
Feature Selection to Predict LED Light Energy Consumption with Specific Light Recipes in Closed Plant Production Systems

 ,
, 

Abstract
:1. Introduction
1.1. LED Lights in Closed Plant Production Systems
1.2. Machine-Learning Modeling
1.2.1. Collecting Data
1.2.2. Preprocessing Data
1.2.3. Building Model
1.2.4. Training Model
1.2.5. Testing Model
1.3. Feature Selection
2. Materials and Methods
2.1. Lighting System Features
2.2. Construction of Experiment
2.3. Min-Max Normalization
2.4. Pearson Correlation
2.5. Variance Threshold
2.6. Mutual Information Gain
2.7. Univariate Linear F-Regression Selection
2.8. Sequential Feature Selection
2.8.1. Linear Regression Model
2.8.2. Decision Tree Regression Model
3. Results
3.1. Energy Consumption Dataset
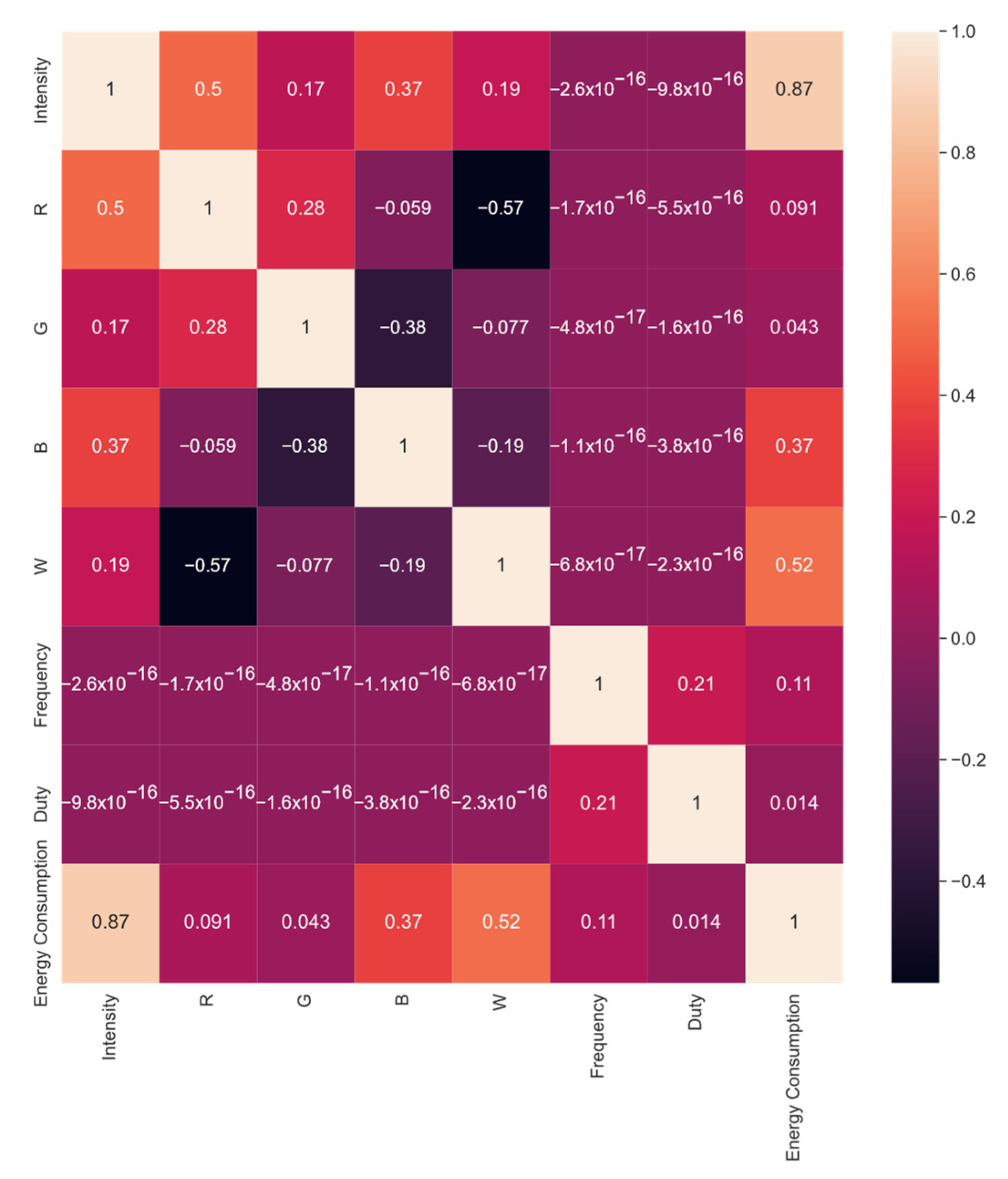
3.2. Person Correlation Results
3.3. Variance Threshold Results
3.4. Mutual Information Gain Results
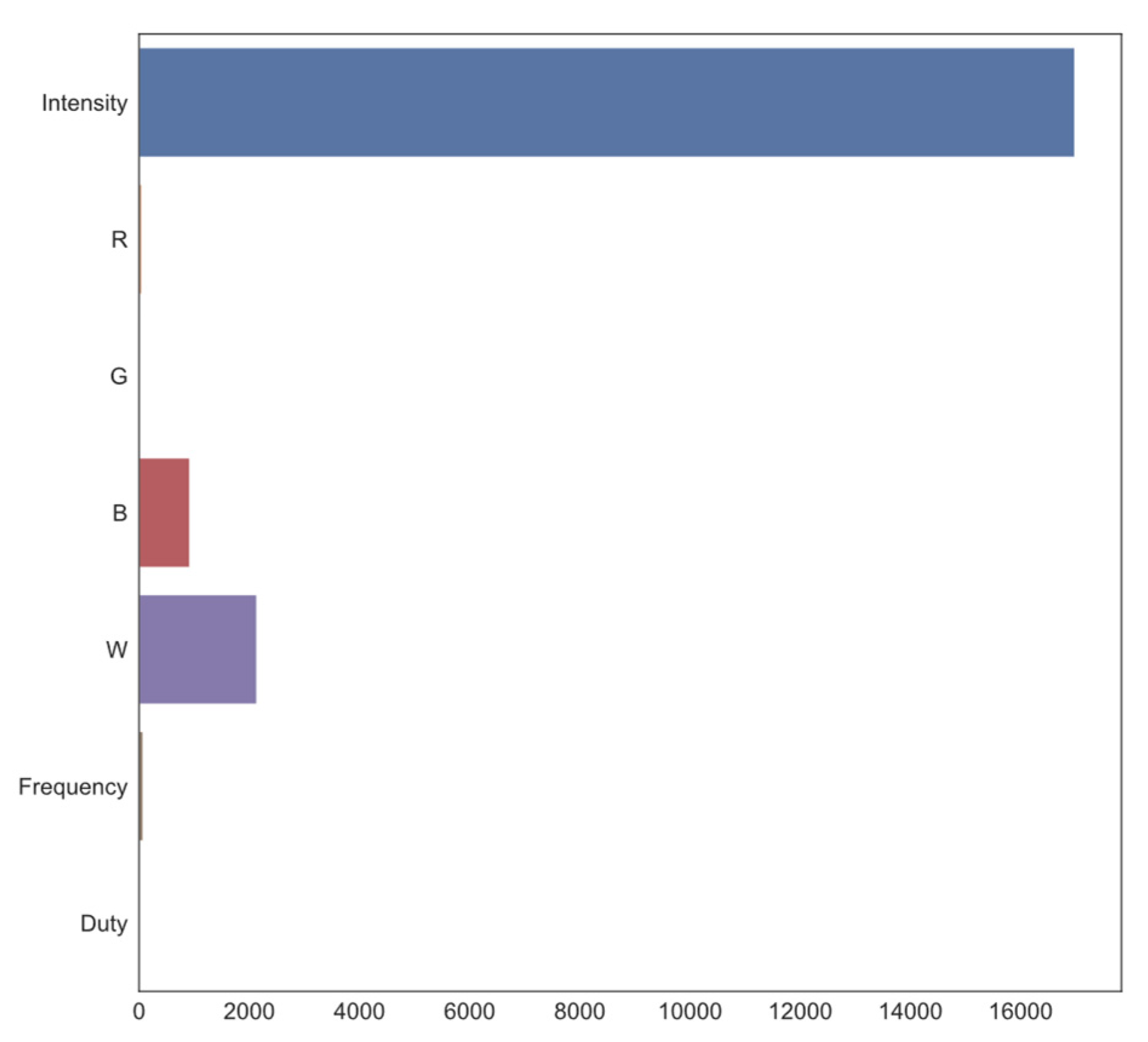
3.5. Univariate Linear F-Regression Results
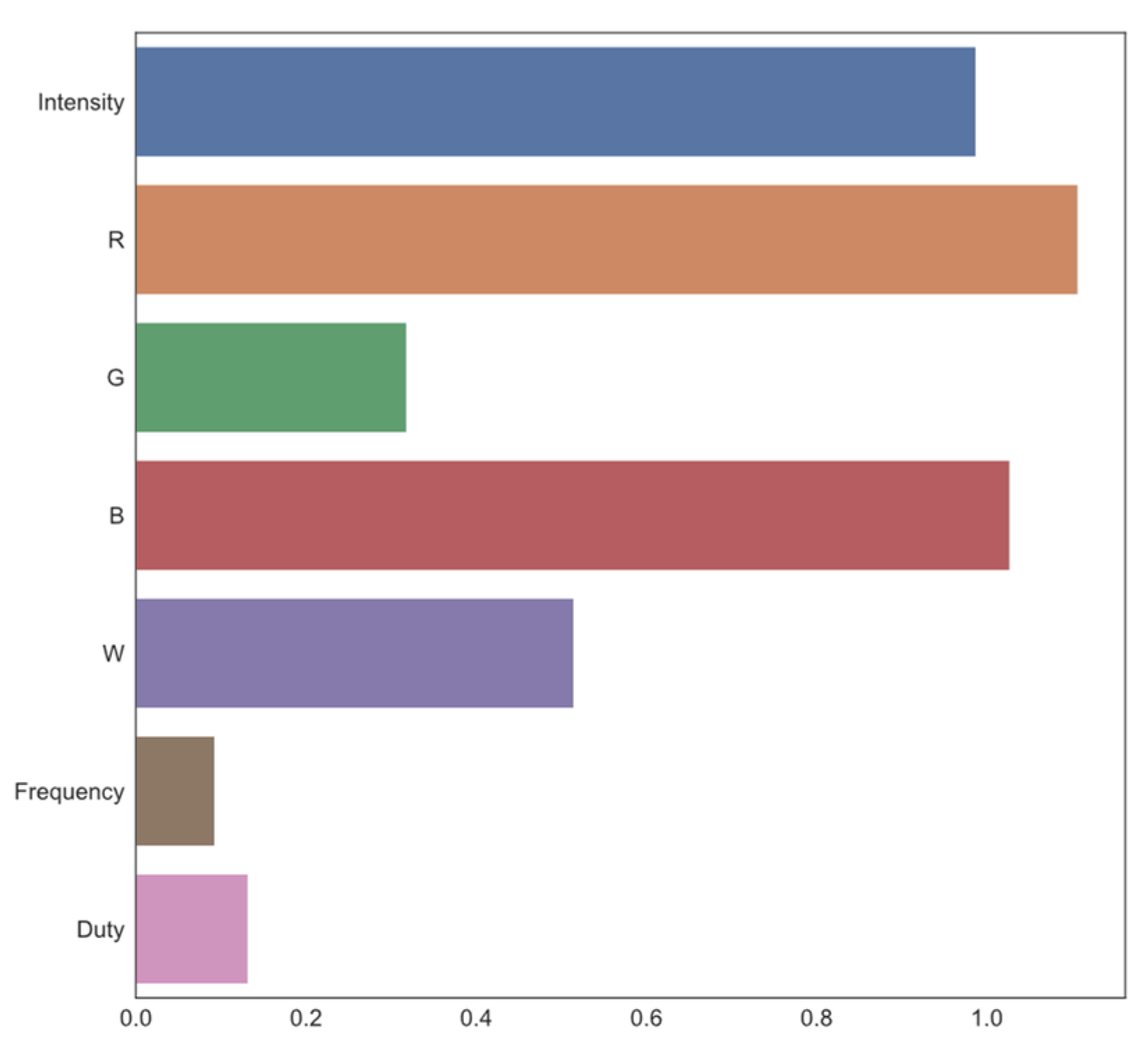
3.6. Sequential Feature Selection Results
3.6.1. Sequential Feature Selection with Linear Regression Model
3.6.2. Sequential Feature Selection with Decision Tree Regression Model
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- FAO. FAO Publications Catalogue; FAO: Quebec City, QC, Canada, 2021. [Google Scholar]
- Massa, G.D.; Kim, H.H.; Wheeler, R.M.; Mitchell, C.A. Plant Productivity in Response to LED Lighting. HortScience 2008, 43, 1951–1956. [Google Scholar] [CrossRef]
- Kozai, T.; Fujiwara, K.; Runkle, E.S. LED Lighting for Urban Agriculture; Springer: Singapore, 2016; ISBN 9789811018480. [Google Scholar]
- Domurath, N.; Schroeder, F.G.; Glatzel, S. Light Response Curves of Selected Plants under Different Light Conditions. Acta Hortic. 2012, 956, 291–298. [Google Scholar] [CrossRef] [Green Version]
- Eaves, J.; Eaves, S. Comparing the Profitability of a Greenhouse to a Vertical Farm in Quebec. Can. J. Agric. Econ. 2018, 66, 43–54. [Google Scholar] [CrossRef]
- Benke, K.; Tomkins, B. Future Food-Production Systems: Vertical Farming and Controlled-Environment Agriculture. Sustain. Sci. Pract. Policy 2017, 13, 13–26. [Google Scholar] [CrossRef] [Green Version]
- Mickens, M.A.; Skoog, E.J.; Reese, L.E.; Barnwell, P.L.; Spencer, L.E.; Massa, G.D.; Wheeler, R.M. A Strategic Approach for Investigating Light Recipes for ‘Outredgeous’ Red Romaine Lettuce Using White and Monochromatic LEDs. Life Sci. Sp. Res. 2018, 19, 53–62. [Google Scholar] [CrossRef] [PubMed]
