
Using a Human Interviewer or an Automatic Interviewer in the Evaluation of Patients with AD from Speech

 ,
,  and
and 
Abstract
1. Introduction
Automatic Interviewers
2. Materials and Methods
2.1. Methods
2.2. Materials
2.2.1. Databases
2.2.2. Human Interviewer
2.2.3. Automatic Interviewer
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Molinuevo Guix, J.L. Role of biomarkers in the early diagnosis of Alzheimer’s disease. Revista Española Geriatría Gerontol. 2011, 46, 39–41. [Google Scholar]
- Weller, J.; Budson, A. Current understanding of Alzheimer’s disease diagnosis and treatment. F1000Research 2018, 7. [Google Scholar] [CrossRef] [PubMed]
- Andersen, C.K.; Wittrup-Jensen, K.U.; Lolk, A.; Andersen, K.; Kragh-Sørensen, P. Ability to perform activities of daily living is the main factor affecting quality of life in patients with dementia. Health Qual. Life Outcomes 2004, 2, 52. [Google Scholar] [CrossRef] [PubMed]
- Laske, C.; Sohrabi, H.R.; Frost, S.M.; López-De-Ipiña, K.; Garrard, P.; Buscema, M.; Dauwels, J.; Soekadar, S.R.; Mueller, S.; Linnemann, C.; et al. Innovative diagnostic tools for early detection of Alzheimer’s disease. Alzheimer’s Dement. 2015, 11, 561–578. [Google Scholar] [CrossRef]
- Hane, F.T.; Robinson, M.; Lee, B.Y.; Bai, O.; Leonenko, Z.; Albert, M.S. Recent Progress in Alzheimer’s Disease Research, Part 3: Diagnosis and Treatment. J. Alzheimer’s Dis. 2017, 57, 645–665. [Google Scholar] [CrossRef] [PubMed]
- Bäckman, L.; Jones, S.; Berger, A.-K.; Laukka, E.J.; Small, B.J. Cognitive impairment in preclinical Alzheimer’s disease: A meta-analysis. Neuropsychology 2005, 19, 520–531. [Google Scholar] [CrossRef]
- Deramecourt, V.; Lebert, F.; Debachy, B.; Mackowiak-Cordoliani, M.A.; Bombois, S.; Kerdraon, O.; Buée, L.; Maurage, C.-A.; Pasquier, F. Prediction of pathology in primary progressive language and speech disorders. Neurology 2009, 74, 42–49. [Google Scholar] [CrossRef]
- Szatloczki, G. Speaking in Alzheimer’s disease, is that an early sign? Importance of changes in language abilities in Alzheimer’s disease. Front. Aging Neurosci. 2015, 7, 1–7. [Google Scholar] [CrossRef]
- Meilan, J.J.; Martinez-Sanchez, F.; Carro, J.; Carcavilla, N.; Ivanova, O. Voice Markers of Lexical Access in Mild Cognitive Impairment and Alzheimer’s Disease. Curr. Alzheimer Res. 2018, 15, 111–119. [Google Scholar] [CrossRef]
- Nebes, R.D.; Brady, C.B.; Huff, F.J. Automatic and attentional mechanisms of semantic priming in alzheimer’s disease. J. Clin. Exp. Neuropsychol. 1989, 11, 219–230. [Google Scholar] [CrossRef]
- McKhann, G.M.; Knopman, D.S.; Chertkow, H.; Hyman, B.T.; Jack, C.R.; Kawas, C.H.; Klunk, W.E.; Koroshetz, W.J.; Manly, J.J.; Mayeux, R.; et al. The diagnosis of dementia due to Alzheimer’s disease: Recommendations from the National Institute on Aging-Alzheimer’s Association workgroups on diagnostic guidelines for Alzheimer’s disease. Alzheimer’s Dement. J. Alzheimer’s Assoc. 2011, 7, 263–269. [Google Scholar] [CrossRef] [PubMed]
- Pulido, M.L.B.; Hernández, J.B.A.; Ballester, M.A.F.; Gonzalez, C.M.T.; Mekyska, J.; Smekal, Z. Alzheimer’s disease and automatic speech analysis: A review. Expert Syst. Appli. 2020, 150, 113213. [Google Scholar] [CrossRef]
- Kim, Y.; Lee, H.; Provost, E.M. Deep learning for robust feature generation in audiovisual emotion recognition. In Proceedings of the Acoustics, Speech and Signal Processing (ICASSP), 2013 IEEE International Conference, Vancouver, BC, Canada, 26–31 May 2013; pp. 3687–3691. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436. [Google Scholar] [CrossRef] [PubMed]
- Brabenec, L.; Mekyska, J.; Galaz, Z.; Rektorova, I. Speech disorders in Parkinson’s disease: Early diagnostics and effects of medication and brain stimulation. J. Neural Transm. 2017, 124, 303–334. [Google Scholar] [CrossRef]
- Khodabakhsh, A.; Yeşil, F.; Güner, E.; Demiroglu, C. Evaluation of linguistic and prosodic features for detection of Alzheimer’s disease in Turkish conversational speech. EURASIP J. Audio Speech Music. Process. 2015, 2015, 189. [Google Scholar] [CrossRef]
- Tanaka, H.; Adachi, H.; Ukita, N.; Kudo, T.; Nakamura, S. Automatic detection of very early stage of dementia through multimodal interaction with computer avatars. In Proceedings of the 18th ACM International Conference on Multimodal Interaction—ICMI 2016, Tokyo, Japan, 12–16 November 2016; pp. 261–265. [Google Scholar]
- Rentoumi, V.; Paliouras, G.; Danasi, E.; Arfani, D.; Fragkopoulou, K.; Varlokosta, S.; Papadatos, S. Automatic detection of linguistic indicators as a means of early detection of Alzheimer’s disease and of related dementias: A computational linguistics analysis. In Proceedings of the Cognitive Infocommunications (CogInfoCom), 8th IEEE International Conference, Debrecen, Hungary, 11–14 September 2017; pp. 33–38. [Google Scholar]
