
Explaining Deep Learning Models for Tabular Data Using Layer-Wise Relevance Propagation


Abstract
:1. Introduction
2. Related Work
3. Proposed Approach
3.1. First Phase
3.1.1. Datasets
Telecom Customer Churn Prediction Dataset (TCCPD)
Credit Card Fraud Detection Dataset (CCFDD)
3.1.2. Pre-Processing
- (1)
- Convert categorical data to numerical data: Where categorical features have more than two values, we create an individual feature for each categorical value, with Yes (1) or No (0) values. The features that were numerical are normalised between 0 and 1 by zero mean and unit variance technique. In TCCPD, there are four features with categorical data. When converted, this results in nine additional features bringing our total dataset features to be 28 (Table 1).
- (2)
- We then apply the SMOTE [54] technique to up-sample the minority class (both datasets) in order to balance the data. SMOTE generates synthetic nearest neighbours for training instances in the minority class in the training set only.
- (3)
- Where numeric features ranges are wider than two-choice binary values e.g., monthly charges, the features are normalised feature-wise in the range of 0 to 1.
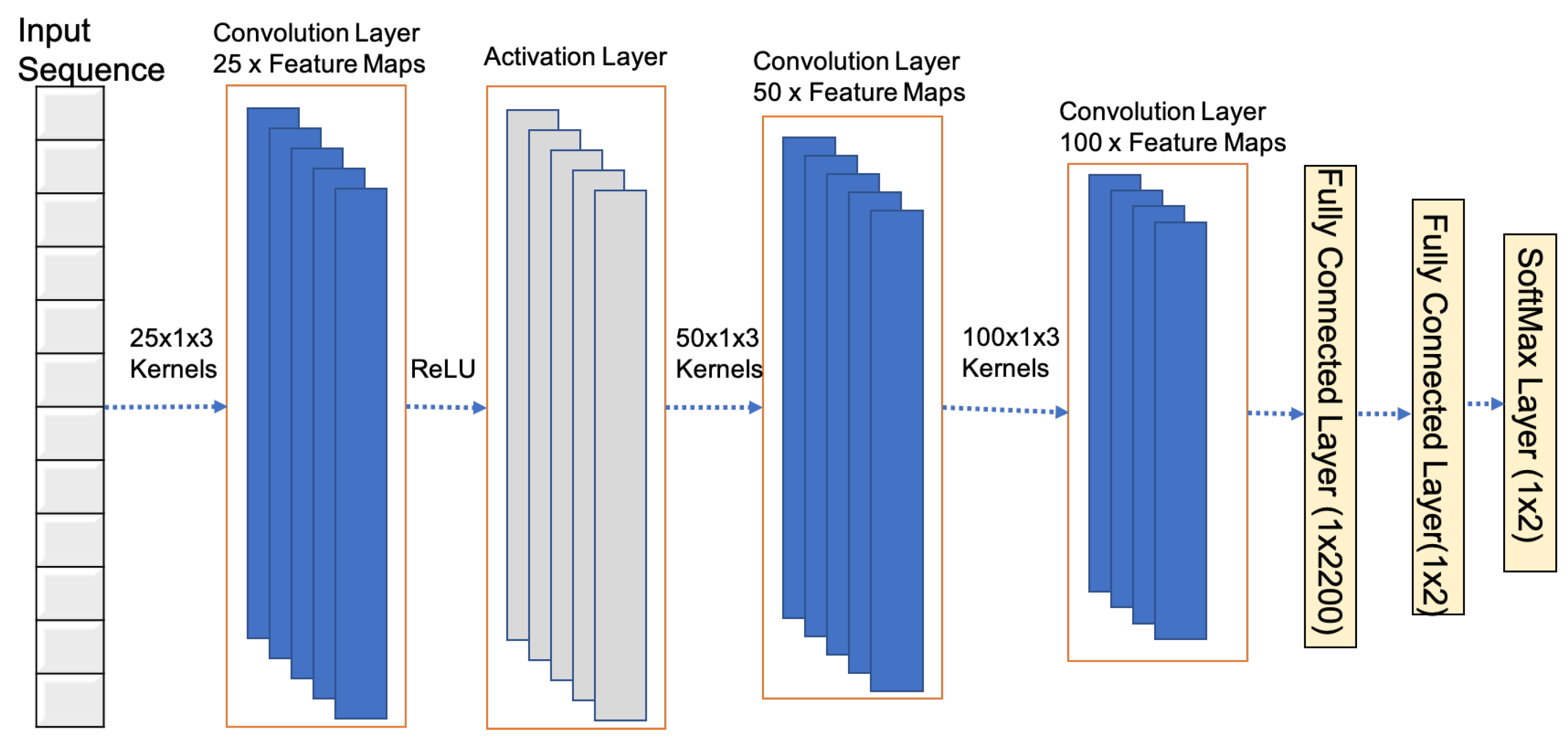
3.1.3. Training 1D-CNN
Proposed Network Structure
3.2. Second Phase
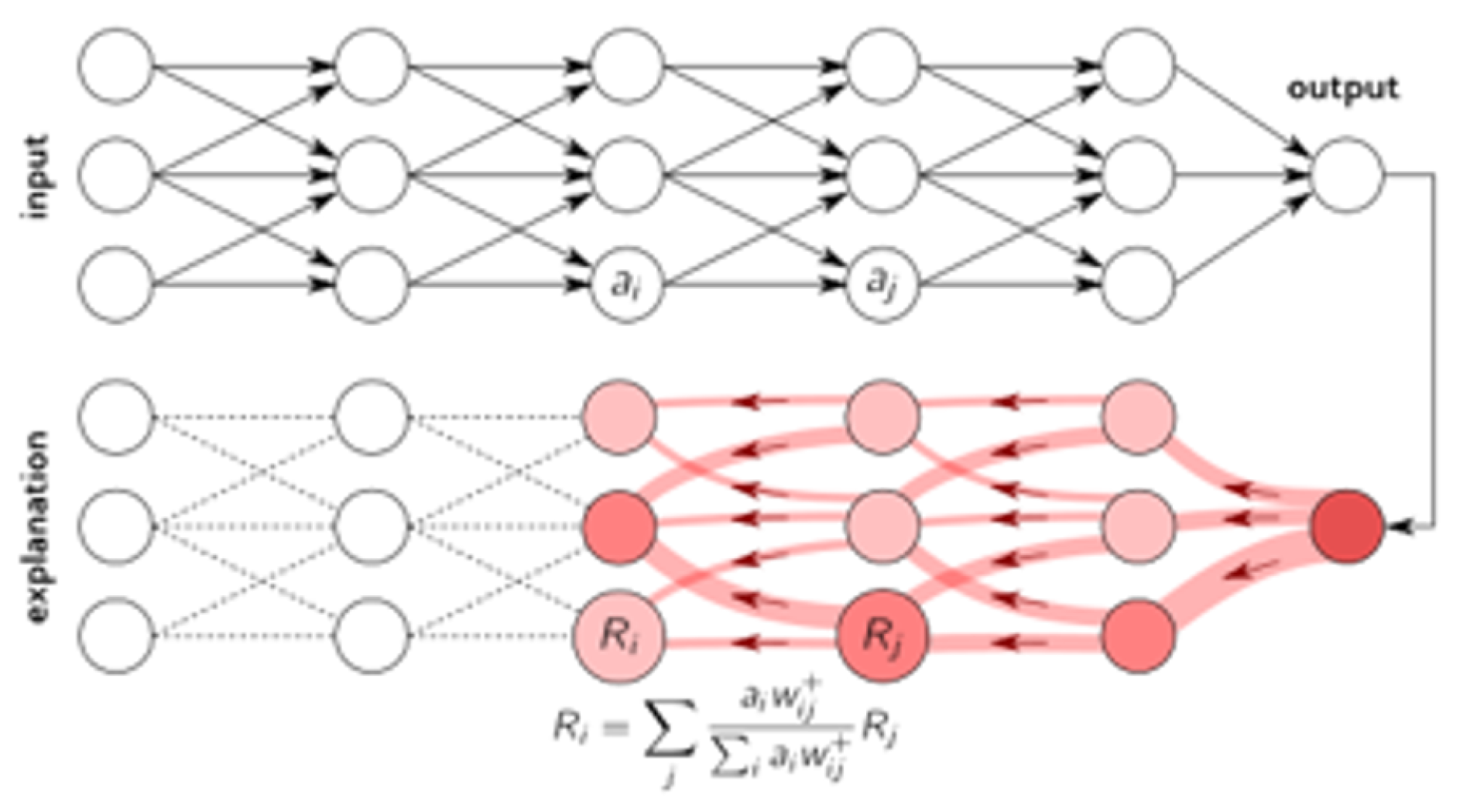
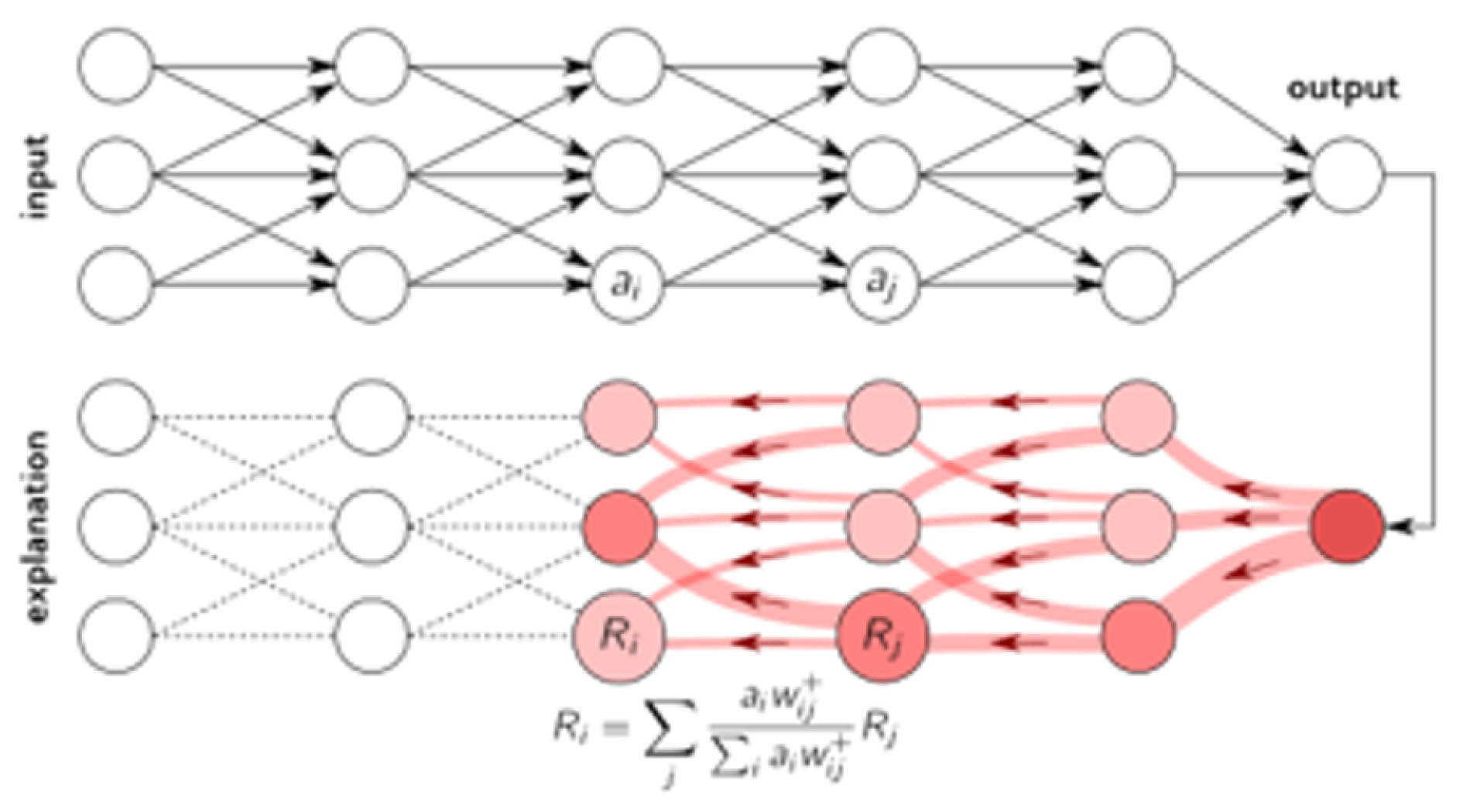
XAI Technique (LRP, SHAP, and LIME)
3.3. Validating the Correctness of LRP’s Highlighted Subset of Features
- 1.
