
Franken-CT: Head and Neck MR-Based Pseudo-CT Synthesis Using Diverse Anatomical Overlapping MR-CT Scans

 , , and
, , and
Abstract
Featured Application
Abstract
1. Introduction
2. Materials and Methods
2.1. Franken-Computerized Tomography (Franken-CT) Approach
2.2. Magnetic Resonance-Computerized Tomography (MR-CT) Datasets
2.2.1. Training Dataset
2.2.2. Validation Dataset
2.2.3. Datasets Preprocessing
- MRI bias correction on the anatomical T1-weighted images (N4ITK MRI Bias Correction, 3D Slicer) to correct for inhomogeneities caused by subject-dependent load interactions and imperfections in radiofrequency coils.
- Resampling of MR and CT images to an isotropic 1 mm space was performed (Resample Scalar Volume, 3D Slicer) to set a common resolution space for all images ((271, 271, 221) pixels) and avoid information loss in the following steps.
- Intra-patient rigid registration to align each MR-CT pair. The method consists of an initial manual registration using characteristic points (Fiducial Registration Wizard, 3D Slicer), an automatic rigid registration step (General Registration Brains, 3D Slicer), and a manual adjustment of the registration (Transforms, 3D Slicer). This is a crucial step and guarantees the correspondence between each anatomical point of both image techniques.
- Reslicing and crop all MR and CT images to a reference image (Resample Image Brains, 3D Slicer) to ensure the same matrix size prior training our network.
- MR histogram matching (MATLAB, MathWorks Inc., Natick, MA, USA) to normalize intensity values between images, especially for those images acquired with different scanners.
- CT intensity normalization from −1024 to 3071 Hounsfield Units (HU) (MATLAB, MathWorks Inc.) to ensure a representation of 4096 gray levels, as defined by HU.
- MR-CT image information matching (MATLAB, MathWorks Inc.) to ensure there is no MR or CT information in areas where one of the modalities is out of the other, so as to ensure that the same anatomical area is represented in both MR and CT.
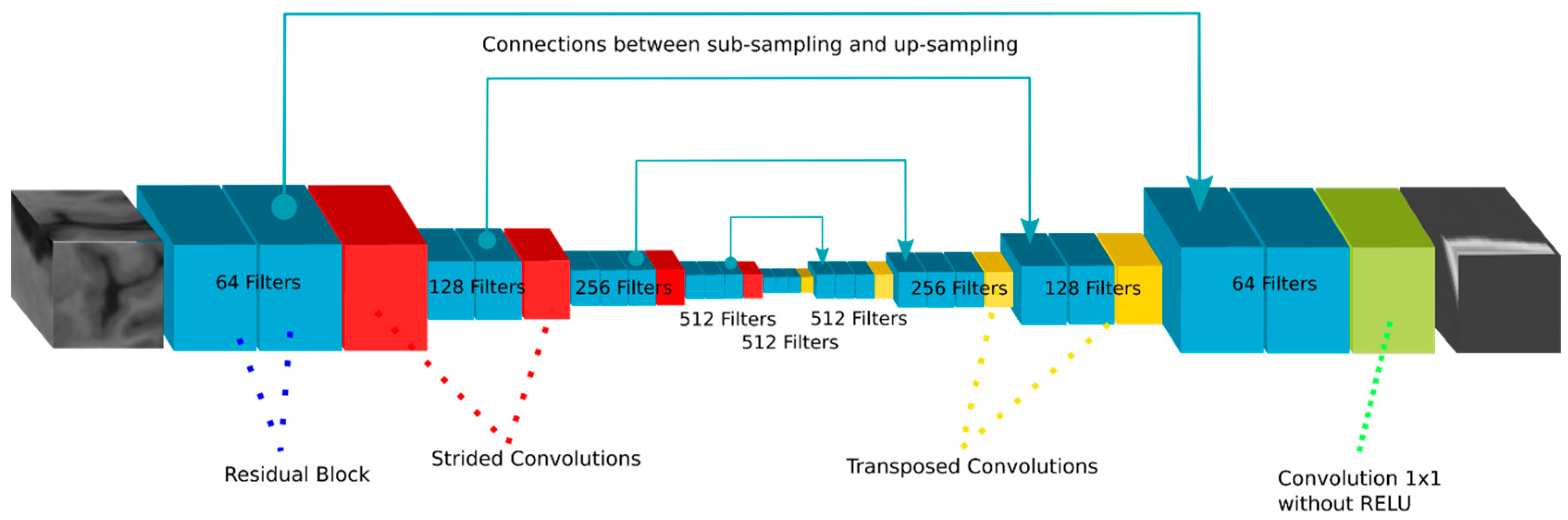
2.3. Pseudo-CT Synthesis
2.4. Training and Reconstruction
2.5. Evaluation
3. Experimental Results
3.1. Convolutional Neural Network (CNN) Results