- De Ipiña, K.L.; Alonso, J.B.; Solé-Casals, J.; Barroso, N.; Faúndez, M.; Ecay, M.; Travieso, C.; Ezeiza, A.; Estanga, A. Alzheimer disease diagnosis based on automatic spontaneous speech analysis. In Proceedings of the International Joint Conference on Computational Intelligence, IJCCI 2012, Barcelona, Spain, 5–7 October 2012; pp. 698–705. [Google Scholar]
- Roy, D.; Pentland, A. Automatic spoken affect classification and analysis. In Proceedings of the Second International Conference on Automatic Face and Gesture Recognition, Killington, VT, USA, 14–16 October 1996; pp. 363–367. [Google Scholar]
- Lopez-De-Ipina, K.; Alonso, J.; Travieso, C.; Egiraun, H.; Ecay, M.; Ezeiza, A.; Barroso, N.; Martinez-Lage, P. Automatic analysis of emotional response based on non-linear speech modeling oriented to Alzheimer disease diagnosis. In Proceedings of the INES 2013—IEEE 17th International Conference on Intelligent Engineering Systems, San Jose, Costarica, 19–21 June 2013; pp. 61–64. [Google Scholar]
- Alonso, J.B.; Cabrera, J.; Medina, M.; Travieso, C.M. New approach in quantification of emotional intensity from the speech signal: Emotional temperature. Expert Syst. Appl. 2015, 42, 9554–9564. [Google Scholar] [CrossRef]
- Lopez-De-Ipiña, K.; Alonso, J.B.; Solé-Casals, J.; Barroso, N.; Henriquez, P.; Faundez-Zanuy, M.; Travieso, C.M.; Ecay-Torres, M.; Martinez-Lage, P.; Eguiraun, H. On Automatic Diagnosis of Alzheimer’s Disease Based on Spontaneous Speech Analysis and Emotional Temperature. Cogn. Comput. 2013, 7, 44–55. [Google Scholar] [CrossRef]
- Sohn, J.; Kim, N.S.; Sung, W. A statistical model-based voice activity detection. IEEE Signal Process. Lett. 1999, 6, 1–3. [Google Scholar] [CrossRef]
- Hernández-Domíngue, L.; García-Canó, E.; Ratt, S.; Sierra-Martínez, G. Detection of Alzheimer’s disease based on automatic analysis of common objects descriptions. In Proceedings of the 7th Workshop on Cognitive Aspects of Computational Language Learning, Berlin, Germany, 11 August 2016; pp. 10–15. [Google Scholar]
- Vincze, V.; Gosztolya, G.; Tóth, L.; Hoffmann, I.; Szatlóczki, G.; Bánréti, Z.; Pákáski, M.; Kálmán, J.; Erk, K.; Smith, N.A. Detecting Mild Cognitive Impairment by Exploiting Linguistic Information from Transcripts. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; pp. 181–187. [Google Scholar]
- Bhaduri, S.; Das, R.; Ghosh, D. Non-Invasive Detection of Alzheimer’s Disease-Multifractality of Emotional Speech. J. Neurol. Neurosci. 2016, 7, 84. [Google Scholar] [CrossRef]
- López-De-Ipiña, K.; Solé-Casals, J.; Eguiraun, H.; Alonso, J.; Travieso, C.; Ezeiza, A.; Barroso, N.; Ecay-Torres, M.; Martinez-Lage, P.; Beitia, B. Feature selection for spontaneous speech analysis to aid in Alzheimer’s disease diagnosis: A fractal dimension approach. Comput. Speech Lang. 2015, 30, 43–60. [Google Scholar] [CrossRef]
- Bertram, L.; McQueen, M.B.; Mullin, K.; Blacker, D.; E Tanzi, R. Systematic meta-analyses of Alzheimer disease genetic association studies: The AlzGene database. Nat. Genet. 2007, 39, 17–23. [Google Scholar] [CrossRef]
- De La Mata, M. Metaanálisis del Sistema Olfatorio Como Diagnóstico Precoz en Parkinson y Alzheimer. Revista de Bioloxía 2016, 8, 102–110. [Google Scholar]
- Al-Hameed, S.; Benaissa, M.; Christensen, H. Simple and robust audio-based detection of biomarkers for Alzheimer’s disease. In Proceedings of the 7th Workshop on Speech and Language Processing for Assistive Technologies (SLPAT), San Francisco, CA, USA, 13 September 2016; pp. 32–36. [Google Scholar]
- Zhou, L.; Fraser, K.C.; Rudzicz, F. Speech Recognition in Alzheimer’s Disease and in its Assessment. In Proceedings of the Interspeech 2016, San Francisco, CA, USA, 12–18 September 2016; pp. 1948–1952. [Google Scholar]
- Hernández-Domínguez, L.; Ratté, S.; Sierra-Martínez, G.; Roche-Bergua, A. Computer-based evaluation of Alzheimer’s disease and mild cognitive impairment patients during a picture description task. Alzheimer’s Dement. Diagn. Assess. Dis. Monit. 2018, 10, 260–268. [Google Scholar] [CrossRef] [PubMed]
- López-De-Ipiña, K.; Martinez-De-Lizarduy, U.; Barroso, N.; Ecay-Torres, M.; Martínez-Lage, P.; Torres, F.; Faundez-Zanuy, M. Automatic analysis of Categorical Verbal Fluency for Mild Cognitive impartment detection: A non-linear language independent approach. In Proceedings of the Bioinspired Intelligence (IWOBI), 4th International Work Conference IEEE, San Sebastian, Spain, 10–12 June 2015; pp. 101–104. [Google Scholar]
- AMI Corpus. 2006. Available online: http://groups.inf.ed.ac.uk/ami/corpus/ (accessed on 26 May 2018).
