1. Introduction
It is ineluctable to contain uncertain parameters and disturbances in practical systems due to modeling errors, external disturbances, and so on [
1]. Thus, it is of great practical significance to study robust control of the uncertain systems. In recent years, the control problem of uncertain systems has been extensively studied. The literature on robust control of uncertain systems mainly includes linear systems and nonlinear systems. For the uncertain linear systems, algebraic Riccati equations (ARE) or linear matrix inequalities (LMI) were mostly used to deal with them in the classical research methods [
2,
3,
4,
5,
6]. In this literature, both matched and mismatched systems were involved. For nonlinear systems, the early research methods include feedback linearization, fuzzy modeling, nonlinear
control, and so on [
7,
8,
9,
10,
11]. However, in recent decades, neural networks (NN) and PI in RL were used to approximate the robust control law numerically [
12,
13,
14].
The PI method in RL was initially utilized to calculate the optimal control law for some deterministic systems. Werbos first proposed an idea of approximating the solution in Bellman’s equation using approximate dynamic programming (ADP) [
15]. There have been many results of using the PI method to calculate the optimal control law for some deterministic systems [
16,
17,
18,
19]. There are two major benefits of using the PI algorithm to deal with such optimal problems. On the one hand, it can effectively solve some problems of the “curse of dimensionality” in engineering control [
20]. On the other hand, it can be utilized to calculate the optimal control law without knowing the system dynamics. In the practice of engineering control, it is difficult to obtain system dynamics accurately. Therefore, it is a good choice to use the PI algorithm to solve unknown model control problems.
Within the last ten years, the PI method was also developed to calculate the robust controller for some uncertain systems, which is based on the optimal control method of robust control [
21]. For an input constraint nonlinear system with continuous time, a novel RL-based algorithm was prosposed to deal with the robust control problem in [
22]. Based on network structure approximation, an online PI algorithm was developed to solve robust control of a class of nonlinear discrete-time uncertain systems in [
23]. Using a data-driven RL algorithm, a robust control scheme was developed for a class of completely unknown dynamic systems with uncertainty in [
24]. In addition, there are many other examples of literature on robust control based on RL, such as [
25,
26,
27]. In all the literature listed above, the solution to the Hamilton Jacobi Bellman (HJB) equation was approximated by neural network. In fact, solving the HJB equation is a key problem in optimal control problem [
28]. The HJB equation is difficult to solve because it is a nonlinear partial differential equation. For a nonlinear system, the HJB equation is solved with neural network approximation in many cases. Meanwhile, for the linear system, ARE is used to solve it instead of a neural network. However, for all we know, most of the current studies have not considered the input uncertainty in system. The input uncertainty does exist in the actual control system.
In this study, a class of continuous-time nonlinear systems with internal and input uncertainties is considered. The main objective is to establish robust control laws for the uncertain systems. By solving the optimal control problem constructed, the robust control problem is converted into calculating an optimal controller. The online PI algorithms are proposed to calculate robust control by approximating the optimal cost with neural network. The convergence of the proposed algorithms is proved. Numerical examples are given to illustrate the availability of the method.
Our main contributions are as follows. First, more general uncertain nonlinear systems are considered, in which the uncertainty entered both the system and the input. For the matched and the mismatched uncertain systems, it is proved that the robust control can be converted into calculating an optimal controller. Second, the online PI algorithms are developed to solve the robust control problem. The neural network is utilized to approximate the optimal cost in PI algorithm, which fulfilled a difficult task of solving the HJB equation.
The rest of this paper is arranged as follows. We formulate the robust control problems and propose some basic results for the issues under consideration in
Section 2. Solving the robust control problem is converted to calculate an optimal control law of a nominal or auxiliary system in
Section 3 and
Section 4. Based on approximating optimal cost with neural network, the online PI algorithms are developed to solve the robust control problem in
Section 5. To support the proposed theoretical framework, we provide some numerical examples in
Section 6. In
Section 7, the study is concluded, and the scope for future research is discussed.
2. Preliminaries and Problem Formulation
Consider an uncertain nonlinear system as follows:
where
is the system state,
is the control input,
,
are known function,
,
are uncertain disturbing function.
The control objective is to establish a robust control law in order that the closed-loop system is asymptotically stable for all allowed uncertain disturbances and .
As a general case, we first make the following assumptions to ensure that the state Equation (
1) is well defined [
1,
29].
Assumption 1. In (1), is Lipschitz continuous with respect to x and u on the set containing the origin. Assumption 2. For the free vibration system, , that is, is the equilibrium point of the free vibration system.
Definition 1. The system (1) is called to satisfy the system dynamics matched condition if there is a function matrix such that Definition 2. System (1) is called to satisfy the input matched condition if there is a function such thatwhere . Definition 3. If the system (1) satisfies the conditions (2) and (3) for any allowed disturbances and , then the system (1) is called a matched uncertain system. Definition 4. If the system (1) does not satisfy the condition (2) or (3) for any allowed disturbances and , then the system (1) is called a mismatched uncertain system. Next, we consider the robust control problem of nonlinear system (
1) with matched and mismatched conditions, respectively.
3. Robust Control of Matched Uncertain Nonlinear Systems
This section considers the problem of robust control when the system (
1) meets the matched conditions (
2) and (
3). By constructing appropriate performance indexes, the problem of robust control is transformed into calculating the optimal control law of a corresponding nominal system. Based on the optimal control of the nominal system, a PI algorithm is proposed to obtain robust feedback controller.
For the nominal system
find the controller
to minimize performance index
where
is the supremum function of uncertainty
, that is
.
The definition of admissible control in optimal control problem is given below [
26].
Definition 5. The control policy is called an admissible control of the system (4) with regard to the performance function (5) on compact set if is continuous on Ω, , it can stabilize the system (4) on , and the performance function (5) is limited for any . According to the performance index (
5), the cost function corresponding to the admissible control
is given by
Taking time derivative on both side of (
6), it follows the Bellman equation
where
is the gradient vector of the cost function
with respect to
x.
Definite Hamiltonian function
Determining the extremum of the Hamiltonian function yields the optimal control function
By substituting (
9) into (
7), it follows that optimal cost
satisfies the following HJB equation
and initial conditions
.
Solving the optimal cost
from the HJB Equation (
10), we can get the solution to the optimal control problem. Thus, the robust control problem can be solved.
The following theorem shows that optimal control is a robust controller for matched uncertain systems.
Theorem 1. Assume that the conditions (2) and (3) hold in system (1) and the solution in HJB Equation (10) exists. Considering the nominal nonlinear system (4) with performance index (5), then the optimal control policy can globally asymptotically stabilize the nonlinear uncertain system (1). That is to say, the closed-loop uncertain system is globally asymptotically stable. Proof. In order to prove the stability with controller
,
is chosen as the Lyapunov function. Considering the performance index (
5),
is obviously positive, and
. Taking time derivative of the function
along closed-loop system (
1), it follows that
Using the matched conditions (
2)and (
3), it follows from (
11) that
From HJB Equation (
10), one can obtain
Substituting (
13) into (
12) yields
It follows from
that
. Therefore, from (
14), we can have -4.6cm0cm
Therefore, by Lyapunov stability theory [
30], the optimal control
can make the matched uncertain system (
1) asymptotically stable. Thus, for a constant
, there is a neighborhood
such that if the state
enters the neighborhood
N, then
when
. However,
cannot stay out of the domain
N forever; otherwise, for all
, there is
. This implies that
Therefore, when
,
. This contradicts that
is positive definite. Consequently, the system (
1) is globally asymptotically stable. □
Remark 1. For matched nonlinear systems, the robust controller can be obtained by solving the optimal cost function from HJB Equation (10). In Section 4, we will use the PI algorithm to solve the HJB equation, which is a difficult partial differential equation. 4. Robust Control of Nonlinear Systems with Mismatched Uncertainties
In this section, we consider the robust control problem when the system (
1) does not satisfy the matched condition (
2). At this time, the system is a mismatched nonlinear uncertain system. By constructing the appropriate auxiliary system and performance index, the robust control for the mismatched uncertain system is transformed into solving optimal control law of an auxiliary system.
Firstly, the following assumptions are given.
Assumption 3. Suppose that the uncertainty of system (1) satisfies , , where is a known function matrix of appropriate dimensions, and are uncertain functions, and . The goal of robust control is to find a control function
, which makes the closed-loop system
globally asymptotically stable for all uncertainties
and
.
In order to obtain the robust controller, an optimal control problem is constructed as follow. For the following auxiliary systems
find the controller
,
, such that the performance index
is minimized, where
is the design parameter,
is a pseudo inverse of the matrix function
. Moreover,
and
are nonnegative functions and satisfy the conditions
According to the performance index (
18), the cost function corresponding to the admissible control
is
The following Bellman equation is obtained by taking the time derivation on both sides of (
20)
where
is the gradient vector of
with respect to
x,
,
.
Defining Hamiltonian functions as
Assuming that the minimum value exists and is unique in (
22), the optimal control law is given by
By substituting (
23) into (
21), the HJB equation is given by
and the initial value
.
Remark 2. Generally, the pseudo-inverse of , will exist if its columns are linearly independent when Assumptions 1 and 2 are true [31]. In practical control systems, the function, , is usually column full-rank. Therefore, the pseudo-inverse of the function is generally satisfied. Furthermore, the pseudo-inverse satisfies . However, it does not satisfy . In addition, the auxiliary system constructed above is not a nominal system, but a compensation control term is added to the nominal system. If we can choose an appropriate parameter
, the optimal cost
can be computed from HJB Equation (
24). Then, we can get the optimal control law of system (
17) with performance index (
18). The following theorem shows that optimal control
is a robust controller for uncertain systems.
