
Review of Visual Saliency Prediction: Development Process from Neurobiological Basis to Deep Models


Abstract
:1. Introduction
- This research focused on the task of saliency prediction, analyzed the psychological and physiological mechanisms related to saliency prediction, introduced the classic models that have been affected by saliency prediction, and determined the impact of these theories on deep learning models.
- The visual saliency model based on deep learning was analyzed in detail, and the performance evaluation measures of the representative experimental datasets and the model under static and dynamic conditions were discussed and summarized, respectively.
- The limitations of the current deep learning model were analyzed, the possible directions for improvement were proposed, new application areas based on the latest progress of deep learning were discussed, and the contribution and significance of saliency prediction with respect to future development trends were presented.
2. Psychological and Neurobiological Basis of Visual Saliency
3. Classic Visual Saliency Models
3.1. Bottom-Up Visual Saliency Models
3.2. Top-Down Visual Saliency Models
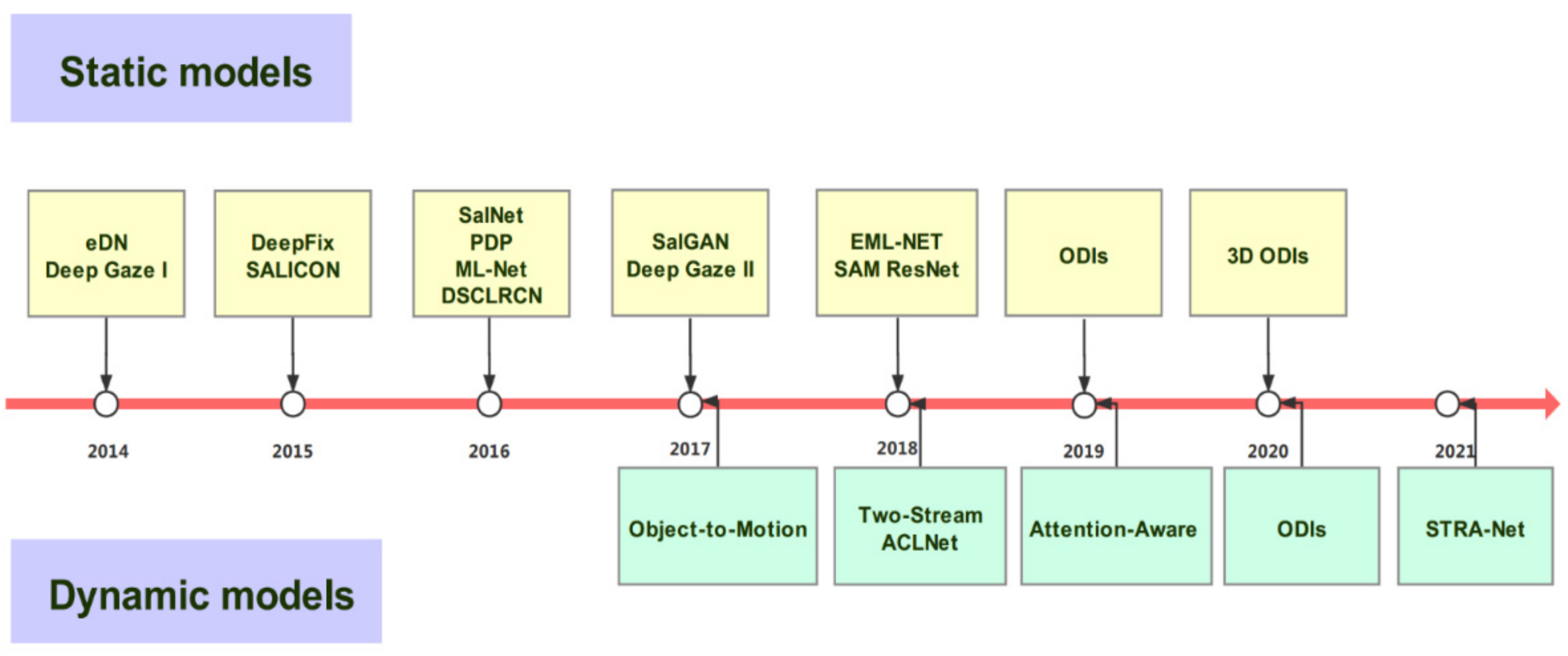
4. Deep Visual Saliency Models
4.1. Static Models
4.2. Dynamic Models
5. Visual Saliency Prediction Datasets
5.1. Static Datasets
- TORONTO dataset: In 2006, Bruce et al. [41] established the TORONTO dataset. It is one of the earliest and most widely used datasets of computer vision. It includes 120 color images with a resolution of 511 × 681. The images contain indoor and outdoor scenes and a total of 20 recorded observers’ eye movement data.
- MIT300 dataset: In 2012, Judd et al. [70] of MIT established the MIT300 dataset. It contains 300 natural images from Flickr’s creation and sharing and the eye movement data of 39 observers. At that time, the MIT300 dataset was the most influential and most widely used in the dataset saliency field. The dataset is generally not used as a training set. However, the model comprising the MIT300 dataset can be evaluated.
- MIT1003 dataset: The MIT1003 dataset was also established by Judd et al. [61]. It contains a total of 1003 images from Flickr’s collection of images and the LabelMe website and the eye movement data of 15 observers. The MIT1003 dataset can be regarded as a supplement to the MIT300 dataset. The MIT1003 and MIT300 datasets can be used as a training set and a test set for performance evaluation, respectively.
- DUT-OMRON dataset: In 2013, Yang et al. [95] established the DUT-OMRON dataset. It contains 5168 images, and each image provides eye movement data of 5 observers. This dataset is annotated with eye movement data, but it mainly focuses on salient object detection, with one or more salient objects and a relatively complex background.
- CAT2000 dataset: The CAT2000 dataset was established by Borji et al. [96]. It contains 2000 images under free observation by 24 observers. Twenty scenes are categorized as cartoon, art, indoor, and outdoor scenes. These categories contain bottom-up attention cues and top-down factors. The different types of images are suitable for a variety of attention behavior studies.
- SALICON dataset: In 2015, Ming et al. [69] established the SALICON dataset. This large mouse tracking dataset for contextual saliency was established by selecting 20,000 images in MS-COCO. It is currently the largest attention dataset in terms of scale and context variability. The difference from the abovementioned databases is that the SALICON dataset does not use an eye tracker to record eye movement data but rather uses the Amazon Mechanical Turk platform; however, the eye movement data recorded by the mouse was used to evaluate the performance of the model. Tavakoli et al. [97] emphasized that problems may arise in evaluating model performance when eye movement data are recorded by the mouse. Nonetheless, the SALICON dataset is the largest dataset in the current field, and it continues to be widely used by current mainstream saliency prediction models based on deep learning technology. The SALICON dataset offers eye movement data for the training set (10,000 pictures) and validation set (5000 pictures), and it can retain the eye movement data of the test set (5000 pictures).