- Folstein, M.F.; Robins, L.N.; Helzer, J.E. The mini-mental state examination. Arch. Gen. Psychiatry 1983, 40, 812. [Google Scholar] [CrossRef] [PubMed]
- Rockwood, K.; Graham, J.E.; Fay, S. Goal setting and attainment in Alzheimer’s disease patients treated with donepezil. J. Neurol. Neurosurg. Psychiatry 2002, 73, 500–507. [Google Scholar] [CrossRef] [PubMed]
- Weiner, J.; Frankenberg, C.; Telaar, D. Towards Automatic Transcription of ILSE―An Interdisciplinary Longitudinal Study of Adult Development and Aging. In Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC’16), Portorož, Slovenia, 23–28 May 2016. [Google Scholar]
- DementiaBank|TalkBank. 2007. Available online: https://dementia.talkbank.org/access/ (accessed on 26 May 2018).
- López-de-Ipiña, K.; Alonso, J.B.; Barroso, N.; Faundez-Zanuy, M.; Ecay, M.; Solé-Casals, J.; Travieso, C.M.; Estanga, A.; Ezeiza, A. New Approaches for Alzheimer’s Disease Diagnosis Based on Automatic Spontaneous Speech Analysis and Emotional Temperature. In Ambient Assisted Living and Home Care; IWAAL 2012; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2012; Volume 7657, pp. 407–414. [Google Scholar]
- López-De-Ipiña, K.; Alonso, J.B.; Barroso, N.; Solé-Casals, J.; Ecay-Torres, M.; Martínez-Lage, P.; Zelarain, F.; Egiraun, H.; Travieso, C.M. Spontaneous speech and emotional response modeling based on one-class classifier oriented to Alzheimer disease diagnosis. In Proceedings of the XIII Mediterranean Conference on Medical and Biological Engineering and Computing, IFMBE Proceedings, Seville, Spain, 23–28 September 2013; Springer: Cham, Switzerland, 2014; Volume 41, pp. 571–574. [Google Scholar]
- López-de-Ipiña, K.; Alonso, J.B.; Travieso, C.M.; Solé-Casals, J.; Egiraun, H.; Faundez-Zanuy, M.; Ezeiza, A.; Barroso, N.; Ecay-Torres, M.; Martinez-Lage, P.; et al. On the Selection of Non-Invasive Methods Based on Speech Analysis Oriented to Automatic Alzheimer Disease Diagnosis. Sensors 2013, 13, 6730–6745. [Google Scholar] [CrossRef]
- Lopez-De-Ipiña, K.; Alonso-Hernández, J.; Solé-Casals, J.; Travieso-González, C.; Ezeiza, A.; Faundez-Zanuy, M.; Calvo, P.; Beitia, B. Feature selection for automatic analysis of emotional response based on nonlinear speech modeling suitable for diagnosis of Alzheimer׳s disease. Neurocomputing 2015, 150, 392–401. [Google Scholar] [CrossRef][Green Version]
- Lopez-De-Ipina, K.; Martinez-De-Lizarduy, U.; Calvo, P.M.; Mekyska, J.; Beitia, B.; Barroso, N.; Estanga, A.; Tainta, M.; Ecay-Torres, M. Advances on Automatic Speech Analysis for Early Detection of Alzheimer Disease: A Non-linear Multi-task Approach. Curr. Alzheimer Res. 2018, 15, 139–148. [Google Scholar] [CrossRef]
- De Lizarduy, U.M.; Salomón, P.C.; Vilda, P.G.; Torres, M.E.; de Ipiña, K.L. Alzumeric: A decision support system for diagnosis and monitoring of cognitive impairment. Loquens 2017, 4, 37. [Google Scholar] [CrossRef]
- Proyectos Fundación CITA Alzheimer. 2017. Available online: http://www.cita-alzheimer.org/investigacion/proyectos (accessed on 26 May 2018).
