
Development of a Multilayer Perceptron Neural Network for Optimal Predictive Modeling in Urban Microcellular Radio Environments

 ,
,  , , , and
, , , and
Abstract
:1. Introduction
- ▪ A distinctive MLP neural network-based path loss model with well-structured implementation network architecture, embedded with the precise transfer function, neuron number, learning algorithm and hidden layers, is developed for optimal path loss approximation between mobile-station and base-station path lengths.
- ▪ The developed MLP neural network model was tested and validated for realistic path loss prediction using extensive experimental signal attenuation loss datasets acquired via field drive test conducted over LTE networks in urban microcellular radio environments and tested using first-order statistical performance indicators.
- ▪ Optimization of the projected model via hyperparameter tuning leveraging the grid search algorithm analyses of the experimental path loss data.
- ▪ Optimal prediction efficacy of the developed MLP neural network model compared with well-structured implementation architecture over standard log-distance models using several first-order statistical performance indicators.
2. Theoretical Background
2.1. Radio Propagation Mechanism
2.2. Log-Distance-Based Path Loss Prediction Models
2.3. Artificial Neural Networks (ANNs)
- High-speed computation adeptness
- Global interconnection of network processing elements
- Robust distributed and asynchronous parallel processing
- High adaptability to non-linear input-data mapping
- Robust noise tolerance
- High fault tolerance utilizing Redundant Information Coding
- Robust in providing real-time operations
- High potential for hardware application
