Dynamic Cooperative Spectrum Sensing Based on Deep Multi-User Reinforcement Learning


Abstract
1. Introduction
2. System Model
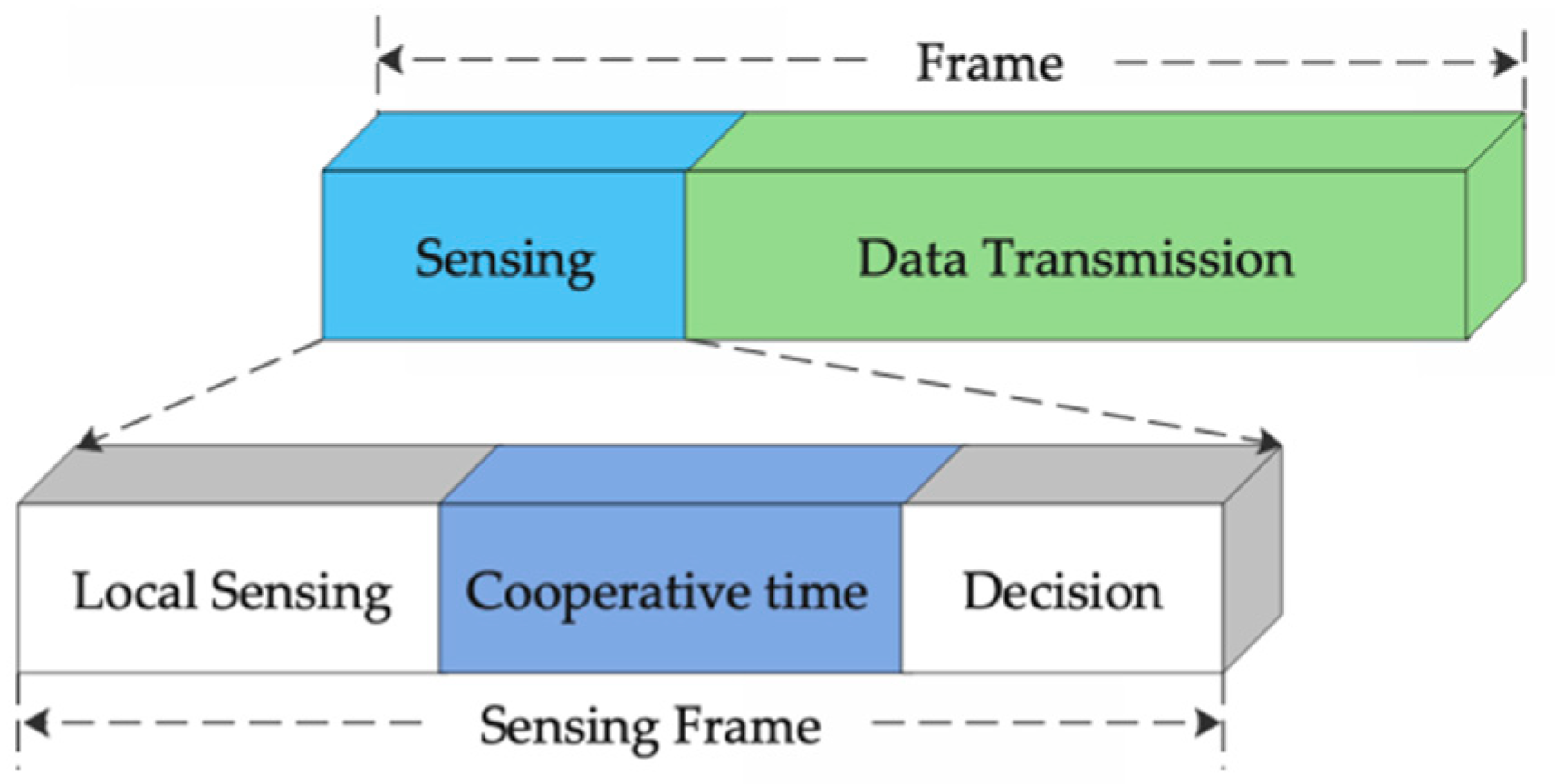
2.1. Cooperative Spectrum Sensing Model
2.2. Deep Reinforcement Learning for DSA
| Algorithm 1 Dynamic multi-channel sensing based on DQN |
| Input: State |
| Output: Action |
| BEGIN Step 1: Initialize experience memory , all parameters of the neural network and Q value of state-action pair |
| Step 2: Initialize as the first state of the current state sequence |
| Step 3: Inputs the channel state into the network, and utilizes the -greedy method to select a action from the current output value |
| Step 4: Perform action and access the channel with the same value as |
| Step 5: Obtain the next state and reward value of the channel environment according to the state and the executive action |
| Step 6: Store the sensing record <,, ,> in the experience memory |
| Step 7: Randomly sample m records from the experience memory , and update the neural network parameters according to (2) and (3) |
| Step 8: Assign the value of to , and repeat step 3 |
| END |
3. The Proposed Deep Multi-User Reinforcement Learning
- stands for state space. It is a matrix with dimension , which expresses the state set of users, and its expression is shown as:
- represents the action set. The actions of users in each time slot form the action matrix, which is expressed as:where , indicating user selects channel for accessing.
- represents the observation space. It is mainly composed of the signal, instant reward, and the remaining capacity of the channel, which are listed as:
- represents the reward space. It is a matrix with a dimension of , representing the reward set of users. Its value is shown as:where represents the reward obtained by selecting the -th user.
