in the analysis.
The most mentioned terms that were analyzed in this study were “charge”, “induction”, “gambling”, “refund”, “update”, “character”, “graphic”, “probability”, “enhancement”, “event”, “customization”, etc. From these terms, appropriate topics were inferred.
Table 2 shows the connections between the terms grouped together as very frequently mentioned in the LDA model.
The topics must be inferred from the grouped terms. This requires a deep understanding and general knowledge of the gameplay of mobile RPGs. In addition, there is a possibility that different inferences may be made with the same data due to the differences in the individual experiences of the inferences.
As most of the big data analysis results showed negative rather than positive content, it was found that Google Play user reviews were used as a place to express users’ direct complaints about the game.
Through the analysis, it was possible to confirm that excellent graphic elements and content that can induce billing are the current development trend and direction for mobile RPGs. In addition, users were more interested in the game’s graphic elements, rewards, and reasonable billing than the game’s inherent game mechanics and gameplay. This confirms that, as was concerned about in this study, rewards and billing factors are considered more importantly than game mechanics or systems in mobile RPGs compared to other genres of mobile games.
10. Conclusions
RPGs are better than other genres of games in terms of users’ continuous play. Therefore, RPGs have advantages in securing profits in a stable way. For this, mobile RPGs are usually developed in a mass-production manner, in contrast with other RPGs that have their own playabilities that each game designer would like to incorporate. Such problems cause user complaints which may eventually affect the profits of game sales and lower the reliability of mobile RPG games themselves.
This study proposes a text mining approach to analyze users’ opinions in order to make suggestions for better improvement of current, massively-produced mobile RPGs in Korea. In order to obtain and analyze data, user reviews are crawled and tokened by using Python and open-source modules, and users’ opinions are figured out by extracting meaningful words. In addition, the LDA topic modeling technique was used to grasp an accurate topic and find meaningful words. This study found the optimum performance of the LDA model by comparing the confusion and consistency scores to evaluate the performance of the LDA model. Data analyzed by the LDA model show correlations between topics by schematizing. This study can analyze and organize relevant topics through the LDA model and obtain the main words composing the topics. It is necessary to enhance the accuracy by improving sophistication in the process of tokening through crawling. In addition, it is necessary to make a comparative analysis of studies based on analysis models. The findings of this study is expected to be used in developing and complementing games of other genres by extracting meaningful data.
Based on the user’s review analysis, the main points that should be taken into consideration for better mobile RPG design are summarized as follows.
- (1)
Graphics (visual) have a great influence on the loyalty of the game.
- (2)
Users are very interested in character-related content.
- (3)
The balance of billing is considered the most sensitive by users.
- (4)
The gameplay of battle is not highly desired by users.
Author Contributions
Conceptualization and methodology, D.Y.; data curation, D.Y.; funding acquisition, J.K.; investigation, D.Y.; supervision, J.K.; visualization, D.Y.; writing—original draft, D.Y.; writing—review and editing, J.K. All authors have read and agreed to the published version of the manuscript.
Funding
This research is supported by Ministry of Culture, Sports and Tourism and the Korea Creative Content Agency (Project Number: R2020040243).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data presented in this study are available on request from the corresponding author.
Acknowledgments
This research is supported by Ministry of Culture, Sports and Tourism and the Korea Creative Content Agency (Project Number: R2020040243); Excerpt submitted thesis by Dong-Hyun, Youm, University of Gachon, Republic of Korea, 2020.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Archak, N.; Ghose, A.; Ipeirotis, P. Deriving the Pricing Power of Product Features by Mining Consumer Reviews. Manag. Sci. 2011, 57, 1485–1509. [Google Scholar] [CrossRef] [Green Version]
- Kim, J.Y.; Kim, D.S. A study on the method for extracting the purpose-specific customized information from online product reviews based on text mining. J. Soc. e-Bus. Stud. 2016, 21, 151–161. [Google Scholar] [CrossRef] [Green Version]
- Navathe, S.B.; Ramez, A.E. Fundamentals of Database Systems with Cdrom and Book; Addison-Wesley Longman Publishing Inc.: Boston, MA, USA, 2001. [Google Scholar]
- Desurvire, H.; Caplan, M.; Toth, J.A. Using Heuristics to evaluate the playability of games. In Proceedings of the CHI’04 Extended Abstracts on Human Factors in Computing Systems, Vienna, Austria, 24–29 April 2004; pp. 1509–1512. [Google Scholar]
- Korhonen, H.; Koivisto, E.M. Playability heuristics for mobile games. In Proceedings of the 8th Conference on Human-Computer Interaction with Mobile Devices and Services, Helsinki, Finland, 12–15 September 2006; pp. 9–16. [Google Scholar]
- Hunicke, R.; Leblanc, M.; Zubeck, R. MDA: A Formal Approach to Game Design and Game Research. In Proceedings of the Game Developers Conference, San Jose, CA, USA, 22–26 March 2004. [Google Scholar]
- Dillon, R. Towards the Definition of a Framework and Grammar for Game Analysis and Design. Int. J. Comput. Inf. Technol. 2014, 3, 161–209. [Google Scholar]
- Li, X.; Zhang, Z.; Stefanidis, K. A Data-Driven Approach for Video Game Playability Analysis Based on Players’ Reviews. Information 2021, 12, 129. [Google Scholar] [CrossRef]
- Google Play. Available online: https://play.google.com (accessed on 18 July 2020).