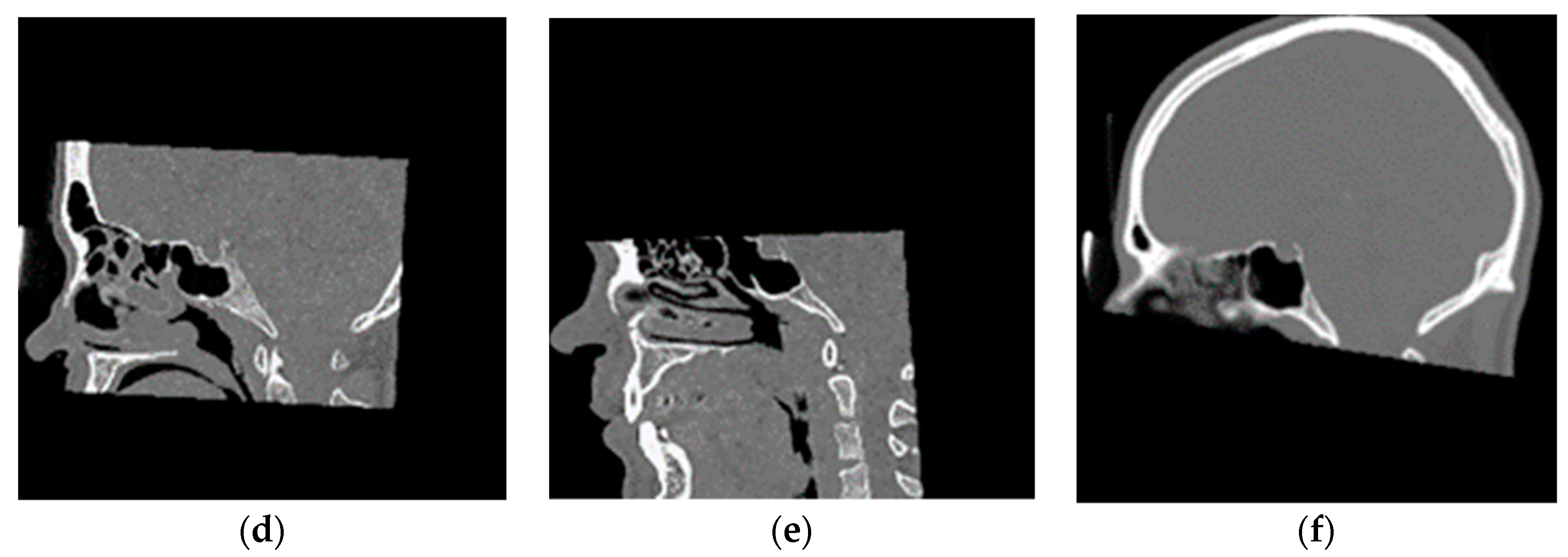
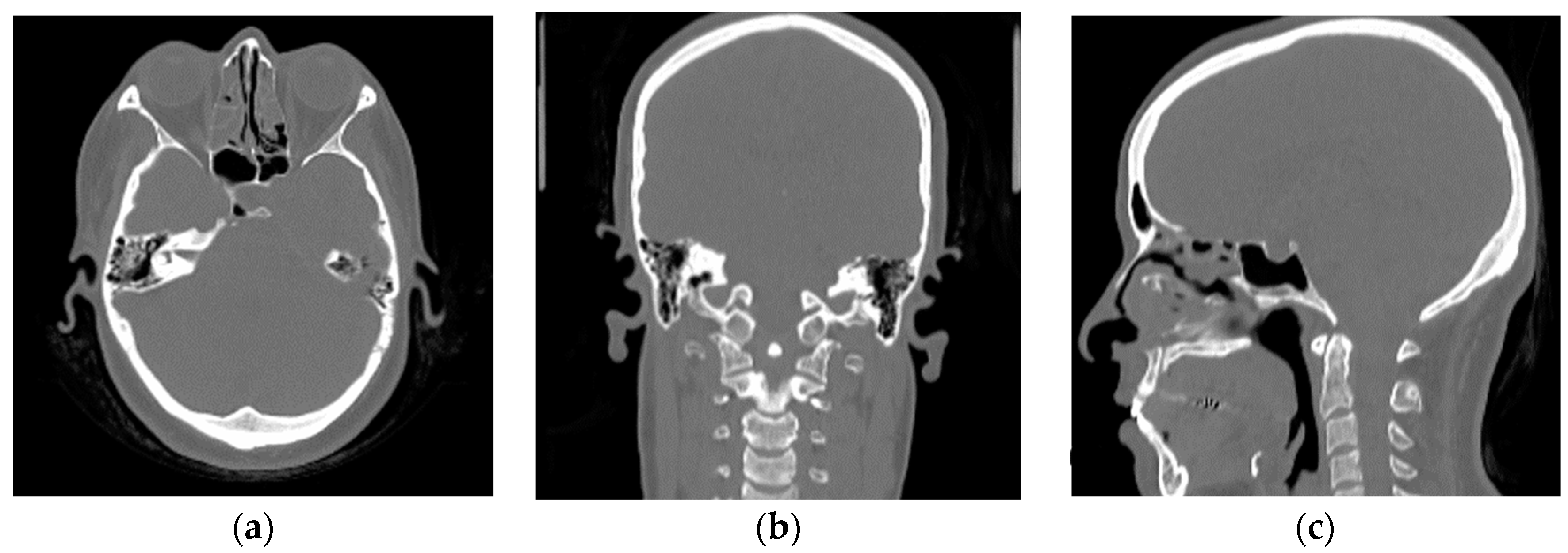
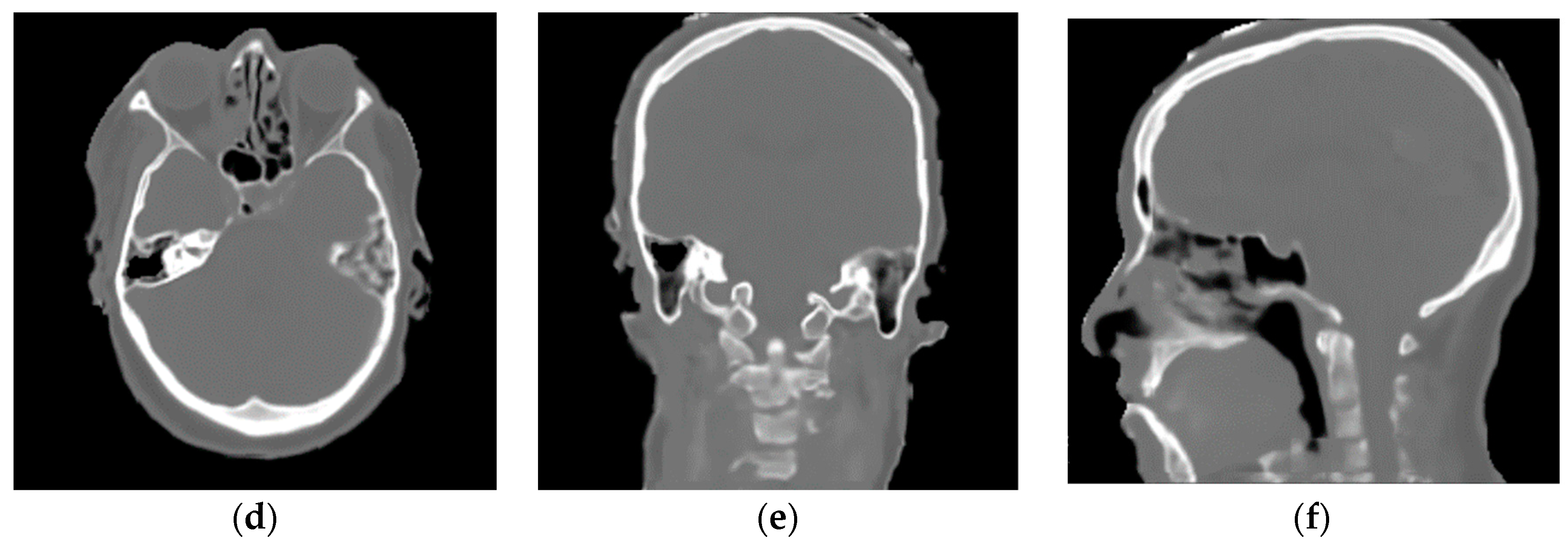
3.2. Franken-CT Approach Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Participant ID | Sex | Age | FOV | CT Scan | CT FOV Size (mm) | CT Voxel Size (mm) | MR Scan | MR Sequence Description | MR FOV Size (mm) | MR Voxel Size (mm) |
|---|---|---|---|---|---|---|---|---|---|---|
| fct-train-01 | F | 31 | neck | Toshiba Aquilion Prime | (271, 271, 291) | (0.53, 0.53, 3.00) | Siemens Biograph mMR 3T | 3D-T1w-MP-RAGE * | (172, 219, 250) | (0.98, 0.98, 0.98) |
| fct-train-02 | F | 52 | Paranasal sinuses | Toshiba Aquilion Prime | (183, 183, 111) | (0.36, 0.36, 0.40) | Siemens Biograph mMR 3T | 3D-T1w-MP-RAGE * | (172, 219, 250) | (0.98, 0.98, 0.98) |
| fct-train-03 | F | 74 | brain | Toshiba Aquilion Prime | (220, 220, 146) | (0.43, 0.43, 1.00) | GE Discovery™ MR750w GEM 3T | 3D-T1w-FSPGR ** | (188, 256, 256) | (1.00, 1.00, 1.00) |
| fct-train-04 | F | 30 | neck | Toshiba Aquilion Prime | (256, 256, 297) | (0.50, 0.50, 0.40) | Siemens Biograph mMR 3T | 3D-T1w-MP-RAGE * | (172, 219, 250) | (0.98, 0.98, 0.98) |
| fct-train-05 | M | 34 | Facial orbits | Toshiba Aquilion Prime | (167, 167, 128) | (0.33, 0.33, 0.40) | Siemens Biograph mMR 3T | 3D-T1w-MP-RAGE * | (168, 236, 270) | (1.05, 1.05, 1.05) |
| fct-train-06 | M | 25 | brain | Toshiba Aquilion Prime | (230, 269, 156) | (0.45, 0.45, 0.78) | Siemens Biograph mMR 3T | 3D-T1w-MP-RAGE * | (188, 219, 250) | (0.98,0.98, 0.98) |
| fct-train-07 | M | 64 | brain | Toshiba Aquilion Prime | (220, 220, 161) | (0.43, 0.43, 1.00) | GE Discovery™ MR750w GEM 3T | 3D-T1w-FSPGR ** | (188, 256, 256) | (1.00, 1.00, 1.00) |
| fct-train-08 | F | 66 | brain | Toshiba Aquilion Prime | (220, 253, 142) | (0.43, 0.43, 0.78) | Siemens Biograph mMR 3T | 3D-T1w-MP-RAGE * | (157, 219, 250) | (0.98, 0.98, 0.98) |
| fct-train-09 | F | 77 | brain | Toshiba Aquilion Prime | (220, 220, 156) | (0.43, 0.43, 1.00) | GE Discovery™ MR750w GEM 3T | 3D-T1w-FSPGR ** | (188, 256, 256) | (1.00, 1.00, 1.00) |
| fct-train-10 | F | 65 | brain | Toshiba Aquilion Prime | (220, 263, 144) | (0.43, 0.43, 0.77) | Siemens Biograph mMR 3T | 3D-T1w-MP-RAGE * | (172, 219, 250) | (0.98, 0.98, 0.98) |