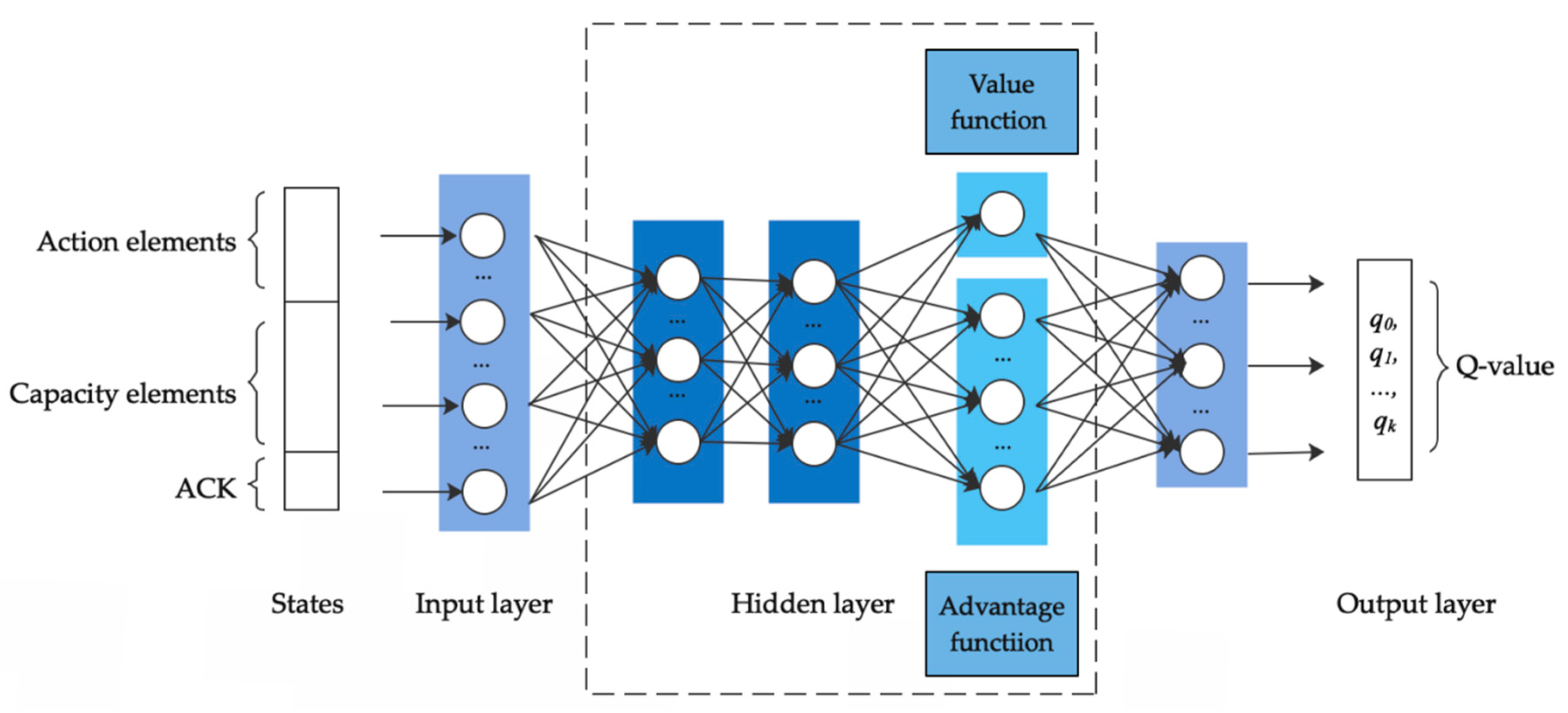
3.1. Architecture of the Proposed DMRL
3.2. Channel Cooperative Module
3.3. DMRL Training
| Algorithm 2 Deep multi-user reinforcement learning for dynamic cooperative spectrum sensing |
| Input: State and parameter values, including channel number , user number , action space size , state space size , exploration probability , buffer space size, hidden layer size, experience memory , and channel environment, etc. |
| Output: Q value, action |
| BEGIN |
| Step 1: Initialization parameter values and channel environment |
| Step 2: Obtain the randomly from the channel environment, and obtain observation and after executing the . Execute the above number, the model can get the next state |
| Step 3: Store the record <,,,> in the experience memory |
| Step 4: Assign to to produce a random number . (1) If the random number is less than the exploration probability , then randomly sample the from the channel environment. (2) If not, input the current state into the neural network and obtain according to Equation (13), then the value is normalized according to Equation (14). is selected according to the maximum value, and the corresponding channel is selected for sensing according to the action. |
| Step 5: Obtain the and according to the selected , and store the record <,,,> in the experience cache |
| Step 6: Sampling from the experience cache, training the network according to the loss function and gradient descent strategy, the specific operations are shown in (16) and (17) |
| Step 7: If the iteration is not over, continue to Step 4 |
| END |
4. Experiment
4.1. Simulation Setup
