1. Introduction
The face plays an important role in visual communication. By looking at the face, a person can automatically extract many nonverbal messages, such as the identity, intent, and emotion of others [
1]. Facial paralysis is known as the inability to move the muscles of the face on one or both sides. This inability can result from nerve damage due to congenital conditions; trauma; or disease, such as stroke, brain tumor, or Bell’s palsy. The problem can affect one or both sides of the face, with the noticeable drooping of the features and problems with speaking, blinking, swallowing saliva, eating, or communicating through natural facial expressions. These physical signs of facial paralysis can provide information to the clinician concerning the state of the patient [
2].
The process of detecting facial paralysis is important in assessing the severity of the facial nerve and muscle malfunction and in order to record physical improvements when treating and monitoring the patient. Computer-based automatic facial paralysis detection is important in developing standardized tools for medical assessment, treatment, and monitoring and to reduce healthcare costs through the inclusion of automatic processes [
2]. Additionally, computer-based systems are expected to provide user-friendly tools, in the near future, for patient monitoring at home.
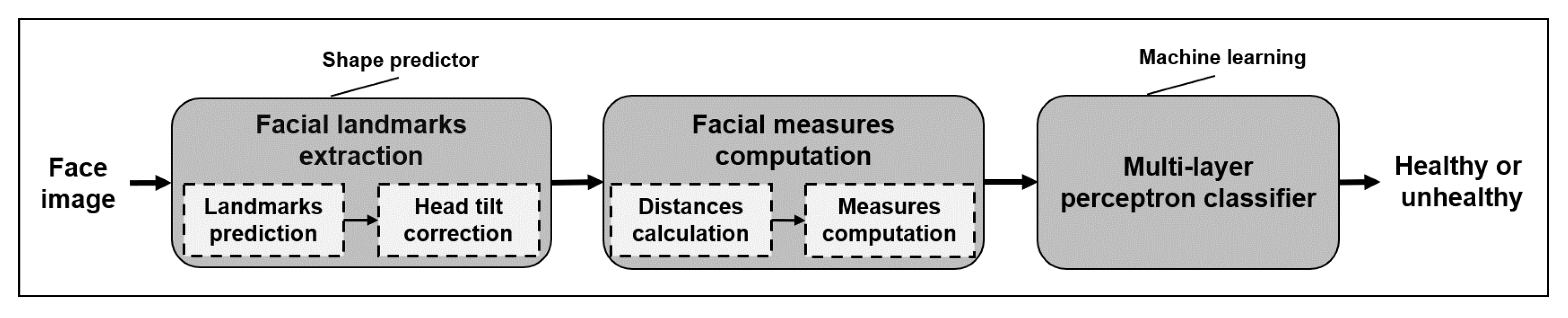
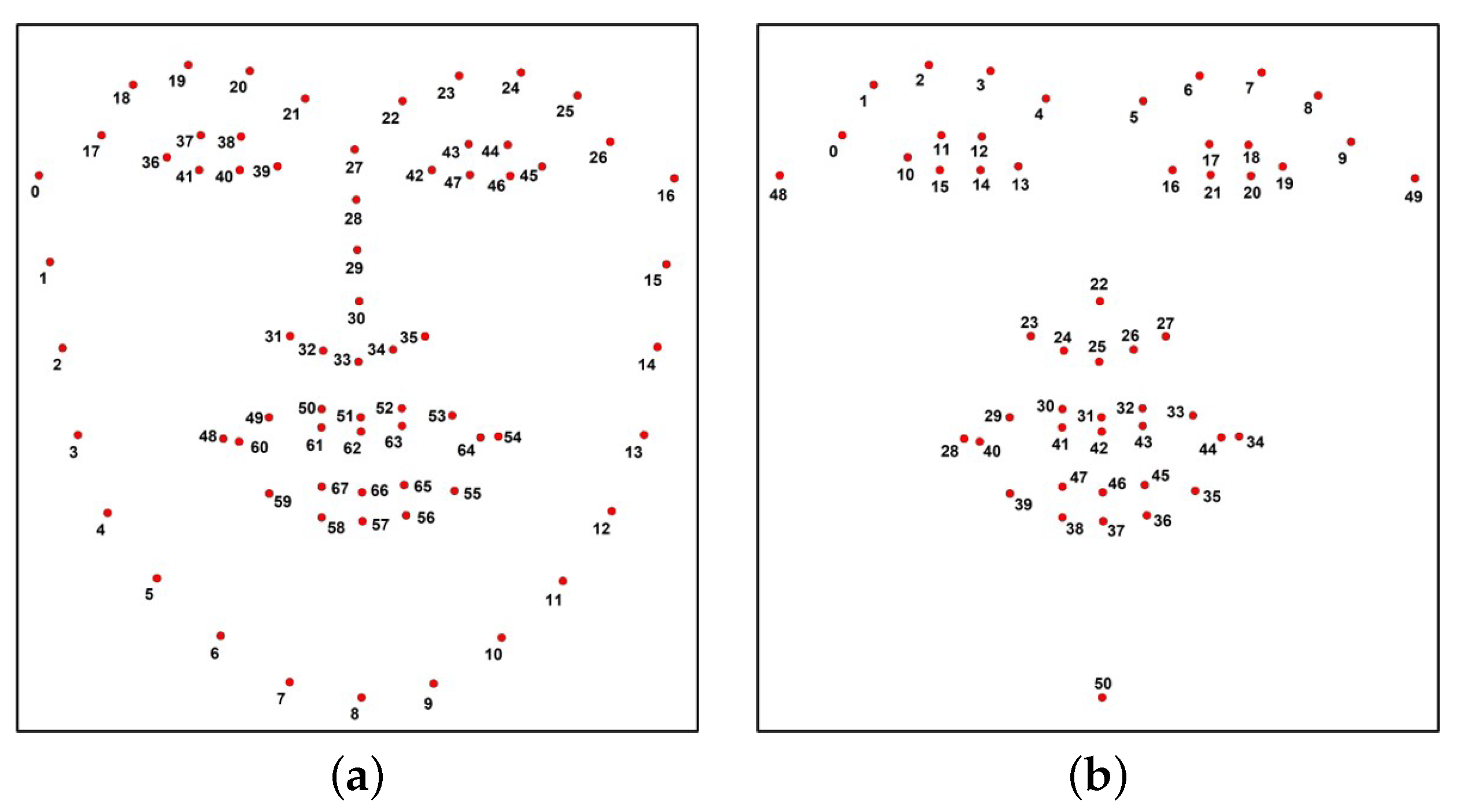
Particularly in the field of computer vision, the analysis of facial signs has motivated a lot of studies on automated facial nerve function assessment from the biomedical visual capture of the face. The visual capture of the face extends from traditional images and video to infrared (thermal imaging) and also depth images (stereo photogrammetry). A few methods based on the use of images perform a process for feature extraction that consists of detecting the face region in the image and later extracting key points (also known as facial landmarks) based on a specific model. There are some publicly available models, also known as shape predictors, that extract facial landmarks using Haar cascades. The 68 points predictor proposed by Matthews and Baker in [
