
Improving Monte Carlo Tree Search with Artificial Neural Networks without Heuristics

 ,
,  ,
,  ,
,  ,
,  and
and 
Abstract
1. Introduction
2. Dots and Boxes
- Two players. There are typically only considered two players, although may not be the case.
- Zero-sum. The gain or loss of a player is exactly balanced by the loss or gain of the other player.
- Perfect information. The state of the game is fully observable to all players.
- Deterministic. There is no randomness in the development of future states.
- Sequential. Players move sequentially in turns.
- Finite. The number of movements must be always finite.
3. Monte Carlo Tree Search Algorithm
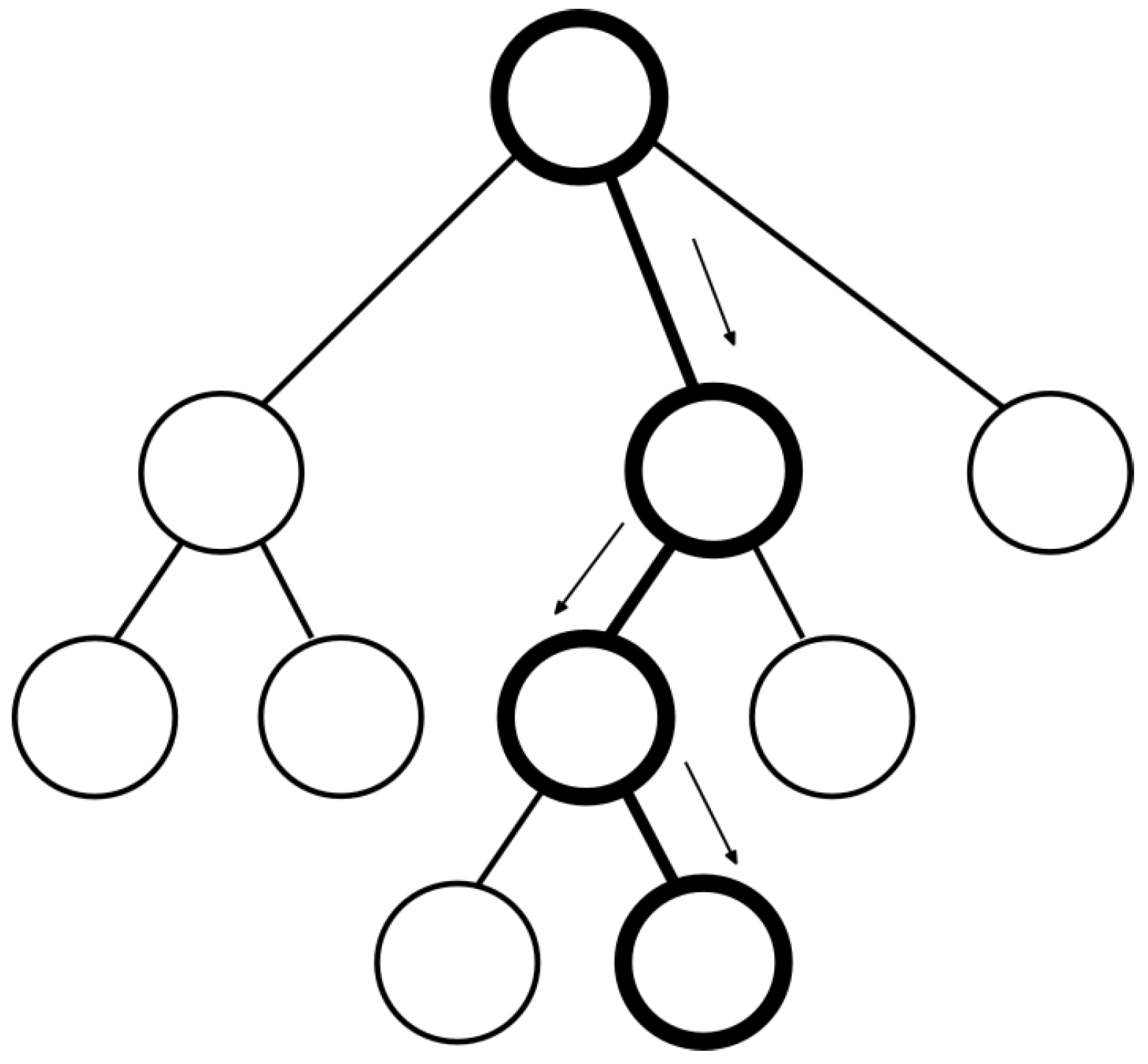
- Selection phase. First, the root node goes through selection phase (Figure 2 and Algorithm 1), where a node is selected based on the biggest Upper Confidence Bounds (UCB) formula value [14]. UCB formula tries to balance exploitation and exploration of the tree thanks to its constant C. This value, according to Browne et al. [14], accomplishes that balance. The way of managing the analysis of a node is characterized by exploitation and