- Byeon, H.S. The Impacts of Artistic Creativity, Scientific Creativity, General Creativity on Perceived Enjoyment and Intention to Reuse: Focused on Role-Playing Game Player. J. Korea Game Soc. 2011, 11, 59–67. [Google Scholar] [CrossRef]
- Role-Playing Game. Available online: https://en.wikipedia.org/wiki/Role-playing_game (accessed on 18 July 2020).
- Kim, G.H.; Lee, N.Y. The Quality Evaluation Model for Mobile RPG; The Korea Institute of Information and Commucation Engineering: Seoul, Korea, 2014; pp. 457–460. [Google Scholar]
- Column-Why is a Chinese-Made Mass-Produced Game a Problem? Acrofan. Available online: https://url.kr/qt6WZw (accessed on 18 July 2020).
- Cheon, Y.J.; Kwak, K.T. Collective Sentiments and Users’ Feedback to Game Contents: Analysis of Mobile Game UX based on Social Big Data Mining. J. Korea Game Soc. 2015, 15, 145–156. [Google Scholar] [CrossRef]
- Ki, D.; Park, C. Two-way interaction between social network service (SNS) and social network game (SNG) users. Asia-Pac. J. Multimed. Serv. Converg. Art Humanit. Sociol. 2019, 9, 1321–1329. [Google Scholar] [CrossRef]
- Jeong, S.H.; Kyung, B.P.; Lee, D.L.; Lee, W.B.; Ryu, S.H. Study for the Transformation and Growth of MMORPGs: TIME FLOW Scenario Design. J. Korea Game Soc. 2015, 15, 79–92. [Google Scholar] [CrossRef]
- Hong, W.E.; Kim, U.H.; Cho, S.H.; Kim, S.S.; Yi, M.Y.; Shin, D.H. Export Control System based on Case Based Reasoning: Design and Evaluation. J. Intell. Inf. Syst. 2014, 20, 109–131. [Google Scholar] [CrossRef] [Green Version]
- Kang, B.; Song, M.; Jho, W. A Study on Opinion Mining of Newspaper Texts based on Topic Modeling. J. Korean Soc. Libr. Inf. Sci. 2013, 47, 315–334. [Google Scholar] [CrossRef] [Green Version]
- Blei, D.; Ng, A.; Jordan, M. Latent dirichlet allocation. Adv. Neural Inf. Process. Syst. 2001, 14, 601–608. [Google Scholar]
- Jelodar, H.; Wang, Y.; Yuan, C.; Feng, X.; Jiang, X.; Li, Y.; Zhao, L. Latent Dirichlet Allocation (LDA) and Topic modeling: Models, applications, a survey. Multimed. Tools Appl. 2019, 78, 15169–15211. [Google Scholar] [CrossRef] [Green Version]
- Park, J.H.; Song, M. A Study on the Research Trends in Library & Information Science in Korea using Topic Modeling. J. Korean Soc. Inf. Manag. 2013, 30, 7–32. [Google Scholar] [CrossRef] [Green Version]
- Blei, D.M.; Carin, L.; Dunson, D.B. Probabilistic Topic Models. IEEE Signal Process. Mag. 2010, 27, 55–65. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tian, K.; Meghan, R.; Denys, P. Using latent dirichlet allocation for automatic categorization of software. In Proceedings of the 2009 6th IEEE International Working Conference on Mining Software Repositories, Vancouver, BC, Canada, 16–17 May 2009; pp. 163–166. [Google Scholar]
- Tirunillai, S.; Tellis, G. Mining Marketing Meaning from Online Chatter: Strategic Brand Analysis of Big Data Using Latent Dirichlet Allocation. J. Mark. Res. 2014, 51, 463–479. [Google Scholar] [CrossRef] [Green Version]
- Bolelli, L.; Ertekin, Ş.; Giles, C.L. Topic and trend detection in text collections using latent dirichlet allocation. In European Conference on Information Retrieval; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2009; Volume 5478, pp. 776–780. [Google Scholar] [CrossRef] [Green Version]
- Somasundaram, K.; Gail, C.M. Automatic categorization of bug reports using latent dirichlet allocation. In Proceedings of the 5th India Software Engineering Conference, Kanpur, India, 22–25 February 2012; pp. 125–130. [Google Scholar] [CrossRef]
- Ali, S.M.; Gupta, N.; Nayak, G.K.; Lenka, R.K. Big data visualization: Tools and challenges. In Proceedings of the 2016 2nd International Conference on Contemporary Computing and Informatics (IC3I), Greater Noida, India, 14–17 December 2016; pp. 656–660. [Google Scholar] [CrossRef]
- Olston, C.; Marc, N. Web Crawling; Now Publishers Inc.: Boston, MA, USA, 2010. [Google Scholar] [CrossRef]
- Lexical Analysis. Available online: https://en.wikipedia.org/wiki/Lexical_analysis#Tokenization (accessed on 18 July 2020).
- Text Tokenization. Available online: https://url.kr/nZJKua (accessed on 18 July 2020).
- Cerda, P.; Gaël, V.; Balázs, K. Similarity encoding for learning with dirty categorical variables. Mach. Learn. 2018, 107, 1477–1494. [Google Scholar] [CrossRef] [Green Version]
- Morphological Analysis and POS Tagging. KoNLPy. Available online: https://url.kr/LGra6k (accessed on 18 July 2020).
- pyLDAvis. Available online: https://pyldavis.readthedocs.io/en/latest/readme.html (accessed on 7 June 2022).
| Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}