1. Introduction
With the advantages of a large span, a short construction period, and easy transportation, steel bridges have been widely used in bridge engineering. Among the various components of steel bridges, bridge decks are more prone to defects than other components during service because they are directly subjected to traffic loads [
1]. Under the influence of various factors such as vehicle load and climatic environment, steel bridge decks will experience different degrees of defects. Cracking, rutting, and other types of fatigue damage, such as fatigue cracks, are the most typical steel bridge deck defects [
2,
3]. If fatigue cracks are not treated in time, they will lead to water and other chemical reagents and steel bridge panel contact [
4]. The steel bridge panel will produce corrosion phenomena, thus affecting the performance of the bridge deck. Severe cracking will also increase the roughness of the bridge deck, affecting driving comfort and safety [
5]. Compared with the rapid progress in construction in China, the management and maintenance technology for such projects are relatively underdeveloped. After defects appear on the bridge deck, domestic bridge management is prone to incorrectly predicting the condition of defects and the future development trends, making it difficult to carry out effective maintenance measures. Therefore, it is essential to carry out research related to identifying defects in steel bridge decks. In recent years, large-span steel bridges have been widely used in China, but the proportion of the overall number of bridges is still small, and most of them are in the early stages of service. Usually, large amounts of data are needed to analyze the defective condition of in-service steel bridge decks. It is difficult to collect data related to steel bridge decks in China. The United States has more developed transportation infrastructure. National Bridge Information Base (NBI) data show that the number of steel bridges in the United States will account for more than 30% of the bridges in the country by 2021 [
6]. The NBI is a database compiled by the Federal Highway Administration that contains data related to the structure type, material type, and condition rating of bridges in each state of the United States [
7]. All of the data are recorded in a uniform standard. Therefore, using the NBI database can provide good data support for predicting and analyzing steel bridge deck defect conditions. Developing a data-driven prediction model can help Chinese bridge managers make better deck maintenance decisions.
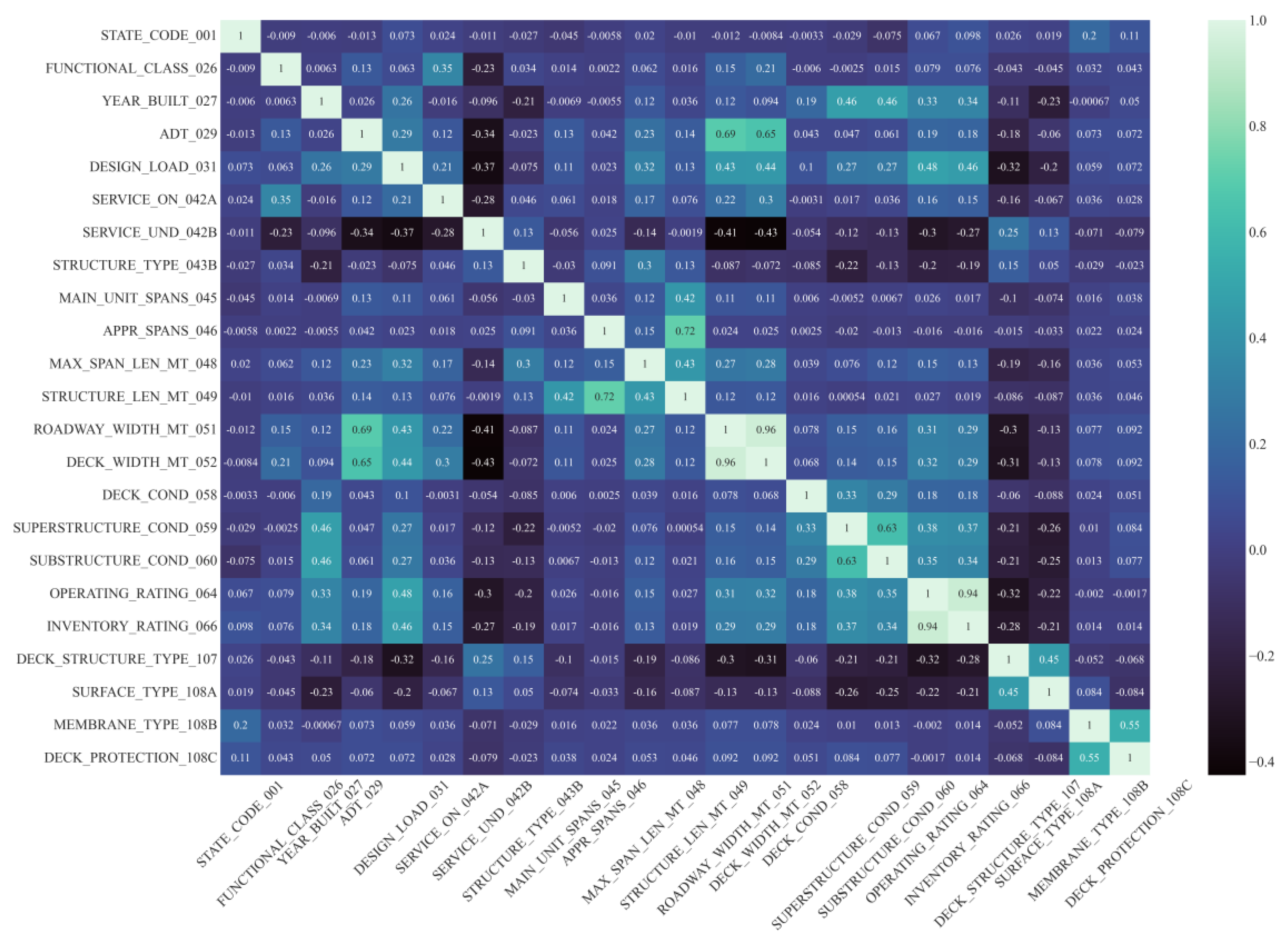
To build a bridge deck defect condition prediction model, it is necessary to establish the interrelationships between deck conditions and various parameters (such as superstructure condition, substructure condition, average daily traffic, structure length, bridge roadway width, and bridge age) of the bridge, but there are significant challenges to making such a model due to the highly nonlinear relationship between the parameters [
8,
9,
10]. However, with the rapid development of artificial intelligence in the last decade, many researchers have started to use machine learning models to solve related problems in the field of civil engineering [
11]. Regarding the issue of bridge deck condition prediction, Ghonima et al. used stochastic parametric binary logistic regression to predict the effects of environmental and structural parameters on the bridge deck condition [
12]. They showed that the developed stochastic parametric model outperformed the traditional binary logistic model. Lavrenz et al. used the multivariate three-stage least squares model to predict the condition of the bridge deck, superstructure, and substructure conditions [
