1. Introduction
Data hiding is a family of techniques aimed at embedding information into digital objects for various application contexts. Digital watermarking, for copyright protection or authentication, and steganography, for covert communication or information storage, are typical applications of data embedding and hiding (see [
1,
2,
3,
4]).
Many algorithms have been devised for watermarking in different kinds of objects like images [
5], audio [
6], video [
7], neural networks [
8] and text data [
9]. These algorithms can be classified according to various properties and characteristics; one of the most important properties is reversibility, i.e., the possibility to obtain the original object after the extraction of the embedded data.
On the other hand, printable string encoding of binary data is a well-known and widely used technique to cope with systems designed to manage only bytes representing printable characters: in other terms, printable string encoding is an encapsulation method to process, in a transparent manner, any possible bit string by systems able to run only printable strings (for example, some mail servers).
Even though printable string encodings and watermarking are widely used techniques in several applications, to the best of our knowledge there are no attempts to combine these techniques for data hiding. The main questions we try to answer are:
- (a)
Can we hide information in string encodings?
- (b)
How much information can we embed in such string encodings?
- (c)
Can we make it reversible?
In this paper, we present a framework defining data and procedures for embedding and retrieving a bit string, which will be called a watermark, from a printable character string built using a binary-to-higher-base representation, like Base45 [
10] and/or Base85 [
11,
12]. The embedding-retrieving process is reversible. Indeed, the original printable character string is restored after the watermark extraction.
The paper is structured as follows: firstly, a brief notation and terminology subsection is presented, then some related works on the topic of printable encodings are briefly discussed.
Section 3 introduces the proposed framework for reversible data embedding and the results of its application are shown in
Section 4. The last section draws some conclusions and proposes some future works.
Notation
In this subsection the notation and terminology used throughout the paper is presented.
Small italic letters denote scalar values, e.g., , , .
Boldface italic capital letters denote sets, e.g., , . The cardinality of a set is denoted as .
An alphabet is denoted with Greek capital letters (e.g., ).
The terms symbol and character are applied interchangeably trying to use the most meaningful in the sentence context.
A word composed from symbols of an alphabet is called a sequence. A sequence of symbols from the alphabet is called binary string.
Capital letters (e.g., , , ) denote sequences of symbols from an alphabet.
Greek letters represent functions, e.g., , .
Specific characters or strings (sequences) of characters are enclosed inside single quotes, e.g., ‘D’ or ‘string<My Header>!’.
The floor operation is denoted as , with , and returns the largest integer not greater than .
2. Related Works
To define the possible applications of the proposed framework to an encoding method, it is useful to recall some of the binary-to-text mappings presently available and used in computer systems.
Base64 was introduced many years ago and standardized in 1992: it encodes
bytes (
bits) with
printable characters each encoding
of the
bits. The characters are thus chosen from a set of
symbols, namely the
letters of the English alphabet, uppercase and lowercase, the
decimal digits and
special characters that may differ among the various standardized applications. The most recent definition of the Base64 encoding may be found in [
13]: in that RFC also the Base32 and Base16 representations are specified. Base32 encodes groups of
bytes (
bits) in
printable characters each representing
bits: thus,
possible characters are needed (the
uppercase letters of the English alphabet and the digits from
to
). For Base64 and Base32 the character ‘=’ is used for padding the encoded string when the number of input bytes is not a multiple of
or
, respectively. Base16 is simply the hexadecimal representation of the input bytes using the decimal digits and the uppercase letters from ‘A’ to ‘F’ (some implementations may differ from [
13] and allow the use of lowercase letters from ‘a’ to ‘f’); by construction this encoding does not need any padding.
Base45 is defined in the work in progress [
10] and is developed for encoding data as text in QR codes. The symbols it uses are the
decimal digits, the
letters of the English alphabet, the space and the other
special characters. The encoding takes pairs of bytes and converts the number in Base45 using
digits (in a little-endian way, i.e., the leftmost character is the least significant); in case of a binary string having odd length then the last byte is converted in
base
digits. It is interesting to note that not all
digit numbers in base
can be converted in a binary number having at maximum
bits: in fact, from the sequence ‘GGW’ (representing
) to the sequence ‘:::’ more than
bits are needed to write the corresponding number in binary format; these sequences are considered unacceptable by the standard and accordingly rejected.
