
Active Learning Based on Crowdsourced Data


Abstract
:1. Introduction
2. The State of the Art
2.1. Active Learning Approaches
2.2. The CenHive System
- Mapping verification [20]—using TGame (https://play.google.com/store/apps/details?id=pl.gda.eti.kask.tgame accessed on 21 December 2021), an Android platform game, designed for Wikipedia–WordNet mapping verification. It supports audio, video, text, and images for both the contents and phrases. The player has to fulfill the task to activate checkpoints in the game. Our tests showed that the solution is viable for mapping verification. During the two-month-long test period, players gave 3731 answers in total to 338 questions. The total number of answers for different mapping types is shown in Table 1.During the tests, we established a procedure for dealing with malicious users. As in the crowdsourcing approach, we have no control over the user actions, and we decided to consider only tasks with multiple solutions. To eliminate blind shots, we took into account only questions that were displayed for at least 5 s—the time needed to actually read the question.
- Image tagging/verification—using 2048 clone (https://kask.eti.pg.gda.pl/cenhive2/2048/ accessed on 21 December 2021). The player, during the game, donates some of his or her computer computation power to create new data in the volunteer computing approach. The downloaded photos were analyzed using Viola-Jones Feature Detection Algorithm using the Haar Cascades [22] algorithm (more specifically using HAAR.js implementation (https://github.com/foo123/HAAR.js accessed on 21 December 2021)). Detected faces were sent back to CenHive and stored as tags, where the original image was tagged with coordinates of the rectangle containing the detected face. The player, when he or she wanted to undo a move, needed to verify the correctness of faces detects. He or she was presented with a random image selected from all of the detection done by any player.During the test period, where tests were done with the help of the research team and students, for 64 multi-person photos, the game players generated 628 face-detects (giving 303 distinct face