
A Graph-Cut-Based Approach to Community Detection in Networks



Abstract
:1. Introduction
2. Prior Works
3. Methods
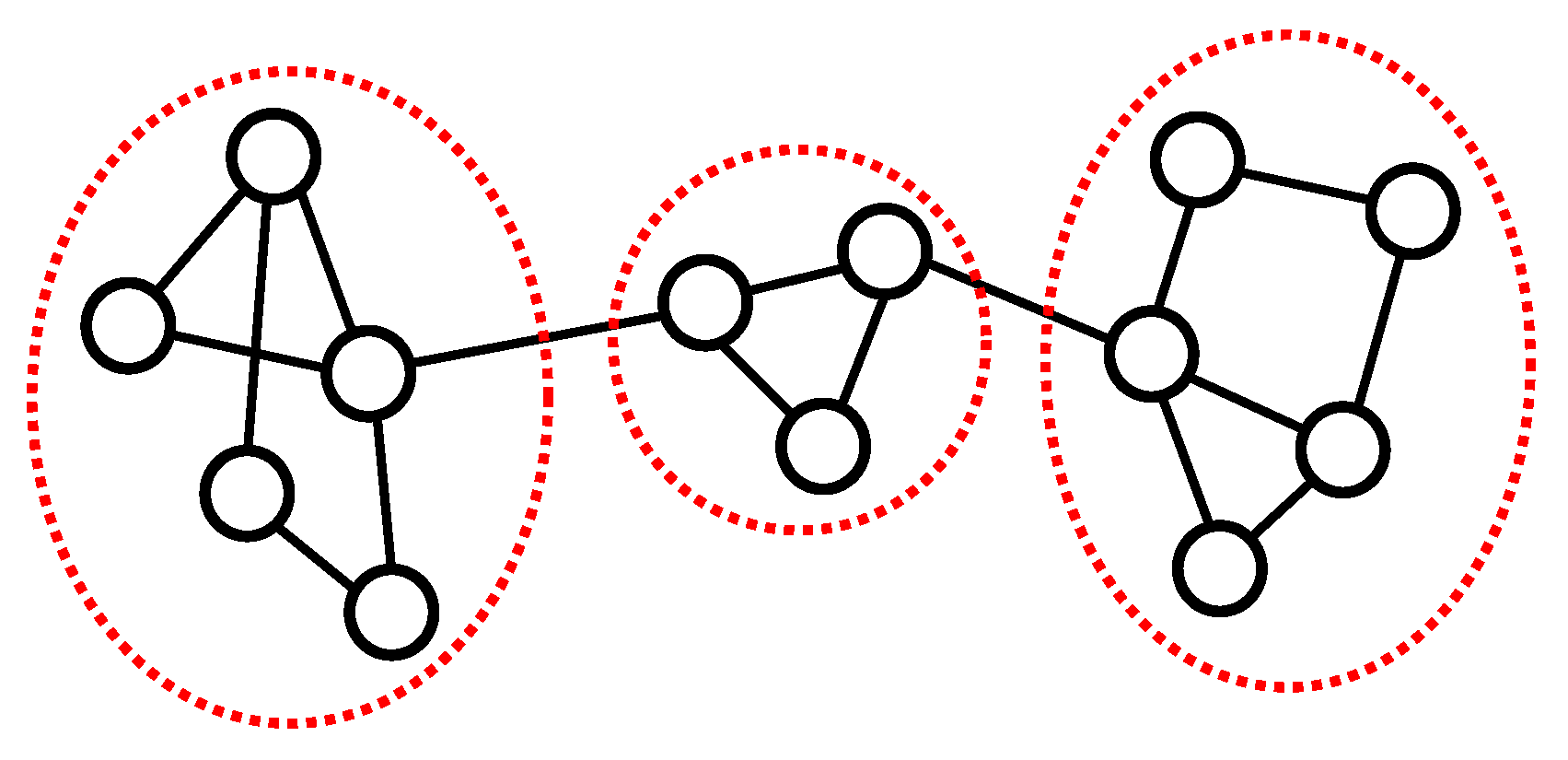
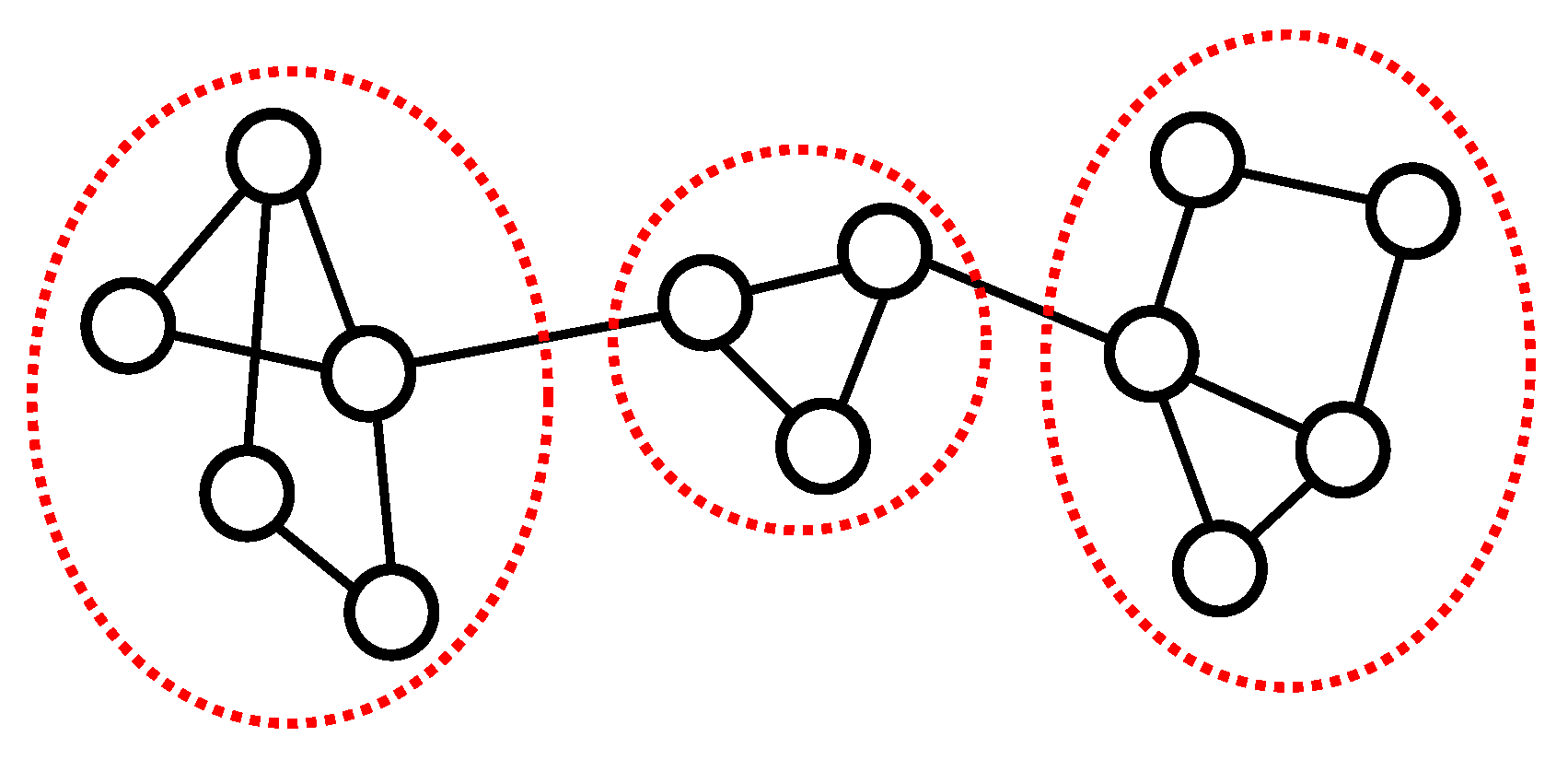
3.1. Network and Community Structure
3.2. Minimum Cut
3.3. The Betweenness Centrality
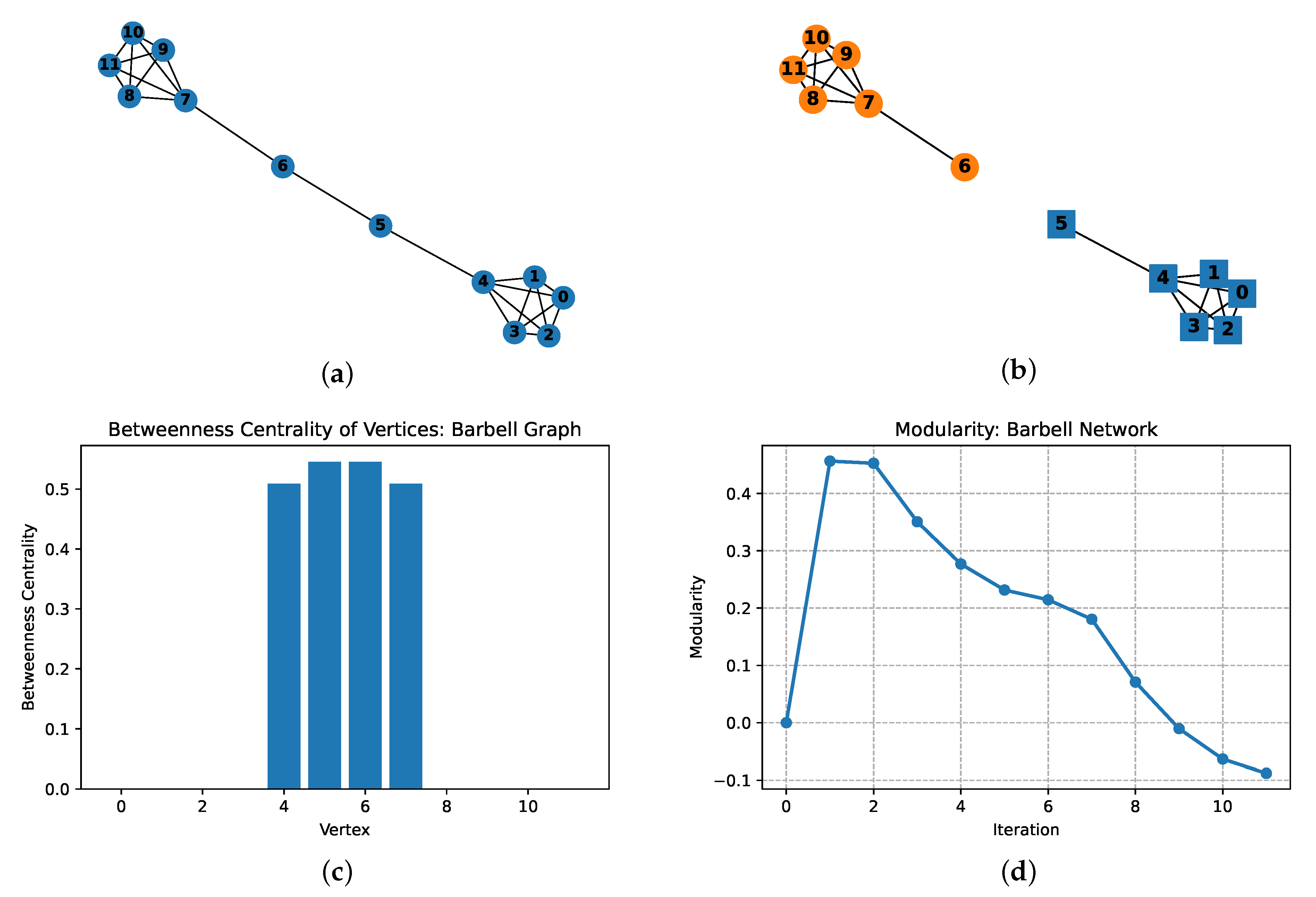
3.4. The DIVIDE-INTO-TWO Algorithm
| Algorithm 1: The DIVIDE-INTO-TWO algorithm. |
Input: A connected graph Output: , a partition of G
|
3.5. Modularity: A Quality Measure
3.6. The Proposed Algorithm
| Algorithm 2: The MCCD algorithm. |
Input: A connected graph Output: , a community structure of G
|
| Algorithm 3: The k-MCCD algorithm. |
Input: A connected graph and a desired number of communities k Output: , a community structure of G
|
4. Results
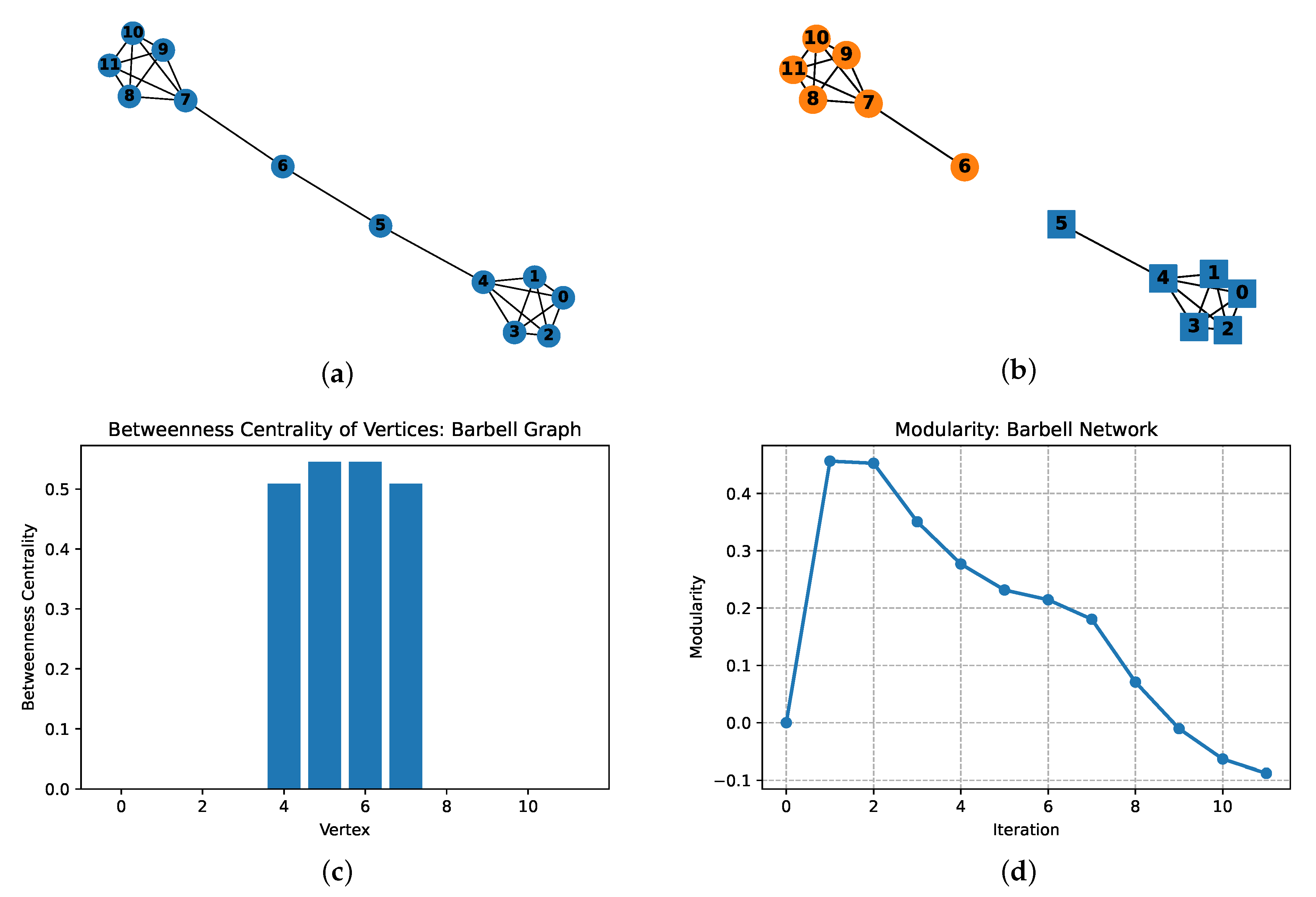
4.1. Example 1: A Simple Network
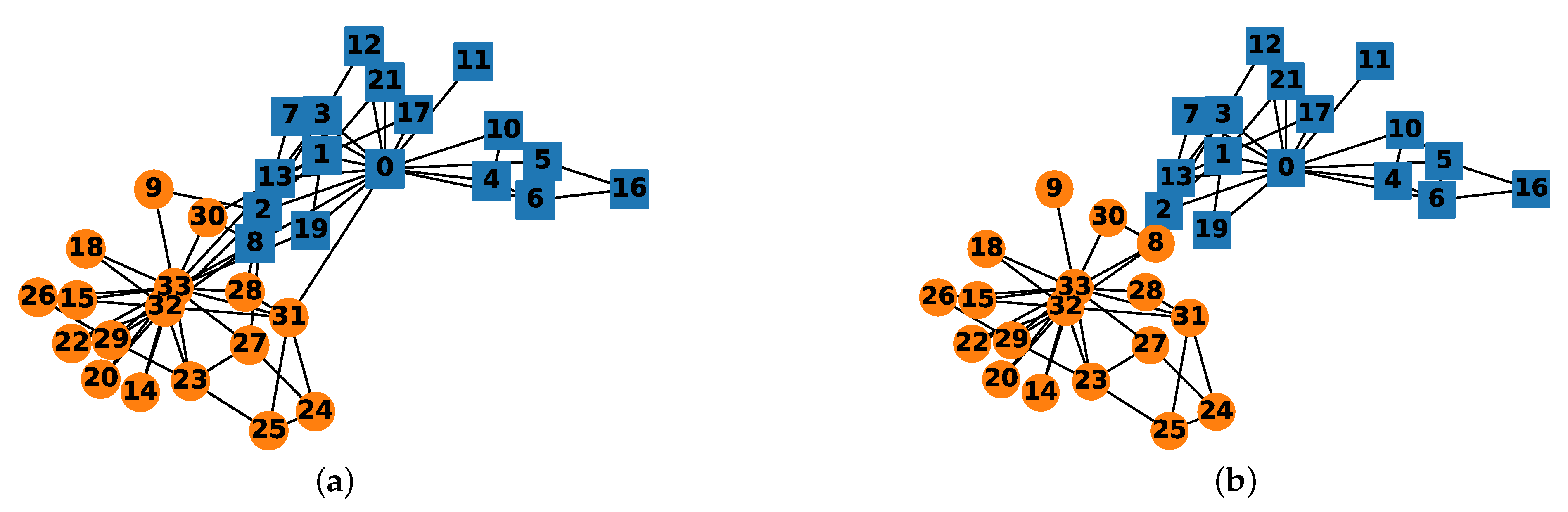
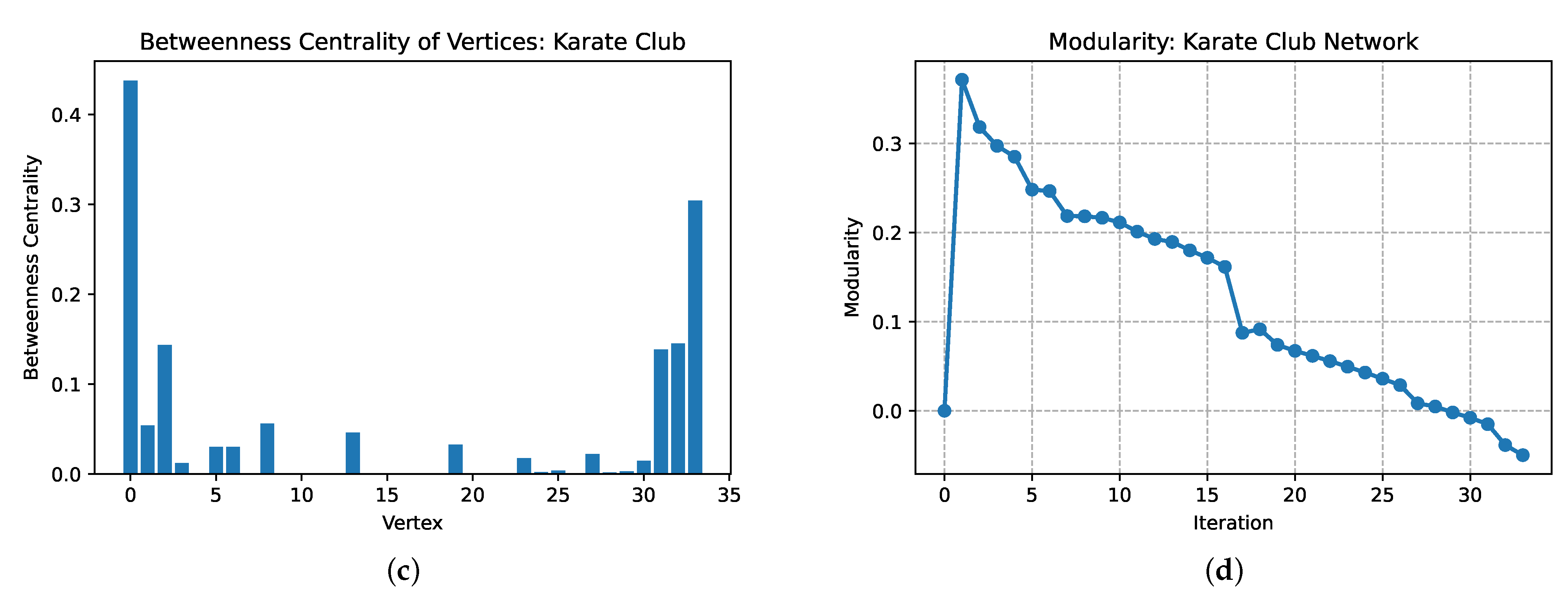
4.2. Example 2: Zachary’s Karate Club Network

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | GN | FN | CNM | DA | MCCD |
|---|---|---|---|---|---|
| Modularity | 0.401 | 0.381 | 0.381 | 0.419 | 0.372 |
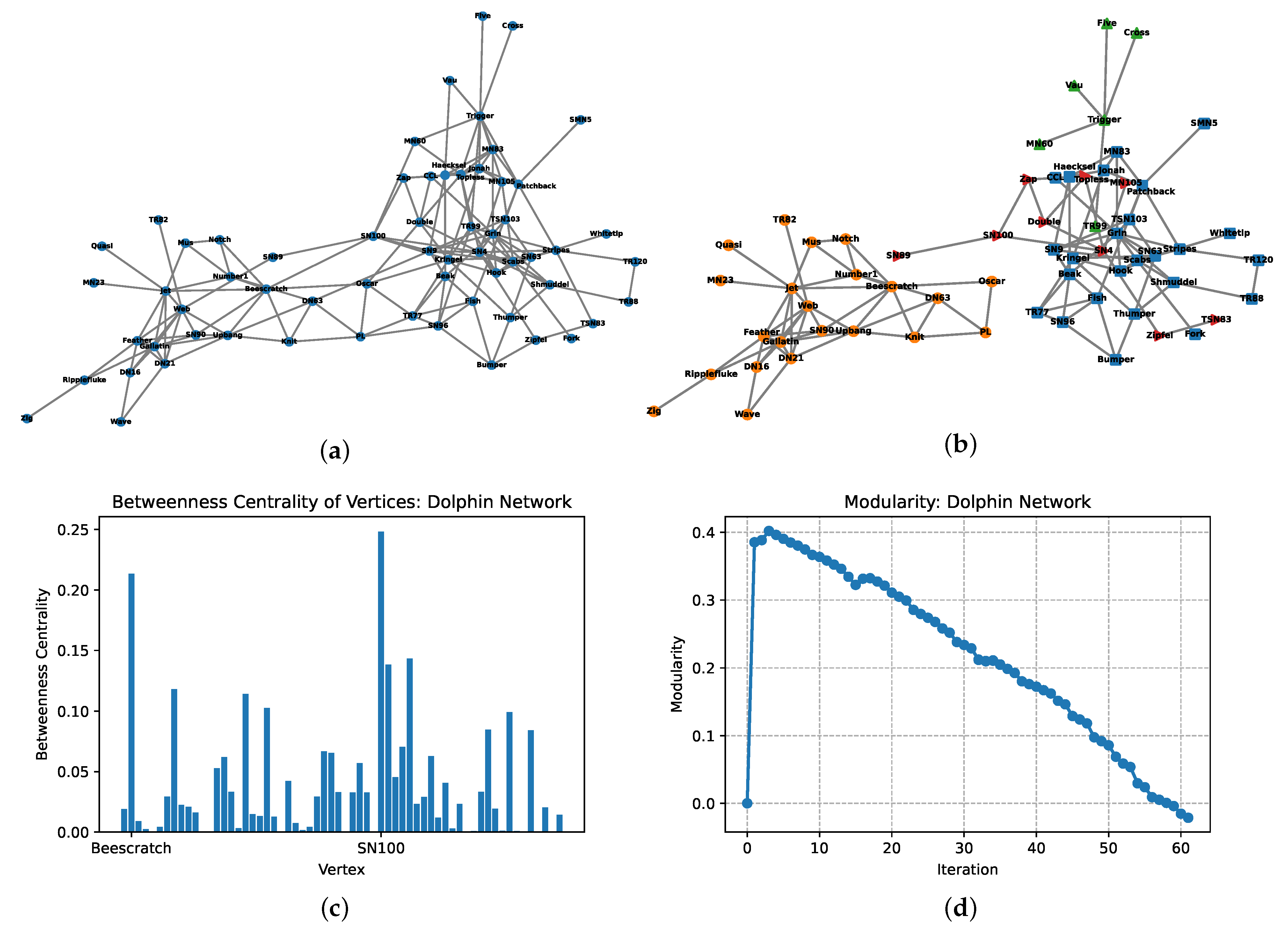
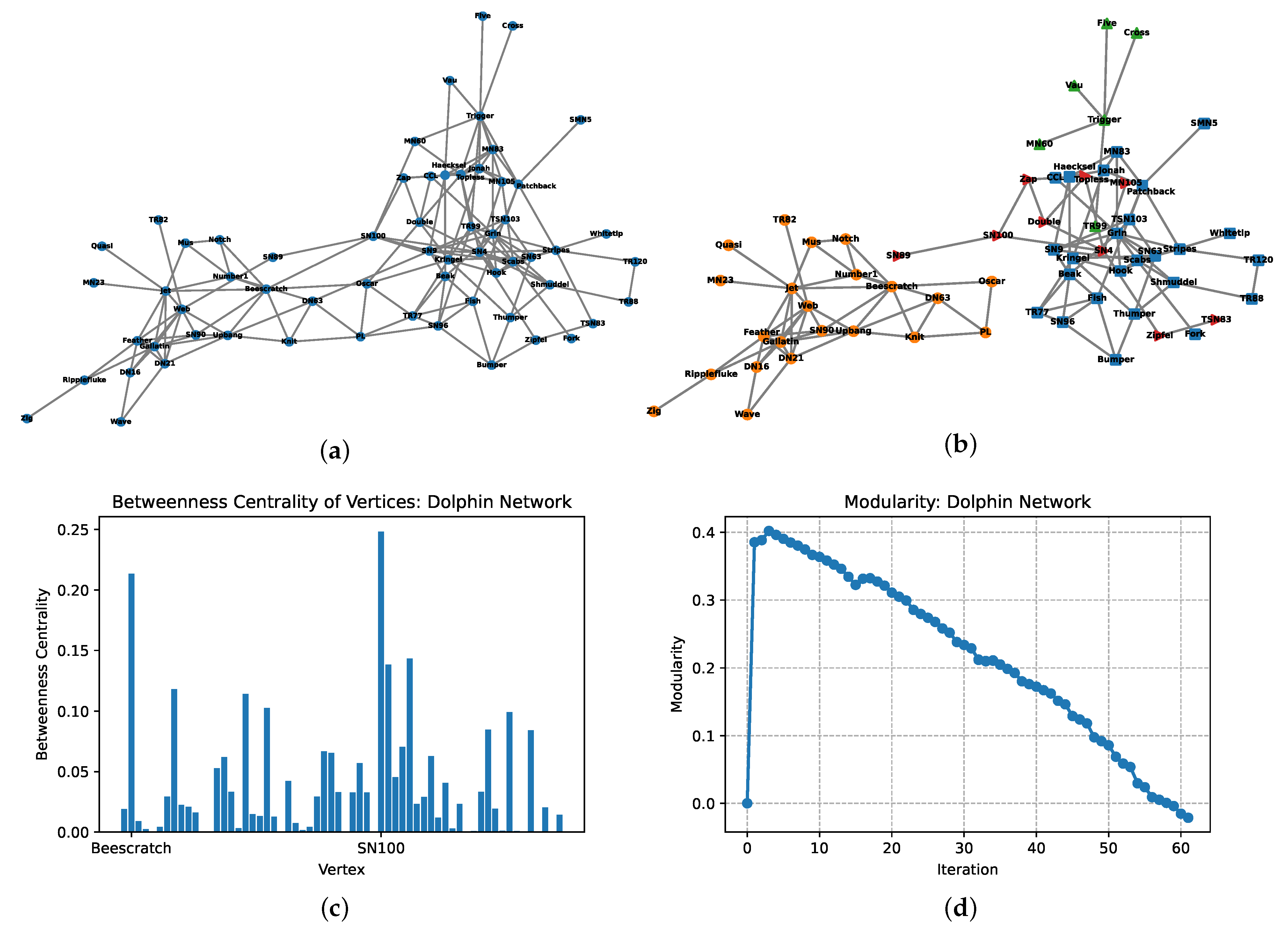
4.3. Example 3: The Social Network of Bottlenose Dolphins
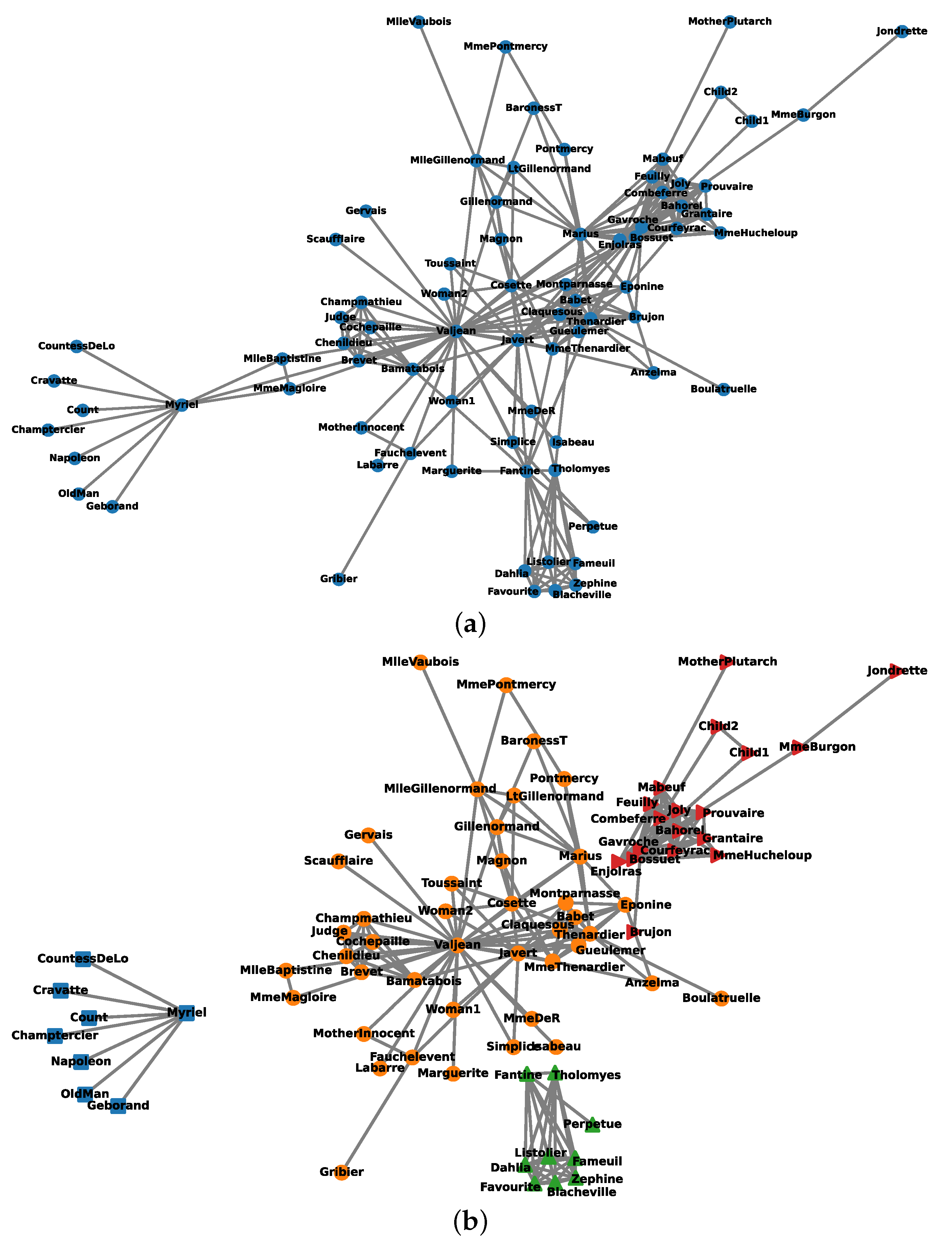
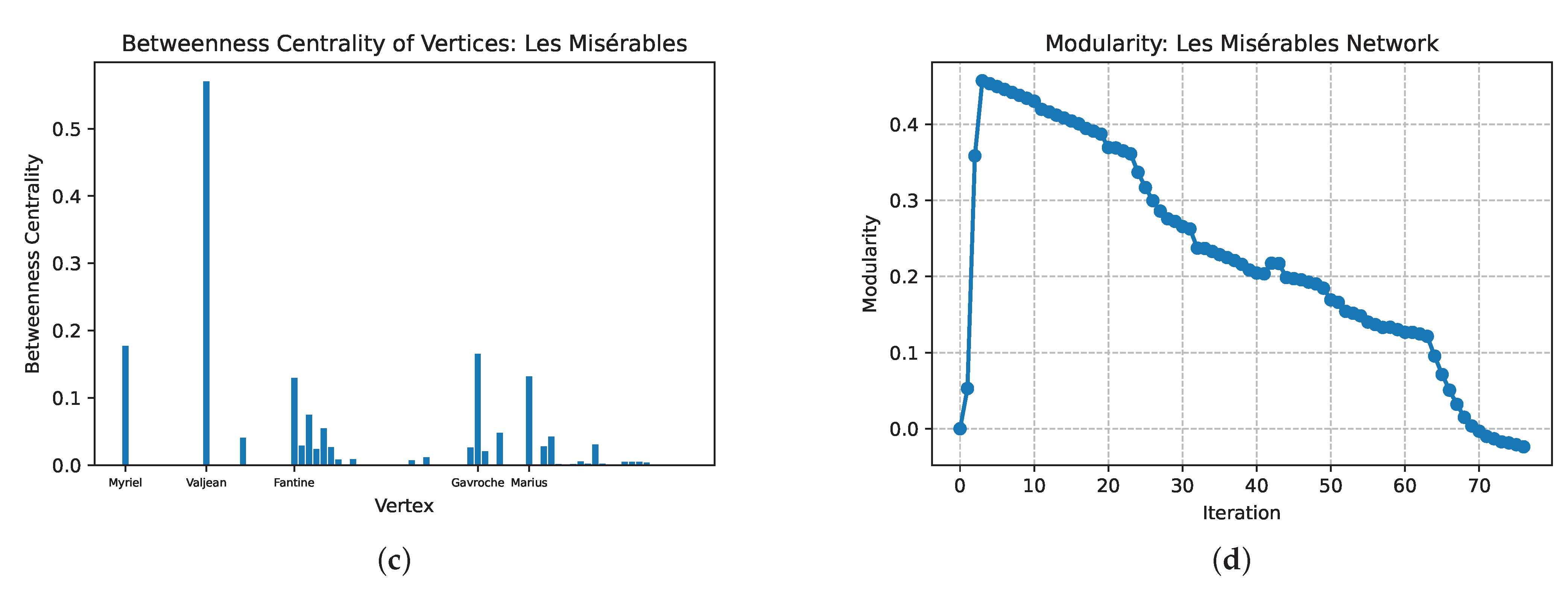
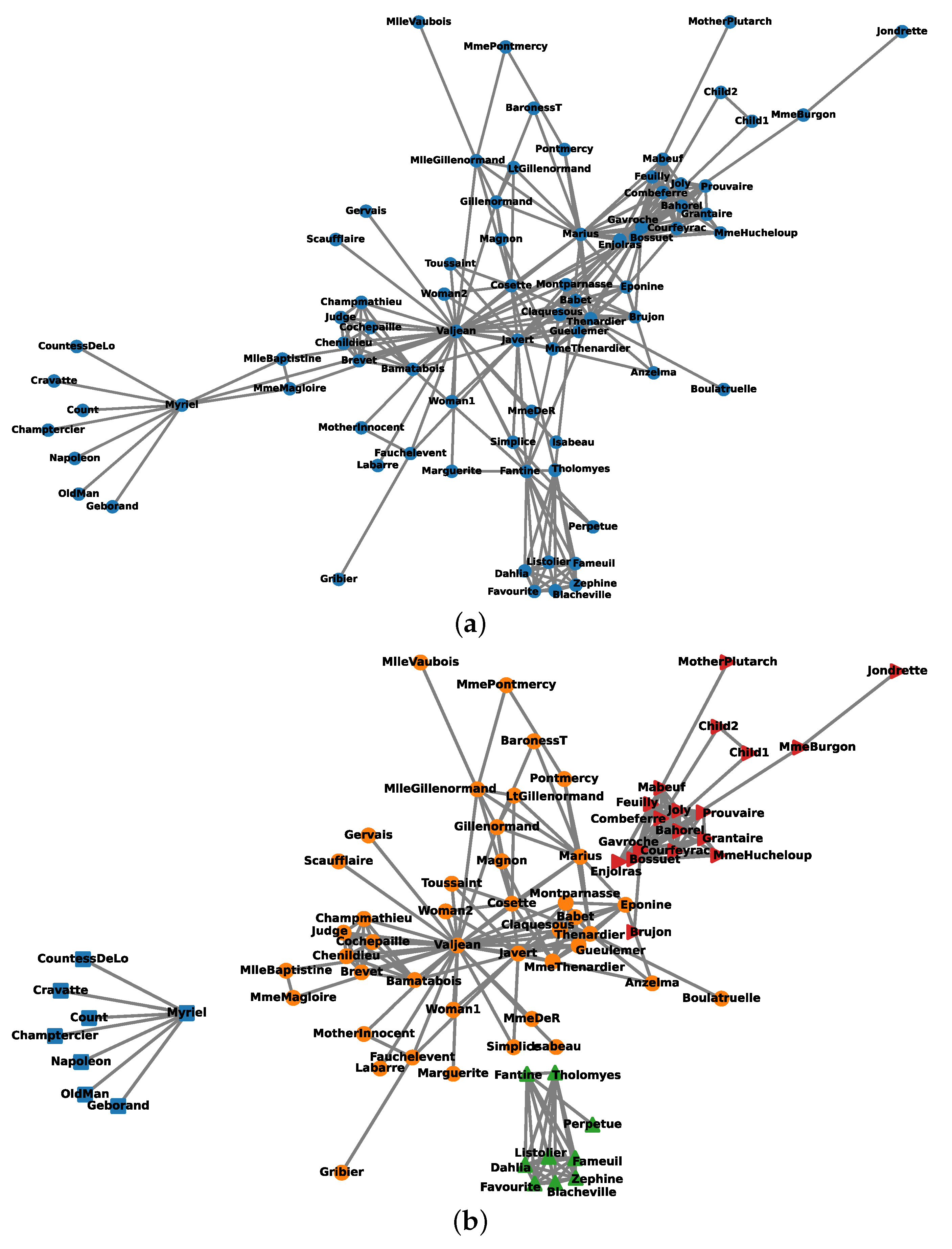
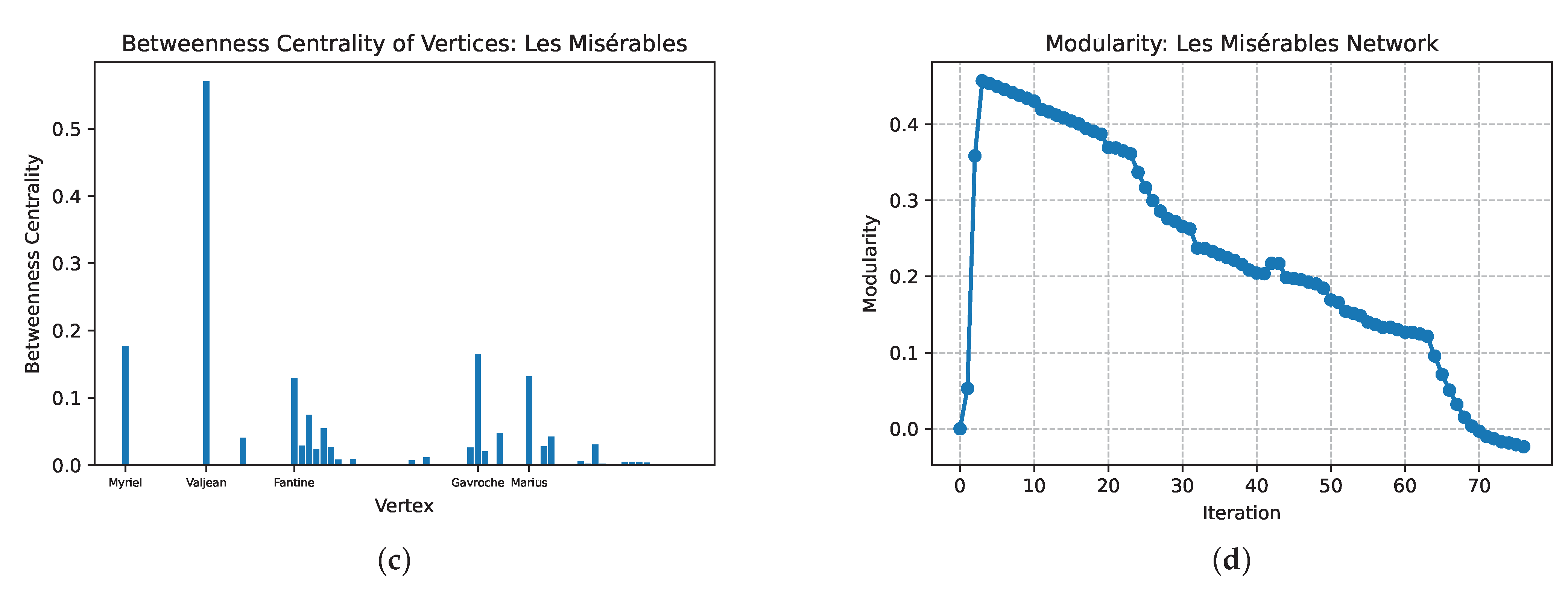
4.4. Example 4: The Characters Network of Les Misérables
5. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| GN | Girvan and Newman |
| LFR | Lancichinetti, Fortunato, and Radicchi |
| MCCD | Minimum Cut-based Community Detection |
| CNM | Clauset, Newman, and Moore |
| DA | Duch and Arenas |
References
- Fortunato, S. Community detection in graphs. Phys. Rep. 2010, 486, 75–174. [Google Scholar] [CrossRef] [Green Version]
- Javed, M.A.; Younis, M.S.; Latif, S.; Qadir, J.; Baig, A. Community detection in networks: A multidisciplinary review. J. Netw. Comput. Appl. 2018, 108, 87–111. [Google Scholar] [CrossRef]
