1. Introduction
Disasters are a persistent threat to human well-being, and disaster resilience is of paramount importance to the public. To achieve disaster resilience, technical and organizational resources play vital roles in securing adequate preparation, adaptable response, and rapid recovery [
1]. During the phases of response and recovery, while disaster scenes are possibly still being unfolded, information collection via disaster reconnaissance is crucial for restoring the functionalities of communities and infrastructure systems. Disaster scenes, however, are perishable as a disaster recedes and recovery efforts progress. Traditional remote sensing (RS) technologies via orbital or airborne imaging sensors have long been recognized as a helpful tool that provides geospatial analytics for improving the efficacy of disaster reconnaissance. In general, RS technologies can provide data that record the disaster scenes, including unfolded hazards (e.g., flood inundation) and disastrous consequences (e.g., building damage). However, traditional RS platforms suffer from long time latency due to revisit periods, orbital maneuver, and the ensuing data processing [
2]. Moreover, due to their orbital or airborne view, it is often impossible for traditional RS sensors to capture the elevation view of built objects (e.g., buildings) and other detailed structural conditions. Therefore, although it is less efficient in terms of spatial coverage, ground-based disaster reconnaissance is not replaceable by traditional remote sensing.
In recent years, two emerging RS technologies are changing the normal of disaster reconnaissance. First, due to the ubiquity of digital cameras, smartphones, body-mounted recording devices, and social networking smart apps, which may be collectively termed smart devices, can seamlessly capture, process, and share images. This nearly real-time imaging can record personal and public events, including disasters. Many researchers in Civil Engineering hence recognize the power of mobile devices for aiding disaster response, infrastructure inspection, and construction monitoring [
3,
4,
5,
6]. The second is the use of small unmanned aerial vehicles (UAVs). As witnessed in recent years, since UAVs can provide high-resolution coverage of ground scenes at low above-ground-level (AGL) heights, many research efforts investigate the application of UAV-based RS [
7,
8,
9,
10]. UAV imaging can be deployed with diverse modes, including survey-grade imaging similar to traditional airborne remote sensing.
Nonetheless, recent trends include using a micro-sized UAV as a flying camera at a very low AGL, which is then similar to the imaging with the use of mobile devices, for example, via the so-called ‘follow-me’ drone [
11]. In this paper, the authors propound that this non-traditional RS practice can conduce to the demand for real-time analytics arising from the post-disaster response and recovery activities. By recognizing their primary characteristic of using small and low-cost devices carried or operated by human users or operators, the term
mobile remote sensing is coined in this effort. It is noted that in this paper, the emphasis is on smart device-based imaging and the disaster-scene images from this venue. In the meantime, this choice is supported by the abundance of such images, as researchers have archived a large volume of mobile imagery data from numerous disaster reconnaissance activities (e.g., as found in DesignSafe-CI, a collaborative cloud-based workspace) [
12].
Mobile RS provides untapped opportunities for extracting relevant information and understanding natural disasters. However, significant differences exist when comparing the processing methods for mobile RS images against traditional ones. First, traditional RS images are generally ortho-rectified and geo-referenced when provided for processing and understanding. Because of such geo-readiness, many application efforts concern
change detection, which is to detect landscape differences at different times for a terrain of interest on the Earth surface. As such, besides basic photogrammetric processing methods, a wide range of digital change-detection methods are found [
13,
14,
15,
16,
17]. Mobile RS images differ from traditional ones in that they are often opportunistically collected. Due to their low-altitude or ground-level capturing mode, numerous images at different perspective angles are necessary for characterizing a local scene. Therefore, the involved processing to obtain a full view of the object (e.g., via a 3-dimensional reconstruction process) is much more complex than processing geo-ready images. Second, although mobile RS images can be geo-tagged via geographical positioning services in smart devices, many social or crowdsourced images are often marked with questionable geo-tags or simply have not geo-tags [
18,
19]. Last, traditional RS images captured at different times can give rise to a time-series coverage for a particular region, whereas mobile RS data lacks such temporal advantages. These differences imply that one cannot use the traditional photogrammetric processing and change-detection methods to deal with mobile RS images that are arranged spatially and temporally non-structural. From this point of view, the process of processing and understanding mobile RS images, including extraction, interpretation, and localization of objects in images, belong to the general
image understanding problem as defined in the computer or machine vision literature [
20,
21]. By borrowing this concept,
image-based disaster-scene understanding is coined in this paper, which is defined as a computational process of extracting information and detecting features or objects from images relevant to interpret a disaster. As will be further elaborated, research gaps exist towards a more cognitive mobile RS-based disaster-scene understanding.
This paper contributes to the knowledge by developing and testing a deep-learning framework to understand disaster scenes. In this framework, the proposed learning models identify two essential properties in a given disaster image (namely the hazard type and the disaster-induced damage level). Performance evaluation reveals the insights in understanding disaster scenes in mobile images, including that the general damage-level classification is more challenging than hazard-type recognition. To achieve the goal, the authors built a multi-hazard disaster database with images from multiple sources, which forms another contribution of this paper. In the following, the specific research problems and challenges are defined. The methodology framework is proposed, including data preparation, network architectures and adjustment for two deep-learning models, and transfer-learning-based training. Three strategically designed deep-learning models are evaluated in this paper, followed by a comprehensive discussion. Conclusions are then given based on the research findings in this paper.
2. Research Problems and Challenges
Disaster scenes from extreme events, such as hurricanes, floods, earthquakes, tsunamis, and tornadoes, are considerably complex. From the perspective of naked eyes, a disaster scene includes countless visual patterns related to built objects, natural hazards, landscapes, human activities, and many others. The semantic attributes for labeling patterns relevant to this effort are named hazard-type and damage-level. The rationale for this proposition is justified as follows by examining the practice of professional reconnaissance activities.
