
Linguistic Patterns and Linguistic Styles for Requirements Specification: Focus on Data Entities


Abstract
1. Introduction
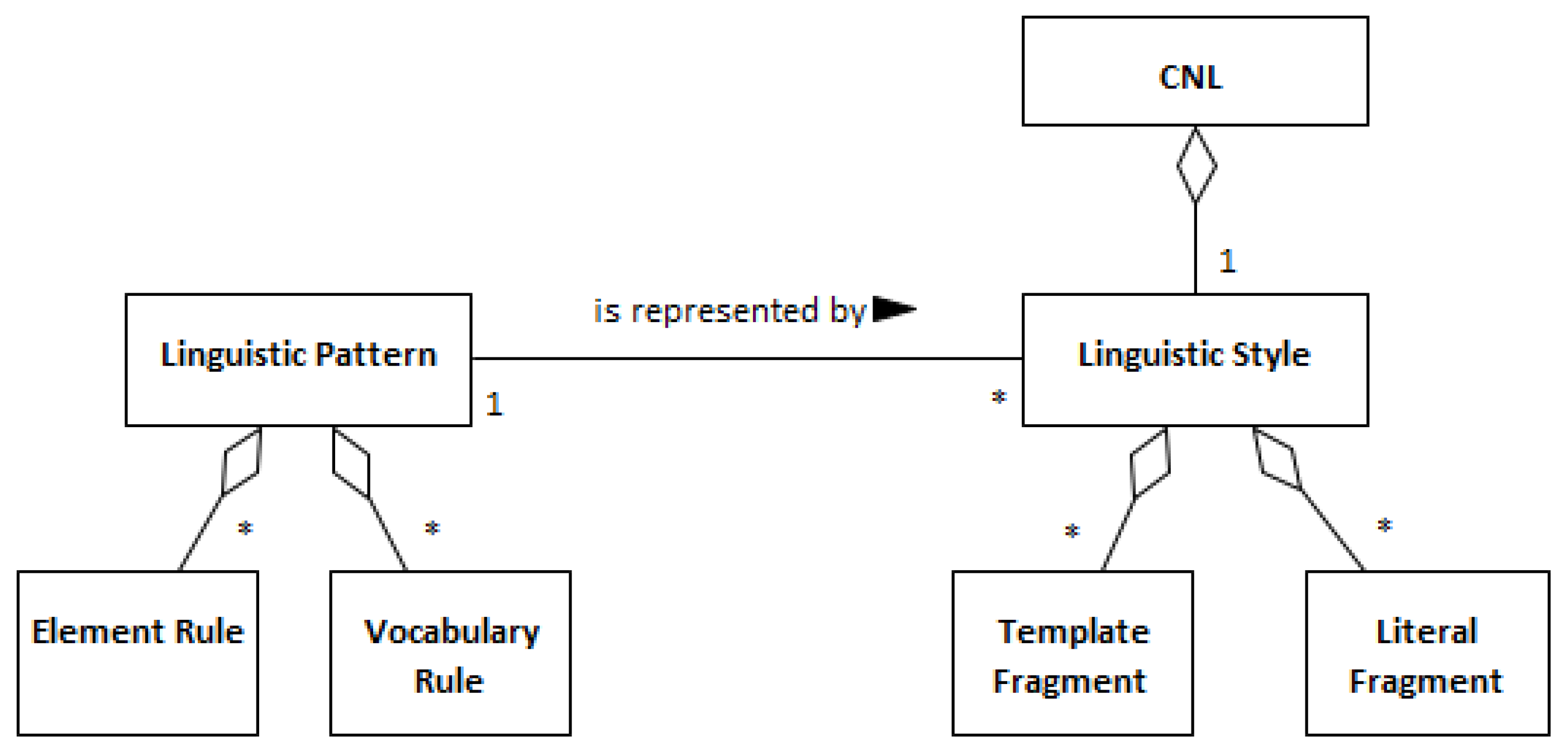
2. Controlled Natural Languages
2.1. CNL-A and CNL-B Languages
KeyUser is a Person Stakeholder.
Customer is a User Actor.
CustomerVIP is a User Actor, extends Customer.
Stakeholder KeyUser (Key User) is a Person, described as a user representative.
Actor Customer is a User, described as a user that buys products from the eShop.
Actor CustomerVIP (Customer VIP) is a User and a Customer, described as a user that buys products from the eShop with a special discount program.
2.2. RSL Language
Stakeholder KeyUser “Key User”: Person [description “a user representative”]
Actor Customer: User [description “a user that buys products from the eShop”]
Actor CustomerVIP “Customer VIP”: User [isA Customer description “a user that buys products from the eShop with a special discount program”]
3. Linguistic Patterns and Linguistic Styles
Actor::
<id:ID> <name:String> <type:ActorType>
<stakeholder:Stakeholder>? <isA:Actor>? <description:String>?
enum ActorType::
User | ExternalSystem
‘Element’ id=ID (name=STRING)? ‘:’ type=ElementType
(‘[‘ ‘isA’ super=[Element])? (‘description’ description=STRING)? [etc.] ‘]’)?
Actor <actor.id> [<actor.name>]? is a <actor.type> [, extends <actor.isA>]? [, associated to the stakeholder <actor.stakeholder>]? [, described as <actor.description>]?.
Actor <id> [<name>]? is a <type> [, extends <isA>]? [, associated to the stakeholder <stakeholder>]? [, described as <description>]?.
‘Actor’ name=ID (nameAlias=STRING)? ‘:’ type=ActorType (‘[‘
(‘isA’ super=[Actor])?
(‘stakeholder’ stakeholder= Stakeholder)
(‘description’ description=STRING)? ‘]’)?
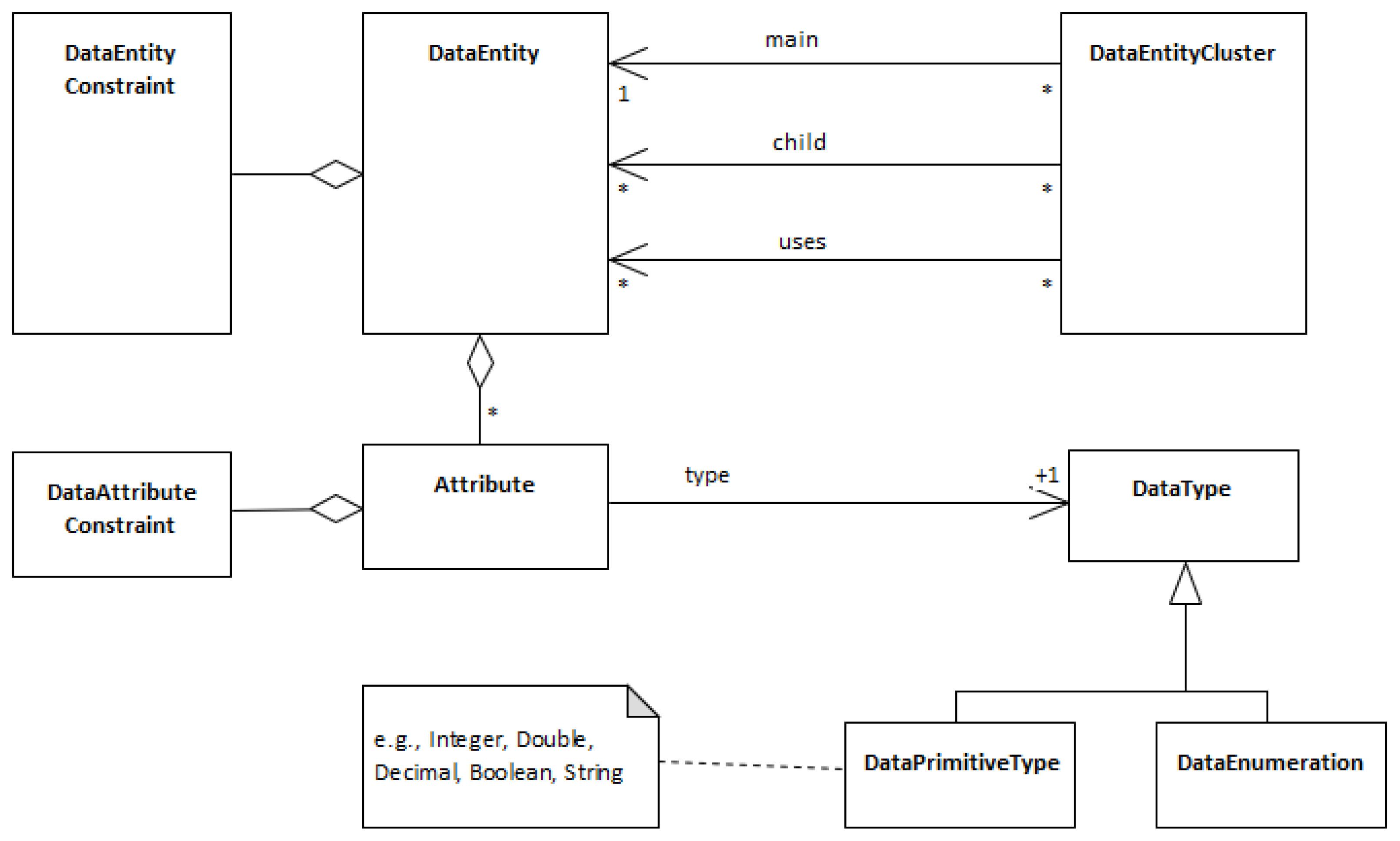
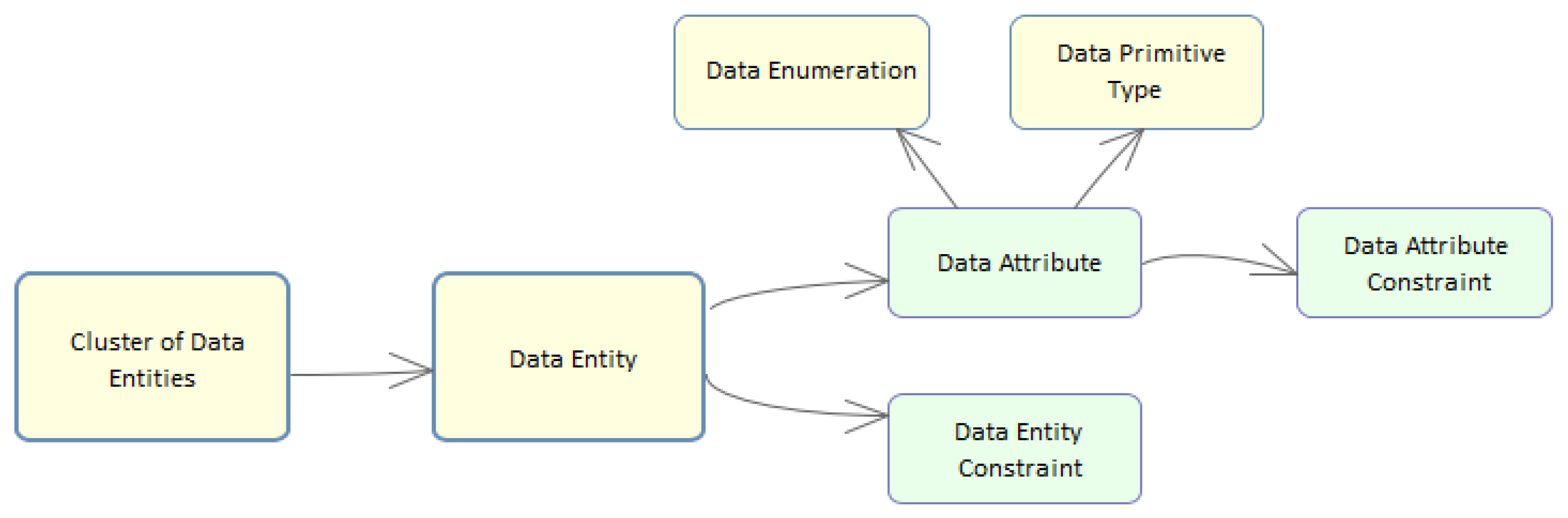
4. Data Entities’ Linguistic Patterns and Linguistic Styles
4.1. Data Entity
4.1.1. Linguistic Pattern
DataEntity::
<id:ID> <name:String>? <type:DataEntityType>
<subType:DataEntitySubType>?
<isA:DataEntity>?
<attributes:DataAttribute>* //see Section 4.2
<constraints:DataEntityConstraint>* //see Section 4.3
<description:String>?
enum DataEntityType:: //see Table 1
Parameter | Reference | Master | Document | Transaction | Other
enum DataEntitySubType:: Regular | Weak
|
lp1
|
4.1.2. Linguistic Styles
Style According to CNL-A (Compact):
<id> [<subType>]? <type> DataEntity [, extends <isA>]?
[, with attributes: <DataAttribute>*]? [, <DataEntityConstraint>]?.
|
ls1-cnl-a
|
Style According to CNL-B (Verbose):
DataEntity <id> (<name>)? Is a [<9ubtype>]?
<type> [ and a <isA>]?
[<DataAttribute>*]? [, <DataEntityConstraint>]?
[, described as <description>]?.
|
ls1-cnl-b
|
Style According to RSL:
‘DataEntity’ name=ID (nameAlias=STRING)? ‘:’ type=DataEntityType
(‘:’ subType=DataEntitySubType)? (‘[‘
(‘isA’ super=[DataEntity | QualifiedName] )?
(attributes+=DataAttribute)*
(constraint=DataEntityConstraint)?
(‘description’ description=STRING)? ‘]’)?
|
ls1-rsl
|
4.1.3. Examples
A VAT consists of the following information: VAT code, rate, name, and value. The VAT rates consider the following values: standard, reduced, and special. […] The system will maintain the following information for products: name, price, VAT rate, VAT value, and size category; a size category consists of one of the following sizes: Small, Regular, Large, ExtraLarge. […] The system will maintain the following information for customers: name, fiscal id, image, bank information, and additional information such as address and personal contacts. A customer can also be defined as a customer VIP, and in this situation, there is a discount tax that can change over time. The operator shall create invoices (with respective details defined as invoice lines). An invoice will have the following information […].