13]. They compared it with the ordinary least squares model, and the results showed that the multivariate three-stage least squares model had higher accuracy. Ranjith et al. used a stochastic Markov chain model to predict the condition of wooden bridges [
14]. The results showed that the developed model had high accuracy. Mohammed Abdelkader et al. used a hybrid Bayesian optimization approach calibrated with the Markov model to predict bridge deck condition [
15]. They concluded that the proposed model outperformed some commonly used Markov models. Huang et al. used statistical methods to determine the factors that lead to defects in bridge decks and developed an ANN-based bridge condition prediction model and a model that could achieve 75% accuracy [
16]. Assaad et al. used ANN and KNN models to predict bridge deck condition; the optimal model was ANN, which achieved an accuracy of 91.44% [
8]. Contreras-Nieto et al. used logistic regression, decision tree, artificial neural network, gradient boosting, and support vector machine models to predict the condition of steel bridge superstructures; the optimal model was a logistic regression model with an accuracy of 73.4% [
17]. Liu used convolutional neural networks to predict the condition of the bridge deck, superstructure, and substructure [
18]. The results showed that the accuracy of the developed model was more than 85%.
Ensemble learning is a machine learning method that combines multiple weak learners to improve the prediction accuracy, and the technique is gaining popularity among researchers in engineering prediction problems [
19]. The following ensemble learning models are currently commonly used: RandomForest, ExtraTree, AdaBoost, GBDT, XGBoost, and LightGBM. RandomForest and ExtraTree use bagging for ensemble learning. Bagging first obtains a sample set by random sampling, then trains it to derive a weak learner, and finally uses the integration strategy to determine the final strong learner [
20]. AdaBoost, GBDT, XGBoost, and LightGBM use boosting for ensemble learning. Boosting first trains a weak learner, assigns greater importance to the wrongly predicted samples in the training results of this weak learner, then uses this adjusted training set to train the next weak learner. Through continuous iterative learning, b weak learners are obtained, and finally, these b weak learners are combined in a weighted manner [
20]. There have been many successful engineering studies using ensemble learning models. Chen et al. used gradient boosting decision trees and random forest models to predict the bond strength of CFRP–steel interfaces and compared them with traditional machine learning models and showed that the models outperformed the traditional models [
21]. Farooq et al. used ensemble learning models to predict the strength of high-performance concrete crafted from waste materials, and the results showed that random forest and decision tree with bagging performed better [
22]. Chen et al. used the XGBoost model to assess the seismic vulnerability of buildings in Kavrepalanchok, Nepal, and the results showed that the developed model had high accuracy [
23]. Gong et al. used the random forest model to predict the international roughness index of asphalt pavement [
24]. The results showed that the developed model was significantly better than the traditional linear regression model. Liang et al. used the GBDT, XGBoost, and LightGBM models to predict the stability of complex rock pillars, and the results showed that the performance of all three algorithms was better [
25].