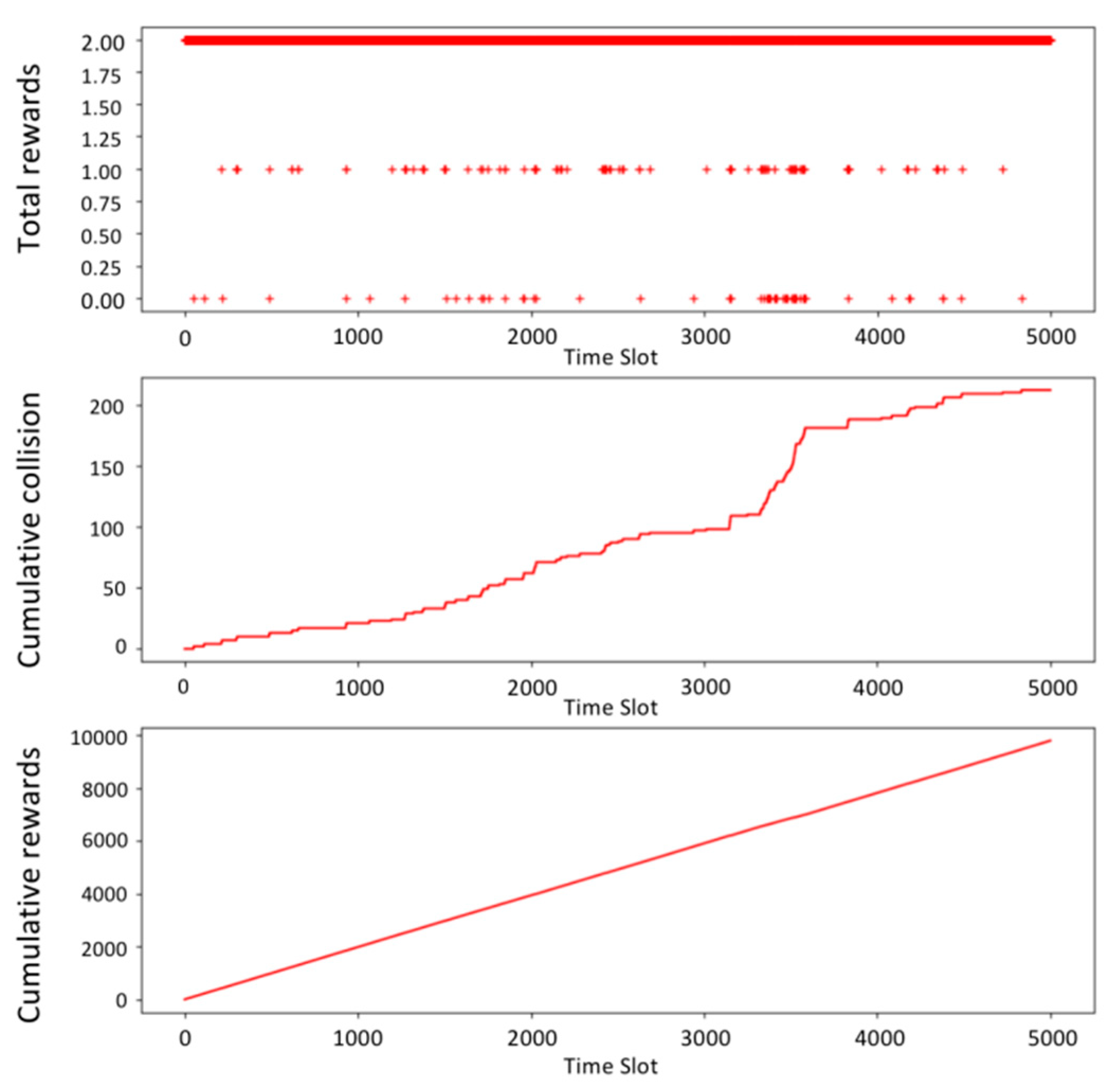
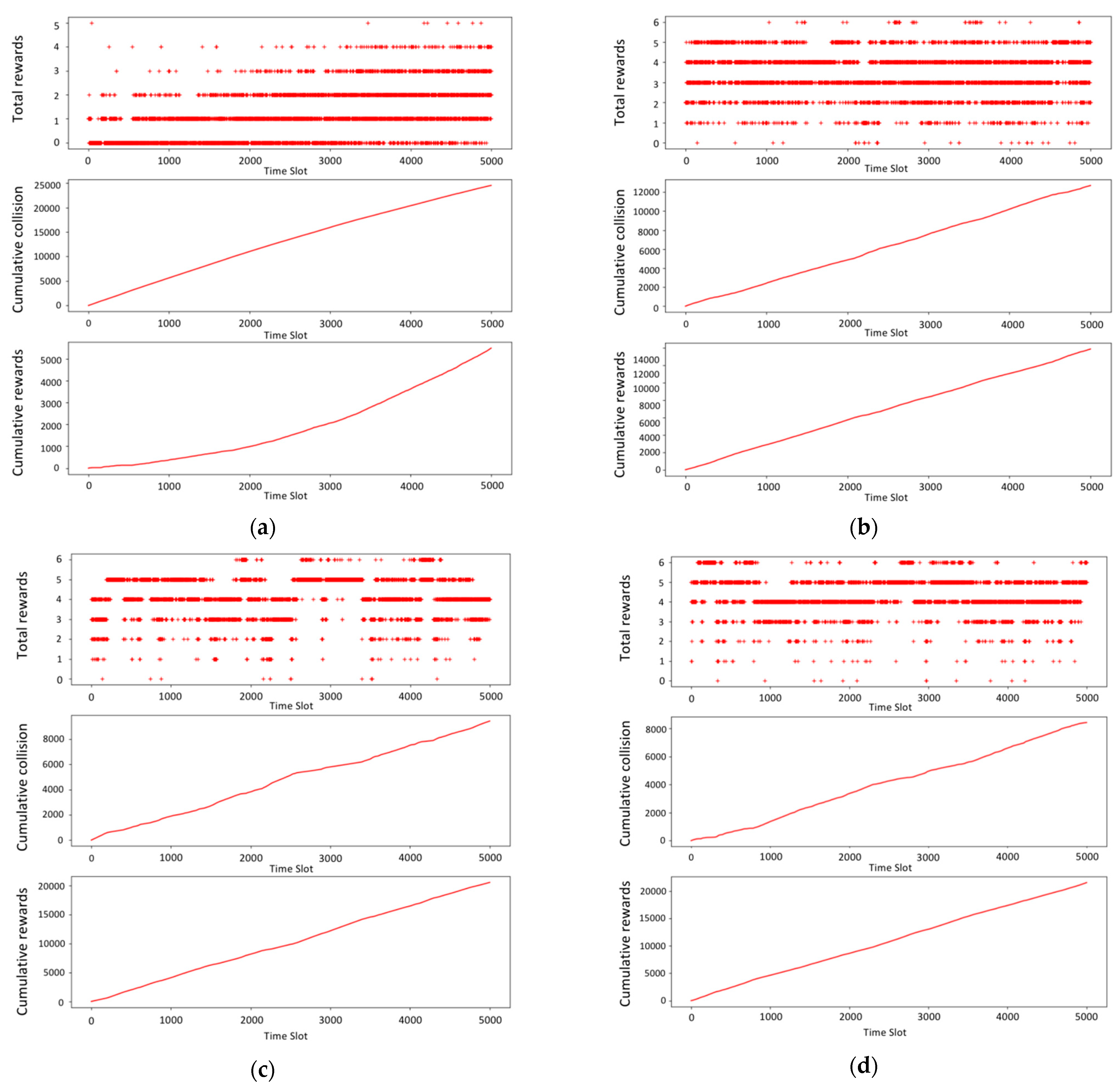
4.2. Simulation Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhao, Q.; Sadler, B.M. A survey of dynamic spectrum access. IEEE Signal Process. Mag. 2007, 24, 79–89. [Google Scholar] [CrossRef]
- Srinivasa, S.; Jafar, S. Cognitive radios for dynamic spectrum access-the throughput potential of cognitive radio: A theoretical perspective. IEEE Commun. Mag. 2007, 45, 73–79. [Google Scholar] [CrossRef]
- Do, V.Q.; Koo, I. Learning Frameworks for cooperative spectrum sensing and energy-efficient data protection in cognitive radio networks. Appl. Sci. 2018, 8, 722. [Google Scholar] [CrossRef]
- Gul, O.M. Average throughput of myopic policy for opportunistic access over block fading channels. IEEE Netw. Lett. 2019, 1, 38–41. [Google Scholar] [CrossRef]
- Kuroda, K.; Kato, H.; Kim, S.J.; Naruse, M.; Hasegawa, M. Improving throughput using multi-armed bandit algorithm for wireless lans. Nonline. Theo. Apps. 2018, 9, 74–81. [Google Scholar] [CrossRef]
- Tian, Z.; Wang, J.; Wang, J.; Song, J. Distributed NOMA-based multi-armed bandit approach for channel access in cognitive radio networks. IEEE Wirel. Commun. Lett. 2019, 8, 1112–1115. [Google Scholar] [CrossRef]
- Wang, K.; Chen, L.; Yu, J.; Win, M. Opportunistic multichannel access with imperfect observation: A fixed point analysis on indexability and index-based policy. In Proceedings of the IEEE INFOCOM 2018-IEEE Conference on Computer Communications, Honolulu, HI, USA, 16–19 April 2018; pp. 1898–1906. [Google Scholar]
- Elmaghraby, H.M.; Liu, K.; Ding, Z. Femtocell scheduling as a restless multiarmed bandit problem using partial channel state observation. In Proceedings of the 2018 IEEE International Conference on Communications (ICC), Kansas City, MO, USA, 20–24 May 2018; pp. 1–6. [Google Scholar]