With the CNL-A Style (ls1-cnl-a):
e_VAT Reference DataEntity.
e_Product Master DataEntity.
e_Customer Master DataEntity.
e_CustomerVIP Master DataEntity, extends e_Customer.
e_Invoice Regular Document DataEntity.
e_InvoiceLine Weak Document DataEntity.
With the CNL-B Style (ls1-cnl-b):
DataEntity e_VAT (VAT Category) is a Reference, described as […]
DataEntity e_Product (Product) is a Master, described as […]
DataEntity e_Customer (Customer) is a Master, described as […]
DataEntity e_CustomerVIP (CustomerVIP) is a Master and a e_Customer, described as […]
DataEntity e_Invoice (Invoice) is a Regular Document, described as […]
DataEntity e_InvoiceLine (InvoiceLine) is a Weak Document, described as […]
4.2. Data Attribute, DataPrimitiveType and DataEnumeration
4.2.1. Linguistic Pattern
DataAttribute::
<id:ID> <name:String>? <type:DataType>
<defaultValue:STRING>?
<constraint:DataAttributeConstraint>? //see Section 4.3
DataType::
DataAttributeType | DataEnumeration
enum DataPrimitiveType::
Integer | Double | Decimal | Boolean | Date | Time | Datetime | String | etc.
DataEnumeration::
<id:ID> <name:String>? <values:STRING>*
|
lp2
|
4.2.2. Linguistic Styles
Style According CNL-A (Compact):
//DataAttribute
<id> [default <defaultValue>)]?
//DataEnumeration
<id> DataEnumeration with values: <values>*.
|
ls2-cnl-a
|
Style According CNL-B (Verbose):
//DataAttribute
attribute <id> (<name>)? is a <type> [, default <defaultValue>)]?
//DataEnumeration
DataEnumeration <id> with values (<values>*)
|
ls2-cnl-b
|
Style According to RSL:
//DataAttribute
‘attribute’ name=ID (nameAlias=STRING)? ‘:’ type=DataType (‘[‘
(‘defaultValue’ defaultValue=STRING)? ‘]’)?
//DataEnumeration
‘DataEnumeration’ name=ID
(‘[‘ ‘values’ values+= STRING (‘,’ values+=STRING)* ‘]’)?
|
ls2-rsl
|
4.2.3. Examples
A VAT consists of the following information: VAT code, rate, name, and value. The VAT rates consider the following values: standard, reduced, and special. […]
The system shall maintain the following information for products: name, price, VAT rate, VAT value, and size category; a size category consists of one of the following sizes: Small, Regular, Large, ExtraLarge. […]
With the CNL-A Style (ls2-cnl-a):
SizeKind DataEnumeration with values: Small Regular Large ExtraLarge.VATRateKind DataEnumeration with values: Standard, Reduced, Special.e_VAT Reference DataEntity with attributes: Code, Rate, Name, Value.
e_Product Master DataEntity with attributes: ID, Name, VATCode, VATValue, valueWithoutVAT, valueWithVAT, size.
With the CNL-B Style (ls2-cnl-b):
DataEnumeration SizeKind with values (Small Regular Large ExtraLarge).DataEnumeration VATRateKind with values (Standard, Reduced, Special).
DataEntity e_VAT (VAT Category) is a Reference
attribute Code is a Integer,
attribute Rate is a DataEnumeration VATRateKind,
attribute Name is a String(30),
attribute Value “VAT Class Value” is a Decimal(2.1).
DataEntity e_Product (Product) is a Master
attribute ID “Product ID” is a Integer,
attribute Name “Name” is a String(50),
attribute VATCode “VAT Code” is a Integer,
attribute VATValue “VAT Value” is a Decimal(2.2),
attribute valueWithoutVAT “Price Without VAT” is a Decimal(16.2),
attribute valueWithVAT “Price With VAT” is a Decimal(16.2),
attribute size “Size Category” is a DataEnumeration SizeKind.
4.3. Data Constraint
4.3.1. Linguistic Pattern
DataEntityConstraint:
<isReadOnly:Boolean>? //false by default
<isEncrypted:Boolean>? //false by default
<checks:Check>*
DataAttributeConstraint::
<multiplicity:STRING>?
<isPrimaryKey:Boolean>? //false by default
<isNotNull:Boolean>? //false by default
<isUnique:Boolean>? //false by default
(<isDerived:Boolean> <expression:String>?) //false by default
<isReadOnly:Boolean>? //false by default
<isEncrypted:Boolean>? //false by default
<foreignKey:ForeignKey>?
