
Coordinating Entrainment Phenomena: Robot Conversation Strategy for Object Recognition


Abstract
1. Introduction
1.1. Implicit and Explicit Dyad: Two Types of Interaction Strategies to Clear the Ambiguity of Referencing Behavior
1.2. Research Questions
- Does the implicit entrainment strategy that exploits entrainment phenomenon improve the performance of indicated object recognition? (Experiment 1)
- Robots can employ either a conversational strategy that explicitly requests additional information or one that encourages implicit human entrainment. Which strategy results in better indicated object recognition, and which strategy do humans prefer the robot use? (Experiment 2)
2. Background
2.1. Lexial Entrainment
2.2. Gestural Entrainment
2.3. Entrainment Inhibition
2.4. Robot Conversation Strategy Exploiting Entrainment Phenomena
- Humans tend to align their speech with their interlocutors. Therefore, robots should talk with useful lexical expressions to identify an object because humans will come to use the same or similar expressions.
- Humans tend to align their gestures with their interlocutors and their gestures increase. Therefore, robots should use pointing gestures because humans will repeat the pointing gestures.
- If robots talk with many lexical expressions, humans tend to speak with fewer lexical expressions. Therefore, although robots should talk with useful lexical expressions to identify an object, they should avoid using too many lexical expressions because humans will decrease their use of lexical expressions in response.
- When aligning with robots’ pointing gestures, humans tend to use fewer lexical expressions in their speech. Therefore, robots should avoid using pointing gestures in situations where the pointing gestures are not useful for identifying an object because humans will decrease their verbal expressions.
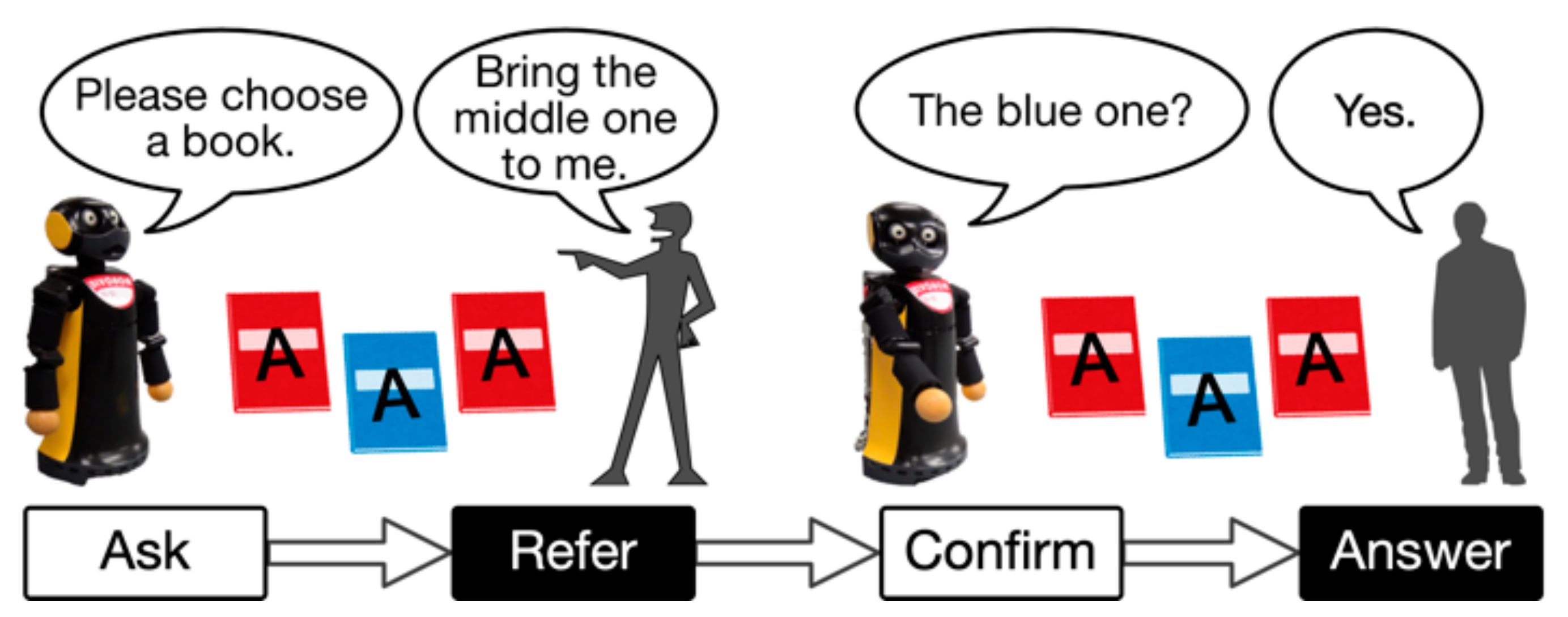
3. Interaction Design
3.1. Object Reference Conversation
3.2. Implicit Entrainment and Explicit Request
3.2.1. Implicit Entrainment
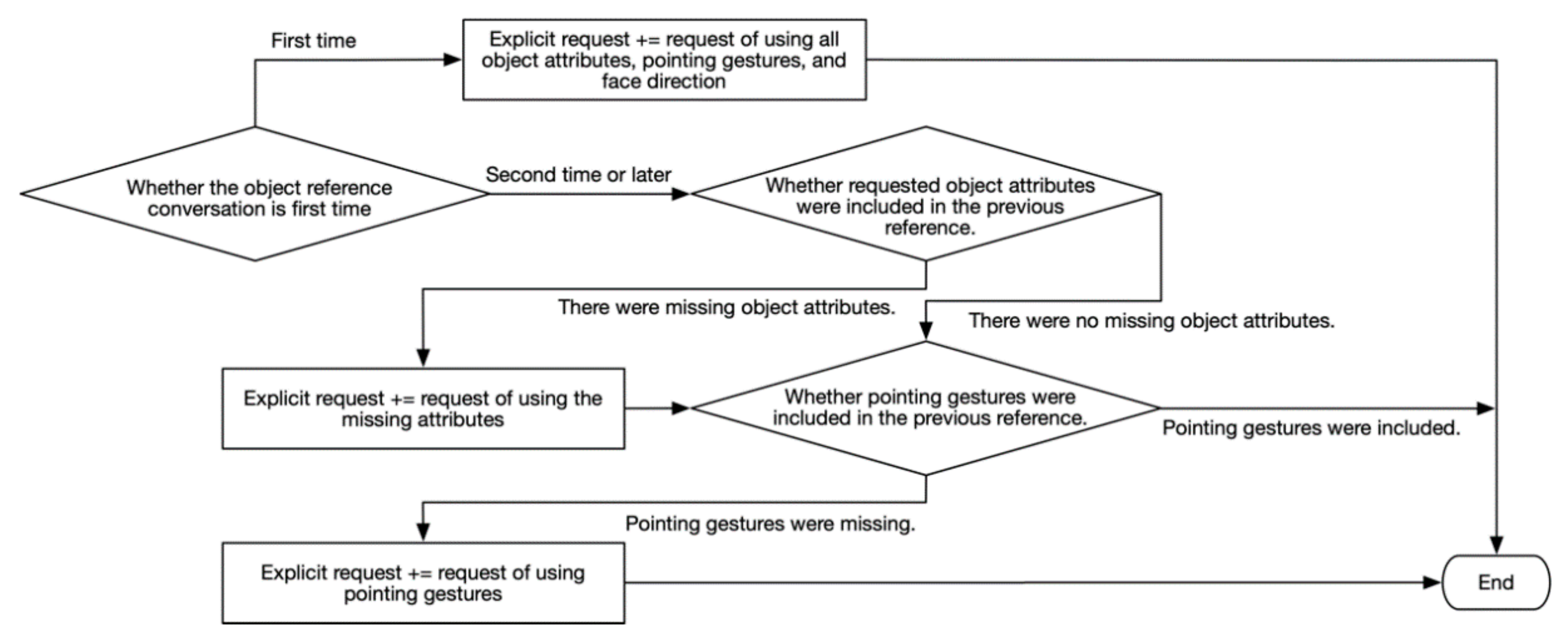
3.2.2. Explicit Request