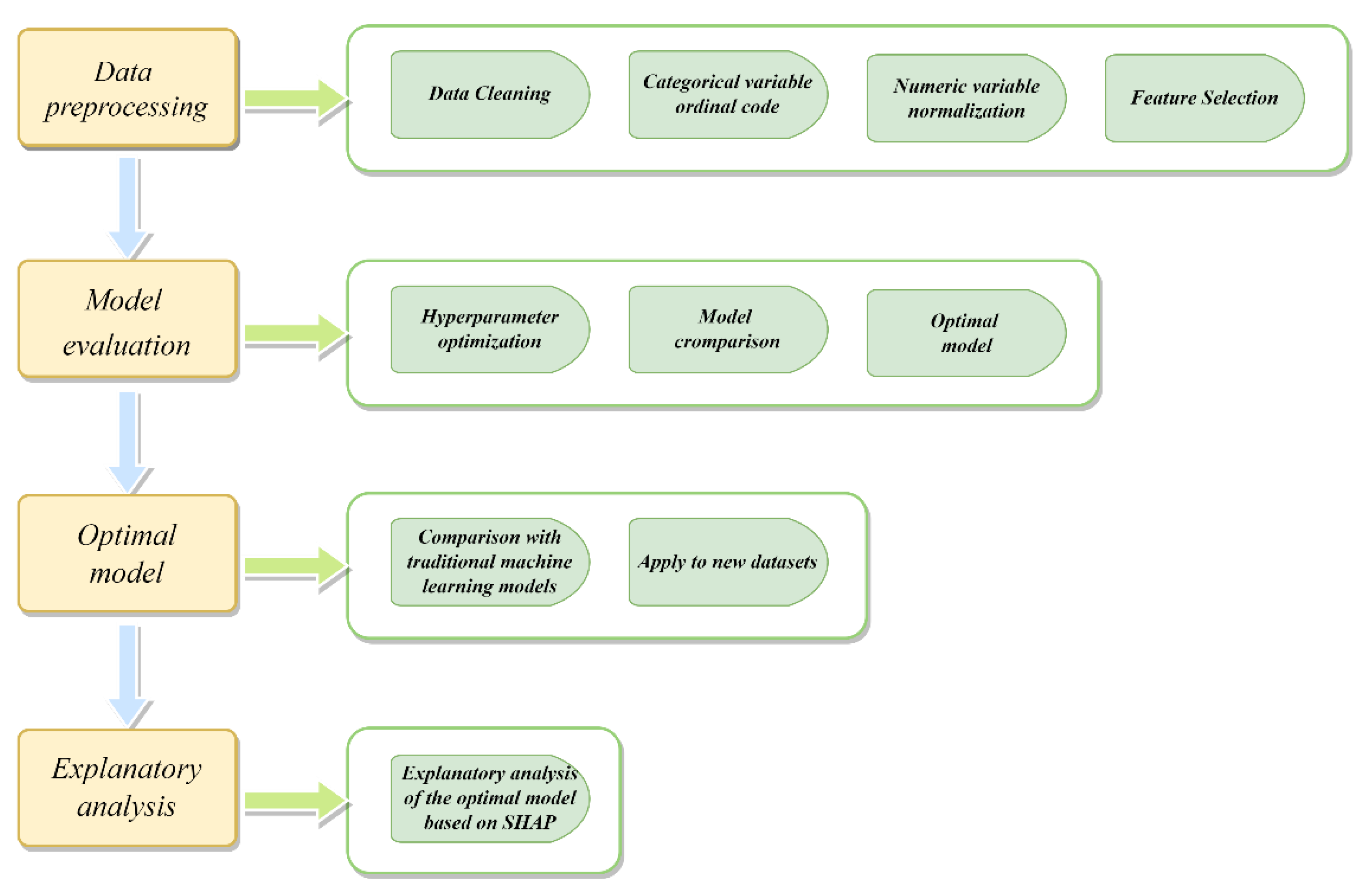
Research on bridge deck condition predictions mainly focuses on bridges with a concrete superstructure and less on bridges with a steel superstructure. Therefore, it is essential to develop a steel bridge deck defect prediction model using an ensemble learning model with good prediction accuracy. In this study, an ensemble-learning-based bridge deck defect prediction model was developed to help bridge managers make more rational and informed steel bridge deck maintenance decisions. This study utilized the latest data from the NBI database for U.S. states for the year 2021 for modeling. It focuses on the following aspects: (1) Addressing the imbalance in the data using the adaptive synthetic sampling method (ADASYN); (2) Six ensemble learning models (RandomForest, ExtraTree, AdaBoost, GBDT, XGBoost, and LightGBM) are established, and the hyperparameters of the models are searched for using the grid search method. The optimal model is determined by comparing the performance evaluation indexes of the six models; (3) The optimal model XGBoost is compared with the traditional machine learning model, and the XGBoost model is applied to the 2019 and 2020 NBI datasets; (4) The interpretable machine learning framework SHAP is used to illustrate the effect of each factor on the condition of the bridge deck defects in the XGBoost model.
5. Conclusions
This study developed an ensemble-learning-based steel bridge deck defect condition prediction model that can help bridge managers make more rational and informed decisions regarding steel bridge deck maintenance. This study explored steel bridge deck defect condition predictions as a dichotomous problem, using the latest data from the NBI database for 2021. The data were first pre-processed, and imbalances in the data were solved using ADASYN. Then, six ensemble learning models (RandomForest, ExtraTree, AdaBoost, GBDT, XGBoost, and LightGBM) were built, the hyperparameters of the models were optimized, and the performance of the six ensemble learning models was compared with determine the optimal prediction model. Next, to demonstrate the superiority of the optimal model performance, the optimal model was compared with traditional machine learning models and previous related studies, and the optimal model was applied to a new dataset. Finally, an explanatory analysis of the optimal model was performed using the SHAP framework. The following conclusions can be drawn from the study:
- (1)
The optimal hyperparameters of the models were determined using the grid search method, and the optimal hyperparameter combinations of six ensemble learning models were obtained.