<checks:Check>*
ForeignKey::
<targetEntity:DataEntity> (<onDeleteType:ForeignKeyOnDeleteType>)?
enum ForeignKeyOnDeleteType::
CASCADE | PROTECT | SET_NULL
|
lp3
|
4.3.2. Linguistic Styles
Style According CNL-A (Compact):
//DataEntityConstraint
([<isReadOnly>? ReadOnly]? [<isEncrypted>? Encrypted]?
[Check (<checks>)]*)
//DataAttributeConstraint
([<multiplicity>]?
[<isPrimaryKey>? PK]? [<isNotNull>? NotNull]? [<isUnique>? Unique]?
[<isDerived>? Derived]?
[<isReadOnly>? ReadOnly]? [<isEncrypted>? Encrypted]?
[FK (<targetEntity>)]?)
|
ls3-cnl-a
|
Style According CNL-B (Verbose):
//DataEntityConstraint
([<isReadOnly>? ReadOnly]? [<isEncrypted>? Encrypted]?
[Check (<checks>)]*)
//DataAttributeConstraint
([multiplicity <multiplicity>]?
[<isPrimaryKey>? PrimaryKey]?
[<isNotNull>? NotNull]? [<isUnique>? Unique]?
[<isDerived>? Derived [(<expression>)]? ]?
[<isReadOnly>? ReadOnly]? [<isEncrypted>? Encrypted]?
[ForeignKey (<targetEntity> [OnDelete <onDeleteType>]?)]?)
|
ls3-cnl-b
|
Style According RSL:
//DataEntityConstraint
(isReadOnly=‘ReadOnly’)?
(isEncrypted=‘Encrypted’)?
(checks+=‘Check’ ‘(‘ checkExpression=STRING ‘)’)*
//DataAttributeConstraint
(‘multiplicity’ multiplicity=Multiplicity)?
(isPrimaryKey=‘PrimaryKey’)?
(isNotNull=‘NotNull’)?
(isUnique=‘Unique’)?
(isDerived=‘Derived’) (‘(‘ ‘from’ expression=STRING) ‘)‘?)?
(isReadOnly=‘ReadOnly’)?
(isEncrypted=‘Encrypted’)?
(foreignKey=ForeignKey)?
(checks+=‘Check’ ‘(‘ checkExpression=STRING ‘)’)*
//ForeignKey
‘ForeignKey’ ‘(‘ entity=[DataEntity]
(‘onDelete’ onDelete= ForeignKeyOnDeleteType )? ‘)’ ;
|
ls3-rsl
|
4.3.3. Examples
With the Style of the CNL-A:
e_VAT is a Reference DataEntity: VATCode (PK), VATName (NotNull), VATValue (NotNull).
e_Product is a Master DataEntity: ID (PK), Name (“1..2”), VATCode (NotNull FK (e_VAT)), VATValue (NotNull Derived), valueWithoutVAT (NotNull), valueWithVAT (NotNull Derived), size.
With the Style of the CNL-B:
DataEntity e_VAT (VAT Category) is a Reference
attribute VATCode “VAT Code” is a Integer (PrimaryKey),
attribute Rate “Rate” is a DataEnumeration VATRateKind,
attribute VATName “VAT Class Name” is a String(30) (NotNull),
attribute VATValue “VAT Class Value” is a Decimal(2.1)(NotNull).
DataEntity e_Product (Product) is a Master
attribute ID “Product ID” is a Integer (PrimaryKey)
attribute Name “Name” is a String(50) (multiplicity “1..2”),
attribute VATCode “VAT Code” is a Integer (NotNull ForeignKey (e_VAT onDelete PROTECT)),
attribute VATValue “VAT Value” is a Decimal(2.2) (NotNull Derived (“e_VAT.VATValue”))
attribute valueWithoutVAT “Price Without VAT” is a Decimal(16.2) (NotNull),
attribute valueWithVAT “Price With VAT” is a Decimal(16.2) (NotNull Derived (“Self.valueWithoutVAT * (1 + Self.VATValue)”)),
attribute size is a DataEnumeration SizeKind.
4.4. Cluster of Data Entities
4.4.1. Linguistic Pattern
DataEntityCluster::
<id:ID> <name:String>? <type:DataEntityClusterType>
<main:DataEntity>
<children:DataEntity>*
<uses:DataEntity>*
<description:String>?
enum DataEntityClusterType::
Parameter | Reference | Master | Document | Transaction | Other;
|
lp4
|
4.4.2. Linguistic Styles
Style According to CNL-A (Compact):
<id> <type> DataEntityCluster with [main <master>]
[, child <children>]* [, uses <uses>]*.
|
ls4-cnl-a
|
Style According to CNL-B (Verbose):
DataEntityCluster <id> (<name>)? is a <type> with
[<master> as the main entity]
[, <children> as child entity]* [, < uses > as uses entity]*
[, <description>]?.
|
ls4-cnl-b
|
Style According to RSL:
‘DataEntityCluster’ name=ID (nameAlias=STRING)? ‘:’ type=
DataEntityClusterType (‘[‘
(main=MainDEntity)
(children+=ChildDEntity)*
(uses+=UseDEntity)*
(‘description’ description=STRING)? ‘]’)?
|
ls4-rsl
|
4.4.3. Examples
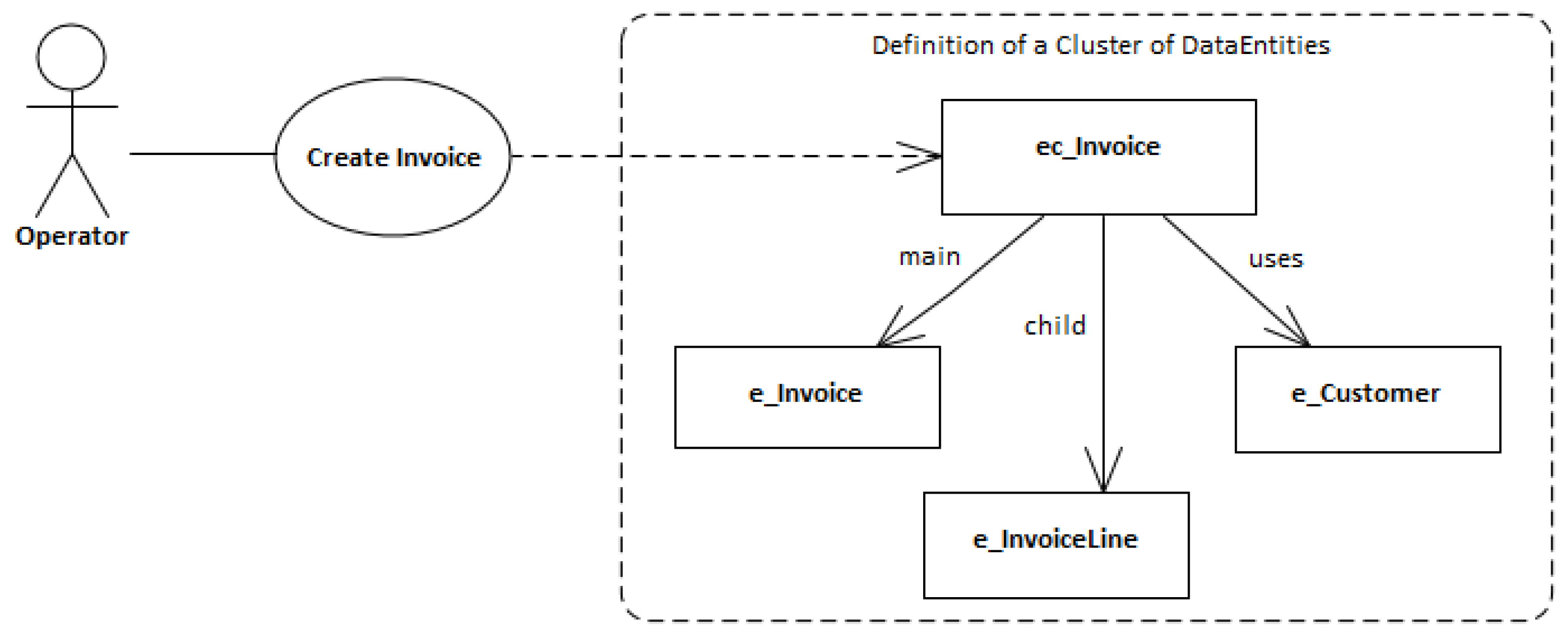
With the Style ls4-cnl-a:
ec_Product Master DataEntityCluster with main e_Product, uses e_VAT.
ec_Invoice Document DataEntityCluster with main e_Invoice, child e_InvoiceLine, uses e_Customer.
With the Style ls4-cnl-b:
DataEntityCluster ec_Product is a Master with e_Product as the main entity, e_VAT as the uses entity.
DataEntityCluster ec_Invoice is a Document with e_Invoice as the main entity, e_InvoiceLine as child entity, e_Customer as the uses entity.
5. Related Work
5.1. Natural Languages
5.2. Formal Method Languages
5.3. Controlled Natural Languages
5.4. Modeling Languages
5.5. CNLs Used in This Paper
5.6. Other Approaches
6. Evaluation Based on a Pilot User Session
6.1. User Session Setup
- The first three questions were focused on the general characterization of the participant.