| fct-train-11 | M | 66 | brain | Toshiba Aquilion Prime | (233, 286, 156) | (0.46, 0.46, 4.73) | Siemens Biograph mMR 3T | 3D-T1w-MP-RAGE * | (172, 219, 250) | (0.98, 0.98, 0.98) |
| fct-train-12 | M | 80 | neck | Toshiba Aquilion Prime | (280, 280, 270) | (0.55, 0.55, 0.30) | GE Signa HDxt 1.5T | 3D-T1w-FSPGR ** | (240, 240, 139) | (0.94, 0.94, 0.60) |
| fct-train-13 | M | 71 | neck | Toshiba Aquilion Prime | (181, 181, 297) | (0.94, 0.94, 0.60) | GE Discovery™ MR750w GEM 3T | 3D-T1w-FSPGR ** | (256, 256, 216) | (0.50, 0.50, 1.00) |
| fct-train-14 | F | 63 | brain | Toshiba Aquilion Prime | (229, 229, 156) | (0.45, 0.45, 0.40) | GE Discovery™ MR750w GEM 3T | 3D-T1w-FSPGR ** | (240, 240, 144) | (0.47, 0.47, 4.00) |
| fct-train-15 | F | 70 | Facial orbits | Toshiba Aquilion Prime | (210, 210, 107) | (0.41, 0.41, 1.00) | Siemens MAGNETOM Espree 1.5T eco | 3D-T1w-MP-RAGE * | (194, 220, 220) | (1.10, 1.15, 1.15) |
| Participant ID | Sex | Age | FOV | CT Scan | CT FOV Size (mm) | CT Voxel Size (mm) | MR Scan | MR Sequence Description | MR FOV Size (mm) | MR Voxel Size (mm) |
|---|---|---|---|---|---|---|---|---|---|---|
| fct-test-01 | M | 21 | full head | Toshiba Aquilion Prime | (271, 271, 235) | (0.53, 0.53, 0.70) | GE Discovery™ MR750w GEM 3T | 3D-T1w-FSPGR ** | (164, 240, 240) | (0.50, 0.47, 0.47) |
| fct-test-02 | F | 46 | full head | Toshiba Aquilion Prime | (220, 220, 251) | (0.43, 0.43, 1.00) | Siemens Biograph mMR 3T | 3D-T1w-MP-RAGE * | (157, 250, 250) | (0.98, 0.98, 0.98) |
| fct-test-03 | M | 83 | full head | Toshiba Aquilion Prime | (245, 245, 265) | (0.48, 0.48, 1.00) | GE Discovery™ MR750w GEM 3T | 3D-T1w-FSPGR ** | (188, 256, 256) | (1.00, 1.00, 1.00) |
| fct-test-04 | F | 38 | full head | Siemens Somatom Sensation 16 | (236, 236, 250) | (0.46, 0.46, 1.00) | GE Signa HDxt 1.5T | 3D-T1w-FSPGR ** | (188, 256, 256) | (1.00, 1.00, 1.00) |
| fct-test-05 | F | 22 | full head | Siemens Somatom Sensation 16 | (271, 271, 221) | (0.53, 0.53, 0.70) | GE Signa HDxt 1.5T | 3D-T1w-FSPGR ** | (271, 271, 221) | (1.00, 1.00, 1.00) |
| fct-test-06 | F | 27 | full head | Siemens Somatom Sensation 16 | (271, 271, 230) | (0.53, 0.53, 0.70) | GE Signa HDxt 1.5T | 3D-T1w-FSPGR ** | (271, 271, 221) | (1.00, 1.00, 1.00) |
