
Medium Transmission Map Matters for Learning to Restore Real-World Underwater Images


Abstract
:1. Introduction
- We improved the use of the medium transmission map. We can obtain good results by relying on the RGB map alone using various preprocessing and color embedding, proving that the MT map is of great significance for learning in a more powerful real-world underwater image restoration network.
- A multitask learning framework is formulated for leveraging the MT map, and a novel multilevel knowledge interaction mechanism is proposed for better mining the guidance from the MT learning space.
- A comparative study on two real-world benchmarks demonstrated the superiority of our MTUR-Net over the state-of-the-art in terms of both restoration quality and inference speed.
2. Materials and Methods
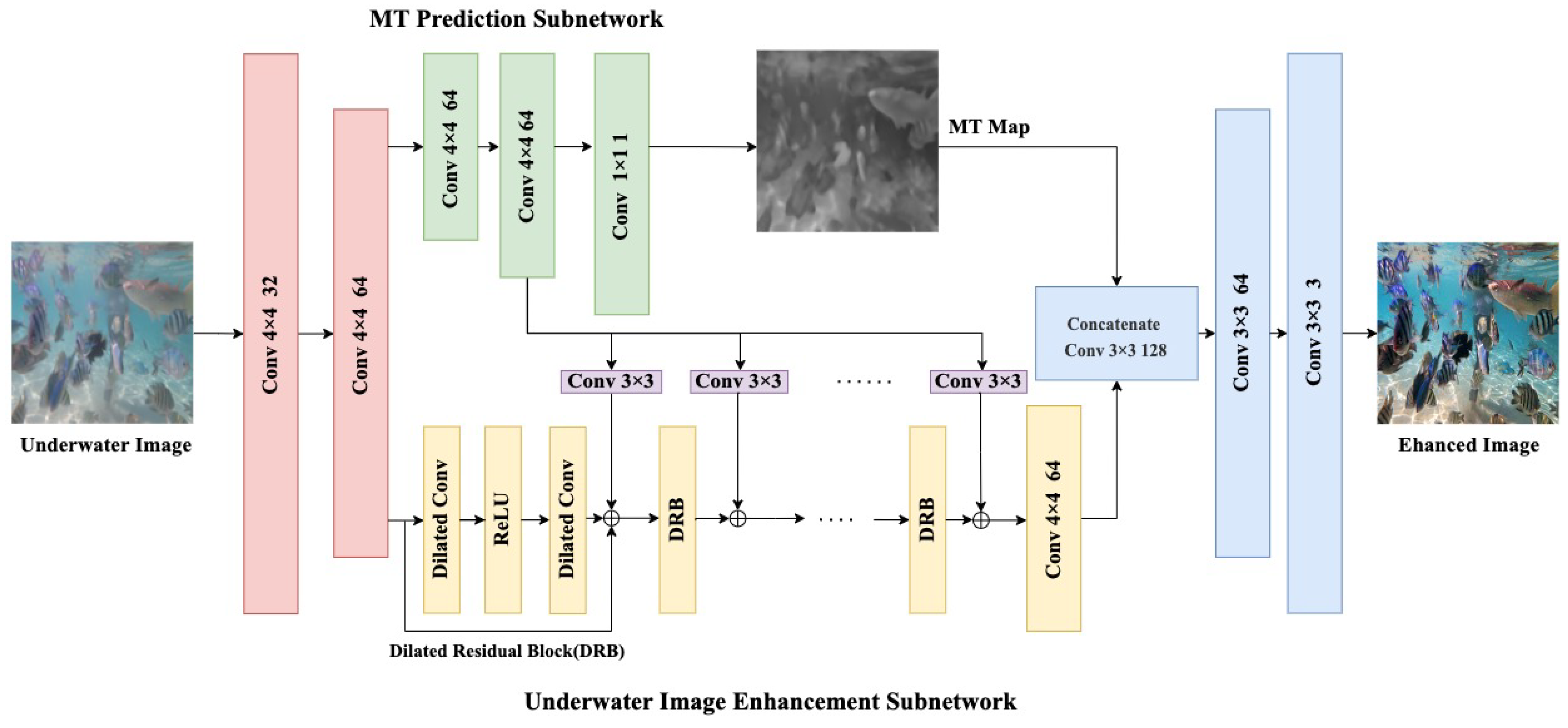
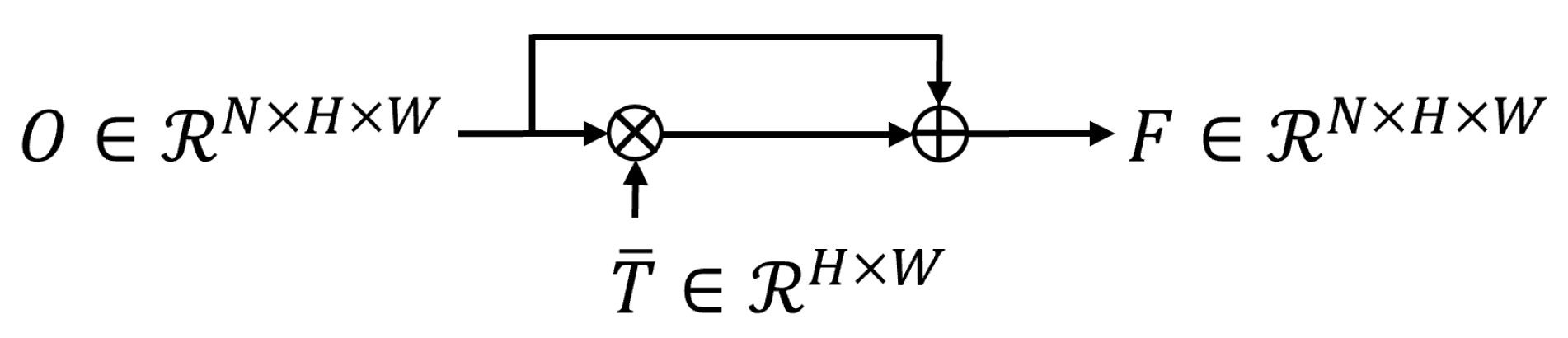
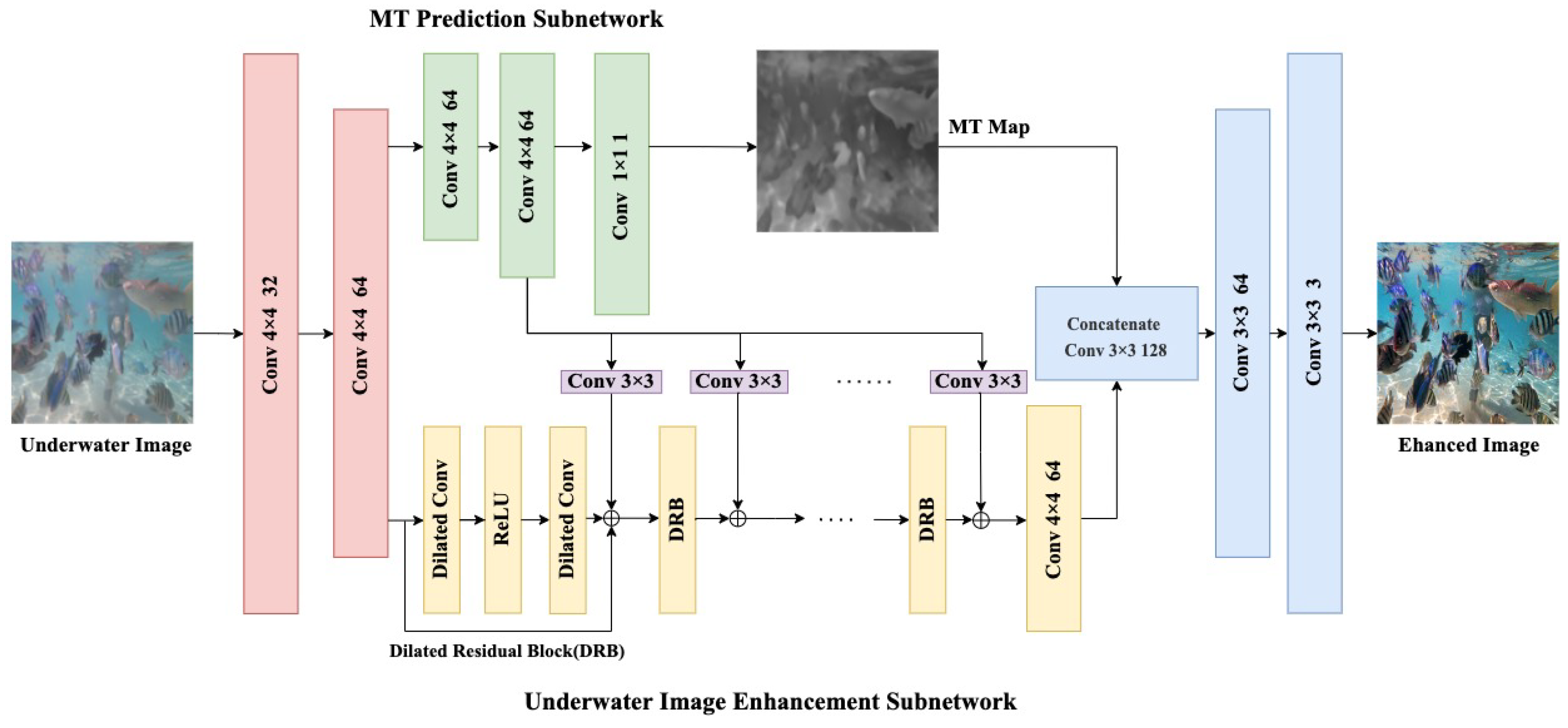
2.1. MT Prediction Subnet
2.2. Underwater Image Enhancement Subnet
3. Results and Discussion
3.1. Parameter Settings
3.2. Experiment Setup
3.3. Comparative Study
3.4. Ablation Study
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| CNN | convolutional neural network |
| GAN | generative adversarial network |
| MT | medium transmission |
| DRB | dilated residual blocks |
| UIEB | underwater image enhancement benchmark |
| PSNR | peak signal–to–noise ratio |
| SSIM | structural similarity |
| FPS | frame per second |
| UCIQE | underwater color image quality evaluation |
| UIQM | underwater image quality measure |
| SAUD | subjectively-annotated UIE benchmark dataset |
References
- Lee, D.; Kim, G.; Kim, D.; Myung, H.; Choi, H.T. Vision-based object detection and tracking for autonomous navigation of underwater robots. Ocean Eng. 2012, 48, 59–68. [Google Scholar] [CrossRef]
- Drews, P., Jr.; do Nascimento, E.; Moraes, F.; Botelho, S.; Campos, M. Transmission Estimation in Underwater Single Images. In Proceedings of the 2013 IEEE International Conference on Computer Vision Workshops, Sydney, NSW, Australia, 2–8 December 2013; pp. 825–830. [Google Scholar] [CrossRef]