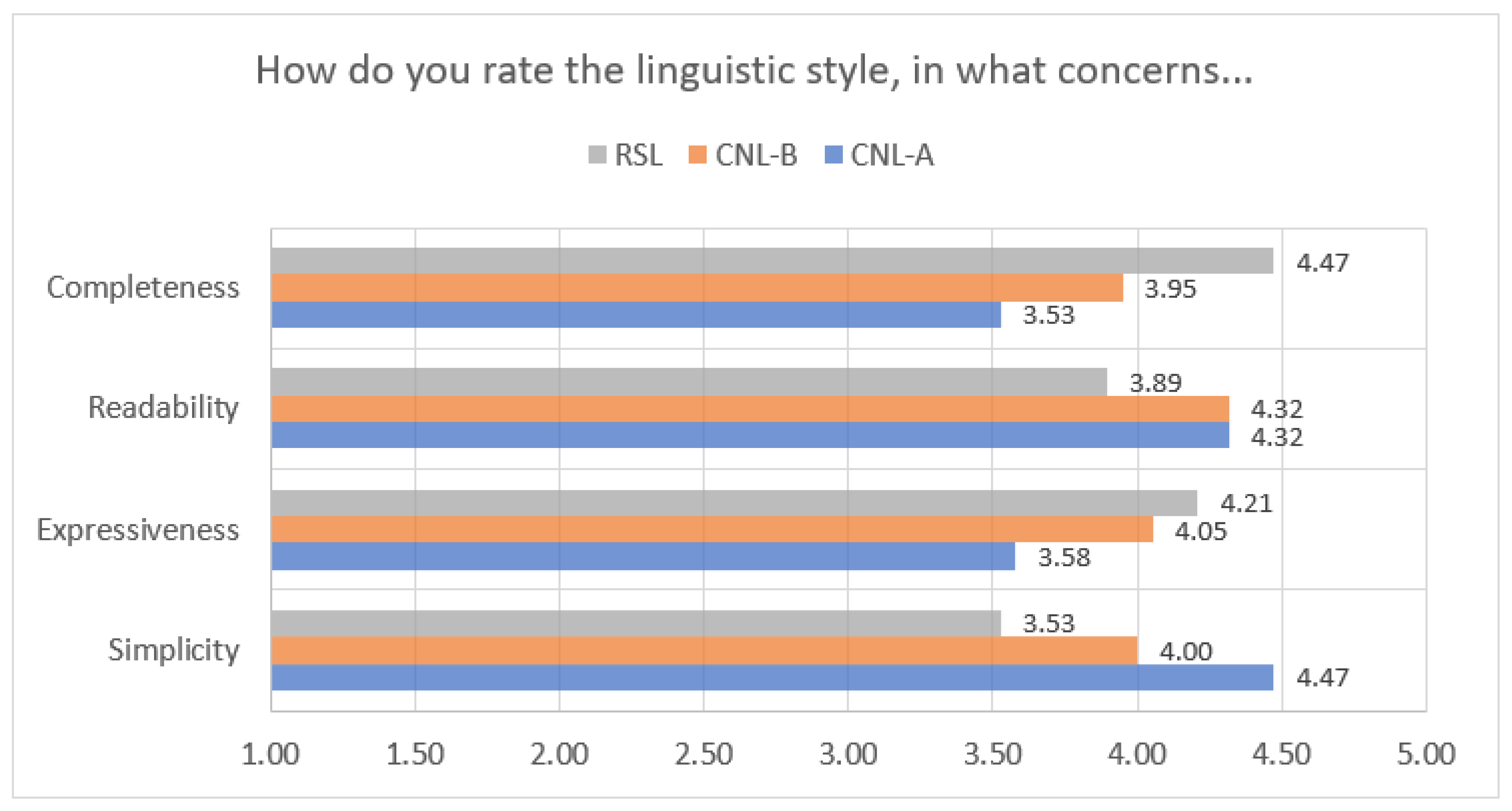
- Five questions directly related to the assessment of the proposed patterns and their styles; we first asked participants to rate in a 5-Likert scale (i.e., from 0 to 5, 0—Do not know, 1-Very Low, 2 -Low, 3-Medium, 4-High, and 5-Very High) how does she rate the proposed linguistic patterns, and How does she rate each linguistic style (i.e., CNL-A, CNL-B, RSL), in what concerns different specific qualities (i.e., simplicity, expressiveness, readability, and completeness).
- Two additional questions were more time-consuming: the participant was challenged to specify some entities informally referred in the case study (and not included in the PDF sent), namely specify the “Invoice”, “InvoiceLine” and “Customer” data entities; finally, the participants were invited to shortly explain her decisions and response.
- The final question asked if the participant had some previous contact with text-based UML notations (e.g., TextUML, Umple, yUML) used for describing domain entities and if she gives advantages to the proposed linguistic styles and notations.
6.2. Questionnaire Analysis
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
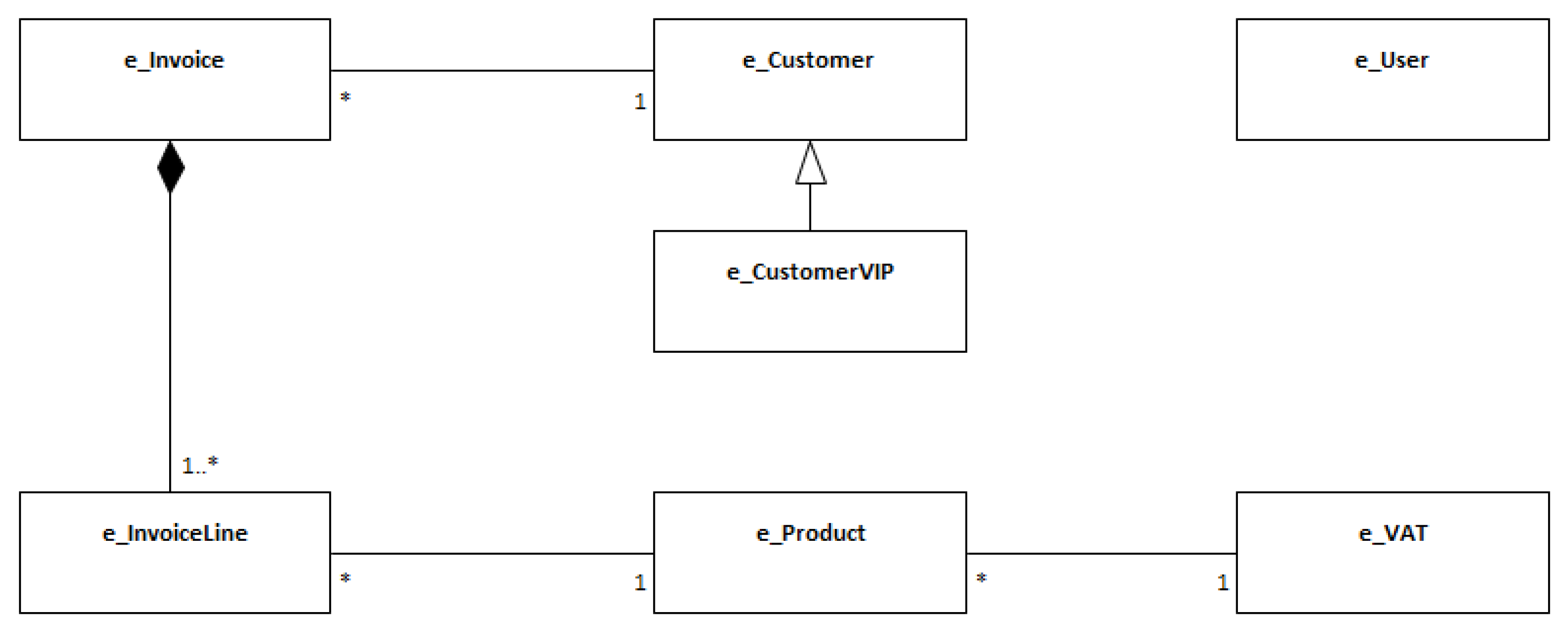
Appendix A. The BillingSystem Running Example
Appendix A.1. Informal and Annotated Informal Description
The BillingSystem is a system that allows its users to manage customers, products, and invoices. A user is someone that has a user account and is assigned to a user role, namely as operator, manager, administrator, and customer […].
The administrator may register users, which involves the following information: first and last names, email address, username, password, and user role […].
A VAT consists of the following information: VAT code, rate, name, and value. The VAT rates consider the following values: standard, reduced, and special. […]
A product consists of the following information: name, price, VAT rate, VAT value, and size category; a size category consists of one of the following values: Small, Regular, Large, ExtraLarge. Product names are strings and prices are decimals. […]
A customer consists of the following information: name, fiscal id, image, bank information, and additional information such as address and personal contacts. A customer can also be defined as a customer VIP, and in this situation, there is a discount tax that can change over time.
The operator shall create invoices with respective details defined as invoice lines.
An invoice shall have the following information: customer id, dates (e.g., of creation, approval, and paid), status (e.g., created, approved, rejected, paid, deleted), total value with and without VAT. Also, an invoice line shall include product id, number of items, product value with and without VAT […].
The BillingSystem is a system that allows its users to manage customers, products, and invoices. A user is someone that has a user account and is assigned to a user role, namely as operator, manager, administrator, and customer […].
The administrator may register users, which involves the following information: first and last names, email address, username, password, and user role […].
A VAT consists of the following information: VAT code, rate, name, and value. The VAT rates consider the following values: standard, reduced, and special. […]
A product consists of the following information: name, price, VAT rate, VAT value, and size category; a size category consists of one of the following values: Small, Regular, Large, and ExtraLarge. Product names are strings and prices are decimals. […]
A customer consists of the following information: name, fiscal id, image, bank information, and additional information such as address and personal contacts. A customer can also be defined as a customer VIP, and in this situation, there is a discount tax that can change over time.