- Satt, A.; Sorrin, A.; Toledo-Ronen, O.; Barkan, O.; Kompatsiaris, I.; Kokonozi, A.; Tsolaki, M. Evaluation of Speech-Based Protocol for Detection of Early-Stage Dementia. In Proceedings of the Interspeech 2013, Lyon, France, 25–29 August 2013; pp. 1692–1696. [Google Scholar]
- Tröger, J.; Linz, N.; Alexandersson, J.; König, A.; Robert, P. Automated speech-based screening for alzheimer’s disease in a care service scenario. In Proceedings of the 11th EAI International Conference on Pervasive Computing Technologies for Healthcare, Barcelona, Spain, 23–26 May 2017; ACM: New York, NY, USA, 2017; pp. 292–297. [Google Scholar]
- Satt, A.; Hoory, R.; König, A.; Aalten, P.; Robert, P.H. Speech-based automatic and robust detection of very early dementia. In Proceedings of the Fifteenth Annual Conference of the International Speech Communication Association, INTERSPEECH-2014, Singapore, 14–18 September 2014; pp. 2538–2542. [Google Scholar]
- König, A.; Satt, A.; Sorin, A.; Hoory, R.; Toledo-Ronen, O.; Derreumaux, A.; Manera, V.; Verhey, F.R.J.; Aalten, P.; Robert, P.H.; et al. Automatic speech analysis for the assessment of patients with predementia and Alzheimer’s disease. Alzheimer’s Dement. Diagn. Assess. Dis. Monit. 2015, 1, 112–124. [Google Scholar] [CrossRef]
- Mirzaei, S.; El Yacoubi, M.; Garcia-Salicetti, S.; Boudy, J.; Muvingi, C.K.S.; Cristancho-Lacroix, V. Automatic speech analysis for early Alzeimer’s disease diagnosis. In Proceedings of the JETSAN 2017, 6e Journées d’Etudes sur la Télésant, Bourges, France, 31 May–1 June 2017; pp. 114–116. [Google Scholar]
- Boyé, M.; Tran, T.M.; Grabar, N. NLP-Oriented Contrastive Study of Linguistic Productions of Alzheimer’s and Control People. In Proceedings of the International Conference on Natural Language Processing. Advances in Natural Language Processing, Warsaw, Poland, 17–19 September 2014; pp. 412–424. [Google Scholar]
- Luz, S. Longitudinal Monitoring and Detection of Alzheimer’s Type Dementia from Spontaneous Speech Data. In Proceedings of the Computer-Based Medical Systems (CBMS), 2017 IEEE 30th International Symposium on IEEE, Thessaloniki, Greece, 22–24 June 2017; pp. 45–46. [Google Scholar]
- Asgari, M.; Kaye, J.; Dodge, H. Predicting mild cognitive impairment from spontaneous spoken utterances. Alzheimer’s Dement. Transl. Res. Clin. Interv. 2017, 3, 219–228. [Google Scholar] [CrossRef]
- Sadeghian, R.; Schaffer, J.D.; Zahorian, S.A. Speech Processing Approach for Diagnosing Dementia in an Early Stage. In Proceedings of the Interspeech 2017, Stockholm, Sweden, 20–24 August 2017; pp. 2705–2709. [Google Scholar]
- Mueller, K.D.; Koscik, R.L.; Hermann, B.P.; Johnson, S.C.; Turkstra, L.S. Declines in Connected Language Are Associated with Very Early Mild Cognitive Impairment: Results from the Wisconsin Registry for Alzheimer’s Prevention. Front. Aging Neurosci. 2018, 9, 437. [Google Scholar] [CrossRef] [PubMed]
- Warnita, T.; Inoue, N.; Shinoda, K. Detecting Alzheimer’s Disease Using Gated Convolutional Neural Network from Audio Data. arXiv 2018, arXiv:1803.11344. Available online: http://arxiv.org/abs/1803.11344 (accessed on 1 May 2018).
- Wankerl, S.; Nöth, E.; Evert, S. An N-gram based approach to the automatic diagnosis of Alzheimer’s disease from spoken language. In Proceedings of the Annual Conference of the International Speech Communication Association, Interspeech 2017, Stockholm, Sweden, 20–24 August 2017. [Google Scholar]
- Yancheva, M. Automatic Assessment of Information Content in Speech for Detection of Dementia of the Alzheimer Type. Master’s Thesis, University of Toronto, Toronto, ON, Canada, 2016. [Google Scholar]
- Abdalla, M.; Rudzicz, F.; Hirst, G. Rhetorical structure and Alzheimer’s disease. Aphasiology 2018, 32, 41–60. [Google Scholar] [CrossRef]
- Sirts, K.; Piguet, O.; Johnson, M. Idea density for predicting Alzheimer’s disease from transcribed speech. arXiv 2017, arXiv:1706.04473. [Google Scholar]
- Thomas, C.; Kešelj, V.; Cercone, N.; Rockwood, K.; Asp, E. Automatic detection and rating of dementia of Alzheimer type through lexical analysis of spontaneous speech. In Proceedings of the IEEE International Conference Mechatronics and Automation, Niagara Falls, ON, Canada, 21 July–1 August 2005; Volume 3, pp. 1569–1574. [Google Scholar]
- Carolinas Conversations Collection. About Who We Are. 2008. Available online: http://carolinaconversations.musc.edu/about/who (accessed on 26 May 2018).