- Mohamed, N.; Jawhar, I.; Al-Jaroodi, J.; Zhang, L. Sensor Network Architectures for Monitoring Underwater Pipelines. Sensors 2011, 11, 10738–10764. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, C.Y.; Guo, J.C.; Cong, R.M.; Pang, Y.W.; Wang, B. Underwater Image Enhancement by Dehazing With Minimum Information Loss and Histogram Distribution Prior. IEEE Trans. Image Process. 2016, 25, 5664–5677. [Google Scholar] [CrossRef] [PubMed]
- Li, C.; Guo, C.; Ren, W.; Cong, R.; Hou, J.; Kwong, S.; Tao, D. An Underwater Image Enhancement Benchmark Dataset and Beyond. IEEE Trans. Image Process. 2020, 29, 4376–4389. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Islam, M.J.; Xia, Y.; Sattar, J. Fast Underwater Image Enhancement for Improved Visual Perception. IEEE Robot. Autom. Lett. 2020, 5, 3227–3234. [Google Scholar] [CrossRef] [Green Version]
- Berman, D.; Levy, D.; Avidan, S.; Treibitz, T. Underwater Single Image Color Restoration Using Haze-Lines and a New Quantitative Dataset. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 2822–2837. [Google Scholar] [CrossRef] [Green Version]
- Li, C.; Anwar, S.; Porikli, F. Underwater scene prior inspired deep underwater image and video enhancement. Pattern Recognit. 2020, 98, 107038. [Google Scholar] [CrossRef]
- Li, C.; Anwar, S.; Hou, J.; Cong, R.; Guo, C.; Ren, W. Underwater Image Enhancement via Medium Transmission-Guided Multi-Color Space Embedding. IEEE Trans. Image Process. 2021, 30, 4985–5000. [Google Scholar] [CrossRef]
- Li, J.; Skinner, K.A.; Eustice, R.M.; Johnson-Roberson, M. WaterGAN: Unsupervised Generative Network to Enable Real-Time Color Correction of Monocular Underwater Images. IEEE Robot. Autom. Lett. 2018, 3, 387–394. [Google Scholar] [CrossRef] [Green Version]