- Wang, K.; Chen, L. On optimality of myopic policy for restless multi-armed bandit problem: An axiomatic approach. IEEE Trans. Signal. Proc. 2012, 60, 300–309. [Google Scholar] [CrossRef]
- Ahmad, S.H.A.; Liu, M.; Javidi, T.; Zhao, Q.; Krishnamachari, B. Optimality of myopic sensing in multichannel opportunistic access. IEEE Trans. Inf. Theory 2009, 55, 4040–4050. [Google Scholar] [CrossRef]
- Liu, K.; Zhao, Q. Indexability of restless bandit problems and optimality of whittle index for dynamic multichannel access. IEEE Trans. Inf. Theory 2010, 56, 5547–5567. [Google Scholar] [CrossRef]
- Wang, J.; Jiang, C.; Zhang, H.; Ren, Y.; Chen, K.C.; Hanzo, L. Thirty years of machine learning: The road to Pareto-optimal wireless networks. IEEE Commun. Surv. Tut. 2020, 22, 1472–1514. [Google Scholar] [CrossRef]
- Zhang, C.; Patras, P.; Haddadi, H. Deep learning in mobile and wireless networking: A survey. IEEE Commun. Surv. Tut. 2019, 21, 2224–2287. [Google Scholar] [CrossRef]
- Sarikhani, R.; Keynia, F. Cooperative spectrum sensing meets machine learning: Deep reinforcement learning approach. IEEE Commun. Lett. 2020, 24, 1459–1462. [Google Scholar] [CrossRef]
- Wang, S.; Lv, T.; Zhang, X.; Lin, Z.; Huang, P. Learning-based multi-channel access in 5G and beyond networks with fast time-varying channels. IEEE Trans. Veh. Tech. 2020, 69, 5203–5218. [Google Scholar] [CrossRef]
- Arulkumaran, K.; Deisenroth, M.P.; Brundage, M.; Barath, A.A. A brief survey of deep reinforcement learning. IEEE Signal Process. Mag. 2017, 34, 26–38. [Google Scholar] [CrossRef]