- Set a threshold value t to be used. This threshold represents a cut-off LRP value above which a feature is determined to have contributed to an individual correct test instance.
- 2.
- Select all instances (with their LRP vectors) that were correctly classified as True Positive (TP).
- 3.
- Apply the threshold t to the relevance values of each feature j of a record in the true positives and true negatives, converting the feature value to 1 if at or above the threshold, else 0. This is and .
- 4.
- Sum the rows which have had features converted with 0 or 1, resulting in one vector r of dimension m, where m is the number of features.
- 5.
- Sort this vector based on the summed values for the features, to produce a numeric ranking of features
- 6.
- Repeat Steps 2–5 for the True Negative (TN) records
- 7.
- Select a total of 16 features (top 8 from TP vector and top 8 from TN vector). In case of an odd number, more are selected from TP (one less from TN features).
4. Results
- (a)
- Show that 1D-CNN can work on structured data and its performance for both the datasets will be shown in the form of accuracy, precision, recall, specificity, and F1-measure,
- (b)
- Discuss the visualised features in a heatmap that play a key role in a decision and assessing the results qualitatively (only on telecom churn dataset because the features of CCFDD are anonymous),
- (c)
- Compare the highlighted features from the heatmaps of LRP, SHAP, and LIME,
- (d)
- Validate that the selected subset of features are really important and can show good results when used as input to a simple classifier (done over TCCPD because we know the domain knowledge and the features names),
- (e)
- Finally, compare the performance with other techniques.
4.1. Performance of 1D-CNN on Structured Data
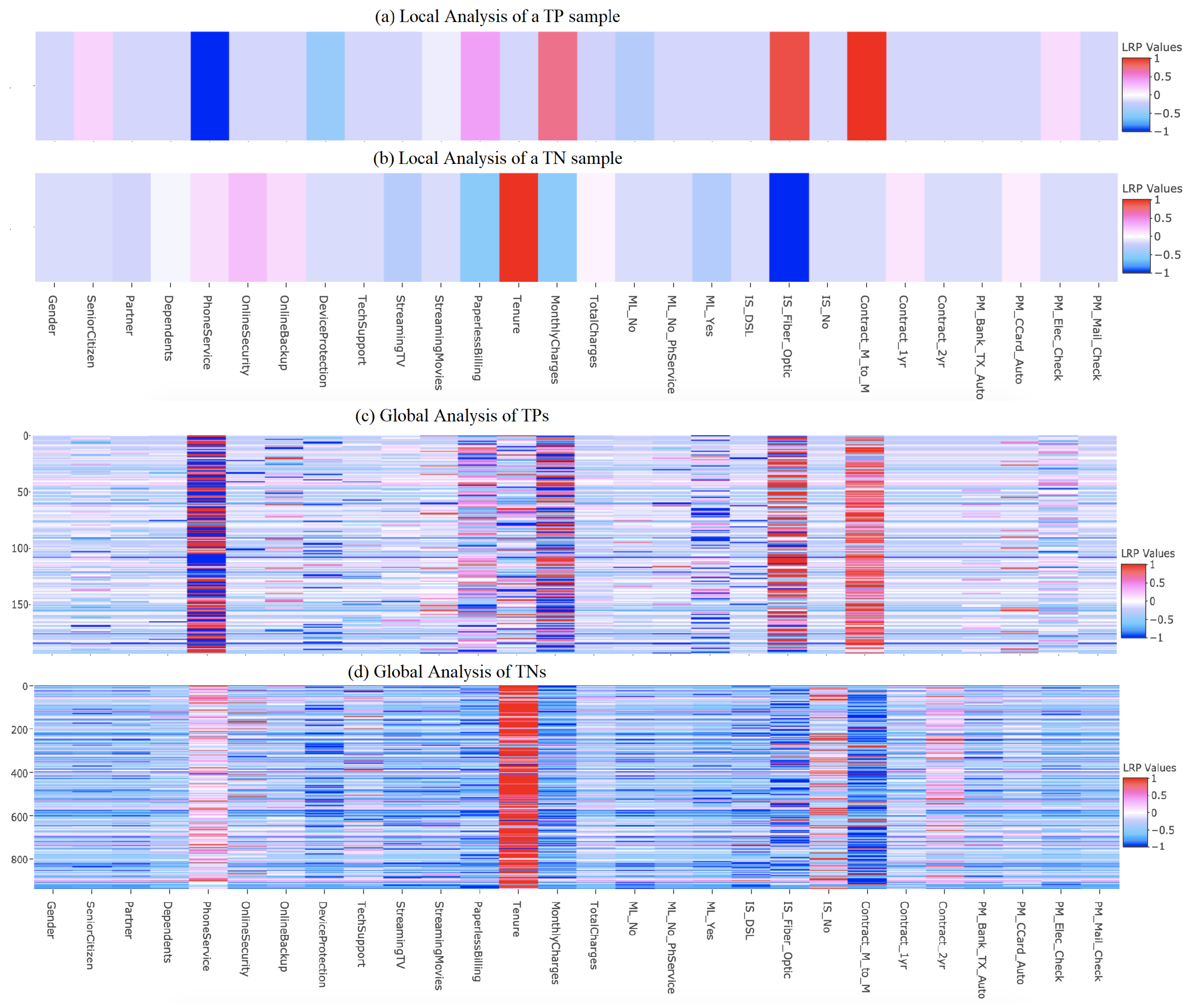
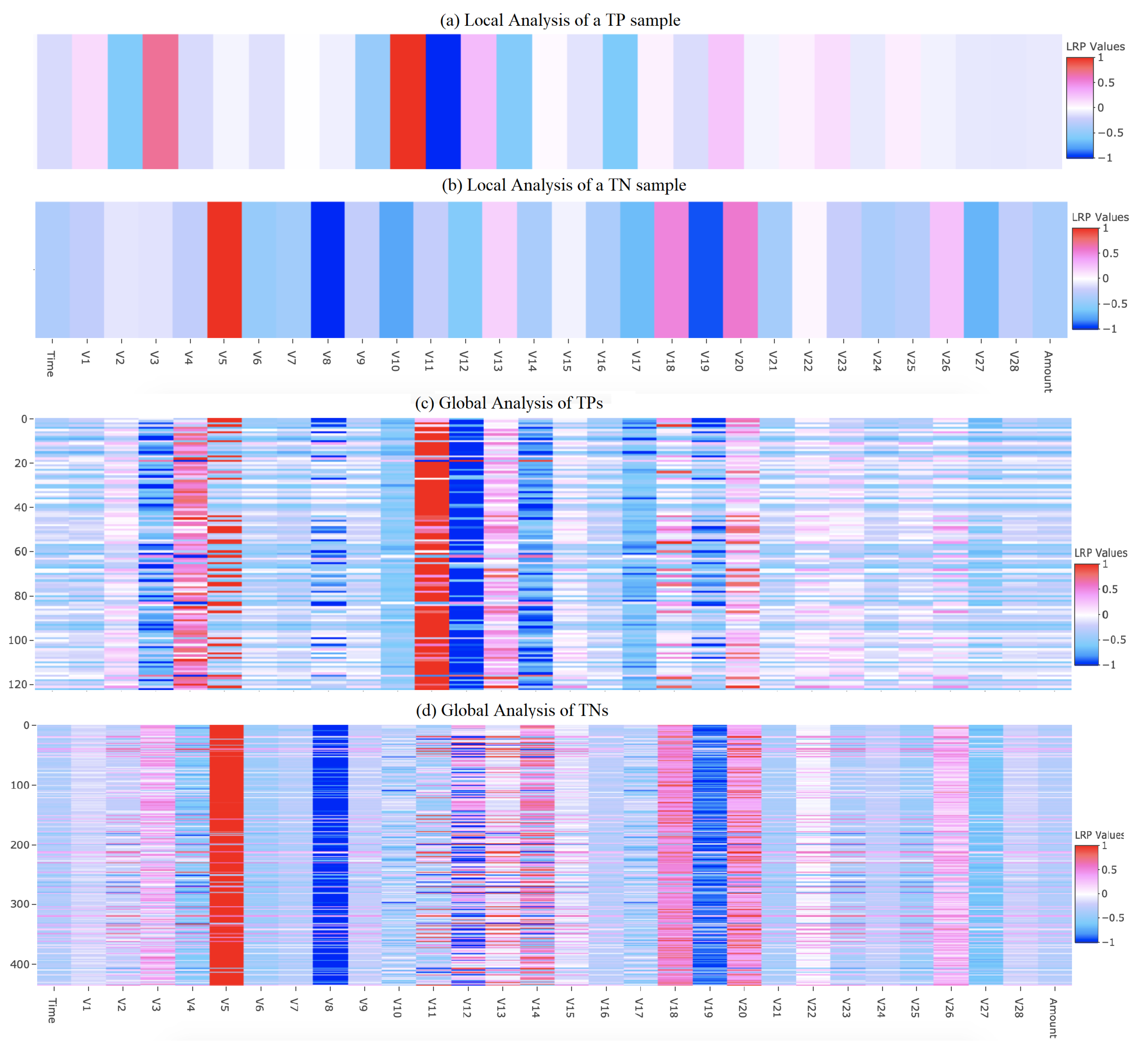
4.2. Visualising Local and Global Heatmaps of Features Using LRP
4.3. Qualitative Comparison of Heatmaps from LRP, SHAP, and LIME
4.4. Validation of the Subset of LRP Highlighted Features Importance
4.5. Comparison with State-of-the-Art
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Gunning, D.; Aha, D. DARPA’s Explainable Artificial Intelligence (XAI) Program. AI Mag. 2019, 40, 44–58. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Kolesnikov, A.; Beyer, L.; Zhai, X.; Puigcerver, J.; Yung, J.; Gelly, S.; Houlsby, N. Large Scale Learning of General Visual Representations for Transfer. arXiv 2019, arXiv:1912.11370. [Google Scholar]
- Xie, S.; Girshick, R.; Dollar, P.; Tu, Z.; He, K. Aggregated Residual Transformations for Deep Neural Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5987–5995. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.; Wang, Y.; Wang, S.; Liang, T.; Zhao, Q.; Tang, Z.; Ling, H. CBNet: A Novel Composite Backbone Network Architecture for Object Detection. arXiv 2019, arXiv:1909.03625. [Google Scholar] [CrossRef]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for MobileNetV3. arXiv 2019, arXiv:1905.02244. [Google Scholar]
- Li, B.; Wu, W.; Wang, Q.; Zhang, F.; Xing, J.; Yan, J. SiamRPN++: Evolution of Siamese Visual Tracking with Very Deep Networks. arXiv 2018, arXiv:1812.11703. [Google Scholar]