- Ahmed, H.A.; Yu-Xin, T.; Qi-Chang, Y. Optimal Control of Environmental Conditions Affecting Lettuce Plant Growth in a Controlled Environment with Artificial Lighting: A Review. S. Afr. J. Bot. 2020, 130, 75–89. [Google Scholar] [CrossRef]
- Meng, Q.; Kelly, N.; Runkle, E.S. Substituting Green or Far-Red Radiation for Blue Radiation Induces Shade Avoidance and Promotes Growth in Lettuce and Kale. Environ. Exp. Bot. 2019, 162, 383–391. [Google Scholar] [CrossRef]
- Graamans, L.; Baeza, E.; van den Dobbelsteen, A.; Tsafaras, I.; Stanghellini, C. Plant Factories versus Greenhouses: Comparison of Resource Use Efficiency. Agric. Syst. 2018, 160, 31–43. [Google Scholar] [CrossRef]
- Avgoustaki, D.D.; Xydis, G. Energy Cost Reduction by Shifting Electricity Demand in Indoor Vertical Farms with Artificial Lighting. Biosyst. Eng. 2021, 211, 219–229. [Google Scholar] [CrossRef]
- Hwang, P.W.; Chen, C.H.; Chang, Y.J. A Study on Energy Strategy of a Plant Factory Using Sustainable Energy Combined with Computational Fluid Dynamics Simulation: An Innovative Practice of Green Information Systems. In Proceedings of the Proceedings of Computing Conference, London, UK, 18–20 July 2017; IEEE: Piscataway, NJ, USA, 2018; pp. 517–522. [Google Scholar]
- Sørensen, J.C.; Kjaer, K.H.; Ottosen, C.O.; Jørgensen, B.N. DynaGrow—Multi-Objective Optimization for Energy Cost-Efficient Control of Supplemental Light in Greenhouses. In Proceedings of the 8th International Joint Conference on Computational Intelligence (IJCCI 2016), Porto, Portugal, 9–11 November 2016; pp. 41–48. [Google Scholar]
- Francik, S.; Kurpaska, S. The Use of Artificial Neural Networks for Forecasting of Air Temperature inside a Heated Foil Tunnel. Sensors 2020, 20, 652. [Google Scholar] [CrossRef] [Green Version]
- Jung, D.H.; Kim, H.S.; Jhin, C.; Kim, H.J.; Park, S.H. Time-Serial Analysis of Deep Neural Network Models for Prediction of Climatic Conditions inside a Greenhouse. Comput. Electron. Agric. 2020, 173, 105402. [Google Scholar] [CrossRef]
- Escamilla-García, A.; Soto-Zarazúa, G.M.; Toledano-Ayala, M.; Rivas-Araiza, E.; Gastélum-Barrios, A. Applications of Artificial Neural Networks in Greenhouse Technology and Overview for Smart Agriculture Development. Appl. Sci. 2020, 10, 3835. [Google Scholar] [CrossRef]
- Singh, V.K.; Tiwari, K.N. Prediction of Greenhouse Micro-Climate Using Artificial Neural Network. Appl. Ecol. Environ. Res. 2017, 15, 767–778. [Google Scholar] [CrossRef]
- Gros, S.; Zanon, M.; Quirynen, R.; Bemporad, A.; Diehl, M. From Linear to Nonlinear MPC: Bridging the Gap via the Real-Time Iteration. Int. J. Control 2020, 93, 62–80. [Google Scholar] [CrossRef]