- Fabbri, C.; Islam, M.J.; Sattar, J. Enhancing underwater imagery using generative adversarial networks. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, QLD, Australia, 21–25 May 2018; pp. 7159–7165. [Google Scholar]
- Li, C.; Guo, J.; Guo, C. Emerging From Water: Underwater Image Color Correction Based on Weakly Supervised Color Transfer. IEEE Signal Process. Lett. 2018, 25, 323–327. [Google Scholar] [CrossRef] [Green Version]
- Guo, Y.; Li, H.; Zhuang, P. Underwater Image Enhancement Using a Multiscale Dense Generative Adversarial Network. IEEE J. Ocean. Eng. 2020, 45, 862–870. [Google Scholar] [CrossRef]
- Hu, X.; Fu, C.W.; Zhu, L.; Heng, P.A. Depth-Attentional Features for Single-Image Rain Removal. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 8014–8023. [Google Scholar] [CrossRef]
- He, K.; Sun, J.; Tang, X. Single Image Haze Removal Using Dark Channel Prior. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 2341–2353. [Google Scholar] [CrossRef] [PubMed]
- Huang, S.C.; Chen, B.H.; Wang, W.J. Visibility Restoration of Single Hazy Images Captured in Real-World Weather Conditions. IEEE Trans. Circuits Syst. Video Technol. 2014, 24, 1814–1824. [Google Scholar] [CrossRef]
- Yang, H.Y.; Chen, P.Y.; Huang, C.C.; Zhuang, Y.Z.; Shiau, Y.H. Low Complexity Underwater Image Enhancement Based on Dark Channel Prior. In Proceedings of the 2011 Second International Conference on Innovations in Bio-inspired Computing and Applications, Shenzhen, China, 16–18 December 2011; pp. 17–20. [Google Scholar] [CrossRef]
- Zhao, X.; Jin, T.; Qu, S. Deriving inherent optical properties from background color and underwater image enhancement. Ocean Eng. 2015, 94, 163–172. [Google Scholar] [CrossRef]
- Fattal, R. Single Image dehazing. ACM Trans. Graph. (TOG) 2008, 27, 1–9. [Google Scholar] [CrossRef]
- Peng, Y.T.; Cao, K.; Cosman, P.C. Generalization of the Dark Channel Prior for Single Image Restoration. IEEE Trans. Image Process. 2018, 27, 2856–2868. [Google Scholar] [CrossRef]