detects). In this case, multiple face-detects are not necessary as they are done arithmetically using the player’s device’s processing power. The detected faces were further verified—for 92 images, we received 181 verification responses and 7 reports.
3. Crowdsourcing Enabled Active Learning
3.1. The Data
- Over 17% of the bees located near the entrances to the hive are partially visible;
- In around 4.2% of cases, the bees overlap;
- About 3% of spotted bees are hard to distinguish from the background due to the color of the surrounding environment;
- Almost 37% of the bees were blurred as they moved faster than the camera frame rate.
3.2. Network Topology and the Training Process
- All images available in the global set are passed to the network, and the bee detection is done;
- All network annotated images are passed to CenHive platform;
- The network annotated images are forwarded to the users, who verify the correctness of the annotation;
- The user answers are used to determine the informative value of each sample and prepare the corrected samples;
- Random subset of user verified and annotated images are added to the training set and removed from the global set;
- The network is trained using the training set obtained in the previous step.
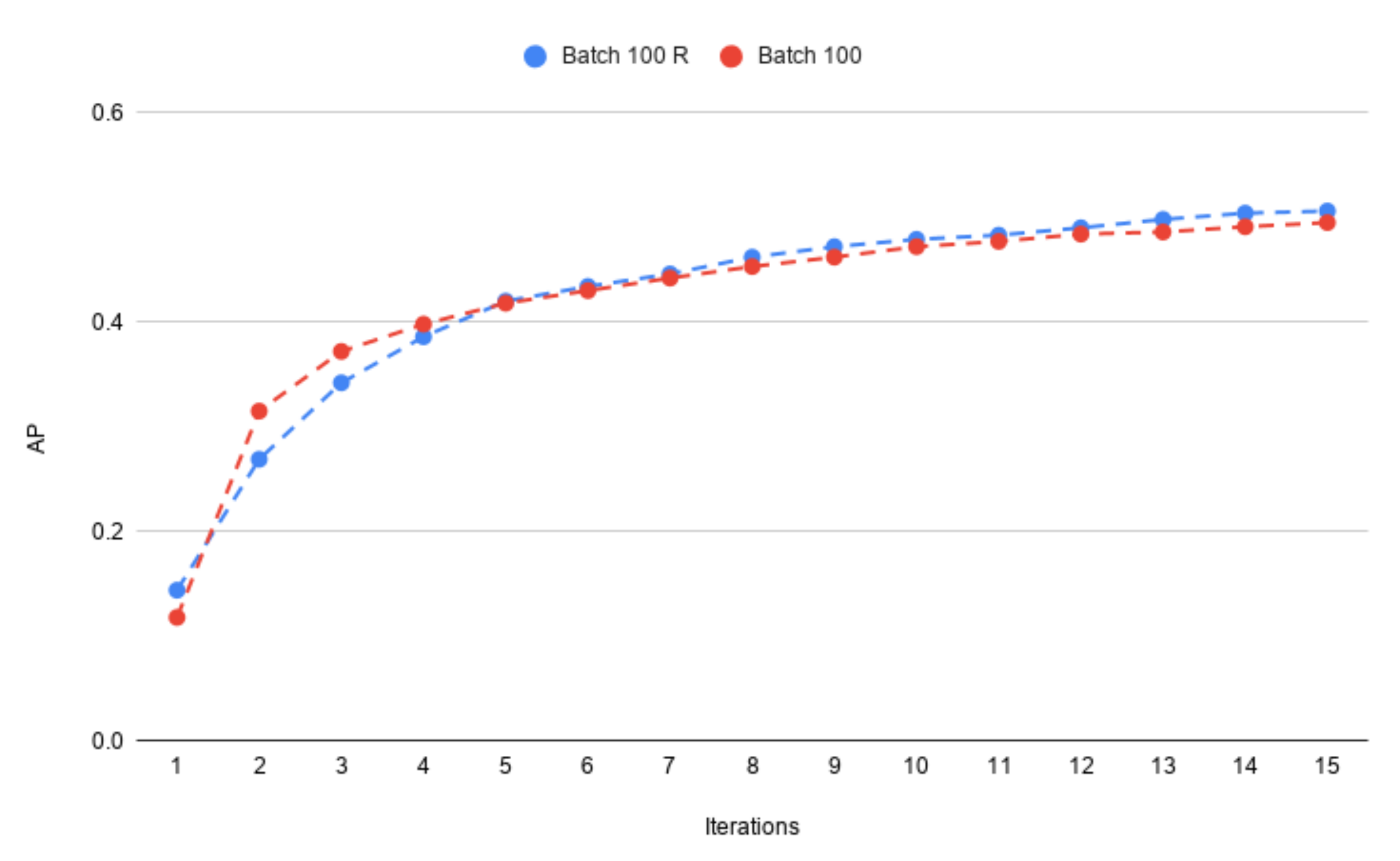
3.3. Active Learning Variant
3.4. The Knowledge of the Crowd—An Oracle
- Simple Yes/No question allowing the user to verify whether the picture contains a bee or not;