Theorem 2. Assume that the mismatched uncertain system (16) satisfies Assumptions 4.1, 4.2 and (19). Consider the auxiliary system (17) corresponding to the performance index (18). There exists a solution in HJB Equation (24) for a selected parameter β, and for a constant satisfying , such that Then, the optimal control policy can globally asymptotically stabilize the nonlinear uncertain system (16). That is to say, the closed-loop uncertain system is globally asymptotically stable. Proof. In order to prove the global asymptotic stability of the closed-loop system,
is chosen as the Lyapunov function. Considering the performance index (
18),
is obviously positive, and
. Taking the time derivative of the function
along the system (
16), we have
Using
yields
by
and
,
It follows from (
24) that
It follows from the basic matrix inequality that
So, it can be obtained from (
26)–(
28) that
Therefore, by Lyapunov stability theory, the optimal control
can make the closed-loop uncertain nonlinear system asymptotically stable. Thus, for a constant
, there is a neighborhood
such that if the state
enters the neighborhood
N, then
when
. However,
cannot stay out of the domain
N forever; otherwise, for all
, there is
. This implies that
Hence, when
,
. This contradicts the positivity of
. Therefore, system (
16) is globally asymptotically stable. We complete the proof. □
5. Neural Networks Approximation in PI Algorithm
In the first two sections, the robust control of uncertain nonlinear systems was transformed into solving the optimal control of an auxiliary system. However, whether the uncertain system is matched or mismatched, the key issue is how to obtain the solution to corresponding HJB equation. As is well known, it is a nonlinear partial differential equation that is hard to solve. Moreover, solving the HJB equation may lead to the curse of dimensionality [
21]. In this section, an online PI algorithm is used to solve the HJB equation iteratively, and neural networks are utilized to approximate the optimal cost in PI algorithm.
5.1. PI Algorithms for Robust Control
For the system with matched uncertainty, the optimal control problem (