- Danon, L.; Díaz-Guilera, A.; Duch, J.; Arenas, A. Comparing community structure identification. J. Stat. Mech. Theory Exp. 2005, 2005, P09008. [Google Scholar] [CrossRef]
- Lancichinetti, A.; Fortunato, S. Community detection algorithms: A comparative analysis. Phys. Rev. E 2009, 80, 056117. [Google Scholar] [CrossRef] [Green Version]
- Yang, B.; Liu, D.; Liu, J. Discovering Communities from Social Networks: Methodologies and Applications. In Handbook of Social Network Technologies and Applications; Furht, B., Ed.; Springer: Boston, MA, USA, 2010; pp. 331–346. [Google Scholar] [CrossRef]
- Cheng, J.; Leng, M.; Li, L.; Zhou, H.; Chen, X. Active Semi-Supervised Community Detection Based on Must-Link and Cannot-Link Constraints. PLoS ONE 2014, 9, e110088. [Google Scholar] [CrossRef]
- Zachary, W.W. An Information Flow Model for Conflict and Fission in Small Groups. J. Anthropol. Res. 1977, 33, 452–473. [Google Scholar] [CrossRef] [Green Version]
- Asur, S.; Parthasarathy, S.; Ucar, D. An Event-Based Framework for Characterizing the Evolutionary Behavior of Interaction Graphs. ACM Trans. Knowl. Discov. Data 2009, 3, 1–36. [Google Scholar] [CrossRef]
- Backstrom, L.; Huttenlocher, D.; Kleinberg, J.; Lan, X. Group Formation in Large Social Networks: Membership, Growth, and Evolution. In Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Philadelphia, PA, USA, 20–23 August 2006; pp. 44–54. [Google Scholar] [CrossRef]
- Dunlavy, D.M.; Kolda, T.G.; Acar, E. Temporal Link Prediction Using Matrix and Tensor Factorizations. ACM Trans. Knowl. Discov. Data 2011, 5, 1–27. [Google Scholar] [CrossRef] [Green Version]
- Fu, W.; Song, L.; Xing, E.P. Dynamic Mixed Membership Blockmodel for Evolving Networks. In Proceedings of the 26th Annual International Conference on Machine Learning, Montreal, QC, Canada, 14–18 June 2009; pp. 329–336. [Google Scholar] [CrossRef]
