1. Introduction
Computational narrative analysis is essential to provide explainable services that deal with narrative multimedia (i.e., creative works that contain stories and are distributed through multimedia). Although stories are key features that influence user affection, the existing applications (e.g., Netflix and Youtube) provide their services only based on metadata, user history, or manual annotations [
1]. Therefore, various studies have attempted to analyze and understand stories computationally. However, most of these studies have remained in statistical analysis rather than meanings of stories and components of the stories. This self-restriction makes them unable to reach analyzing plot structures (i.e., how events in stories are logically connected).
Most of the existing studies analyzed stories based on social networks between characters (called as character networks) that appeared in narrative multimedia [
2,
3,
4,
5,
6,
7,
8,
9,
10,
11,
12,
13]. This approach is based on an intuition that stories are developed by interactions between characters [
14]. Character networks exhibited a noticeable performance in extracting fragmentary information from stories, e.g., importance of characters [
2,
4,
15], communities among characters [
2,
3,
6], major events [
6,
16], and so on. Nevertheless, features that character networks reflect are far not only from stories (i.e., a series of events that happen in the narrative world) but also from plots (i.e., a series of events that are logically connected). Since they have not considered context and story lines, this problem is inevitable. Moreover, stories consist of multiple story lines, and the story lines are complicatedly entangled, as described in
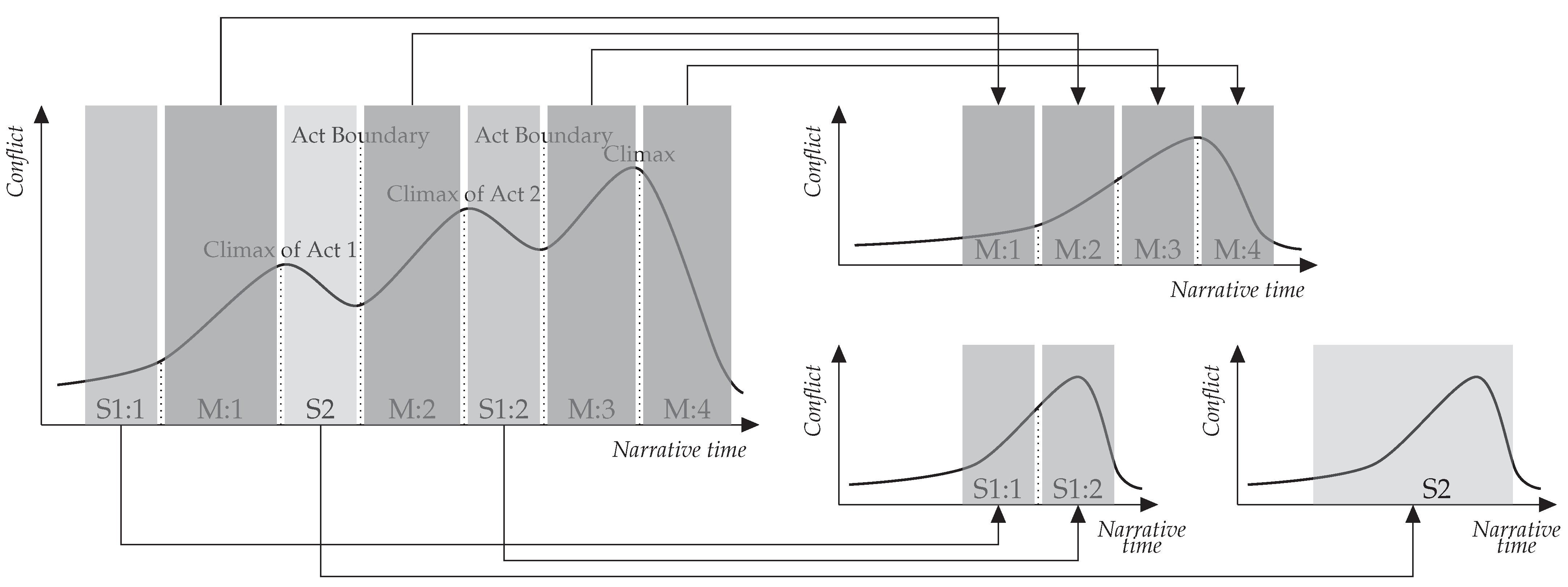
Figure 1. This point creates difficulties in computationally analyzing stories’ context.
To analyze stories’ context, a few studies [
10,
11,
18] have attempted to reveal plot structures of narrative works. They concentrated on discriminating story lines in a story. Although story lines in a story describe events in the same narrative world, they also have independent narrative arcs, as illustrated in
Figure 1. Therefore, classifying events into story lines, which are sets of more logically connected events, is a starting point for analyzing plot structures and understanding stories’ context.
Some story lines present events around protagonists, and others deal with side branches of a story. If a story line is more focused on events related to protagonists and main conflicts, we call it ‘main plot.’ The other story lines are called ‘subplots.’ The ’plot structure’ indicates the way in which a story is interwoven with multiple subplots. Each main plot and subplot is split into multiple fragments, and authors/directors present the fragments alternatively.
A fundamental principle for composing a plot structure is that events in a story must be located to escalate conflicts around its protagonist. Therefore, models for typical plot structures (e.g., Freytag’s pyramid [
19] and arch plot [
17]) commonly say that conflicts in a story should be intensified until the climax and then resolved. In most of the stories, a climax is placed much closer to a denouement than an exposition to maintain users’ interests until the end [
17]. Nevertheless, if conflicts are gradually escalated until the climax, users will be exhausted. Thus, in practice, authors/directors control conflicts in stories by interweaving multiple story lines, as displayed in
Figure 1.
