
Sequential Recommendations on GitHub Repository


Abstract
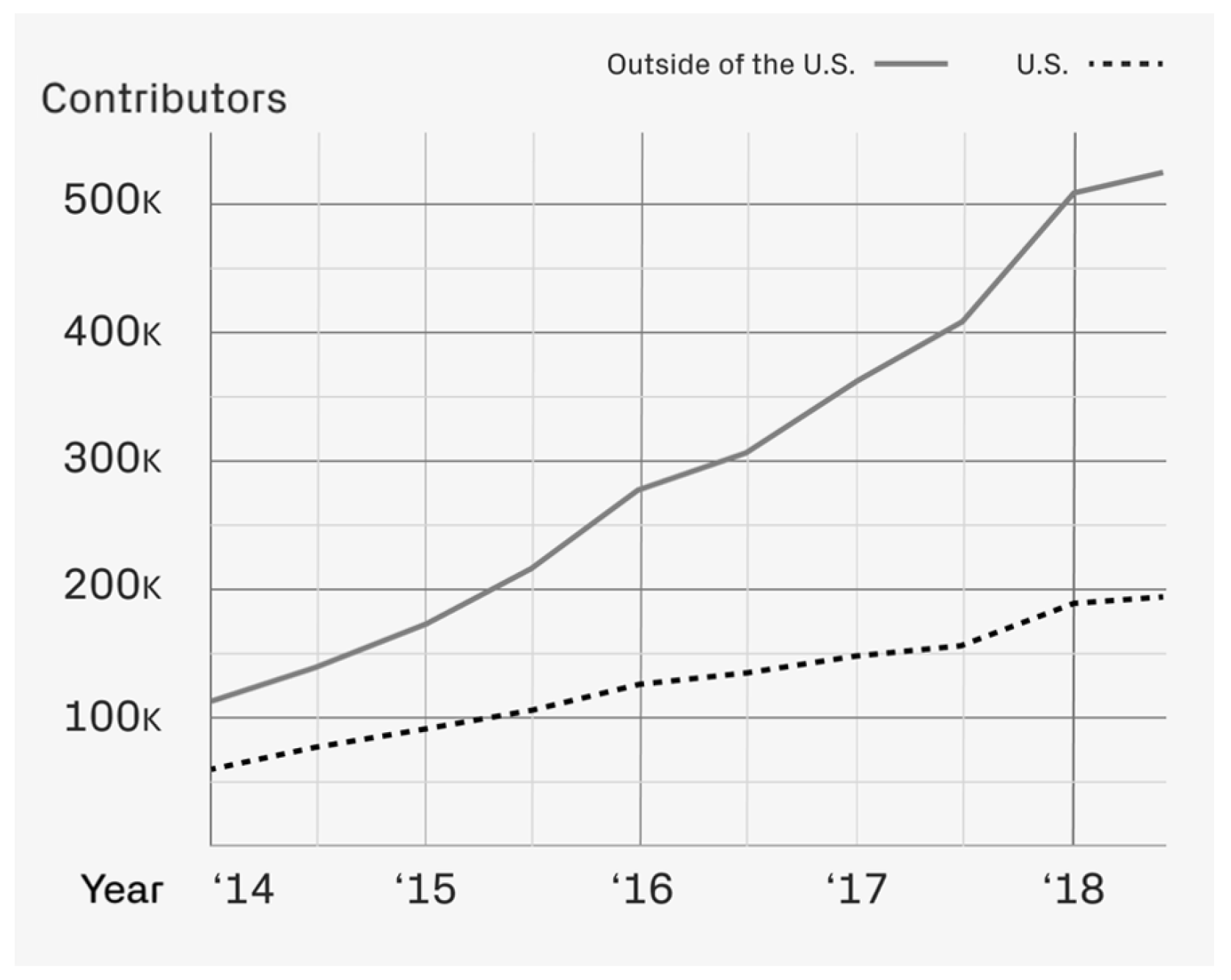
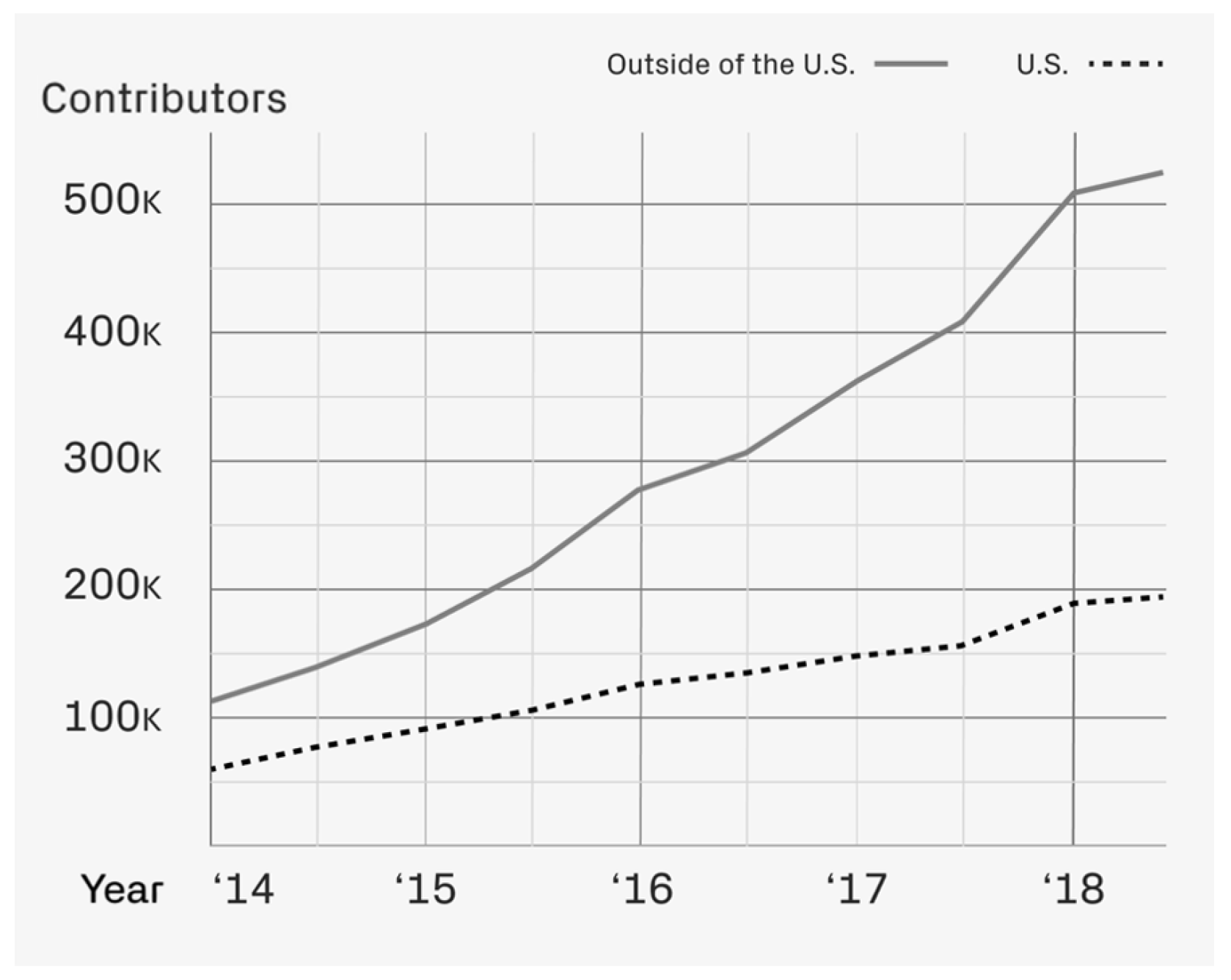
:1. Introduction
- As far as we are aware, we are the first to provide a large-scaled GitHub dataset for a recommendation system. We