- EMOd dataset: The EMOd dataset is a new dataset proposed by Fan et al. [98]. It contains 1019 emotional images with target-level and image-level annotations. It was designed for studying visual saliency and image emotion. In the image labeling process of the EMOd dataset, the main target objects in each image are labeled with attributes, such as target contour, target name, emotional category (negative, neutral, or positive), and semantic category. The four semantic categories are as follows: the target directly related to humans, the target related to human non-visual perception, the target designed to attract attention or interact with humans, and the target with implicit signs. Each target is coded to have one or more categories. Furthermore, the EMOd dataset has a total of 4302 targets with fine contours, emotional labels, and semantic labels. The number of positive, neutral, and negative targets are 839, 2429, and 1034, respectively.
5.2. Dynamic Datasets
- DIEM dataset: The DIEM dataset was established in 2011 by Mital et al. [99]. It contains a total of 84 videos, including advertisements, movie trailers, and documentaries, among others. A total of 50 observers have provided eye movement data through free viewing. The scene content and data scale are both limited.
- UCF-sports dataset: The UCF-sports dataset was established by Mathe et al. [100]. The dataset contains 150 videos, including 9 common sports categories. Different from the DIEM dataset, the observation object in the UCF-sports dataset is prompted by time-based actions in the video during the viewing process. The result is found to be purposeful.
- Hollywood-2 dataset: The Hollywood-2 dataset was also established in 2012 by Mathe et al. [100]. The dataset contains 1770 videos that are labeled according to 12 action categories, such as eating and running, among others. Unlike the UCF-sports dataset, the observation objects of the Hollywood-2 dataset are divided into three groups: free viewing, human action annotation, and video content annotation. The human-eye focus data are in the free viewing mode only and accounts for a small proportion of all of the data.
- DHF1K dataset: The DHF1K dataset was established by Wang et al. [92] in 2018. The dataset consists of a total of 1000 video sequences watched by 17 observers and covers seven main categories and 150 scene sub-categories. The video contains 582,605 frames with a total duration of 19,420 s. The DHF1K dataset also provides calibration for movement mode and number of objects, among others, thus providing convenience for studying high-level information of the dynamic attention mechanism.
- LEDOV dataset: The LEDOV dataset [101] was established by Wang et al. in 2018. It includes daily activities, sports, social activities, art performances, and other content. A total of 538 videos, with a resolution of 720px, contain a total of 179,336 frames of video and 5,058,178 gaze locations.
6. Evaluation Measures for Visual Saliency Prediction
- AUC-Judd: Judd et al. [102] proposed a variant of the AUC called AUC-Judd. For a given threshold, the true-positive probability is the ratio of the pixels predicted as significant on all true-valued salient points, whereas the false-positive probability is the ratio of pixels predicted as significant on non-salient points.
- AUC-Borji: Borji et al. [103] proposed another variant of the AUC called AUC-Borji. This variant uses the uniform random sampling of non-focus points to calculate the false positive rate and defines the saliency mapping value above the threshold of these pixels as false positive. The false positive calculation in AUC-Borji is a discrete approximation of the calculation in AUC-Judd. Due to the use of random sampling, the same model may be evaluated with different results.
- Shuffled AUC: Shuffled AUC (sAUC) [97] is also a commonly used AUC variant. It reduces the sensitivity of the AUC to the center shift by sampling the salient point distribution of other images.
- Normalized Scanpath Saliency (NSS): NSS is a unique evaluation measure of saliency prediction. It is used to calculate the average normalized significance value at the point of interest [104]. The calculation formula of NSS is
- Linear Correlation Coefficient (CC):The CC is the statistic used to measure the linear correlation between two random variables. For the significance prediction evaluation, the prediction significance map (P) and the true value view (G) can be regarded as the two random variables. The calculation formula of CC is
- Earth Movers Distance (EMD): EMD [105] represents the distance between the two 2D maps denoted by G and S, and it calculates the minimum cost of converting the estimated probability distribution of the saliency map S into the probability distribution of the GT map denoted by G. Therefore, a low EMD corresponds to a high-quality saliency map. In saliency prediction, EMD represents the minimum cost of converting the probability distribution of the saliency map into human-eye attention maps called the fixation map.
- Kullback–Leibler (KL) Divergence: KL divergence is a general information theory measurement corresponding to the difference between two probability distributions. The calculation formula of KL is
- (6) Similarity Metric (SIM): SIM measures the similarity between two distributions. After normalizing the input map, SIM is calculated as the sum of the minimum values at each pixel. The calculation formula of SIM is
7. Performance of Visual Saliency Prediction Models
8. Commonalities and Limitations of the Deep Saliency Models
- 1.
- New Datasets: Datasets are extremely important to model performance [120]. The GT and measurement prediction errors obtained from the data have a significant impact on the model performance. In earlier years, the collection of saliency datasets relied on eye tracking data, and the datasets had fewer images. Although the emergence of SALICON improved the result, the gap remains to be an order of magnitude with respect to datasets in related fields (e.g., ImageNet). The JFT-300M dataset recently collected by Sun et al. [121] contains 300 million images, and it performs the target recognition model that is trained on this dataset well. The difference in performance between the use of eye tracking data and similar SALICON data collected with mouse clicks is clearly controversial.
- 2.
- Multi-modal approaches: With the development of saliency prediction in the dynamic field, an increasing number of features in different modes, such as vision, hearing, and subtitles, can be used to train models. This multi-modal feature input mode has proven to be an effective way to improve model performance. Coutrot et al. [122] used audio data to help video prediction. The shared attention proposed by Gorji et al. [79] could effectively improve model performance.
- 3.
- Visualization: The black box model of deep learning is difficult to present in a manner that humans can understand. However, saliency prediction itself is a representation of visual concepts. Visualized CNNs have many benefits for understanding models, including the meaning of filters, visual patterns, or visual concepts. Bylinskii et al. [123] designed a visual dataset and found that a specific type of database may be better for training. Visualization can help us better understand a model, and it also brings the possibility of proposing better models and databases.
- 4.