Base85, also called Ascii85 in [
11], encodes
bytes using
characters from an alphabet of
symbols (a subset of the ASCII characters, from the code
, ‘!’, to the code
, ‘u’). An exception is made for the binary value
which, instead of being encoded as ‘!!!!!’, is encoded as ‘z’. The version of this coding presented in [
11] uses a delimiter (namely ‘~>’) to mark the ending of the character sequence. Moreover, to cope with binary strings having a length that is not a multiple of
, a particular padding method in encoding and decoding is used. During decoding, a ‘z’ character in a
-character sequence is an error. Also, as in the analogous case of Base45, a
-character sequence decoding to a value greater than or equal to
is regarded as an error and not accepted. The base
is also used in an encoding of IPv6 addresses [
12].
Encodings using Base91 are presented in [
14,
15]. In [
14], the authors propose an encoding that splits the input binary string into
-bit words and encodes the resulting binary numbers in pairs of characters using an alphabet of
symbols (the printable ASCII characters from ‘!’ to ‘~’ excluding ‘-’, ‘=’ and ‘.’). To cope with bit strings having a length not being a multiple of
, 12 pairs are reserved to encode how many unused bits are present in the last
-bit word: this encoding leaves
unused Base91 pairs. The encoding used in the source code in [
15] makes use of all the
character pairs; in fact,
bits are encoded with
Base91 characters unless the value to be encoded is less than
: in that case
bits are encoded adding as a significant bit one more bit from the binary string to encode. This implies the use of
. pairs of Base91 characters saturating all the possible configurations.
Base58 is an encoding introduced for the Bitcoin cryptocurrency (as referred to in [
16]) by S. Nakamoto and described in the work in progress [
17]. The objective of this encoding is to represent meaningful data types of the protocol in a human readable format that would not allow any ambiguities when written, thus, starting from the Base64 alphabet, the special characters ‘+’ and ‘/’ are taken out (to avoid ambiguities in URLs or file system paths [
17]) along with ‘0′ (zero), ‘O’ (uppercase o), ‘I’ (uppercase i), ‘l’ (lowercase L) for possible ambiguities when reading or writing data by humans. Thus, the Base58 alphabet described in [
17] totals the following
symbols: the 9 digits from ‘1′ to ‘9′, the
uppercase letters of the English alphabet (i.e., without ‘I’ and ‘O’) and the
lowercase letters of the English alphabet (i.e., without ‘l’). The data represented as a byte string is interpreted as a sequence of symbols (bytes) in base
which is transformed in Base58 with a base conversion algorithm: to avoid the loss of the leading zeros (if present, e.g., ‘00A23′) in the encoding, a string of ‘1′ symbols represents how many null bytes compose the prefix of the byte string. As a side note, some applications developed a Base56 encoding where also the characters ‘1′ (one) and ‘o’ (lowercase O) are removed from the Base58 alphabet.
The Base62 encoding uses as symbols the
decimal digits and the
letters from the English alphabet both uppercase and lowercase. In [
18], the author presents UTF-62, a transformation for ISO 10646 (the Universal coded character set, UCS). When a character code is contained into
bytes (UCS-2) it is represented with
Base62 symbols (the leftmost one having its Most Significant Bit, MSB, valued
); instead, for encoding UCS-4 characters (
bits)
Base62 symbols are used (the leftmost one having its Most Significant Bits valued
). In [
19] a data stream is encoded examining groups of
bits at a time using Base62 characters. The first
binary configurations (namely from
to
) are mapped directly to the Base62 alphabet in the corresponding character position. The
bit configuration
is represented with the second to last Base62 character whilst the
configuration is encoded with the last Base62 character: in both cases the sixth bit becomes the first bit of the next group. Note that this encoding operates one Base62 character at a time thus all the Base62 characters sequences are possible while in [
18] even keeping the MSBs according to the proposed representation (
for UCS-2 and
for UCS-4):
when using UCS-2 encoding the possible Base62 sequences are to represent different binary strings, and
for UCS-4 the possible sequences are to represent different binary strings.
This fact leads to a redundancy in the resulting representation allowing extra bits (e.g., data like a watermark) to be stored without impacting on the reversibility of the method: this data hiding capacity is summarized for the main encodings discussed so far in the column Available configurations of
Table 1.
3. The Proposed Framework
Suppose one wants to represent binary strings of fixed length
with sequences of fixed length
using the
symbols from an alphabet
(for example, the
printable symbols of the Base45 system [
10]). Then, the following constraint must be satisfied:
The passive redundancy (i.e., the number of sequences of
symbols from
not representing any binary string of length
) of this encoding according to [
20] is:
Note that in the rest of the paper we will assume that the binary strings of length have all the same probability as is the case for compressed and/or encrypted data.
Thus, the exceeding sequences that do not represent one of binary strings may be used to embed extra data bits in the flow of symbols from : these bits may carry, for example, a watermark, a signature, a message authentication code, a cyclic redundancy check, or any extra information an application may need.