- Ouammi, A.; Achour, Y.; Zejli, D.; Dagdougui, H. Supervisory Model Predictive Control for Optimal Energy Management of Networked Smart Greenhouses Integrated Microgrid. IEEE Trans. Autom. Sci. Eng. 2020, 17, 117–128. [Google Scholar] [CrossRef]
- Xu, H.; Zhai, Z.; Wang, K.; Ren, S.; Wang, H. Multiobjective Distributed Model Predictive Control Method for Facility Environment Control Based on Cooperative Game Theory. Turk. J. Electr. Eng. Comput. Sci. 2017, 25, 4160–4171. [Google Scholar] [CrossRef]
- Lin, D.; Zhang, L.; Xia, X. Hierarchical Model Predictive Control of Venlo-Type Greenhouse Climate for Improving Energy Efficiency and Reducing Operating Cost. J. Clean. Prod. 2020, 264, 121513. [Google Scholar] [CrossRef]
- Mosavi, A.; Ozturk, P.; Chau, K.W. Flood Prediction Using Machine Learning Models: Literature Review. Water 2018, 10, 1536. [Google Scholar] [CrossRef] [Green Version]
- Hosseinzadeh, A.; Zhou, J.L.; Altaee, A.; Li, D. Machine Learning Modeling and Analysis of Biohydrogen Production from Wastewater by Dark Fermentation Process. Bioresour. Technol. 2022, 343, 126111. [Google Scholar] [CrossRef]
- Alizamir, M.; Kisi, O.; Ahmed, A.N.; Mert, C.; Fai, C.M.; Kim, S.; Kim, N.W.; El-Shafie, A. Advanced Machine Learning Model for Better Prediction Accuracy of Soil Temperature at Different Depths. PLoS ONE 2020, 15, e0231055. [Google Scholar] [CrossRef] [Green Version]
- Nemati, S.; Holder, A.; Razmi, F.; Stanley, M.D.; Clifford, G.D.; Buchman, T.G. An Interpretable Machine Learning Model for Accurate Prediction of Sepsis in the ICU. Crit. Care Med. 2018, 46, 547. [Google Scholar] [CrossRef] [PubMed]
- Sneha, N.; Gangil, T. Analysis of Diabetes Mellitus for Early Prediction Using Optimal Features Selection. J. Big Data 2019, 6, 13. [Google Scholar] [CrossRef]
- Haq, A.U.; Li, J.; Memon, M.H.; Hunain Memon, M.; Khan, J.; Marium, S.M. Heart Disease Prediction System Using Model of Machine Learning and Sequential Backward Selection Algorithm for Features Selection. In Proceedings of the 2019 IEEE 5th International Conference for Convergence in Technology, Bombay, India, 29–31 March 2019. [Google Scholar] [CrossRef]
- Fan, X.; Wang, X.; Zhang, X.; Yu, P.A. Machine Learning Based Water Pipe Failure Prediction: The Effects of Engineering, Geology, Climate and Socio-Economic Factors. Reliab. Eng. Syst. Saf. 2022, 219, 108185. [Google Scholar] [CrossRef]
- Ahmed, H.W.; Alamire, J.H. A Review of Machine Learning Models in the Air Quality Research. Int. J. Adv. Res. Comput. Eng. Technol. 2020, 9, 30–36. [Google Scholar]
- Zoabi, Y.; Deri-Rozov, S.; Shomron, N. Machine Learning-Based Prediction of COVID-19 Diagnosis Based on Symptoms. npj Digit. Med. 2021, 4, 3. [Google Scholar] [CrossRef] [PubMed]