- Understand high-level semantics: The deep saliency models are good at extracting common features, such as humans and textures, among others. The saliency predictor can also be used to handle these features. However, as shown in Figure 5, the most interesting or significant parts of an image are not necessarily all of these features. Human visual models often entail a reasoning process based on sensory stimuli. To establish the reason behind the relative importance of image regions on the saliency model, researchers can use higher-level features, such as emotions, gaze direction, and body posture. Moreover, aiming to approach the human-level saliency prediction, researchers need to carry out cognitive attention research to help overcome the aforementioned limitations. A few useful explorations have been offered. For example, Zhao [98] showed through his experimental results that emotion has a priority effect. Nonetheless, the existing saliency model still cannot fully explain the high-level semantics in the scene. The concept of “semantic gap” and the process of determining the relative importance of objects still cannot be resolved; moreover, whether the saliency in natural scenes is guided by objects or low-level features is a matter of debate [124]. The research on the saliency prediction task is closely related to cognitive disciplines, and its findings can help to improve the subsequent various visual research.
9. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Itti, L.; Koch, C. Computational modelling of visual attention. Nat. Rev. Neurosci. 2001, 2, 194–203. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sziklai, G.C. Some studies in the speed of visual perception. IRE Trans. Inf. Theory 1956, 76, 125–128. [Google Scholar] [CrossRef]
- Koch, K.; Mclean, J.; Segev, R.; Freed, M.A.; Michael, I.I.; Balasubramanian, V.; Sterling, P. How Much the Eye Tells the Brain. Curr. Biol. 2006, 16, 1428–1434. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Itti, L. A model of saliency-based visual attention for rapid scene analysis. IEEE Trans. 1998, 20, 1254–1259. [Google Scholar] [CrossRef] [Green Version]
- Han, J.; Ngan, K.N.; Li, M.; Zhang, H.J. Unsupervised extraction of visual attention objects in color images. IEEE Trans. Circuits Syst. Video Technol. 2005, 16, 141–145. [Google Scholar] [CrossRef]
- Jung, C.; Kim, C. A Unified Spectral-Domain Approach for Saliency Detection and Its Application to Automatic Object Segmentation. IEEE Trans. Image Process. A Publ. IEEE Signal Process. Soc. 2012, 21, 1272–1283. [Google Scholar] [CrossRef]
- Siagian, C.; Itti, L. Biologically Inspired Mobile Robot Vision Localization. IEEE Trans. Robot. 2009, 25, 861–873. [Google Scholar] [CrossRef] [Green Version]
- Koch, C.; Ullman, S. Shifts in Selective Visual Attention: Towards the Underlying Neural Circuitry. Hum. Neurobiol. 1987, 4, 219–227. [Google Scholar]
- Tong, Y.; Cheikh, F.A.; Guraya, F.; Konik, H.; Trémeau, A. A Spatiotemporal Saliency Model for Video Surveillance. Cogn. Comput. 2011, 3, 241–263. [Google Scholar]
- Itti, L. Automatic foveation for video compression using a neurobiological model of visual attention. IEEE Trans. Image Process. 2004, 13, 1304–1318. [Google Scholar] [CrossRef] [Green Version]
- Monga, V.; Evans, B.L. Perceptual Image Hashing Via Feature Points: Performance Evaluation and Tradeoffs. IEEE Trans. Image Process. A Publ. IEEE Signal Process. Soc. 2006, 15, 3452–3465. [Google Scholar] [CrossRef]
- Wang, W.; Shen, J.; Dong, X.; Borji, A.; Yang, R. Inferring Salient Objects from Human Fixations. Inferring salient objects from human fixations. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 1913–1927. [Google Scholar] [CrossRef]
- Wang, W.; Shen, J.; Lu, X.; Hoi, S.C.H.; Ling, H. Paying Attention to Video Object Pattern Understanding. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 2413–2428. [Google Scholar] [CrossRef]
- Wang, W.; Shen, J.; Ling, H. A Deep Network Solution for Attention and Aesthetics Aware Photo Cropping. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 1531–1544. [Google Scholar] [CrossRef]
- Wang, K.; Ma, S.; Chen, J.; Lu, J. Salient Bundle Adjustment for Visual SLAM. IEEE Trans. Instrum. Meas. 2020, 70, 1–9. [Google Scholar] [CrossRef]
- Aksoy, E.; Yazc, A.; Kasap, M. See, Attend and Brake: An Attention-based Saliency Map Prediction Model for End-to-End Driving. arXiv 2020, arXiv:2002.11020. [Google Scholar]
- Lu, J.; Yang, J.; Batra, D.; Parikh, D. Hierarchical co-attention for visual question answering. Adv. Neural Inf. Process. Syst. 2016, 29, 289–297. [Google Scholar]
- Wang, S.; Jiang, M.; Duchesne, X.; Laugeson, E.; Kennedy, D.; Adolphs, R.; Zhao, Q. Atypical Visual Saliency in Autism Spectrum Disorder Quantified through Model-Based Eye Tracking. Neuron 2015, 88, 604–616. [Google Scholar] [CrossRef] [Green Version]
- Jia, Z.; Lin, Y.; Wang, J.; Wang, X.; Xie, P.; Zhang, Y. SalientSleepNet: Multimodal Salient Wave Detection Network for Sleep Staging. arXiv 2021, arXiv:2105.13864. [Google Scholar]
- Wang, W.; Lai, Q.; Fu, H.; Shen, J.; Yang, R. Salient Object Detection in the Deep Learning Era: An In-depth Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 1448–1457. [Google Scholar] [CrossRef]
- Wang, W.; Shen, J.; Cheng, M.M.; Shao, L. An Iterative and Cooperative Top-Down and Bottom-Up Inference Network for Salient Object Detection. In Proceedings of the CVPR19, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Wang, W.; Zhao, S.; Shen, J.; Hoi, S.; Borji, A. Salient Object Detection With Pyramid Attention and Salient Edges. In Proceedings of the CVPR19, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Zhang, J.; Dai, Y.; Yu, X.; Harandi, M.; Barnes, N.; Hartley, R. Uncertainty-Aware Deep Calibrated Salient Object Detection. arXiv 2020, arXiv:2012.06020. [Google Scholar]
- Zhang, P.; Liu, W.; Zeng, Y.; Lei, Y.; Lu, H. Looking for the Detail and Context Devils: High-Resolution Salient Object Detection. IEEE Trans. Image Process. 2021, 30, 3204–3216. [Google Scholar] [CrossRef]
- Treisman, A.M.; Gelade, G. A feature-integration theory of attention. Cogn. Psychol. 1980, 12, 97–136. [Google Scholar] [CrossRef]