References
- Izquierdo-Garcia, D.; Catana, C. MR Imaging–Guided Attenuation Correction of PET Data in PET/MR Imaging. PET Clin. 2016, 11, 129–149. [Google Scholar] [CrossRef] [PubMed]
- Teuho, J.; Torrado-Carvajal, A.; Herzog, H.; Anazodo, U.; Klén, R.; Iida, H.; Teräs, M. Magnetic Resonance-Based Attenuation Correction and Scatter Correction in Neurological Positron Emission Tomography/Magnetic Resonance Imaging—Current Status With Emerging Applications. Front. Phys. 2020, 7, 7. [Google Scholar] [CrossRef]
- Torrado-Carvajal, A. Importance of attenuation correction in PET/MR image quantification: Methods and applications. Rev. Esp. Med. Nucl. Imagen Mol. 2020, 39, 163–168. [Google Scholar] [CrossRef] [PubMed]
- Berker, Y.; Franke, J.; Salomon, A.; Palmowski, M.; Donker, H.C.W.; Temur, Y.; Mottaghy, F.M.; Kuhl, C.; Izquierdo-Garcia, D.; Fayad, Z.A.; et al. MRI-Based Attenuation Correction for Hybrid PET/MRI Systems: A 4-Class Tissue Segmentation Technique Using a Combined Ultrashort-Echo-Time/Dixon MRI Sequence. J. Nucl. Med. 2012, 53, 796–804. [Google Scholar] [CrossRef]
- Hsu, S.-H.; Cao, Y.; Huang, K.; Feng, M.; Balter, J.M. Investigation of a method for generating synthetic CT models from MRI scans of the head and neck for radiation therapy. Phys. Med. Biol. 2013, 58, 8419–8435. [Google Scholar] [CrossRef]
- Zheng, W.; Kim, J.P.; Kadbi, M.; Movsas, B.; Chetty, I.J.; Glide-Hurst, C.K. Magnetic Resonance–Based Automatic Air Segmentation for Generation of Synthetic Computed Tomography Scans in the Head Region. Int. J. Radiat. Oncol. 2015, 93, 497–506. [Google Scholar] [CrossRef]
- Ladefoged, C.N.; Benoit, D.; Law, I.; Holm, S.; Kjær, A.; Højgaard, L.; Hansen, A.; Andersen, F.L. Region specific optimization of continuous linear attenuation coefficients based on UTE (RESOLUTE): Application to PET/MR brain imaging. Phys. Med. Biol. 2015, 60, 8047–8065. [Google Scholar] [CrossRef] [PubMed]
- Merida, I.; Costes, N.; Heckemann, R.; Hammers, A. Pseudo-CT generation in brain MR-PET attenuation correction: Comparison of several multi-atlas methods. EJNMMI Phys. 2015, 2, 1. [Google Scholar] [CrossRef] [PubMed]