- Mahesh, B. Machine Learning Algorithms—A Review. Int. J. Sci. Res. 2020, 9, 381–386. [Google Scholar] [CrossRef]
- Ahmad, A.; Khan, M.; Paul, A.; Din, S.; Rathore, M.M.; Jeon, G.; Choi, G.S. Toward Modeling and Optimization of Features Selection in Big Data Based Social Internet of Things. Future Gener. Comput. Syst. 2018, 82, 715–726. [Google Scholar] [CrossRef]
- Khan, M.A.; Kadry, S.; Alhaisoni, M.; Nam, Y.; Zhang, Y.; Rajinikanth, V.; Sarfraz, M.S. Computer-Aided Gastrointestinal Diseases Analysis from Wireless Capsule Endoscopy: A Framework of Best Features Selection. IEEE Access 2020, 8, 132850–132859. [Google Scholar] [CrossRef]
- Genova, K.; Cole, F.; Maschinot, A.; Sarna, A.; Vlasic, D.; Freeman, W.T. Unsupervised Training for 3D Morphable Model Regression. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8377–8386. [Google Scholar]
- Gehrig, D.; Gehrig, M.; Hidalgo-Carrio, J.; Scaramuzza, D. Video to Events: Recycling Video Datasets for Event Cameras. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 3586–3595. [Google Scholar]
- Simao, M.; Mendes, N.; Gibaru, O.; Neto, P. A Review on Electromyography Decoding and Pattern Recognition for Human-Machine Interaction. IEEE Access 2019, 7, 39564–39582. [Google Scholar] [CrossRef]
- Combes, P.P.; Gobillon, L.; Zylberberg, Y. Urban Economics in a Historical Perspective: Recovering Data with Machine Learning. Reg. Sci. Urban Econ. 2021, 94, 103711. [Google Scholar] [CrossRef]
- Uysal, A.K.; Gunal, S. The Impact of Preprocessing on Text Classification. Inf. Process. Manag. 2014, 50, 104–112. [Google Scholar] [CrossRef]
- Zhang, X.; Zhao, Z.; Wang, Z.; Wang, X. Fault Detection and Identification Method for Quadcopter Based on Airframe Vibration Signals. Sensors 2021, 21, 581. [Google Scholar] [CrossRef] [PubMed]
- Choras, R.S. A Survey on Methods of Image Processing and Recognition for Personal Identification. In Machine Learning and Biometrics; IntechOpen: Vienna, Austria, 2018. [Google Scholar] [CrossRef]
- Mohammed, B.; Hasan, S.; Mohsin Abdulazeez, A. A Review of Principal Component Analysis Algorithm for Dimensionality Reduction. J. Soft Comput. Data Min. 2021, 2, 20–30. [Google Scholar] [CrossRef]
- García, S.; Luengo, J.; Herrera, F. Data Preprocessing in Data Mining; Springer: Cham, Switzerland, 2015; Volume 72, ISBN 9783319102467. [Google Scholar]
- Arslan, S.; Ozturk, C. Feature Selection for Classification with Artificial Bee Colony Programming. In Swarm Intelligence-Recent Advances, New Perspectives and Applications; IntechOpen: Vienna, Austria, 2019. [Google Scholar] [CrossRef] [Green Version]