- Treisman, A. Feature binding, attention and object perception. Philos. Trans. R. Soc. B Biol. Sci. 1998, 353, 1295–1306. [Google Scholar] [CrossRef] [Green Version]
- Wolfe, J.M. Guided Search 2.0 A revised model of visual search. Psychon. Bull. Rev. 1994, 1, 202–238. [Google Scholar] [CrossRef] [Green Version]
- Harel, J.; Koch, C.; Perona, P. Graph-Based Visual Saliency. In Proceedings of the IEEE Conference on Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 4–9 December 2006. [Google Scholar]
- Ma, Y.F. Contrast-based image attention analysis by using fuzzy growing. In Proceedings of the 11th Annual ACM International Conference on Multimedia, Berkeley, CA, USA, 2–8 November 2003. [Google Scholar]
- Liu, T.; Yuan, Z.; Sun, J.; Wang, J.; Zheng, N.; Tang, X.; Shum, H.-Y. Learning to detect a salient object. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 353–367. [Google Scholar]
- Borji, A.; Itti, L. Exploiting local and global patch rarities for saliency detection. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012. [Google Scholar]
- Zhang, J.; Sclaroff, S. Saliency Detection: A Boolean Map Approach. In Proceedings of the 2013 IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013. [Google Scholar]
- Zhai, Y.; Shah, M. Visual attention detection in video sequences using spatiotemporal cues. In Proceedings of the 14th ACM International Conference on Multimedia, Santa Barbara, CA, USA, 23–27 October 2006. [Google Scholar]
- Wei, Y.; Jie, F.; Tao, L.; Jian, S. Salient object detection by composition. In Proceedings of the IEEE International Conference on Computer Vision, ICCV 2011, Barcelona, Spain, 6–13 November 2011. [Google Scholar]
- Margolin, R.; Tal, A.; Zelnik-Manor, L. What Makes a Patch Distinct? In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Portland, OR, USA, 23–28 June 2013. [Google Scholar]
- Achanta, R.; Hemami, S.; Estrada, F.; Su¨Sstrunk, S. Frequency-tuned salient region detection. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 1597–1604. [Google Scholar]
- Cheng, M.M.; Zhang, G.X.; Mitra, N.J.; Huang, X.; Hu, S.M. Global Contrast Based Salient Region Detection. In Proceedings of the Computer Vision and Pattern Recognition, Colorado Springs, CO, USA, 20–25 June 2011. [Google Scholar]
- Zhi, L.; Zhang, X.; Luo, S.; Meur, O.L. Superpixel-Based Spatiotemporal Saliency Detection. IEEE Trans. Circuits Syst. Video Technol. 2014, 24, 1522–1540. [Google Scholar]
- Ren, Z.; Hu, Y.; Chia, L.T.; Rajan, D. Improved saliency detection based on superpixel clustering and saliency propagation. In Proceedings of the Acm International Conference on Multimedia, Firenze, Italy, 25–29 October 2010. [Google Scholar]
- Huang, G.; Pun, C.M.; Lin, C. Unsupervised video co-segmentation based on superpixel co-saliency and region merging. Multimed. Tools Appl. 2016, 76, 12941–12964. [Google Scholar] [CrossRef]
- Bruce, N.D.B.; Tsotsos, J.K. Saliency Based on Information Maximization. In Proceedings of the Advances in Neural Information Processing Systems 18, Vancouver, BC, Canada, 5–8 December 2005. [Google Scholar]
- Hou, X. Dynamic visual attention: Searching for coding length increments. In Proceedings of the Advances in Neural Information Processing Systems (NIPS, 2008), Vancouver, BC, Canada, 8–10 December 2008; pp. 681–688. [Google Scholar]
- Mancas, M.; Mancas-Thillou, C.; Gosselin, B.; Macq, B.M. A Rarity-Based Visual Attention Map–Application to Texture Description. In Proceedings of the International Conference on Image Processing, ICIP 2006, Atlanta, GA, USA, 8–11 October 2006. [Google Scholar]
- Seo, H.J.; Milanfar, P. Nonparametric bottom-up saliency detection by self-resemblance. In Proceedings of the 2009 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Miami, FL, USA, 20–25 June 2009; pp. 45–52. [Google Scholar]
- Rosenholtz, R.; Nagy, A.L.; Bell, N.R. The effect of background color on asymmetries in color search. J. Vis. 2004, 4, 224–240. [Google Scholar] [CrossRef] [PubMed]
- Hou, X.; Zhang, L. Saliency Detection: A Spectral Residual Approach. In Proceedings of the IEEE Conference on Computer Vision & Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007. [Google Scholar]
- Guo, C.; Qi, M.; Zhang, L. Spatio-temporal Saliency detection using phase spectrum of quaternion fourier transform. In Proceedings of the IEEE Conference on Computer Vision & Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008. [Google Scholar]
- Holtzman-Gazit, M.; Zelnik-Manor, L.; Yavneh, I. Salient Edges: A Multi Scale Approach. In Proceedings of the 11th European Conference on Computer Vision, Crete, Greece, 5–11 September 2010; p. 4310. [Google Scholar]
- Sclaroff, J. Exploiting Surroundedness for Saliency Detection: A Boolean Map Approach. IEEE Comput. Soc. 2016, 38, 889–902. [Google Scholar]
- Borji, A.; Itti, L. State-of-the-Art in Visual Attention Modeling. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 185–207. [Google Scholar] [CrossRef]
- Oliva, A.; Torralba, A.; Castelhano, M.S.; Henderson, J.M. Top-down control of visual attention in object detection. In Proceedings of the International Conference on Image Processing, Barcelona, Spain, 14–18 September 2003; pp. I 253–256. [Google Scholar]
- Ehinger, K.A.; Hidalgo-Sotelo, B.; Torralba, A.; Oliva, A. Modelling search for people in 900 scenes: A combined source model of eye guidance. Vis. Cogn. 2009, 17, 945–978. [Google Scholar] [CrossRef] [Green Version]
- Xie, Y.; Lu, H.; Yang, M.H. Bayesian Saliency via Low and Mid Level Cues. IEEE Trans. Image Process. A Publ. IEEE Signal Process. Soc. 2013, 22, 1689–1698. [Google Scholar]
- Zhang, L.; Tong, M.; Marks, H.; Tim, K.; Shan, H.; Cottrell, G. SUN: A Bayesian framework for saliency using natural statistics. J. Vis. 2008, 8, 32. [Google Scholar] [CrossRef] [Green Version]
- Gao, D.; Vasconcelos, N. Discriminant Saliency for Visual Recognition from Cluttered Scenes. In Proceedings of the Advances in Neural Information Processing Systems 17 [Neural Information Processing Systems, NIPS 2004], Vancouver, BC, Canada, 12–18 December 2004. [Google Scholar]