- Capable of deriving meaning from the imprecise or complicated dataset
- High capacity to learn, recall and generalize input data training pattern
3. Methodology
- Acquire the path loss datasets
- Preprocessing the dataset and splitting
- Obtain the MLP neural network model.
- Identify the adaptive learning algorithms for MLP neural network model training and testing
- Identify the modelling hyperparameters
- Select a hyperparameter tuning algorithm for the model (e.g., Bayesian optimization search, grid search, etc.).
- Obtain a set of the tuned best hyperparameter values.
- Train the model to obtain the best hyperparameter values combination.
- Appraise and validate the accuracy of the training process.
- Repeat the process to optimal configuration and best-desired results for the model.
- Engage the model with well-structured implementation network architecture, learning algorithm and set of the tuned best hyperparameter values to conductive predictive path loss modelling.
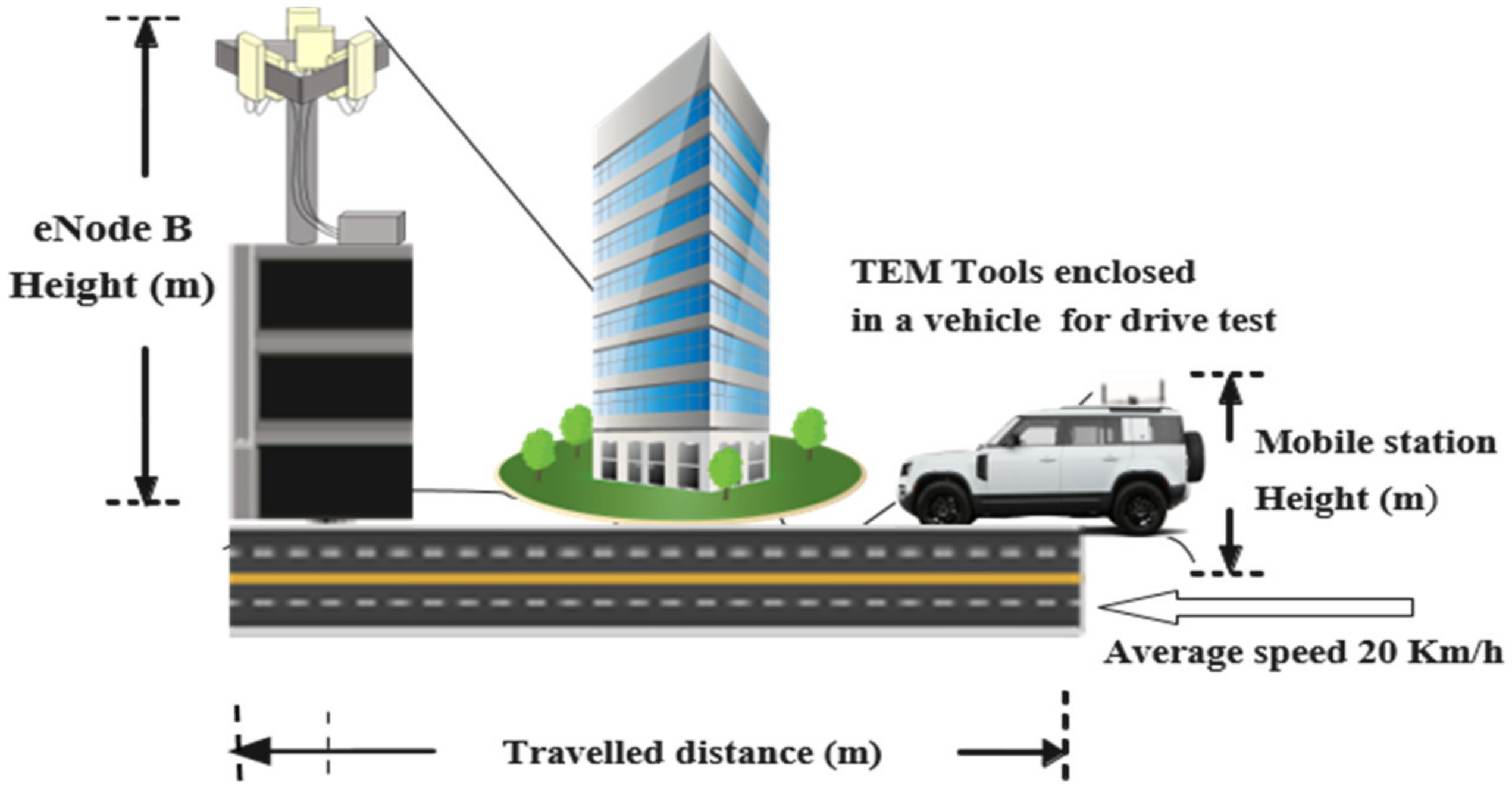
3.1. Data Collection
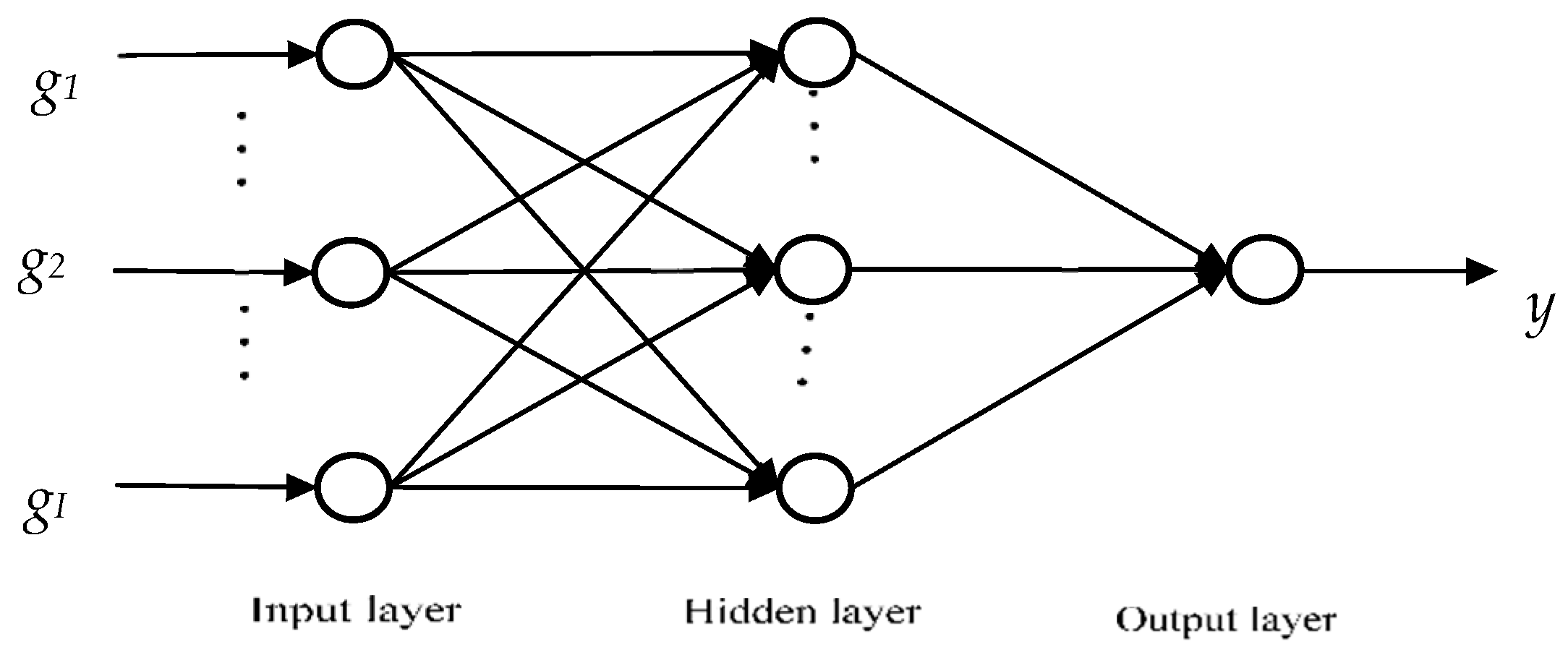
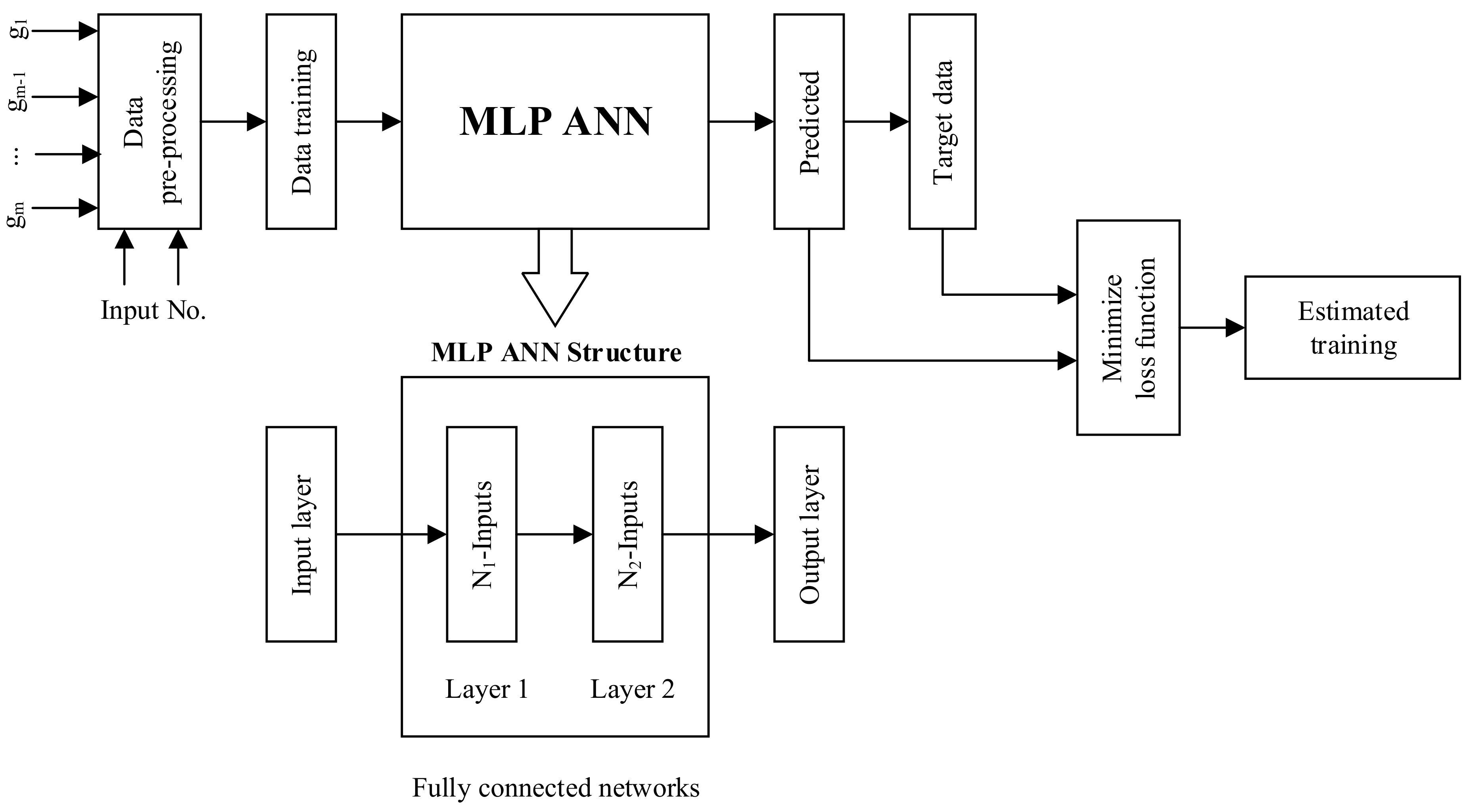
3.2. The MLP Neural Network Model
3.3. MLP Modelling Parameters and Search Space
3.3.1. The Hidden Layers
3.3.2. Neurons Number in the Hidden Layers
3.3.3. Transfer Function
3.3.4. Learning Rate
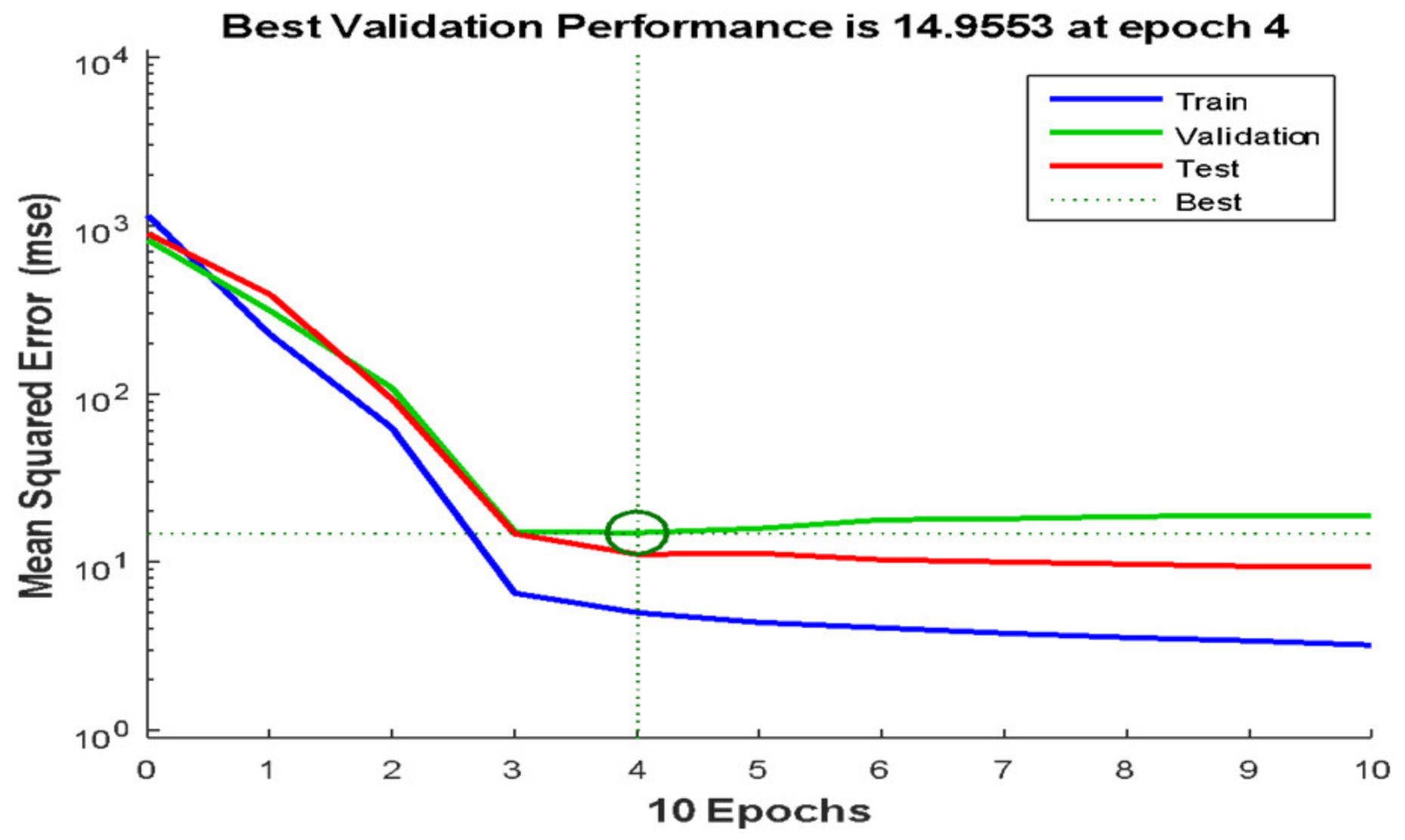
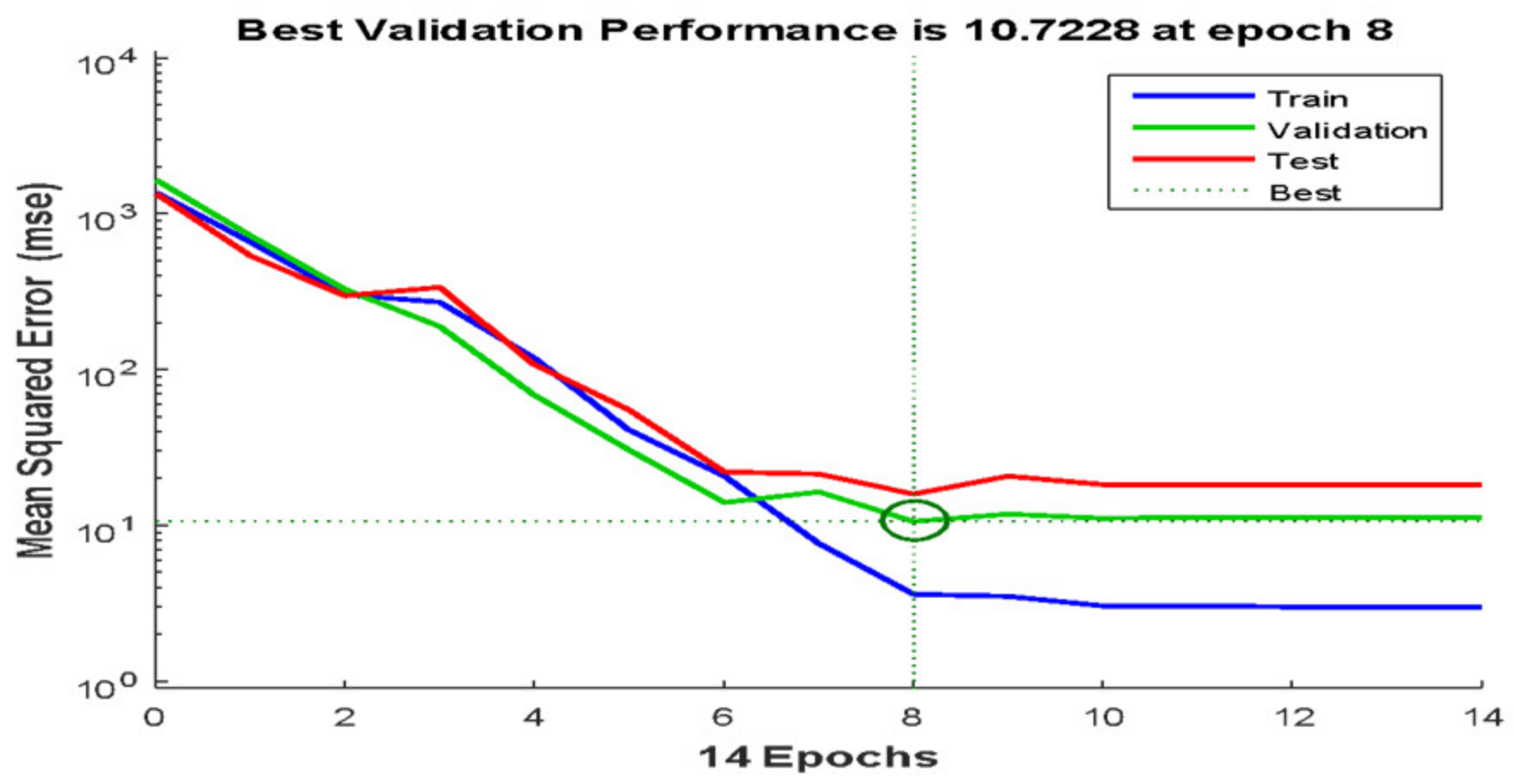
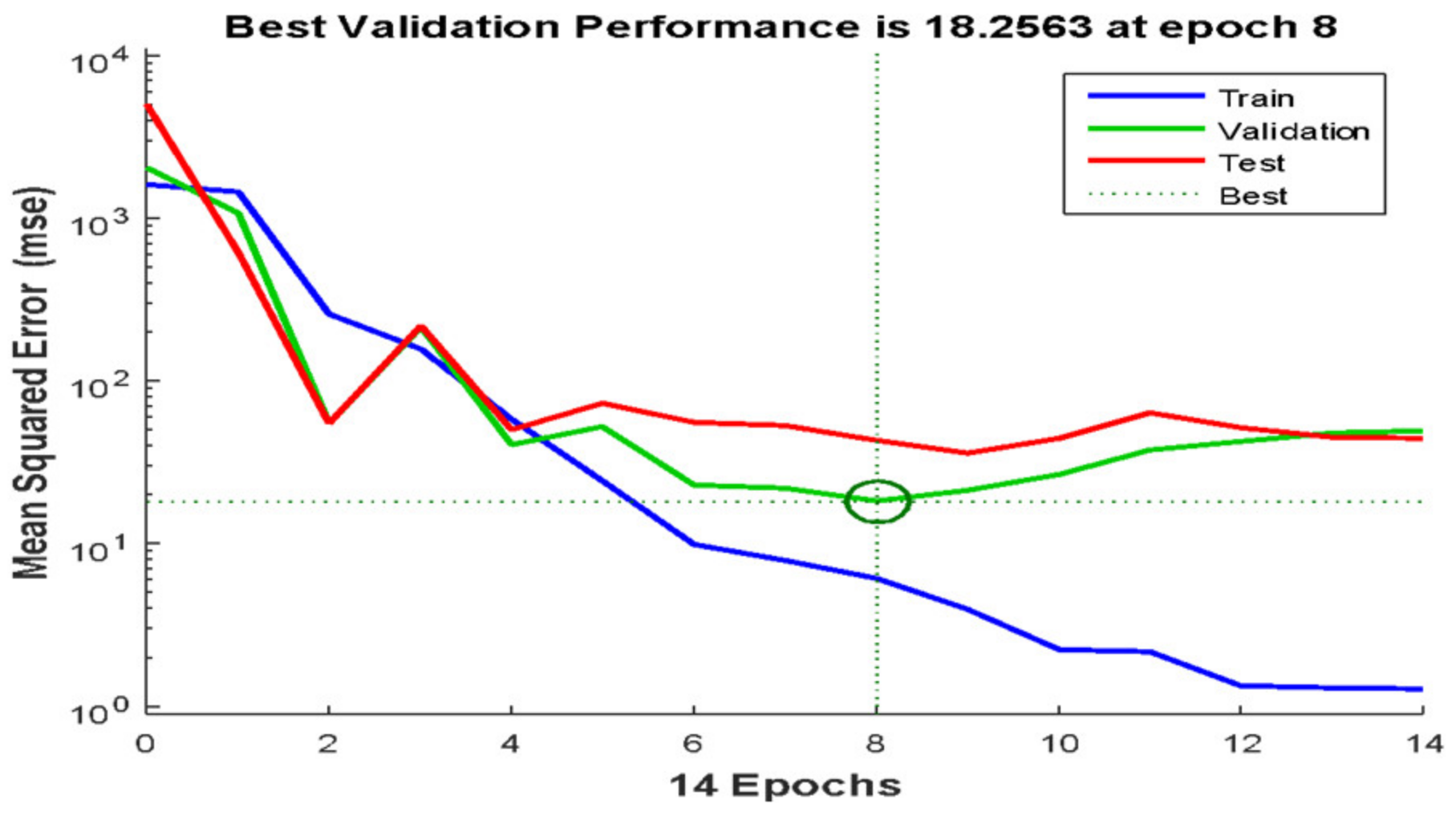
3.4. Hyperparameter Tuning
3.5. MLP Learning Algorithms
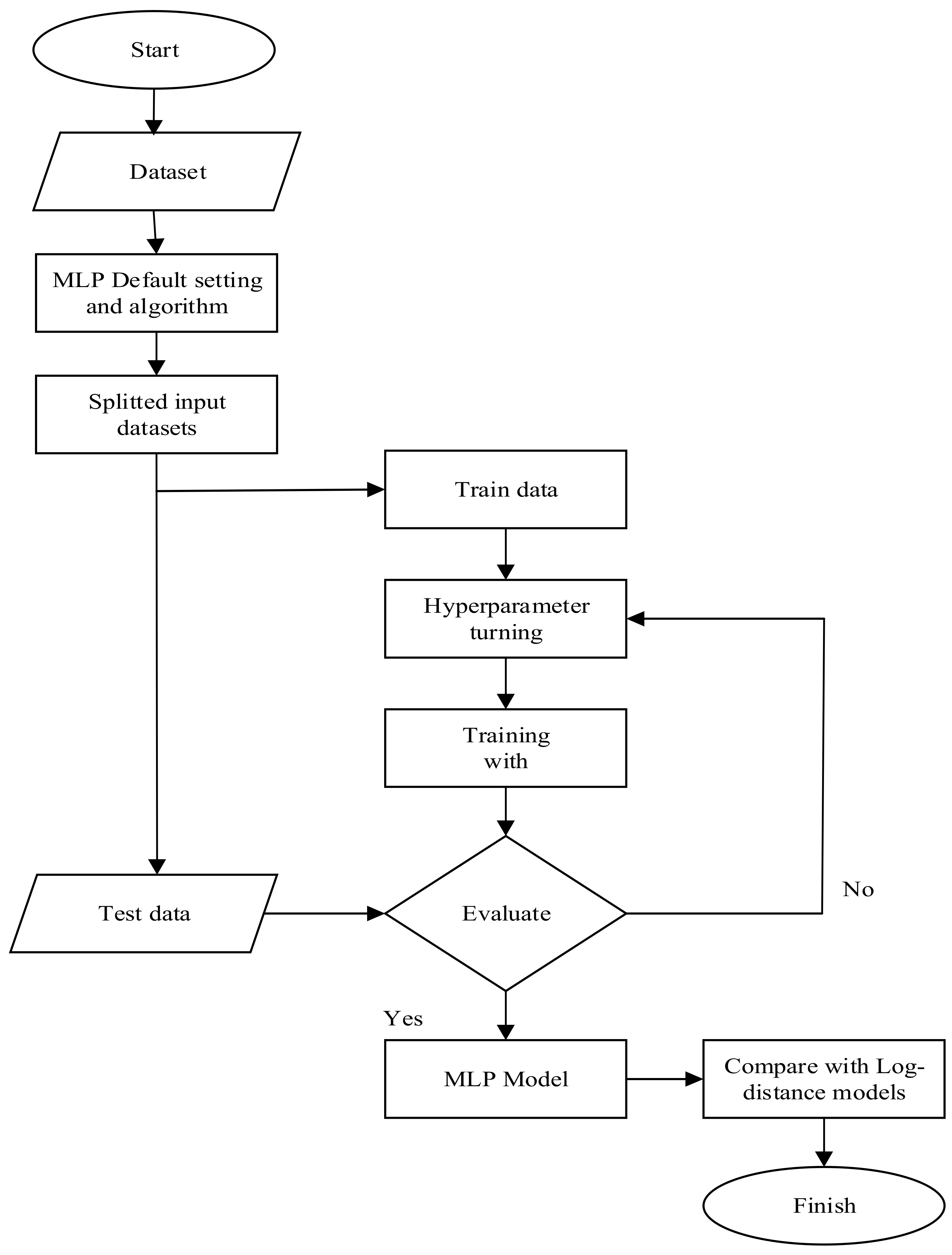
3.6. MLP Network Model Implementation Process
4. Results and Discussions
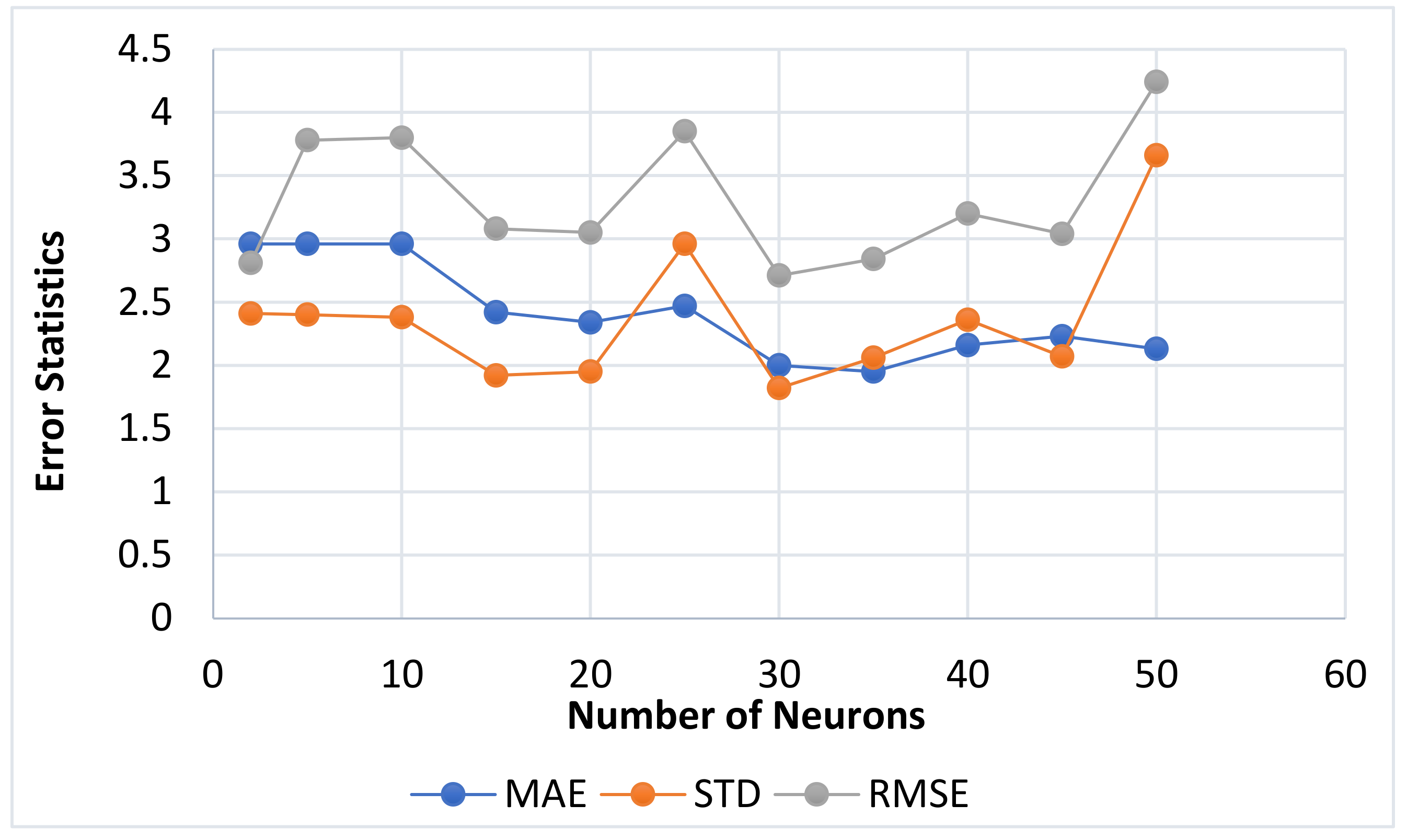
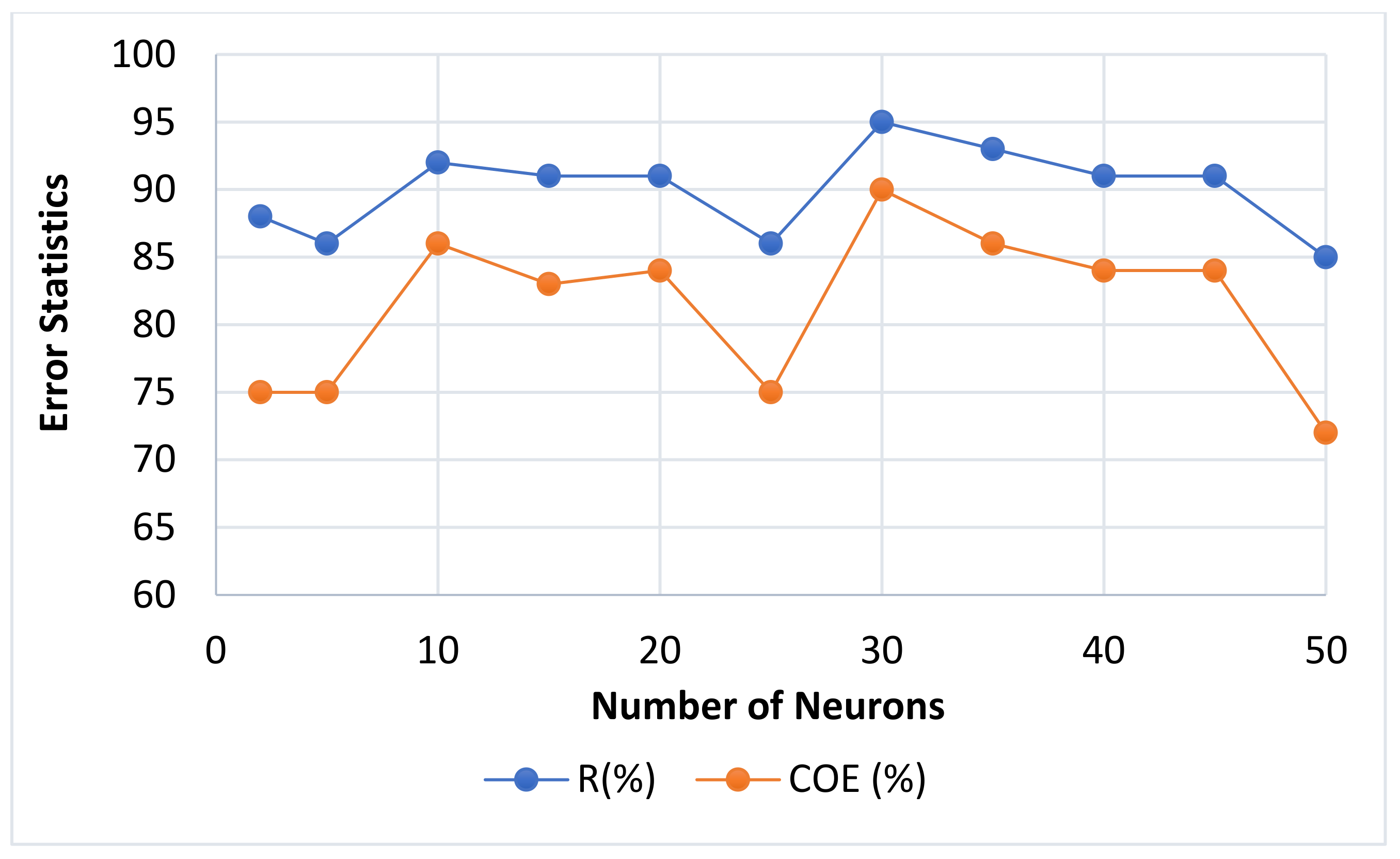
4.1. Neurons Number Impact
4.2. Transfer Function Impact