exploration. Exploitation of the tree nodes refers to grow the tree in depth from a promising node, while exploration refers to grow the tree in width checking unvisited nodes. UCB formula is composed by two terms which influence the trend of MCTS about exploring or exploiting nodes. We can control and balance it with constant C (the bigger, the more expanded nodes) considering the needed information and computational cost. The adjusted value of C is 1.41 [28].
Algorithm 1 Selection phase function SELECTION(node) while node has children do node = child of node with biggest UCB end whilereturn node end function - Expansion phase. In expansion phase (Figure 3 and Algorithm 2), if a node has been visited, i.e., it has been simulated, their children (or possible next states) are generated and added to the tree. Otherwise, it continues to the next phase.
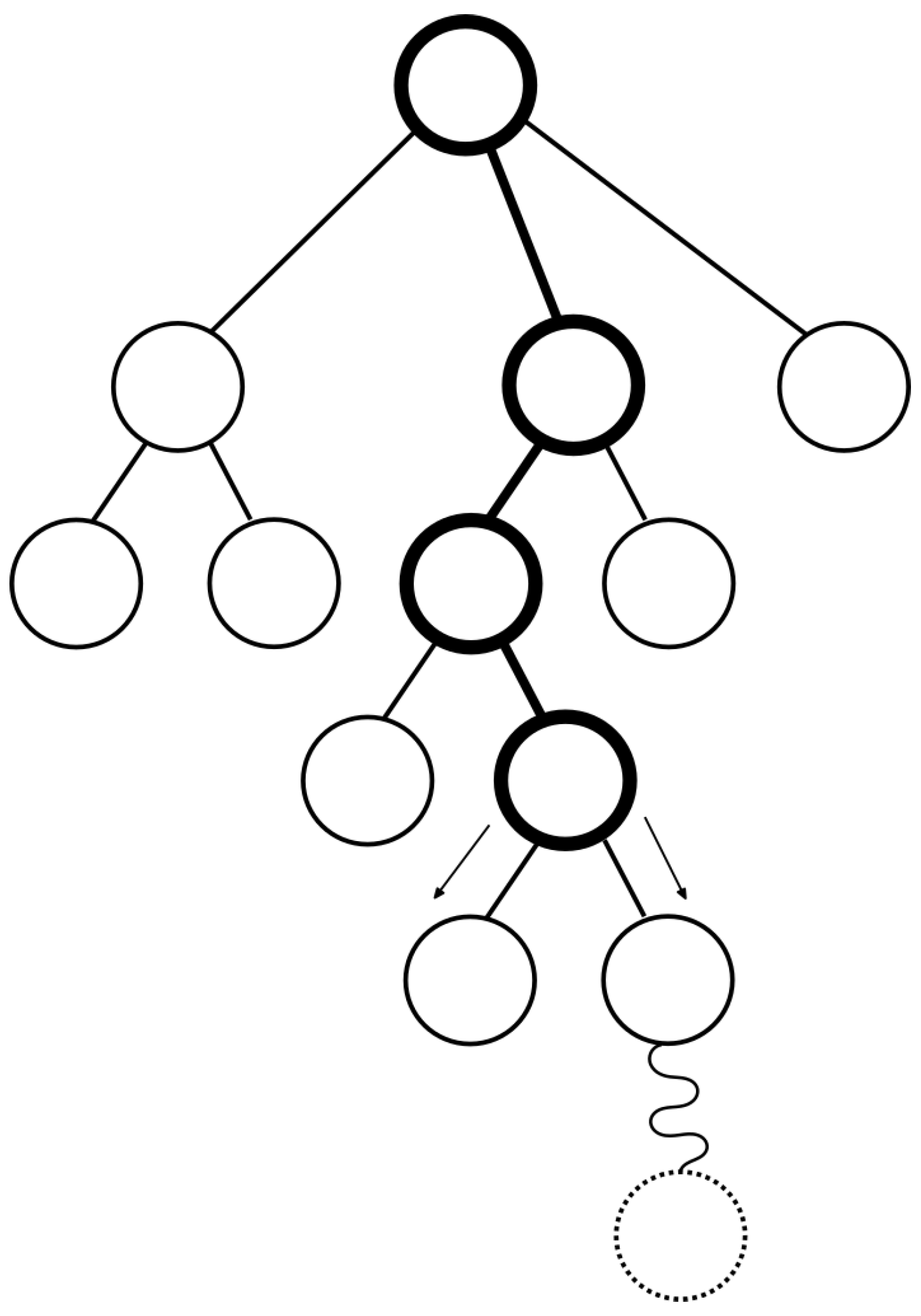
Algorithm 2 Expansion phase function EXPANSION(node) if is node visited then generate children of node end if end function - Simulation phase. In simulation phase (Figure 4 and Algorithm 3) if selected node is expanded, a random child