The existing studies [
10,
11,
18] attempted to distinguish main plots and subplots based on the changes in the social relationships of characters. This approach is based on a notion that each main plot and subplot has its own protagonists and main characters [
17]. Although this notion is a clear and obvious fact in narratology studies, we cannot assure the accuracy of the methods based on this notion. To classify scenes into main plots and subplots, Sang and Xu [
18] compared scenes based on the occurrence frequency of characters, and Lee and Jung [
10] compared structures of character networks in each scene (in narratology studies [
14,
17], a scene is defined as a period without changes in backgrounds. In addition, a scene describes a concluded event that happened in a spatio-temporal background. Therefore, we use a scene as the smallest unit of a story to distinguish events in the story.). However, both of the methods could not exhibit a reliable accuracy [
11]. As Bost et al. [
16] discussed, social relationships between characters change according to stories’ development, and these changes are more dramatic around major events.
To solve this problem, we focus on that each main plot and subplot has its own plot structure [
17]. Thus, they also have their own conflicts, climaxes, protagonists, and so on. According to Robert McKee [
17], conflicts and events are also designed to jeopardize the everyday lives of protagonists and cause changes in characters’ personalities in a consistent direction. Our problem (i.e., changes in social relationships) is only the result of the changes in personalities. These points indicate that characters will show gradual changes in each main plot and subplot. Therefore, if we can discover features that reflect the characters’ personalities, we also can classify scenes by making the features show gradual increments or decrements. The fundamental assumption of this study can be clarified as follows:
Assumption 1 (Dynamic Changes in Personalities of Characters). Conflicts in a story are designed to motivate so that its protagonist or main character changes himself/herself. In most of the stories, this change is uni-directional. Thus, if a character’s personality is not static, this change progresses from a state (A) to another state (B) according to narrative time from an inciting incident to the climax of the story. At the climax, the change is concluded as A, B, or somewhere else between A and B.
Assumption 2 (Independence of Subplots). A story is mostly interwoven with a main plot and multiple subplots. Although the subplots function to support the main plot, they are also independent story lines with their own conflicts, protagonists, and main characters. Therefore, characters’ personalities exhibit uni-directional tendencies in a single subplot.
Nevertheless, in real narrative works, main plots and subplots are complicatedly entangled, and transitions between them frequently happen. Thus, if we analyze characters’ changes according to scenes’ order, the changes might seem irregular and noisy. We use this problem to solve the problem itself. If a plot structure is impeccably decomposed into main plots and subplots, characters’ personalities will show gradual changes in each of them.
Based on this notion, we propose methods for computationally decomposing the plot structures of stories. First, we suggest features for capturing changes in characters’ personalities. By drawing trend curves of the features, we can reveal ways how the characters change. Then, we extract the primary story line by knocking out noisy scenes, which are far from the trend curves. By iteratively conducting this process, we discover main plots and subplots, one-by-one. We have validated these assumptions and evaluated the proposed methods based on real movies.
This study focuses on enabling an in-depth analysis of narrative multimedia by revealing plot structures. However, plot structure decomposition can also improve practical applications of computational narrative analysis. For example, the existing methods for story-based summarization [
12,
20,
21,
22,
23] concentrated on extracting more important scenes than others. They employed various criteria to measure importance, such as whether protagonists appear in the scenes. However, since they do not consider causalities between scenes, they cannot deal with the abstractive summarization. The proposed methods can be applied to resolving this issue because a story line is a set of scenes that have causal relationships. This point is similar in other applications: Story-based recommendation [
6] or indexing [
13,
24]. We will present more details in
Section 5 with further research directions.
The remainder of this paper is organized as follows.
Section 2 presents the backgrounds of this study and the existing studies for analyzing plots. In
Section 3, we propose the features for fictional characters’ personalities and the methods for decomposing plot structures by analyzing changes in the personalities. In
Section 4, we evaluate the proposed methods and validate our assumptions.
Section 5 presents concluding remarks and further research directions.
3. Plot Structure Decomposition-Based Personalities of Characters
Plot structures of narrative works are interwoven with multiple story lines (subplots). This study aims to decompose plot structures into subplots and discover the primary subplot (main plot). We conduct the decomposition by analyzing dynamic changes in character personalities. This approach is based on two assumptions. The previous studies [
10,
11,
18] attempted to discriminate subplots based on the consistency of social relationships between characters. Nevertheless, these studies overlooked that (i) relationships of characters significantly change around major events (e.g., inciting incidents or climaxes), and (ii) not all the main characters are involved in all the events in a subplot. We solve this problem with an assumption that the protagonists and main characters of a subplot will be consistently and relatively more important than other characters in the subplot.
Second, characters change according to the stories’ flows, but they mostly show gradual changes until the end or return to the original states after climaxes [
17,
28]. Furthermore, the changes usually happen to the protagonists and main characters. Roughly speaking, a character can have various roles in each subplot, and, in a subplot, their personality will be static or will gradually change. Thereby, if we have a measurement for quantifying the personality, the measurement for a character in a subplot will be linear or convex for the narrative time.
Therefore, we first attempt to discover features that can reflect personality changes. We assume that changes in social relationships of characters are the results of changes in their personalities. Based on the features, we propose methods for (i) detecting transitions between subplots and (ii) clustering scenes into subplots.
3.1. Revealing Personality Changes of Characters
The existing studies for discovering connectivity between events (scenes) have assumed that correlated scenes present the similar social relationships of characters [
10,
11,
18]. However, as discussed in the previous sections, social relationships change even in a story line, particularly around major events [
16]. In addition, not all characters in a story line consistently appear in all of the scenes of the story line.
To solve this problem, we attempt to utilize the changes themselves. From Assumptions 1 and 2, we suppose that changes in social relationships are results of changes in personalities of characters, and the changes are uni-directional (e.g., passiveness to activeness) at least in each story line. Therefore, in this section, we propose three features for detecting the personality changes of characters.
