
Generating Robotic Speech Prosody for Human Robot Interaction: A Preliminary Study


Abstract
1. Introduction
1.1. Voice via Intelligent Systems
1.2. Novel Method for Specific Group of People
1.3. Contributions and Paper Overview
2. Literature Reviews on Speech Prosody and Robot
3. Method
3.1. Hypothesis
3.2. Materials
3.3. Protocols
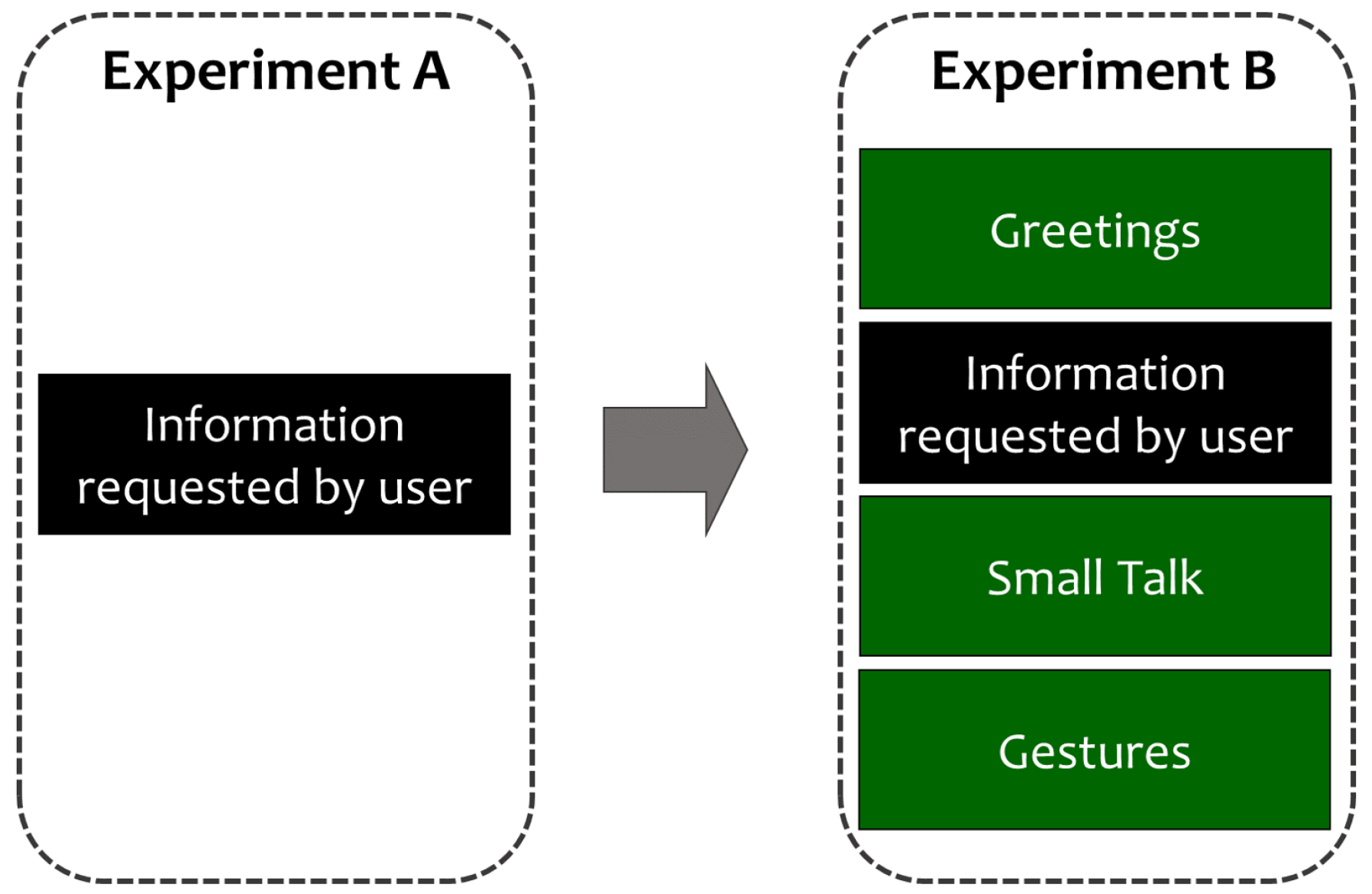
3.3.1. Experiment A
I will tell you tomorrow’s weather. Hokkaido will be snowy due to low pressure. Tohoku will be snowy due to cold weather. Kanto will be cloudy with the influence of cold. Chubu will be covered with high pressure and it will be sunny. Kinki will be rainy due to the influence of an atmospheric pressure valley. Chugoku will be rainy due to cold air. Shikoku will be covered with high pressure and it will be sunny. Kyushu will be rainy due to moist air. Okinawa will be cloudy with the influence of moist air. It was the weather forecast.