- Chakraborty, T.; Chakraborty, A. OverCite: Finding Overlapping Communities in Citation Network. In Proceedings of the 2013 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining, Niagara, ON, Canada, 25–28 August 2013; pp. 1124–1131. [Google Scholar] [CrossRef]
- Yang, J.; Leskovec, J. Overlapping Community Detection at Scale: A Nonnegative Matrix Factorization Approach. In Proceedings of the Sixth ACM International Conference on Web Search and Data Mining, Rome, Italy, 4–8 February 2013; pp. 587–596. [Google Scholar] [CrossRef]
- Maity, S.; Rath, S.K. Extended Clique percolation method to detect overlapping community structure. In Proceedings of the 2014 International Conference on Advances in Computing, Communications and Informatics (ICACCI), Delhi, India, 24–27 September 2014; pp. 31–37. [Google Scholar] [CrossRef]
- Gulbahce, N.; Lehmann, S. The art of community detection. BioEssays 2008, 30, 934–938. [Google Scholar] [CrossRef] [Green Version]
- Papadopoulos, S.; Kompatsiaris, Y.; Vakali, A.; Spyridonos, P. Community detection in Social Media: Performance and application considerations. Data Min. Knowl. Discov. 2012, 24, 515–554. [Google Scholar] [CrossRef]
- Chintalapudi, S.R.; Prasad, M.H.M.K. A survey on community detection algorithms in large scale real world networks. In Proceedings of the 2015 2nd International Conference on Computing for Sustainable Global Development (INDIACom), New Delhi, India, 11–13 March 2015; pp. 1323–1327. [Google Scholar]
- Plantié, M.; Crampes, M. Survey on Social Community Detection. In Social Media Retrieval; Ramzan, N., van Zwol, R., Lee, J.S., Clüver, K., Hua, X.S., Eds.; Springer: London, UK, 2013; pp. 65–85. [Google Scholar] [CrossRef] [Green Version]
- Yang, Z.; Algesheimer, R.; Tessone, C. A Comparative Analysis of Community Detection Algorithms on Artificial Networks. Sci. Rep. 2016, 6, 30750. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wu, Z.; Leahy, R. An optimal graph theoretic approach to data clustering: Theory and its application to image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 1993, 15, 1101–1113. [Google Scholar] [CrossRef] [Green Version]