First, we define a feature that can be relatively robust to personality changes. According to McKee [
17,
28], each main plot and subplot has its own protagonist and main characters, and these roles are static. The existing studies [
2,
4,
15] defined ‘importance of characters’ as node centrality of the characters in their social network, in order to classify characters into the roles (e.g., protagonist, main, minor, and extra characters). Thus, in other words, although a protagonist and a main character established a new relationship after a climax, the protagonist will still have higher centrality than the main character. In addition, regardless of absences of a few characters in a few scenes, the relative importance of each character is consistent; when
,
, and
are the protagonist, main, and minor characters of a story line, respectively,
will have higher centrality than
in most scenes in the story line whether
appear with them or not. We measure the importance by using how many interactions (e.g., dialogues and conversations) each character is involved in (i.e., degree centrality).
In the movie ‘The Godfather’ (1972), the protagonist ‘Michael Corleone’ gradually changes from a passive stance to an active stance for his family business. In the character networks of this movie, the out-degree of ‘Michael Corleone’ becomes larger according to the flow of the stories, compared to its in-degree. However, when we simply see interaction frequency, ‘Michael Corleone’ has been consistently involved in most of the dialogues and conversations within the scenes that he appears in.
To measure importance, we consider the interaction frequency in terms of two aspects: The number of dialogues (
in Equation (
2)) and conversations (
in Equation (
2)) that each character is involved in.
provides us how salient
was in a scene. Although
was mostly a listener, authors/directors might not place them without any reason. We have also supposed that a scene describes an event due to the difficulties in discriminating and segmenting events. However, events consist of smaller events, and the events compose bigger events.
lets us know whether
participates in all minor events happened in a scene.
For assessing consistency of characters’ importance, we have to normalize the importance. The normalized importance is called ‘relative importance’ and is defined as follows:
Definition 3 (Relative Importance).
Relative importance of during () indicates how important was on compared with other characters that appeared in . For a scene , when and indicate the number of dialogues and conversations that participated in during , respectively, is estimated by a linear combination of normalized and . We can also compose a vector for representing the importance of all the characters that appeared in . This can be formulated as:where denotes a weighting factor for conversations. In addition, when , . Thus, has a higher value, as characters have a relatively larger portion for events described in . includes importance based on two features: Dialogue and conversations. At this moment, we cannot assure which feature is more robust to changes in the social relationships of characters. Thus, we will conduct a hyper-parameter search to find out the optimal based on experiments with real movies.
The relative importance and features used in the existing studies [
6,
10,
11,
18,
48] have commonly relied on only changes in social relationships between characters. However, as discussed in various studies [
16,
17], social relationships significantly change around major events. Moreover, strictly speaking, the changes in relationships are a partial reflection of changes in the inner sides of the characters [
17,
28].
Furthermore, McKee [
17] said that characters in stories are designed and allocated to cause events and escalate conflicts around their protagonists. Thus, the events are drawn to raise inner or outer conflicts around protagonists, and changes caused by the conflicts are concentrated mostly on protagonists and main characters rather than minor ones, which are far from protagonists.
However, it is challenging to quantify changes in the personalities of characters. Although various methods have been proposed to recognize the meanings of facial and vocal expressions of actors/actresses or emotional words in dialogues, these methods have still focused on meanings of a single expression rather than pragmatic meanings [
49,
50]. Dialogues in visual narrative works are closer to everyday language than in textual narrative works (e.g., novels) [
17,
28]. Thus, it is difficult to simply use emotional words in narrative works for detecting personality changes or analyzing plot structures, as case studies on novels [
42,
43,
44,
46].
This study applies simple statistical features, which are already validated by the existing studies in the computational narrative analysis. We measure inner changes of characters by using (i) average lengths of dialogues [
28,
41,
51] and (ii) ratios of out-degree for in-degree [
47]. Although these features are simple and intuitive, they have exhibited reliable performance for analyzing flows of stories in the existing studies.
The average length of dialogues is based on ‘two clock theory’ in psychology studies [
41]. However, its concept is quite intuitive and obvious. Let suppose that there is an action movie, and dialogue in the movie is mostly exclamations. If the protagonist and antagonist exchange a long piece of dialogue in a scene, the scene might be a major event (e.g., revealing secrets, resolving conflicts, and so on). Zvi Lotker [
41] and Liu et al. [
51] have attempted to detect major events in stories based on the average lengths of all dialogues in each scene. However, they conducted experiments with narrative works that have relatively simple plot structures with few subplots (e.g., plays of Shakespeare and TV animation series). Thus, in this study, we analyze both the average dialogue lengths (i) for all characters and (ii) for each character. This feature can be defined, as follows:
Definition 4 (Average Lengths of Dialogue).
The average length of dialogue spoken by during () indicates how long is in feeling of . For a scene , when and indicate the number of dialogues spoken by and the number of words in the dialogues, respectively, is estimated by a ratio of for . In addition, by averaging lengths of all the dialogues in (), we can represent changes in tempos of storytelling [11,41]. This can be formulated as:In addition, when , .
We anticipate that the average length of dialogues gets larger, when inner conflicts of a character become intensified. Furthermore, as external conflicts escalate, the average length might be smaller.
The ratio of out-degree for in-degree is widely-used in the SNA (Social Network Analysis) area for estimating the ‘activeness’ of users or entities. Marks [
47] has discussed that the activeness of main characters gradually fluctuates with changes in the personalities of the characters based on various real movies. If a character is active, they will speak dialogues more frequently than listen to the dialogues of other characters, and the character’s out-degree will be higher than their in-degree. As we discussed, ‘Michael Corleone’ in ‘The Godfather’ (1972) shows gradual changes in his stance for the family business (from passive to active). These changes are exposed when he starts participating in conversations within his family as a speaker rather than a listener. As a contrary case, ‘Clark Kent’ in ‘Superman’ (1978) is a static character and always leads most of the events. Thus, ‘Clark Kent’ has a higher out-degree than in-degree consistently. For the normalization, we measure the activeness as a ratio of the number of spoken dialogues for the number of dialogues both spoken and listened to. This feature can be defined, as follows:
Definition 5 (Ratios of Out-degrees for In-degrees).