The operator shall create invoices with respective details defined as invoice lines.
An invoice shall have the following information: customer id, dates (e.g., of creation, approval, and paid), status (e.g., created, approved, rejected, paid, deleted), total value with and without VAT. Also, an invoice line shall include product id, number of items, product value with and without VAT […].
Appendix A.2. Data Entities Represented with a Compact Writing Style (CNL-A)
DataEnumerations:
UserRoleKind DataEnumeration with values: Admin, Manager, Operator, Customer.
VATRateKind DataEnumeration with values: Standard, Reduced, Special.
SizeKind DataEnumeration with values: Small Regular Large ExtraLarge.
InvoiceStatusKind DataEnumeration with values: Pending, Approved, Rejected, Paid, Deleted.
DataEntities:
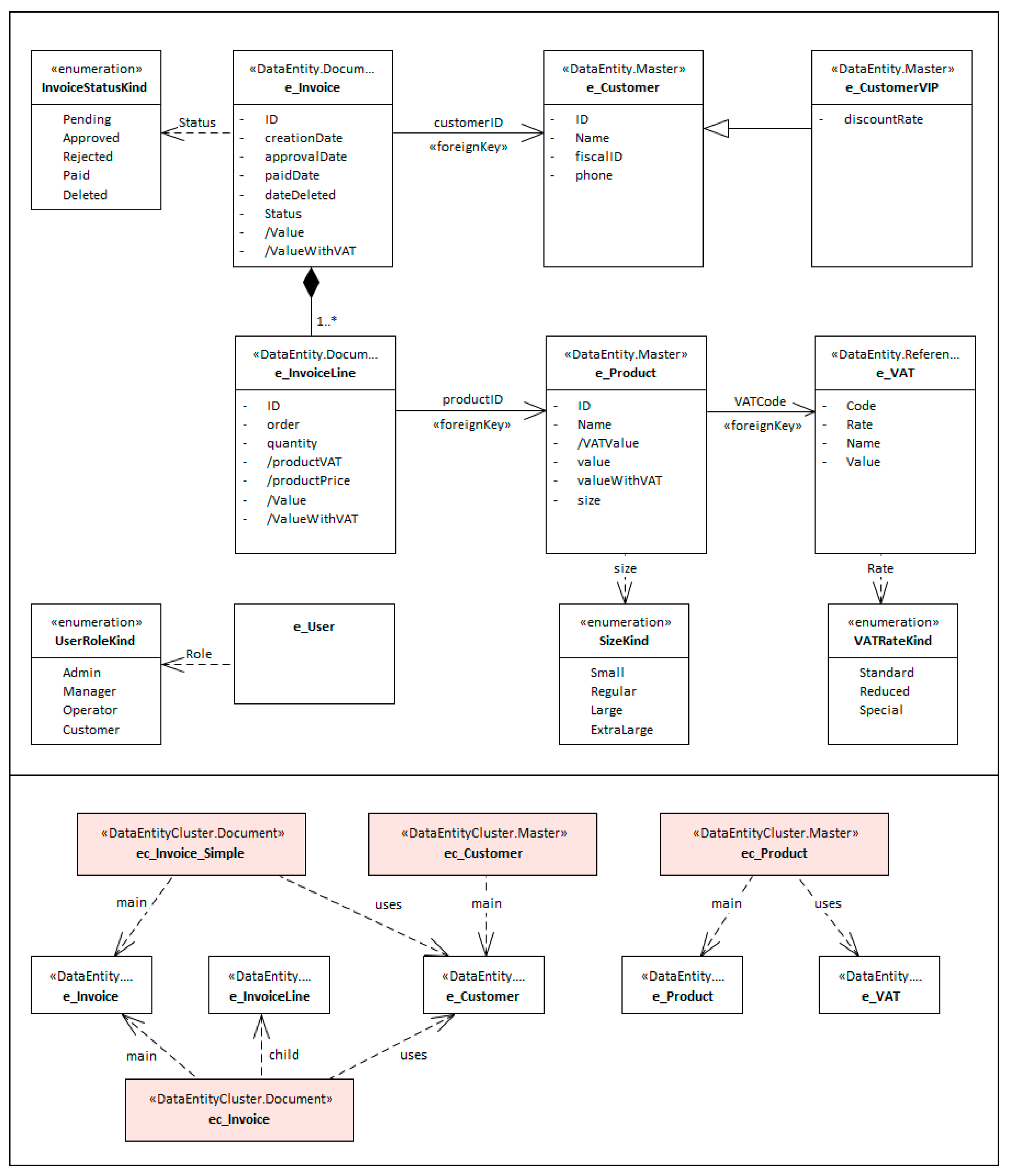
e_VAT Reference DataEntity with attributes: Code (PK), Rate (NotNull), Name, Value (NotNull).
e_Product Master DataEntity with attributes: ID (PK), Name (“1..2”), VATCode (NotNull FK(e_VAT)), VATValue (NotNull Derived), valueWithoutVAT (NotNull), valueWithVAT (NotNull Derived), size.
e_Invoice is a Regular Document DataEntity with attributes: ID (PK), customerId (NotNull FK(e_Customer)), creationDate (NotNull), approvalDate, paidDate, status, valueWithoutVAT (Derived), valueWithVAT (Derived).
e_InvoiceLine is a Weak Document DataEntity with attributes: ID (PK), invoiceID (NotNull FK(e_Invoice)),productID (NotNull FK(e_Product)), numberItems, productVAT (NotNull Derived), productPriceWithoutVAT (NotNull Derived).
e_Customer is a Master DataEntity […].
e_CustomerVIP is a Master DataEntity, extends e_Customer […].
e_User is a Master DataEntity […].
DataEntityClusters:
ec_Customer Master DataEntityCluster with main e_Customer.
ec_Product Master DataEntityCluster with main e_Product, uses e_VAT.
ec_Invoice is a Document DataEntityCluster with main e_Invoice, child e_InvoiceLine, uses e_Customer.
ec_Invoice_Simple Document DataEntityCluster with main e_Invoice, uses e_Customer.
Appendix A.3. Data Entities Represented with a Verbose Writing Style (CNL-B)
DataEnumerations:
DataEnumeration UserRoleKind with values (Admin, Manager, Operator, Customer)
DataEnumeration VATRateKind with values (Standard, Reduced, Special)
DataEnumeration SizeKind with values (Small, Regular, Large, ExtraLarge)
DataEnumeration InvoiceStatusKind with values (Pending, Approved, Rejected, Paid, Deleted)
DataEntities:
DataEntity e_VAT (VAT Category) is a Reference
attribute Code is a Integer (PrimaryKey),
attribute Rate is a DataEnumeration VATRateKind,
attribute Name is a String(30),
attribute Value is a Decimal(2.1)(NotNull).
DataEntity e_Product (Product) is a Master
attribute ID is a Integer (PrimaryKey),
attribute Name is a String(50) (multiplicity “1..2”),
attribute VATCode is a Integer (NotNull ForeignKey (e_VAT onDelete PROTECT)),
attribute VATValue is a Decimal(2.2) (NotNull Derived (“e_VAT.VATValue”)),
attribute value is a Decimal(16.2) (NotNull),
attribute valueWithVAT is a Decimal(16.2) (NotNull Derived (“value*(1+VATValue)”)),
attribute size is a DataEnumeration SizeKind.
DataEntity e_Invoice (Invoice) is a Regular Document
attribute ID is a Integer (PrimaryKey),
attribute customerId is a Integer (NotNull ForeignKey (e_Customer onDelete PROTECT)),
attribute creationDate is a Date (NotNull),
attribute approvalDate is a Date,
attribute paidDate is a Date,
attribute status is a DataEnumeration InvoiceStatusKind,
attribute Value is a Decimal (Derived (“Sum all InvoiceLine->Value of current invoice”)),
attribute ValueWithVAT is a Decimal (Derived (“Sum all (InvoiceLine->ValueWithVAT) of current invoice”)).
DataEntity e_InvoiceLine (Invoice Line) is a Weak Document
attribute ID is a Integer (PrimaryKey),
attribute invoiceID is a Integer (NotNull ForeignKey (e_Invoice onDelete CASCADE)),
attribute productID is a Integer (NotNull ForeignKey (e_Product)),
attribute quantity is a Integer,
attribute productVAT is a Decimal (Derived (“productID->VATCode->Value”)),
attribute productPrice is a Decimal (Derived (“productID->Value”)),
attribute Value is a Decimal (Derived (“quantity * productPrice”)),
attribute ValueWithVAT is a Decimal (Derived (“Value * (1+ productVAT)”)).
DataEntity e_Customer (Customer) is a Master […].
DataEntity e_CustomerVIP (CustomerVIP) is a Master and a e_Customer […].
DataEntity e_User (User) is a Master […].
DataEntityClusters:
DataEntityCluster ec_Customer is a Master with e_Customer as the main entity.
DataEntityCluster ec_Product is a Master with e_Product as the main entity, e_VAT as uses entity.
DataEntityCluster ec_Invoice is a Document with e_Invoice as main entity, e_InvoiceLine as child entity, e_Customer as uses entity.
DataEntityCluster ec_Invoice_Simple is a Document with e_Invoice as the main entity, e_Customer as uses entity.