- Shen, H.; Cheng, X.; Cai, K.; Hu, M.B. Detect overlapping and hierarchical community structure in networks. Phys. A Stat. Mech. Its Appl. 2009, 388, 1706–1712. [Google Scholar] [CrossRef] [Green Version]
- Ahn, Y.Y.; Bagrow, J.P.; Lehmann, S. Link communities reveal multiscale complexity in networks. Nature 2010, 466, 761–764. [Google Scholar] [CrossRef] [Green Version]
- Barabási, A.L.; Albert, R. Emergence of Scaling in Random Networks. Science 1999, 286, 509–512. [Google Scholar] [CrossRef] [Green Version]
- Hastie, T.; Friedman, J.; Tibshirani, R. The Elements of Statistical Learning; Springer: New York, NY, USA, 2009. [Google Scholar] [CrossRef]
- Newman, M.E.J.; Girvan, M. Finding and evaluating community structure in networks. Phys. Rev. E 2004, 69, 026113. [Google Scholar] [CrossRef] [Green Version]
- Newman, M.E.J. Properties of highly clustered networks. Phys. Rev. E 2003, 68, 026121. [Google Scholar] [CrossRef] [Green Version]
- Newman, M.E.J. Fast algorithm for detecting community structure in networks. Phys. Rev. E 2004, 69, 066133. [Google Scholar] [CrossRef] [Green Version]
- Newman, M.E.J. Analysis of weighted networks. Phys. Rev. E 2004, 70, 056131. [Google Scholar] [CrossRef] [Green Version]
- Tyler, J.R.; Wilkinson, D.M.; Huberman, B.A. E-Mail as Spectroscopy: Automated Discovery of Community Structure within Organizations. Inf. Soc. 2005, 21, 143–153. [Google Scholar] [CrossRef] [Green Version]
- Wilkinson, D.M.; Huberman, B.A. A method for finding communities of related genes. Proc. Natl. Acad. Sci. USA 2004, 101, 5241–5248. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rattigan, M.J.; Maier, M.; Jensen, D. Graph Clustering with Network Structure Indices. In Proceedings of the 24th International Conference on Machine Learning, Corvalis, OR, USA, 20–24 June 2007; pp. 783–790. [Google Scholar] [CrossRef]
- Shi, J.; Malik, J. Normalized cuts and image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 888–905. [Google Scholar]
