
A New Real-Time Detection and Tracking Method in Videos for Small Target Traffic Signs



Abstract
Featured Application
Abstract
1. Introduction
2. Materials and Methods
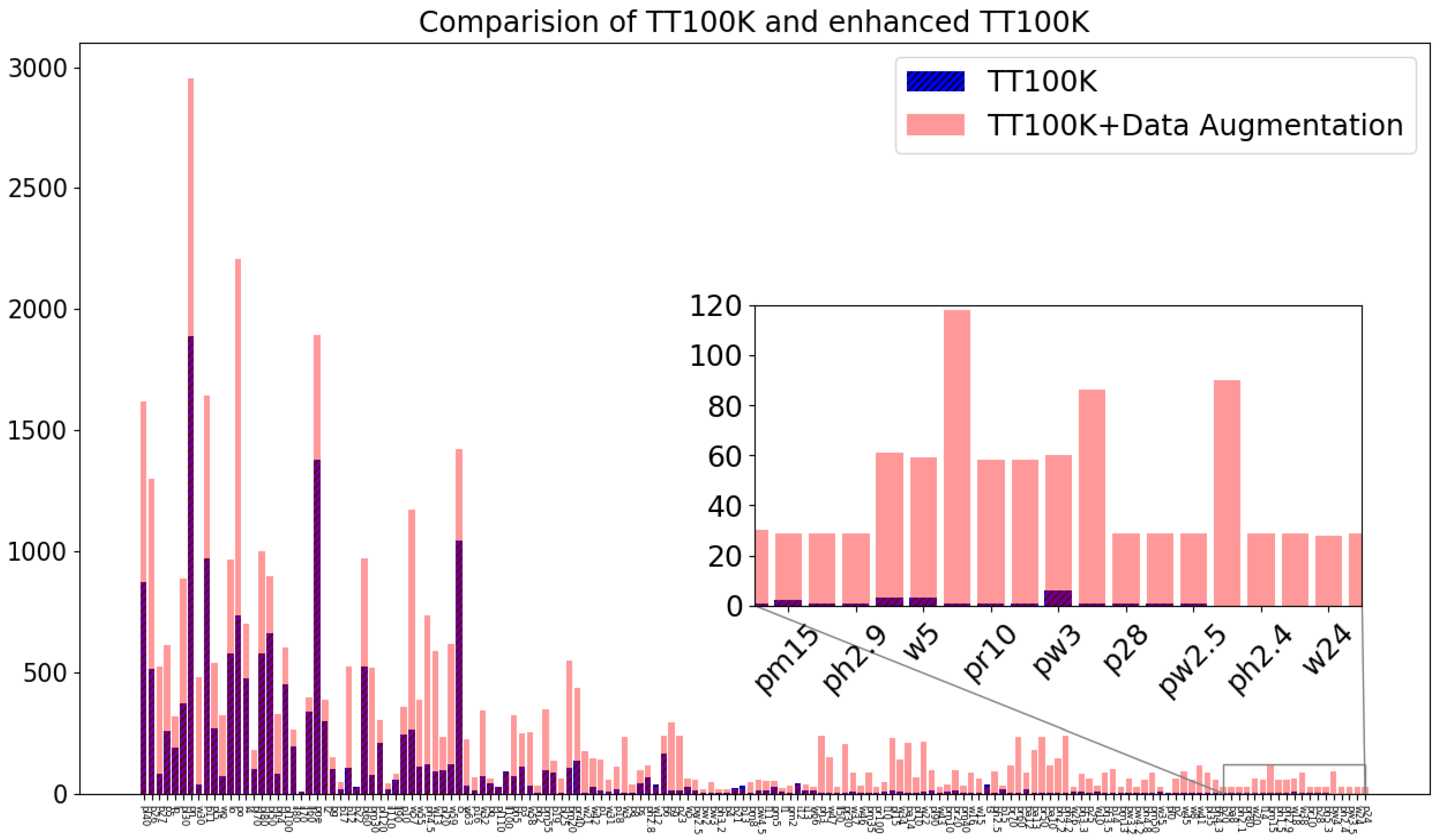
2.1. Fine-Grained Classifications and Sample Equalizations
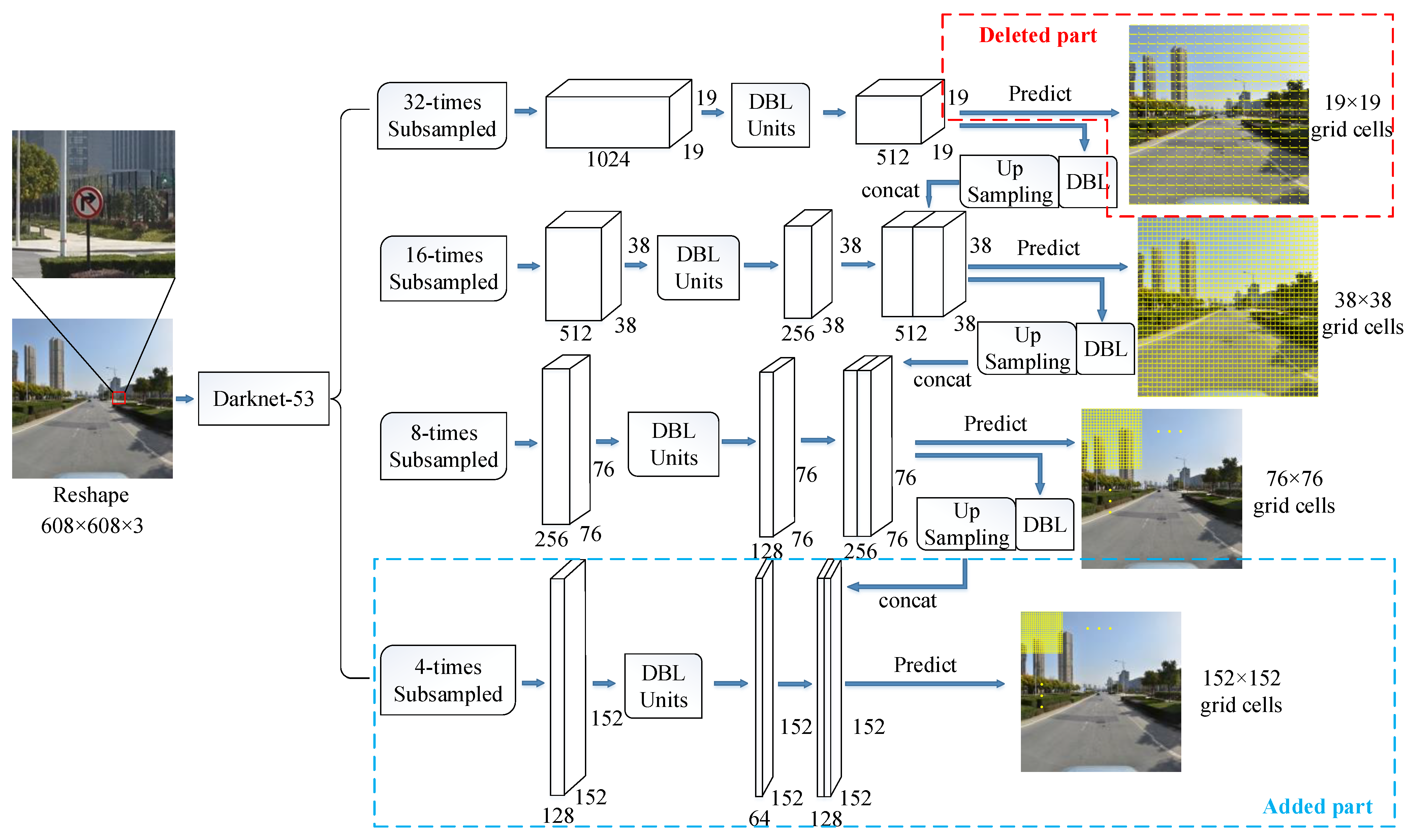
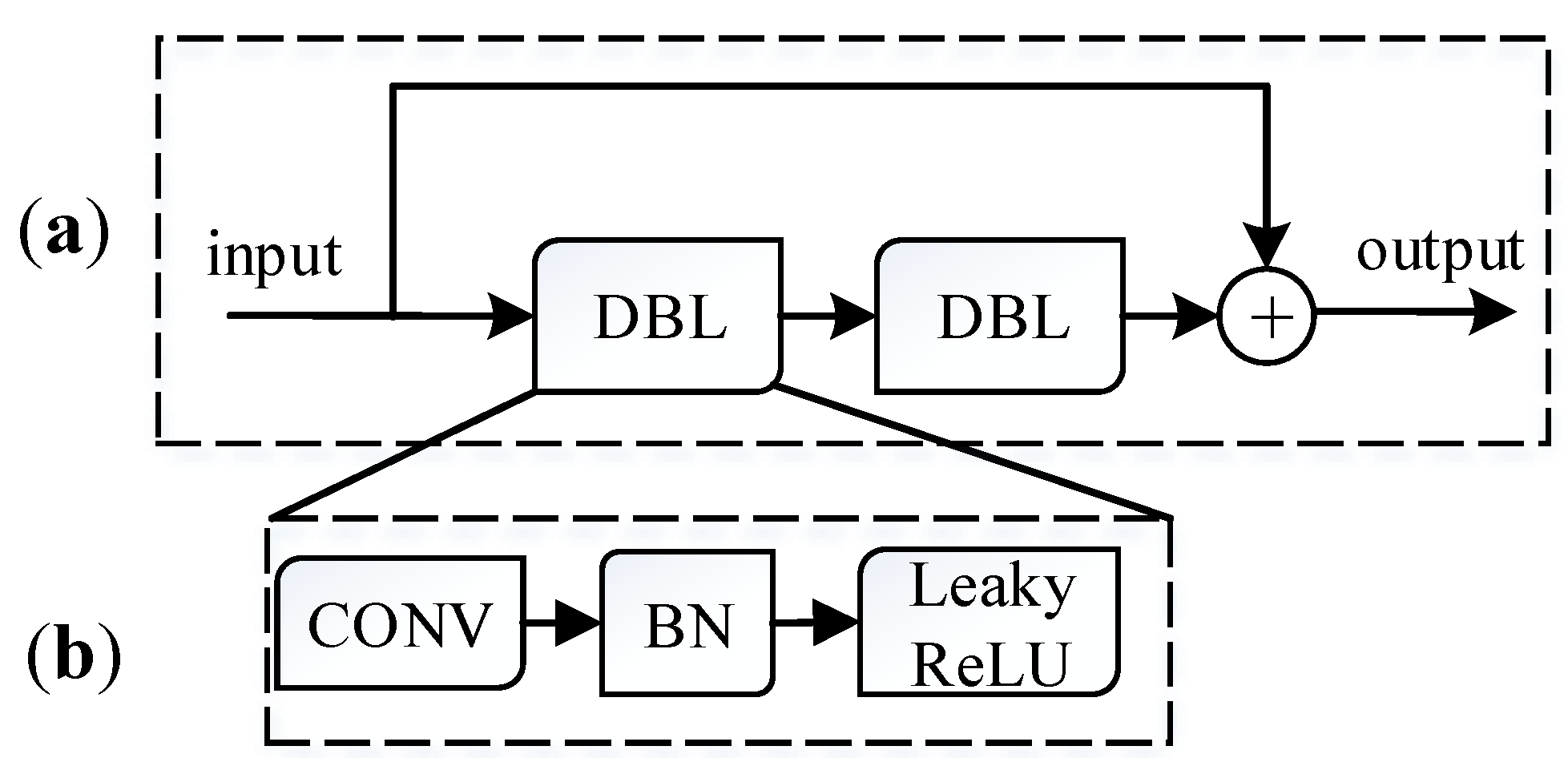
2.2. The Improvement of YOLOv3
2.3. Loss Function
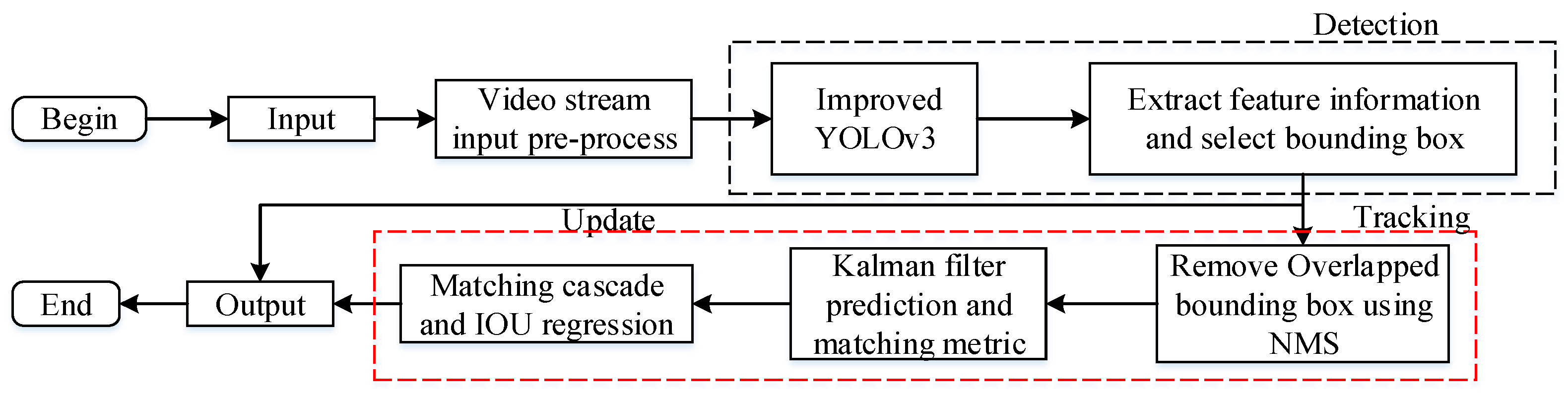
2.4. The Improvement of Detection Method with Multi-Object Tracking
| Algorithm 1 Detection and Tracking |
| Input: input = (width, height, channel, batch) Output: output = (matched detections, unmatched detections) |
| 1: Width, Height, Channel, Batch |
| 2: Compute Box = |
| 3: Bounding BoxLogic regression (Dimension priors, location prediction) |
| 4: Compute Loss function = using (1) |
| 5: Detection indices , Track indices , Maximum age |
| 6: Compute gate matrix using (7) and (9) |
| 7: Compute cost matrix using (10) |
| 8: Initialize set of matched detections |
| 9: Initialize set of unmatched detections |
| 10: for do |
| 11: Select tracks by age |
| 12: |
| 13: |
| 14: |
| 15: end for |
| 16: return |
3. Results
3.1. Experimental Setups
3.2. Effectiveness Analyses
3.2.1. Small Sample Equalization
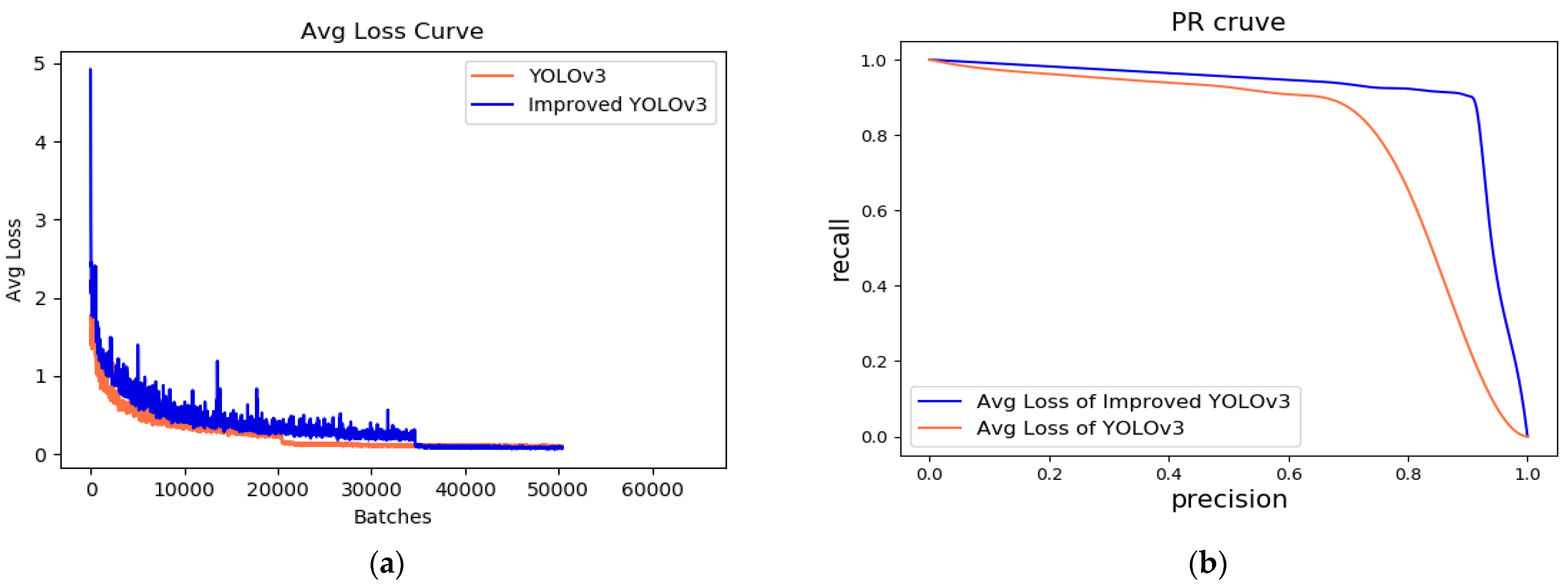
3.2.2. Comparisons of YOLOv3 Detection Results before and after Improvements
3.2.3. Comparison with State-Of-The-Art Methods
3.2.4. Comparisons of Detection Results with or without Deep-Sort
4. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Sugiharto, A.; Harjoko, A. Traffic Sign Detection Based on HOG and PHOG Using Binary SVM and k-NN. In Proceedings of the 2016 3rd International Conference on Information Technology, Computer, and Electrical Engineering (ICITACEE), Semarang, Indonesia, 19–20 October 2016. [Google Scholar]
- Khan, J.F.; Bhuiyan, S.M.A.; Adhami, R.R. Image Segmentation and Shape Analysis for Road-Sign Detection. IEEE Trans. Intell. Transp. Syst. 2010, 12, 83–96. [Google Scholar] [CrossRef]
- De La Escalera, A.; Moreno, L.E.; Salichs, M.A.; Armingol, J.M. Road traffic sign detection and classification. IEEE Trans. Ind. Electron. 1997, 44, 848–859. [Google Scholar] [CrossRef]