- Gao, D.; Vasconcelos, N. Decision-Theoretic Saliency: Computational Principles, Biological Plausibility, and Implications for Neurophysiology and Psychophysics. Neural Comput. 2014, 21, 239–271. [Google Scholar] [CrossRef]
- Kim, H.; Kim, Y.; Sim, J.Y.; Kim, C.S. Spatiotemporal saliency in dynamic scenes. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 32, 171–177. [Google Scholar]
- Gu, E.; Wang, J.; Badler, N.I. Generating Sequence of Eye Fixations Using Decision-theoretic Attention Model. In Proceedings of the IEEE Computer Society Conference on Computer Vision & Pattern Recognition, San Diego, CA, USA, 20–26 June 2005. [Google Scholar]
- Kienzle, W.; Franz, M.O.; Scholkopf, B.; Wichmann, F.A. Center-surround patterns emerge as optimal predictors for human saccade targets. J. Vis. 2009, 9, 1–15. [Google Scholar] [CrossRef] [Green Version]
- Peters, R.J.; Itti, L. Beyond bottom-up: Incorporating task-dependent influences into a computational model of spatial attention. In Proceedings of the IEEE Conference on Computer Vision & Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007. [Google Scholar]
- Judd, T.; Ehinger, K.; Durand, F.; Torralba, A. Learning to Predict Where Humans Look. In Proceedings of the IEEE 12th International Conference on Computer Vision, ICCV 2009, Kyoto, Japan, 27 September–4 October 2009. [Google Scholar]
- Vig, E.; Dorr, M.; Cox, D. Large-Scale Optimization of Hierarchical Features for Saliency Prediction in Natural Images. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Kümmerer, M.; Theis, L.; Bethge, M. Deep Gaze I: Boosting Saliency Prediction with Feature Maps Trained on ImageNet. arXiv 2014, arXiv:1411.1045. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Jia, D.; Wei, D.; Socher, R.; Li, L.J.; Kai, L.; Li, F.F. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Kruthiventi, S.; Ayush, K.; Babu, R.V. DeepFix: A Fully Convolutional Neural Network for Predicting Human Eye Fixations. IEEE Trans. Image Process. 2017, 26, 4446–4456. [Google Scholar] [CrossRef] [Green Version]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Kümmerer, M.; Wallis, T.; Bethge, M. DeepGaze II: Reading fixations from deep features trained on object recognition. arXiv 2016, arXiv:1610.01563. [Google Scholar]
- Ming, J.; Huang, S.; Duan, J.; Qi, Z. SALICON: Saliency in Context. In Proceedings of the Computer Vision & Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Azam, S.; Gilani, S.O.; Jeon, M.; Yousaf, R.; Kim, J.-B. A Benchmark of Computational Models of Saliency to Predict Human Fixations in Videos. In VISIGRAPP (4: VISAPP); SCITEPRESS—Science and Technology Publications, Lda.: Setúbal, Portugal, 2016; pp. 134–142. [Google Scholar]
- Pan, J.; Mcguinness, K.; Sayrol, E.; O’Connor, N.; Giro-I-Nieto, X. Shallow and Deep Convolutional Networks for Saliency Prediction. arXiv 2016, arXiv:1603.00845. [Google Scholar]
- Jetley, S.; Murray, N.; Vig, E. End-to-end saliency mapping via probability distribution prediction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 5753–5761. [Google Scholar]
- Liu, N.; Han, J. A Deep Spatial Contextual Long-Term Recurrent Convolutional Network for Saliency Detection. IEEE Trans. Image Process. A Publ. IEEE Signal Process. Soc. 2018, 27, 3264–3274. [Google Scholar] [CrossRef] [Green Version]
- Cornia, M.; Baraldi, L.; Serra, G.; Cucchiara, R. A Deep Multi-Level Network for Saliency Prediction. In Proceedings of the International Conference on Pattern Recognition, Cancun, Mexico, 4–8 December 2016. [Google Scholar]
- Marcella, C.; Lorenzo, B.; Giuseppe, S.; Rita, C. Predicting Human Eye Fixations via an LSTM-based Saliency Attentive Model. IEEE Trans. Image Process. 2016, 27, 5142–5154. [Google Scholar]
- Pan, J.; Canton, C.; Mcguinness, K.; O’Connor, N.E.; Giro-I-Nieto, X. SalGAN: Visual Saliency Prediction with Generative Adversarial Networks. arXiv 2017, arXiv:1701.01081. [Google Scholar]
- Jia, S.; Bruce, N.D.B. EML-NET:An Expandable Multi-Layer NETwork for Saliency Prediction. arXiv 2018, arXiv:1805.01047. [Google Scholar]
- Wenguan; Wang; Jianbing; Shen. Deep Visual Attention Prediction. IEEE Trans. Image Process. 2017, 27, 2368–2378. [Google Scholar]
- Gorji, S.; Clark, J.J. Attentional Push: A Deep Convolutional Network for Augmenting Image Salience with Shared Attention Modeling in Social Scenes. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Dodge, S.; Karam, L. Visual Saliency Prediction Using a Mixture of Deep Neural Networks. IEEE Trans. Image Process. 2017, 27, 4080–4090. [Google Scholar] [CrossRef]
- Mahdi, A.; Qin, J.; Crosby, G. DeepFeat: A bottom-up and top-down saliency model based on deep features of convolutional neural networks. IEEE Trans. Cogn. Dev. Syst. 2019, 12, 54–63. [Google Scholar] [CrossRef]
- Aka, B.; Msa, B.; Kd, C.; Rgab, D. Contextual encoder–decoder network for visual saliency prediction. Neural Netw. 2020, 129, 261–270. [Google Scholar]
- Gao, D.; Mahadevan, V.; Vasconcelos, N. The discriminant center-surround hypothesis for bottom-up saliency. In Proceedings of the Advances in Neural Information Processing Systems 20, Proceedings of the Twenty-First Annual Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 3–6 December 2007. [Google Scholar]
- Seo, H.J.; Milanfar, P. Using local regression kernels for statistical object detection. In Proceedings of the IEEE International Conference on Image Processing, San Diego, CA, USA, 12–15 October 2008. [Google Scholar]
- Bak, C.; Kocak, A.; Erdem, E.; Erdem, A. Spatio-temporal saliency networks for dynamic saliency prediction. IEEE Trans. Multimed. 2017, 20, 1688–1698. [Google Scholar] [CrossRef] [Green Version]
- Chaabouni, S.; Benois-Pineau, J.; Amar, C.B. Transfer learning with deep networks for saliency prediction in natural vide. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016. [Google Scholar]
- Leifman, G.; Rudoy, D.; Swedish, T.; Bayro-Corrochano, E.; Raskar, R. Learning Gaze Transitions from Depth to Improve Video Saliency Estimation. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Lai, Q.; Wang, W.; Sun, H.; Shen, J. Video Saliency Prediction using Spatiotemporal Residual Attentive Networks. IEEE Trans. Image Process. 2019, 29, 1113–1126. [Google Scholar] [CrossRef] [PubMed]