Appendix A.4. Data Entities Represented with a Rigorous Writing Style (RSL)
DataEnumerations:
DataEnumeration UserRoleKind values (“Admin”, “Manager”, “Operator”, “Customer”)
DataEnumeration VATRateKind values (“Standard”, “Reduced”, “Special”)
DataEnumeration SizeKind values (“Small”, “Regular”, “Large”, “ExtraLarge”)
DataEnumeration InvoiceStatusKind values (“Pending”, “Approved”, “Rejected”, “Paid”, “Deleted”)
DataEntities:
DataEntity e_VAT: Reference [
attribute Code “Code”: Integer
attribute Rate “Rate”: DataEnumeration VATRateKind
attribute Name “Name”: String(30)
attribute Value “Value”: Decimal(2.1) [constraints (NotNull)]
description “VAT Categories”]
DataEntity e_Product: Master [
attribute ID: Integer [constraints (PrimaryKey)]
attribute Name: String(50) [constraints (multiplicity “1..2”)]
attribute VATCode: Integer [constraints (NotNull ForeignKey (e_VAT))]
attribute VATValue: Decimal [constraints (NotNull Derived (“e_VAT.VATValue”))]
attribute Value “Price Without VAT”: Decimal(16.2) [constraints (NotNull) ]
attribute ValueWithVAT “Price With VAT”: Decimal(16.2) [constraints (NotNull Derived (“Value * (1+VATValue)”))]
attribute size: DataEnumeration SizeKind ]
DataEntity e_Invoice: Document: Regular [
attribute ID “Invoice ID”: Integer [constraints (PrimaryKey)]
attribute customer: Integer [constraints (NotNull ForeignKey (e_Customer onDelete PROTECT))]
attribute creationDate “Creation Date”: Date [defaultValue “today” constraints (NotNull)]
attribute approvalDate “Approval Date”: Date
attribute dateIssue “Issue Date”: Date
attribute paidDate “Payment Date”: Date
attribute Status: DataEnumeration InvoiceStatusKind
attribute Value “Total Value Without VAT”: Decimal(16.2) [constraints (NotNull Derived (“Sum all InvoiceLine->Value of current invoice”))]
attribute ValueWithVAT “Total Value With VAT”: Decimal(16.2) [constraints (NotNull Derived (“Sum all InvoiceLine->ValueWithVAT of current invoice”))] ]
DataEntity e_InvoiceLine: Document: Weak [
attribute ID: Integer [constraints (PrimaryKey)]
attribute invoiceID: Integer [constraints (NotNull ForeignKey (e_Invoice onDelete CASCADE))]
attribute order “InvoiceLine Order”: Integer [constraints (NotNull)]
attribute productID: Integer [constraints (NotNull ForeignKey (e_Product onDelete PROTECT))]
attribute quantity “Number of Itens”: Integer
attribute productVAT: Decimal [constraints (Derived (“productID->VATCode->Value”))]
attribute productPrice: Decimal [constraints (Derived (“productID->Value”))]
attribute Value: Decimal [constraints (Derived (“quantity * productPrice”))]
attribute ValueWithVAT: Decimal [constraints (Derived (“Value * (1+ productVAT)”))]
description “InvoiceLines”]
DataEntity e_Customer: Master […]
DataEntity e_CustomerVIP: Master […]
DataEntity e_User: Master […]
DataEntityClusters:
DataEntityCluster ec_Customer: Master [main e_Customer]
DataEntityCluster ec_Product: Master [main e_Product uses e_VAT]
DataEntityCluster ec_Invoice: Document [main e_Invoice child e_InvoiceLine uses e_Customer]
DataEntityCluster ec_Invoice_Simple: Document [main e_Invoice uses e_Customer]
Appendix A.5. Data entities represented visually (based on the UML language)

Appendix B. Summary of Linguistic Patterns for Requirements Specification: Focus on Data Entities
Appendix B.1. Linguistic Patterns
DataEntity
DataAttribute
DataAttributeType
DataAttributeConstraint
DataEntityConstraint
DataEntityCluster
DataPrimitiveType
DataEnumeration
Appendix B.2. Common Vocabulary
DataEntity
DataEntityType: Parameter | Reference | Master | Document | Transaction
DataEntitySubType: Regular | Weak
DataAttribute:
DataAttributeType: DataPrimitiveType | DataEnumeration
DataAttributeConstraint:
Multiplicity(<expression>),
PrimaryKey, NotNull, Unique, ReadOnly, Encrypted,
Derived(<expression>),
ForeignKey(targetDataEntity, onDeleteType(CASCADE | PROTECT | SET_NULL)),
Check(<expression>)
DataEntityConstraint:
ReadOnly, Encrypted,
Check(<expression>)
DataEntityCluster:
DataEntityClusterType: Parameter | Reference | Master | Document | Transaction
main:DataEntity
details:DataEntity
references:DataEntity
DataPrimitiveType: Integer | Double | Boolean | Date | Time | Datetime | String | etc.
DataEnumeration
Appendix B.3. Data Entities’ Linguistic Patterns defined with CNL-B Notation
DataEnumerations:
DataEnumeration DataEntityType with values
(Parameter, Reference, Master, Document, Transaction, Other).
DataEnumeration DataEntitySubType with values
(Regular, Weak, Other).
DataEnumeration DataEntityClusterType with values
(Parameter, Reference, Master, Document, Transaction, Other).
DataEnumeration DataAttributeType with values
(Integer, Double, Decimal, Boolean, Date, Time, Datetime, String).
DataEnumeration ForeignKeyOnDeleteType with values
(CASCADE, PROTECT, SET_NULL, SET_DEFAULT).
DataEntities:
DataEntity DataEnumeration is a Reference
attribute id is a String (NotNull Unique),
attribute name is a String,
attribute values is a String (multiplicity "1..*"),
attribute description is a String.
DataEntity DataEntity is a Regular Master
attribute id is a String (NotNull Unique),
attribute name is a String,
attribute type is a DataEnumeration DataEntityType (NotNull),
attribute subType is a DataEnumeration DataEntitySubType,
attribute isA is a String (ForeignKey (DataEntity onDelete PROTECT)),
attribute description is a String.
DataEntity DataAttribute is a Weak Master
attribute id is a String (NotNull Unique),
attribute name is a String,
attribute type is a DataEnumeration DataAttributeType,
attribute typeAlternative is a String,
attribute defaultValue is a String,
attribute multiplicity is a String,
attribute isPrimaryKey is a Boolean,
attribute isNotNull is a Boolean,
attribute isUnique is a Boolean,
attribute isDerived is a Boolean,
attribute isReadOnly is a Boolean,
attribute isEncrypted is a Boolean,
attribute foreignKey_Target is a String (ForeignKey (DataEntity)),
attribute foreignKey_onDeleteType DataEnumeration ForeignKeyOnDeleteType,
attribute checkExpressions is a String (multiplicity "*").
DataEntity DataEntityCluster is a Master
attribute id is a String (NotNull Unique),
attribute type is a DataEnumeration DataEntityClusterType,
attribute main is a String (ForeignKey (DataEntity)),
attribute children is a String (multiplicity "*" ForeignKey (DataEntity)),
attribute uses is a String (multiplicity "*" ForeignKey (DataEntity)),
attribute description is a String.