- Berkaya, S.K.; Gunduz, H.; Ozsen, O.; Akinlar, C.; Gunal, S. On circular traffic sign detection and recognition. Expert Syst. Appl. 2016, 48, 67–75. [Google Scholar] [CrossRef]
- Wang, C. Research and application of traffic sign detection and recognition based on deep learning. In Proceedings of the 2018 International Conference on Robots & Intelligent System (ICRIS), Changsha, China, 26–27 May 2018. [Google Scholar]
- Zhao, Z.-Q.; Zheng, P.; Xu, S.-T.; Wu, X. Object Detection with Deep Learning: A Review. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern. Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision(ICCV), Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S. SSD: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision(ECCV), Amsterdam, The Netherlands, 8–16 October 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Miao, F.; Tian, Y.; Jin, L. Vehicle Direction Detection Based on YOLOv3. In Proceedings of the 2019 11th International Conference on Intelligent Human-Machine Systems and Cybernetics (IHMSC), Zhejiang, China, 24–25 August 2019; pp. 268–271. [Google Scholar]
- Yang, T.; Long, X.; Sangaiah, A.K.; Zheng, Z.; Tong, C. Deep detection network for real-life traffic sign in vehicular networks. Comput. Netw. 2018, 136, 95–104. [Google Scholar] [CrossRef]
- Lu, Y.; Lu, J.; Zhang, S.; Hall, P. Traffic signal detection and classification in street views using an attention model. Comput. Vis. Media 2018, 4, 253–266. [Google Scholar] [CrossRef]
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal visual object classes (VOC) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Gauen, K.; Dailey, R.; Laiman, J.; Zi, Y.; Asokan, N.; Lu, Y.H.; Thiruvathukal, G.K.; Shyu, M.L.; Chen, S.C. Comparison of visual datasets for machine learning. In Proceedings of the 2017 IEEE International Conference on Information Reuse and Integration (IRI), San Diego, CA, USA, 4–6 August 2017; pp. 346–355. [Google Scholar]
- Zhang, J.; Xie, Z.; Sun, J.; Zou, X.; Wang, J. A Cascaded R-CNN With Multiscale Attention and Imbalanced Samples for Traffic Sign Detection. IEEE Access 2020, 8, 29742–29754. [Google Scholar] [CrossRef]