The ratio of out-degree of for its in-degree on () indicates how active ’s stance is during . For a scene , when and indicate the number of dialogues spoken by and of all the dialogues spoken and listened by , respectively, is estimated by a ratio of for . In addition, using the entropy of for all characters in , we can represent whether interactions in is led by few characters or all the characters have a right to speak. This can be formulated as:In addition, when , .
Conclusively, a feature vector for personality changes of characters on a scene
(
) can be formulated as:
where ⊕ indicates the concatenation operation between vectors. For the proposed features, we assume that relative importance (Definition 3) will be consistent in each main plot and subplot. The other two features (Definitions 4 and 5) will show gradual and uni-directional changes in each story line.
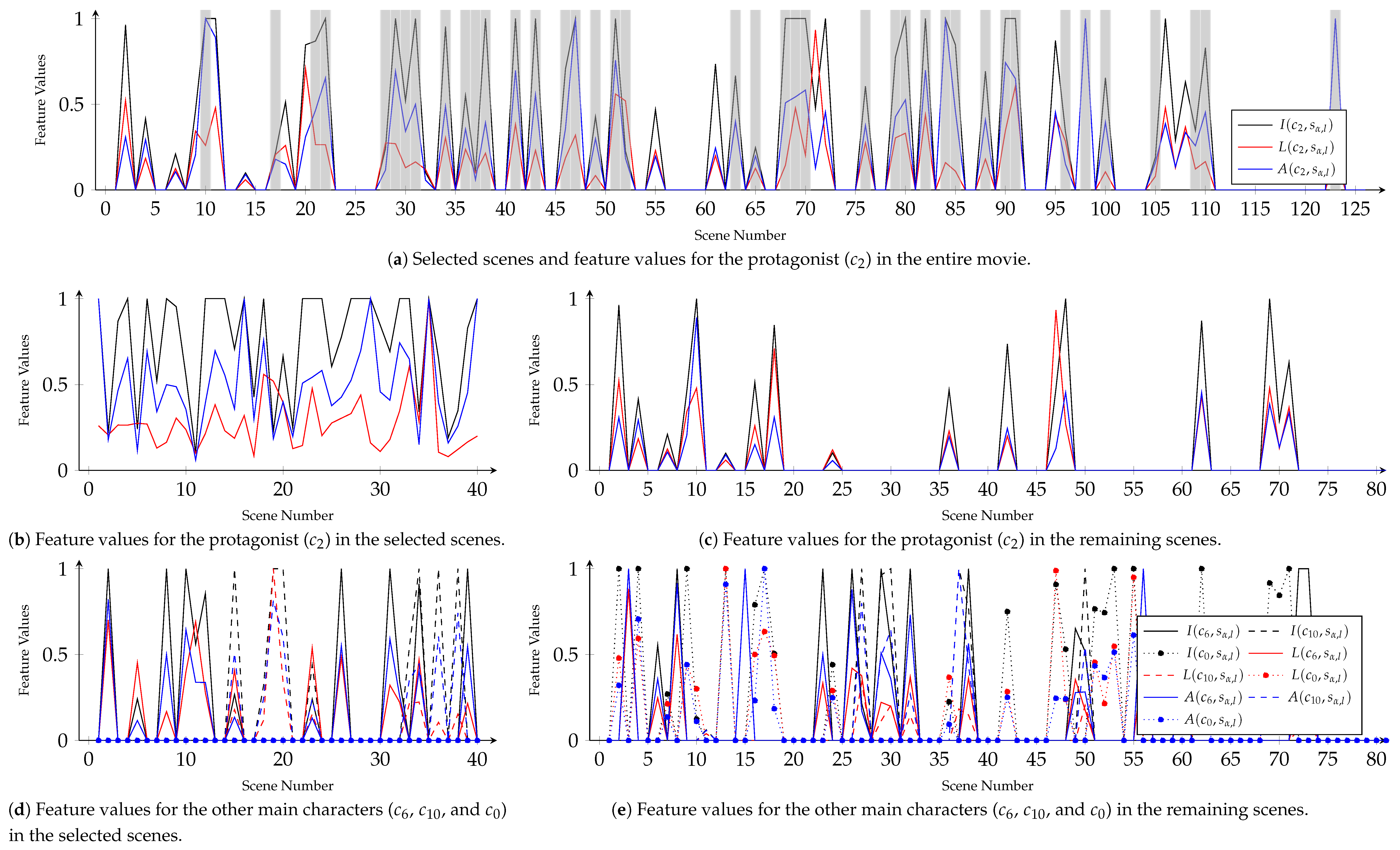
Figure 3 presents time-sequential changes in the proposed features within a real movie, ‘Good Will Hunting’ (1997). In the following sections, we propose methods for discovering main plots and subplots based on the proposed features.
3.2. Plot Structure Decomposition
To discover the main plots and subplots, we concentrate on a point that the personalities of protagonists or main characters change according to stories’ development, and the changes have consistent directions, at least in each story line. Obviously, in some stories, the personalities of the main characters do not change (e.g., the ‘Superman’ series) or come back to the beginning. Nevertheless, most of the stories have one common point: The inner changes are caused by inciting incidents and gradually progress until the denouement. Thereby, when we define time-serial functions based on the proposed features and narrative time, the functions’ shapes will be linear or convex in a story line.