References
- Pohl, K. Requirements Engineering: Fundamentals, Principles, and Techniques; Springer: Berlin/Heidelberg, Germany, 2010. [Google Scholar]
- Robertson, S.; Robertson, J. Mastering the Requirements Process, 2nd ed.; Addison-Wesley: Boston, MA, USA, 2006. [Google Scholar]
- Eveleens, L.; Verhoef, C. The Rise and Fall of the Chaos Report Figures. IEEE Softw. 2010, 27, 30. [Google Scholar] [CrossRef]
- Standish Group. Chaos Summary 2009 Report: The 10 Laws of Chaos; Standish Group: Boston, MA, USA, 2009. [Google Scholar]
- Kovitz, B. Practical Software Requirements: Manual of Content and Style; Manning: Shelter Island, NY, USA, 1998. [Google Scholar]
- Withall, S. Software Requirements Patterns; Microsoft Press: Redmond, WA, USA, 2007. [Google Scholar]
- Verelst, J.; Silva, A.R.; Mannaert, H.; Ferreira, D.A.; Huysmans, P. Identifying Combinatorial Effects in Requirements Engineering. In Proceedings of the Third Enterprise Engineering Working Conference (EEWC 2013), Luxembourg, 13–14 May 2013. [Google Scholar]
- Luisa, M.; Mariangela, F.; Pierluigi, N.I. Market research for requirements analysis using linguistic tools. Requir. Eng. 2004, 9, 40–56. [Google Scholar] [CrossRef]
- Fernández, D.M.; Wagner, S.; Kalinowski, M.; Felderer, M.; Mafra, P.; Vetrò, A.; Conte, T.; Christiansson, M.T.; Greer, D.; Lassenius, C.; et al. Naming the Pain in Requirements Engineering: Contemporary Problems, Causes, and Effects in Practice. Empir. Softw. Eng. 2017, 22, 2298–2338. [Google Scholar] [CrossRef]
- Zhao, L.; Alhoshan, W.; Ferrari, A.; Letsholo, K.J.; Ajagbe, M.A.; Chioasca, E.V.; Batista-Navarro, R.T. Natural Language Processing (NLP) for Requirements Engineering: A Systematic Mapping Study. arXiv 2020, arXiv:2004.01099. [Google Scholar]
- Videira, C.; Silva, A.R. Patterns and metamodel for a natural-language-based requirements specification language. In Proceedings of the 17th Conference on Advanced Information Systems Engineering (CAiSE’05 Forum), Porto, Portugal, 13–17 June 2005. [Google Scholar]
- Videira, C.; Ferreira, D.; Silva, A.R. A linguistic patterns approach for requirements specification. In Proceedings of the 32nd Euromicro Conference on Software Engineering and Advanced Applications (Euromicro’2006), Cavtat, Croatia, 29 August–1 September 2006. [Google Scholar]
- Chung, L.; Nixon, B.A.; Yu, E.; Mylopoulos, J. Non-Functional Requirements in Software Engineering; Kluwer Academic: Dordrecht, The Netherlands, 2000. [Google Scholar]
- Cockburn, A. Writing Effective Use Cases; Addison-Wesley: Boston, MA, USA, 2001. [Google Scholar]
- Fernandes, J.M.; Machado, R.J. Requirements in Engineering Projects; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- DeCapua, A. Grammar for Teachers: A Guide to American English for Native and Non-Native Speakers; Springer: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- Durán, A.; Bernárdez, B.; Toro, M.; Corchuelo, R.; Ruiz, A.; Pérez, J. Expressing customer requirements using natural language requirements templates and patterns. In Proceedings of the 3rd IMACS/IEEE International Multiconference on: Circuits, Systems, Communications and Computers (CSCC’99), Athens, Greece, 4–8 July 1999. [Google Scholar]
- Silva, A.R. Linguistic Patterns and Linguistic Styles for Requirements Specification (I): An Application Case with the Rigorous RSL/Business-level Language. In Proceedings of the 22nd European Conference on Pattern Languages of Programs (EuroPLOP’2017), Irsee, Germany, 12–16 July 2017. [Google Scholar]
- Chen, P. The entity-relationship model—toward a unified view of data. ACM Trans. Database Syst. 1976, 1, 9–36. [Google Scholar] [CrossRef]
- Chen, P. English Sentence Structure and Entity-Relationship Diagrams. Inf. Sci. 1983, 29, 127–149. [Google Scholar] [CrossRef]
- Object Management Group. Unified Modeling Language; Version 2.5.1; OMG: Milford, MA, USA, 2017; Available online: http://www.omg.org/spec/UML/ (accessed on 15 April 2021).
- McGuinness, D.L.; Van Harmelen, F. OWL web ontology language overview. W3C Recomm. 2004, 10, 1–22. [Google Scholar]
- Hitzler, P.; Krötzsch, M.; Parsia, B.; Patel-Schneider, P.F.; Rudolph, S. OWL 2 web ontology language primer. W3C Recomm. 2009, 27, 123. [Google Scholar]
- International Organization for Standardization. ISO/IEC 9075-1:2016: Information Technology—Database Languages—SQL—Part 1: Framework (SQL/Framework); ISO: Geneva, Switzerland, 2016. [Google Scholar]
- Da Silva, A.R. Model-driven engineering: A survey supported by the unified conceptual model. Comput. Lang. Syst. Struct. 2015, 43, 139–155. [Google Scholar]
- Hutchinson, J.; Rouncefield, M.; Whittle, J. Model-driven engineering practices in industry. In Proceedings of the 33rd International Conference on Software Engineering, Honolulu, HI, USA, 21–28 May 2011; pp. 633–642. [Google Scholar]
- Bozyiğit, F.; Aktaş, Ö.; Kılınç, D. Linking software requirements and conceptual models: A systematic literature review. Eng. Sci. Technol. Int. J. 2021, 24, 71–82. [Google Scholar]
- Bork, D.; Karagiannis, D.; Pittl, B. A survey of modeling language specification techniques. Inf. Syst. 2020, 87, 101425. [Google Scholar] [CrossRef]
- Schön, E.M.; Thomaschewski, J.; Escalona, M.J. Agile Requirements Engineering: A systematic literature review. Comput. Stand. Interfaces 2017, 49, 79–91. [Google Scholar] [CrossRef]
- Cabot, J. Text to UML and Other “Diagrams as Code” Tools—Fastest Way to Create Your Models. 2020. Available online: https://modeling-languages.com/ (accessed on 1 April 2021).
- Fuchs, N.E.; Kaljurand, K.; Kuhn, T. Attempto controlled English for knowledge representation. In Proceedings of the 4th International Reasoning Web Summer School 2008, Venice, Italy, 7–11 September 2008; pp. 104–124. [Google Scholar]
- Schneider, S. The B-Method: An Introduction; Palgrave Macmillan: London, UK, 2001. [Google Scholar]
- Kuhn, T. A Survey and Classification of Controlled Natural Languages. Comput. Linguist. 2014, 40, 121–170. [Google Scholar] [CrossRef]
- Silva, A.R. Rigorous Specification of Use Cases with the RSL Language. In Proceedings of the 28th International Conference on Information Systems Development (ISD’2019), Toulon, France, 28–30 August 2019. [Google Scholar]
- Bettini, L. Implementing Domain-Specific Languages with Xtext and Xtend; Packt Publishing Ltd.: Birmingham, UK, 2016. [Google Scholar]
- Microsoft. Data Entities Overview: Categories of Entities, Dynamics 365 White Paper. 2019. Available online: https://docs.microsoft.com/en-us/dynamics365/fin-ops-core/dev-itpro/data-entities/data-entities#categories-of-entities (accessed on 1 April 2021).
- Ramakrishnan, R.; Gehrke, J. Database Management Systems, 3rd ed.; McGraw-Hill: New York, NY, USA, 2012. [Google Scholar]
- Connolly, T.M.; Begg, C.E. Database Systems: A Practical Approach to Design, Implementation, and Management, 6th ed.; Pearson Education: London, UK, 2014. [Google Scholar]
- Lamsweerde, A. Requirements Engineering: From System Goals to UML Models to Software Specifications; Wiley: Hoboken, NJ, USA, 2009. [Google Scholar]
- Institute of Electrical and Electronics Engineers. IEEE Std 830-1998, IEEE Recommended Practice for Software Requirements Specifications; IEEE: New York, NY, USA, 1998. [Google Scholar]
- Mernik, M.; Heering, J.; Sloane, A. When and how to develop domain-specific languages. ACM Comput. Surv. 2005, 37, 316–344. [Google Scholar] [CrossRef]
- Ribeiro, A.; Silva, A.; da Silva, A.R. Data Modeling and Data Analytics: A Survey from a Big Data Perspective. J. Softw. Eng. Appl. 2015, 8, 617–634. [Google Scholar] [CrossRef]
- Tudorache, T. Ontology engineering: Current state, challenges, and future directions. Semant. Web 2020, 11, 1–14. [Google Scholar] [CrossRef]
- Vigo, M.; Bail, S.; Jay, C.; Stevens, R.D. Overcoming the pitfalls of ontology authoring: Strategies and implications for tool design. Int. J. Hum. Comput. Stud. 2014, 72, 835–845. [Google Scholar] [CrossRef]
- Jackson, D. Software Abstractions: Logic, Language, and Analysis; The MIT Press: Cambridge, MA, USA, 2012. [Google Scholar]
- Abrial, J.-R.; Lee, M.K.O.; Neilson, D.S.; Scharbach, P.N.; Sørensen, I.H. The B-method. In Proceedings of the 4th International Symposium of VDM Europe (VDM’91), Noordwijkerhout, The Netherlands, 21–25 October 1991. [Google Scholar]
- Foster, H.D.; Krolnik, A.C.; Lacey, D.J. Assertion-Based Design; Springer: Berlin/Heidelberg, Germany, 2004. [Google Scholar]
- Sommerville, I.; Sawyer, P. Requirements Engineering: A Good Practice Guide; Wiley: Hoboken, NJ, USA, 1997. [Google Scholar]
- Schwitter, R. Controlled natural languages for knowledge representation. In Proceedings of the COLING ‘10: Proceedings of the 23rd International Conference on Computational Linguistics, Beijing, China, 23–27 August 2021; Association for Computational Linguistics: Stroudsburg, PA, USA, 2010; pp. 1113–1121. [Google Scholar]
- Hossain, B.A.; Schwitter, R. Semantic Round-Tripping in Conceptual Modelling Using Restricted Natural Language. In Proceedings of the Australasian Database Conference, Melbourne, VIC, Australia, 3–7 February 2020; pp. 3–15. [Google Scholar]
- Savić, D.; Vlajić, S.; Lazarević, S.; Antović, I.; Stanojević, V.; Milić, M.; Silva, A.R. SilabMDD: A Use Case Model-Driven Approach. In Proceedings of the ICIST 2015 5th International Conference on Information Society and Technology, Kopaonik, Serbia, 8–11 March 2015. [Google Scholar]
- Object Management Group. System Modeling Language; Version 1.5; OMG: Milford, MA, USA, 2017; Available online: http://www.omg.org/spec/SysML/ (accessed on 1 April 2021).