- Ibrahem, H.; Salem, A.; Kang, H.S. Weakly Supervised Traffic Sign Detection in Real Time Using Single CNN Architecture for Multiple Purposes. In Proceedings of the 2020 IEEE International Conference on Consumer Electronics (ICCE), Las Vegas, NV, USA, 4–6 January 2020; pp. 1–4. [Google Scholar]
- Houben, S.; Stallkamp, J.; Salmen, J.; Schlipsing, M.; Igel, C. Detection of traffic signs in realworld images: The German Traffic Sign Detection Benchmark. In Proceedings of the 2013 International Joint Conference on Neural Networks (IJCNN), Dallas, TX, USA, 4–9 August 2013; pp. 1–8. [Google Scholar]
- Li, Y.; Wang, J.; Xing, T. TAD16K: An enhanced benchmark for autonomous driving. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 2344–2348. [Google Scholar]
- Zhu, Z.; Liang, D.; Zhang, S.; Huang, X.; Hu, S. Traffic-sign detection and classification in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; Volume 1, pp. 2110–2118. [Google Scholar]
- Liu, L.; Wang, Y.; Li, K.; Li, J. Focus First: Coarse-to-Fine Traffic Sign Detection with Stepwise Learning. IEEE Access 2020, 8, 171170–171183. [Google Scholar] [CrossRef]
- Jin, Y.; Fu, Y.; Wang, W.; Guo, J.; Ren, C.; Xiang, X. Multi-Feature Fusion and Enhancement Single Shot Detector for Traffic Sign Recognition. IEEE Access 2020, 8, 38931–38940. [Google Scholar] [CrossRef]
- Li, J.; Liang, X.; Wei, Y.; Xu, T.; Feng, J.; Yan, S. Perceptual generative adversarial networks for small object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; Volume 1, pp. 1951–1959. [Google Scholar]
- Li, G.; Li, S.E.; Zou, R.; Liao, Y.; Cheng, B. Detection of road traffic participants using cost-effective arrayed ultrasonic sensors in low-speed traffic situations. Mech. Syst. Signal Process. 2019, 132, 535–545. [Google Scholar] [CrossRef]
- Yuan, Y.; Xiong, Z.; Wang, Q. VSSA-NET: Vertical Spatial Sequence Attention Network for Traffic Sign Detection. IEEE Trans. Image Proc. 2019, 28, 3423–3434. [Google Scholar] [CrossRef] [PubMed]
- Zhu, H.; Zhang, J.; Xu, G.; Deng, L. Balanced Ring Top-Hat Transformation for Infrared Small-Target Detection With Guided Filter Kernel. IEEE Trans. Aerosp. Electron. Syst. 2020, 56, 3892–3903. [Google Scholar] [CrossRef]
- Deng, H.; Sun, X.; Zhou, X. A Multiscale Fuzzy Metric for Detecting Small Infrared Targets Against Chaotic Cloudy/Sea-Sky Backgrounds. IEEE Trans. Cybern. 2018, 49, 1694–1707. [Google Scholar] [CrossRef]