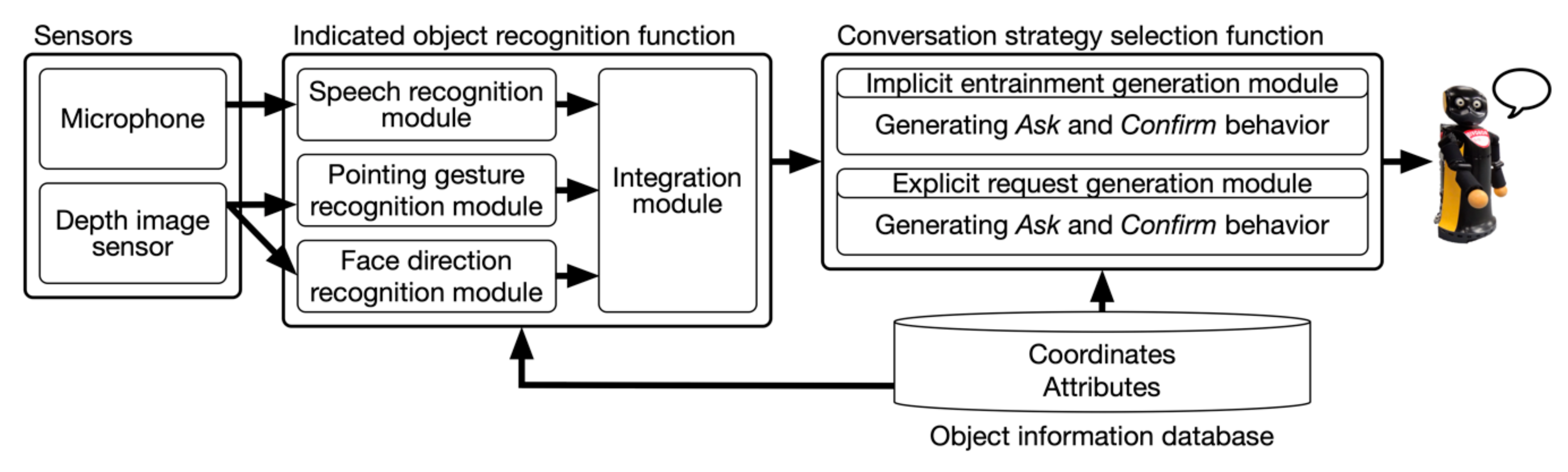
4. System Design
4.1. Robot
4.2. Indicated Object Recognition
4.2.1. Speech Recognition Module
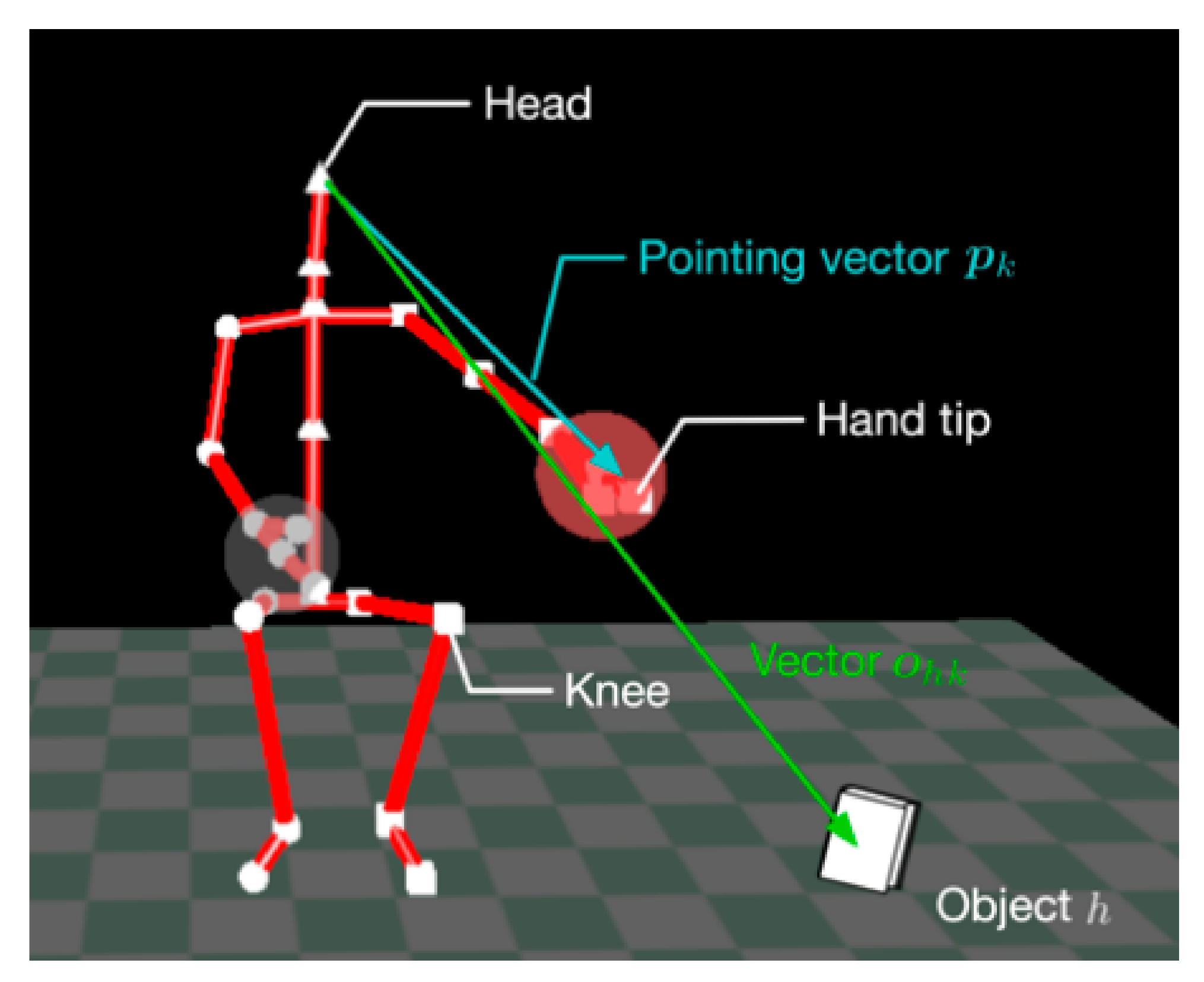
4.2.2. Pointing Gesture Recognition Module
4.2.3. Face Direction Recognition Module
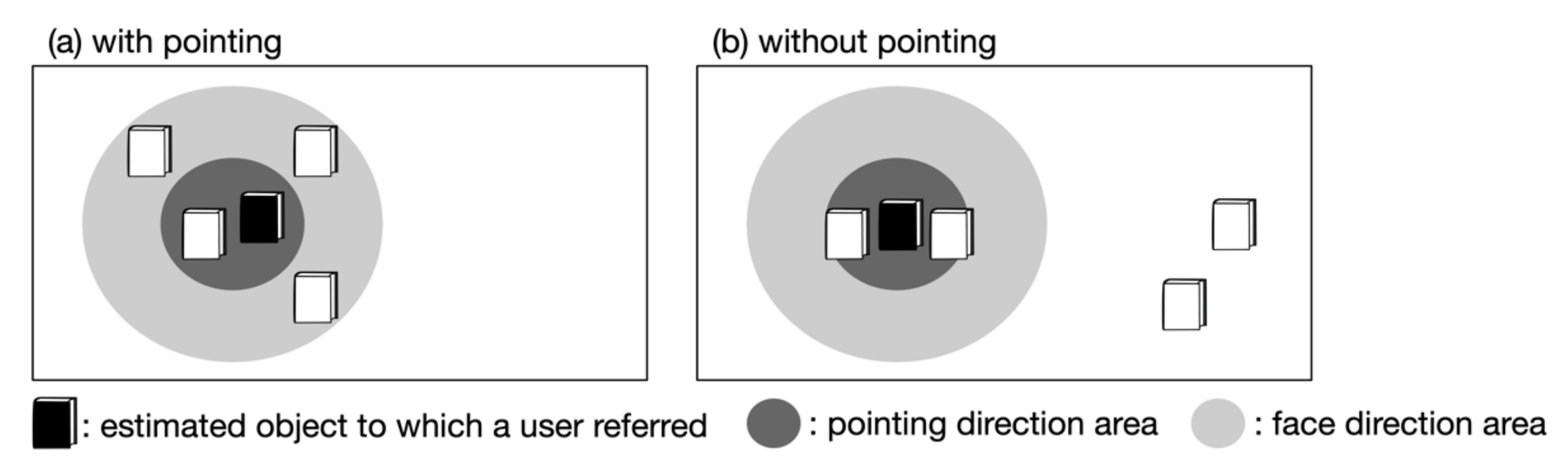
4.2.4. Integration Module
4.3. Conversation Strategy Selection Function
4.3.1. Implicit Entrainment Generation Module
Deciding whether to Use a Pointing Gesture
Deciding Which Object Attributes to Use in the Confirmation Speech
4.3.2. Explicit Request Generation Module
5. Experiment 1
5.1. Experiment Settings
5.1.1. Hypothesis and Prediction
5.1.2. Conditions
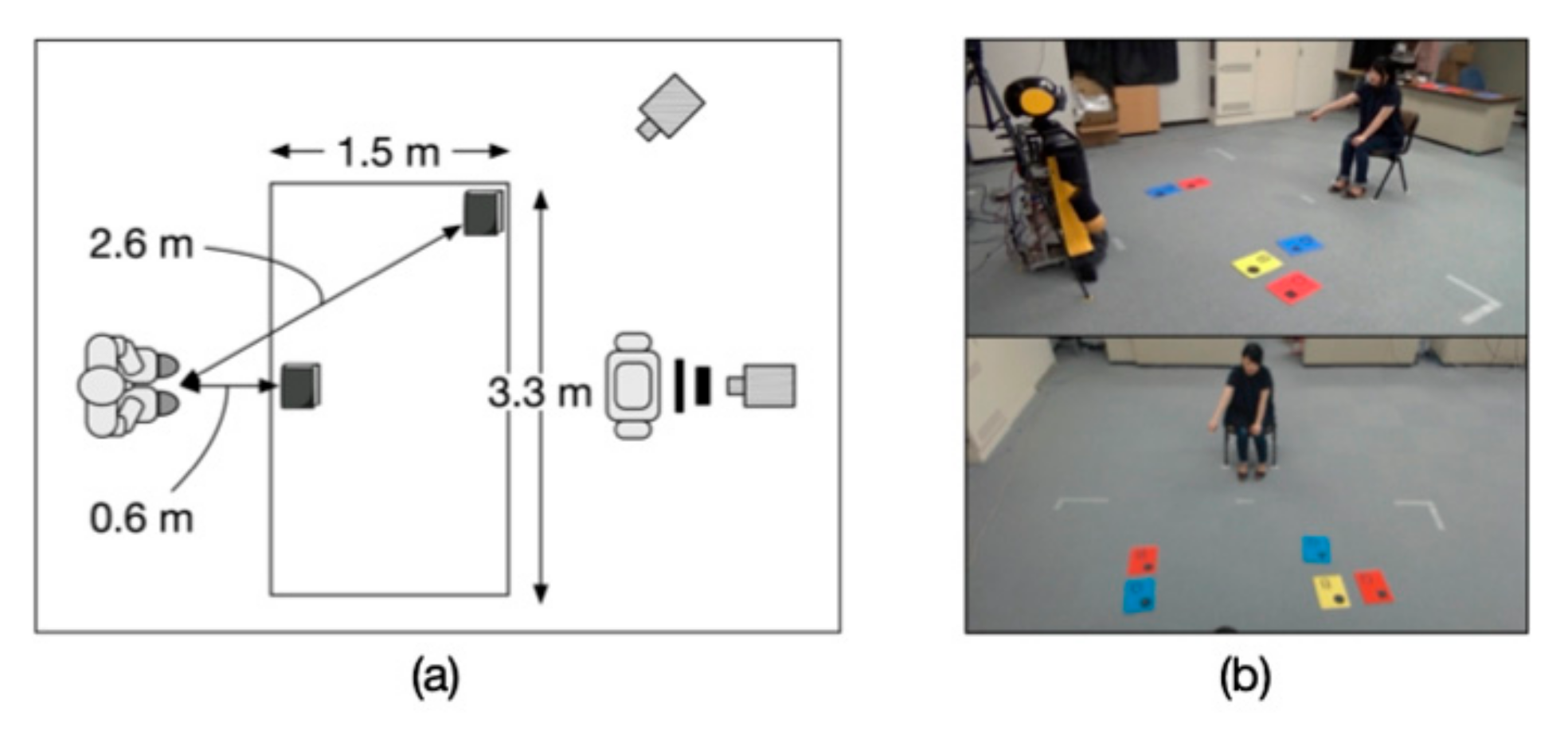
5.1.3. Environment
5.1.4. Procedure
5.1.5. Measurement
5.1.6. Participants
5.2. Results
5.2.1. Verification of Prediction
5.2.2. Number of Object Attributes and Pointing Gestures in Humans’ Reference Behaviors
5.2.3. Change of Referencing Style through Interaction
5.3. Discussion
5.3.1. Implication
5.3.2. Influence of System Parameters on the Results
6. Experiment 2
6.1. Experiment Settings
6.1.1. Hypothesis and Prediction
6.1.2. Conditions
6.1.3. Environment
6.1.4. Procedure
- Participant selects and arranges five books.
- Participant has 10 object reference conversations under condition A.
- Participant selects and arranges five books.
- Participant has 10 object reference conversations under condition B.
6.1.5. Measurement
Recognition Performance
Impression of Conversations
- The conversation with the robot was a load (load).
- The conversation with the robot was troublesome (troublesome).
- It was easy to make a reference to a book (easiness).
- The conversation with the robot was difficult (difficulty).
- The conversation with the robot was natural (natural).
- The conversation with the robot was easy to understand (understandability).
- I felt familiarity with the robot (familiarity).
- Overall impression of conversation (overall impression).
6.1.6. Participants
6.2. Results
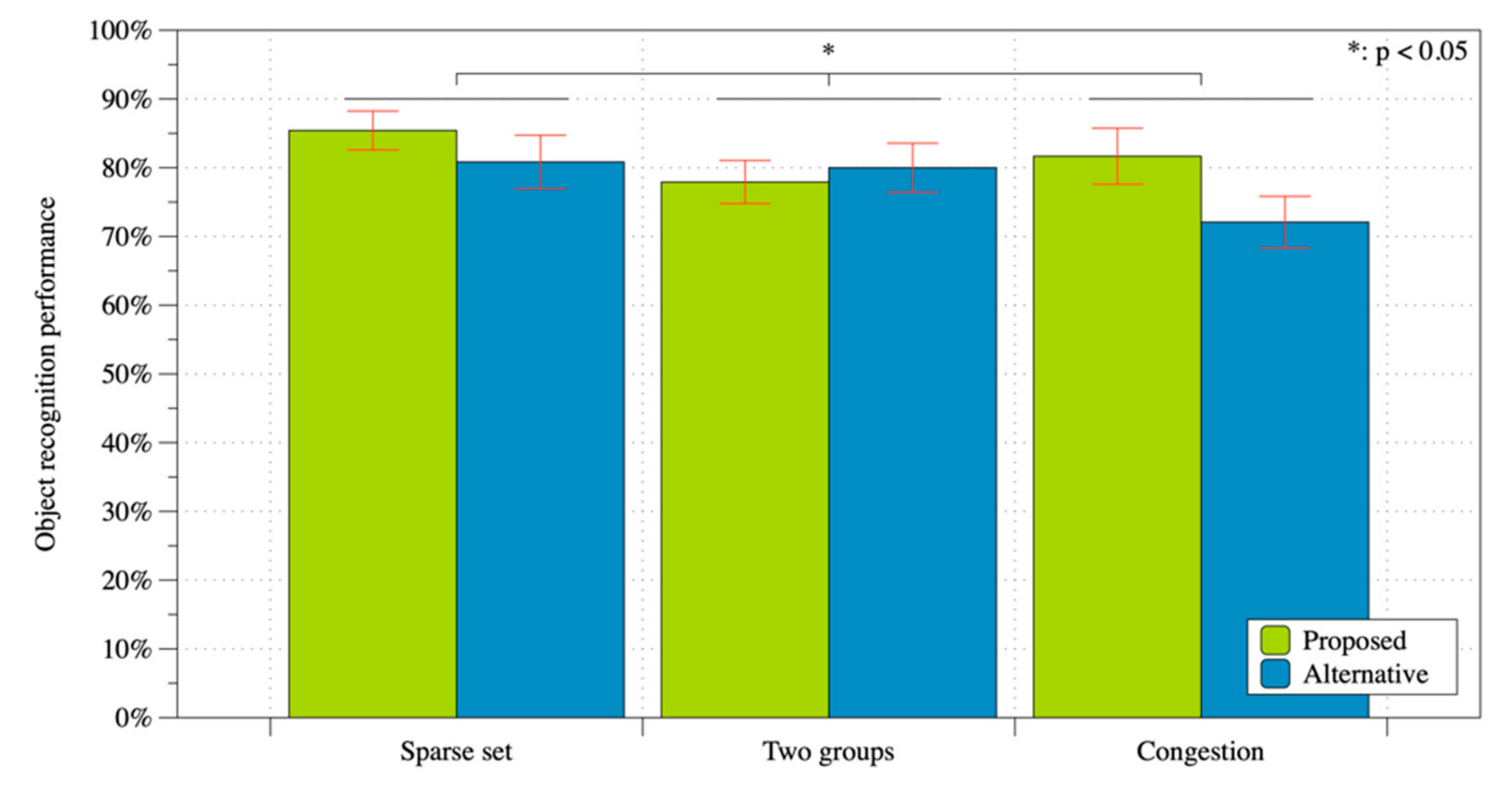
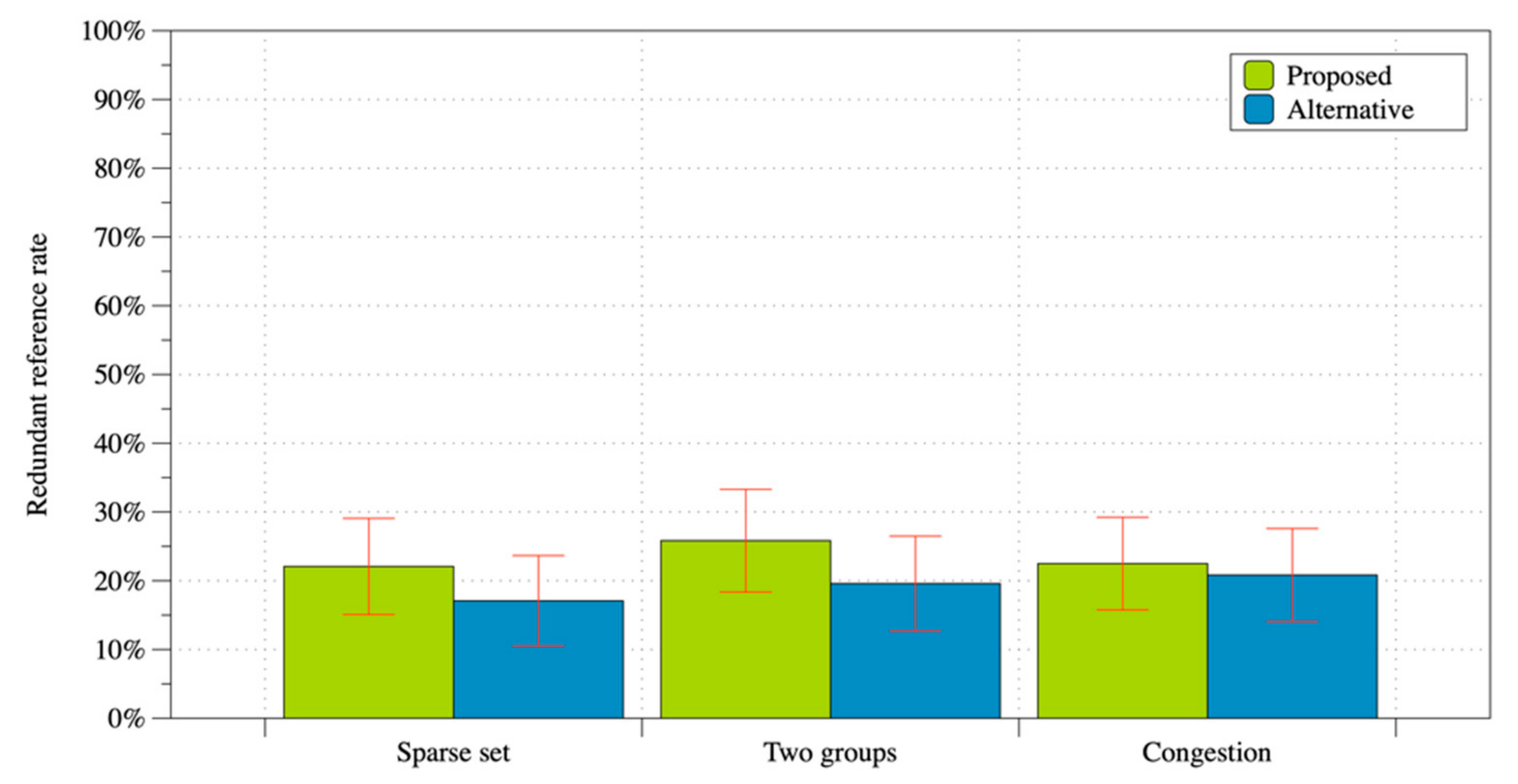
6.2.1. Verification of Prediction 2-1