- Silver, D.; Huang, A.; Maddison, C.J.; Guez, A.; Sifre, L.; van den Driessche, G.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Lanctot, M.; et al. Mastering the game of Go with deep neural networks and tree search. Nature 2016, 529, 484–489. [Google Scholar] [CrossRef]
- Liu, J.; Chao, F.; Lin, Y.C.; Lin, C.M. Stock Prices Prediction using Deep Learning Models. arXiv 2019, arXiv:1909.12227. [Google Scholar]
- Fang, X.; Yuan, Z. Performance enhancing techniques for deep learning models in time series forecasting. Eng. Appl. Artif. Intell. 2019, 85, 533–542. [Google Scholar] [CrossRef]
- Gasparin, A.; Lukovic, S.; Alippi, C. Deep Learning for Time Series Forecasting: The Electric Load Case. arXiv 2019, arXiv:1907.09207. [Google Scholar] [CrossRef]
- Liu, Y.; Kohlberger, T.; Norouzi, M.; Dahl, G.E.; Smith, J.L.; Mohtashamian, A.; Olson, N.; Peng, L.H.; Hipp, J.D.; Stumpe, M.C. Artificial intelligence–based breast cancer nodal metastasis detection insights into the black box for pathologists. Arch. Pathol. Lab. Med. 2019, 143, 859–868. [Google Scholar] [CrossRef] [Green Version]
- Baehrens, D.; Schroeter, T.; Harmeling, S.; Kawanabe, M.; Hansen, K.; Müller, K.R. How to Explain Individual Classification Decisions. J. Mach. Learn. Res. 2010, 11, 1803–1831. [Google Scholar]
- Malgieri, G. Automated decision-making in the EU Member States: The right to explanation and other “suitable safeguards” in the national legislations. Comput. Law Secur. Rev. 2019, 35, 105327. [Google Scholar] [CrossRef]
- Tjoa, E.; Guan, C. A Survey on Explainable Artificial Intelligence (XAI): Towards Medical XAI. arXiv 2019, arXiv:1907.07374. [Google Scholar] [CrossRef]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Mitchell, M.; Wu, S.; Zaldivar, A.; Barnes, P.; Vasserman, L.; Hutchinson, B.; Spitzer, E.; Raji, I.D.; Gebru, T. Model Cards for Model Reporting. In Proceedings of the Conference on Fairness, Accountability, and Transparency—FAT* ’19, Atlanta, GA, USA, 29–31 January 2019; pp. 220–229. [Google Scholar]
- Guidotti, R.; Monreale, A.; Ruggieri, S.; Turini, F.; Giannotti, F.; Pedreschi, D. A survey of methods for explaining black box models. ACM Comput. Surv. 2018, 51, 1–42. [Google Scholar] [CrossRef] [Green Version]
- Barredo Arrieta, A.; Díaz-Rodríguez, N.; Del Ser, J.; Bennetot, A.; Tabik, S.; Barbado, A.; Garcia, S.; Gil-Lopez, S.; Molina, D.; Benjamins, R.; et al. Explainable Artificial Intelligence (XAI): Concepts, taxonomies, opportunities and challenges toward responsible AI. Inf. Fusion 2020, 58, 82–115. [Google Scholar] [CrossRef] [Green Version]
- Shrikumar, A.; Greenside, P.; Kundaje, A. Learning Important Features Through Propagating Activation Differences. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; Precup, D., Teh, Y.W., Eds.; International Convention Centre: Sydney, Australia, 2017; Volume 70, pp. 3145–3153. [Google Scholar]
- Guo, W.; Mu, D.; Xu, J.; Su, P.; Wang, G.; Xing, X. LEMNA: Explaining Deep Learning Based Security Applications. In Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security, Toronto, ON, Canada, 15–19 October 2018; Association for Computing Machinery: New York, NY, USA, 2018; pp. 364–379. [Google Scholar] [CrossRef]
- Plumb, G.; Molitor, D.; Talwalkar, A. Supervised Local Modeling for Interpretability. arXiv 2018, arXiv:1807.02910. [Google Scholar]