- Liu, L.; Tang, X.; Xie, J.; Gao, X.; Zhao, W.; Mo, F.; Zhang, G. Deep-Learning and Depth-Map Based Approach for Detection and 3-D Localization of Small Traffic Signs. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 2096–2111. [Google Scholar] [CrossRef]
- Zhao, J.; Xu, H.; Liu, H.; Wu, J.; Zheng, Y.; Wu, D. Detection and tracking of pedestrians and vehicles using roadside LiDAR sensors. Transp. Res. Part C: Emerg. Technol. 2019, 100, 68–87. [Google Scholar] [CrossRef]
- Li, G.; Xie, H.; Yan, W.; Chang, Y.; Qu, X. Detection of Road Objects With Small Appearance in Images for Autonomous Driving in Various Traffic Situations Using a Deep Learning Based Approach. IEEE Access 2020, 8, 211164–211172. [Google Scholar] [CrossRef]
- Hu, Q.; Paisitkriangkrai, S.; Shen, C.; Hengel, A.V.D.; Porikli, F. Fast Detection of Multiple Objects in Traffic Scenes With a Common Detection Framework. IEEE Trans. Intell. Transp. Syst. 2015, 17, 1002–1014. [Google Scholar] [CrossRef]
- Tong, K.; Wu, Y.; Zhou, F. Recent advances in small object detection based on deep learning: A review. Image Vis. Comput. 2020, 97, 103910. [Google Scholar] [CrossRef]
- Tian, W.; Lauer, M.; Chen, L. Online Multi-Object Tracking Using Joint Domain Information in Traffic Scenarios. IEEE Trans. Intell. Transp. Syst. 2019, 21, 374–384. [Google Scholar] [CrossRef]
- Zhang, Y. Detection and Tracking of Human Motion Targets in Video Images Based on Camshift Algorithms. IEEE Sens. J. 2019, 20, 11887–11893. [Google Scholar] [CrossRef]
- Dong, X.; Shen, J.; Yu, D.; Wang, W.; Liu, J.; Huang, H. Occlusion-Aware Real-Time Object Tracking. IEEE Trans. Multimed. 2016, 19, 763–771. [Google Scholar] [CrossRef]
- Harikrishnan, P.M.; Thomas, A.; Gopi, V.P.; Palanisamy, P. Fast approach for moving vehicle localization and bounding box estimation in highway traffic videos. Signal Image Video Process. 2021, 1–8. [Google Scholar] [CrossRef]
- Ciaparrone, G.; Sánchez, F.L.; Tabik, S.; Troiano, L.; Tagliaferri, R.; Herrera, F. Deep learning in video multi-object tracking: A survey. Neurocomputing 2020, 381, 61–88. [Google Scholar] [CrossRef]