It is a cognitive process when professionals in a disaster field conduct digital recording via cameras or smart apps, e.g., Fulcrum [
22]. To the trained eyes of professional engineers, their attention can be quickly paid to the visual patterns of interest, the built objects, the apparent damage features (e.g., cracking or debris), and other clues that are relevant to damage due to the extraordinary intelligence of human beings and their professional training. For example, a post-tsunami image often contains inundation marks or water-related textures, whereas the post-earthquake images usually show conspicuous cracking in buildings or cluttered debris. For tornado scenes, the damaging effects usually lie on the roof or the upper area of buildings, showing peeled surface materials due to wind blowing and shearing. In sum, professionals often act as a detective while conducting a forensic engineering process. In this process, they record the consequential evidence of damage in built objects using digital images. They further look for cues that cause the damage, namely the causal evidence of hazardous factors, which may co-exist in the same image of damaged objects or are recorded in different images. Second, this cognitive process continues in written reports by professionals, where the images are often showcased with captions or descriptions. Domain knowledge is more involved in this process, wherein the engineers tend to use a necessary number of images to analyze the common evidence of hazards and damage in images, then remark the intensity of the hazard and the degree of damage rationally, and even further, infer the underlying contributing factors, such as structural materials and geological conditions. Indeed, this has been called a
learning from disaster in engineering communities as demonstrated in many disaster reconnaissance reports (e.g., [
23]).
This cognitive understanding and learning process rarely occurs when the crowd conducts it as they lack domain knowledge. Also, even it is conducted by professionals, they may seek to excessively record disaster scenes yet without describing and reporting all images. As mentioned earlier, digital archives and social networks to this date have stored a colossal volume of images recording extreme events in recent years, which are not exploited or analyzed in the foreseeable future. This accumulation will inevitably be explosive with the advent of ubiquitous use of personal RT devices, for example, body-mounted or flying micro-UAV cameras.
In this paper, inspired by the practical cognitive process of disaster-scene understanding, the authors argue an identifiable causality pair in a disaster-scene image, the hazard applied to and the damage sustained by built objects in images. This identifiable causality, more specifically termed disaster-scene mechanics, gives rise to the fundamental research question in this effort: does a computer-vision-based identification process exist that can process and identify hazard and damage related attributes in a disaster-scene image? To accommodate a computer-vision understanding process, the attributes are reduced to be categorical. As such, two identification tasks are defined in this paper:
- (1)
Given a disaster-scene image, one essential task is to recognize the contextual and causal property embedded in the image, namely the Hazard-Type.
- (2)
The ensuing identification is to estimate the damage-level for an object (e.g., a building).
It is noted that compared with human-based understanding found in professional reconnaissance reports, the underlying intelligence is much reduced in the two fundamental problems defined above. Regardless, significant challenges exist toward the images-based disaster-scene understanding process.
The challenges come from two interwoven factors: the scene complexity and the class variations. To illustrate the image complexity and the uncertainties, sample disaster-scene images are shown in
Figure 1, which are manually labeled with hazard-type and damage-level. Observing
Figure 1 and other disaster-scene images, the first impression is that image contents in these images are considerably rich, containing any possible objects in natural scenes. Therefore, understanding these images belong to the classical scene understanding problem in Computer Vision [
24,
25], which is still being tackled today [
26]. In terms of variations, as one inspects the image samples in
Figure 2, it is relatively easy to distinguish the hazard-type if the images show visual cues of water, debris, building, and vegetation patterns. However, when labeling damage-level, it is observed that the ‘Major’ or ‘Minor’ damage-level is relatively easy to identify, whereas the ‘Moderate’ possess significant uncertainties between different observers or even the same observer at different moments, which are collectively called inter-class variations. As one inspects more images, the variations are extensively observed within images that fall in the same class in terms of either the same hazard-type or damage-level, known as intra-class variations [
27]. The effects of these variations are two-fold. First, human-based labeling is more likely to be erroneous, which increases the theoretical lower-bound decision errors. Second, they challenge any machine-learning candidate model if it has a low capacity in representing the complexity or weak discriminative power to deal with the class variations.
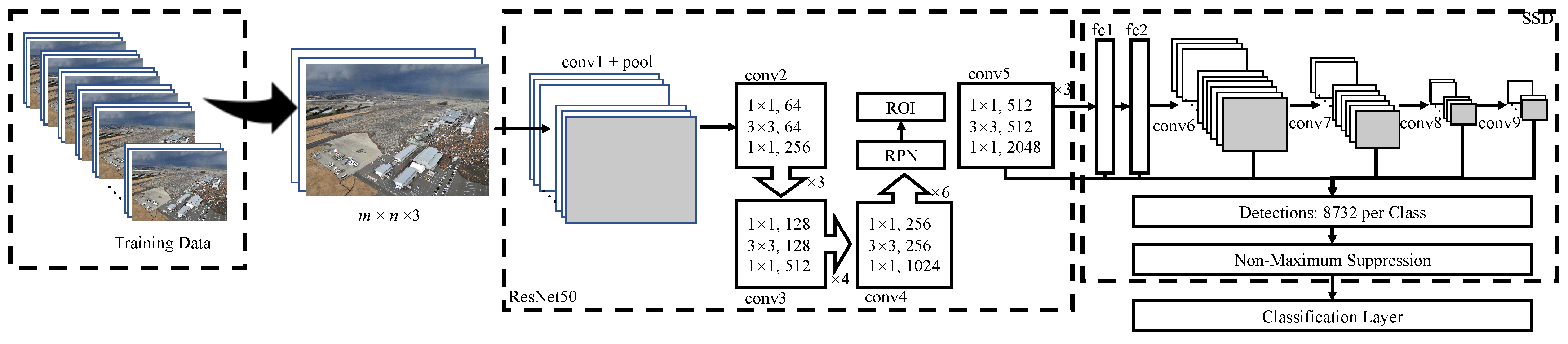
The scene complexity and the conjunct inter-class and intra-class variations pose significant challenges in constructing a supervised learning-based model. Such a model should be high-capacity to encode the complexity in images and be sufficiently discriminative to identify class boundaries in the feature space. By considering these demands, the bounding-box-based object-detection models are selected in this paper. A review of related background is given in the following.