- von Luxburg, U. A tutorial on spectral clustering. Stat. Comput. 2007, 17, 395–416. [Google Scholar] [CrossRef]
- Donath, W.E.; Hoffman, A.J. Lower Bounds for the Partitioning of Graphs. IBM J. Res. Dev. 1973, 17, 420–425. [Google Scholar] [CrossRef]
- Fiedler, M. Algebraic connectivity of graphs. Czechoslov. Math. J. 1973, 23, 298–305. [Google Scholar] [CrossRef]
- Barnard, S.T.; Pothen, A.; Simon, H. A spectral algorithm for envelope reduction of sparse matrices. Numer. Linear Algebra Appl. 1995, 2, 317–334. [Google Scholar] [CrossRef] [Green Version]
- Meilă, M.; Shi, J. A random walks view of spectral segmentation. In Proceedings of the 8th International Workshop on Artificial Intelligence and Statistics, Key West, FL, USA, 4–7 January 2001; pp. 203–208. [Google Scholar]
- Ng, A.; Jordan, M.; Weiss, Y. On Spectral Clustering: Analysis and an algorithm. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 3–8 December 2001; Volume 14. [Google Scholar]
- Pothen, A. Graph Partitioning Algorithms with Applications to Scientific Computing. In Parallel Numerical Algorithms; Keyes, D.E., Sameh, A., Venkatakrishnan, V., Eds.; Springer: Dordrecht, The Netherlands, 1997; pp. 323–368. [Google Scholar] [CrossRef]
- Kernighan, B.W.; Lin, S. An Efficient Heuristic Procedure for Partitioning Graphs. Bell Syst. Tech. J. 1970, 49, 291–307. [Google Scholar] [CrossRef]
- Guimerà, R.; Nunes Amaral, L.A. Functional cartography of complex metabolic networks. Nature 2005, 433, 895–900. [Google Scholar] [CrossRef] [Green Version]
- Clauset, A.; Newman, M.E.J.; Moore, C. Finding community structure in very large networks. Phys. Rev. E 2004, 70, 066111. [Google Scholar] [CrossRef] [Green Version]
- Newman, M.E.J. Detecting community structure in networks. Eur. Phys. J. B Condens. Matter 2004, 38, 321–330. [Google Scholar] [CrossRef]
- Boettcher, S.; Percus, A.G. Extremal optimization for graph partitioning. Phys. Rev. E 2001, 64, 026114. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, J.; Liu, T. Detecting community structure in complex networks using simulated annealing with k-means algorithms. Phys. A Stat. Mech. Its Appl. 2010, 389, 2300–2309. [Google Scholar] [CrossRef]