- Yang, H.; Li, J.; Liu, J.; Zhang, Y.; Wu, X.; Pei, Z. Multi-Pedestrian Tracking Based on Improved Two Step Data Association. IEEE Access 2019, 7, 100780–100794. [Google Scholar] [CrossRef]
- Fernández-Sanjurjo, M.; Bosquet, B.; Mucientes, M.; Brea, V.M. Real-time visual detection and tracking system for traffic monitoring. Eng. Appl. Artif. Intell. 2019, 85, 410–420. [Google Scholar] [CrossRef]
- Ma, Q.; Zou, Q.; Wang, N.; Guan, Q.; Pei, Y. Looking ahead: Joint small group detection and tracking in crowd scenes. J. Vis. Commun. Image Represent. 2020, 72, 102876. [Google Scholar] [CrossRef]
- Griffin, B.A.; Corso, J.J. Bubblenets: Learning to select the guidance frame in video object segmentation by deep sorting frames. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 8914–8923. [Google Scholar]
- Huang, H.; Yang, M.; Wang, C.; Wang, B. A unified hierarchical convolutional neural network for fine-grained traffic sign detection. In Proceedings of the 2018 Chinese Automation Congress (CAC), Xi’an, China, 30 November–2 December 2018; pp. 2733–2738. [Google Scholar]
- Snell, J.; Swersky, K.; Zemel, R.S. Prototypical networks for few-shot learning. In Proceedings of the 31st Annual Conference on Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Song, S.; Zhu, J.; Li, X.; Huang, Q. Integrate MSRCR and Mask R-CNN to Recognize Underwater Creatures on Small Sample Datasets. IEEE Access 2020, 8, 172848–172858. [Google Scholar] [CrossRef]
- Hendrycks, D.; Dietterich, T.G. Benchmarking Neural Network Robustness to Common Corruptions and Surface Variations. 2018. Available online: https://arxiv.org/abs/1807.01697 (accessed on 27 April 2019).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; Volume 1, pp. 770–778. [Google Scholar]
- Wan, J.; Ding, W.; Zhu, H.; Xia, M.; Huang, Z.; Tian, L.; Zhu, Y.; Wang, H. An Efficient Small Traffic Sign Detection Method Based on YOLOv3. J. Signal Process. Syst. 2020, 1–13. [Google Scholar] [CrossRef]
- Hou, X.; Wang, Y.; Chau, L.P. Vehicle Tracking Using Deep SORT with Low Confidence Track Filtering. In Proceedings of the 2019 16th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Taipei, Taiwan, 18–21 September 2019; pp. 1–6. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Wang, G.; Xiong, Z.; Liu, D.; Luo, C. Cascade mask generation framework for fast small object detection. In Proceedings of the 2018 IEEE International Conference on Multimedia and Expo (ICME), San Diego, CA, USA, 23–27 July 2018; pp. 1–6. [Google Scholar]