is taken, else the selected node is taken itself. Then, next states are randomly chosen until it reaches a terminal state. Besides the random technique, it can be used with improved systems. This will be studied in Section 3.1.
Algorithm 3 Simulation phase function SIMULATION(node) while node state is not final do get next node random node = next node end whilereturn node state end function - Backpropagation phase. In backpropagation phase (Figure 5 and Algorithm 4), the value obtained at simulation phase is propagated from leaves to root of the tree updating the values of the nodes: visits and victories.
Algorithm 4 Backpropagation phase function backpropagation(node) while node is not null do increment node score increment node visits node = parent node end while end function
3.1. MCTS and Neural Networks
- Policy network is used to predict if a move corresponds to an expert human move. It was trained with human moves data sets and considers the previous state and the final state after the move. Its output is a probability of belonging to the mentioned data set.
- Value network is used to predict the probability of winning given a certain state. It was trained with game states result of playing again itself, choosing each move with the help of the policy network.
4. Background
5. Proposal
5.1. Monte Carlo
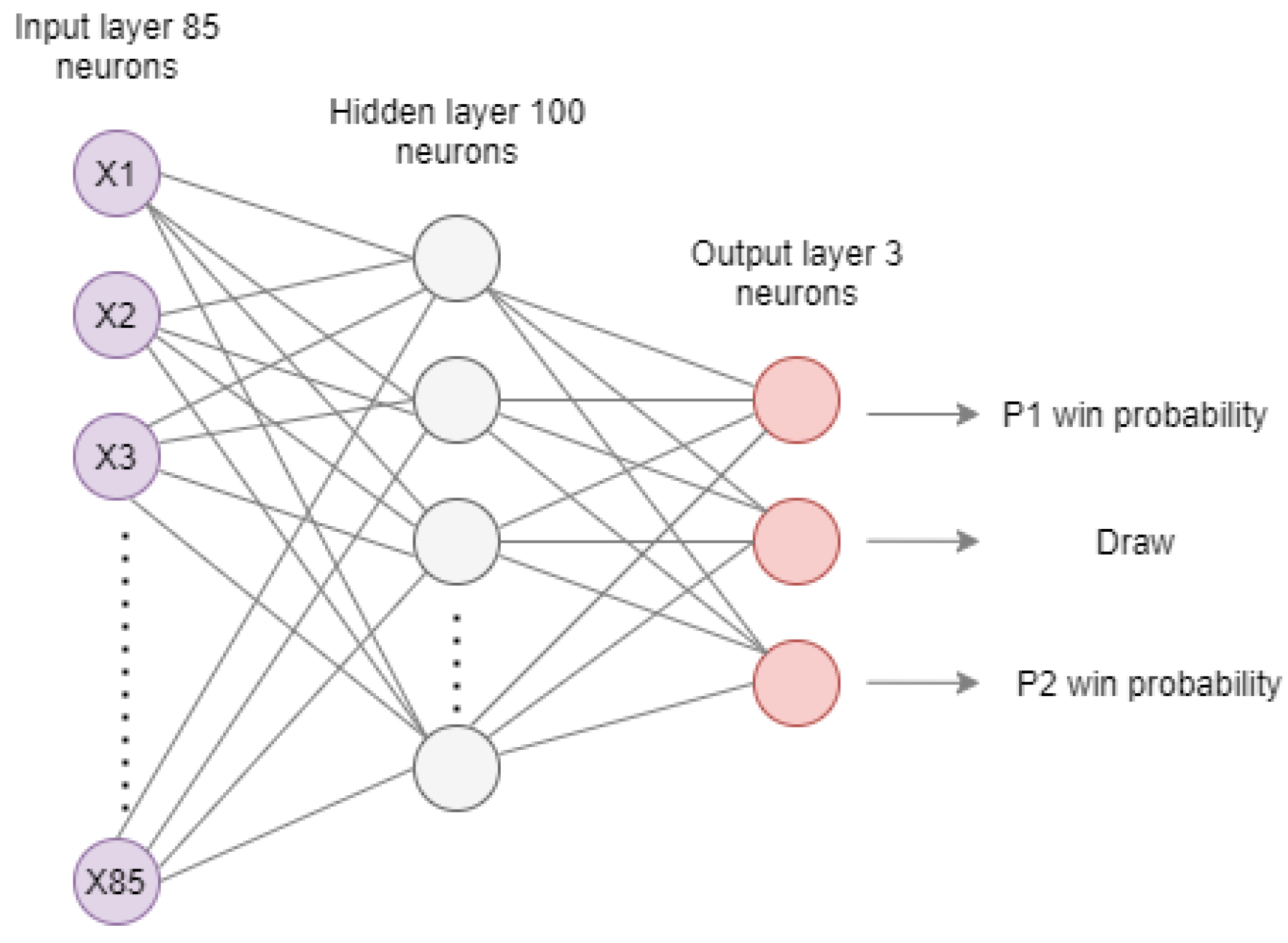
5.2. Artificial Neural Network Configuration
| Algorithm 5 ANN applied on MCTS |
| function simulation(node) |
| while node state is not final do |
| probability = ANN(node state) |
| if probability >= threshold then return node state |
| end if |
| get next node random |
| node = next node |
| end whilereturn node state |
| end function |
6. Materials and Methods
6.1. Materials
6.2. Methods
6.2.1. Sets of Tests
- MCTS without ANN and no double counter. The system makes use of MCTS without calling ANN in simulation phase and with a unique counter. We test it varying number of iterations.
- MCTS without ANN. The system makes use of MCTS without calling ANN in simulation phase at all. We test it varying number of iterations.
- MCTS with ANN. The system makes use of MCTS calling ANN in simulation phase. This is the final stage of the system. We test it varying number of iterations and ANN threshold.