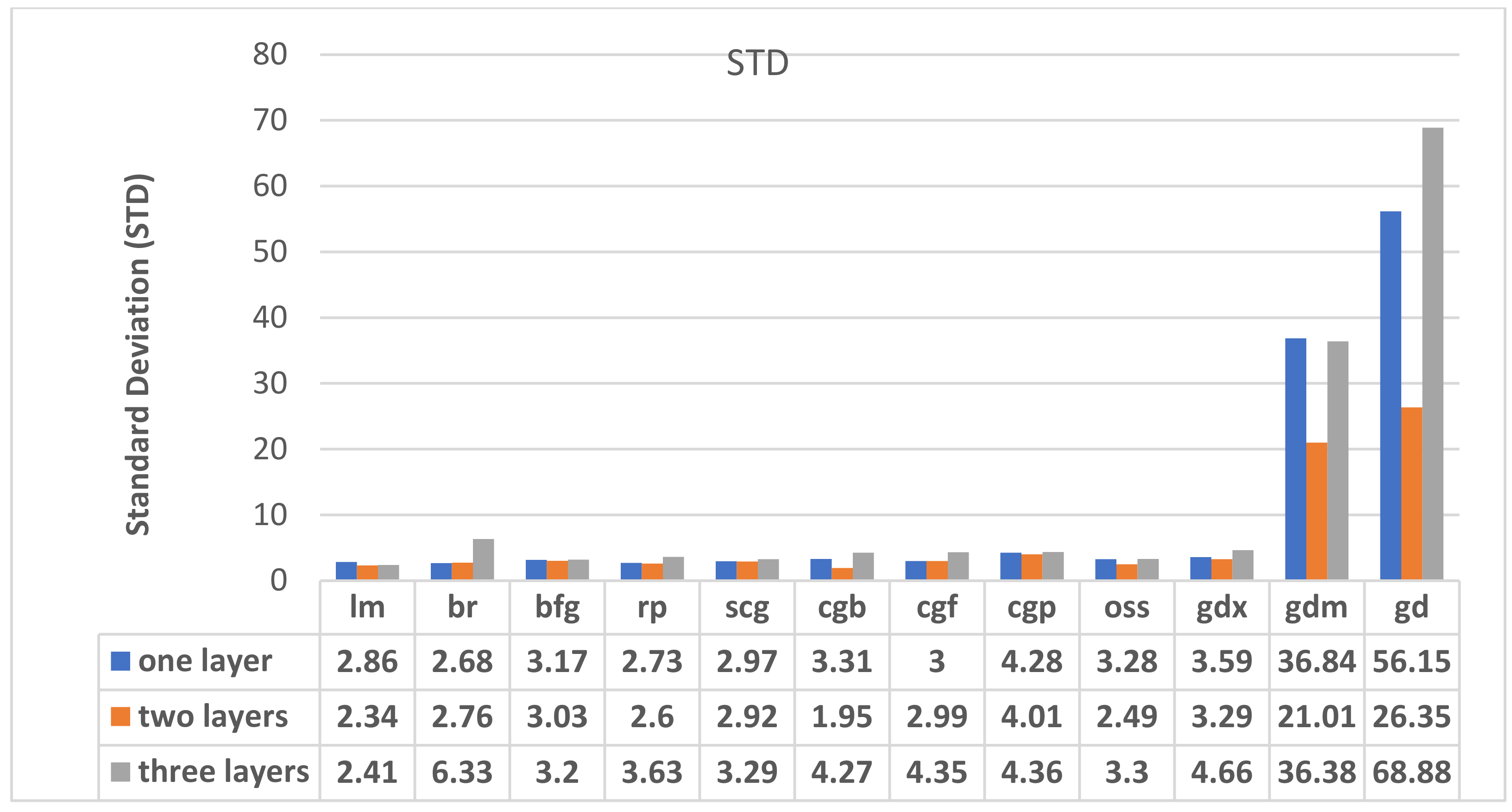
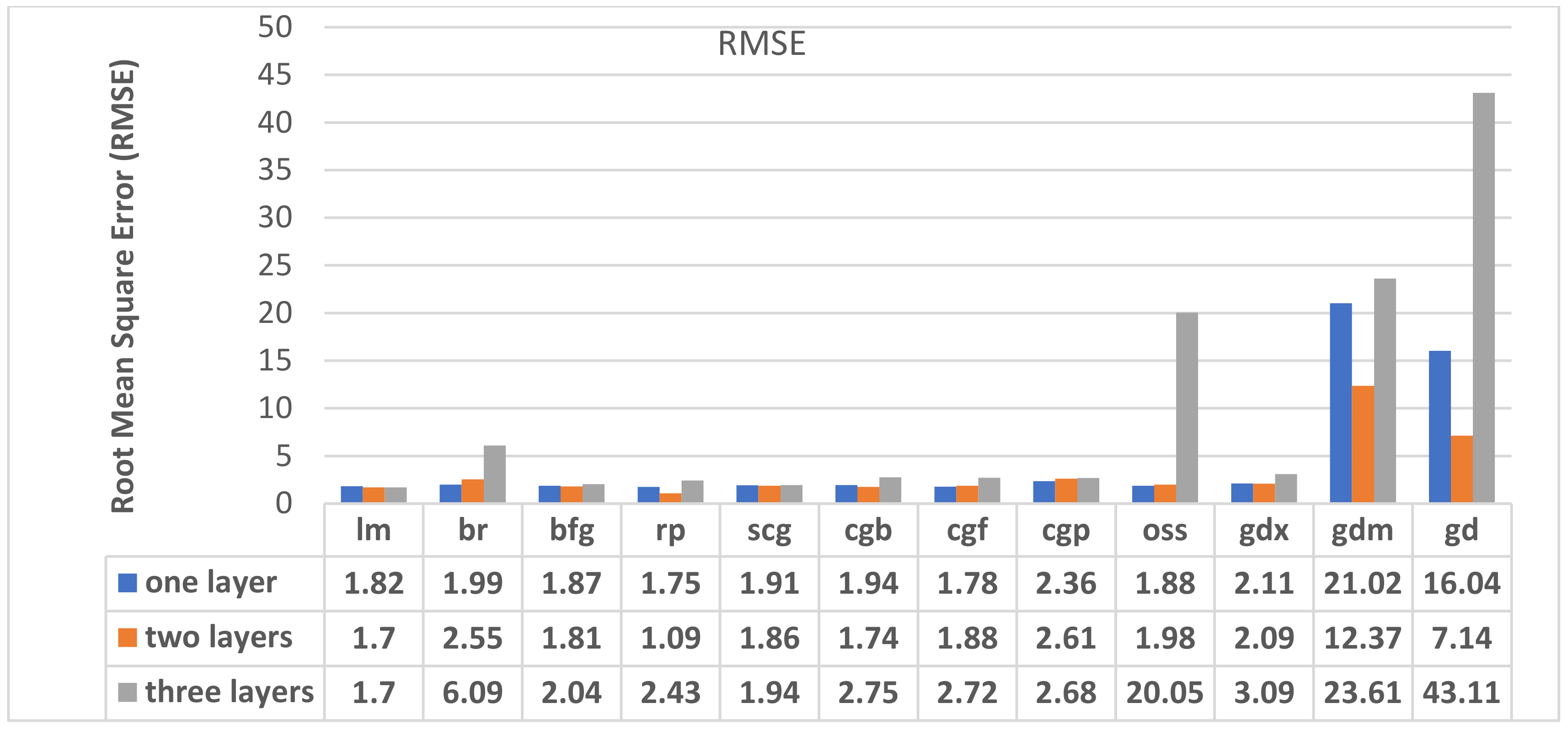
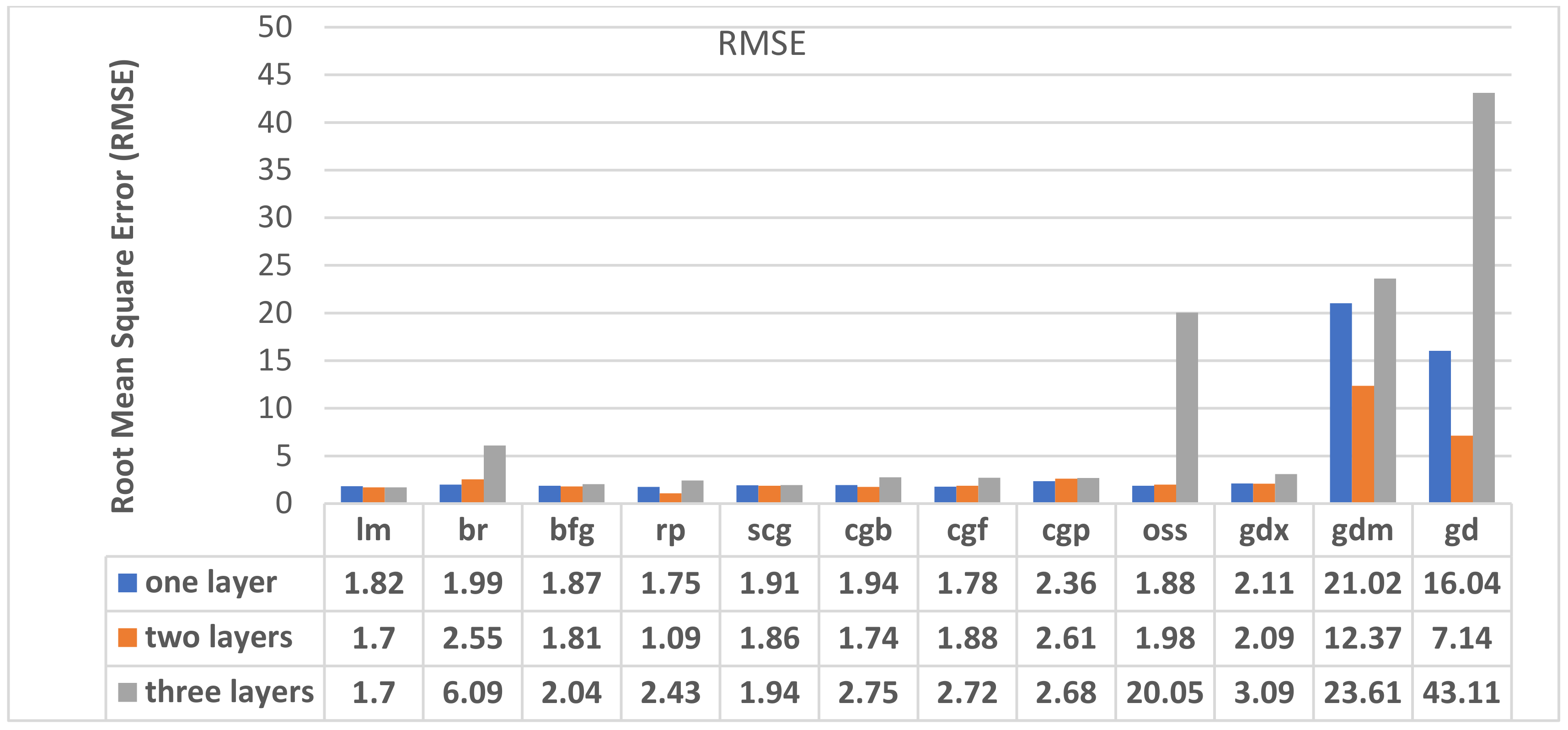
4.3. Training Algorithm and Hidden Layers Number Impact
4.4. Performance of Grid Search Algorithm and Bayesian Optimisation Search Algorithm for Hyperparameter Tuning
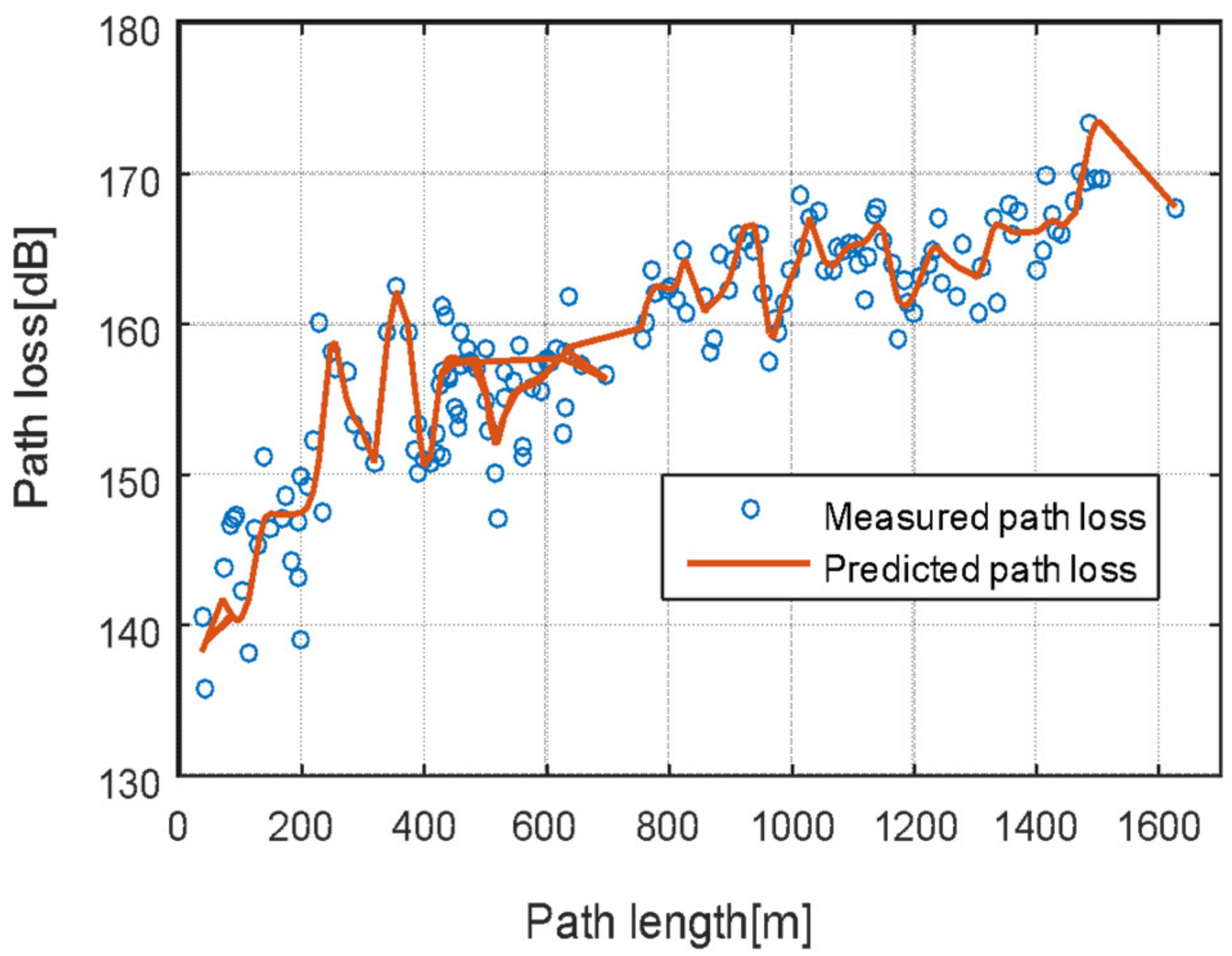
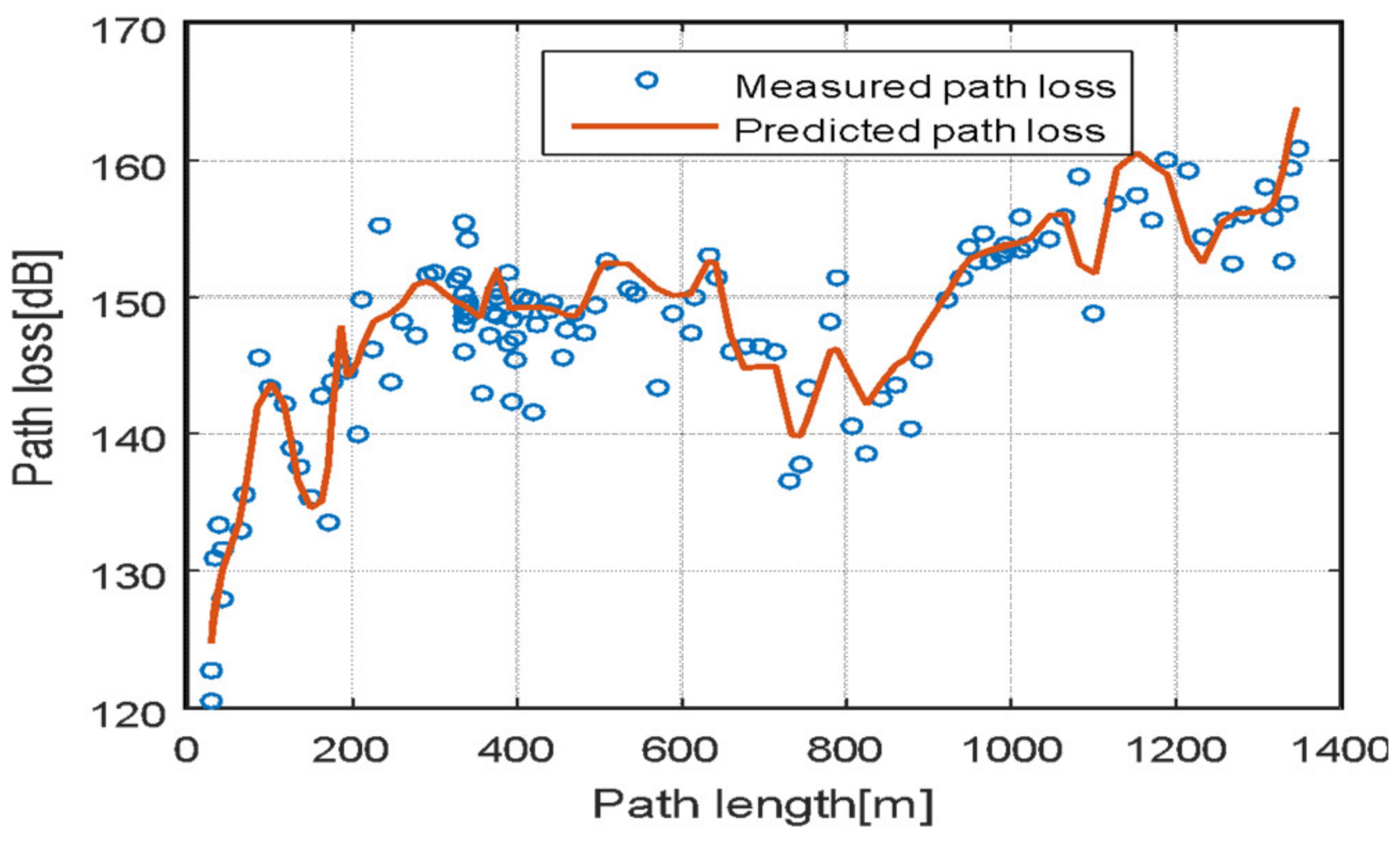
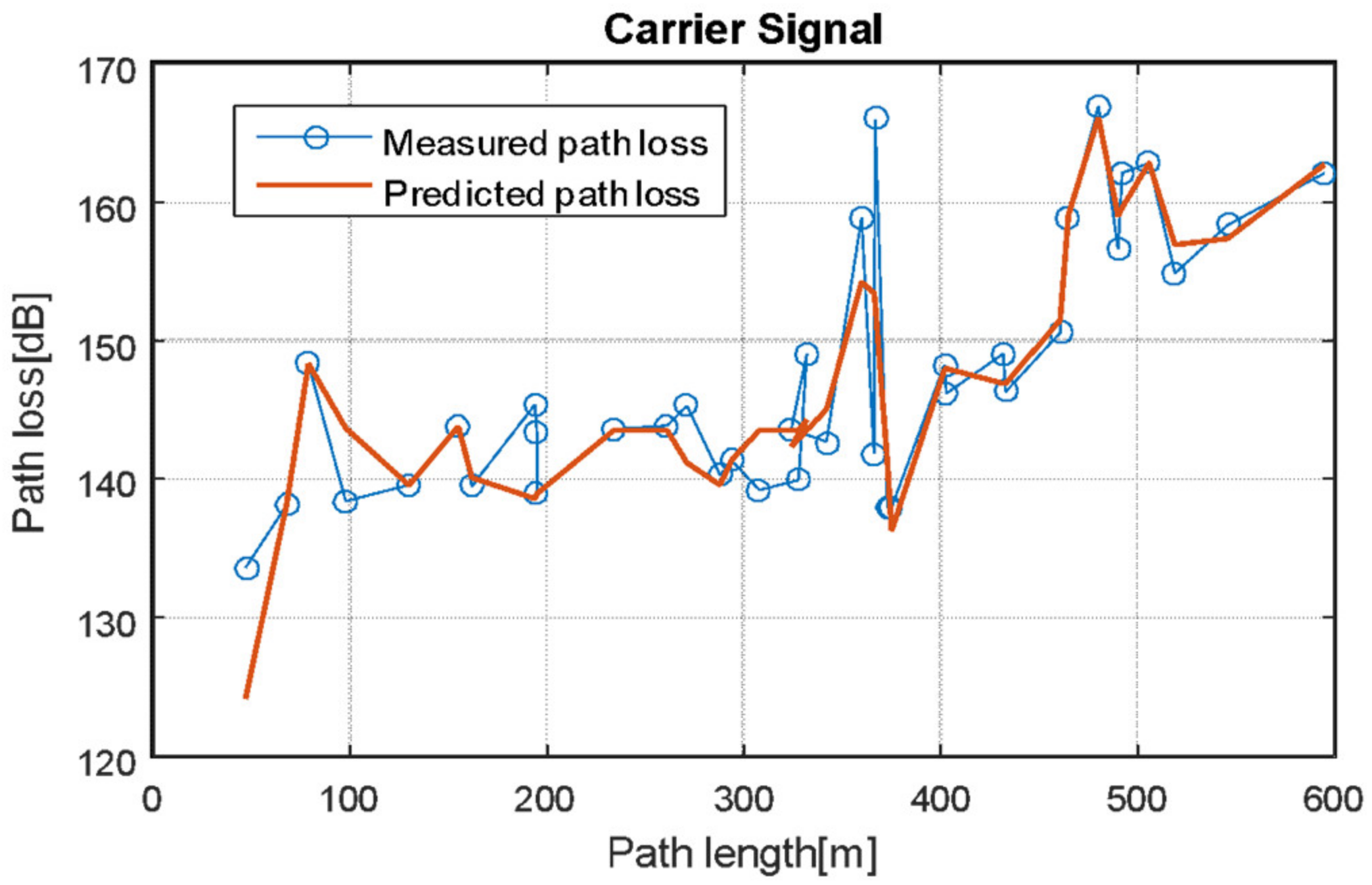
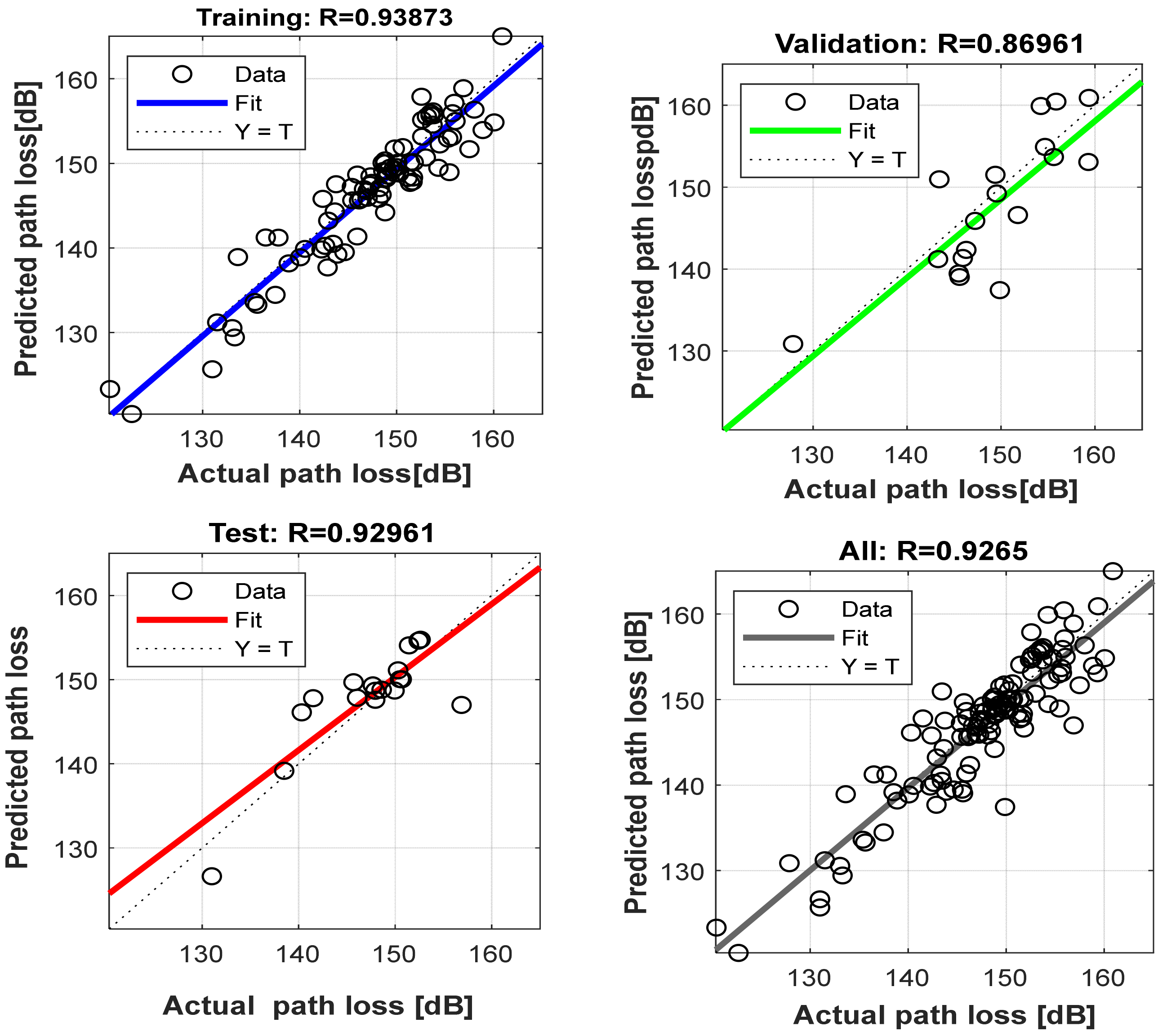
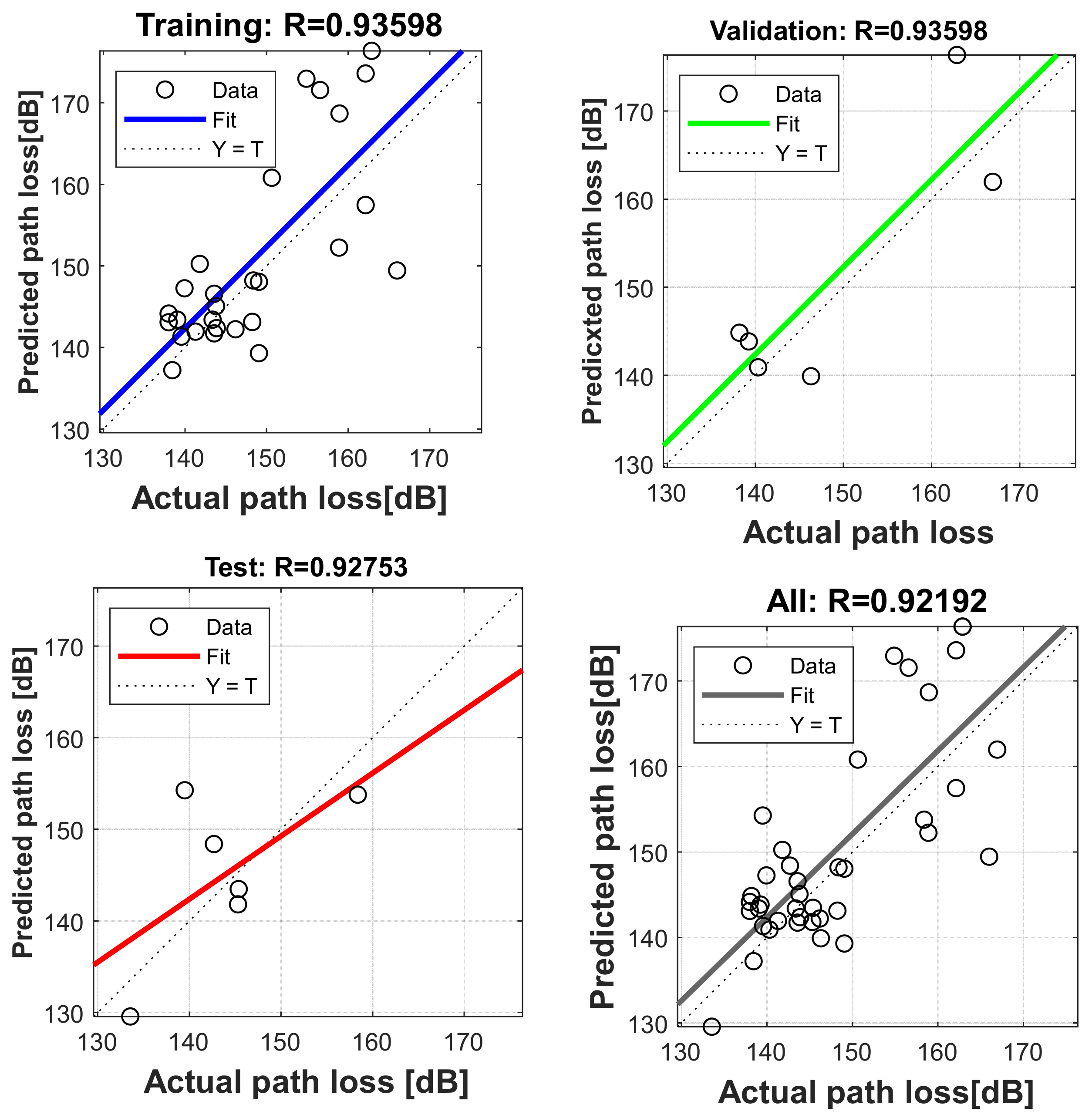
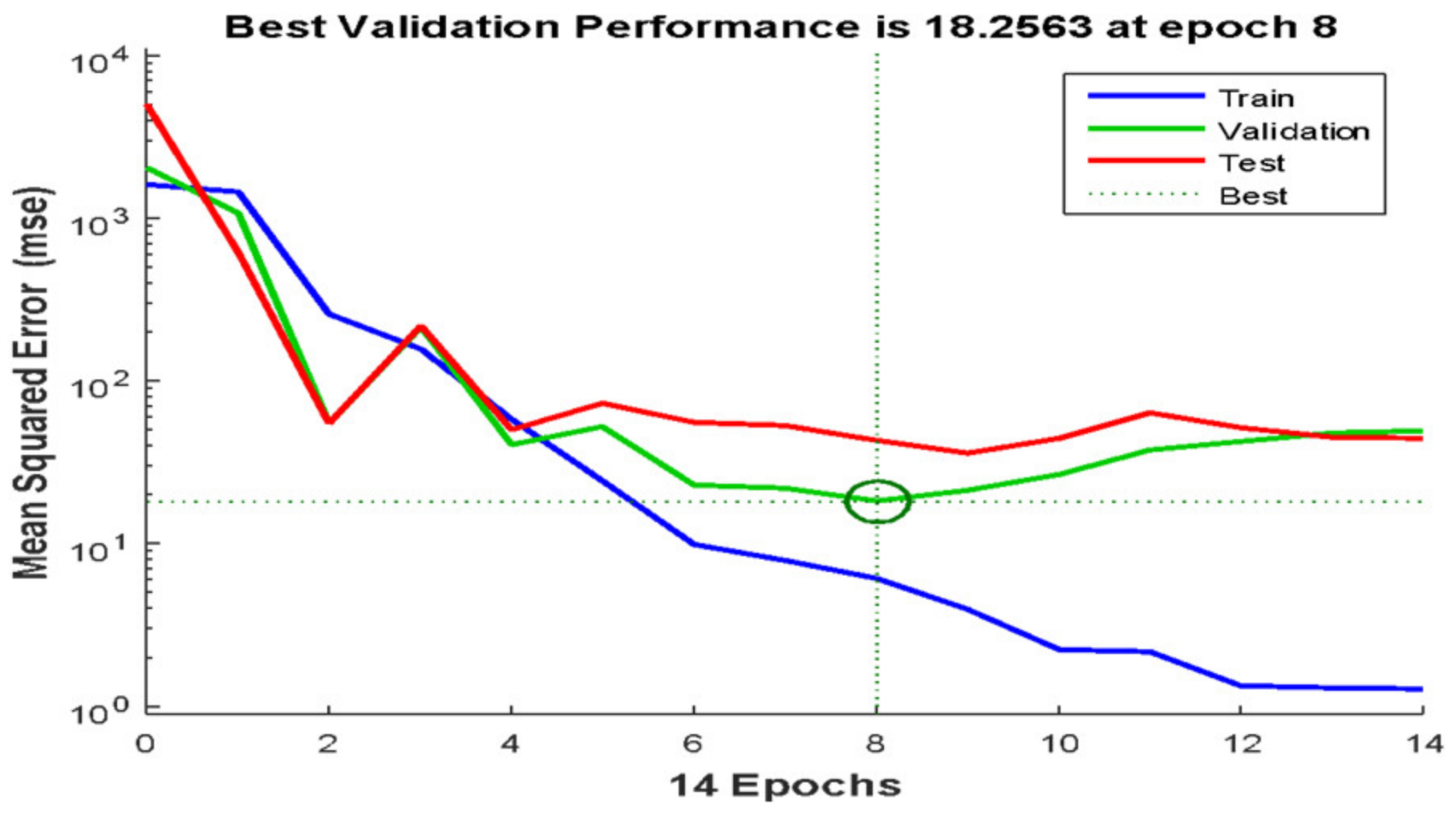
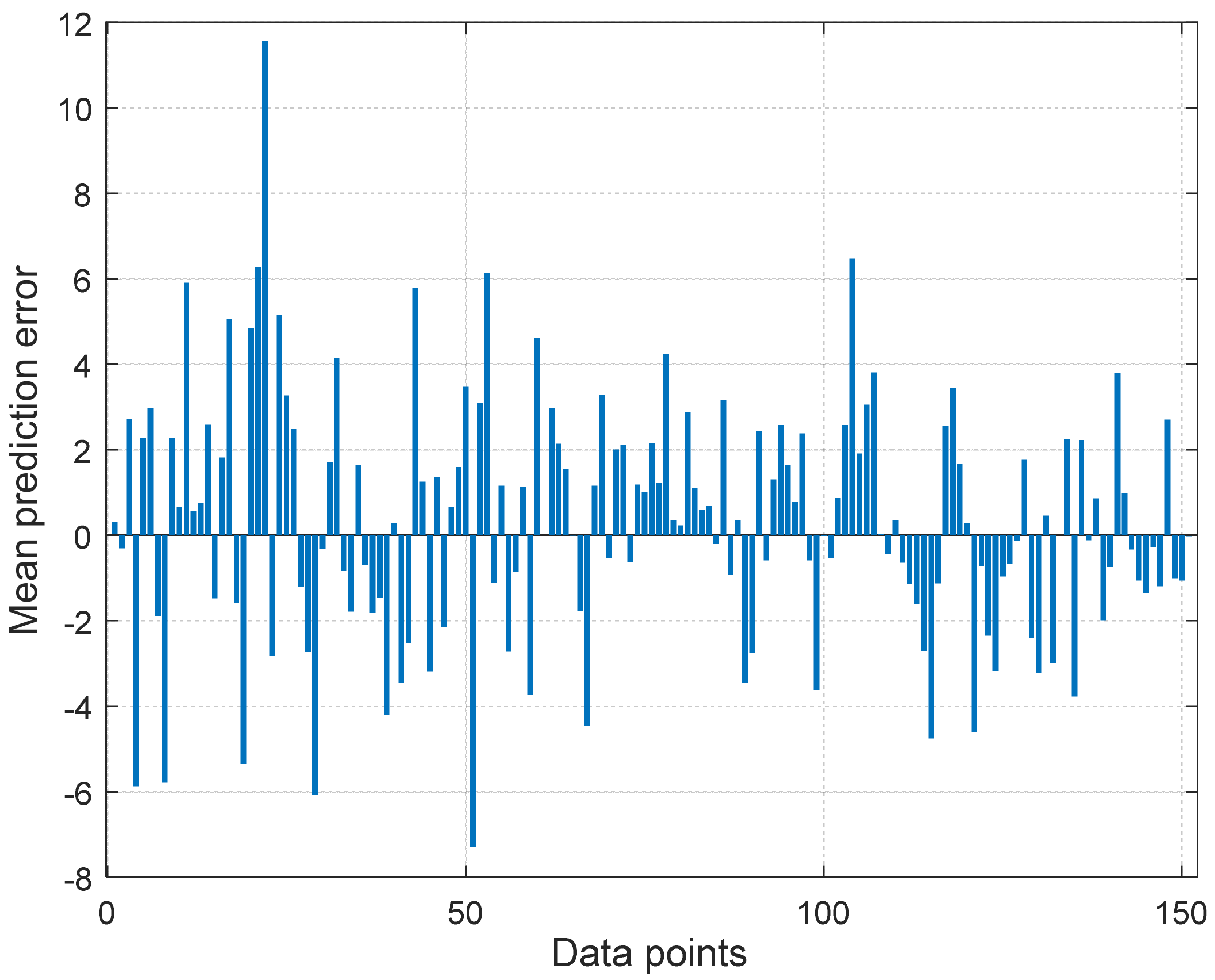
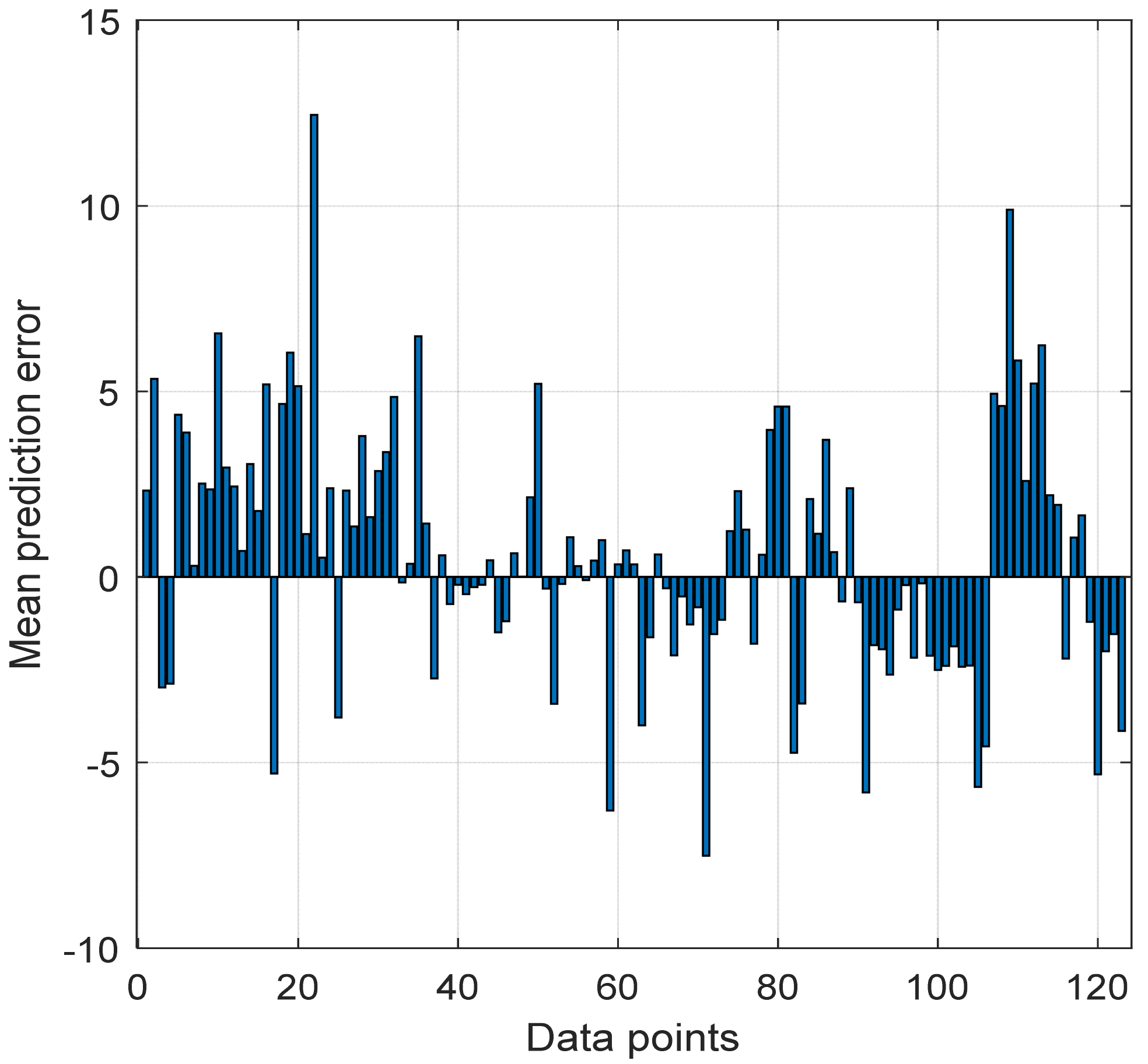
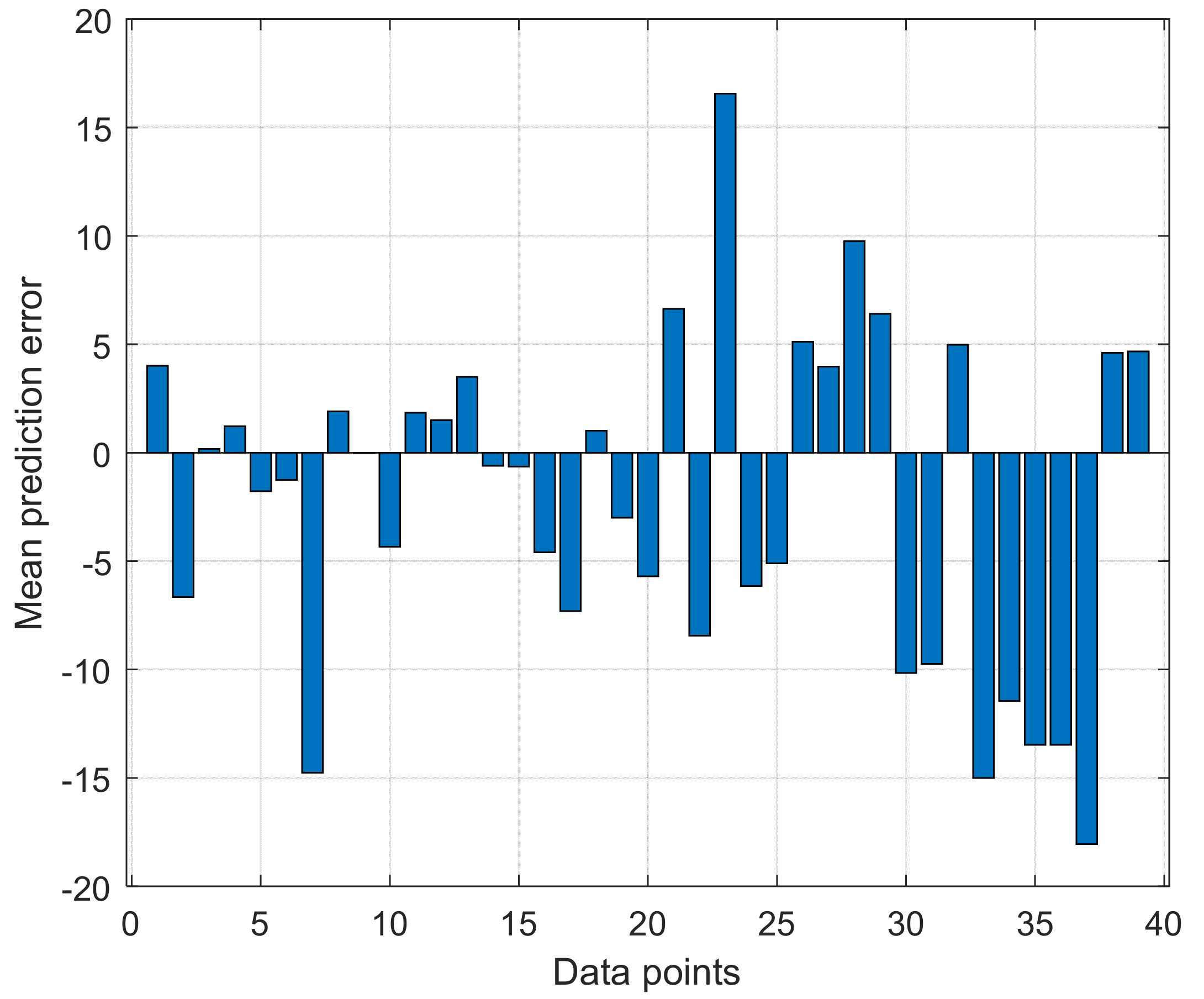
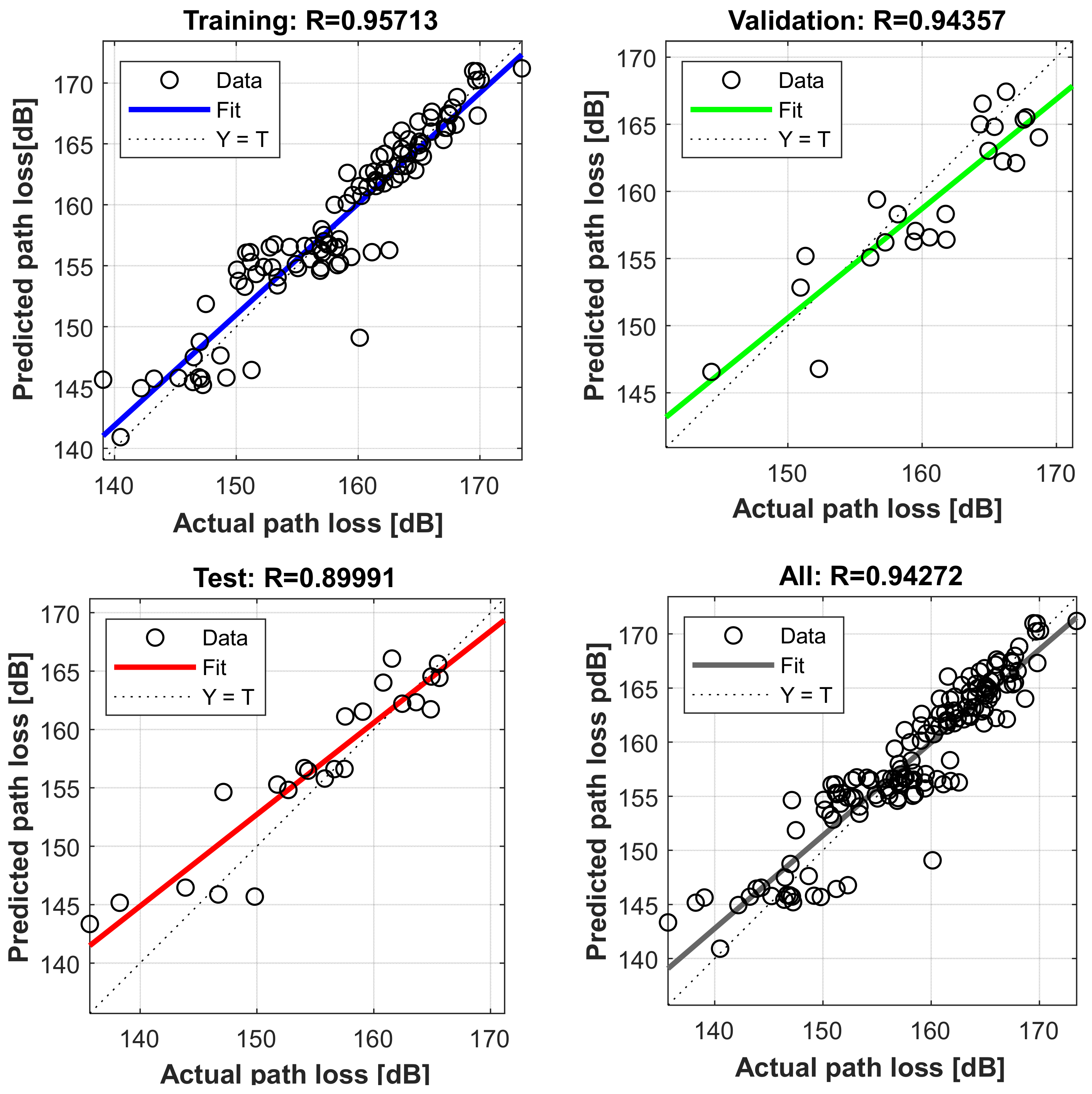
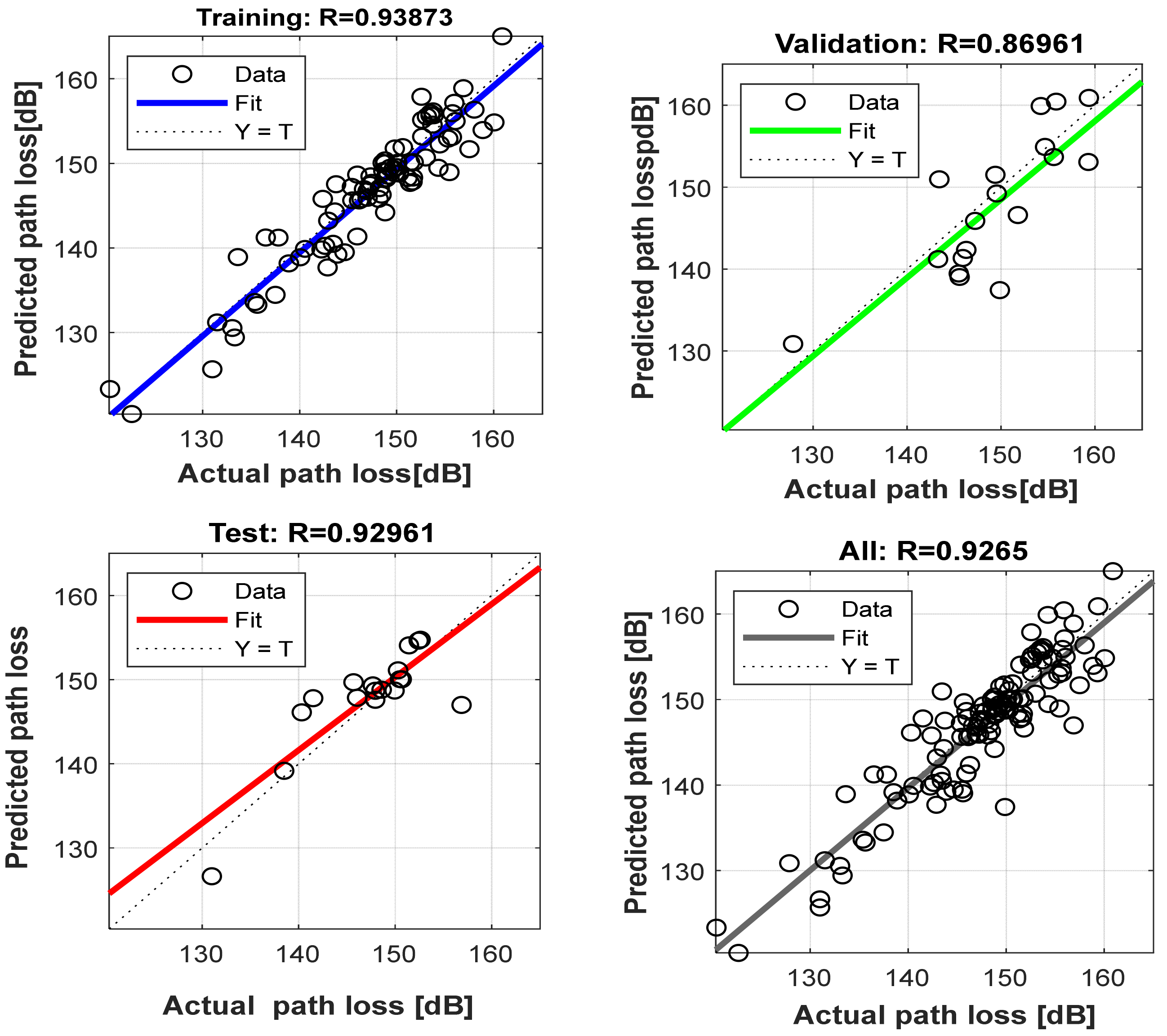
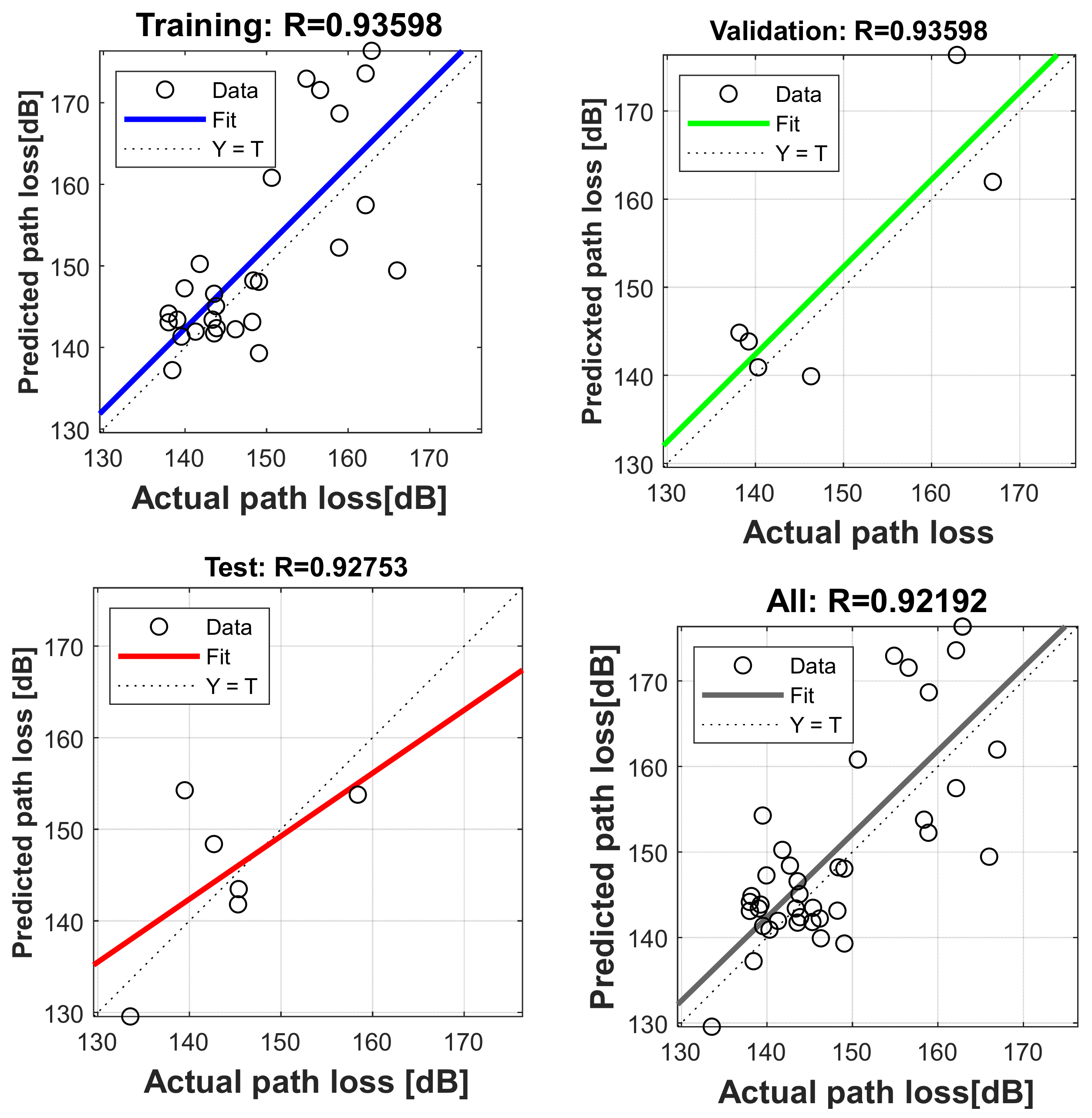
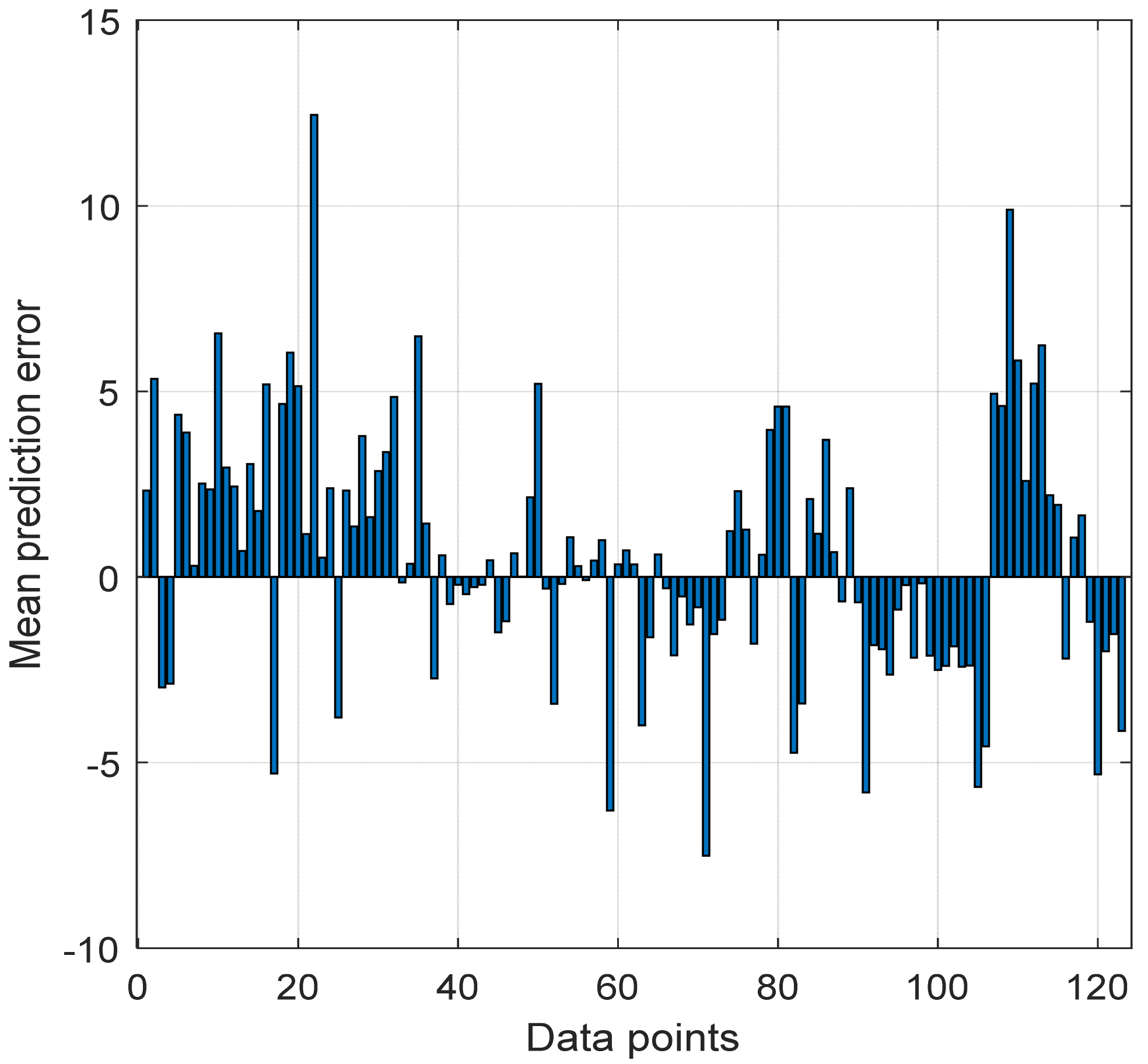
4.5. Evaluation of Proposed Neural Network Model at Different Locations