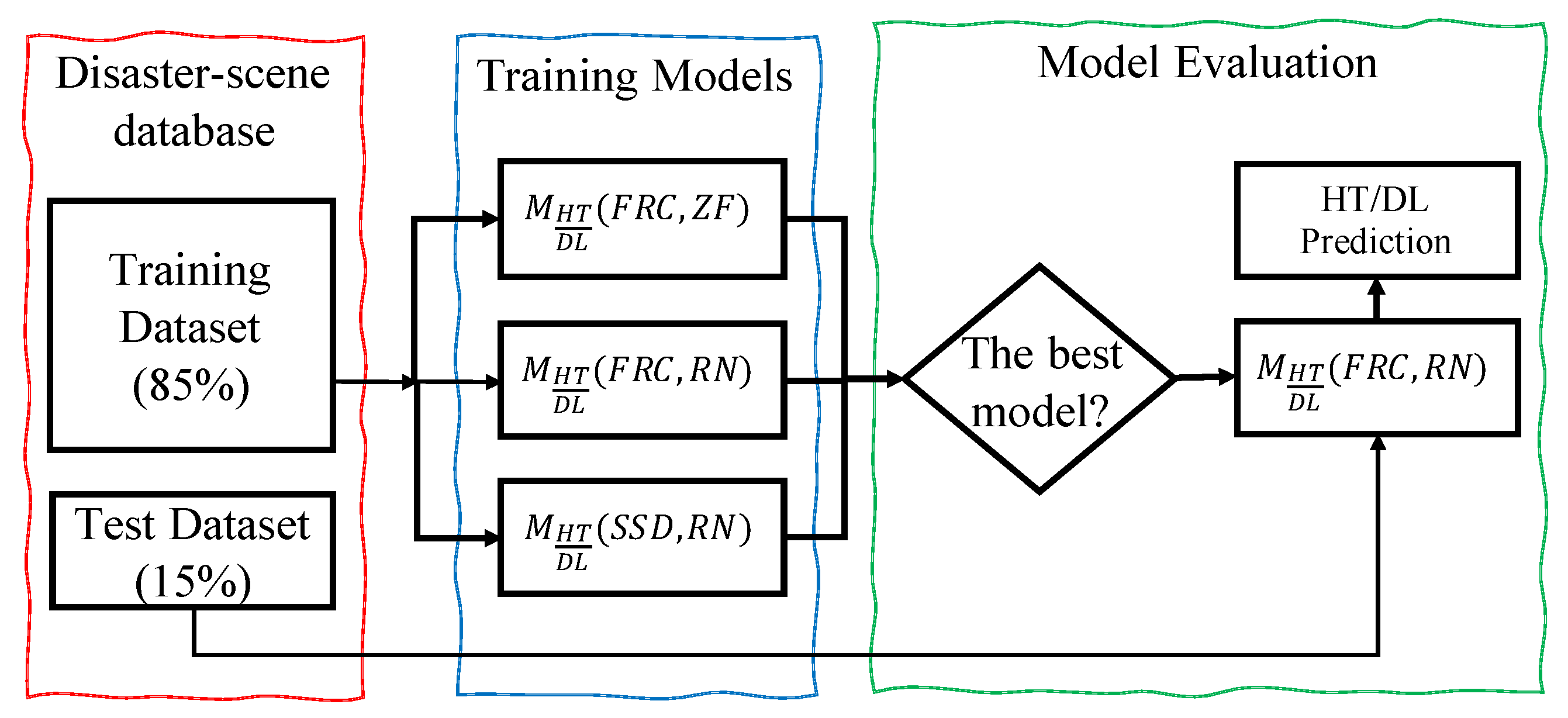
4. Performance Evaluation
With the deep-learning models defined previously, this section aims to conduct experimental testing based on the multi-hazard disaster-scene dataset prepared in this work. Quantitative performance measures and graphical analytics are used for this purpose. It is noted that similar to the conventional treatment in bounding-box-based objection detection, it is the class labels that are evaluated. Bounding boxes are used as a visual reference to exam if proper attention zones are produced.
4.1. Performance Measures
The simplest and basic performance measures are based on the calculation of prediction rates given a set of known class labels and classification labels, resulting in the counting of four prediction consequences, including the number of true-positive (TP), true-negative (TN), false-negative (FN), and false-positive (FP) predictions. With these counts, simple accuracy measures, including the confusion matrix, the Overall Accuracy (), and the Average Accuracy (), can be defined. These simple accuracy measures may be misleading in practice, particularly when the learning data is imbalanced. In this work, a comprehensive set of performance metrics, including scalar and graphic metrics, are adopted.
Precision and recall are improved performance measures in the field of information retrieval and statistical classification, also widely used in the deep-learning-based object-detection literature. The precision is the ratio of the number of positive samples to the total number retrieved (defined as ). It reflects the ability of a model to predict only the relevant instances. The recall rate refers to the ratio of the number of positive samples retrieved and the number of all truly positive samples in the dataset (defined as . The recall indicates the ability of a model to find all relevant instances. The two measures are coupled; in general, when both measures approach 1, they reflect a more accurate model. However, practical models often achieve higher precision and low recall or vice versa. Based on precision and recall, the score, which is the harmonic mean of precision and recall, quantifies the balanced performance of a classification model.