- (2)
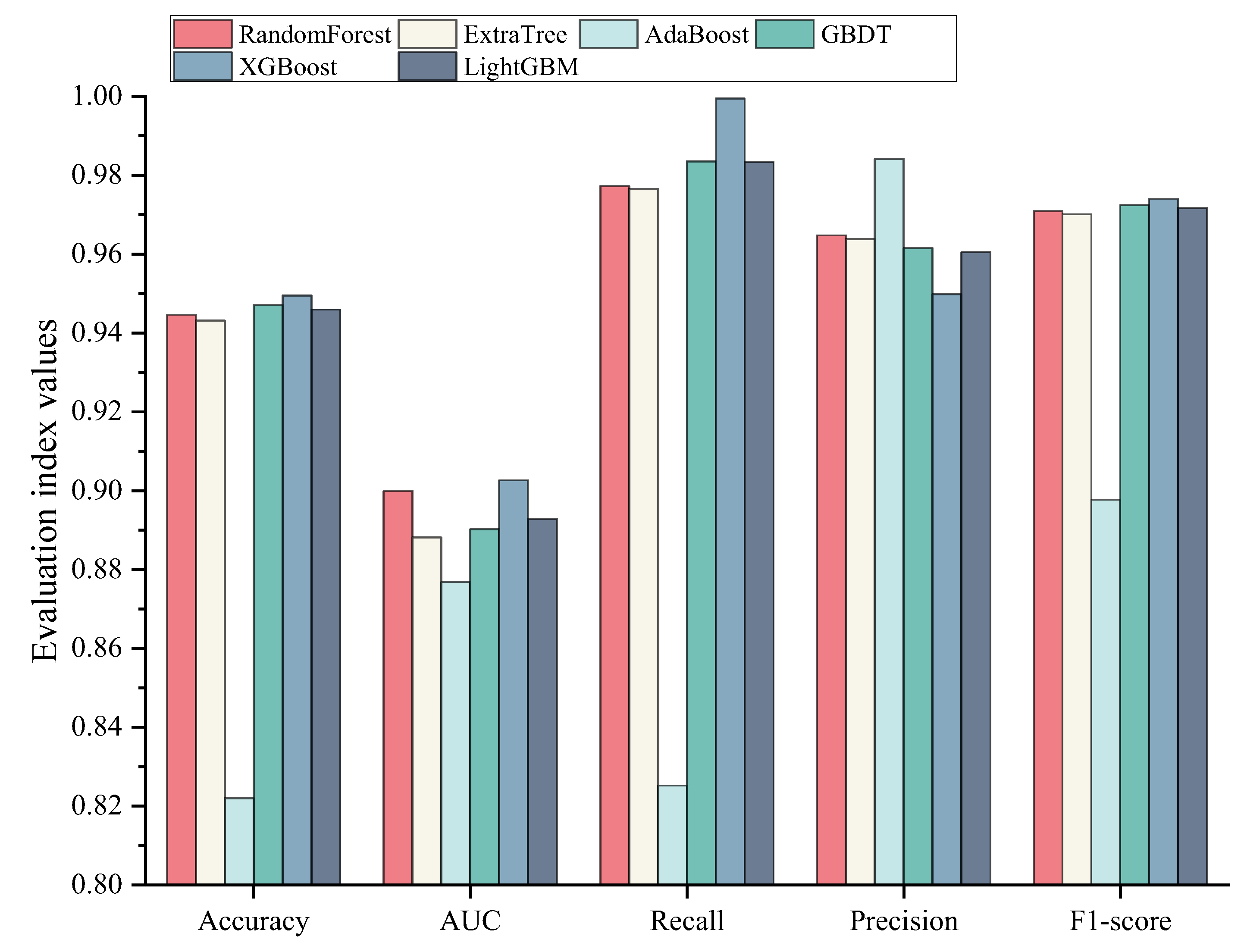
The optimal prediction model is XGBoost, with a model accuracy of 0.9495, an AUC of 0.9026, and an F1-Score of 0.9740. The performance of the model is improved compared with traditional machine learning models, and the comparison with previous studies also demonstrated the superiority of the model’s performance. The XGBoost model also performed well on the 2019 and 2020 NBI datasets, showing that the model has good generalization performance, indicating that the model has good generalization performance. Therefore, the XGBoost model developed in this study can be used as an accurate method to predict the condition of steel bridge deck defects.