- Question about how many bees the user sees on the image and thus allowing verification with the number of objects detected by the network;
- More complex tasks allowing marking of the bees on the images never before seen by the network.
4. The Proposed Model Improvement Process
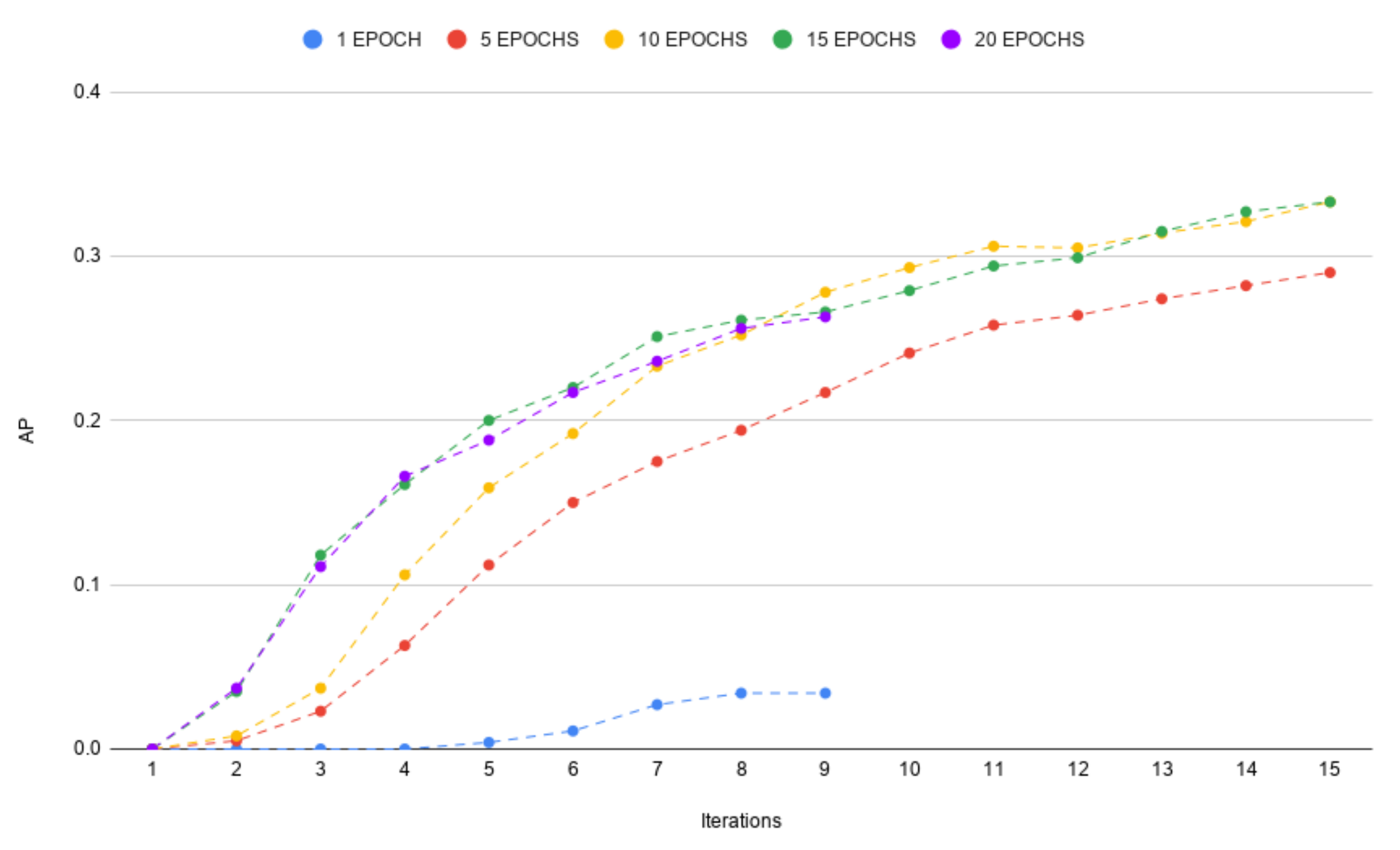
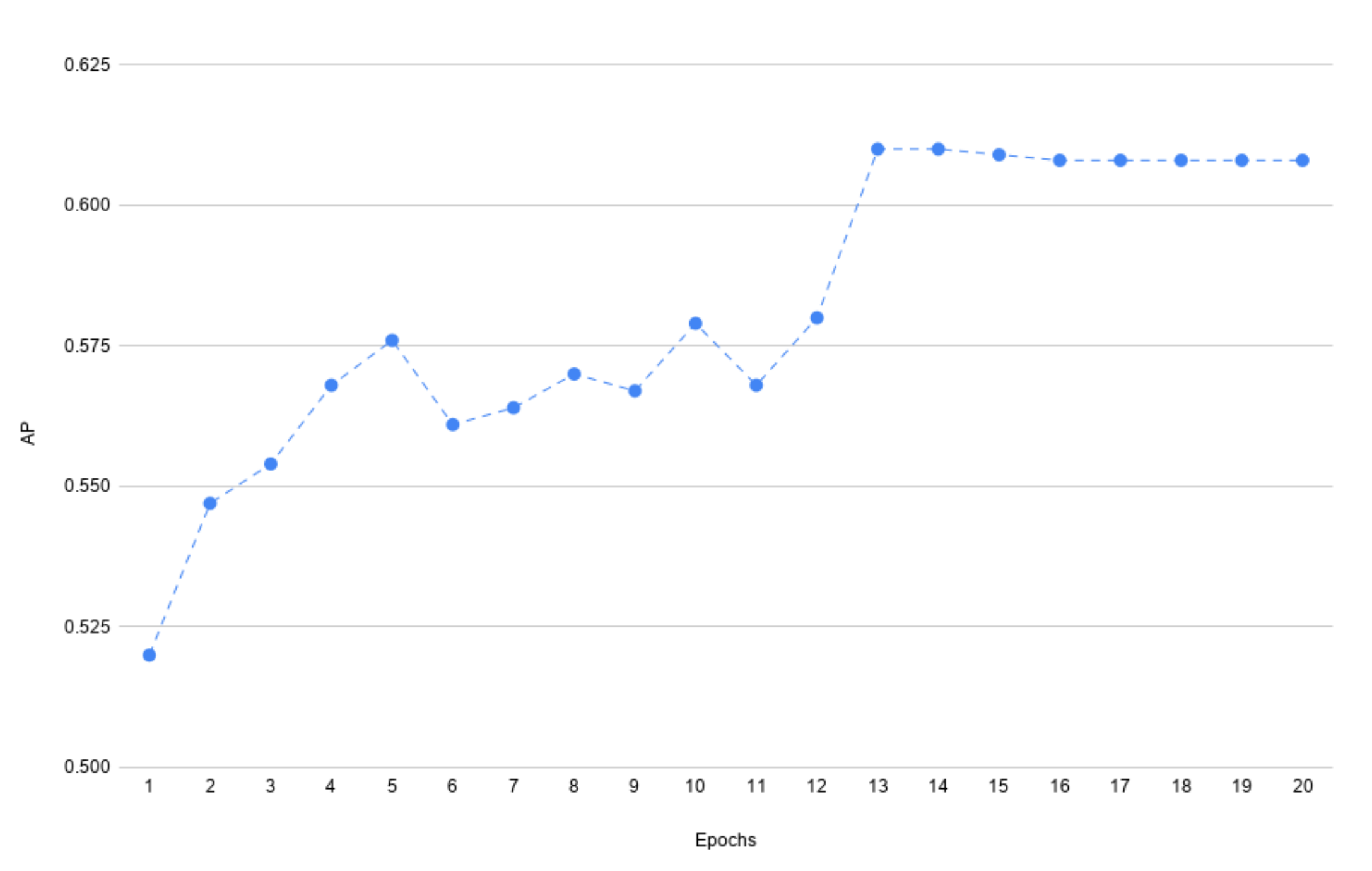
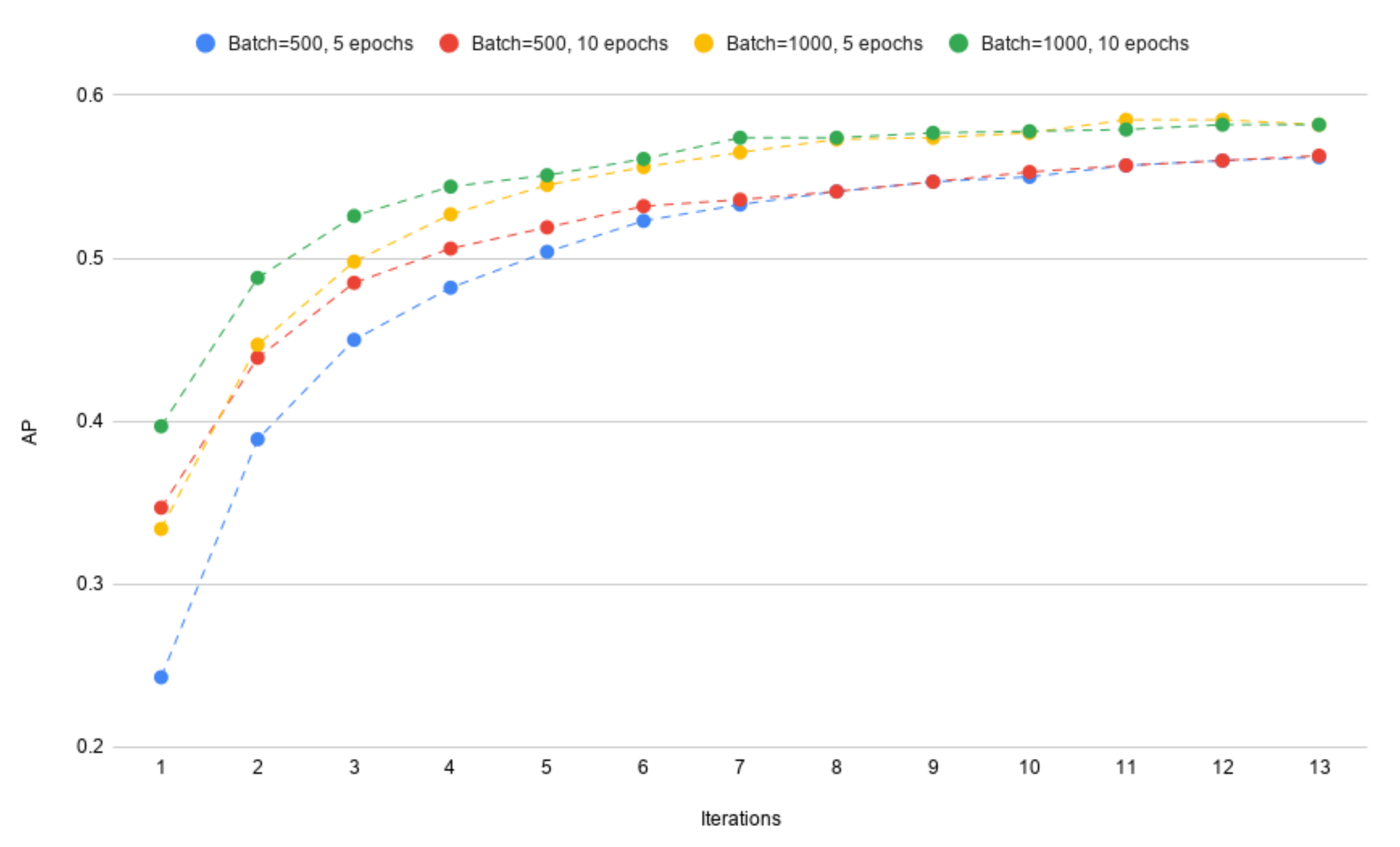
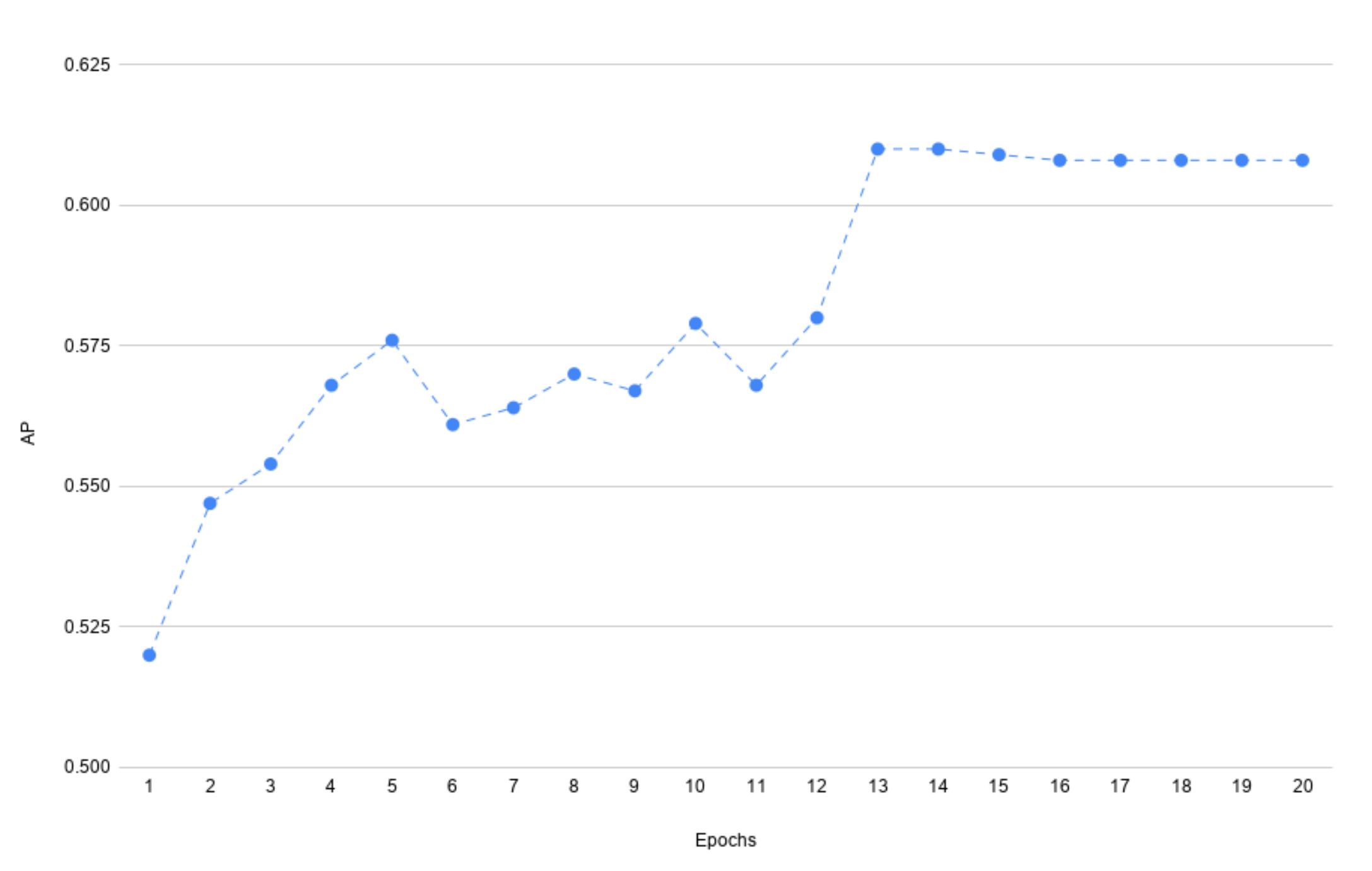
4.1. Number of Epochs in Each Iterations
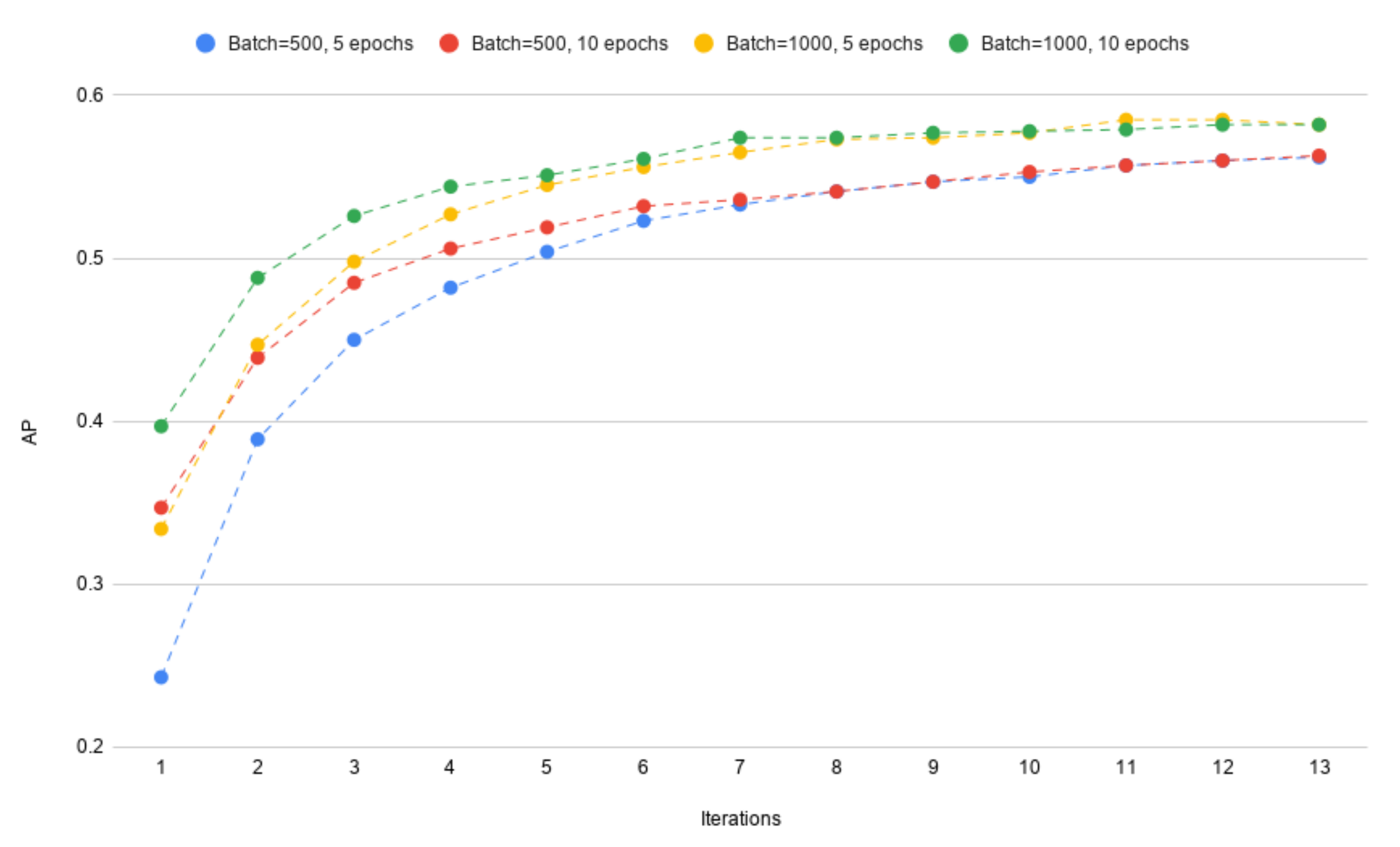
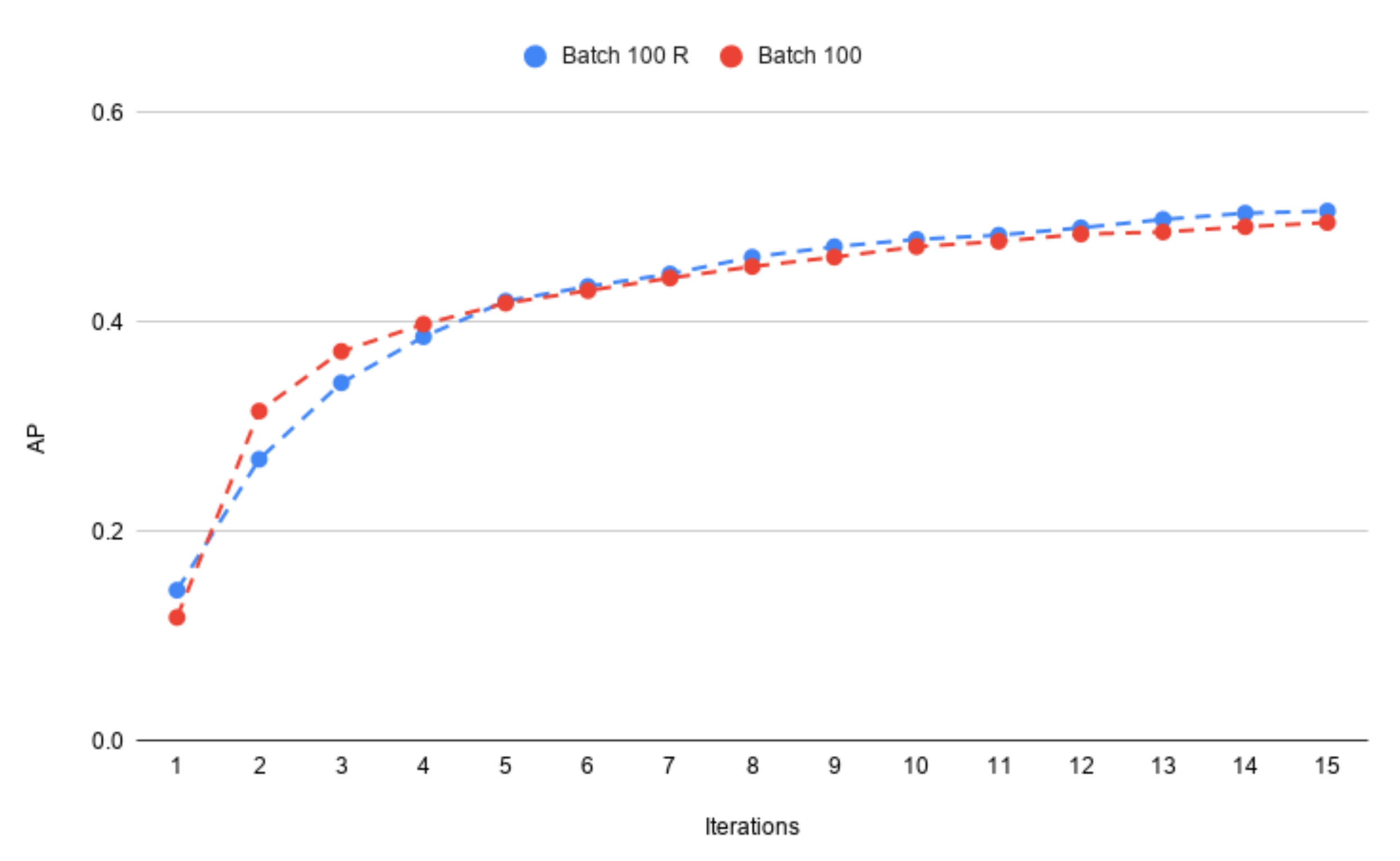
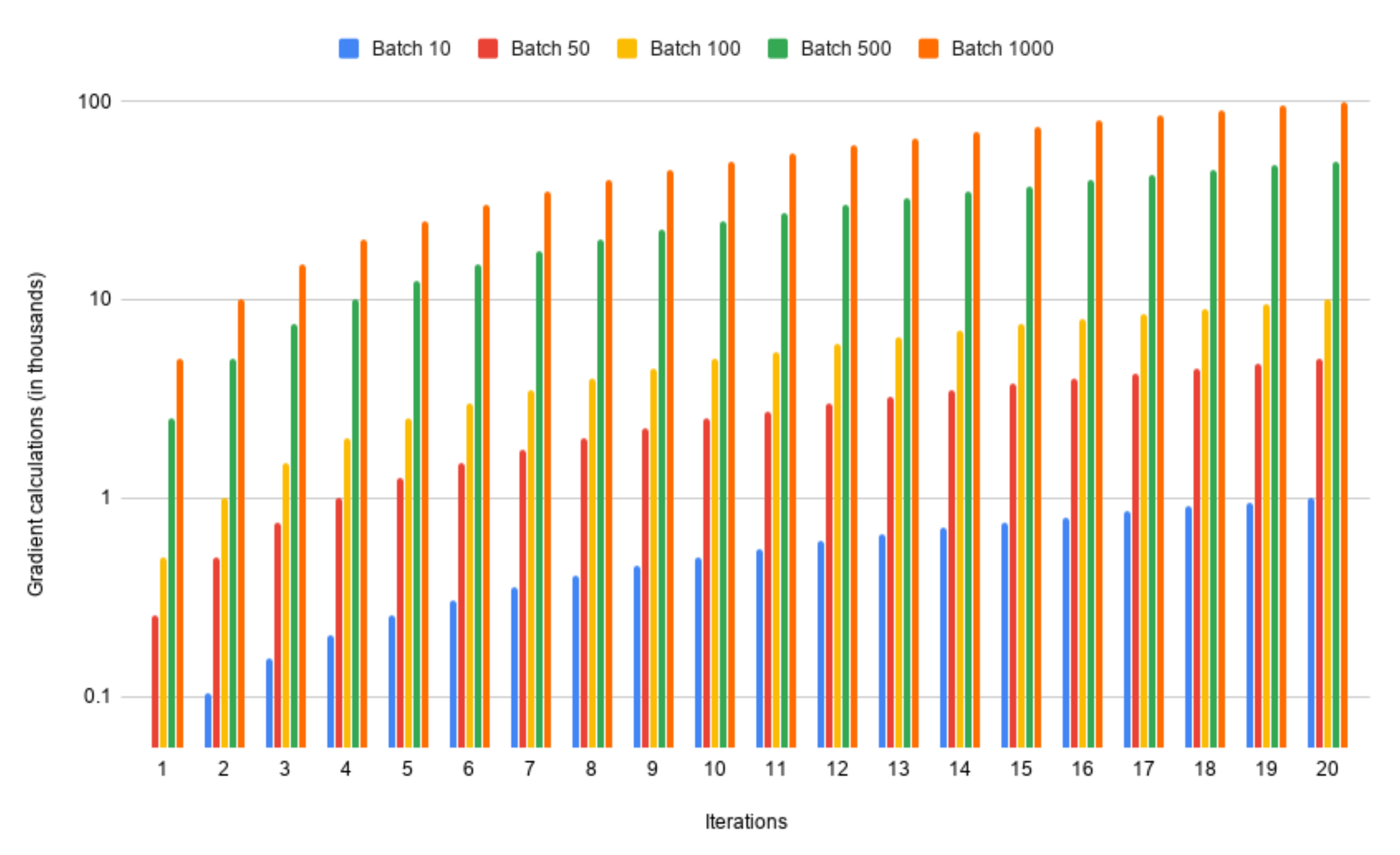
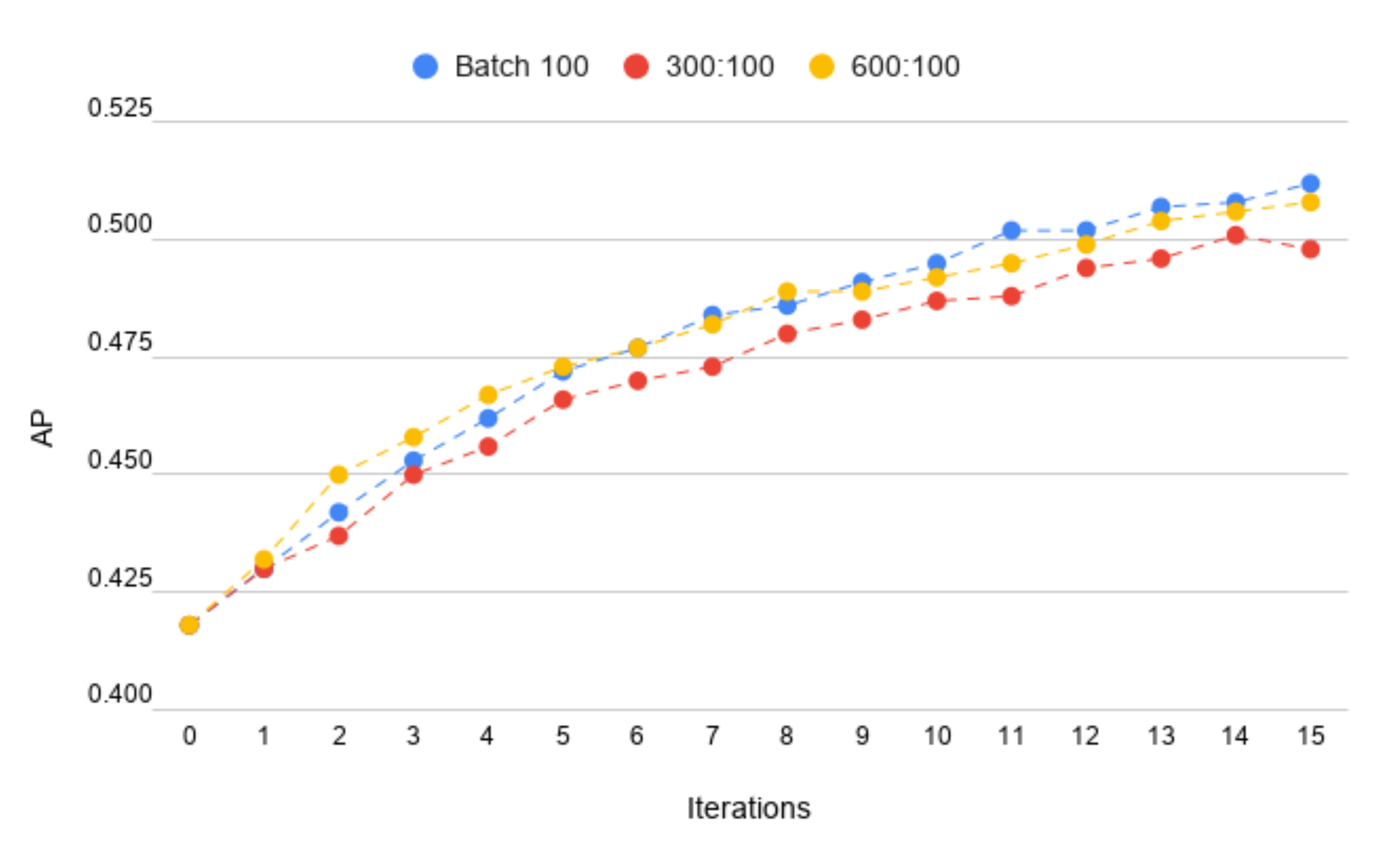
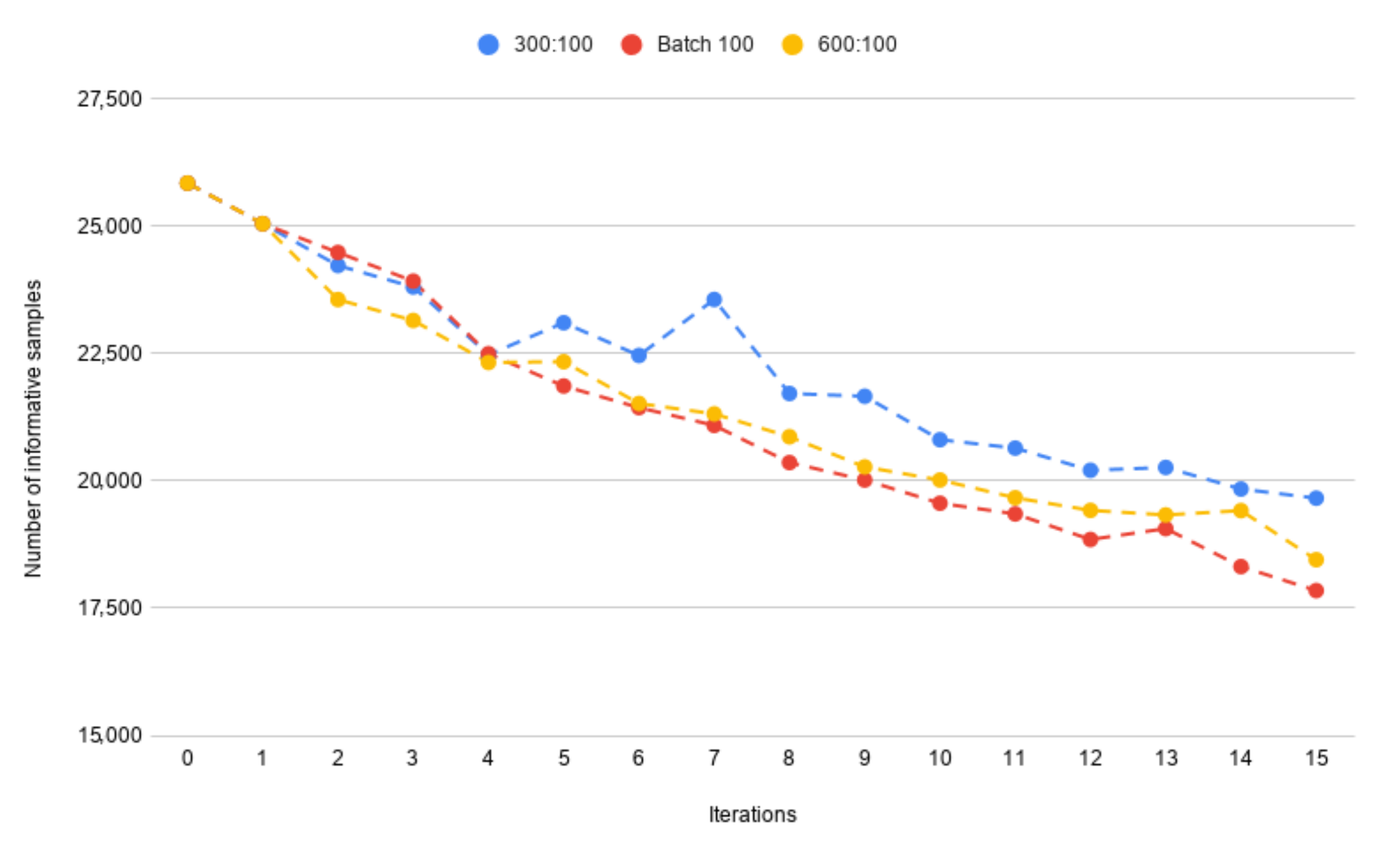