6.2.2. System Comparison
6.2.3. Selected Games
7. Results and Discussion
7.1. MCTS without ANN and No Double Counter
7.2. MCTS without ANN
7.3. MCTS with ANN
8. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Szita, I.; Chaslot, G.; Spronck, P. Monte Carlo Tree Search in Settlers of Catan. In Advances in Computer Games; Springer: Berlin/Heidelberg, Germany, 2009; pp. 21–32. [Google Scholar]
- Fu, M.C. Alphago and Monte Carlo Tree Search: The simulation optimization perspective. In Proceedings of the 2016 Winter Simulation Conference (WSC) 2016, Washington, DC, USA, 11–14 December 2016; pp. 659–670. [Google Scholar] [CrossRef]
- Risi, S.; Preuss, M. From chess and atari to starcraft and beyond: How game AI is driving the world of AI. KI-Künstliche Intell. 2020, 34, 7–17. [Google Scholar] [CrossRef]
- Muhammad, A.K.Y.K. Cardiac Arrhythmia Disease Classification Using LSTM Deep Learning Approach. Comput. Mater. Contin. 2021, 67, 427–443. [Google Scholar] [CrossRef]
- Reddy, S.; Allan, S.; Coghlan, S.; Cooper, P. A governance model for the application of AI in health care. J. Am. Med. Inform. Assoc. 2019, 27, 491–497. [Google Scholar] [CrossRef]
- Myerson, R.B. Game Theory; Harvard University Press: Harvard, UK, 2013. [Google Scholar]
- Sohrabi, M.K.; Azgomi, H. A survey on the combined use of optimization methods and game theory. Arch. Comput. Methods Eng. 2020, 27, 59–80. [Google Scholar] [CrossRef]
- Neumann, J.V. Zur theorie der gesellschaftsspiele. Math. Ann. 1928, 100, 295–320. [Google Scholar] [CrossRef]
- Althöfer, I. An incremental negamax algorithm. Artif. Intell. 1990, 43, 57–65. [Google Scholar] [CrossRef]
- Knuth, D.E.; Moore, R.W. An analysis of alpha-beta pruning. Artif. Intell. 1975, 6, 293–326. [Google Scholar] [CrossRef]
- Reinefeld, A. Spielbaum-Suchverfahren; Springer: Berlin/Heidelberg, Germany, 2013; Volume 200. [Google Scholar]
- Plaat, A.; Schaeffer, J.; Pijls, W.; De Bruin, A. Best-First Fixed-Depth Minimax Algorithms. Artif. Intell. 1996, 87, 255–293. [Google Scholar] [CrossRef]
- Metropolis, N.; Ulam, S. The Monte Carlo method. J. Am. Stat. Assoc. 1949, 44, 335–341. [Google Scholar] [CrossRef] [PubMed]
- Browne, C.B.; Powley, E.; Whitehouse, D.; Lucas, S.M.; Cowling, P.I.; Rohlfshagen, P.; Tavener, S.; Perez, D.; Samothrakis, S.; Colton, S. A survey of Monte Carlo Tree Search methods. IEEE Trans. Comput. Intell. AI Games 2012, 4, 1–43. [Google Scholar] [CrossRef]
- Kim, M.J.; Ahn, C.W. Hybrid fighting game AI using a genetic algorithm and Monte Carlo tree search. In Proceedings of the Genetic and Evolutionary Computation Conference Companion 2018, Kyoto, Japan, 15–19 July 2018; pp. 129–130. [Google Scholar]
- Bobadilla, J.; Ortega, F.; Gutiérrez, A.; Alonso, S. Classification-based Deep Neural Network Architecture for Collaborative Filtering Recommender Systems. Int. J. Interact. Multimed. Artif. Intell. 2020, 6, 68–77. [Google Scholar] [CrossRef]