- Burgos, N.; Cardoso, M.J.; Thielemans, K.; Modat, M.; Pedemonte, S.; Dickson, J.; Barnes, A.; Ahmed, R.; Mahoney, C.J.; Schott, J.M.; et al. Attenuation Correction Synthesis for Hybrid PET-MR Scanners: Application to Brain Studies. IEEE Trans. Med. Imaging 2014, 33, 2332–2341. [Google Scholar] [CrossRef] [PubMed]
- Uh, J.; Merchant, T.E.; Li, Y.; Li, X.; Hua, C. MRI-based treatment planning with pseudo CT generated through atlas registration. Med. Phys. 2014, 41, 051711. [Google Scholar] [CrossRef]
- Torrado-Carvajal, A.; Herraiz, J.L.; Alcain, E.; Montemayor, A.S.; Garcia-Cañamaque, L.; Hernandez-Tamames, J.A.; Rozenholc, Y.; Malpica, N. Fast Patch-Based Pseudo-CT Synthesis from T1-Weighted MR Images for PET/MR Attenuation Correction in Brain Studies. J. Nucl. Med. 2015, 57, 136–143. [Google Scholar] [CrossRef]
- Sjölund, J.; Forsberg, D.; Andersson, M.; Knutsson, H. Generating patient specific pseudo-CT of the head from MR using atlas-based regression. Phys. Med. Biol. 2015, 60, 825–839. [Google Scholar] [CrossRef] [PubMed]
- Torrado-Carvajal, A.; Herraiz, J.L.; Hernández-Tamames, J.A.; José-Estépar, R.S.; Eryaman, Y.; Rozenholc, Y.; Adalsteinsson, E.; Wald, L.L.; Malpica, N. Multi-atlas and label fusion approach for patient-specific MRI based skull estimation. Magn. Reson. Med. 2015, 75, 1797–1807. [Google Scholar] [CrossRef] [PubMed]
- Izquierdo-Garcia, D.; Hansen, A.E.; Förster, S.; Benoit, D.; Schachoff, S.; Fürst, S.; Chen, K.T.; Chonde, D.B.; Catana, C. An SPM8-based approach for attenuation correction combining segmentation and nonrigid template formation: Application to simultaneous PET/MR brain imaging. J. Nucl. Med. 2014, 55, 1825–1830. [Google Scholar] [CrossRef] [PubMed]
- Kapanen, M.; Tenhunen, M. T1/T2*-weighted MRI provides clinically relevant pseudo-CT density data for the pelvic bones in MRI-only based radiotherapy treatment planning. Acta Oncol. 2012, 52, 612–618. [Google Scholar] [CrossRef]
- Johansson, A.; Garpebring, A.; Karlsson, M.; Asklund, T.; Nyholm, T. Improved quality of computed tomography substitute derived from magnetic resonance (MR) data by incorporation of spatial information—Potential application for MR-only radiotherapy and attenuation correction in positron emission tomography. Acta Oncol. 2013, 52, 1369–1373. [Google Scholar] [CrossRef]