First, we define time-serial functions for each character for the three features:
,
, and
. If we reduce the domains of these functions from an entire narrative work (
) to a main plot or subplot in
(
or
), the three functions will be linear or convex for narrative time (
l). Thus, we subsequently conduct the linear and quadratic regression for the functions. By searching for an optimal regression model, we can trace the personality changes of each character in the most significant story line, which is latent in the search space. For example, if we conduct regression for an entire story, we will obtain the directions of changes in its main plot. When
indicates the
i-th component of the feature vector (in Equation (
10)), this can be formulated as:
where
indicates a current search space,
denotes a predicted value of the
i-th component on
, and
refers to a loss of the regression model for the
i-th components, which is measured by
l-2 norm (mean square error). The regression model, which represents a tendency of the
i-th components in the search space (
), is determined by searching models and parameters that make
minimized.
Based on the regression models, each main plot and subplot is discovered by discarding scenes with significantly higher errors than the other scenes. Simply speaking, we (i) find dominant tendencies of characters’ personality changes and (ii) filter scenes that do not accord with the tendencies. Therefore, we first compose vectors to represent errors of each scene for the features and their regression models. The vector for a scene
(
) can be formulated as:
Each component of
is calculated by
l-2 norm; e.g.,
. Then, using the support vector clustering (SVC) [
52], we categorize scenes into two groups that follow the tendencies and do not follow.
Based on the group, which is out of the tendencies, we redefine the search space and conduct the regression and classification again; , where denotes the newly discovered story line. According to changes in the number of scenes in the search space, we have to assign temporal indices for the scenes in each iteration; . The temporal index has to preserve the original order of scenes. Thus, when two scenes ( and ) are in , . By iterating these procedures, we obtain a main plot or subplot on each iteration.
In addition, the changes of personalities mostly happen in protagonists or main characters [
17]. To emphasize the fluctuation in personalities, we use only main characters (including protagonists) for the regression and classification. The main characters are found by their centrality on character networks, as with the existing studies [
2,
4,
11,
15]. A set of the main characters is redefined on every iteration according to changes in the search space and the targeted story line. In addition, the character network defined in this study contains multiple weights on its edges. For measuring centrality degrees of characters, we only use the number of words spoken by each character (
in Equation (
2)).
The iterations are conducted, while scenes in the discovered story line show more distinct tendencies than all the scenes in the search space. Therefore, when
is a story line discovered from
, we conduct the regression for
, again. Then, if a loss for
(
) is smaller than the loss for
(
), we move on to the next iteration. Otherwise, we discard
and finish the plot structure decomposition. For the two losses, errors for each scene (
) are composed based on different regression models, which are trained in
and
, respectively. Algorithm 1 describes the overall procedures of the proposed plot structure decomposition method. Furthermore,
Figure 4 illustrates an empirical example of the plot structure decomposition for ‘Good Will Hunting’ (1997).
| Algorithm 1 Plot Structure Decomposition |
- 1:
procedureDecomposition() - 2:
Initialization - 3:
do - 4:
- 5:
Assign temporal indices () for scenes in ; . - 6:
for do - 7:
Conduct linear and quadratic regression for the i-th feature in Equation ( 10) - 7:
- 8:
Choose adequate regression model which makes a lower MSE (Equation (12)). - 9:
Calculate MSE for each scene; . - 10:
Compose error vectors for each scene (Equation ( 13)). - 11:
Conduct the SVC for all the scenes in according to errors of the scenes. - 12:
- 13:
Conduct Line 5 to 10 for . - 14:
, - 15:
while
|
From the decomposition method, we can obtain story lines in order of their significance. When a story line is extracted by the proposed method, the story line describes more dominant personality changes of characters than the remaining ones, which have not been derived yet. Therefore, the most straightforward approach is designating the firstly-discovered story line as a main plot. This approach will be efficient since most of the commercial narrative works present a single protagonist and a single main plot [
17,
28]. However, there are also various genres and formats that employ multiple protagonists and main plots, such as omnibus movies. Therefore, the proposed methods are designed to cope with a plurality of protagonists and main plots.
Regarding our research problems, we simply defined a main plot as a story line that is more tightly connected with protagonists and main conflicts of a story than the other story lines. However, this definition is not clear enough to distinguish main plots from story lines discovered by the proposed decomposition method. For a computational definition of the main plot, we focus on that the main conflicts will cause far more significant changes in protagonists and main characters than the other minor events. A main plot is defined, as follows:
Definition 6 (Main Plot).
When is the n-th main plot in , protagonists and main characters of show far more significant changes in their personalities during than during other subplots. Thus, there will be a noticeable gap between main plots and subplots in terms of ranges of personality fluctuations. When indicates a degree of personality fluctuation in main characters during , we first reorder story lines in descending order according to . The biggest gap in can be searched by:Subsequently, we can determine as a main plot.
The personality fluctuation is estimated by the two proposed features for character personalities: (i) The average lengths of dialogues (Definition 4) and (ii) the ratios of out-degrees for in-degrees (Definition 5). First, we measure a range of fluctuation in each main character with each feature. Then, we aggregate the ranges by summation. This can be formulated as:
where
is a set of main characters composed for the entire
. If a story has numerous main characters whose personalities dynamically change, and these main characters are scattered over plural story lines,
is difficult in showing significant differences between main plots and subplots. We can deal with this by applying weighting factors based on characters’ centrality (to emphasize protagonists).
Additionally, Lee [
11] supposed that main plots include more scenes and have more frequent interactions between main characters than subplots. This statement seems obvious. Therefore, we also use (i) the number of scenes and (ii) the number of words spoken by main characters in each main plot and subplot as features for discriminating main plots. In the evaluation section, we will validate whether these two features improve the accuracy for distinguishing the main plots. These two features are measured and normalized as:
where
indicates the number of words in the dialogues spoken by
on corresponding scenes (e.g.,
on numerator). We simply combine the three features (
,
, and
) by using the arithmetic mean.