4) with (
5) is considered. For any admissible control, the corresponding cost function can be expressed as
where
is a selected constant. Therefore, it follows that
Based on the integral reinforcement relationship (
29) and optimal control (
9), the PI algorithm of robust control for matched uncertain nonlinear systems is given below.
The convergence of Algorithm 1 is illustrated as follows. The following conclusion gives an equivalent form of the Bellman Equation (
30).
| Algorithm 1 PI algorithm of robust control for matched uncertain nonlinear systems |
- (1)
Select supremum to satisfy ; - (2)
Initialization: for the nominal nonlinear system ( 4), select an initial stabilization control ; - (3)
Policy evaluation: for control input , calculate cost from the Bellman equation
- (4)
Policy improvement: compute the control law using
By repeatedly iterating between ( 30) and ( 31), until the control input is convergent.
|
Proposition 1. Suppose that is a stabilization controller of nominal system (4). Then the optimal cost solved from (30) is equivalent to solving the following equation Proof. Dividing both sides of (
30) by
T and finding the limit yields
From the definition of function limit and L’Hospital’s rule, we can get
Thus, we can deduce (
32) from (
30). On the other hand, along the stable system
, finding the time derivative of
yields
Integrating both sides from
t to
, yields
Therefore, we can get the following result from (
32)
This proves that (
32) can deduce (
30). □
According to [
32,
33,
34], if the initial stabilization control policy is given
, then the follow-up control policy calculated by the iterative relations of (
30) and (
31) is also a stabilizing control policy, and cost sequence
calculated by iteration converges to the optimal cost. By Proposition 1, it is known that (
30) and (
32) are equivalent, so the iterative relations (
30) and (
31) in Algorithm 1 converge to the optimal control and optimal cost.
Similarly, we give a PI algorithm of robust control for nonlinear systems with mismatched uncertainties.
The steps of policy evaluation (
34) and policy improvement (