- Chen, A.; Beatty, J. Visual Models for Software Requirements; Microsoft Press: Redmond, WA, USA, 2012. [Google Scholar]
- Ribeiro, A.; Silva, A.R. XIS-Mobile: A DSL for Mobile Applications. In Proceedings of the 29th Annual ACM Symposium on Applied Computing (SAC), Gyeongju, Korea, 24–28 March 2014. [Google Scholar]
- Ribeiro, A.; Silva, A.R. Evaluation of XIS-Mobile, a Domain Specific Language for Mobile Application Development. J. Softw. Eng. Appl. 2014, 7, 906–919. [Google Scholar] [CrossRef]
- Seixas, J.; Ribeiro, A.; Silva, A.R. A Model-Driven Approach for Developing Responsive Web Apps. In Proceedings of the 14th International Conference on Evaluation of Novel Approaches to Software Engineering (ENASE’2019), Heraklion, Greece, 4–5 May 2019. [Google Scholar]
- Silva, A.R.; Saraiva, J.; Silva, R.; Martins, C. XIS—UML Profile for eXtreme Modeling Interactive Systems. In Proceedings of the 4th International Workshop on Model Based Methodologies for Pervasive and Embedded Software (MOMPES’2007), Braga, Portugal, 31 March 2007. [Google Scholar]
- Gamito, I.; Silva, A.R. From Rigorous Requirements and User Interfaces Specifications into Software Business Applications. 2020. In Proceedings of the 13th International Conference on the Quality of Information and Communications Technology (QUATIC’2020), Braga, Portugal, 8–11 September 2020. [Google Scholar]
- Wang, Q.; Mao, Z.; Wang, B.; Guo, L. Knowledge graph embedding: A survey of approaches and applications. IEEE Trans. Knowl. Data Eng. 2017, 29, 2724–2743. [Google Scholar] [CrossRef]
- Hogan, A.; Blomqvist, E.; Cochez, M.; d’Amato, C.; de Melo, G.; Gutierrez, C.; Gayo, J.E.L.; Kirrane, S.; Neumaier, S.; Polleres, A.; et al. Knowledge graphs. arXiv 2020, arXiv:2003.02320. [Google Scholar]
- Pan, Z.; Zhuang, X.; Ren, J.; Zhang, X. Pattern-Based Knowledge Graph Embedding for Non-functional Requirements. In Proceedings of the 6th International Conference on Dependable Systems and Their Applications (DSA’2019), Harbin, China, 3–6 January 2020. [Google Scholar]
- Guo, C.; He, T.; Yuan, W.; Guo, Y.; Hao, R. Crowdsourced requirements generation for automatic testing via knowledge graph. In Proceedings of the 29th ACM SIGSOFT International Symposium on Software Testing and Analysis, Virtual Conference, Los Angeles, CA, USA, 18–22 July 2020. [Google Scholar]
- Yanuarifiani, A.P.; Chua, F.F.; Chan, G.Y. Feasibility Analysis of a Rule-Based Ontology Framework (ROF) for Au-to-Generation of Requirements Specification. In Proceedings of the 2020 IEEE 2nd International Conference on Artificial Intelligence in Engineering and Technology (IICAIET’2020), Kota Kinabalu, Malaysia, 26–27 September 2020. [Google Scholar]
- Kim, B.J.; Lee, S.W. Understanding and recommending security requirements from problem domain ontology: A cognitive three-layered approach. J. Syst. Softw. 2020, 169, 110695. [Google Scholar] [CrossRef]
- Gonçalves, L.; Silva, A. Towards a Catalogue of Reusable Security Requirements, Risks and Vulnerabilities. In Proceedings of the 27th International Conference on Information Systems Development (ISD’2018), Lund, Sweden, 22–24 August 2018. [Google Scholar]
- Liu, Y.; Liu, L.; Liu, H.; Li, S. Information recommendation based on domain knowledge in app descriptions for improving the quality of requirements. IEEE Access 2019, 7, 9501–9514. [Google Scholar] [CrossRef]
- Nielsen, J.; Landauer, T.K. A Mathematical Model of the Finding of Usability Problems. In Proceedings of the INTERACT’93 and CHI’93 Conference on Human Factors in Computing Systems, Amsterdam, The Netherlands, 24–29 April 1993. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Description |
|---|---|
| Parameter | Data entity used to define functional or behavioral parameters, for instance, required to set up a deployment or a module for a specific customer; usually, data that contain only one item, where the attributes are values for settings. Common examples of this type are company configuration or application-specific parameters. |
| Reference | Data entity is used to define simple reference data of small quantities, which is required to operate a business process. Common examples of this type are units, dimensions, postal codes, tax codes. |
| Master | Data entity is used to define data assets of the business; in general, these are the “nouns” of the business, which typically fall into categories such as people, places, and concepts. Common examples of this type are customers, vendors, projects, products. |
| Document | Data entity is used to define the operational data of the business, like documents that have complex structures, such as several line items for each header record, and data that is converted into transactions later. Common examples of this type are invoice orders, purchase orders, open balances, blogs, and journals. |
| Transaction | Data entity used to define operational transaction data of the business, like posted transactions. Common examples of this type are closed invoices, closed orders, historical data. |
| Language Category | Language | Scope | Definition (Meta-Language) | Concrete Syntax | PENS Classification |
|---|---|---|---|---|---|
| Natural Language | English | General Communication | [Implicit] | Textual [Tabular] | P1E5N5S1 |
| Formal Language | B Method | Software Engineering | Explicit (BNF Grammar) | Textual | P5E1N1S4 |
| CNL | ACE | Knowledge Representation | Explicit (Rules) | Textual [Tabular] | P4E3N4S3 |
| RNL-ER | Data Modeling | Explicit (Rules) | Textual | P3E2N4S3 | |
| SilabREQ | Software Engineering | Explicit (BNF Grammar) | Textual [Tabular] | P4E2N2S4 | |
| Modeling Language | UML | Software Engineering | Explicit (MOF) | Graphical | P3E3N1S3 |
| SysML | Systems Engineering | Explicit (UML) | Graphical | P3E3N1S3 | |
| RML | Requirements Engineering | [Implicit] | Graphical, Tabular, Form | P2E3N2S2 | |
| XIS* | Software Engineering | Explicit (UML) | Graphical | P4E2N1S3 | |
| CNLs showed in the paper | CNL-A | Requirements Engineering | [Implicit] | Textual [Tabular] | P3E3N4S3 |
| CNL-B | Requirements Engineering | [Implicit] | Textual [Tabular] | P3E4N4S3 | |
| RSL | Requirements Engineering | Explicit (BNF Grammar) | Textual [Tabular, Graphical] | P4E4N3S4 |
| Language Category | Language | Data Entity | DataEntity Cluster | Data Enumeration | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Concept | Type | isA | Constraint | Data Attribute | Concept | Type | Entity Roles | |||||
| Concept | Type | Constraint | ||||||||||
| Natural Language | English | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA |
| Formal Language | B Method | Abstract Machine | N | N | Y: Assertion, Invariant | Property | N | Y: Assertion, Invariant | NA | NA | NA | N |
| CNL | ACE | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA |
| RNL-ER | Entity | N | N | N | Attribute | Y | Y: Multiplicity | N | N | N | N | |
| SilabREQ | Data Concept | N | Y | N | Attribute | Y | N | N | N | N | N | |
| Modeling Language | UML | Class | N | Y | Y: Any Constraint | Attribute | Y | Y: Multiplicity, Derived, Any | N | N | N | Y |
| SysML | Class, Block | N | Y | Y: Any Constraint | Attribute | Y | Y: Multiplicity, Derived, Any | N | N | N | Y | |
| RML | Business Data Object | N | N | Business Rule | Field | Y | Property, Business Rule | N | N | N | N | |
| XIS* | Entity | N | Y | N | Entity Attribute | Y | Y: PK, Null | Business Entity | N | Y | Y | |
| CNLs showed in the paper | CNL-A | Data Entity | Y | Y | Y | Data Attribute | N | Y All | Data Entity Cluster | Y | Y | Y |
| CNL-B | Data Entity | Y | Y | Y | Data Attribute | Y | Y: All | Data Entity Cluster | Y | Y | Y | |
| RSL | Data Entity | Y | Y | Y | Data Attribute | Y | Y: All | Data Entity Cluster | Y | Y | Y | |
| Linguistic Patterns | Result |
|---|---|
| Data Entity (lp1) | 4.58 |
| DataAttribute… (lp2) | 4.00 |
| Data Constraint (lp3) | 3.74 |
| Cluster of Data Entities (lp4) | 4.53 |
| Styles | Simplicity | Expressiveness | Readability | Completeness |
|---|---|---|---|---|
| CNL-A | 4.47 | 3.58 | 4.32 | 3.54 |
| CNL-B | 4.00 | 4.05 | 4.32 | 3.95 |
| RSL | 3.53 | 4.21 | 3.89 | 4.47 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
da Silva, A.R.; Savić, D. Linguistic Patterns and Linguistic Styles for Requirements Specification: Focus on Data Entities. Appl. Sci. 2021, 11, 4119. https://doi.org/10.3390/app11094119
da Silva AR, Savić D. Linguistic Patterns and Linguistic Styles for Requirements Specification: Focus on Data Entities. Applied Sciences. 2021; 11(9):4119. https://doi.org/10.3390/app11094119
Chicago/Turabian Styleda Silva, Alberto Rodrigues, and Dušan Savić. 2021. "Linguistic Patterns and Linguistic Styles for Requirements Specification: Focus on Data Entities" Applied Sciences 11, no. 9: 4119. https://doi.org/10.3390/app11094119
APA Styleda Silva, A. R., & Savić, D. (2021). Linguistic Patterns and Linguistic Styles for Requirements Specification: Focus on Data Entities. Applied Sciences, 11(9), 4119. https://doi.org/10.3390/app11094119