
An Empirical Evaluation of Document Embeddings and Similarity Metrics for Scientific Articles


Abstract
:1. Introduction
- Evaluate and compare a number of document embedding techniques for text similarity evaluation.
- Evaluate and compare a set of similarity functions for document comparison.
- Measure the performance of a set of word embeddings and similarity metrics on a regular computer.
2. Basic Notions of Similarity Measures
- 1.
- Non-negativity: ;
- 2.
- Identity of indiscernibles: ;
- 3.
- Symmetry: ;
- 4.
- Triangle inequality: .
3. Related Work
4. Embeddings and Measures
4.1. Embeddings
4.2. Similarity Measures
- if, and only if, x is very similar to y;
- if, and only if, ;
4.3. Selected Embeddings and Similarity Measures
5. Empirical Evaluation
5.1. Implementations
5.2. Selected Data
5.3. Cleaning
5.4. Training
6. Task I–Validation
6.1. Data
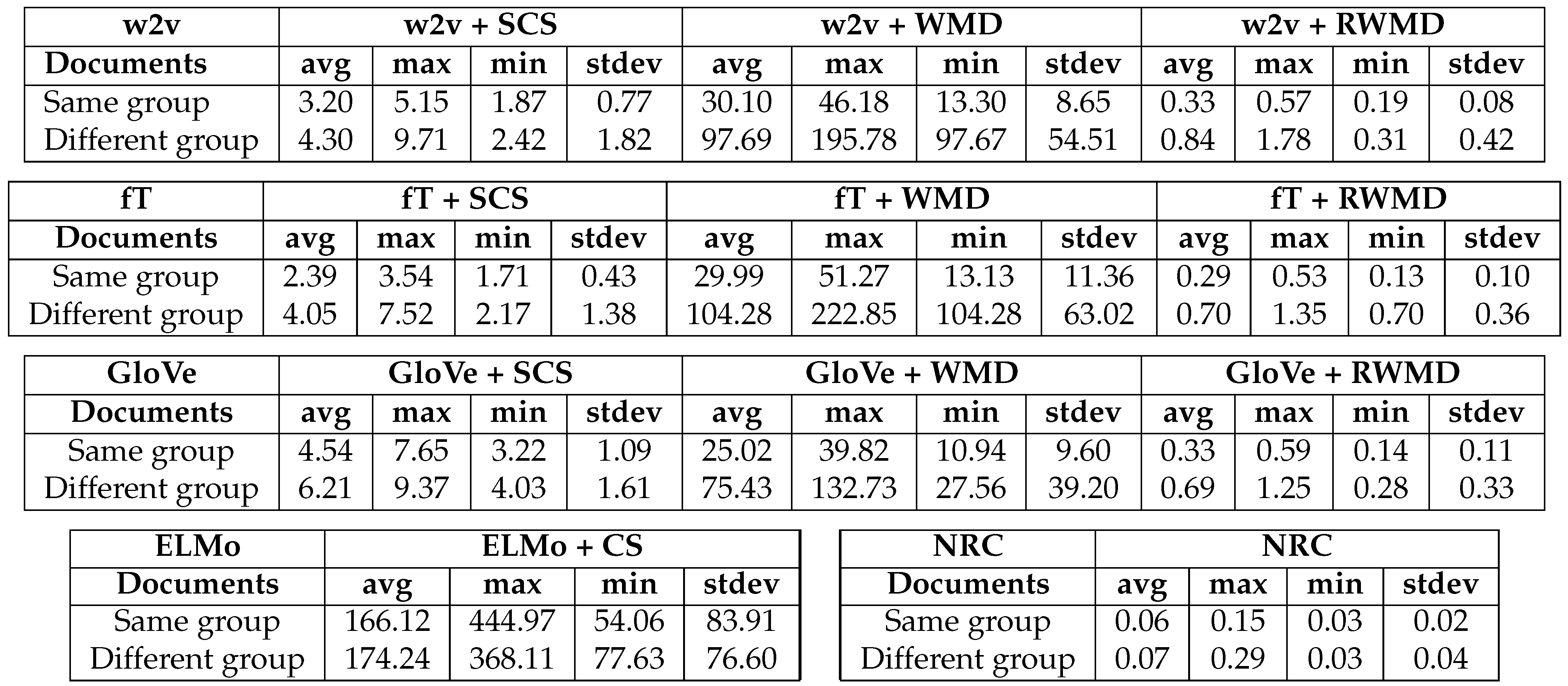
6.2. Performance Analysis
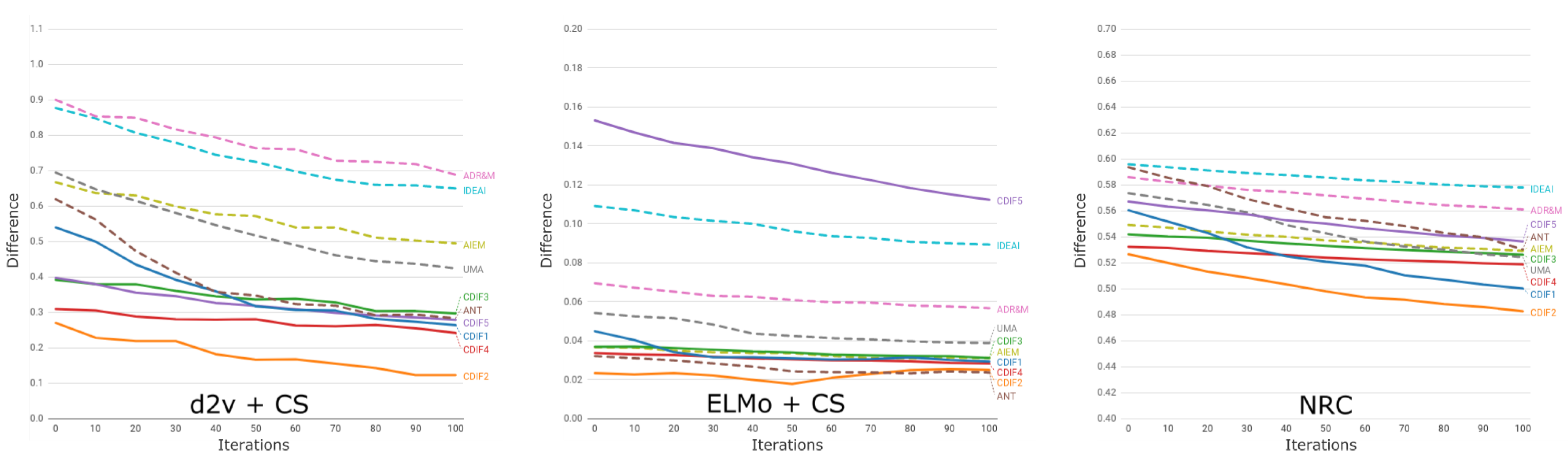
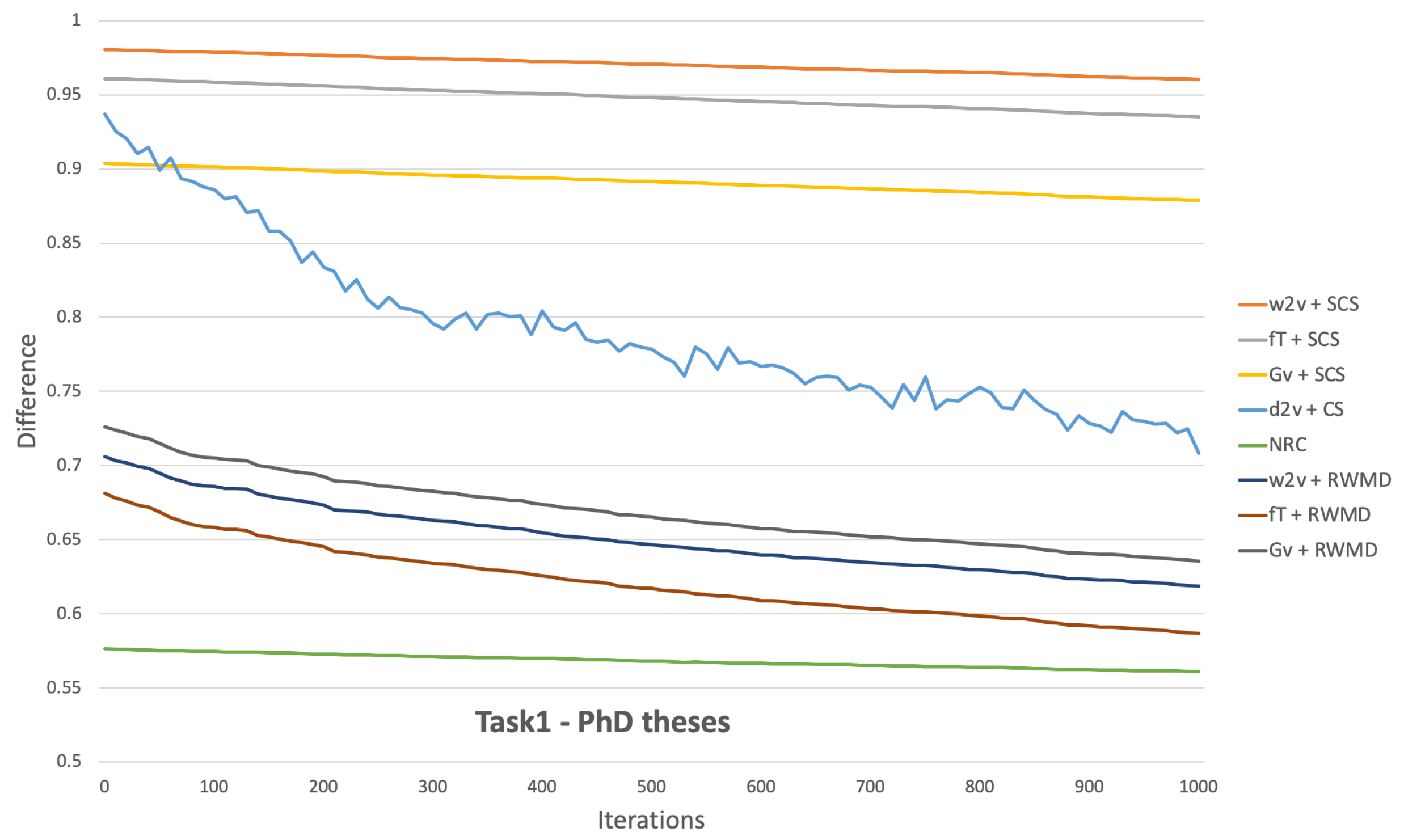
6.3. Analysis of Results
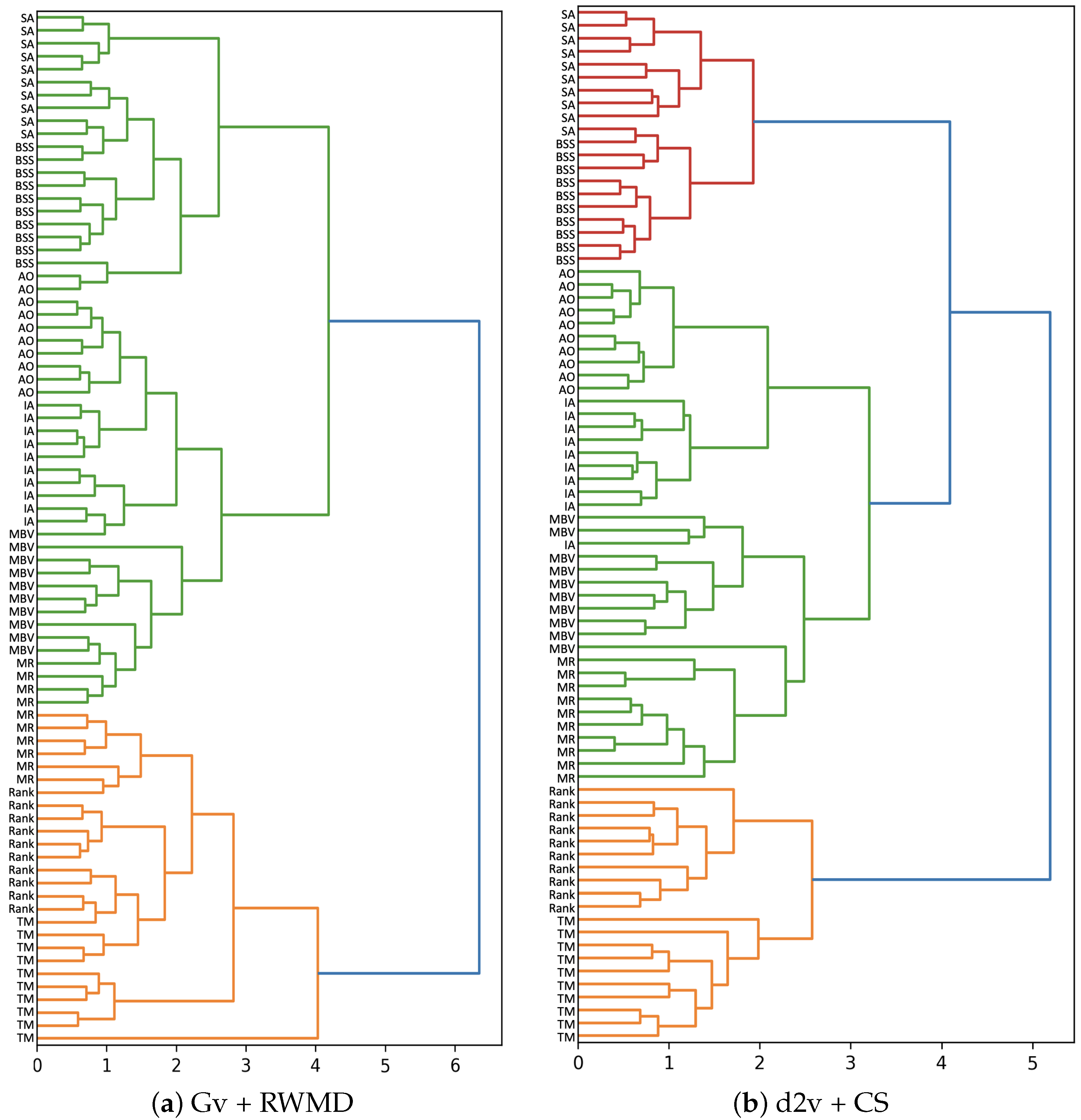
7. Task II–Clustering
7.1. Data
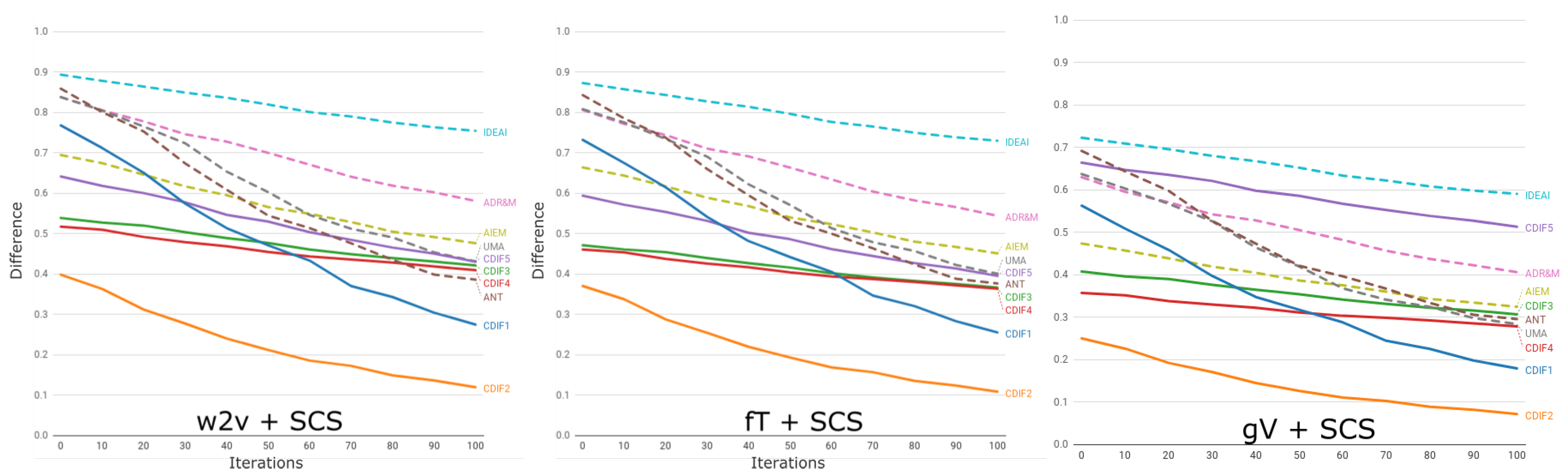