- Weiner, J.; Herff, C.; Schultz, T. Speech-Based Detection of Alzheimer’s Disease in Conversational German. In Proceedings of the Interspeech 2016, San Francisco, CA, USA, 12–18 September 2016; pp. 1938–1942. [Google Scholar]
- Meilán, J.J.G.; Martínez-Sánchez, F.; Carro, J.; Sánchez, J.A.; Pérez, E. Acoustic Markers Associated with Impairment in Language Processing in Alzheimer’s Disease. Span. J. Psychol. 2012, 15, 487–494. [Google Scholar] [CrossRef] [PubMed]
- Martínez-Sánchez, F.; Meilán, J.J.G.; Vera-Ferrandiz, J.A.; Carro, J.; Pujante-Valverde, I.M.; Ivanova, O.; Carcavilla, N. Speech rhythm alterations in Spanish-speaking individuals with Alzheimer’s disease. Aging Neuropsychol. Cogn. 2016, 24, 418–434. [Google Scholar] [CrossRef] [PubMed]
- Peraita, H.; Grasso, L. Corpus lingüístico de definiciones de categorías semánticas de personas mayores sanas y con la enfermedad del alzheimer; Technical Report; Fundación BBVA: Bilbao, Spain, 2010. [Google Scholar]
- Toledo, C.M.; Aluisio, S.M.; dos Santos, L.B.; Brucki, S.M.D.; Tres, E.S.; de Oliveira, M.O.; Mansur, L.L. Analysis of macrolinguistic aspects of narratives from individuals with Alzheimer’s disease, mild cognitive impairment, and no cognitive impairment. Alzheimer’s Dement. Diagnosis, Assess. Dis. Monit. 2018, 10, 31–40. [Google Scholar] [CrossRef]
- Beltrami, D.; Calzà, L.; Gagliardi, G.; Ghidoni, E.; Marcello, N.; Favretti, R.R.; Tamburini, F. Automatic Identification of Mild Cognitive Impairment through the Analysis of Italian Spontaneous Speech Productions. In Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC’16), Portorož, Slovenia, 23–28 May 2016; pp. 2089–2093. [Google Scholar]
- Nasrolahzadeh, M.; Mohammadpoory, Z.; Haddadnia, J. A novel method for early diagnosis of Alzheimer’s disease based on higher-order spectral estimation of spontaneous speech signals. Cogn. Neurodynamics 2016, 10, 495–503. [Google Scholar] [CrossRef]
- Kato, S.; Homma, A.; Sakuma, T.T. Easy Screening for Mild Alzheimer’s Disease and Mild Cognitive Impairment from Elderly Speech. Curr. Alzheimer Res. 2018, 15, 104–110. [Google Scholar] [CrossRef]
- Graovac, J.; Kovacevic, J.; Lazetic, G.P. Machine learning-based approach to help diagnosing Alzheimer’s disease through spontaneous speech analysis. In Proceedings of the Belgrade BioInformatics Conference, Belgrade, Serbia, 20–24 June 2016; p. 111. [Google Scholar]
- Gosztolya, G.; Tóth, L.; Grósz, T.; Vincze, V.; Hoffmann, I.; Szatlóczki, G.; Pákáski, M.; Kálmán, J. Detecting Mild Cognitive Impairment from Spontaneous Speech by Correlation-Based Phonetic Feature Selection. In Proceedings of the Interspeech 2016, San Francisco, CA, USA, 12–18 September 2016; pp. 107–111. [Google Scholar]
- Toth, L.; Hoffmann, I.; Gosztolya, G.; Vincze, V.; Szatloczki, G.; Banreti, Z. A speech recognition-based solution for the automatic detection of mild cognitive impairment from spontaneous speech. Curr. Alzheimer Res. 2018, 15, 130–138. [Google Scholar] [CrossRef] [PubMed]
- Tóth, L.; Gosztolya, G.; Vincze, V.; Hoffmann, I.; Szatloczki, G.; Biro, E.; Zsura, F.; Pakaski, M.; Kalman, J. Automatic Detection of Mild Cognitive Impairment from Spontaneous Speech Using ASR. In Proceedings of the Sixteenth Annual Conference of the International Speech Communication Association, Interspeech-2015, Dresden, Germany, 6–10 September 2015; pp. 2694–2698. [Google Scholar]
- St-Pierre, M.-C.; Ska, B.; Béland, R. Lack of coherence in the narrative discourse of patients with dementia of the Alzheimer’s type. J. Multiling. Commun. Disord. 2005, 3, 211–215. [Google Scholar] [CrossRef]
- Malekzadeh, G.; Arsalan, G.; Shahabi, M. A comparative study on the use of cohesion devices by normal age persian natives and those suffering from Alzheimer’s disease. J. Med. Sci. Islam. Azad Univ. Mashhad 2009, 5, 153–161. [Google Scholar]
- Ahangar, A.; Morteza, S.; Fadaki, J.; Sehhati, A. The Comparison of Morpho-Syntactic Patterns Device Comprehension in Speech of Alzheimer and Normal Elderly People. Zahedan J. Res. Med. Sci. 2018, 20, e9535. [Google Scholar] [CrossRef]
- Khodabakhsh, A.; Demiroglu, C. Analysis of Speech-Based Measures for Detecting and Monitoring Alzheimer’s Disease. In Data Mining in Clinical Medicine; Humana Press: New York, NY, USA, 2015; pp. 159–173. [Google Scholar]
- König, A.; Satt, A.; David, R.; Robert, P. O4-12-02: Innovative Voice Analytics for the Assessment and Monitoring of Cognitive Decline in People with Dementia and Mild Cognitive Impairment. Alzheimer’s Dement. 2016, 12, P363. [Google Scholar] [CrossRef]
- Aluisio, S.M.; Cunha, A.; Toledo, C.; Scarton, C. A computational tool for automated language production analysis aimed at dementia diagnosis. In Proceedings of the International Conference on Computational Processing of the Portuguese Language, XII, Demonstration Session, Tomar, Portugal, 13–16 July 2016. [Google Scholar]