- Guidotti, R.; Monreale, A.; Ruggieri, S.; Pedreschi, D.; Turini, F.; Giannotti, F. Local Rule-Based Explanations of Black Box Decision Systems. arXiv 2018, arXiv:1805.10820. [Google Scholar]
- Chen, J.; Song, L.; Wainwright, M.; Jordan, M. Learning to explain: An information-theoretic perspective on model interpretation. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 883–892. [Google Scholar]
- Lundberg, S.M.; Erion, G.; Chen, H.; DeGrave, A.; Prutkin, J.M.; Nair, B.; Katz, R.; Himmelfarb, J.; Bansal, N.; Lee, S.I. Explainable AI for Trees: From Local Explanations to Global Understanding. arXiv 2019, arXiv:1905.04610. [Google Scholar] [CrossRef]
- Gilpin, L.H.; Bau, D.; Yuan, B.Z.; Bajwa, A.; Specter, M.; Kagal, L. Explaining Explanations: An Overview of Interpretability of Machine Learning. In Proceedings of the 2018 IEEE 5th International Conference on Data Science and Advanced Analytics (DSAA), Turin, Italy, 1–3 October 2018; pp. 80–89. [Google Scholar]
- El-assady, M.; Jentner, W.; Kehlbeck, R.; Schlegel, U. Towards XAI: Structuring the Processes of Explanations. In Proceedings of the ACM Workshop on Human-Centered Machine Learning, Glasgow, UK, 4 May 2019. [Google Scholar]
- Watson, D.S.; Krutzinna, J.; Bruce, I.N.; Griffiths, C.E.; McInnes, I.B.; Barnes, M.R.; Floridi, L. Clinical applications of machine learning algorithms: Beyond the black box. BMJ 2019, 364, l886. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mittelstadt, B.; Russell, C.; Wachter, S. Explaining explanations in AI. In Proceedings of the 2019 Conference on Fairness, Accountability, and Transparency, Atlanta, GA, USA, 29–31 January 2019; pp. 279–288. [Google Scholar]
- Samek, W.; Müller, K.R. Towards Explainable Artificial Intelligence. In Lecture Notes in Computer Science, Proceedings of the Explainable AI: Interpreting, Explaining and Visualizing Deep Learning; Springer: Cham, Switzerland, 2019; pp. 5–22. [Google Scholar]
- Lapuschkin, S.; Wäldchen, S.; Binder, A.; Montavon, G.; Samek, W.; Müller, K.R. Unmasking Clever Hans predictors and assessing what machines really learn. Nat. Commun. 2019, 10, 1096. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why Should I Trust You?”: Explaining the Predictions of Any Classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar]
- Lundberg, S.M.; Lee, S.I. A Unified Approach to Interpreting Model Predictions. In Advances in Neural Information Processing Systems 30; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: New York, NY, USA, 2017; pp. 4765–4774. [Google Scholar]
- Tian, Y.; Liu, G. MANE: Model-Agnostic Non-linear Explanations for Deep Learning Model. In Proceedings of the 2020 IEEE World Congress on Services (SERVICES), Beijing, China, 18–23 October 2020; pp. 33–36. [Google Scholar] [CrossRef]
- Simonyan, K.; Vedaldi, A.; Zisserman, A. Deep inside convolutional networks: Visualising image classification models and saliency maps. In Proceedings of the 2nd International Conference on Learning Representations, ICLR 2014-Workshop Track Proceedings, Banff, AB, Canada, 14–16 April 2014; pp. 1–8. [Google Scholar]
- Arras, L.; Montavon, G.; Müller, K.R.; Samek, W. Explaining Recurrent Neural Network Predictions in Sentiment Analysis. arXiv 2018, arXiv:1706.07206. [Google Scholar]