- Olvera-Gonzalez, E.; Rivera, M.M.; Escalante-Garcia, N.; Flores-Gallegos, E. Modeling Energy LED Light Consumption Based on an Artificial Intelligent Method Applied to Closed Plant Production System. Appl. Sci. 2021, 11, 2735. [Google Scholar] [CrossRef]
- Jia, K.; Yang, L.; Liang, S.; Xiao, Z.; Zhao, X.; Yao, Y.; Zhang, X.; Jiang, B.; Liu, D. Long-Term Global Land Surface Satellite (GLASS) Fractional Vegetation Cover Product Derived From MODIS and AVHRR Data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 12, 508–518. [Google Scholar] [CrossRef]
- Kappal, S. Data Normalization Using Median Median Absolute Deviation MMAD Based Z-Score for Robust Predictions vs. Min—Max Normalization. Lond. J. Res. Sci. Nat. Form. 2019, 19, 39–44. [Google Scholar]
- Saranya, C.; Manikandan, G. A Study on Normalization Techniques for Privacy Preserving Data Mining. Int. J. Eng. Technol. 2013, 5, 2701–2704. [Google Scholar]
- Curran-Everett, D. Explorations in Statistics: Hypothesis Tests and P Values. Am. J. Physiol. Adv. Physiol. Educ. 2009, 33, 81–86. [Google Scholar] [CrossRef] [Green Version]
- Kumar, S.C.; Ramasree, R.J. Dimensionality Reduction in Automated Evaluation of Descriptive Answers through Zero Variance, near Zero Variance and Non Frequent Words Techniques-a Comparison. In Proceedings of the 2015 IEEE 9th International Conference on Intelligent Systems and Control (ISCO), Coimbatore, India, 9–10 January 2015. [Google Scholar] [CrossRef]
- Roberts, A.G.K.; Catchpoole, D.R.; Kennedy, P.J. Variance-Based Feature Selection for Classification of Cancer Subtypes Using Gene Expression Data. In Proceedings of the International Joint Conference on Neural Networks, Rio de Janeiro, Brazil, 8–13 July 2018. [Google Scholar] [CrossRef]
- Siti Ambarwati, Y.; Uyun, S. Feature Selection on Magelang Duck Egg Candling Image Using Variance Threshold Method. In Proceedings of the 2020 3rd International Seminar on Research of Information Technology and Intelligent Systems, Yogyakarta, Indonesia, 10–11 December 2020; pp. 694–699. [Google Scholar] [CrossRef]
- Bewick, V.; Cheek, L.; Ball, J. Statistics Review 9: One-Way Analysis of Variance. Crit. Care 2004, 8, 130–136. [Google Scholar] [CrossRef] [Green Version]
- Chehreh Chelgani, S.; Shahbazi, B.; Hadavandi, E. Support Vector Regression Modeling of Coal Flotation Based on Variable Importance Measurements by Mutual Information Method. Measurement 2018, 114, 102–108. [Google Scholar] [CrossRef]
- Mamun, M.M.R.K.; Alouani, A.T. Cuffless Blood Pressure Measurement Using Linear and Nonlinear Optimized Feature Selection. Diagnostics 2022, 12, 408. [Google Scholar] [CrossRef] [PubMed]