3.3.2. Experiment B
Hello. My name is Nao. Can you tell me your name? I am a humanoid robot. Have you ever seen me somewhere? Recently, there are some friends who started working at the hotel. There are some friends playing soccer. Don’t you think that this figure looks like a Pepper robot? Actually, I was built by the same company with Pepper robot. Pepper is like a brother. Pepper is also the same robot as I am talking to everyone in various places, such as a company and nursing home. I also like chatting with everyone. That’s it. I want to know more about you. Now, I will ask you a couple of questions, so please answer to my questions. Thank you. Well then, what’s your favorite color? (pause a little bit) I like that color! In addition, I like blue. I think that is cool. Alright, I will ask another question. What’s your favorite food? (pause a little bit) Alright. I have not eaten yet, but I’d like to eat hot pot. By the way, I saw the weather forecast for tomorrow on today’s news. Let tell you. The weather tomorrow is cloudy, the probability of precipitation is 30 percent. If you go out, I think it would be better to have an umbrella. In addition, it seems to be tomorrow, so it is better to keep your cold measures steady. It is about time to have the questionnaire answered. Today, thank you for chatting with me. Then, please answer the questionnaire from now.
4. Results
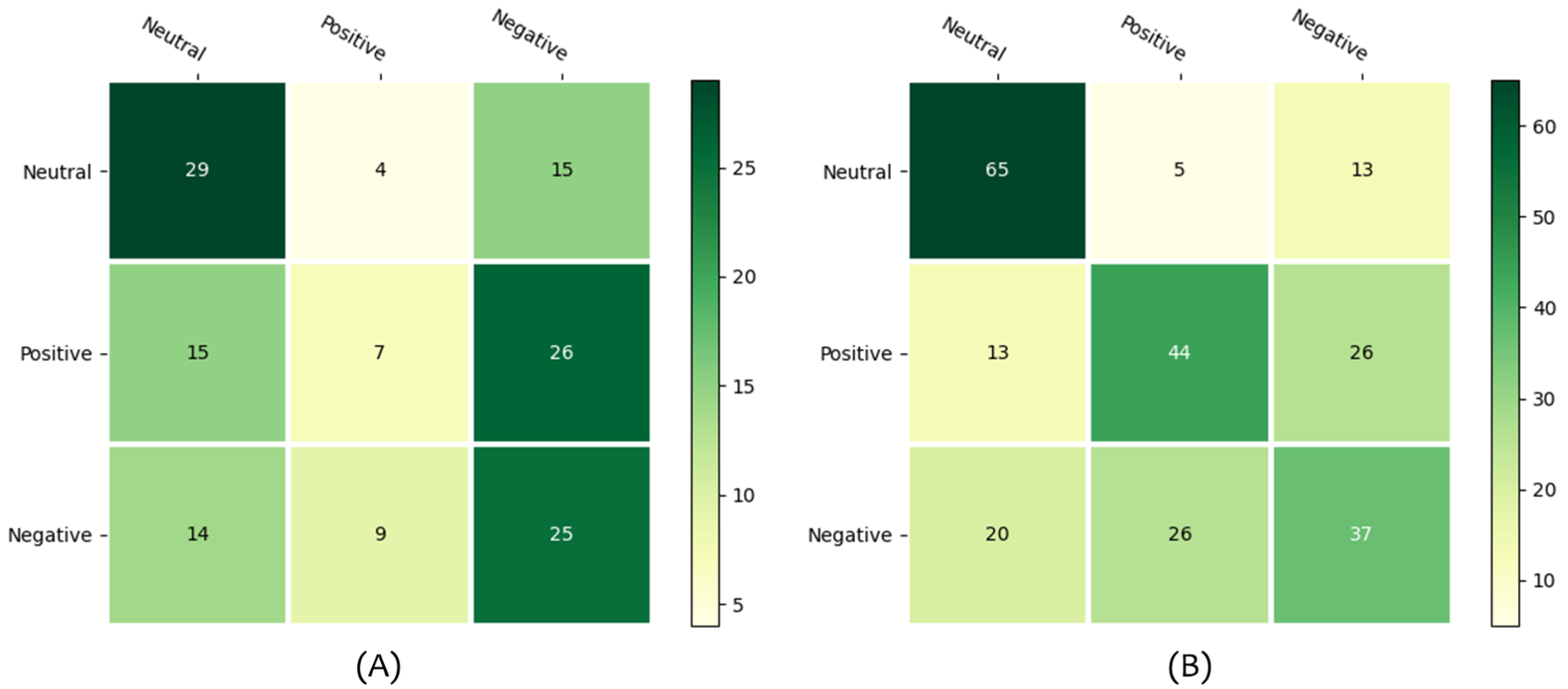
4.1. Experiment A
4.2. Experiment B
5. Discussion
6. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ahn, H.S.; Lee, M.H.; Broadbent, E.; MacDonald, B.A. Is Entertainment Services of a Healthcare Service Robot for Older People Useful to Young People? In Proceedings of the IEEE International Conference on Robotic Computing (IRC), Taichung, Taiwan, 10–12 April 2017; pp. 330–335. [Google Scholar]
- Joh, E.E. Private Security Robots, Artificial Intelligence, and Deadly Force. UCDL Rev. 2017, 51, 569. [Google Scholar]
- Matarić, M.J. Socially assistive robotics: Human augmentation versus automation. Sci. Robot. 2017, 2, eaam5410. [Google Scholar] [CrossRef]
- Moyle, W.; Arnautovska, U.; Ownsworth, T.; Jones, C. Potential of telepresence robots to enhance social connectedness in older adults with dementia: An integrative review of feasibility. Int. Psychogeriatr. 2017, 29, 1951–1964. [Google Scholar] [CrossRef]
- Cudd, P.; De Witte, L. Robots for Elderly Care: Their Level of Social Interactions and the Targeted End User. Harnessing Power Technol. Improv. Lives 2017, 242, 472. [Google Scholar]
- Bedaf, S.M. The Future is Now: The Potential of Service Robots in Elderly Care. Ph.D. Thesis, Maastricht University, Maastricht, The Netherlands, 2017. [Google Scholar]
- Wada, K.; Shibata, T.; Saito, T.; Tanie, K. Psychological and social effects of robot assisted activity to elderly people who stay at a health service facility for the aged. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA’03), Barcelona, Spain, 18–22 April 2003; Volume 3, pp. 3996–4001. [Google Scholar]