- Maheshan, M.; Harish, B.; Nagadarshan, N. A Convolution Neural Network Engine for Sclera Recognition. Int. J. Interact. Multimed. Artif. Intell. 2020, 6, 78–83. [Google Scholar] [CrossRef]
- Silver, D.; Huang, A.; Maddison, C.J.; Guez, A.; Sifre, L.; Van Den Driessche, G.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Lanctot, M.; et al. Mastering the game of Go with deep neural networks and tree search. Nature 2016, 529, 484. [Google Scholar] [CrossRef] [PubMed]
- Silver, D.; Schrittwieser, J.; Simonyan, K.; Antonoglou, I.; Huang, A.; Guez, A.; Hubert, T.; Baker, L.; Lai, M.; Bolton, A.; et al. Mastering the game of go without human knowledge. Nature 2017, 550, 354–359. [Google Scholar] [CrossRef]
- Grill, J.B.; Altché, F.; Tang, Y.; Hubert, T.; Valko, M.; Antonoglou, I.; Munos, R. Monte Carlo Tree Search as Regularized Policy Optimization. PMLR 2020, 119, 3769–3778. [Google Scholar]
- Świechowski, M.; Mańdziuk, J. Self-Adaptation of Playing Strategies in General Game Playing. IEEE Trans. Comput. Intell. AI Games 2014, 6, 367–381. [Google Scholar] [CrossRef]
- Świechowski, M.; Mańdziuk, J.; Ong, Y.S. Specialization of a UCT-Based General Game Playing Program to Single-Player Games. IEEE Trans. Comput. Intell. AI Games 2016, 8, 218–228. [Google Scholar] [CrossRef]
- Walędzik, K.; Mańdziuk, J. An Automatically Generated Evaluation Function in General Game Playing. IEEE Trans. Comput. Intell. AI Games 2014, 6, 258–270. [Google Scholar] [CrossRef]
- Tanabe, Y.; Yoshizoe, K.; Imai, H. A study on security evaluation methodology for image-based biometrics authentication systems. In Proceedings of the 2009 IEEE 3rd International Conference on Biometrics: Theory, Applications, and Systems 2009, Washington, DC, USA, 28–30 September 2009; pp. 1–6. [Google Scholar] [CrossRef]
- Berlekamp, E.R. The Dots and Boxes Game: Sophisticated Child’s Play; AK Peters/CRC Press: Boca Raton, FL, USA, 2000. [Google Scholar]
- Kuhn, H.W. Classics in Game Theory; Princeton University Press: Princeton, NJ, USA, 1997. [Google Scholar]
- Lucas, W. L’arithmétique amusante. Nature 1895, 53, 79. [Google Scholar] [CrossRef]
- Kocsis, L.; Szepesvári, C.; Willemson, J. Improved Monte Carlo Search. Univ. Tartu Estonia Tech. Rep. 2006, 1. [Google Scholar]
- Berlekamp, E.R.; Conway, J.H.; Guy, R.K. Winning Ways for Your Mathematical Plays; AK Peters/CRC Press: Boca Raton, FL, USA, 2004; Volume 4. [Google Scholar]
- Bossomaier, T.; Knittel, A.; Harre, M.; Snyder, A. An evolutionary agent approach to Dots and Boxes. In Proceedings of the IASTED International Conference on Software Engineering and Applications, Dallas, TX, USA, 13–15 November 2006. [Google Scholar]
- Barker, J.K.; Korf, R.E. Solving Dots and Boxes. In Proceedings of the Twenty-Sixth AAAI Conference on Artificial Intelligence, Toronto, ON, Canada, 22–26 July 2012. [Google Scholar]