6.2.2. Verification of Prediction 2-2
6.3. Discussion
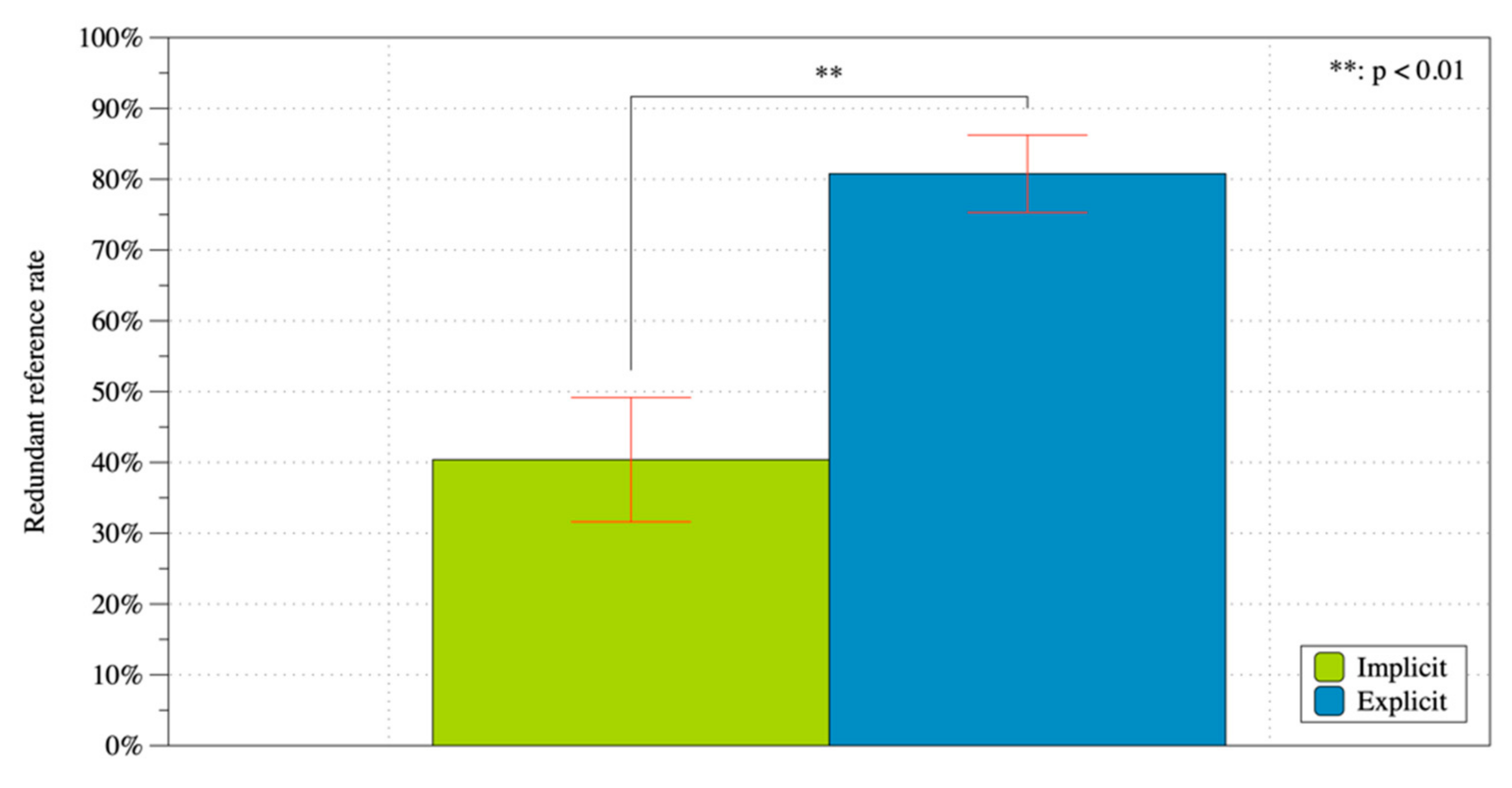
6.3.1. Comparison between Explicit Request and Implicit Entrainment
6.3.2. Comparison of Referencing Style
7. General Discussion
8. Conclusions
- The proposed strategy implicitly elicits redundant references and improves the performance of the indicated object recognition.
- Even though the proposed strategy forms better impressions than the other interactive strategy that explicitly requests clarifications when people refer to objects, the recognition performances of the two strategies are not significantly different.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hatori, J.; Kikuchi, Y.; Kobayashi, S.; Takahashi, K.; Tsuboi, Y.; Unno, Y.; Ko, W.; Tan, J. Interactively Picking Real-World Objects with Unconstrained Spoken Language Instructions. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 3774–3781. [Google Scholar]
- Nickel, K.; Stiefelhagen, R. Visual recognition of pointing gestures for human-robot interaction. Image Vis. Comput. 2007, 25, 1875–1884. [Google Scholar] [CrossRef]
- Schauerte, B.; Fink, G.A. Focusing computational visual attention in multi-modal human-robot interaction. In Proceedings of the International Conference on Multimodal Interfaces and the Workshop on Machine Learning for Multimodal Interaction on ICMI-MLMI ’10 Association for Computing Machinery (ACM), Beijing, China, 8–12 November 2010; p. 6. [Google Scholar]
- Iwahashi, N. A method for the coupling of belief systems through human-robot language interaction. In Proceedings of the The 12th IEEE International Workshop on Robot and Human Interactive Communication, ROMAN 2003, Millbrae, CA, USA, 2 November 2003; pp. 385–390. [Google Scholar]
- Furnas, G.W.; Landauer, T.K.; Gomez, L.M.; Dumais, S.T. The vocabulary problem in human-system communication. Commun. ACM 1987, 30, 964–971. [Google Scholar] [CrossRef]
- Shinozawa, K.; Miyashita, T.; Kakio, M.; Hagita, N. User specification method and humanoid confirmation behavior. In Proceedings of the 2007 7th IEEE-RAS International Conference on Humanoid Robots, Pittsburgh, PA, USA, 29 November–1 December 2007; pp. 366–370. [Google Scholar]