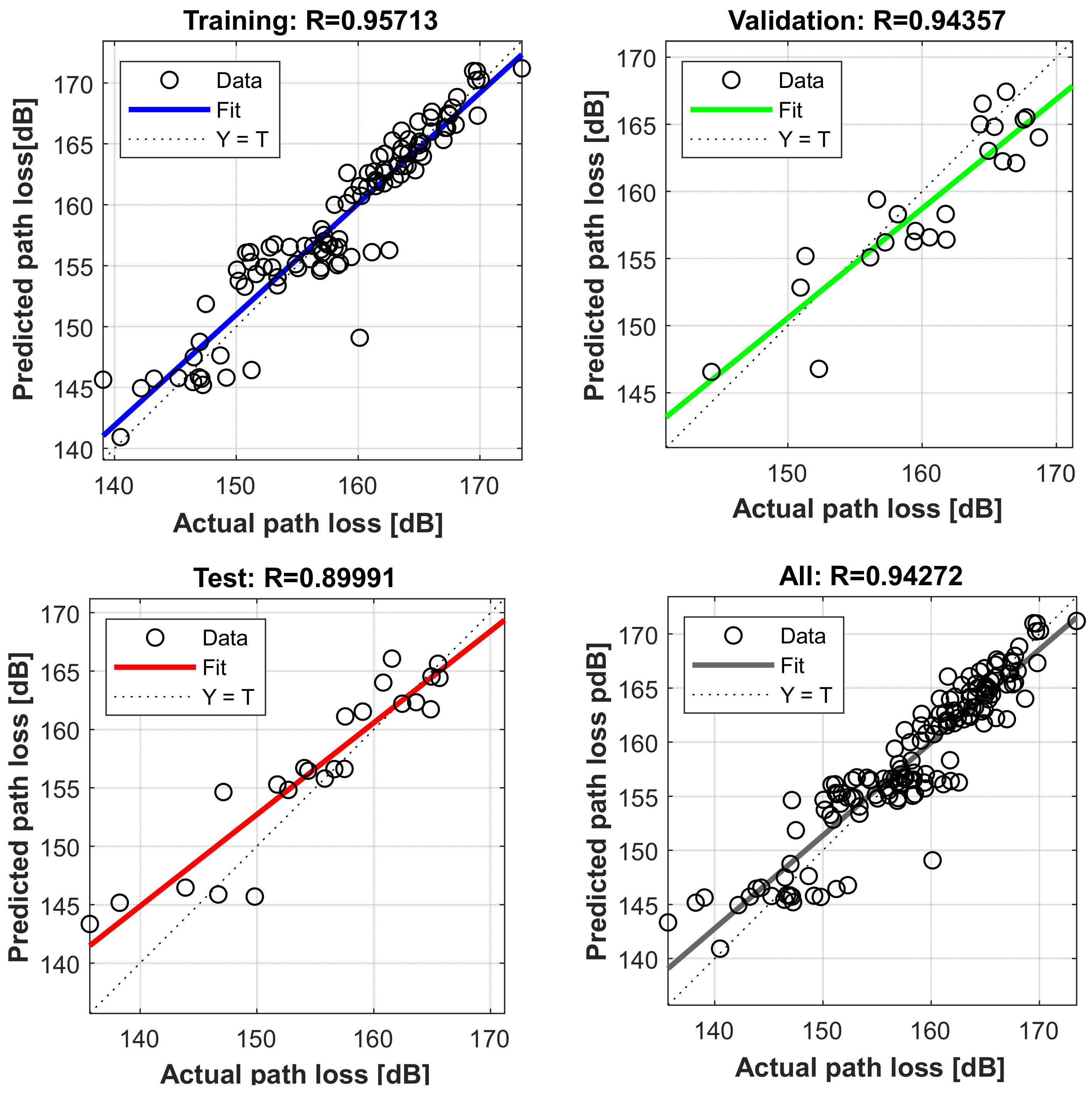
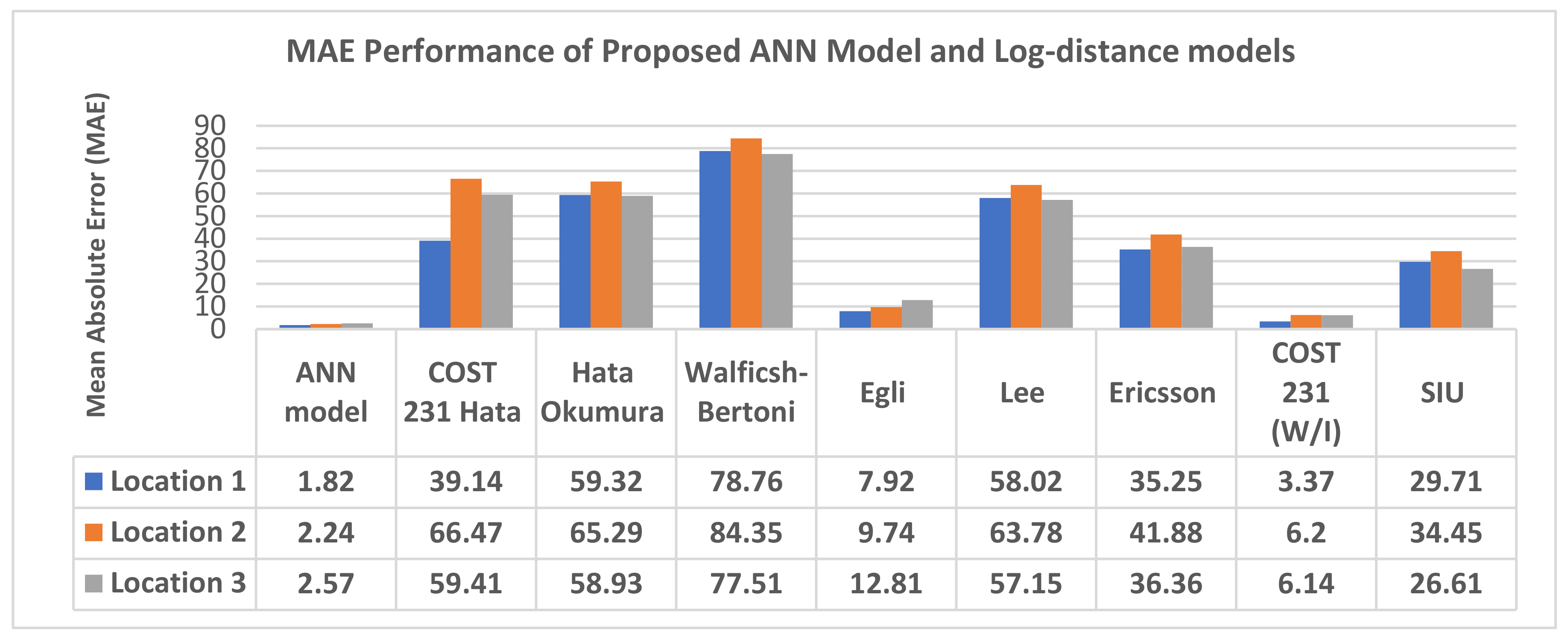
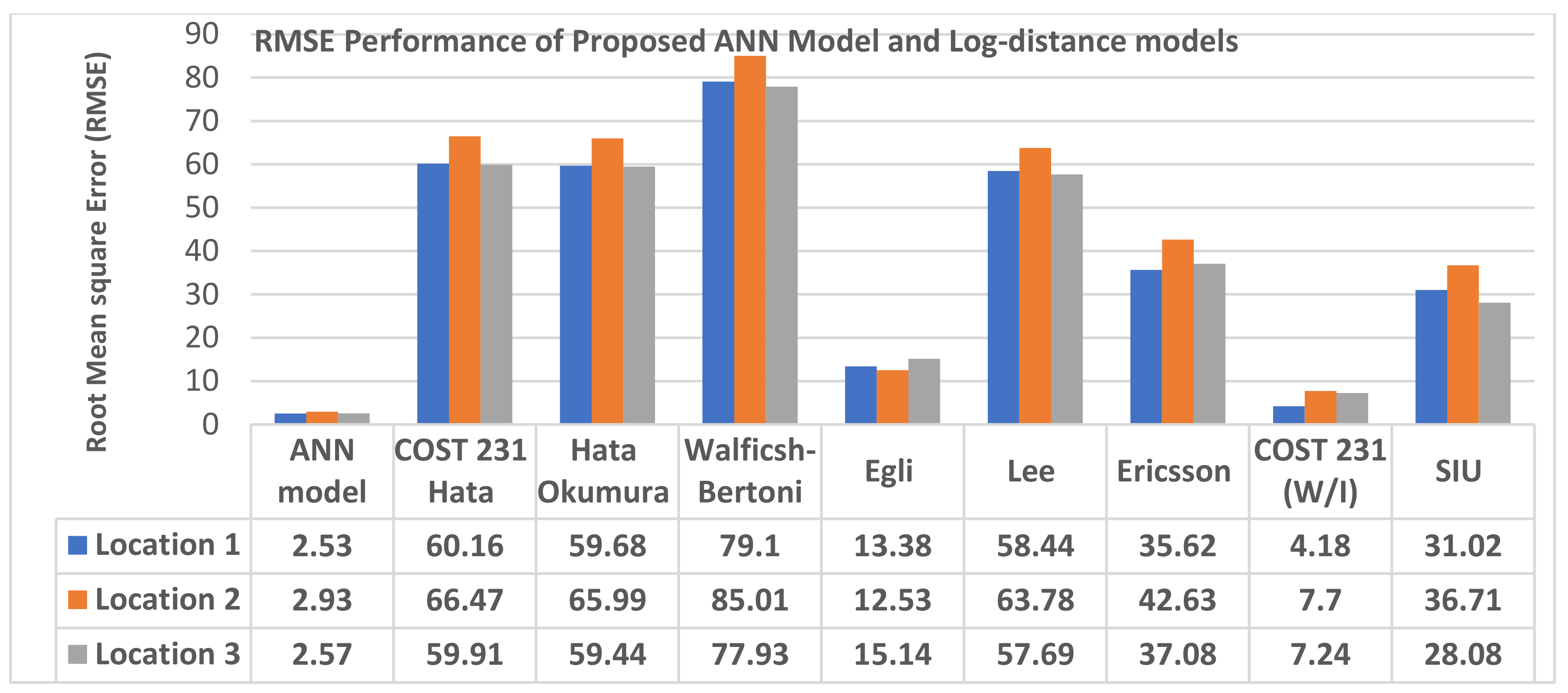
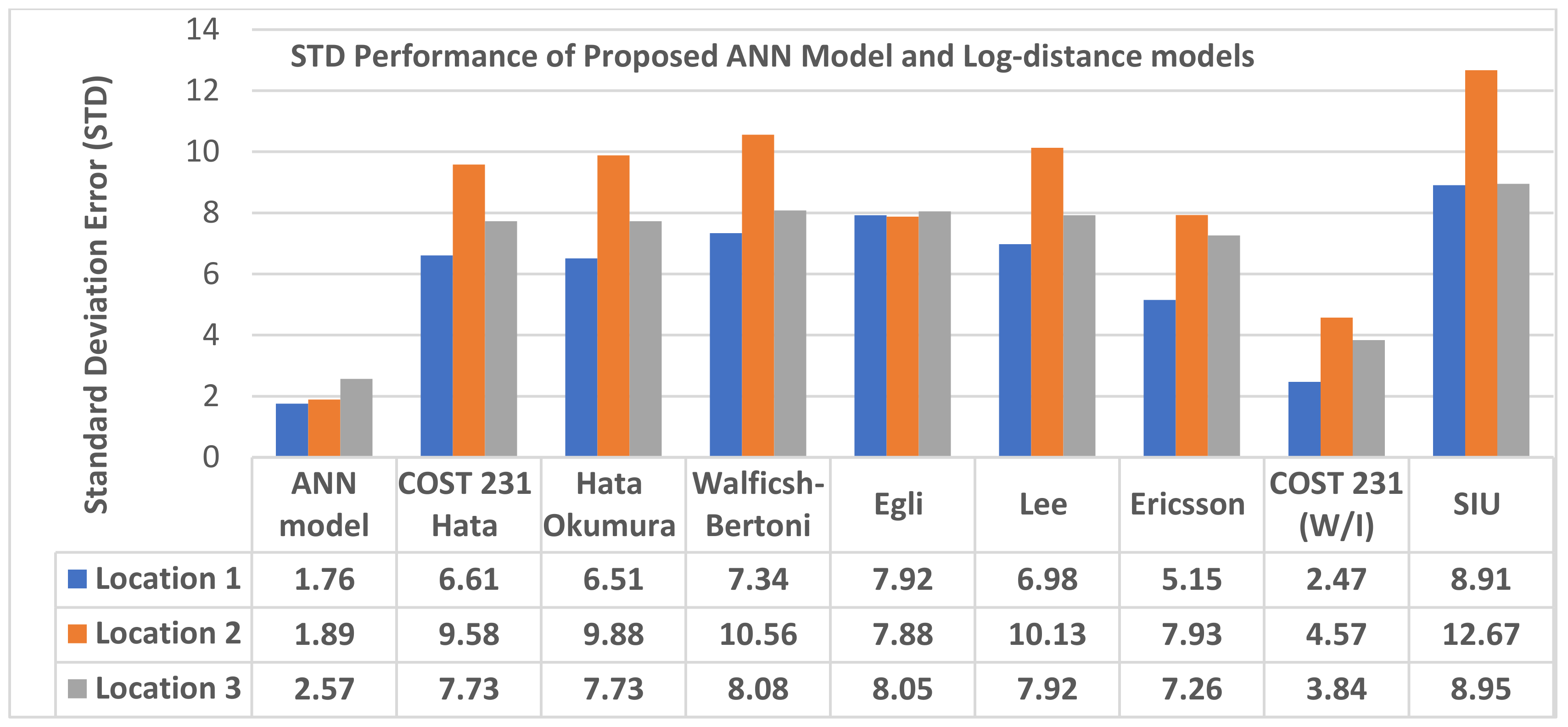
4.6. Comparison of Prediction Accuracy of Proposed Neural Network Model with Log-Distance Models
5. Conclusions
- MLPANN-based path loss model with well-structured implementation network architecture, empowered with the right hyperparameter tuning algorithm is better than the standard long-distance path loss models
- the choice of both MLP-ANN modelling structure and selection of training algorithms do have a clear impact on the quality of its prediction proficiency. Specifically, in terms of MAE, RMSE and STD statistical values, the proposed model yielded up to 50% performance prediction accuracies improvement over the standard models on the acquired LTE path loss datasets.