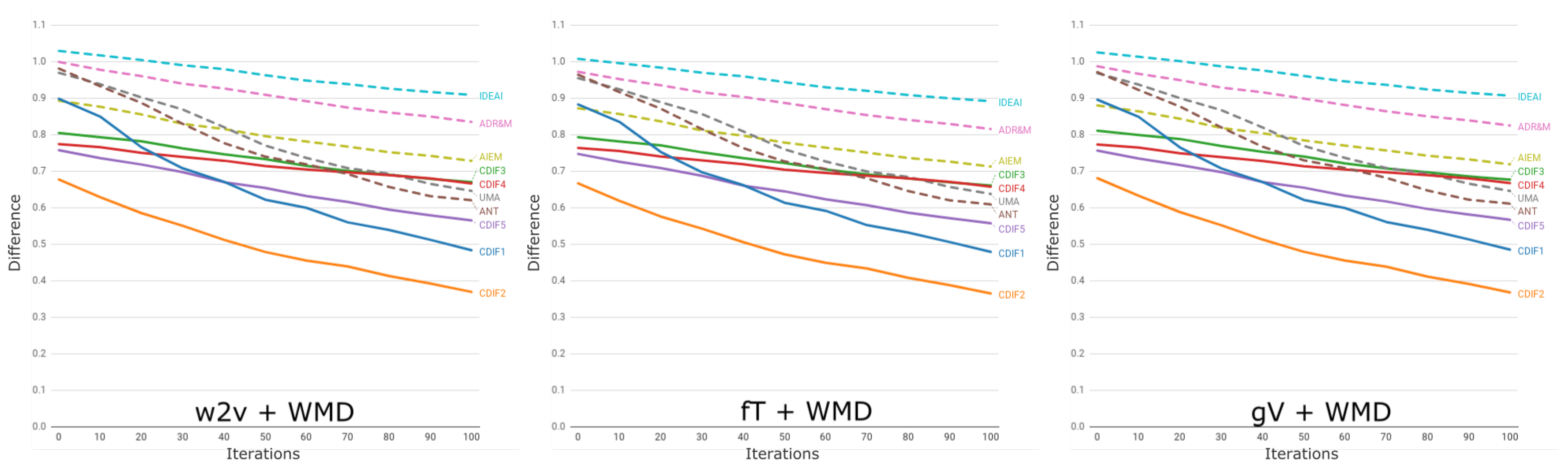
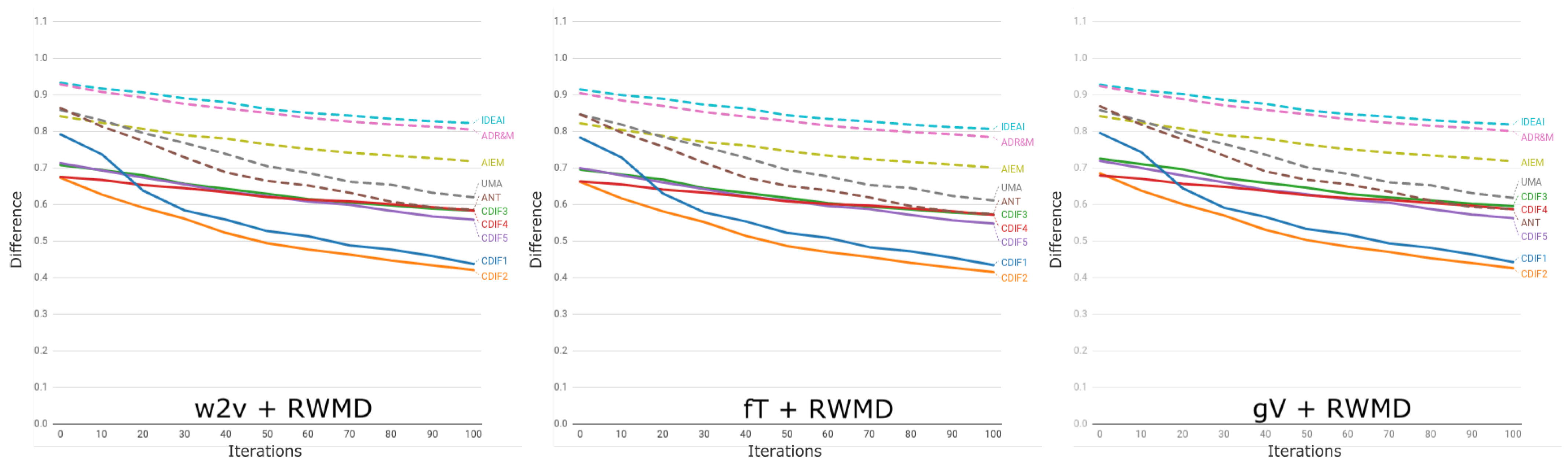
7.2. Execution
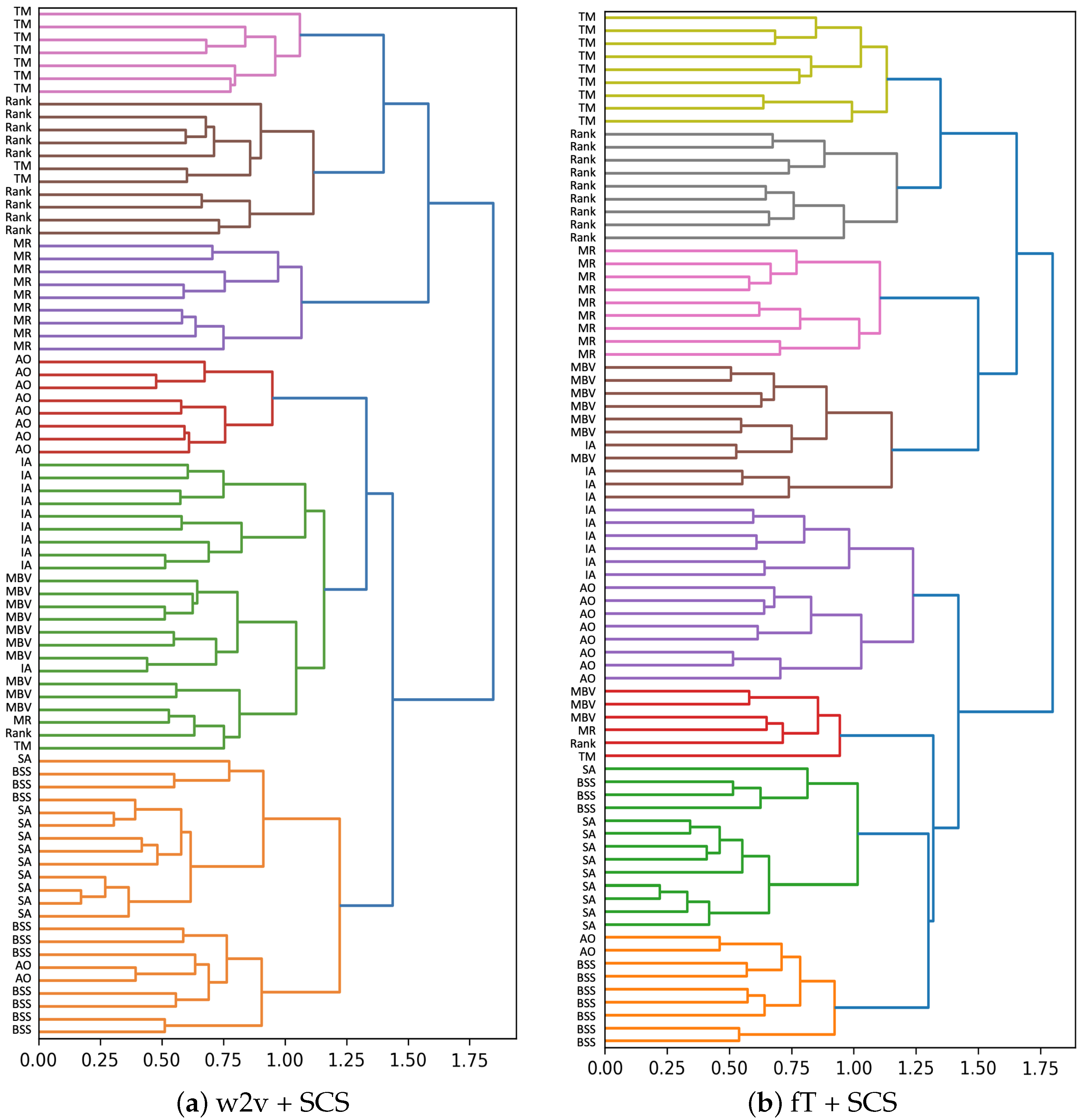
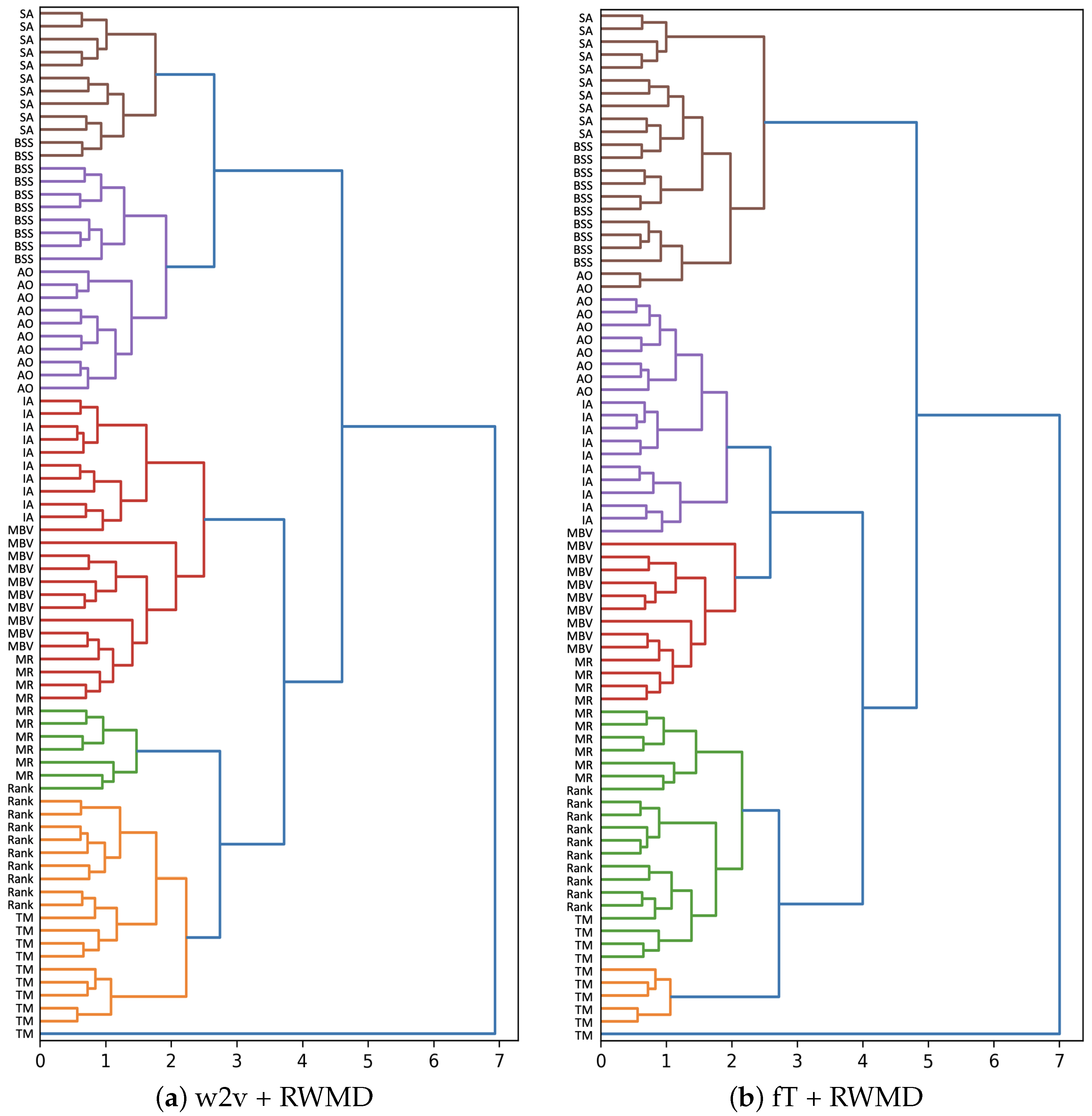
7.3. Analysis of Results
8. Discussion
9. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| BERT | Bidirectional Encoder Representations from Transformer |
| BoW | Bag-of-Words |
| CBOW | Continuous Bag-of-Words |
| CS | Cosine Similarity |
| CSG | Continuous Skip–Gram Model |
| d2v | doc2vec embedding |
| ELMo | Embeddings from Language Models |
| EMD | Earth Mover’s Distance |
| fT | Fast Text embedding |
| GV | Global Vectors embedding |
| LDA | Latent Dirichlet Allocation |
| LSA | Latent Semantic Analysis |
| NLP | Natural Language Processing |
| NNLM | Neural Network Language Models |
| NRC | Normalized Relative Compression |
| RNN | Recurrent Neural Network |
| RWMD | Relaxed Words Mover’s Distance |
| SCS | Soft Cosine Similarity |
| WMD | Words Mover’s Distance |
| VSM | Vector Space Model |
Appendix A. Training Details
Appendix B. Papers Used in Task I
- CFID1: “Thermo-fluid numerical simulation of the crotch absorbers’ cooling pinholes for alba storage ring” by Escaler et al.