- Wu, E.; Han, Y.; Whitney, D.; Oberlin, J.; MacGlashan, J.; Tellex, S. Robotic Social Feedback for Object Specification. In Proceedings of the AAAI Fall Symposia, Providence, RI, USA, 12–14 November 2015. [Google Scholar]
- Kuno, Y.; Sakata, K.; Kobayashi, Y. Object recognition in service robots: Conducting verbal interaction on color and spatial relationship. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision Workshops, ICCV Workshops, Kyoto, Japan, 27 September–4 October 2009; pp. 2025–2031. [Google Scholar]
- Whitney, D.; Rosen, E.; MacGlashan, J.; Wong, L.L.S.; Tellex, S. Reducing errors in object-fetching interactions through social feedback. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 1006–1013. [Google Scholar]
- Garrod, S.; Anderson, A. Saying what you mean in dialogue: A study in conceptual and semantic coordination. Cognition 1987, 27, 181–218. [Google Scholar] [CrossRef]
- Brennan, S.E. Lexical Entrainment in Spontaneous Dialog. Proc. ISSD 1996, 96, 41–44. [Google Scholar]
- Brennan, S.E.; Clark, H.H. Conceptual pacts and lexical choice in conversation. J. Exp. Psychol. Learn. Mem. Cogn. 1996, 22, 1482–1493. [Google Scholar] [CrossRef] [PubMed]
- Branigan, H.P.; Pickering, M.J.; Cleland, A.A. Syntactic co-ordination in dialogue. Cognition 2000, 75, B13–B25. [Google Scholar] [CrossRef]
- Scheflen, A.E. The Significance of Posture in Communication Systems†. Psychiatry 1964, 27, 316–331. [Google Scholar] [CrossRef] [PubMed]
- Kendon, A. Movement coordination in social interaction: Some examples described. Acta Psychol. 1970, 32, 101–125. [Google Scholar] [CrossRef]
- Bergmann, K.; Kopp, S. Gestural Alignment in Natural Dialogue. Proc. Ann. Meet. Cogn. Sci. Soc. 2012, 34, 1326–1331. [Google Scholar]
- Levitan, R. Entrainment in Spoken Dialogue Systems: Adopting, Predicting and Influencing User Behavior. In Proceedings of the 2013 NAACL HLT Student Research Workshop, Atlanta, GA, USA, 13 June 2013; pp. 84–90. [Google Scholar]