- Das, A.; Ghosh, S.C.; Das, N.; Barman, A.D. Q-learning based co-operative spectrum mobility in cognitive radio networks. In Proceedings of the 2017 IEEE 42nd Conference on Local Computer Networks (LCN), Singapore, 9–12 October 2017; pp. 502–505. [Google Scholar]
- Li, F.; Lam, K.Y.; Sheng, Z.; Zhang, X.; Zhao, K.; Wang, L. Q-learning-based dynamic spectrum access in cognitive industrial Internet of Things. Mob. Netw. Appl. 2018, 23, 1636–1644. [Google Scholar] [CrossRef]
- Su, Z.; Dai, M.; Xu, Q.; Li, R.; Fu, S. Q-learning-based spectrum access for content delivery in mobile networks. IEEE Transa. Cogn. Commun. Netw. 2020, 6, 35–47. [Google Scholar] [CrossRef]
- Shi, Z.; Xie, X.; Kadoch, M.; Cheriet, M. A spectrum resource sharing algorithm for IoT networks based on reinforcement learning. In Proceedings of the 2020 International Wireless Communications and Mobile Computing (IWCMC), Limassol, Cyprus, 15–19 June 2020; pp. 1019–1024. [Google Scholar]
- Li, Y.; Xu, Y.; Xu, Y.; Liu, X.; Wang, X.; Li, W.; Anpalagan, A. Dynamic spectrum anti-Jamming in broadband communications: A hierarchical deep reinforcement learning approach. IEEE Wirel. Commun. Lett. 2020, 9, 1616–1619. [Google Scholar] [CrossRef]
- Challita, U.; Dong, L.; Saad, W. Proactive resource management in LTE-U systems: A deep learning perspective. arXiv 2017, arXiv:1702.07031, 1–29. [Google Scholar]
- Li, Y.; Zhang, W.; Wang, C.X.; Sun, J.; Liu, Y. Deep reinforcement learning for dynamic spectrum sensing and aggregation in multi-channel wireless networks. IEEE Trans. Cogn. Commun. Netw. 2020, 6, 464–475. [Google Scholar] [CrossRef]
- Xu, Y.; Yu, J.; Buehrer, R.M. The Application of deep reinforcement learning to distributed spectrum access in dynamic heterogeneous environments with partial observations. IEEE Trans. Wirel. Commun. 2020, 19, 4494–4506. [Google Scholar] [CrossRef]