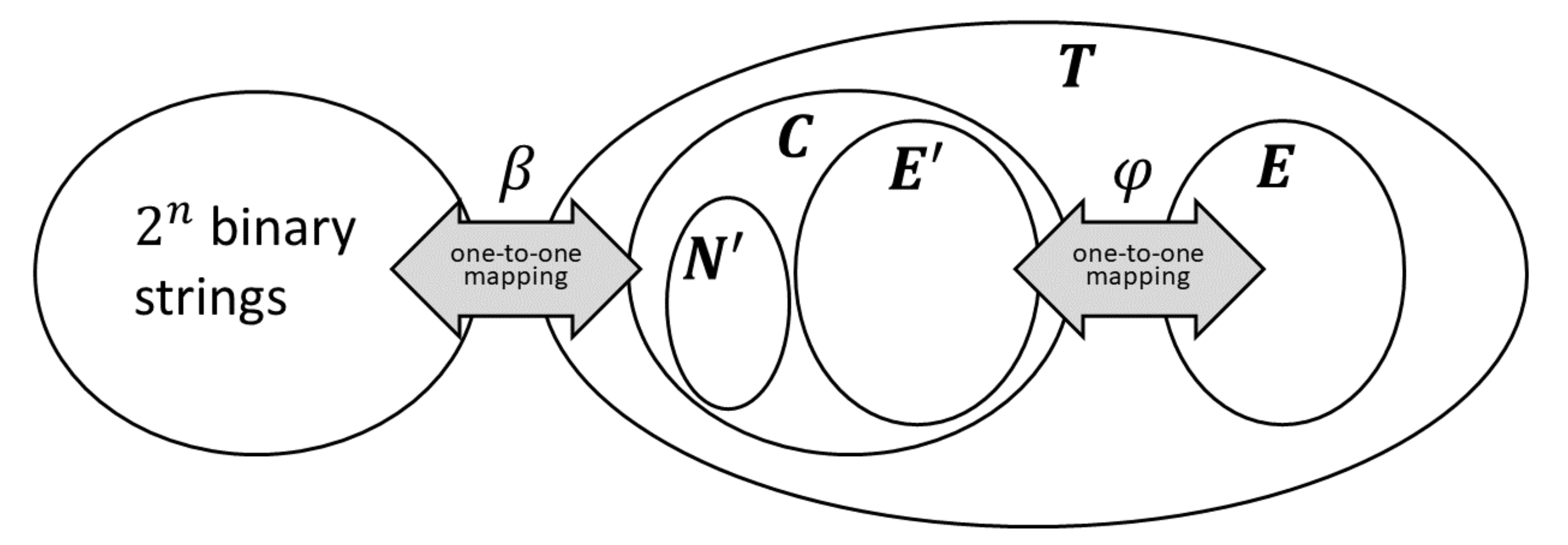
Let us consider a generic sequence of symbols from the alphabet , and define the following sets:
, the set of all possible sequences of symbols, having cardinality ;
, the subset of containing the sequences used to encode the binary strings (obviously having cardinality ): the mapping is defined with a bijective function ;
, the subset of containing the exceeding sequences that are not used to represent the binary strings.
The sets and constitute a partition of . To exploit the redundancy in this coding the set is further partitioned into two subsets:
, a subset of cardinality containing the sequences put in one-to-one correspondence with the sequences in by a bijective mapping function ;
, the subset of the remaining sequences in having no corresponding sequence in .
In the present work every sequence in is put in relation with at most one sequence in . Moreover, we assume that the encoding is frugal in the sense that is not lower than . The extension to a mapping allowing for more than one sequence in to be associated to some sequence in is left as a further development, as it will be discussed in the conclusions.
The structure and the relationship among these sets is shown in
Figure 1.
When encoding an bits binary string mapped through to an symbols (belonging to ) sequence , if it is possible to embed one extra bit of information saving (for ) or (for ) depending on the bit value (if , i.e., , no bit can be embedded).
The decoding can be performed by reversing the previous operations: if the sequence then the original binary sequence is restored with , if then a valued bit is extracted and the original binary sequence is restored with , otherwise , a valued bit is extracted and the original binary sequence is restored with .
The pseudo-code description of the encoding and decoding algorithms are presented in the following Algorithms 1 and 2.
| Algorithm 1: Pseudo-code of the encoding algorithm |
| Encodingalgorithm |
Input: set of binary strings to be encoded, , E, , , is a binary string of
bits to be embedded.
While there are binary strings to be encoded select next one and call it
;
If then
Get next bit b from W ;
If then ;
Output ; |
| Algorithm 2: Pseudo-code of the decoding algorithm |
Decoding algorithm
Input: set of sequences to be decoded, , E, , .