- Lopes, J.; Eskenazi, M.; Trancoso, I. From rule-based to data-driven lexical entrainment models in spoken dialog systems. Comput. Speech Lang. 2015, 31, 87–112. [Google Scholar] [CrossRef]
- Fandrianto, A.; Eskenazi, M. Prosodic Entrainment in an Information-Driven Dialog System. In Proceedings of the 13th Annual Conference of the International Speech Communication Association, Portland, OR, USA, 9–13 September 2012. [Google Scholar]
- Lopes, J.; Eskenazi, M.; Trancoso, I. Automated two-way entrainment to improve spoken dialog system performance. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 8372–8376. [Google Scholar]
- Kimoto, M.; Iio, T.; Shiomi, M.; Tanev, I.; Shimohara, K.; Hagita, N. Improvement of Object Reference Recognition through Human Robot Alignment. In Proceedings of the 2015 24th IEEE International Symposium on Robot and Human Interactive Communication (RO-MAN), Kobe, Japan, 31 August–4 September 2015; pp. 337–342. [Google Scholar]
- Kimoto, M.; Iio, T.; Shiomi, M.; Tanev, I.; Shimohara, K.; Hagita, N. Alignment Approach Comparison between Implicit and Explicit Suggestions in Object Reference Conversations. In Proceedings of the 4th International Conference on Human Agent Interaction, Association for Computing Machinery (ACM), Singapore, 4–7 October 2016; pp. 193–200. [Google Scholar]
- Kimoto, M.; Iio, T.; Shiomi, M.; Tanev, I.; Shimohara, K.; Hagita, N. Robot Confirmation Behavior to Improve Object Reference Recognition. J. Robot. Soc. Jpn. 2017, 35, 681–692. [Google Scholar] [CrossRef]
- Kimoto, M.; Iio, T.; Shiomi, M.; Tanev, I.; Shimohara, K.; Hagita, N. Conversation Strategy Comparison between Explicit Request and Implicit Alignment in Object Reference Conversation. J. Robot. Soc. Jpn. 2018, 36, 441–452. [Google Scholar] [CrossRef]
- Branigan, H.P.; Pickering, M.J.; Pearson, J.; McLean, J.F. Linguistic alignment between people and computers. J. Pragmat. 2010, 42, 2355–2368. [Google Scholar] [CrossRef]
- Brennan, S.E. Conversation with and through computers. User Model. User-Adapt. Interact. 1991, 1, 67–86. [Google Scholar] [CrossRef]