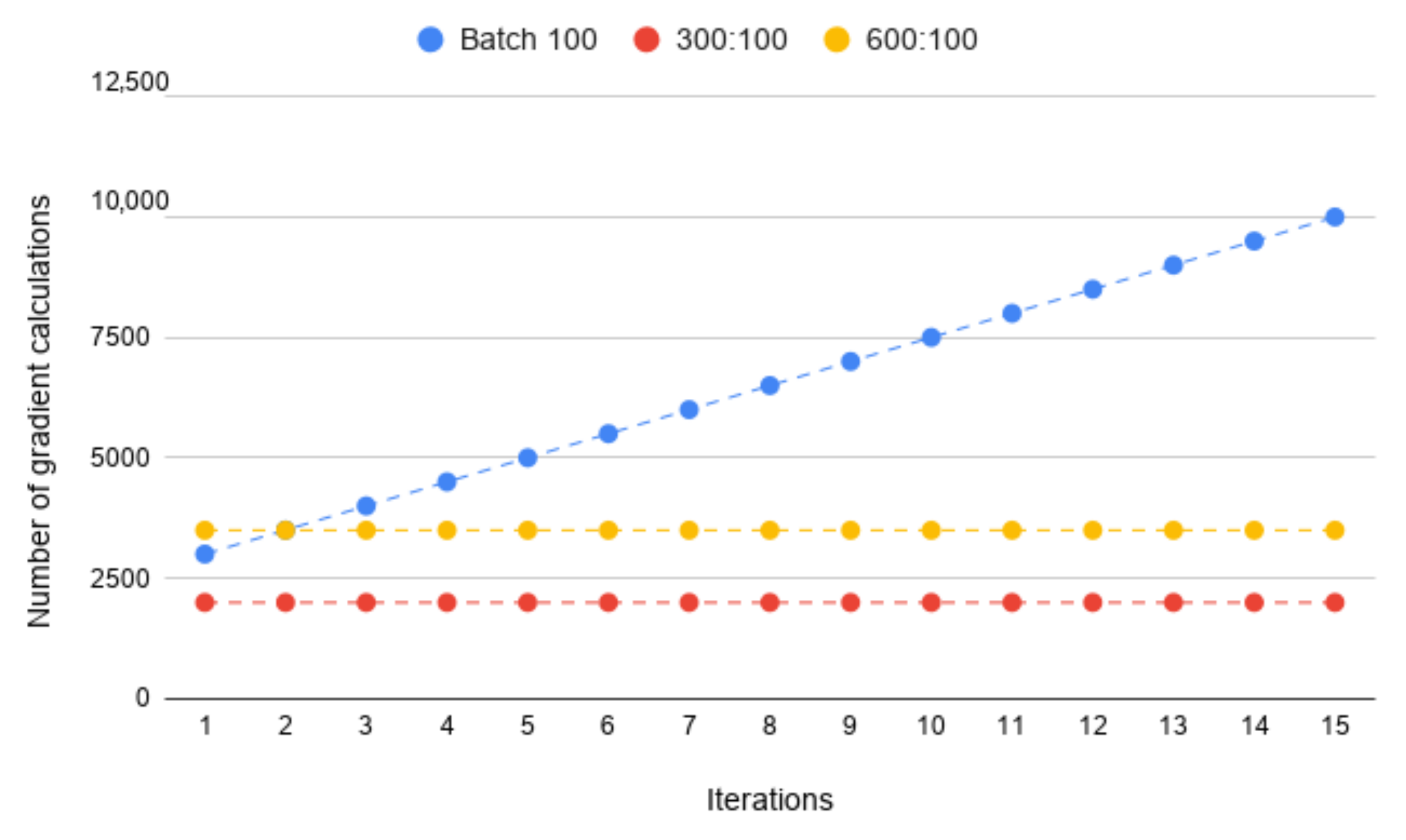
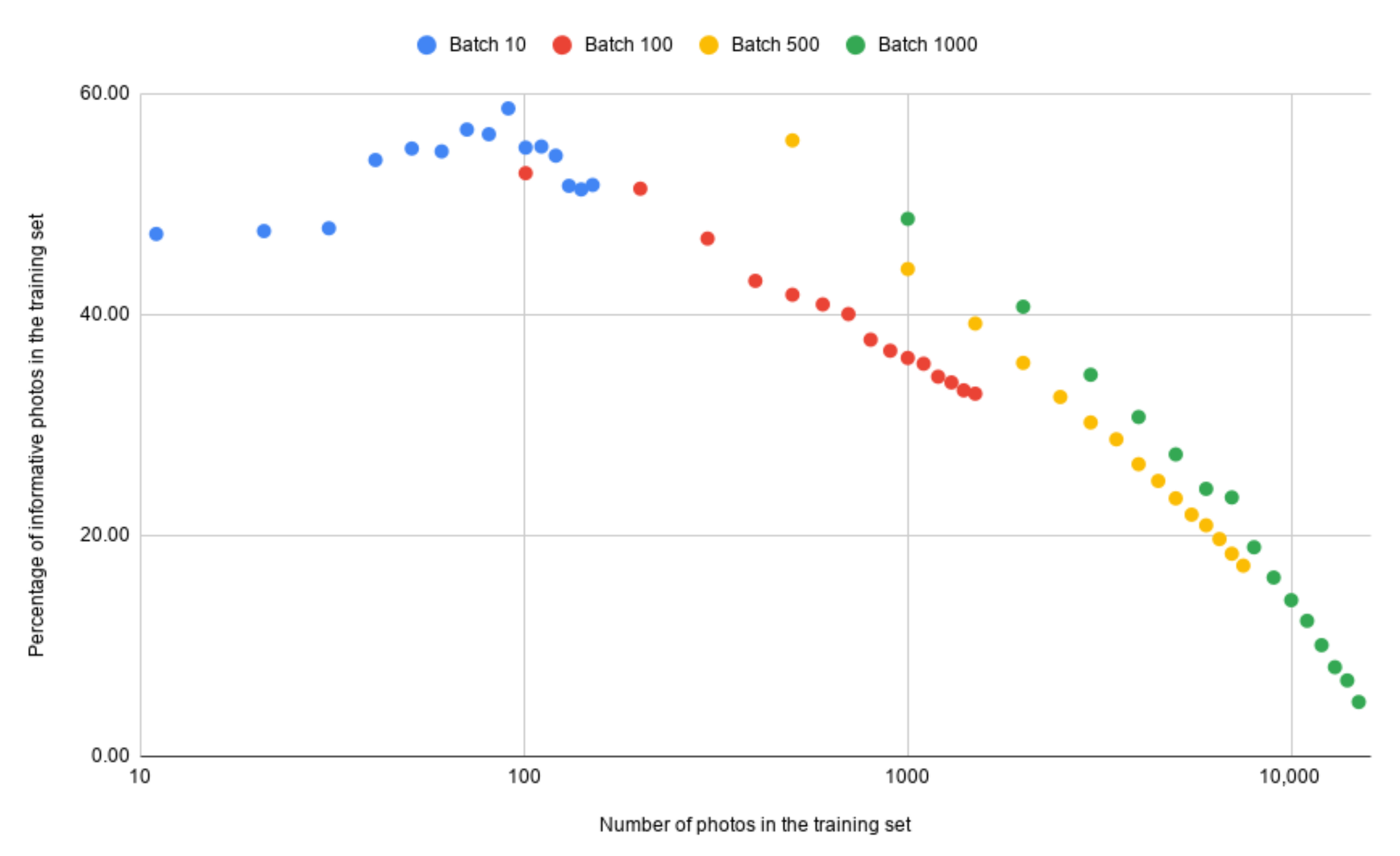
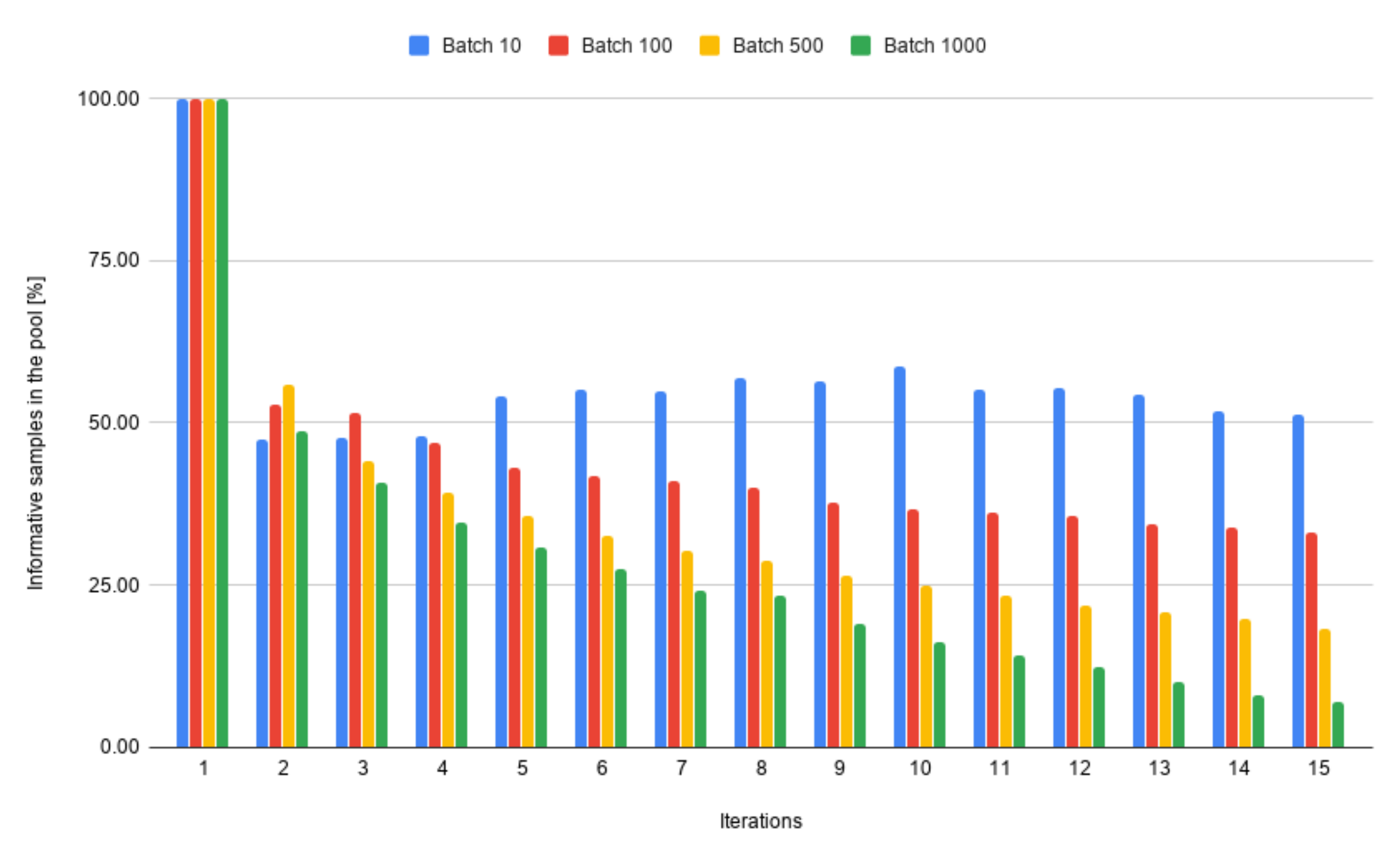
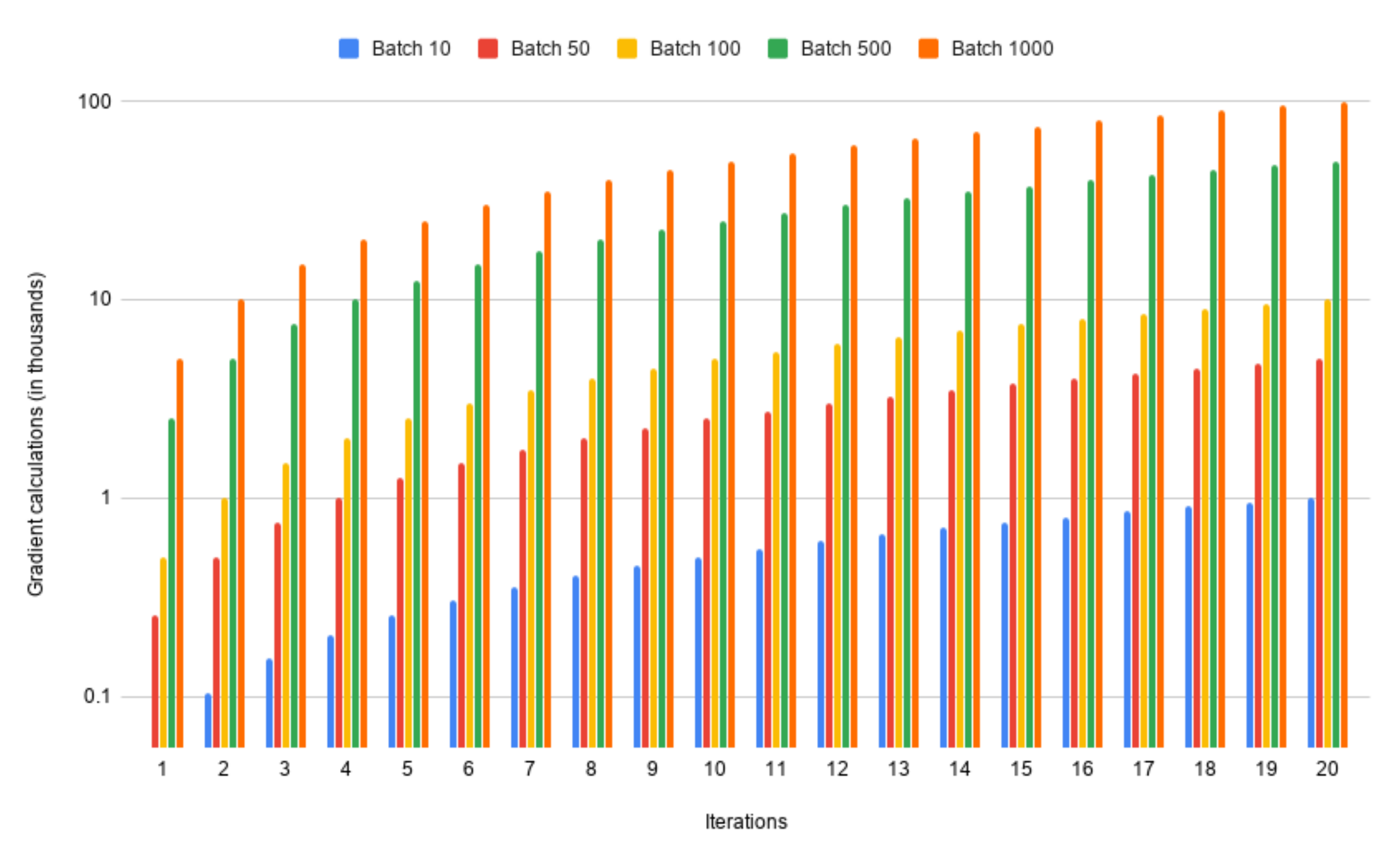
4.2. The Batch Size
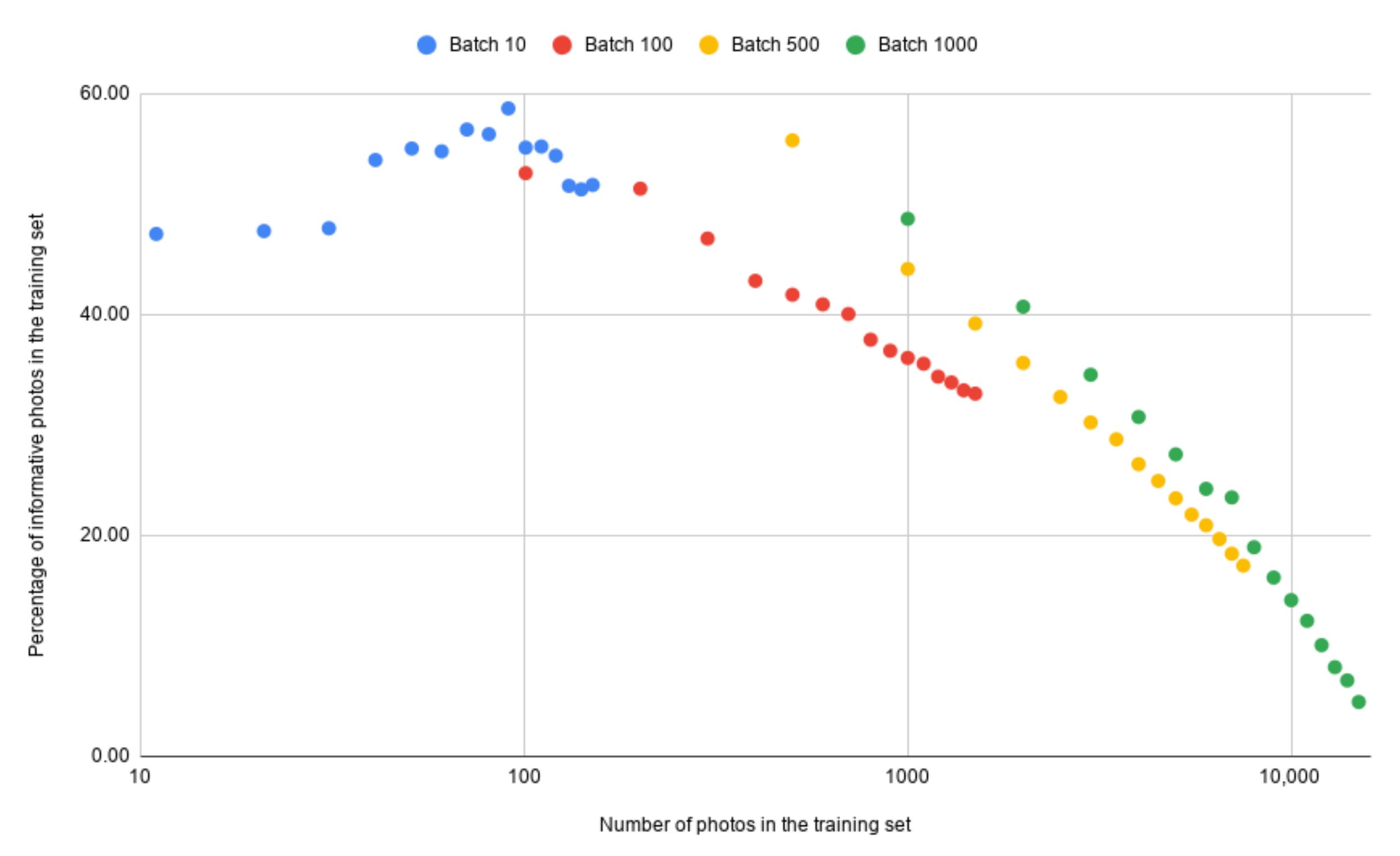
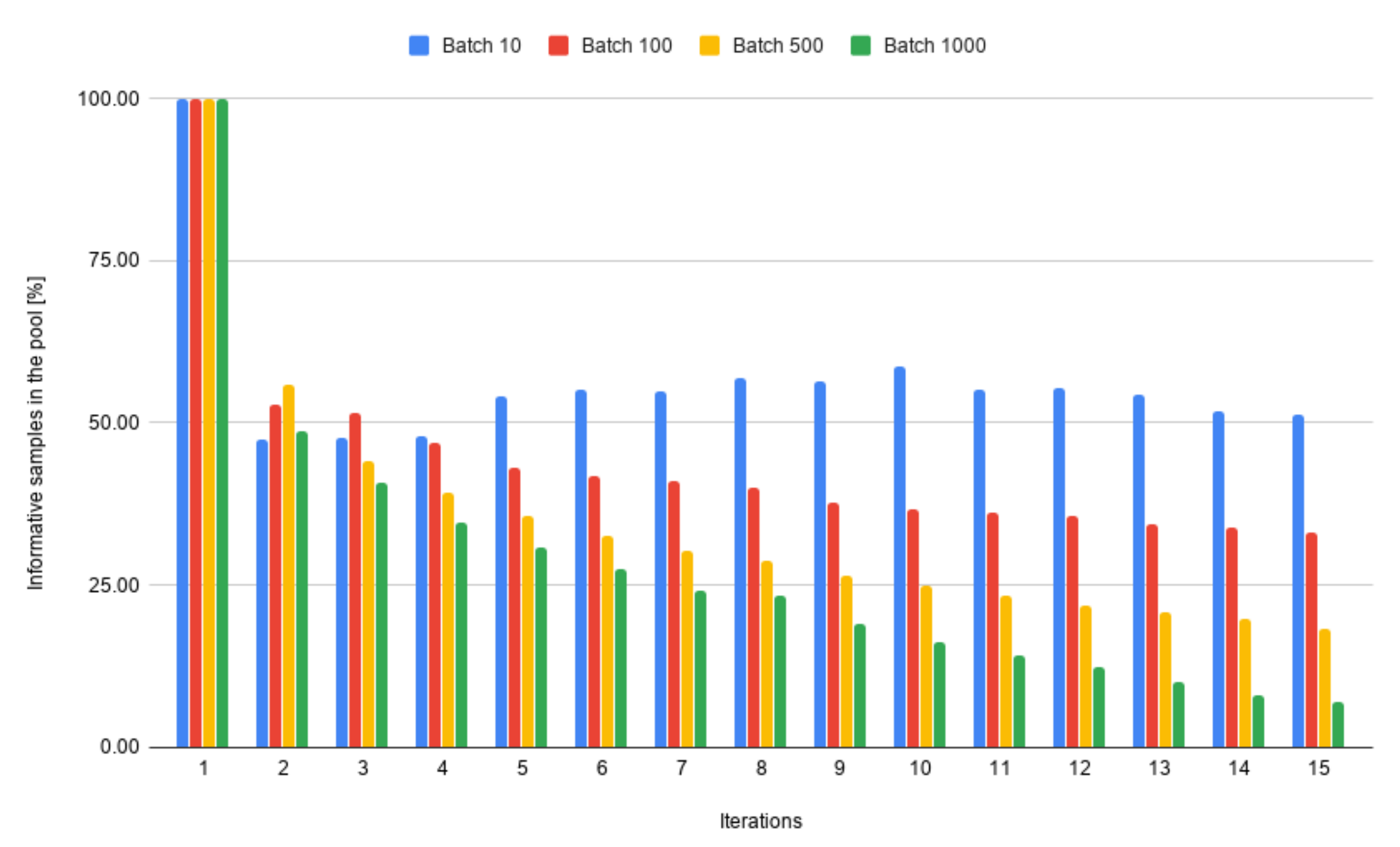
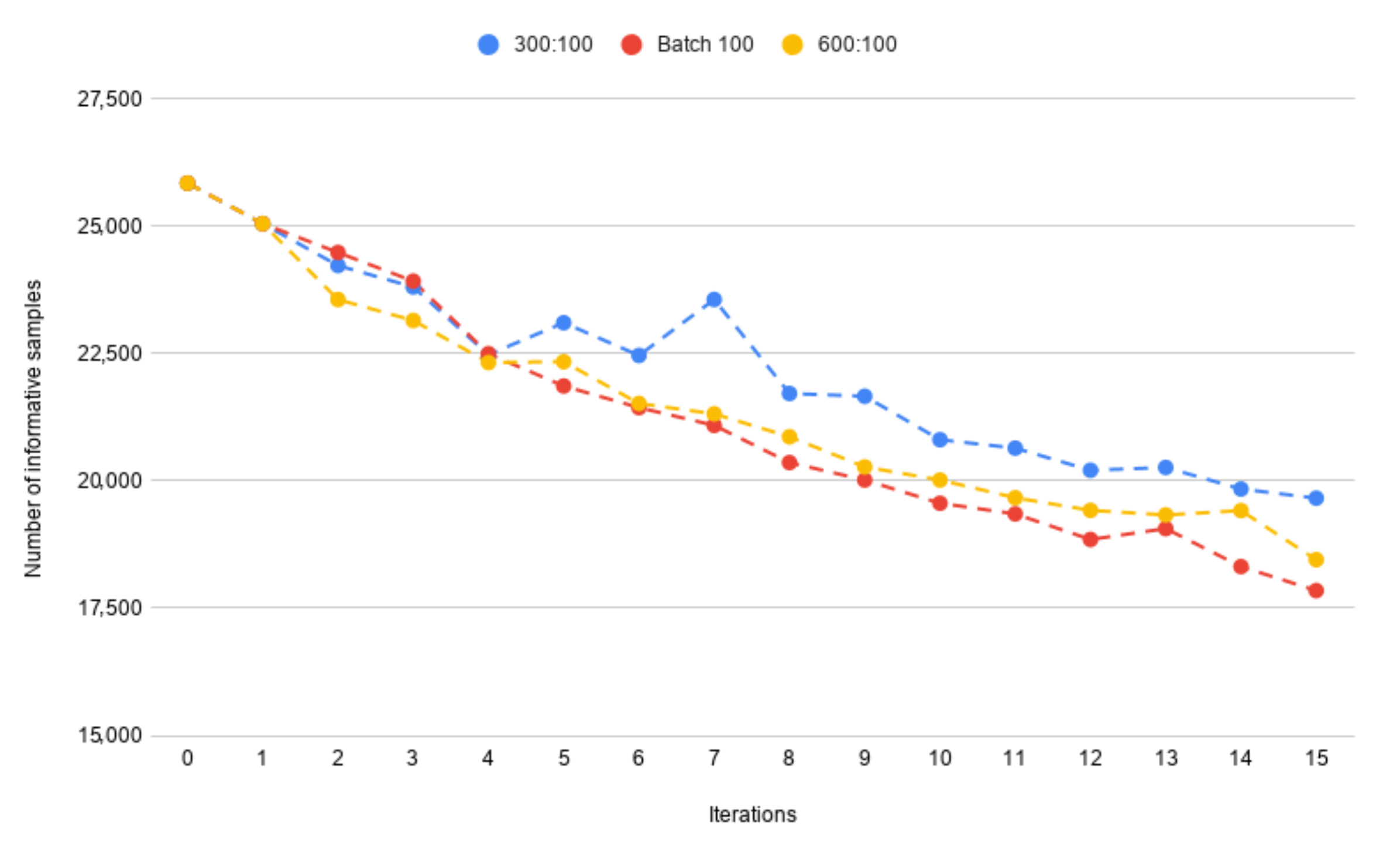
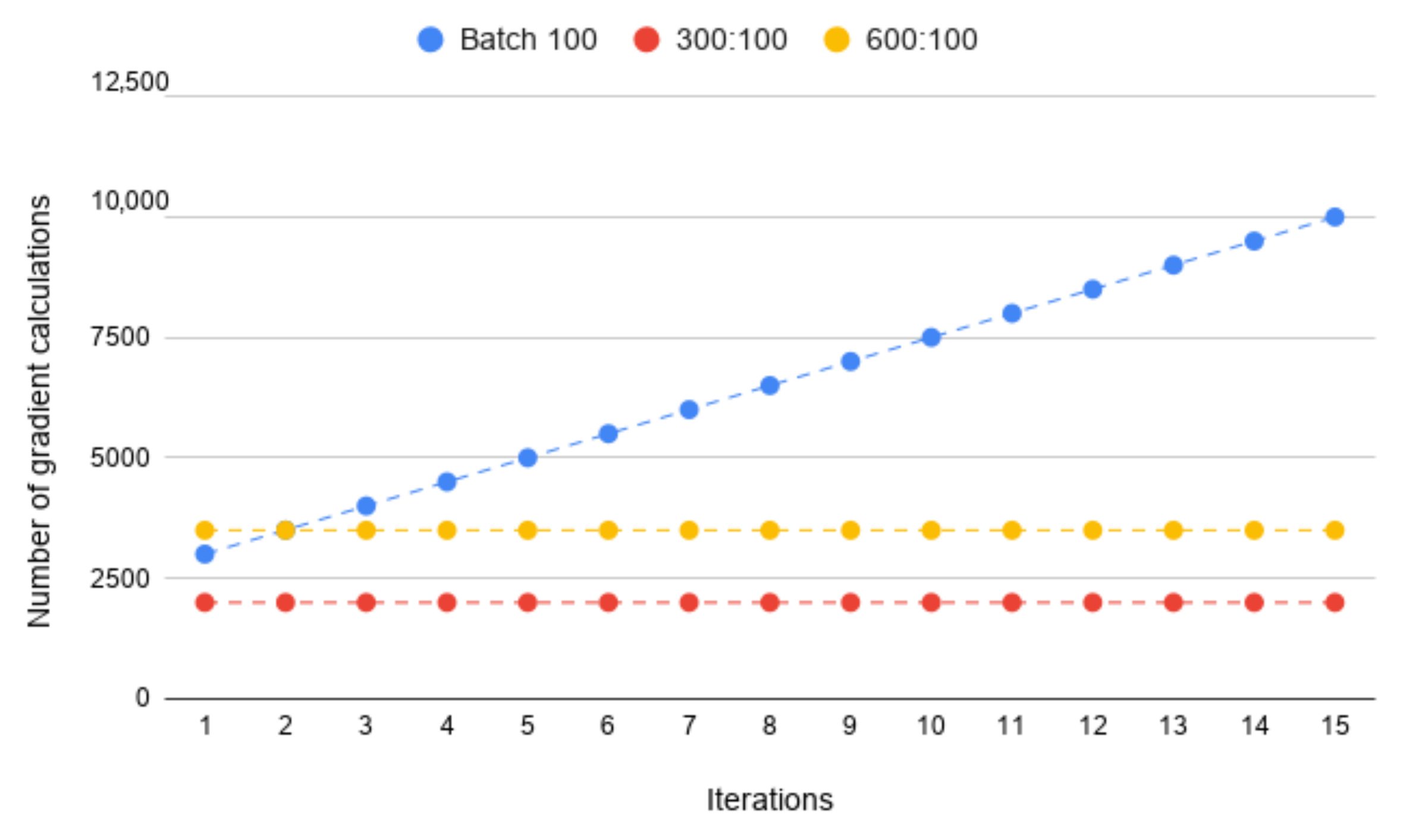
4.3. Iteration Time Optimization
4.3.1. Detection Optimization
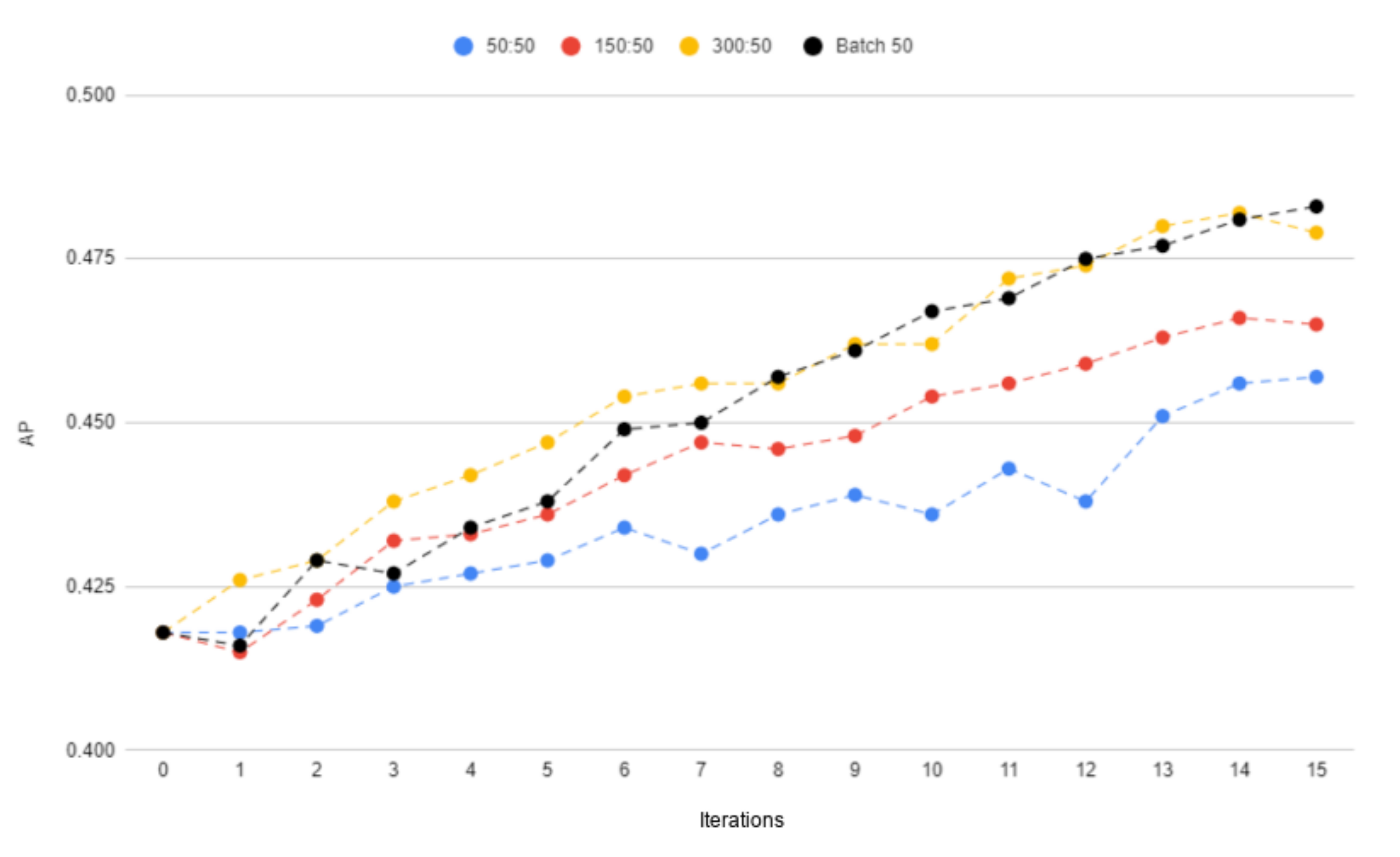
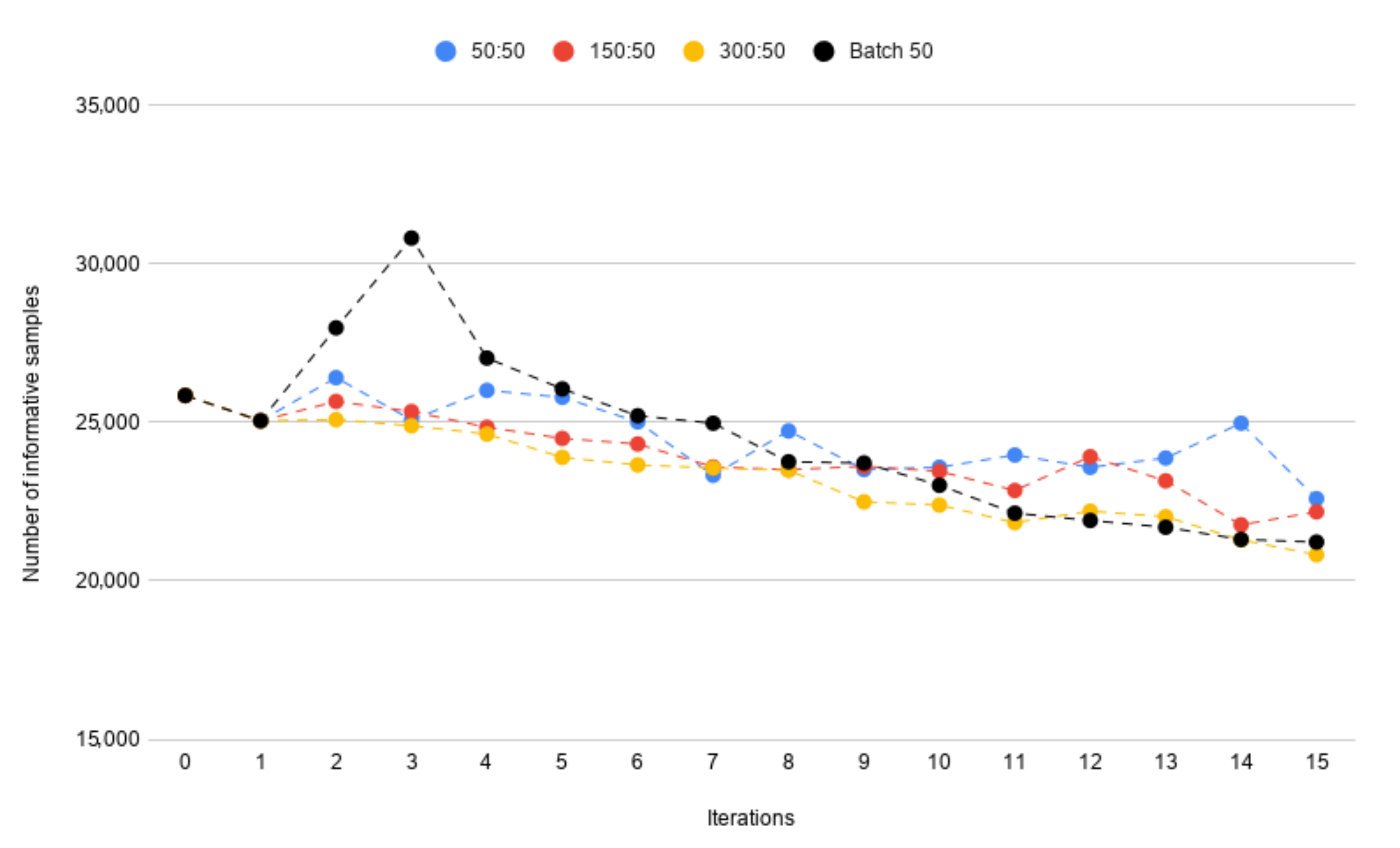
4.3.2. Training Time
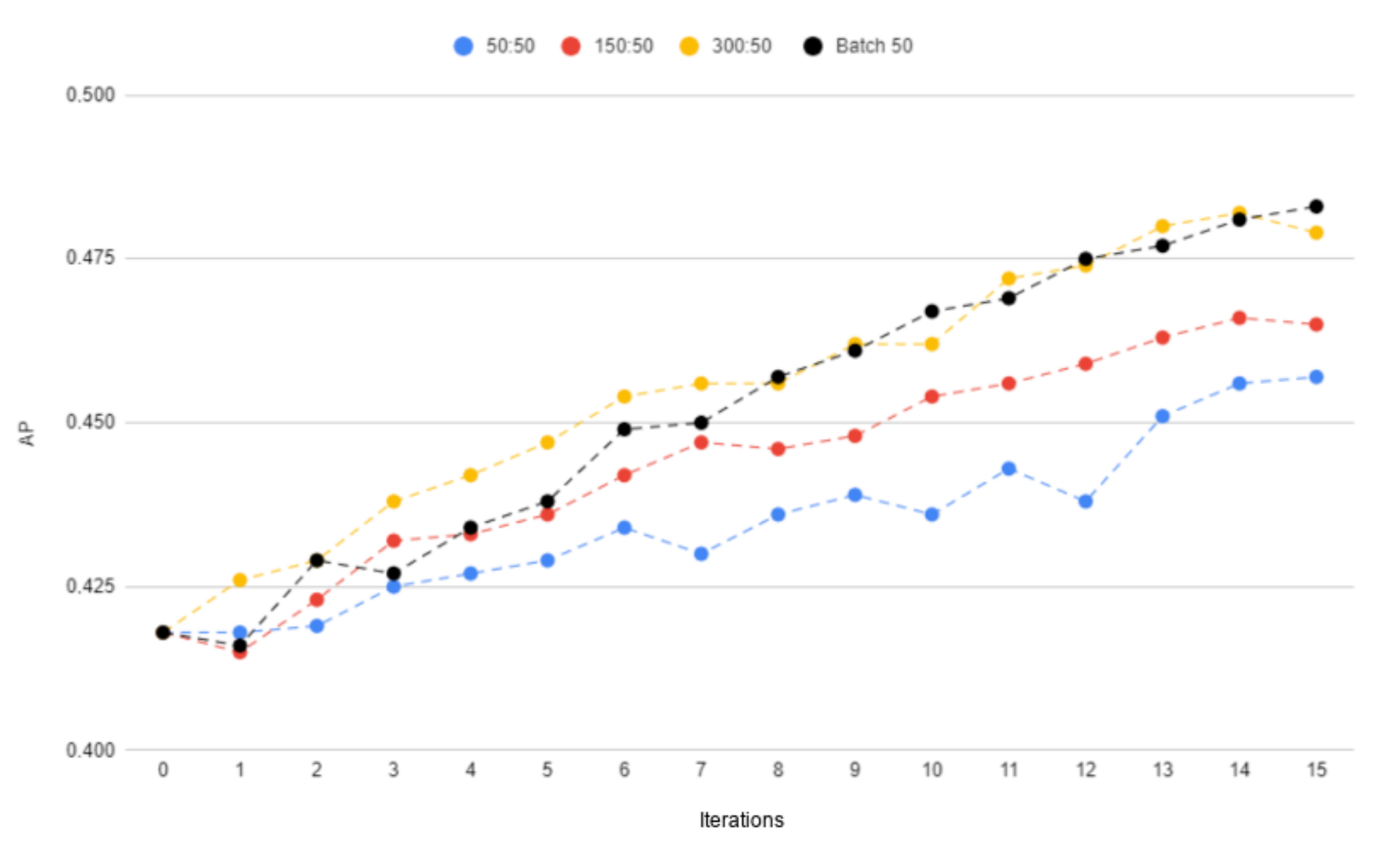
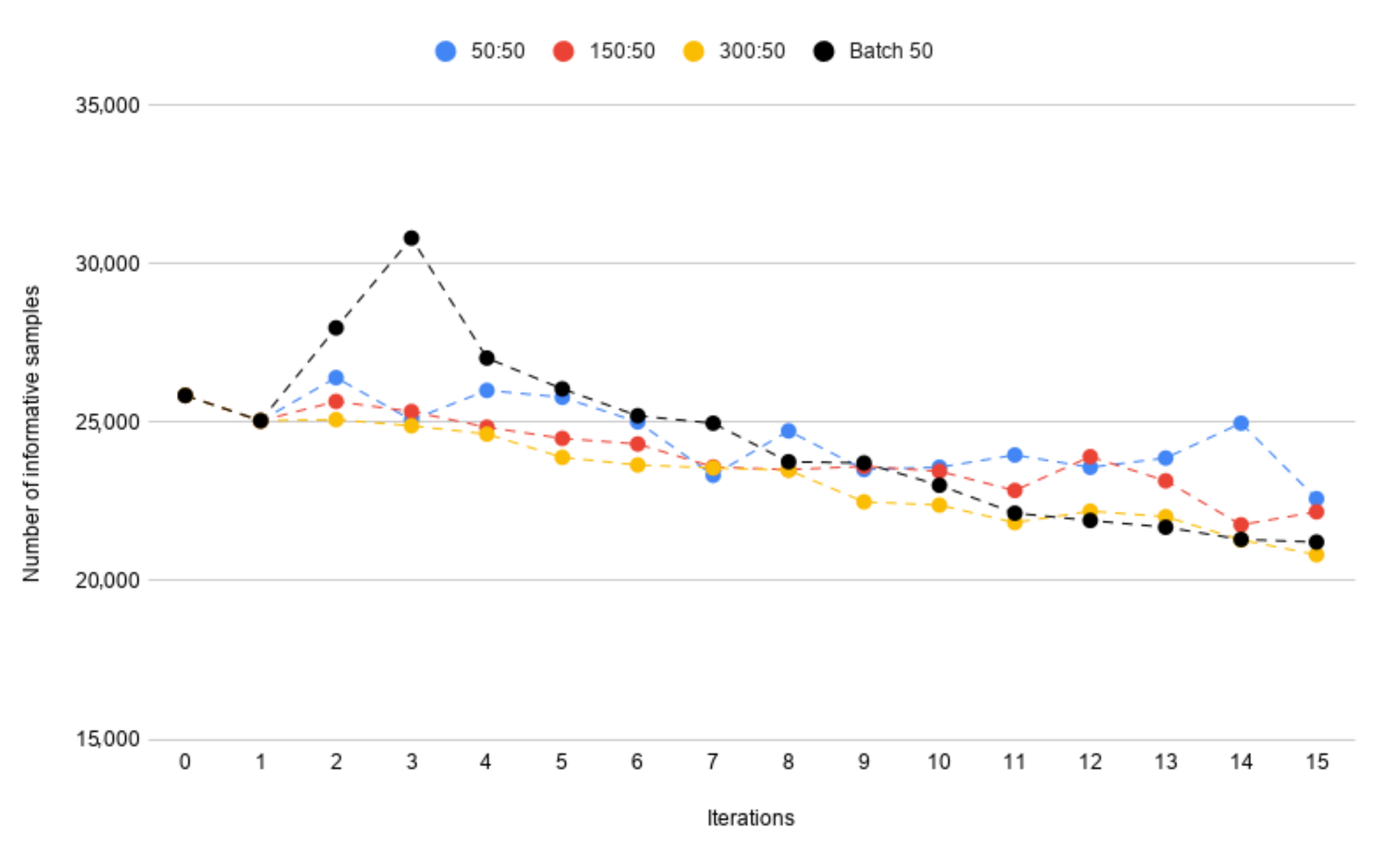
- 50:50—50 known samples and 50 new samples,
- 150:50—150 known samples and 50 new samples,
- 300:50—300 known samples and 50 new samples.