- CFID2: “Failure investigation of a Francis turbine under the cavitation conditions” by Liu et al.
- CFID3: “Condition monitoring of pump-turbines. New challenges” by Egusquiza et al.
- CFID4: “Transmission of high frequency vibrations in rotating systems. Application to cavitation detection in hydraulic turbines” by Valentín et al.
- CFID5: “Experimental mode shape determination of a cantilevered hydrofoil under different flow conditions” by De La Torre et al.
- ANT–“The 234U neutron capture cross section measurement at the n TOF facility” by Lampoudis et al.
- ADR&M–“Turning barriers into alleyways: unsolved transitions from old Barcelona to the post-Cerdà city” by Millán et al.
- UMA–“What to be considered when you buy a sprayer: the SPISE advice” by Gil et al.
- AIEM–“A Framework for Structural Systems Based on the Principles of Statistical Mechanics” by Andújar et al.
- IDEAI–“A model for continuous monitoring of patients with major depression in short and long term periods” by Múgica et al.
Appendix C. Papers Used in Task II
Appendix C.1. Ambient Occlusion
- McGuire, M., Osman, B., Bukowski, M., & Hennessy, P. (2011, August). The alchemy screen-space ambient obscurance algorithm. In Proceedings of the ACM SIGGRAPH Symposium on High-Performance Graphics (pp. 25–32).
- Zhang, D., Xian, C., Luo, G., Xiong, Y., & Han, C. (2020). DeepAO: Efficient screen space ambient occlusion generation via deep network. IEEE Access, 8, 64434–64441.
- Diaz, J., Vazquez, P. P., Navazo, I., & Duguet, F. (2010). Real-time ambient occlusion and halos with summed area tables. Computers & Graphics, 34(4), 337–350.
- Schott, M., Pegoraro, V., Hansen, C., Boulanger, K., & Bouatouch, K. (2009, June). A directional occlusion shading model for interactive direct volume rendering. In Computer Graphics Forum (Vol. 28, No. 3, pp. 855-862). Oxford, UK: Blackwell Publishing Ltd.
- Doronin, O., Kara, P. A., Barsi, A., & Martini, M. G. (2017). Screen-space ambient occlusion for light field displays.
- Umenhoffer, T., Tóth, B., & Szirmay-Kalos, L. (2009, April). Efficient methods for ambient lighting. In Proceedings of the 25th Spring Conference on Computer Graphics (pp. 87–94).
- Ropinski, T., Kasten, J., & Hinrichs, K. (2008). Efficient shadows for gpu-based volume raycasting.
- Reinbothe, C. K., Boubekeur, T., & Alexa, M. (2009). Hybrid Ambient Occlusion. Eurographics (Areas Papers), 5.
- Luft, T., Colditz, C., & Deussen, O. (2006). Image enhancement by unsharp masking the depth buffer. ACM Transactions on Graphics (TOG), 25(3), 1206–1213.
- Bauer, F., Knuth, M., Kuijper, A., & Bender, J. (2013, November). Screen-space ambient occlusion using a-buffer techniques. In 2013 International Conference on Computer-Aided Design and Computer Graphics (pp. 140–147). IEEE.
Appendix C.2. Immersive Analytics
- Goddard, T. D., Brilliant, A. A., Skillman, T. L., Vergenz, S., Tyrwhitt-Drake, J., Meng, E. C., & Ferrin, T. E. (2018). Molecular visualization on the holodeck. Journal of molecular biology, 430(21), 3982–3996.
- Richardson, M., Jacoby, D., & Coady, Y. (2018, November). Retrofitting Realities: Affordances and Limitations in Porting an Interactive Geospatial Visualization from Augmented to Virtual Reality. In 2018 IEEE 9th Annual Information Technology, Electronics and Mobile Communication Conference (IEMCON) (pp. 1081–1087). IEEE.
- Billinghurst, M., Cordeil, M., Bezerianos, A., & Margolis, T. (2018). Collaborative immersive analytics. In Immersive Analytics (pp. 221–257). Springer, Cham.
- Liu, J., Dwyer, T., Marriott, K., Millar, J., & Haworth, A. (2017). Understanding the relationship between interactive optimization and visual analytics in the context of prostate brachytherapy. IEEE transactions on visualization and computer graphics, 24(1), 319–329.
- Marai, G. E., Leigh, J., & Johnson, A. (2019). Immersive analytics lessons from the electronic visualization laboratory: a 25-year perspective. IEEE computer graphics and applications, 39(3), 54–66.
- Cordeil, M., Cunningham, A., Bach, B., Hurter, C., Thomas, B. H., Marriott, K., & Dwyer, T. (2019, March). IATK: An immersive analytics toolkit. In 2019 IEEE Conference on Virtual Reality and 3D User Interfaces (VR) (pp. 200–209). IEEE.
- Dwyer, T., Marriott, K., Isenberg, T., Klein, K., Riche, N., Schreiber, F., ... & Thomas, B. H. (2018). Immersive analytics: An introduction. In Immersive analytics (pp. 1–23). Springer, Cham.
- Tadeja, S. K., Kipouros, T., & Kristensson, P. O. (2019, May). Exploring parallel coordinates plots in virtual reality. In Extended Abstracts of the 2019 CHI Conference on Human Factors in Computing Systems (pp. 1–6).
- Gračanin, D. (2018, July). Immersion versus embodiment: Embodied cognition for immersive analytics in mixed reality environments. In International Conference on Augmented Cognition (pp. 355–368). Springer, Cham.
Appendix C.3. Mobile Rendering
- Noon, C. J. (2012). A volume rendering engine for desktops, laptops, mobile devices and immersive virtual reality systems using GPU-based volume raycasting. Iowa State University.
- Noguera, J. M., Jiménez, J. R., Ogáyar, C. J., & Segura, R. J. (2012, February). Volume Rendering Strategies on Mobile Devices. In GRAPP/IVAPP (pp. 447–452).
- Pattrasitidecha, A. (2014). Comparison and evaluation of 3D mobile game engines (Master’s thesis).
- Noguera, J. M., & Jimenez, J. R. (2015). Mobile volume rendering: past, present and future. IEEE transactions on visualization and computer graphics, 22(2), 1164–1178.
- Schultz, C., & Bailey, M. (2016). Interacting with Large 3D Datasets on a Mobile Device. IEEE computer graphics and applications, 36(5), 19-23.
- Xin, Y., & Wong, H. C. (2016, October). Intuitive volume rendering on mobile devices. In 2016 9th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics (CISP-BMEI) (pp. 696–701). IEEE.
- Lee, W. J., Hwang, S. J., Shin, Y., Ryu, S., & Ihm, I. (2016). Adaptive multi-rate ray sampling on mobile ray tracing GPU. In SIGGRAPH ASIA 2016 Mobile Graphics and Interactive Applications (pp. 1–6).