- The selection of adaptive learning tuning hyperparameters of MLP-ANN and the tuning algorithm both have an impact on its overall predictive modelling capacity.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Molisch, A.F. Wireless Communications, 2nd ed.; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2012; ISBN 9780470741870. [Google Scholar]
- Goldsmith, A.J. Wireless Communications; Cambridge University Press: Cambridge, UK, 2005. [Google Scholar]
- Isabona, J.; Imoize, A.L.; Ojo, S.; Lee, C.-C.; Li, C.-T. Atmospheric Propagation Modelling for Terrestrial Radio Frequency Communication Links in a Tropical Wet and Dry Savanna Climate. Information 2022, 13, 141. [Google Scholar] [CrossRef]
- Isabona, J.; Konyeha, C.C.; Chinule, C.B.; Isaiah, G.P. Radio field strength propagation data and pathloss calculation methods in UMTS network. Adv. Phys. Theor. Appl. 2013, 21, 54–68. [Google Scholar]
- Nawrocki, M.; Aghvami, H.; Dohler, M. Understanding UMTS Radio Network Modelling, Planning and Automated Optimisation: Theory and Practice; John Wiley & Sons: Hoboken, NJ, USA, 2006. [Google Scholar]
- Nawrocki, M.J.; Dohler, M.; Aghvami, A.H. Modern approaches to radio network modelling and planning. In Understanding UMTS Radio Network Modelling, Planning and Automated Optimisation: Theory and Practice; John Wiley & Sons: Hoboken, NJ, USA, 2006; p. 3. [Google Scholar]
- Sharma, P.K.; Singh, R.K. Comparative analysis of propagation path loss models with field measured data. Int. J. Eng. Sci. Technol. 2010, 2, 2008–2013. [Google Scholar]
- Ajose, S.O.; Imoize, A.L. Propagation measurements and modelling at 1800 MHz in Lagos Nigeria. Int. J. Wirel. Mob. Comput. 2013, 6, 165–174. [Google Scholar] [CrossRef]
- Ojo, S.; Imoize, A.; Alienyi, D. Radial basis function neural network path loss prediction model for LTE networks in multitransmitter signal propagation environments. Int. J. Commun. Syst. 2021, 34, e4680. [Google Scholar] [CrossRef]
- Imoize, A.L.; Ibhaze, A.E.; Nwosu, P.O.; Ajose, S.O. Determination of Best-fit Propagation Models for Pathloss Prediction of a 4G LTE Network in Suburban and Urban Areas of Lagos, Nigeria. West Indian J. Eng. 2019, 41, 13–21. [Google Scholar]
- Ibhaze, A.E.; Imoize, A.L.; Ajose, S.O.; John, S.N.; Ndujiuba, C.U.; Idachaba, F.E. An Empirical Propagation Model for Path Loss Prediction at 2100 MHz in a Dense Urban Environment. Indian J. Sci. Technol. 2017, 10, 1–9. [Google Scholar] [CrossRef]
- Rathore, M.M.; Paul, A.; Rho, S.; Khan, M.; Vimal, S.; Shah, S.A. Smart traffic control: Identifying driving-violations using fog devices with vehicular cameras in smart cities. Sustain. Cities Soc. 2021, 71, 102986. [Google Scholar] [CrossRef]
- Imoize, A.L.; Tofade, S.O.; Ughegbe, G.U.; Anyasi, F.I.; Isabona, J. Updating analysis of key performance indicators of 4G LTE network with the prediction of missing values of critical network parameters based on experimental data from a dense urban environment. Data Br. 2022, 42, 108240. [Google Scholar] [CrossRef]
- Fujimoto, K. Mobile Antenna Systems Handbook; Artech House: Norwood, MA, USA, 2008; ISBN 1596931272. [Google Scholar]
- Tataria, H.; Haneda, K.; Molisch, A.F.; Shafi, M.; Tufvesson, F. Standardization of Propagation Models for Terrestrial Cellular Systems: A Historical Perspective. Int. J. Wirel. Inf. Networks 2021, 28, 20–44. [Google Scholar] [CrossRef]
- Hanci, B.Y.; Cavdar, I.H. Mobile radio propagation measurements and tuning the path loss model in urban areas at GSM-900 band in Istanbul-Turkey. In Proceedings of the IEEE 60th Vehicular Technology Conference, 2004, VTC2004-Fall, Los Angeles, CA, USA, 26–29 September 2004; Volume 1, pp. 139–143. [Google Scholar]
- Ekpenyong, M.; Isabona, J.; Ekong, E. On Propagation Path Loss Models For 3-G Based Wireless Networks: A Comparative Analysis. Comput. Sci. Telecommun. 2010, 25, 74–84. [Google Scholar]
- Isabona, J. Wavelet Generalized Regression Neural Network Approach for Robust Field Strength Prediction. Wirel. Pers. Commun. 2020, 114, 3635–3653. [Google Scholar] [CrossRef]
- Imoize, A.L.; Oseni, A.I. Investigation and pathloss modeling of fourth generation long term evolution network along major highways in Lagos Nigeria. Ife J. Sci. 2019, 21, 39–60. [Google Scholar] [CrossRef]
- Imoize, A.L.; Ogunfuwa, T.E. Propagation measurements of a 4G LTE network in Lagoon environment. Niger. J. Technol. Dev. 2019, 16, 1–9. [Google Scholar] [CrossRef] [Green Version]
- Imoize, A.L.; Dosunmu, A.I. Path Loss Characterization of Long Term Evolution Network for. Jordan J. Electr. Eng. 2018, 4, 114–128. [Google Scholar]
- Ekpenyong, M.E.; Robinson, S.; Isabona, J. Macrocellular propagation prediction for wireless communications in urban environments. J. Comput. Sci. Technol. 2010, 10, 130–136. [Google Scholar]
- Nadir, Z. Empirical pathloss characterization for Oman. In Proceedings of the 2012 Computing, Communications and Applications Conference, Tamilnadu, India, 22–24 February 2012; pp. 133–137. [Google Scholar] [CrossRef]
- Hunter, D.; Yu, H.; Pukish III, M.S.; Kolbusz, J.; Wilamowski, B.M. Selection of proper neural network sizes and architectures—A comparative study. IEEE Trans. Ind. Informatics 2012, 8, 228–240. [Google Scholar] [CrossRef]
- Imoize, A.L.; Ibhaze, A.E.; Atayero, A.A.; Kavitha, K.V.N. Standard Propagation Channel Models for MIMO Communication Systems. Wirel. Commun. Mob. Comput. 2021, 2021, 8838792. [Google Scholar] [CrossRef]
- Khan, N.; Haq, I.U.; Khan, S.U.; Rho, S.; Lee, M.Y.; Baik, S.W. DB-Net: A novel dilated CNN based multi-step forecasting model for power consumption in integrated local energy systems. Int. J. Electr. Power Energy Syst. 2021, 133, 107023. [Google Scholar] [CrossRef]
- Jo, H.-S.; Park, C.; Lee, E.; Choi, H.K.; Park, J. Path loss prediction based on machine learning techniques: Principal component analysis, artificial neural network, and Gaussian process. Sensors 2020, 20, 1927. [Google Scholar] [CrossRef] [Green Version]
- Guo, D.; Zhang, Y.; Xiang, Q.; Li, Z. Improved radio frequency identification indoor localization method via radial basis function neural network. Math. Probl. Eng. 2014, 2014, 420482. [Google Scholar] [CrossRef] [Green Version]
- Guo, Y.; Liu, Y.; Li, S. Modeling and Simulation of Terahertz Indoor Wireless Channel Based on Radial Basis Function Neural Network. In Proceedings of the 2021 International Conference on Microwave and Millimeter Wave Technology (ICMMT), Nanjing, China, 23–26 May 2021; pp. 1–3. [Google Scholar]
- Annepu, V.; Rajesh, A.; Bagadi, K. Radial basis function-based node localization for unmanned aerial vehicle-assisted 5G wireless sensor networks. Neural Comput. Appl. 2021, 33, 12333–12346. [Google Scholar] [CrossRef]
- Huang, G.-B. Learning capability and storage capacity of two-hidden-layer feedforward networks. IEEE Trans. Neural Netw. 2003, 14, 274–281. [Google Scholar] [CrossRef] [Green Version]
- Abhayawardhana, V.S.; Wassellt, I.J.; Crosby, D.; Sellars, M.P.; Brown, M.G. Comparison of empirical propagation path loss models for fixed wireless access systems. In Proceedings of the IEEE Vehicular Technology Conference, Stockholm, Sweden, 30 May–1 June 2005; Volume 61, pp. 73–77. [Google Scholar]
- Hinga, S.K.; Atayero, A.A. Deterministic 5G mmWave Large-Scale 3D Path Loss Model for Lagos Island, Nigeria. IEEE Access 2021, 9, 134270–134288. [Google Scholar] [CrossRef]
- Haykin, S. Neural networks: A guided tour. Soft Comput. Intell. Syst. theory Appl. 1999, 71, 71–80. [Google Scholar]
- Isabona, J.; Osaigbovo, A.I. Investigating predictive capabilities of RBFNN, MLPNN and GRNN models for LTE cellular network radio signal power datasets. FUOYE J. Eng. Technol. 2019, 4, 155–159. [Google Scholar] [CrossRef]
- Sotiroudis, S.P.; Goudos, S.K.; Gotsis, K.A.; Siakavara, K.; Sahalos, J.N. Modeling by optimal artificial neural networks the prediction of propagation path loss in urban environments. In Proceedings of the 2013 IEEE-APS Topical Conference on Antennas and Propagation in Wireless Communications (APWC), Turin, Italy, 9–13 September 2013; pp. 599–602. [Google Scholar]
- Isabona, J.; Imoize, A.L. Terrain-based adaption of propagation model loss parameters using non-linear square regression. J. Eng. Appl. Sci. 2021, 68, 33. [Google Scholar] [CrossRef]
- Phillips, C.; Sicker, D.; Grunwald, D. A Survey of Wireless Path Loss Prediction and Coverage Mapping Methods. IEEE Commun. Surv. Tutorials 2013, 15, 255–270. [Google Scholar] [CrossRef]
- Imoize, A.L.; Oyedare, T.; Ezekafor, C.G.; Shetty, S. Deployment of an Energy Efficient Routing Protocol for Wireless Sensor Networks Operating in a Resource Constrained Environment. Trans. Networks Commun. 2019, 7, 34–50. [Google Scholar] [CrossRef] [Green Version]
- Imoize, A.L.; Ajibola, O.A.; Oyedare, T.R.; Ogbebor, J.O.; Ajose, S.O. Development of an Energy-Efficient Wireless Sensor Network Model for Perimeter Surveillance. Int. J. Electr. Eng. Appl. Sci. 2021, 4, 1–17. [Google Scholar]
- Imoize, A.L. Analysis of Propagation Models for Mobile Radio Reception at 1800MHz. Master’s Thesis, University of Lagos, Lagos, Nigeria, 2011. [Google Scholar]
- Isabona, J.; Ojuh, D. Adaptation of Propagation Model Parameters toward Efficient Cellular Network Planning using Robust LAD Algorithm. Int. J. Wirel. Microw. Technol. 2020, 10, 13–24. [Google Scholar] [CrossRef]
- Imoize, A.L.; Orolu, K.; Atayero, A.A.-A. Analysis of key performance indicators of a 4G LTE network based on experimental data obtained from a densely populated smart city. Data Br. 2020, 29, 105304. [Google Scholar] [CrossRef] [PubMed]
- Ojo, S.; Akkaya, M.; Sopuru, J.C. An ensemble machine learning approach for enhanced path loss predictions for 4G LTE wireless networks. Int. J. Commun. Syst. 2022, 35, e5101. [Google Scholar] [CrossRef]
- Ebhota, V.C.; Isabona, J.; Srivastava, V.M. Improved adaptive signal power loss prediction using combined vector statistics based smoothing and neural network approach. Prog. Electromagn. Res. C 2018, 82, 155–169. [Google Scholar] [CrossRef] [Green Version]
- Ebhota, V.C.; Isabona, J.; Srivastava, V.M. Base line knowledge on propagation modelling and prediction techniques in wireless communication networks. J. Eng. Appl. Sci. 2018, 13, 1919–1934. [Google Scholar]
- Coskun, N.; Yildirim, T. The effects of training algorithms in MLP network on image classification. In Proceedings of the International Joint Conference on Neural Networks, Portland, OR, USA, 20–24 July 2003; Volume 2, pp. 1223–1226. [Google Scholar]
- Salman, M.A.; Popoola, S.I.; Faruk, N.; Surajudeen-Bakinde, N.T.; Oloyede, A.A.; Olawoyin, L.A. Adaptive Neuro-Fuzzy model for path loss prediction in the VHF band. In Proceedings of the 2017 International Conference on Computing Networking and Informatics (ICCNI), Lagos, Nigeria, 29–31 October 2017; pp. 1–6. [Google Scholar]
- Aldossari, S.; Chen, K.-C. Predicting the path loss of wireless channel models using machine learning techniques in mmwave urban communications. In Proceedings of the 2019 22nd International Symposium on Wireless Personal Multimedia Communications (WPMC), Lisbon, Portugal, 24–27 November 2019; pp. 1–6. [Google Scholar]
- Ahmadien, O.; Ates, H.F.; Baykas, T.; Gunturk, B.K. Predicting Path Loss Distribution of an Area From Satellite Images Using Deep Learning. IEEE Access 2020, 8, 64982–64991. [Google Scholar] [CrossRef]
- Turan, B.; Coleri, S. Machine learning based channel modeling for vehicular visible light communication. IEEE Trans. Veh. Technol. 2021, 70, 9659–9672. [Google Scholar] [CrossRef]
- Ates, H.F.; Hashir, S.M.; Baykas, T.; Gunturk, B.K. Path loss exponent and shadowing factor prediction from satellite images using deep learning. IEEE Access 2019, 7, 101366–101375. [Google Scholar] [CrossRef]
- Huang, J.; Cao, Y.; Raimundo, X.; Cheema, A.; Salous, S. Rain statistics investigation and rain attenuation modeling for millimeter wave short-range fixed links. IEEE Access 2019, 7, 156110–156120. [Google Scholar] [CrossRef]
- Zhang, Y.; Wen, J.; Yang, G.; He, Z.; Wang, J. Path loss prediction based on machine learning: Principle, method, and data expansion. Appl. Sci. 2019, 9, 1908. [Google Scholar] [CrossRef] [Green Version]