3] is widely known and employed in the field of facial analysis. In the literature, some authors create their own shape predictor to extract facial landmarks with a better performance of the task [
4]. In a common approach, the extraction of facial landmarks is a crucial step, because these key points are used to compute other measures, such as the distances, angles, and areas between the landmarks. In the facial analysis process, those measures are fed into a classifier to train it and to detect facial nerve damage, and, later, its severity.
To achieve the automatic classification of facial nerve damage, it is necessary for a clinical practitioner to evaluate a set of facial images to label them as healthy or unhealthy faces. With annotated data, any classifier could be trained using the extracted facial measures and the labels to detect facial nerve damage in a new image. Although a variety of automated facial nerve function assessment solutions have been proposed, their outcomes fall into two main categories: (1) non-semantic numerical values quantifying static, dynamic, and synkinetic facial features; (2) semantic grade of facial nerve function designed by the clinician [
5]. Most existing solutions belong to the first category; however, most of these solutions stay at the method discussion phase, and only a few of them have been implemented into prototypes—for example, the
Emotrics software [
6]. Solutions in the second category aim to quantify the facial nerve function according to a specific facial nerve grading scale designed by clinicians. To achieve this target, machine learning techniques should be applied to build a predictive model which is trained on labelled data and capable of making predictions on new data. Here, the data are facial images from either a healthy subject or a facial palsy patient, and the prediction is a binary decision (healthy or patient) or it could be the grade of facial nerve function. Classifiers for these applications are based on the methods of support vector machine (SVM), artificial neural network (ANN), k-nearest-neighbor (KNN), or hybrid classifier [
5]. For a new subject, a typical system extracts computational features from the facial data then calls a pre-trained classifier to map the features to the facial nerve malfunction.