- (3)
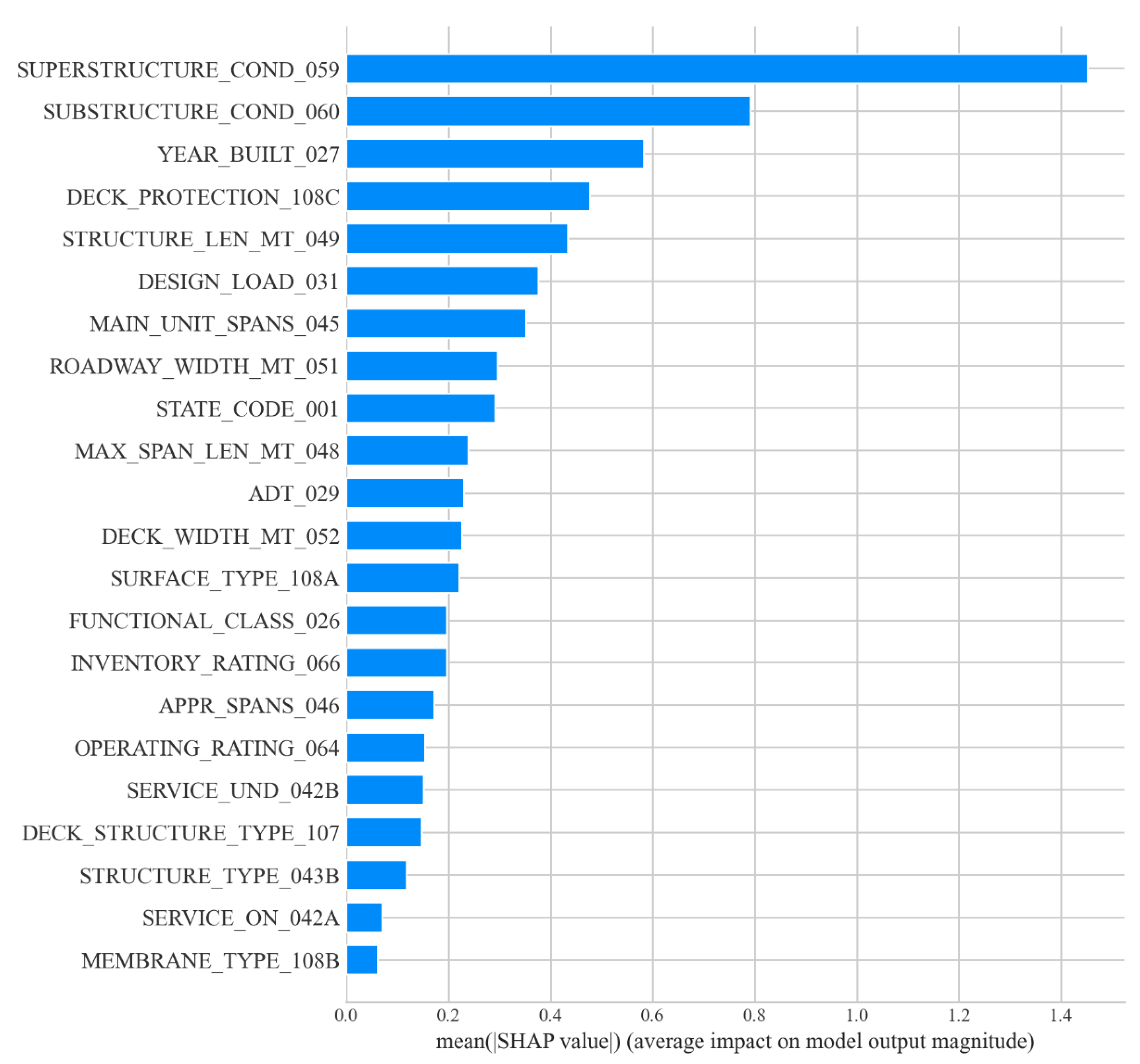
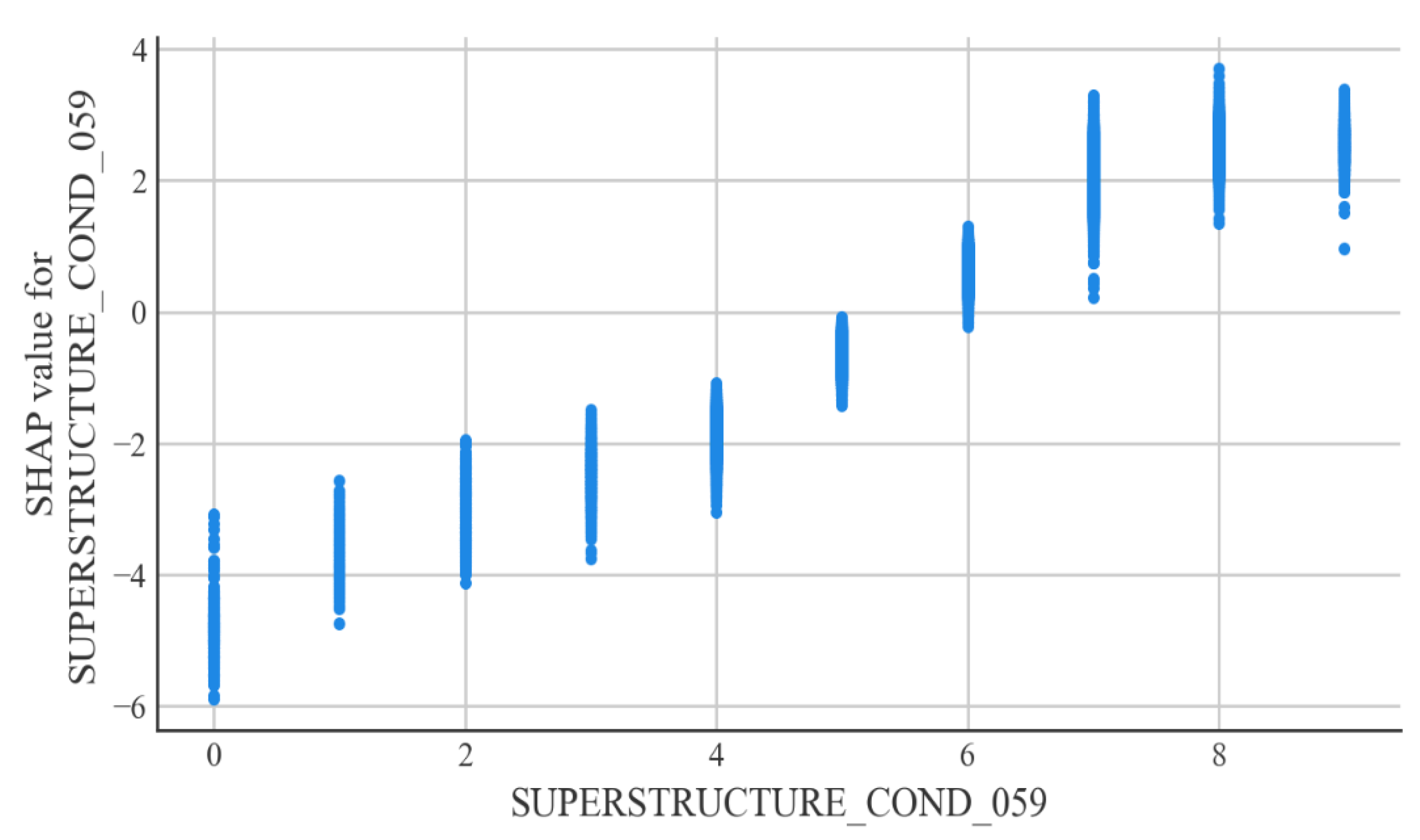
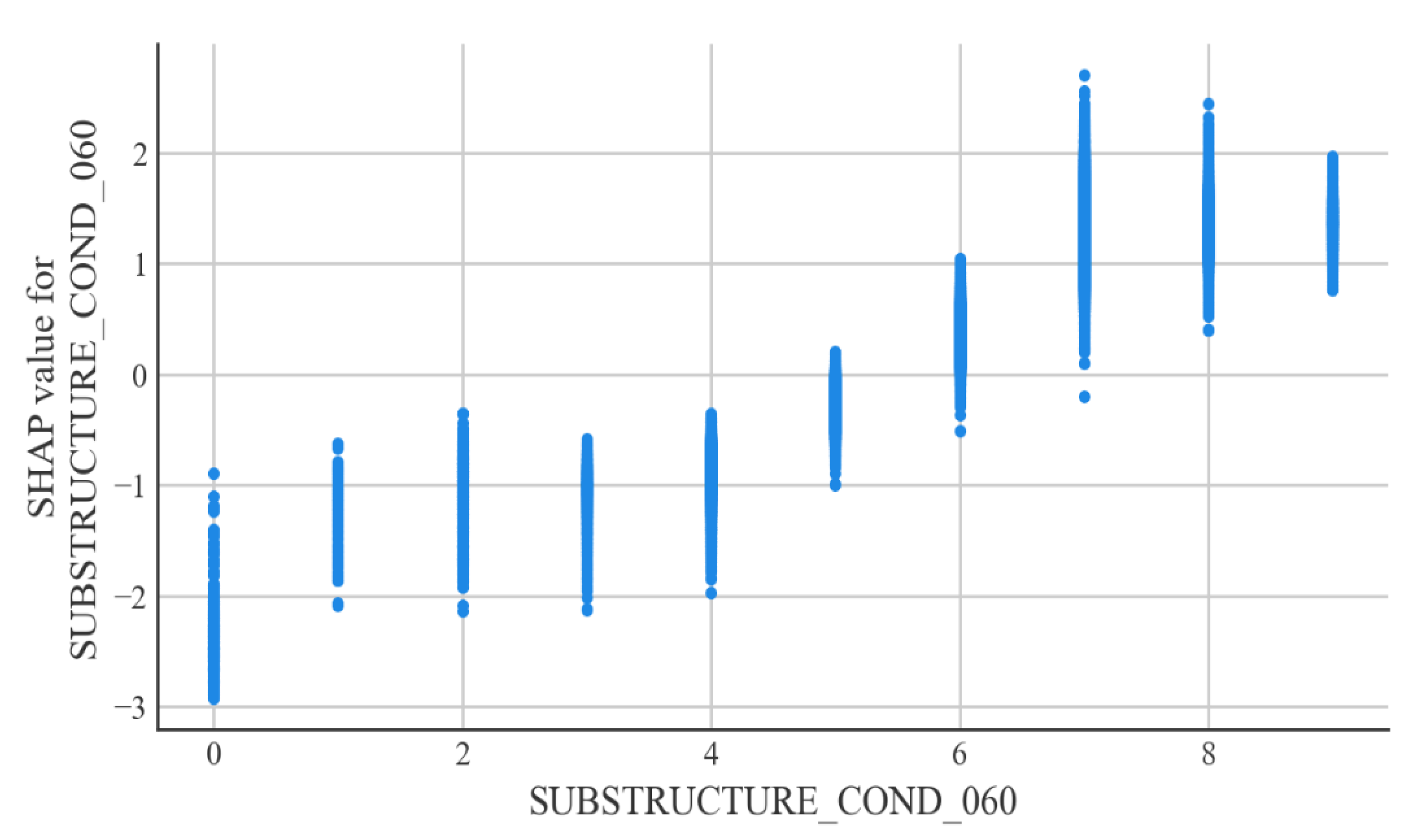
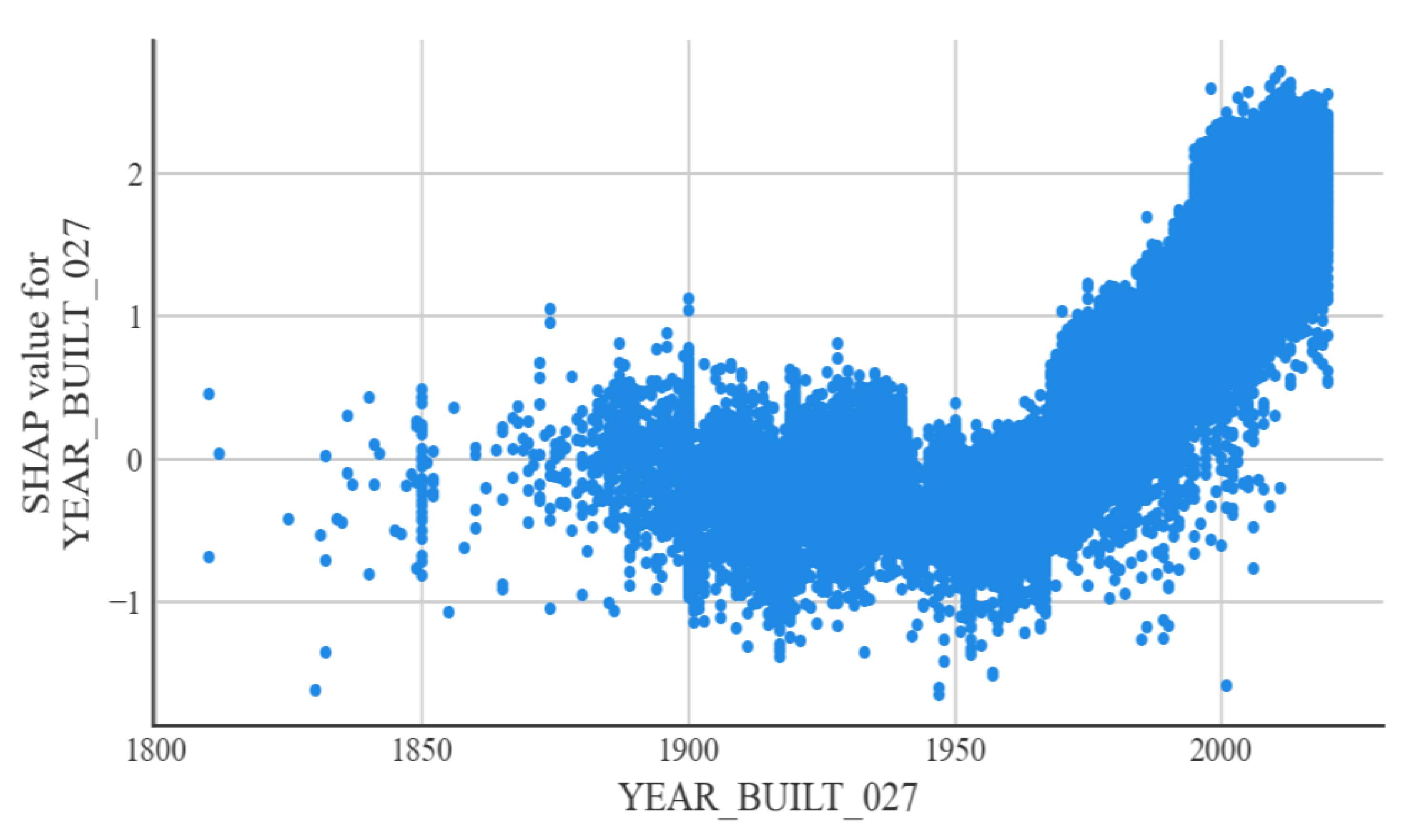
According to the interpretable machine learning framework SHAP, the most important factor affecting the condition of steel bridge deck defects is the condition of the bridge superstructure. Relatively minor factors are the condition of the bridge substructure and the year of bridge construction. The better the condition of the superstructure and substructure of a steel bridge, the less likely the bridge deck is to be defective. The older the steel bridge deck is, the more likely it is that it will have defects. The explanatory analysis of the model is consistent with the actual situation in engineering applications and can justify the developed model.