The precision and recall can be evaluated using a default threshold value (i.e., 0.5) in the classification layer. By varying the underlying classification threshold, a precision-recall curve (PRC) can be plotted. Technically, a maximal F-1 measurement (and the optimal threshold) can be recognized from this PRC curve. Another graphical evaluation approach, called the Receiver Operating Characteristic (ROC) curve, is often used in the literature on machine learning. A ROC is created by plotting the true-positive rate (which is the same as the recall measure) against the false-positive rate, during which the classification threshold varies as well. Given a PRC or ROC associated with an acceptable classification model, one usually observes that as the recall (or the true-positive rate) increases, the precision decreases, and the false-positive rate increases. Last, it is noted that with the ROC curve, the area under the ROC curve () can be used as a lumped measure that indicates the overall capacity of the model. In this paper, the baseline confusion matrices, four performance statistics , score, , and , and two graphical curves (PRC and ROC curves) are used as performance measures.
4.2. Model Performance
The performance of the predictive models for hazard-type and damage-level classification is evaluated separately in this section. In each case, besides the straightforward confusion matrix, the scalar accuracy measures, including the score, the overall accuracy (), the average accuracy (), and the area under the ROC curve () are jointly considered. The graphical ROC and PRC of the best models selected in this paper are further used to examine the model capacity and robustness.
4.2.1. Hazard-Type Prediction Performance
Three hazard-type prediction models are assessed herein (
Table 1).
Figure 7 demonstrates four sample prediction results from
. In each predicted instance, both ground-truth and predicted information are annotated, including the bounding boxes, the class labels, and the prediction scores. Regarding the bounding-box prediction, first, it is observed that our strategy of emphasizing the spatial boundaries of damaged buildings is largely confirmed. In all cases, the bounding boxes tend to envelop the buildings. It is observed that for tornado scenes, as illustrated in
Figure 7a,b, both bounding boxes and hazard-type are more accurately detected. For earthquake and tsunami scenes, instances exist that are challenging to differentiate for human analysts if one inspects
Figure 7c,d. Nonetheless, the model largely has learned the salient differences in terms of geometric distinction of debris patterns. In addition, while outlining the bounding box in
Figure 7d, it seems that the analyst emphasizes the salient region that can inform the tsunami hazard-type. Therefore, a smaller box is given. In terms of discriminating its damage-level, it is excessively small.
Based on the testing data, the accuracy measurements are reported in two tables.
Table 2 reports the confusion matrix for each hazard-type model. In