35) are iteratively calculated until the policy improvement step does not change the current policy. The optimal cost function is calculated as
, then
is the robust control law.
The convergence proof of Algorithm 2 is similar to Algorithm 1, which will not be repeated here.
| Algorithm 2 PI algorithm of robust control for nonlinear systems with mismatched uncertainties |
- (1)
Decompose the uncertainty properly so that and , select constant parameter , such that , and then calculate the nonnegative function and according to ( 19); - (2)
For auxiliary system ( 17), select an initial stabilization control policy ; - (3)
Policy evaluation: Give a control policy , the cost is solved from the following Bellman equation
- (4)
Policy improvement: Calculate the control policy using the following update law
- (5)
Check if the condition is satisfied. Return to step (1) and select the larger constants and when it does not hold.
|
Remark 3. In Step (3) of Algorithm 1 or Algorithm 2, solving from (30) or (34) can be transformed into a least squares problem [17]. By reading enough data online along the system trajectory, the cost function can be calculated by using the least square principle. However, the cost has no specific expressions. In next subsection, along the system trajectory, online reading of sufficient data on the interval , the cost can be approximated by neural network in PI algorithms. Moreover, implementation of the algorithm does not need to know the system dynamics function . 5.2. Neural Network Approximation of Optimal Cost in PI Algorithm
In the implementation of the PI algorithms, we need to use the data of the nominal system and use the least square method to solve the cost function. However, the cost function of nonlinear optimal control problem has no specific form. Therefore, it is necessary to use neural network structure to approximate the cost function, carry out policy iteration, update weights, and then obtain the approximate optimal cost function. In this subsection, neural network is utilized to approximate the optimal cost in the corresponding HJB equation.
Based on the continuous approximation theory of neural network [