- Bazzani, L.; Larochelle, H.; Torresani, L. Recurrent Mixture Density Network for Spatiotemporal Visual Attention. arXiv 2016, arXiv:1603.08199. [Google Scholar]
- Jiang, L.; Xu, M.; Wang, Z. Predicting Video Saliency with Object-to-Motion CNN and Two-layer Convolutional LSTM. arXiv 2017, arXiv:1709.06316. [Google Scholar]
- Gorji, S.; Clark, J.J. Going from Image to Video Saliency: Augmenting Image Salience with Dynamic Attentional Push. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Wang, W.; Shen, J.; Fang, G.; Cheng, M.M.; Borji, A. Revisiting Video Saliency: A Large-Scale Benchmark and a New Model. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Zhang, K. A Spatial-Temporal Recurrent Neural Network for Video Saliency Prediction. IEEE Trans. Image Process. 2020, 30, 572–587. [Google Scholar] [CrossRef]
- Xu, M.; Yang, L.; Tao, X.; Duan, Y.; Wang, Z. Saliency Prediction on Omnidirectional Image With Generative Adversarial Imitation Learning. IEEE Trans. Image Process. 2021, 30, 2087–2102. [Google Scholar] [CrossRef]
- Yang, C.; Zhang, L.; Lu, H.; Ruan, X.; Yang, M.H. Saliency Detection via Graph-Based Manifold Ranking. In Proceedings of the Computer Vision & Pattern Recognition, Portland, OR, USA, 23–28 June 2013. [Google Scholar]
- Borji, A.; Itti, L. CAT2000: A Large Scale Fixation Dataset for Boosting Saliency Research. arXiv 2015, arXiv:1505.03581. [Google Scholar]
- Borji, A.; Tavakoli, H.R.; Sihite, D.N.; Itti, L. Analysis of Scores, Datasets, and Models in Visual Saliency Prediction. In Proceedings of the IEEE International Conference on Computer Vision, Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Fan, S.; Shen, Z.; Ming, J.; Koenig, B.L.; Qi, Z. Emotional Attention: A Study of Image Sentiment and Visual Attention. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Mital, P.K.; Smith, T.J.; Hill, R.L.; Henderson, J.M. Clustering of Gaze During Dynamic Scene Viewing is Predicted by Motion. Cogn. Comput. 2011, 3, 5–24. [Google Scholar] [CrossRef]
- Mathe, S.; Sminchisescu, C. Actions in the Eye: Dynamic Gaze Datasets and Learnt Saliency Models for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1408–1424. [Google Scholar] [CrossRef] [Green Version]
- Jiang, L.; Xu, M.; Liu, T.; Qiao, M.; Wang, Z. Deepvs: A deep learning based video saliency prediction approach. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 602–617. [Google Scholar]
- Judd, T.; Durand, F.; Torralba, A. A Benchmark of Computational Models of Saliency to Predict Human Fixations; Technical Report MIT-CSAIL-TR-2012-001; MIT Libraries: Cambridge, MA, USA, 2012. [Google Scholar]
- Borji, A.; Sihite, D.N.; Itti, L. Quantitative Analysis of Human-Model Agreement in Visual Saliency Modeling: A Comparative Study. IEEE Trans. Image Process. 2013, 22, 55–69. [Google Scholar] [CrossRef] [Green Version]
- Peters, R.J.; Iyer, A.; Itti, L.; Koch, C. Components of bottom-up gaze allocation in natural images. Vis. Res. 2005, 45, 2397–2416. [Google Scholar] [CrossRef] [Green Version]
- Rubner, Y.; Tomasi, C.; Guibas, L.J. The Earth Mover’s Distance as a Metric for Image Retrieval. Int. J. Comput. Vis. 2000, 40, 99–121. [Google Scholar] [CrossRef]
- Tavakoli, H.R.; Borji, A.; Laaksonen, J.; Rahtu, E. Exploiting inter-image similarity and ensemble of extreme learners for fixation prediction using deep features. Neurocomputing 2017, 244, 10–18. [Google Scholar] [CrossRef] [Green Version]
- Zanca, D.; Gori, M. Variational Laws of Visual Attention for Dynamic Scenes. In Proceedings of the NIPS 2017, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Shu, F.; Jia, L.; Tian, Y.; Huang, T.; Chen, X. Learning Discriminative Subspaces on Random Contrasts for Image Saliency Analysis. IEEE Trans. Neural Netw. Learn. Syst. 2017, 28, 1095–1108. [Google Scholar]
- Tavakoli, H.R.; Rahtu, E.; Heikkilä, J. Fast and efficient saliency detection using sparse sampling and kernel density estimation. In Proceedings of the Scandinavian Conference on Image Analysis, Ystad, Sweden, 23–27 May 2011; pp. 666–675. [Google Scholar]
- Aboudib, A.; Gripon, V.; Coppin, G. A model of bottom-up visual attention using cortical magnification. In Proceedings of the IEEE International Conference on Acoustics, South Brisbane, QLD, Australia, 19–24 April 2015. [Google Scholar]
- Goferman, S.; Zelnik-Manor, L.; Tal, A. Context-aware saliency detection. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 34, 1915–1926. [Google Scholar] [CrossRef] [Green Version]
- Garcia-Diaz, A.; Leboran, V.; Fdez-Vidal, X.R.; Pardo, X.M. On the relationship between optical variability, visual saliency, and eye fixations: A computational approach. J. Vis. 2012, 12, 17. [Google Scholar] [CrossRef] [Green Version]
- Lopez-Garcia, F.; Fdez-Vidal, X.R.; Pardo, X.M.; Dosil, R. Scene recognition through visual attention and image features: A comparison between sift and surf approaches. Object Recognit. 2011, 4, 185–200. [Google Scholar]
- Fang, Y.; Wang, Z.; Lin, W. Video Saliency Incorporating Spatiotemporal Cues and Uncertainty Weighting. In Proceedings of the 2013 IEEE International Conference on Multimedia and Expo (ICME), San Jose, CA, USA, 15–19 July 2013. [Google Scholar]
- Rudoy, D.; Dan, B.G.; Shechtman, E.; Zelnik-Manor, L. Learning Video Saliency from Human Gaze Using Candidate Selection. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013. [Google Scholar]
- Leboran, V.; Garcia-Diaz, A.; Fdez-Vidal, X.R.; Pardo, X.M. Dynamic whitening saliency. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 893–907. [Google Scholar] [CrossRef]
- Dedieu, J.F.; Gazin, C.; Rigolet, M.; Galibert, F. A Novel Multiresolution Spatiotemporal Saliency Detection Model and Its Applications in Image and Video Compression. Oncogene 1988, 3, 523–529. [Google Scholar]
- Khatoonabadi, S.H.; Vasconcelos, N.; Bajic, I.V.; Shan, N.Y. How many bits does it take for a stimulus to be salient? In Proceedings of the 2015 IEEE Conference on Computer Vision & Pattern Recognition, Boston, MA, USA, 7–12 June 2015.