There are some works that use facial landmarks (i.e., facial key points extraction), before performing facial analysis [
6,
7,
8]. There are other works that specifically intend to detect facial paralysis as a binary classification problem. Kim et al. proposed a smartphone-based automatic diagnosis system that consists of three modules: facial landmark detector, feature extractor based on facial regions, and a classifier [
9]. Three facial movements were analyzed: resting, smiling, and raising the eyebrows. The system was evaluated on a private database with 23 facial palsy patients and 13 healthy volunteers. The authors reported their highest classification accuracy at 88.9%. Hsu et al. proposed a deep learning solution for the detection of facial palsy using a regular camera [
10]. They formulated the facial palsy identification as an object detection problem and considered the deformation regions cause by facial palsy, or simply the palsy regions, on a patient’s face as the target objects. Their proposed solution is a hierarchical network composed of three components: face detection, facial landmark detection, and local palsy region detection. The authors reported a 93% of prediction accuracy in their private database. Barbosa et al. proposed a method to classify facial paralysis in two stages: the discrimination of healthy from unhealthy subjects, and then, facial palsy classification among unhealthy subjects [
11]. They used four facial expressions (at rest, raising the eyebrows, screwing up the nose, and smiling) to measure symmetry. They built a classification model by combining a rule-based approach and a machine learning method (hybrid classifier). The authors reported an up to 98.12% sensitivity in the discrimination among healthy and unhealthy in their private database.
In this work, we aim to detect facial paralysis in a set of face images, meaning that we aim to identify if the subject is healthy or a patient (binary classification). In this methodology, the evaluation of the input image is performed independently of the facial movement executed by the patient, different from other works which use a set of facial gestures to compute symmetry variations between expressions, then they detect facial paralysis. Our system measures extracted facial landmarks using simple mathematical operations that keep the implementation uncomplicated but that are still effective. Our facial measures aim to detect the level of asymmetry between the two sides of the face and also characterize facial gestures so that the learning algorithm is able to relate each asymmetry level with the expression found in the image. The proposed measures extract information from the eyebrows, eyes, nose, and mouth; they are not divided by specific regions and do not have pre-marked zones, as other authors propose. Our classification approach is based on a multi-layer perceptron, which provides a label as an output.
The contributions of this research are: a set of facial measures, easily computed from facial landmarks, for the binary classification of facial paralysis independently of the facial movement performed by the subject; evaluation using two public image databases; and a classification model to detect facial paralysis. The remainder of the paper is organized as follows:
Section 2 describes the proposed methodology,
Section 3 introduces our findings and discussion, and finally
Section 4 provides concluding remarks.
3. Experiments and Results
There are a number of methodologies aiming to detect facial paralysis in a photograph. However, collaboration among the research community has been difficult due to the unavailability of public datasets, mainly because of patient privacy as many patients would prefer not to share their biometrical data. This situation motivated us to test our classification system on two different databases that recently became publicly available. Some remarks on such databases are given here.
First, we used the Massachusetts Eye and Ear Infirmary (MEEI) database, which is an open source set of facial photographs and videos representing the entire spectrum of flaccid and nonflaccid facial palsy collected by Greene et al. and introduced in [
19]. The MEEI database was released to serve as a resource for facial palsy education and research. Initially, to demonstrate the utility of the database the relationship between the level of facial function and the perceived emotion expression was successfully characterized using a machine learning-based algorithm [
19]. Later, the MEEI database was employed to develop a novel machine learning algorithm for the fast and accurate localization of facial landmarks in photographs of facial palsy patients; the improved shape predictor represents the first step toward an automatic system for computer-aided assessment in facial palsy [
12]. In order to determine an agreement between the facial function evaluation using high-quality photographs and using in-person evaluation, the MEEI database was employed. The authors demonstrated that facial symmetry in facial palsy patients can be monitored using standardized frontal photographs [
20]. Recently, the MEEI database was also employed to compare a clinician evaluation against machine learning–derived automated assessments in frontal photographs. The authors of [
21] concluded that automated scores predicted more asymmetry in normal patients and less asymmetry in patients with flaccid palsy and synkinesis compared to clinician grading. Automated assessments hold promise for the standardization of facial palsy outcome measures and may eliminate the observer bias seen in clinician-graded scales. The database is composed of 480 high-resolution images from 60 participants, 10 healthy subjects, and 50 patients (25 suffering from flaccid and 25 from nonflaccid paralysis), each one performing 8 different facial movements: (1) at rest, (2) eyebrow elevation, (3) light effort eye closure, (4) full effort closure, (5) light effort smile, (6) full effort smile, (7) pucker, and (8) lip depression. This image database was used to design our classification system. To the best of our knowledge, there is no other publicly available database with these characteristics.
Second, the Toronto NeuroFace (TNF) is also a publicly available dataset, collected by Bandini et al. and introduced in [
22], which aims to assess neurological disorders. Similarly to the MEEI dataset, the Toronto NeuroFace dataset was released to foster the development of novel and robust approaches for face alignment and oro-facial assessments that can be used to track and analyze facial movements in clinical populations suffering from amyotrophic lateral sclerosis and other neurological diseases. Authors in [
22] analyzed the importance of using algorithms trained with data from the target population in order to improve the localization of facial landmarks and also the accuracy in face alignment. The TNF dataset consists of 261 videos, clinical scores per video, and more than 3300 annotated frames of faces from individuals performing oro-facial tasks typical of the clinical assessment.