- Hachaj, T. (2014). Real-time exploration and management of large medical volumetric datasets on small mobile devices—evaluation of remote volume rendering approach. International Journal of Information Management, 34(3), 336–343.
- Heller, F., Jevanesan, J., Dietrich, P., & Borchers, J. (2016, September). Where are we? evaluating the current rendering fidelity of mobile audio augmented reality systems. In Proceedings of the 18th International Conference on Human–Computer Interaction with Mobile Devices and Services (pp. 278–282).
- Lee, W. J., Hwang, S. J., Shin, Y., Yoo, J. J., & Ryu, S. (2017, January). Fast stereoscopic rendering on mobile ray tracing GPU for virtual reality applications. In 2017 IEEE International Conference on Consumer Electronics (ICCE) (pp. 355–357). IEEE.
Appendix C.4. Molecular and Biological Visualization
- Hülsmann, M., Köddermann, T., Vrabec, J., & Reith, D. (2010). GROW: A gradient-based optimization workflow for the automated development of molecular models. Computer Physics Communications, 181(3), 499–513.
- Reith, D., & Kirschner, K. N. (2011). A modern workflow for force-field development–Bridging quantum mechanics and atomistic computational models. Computer Physics Communications, 182(10), 2184–2191.
- Hanwell, M. D., Curtis, D. E., Lonie, D. C., Vandermeersch, T., Zurek, E., & Hutchison, G. R. (2012). Avogadro: an advanced semantic chemical editor, visualization, and analysis platform. Journal of cheminformatics, 4(1), 1–17.
- Goodstadt, M., & Marti-Renom, M. A. (2017). Challenges for visualizing three-dimensional data in genomic browsers. FEBS letters, 591(17), 2505–2519.
- Stone, M. (2012). In color perception, size matters. IEEE Computer Graphics and Applications, March/April 2012.
- Knoll, A., Wald, I., Navrátil, P. A., Papka, M. E., & Gaither, K. P. (2013, November). Ray tracing and volume rendering large molecular data on multicore and many-core architectures. In Proceedings of the 8th International Workshop on Ultrascale Visualization (pp. 1–8).
- Mohammed, H., Al-Awami, A. K., Beyer, J., Cali, C., Magistretti, P., Pfister, H., & Hadwiger, M. (2017). Abstractocyte: A visual tool for exploring nanoscale astroglial cells. IEEE transactions on visualization and computer graphics, 24(1), 853–861.
- Bezerianos, A., Isenberg, P., Chapuis, O., & Willett, W. (2013, April). Perceptual affordances of wall-sized displays for visualization applications: Color. In Proceedings of the CHI Workshop on Interactive, Ultra-High-Resolution Displays (PowerWall).
- Schatz, K., Krone, M., Pleiss, J., & Ertl, T. (2019). Interactive visualization of biomolecules’ dynamic and complex properties. The European Physical Journal Special Topics, 227(14), 1725–1739.
- Xiao-Zhong Shen. (2010). Comparison of protein surface visualization techniques in different environments (tools). INF358 Seminar in Visualization.
- Xu, C., Liu, Y. P., Jiang, Z., Sun, G., Jiang, L., & Liang, R. (2020). Visual interactive exploration and clustering of brain fiber tracts. Journal of Visualization, 23(3), 491–506.
Appendix C.5. Rankings Visualization
- Han, D., Pan, J., Guo, F., Luo, X., Wu, Y., Zheng, W., & Chen, W. (2019). Rankbrushers: Interactive analysis of temporal ranking ensembles. Journal of Visualization, 22(6), 1241–1255.
- Gratzl, S., Lex, A., Gehlenborg, N., Pfister, H., & Streit, M. (2013). Lineup: Visual analysis of multi-attribute rankings. IEEE transactions on visualization and computer graphics, 19(12), 2277–2286.
- Wall, E., Das, S., Chawla, R., Kalidindi, B., Brown, E. T., & Endert, A. (2017). Podium: Ranking data using mixed-initiative visual analytics. IEEE transactions on visualization and computer graphics, 24(1), 288–297.
- Bačík, V., & Klobučník, M. (2018). Possibilities of using selected visualization methods for historical analysis of sporting event–an example of stage cycling race Tour de France.
- Batty, M. (2006). Rank clocks. Nature, 444(7119), 592–596.
- Shi, C., Cui, W., Liu, S., Xu, P., Chen, W., & Qu, H. (2012). Rankexplorer: Visualization of ranking changes in large time series data. IEEE Transactions on Visualization and Computer Graphics, 18(12), 2669–2678.
- Miranda, F., Lins, L., Klosowski, J. T., & Silva, C. T. (2017). Topkube: A rank-aware data cube for real-time exploration of spatiotemporal data. IEEE Transactions on visualization and computer graphics, 24(3), 1394–1407.
- Gousie, M. B., Grady, J., & Branagan, M. (2014, February). Visualizing trends and clusters in ranked time-series data. In Visualization and Data Analysis 2014 (Vol. 9017, p. 90170F). International Society for Optics and Photonics.
- Lei, H., Xia, J., Guo, F., Zou, Y., Chen, W., & Liu, Z. (2016). Visual exploration of latent ranking evolutions in time series. Journal of Visualization, 19(4), 783–795.
- Chen, Y., Xu, P., & Ren, L. (2017). Sequence synopsis: Optimize visual summary of temporal event data. IEEE transactions on visualization and computer graphics, 24(1), 45–55.
Appendix C.6. Bicycle Sharing Systems
- Feng, Y., Affonso, R. C., & Zolghadri, M. (2017). Analysis of bike sharing system by clustering: the Vélib’case. IFAC-PapersOnLine, 50(1), 12422–12427.
- Midgley, P. (2011). Bicycle-sharing schemes: enhancing sustainable mobility in urban areas. United Nations, Department of Economic and Social Affairs, 8, 1–12.
- Frade, I., & Ribeiro, A. (2014). Bicycle sharing systems demand. Procedia-Social and Behavioral Sciences, 111, 518–527.
- How land-use and urban form impact bicycle flows: Evidence from the bicycle-sharing system (BIXI) in Montreal
- Younes, H., Zou, Z., Wu, J., & Baiocchi, G. (2020). Comparing the temporal determinants of dockless scooter-share and station-based bike-share in Washington, DC. Transportation Research Part A: Policy and Practice, 134, 308–320.
- Saas, A., Guitart, A., & Periánez, A. (2016, September). Discovering playing patterns: Time series clustering of free-to-play game data. In 2016 IEEE Conference on Computational Intelligence and Games (CIG) (pp. 1–8). IEEE.
- O’brien, O., Cheshire, J., & Batty, M. (2014). Mining bicycle sharing data for generating insights into sustainable transport systems. Journal of Transport Geography, 34, 262–273.
- Froehlich, J. E., Neumann, J., & Oliver, N. (2009, June). Sensing and predicting the pulse of the city through shared bicycling. In Twenty-First International Joint Conference on Artificial Intelligence.
- Boufidis, N., Nikiforiadis, A., Chrysostomou, K., & Aifadopoulou, G. (2020). Development of a station-level demand prediction and visualization tool to support bike-sharing systems’ operators. Transportation Research Procedia, 47, 51–58.
- Wood, J., Beecham, R., & Dykes, J. (2014). Moving beyond sequential design: Reflections on a rich multichannel approach to data visualization. IEEE transactions on visualization and computer graphics, 20(12), 2171–2180.