- Newman, M.E.J. Modularity and community structure in networks. Proc. Natl. Acad. Sci. USA 2006, 103, 8577–8582. [Google Scholar] [CrossRef] [Green Version]
- Liu, C.; Liu, J.; Jiang, Z. A Multiobjective Evolutionary Algorithm Based on Similarity for Community Detection From Signed Social Networks. IEEE Trans. Cybern. 2014, 44, 2274–2287. [Google Scholar] [CrossRef]
- Pizzuti, C. GA-Net: A Genetic Algorithm for Community Detection in Social Networks. In Proceedings of the Parallel Problem Solving from Nature—PPSN X, Dortmund, Germany, 13–17 September 2008; pp. 1081–1090. [Google Scholar]
- Gong, M.; Fu, B.; Jiao, L.; Du, H. Memetic algorithm for community detection in networks. Phys. Rev. E 2011, 84, 056101. [Google Scholar] [CrossRef] [Green Version]
- Gong, M.; Ma, L.; Zhang, Q.; Jiao, L. Community detection in networks by using multiobjective evolutionary algorithm with decomposition. Phys. A Stat. Mech. Appl. 2012, 391, 4050–4060. [Google Scholar] [CrossRef]
- Zeng, Y.; Liu, J. Community Detection from Signed Social Networks Using a Multi-objective Evolutionary Algorithm. In Proceedings of the 18th Asia Pacific Symposium on Intelligent and Evolutionary Systems, Singapore, 10–12 November 2014; Volume 1, pp. 259–270. [Google Scholar]
- Hughes, B.D. Random Walks and Random Environments: Random Walks; Oxford University Press: Oxford, UK, 1995; Volume 1. [Google Scholar]
- Zhou, H. Distance, dissimilarity index, and network community structure. Phys. Rev. E 2003, 67, 061901. [Google Scholar] [CrossRef] [Green Version]
- Zhou, H.; Lipowsky, R. Network Brownian Motion: A New Method to Measure Vertex-Vertex Proximity and to Identify Communities and Subcommunities. In Proceedings of the Computational Science—ICCS 2004, Kraków, Poland, 6–9 June 2004; pp. 1062–1069. [Google Scholar]