To the best of our knowledge, neither the MEEI database or the TNF dataset have been employed to specifically detect facial paralysis in frontal face photography. It is worth noticing that both databases intend to facilitate information for the development of clinical applications; however, they are not equivalent in terms of image quality, lighting, and pose conditions, and the tasks performed by the participants are not equivalent. In other words, both databases are not directly comparable for our classification problem, but they were helpful in the design process.
As stated before, in
Section 2.3, the Weka suite was employed at the design stage of our MLP classifier. The suite allowed us to analyze the performance of the MLP classifier parameters—in this case the function named
CVParameterSelection was employed [
18]. As a result of the analysis, the configuration values were set as learning rate
, momentum
, training time
, seed
, and hidden layers
. It might be relevant to mention that the 29 features were selected from a set of symmetry measures after evaluating the worth of the features using the strategy implemented by the function named
ClassifierAttributeEval [
18].
Using the 10-fold cross-validation technique, the MLP classifier was trained with 640 samples computed from the MEEI database. Cross-validation is a statistical method used to estimate the performance of machine learning models on new data; it is a widely known technique used to train and evaluate. Later, it was observed that the MLP function did not perform sequential learning, resulting in a negative impact on the classifier performance because the available dataset was unbalanced. That is, there were fewer healthy samples compared to the unhealthy ones (80 vs. 400). To overcome this situation, the healthy set was replicated three times with a sample augmentation process. Similar to the process suggested in [
9,
16], the healthy images were rotated in two opposite directions, increasing the amount of available data and also verifying that our algorithm was invariant to rotation. In previous experiments, it was observed that increasing the amount of healthy instances by three times is enough to learn and discriminate this class without over fitting. In the end, the training of the MLP classifier was executed with 640 samples (240 healthy and 400 unhealthy instances).
In
Table 2, the performance of the model for the testing part of the data for each fold is presented. There, TN stands for true negative (i.e., healthy samples), TP stands for true positive (i.e., unhealthy samples), and false negative (FN) and false positive (FP) are incorrectly classified samples. Here, the worst performance is 84.37% for the 1st fold and the best is 100% for the 5th fold. The average performance of this methodology is 94.06%, as shown in
Table 2. After evaluating our MLP classifier with the original 480 samples, there is a 99.79% correct classification of the MEEI database, yielding a sensitivity of 99.75% and a specificity of 100%. The confusion matrix of test on the actual MEEI database is given in
Table 3.
It was already mentioned that the Toronto NeuroFace (TNF) is a database collected for clinical assessment, and to the best of our understanding and the information provided by the authors, the subset called
Stroke can be used to evaluate our methodology. There are 8 subjects with facial asymmetry and 3 participants without it—in total, 817 asymmetrical samples and 219 symmetrical ones. It is important to notice that the TNF images refer to frames extracted from the subjects videos performing oro-facial tasks. Following the proposed methodology, a 10-fold cross-validation technique was employed to train another MLP classifier using samples computed from the TNF database. In
Table 4, the performance of the model on the testing part of the data for each fold is presented. Here, the worst performance was 94.56% for the 5th fold and the best was 98.65% for the 3rd fold. The average performance of this methodology for the second dataset was 97.22%, as shown in
Table 4. A 98.55% correct classification was found after evaluating the MLP classifier with the original 1036 samples. The confusion matrix of the test on the actual TNF database is described in
Table 5, which yields a sensitivity of 98.29% and a specificity of 99.54%, proving that our methodology to design a binary classifier to detect facial paralysis can be extended to other databases of face photographs with an outstanding performance.
Our methodology detects facial asymmetry levels within an image independently of the gesture performed by the subject, while most of the other methods compute facial asymmetry levels from a set of different facial gestures from the same subject. If we focus on the facial paralysis detection systems (i.e., a binary classification) that compute facial landmarks at some point of their processing, we can put together a summary of three methodologies, as previously introduced in
Section 1; such relation is shown in
Table 6. We observe that a direct comparison of methods in this table is not feasible because of discrepancies in the goals and metrics used; nonetheless, we include the results of works closer to ours. Those methods compute facial landmarks at some point of their process but train their shape predictor model on their own private dataset (e.g., [
9,
10,
11]). Those different performance measures obtained from our tests and shown in
Table 6 lead us to suggest that our method exhibits a better performance or, at least, one similar to that of other approaches.








{kind=link}
{kind=link}
{kind=link}