Appendix C.7. Sports Analytics
- Perin, C., Vuillemot, R., Stolper, C. D., Stasko, J. T., Wood, J., & Carpendale, S. (2018, June). State of the art of sports data visualization. In Computer Graphics Forum (Vol. 37, No. 3, pp. 663–686).
- Chung, D. H., Parry, M. L., Griffiths, I. W., Laramee, R. S., Bown, R., Legg, P. A., & Chen, M. (2015). Knowledge-assisted ranking: A visual analytic application for sports event data. IEEE Computer Graphics and Applications, 36(3), 72–82.
- Grignard, A., Macià, N., Alonso Pastor, L., Noyman, A., Zhang, Y., & Larson, K. (2018, July). Cityscope andorra: a multi-level interactive and tangible agent-based visualization. In Proceedings of the 17th International Conference on Autonomous Agents and MultiAgent Systems (pp. 1939–1940).
- Dietrich, C., Koop, D., Vo, H. T., & Silva, C. T. (2014, October). Baseball4d: A tool for baseball game reconstruction & visualization. In 2014 IEEE Conference on Visual Analytics Science and Technology (VAST) (pp. 23–32). IEEE.
- Beecham, R., & Wood, J. (2014). Characterising group-cycling journeys using interactive graphics. Transportation Research Part C: Emerging Technologies, 47, 194–206.
- Pileggi, H., Stolper, C. D., Boyle, J. M., & Stasko, J. T. (2012). Snapshot: Visualization to propel ice hockey analytics. IEEE Transactions on Visualization and Computer Graphics, 18(12), 2819–2828.
- Carlis, J. V., & Konstan, J. A. (1998, November). Interactive visualization of serial periodic data. In Proceedings of the 11th annual ACM symposium on User interface software and technology (pp. 29–38).
- Dendir, S. (2016). When do soccer players peak? A note. Journal of Sports Analytics, 2(2), 89–105.
- Bruce, S. (2016). A scalable framework for NBA player and team comparisons using player tracking data. Journal of Sports Analytics, 2(2), 107–119.
- McFarlane, P. (2019). Evaluating NBA end-of-game decision-making. Journal of Sports Analytics, 5(1), 17–22.
Appendix C.8. Analysis and Visualization of Transportation Methods
- Woodcock, J., Tainio, M., Cheshire, J., O’Brien, O., & Goodman, A. (2014). Health effects of the London bicycle sharing system: health impact modelling study. Bmj, 348.
- Xie, X. F., & Wang, Z. J. (2015). An empirical study of combining participatory and physical sensing to better understand and improve urban mobility networks (No. 15-3238).
- Shi, X., Wang, Y., Lv, F., Liu, W., Seng, D., & Lin, F. (2019). Finding communities in bicycle sharing system. Journal of Visualization, 22(6), 1177–1192.
- Shi, X., Lv, F., Seng, D., Xing, B., & Chen, B. (2019). Visual exploration of mobility dynamics based on multi-source mobility datasets and POI information. Journal of Visualization, 22(6), 1209-1223.
- Corcoran, J., Li, T., Rohde, D., Charles-Edwards, E., & Mateo-Babiano, D. (2014). Spatio-temporal patterns of a Public Bicycle Sharing Program: the effect of weather and calendar events. Journal of Transport Geography, 41, 292–305.
- Zaltz Austwick, M., O’Brien, O., Strano, E., & Viana, M. (2013). The structure of spatial networks and communities in bicycle sharing systems. PloS one, 8(9), e74685.
- Beecham, R., Wood, J., & Bowerman, A. (2014). Studying commuting behaviours using collaborative visual analytics. Computers, Environment and Urban Systems, 47, 5–15.
- SEo, J., Shneiderman, B. (2001). Understanding hierarchical clustering results by interactive exploration of dendrograms: A case study with Genomic Microarray Data", Technical Report, Human–Computer Interaction Laboratory, Institute for Advanced Computer Studies, University of Maryland, College Park, MD 20742 USA
- Oliveira, G. N., Sotomayor, J. L., Torchelsen, R. P., Silva, C. T., & Comba, J. L. (2016). Visual analysis of bike-sharing systems. Computers & Graphics, 60, 119–129.
References
- Rydning, D.R.J.G.J. The Digitization of the World from Edge to Core; International Data Corporation: Framingham, MA, USA, 2018; p. 16. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 NAACL HLT, Vol 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Cilibrasi, R.; Vitányi, P.M. Clustering by compression. IEEE Trans. Inf. Theory 2005, 51, 1523–1545. [Google Scholar] [CrossRef] [Green Version]
- Grnarova, P.; Schmidt, F.; Hyland, S.L.; Eickhoff, C. Neural Document Embeddings for Intensive Care Patient Mortality Prediction. arXiv 2016, arXiv:1612.00467. [Google Scholar]
- Zhang, W.E.; Sheng, Q.Z.; Lau, J.H.; Abebe, E. Detecting duplicate posts in programming QA communities via latent semantics and association rules. In Proceedings of the 26th International Conference on World Wide Web, Perth, Australia, 3–7 April 2017; pp. 1221–1229. [Google Scholar]
- Strubell, E.; Ganesh, A.; McCallum, A. Energy and Policy Considerations for Deep Learning in NLP. arXiv 2019, arXiv:1906.02243. [Google Scholar]
- Alvarez, J.E.; Bast, H. A Review of Word Embedding and Document Similarity Algorithms Applied to Academic Text. Bachelor’s Thesis, University of Freiburg, Breisgau, Germany, 2017. [Google Scholar]
- Dai, A.M.; Olah, C.; Le, Q.V. Document embedding with paragraph vectors. arXiv 2015, arXiv:1507.07998. [Google Scholar]
- Shahmirzadi, O.; Lugowski, A.; Younge, K. Text Similarity in Vector Space Models: A Comparative Study. In Proceedings of the IEEE-ICMLA (18th International Conference on Machine Learning and Applications 2019), Boca Raton, FL, USA, 16–19 December 2019. [Google Scholar]
- Vázquez, P.P. Visual analysis of research paper collections using normalized relative compression. Entropy 2019, 21, 612. [Google Scholar] [CrossRef] [Green Version]
- Lau, J.H.; Baldwin, T. An Empirical Evaluation of doc2vec with Practical Insights into Document Embedding Generation. arXiv 2016, arXiv:1607.05368. [Google Scholar]
- Arora, S.; Liang, Y.; Ma, T. A simple but tough-to-beat baseline for sentence embeddings. In Proceedings of the 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, 24–26 April 2017. [Google Scholar]
- Kiros, R.; Zhu, Y.; Salakhutdinov, R.; Zemel, R.S.; Torralba, A.; Urtasun, R.; Fidler, S. Skip-thought vectors. In Proceedings of the 28th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; Volume 2, pp. 3294–3302. [Google Scholar]
- Wieting, J.; Bansal, M.; Gimpel, K.; Livescu, K. Towards Universal Paraphrastic Sentence Embeddings. In Proceedings of the 4th International Conference on Learning Representations, ICLR 2016, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Le, Q.V.; Mikolov, T. Distributed Representations of Sentences and Documents. In Proceedings of the 31st International Conference on Machine Learning, Beijing, China, 21–26 June 2014; pp. 1188–1196. [Google Scholar]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C. GloVe: Global Vectors for Word Representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar] [CrossRef]
- Levy, O.; Goldberg, Y.; Dagan, I. Improving distributional similarity with lessons learned from word embeddings. Trans. Assoc. Comput. Linguist. 2015, 3, 211–225. [Google Scholar] [CrossRef]
- Baroni, M.; Dinu, G.; Kruszewski, G. Don’t count, predict! a systematic comparison of context-counting vs. In context-predicting semantic vectors. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Baltimore, MD, USA, 22–27 June 2014; pp. 238–247. [Google Scholar]
- Naili, M.; Chaibi, A.H.; Ghezala, H.H.B. Comparative study of word embedding methods in topic segmentation. Procedia Comput. Sci. 2017, 112, 340–349. [Google Scholar] [CrossRef]
- Deerwester, S.; Dumais, S.T.; Furnas, G.W.; Landauer, T.K.; Harshman, R. Indexing by latent semantic analysis. J. Am. Soc. Inf. Sci. 1990, 41, 391–407. [Google Scholar] [CrossRef]
- Chen, M. Efficient Vector Representation for Documents through Corruption. ICLR (Poster). 2017. Available online: https://arxiv.org/abs/1707.02377 (accessed on 1 March 2022).