- Pons, P.; Latapy, M. Computing Communities in Large Networks Using Random Walks. In Proceedings of the Computer and Information Sciences—ISCIS 2005, Istanbul, Turkey, 26–28 October 2005; pp. 284–293. [Google Scholar]
- Girvan, M.; Newman, M.E.J. Community structure in social and biological networks. Proc. Natl. Acad. Sci. USA 2002, 99, 7821–7826. [Google Scholar] [CrossRef] [Green Version]
- Lancichinetti, A.; Fortunato, S.; Radicchi, F. Benchmark graphs for testing community detection algorithms. Phys. Rev. E 2008, 78, 046110. [Google Scholar] [CrossRef] [Green Version]
- Fulkerson, D.R.; Ford, L.R. Flows in Networks; Princeton University Press: Princeton, NJ, USA, 1962. [Google Scholar]
- Dinic, E.A. Algorithm for solution of a problem of maximum flow in networks with power estimation. Soviet Math. Doklady 1970, 11, 1277–1280. [Google Scholar]
- Edmonds, J.; Karp, R.M. Theoretical improvements in algorithmic efficiency for network flow problems. J. ACM 1972, 19, 248–264. [Google Scholar] [CrossRef]
- Nagamochi, H.; Ibaraki, T. Computing edge-connectivity in multigraphs and capacitated graphs. SIAM J. Discret. Math. 1992, 5, 54–66. [Google Scholar] [CrossRef]
- Stoer, M.; Wagner, F. A Simple Min-Cut Algorithm. J. ACM 1997, 44, 585–591. [Google Scholar] [CrossRef]
- Freeman, L.C. A Set of Measures of Centrality Based on Betweenness. Sociometry 1977, 40, 35. [Google Scholar] [CrossRef]
- Brandes, U. A faster algorithm for betweenness centrality. J. Math. Sociol. 2001, 25, 163–177. [Google Scholar] [CrossRef]
- Brandes, U. On variants of shortest-path betweenness centrality and their generic computation. Soc. Netw. 2008, 30, 136–145. [Google Scholar] [CrossRef] [Green Version]
- Newman, M.E.J. Mixing patterns in networks. Phys. Rev. E 2003, 67, 026126. [Google Scholar] [CrossRef] [Green Version]
- Wilf, H.S. The Editor’s Corner: The White Screen Problem. Am. Math. Mon. 1989, 96, 704. [Google Scholar] [CrossRef]
- Ghosh, A.; Boyd, S.; Saberi, A. Minimizing Effective Resistance of a Graph. SIAM Rev. 2008, 50, 37–66. [Google Scholar] [CrossRef] [Green Version]