35], a single neural network is utilized to approximate the optimal cost in HJB equation. For matched uncertain systems, suppose that the solution
of HJB Equation (
10) is smooth positive definite, and the optimal cost function on compact set
is expressed as
where
is an unknown ideal weight, and
is a linear independent basis vector function. It is assumed that
is continuous,
, and
is the error vector of neural network reconstruction. Thus, the gradient of the optimal cost function (
36) can be expressed as
where
. On the basis of approximation property of neural network [
35,
36], when the number of neurons in hidden layer
, the approximation error
,
. Substituting (
36) and (
37) into (
9), the optimal control is rewritten as follows
Assume that
is an estimated value of the ideal weight
W. Since the ideal weight
W in (
36) is unknown, the cost function of the
iteration in Algorithm 1 is expressed as
Using the approximation of neural network in cost function, the Bellman Equation (
30) in Algorithm 1 is rewritten as follows
where
. Since the above formula uses neural network to approximate the cost function, the residual error caused by neural network approximation is
In order to obtain the neural network weight parameters of approximation function, the following objective functions can be minimized in the meaning of least square
that is
. Using the definition of inner product, it can be rewritten as
It follows from properties of the internal product that
where
. Therefore,
So far, the neural network weight parameters of approximation function
can be calculated. Thus, the update control policy can be obtained from (
35)
According to [
32,
33,
35,
36], using the policy iteration of RL algorithm, the cost sequence
converges to the optimal cost
, and the control sequence
converges to the optimal control function
.
For mismatched uncertain systems, similar neural network approximation can be used.
6. Simulation Examples
Some simulation examples are presented to verify the feasibility of the robust control design method for uncertain nonlinear systems in this section.
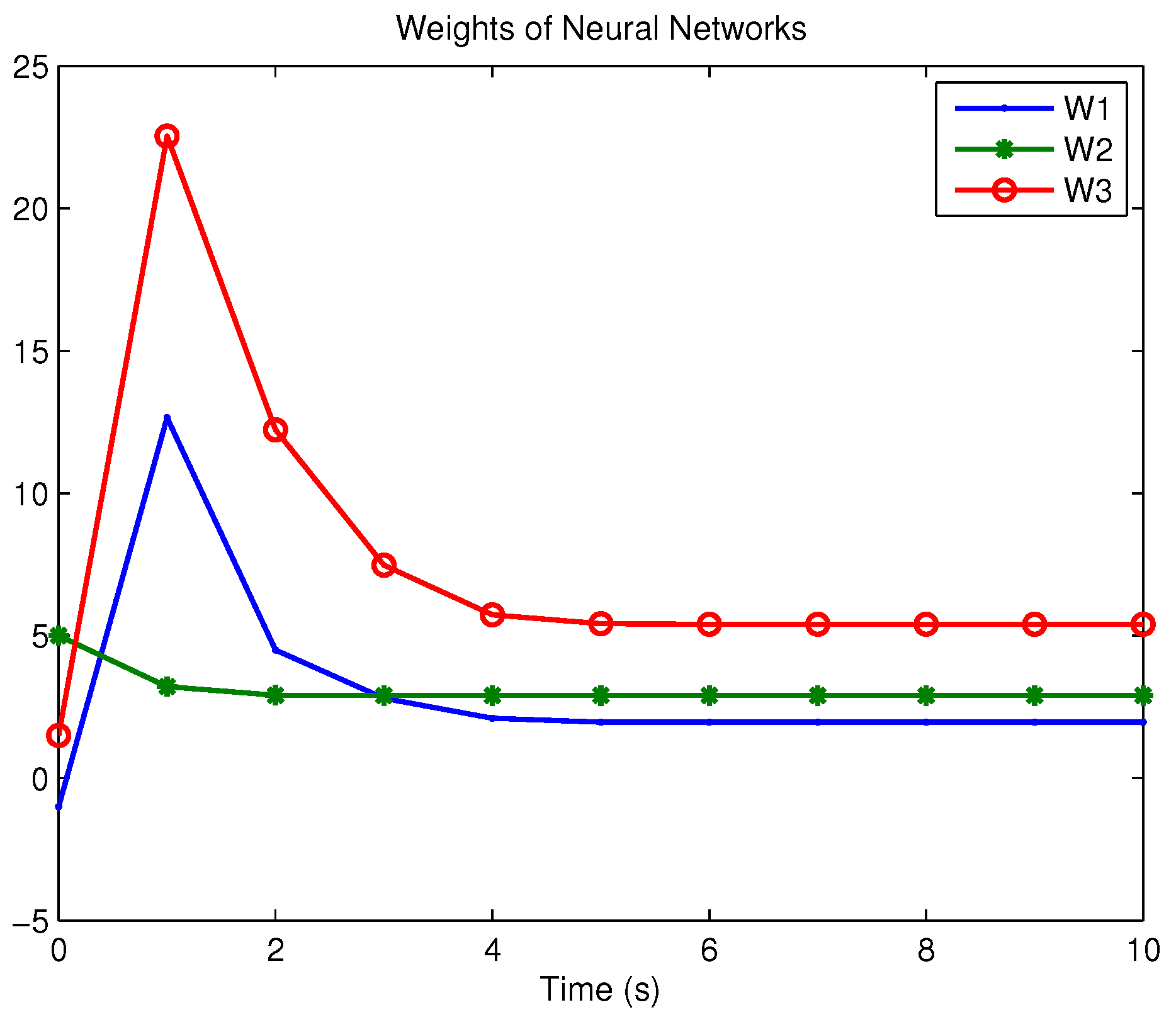