- Aluísio, S.; Cunha, A.; Scarton, C. Evaluating Progression of Alzheimer’s Disease by Regression and Classification Methods in a Narrative Language Test in Portuguese. In Proceedings of the International Conference on Computational Processing of the Portuguse Language, Tomar, Portugal, 13–16 July 2016; pp. 109–114. [Google Scholar]
- Nasrolahzadeh, M.; Mohammadpoori, Z.; Haddadnia, J. Analysis of mean square error surface and its corresponding contour plots of spontaneous speech signals in Alzheimer’s disease with adaptive wiener filter. Comput. Hum. Behav. 2016, 61, 364–371. [Google Scholar] [CrossRef]
- De Looze, C.; Kelly, F.; Crosby, L.; Vourdanou, A.; Coen, R.F.; Walsh, C.; Lawlor, B.A.; Reilly, R.B. Changes in Speech Chunking in Reading Aloud is a Marker of Mild Cognitive Impairment and Mild-to-Moderate Alzheimer’s Disease. Curr. Alzheimer Res. 2018, 15, 828–847. [Google Scholar] [CrossRef]
- Becker, J.T.; Boiler, F.; Lopez, O.L.; Saxton, J.; Mcgonigle, K.L. The Natural History of Alzheimer’s Disease: Description of Study Cohort and Accuracy of Diagnosis. Arch. Neurol. 1994, 51, 585–594. [Google Scholar] [CrossRef]
- DeVault, D.; Artstein, R.; Benn, G.; Dey, T.; Fast, E.; Gainer, A.; Georgila, K.; Gratch, J.; Hartholt, A.; Lhommet, M.; et al. SimSensei kiosk: A virtual human interviewer for healthcare decision support. In Proceedings of the 13th International Conference on Autonomous Agents and Multiagent Systems, AAMAS 2014, Paris, France, 5–9 May 2014; Volume 2, pp. 1061–1068. [Google Scholar]
- Huggins-Daines, D.; Kumar, M.; Chan, A.; Black, A.W.; Ravishankar, M.; Rudnicky, A.I. Pocketsphinx: A free, real-time continuous speech recognition system for hand-held devices. In Proceedings of the IEEE International Conference on Acoustics Speech and Signal Processing, ICASSP 2006, Toulouse, France, 14–19 May 2006; pp. 185–188. [Google Scholar]
- Littlewort, G.; Whitehill, J.; Wu, T.; Fasel, I.; Frank, M.; Movellan, J.; Bartlett, M. The computer expression recognition toolbox (CERT). In Proceedings of the IEEE International Conference on Automatic Face and Gesture Recognition and Workshops, FG, Santa Barbara, CA, USA, 21–25 March 2011; pp. 298–305. [Google Scholar]
- Stone, M. Specifying Generation of Referring Expressions by Example. In Proceedings of the AAAI Spring Symposium on Natural Language Generation in Spoken and Written Dialogue, Palo Alto, CA, USA, 24–26 March 2003; pp. 133–140. [Google Scholar]
- Wiki—SAIBA—Mindmakers. Available online: http://mindmakers.com/projects/SAIBA (accessed on 1 April 2021).
- Bickmore, T.; Schulman, D.; Shaw, G. DTask and litebody: Open source, standards-based tools for building web-deployed embodied conversational agents. In Proceedings of the IVA 2009, Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), Amsterdam, The Netherlands, 14–16 September 2009; Volume 5773 LNAI, pp. 425–431. [Google Scholar]
- Poggi, I.; Pelachaud, C.; de Rosis, F.; Carofiglio, V.; de Carolis, B. Greta. A Believable Embodied Conversational Agent; Springer: Dordrecht, The Netherlands, 2005; pp. 3–25. [Google Scholar]
- Schröder, M. The Semaine Api: Towards a Standards-Based Framework for Building Emotion-Oriented Systems. Adv. Human-Computer Interact. 2010, 2010, 1–21. [Google Scholar] [CrossRef]
- Hartholt, A.; Traum, D.; Marsella, S.C.; Shapiro, A.; Stratou, G.; Leuski, A.; Morency, L.P.; Gratch, J. All together now: Introducing the virtual human toolkit. In Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Dordrecht, The Netherlands, 2013; Volume 8108 LNAI, pp. 368–381. [Google Scholar]
- IBM. SimpleC Advancing Memory Care with IBM Watson and IBM Cloud Solutions. Available online: https://www.ibm.com/case-studies/w796019n50088s93 (accessed on 15 June 2019).
- Wilcoxon, F. Some rapid approximate statistical procedures. Ann. N. Y. Acad. Sci. 1950, 52, 808–814. [Google Scholar] [CrossRef]
- Lazar, N.A. Basic Statistical Analysis. In The Statistical Analysis of Functional MRI Data; Springer: Berlin/Heidelberg, Germany, 2008; pp. 1–36. [Google Scholar]
- Sarhan, A.E. Estimation of the Mean and Standard Deviation by Order Statistics. Ann. Math. Statist. 1954, 25, 317–328. [Google Scholar] [CrossRef]
- Groeneveld, R.A.; Meeden, G. Measuring Skewness and Kurtosis. Statistician 1984, 33, 391. [Google Scholar] [CrossRef]
- Wonnacott, T.H.; Wonnacott, R.J. Introductory Statistics, 5th ed.; Part I Basic Probability and Statistics 1 The Nature of Statistics; John Wiley and Sons: Hoboken, NJ, USA, 1990. [Google Scholar]
- Corder, G.; Foreman, D. Nonparametric Statistics: A Step-by-Step Approach; Wiley: Hoboken, NJ, USA, 2014. [Google Scholar]
- Ozone. Auricular Rage ST—Ozone Gaming. Available online: https://www.ozonegaming.com/es/product/rage-st (accessed on 5 November 2019).