- Zeiler, M.D.; Krishnan, D.; Taylor, G.W.; Fergus, R. Deconvolutional networks. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010. [Google Scholar]
- Zeiler, M.D.; Taylor, G.W.; Fergus, R. Adaptive deconvolutional networks for mid and high level feature learning. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2018–2025. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In Lecture Notes in Computer Science, Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Cham, Switzerland, 2014; pp. 818–833. [Google Scholar]
- Zhang, Q.; Wu, Y.N.; Zhu, S. Interpretable Convolutional Neural Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–20 June 2018; pp. 8827–8836. [Google Scholar]
- Bach, S.; Binder, A.; Montavon, G.; Klauschen, F.; Müller, K.R.; Samek, W.; Suárez, O.D. On Pixel-Wise Explanations for Non-Linear Classifier Decisions by Layer-Wise Relevance Propagation. PLoS ONE 2015, 10, e0130140. [Google Scholar] [CrossRef] [Green Version]
- Siddiqui, S.A.; Mercier, D.; Munir, M.; Dengel, A.; Ahmed, S. TSViz: Demystification of deep learning models for time-series analysis. IEEE Access 2019, 7, 67027–67040. [Google Scholar] [CrossRef]
- Berg, D. Bankruptcy prediction by generalized additive models. Appl. Stoch. Model. Bus. Ind. 2007, 23, 129–143. [Google Scholar] [CrossRef] [Green Version]
- Calabrese, R. Estimating Bank Loans Loss Given Default by Generalized Additive Models; UCD Geary Institute Discussion Paper Series, WP2012/24; University of Milano-Bicocca: Milano, Italy, 2012. [Google Scholar]
- Taylan, P.; Weber, G.W.; Beck, A. New approaches to regression by generalized additive models and continuous optimization for modern applications in finance, science and technology. Optimization 2007, 56, 675–698. [Google Scholar] [CrossRef]
- Bussmann, N.; Giudici, P.; Marinelli, D.; Papenbrock, J. Explainable AI in Credit Risk Management. SSRN Electron. J. 2020. [Google Scholar] [CrossRef]
- Kraus, M.; Feuerriegel, S. Decision support from financial disclosures with deep neural networks and transfer learning. Decis. Support Syst. 2017, 104, 38–48. [Google Scholar] [CrossRef] [Green Version]
- Kumar, D.; Taylor, G.W.; Wong, A. Opening the Black Box of Financial AI with CLEAR-Trade: A CLass-Enhanced Attentive Response Approach for Explaining and Visualizing Deep Learning-Driven Stock Market Prediction. J. Comput. Vis. Imaging Syst. 2017, 3, 2–4. [Google Scholar] [CrossRef]
- Poerner, N.; Schütze, H.; Roth, B. Evaluating neural network explanation methods using hybrid documents and morphosyntactic agreement. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Melbourne, Australia, 15–20 July 2018; Association for Computational Linguistics: Melbourne, Australia, 2018; pp. 340–350. [Google Scholar] [CrossRef] [Green Version]
- Ullah, I.; Aboalsamh, H.; Hussain, M.; Muhammad, G.; Bebis, G. Gender Classification from Facial Images Using Texture Descriptors. J. Internet Technol. 2014, 15, 801–811. [Google Scholar]
- Nguyen, T.; Park, E.A.; Han, J.; Park, D.C.; Min, S.Y. Object detection using scale invariant feature transform. In Genetic and Evolutionary Computing; Springer: Berlin/Heidelberg, Germany, 2014; pp. 65–72. [Google Scholar]
- Bandi, A. Telecom Churn Prediction dataset. 2019. Available online: https://www.kaggle.com/bandiatindra/telecom-churn-prediction/data (accessed on 15 December 2021).