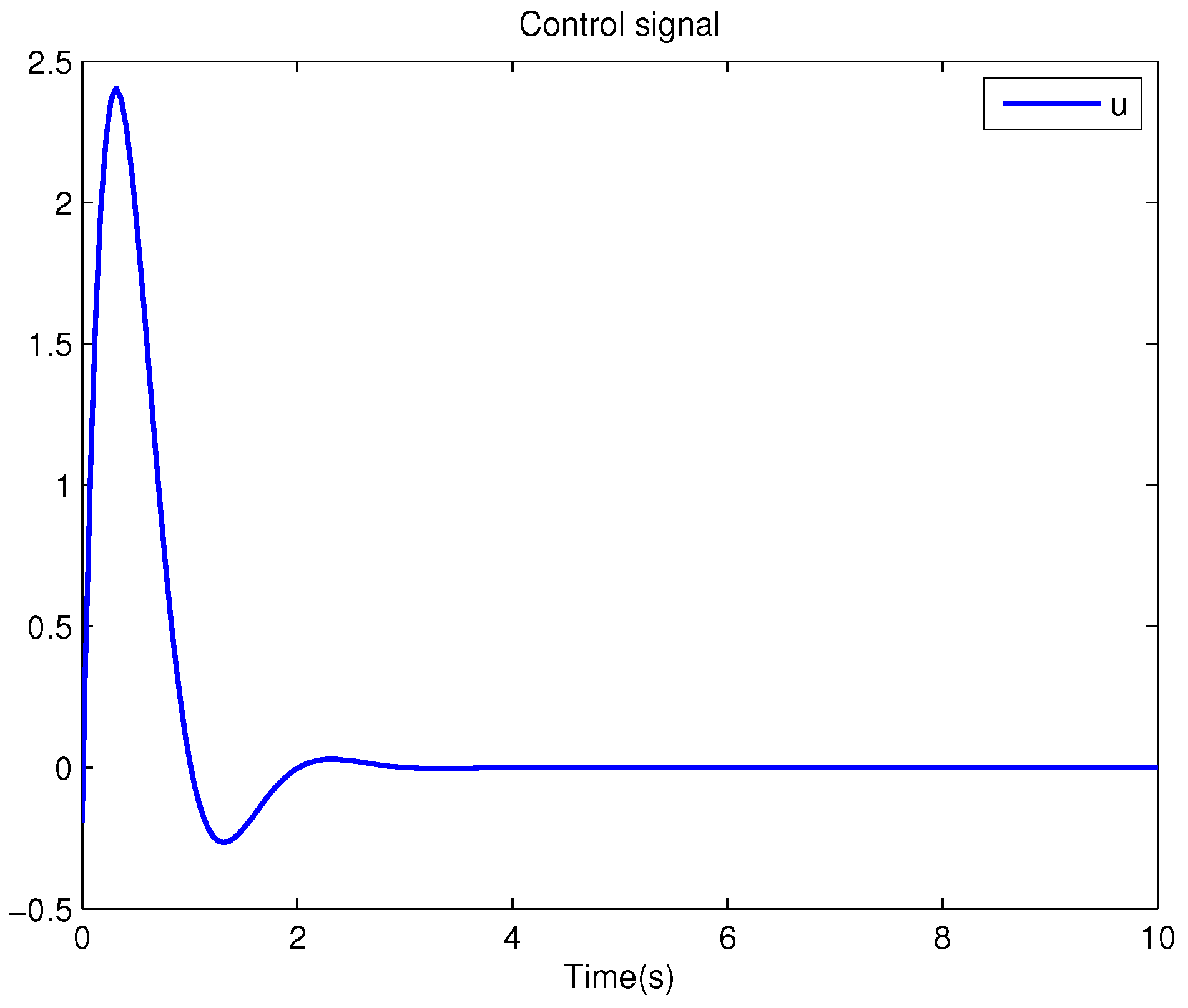
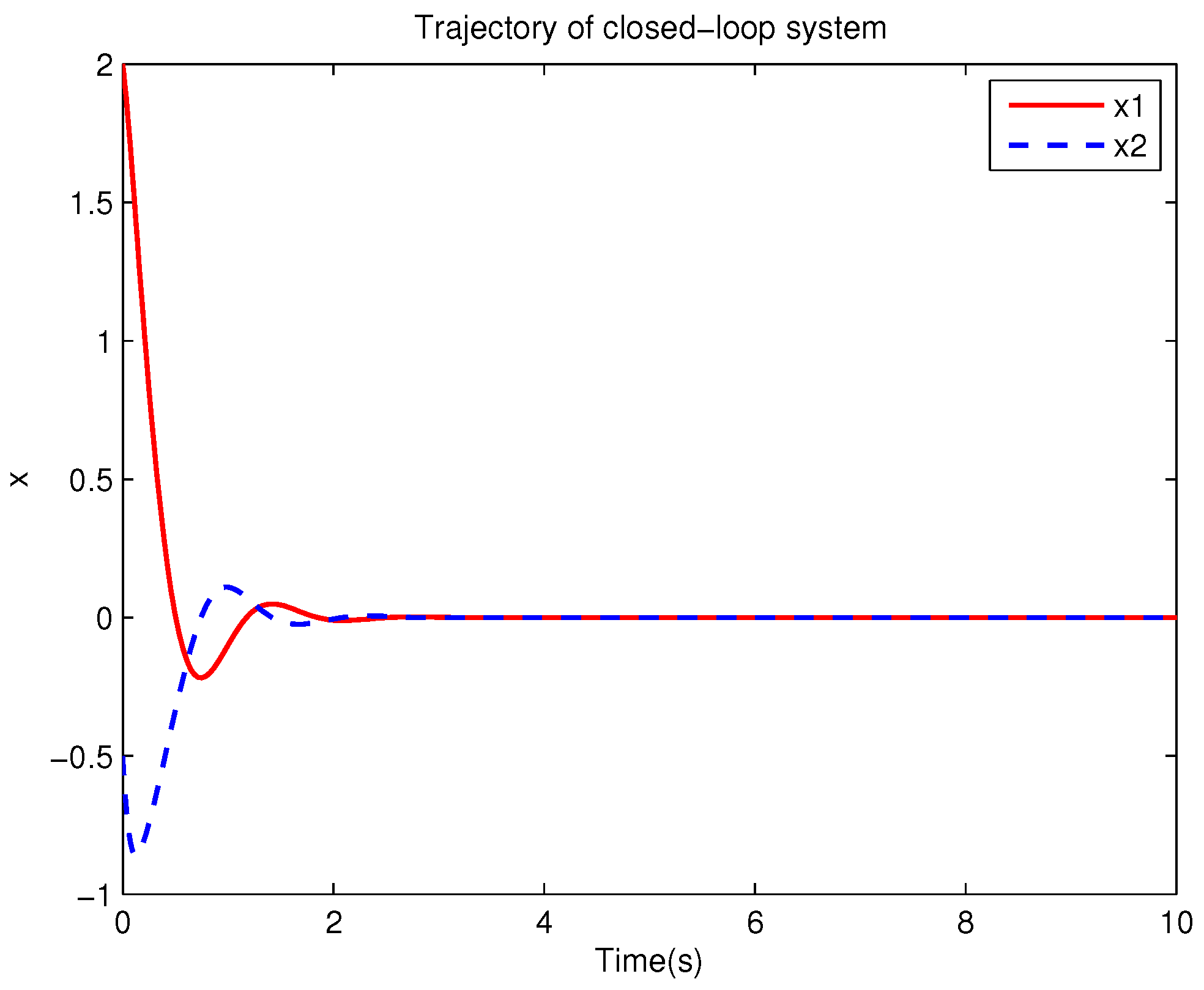
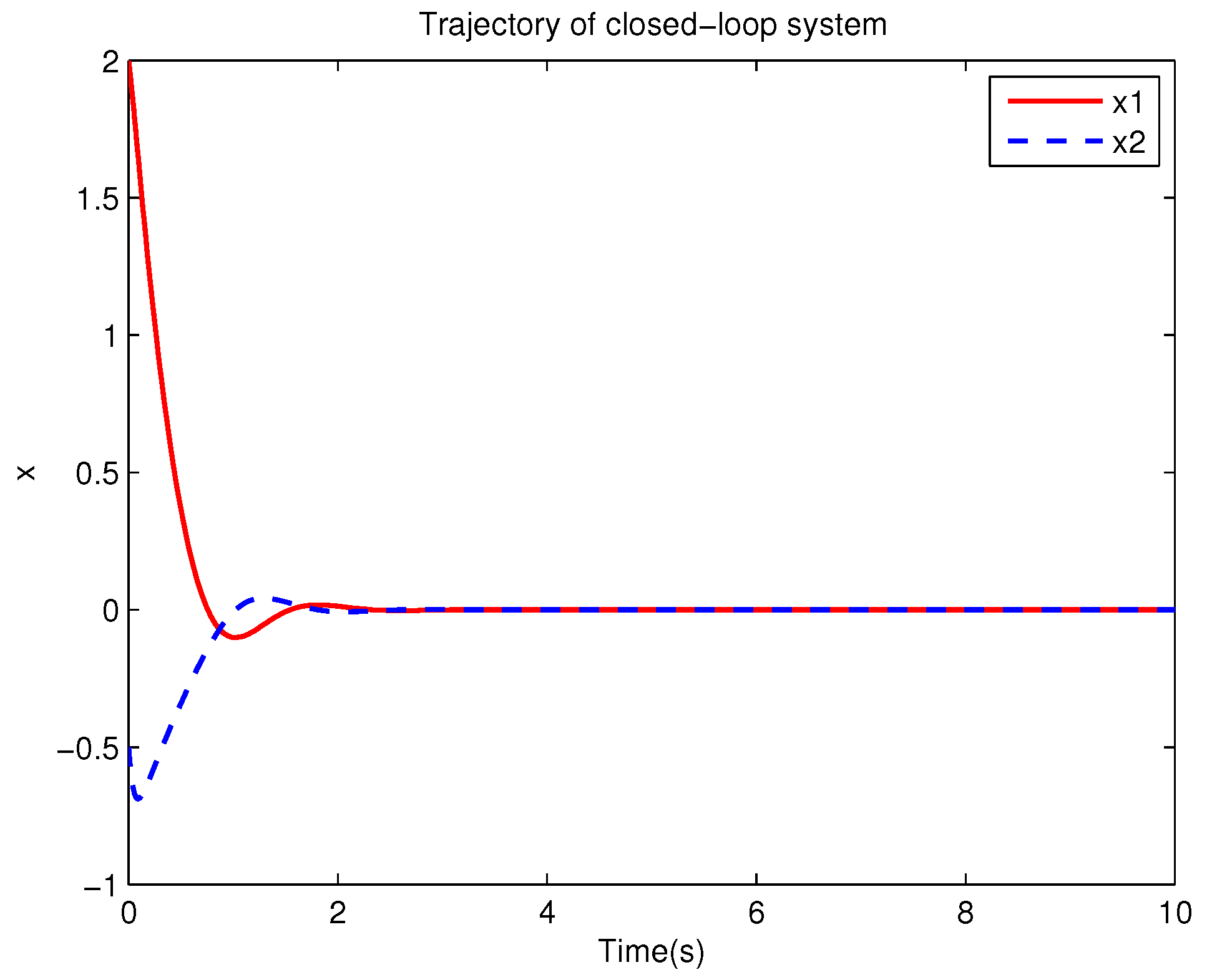
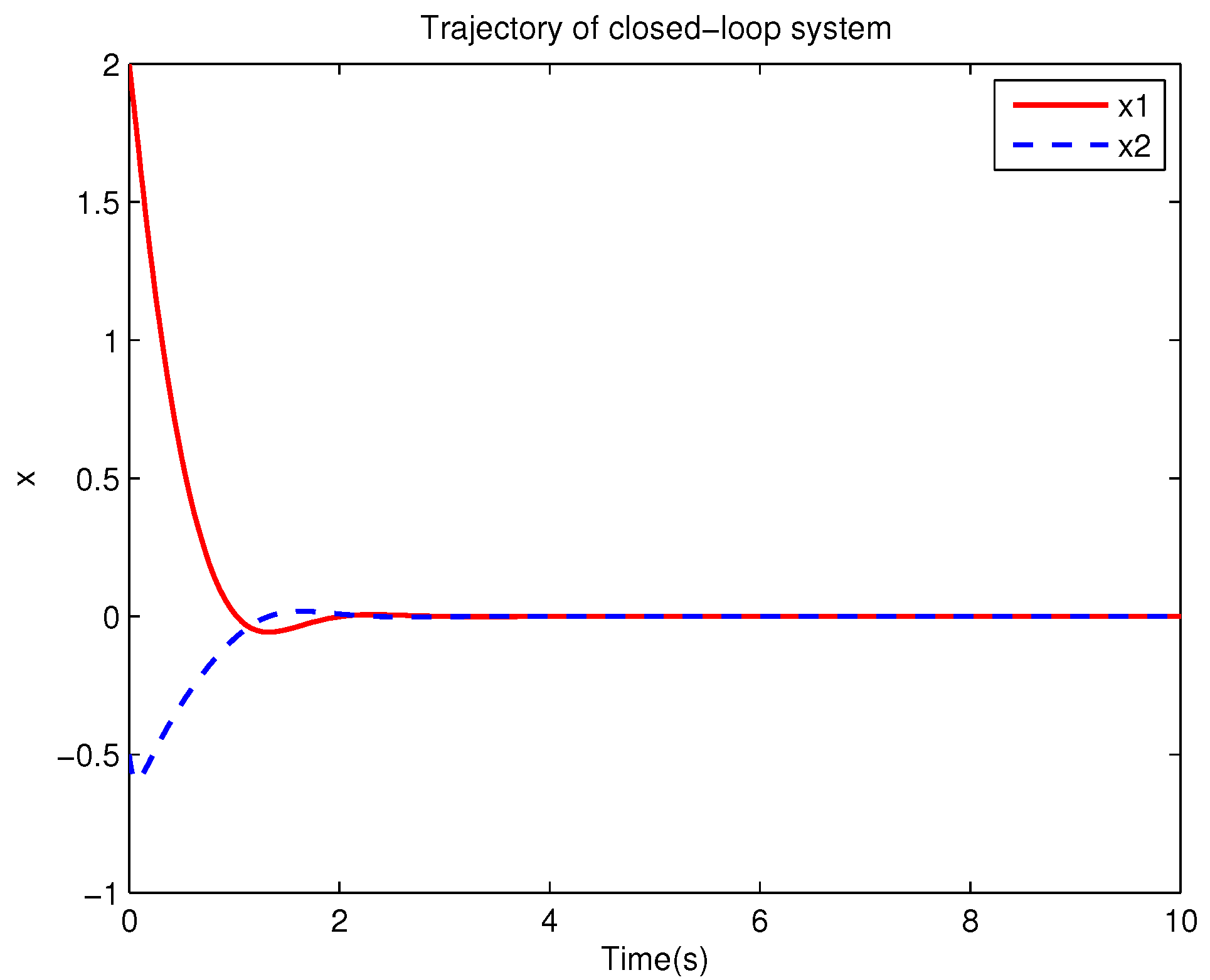
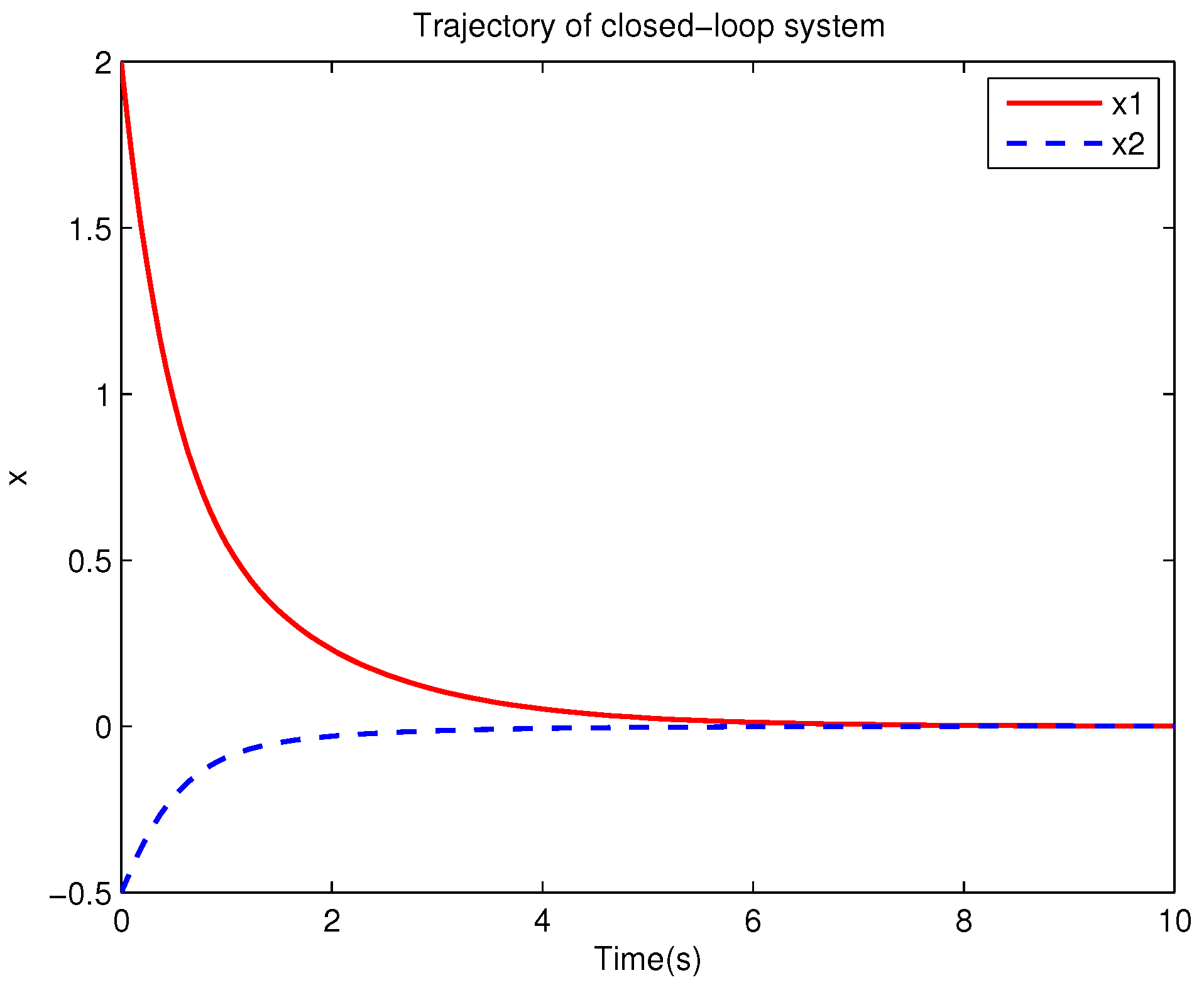
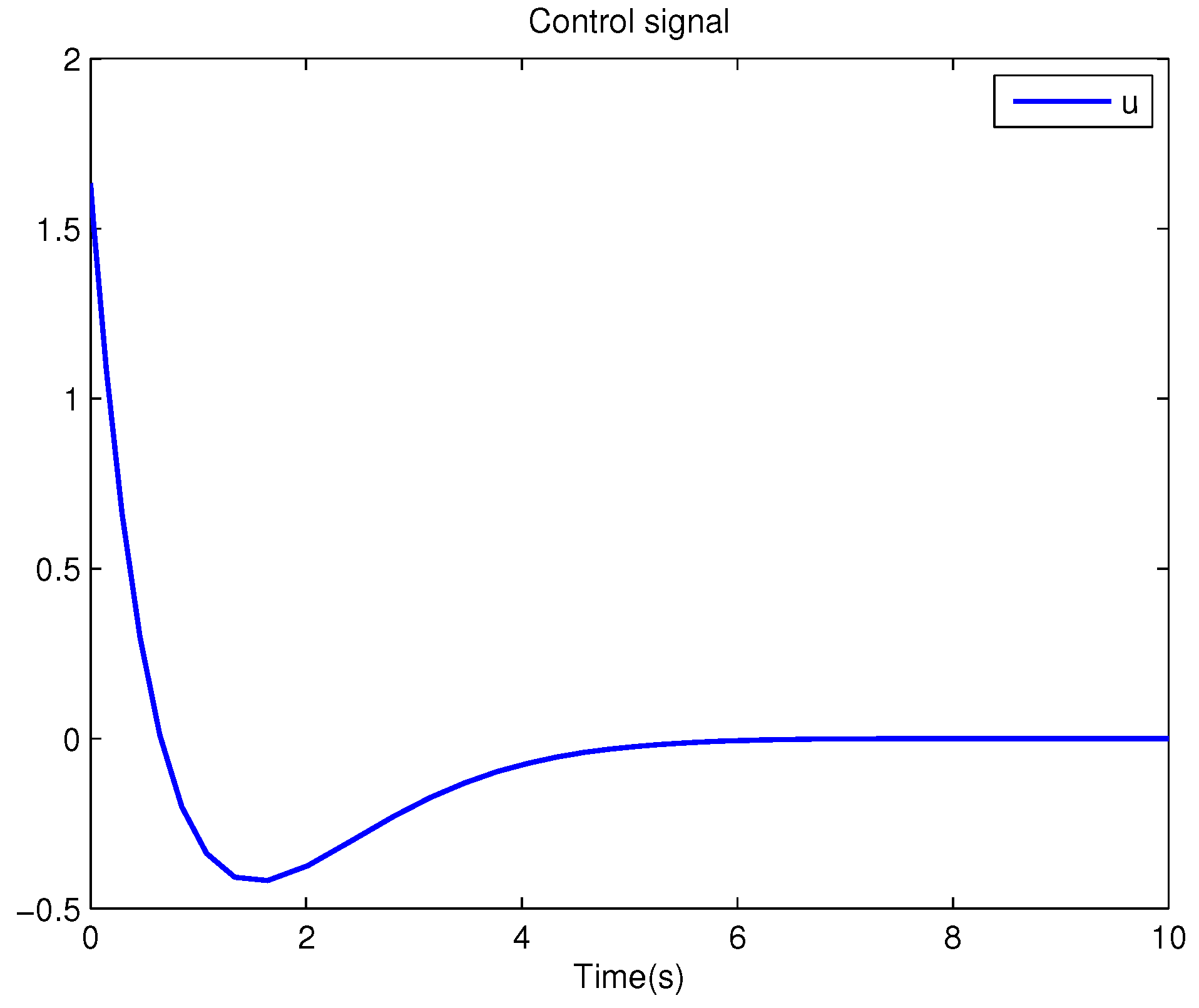
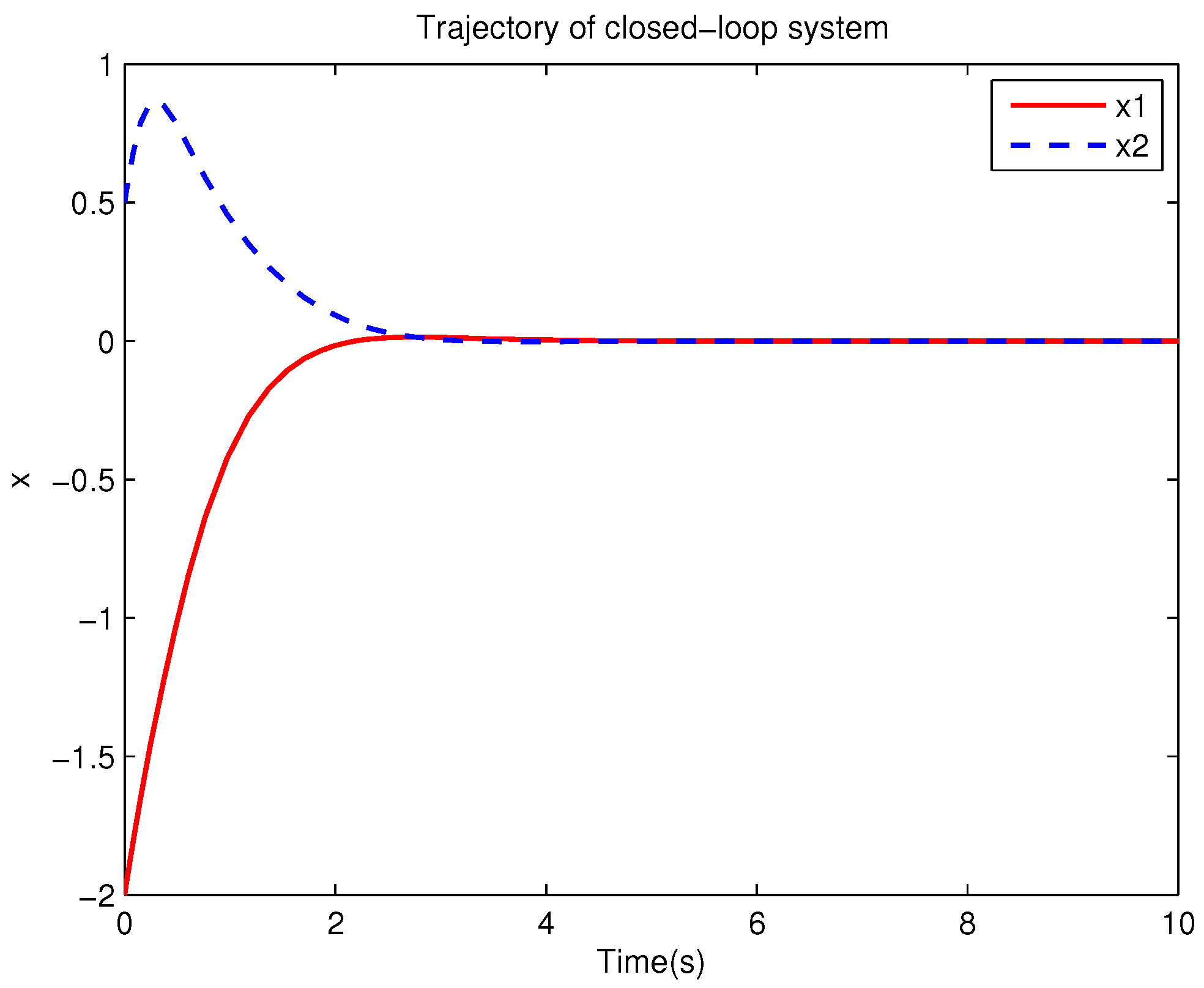
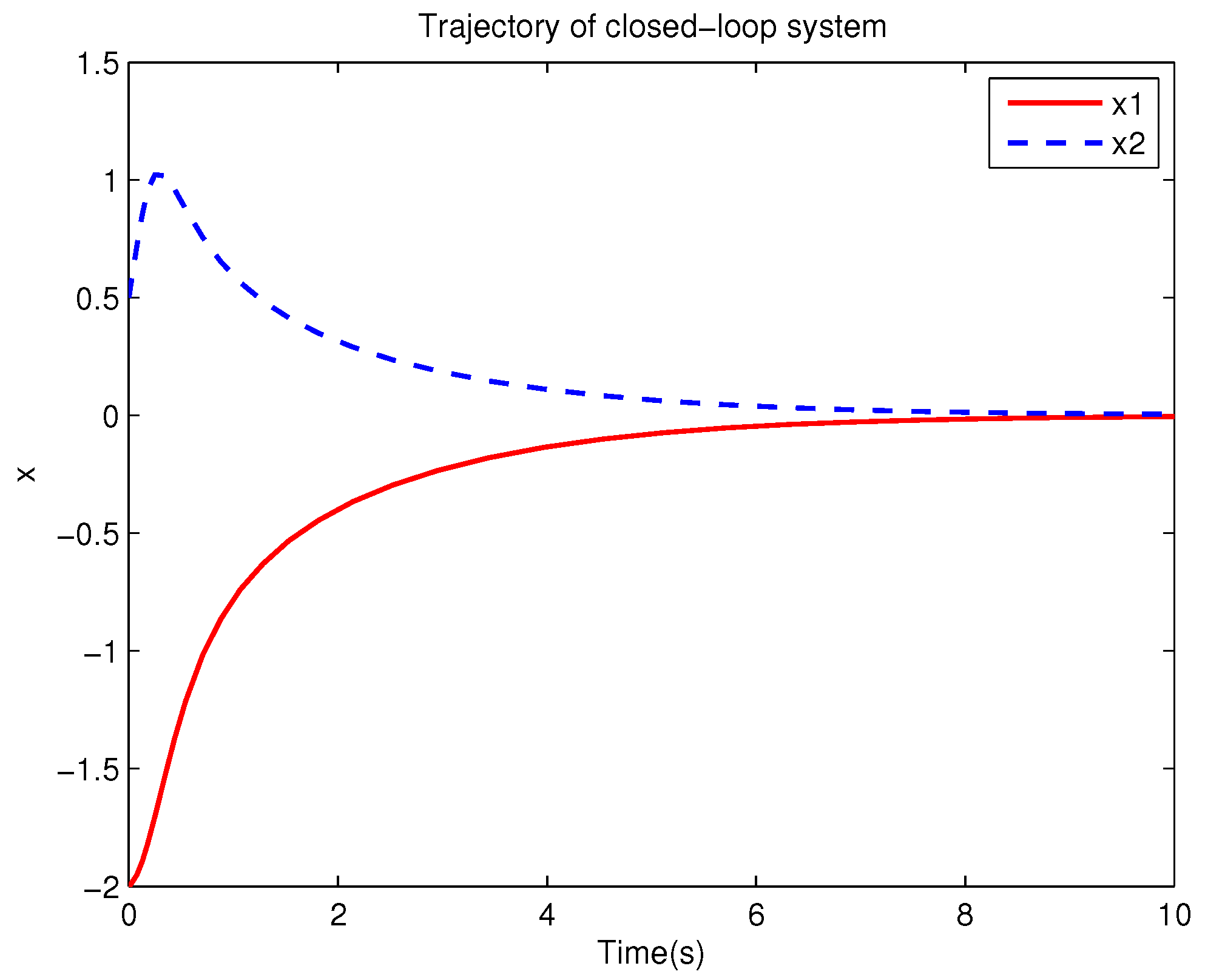
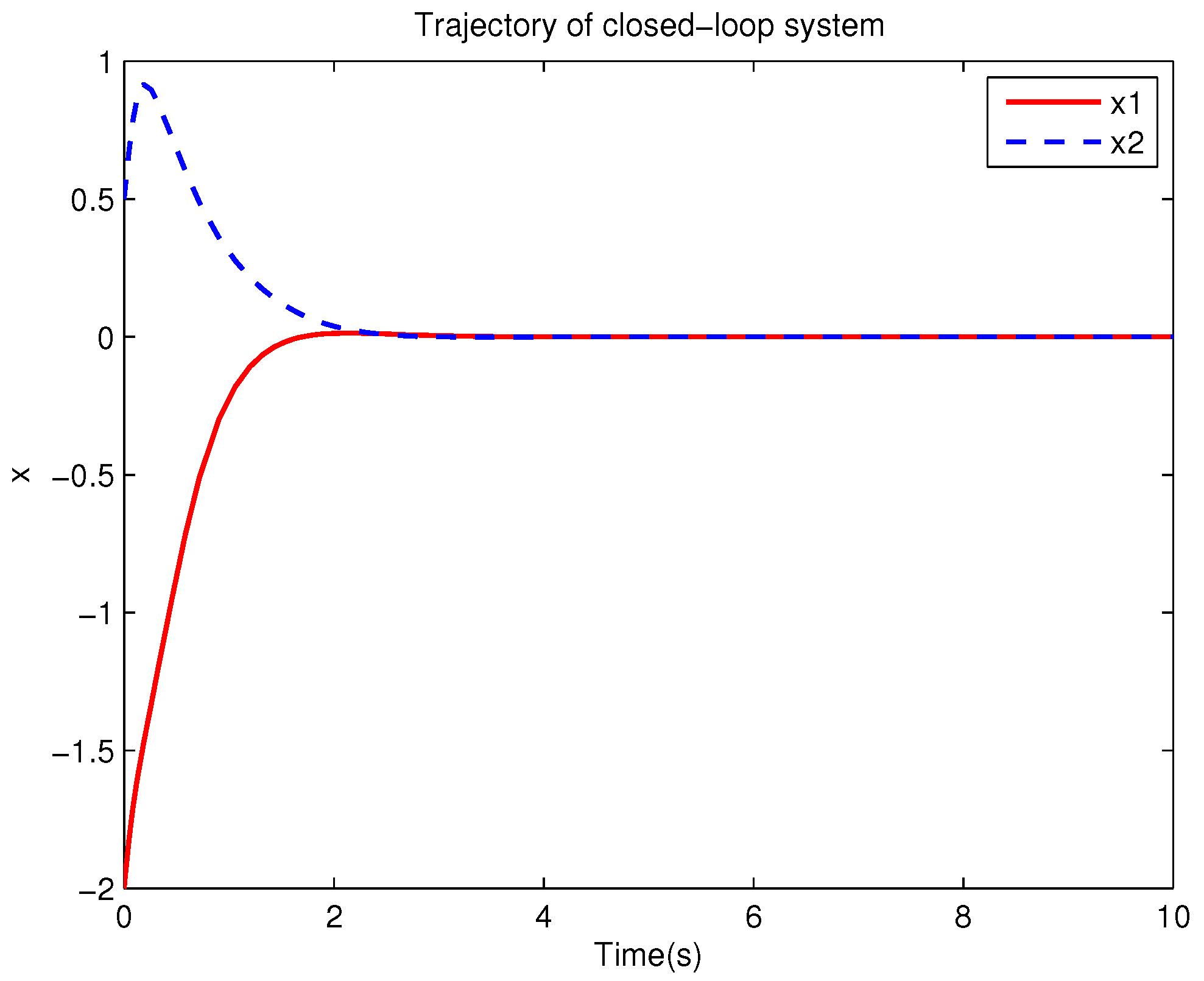
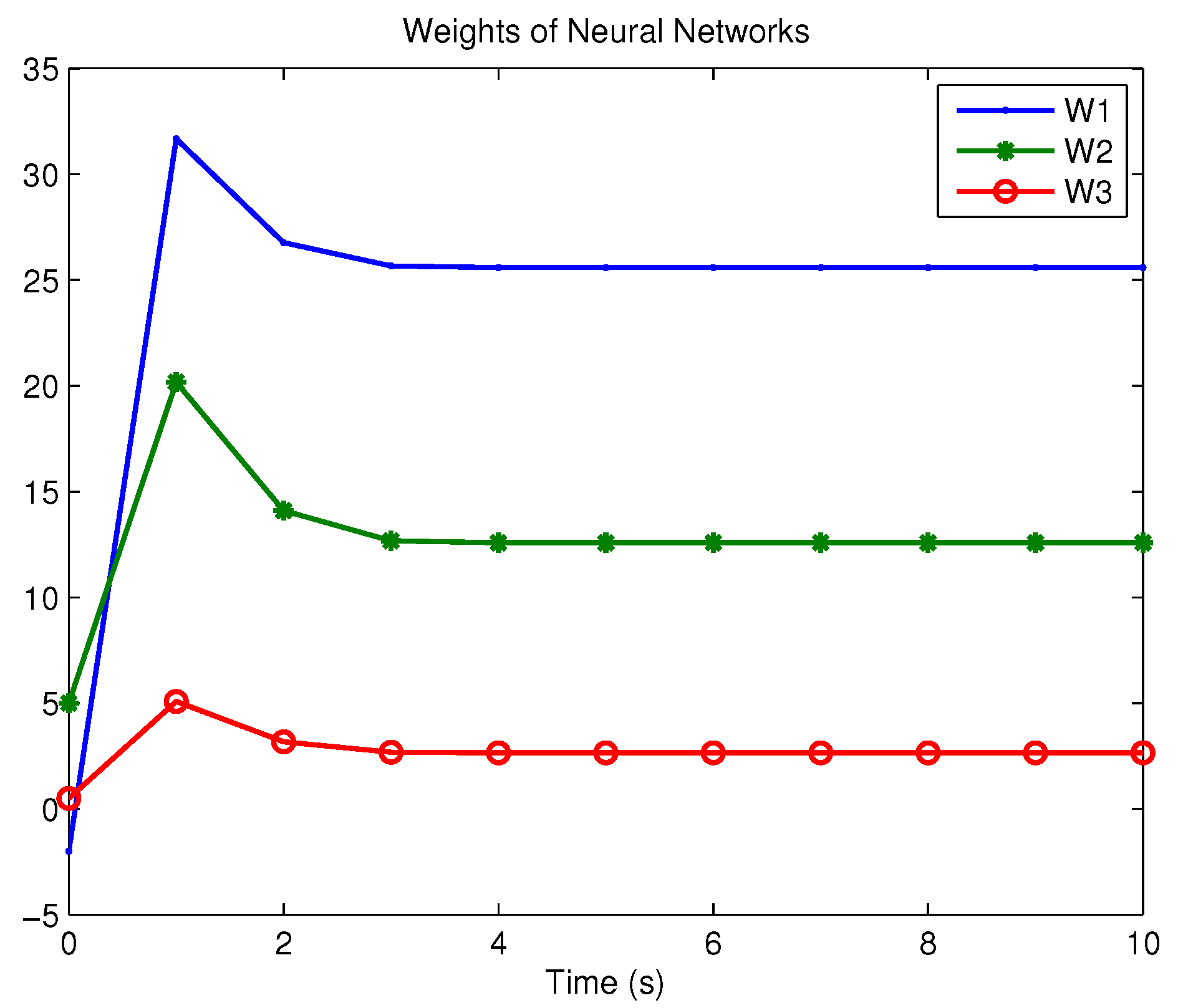
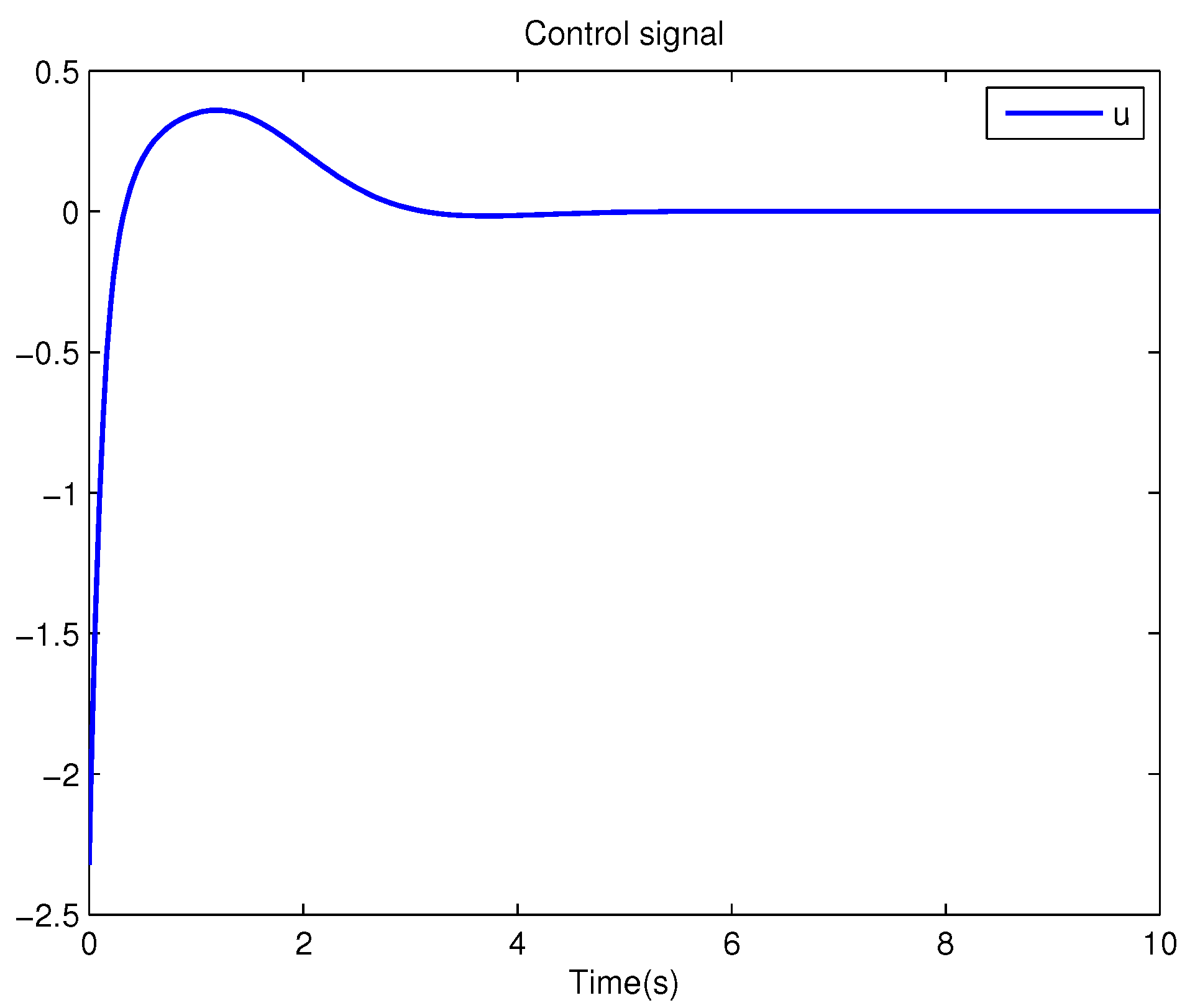
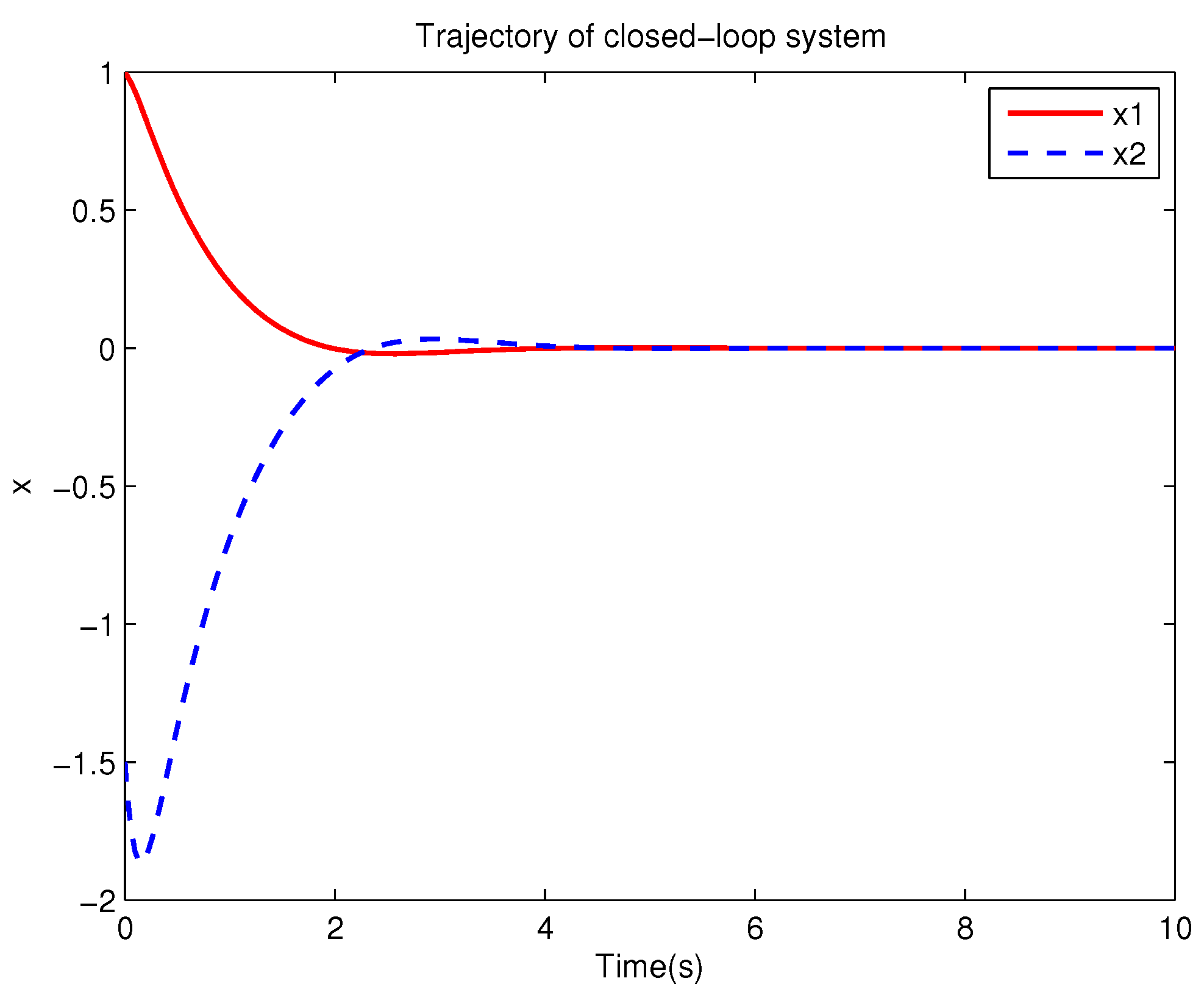
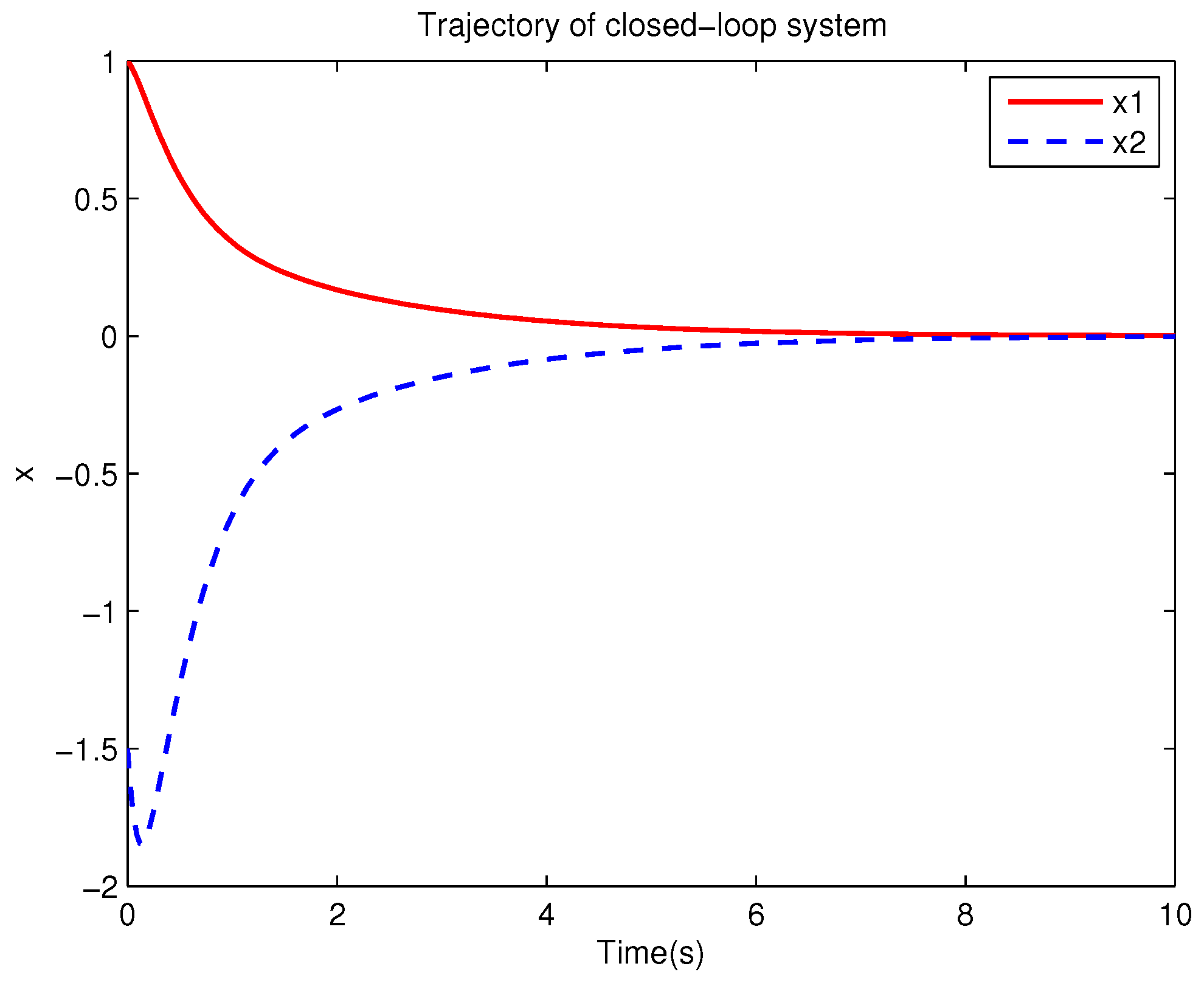
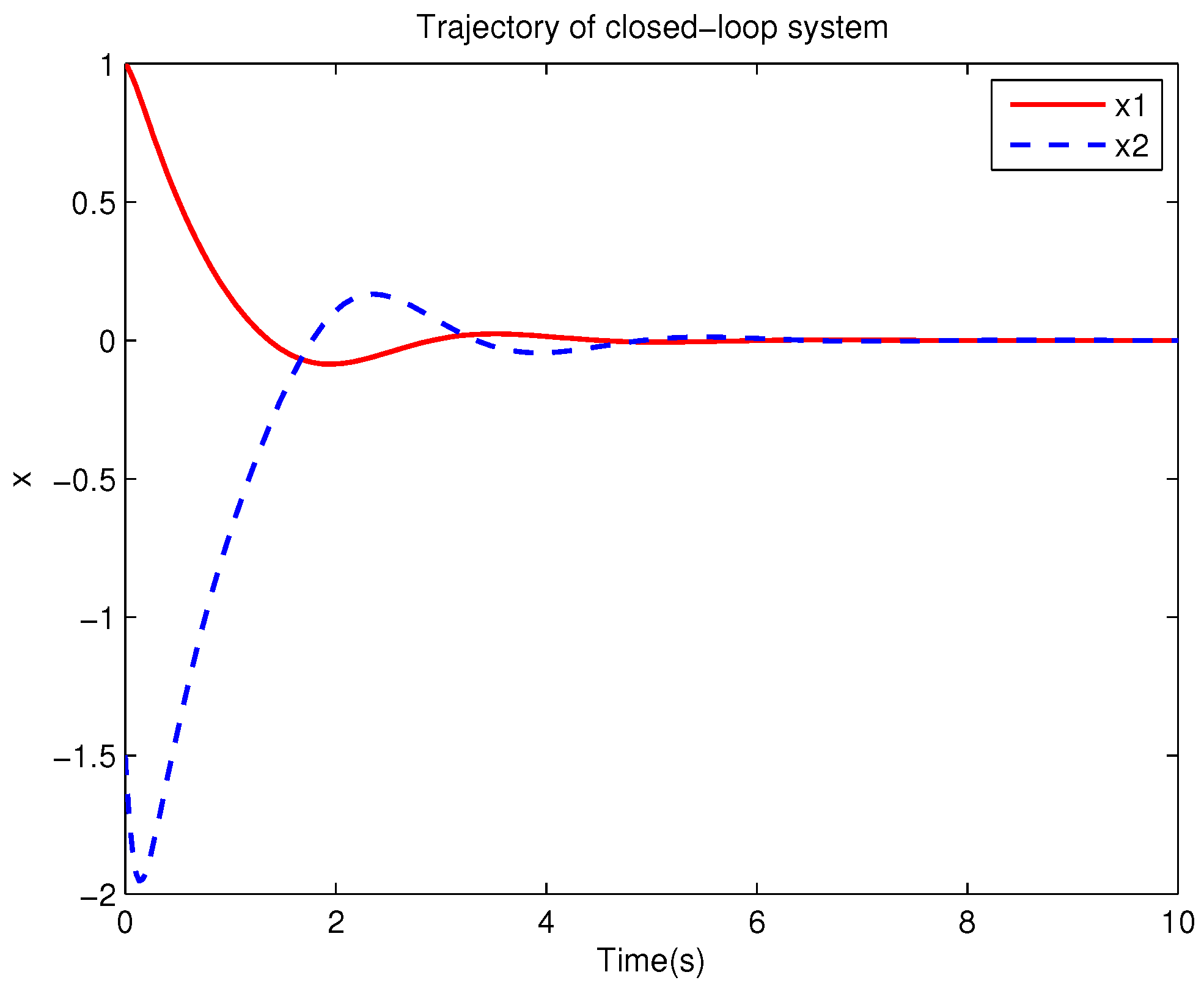
Example 1. Consider the following uncertain nonlinear systemswhere is the system state, is the uncertain disturbance function of the system, is input uncertainty function, , . Obviously,where , , . Moreover, . Thus, the original robust control problem is converted into calculating optimal control law. For nominal systemfind the control function u, such that the performance indexis minimized. In order to solve the robust control problem by using Algorithm 1, it is assumed that the optimal cost function has a neural network structure: , where , . The initial weight is taken as , and the initial state of system . The neural network weights are calculated iteratively by MATLAB. In each iteration, 10 sets of data samples are collected along the nominal system trajectory to perform the batch least squares problem. After five iterations, the weight converges to . The robust control law of uncertain system (47) is . The convergence process of neural network weight is shown in Figure 1, while the changing process of control signal is shown in Figure 2. The uncertain parameter and in uncertain system (47) take different values, the state trajectories of the closed-loop system are obtained by the robust control law. Figure 3 shows the trajectory of the closed-loop system when , . Figure 4 shows the trajectory of the closed-loop system when , . Figure 5 shows the trajectory of the closed-loop system when , . Figure 6 shows the trajectory of the closed-loop system is , . From these figures, we can see that the closed-loop system is stable, which shows the