- Zhuang, Y.; Li, S.; Peters, T.V.; Zhang, C. Improving Monte Carlo Tree Search for Dots and Boxes with a novel board representation and artificial neural networks. In Proceedings of the 2015 IEEE Conference on Computational Intelligence and Games (CIG), Tainan, Taiwan, 31 August–2 September 2015; pp. 314–321. [Google Scholar]
- Auer, P.; Cesa-Bianchi, N.; Fischer, P. Finite-time analysis of the multiarmed bandit problem. Mach. Learn. 2002, 47, 235–256. [Google Scholar] [CrossRef]
- Coquelin, P.; Munos, R. Bandit Algorithms for Tree Search. CoRR 2007, abs/cs/0703062. [Google Scholar]
- Lu, J.; Yin, H. Using heuristic solver to optimize Monte Carlo Tree Search in Dots and Boxes. In Proceedings of the 2016 Chinese Control and Decision Conference (CCDC), Yinchuan, China, 28–30 May 2016; pp. 4288–4291. [Google Scholar]
- Agrawal, P.; Ziegler, U. Performance of the Parallelized Monte Carlo Tree Search Approach for Dots and Boxes; Western Kentucky University: Bowling Green, KY, USA, 2018. [Google Scholar]
- Li, S.; Zhang, Y.; Ding, M.; Dai, P. Research on integrated computer game algorithm for dots and boxes. J. Eng. 2020, 2020, 601–606. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, S.; Xiong, X. A Study on the Game System of Dots and Boxes Based on Reinforcement Learning. In Proceedings of the 2019 Chinese Control And Decision Conference (CCDC), Nanchang, China, 3–5 June 2019; pp. 6319–6322. [Google Scholar]
- Li, S.; Li, D.; Yuan, X. Research and Implementation of Dots and Boxes Game System. JSW 2012, 7, 256–262. [Google Scholar] [CrossRef]
- Bi, F.; Wang, Y.; Chen, W. Adaptive genetic algorithm to optimize the parameters of evaluation function of Dots and Boxes. In Proceedings of the International Conference on Heterogeneous Networking for Quality, Reliability, Security and Robustness, Seoul, Korea, 7–8 July 2016; pp. 416–425. [Google Scholar]
- Allcock, D. Best play in Dots and Boxes endgames. arXiv 2018, arXiv:1811.10747. [Google Scholar]
- Collette, S.; Demaine, E.D.; Demaine, M.L.; Langerman, S. Narrow Misere Dots and Boxes. Games No Chance 4 2015, 63, 57. [Google Scholar]
- Gao, M.; Li, S.; Ding, M.; Kun, M. The Dots and Boxes Records Storing Standard Format for Machine Learning and The Design and Implementation of Its Generation Tool. J. Phys. Conf. Ser. 2019, 1176, 032009. [Google Scholar] [CrossRef]
- Arrington, R.; Langley, C.; Bogaerts, S. Using domain knowledge to improve Monte Carlo Tree Search performance in parameterized poker squares. In Proceedings of the 30th AAAI Conference on Artificial Intelligence, AAAI 2016, Phoenix, AZ, USA, 12–17 February 2016; pp. 4065–4070. [Google Scholar]
- Berlekamp, E.; Scott, K. Forcing Your Opponent to Stay in Control of a Loony Dots and Boxes Endgame. In Proceedings of the MSRI Workshop on Combinatorial Games; 2002. Available online: https://www.semanticscholar.org/paper/Forcing-Your-Opponent-to-Stay-in-Control-of-a-Loony-Berlekamp-Scott/2979cb648924108cb09c5a5cc4599da2a6e4bc02 (accessed on 23 February 2021).