- Navalpakkam, B.K.; Braun, H.; Kuwert, T.; Quick, H.H. Magnetic Resonance–Based Attenuation Correction for PET/MR Hybrid Imaging Using Continuous Valued Attenuation Maps. Investig. Radiol. 2013, 48, 323–332. [Google Scholar] [CrossRef]
- Han, X. MR-based synthetic CT generation using a deep convolutional neural network method. Med. Phys. 2017, 44, 1408–1419. [Google Scholar] [CrossRef] [PubMed]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Han, X. TU-AB-BRA-02: An Efficient Atlas-Based Synthetic CT Generation Method. Med. Phys. 2016, 43, 3733. [Google Scholar] [CrossRef]
- Liu, F.; Hyungseok, J.; Kijowski, R.; Bradshaw, T.; Mcmillan, A.B. Deep Learning MR Imaging—Based Attenuation. Radiology 2018, 286, 676–684. [Google Scholar] [CrossRef] [PubMed]
- Torrado-Carvajal, A.; Vera-Olmos, J.; Izquierdo-Garcia, D.; Catalano, O.A.; Morales, M.A.; Margolin, J.; Soricelli, A.; Salvatore, M.; Malpica, N.; Catana, C. Dixon-vibe deep learning (divide) pseudo-CT synthesis for pelvis PET/MR attenuation correction. J. Nucl. Med. 2019, 60, 429–435. [Google Scholar] [CrossRef]
- Nie, D.; Trullo, R.; Lian, J.; Wang, L.; Petitjean, C.; Ruan, S.; Wang, Q.; Shen, D. Medical Image Synthesis with Deep Convolutional Adversarial Networks. IEEE Trans. Biomed. Eng. 2018, 65, 2720–2730. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- Imaging, N.; Angeles, L. Auto-context and Its Application to High-level Vision Tasks and 3D Brain Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1744–1757. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Emami, H.; Dong, M.; Nejad-Davarani, S.P.; Glide-Hurst, C.K. Generating synthetic CTs from magnetic resonance images using generative adversarial networks. Med. Phys. 2018, 45, 3627–3636. [Google Scholar] [CrossRef] [PubMed]
- Morone, M.; Bali, M.A.; Tunariu, N.; Messiou, C.; Blackledge, M.; Grazioli, L.; Koh, D.-M. Whole-Body MRI: Current Applications in Oncology. Am. J. Roentgenol. 2017, 209, W336–W349. [Google Scholar] [CrossRef]