- Zhang, H.; Qin, L.; Li, J.; Guo, Y.; Zhou, Y.; Zhang, J.; Xu, Z. Real-Time Detection Method for Small Traffic Signs Based on Yolov3. IEEE Access 2020, 8, 64145–64156. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Augmentation | TP | FP | FN | P | R |
|---|---|---|---|---|---|
| - | 1524 | 586 | 461 | 0.72 | 0.77 |
| Image corruption | 2474 | 591 | 592 | 0.81 | 0.81 |
| Detection Algorithm | P | R | mAP | Speed | FPS |
|---|---|---|---|---|---|
| YOLOv3 | 0.81 | 0.81 | 0.704 | 0.0269s | 37.94 |
| Ours | 0.91 | 0.90 | 0.8476 | 0.0323s | 24.22 |
| Size | Precision 1 | Precision 2 | Recall 1 | Recall 2 | mAP 1 | mAP 2 |
|---|---|---|---|---|---|---|
| (0,32] | 0.64 | 0.74 | 0.67 | 0.76 | 0.62 | 0.75 |
| (32,96] | 0.83 | 0.94 | 0.84 | 0.92 | 0.81 | 0.87 |
| (96,400] | 0.85 | 0.93 | 0.86 | 0.94 | 0.83 | 0.88 |
| Model | P | R | mAP | Speed | FPS | Classes |
|---|---|---|---|---|---|---|
| Lu et al. [16] | 0.917 | 0.834 | 0.870 | 0.26 s | 3.85 | 45 |
| Zhu_model [23] | 0.91 | 0.93 | 0.93 | 10.83s | 5 | 45 |
| Li et al. [26] | 0.879 | 0.93 | 0.93 | - | <1.6 | 45 |
| Wang et al. [53] | 0.927 | 0.868 | - | - | 9.6 | 45 |
| MSA-YOLOv3 [54] | 0.825 | 0.841 | 0.863 | 0.042s | 23.87 | 45 |
| Ours1 | 0.91 | 0.92 | 0.9177 | 0.027 s | 29.33 | 45 |
| Ours2 | 0.91 | 0.90 | 0.8476 | 0.0323s | 24.22 | 152 |
| Class | io | i1 | i2 | i3 | i4 | i5 | i10 | i11 | i12 | i13 | i14 |
| Zhu [23] | - | - | 77.68 | - | 88.04 | 93.04 | - | - | - | - | - |
| Ours1 | 78.41 | 100.0 | 93.73 | 0 | 90.97 | 96.58 | 66.67 | 0 | 0 | 0 | 0 |
| Ours2 | 88.84 | 100.0 | 89.04 | 100.0 | 91.1 | 97.99 | 100.0 | 0 | 100.0 | 83.33 | 100.0 |
| Class | i15 | il50 | il60 | il70 | il80 | il90 | il100 | il110 | il120 | ip | p1 |
| Zhu [23] | - | - | 86.97 | - | 85.16 | - | - | 50.00 | - | 82.31 | - |
| Ours1 | 0 | 0 | 93.33 | 0 | 85.71 | 91.67 | 100.0 | 100.0 | 0 | 71.98 | 50.00 |
| Ours2 | 0 | 50.0 | 96.87 | 0 | 85.98 | 77.54 | 88.89 | 76.0 | 0 | 91.81 | 84.21 |
| Class | p2 | p3 | p4 | p5 | p6 | p7 | p8 | p9 | p10 | p11 | p12 |
| Zhu [23] | - | - | - | - | - | - | - | - | 78.72 | 87.47 | 86.50 |