- Xiong, H.; Fan, C.; Chen, H.; Yang, Y.; ANTWI, C.O.; Fan, X. A Novel Approach to Air Passenger Index Prediction: Based on Mutual Information Principle and Support Vector Regression Blended Model. SAGE Open 2022, 12. [Google Scholar] [CrossRef]
- Toğaçar, M.; Ergen, B.; Cömert, Z. Classification of Flower Species by Using Features Extracted from the Intersection of Feature Selection Methods in Convolutional Neural Network Models. Measurement 2020, 158, 107703. [Google Scholar] [CrossRef]
- Khaire, U.M.; Dhanalakshmi, R. Stability of Feature Selection Algorithm: A Review. J. King Saud Univ. Comput. Inf. Sci. 2019, 34, 1060–1073. [Google Scholar] [CrossRef]
- Wang, M.; Lu, Y.; Qin, J. A Dynamic MLP-Based DDoS Attack Detection Method Using Feature Selection and Feedback. Comput. Secur. 2020, 88, 101645. [Google Scholar] [CrossRef]
- Zhang, D.; Khalili, A.; Asgharian, M. Post-Model-Selection Inference in Linear Regression Models: An Integrated Review. Stat. Surv. 2022, 16, 86–136. [Google Scholar] [CrossRef]
- Darwin, D.; Christian, D.; Chandra, W.; Nababan, M. Comparison of Decision Tree and Linear Regression Algorithms in the Case of Spread Prediction of COVID-19 in Indonesia. J. Comput. Netw. Archit. High Perform. Comput. 2022, 4, 1–12. [Google Scholar] [CrossRef]
- Johnson, R.W. Alternate Forms of the One-Way ANOVA F and Kruskal-Wallis Test Statistics. J. Stat. Data Sci. Educ. 2022, 30, 82–85. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Intensity (A) (µmol m−2 s−1) | Light Color Percentage (%) | Frequency (Hz) | Duty Cycle (%) | Energy Consumption (Wh) | |||
|---|---|---|---|---|---|---|---|
| R | G | B | W | ||||
| 50 | 45 | 0 | 5 | 0 | 0 | 0 | 23.5 |
| 50 | 41.5 | 0 | 8.5 | 0 | 0 | 0 | 23.4 |
| 50 | 30 | 0 | 20 | 0 | 0 | 0 | 23.9 |
| 50 | 0 | 0 | 21.5 | 28.5 | 0 | 0 | 25.1 |
| 50 | 33.5 | 11 | 5.5 | 0 | 0 | 0 | 24.4 |
| 50 | 33.5 | 16.5 | 0 | 0 | 0 | 0 | 23.4 |
| 50 | 0 | 0 | 0 | 50 | 0 | 0 | 24.5 |
| 50 | 25 | 0 | 25 | 0 | 0 | 0 | 23.9 |
| 50 | 35 | 0 | 15 | 0 | 0 | 0 | 33.5 |
| 50 | 15 | 0 | 35 | 0 | 0 | 0 | 24.1 |
| 50 | 45 | 0 | 5 | 0 | 100 | 40 | 20.7 |
| 50 | 41.5 | 0 | 8.5 | 0 | 100 | 40 | 20.6 |
| 50 | 30 | 0 | 20 | 0 | 100 | 40 | 20.9 |
| 50 | 0 | 0 | 21.5 | 28.5 | 100 | 40 | 22.2 |
| 50 | 33.5 | 11 | 5.5 | 0 | 100 | 40 | 21.1 |
| Intensity (A) (µmol m−2 s−1) | R | G | B | W | Frequency (Hz) | Duty (%) | Energy Consumption (Wh) |
|---|---|---|---|---|---|---|---|
| 0.000 | 0.256 | 0.000 | 0.039 | 0.000 | 0.000 | 0.000 | 0.085 |
| 0.000 | 0.236 | 0.000 | 0.066 | 0.000 | 0.000 | 0.000 | 0.082 |