- Das, R.; Tuna, A.; Demirel, S.; Netas, A.S.K.; Yurdakul, M.K. A Survey on the Internet of Things Solutions for the Elderly and Disabled: Applications, Prospects, and Challenges. Int. J. Comput. Netw. Appl. (IJCNA) 2017, 4, 84–92. [Google Scholar] [CrossRef]
- Lewis, L.; Metzler, T.; Cook, L. Evaluating Human-Robot Interaction Using a Robot Exercise Instructor at a Senior Living Community. In Proceedings of the International Conference on Intelligent Robotics and Applications (ICIRA 2016), Tokyo, Japan, 22–24 August 2016; pp. 15–25. [Google Scholar]
- Crumpton, J.; Bethel, C.L. A survey of using vocal prosody to convey emotion in robot speech. Int. J. Soc. Robot. 2016, 8, 271–285. [Google Scholar] [CrossRef]
- Christensen, H.I.; Okamura, A.; Mataric, M.; Kumar, V.; Hager, G.; Choset, H. Next generation robotics. arXiv 2016, arXiv:1606.09205. [Google Scholar]
- Hammer, S.; Kirchner, K.; André, E.; Lugrin, B. Touch or Talk: Comparing Social Robots and Tablet PCs for an Elderly Assistant Recommender System. In Proceedings of the 2017 ACM/IEEE International Conference on Human-Robot Interaction (HRI 2017), Vienna, Austria, 6–9 March 2017; pp. 129–130. [Google Scholar]
- Ishiguro, N. Care robots in Japanese elderly care. In The Routledge Handbook of Social Care Work around the World; Taylor & Francis Group: London, UK, 2017; p. 256. [Google Scholar]
- Ishi, C.; Arai, J.; Hagita, N. Prosodic analysis of attention-drawing speech. In Proceedings of the 2017 Annual Conference of the International Speech Communication Association, Stockholm, Sweden, 20–24 August 2017; pp. 909–913. [Google Scholar]
- Ray, C.; Mondada, F.; Siegwart, R. What do people expect from robots? In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, 2008 (IROS 2008), Nice, France, 22–26 September 2008; pp. 3816–3821. [Google Scholar]
- Ito, R.; Komatani, K.; Kawahara, T.; Okuno, H.G. Analysis and Detection of Emotional States in Spoken Dialogue with Robot. Inf. Process. Soc. Jpn. SLP 2003, 2003, 107–112. (In Japanese) [Google Scholar]
- Kimura, H.; Tomita, Y.; Honda, S. Synthesis of emotional voice by changing the parameters in the characteristics of vocal cords and vocal tract. Jpn. J. Ergon. 1996, 32, 319–325. (In Japanese) [Google Scholar]
- Mitchell, R.L.; Xu, Y. What is the Value of Embedding Artificial Emotional Prosody in Human–Computer Interactions? Implications for Theory and Design in Psychological Science. Front. Psychol. 2015, 6, 1750. [Google Scholar] [CrossRef] [PubMed]
- Recupero, D.R.; Spiga, F. Knowledge acquisition from parsing natural language expressions for humanoid robot action commands. Inf. Process. Manag. 2020, 57, 102094. [Google Scholar] [CrossRef]
- Pullin, G.; Cook, A. The value of visualizing tone of voice. Logop. Phoniatr. Vocol. 2013, 38, 105–114. [Google Scholar] [CrossRef] [PubMed]
- Moriyama, T.; Mori, S.; Ozawa, S. A Synthesis Method of Emotional Speech Using Subspace Constraints in Prosody. J. Inf. Process. Soc. Jpn. 2009, 50, 1181–1191. [Google Scholar]