| Ours1 | 35 | 77.78 | 0 | 93.97 | 4.86 | 0 | 0 | 70.0 | 86.76 | 83.25 | 50.00 |
| Ours2 | 100.0 | 99.76 | 0 | 85.47 | 80.40 | 0 | 100.0 | 100.0 | 79.18 | 86.73 | 93.63 |
| Class | p13 | p14 | p15 | p16 | p17 | p18 | p19 | p20 | p21 | p22 | p23 |
| Zhu [23] | - | - | - | - | - | - | - | - | - | - | - |
| Ours1 | 0 | 0 | 0 | 0 | 100.0 | 83.33 | 38.27 | 0 | 0 | 100.0 | 85.21 |
| Ours2 | 0 | 75.0 | 0 | 100.0 | 60.0 | 83.33 | 77.26 | 66.67 | 0 | 70.54 | 83.05 |
| Class | p24 | p25 | p26 | p27 | p28 | p29 | pa10 | pa12 | pa13 | pa14 | pb |
| Zhu [23] | - | - | - | - | - | - | - | - | - | - | - |
| Ours1 | 0 | 100.0 | 0 | 100.0 | 0 | 0 | 0 | 0 | 50 | 83.33 | 100.0 |
| Ours2 | 100.0 | 91.67 | 93.61 | 99.94 | 100.0 | 0 | 100.0 | 100.0 | 100.0 | 92.38 | 82.36 |
| Class | pc | pe | pg | ph1.5 | ph2 | ph2.1 | ph2.2 | ph2.5 | ph2.8 | ph2.9 | ph3 |
| Zhu [23] | - | - | - | - | - | - | - | - | - | - | - |
| Ours1 | 0 | 0 | 52.08 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 100.0 |
| Ours2 | 0 | 0 | 88.24 | 100.0 | 75.00 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 |
| Class | ph3.3 | ph3.5 | ph4 | ph4.2 | ph4.5 | ph4.8 | ph4.3 | ph2.4 | wo | ph5 | ph5.3 |
| Zhu [23] | - | - | 71.92 | - | 76.53 | - | - | - | - | 66.25 | - |
| Ours1 | 0 | 0 | 56.67 | 0 | 83.33 | 0 | 0 | 0 | 83.33 | 93.06 | 0 |
| Ours2 | 100.0 | 100.0 | 88.33 | 100.0 | 96.40 | 100.0 | 100.0 | 100.0 | 80.33 | 93.82 | 100.0 |
| Class | pl5 | pl10 | pl15 | pl20 | pl25 | pl30 | pl35 | pl40 | pl50 | pl60 | pl70 |
| Zhu [23] | - | - | - | 74.53 | - | 86.84 | - | 90.23 | 89.38 | 79.44 | 87.22 |
| Ours1 | 83.92 | 0 | 25 | 47.69 | 0 | 76.92 | 0 | 86.44 | 85.09 | 72.97 | 65.95 |
| Ours2 | 82.25 | 100.0 | 94.73 | 67.67 | 100.0 | 84.91 | 80.00 | 87.01 | 86.71 | 81.96 | 88.24 |
| Class | pl80 | pl90 | pl100 | pl110 | pl120 | pm15 | pm35 | pm40 | pm50 | pm10 | pm20 |
| Zhu [23] | 87.39 | - | 92.48 | - | 93.92 | - | - | - | - | - | 83.96 |
| Ours1 | 67.79 | 66.67 | 83.51 | 91.67 | 81.90 | 0 | 0 | 0 | 0 | 0 | 56.43 |
| Ours2 | 80.67 | 89.32 | 87.19 | 66.67 | 74.70 | 100.0 | 100.0 | 100.0 | 100.0 | 85.71 | 89.63 |
| Class | pm30 | pm55 | po | pn | pne | pnl | pr10 | pr20 | pr50 | pr70 | pr80 |
| Zhu [23] | 87.62 | 79.99 | - | 89.75 | 91.16 | - | - | - | - | - | - |