- Nguyen, D.C.; Cheng, P.; Ding, M.; Lopez-Perez, D.; Pathirana, P.N.; Li, J.; Seneviratne, A.; Li, Y.; Poor, H.V. Enabling AI in future wireless networks: A data life cycle perspective. IEEE Commun. Surv. Tutor. 2020, 23, 553–595. [Google Scholar] [CrossRef]
- Ferreira, G.P.; Matos, L.J.; Silva, J.M.M. Improvement of outdoor signal strength prediction in UHF band by artificial neural network. IEEE Trans. Antennas Propag. 2016, 64, 5404–5410. [Google Scholar] [CrossRef]
- Singh, H.; Gupta, S.; Dhawan, C.; Mishra, A. Path loss prediction in smart campus environment: Machine learning-based approaches. In Proceedings of the 2020 IEEE 91st Vehicular Technology Conference (VTC2020-Spring), Antwerp, Belgium, 25–28 May 2020; pp. 1–5. [Google Scholar]
- Thrane, J.; Zibar, D.; Christiansen, H.L. Model-aided deep learning method for path loss prediction in mobile communication systems at 2.6 GHz. IEEE Access 2020, 8, 7925–7936. [Google Scholar] [CrossRef]
- Shrestha, A.; Mahmood, A. Review of deep learning algorithms and architectures. IEEE Access 2019, 7, 53040–53065. [Google Scholar] [CrossRef]
- Nguyen, C.; Cheema, A.A. A deep neural network-based multi-frequency path loss prediction model from 0.8 GHz to 70 GHz. Sensors 2021, 21, 5100. [Google Scholar] [CrossRef]
- Challita, U.; Dong, L.; Saad, W. Deep learning for proactive resource allocation in LTE-U networks. In Proceedings of the European Wireless Technology Conference, Dresden, Germany, 15 May 2017. [Google Scholar]
- Song, W.; Zeng, F.; Hu, J.; Wang, Z.; Mao, X. An unsupervised-learning-based method for multi-hop wireless broadcast relay selection in urban vehicular networks. In Proceedings of the 2017 IEEE 85th Vehicular Technology Conference (VTC Spring), Sydney, NSW, Australia, 4–7 June 2017; pp. 1–5. [Google Scholar]
- Ebhota, V.C.; Isabona, J.; Srivastava, V.M. Environment-Adaptation Based Hybrid Neural Network Predictor for Signal Propagation Loss Prediction in Cluttered and Open Urban Microcells. Wirel. Pers. Commun. 2019, 104, 935–948. [Google Scholar] [CrossRef]
- Isabona, J.; Babalola, M. Statistical Tuning of Walfisch-Bertoni Pathloss Model based on Building and Street Geometry Parameters in Built-up Terrains. Am. J. Phys. Appl. 2013, 1, 10–16. [Google Scholar]
- Bird, J. Engineering Mathematics, 5th ed.; Newness: Los Angeles, CA, USA, 2010; ISBN 9780750681520. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Site 1 | Site 2 | Site 3 |
|---|---|---|---|
| BS Operation Transmitting Frequency (MHz) | 2600 | 2600 | 2600 |
| BS Antenna Height (m) | 28 | 30 | 45 |
| MS Antenna Height (m) | 1.5 | 1.5 | 1.5 |
| BS antenna gain (dBi) | 17.5 | 17.5 | 17.5 |
| MS antenna gain (dBi) | 0 | 0 | 0 |
| MS Transmit power (dB) | 30 | 30 | 30 |
| BS Transmit power (dB) | 43 | 43 | 43 |
| Transmitter cable loss (dB) | 0.5 | 0.5 | 0.5 |
| Feeder Loss (dB) | 3 | 3 | 3 |
| Learning Algorithm | Weight Adaptation | Training Acronym |
|---|---|---|
| Levenberg–Marquardt (lm) | The weight of the lm algorithm is updated via: where the Hessian matrix, . | trainlm |
| Bayesian Regularization (br) | The br approach involves the modification of the performance function,
plus regularisation term where & are special function parameters and a regularisation term, | trainbr |
| Polak–Ribiere Conjugate Gradient (cgp) | The weight of cgp algorithm is updated by: With = and | traincgp |
| Fletcher-Powell Conjugate Gradient (cgf) | The weight of scg algorithm is updated by: With = and | traincgf |
| Scaled Conjugate Gradient (scg) | The weight of scg algorithm is updated by: | trainscg |
| Resilient Backpropagation (rp) | With RP algorithm, weight update is by where = individual step size for weight adaptation | trainrp |
| BFGS Quasi-Newton (bfg) | bfg weight update is accomplished via where indicates the Hessian matrix inversion on iteration q. | trainbfg |
| Conjugate gradient with Powell/Beale Restarts (cgb) | The cgb employs update search direction by: | traincgb |
| Gradient Descent with Adaptive Learning Rate (gda) | gda weight update is accomplish via where indicates the user-defined momentum factor and it ranges from 0 to 1 | taingda |
| Gradient Descent Variable Learning Rate (gdx) | With gdx algorithm, weight update is by where = individual step size for weight adaptation and = variable learning rate | traingdx |
| One Step Secant (oss) | With oss algorithm, weight update is by where = Hessian matrix (2nd derivatives) | trainoss |
| Gradient Descent with Momentum (gdm) | gdm weight update is accomplish via where indicates the user-defined momentum factor and it ranges from 0 to 1 | traingdm |
| Gradient Descent (gd) | With gm algorithm, weight update is by where = learning rate | traingd |
| Training | Testing | Overall Performance | |||||||
|---|---|---|---|---|---|---|---|---|---|
| No of Neurons | MSE | R | MSE | R | MAE | STD | RMSE | R | COE (%) |
| 2 | 12.91 | 0.8874 | 23.22 | 0.7913 | 2.96 | 2.41 | 3.81 | 0.8637 | 75 |
| 5 | 12.22 | 0.8643 | 11.93 | 0.9205 | 2.92 | 2.40 | 3.78 | 0.8637 | 75 |
| 10 | 7.32 | 0.9320 | 8.01 | 0.8900 | 2.96 | 2.38 | 3.80 | 0.9251 | 86 |
| 15 | 7.95 | 0.9229 | 15.72 | 0.8339 | 2.41 | 1.92 | 3.08 | 0.9117 | 83 |
| 20 | 8.59 | 0.9247 | 13.79 | 0.9186 | 2.34 | 1.95 | 3.05 | 0.9148 | 84 |
| 25 | 7.83 | 0.9296 | 53.08 | 0.4865 | 2.47 | 2.96 | 3.85 | 0.8635 | 75 |
| 30 | 5.08 | 0.9591 | 17.06 | 0.8558 | 2.00 | 1.82 | 2.71 | 0.9499 | 90 |
| 35 | 4.88 | 0.9531 | 22.45 | 0.8482 | 1.95 | 2.06 | 2.84 | 0.9255 | 86 |
| 40 | 7.29 | 0.9360 | 14.31 | 0.7973 | 2.16 | 2.36 | 3.20 | 0.9132 | 84 |
| 45 | 7.95 | 0.9315 | 11.06 | 0.8257 | 2.23 | 2.07 | 3.04 | 0.9143 | 84 |
| 50 | 3.62 | 0.9673 | 21.07 | 0.7624 | 2.13 | 3.66 | 4.24 | 0.8498 | 72 |
| Training | Testing | Overall Performance | ||||||
|---|---|---|---|---|---|---|---|---|
| Transfer Function | MSE | R | MSE | R | MAE | STD | RMSE | R |
| purelin | 19.74 | 0.8614 | 18.29 | 0.8692 | 3.36 | 2.65 | 4.28 | 0.8636 |
| tansig | 6.82 | 0.9366 | 26.07 | 0.7865 | 2.19 | 2.45 | 3.29 | 0.9073 |
| logsig | 4.62 | 0.9594 | 23.09 | 0.7812 | 2.15 | 2.30 | 3.15 | 0.9106 |
| purelin-purelin | 20.33 | 0.8715 | 13.09 | 0.8964 | 3.59 | 2.75 | 4.52 | 0.8637 |
| purelin-tagsig | 7.83 | 0.9325 | 12.20 | 0.8539 | 2.38 | 1.80 | 2.99 | 0.9173 |
| purelin-logsig | 9.18 | 0.9173 | 20.24 | 0.8755 | 2.52 | 2.02 | 3.24 | 0.9026 |
| tansig-tansig | 3.18 | 0.9697 | 20.17 | 0.8643 | 1.82 | 1.89 | 2.63 | 0.9365 |
| tansig-logsig | 3.23 | 0.9697 | 23.65 | 0.8094 | 1.82 | 2.18 | 2.84 | 0.9266 |
| tansig-purelin | 6.39 | 0.7622 | 10.28 | 0.6907 | 2.04 | 1.82 | 2.73 | 0.9315 |
| logsig-logsig | 4.82 | 0.9511 | 10.31 | 0.9382 | 1.76 | 1.63 | 2.40 | 0.9290 |
| logsig-tansig | 3.97 | 0.9669 | 12.96 | 0.8467 | 1.60 | 1.70 | 2.34 | 0.9499 |
| logsig-pureline | 6.01 | 0.9430 | 16.45 | 0.8471 | 2.18 | 1.91 | 2.90 | 0.9222 |
| purelin-purelin-purelin | 13.07 | 0.8804 | 18.34 | 0.8413 | 2.93 | 2.39 | 3.78 | 0.8637 |
| tansig-tangsig-tansig | 5.87 | 0.9487 | 8.89 | 0.9181 | 1.88 | 1.78 | 2.59 | 0.9283 |
| tansig-tansig-purelin | 6.38 | 0.9337 | 17.89 | 0.8607 | 2.17 | 2.06 | 2.76 | 0.9200 |
| tangsig-tansig-logsig | 5.11 | 0.9568 | 8.98 | 0.8907 | 1.92 | 1.93 | 2.72 | 0.9318 |
| logsig-logsig-logsig | 7.18 | 0.9358 | 13.86 | 0.9187 | 2.15 | 1.85 | 2.83 | 0.9285 |
| logsig-logsig-purelin | 9.12 | 0.9238 | 98.48 | 0.6384 | 2.91 | 4.03 | 4.97 | 0.8049 |
| logsig-tansig-tansig | 5.34 | 0.9489 | 7.52 | 0.9429 | 2.18 | 1.92 | 2.90 | 0.9245 |
| logsig-tansig-logsig | 6.90 | 0.9428 | 3.97 | 0.9467 | 1.98 | 1.75 | 2.67 | 0.9340 |
| tansig-logsig-tansig | 6.53 | 0.9433 | 3.68 | 0.9468 | 1.97 | 1.56 | 2.47 | 0.9445 |
| logsic-tansig-purelin | 6.92 | 0.9392 | 11.34 | 0.9093 | 2.09 | 2.02 | 2.90 | 0.9222 |
| purelin-logsig-tansig | 25.57 | 0.8583 | 25.94 | 0.8707 | 3.28 | 3.58 | 4.86 | 0.8597 |
| Training | Testing | Overall Performance | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Training Algorithm | No of Hidden Layers | MSE | R | MSE | R | MAE | STD | MSE | R |
| lm | 1 | 7.65 | 0.9359 | 11.55 | 0.9033 | 2.20 | 1.82 | 2.86 | 0.9248 |
| 2 | 3.97 | 0.9669 | 12.96 | 0.8467 | 1.60 | 1.70 | 2.34 | 0.9499 | |
| 3 | 3.94 | 0.9632 | 9.31 | 0.9311 | 1.71 | 1.70 | 2.41 | 0.9473 | |
| Br | 1 | 3.72 | 0.9660 | 26.59 | 0.7560 | 1.79 | 1.99 | 2.68 | 0.9340 |
| 2 | 0.57 | 0.9953 | 47.07 | 0.7562 | 1.05 | 2.55 | 2.76 | 0.9408 | |
| 3 | 0.92 | 0.9919 | 25.68 | 0.3075 | 1.73 | 6.09 | 6.33 | 0.7557 | |
| Bfg | 1 | 7.88 | 0.9252 | 14.88 | 0.9070 | 2.56 | 1.87 | 3.17 | 0.9076 |
| 2 | 9.12 | 0.9092 | 12.92 | 0.8869 | 2.42 | 1.81 | 3.03 | 0.9149 | |
| 3 | 10.04 | 0.9159 | 10.93 | 0.8425 | 2.45 | 2.04 | 3.20 | 0.9045 | |
| Rp | 1 | 7.68 | 0.9316 | 5.03 | 0.9601 | 2.09 | 1.75 | 2.73 | 0.9323 |
| 2 | 4.38 | 0.9339 | 17.02 | 0.9123 | 1.90 | 1.09 | 2.60 | 0.9456 | |
| 3 | 5.03 | 0.9052 | 28.59 | 0.8816 | 2.69 | 2.43 | 3.63 | 0.8755 | |
| Scg | 1 | 7.85 | 0.9282 | 11.08 | 0.8608 | 2.26 | 1.91 | 2.97 | 0.9185 |
| 2 | 6.69 | 0.9373 | 13.52 | 0.7531 | 2.26 | 1.86 | 2.92 | 0.9209 | |
| 3 | 11.16 | 0.8951 | 9.65 | 0.8951 | 2.66 | 1.94 | 3.29 | 0.9005 | |
| Cgb | 1 | 9.01 | 0.9168 | 14.75 | 0.8882 | 2.49 | 1.94 | 3.31 | 0.9089 |
| 2 | 8.30 | 0.9293 | 8.89 | 0.9233 | 2.36 | 1.74 | 1.95 | 0.9202 | |
| 3 | 16.36 | 0.8460 | 29.72 | 0.8814 | 3.26 | 2.75 | 4.27 | 0.8510 | |
| Cgf | 1 | 8.44 | 0.9186 | 12.65 | 0.9079 | 2.42 | 1.78 | 3.00 | 0.9165 |
| 2 | 9.15 | 0.9152 | 8.93 | 0.9204 | 2.33 | 1.88 | 2.99 | 0.9168 | |
| 3 | 17.84 | 0.8274 | 21.14 | 0.8596 | 3.39 | 2.72 | 4.35 | 0.8449 | |
| Cgp | 1 | 18.22 | 0.8496 | 23.49 | 0.7818 | 3.57 | 2.36 | 4.28 | 0.8426 |
| 2 | 17.19 | 0.8472 | 11.26 | 0.9039 | 3.05 | 2.61 | 4.01 | 0.8482 | |
| 3 | 38.02 | 0.7463 | 36.79 | 0.7099 | 3.06 | 2.61 | 4.00 | 0.7486 | |
| Oss | 1 | 9.53 | 0.9167 | 12.55 | 0.8703 | 2.70 | 1.88 | 3.28 | 0.9015 |
| 2 | 9.06 | 0.9161 | 9.77 | 0.9116 | 2.49 | 1.98 | 2.49 | 0.9055 | |
| 3 | 10.16 | 0.9101 | 16.90 | 0.8084 | 2.59 | 20.05 | 3.30 | 0.8984 | |
| Gdx | 1 | 11.82 | 0.8805 | 15.02 | 0.8584 | 2.91 | 2.11 | 3.59 | 0.8794 |
| 2 | 9.59 | 0.9060 | 18.15 | 0.8430 | 2.54 | 2.09 | 3.29 | 0.8982 | |
| 3 | 18.60 | 0.8286 | 12.07 | 0.8252 | 3.50 | 3.09 | 4.66 | 0.8113 | |
| Gdm | 1 | 1.42 × 103 | 0.8008 | 1.26 × 103 | 0.7041 | 30.26 | 21.02 | 36.84 | 0.7870 |
| 2 | 447.60 | 0.7801 | 571.30 | 0.5385 | 16.97 | 12.37 | 21.01 | 0.8034 | |
| 3 | 1.22 × 103 | 0.4340 | 1.5 × 103 | 1.5 × 103 | 26.67 | 23.61 | 36.38 | 0.4504 | |
| Gd | 1 | 2.94 × 103 | 0.7238 | 3.08 × 103 | 0.5882 | 53.81 | 16.04 | 56.15 | 0.6286 |
| 2 | 655.14 | 0.8583 | 724.47 | 0.8268 | 25.67 | 7.14 | 26.35 | 0.8124 | |
| 3 | 468.86 | 0.7885 | 433.89 | 0.7589 | 53.72 | 43.11 | 68.88 | 0.7890 | |
| Training | Testing | Overall Performance | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Hyperparmeter Tuning Algorithm | MLP Algorithm | MSE | R | MSE | R | MAE | STD | MSE | R |
| Grid Search | lm | 3.97 | 0.9669 | 12.96 | 0.8467 | 1.60 | 1.70 | 2.34 | 0.9499 |
| br | 0.57 | 0.9953 | 47.07 | 0.7562 | 1.05 | 2.55 | 2.76 | 0.9408 | |
| Bayessian Optimisation search | lm | 5.20 | 0.9565 | 16.73 | 0.8355 | 2.29 | 4.90 | ||
| br | 3.52 | 0.9669 | 18.84 | 0.8567 | 3.40 | 4.24 | |||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Isabona, J.; Imoize, A.L.; Ojo, S.; Karunwi, O.; Kim, Y.; Lee, C.-C.; Li, C.-T. Development of a Multilayer Perceptron Neural Network for Optimal Predictive Modeling in Urban Microcellular Radio Environments. Appl. Sci. 2022, 12, 5713. https://doi.org/10.3390/app12115713
Isabona J, Imoize AL, Ojo S, Karunwi O, Kim Y, Lee C-C, Li C-T. Development of a Multilayer Perceptron Neural Network for Optimal Predictive Modeling in Urban Microcellular Radio Environments. Applied Sciences. 2022; 12(11):5713. https://doi.org/10.3390/app12115713
Chicago/Turabian StyleIsabona, Joseph, Agbotiname Lucky Imoize, Stephen Ojo, Olukayode Karunwi, Yongsung Kim, Cheng-Chi Lee, and Chun-Ta Li. 2022. "Development of a Multilayer Perceptron Neural Network for Optimal Predictive Modeling in Urban Microcellular Radio Environments" Applied Sciences 12, no. 11: 5713. https://doi.org/10.3390/app12115713