- Wu, Y.; He, K. Group Normalization. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Klambauer, G.; Unterthiner, T.; Mayr, A.; Hochreiter, S. Self-Normalizing Neural Networks; Curran Associates Inc.: Red Hook, NY, USA, 2017; pp. 972–981. [Google Scholar]
- Yu, F.; Koltun, V.; Funkhouser, T. Dilated Residual Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 636–644. [Google Scholar] [CrossRef] [Green Version]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef] [Green Version]
- Wang, P.; Chen, P.; Yuan, Y.; Liu, D.; Huang, Z.; Hou, X.; Cottrell, G. Understanding Convolution for Semantic Segmentation. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 1451–1460. [Google Scholar] [CrossRef] [Green Version]
- Wang, Z.; Bovik, A.; Sheikh, H.; Simoncelli, E. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [Green Version]
- Yang, M.; Sowmya, A. An Underwater Color Image Quality Evaluation Metric. IEEE Trans. Image Process. 2015, 24, 6062–6071. [Google Scholar] [CrossRef]
- Panetta, K.; Gao, C.; Agaian, S. Human-Visual-System-Inspired Underwater Image Quality Measures. IEEE J. Ocean. Eng. 2016, 41, 541–551. [Google Scholar] [CrossRef]
- Jiang, Q.; Gu, Y.; Li, C.; Cong, R.; Shao, F. Underwater Image Enhancement Quality Evaluation: Benchmark Dataset and Objective Metric. IEEE Trans. Circuits Syst. Video Technol. 2022. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | PSNR | SSIM | FPS |
|---|---|---|---|
| Original | 16.15 (+0.00) | 0.7407 (+0.0000) | – |
| UDCP [2] | 10.66 (−5.49) | 0.4827 (−0.2580) | 0.1 |
| WaterNet [5] | 16.11 (−0.04) | 0.7872 (+0.0465) | 8.3 |
| Ucolor [9] | 21.04 (+4.89) | 0.8865 (+0.1458) | 1.7 |
| UGAN [11] | 21.03 (+4.88) | 0.8637 (+0.1230) | 190 |
| FUnIE-GAN [6] | 16.75 (+0.60) | 0.8160 (+0.0753) | 307 |
| MTUR-Net | 22.60 (+6.45) | 0.9008 (+0.1601) | 30.3 |
| Methods | UCIQE | UIQM |
|---|---|---|
| Original | 0.5149 (+0.0000) | 1.898 (+0.000) |
| UDCP [2] | 0.5306 (+0.0157) | 1.156 (−0.742) |
| WaterNet [5] | 0.5489 (+0.0340) | 2.405 (+0.507) |