| Ours1 | 30.57 | 84.92 | 67.56 | 93.04 | 96.19 | 0 | 0 | 66.67 | 100 | 0 | 0 |
| Ours2 | 92.63 | 95.75 | 88.52 | 95.79 | 95.10 | 0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 |
| Class | pr100 | pr40 | pr30 | pr60 | ps | pw3 | pw3.2 | pw3.5 | pw4 | pw4.2 | w3 |
| Zhu [23] | - | 87.16 | - | - | - | - | - | - | - | - | - |
| Ours1 | 0 | 100.0 | 50 | 0 | 12.50 | 0 | 0 | 0 | 0 | 0 | 0 |
| Ours2 | 100.0 | 100.0 | 98.77 | 100.0 | 75.00 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 0 |
| Class | w5 | w8 | w10 | w12 | w13 | w16 | w18 | w20 | w21 | w22 | w24 |
| Zhu [23] | - | - | - | - | 77.69 | - | - | - | - | - | - |
| Ours1 | 0 | 0 | 0 | 0 | 0 | 89.14 | 0 | 0 | 0 | 0 | 50 |
| Ours2 | 100.0 | 0 | 100.0 | 100.0 | 100.0 | 97.37 | 100.0 | 100.0 | 100.0 | 100.0 | 90.0 |
| Class | w26 | w30 | w31 | w32 | w34 | w35 | w37 | w38 | w41 | w42 | w43 |
| Zhu [23] | - | - | - | 54.56 | - | - | - | - | - | - | - |
| Ours1 | 0 | 0 | 75 | 0 | 50 | 0 | 0 | 0 | 0 | 0 | 0 |
| Ours2 | 100.0 | 100.0 | 95.78 | 100.0 | 96.42 | 100.0 | 0 | 100.0 | 100.0 | 80.0 | 86.92 |
| Class | w45 | w46 | w47 | w55 | w57 | w58 | w59 | w63 | w66 | - | - |
| Zhu [23] | - | - | - | - | - | - | - | - | - | - | - |
| Ours1 | 0 | 100.0 | 0 | 0 | 85.19 | 87.54 | 80.0 | 90.38 | 0 | - | - |
| Ours2 | 100.0 | 83.33 | 50.00 | 84.62 | 93.54 | 96.08 | 90.93 | 99.48 | 87.50 | - | - |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Song, S.; Li, Y.; Huang, Q.; Li, G. A New Real-Time Detection and Tracking Method in Videos for Small Target Traffic Signs. Appl. Sci. 2021, 11, 3061. https://doi.org/10.3390/app11073061
Song S, Li Y, Huang Q, Li G. A New Real-Time Detection and Tracking Method in Videos for Small Target Traffic Signs. Applied Sciences. 2021; 11(7):3061. https://doi.org/10.3390/app11073061
Chicago/Turabian StyleSong, Shaojian, Yuanchao Li, Qingbao Huang, and Gang Li. 2021. "A New Real-Time Detection and Tracking Method in Videos for Small Target Traffic Signs" Applied Sciences 11, no. 7: 3061. https://doi.org/10.3390/app11073061
APA StyleSong, S., Li, Y., Huang, Q., & Li, G. (2021). A New Real-Time Detection and Tracking Method in Videos for Small Target Traffic Signs. Applied Sciences, 11(7), 3061. https://doi.org/10.3390/app11073061