- ULB, Machine Learning Group. Credit Card Fraud Detection Dataset. 2021. Available online: https://www.kaggle.com/mlg-ulb/creditcardfraud (accessed on 15 December 2021).
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Ullah, I.; Petrosino, A. About pyramid structure in convolutional neural networks. In Proceedings of the 2016 International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016; pp. 1318–1324. [Google Scholar]
- Bandi, A. Telecom Churn Prediction. 2019. Available online: https://www.kaggle.com/bandiatindra/telecom-churn-prediction#EDA-and-Prediction (accessed on 15 December 2021).
- Bachmann, M.J. Credit Fraud || Dealing with Imbalanced Datasets. 2019. Available online: https://www.kaggle.com/janiobachmann/credit-fraud-dealing-with-imbalanced-datasets (accessed on 15 December 2021).
- Arga, P. Credit Card Fraud Detection. 2016. Available online: https://www.kaggle.com/joparga3/in-depth-skewed-data-classif-93-recall-acc-now (accessed on 15 December 2021).
- Sanagapati, P. Anomaly Detection—Credit Card Fraud Analysis. 2019. Available online: https://www.kaggle.com/pavansanagapati/anomaly-detection-credit-card-fraud-analysis (accessed on 25 August 2020).
- Media, V. 250 MB Broadband. 2021. Available online: https://www.virginmedia.ie/broadband/buy-a-broadband-package/250-mb-broadband/ (accessed on 15 December 2021).
- Mckeever, S.; Ullah, I.; Rios, A. XPlainIT—A demonstrator for explaining deep learning models trained over structured data. In Proceedings of the Demo Session of Machine Learning and Multimedia, at 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021. [Google Scholar]
- Raj, P. Telecom Churn Prediction. 2019. Available online: https://www.kaggle.com/pavanraj159/telecom-customer-churn-prediction/notebook (accessed on 25 August 2020).
- Mohammad, N.I.; Ismail, S.A.; Kama, M.N.; Yusop, O.M.; Azmi, A. Customer Churn Prediction In Telecommunication Industry Using Machine Learning Classifiers. In Proceedings of the 3rd International Conference on Vision, Image and Signal Processing, Vancouver, BC, Canada, 26–28 August 2019; Association for Computing Machinery: New York, NY, USA, 2019. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | # of Samples | # +ive Sam | # −ive Sam | %+ive vs. %−ive | O-F | N-F |
|---|---|---|---|---|---|---|
| TCCPD | 7043 | 1869 | 5174 | 26.58 vs. 73.42% | 19 | 28 |
| CCFDD | 285,299 | 492 | 284,807 | 0.172 vs. 99.83% | 30 | 30 |
| Model Name | LR | BatchSize | Iterations | Network Structure |
|---|---|---|---|---|
| M-1D-CNN-1-28 | 0.00001 | 300 | 15,000 | C25-C50-C100-F2200-O2 |
| M-1D-CNN-2-28 | 0.00001 | 200 | 15,000 | C25-C50-C100-F2200-F500-F10-O2 |
| M-1D-CNN-3-16 | 0.00001 | 300 | 15,000 | C25-C50-C100-F200-O2 |
| M-1D-CNN-4-16 | 0.00001 | 300 | 15,000 | C25-C50-C100-C200-F1600-F800-O2 |
| M-1D-CNN-1-31 | 0.00001 | 300 | 15,000 | C25-C50-C100-C200-F4400-O2 |
| M-1D-CNN-2-31 | 0.0001 | 300 | 15,000 | C25-C50-C100-C200-F4400-O2 |
| M-1D-CNN-3-31 | 0.0001 | 200 | 15,000 | C25-C50-C100-C200-F4400-O2 |
| Model Name | Train/Test | Acc | Preci | Recall | Speci | F1-Score | Cross-V |
|---|---|---|---|---|---|---|---|
| M-1D-CNN-1-28 * | 80/20 | 0.8264 | 0.7011 | 0.6189 | 0.9028 | 0.657 | Yes |
| M-1D-CNN-2-28 * | 80/20 | 0.8041 | 0.6727 | 0.5497 | 0.8985 | 0.5978 | Yes |
| Logistic Regression-28 * | 80/20 | 0.7993 | 0.6616 | 0.5221 | 0.9015 | 0.583 | Yes |
| Decision Tree-28 * | 80/20 | 0.7864 | 0.6875 | 0.3794 | 0.9363 | 0.4881 | Yes |
| Random Forest-28 * | 80/20 | 0.7773 | 0.7172 | 0.2842 | 0.9588 | 0.4066 | Yes |
| SVM Linear-28 * | 80/20 | 0.7973 | 0.656 | 0.5209 | 0.8991 | 0.5802 | Yes |
| SVM RBF-28 * | 80/20 | 0.7785 | 0.6358 | 0.4159 | 0.9122 | 0.5023 | Yes |
| XG Boost-28 * | 80/20 | 0.7649 | 0.5727 | 0.4956 | 0.8641 | 0.5311 | Yes |
| Results in Literature | – | – | – | – | – | – | – |
| Logistic Regression [62] | 75/25 | 0.8003 | 0.6796 | 0.5367 | – | 0.5998 | No |
| Random Forest [62] | 75/25 | 0.7975 | 0.6694 | 0.4796 | – | 0.569 | No |
| SVM RBF [62] | 75/25 | 0.7622 | 0.5837 | 0.5122 | – | 0.5457 | No |
| Logistic Regression [56] | 70/30 | 0.8075 | – | – | – | – | No |
| Random Forest [56] | 80/20 | 0.8088 | – | – | – | No | |
| SVM | 80/20 | 0.8201 | – | – | – | – | No |