effectiveness of the robust control law. In this example, because of the linear property of the nominal system, MATLAB software can be used to solve LQR problem directly. With this method, the optimal control is calculated as . It is almost the same as the result of neural network approximation, which shows the validity of Algorithm 1.
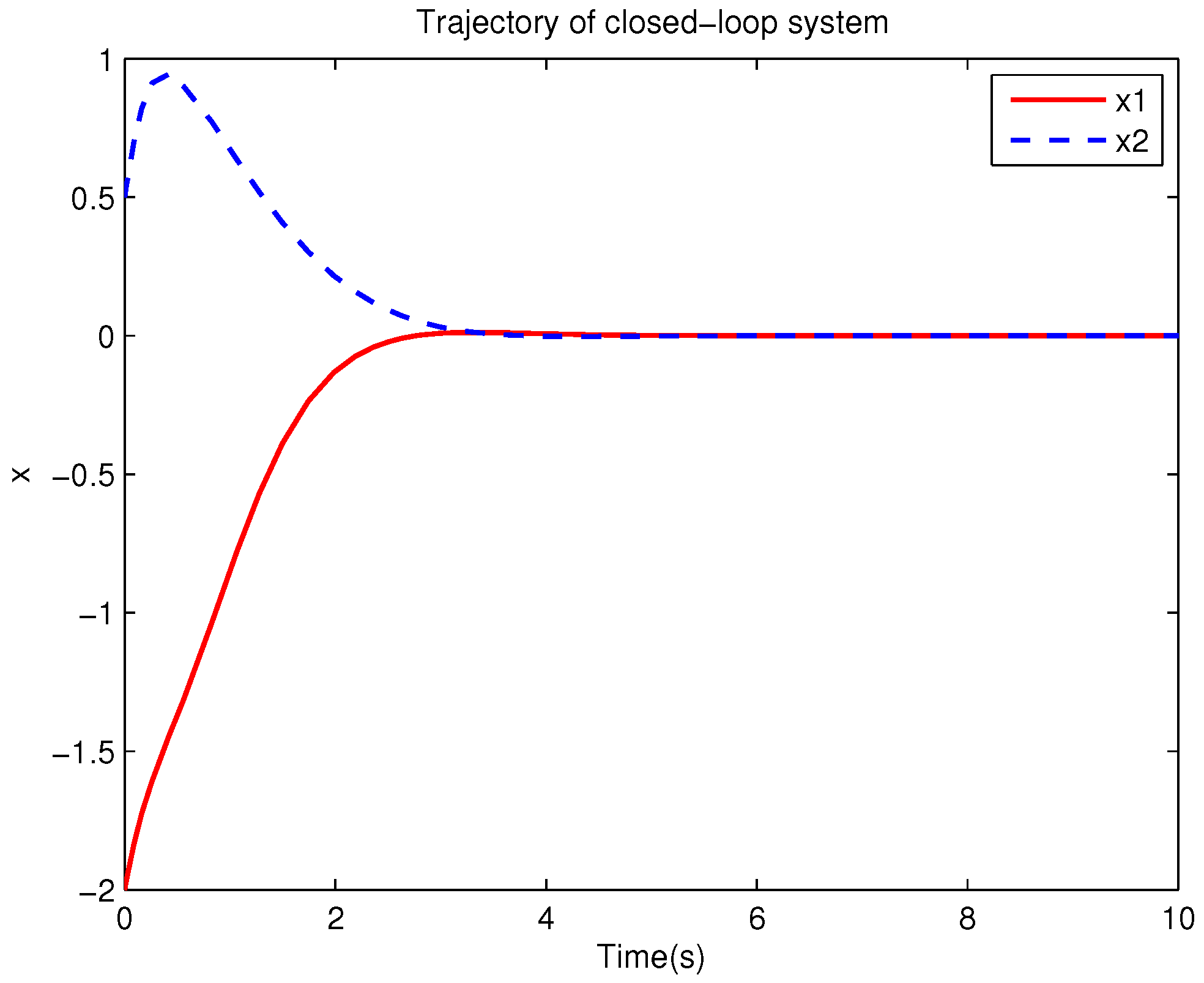
Example 2. Consider the following uncertain nonlinear systemswhere is the system state, , , . Let , . It is easy to know that the system (51) is a mismatched system. The uncertain disturbance of the system is decomposed aswhere, , , , . Moreover, and are calculated as follows.and Select the parameter . Then the original robust control problem is converted into solving an optimal control problem. For the auxiliary systemfind the control policy, , such that the following performance index is minimized In order to obtain the obust control law by using Algorithm 2, it is assumed that the optimal cost function has a neural network structure: , where , . The initial weight is taken as , and the initial state of system is chosen as . The neural network weights are calculated iteratively by MATLAB. In each iteration, 10 sets of data samples are collected along the nominal system trajectory to perform the batch least squares problem. After six iterations, the weight converges to . The optimal control of the auxiliary system is calculated as . The robust control law of the original uncertain system is . The convergence process of neural network weight is shown in Figure 7, while the changing process of control signal is shown in Figure 8. The uncertain parameters , and in uncertain system (51) take different values, the state trajectories of the closed-loop system are obtained by the robust control law. Figure 9 shows the trajectory of the closed-loop system when , and . Figure 10 shows the trajectory of the closed-loop system when , and . Figure 11 shows the trajectory of the closed-loop system when , and . Figure 12 shows the trajectory of the closed-loop system when , and . From these figures, we can see that the closed-loop system is stable, which shows