- Raj, V.; Dias, I.; Tholeti, T.; Kalyani, S. Spectrum access in cognitive radio using a two-stage reinforcement learning approach. IEEE J. Selec. Top. Sign. Proc. 2018, 12, 20–34. [Google Scholar] [CrossRef]
- Luong, N.C.; Hoang, D.T.; Gong, S.; Niyato, D.; Wang, P.; Liang, Y.C.; Kim, D.I. Applications of deep reinforcement learning in communications and networking: A Survey. IEEE Commun. Surv. Tuts. 2019, 21, 3133–3174. [Google Scholar] [CrossRef]
- Wang, S.; Liu, H.; Gomes, P.H.; Krishnamachari, B. Deep reinforcement learning for dynamic multichannel access. In Proceedings of the International Conference on Computing, Networking and Communications (ICNC), Silicon Valley, CA, USA, 26–29 January 2017; pp. 599–603. [Google Scholar]
- Schaul, T.; Quan, J.; Antonoglou, I.; Silver, D. Prioritized experienc replay. arXiv 2016, arXiv:1511.05952. [Google Scholar]
- Ye, H.; Li, G.Y. Deep reinforcement learning for resource allocation in V2V communications. In Proceedings of the 2018 IEEE International Conference on Communications (ICC), Kansas City, MO, USA, 20–24 May 2018; pp. 1–6. [Google Scholar]
- Liu, S.; Hu, X.; Wang, W. Deep reinforcement learning based dynamic channel allocation algorithm in multibeam satellite systems. IEEE Access 2018, 6, 15733–15742. [Google Scholar] [CrossRef]
- Shi, Z.; Xie, X.; Lu, H.; Yang, H.; Kadoch, M.; Cheriet, M. Deep reinforcement learning based spectrum resource management for industrial internet of things. IEEE Inter. Things J. 2020, 8, 3476–3489. [Google Scholar] [CrossRef]
- Zhu, J.; Song, Y.; Jiang, D.; Song, H. A new deep Q-learningbased transmission scheduling mechanism for the cognitive Internet of Things. IEEE Inter. Things J. 2017, 5, 2375–2385. [Google Scholar] [CrossRef]