- Seo, H.J.; Milanfar, P. Static and space-time visual saliency detection by self-resemblance. J. Vis. 2009, 9, 15. [Google Scholar] [CrossRef] [Green Version]
- Bruce, N.D.B.; Wloka, C.; Frosst, N.; Rahman, S.; Tsotsos, J.K. On computational modeling of visual saliency: Examining what’s right, and what’s left. Vis. Res. 2015, 116, 95–112. [Google Scholar] [CrossRef]
- Sun, C.; Shrivastava, A.; Singh, S.; Gupta, A. Revisiting Unreasonable Effectiveness of Data in Deep Learning Era. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Coutrot, A.; Guyader, N. How saliency, faces, and sound influence gaze in dynamic social scenes. J. Vis. 2014, 14, 5. [Google Scholar] [CrossRef]
- Bylinskii, Z.; Alsheikh, S.; Madan, S.; Recasens, A.; Zhong, K.; Pfister, H.; Durand, F.; Oliva, A. Understanding Infographics through Textual and Visual Tag Prediction. arXiv 2017, arXiv:1709.09215. [Google Scholar]
- Stoll, J.; Thrun, M.; Nuthmann, A.; Einhäuser, W. Overt attention in natural scenes: Objects dominate features. Vis. Res. An. Int. J. Vis. Sci. 2015, 107, 36–48. [Google Scholar] [CrossRef] [Green Version]
- Wei, W.; Liu, Z.; Huang, L.; Nebout, A.; Meur, O.L. Saliency Prediction via Multi-Level Features and Deep Supervision for Children with Autism Spectrum Disorder. In Proceedings of the 2019 IEEE International Conference on Multimedia & Expo Workshops (ICMEW), Shanghai, China, 8–12 July 2019. [Google Scholar]
- O’Shea, A.; Lightbody, G.; Boylan, G.; Temko, A. Neonatal seizure detection from raw multi-channel EEG using a fully convolutional architecture. arXiv 2021, arXiv:2105.13854. [Google Scholar] [CrossRef]
- Theis, L.; Korshunova, I.; Tejani, A.; Huszár, F. Faster gaze prediction with dense networks and Fisher pruning. arXiv 2018, arXiv:1801.05787. [Google Scholar]
- Fan, L.; Chen, Y.; Wei, P.; Wang, W.; Zhu, S.C. Inferring Shared Attention in Social Scene Videos. In Proceedings of the IEEE CVPR, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Fan, L.; Wang, W.; Huang, S.; Tang, X.; Zhu, S.C. Understanding Human Gaze Communication by Spatio-Temporal Graph Reasoning. arVix 2019, arXiv:1909.02144. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Evaluation Measures | Location Based | Distribution Based | Similarity | Continuous Ground-Truth |
|---|---|---|---|---|
| AUC-Judd | √ | √ | √ | √ |
| AUC-Borji | √ | √ | ||
| sAUC | √ | √ | ||
| EMD | √ | √ | ||
| NSS | √ | √ | ||
| CC | √ | √ | √ | |
| SIM | √ | √ | √ | |
| KL | √ | √ |
| Model Name | AUC- Judd | AUC- Borji | sAUC | SIM | EMD | CC | NSS | KL |
|---|---|---|---|---|---|---|---|---|
| infinite humans | 0.92 | 0.88 | 0.81 | 1 | 0 | 1 | 3.29 | 0 |
| Deep Gaze II [68] | 0.88 | 0.86 | 0.72 | 0.46 | 3.98 | 0.52 | 1.29 | 0.96 |
| EML-NET [77] | 0.88 | 0.77 | 0.7 | 0.68 | 1.84 | 0.79 | 2.47 | 0.84 |
| DeepFix [66] | 0.87 | 0.8 | 0.71 | 0.67 | 2.04 | 0.78 | 2.26 | 0.63 |
| SALICON [69] | 0.87 | 0.85 | 0.74 | 0.6 | 2.62 | 0.74 | 2.12 | 0.54 |
| SAM-ResNet [75] | 0.87 | 0.78 | 0.7 | 0.68 | 2.15 | 0.78 | 2.34 | 1.27 |
| SAM-VGG [75] | 0.87 | 0.78 | 0.71 | 0.67 | 2.14 | 0.77 | 2.3 | 1.13 |
| SalGAN [76] | 0.86 | 0.81 | 0.72 | 0.63 | 2.29 | 0.73 | 2.04 | 1.07 |
| ML-Net [74] | 0.85 | 0.75 | 0.7 | 0.59 | 2.63 | 0.67 | 2.05 | 1.1 |
| Deep Gaze I [63] | 0.84 | 0.83 | 0.66 | 0.39 | 4.97 | 0.48 | 1.22 | 1.23 |
| SalNet [71] | 0.83 | 0.82 | 0.69 | 0.52 | 3.31 | 0.58 | 1.51 | 0.81 |
| eDN [62] | 0.82 | 0.81 | 0.62 | 0.41 | 4.56 | 0.45 | 1.14 | 1.1 |
| Judd Model [61] | 0.81 | 0.8 | 0.6 | 0.42 | 4.45 | 0.47 | 1.18 | 1.12 |
| GBVS [28] | 0.81 | 0.8 | 0.63 | 0.48 | 3.51 | 0.48 | 1.24 | 0.87 |
| AIM [41] | 0.77 | 0.75 | 0.66 | 0.4 | 4.73 | 0.31 | 0.79 | 1.18 |
| IttiKoch2 [4] | 0.75 | 0.74 | 0.63 | 0.44 | 4.26 | 0.37 | 0.97 | 1.03 |
| SUN saliency [54] | 0.67 | 0.66 | 0.61 | 0.38 | 5.1 | 0.25 | 0.68 | 1.27 |
| Model Name | AUC- Judd | AUC- Borji | sAUC | SIM | EMD | CC | NSS | KL |