A method for discriminating the main plots based on the three features is mostly similar to the method for categorizing characters according to their importance in the existing studies [
2,
4,
11,
15]. We sort all discovered story lines in descending order according to the values of the features. We calculate gaps of the feature values between story lines, which are adjacent in order. Finally, we can find out the biggest gap that separates the main plots and subplots.
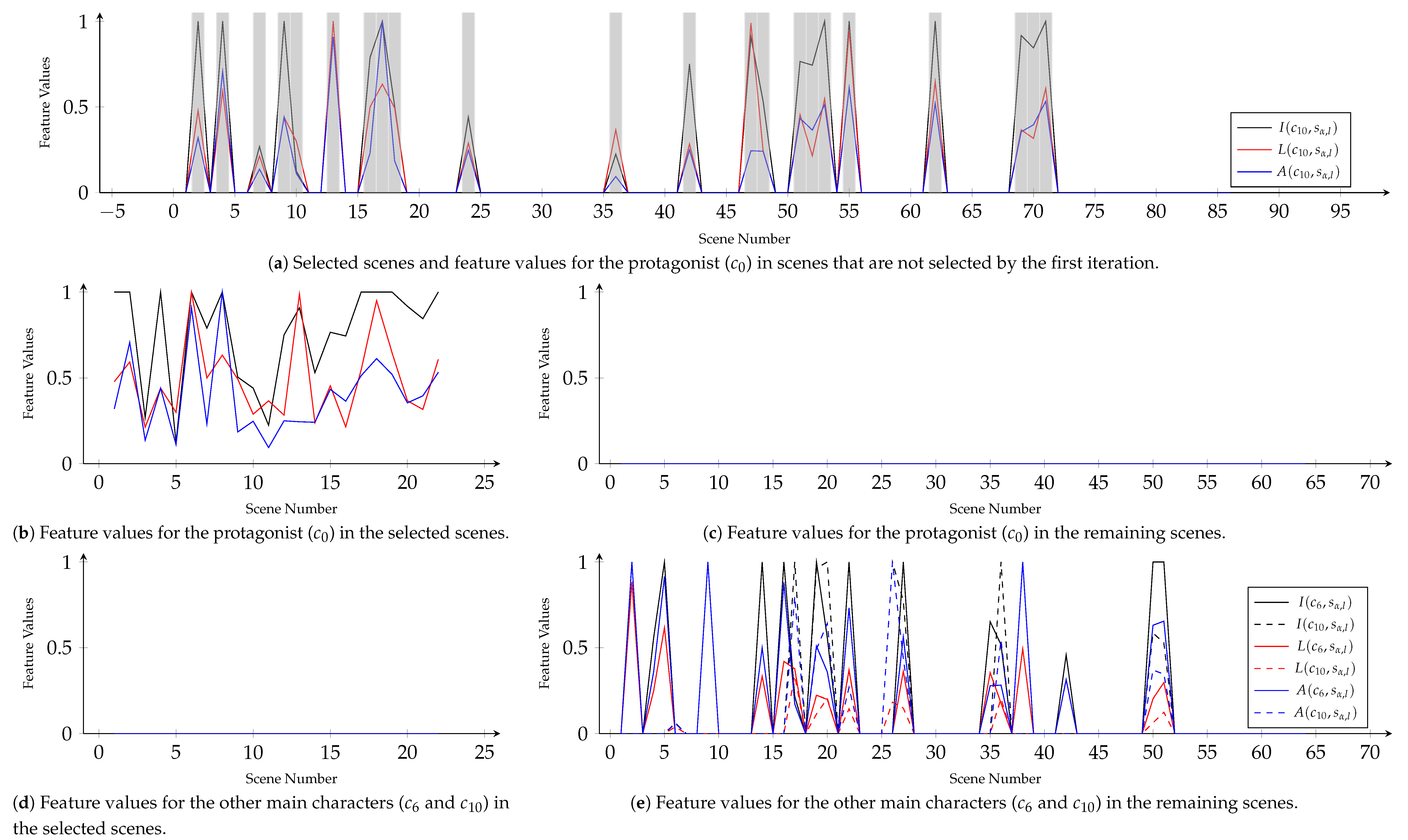
Figure 4 and
Figure 5 show the result of the main plot discrimination for ‘Good Will Hunting’ (1997).
Figure 3 presents the values of three features for main characters that appeared in ‘Good Will Hunting’ (1997). Then,
Figure 4 and
Figure 5 present story lines discovered at the first and second iterations of the proposed decomposition method.
Figure 4a shows selected scenes as a part of the first story line and values of the proposed features for ‘Will’, which is the protagonist of both the entire movie and the extracted story line. As with
Figure 3, the feature values show irregular tendencies when we observe all the scenes. However, after the first iteration, the features show relatively distinguishing tendencies. Significantly, as shown in
Figure 4b, the average length of dialogues spoken by ‘Will’ gradually increases. In
Figure 4c, ‘Will’ appeared in a part of the remaining scenes. However, comparing
Figure 4c,e, we also can see that other main characters have higher feature values in most of those scenes than ‘Will.’ Similar to
Figure 3, the other main characters still show irregular tendencies in both of the selected and remaining scenes, as shown in
Figure 4d,e. This point makes it difficult to say that the first story line describes relationships between ‘Will’ and other characters.We conjecture that scenes in the first story line describe events that are more connected to ‘Will’ than the others.
Figure 5a illustrates selected scenes as the second story line. The protagonist of this story line was ‘Chuckie’ (
). Moreover, interestingly, ‘Chuckie’ does not appear in the remaining scenes of the second iteration. The other main characters, ‘Sean’ and ‘Lambeau’ (
and
), only appeared in the remaining scenes. Considering the appearance of ‘Will’, the second story line describes relationships between ‘Will’ and ‘Chuckie’, the remaining scenes seem to depict events between ‘Will’, ‘Sean’, and ‘Lambeau’ or between ‘Sean’ and ‘Lambeau.’ The remaining scenes still contain scenes in which ‘Sean’ and ‘Lambeau’ do not appear. Through the third iteration, we obtained a story line which ‘Will’ is its protagonist again. This story line describes relationships between ‘Will’ and ‘Skylar.’