the effectiveness of the robust control law. The nominal system is also a linear system, so MATLAB software can be used to solve LQR problem directly. With this method, the optimal control is calculated as . It has little difference with the approximate result of neural network, which shows the validity of Algorithm 2.
The nominal systems corresponding to the above two examples are linear systems. The following is an example with nonlinear nominal system.
Example 3. Consider the following uncertain nonlinear systemswhere is the system state, is the uncertain disturbance function of the system, is input uncertainty function, , . Obviously,where , , . Moreover, . Thus, the original robust control problem is converted into calculating optimal control law. For nominal systemfind the control function u, such that the performance indexis minimized. In order to solve the robust control problem by using Algorithm 1, it is assumed that the optimal cost function has a neural network structure: , where , . The initial weight is taken as , and the initial state of system . The neural network weights are calculated iteratively by MATLAB. In each iteration, 10 sets of data samples are collected along the nominal system trajectory to perform the batch least squares problem. After five iterations, the weight converges to . The robust control law of uncertain system (55) is . The convergence process of neural network weight is shown in Figure 13, while the changing process of control signal is shown in Figure 14. The uncertain parameter and in uncertain system (55) take different values, the state trajectories of the closed-loop system are obtained by the robust control law. Figure 15 shows the trajectory of the closed-loop system when , . Figure 16 shows the trajectory of the closed-loop system when , . Figure 17 shows the trajectory of the closed-loop system when , . Figure 18 shows the trajectory of the closed-loop system is , . From these figures, we can see that the closed-loop system is stable, which shows the effectiveness of the robust control law. 


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

