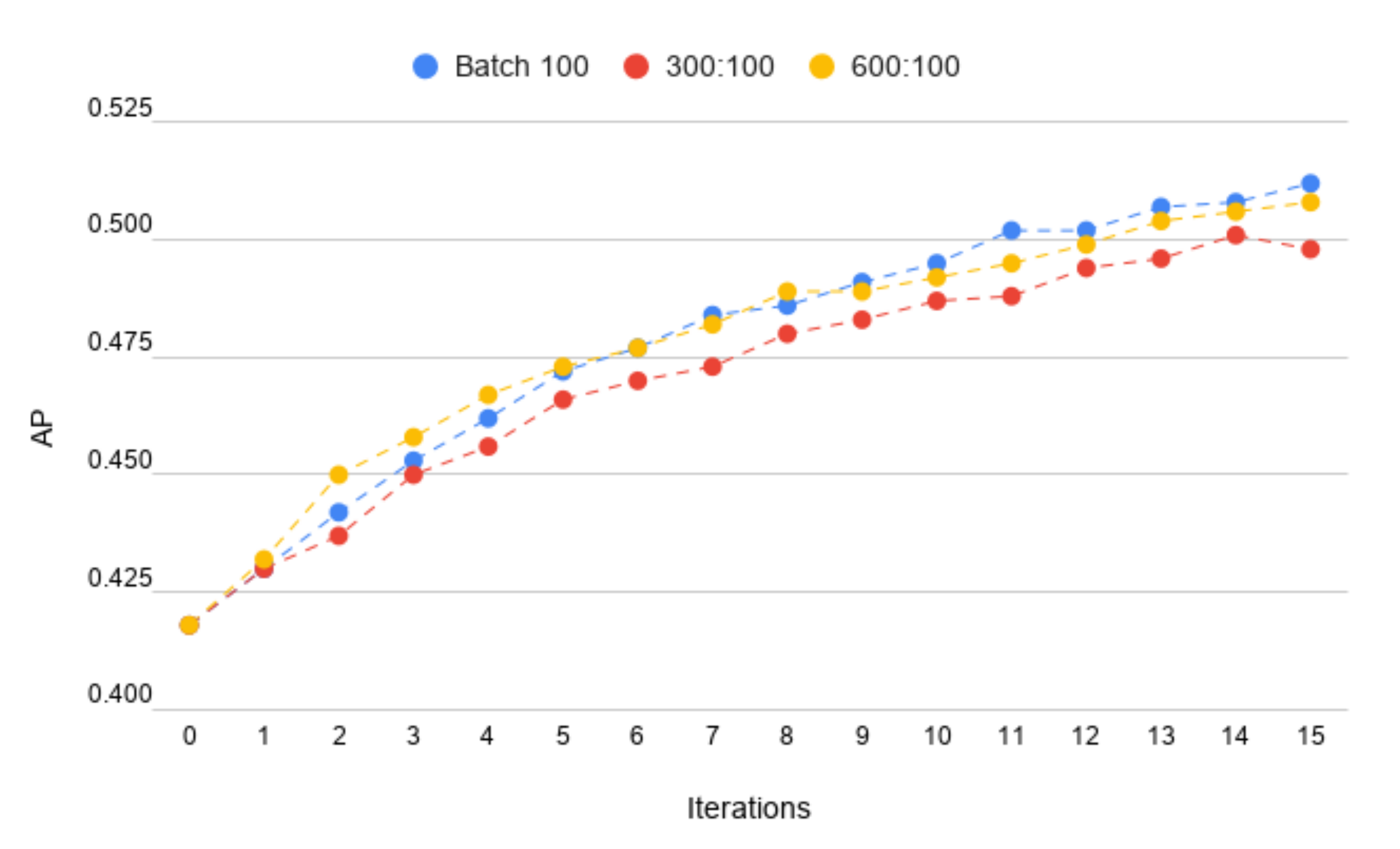
4.4. Final Model Parameters
5. Results
6. Conclusions and Future Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lanier, J. Who Owns the Future? Simon and Schuster: New York, NY, USA, 2014. [Google Scholar]
- Mey, A.; Loog, M. Improvability through semi-supervised learning: A survey of theoretical results. arXiv 2019, arXiv:1908.09574. [Google Scholar]
- Dziubich, T.; Bialas, P.; Znaniecki, L.; Halman, J.; Brzezinski, J. Abdominal Aortic Aneurysm Segmentation from Contrast-Enhanced Computed Tomography Angiography Using Deep Convolutional Networks. In Proceedings of the ADBIS, TPDL and EDA 2020 Common Workshops and Doctoral Consortium—International Workshops: DOING, MADEISD, SKG, BBIGAP, SIMPDA, AIMinScience 2020 and Doctoral Consortium, Lyon, France, 25–27 August 2020; Communications in Computer and Information, Science; Bellatreche, L., Bieliková, M., Boussaïd, O., Catania, B., Darmont, J., Demidova, E., Duchateau, F., Hall, M.M., Mercun, T., Novikov, B., et al., Eds.; Springer: Warsaw, Poland, 2020; Volume 1260, pp. 158–168. [Google Scholar] [CrossRef]
- Kellenberger, B.; Marcos, D.; Lobry, S.; Tuia, D. Half a percent of labels is enough: Efficient animal detection in UAV imagery using deep CNNs and active learning. IEEE Trans. Geosci. Remote Sens. 2019, 57, 9524–9533. [Google Scholar] [CrossRef] [Green Version]
- Settles, B. Active Learning Literature Survey; Technical report; University of Wisconsin-Madison Department of Computer Sciences: Wisconsin, WI, USA, 2009. [Google Scholar]
- Hasenjäger, M.; Ritter, H. Active learning in neural networks. In New Learning Paradigms in Soft Computing; Springer: Berlin/Heidelberg, Germany, 2002; pp. 137–169. [Google Scholar]
- Lewis, D.D.; Gale, W.A. A Sequential Algorithm for Training Text Classifiers; SIGIR’94; Springer: Berlin/Heidelberg, Germany, 1994; pp. 3–12. [Google Scholar]
- Freytag, A.; Rodner, E.; Denzler, J. Selecting Influential Examples: Active Learning with Expected Model Output Changes; European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2014; pp. 562–577. [Google Scholar]
- Roy, N.; McCallum, A. Toward Optimal Active Learning through Monte Carlo Estimation of Error Reduction; ICML: Williamstown, Australia, 2001; pp. 441–448. [Google Scholar]
- Sener, O.; Savarese, S. Active learning for convolutional neural networks: A core-set approach. arXiv 2017, arXiv:1708.00489. [Google Scholar]
- Makili, L.E.; Sánchez, J.A.V.; Dormido-Canto, S. Active learning using conformal predictors: Application to image classification. Fusion Sci. Technol. 2012, 62, 347–355. [Google Scholar] [CrossRef]
- Konyushkova, K.; Sznitman, R.; Fua, P. Learning Active Learning from Real and Synthetic Data. arXiv 2017, arXiv:1703.03365. [Google Scholar]
- Desreumaux, L.; Lemaire, V. Learning active learning at the crossroads? evaluation and discussion. arXiv 2020, arXiv:2012.09631. [Google Scholar]
- Konyushkova, K.; Sznitman, R.; Fua, P. Discovering General-Purpose Active Learning Strategies. arXiv 2018, arXiv:1810.04114. [Google Scholar]
- Von Ahn, L. Games with a purpose. Computer 2006, 39, 92–94. [Google Scholar] [CrossRef]
- Von Ahn, L.; Maurer, B.; McMillen, C.; Abraham, D.; Blum, M. Recaptcha: Human-based character recognition via web security measures. Science 2008, 321, 1465–1468. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Curtis, V. Motivation to participate in an online citizen science game: A study of Foldit. Sci. Commun. 2015, 37, 723–746. [Google Scholar] [CrossRef]
- Boiński, T.; Szymański, J. Collaborative Data Acquisition and Learning Support. In International Journal of Computer Information Systems and Industrial Management Applications; Springer: Cham, Switzerland, 2020; pp. 220–229. [Google Scholar] [CrossRef]
- Boiński, T. Game with a Purpose for mappings verification. In Proceedings of the 2016 IEEE Federated Conference on Computer Science and Information Systems (FedCSIS), Gdańsk, Poland, 11–14 September 2016; pp. 405–409. [Google Scholar]
- Szymański, J.; Boiński, T. Crowdsourcing-Based Evaluation of Automatic References Between WordNet and Wikipedia. Int. J. Softw. Eng. Knowl. Eng. 2019, 29, 317–344. [Google Scholar] [CrossRef]
- Jagoda, J.; Boiński, T. Assessing Word Difficulty for Quiz-Like Game. In Semantic Keyword-Based Search on Structured Data Sources: IKC: International KEYSTONE Conference on Semantic Keyword-Based Search on Structured Data Sources; Springer: Cham, Switzerland, 2018; Volume 10546, pp. 70–79. [Google Scholar] [CrossRef]
- Soo, S. Object Detection Using Haar-Cascade Classifier; Institute of Computer Science, University of Tartu: Tartu, Estonia, 2014; Volume 2, pp. 1–12. [Google Scholar]
- Cejrowski, T.; Szymanski, J.; Logofătu, D. Buzz-based recognition of the honeybee colony circadian rhythm. Comput. Electron. Agric. 2020, 175, 105586. [Google Scholar] [CrossRef]
- Boiński, T.; Szymański, J. Video Recordings of Bees at Entrance to Hives. 2019. Available online: https://mostwiedzy.pl/en/open-research-data/video-recordings-of-bees-at-entrance-to-hives,10291020481048462-0 (accessed on 10 July 2020).
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Goldman, E.; Herzig, R.; Eisenschtat, A.; Goldberger, J.; Hassner, T. Precise detection in densely packed scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5227–5236. [Google Scholar]
- Facebook AI Research. Detectron. 2020. Available online: https://github.com/facebookresearch/detectron (accessed on 15 July 2020).
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Deng, J.; Russakovsky, O.; Krause, J.; Bernstein, M.; Berg, A.C.; Li, F.F. Scalable Multi-Label Annotation. In Proceedings of the ACM Conference on Human Factors in Computing Systems (CHI), Toronto, ON, Canada, 26 April–1 May 2014. [Google Scholar]
- Käding, C.; Rodner, E.; Freytag, A.; Denzler, J. Fine-Tuning Deep Neural Networks in Continuous Learning Scenarios; Asian Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 588–605. [Google Scholar]
- Brust, C.A.; Käding, C.; Denzler, J. Active learning for deep object detection. arXiv 2018, arXiv:1809.09875. [Google Scholar]
- Desai, S.V.; Chandra, A.L.; Guo, W.; Ninomiya, S.; Balasubramanian, V.N. An adaptive supervision framework for active learning in object detection. arXiv 2019, arXiv:1908.02454. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Question Type | Questions | Answers | Answers per Question | Reports | Blind Shots | Blind Shots % |
|---|---|---|---|---|---|---|
| Extended mappings | 239 | 3308 | 13.84 | 625 | 16 | 0.48 |
| Yes/No | 99 | 423 | 4.27 | 10 | 12 | 2.84 |
| Total | 338 | 3731 | 11.04 | 685 | 62 | 1.34 |
| Training Set | Validation Set | Test Set | |
|---|---|---|---|
| Images | 60,422 | 17,292 | 7458 |
| Bees | 71,105 | 19,841 | 6741 |
| Approach | AP—Validation Set | AP—Test Set | No of Photos |
|---|---|---|---|
| Conventional | 0.61 | 0.457 | 60,422 |
| Active Learning | 0.572 | 0.425 | 8266 |
| Active Learning/Conventional (%) | 93.8 | 93.0 | 13.7 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Boiński, T.M.; Szymański, J.; Krauzewicz, A. Active Learning Based on Crowdsourced Data. Appl. Sci. 2022, 12, 409. https://doi.org/10.3390/app12010409
Boiński TM, Szymański J, Krauzewicz A. Active Learning Based on Crowdsourced Data. Applied Sciences. 2022; 12(1):409. https://doi.org/10.3390/app12010409
Chicago/Turabian StyleBoiński, Tomasz Maria, Julian Szymański, and Agata Krauzewicz. 2022. "Active Learning Based on Crowdsourced Data" Applied Sciences 12, no. 1: 409. https://doi.org/10.3390/app12010409
APA StyleBoiński, T. M., Szymański, J., & Krauzewicz, A. (2022). Active Learning Based on Crowdsourced Data. Applied Sciences, 12(1), 409. https://doi.org/10.3390/app12010409