- Alcaín, E.; Torrado-Carvajal, A.; Montemayor, A.S.; Malpica, N. Real-time patch-based medical image modality propagation by GPU computing. J. Real-Time Image Process. 2017, 13, 193–204. [Google Scholar] [CrossRef]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Ladefoged, C.N.; Hansen, A.E.; Henriksen, O.M.; Bruun, F.J.; Eikenes, L.; Øen, S.K.; Karlberg, A.; Højgaard, L.; Law, I.; Andersen, F.L. AI-driven attenuation correction for brain PET/MRI: Clinical evaluation of a dementia cohort and importance of the training group size. NeuroImage 2020, 222, 117221. [Google Scholar] [CrossRef]
- Ladefoged, C.N.; Law, I.; Anazodo, U.; Lawrence, K.S.; Izquierdo-Garcia, D.; Catana, C.; Burgos, N.; Cardoso, M.J.; Ourselin, S.; Hutton, B.; et al. A multi-centre evaluation of eleven clinically feasible brain PET/MRI attenuation correction techniques using a large cohort of patients. NeuroImage 2017, 147, 346–359. [Google Scholar] [CrossRef] [PubMed]
- Lee, J.S. A Review of Deep-Learning-Based Approaches for Attenuation Correction in Positron Emission Tomography. IEEE Trans. Radiat. Plasma Med. Sci. 2021, 5, 160–184. [Google Scholar] [CrossRef]
- Lei, Y.; Shu, H.-K.; Tian, S.; Wang, T.; Liu, T.; Mao, H.; Shim, H.; Curran, W.J.; Yang, X. Pseudo CT Estimation using Patch-based Joint Dictionary Learning. In Proceedings of the 2018 40th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Honolulu, HI, USA, 18–21 July 2018; pp. 5150–5153. [Google Scholar] [CrossRef]
- Tie, X.; Lam, S.; Zhang, Y.; Lee, K.; Au, K.; Cai, J. Pseudo-CT generation from multi-parametric MRI using a novel multi-channel multi-path conditional generative adversarial network for nasopharyngeal carcinoma patients. Med. Phys. 2020, 47, 1750–1762. [Google Scholar] [CrossRef] [PubMed]
- Wiesinger, F.; Bylund, M.; Yang, J.; Kaushik, S.; Shanbhag, D.; Ahn, S.; Jonsson, J.H.; Lundman, J.A.; Hope, T.; Nyholm, T.; et al. Zero TE-based pseudo-CT image conversion in the head and its application in PET/MR attenuation correction and MR-guided radiation therapy planning. Magn. Reson. Med. 2018, 80, 1440–1451. [Google Scholar] [CrossRef] [PubMed]
- Vera-Olmos, J. Deep Learning Technologies for Imaging Biomarkers in Medicine. Ph.D. Thesis, Universidad Rey Juan Carlos, Madrid, Spain, 2020. [Google Scholar]












| Participant ID | Sex | Age | Field of View (FOV) |