- García-Díaz, V.; Núñez-Valdez, E.R.; García, C.G.; Gómez-Gómez, A.; Crespo, R.G. JGraphs: A Toolset to Work with Monte-Carlo Tree Search-Based Algorithms. Int. J. Uncertain. Fuzziness Knowl. Based Syst. 2020, 28, 1–22. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Their Contribution | Our Contribution | |
|---|---|---|
| Bossomaier and Knittel [30] | The authors use an intelligent rule-based agent. | Our approach uses MCTS. |
| Barker and Korf [31] | The authors use Alpha-Beta with domain-based heuristics such as chains and symmetries | Our approach uses MCTS without information about the game |
| Zhuang et al. [32] | The authors use heuristics to represent the board and pre-classify the nodes. They also use an auxiliary greedy policy and a different method of data generation (see Section 6.2.2). | Our approach does not use any heuristic neither auxiliary method. |
| Lu and Yin [35] | The authors use an approach which reduces the MCTS search space considering the implemented domain-based heuristics. | Our approach reduces the search space applying an ANN which can be trained no matter the domain. |
| Agrawal and Ziegler [36] | The authors focus on MCTS parallelization. | Our approach does not explore MCTS parallelization. |
| Zhang et al. [38] | The authors evaluate a network based on AlphaZero against a MCTS implementation. They focus on generating a good quality data set. | Our approach uses an ANN (see Section 5.2) integrated in MCTS. |
| Li et al. [37] | The authors propose two implementations of MCTS integrated with a value net and a policy net. They use Alpha-Beta as an auxiliary method. | Our approach proposes other integration of ANN in MCTS and with no auxiliary algorithms. |
| Meaning | Board | Array |
|---|---|---|
| P1 move | 1 | 0.25 |
| P2 move | 2 | 0.25 |
| Free position | 0 | 0.0 |
| Box closed by P1 | 3 | 0.5 |
| Box closed by P2 | 4 | 0.75 |
| Free box | 5 | 1.0 |
| MCTS ITERATIONS | W. P1 | W. P2 | DRAW |
|---|---|---|---|
| 10K | 100 | 0 | 0 |
| 100K | 100 | 0 | 0 |
| MCTS ITERATIONS | WIN P1 | WIN P2 | DRAW | MEAN TIME PER MOVE (P1) (ms) | MEAN TIME PER MOVE (P2) (ms) |
|---|---|---|---|---|---|
| 1K | 95 | 5 | 0 | 247 | 13 |
| 5K | 86 | 14 | 0 | 263 | 67 |
| 10K | 72 | 28 | 0 | 267 | 129 |
| 30K | 65 | 35 | 0 | 286 | 363 |
| 50k | 52 | 48 | 0 | 315 | 586 |
| 100K | 51 | 49 | 0 | 323 | 1226 |
| MCTS IT. | GOOD PRED. | WIN P1 | WIN P2 | DRAW | TIME P1 | TIME P2 | U. NOT IN TRA. | T. NOT IN TRA. |
|---|---|---|---|---|---|---|---|---|
| 5K | 2430 | 46 | 54 | 0 | 384 | 734 | 384 | 734 |
| 10K | 5553 | 34 | 66 | 0 | 416 | 1451 | 816 | 1816 |
| 30K | 17,885 | 25 | 75 | 0 | 423 | 4336 | 795 | 1851 |
| 50K | 30,410 | 19 | 81 | 0 | 448 | 7345 | 822 | 1859 |
| 70K | 41,093 | 18 | 82 | 0 | 453 | 10,260 | 784 | 1867 |
| Winning Rate of QDab | |
|---|---|
| QDab vs. Dabble | 100% |
| QDab vs. PRxBoxes | 90% |
| QDab vs. MCTS | 100% |
| QDab vs. our system | 19% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cotarelo, A.; García-Díaz, V.; Núñez-Valdez, E.R.; González García, C.; Gómez, A.; Chun-Wei Lin, J. Improving Monte Carlo Tree Search with Artificial Neural Networks without Heuristics. Appl. Sci. 2021, 11, 2056. https://doi.org/10.3390/app11052056
Cotarelo A, García-Díaz V, Núñez-Valdez ER, González García C, Gómez A, Chun-Wei Lin J. Improving Monte Carlo Tree Search with Artificial Neural Networks without Heuristics. Applied Sciences. 2021; 11(5):2056. https://doi.org/10.3390/app11052056
Chicago/Turabian StyleCotarelo, Alba, Vicente García-Díaz, Edward Rolando Núñez-Valdez, Cristian González García, Alberto Gómez, and Jerry Chun-Wei Lin. 2021. "Improving Monte Carlo Tree Search with Artificial Neural Networks without Heuristics" Applied Sciences 11, no. 5: 2056. https://doi.org/10.3390/app11052056
APA StyleCotarelo, A., García-Díaz, V., Núñez-Valdez, E. R., González García, C., Gómez, A., & Chun-Wei Lin, J. (2021). Improving Monte Carlo Tree Search with Artificial Neural Networks without Heuristics. Applied Sciences, 11(5), 2056. https://doi.org/10.3390/app11052056