Conclusively, we decomposed ‘Good Will Hunting’ (1997) into the four story lines. We asked experts in narratology to decompose this movie. Obviously, the experts’ results were different from the results of the proposed method in terms of selecting scenes in each story line. However, the main difference was that the experts divided the third story line into two parts: (i) Events between ‘Will’, ‘Sean’, and ‘Lambeau’ and (ii) conflicts between ‘Sean’ and ‘Lambeau.’ This result shows that the proposed method effectively analyzes the plot structure but should be improved. Detailed evaluation for the proposed method will be presented in the following section.
4. Evaluation
We evaluated the plot structure decomposition methods based on real movies. We also could implicitly evaluate the proposed features based on the performance of the plot structure decomposition methods. The implicit evaluation is difficult to exhibit whether the proposed features can reflect characters’ personalities and trace changes in the personalities. However, as discussed in
Section 3.1, the proposed features are generalizations of the existing features for analyzing characters and events. Thus, correlations of the three features with characters’ personalities and stories’ context have been validated in the existing studies [
2,
4,
15,
41,
47,
51]. Moreover, it is challenging to collect reliable and large-scale data for characters’ personalities in each scene. Therefore, this study focuses on the accuracy of the proposed plot structure decomposition methods, and we evaluated features in terms of their contribution to the decomposition methods by conducting ablation tests for the features.
To assess the accuracy, we need ground truth data for the story lines of each scene. However, there have not been any benchmark dataset that include story line information at the extent of our knowledge. In addition, since classifying scenes into story lines is too abstruse for general users, we could not conduct large-scale questionnaire surveys. Therefore, we composed an expert group that consists of scholars who are faculty members of Chung-Ang University, Inha University, Kookmin University, and Sungkyunkwan University and have expertise in narratology, literature, or film studies. We compared the results of the proposed methods with ground truth annotated by the experts.
Table 1 presents a list of the movies applied as experimental subjects.
Movies were our experimental subject since it is one of the most popular and accessible narrative multimedia. We selected the movies under the expert group’s supervision to make the dataset evenly distributed over various genres and kinds of stories. We asked the experts to suggest movies that are well-known and have multiple story lines. Since most of the suggested movies were in the drama genre, we attempted to make our experimental subjects as diverse as possible within the drama genre (e.g., crime and drama, comedy and drama, etc.). We also had to choose movies that had their scripts accessible online. Scripts and metadata of the movies were mainly acquired from IMSDb (
https://www.imsdb.com/ (accessed on 11 February 2021)) and IMDb (
https://www.imdb.com/ (accessed on 11 February 2021)), respectively. Then, we extracted character networks of the movies by using CharNet-Extractor, which is available through a GitHub repository (
https://github.com/O-JounLee/CharNet-Extractor (accessed on 11 February 2021) and
https://github.com/O-JounLee/CharNetBuilder (accessed on 11 February 2021)). The repository also includes underlying data of our running examples (
Figure 2,
Figure 3,
Figure 4 and
Figure 5). Furthermore, manual annotations of plot structures were composed for each scene in the movies. The schema of the annotation is presented in
Table 2.
To evaluate the effectiveness of the proposed methods for plot structure decomposition, we compared the proposed methods’ accuracy with two existing ones [
10,
11,
18]. As a comparison group, we first used a method proposed by Sang and Xu [
18]. They applied the HMM (Hidden Markov Model) on the occurrence frequency of characters to discover ‘sub-stories.’ Another existing method has been proposed by Lee and Jung [
10]. They embedded social relationships between characters by learning representations of structures of character networks. Then, they clustered scenes into main plots and subplots by using vector representations.
The accuracy of each method was assessed by the precision, recall, and measure for each movie. For a movie, the precision and recall are calculated by and , respectively, where indicates the n-th story line annotated by the expert group, and denotes discovered by the decomposition methods. However, these methods are not supervised, and their results do not correspond to the manually-annotated story lines. Thereby, we have to match the manual annotations with results of the decomposition methods. is determined by and . Finally, the measure is calculated by the harmonic mean of the precision and recall.
To exhibit the effectiveness of the proposed features, we also evaluated each feature’s contribution to the plot structure decomposition by conducting the ablation tests. Thus, we assessed the proposed methods’ accuracy in cases where only a part of the features was used. We have proposed the three features: The relative importance (
I, Definition 3), the average lengths of dialogues (
L, Definition 4), and the ratios of out-degrees for in-degrees (
A, Definition 5), and the assessment was conducted on all possible combinations:
I,
L,
A,
,
,
, and
.
Table 3 presents experimental results for 12 movies in our dataset.
The proposed methods distinctly outperformed the HMM-based method [
18] for most of the movies (in terms of the average
measure, 0.77 and 0.71). The HMM-based method exhibited better performance than the proposed one for only ‘Iron Man’ (2008) (
). By supposing the story lines as hidden states, this method learns conditional probabilities of story lines for characters’ occurrences. As discussed using our running examples (
Figure 3,
Figure 4 and
Figure 5), not all protagonists and main characters of a subplot appear in every scene of the subplot, and characters can be the protagonists and main characters of multiple subplots. As shown in
Figure 4b, after the proposed method extract the main plot of ‘Good Will Hunting’ (1997), ‘Will’ still has high relative importance in many remaining scenes. This point is the same for ‘Sean’, ‘Lambeau’, and ‘Chuckie’.