Table 3, four accuracy measures are listed, including the AUC based on the ROC curve as a measure of model capacity, the
score as the primary accuracy measure, and the
as a simple accuracy measure. These three measures are calculated as different class labels (the hazard-type of Tornado, Tsunami, and Earthquake). Then the overall accuracy measure,
, is given for each model. The following observations are summarized based on these performance measurements.
First, the high scores of both the FRC-based models signify their higher prediction capacities than the SSD model at all hazard types. In terms of the scores, the FRC-based models again show much greater accuracy than the SSD model. If the scores alone are compared, one may see that when the Resnet-50 is used as the feature extractor, slightly better classification accuracy is observed than the ZF-based model. The measure shows a consistent trend as the score. On the other hand, when the SSD model is concerned, even with the more competitive feature extractor (ResNet-50), its accuracy drops significantly. Based on this evidence, it is argued that the use of Faster R-CNN as the basis for hazard-type prediction is superior to the SSD-based architecture.
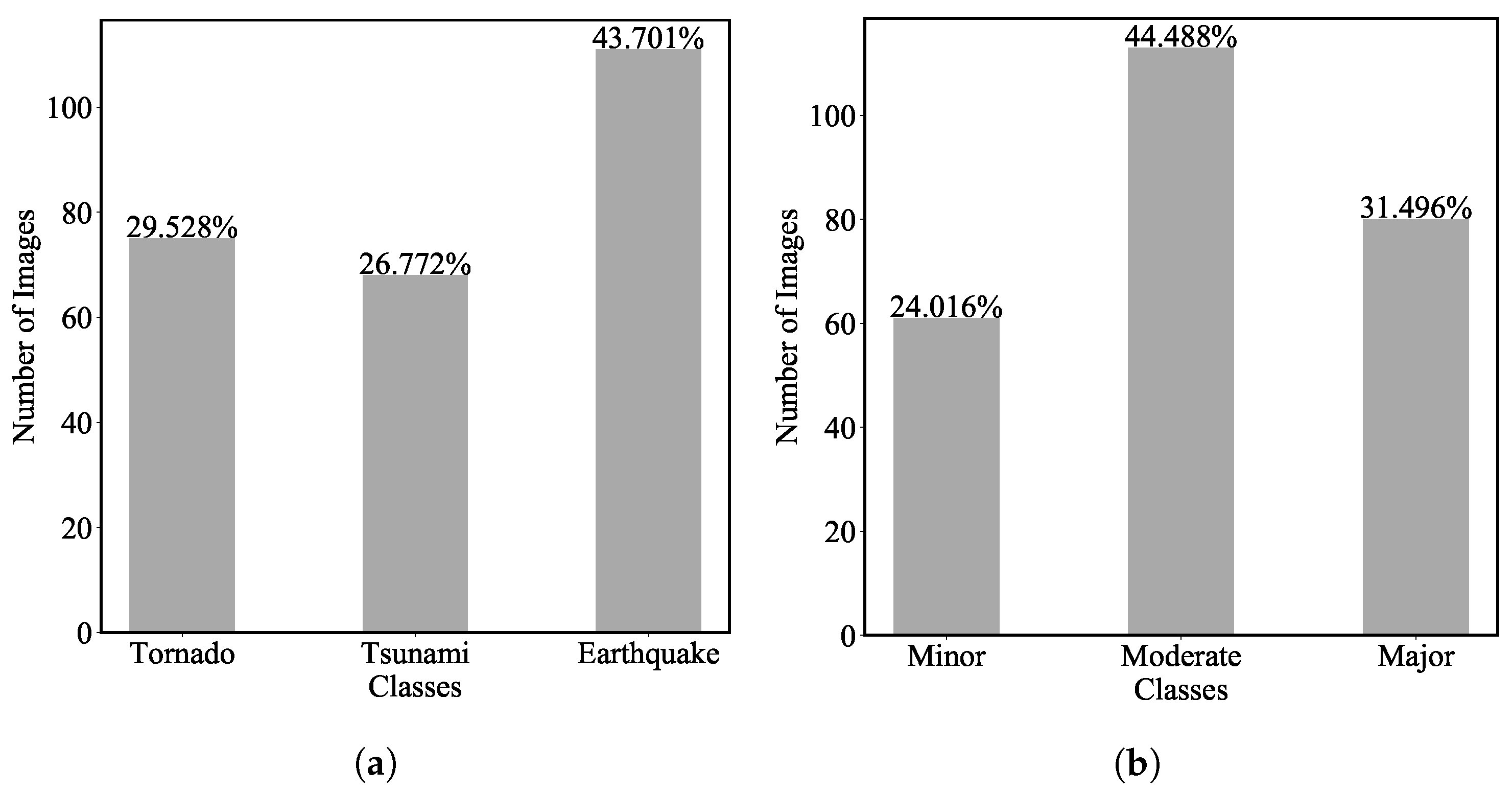
Between the two Faster R-CNN models, and , it can be seen that this hazard-type detector is more sensitive to the tornado disaster than to the earthquake disaster, and the last is the tsunami disaster. To comprehend this observation, the percentages of images of different hazard types in the learning datasets may provide some insight. It is found that the earthquake images are about 42% of the total samples, tornado images about 25%, and tsunami images around 33%. This indicates that the data is relatively not well-balanced but not severely imbalanced, implying that data imbalance does not sufficiently explain the lowest performance in tsunami disaster prediction. By visually inspecting the images and further reflecting on the strategy of using building-focused bounding boxes when annotating the data, the authors speculate that for a tsunami image, by the mandatory attention of the visual cues on building objects using bounding boxes, this treatment may tend to miss other important visual cues, particularly water. In other words, by confining the visual cues within the bounding boxes for only the buildings, more subjective uncertainties are introduced to discriminate tsunami scenes against the other two.
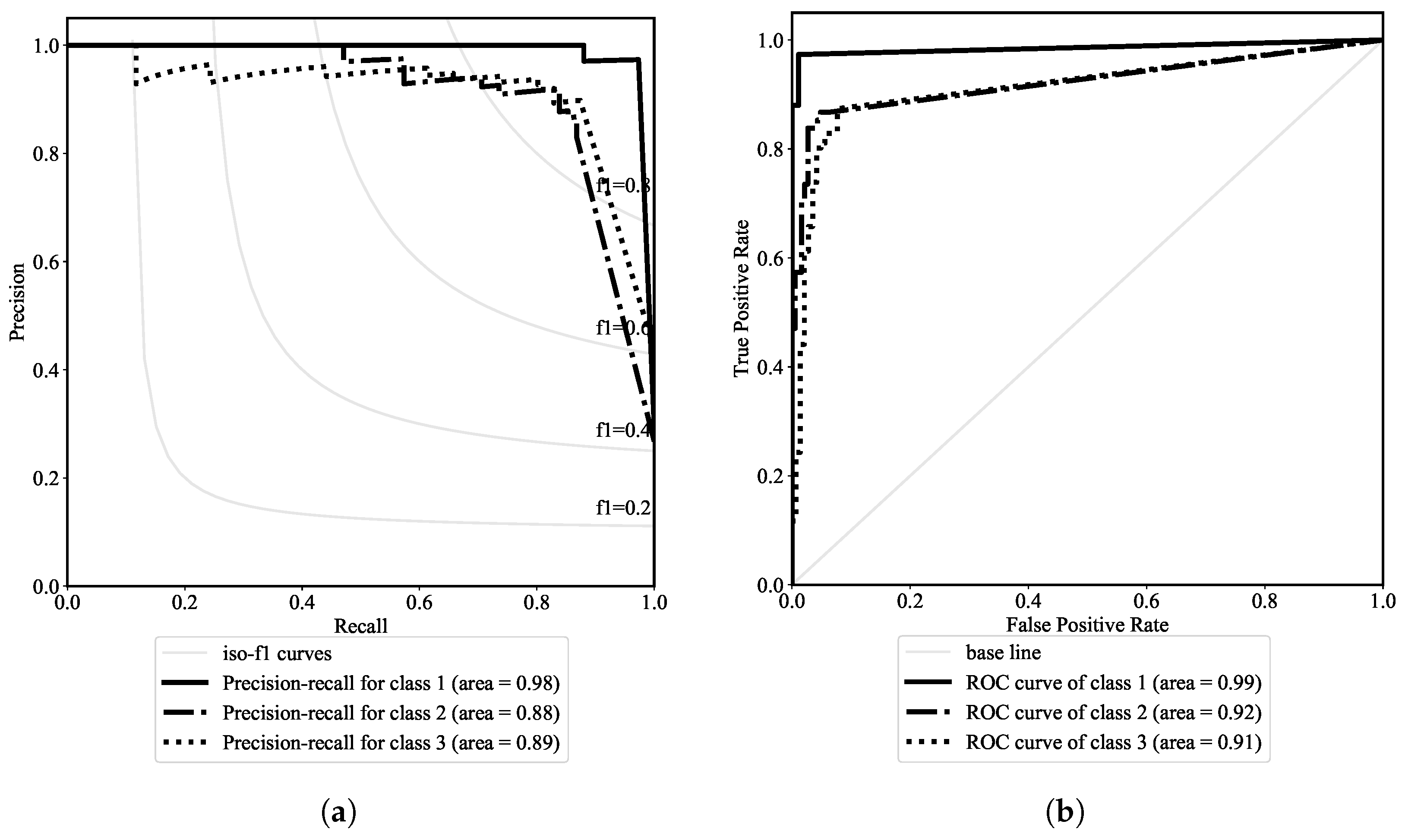
As observed previously, the best model for hazard-type prediction is
. To better assess its capacity and robustness, the PRC and ROC curves are illustrated in
Figure 8. In the PRC plot, the iso-contours of the
values with various classification thresholds are illustrated, which lead to the
contours of 0.2, 0.4, 0.6, and 0.8. The baseline prediction line is marked in the ROC lines, indicating that any ROC above this diagonal line implies a useful classification model. From PRC and ROC plots, which are overall monotonic and symmetrically concave, it is evident that the model consistently has a strong capacity and robustness at most select thresholds.