- Universidad de Las Palmas de Gran Canaria. Memoria Digital de Canarias—mdC. Available online: https://mdc.ulpgc.es/ (accessed on 11 December 2019).
- Yasuda, K.; Kuwabara, K.; Kuwahara, N.; Abe, S.; Tetsutani, N. Effectiveness of personalised reminiscence photo videos for individuals with dementia. Neuropsychol. Rehabil. 2009, 19, 603–619. [Google Scholar] [CrossRef]
- Gowans, G.; Campbell, J.; Alm, N.; Dye, R.; Astell, A.; Ellis, M. Designing a multimedia conversation aid for reminiscence therapy in dementia care environments. In Proceedings of the Conference on Human Factors in Computing Systems, Vienna Austria, 24–29 April 2004; pp. 825–836. [Google Scholar]
- Davis, B.H.; Shenk, D. Beyond reminiscence: Using generic video to elicit conversational language. Am. J. Alzheimer’s Dis. Other Demen. 2015, 30, 61–68. [Google Scholar] [CrossRef] [PubMed]
- Irazoki, E.; A Garcia-Casal, J.; Sanchez-Meca, J.; Franco-Martin, M. Efficacy of group reminiscence therapy for people with dementia. Systematic literature review and meta-analysis. Rev. Neurol. 2017, 65, 447–456. [Google Scholar] [PubMed]
- Gogate, M.; Dashtipour, K.; Hussain, A. Visual Speech in Real Noisy Environments (VISION): A Novel Benchmark Dataset and Deep Learning-based Baseline System. In Proceedings of the Interspeech 2020, Shanghai, China, 14–18 September 2020. [Google Scholar]
- Watanabe, S.; Mandel, M.; Barker, J.; Vincent, E.; Arora, A.; Chang, X.; Khudanpur, S.; Manohar, V.; Povey, D.; Raj, D.; et al. CHiME-6 Challenge:Tackling Multispeaker Speech Recognition for Unsegmented Recordings. In Proceedings of the 6th International Workshop on Speech Processing in Everyday Environments (CHiME 2020), Barcelona, Spain, 4 May 2020. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| DataBase | Interviewer | Long/Transv | Language | Task | HC | MCI | AD | References |
|---|---|---|---|---|---|---|---|---|
| M/F | M/F | M/F | ||||||
| SAIOTEK | Human | Cross sectional | Multilingual | SS | 5 | - | 3 | [19,40] |
| AZTIAHO | SS | 50 | - | 20 | [23,28,41,42,43,44] | |||
| PGA-OREKA | cVF | 26/36 | - | 17/21 | [45] | |||
| MINI-PGA | SS | 12 | 6 | [46] | ||||
| - | Human | Cross sectional | Greek | SS | 30 | - | 30 | [18] |
| Dem@care | Human | Cross sectional | Greek | Mixed | 4/15 | 12/31 | 3/24 | [47] |
| Cross sectional | French | Mixed | 6/9 | 11/12 | 13/13 | [48,49,50] | ||
| - | Human | Cross sectional | French | Reading | 14 | 14 | 14 | [51] |
| - | Human | Cross sectional | French | SS | 5 | - | 5 | [52] |
| *TRANSC | Human | Longitudinal | - | SS | 184 * | - | 214 * | [53] |
| ClinicalTrials.gov | Human | Longitudinal | English | SS | 27 | 14 | - | [54] |
| - | Human | Cross sectional | English | SS | 46 | - | 26 | [55] |
| WRAP | Human | Longitudinal | English | SS | 200 | - | 64 | [56] |
| Pitt (DB) | Human | Longitudinal | English | SS | 74 | 19 | 169 | [31,32,33,39,57,58,59,60,61] |
| Kempler (DB) | Human | Cross sectional | English | SS | - | - | 6 | |
| Lu (DB) | Human | Cross sectional | Mandarin | SS | - | - | 52 | |
| Lu (DB) | Human | Cross sectional | Taiwanese | SS | - | - | 16 | |
| PerLA (DB) | Human | Cross sectional | Spanish | SS | - | - | 21 | |
| ACADIE | Human | Longitudinal | English | SS | - | - | 95 | [62] |
| AMI | Human | Cross sectional | English | SS | 20 | - | 20 | [61] |
| CCC | Human | Cross sectional | English | SS | 10 | - | 55 | [63,60] |