Thus, errors of the HMM-based method mostly occurred on the main plots of the movies. If a narrative work has a relatively simple main plot, or its characters are bound to specific story lines, the HMM-based method will perform at high accuracy. We can find these character relationships from stories describing conflicts between distinct sides (e.g., ‘Kung Fu Panda’ (2008) and ‘The Bourne Identity’ (2002) [
9]). However, the HMM-based method is too difficult to be generally applied to various types of stories.
The HMM-based method performed high recall, compared with its precision (on average, 0.77 and 0.66). The proposed methods also exhibited high recall and low precision (on average, 0.81 and 0.75). Nevertheless, the proposed methods’ gap between recall and precision was smaller than the two existing methods (Proposed: 0.06, HMM-based: 0.11, and Embedding-based: 0.09). The low precision of the HMM-based method could come from that this method overlooked that characters can be protagonists or main characters of multiple story lines. Its high recall also supports this conjecture. Although this method is useful for detecting scenes where protagonists and main characters of story lines appear, it will confuse cases where the protagonists and main characters appear in other story lines. Among the proposed features, the relative importance (I) is similar to the HMM-based method. However, the other two features can let the proposed methods know whether characters have similar personalities in both the target story line and the target scene.
The embedding-based method [
10] showed a similar but slightly lower performance than the proposed one (in terms of the average
measure, 0.75 and 0.77). As with the other two methods, the embedding-based one also exhibited a higher recall than precision (on average, 0.80 and 0.71). This also method outperformed the HMM-based method in terms of the average precision, recall, and
measure. This result shows that the relationships of characters are more effective for the plot structure decomposition than their occurrences. When the same characters appear on two scenes in different story lines, the characters’ occurrence frequencies of the two scenes are identical, but the characters will have different relationships in the two scenes.
There is one more tricky case, where only a part of characters related to a story line appear in its scene (e.g., small talks between minor characters). We conjectured that both proposed and embedding-based methods can deal with this case well since both methods can observe that the characters’ behaviors are different according to story lines. This conjecture was the same for the above problem (i.e., characters appearing in multiple story lines). However, the proposed methods outperformed the embedding-based method in terms of their precision (on average, 0.75 and 0.71), comparing with their similar recall (on average, 0.81 and 0.80). To find reasons for these unexpected results, we examined subplots extracted by the two methods. As shown in our running examples (
Figure 4 and
Figure 5), personalities and occurrences of characters were more constant in the subplots than in the main plot. Although we assumed that the main plot would show the most gradual changes of characters, the main plots were the noisiest among the story lines extracted from our dataset. Thus, the first iteration of the proposed methods was close to collecting ‘noisy’ scenes that do not fit on subplots. Nevertheless, the embedding-based method made a few meaningless story lines that consist of insignificant scenes (e.g., showing backgrounds).
Among the seven combinations of the proposed features (I, L, A, , , , and ), the case exhibited the highest performance in terms of the average precision, recall, and measure; was the second highest. Cases with I performed a higher accuracy than cases with A in terms of all three metrics. This result might come from that I had more distinct changes than A, as shown in running examples. Standard deviations of I and A values were 0.24 and 0.19, respectively. Among the I, L, and A cases, I exhibited the highest accuracy, and L performed the lowest accuracy in terms of all the three metrics. However, when L was used with the other features, it improved accuracy. Among the , , and cases, and exhibited the best and worst performance, respectively, in terms of all three metrics. This result indicates that personalty aspects reflected by L are also meaningful features for the plot structure decomposition. Additionally, cases with L exhibited a lower performance on ‘Iron Man’ (2008) () particularly. is only one action movie in our dataset, and the others are drama movies. Generally speaking, dialogues of action movies are shorter than drama movies. Thus, standard deviations of L values on and the other movies were 0.13 and 0.17, respectively. This low resolution might be the reason for the low accuracy.
This study has also proposed a method for distinguishing main plots from the other story lines. According to the manual annotations, all the movies in our dataset have a single main plot. Thus, evaluating accuracy of this method for each movie might be meaningless. The proposed methods for detecting main plots employs only two features:
L and
A. Also, among the existing studies, only Lee and Jung [
10] have proposed a method for discriminating main plots, to the extent of our knowledge. Therefore, we evaluated accuracy of the embedding-based method [
10] and three possible cases:
L,
A, and
.
The accuracy was assessed by the precision, recall, and
measure. The precision and recall were measured by
and
, respectively, where
M indicates a set of manually-annotated main plots and
denotes a set of automatically-discovered ones. The
measure was obtained by the harmonic mean of the precision and recall. As with the above experiment, whether an annotated main plot corresponds to a discovered one is determined by the number of scenes belonging to an intersection between them.
Table 4 presents experimental results for 12 movies in our dataset.
For discovering the main plots, all the cases exhibited the perfect accuracy. In interpreting this result, we have to consider two points. Since this experiment is for choosing a main plot from a few subplots, it is a simple task compared to the previous experiment that classifies a few hundreds of scenes into the subplots. Second, as discussed in
Section 3.2, the main plots are easily distinguishable, and the proposed method for discriminating main plots is to handle exceptions, such as omnibus movies. Therefore, this result shows that the main plots have distinctive differences from the subplots, rather than that the proposed and existing methods are effective. If we have reasonable measurements for the narrative significance and methods for the plot structure decomposition, we may not need complicated methods for distinguishing the main plots from the other story lines.
This result could come from that all 12 movies have a single main plot. If we conducted this experiment on narrative works with multiple main plots (e.g., omnibus movies), we might obtain different results. Also, our experimental subjects barely include action movies (only ; ‘Iron Man’ (2008)). Action movies (mainly Hollywood blockbusters) describe events by using characters’ behaviors rather than interactions between the characters. In lots of action movies, antagonists are hidden until their climaxes, and most of their scenes concentrate on the protagonists (e.g., ‘Bourne’ series). We assume that the proposed methods will not be able to show a high accuracy for Hollywood blockbusters. In future work, we will extend the diversity and amount of experimental subjects.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}