- Wang, S.; Liu, H.; Gomes, P.H.; Krishnamachari, B. Deep reinforcement learning for dynamic multichannel access in wireless networks. IEEE Trans. Cogn. Commun. Netw. 2018, 4, 257–265. [Google Scholar] [CrossRef]
- Zhong, C.; Lu, Z.; Gursoy, M.C.; Velipasalar, S. Actor-Critic deep reinforcement learning for dynamic multichannel access. In Proceedings of the 2018 IEEE Global Conference on Signal and Information Processing (GlobalSIP), Anaheim, CA, USA, 26–29 November 2018; pp. 599–603. [Google Scholar]
- Chang, H.; Song, H.; Yi, Y.; Zhang, J.; He, H.; Liu, L. Distributive dynamic spectrum access through deep reinforcement learning: A reservoir computing-based approach. IEEE Inter. Things J. 2019, 6, 1938–1948. [Google Scholar] [CrossRef]
- Naparstek, O.; Kobi, C. Deep multi-user reinforcement learning for dynamic spectrum access in multichannel wireless networks. In Proceedings of the GLOBECOM 2017–2017 IEEE Global Communications Conference, Singapore, 4–8 December 2017; pp. 1–7. [Google Scholar]
- Huang, X.L.; Li, Y.X.; Gao, Y.; Tang, X.W. Q-learning based spectrum access for multimedia transmission over cognitive radio networks. IEEE Trans. Cogn. Commun. Netw. 2020. [Google Scholar] [CrossRef]
- Aref, M.A.; Jayaweera, S.K.; Machuzak, S. Multi-agent reinforcement learning based cognitive anti-jamming. In Proceedings of the 2017 IEEE Wireless Communications and Networking Conference (WCNC), San Francisco, CA, USA, 19–22 March 2017; pp. 1–6. [Google Scholar]
- Zhang, Y.; Cai, P.; Pan, C.; Zhang, S. Multi-agent deep reinforcement learning-based cooperative spectrum sensing with upper confidence bound exploration. IEEE Access 2019, 7, 118898–118906. [Google Scholar] [CrossRef]