;
While there are sequences to be decoded select next one and call it
If then
;
;
else If then ;
;
Output ;
Output ; |
By assuming a uniform distribution for the input binary strings, an average payload of
bits per binary string (bpbs) may be embedded in the output sequence. The corresponding payload per byte (bit per byte, bpb) can be computed as:
The payload referred to the output symbols (bit per symbol, bps) is:
For example, Base45 as defined in [
10] encodes
bits in
symbols (with
) thus
bpbs,
bpb,
bps. In case of Base85,
,
,
leading to
bpbs,
bpb,
bps.
For Base64 encoding [
13] all the output sequences are used to encode the input binary strings thus it is not possible to apply the proposed method for data embedding (
,
,
).
4. Experimental Results
In this section, we report on experimental results by applying the proposed framework to Base45 and Base85 encodings: as previously said, the set is built with assuming a uniform distribution of the binary strings. This choice was made because it is general and makes no assumptions on the possible distribution of the binary strings: we will discuss the possibility to increase the payload with mapping on the set of the most probable sequences in for specific domain contexts, like encodings of TIFF or JPEG images.
Anyway, we tested three different mappings called Map , Map and Map . When Map is used the set consists of the sequences mapped to the binary strings counting from with an increment of . Map maps the sequences in to the first binary strings while Map puts in correspondence with the last binary strings.
Table 2,
Table 3 and
Table 4 report the averaged results from embeddings using Base45 and Base85 encodings into a set of
colour images of size
in JPEG, TIFF and PNG formats, respectively. The first column reports the string encoding, the second and third columns report the average payload in bpb and in bps, respectively. The fourth column reports the used mapping, while the fifth column reports when the experimental average payload is greater (+, ++) or less (−, −−) than the expected one. As it can be seen from the values shown in columns
and
, the results are in line with the expected theoretical values (
and
) computed in the previous section.
In almost all cases, Map and Map mappings result in a higher average payload than the expected one for image files. It should be pointed out that for Base85, Map 2 mapping behaves quite differently for TIFF compared to PNG image formats: in the former case, the average payload is much greater ( times) than the expected one, while in the latter is much smaller ( times).
Similar results for compressed files (in .zip, .bz2, .gz and .tgz formats) of various sizes are reported in
Table 5,
Table 6,
Table 7 and
Table 8. By contrast with the image case, it seems that the best mapping depends on the compressed file format: for .zip and .bz2 file format, Map
and Map
give better payload than expected, while for .gz file format Map
is the best.
We also performed an evaluation for the embedding into Base45 encoded files (for Base85 encoded files we did not perform such a test, because the statistics required a very large number of data and a histogram for entries). By using a mapping onto the set of the most probable sequences in for the set of JPEG images, the resulting payload is bpb, that is significantly larger than with the uniform distribution. Analogously, an optimized mapping for a set of compressed files resulted in a payload of bpb. In this case, it is much closer to the theorical payload ( bpb) for uniform input data distribution. Obviously, the function specifying the mapping onto the most probable sequences in needs to be shared between encoder and decoder.
Possible Applications
Several possible applications of the presented data hiding framework can be envisaged. Here, we describe a commercial application. Let us suppose we have a set of different kinds of objects, each one described by a multimedia record: for example, the products sold in a shop may be described by their name, producer, weight/capacity, price and, possibly, a small icon. These data can be compressed, e.g., in zip format, and encoded, through Base45, in a sequence of symbols represented by a QR (Quick Response) code that can be printed on or near the object (like the shelf where the object is displayed). To avoid forging of QR codes, the zip compressed data can be signed with ECDSA [
21,
22] and the signature embedded in the Base45 sequence using the proposed framework (
Figure 2).
We performed some tests showing the possibility to embed an ECDSA signature of bits (computed from a key of length bits) into a compressed Base45 encoded string. In case the compressed string is not long enough for storing the signature, padding bytes are added to complete the signature embedding (the padding bytes are binary strings mapped by to the set to maximize the payload). To correctly restore the original compressed string two bytes containing its length are prefixed before Base45 encoding.
Thus, the QR code may be read (for example, with a smartphone app), the signature and the compressed data extracted from the Base45 encoding, and finally the signature can be verified: if the signature is correct the compressed data are decompressed and the original record is shown to the user to give her the information on the tagged object.
Another application of the proposed method is the embedding of extra data into Base85 encoded files: metadata, signatures, integrity protection data are examples of information that can use the extra space obtained with the proposed framework.



{kind=link}
{kind=link}