|---|---|---|---|---|---|---|---|---|
| infinite humans | 0.9 | 0.84 | 0.62 | 1 | 0 | 1 | 2.85 | 0 |
| SAM-ResNet [75] | 0.88 | 0.8 | 0.58 | 0.77 | 1.04 | 0.89 | 2.38 | 0.56 |
| SAM-VGG [75] | 0.88 | 0.79 | 0.58 | 0.76 | 1.07 | 0.89 | 2.38 | 0.54 |
| MSI-Net [82] | 0.88 | 0.82 | 0.59 | 0.75 | 1.07 | 0.87 | 2.3 | 0.36 |
| EML-NET [77] | 0.87 | 0.79 | 0.59 | 0.75 | 1.05 | 0.88 | 2.38 | 0.96 |
| DeepFix [66] | 0.87 | 0.81 | 0.58 | 0.74 | 1.15 | 0.87 | 2.28 | 0.37 |
| BMS [49] | 0.85 | 0.84 | 0.59 | 0.61 | 1.95 | 0.67 | 1.67 | 0.83 |
| eDN [62] | 0.85 | 0.84 | 0.55 | 0.52 | 2.64 | 0.54 | 1.3 | 0.97 |
| iSEEL [106] | 0.84 | 0.81 | 0.59 | 0.62 | 1.78 | 0.66 | 1.67 | 0.92 |
| Judd Model [61] | 0.84 | 0.84 | 0.56 | 0.46 | 3.6 | 0.54 | 1.3 | 0.94 |
| EYMOL [107] | 0.83 | 0.76 | 0.51 | 0.61 | 1.91 | 0.72 | 1.78 | 1.67 |
| LDS [108] | 0.83 | 0.79 | 0.56 | 0.58 | 2.09 | 0.62 | 1.54 | 0.79 |
| FES [109] | 0.82 | 0.76 | 0.54 | 0.57 | 2.24 | 0.64 | 1.61 | 2.1 |
| Aboudib Magn [110] | 0.81 | 0.77 | 0.55 | 0.58 | 2.1 | 0.64 | 1.57 | 1.41 |
| GBVS [28] | 0.8 | 0.79 | 0.58 | 0.51 | 2.99 | 0.5 | 1.23 | 0.8 |
| Context-Aware saliency [111] | 0.77 | 0.76 | 0.6 | 0.5 | 3.09 | 0.42 | 1.07 | 1.04 |
| IttiKoch2 [4] | 0.77 | 0.76 | 0.59 | 0.48 | 3.44 | 0.42 | 1.06 | 0.92 |
| AWS [112] | 0.76 | 0.75 | 0.61 | 0.49 | 3.36 | 0.42 | 1.09 | 0.94 |
| AIM [41] | 0.76 | 0.75 | 0.6 | 0.44 | 3.69 | 0.36 | 0.89 | 1.13 |
| WMAP [113] | 0.75 | 0.69 | 0.6 | 0.47 | 3.28 | 0.38 | 1.01 | 1.65 |
| Torralba saliency [51] | 0.72 | 0.71 | 0.58 | 0.45 | 3.44 | 0.33 | 0.85 | 1.6 |
| Murray model [72] | 0.7 | 0.7 | 0.59 | 0.43 | 3.79 | 0.3 | 0.77 | 1.14 |
| SUN saliency [54] | 0.7 | 0.69 | 0.57 | 0.43 | 3.42 | 0.3 | 0.77 | 2.22 |
| Achanta [36] | 0.57 | 0.55 | 0.52 | 0.33 | 4.46 | 0.11 | 0.29 | 2.31 |
| IttiKoch [4] | 0.56 | 0.53 | 0.52 | 0.34 | 4.66 | 0.09 | 0.25 | 6.71 |
| Model Name | AUC- Judd | sAUC | CC | NSS | SIM | |
|---|---|---|---|---|---|---|
| Static | DVA [78] | 0.86 | 0.595 | 0.358 | 2.013 | 0.262 |
| Models | SALICON [69] | 0.857 | 0.59 | 0.327 | 1.901 | 0.232 |
| JuntingNet [71] | 0.855 | 0.592 | 0.331 | 1.775 | 0.201 | |
| Shallow-Net [71] | 0.833 | 0.529 | 0.295 | 1.509 | 0.182 | |
| GBVS [28] | 0.828 | 0.554 | 0.283 | 1.474 | 0.186 | |
| ITTI [4] | 0.774 | 0.553 | 0.233 | 1.207 | 0.162 | |
| Dynamic | ACLNet [92] | 0.89 | 0.601 | 0.434 | 2.354 | 0.315 |
| Models | OM-CMM [90] | 0.856 | 0.583 | 0.344 | 1.911 | 0.256 |
| Two-stream [85] | 0.834 | 0.581 | 0.325 | 1.632 | 0.197 | |
| FANG [114] | 0.819 | 0.537 | 0.273 | 1.539 | 0.198 | |
| RUDOY [115] | 0.769 | 0.501 | 0.285 | 1.498 | 0.214 | |
| STRA [88] | 0.895 | 0.663 | 0.458 | 2.588 | 0.355 | |
| AWS-D [116] | 0.703 | 0.513 | 0.174 | 0.94 | 0.157 | |
| PQFT [117] | 0.699 | 0.562 | 0.137 | 0.749 | 0.139 | |
| OBDL [118] | 0.638 | 0.5 | 0.117 | 0.495 | 0.171 | |
| SEO [119] | 0.635 | 0.499 | 0.07 | 0.334 | 0.142 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yan, F.; Chen, C.; Xiao, P.; Qi, S.; Wang, Z.; Xiao, R. Review of Visual Saliency Prediction: Development Process from Neurobiological Basis to Deep Models. Appl. Sci. 2022, 12, 309. https://doi.org/10.3390/app12010309
Yan F, Chen C, Xiao P, Qi S, Wang Z, Xiao R. Review of Visual Saliency Prediction: Development Process from Neurobiological Basis to Deep Models. Applied Sciences. 2022; 12(1):309. https://doi.org/10.3390/app12010309
Chicago/Turabian StyleYan, Fei, Cheng Chen, Peng Xiao, Siyu Qi, Zhiliang Wang, and Ruoxiu Xiao. 2022. "Review of Visual Saliency Prediction: Development Process from Neurobiological Basis to Deep Models" Applied Sciences 12, no. 1: 309. https://doi.org/10.3390/app12010309
APA StyleYan, F., Chen, C., Xiao, P., Qi, S., Wang, Z., & Xiao, R. (2022). Review of Visual Saliency Prediction: Development Process from Neurobiological Basis to Deep Models. Applied Sciences, 12(1), 309. https://doi.org/10.3390/app12010309