|---|---|---|---|
| fct-train-01 | F | 31 | neck |
| fct-train-02 | F | 52 | paranasal sinuses |
| fct-train-03 | F | 74 | brain |
| fct-train-04 | F | 30 | neck |
| fct-train-05 | M | 34 | facial orbits |
| fct-train-06 | M | 25 | brain |
| fct-train-07 | M | 64 | brain |
| fct-train-08 | F | 66 | brain |
| fct-train-09 | F | 77 | brain |
| fct-train-10 | F | 65 | brain |
| fct-train-11 | M | 66 | brain |
| fct-train-12 | M | 80 | neck |
| fct-train-13 | M | 71 | neck |
| fct-train-14 | F | 63 | brain |
| fct-train-15 | F | 70 | facial orbits |
| Participant ID | Sex | Age | FOV |
|---|---|---|---|
| fct-test-01 | M | 21 | full head |
| fct-test-02 | F | 46 | full head |
| fct-test-03 | M | 83 | full head |
| fct-test-04 | F | 38 | full head |
| fct-test-05 | F | 22 | full head |
| fct-test-06 | F | 27 | full head |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Martinez-Girones, P.M.; Vera-Olmos, J.; Gil-Correa, M.; Ramos, A.; Garcia-Cañamaque, L.; Izquierdo-Garcia, D.; Malpica, N.; Torrado-Carvajal, A. Franken-CT: Head and Neck MR-Based Pseudo-CT Synthesis Using Diverse Anatomical Overlapping MR-CT Scans. Appl. Sci. 2021, 11, 3508. https://doi.org/10.3390/app11083508
Martinez-Girones PM, Vera-Olmos J, Gil-Correa M, Ramos A, Garcia-Cañamaque L, Izquierdo-Garcia D, Malpica N, Torrado-Carvajal A. Franken-CT: Head and Neck MR-Based Pseudo-CT Synthesis Using Diverse Anatomical Overlapping MR-CT Scans. Applied Sciences. 2021; 11(8):3508. https://doi.org/10.3390/app11083508
Chicago/Turabian StyleMartinez-Girones, Pedro Miguel, Javier Vera-Olmos, Mario Gil-Correa, Ana Ramos, Lina Garcia-Cañamaque, David Izquierdo-Garcia, Norberto Malpica, and Angel Torrado-Carvajal. 2021. "Franken-CT: Head and Neck MR-Based Pseudo-CT Synthesis Using Diverse Anatomical Overlapping MR-CT Scans" Applied Sciences 11, no. 8: 3508. https://doi.org/10.3390/app11083508
APA StyleMartinez-Girones, P. M., Vera-Olmos, J., Gil-Correa, M., Ramos, A., Garcia-Cañamaque, L., Izquierdo-Garcia, D., Malpica, N., & Torrado-Carvajal, A. (2021). Franken-CT: Head and Neck MR-Based Pseudo-CT Synthesis Using Diverse Anatomical Overlapping MR-CT Scans. Applied Sciences, 11(8), 3508. https://doi.org/10.3390/app11083508