| 0.000 | 0.171 | 0.000 | 0.154 | 0.000 | 0.000 | 0.000 | 0.097 |
| 0.000 | 0.000 | 0.000 | 0.166 | 0.154 | 0.000 | 0.000 | 0.132 |
| 0.000 | 0.191 | 0.180 | 0.042 | 0.000 | 0.000 | 0.000 | 0.111 |
| 0.000 | 0.191 | 0.270 | 0.000 | 0.000 | 0.000 | 0.000 | 0.082 |
| 0.000 | 0.000 | 0.000 | 0.000 | 0.270 | 0.000 | 0.000 | 0.114 |
| 0.000 | 0.142 | 0.000 | 0.193 | 0.000 | 0.000 | 0.000 | 0.097 |
| 0.000 | 0.199 | 0.000 | 0.116 | 0.000 | 0.000 | 0.000 | 0.378 |
| 0.000 | 0.085 | 0.000 | 0.270 | 0.000 | 0.000 | 0.000 | 0.103 |
| 0.000 | 0.256 | 0.000 | 0.039 | 0.000 | 0.100 | 0.444 | 0.003 |
| 0.000 | 0.236 | 0.000 | 0.066 | 0.000 | 0.100 | 0.444 | 0.000 |
| 0.000 | 0.171 | 0.000 | 0.154 | 0.000 | 0.100 | 0.444 | 0.009 |
| 0.000 | 0.000 | 0.000 | 0.166 | 0.154 | 0.100 | 0.444 | 0.047 |
| 0.000 | 0.191 | 0.180 | 0.042 | 0.000 | 0.100 | 0.444 | 0.015 |
| Elimination Order | Input | ||
|---|---|---|---|
| 7th | Intensity | 0.865312 | 0 |
| 3rd | R | 0.091069 | 5.64 × 10−12 |
| 2nd | G | 0.043198 | 0.001106 |
| 5th | B | 0.372963 | 1.3 × 10−187 |
| 6th | W | 0.522086 | 0 |
| 4th | Frequency | 0.110005 | 8.18 × 10−17 |
| 1st | Duty cycle | 0.014195 | 0.283926 |
| Elimination Order | Variable | Variance | Threshold | Image |
|---|---|---|---|---|
| 1st | W | 0.05079 | 0.051 |  |
| 2nd | G | 0.05490 | 0.055 |  |
| 3rd | B | 0.05546 | 0.056 |  |
| 4th | Duty cycle | 0.06012 | 0.061 |  |
| 5th | R | 0.06479 | 0.065 |  |
| 6th | Intensity | 0.10185 | 0.110 |  |
| 7th | Frequency | 0.14260 | N/A | N/A |
| Elimination Order | Input | |
|---|---|---|
| 5th | Intensity | 0.987600 |
| 7th | R | 1.107432 |
| 3rd | G | 0.318185 |
| 6th | B | 1.027326 |
| 4th | W | 0.514607 |
| 1st | Frequency | 0.092839 |
| 2nd | Duty | 0.131858 |
| Elimination Order | Input | ||
|---|---|---|---|
| 7th | Intensity | 16,981.875086 | 0 |
| 3rd | R | 47.651943 | 5.643556 × 10−12 |
| 2nd | G | 10.652646 | 1.105620 × 10−3 |
| 5th | B | 920.664903 | 1.349950 × 10−187 |
| 6th | W | 2135.097576 | 0 |
| 4th | Frequency | 69.796609 | 8.176545 × 10−17 |
| 1st | Duty cycle | 1.148417 | 2.839262 × 10−1 |
| Elimination Order | Variable | Image |
|---|---|---|
| 1st | Duty cycle |  |
| 2nd | W |  |
| 3rd | G |  |
| 4th | B |  |
| 5th | Frequency |  |
| 6th | R |  |
| 7th | Intensity | N/A |
| Elimination Order | Variable | Image |
|---|---|---|
| 1st | R |  |
| 2nd | B |  |
| 3rd | Duty cycle |  |
| 4th | Frequency |  |
| 5th | G |  |
| 6th | W |  |
| 7th | Intensity | N/A |
| Elimination Order | Variable | Image |
|---|---|---|
| 1st | W |  |
| 2nd | B |  |
| 3rd | G |  |
| 4th | Duty cycle |  |