| ILSE | Human | Longitudinal | German | SS | 80 | 13 | 5 | [64] |
| CREA-IMSERSO | Human | Cross sectional | Spanish | Reading | - | - | 21 | [65] |
| - | Human | Cross sectional | Spanish | Reading | 82 | - | 45 | [66] |
| - | Human | Cross sectional | Spanish | Mixed | 29 | - | 34 | [25,67] |
| Cinderella | Human | Cross sectional | Portuguese | SS | 20 | 20 | 20 | [68] |
| OPLON | Human | Cross sectional | Italian | Mixed | 48 | 48 | [69] | |
| - | Human | Cross sectional | Iranian | SS | 15/15 | - | 16/14 | [70] |
| - | Automated | Cross sectional | Japanese | SS | 7/3 | - | 9/1 | [17] |
| - | Human | Cross sectional | Japanese | SS | 73/200 | [71] | ||
| BELBI | Human | Cross sectional | Serbian | SS | - | - | 12 | [72] |
| BEA | Human | Cross sectional | Hungarian | SS | 13/23 | 16/32 | - | [26,73,74,75] |
| - | Human | Cross sectional | Turkish | SS | 31/20 | - | 18/10 | [16] |
| - | Human | Cross sectional | French | SS | 29 | - | 29 | [76] |
| - | Human | Cross sectional | Persian | SS | 0/6 | - | 0/6 | [77,78] |
| Others studies using unknown databases | ||||||||
| [79,80,81,82,83] | ||||||||
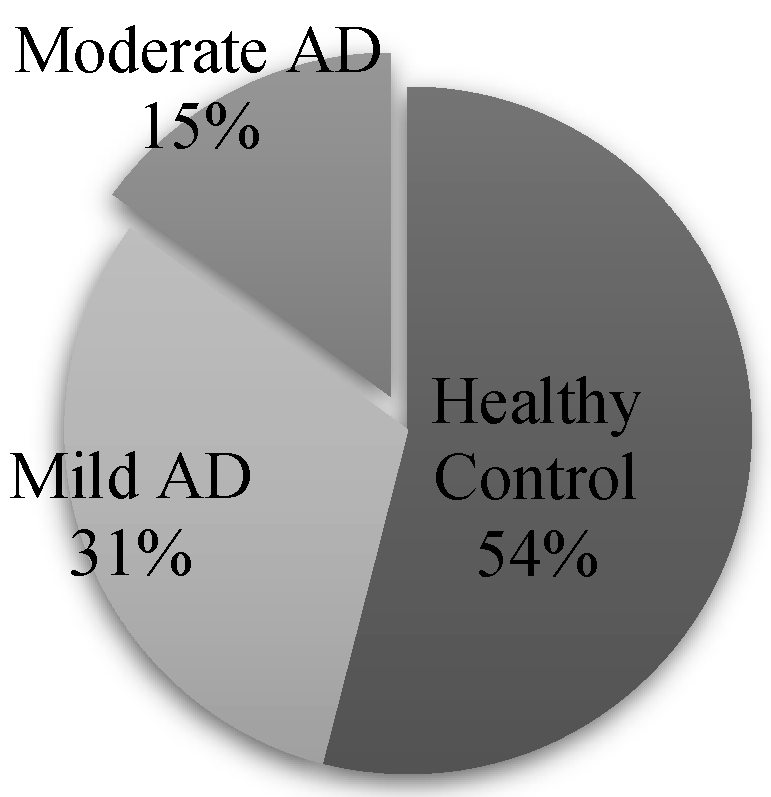
| Polulation | Women | Men | ||
|---|---|---|---|---|
| Healthy control | 46 | 23 | 23 | |
| AD patients | Mild | 26 | 19 | 7 |
| Moderate | 15 | 3 | 12 | |
| HC | AD | |||
|---|---|---|---|---|
| Variable | Human Interviewer | Automatic Interviewer | Human Interviewer | Automatic Interviewer |
| 1.79 (0.53) | 1.8 (0.76) | 1.42 (0.39) | 1.36 (0.45) | |
| 1.6 (1.32) | 1.33 (1.40) | 0.93 (0.47) | 0.9 (1.01) | |
| 0.81 (0.56) | 0.49 (0.59) | 0.9 (0.46) | 0.47 (0.64) | |
| 3.3 (1.52) | 2.3 (1.1) | 3.37 (1.41) | 2.35 (1.17) | |
| 0.71 (0.1) | 0.7 (0.12) | 0.48 (0.14) | 0.47 (0.18) | |
| Variable | Human Interviewer | Automatic Interviewer |
|---|---|---|
 |  | |
 |  | |
 |  | |
 |  | |
 |  |
| Human Interviewer | Automatic Interviewer | |||
|---|---|---|---|---|
| Variable | z | Prob |z| | z | Prob |z| |
| 3.05 | 0.002 | 5.77 | 0 | |
| 2.79 | 0.005 | 3.94 | 0 | |
| −0.57 | 0.565 | 0.47 | 0.637 | |
| −0.80 | 0.418 | 0.65 | 0.515 | |
| 5.87 | 0 | 9.64 | 0 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alonso-Hernández, J.B.; Barragán-Pulido, M.L.; Gil-Bordón, J.M.; Ferrer-Ballester, M.Á.; Travieso-González, C.M. Using a Human Interviewer or an Automatic Interviewer in the Evaluation of Patients with AD from Speech. Appl. Sci. 2021, 11, 3228. https://doi.org/10.3390/app11073228
Alonso-Hernández JB, Barragán-Pulido ML, Gil-Bordón JM, Ferrer-Ballester MÁ, Travieso-González CM. Using a Human Interviewer or an Automatic Interviewer in the Evaluation of Patients with AD from Speech. Applied Sciences. 2021; 11(7):3228. https://doi.org/10.3390/app11073228
Chicago/Turabian StyleAlonso-Hernández, Jesús B., María Luisa Barragán-Pulido, José Manuel Gil-Bordón, Miguel Ángel Ferrer-Ballester, and Carlos M. Travieso-González. 2021. "Using a Human Interviewer or an Automatic Interviewer in the Evaluation of Patients with AD from Speech" Applied Sciences 11, no. 7: 3228. https://doi.org/10.3390/app11073228
APA StyleAlonso-Hernández, J. B., Barragán-Pulido, M. L., Gil-Bordón, J. M., Ferrer-Ballester, M. Á., & Travieso-González, C. M. (2021). Using a Human Interviewer or an Automatic Interviewer in the Evaluation of Patients with AD from Speech. Applied Sciences, 11(7), 3228. https://doi.org/10.3390/app11073228