- Wang, Z.; Schaul, T.; Hessel, M.; Van Hasselt, H.; Lanctot, M.; De Freitas, N. Dueling network architectures for deep reinforcement learning. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 1–9. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Parameters | Value |
|---|---|---|
| Number of authorized channels | 2, 6 | |
| Total number of time slots | 100,000 | |
| Number of secondary users | 3, 10 | |
| Experience cache size | 1000 | |
| Batch size | 25 | |
| Hidden layer size | 150 | |
| State-space size | 6, 14 | |
| Discount factor | 0.9 | |
| Action space size | 3, 7 | |
| Exploration rate | 0.15 |
| Number of Channels | Users | Number of Iterations | Step Count | Batch Size |
|---|---|---|---|---|
| 2 | 3 | 20 | 5000 | 25 |
| 6 | 10 | 20 | 5000 | 25 |
| Models | Average Cumulative Collision Rate | Average Cumulative Reward |
|---|---|---|
| MARL | 0.37 | 0.83 |
| MADRL | 0.24 | 0.86 |
| DMRL | 0.06 | 0.91 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, S.; He, J.; Wu, J. Dynamic Cooperative Spectrum Sensing Based on Deep Multi-User Reinforcement Learning. Appl. Sci. 2021, 11, 1884. https://doi.org/10.3390/app11041884
Liu S, He J, Wu J. Dynamic Cooperative Spectrum Sensing Based on Deep Multi-User Reinforcement Learning. Applied Sciences. 2021; 11(4):1884. https://doi.org/10.3390/app11041884
Chicago/Turabian StyleLiu, Shuai, Jing He, and Jiayun Wu. 2021. "Dynamic Cooperative Spectrum Sensing Based on Deep Multi-User Reinforcement Learning" Applied Sciences 11, no. 4: 1884. https://doi.org/10.3390/app11041884
APA StyleLiu, S., He, J., & Wu, J. (2021). Dynamic Cooperative Spectrum Sensing Based on Deep Multi-User Reinforcement Learning. Applied Sciences, 11(4), 1884. https://doi.org/10.3390/app11041884