- Iio, T.; Shiomi, M.; Shinozawa, K.; Shimohara, K.; Miki, M.; Hagita, N. Lexical Entrainment in Human Robot Interaction. Int. J. Soc. Robot. 2014, 7, 253–263. [Google Scholar] [CrossRef]
- Brandstetter, J.; Beckner, C.; Sandoval, E.B.; Bartneck, C. Persistent Lexical Entrainment in HRI. In Proceedings of the 2017 ACM/IEEE International Conference on Human-Robot Interaction, Association for Computing Machinery (ACM), Vienna, Austria, 6–9 March 2017; pp. 63–72. [Google Scholar]
- Clark, H.H.; Brennan, S.E. Grounding in Communication; American Psychological Association: Washington, DC, USA, 1991; pp. 127–149. [Google Scholar]
- Garrod, S.; Pickering, M.J. Joint Action, Interactive Alignment and Dialog. Top. Cogn. Sci. 2009, 1, 292–304. [Google Scholar] [CrossRef] [PubMed]
- Charny, J.E. Psychosomatic Manifestations of Rapport in Psychotherapy. Psychosom. Med. 1966, 28, 305–315. [Google Scholar] [CrossRef] [PubMed]
- Breazeal, C. Regulation and Entrainment in Human—Robot Interaction. Int. J. Robot. Res. 2002, 21, 883–902. [Google Scholar] [CrossRef]
- Ono, T.; Imai, M.; Ishiguro, H. A Model of Embodied Communications with Gestures between Human and Robots. Proc. 23rd Ann. Meet. Cogn. Sci. Soc. 2001, 732–737. [Google Scholar]
- Iio, T.; Shiomi, M.; Shinozawa, K.; Akimoto, T.; Shimohara, K.; Hagita, N. Investigating Entrainment of People’s Pointing Gestures by Robot’s Gestures Using a WOZ Method. Int. J. Soc. Robot. 2011, 3, 405–414. [Google Scholar] [CrossRef]
- Holler, J.; Wilkin, K. Co-Speech Gesture Mimicry in the Process of Collaborative Referring During Face-to-Face Dialogue. J. Nonverbal Behav. 2011, 35, 133–153. [Google Scholar] [CrossRef]
- Kawai, H.; Toda, T.; Ni, J.; Tsuzaki, M.; Tokuda, K. XIMERA: A New TTS from ATR Based on Corpus-Based Technologies. In Proceedings of the 5th ISCA ITRW on Speech Synthesis, Pittsburgh, PA, USA, 14–16 June 2004; pp. 179–184. [Google Scholar]
- Lee, A.; Kawahara, T. Recent Development of Open-Source Speech Recognition Engine Julius. In Proceedings of the APSIPA ASC 2009: Asia-Pacific Signal and Information Processing Association, 2009 Annual Summit and Conference, Sapporo, Japan, 4–7 October 2009; pp. 131–137. [Google Scholar]