- Vinciarelli, A.; Pantic, M.; Bourlard, H.; Pentland, A. Social signal processing: State-of-the-art and future perspectives of an emerging domain. In Proceedings of the 16th ACM International Conference on Multimedia, Vancouver, BC, Canada, 27–31 October 2008; pp. 1061–1070. [Google Scholar]
- Clinard, C.G.; Cotter, C.M. Neural representation of dynamic frequency is degraded in older adults. Hear. Res. 2015, 323, 91–98. [Google Scholar] [CrossRef]
- Crumpton, J.; Bethel, C.L. Validation of vocal prosody modifications to communicate emotion in robot speech. In Proceedings of the 2015 International Conference on Collaboration Technologies and Systems (CTS), Atlanta, GA, USA, 1–5 June 2015; pp. 39–46. [Google Scholar]
- Tielman, M.; Neerincx, M.; Meyer, J.J.; Looije, R. Adaptive emotional expression in robot-child interaction. In Proceedings of the 2014 ACM/IEEE International Conference on Human-Robot Interaction, Bielefeld, Germany, 3–6 March 2014; pp. 407–414. [Google Scholar]
- Tejima, N. Rehabilitation Robots for the Elderly-Trend and Futre. J. JSPE 1999, 65, 507–511. (In Japanese) [Google Scholar]
- Sperber, D.; Wilson, D. Précis of relevance: Communication and cognition. Behav. Brain Sci. 1987, 10, 697–710. [Google Scholar] [CrossRef]
- Kitayama, S.; Ishii, K. Word and voice: Spontaneous attention to emotional utterances in two languages. Cogn. Emot. 2002, 16, 29–59. [Google Scholar] [CrossRef]
- Suzuki, T.; Tamura, N. Features of emotional voices: Focus in differences between expression and recognition. Jpn. J. Psychol. 2006, 77, 149–156. (In Japanese) [Google Scholar] [CrossRef][Green Version]
- Eyben, F.; Wöllmer, M.; Schuller, B. Opensmile: The munich versatile and fast open-source audio feature extractor. In Proceedings of the 18th ACM International Conference on Multimedia, Firenze, Italy, 25–29 October 2010; pp. 1459–1462. [Google Scholar]
- Schuller, B.; Steidl, S.; Batliner, A. The interspeech 2009 emotion challenge. In Proceedings of the 10th Annual Conference of the International Speech Communication Association, Brighton, UK, 6–10 September 2009. [Google Scholar]
- Nhat, T.B.; Mera, K.; Kurosawa, Y.; Takezawa, T. Natural Language Dialogue System considering Emotion: Guessed from Acoustic Features. In Proceedings of the Human-Agent Interaction Symposium 2014 (HAI’14), Tsukuba, Japan, 28–31 October 2014. [Google Scholar]
- Hall, M.; Frank, E.; Holmes, G.; Pfahringer, B.; Reutemann, P.; Witten, I.H. The WEKA data mining software: An update. ACM SIGKDD Explor. Newsl. 2009, 11, 10–18. [Google Scholar] [CrossRef]
- Platt, J. Sequential Minimal Optimization: A Fast Algorithm for Training Support Vector Machines; Microsoft: Redmond, WA, USA, 1998. [Google Scholar]
- Hold, B.; Schleidt, M. The importance of human odour in non-verbal communication. Ethology 1977, 43, 225–238. [Google Scholar] [CrossRef] [PubMed]