4.2.2. Damage-Level Prediction Performance
Three damage-level prediction models are assessed herein (
Table 1).
Figure 9 first demonstrates the damage-level prediction results using the same four sample inputs as in
Figure 8 using the damage prediction model
. As shown earlier, the bounding boxes tend to envelop the buildings with different damage features. It is interesting to note that in
Figure 9d, the damage prediction model chooses a much different bounding box and reports a correct damage level. In contrast, the underlying bounding-box emphasizes tsunami hazard features, and an erroneous damage level is given as ‘ground-truth’. This implies the subjective variability introduced by human annotators.
The performance measurements are reported in terms of the confusion matrices and scalar measures in
Table 4 and
Table 5, respectively. The most significant observation is that damage-level prediction performance decreases considerably compared to the hazard-type prediction over the testing data. In terms of both the
,
score, the
’s, and
’s, none of the performance measurement exceeds 0.9. Nonetheless, the model with the highest performance values is found in
, which shows moderate performance with an overall accuracy of 62.6% and
and
scores both greater than 0.5 at all damage-level predictions, albeit an alarming accuracy at predicting moderate-level damage. The two other damage-level prediction models,
and
, manifest unsatisfactory prediction performance. This implies that the ‘strong’ Faster R-CNN model with a ‘moderate’ ZF feature extractor or the ‘normal’ SSD model with a ‘strong’ Resnet feature extractor cannot sufficiently discriminate damage-level as human experts can do. The model
with a strong feature extractor and a strong region-proposal model can correctly detect damage-level. If one scrutinizes all the model performance measurements, even with two non-satisfactory models, it is evident that predicting moderate-level damage poses to be the most challenging one. This aspect, as well as the overall moderate performance, is further discussed later.
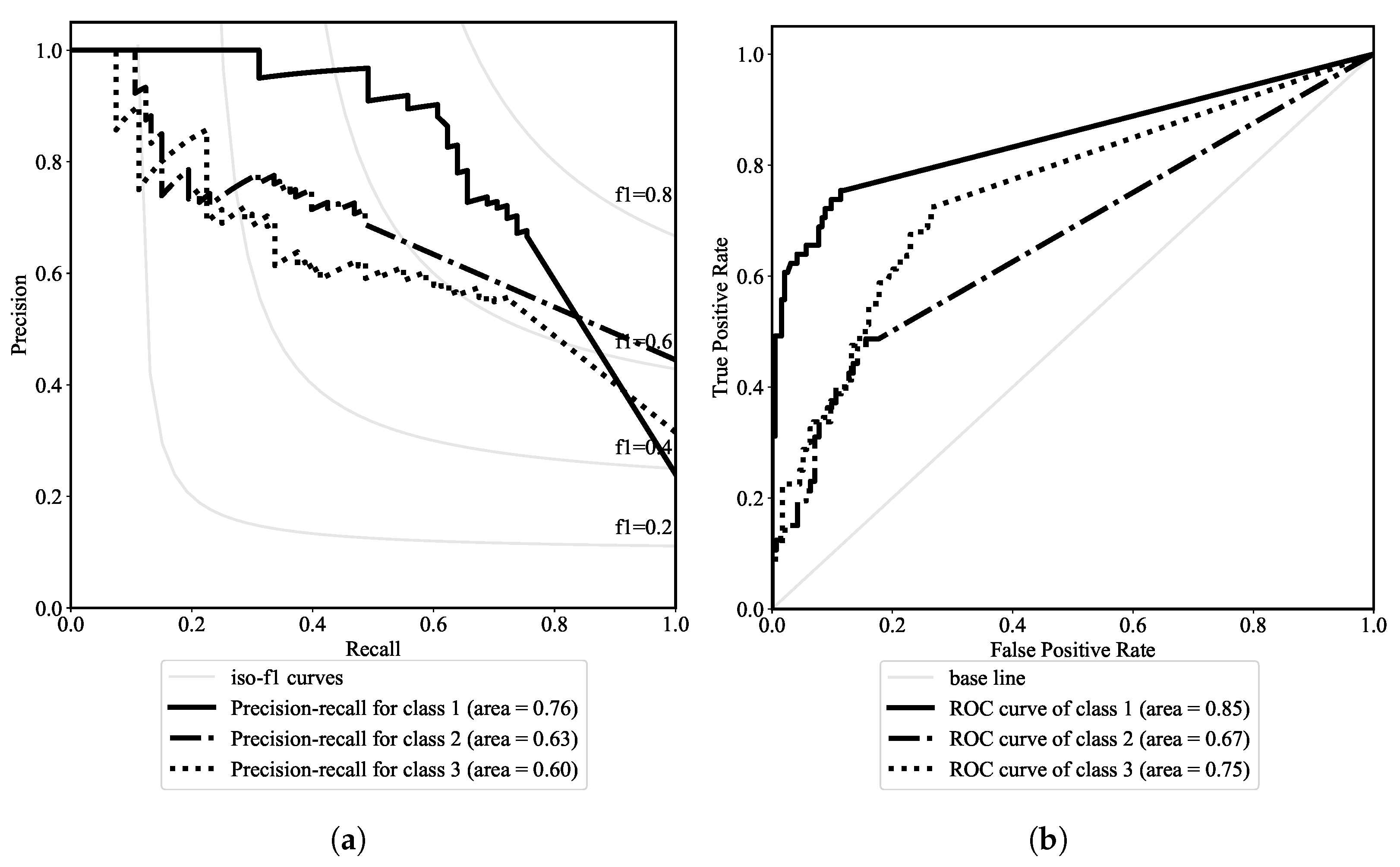
The ROC and PRC plots in
Figure 10 further illustrate the moderate predictive capacity of the model
. Compared to the ROC and PRC plots for the best hazard-type model
, it is seen that both predictive capacity and robustness degrade. Moreover, both graphical analytics show a relatively high capacity to predict minor-damaged buildings, moderate in major-damage prediction, and less satisfactory in minor-damage prediction at all possible variable classification thresholds.