| Ucolor [9] | 0.5468 (+0.0319) | 2.450 (+0.552) |
| UGAN [11] | 0.5989 (+0.0840) | 3.114 (+1.216) |
| FUnIE-GAN [6] | 0.5622 (+0.0473) | 2.704 (+0.806) |
| MTUR-Net | 0.5868 (+0.0719) | 2.752 (+0.854) |
| Methods | UCIQE | UIQM |
|---|---|---|
| Original | 0.5247 (+0.0000) | 2.740 (+0.000) |
| UDCP [2] | 0.5808 (+0.0561) | 1.875 (−0.865) |
| WaterNet [5] | 0.5150 (−0.0097) | 2.651 (−0.089) |
| Ucolor [9] | 0.5790 (+0.0543) | 3.272 (+0.532) |
| UGAN [11] | 0.6083 (+0.0836) | 3.251 (+0.511) |
| FUnIE-GAN [6] | 0.5905 (+0.0658) | 3.111 (+0.371) |
| MTUR-Net | 0.6071 (+0.0824) | 3.166 (+0.426) |
| Methods | PSNR | SSIM |
|---|---|---|
| MTUR-Net | 22.60 (+0.00) | 0.9008 (+0.0000) |
| Basic | 22.17 (−0.43) | 0.8893 (−0.0115) |
| w/o skip connection | 22.15 (−0.45) | 0.8897 (−0.0111) |
| w/o concat | 21.63 (−0.97) | 0.8820 (−0.0188) |
| w/o conv2d after concat | 22.23 (−0.37) | 0.8950 (−0.0058) |
| DRB blocks addition | 21.75 (−0.85) | 0.8890 (−0.0118) |
| DRB blocks concat | 21.92 (−0.67) | 0.8911 (−0.0097) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yan, K.; Liang, L.; Zheng, Z.; Wang, G.; Yang, Y. Medium Transmission Map Matters for Learning to Restore Real-World Underwater Images. Appl. Sci. 2022, 12, 5420. https://doi.org/10.3390/app12115420
Yan K, Liang L, Zheng Z, Wang G, Yang Y. Medium Transmission Map Matters for Learning to Restore Real-World Underwater Images. Applied Sciences. 2022; 12(11):5420. https://doi.org/10.3390/app12115420
Chicago/Turabian StyleYan, Kai, Lanyue Liang, Ziqiang Zheng, Guoqing Wang, and Yang Yang. 2022. "Medium Transmission Map Matters for Learning to Restore Real-World Underwater Images" Applied Sciences 12, no. 11: 5420. https://doi.org/10.3390/app12115420
APA StyleYan, K., Liang, L., Zheng, Z., Wang, G., & Yang, Y. (2022). Medium Transmission Map Matters for Learning to Restore Real-World Underwater Images. Applied Sciences, 12(11), 5420. https://doi.org/10.3390/app12115420