- Breazeal, C.; Kidd, C.D.; Thomaz, A.L.; Hoffman, G.; Berlin, M. Effects of nonverbal communication on efficiency and robustness in human-robot teamwork. In Proceedings of the 2005 IEEE/RSJ International Conference on Intelligent Robots and Systems, 2005.(IROS 2005), Edmonton, AB, Canada, 2–6 August 2005; pp. 708–713. [Google Scholar]
- McDuff, D.; Mahmoud, A.; Mavadati, M.; Amr, M.; Turcot, J.; Kaliouby, R.E. AFFDEX SDK: A cross-platform real-time multi-face expression recognition toolkit. In Proceedings of the 2016 CHI Conference Extended Abstracts on Human Factors in Computing Systems, San Jose, CA, USA, 7–12 May 2016; pp. 3723–3726. [Google Scholar]
- Magdin, M.; Benko, L.; Koprda, Š. A case study of facial emotion classification using affdex. Sensors 2019, 19, 2140. [Google Scholar] [CrossRef] [PubMed]
- Lopez-Rincon, A. Emotion recognition using facial expressions in children using the NAO Robot. In Proceedings of the 2019 International Conference on Electronics, Communications and Computers (CONIELECOMP 2019), Cholula, Mexico, 27 February–1 March 2019; pp. 146–153. [Google Scholar]
- Dupré, D.; Krumhuber, E.G.; Küster, D.; McKeown, G.J. A performance comparison of eight commercially available automatic classifiers for facial affect recognition. PLoS ONE 2020, 15, e0231968. [Google Scholar] [CrossRef] [PubMed]
- Kominek, J.; Black, A.W. The CMU Arctic speech databases. In Proceedings of the Fifth ISCA Workshop on Speech Synthesis, Pittsburgh, PA, USA, 14–16 June 2004. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Neutral | Positive (Joy) | Negative (Sadness) | |
|---|---|---|---|
| Pitch (Hz) | 292 | 314 | 251 |
| Timing (%) | 100 | 100 | 100 |
| Loudness (%) | 100 | 100 | 100 |
| Dataset from Section 3.3.1 | Dataset from Section 3.3.2 | |||||
|---|---|---|---|---|---|---|
| Precision | Recall | F-Measure | Precision | Recall | F-Measure | |
| Neutral | 0.500 | 0.604 | 0.547 | 0.663 | 0.783 | 0.718 |
| Positive | 0.350 | 0.146 | 0.206 | 0.587 | 0.530 | 0.557 |
| Negative | 0.410 | 0.424 | 0.397 | 0.487 | 0.446 | 0.465 |
| Subject No. | Anger | Sadness | Fear | Joy |
|---|---|---|---|---|
| Subject 1 | 2.246 | 175.426 | 81.646 | 43.972 |
| Subject 2 | 0 | 22.494 | 166.242 | 124.071 |
| Subject 3 | 2.277 | 277.787 | 28.271 | 0 |
| Negative Face | Positive Face | |
|---|---|---|
| Neutral voice | 259 | 44 |
| Positive voice | 193 | 124 |
| Negative voice | 308 | 0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, J. Generating Robotic Speech Prosody for Human Robot Interaction: A Preliminary Study. Appl. Sci. 2021, 11, 3468. https://doi.org/10.3390/app11083468
Lee J. Generating Robotic Speech Prosody for Human Robot Interaction: A Preliminary Study. Applied Sciences. 2021; 11(8):3468. https://doi.org/10.3390/app11083468
Chicago/Turabian StyleLee, Jaeryoung. 2021. "Generating Robotic Speech Prosody for Human Robot Interaction: A Preliminary Study" Applied Sciences 11, no. 8: 3468. https://doi.org/10.3390/app11083468
APA StyleLee, J. (2021). Generating Robotic Speech Prosody for Human Robot Interaction: A Preliminary Study. Applied Sciences, 11(8), 3468. https://doi.org/10.3390/app11083468