4.3. Observation
The primary observations from the experiments above are multi-fold, which are listed below:
Hazard-type detection achieves statistically high performance over hazard-type (very high accuracy on tornado-wind scenes, high on the earthquake scene, and weak on the Tsunami-wave scene), and the best model architecture is .
Damage-level prediction retains moderate yet explainable performance; nonetheless, the model secures acceptable performance on minor- and detecting major-damage level.
The bounding-box-based detection is overall satisfactory and sufficiently captures the attention zones in disaster-scene images.
Regarding the three-model architecture for the two disaster-scene understanding tasks, it is observed too that Faster R-CNN as a general object-detection architecture with outputs of both bounding boxes and class labels has a superior performance.
More explanations and limitations in the proposed methodology framework are discussed in the following.
5. Discussion
5.1. Justification of Accuracy
First, to enlighten the discussion regarding the accuracy of image-based damage classification, the authors retrieve relevant accuracy results from the literature. It is noted that again there are no similar efforts that use mobile RS images. Ref. [
43] reviewed many efforts, where categorical structural damage was classified using traditional RS images. First, the average or overall accuracy ranged from 70% to 90%, depending on the availability and quality of the data; higher rates were usually a result of possessing high-quality pre- and post-event data. Ref. [
44] conducted damage classification using synthetic aperture radar (SAR) images before and after the 2011 Tohoku Earthquake and Tsunami in Japan. With a traditional machine-learning framework, they reported an average accuracy of 71.1% using the F-1 score. Ref. [
45] proposed a deep-learning-based damage detection workflow using the same type of data over the tsunami-related damage as in [
44]. They reported a damage-level recognition accuracy of 74.8% over three damaging classes. Ref. [
46] identified the significance of fusing the Digital Elevation Model (DEM) with SAR data for damage mapping. In terms of four levels of building damage for an Indonesia tsunami, they reported a higher overall accuracy (>90%) yet a low average accuracy (around 67%). Given such comparison, the authors of this paper argue that towards an image-based classification of structural damage for built objects, an OA measurement of
) as reported by the model
is not surprisingly low.
To further explain this, three vital differences between traditional RS images and mobile RS images are argued below, which render mobile RS-based damage detection more challenging.
Bitemporal GIS-ready RT images vs. non-structured mobile images. In traditional RT images, the bitemporal pairs are usually both ortho-rectified and co-registered; therefore, bitemporal pixels for the same objects may only subject to misalignment of a few pixels, which significantly constrains the degree of errors. In the case of mobile images, there are no bitemporal pairs, and the damage is opportunistically captured from an arbitrary perspective of a built object. This difference leads to overall much more uncertainties in mobile RS images towards damage interpretation.
Bounded vs. unbounded scene complexity. In traditional RT images, most multi-story building objects in the nadir or off-nadir views only show the roof level damage with minimal building elevation coverage. This implies that the structural characteristics are primarily in terms of lines, edges, and corners at the roofs of buildings, which are low-level visual features. When damage occurs, these low-level features are distorted or modified. In mobile images, however, the scene complexity is mounted dramatically, and the involved features are at a high-level, including parts of objects, adjacent objects, and potential relations between adjacent parts or objects.
Hazard specific vs. hazard-agnostic damage-level. In most RT-based damage-level classification, the hazard-type comes from a single event, and the damage for built objects is extracted from bitemporal images. In this work, treating the damage-level agnostic to hazard-type leads to significant intra-class variations, which are much less significant when using traditional RS images.
Secondly, it is explainable that hazard-type prediction models perform better than the damage-level models in this work. For this performance disparity, three empirical reasons are speculated herein. First, visual clues that imply hazard-type in disaster-scene images are more abundant and distinct than those possibly exploitable for discriminating damage-level. Second, the damage-level semantically imply an increasing order of damage severity. This renders secondary yet significant overlapping in the underlying decision boundaries in the high-dimensional feature space, namely inter-class variations. Third, treating the damage-level not specific but agnostic to hazard-type leads to significant intra-class variations. These three conjunct reasons are believed to corroborate that generic damage-level are much more challenging to learn than hazard types given the same disaster-scene database.
5.2. Suggestions for Future Research
Tornado-scene images in this work should be augmented to include more complexity. It is noticed that when predicting the tornado scenes, very high accuracy is achieved (with an
up to 0.973 and an
score of 0.970;
Table 2). The prediction accuracy is high on earthquake-scene prediction (
= 0.873;
score = 0.994); then the least on tsunami-scene (
= 0.867;
score = 0.849). This ranked trend in prediction accuracy essentially coincides with the scene complexity, from low to high: Tornado-wind, Tsunami-wave, and Earthquake-shaking scenes. Essentially, although the disaster-scene database created in this work contains images for events around the world, they are still limited in terms of diversity. Specifically, the tornado-scene images came from a single event and were taken within residential areas from one town (Moore, Oklahoma). Regardless of the relative complexity, nearly all buildings in images are residences captured from their front view. More diversity is in the earthquake scenes from urban settings of two quite different countries, Haiti and New Zealand. Similarly, the tsunami images came from two countries as well, coastal towns in Japan and Indonesia. These distinctions in imagery-scene complexity in terms of their sources and characteristics explain the observed performance. It is suggested that a different source for tornado-scene images may be included to augment the scene complexity.