- Howard, I.P.; Rogers, B.J. Binocular Vision and Stereopsis; Oxford University: Oxford, MS, USA, 1995; ISBN 195084764. [Google Scholar]
- Sugiyama, O.; Kanda, T.; Imai, M.; Ishiguro, H.; Hagita, N.; Anzai, Y. Humanlike conversation with gestures and verbal cues based on a three-layer attention-drawing model. Connect. Sci. 2006, 18, 379–402. [Google Scholar] [CrossRef]
- Ball, K.K.; Wadley, V.G.; Edwards, J.D. Advances in Technology Used to Assess and Retrain Older Drivers. Gerontechnology 2002, 1, 251–261. [Google Scholar] [CrossRef]
- Sanders, A.F. Some Aspects of the Selective Process in the Functional Visual Field. Ergonomics 1970, 13, 101–117. [Google Scholar] [CrossRef] [PubMed]
- Seya, Y.; Watanabe, K. Objective and Subjective Sizes of the Effective Visual Field during Game Playing Measured by the Gaze-contingent Window Method. Int. J. Affect. Eng. 2013, 12, 11–19. [Google Scholar] [CrossRef]
- Iio, T.; Shiomi, M.; Shinozawa, K.; Miyashita, T.; Akimoto, T.; Hagita, N. Lexical entrainment in human-robot interaction: Can robots entrain human vocabulary? In Proceedings of the 2009 IEEE/RSJ International Conference on Intelligent Robots and Systems, St. Louis, MO, USA, 10–15 October 2009; pp. 3727–3734. [Google Scholar]
- Dogan, F.I.; Kalkan, S.; Leite, I. Learning to Generate Unambiguous Spatial Referring Expressions for Real-World Environments. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; pp. 4992–4999. [Google Scholar]
- Gorniak, P.J. The Affordance-Based Concept. Ph.D. Thesis, Massachusetts Institute of Technology, Cambridge, MA, USA, 2005. [Google Scholar]
- Mavridis, N.; Roy, D. Grounded Situation Models for Robots: Where words and percepts meet. In Proceedings of the 2006 IEEE/RSJ International Conference on Intelligent Robots and Systems, Beijing, China, 9–15 October 2006; pp. 4690–4697. [Google Scholar]
- Mavridis, N. Grounded Situation Models for Situated Conversational Assistants. Ph.D. Thesis, Massachusetts Institute of Technology, Cambridge, MA, USA, 2007. [Google Scholar]