| 5th | Frequency |  |
| 6th | R |  |
| 7th | Intensity | N/A |
| Elimination Order | Variable | Image |
|---|---|---|
| 1st | W |  |
| 2nd | B |  |
| 3rd | Frequency |  |
| 4th | G |  |
| 5th | Duty cycle |  |
| 6th | R |  |
| 7th | Intensity | N/A |
| Elimination Order | Variable | Image |
|---|---|---|
| 1st | W |  |
| 2nd | G |  |
| 3rd | Duty cycle |  |
| 4th | B |  |
| 5th | Frequency |  |
| 6th | R |  |
| 7th | Intensity | N/A |
| Feature | Pearson Correlation | Variance Threshold | Univariate Linear F-Regression | Sequential Backward Linear | Mean |
|---|---|---|---|---|---|
| Intensity | 7 | 6 | 7 | 7 | 6.8 |
| R | 3 | 5 | 3 | 6 | 4 |
| G | 2 | 2 | 2 | 3 | 2.2 |
| B | 5 | 3 | 5 | 4 | 4.4 |
| W | 6 | 1 | 6 | 2 | 4.2 |
| Frequency | 4 | 7 | 4 | 5 | 4.8 |
| Duty cycle | 1 | 4 | 1 | 1 | 1.6 |
| Feature | Variance Threshold | Mutual Information Gain | Sequential Backward Deep Tree Values | Mean | |||
|---|---|---|---|---|---|---|---|
| 2 | 3 | 4 | 5 | ||||
| Intensity | 6 | 5 | 7 | 7 | 7 | 7 | 6.5 |
| R | 5 | 7 | 1 | 6 | 6 | 6 | 5.17 |
| G | 2 | 3 | 5 | 3 | 4 | 2 | 3.17 |
| B | 3 | 6 | 2 | 2 | 2 | 4 | 3.17 |
| W | 1 | 4 | 6 | 1 | 1 | 1 | 2.33 |
| Frequency | 7 | 1 | 4 | 5 | 3 | 5 | 4.17 |
| Duty cycle | 4 | 2 | 3 | 4 | 5 | 3 | 3.5 |
| Group | ||
|---|---|---|
| Linear | 16.27232 | 0.012364 |
| Nonlinear | 17.65278 | 0.007161 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Montes Rivera, M.; Escalante-Garcia, N.; Dena-Aguilar, J.A.; Olvera-Gonzalez, E.; Vacas-Jacques, P. Feature Selection to Predict LED Light Energy Consumption with Specific Light Recipes in Closed Plant Production Systems. Appl. Sci. 2022, 12, 5901. https://doi.org/10.3390/app12125901
Montes Rivera M, Escalante-Garcia N, Dena-Aguilar JA, Olvera-Gonzalez E, Vacas-Jacques P. Feature Selection to Predict LED Light Energy Consumption with Specific Light Recipes in Closed Plant Production Systems. Applied Sciences. 2022; 12(12):5901. https://doi.org/10.3390/app12125901
Chicago/Turabian StyleMontes Rivera, Martín, Nivia Escalante-Garcia, José Alonso Dena-Aguilar, Ernesto Olvera-Gonzalez, and Paulino Vacas-Jacques. 2022. "Feature Selection to Predict LED Light Energy Consumption with Specific Light Recipes in Closed Plant Production Systems" Applied Sciences 12, no. 12: 5901. https://doi.org/10.3390/app12125901
APA StyleMontes Rivera, M., Escalante-Garcia, N., Dena-Aguilar, J. A., Olvera-Gonzalez, E., & Vacas-Jacques, P. (2022). Feature Selection to Predict LED Light Energy Consumption with Specific Light Recipes in Closed Plant Production Systems. Applied Sciences, 12(12), 5901. https://doi.org/10.3390/app12125901