More flexible bounding-box-based annotations may be designed for very complex disaster-scene images. When the tsunami-wave scene is classified, relatively lower performance is observed with all the three models used. The authors speculate that by annotating bounding boxes and focusing on building objects, the tsunami-specific visual cues, particularly flood-borne debris, tend to be missed by the bounding boxes. The authors argue that this can reduce prediction performance about the tsunami scenes. As observed in
Figure 7d and
Figure 9d, bounding boxes are predicted differently from the human annotation. This is inevitably due to arbitrary and subjective variations in a subjective human-based process. The models learn the most plausible bounding box statistically in this tsunami-scene image. For damage-level prediction, however, the model chooses the bounding box with the damage-level of the maximum score value, and a much different box is predicted yet with a correct prediction (relative to the mislabeled label by a human analyst). This implies the disadvantage of the proposed simplified annotation process for the human analyst in this work. It is suggested that for very complex disaster scenes, such as hydraulic hazards induced disasters (e.g., flooding, tsunami, and storm surges), multiple and different bounding boxes can be used for characterizing the hazard-type and building damage. This treatment is left for future research.
Hierarchical and fine-grained semantic labeling should be pursued in future research. Related to hazard types, a hierarchical scheme may be designed based on event type; for example, for an earthquake-event scene, the hazard labels may include: shaking, land sliding, liquefaction, ground sinking; whereas related to disaster types, specific damage types may be classified according to element types and location; for example, for buildings, these may include structural beam, wall, or foundation damage and nonstructural-element damage. Nonetheless, this fine-grained labeling demands a much larger-scale database and a more sophisticated model.
Data imbalance in disaster-scene images is intrinsic. First, it is due to the nature of hazards in their frequency; for instance, the returning period of a strong earthquake is much more extended than a windstorm. Second, after an intense event, crowdsourced images from the general public are more focused on severely damaged buildings due to physiological preferences. In recent years, innovative loss functions were proposed that deal with dense objects in images with a high ratio between the foreground objects and background objects [
47]. However, in this work, the imbalance occurs within different built objects, which are mainly in the foreground. Future research is needed, and the work of [
47] provides an inspiring direction by tuning the loss function.
5.3. Understanding UAV Images
It is asserted in this paper that UAVs are becoming a personal RT platform and a standard tool in professional disaster reconnaissance activities in recent years. In practice, UAVs-based RS images possess special characteristics due to their much flexible imaging geometrics. In general, UAV images according to their coverage and imaging heights can be categorized into three types: (T1) elevation view of buildings if the imaging UAV captures at an AGL height comparable to building heights; (T2) overhead view of one or several buildings when the AGL heights are higher than buildings; (T3), aerial view of a large number of buildings when the AGL is much high (e.g., hundreds of feet above ground). In general, the authors state that the developed models in this work should work well for UAV images from the first category (T1) as they are similar to any ground-level mobile images. For images in T2, the images may still be similar to the mobile images in this paper as one may capture images at a higher ground than buildings. For T3, they should be processed first using photogrammetric methods used for traditional RS images.
In this effort, the models
and
developed previously are applied to some sample UAV images, which were captured from a recent tornado disaster reconnaissance (Jefferson City, Missouri). The images were shot at a low altitude over an apartment complex. As shown in
Figure 11a, two of three damaged buildings are classified correctly as the tornado hazard-type. The lower left one is classified as the tsunami type because its roof is disappeared, which is a scene not appeared in the tornado-scene images in this paper (that were captured mostly with the front view). For damage-level classification, three buildings are detected in
Figure 11b; the predicted damage-level conform to the hazard-agnostic damage classification. This extrapolation effort demonstrates that UAV images may deserve some specific processing to improve accuracy. One possible solution is to exploit the 3-dimensional (3D) embeddings hidden in many overlapped UAV images hence a 3D reconstruction of the scene can be obtained [
8,
48]. With 3D image-based learning, more granular and representative features may positively augment the model accuracy.
6. Conclusions
In this work, the authors explore the feasibility of a quantitative understanding of disaster scenes from mobile images. To deal with the significant complexity and uncertainties in disaster-scene images, this paper proposes adopting advanced deep-learning models to identify both hazard-type and damage-level embedded in images.
The authors develop three deep-learning models for two disaster-scene understanding tasks: hazard-type identification and damage-level estimation. The following conclusions are resolved by assessing the performance of the two tasks based on quantitative performance measures. First, the performance of the models demonstrates that disaster scenes in mobile RS practice can be modeled, and predictive models with acceptable performance are feasible. Second, it is concluded that hazard-type can be identified with high accuracy due to the underlying abundant visual characteristics. On the other hand, relatively modest performance is observed when the models predict damage level. Empirical explanations are provided, including that the proposed damage-level scaling is agnostic to hazard types and possesses much inter- and intra-class variations. Last, it is observed that the Faster R-CNN architecture with a Resnet-50 CNN as the feature extract excels with the highest performance in this effort.
With these conclusions, the authors expect that higher-performance predictive models for disaster-scene learning can be developed by enhancing data volume, veracity, and better-suited deep-learning architectures. The proposed concept of mobile imaging-based disaster-scene understanding and the developed frameworks in this paper can facilitate the automation of imaging activities conducted by either professionals or the general public as smart and mobile devices become ubiquitous, enabling data-driven resilience of disaster response.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}