- Herbster, M.; Pontil, M. Prediction on a Graph with a Perceptron. In Proceedings of the Advances in Neural Information Processing Systems 19 (NIPS 2006), Vancouver, BC, Canada, 4–7 December 2006. [Google Scholar]
- Ford, L.R.; Fulkerson, D.R. Maximal Flow Through a Network. Can. J. Math. 1956, 8, 399–404. [Google Scholar] [CrossRef]
- Ford, L.R.; Fulkerson, D.R. A Simple Algorithm for Finding Maximal Network Flows and an Application to the Hitchcock Problem. Can. J. Math. 1957, 9, 210–218. [Google Scholar] [CrossRef] [Green Version]
- Duch, J.; Arenas, A. Community detection in complex networks using extremal optimization. Phys. Rev. E 2005, 72, 027104. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lusseau, D. The emergent properties of a dolphin social network. Proc. R. Soc. Lond. Ser. B Biol. Sci. 2003, 270, S186–S188. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lusseau, D.; Schneider, K.; Boisseau, O.J.; Haase, P.; Slooten, E.; Dawson, S.M. The bottlenose dolphin community of Doubtful Sound features a large proportion of long-lasting associations. Behav. Ecol. Sociobiol. 2003, 54, 396–405. [Google Scholar] [CrossRef]
- Knuth, D.E. The Stanford GraphBase: A Platform for Combinatorial Computing; ACM Press: New York, NY, USA, 1993; Volume 1. [Google Scholar]


Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shin, H.; Park, J.; Kang, D. A Graph-Cut-Based Approach to Community Detection in Networks. Appl. Sci. 2022, 12, 6218. https://doi.org/10.3390/app12126218
Shin H, Park J, Kang D. A Graph-Cut-Based Approach to Community Detection in Networks. Applied Sciences. 2022; 12(12):6218. https://doi.org/10.3390/app12126218
Chicago/Turabian StyleShin, Hyungsik, Jeryang Park, and Dongwoo Kang. 2022. "A Graph-Cut-Based Approach to Community Detection in Networks" Applied Sciences 12, no. 12: 6218. https://doi.org/10.3390/app12126218
APA StyleShin, H., Park, J., & Kang, D. (2022). A Graph-Cut-Based Approach to Community Detection in Networks. Applied Sciences, 12(12), 6218. https://doi.org/10.3390/app12126218