- Mavridis, N.; Dong, H. To ask or to sense? Planning to integrate speech and sensorimotor acts. In Proceedings of the 2012 IV International Congress on Ultra Modern Telecommunications and Control Systems, Sankt Petersburg, Russia, 3–5 October 2012; pp. 227–233. [Google Scholar]
- Hashimoto, M.; Yamano, M.; Usui, T. Effects of emotional synchronization in human-robot KANSEI communications. In Proceedings of the RO-MAN 2009-The 18th IEEE International Symposium on Robot and Human Interactive Communication, Toyama, Japan, 27 September–2 October 2009; pp. 52–57. [Google Scholar]
- Costa, S.; Brunete, A.; Bae, B.-C.; Mavridis, N. Emotional Storytelling Using Virtual and Robotic Agents. Int. J. Hum. Robot. 2018, 15. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sparse Set | Two Groups | Congestion | |
|---|---|---|---|
| Proposed | 1.5 (0.17) | 1.6 (0.16) | 1.7 (0.16) |
| Alternative | 1.5 (0.17) | 1.5 (0.16) | 1.6 (0.16) |
| Sparse Set | Two Groups | Congestion | |
|---|---|---|---|
| Proposed | 0.69 (0.081) | 0.68 (0.076) | 0.65 (0.083) |
| Alternative | 0.67 (0.079) | 0.70 (0.081) | 0.57 (0.094) |
| Implicit | Explicit | |
|---|---|---|
| Attributes | 2.5 (0.12) | 2.6 (0.11) |
| Pointing gestures | 0.58 (0.093) | 0.98 (0.016) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kimoto, M.; Iio, T.; Shiomi, M.; Shimohara, K. Coordinating Entrainment Phenomena: Robot Conversation Strategy for Object Recognition. Appl. Sci. 2021, 11, 2358. https://doi.org/10.3390/app11052358
Kimoto M, Iio T, Shiomi M, Shimohara K. Coordinating Entrainment Phenomena: Robot Conversation Strategy for Object Recognition. Applied Sciences. 2021; 11(5):2358. https://doi.org/10.3390/app11052358
Chicago/Turabian StyleKimoto, Mitsuhiko, Takamasa Iio, Masahiro Shiomi, and Katsunori Shimohara. 2021. "Coordinating Entrainment Phenomena: Robot Conversation Strategy for Object Recognition" Applied Sciences 11, no. 5: 2358. https://doi.org/10.3390/app11052358
APA StyleKimoto, M., Iio, T., Shiomi, M., & Shimohara, K. (2021). Coordinating Entrainment Phenomena: Robot Conversation Strategy for Object Recognition. Applied Sciences, 11(5), 2358. https://doi.org/10.3390/app11052358