- Kusner, M.; Sun, Y.; Kolkin, N.; Weinberger, K. From word embeddings to document distances. In Proceedings of the International Conference on Machine Learning, Lille, France, 7–9 July 2015; pp. 957–966. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. In Proceedings of the 1st ICLR, Scottsdale, Arizona, USA, 2–4 May 2013. [Google Scholar]
- Bojanowski, P.; Grave, E.; Joulin, A.; Mikolov, T. Enriching word vectors with subword information. Trans. Assoc. Comput. Linguist. 2017, 5, 135–146. [Google Scholar] [CrossRef] [Green Version]
- Peters, M.E.; Neumann, M.; Iyyer, M.; Gardner, M.; Clark, C.; Lee, K.; Zettlemoyer, L. Deep Contextualized Word Representations. arXiv 2018, arXiv:1802.05365. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Lan, Z.; Chen, M.; Goodman, S.; Gimpel, K.; Sharma, P.; Soricut, R. Albert: A lite bert for self-supervised learning of language representations. arXiv 2019, arXiv:1909.11942. [Google Scholar]
- Dai, Z.; Yang, Z.; Yang, Y.; Carbonell, J.; Le, Q.V.; Salakhutdinov, R. Transformer-xl: Attentive language models beyond a fixed-length context. arXiv 2019, arXiv:1901.02860. [Google Scholar]
- Yang, Z.; Dai, Z.; Yang, Y.; Carbonell, J.; Salakhutdinov, R.; Le, Q.V. XLNet: Generalized Autoregressive Pretraining for Language Understanding. arXiv 2020, arXiv:1906.08237. [Google Scholar]
- Beltagy, I.; Peters, M.E.; Cohan, A. Longformer: The long-document transformer. arXiv 2020, arXiv:2004.05150. [Google Scholar]
- Reimers, N.; Gurevych, I.; Reimers, N.; Gurevych, I.; Thakur, N.; Reimers, N.; Daxenberger, J.; Gurevych, I.; Reimers, N.; Gurevych, I.; et al. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing, Association for Computational Linguistics, Hong Kong, China, 3–7 November 2019; pp. 671–688. [Google Scholar]
- Sidorov, G.; Gelbukh, A.; Gómez-Adorno, H.; Pinto, D. Soft similarity and soft cosine measure: Similarity of features in vector space model. Comput. Sist. 2014, 18, 491–504. [Google Scholar] [CrossRef]
- Rubner, Y.; Tomasi, C.; Guibas, L.J. A metric for distributions with applications to image databases. In Proceedings of the Sixth International Conference on Computer Vision (IEEE Cat. No. 98CH36271), Bombay, India, 7 January 1998; pp. 59–66. [Google Scholar]
- Pinho, A.J.; Pratas, D.; Ferreira, P.J. Authorship attribution using relative compression. In Proceedings of the 2016 Data Compression Conference (DCC), Snowbird, UT, USA, 30 March–1 April 2016; pp. 329–338. [Google Scholar]
- Sokal, R.R.; Rohlf, F.J. The comparison of dendrograms by objective methods. Taxon 1962, 11, 33–40. [Google Scholar] [CrossRef]
- Wu, L.; Yen, I.E.; Xu, K.; Xu, F.; Balakrishnan, A.; Chen, P.Y.; Ravikumar, P.; Witbrock, M.J. Word mover’s embedding: From word2vec to document embedding. arXiv 2018, arXiv:1811.01713. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Purpose | Metric | Data Format | Time Complexity | Memory Complexity |
|---|---|---|---|---|---|
| CS | General (features) | No | Vector | ||
| SCS | General (features) | No | Vector | ||
| WMD | Text | Yes | Text | ||
| RWMD | Text | Yes | Text | ||
| NRC | General (files) | No | Bytes |
| SCS | WMD | RWMD | CS | NRC | |
|---|---|---|---|---|---|
| w2v | ✓ | ✓ | ✓ | ||
| fT | ✓ | ✓ | ✓ | ||
| GV | ✓ | ✓ | ✓ | ||
| d2v | ✓ | ||||
| ELMo | ✓ | ||||
| NRC | ✓ |
| w2v | fT | GV | d2v | ELMo | |
|---|---|---|---|---|---|
| Vector size | 300 | 1024 | |||
| Window size | 7 | 5 | - | ||
| Min vocabulary count | 4 | - | |||
| Corpus count | 398,387 | 793471 | |||
| Corpus total words | 4,366,988 | 1B | |||
| Training epochs | 10 | - | |||
| Architecture | CSG | CSG | - | PV-DM | - |
| SCS | WMD | RWMD | CS | NRC | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| w2v | fT | GV | w2v | fT | GV | w2v | fT | GV | d2v | ELMo | ||
| 17,986 | 19,680 | 32,810 | >1 h | >1 h | >1 h | 59,137 | 50,750 | 50,653 | 0.648 | >1 h | 0.8489 | |
| 1598 | 0.969 | 0.695 | - | - | - | 4787 | 3288 | 3551 | 0.009 | - | 0.131 | |
| Distance | SCS | WMD | RWMD | CS | NRC | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Embedding | w2v | fT | GV | w2v | fT | GV | w2v | fT | GV | d2v | ELMo | |
| Task 1–Article/thesis comparison | + | + | + | ∼ | ∼ | ∼ | ∼ | ∼ | ∼ | +* | - | ∼ |
| Task 2–Clustering | ∼ | ∼ | + | ? | ∼ | ∼ | ∼ | + | ? | ∼ | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gómez, J.; Vázquez, P.-P. An Empirical Evaluation of Document Embeddings and Similarity Metrics for Scientific Articles. Appl. Sci. 2022, 12, 5664. https://doi.org/10.3390/app12115664
Gómez J, Vázquez P-P. An Empirical Evaluation of Document Embeddings and Similarity Metrics for Scientific Articles. Applied Sciences. 2022; 12(11):5664. https://doi.org/10.3390/app12115664
Chicago/Turabian StyleGómez, Joaquin, and Pere-Pau Vázquez. 2022. "An Empirical Evaluation of Document Embeddings and Similarity Metrics for Scientific Articles" Applied Sciences 12, no. 11: 5664. https://doi.org/10.3390/app12115664
APA StyleGómez, J., & Vázquez, P.-P. (2022). An Empirical Evaluation of Document Embeddings and Similarity Metrics for Scientific Articles. Applied Sciences, 12(11), 5664. https://doi.org/10.3390/app12115664