The ensemble learning model developed using this study can help bridge managers to accurately predict the condition of steel bridge deck defects. Additionally, based on the important factors affecting the condition of steel bridge decks obtained in this study, bridge managers should prioritize the maintenance of each steel bridge component when making maintenance decisions and ensure the rational use of funds. Steel bridges have a lot of room for development in China, and as the number of steel bridges in China rises, it is important to establish a database of the steel bridges in China. The future use of the Chinese steel bridge database to build a bridge deck condition prediction model will be more beneficial for Chinese bridge managers in making steel bridge deck maintenance decisions.
Contemporary assessments of bridge defects are usually carried out by manual inspection methods, which are highly subjective [
41]. To solve this problem, sensor-based detection methods and computer-vision-based detection methods can also be used to obtain bridge assessment data [
42]. The models developed in this study can also be used in conjunction with these detection techniques.



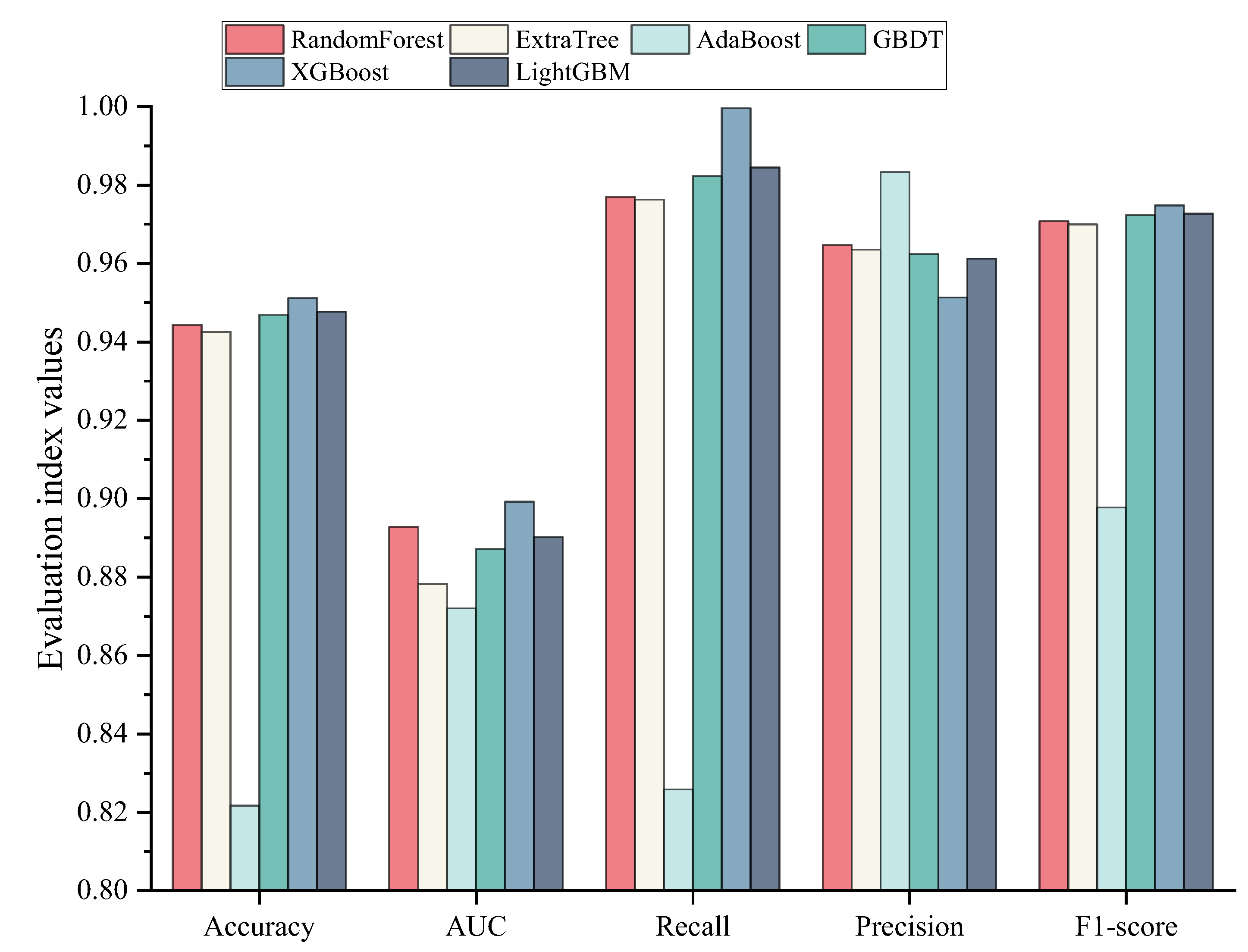

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}