| ADA Boost [56] | 80/20 | 0.8153 | – | – | – | – | No |
| XG Boost-28 [56] | 80/20 | 0.8294 | – | – | – | – | No |
| Logistic Regression [63] | 80/20 | 0.8005 | – | – | – | – | No |
| Reduced Features Results | – | – | – | – | – | – | – |
| M-1D-CNN-4-16 * | 80/20 | 0.8462 | 0.7339 | 0.6718 | 0.9104 | 0.7014 | Yes |
| M-1D-CNN-5-16 * | 80/20 | 0.8554 | 0.7399 | 0.713 | 0.908 | 0.726 | Yes |
| Logistic Regression-16 * | 80/20 | 0.7996 | 0.6633 | 0.52 | 0.9026 | 0.5823 | Yes |
| Decision Tree-16 * | 80/20 | 0.7871 | 0.6911 | 0.3788 | 0.9374 | 0.4886 | Yes |
| Random Forest-16 * | 80/20 | 0.7807 | 0.7058 | 0.3139 | 0.9521 | 0.4337 | Yes |
| SVM-16 * | 80/20 | 0.7986 | 0.6571 | 0.5278 | 0.8984 | 0.5849 | Yes |
| XG Boost-16 * | 80/20 | 0.7618 | 0.5645 | 0.5035 | 0.8569 | 0.532 | Yes |
| Model Name | Train/Test | Acc | Prec | Recall | Spec | F1-Score | Cross-V |
|---|---|---|---|---|---|---|---|
| M-1D-CNN-1-31 * | 80/20 | 0.9991 | 0.6732 | 0.9520 | 0.9992 | 0.7866 | Yes |
| M-1D-CNN-2-31 * | 80/20 | 0.9989 | 0.6507 | 0.8779 | 0.9992 | 0.7446 | Yes |
| M-1D-CNN-3-31 * | 80/20 | 0.9987 | 0.6079 | 0.8553 | 0.9990 | 0.7037 | Yes |
| Logistic Regression-31 * | 80/20 | 0.9229 | 0.0201 | 0.9044 | 0.9230 | 0.0393 | Yes |
| Decision Tree-31 * | 80/20 | 0.9651 | 0.0442 | 0.8762 | 0.9652 | 0.0840 | Yes |
| Random Forest-31 * | 80/20 | 0.9946 | 0.2232 | 0.8579 | 0.9948 | 0.3533 | Yes |
| Gaussian NB-31 * | 80/20 | 0.9748 | 0.0550 | 0.8474 | 0.9751 | 0.1033 | Yes |
| Logistic Regression [57] | 80/20 | 0.81 | 0.76 | 0.9 | – | 0.82 | No |
| Isolation Forest [59] | 70/30 | 0.997 | – | – | – | 0.63 | No |
| Local Outlier Forest [59] | 70/30 | 0.996 | – | – | – | 0.51 | No |
| SVM [59] | 70/30 | 0.7009 | – | – | – | 0.41 | No |
| Contract_M_to_M | PhoneService | IS_Fiber_Optic | MonthlyCharges | PaperlessBilling | Tenure | PM_CCard_Auto | OnlineBackup | StreamingMovies | ML_Yes | PM_Elec_Check | ML_No_PhService | ML_No | PM_Bank_TX_Auto | StreamingTV | TechSupport | DeviceProtection | Dependents | OnlineSecurity | Partner | SeniorCitizen | PM_Mail_Check | TotalCharges | IS_DSL | IS_No | Contract_1yr | Contract_2yr | Gender | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| LRP | 28 | 27 | 26 | 25 | 24 | 23 | 22 | 21 | 20 | 19 | 18 | 17 | 16 | 12 | 12 | 12 | 12 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| LIME | 26 | 22 | 25 | 1 | 1 | 24 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 21 | 1 | 1 | 23 | 1 | 1 | 1 | 1 | 1 | 26 | 1 | 26 | 1 |
| SHAP | 26 | 25 | 28 | 23 | 1 | 27 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 24 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| V11 | V4 | V5 | V20 | V13 | V18 | V14 | V12 | V3 | V26 | V22 | V2 | V6 | V7 | V8 | V9 | V10 | V1 | Amount | V28 | V15 | V16 | V17 | V19 | V21 | V23 | V24 | V25 | V27 | Time | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| LRP | 30 | 29 | 28 | 27 | 26 | 25 | 24 | 23 | 21 | 21 | 20 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| LIME | 30 | 25 | 1 | 1 | 23 | 1 | 27 | 29 | 24 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 28 | 1 | 1 | 1 | 1 | 1 | 25 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| SHAP | 28 | 27 | 1 | 1 | 25 | 1 | 28 | 30 | 24 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 23 | 1 | 1 | 1 | 1 | 1 | 26 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ullah, I.; Rios, A.; Gala, V.; Mckeever, S. Explaining Deep Learning Models for Tabular Data Using Layer-Wise Relevance Propagation. Appl. Sci. 2022, 12, 136. https://doi.org/10.3390/app12010136
Ullah I, Rios A, Gala V, Mckeever S. Explaining Deep Learning Models for Tabular Data Using Layer-Wise Relevance Propagation. Applied Sciences. 2022; 12(1):136. https://doi.org/10.3390/app12010136
Chicago/Turabian StyleUllah, Ihsan, Andre Rios, Vaibhav Gala, and Susan Mckeever. 2022. "Explaining Deep Learning Models for Tabular Data Using Layer-Wise Relevance Propagation" Applied Sciences 12, no. 1: 136. https://doi.org/10.3390/app12010136
APA StyleUllah, I., Rios, A., Gala, V., & Mckeever, S. (2022). Explaining Deep Learning Models for Tabular Data Using Layer-Wise Relevance Propagation. Applied Sciences, 12(1), 136. https://doi.org/10.3390/app12010136