provide two different scales of the dataset, which contains approximately 19 million interactions with over 230,000 users and 102,000 repositories.
- We present an in-depth experiment on recommendations with the GitHub dataset.
- We introduce the potential of sequential recommendations in the researchers’ platform.
2. Related Works
2.1. Recommendations in GitHub
2.2. General Recommendation Systems
2.3. Sequential Recommendation Systems
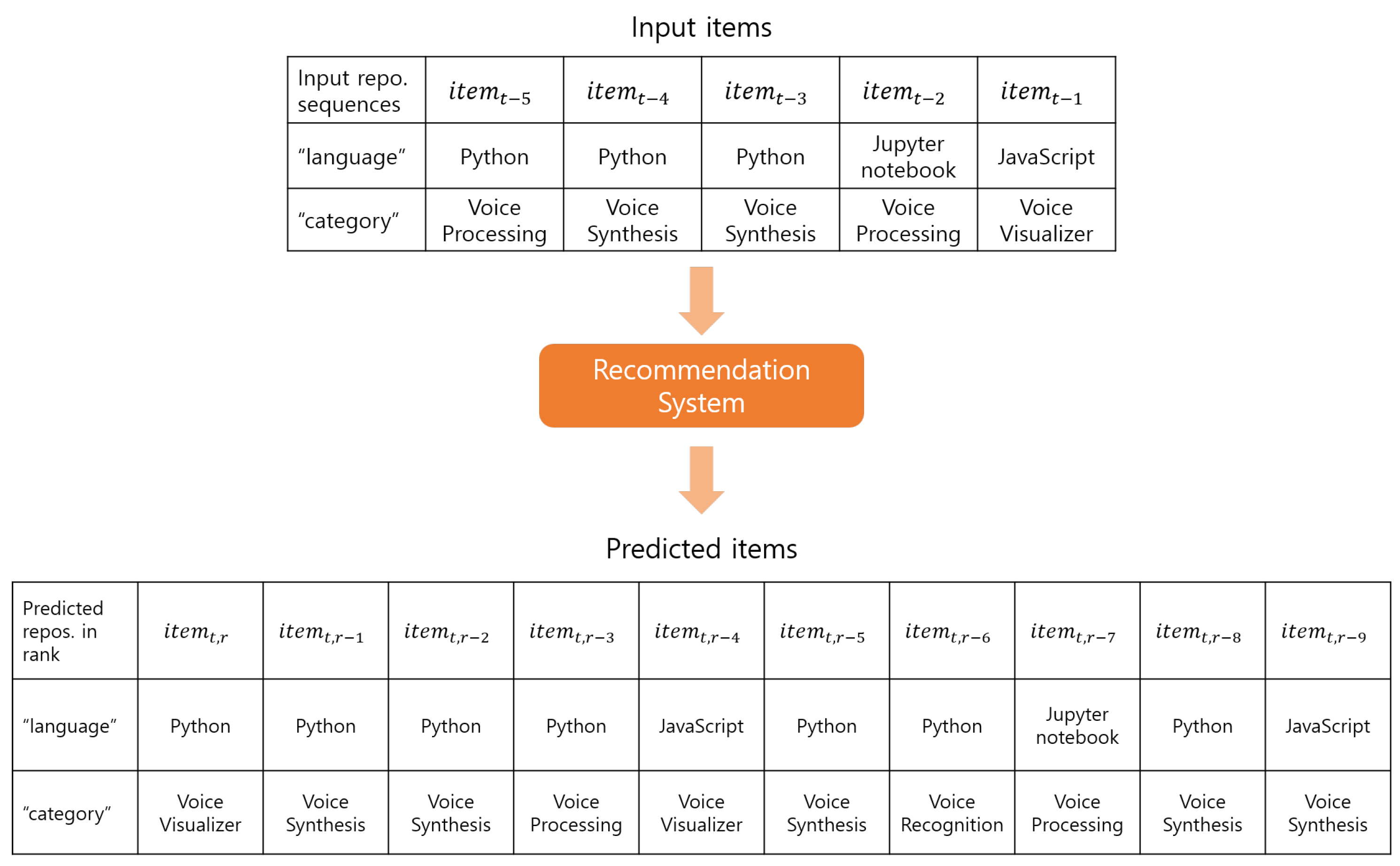
3. Dataset and Models
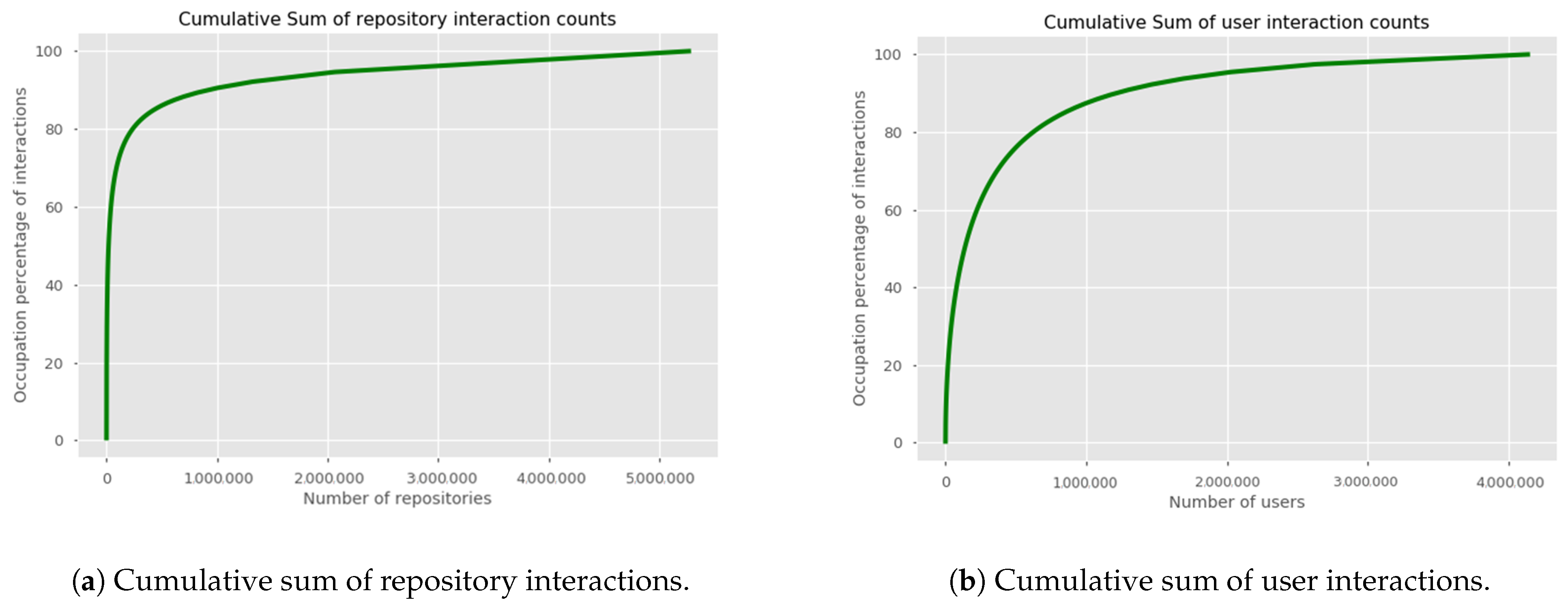
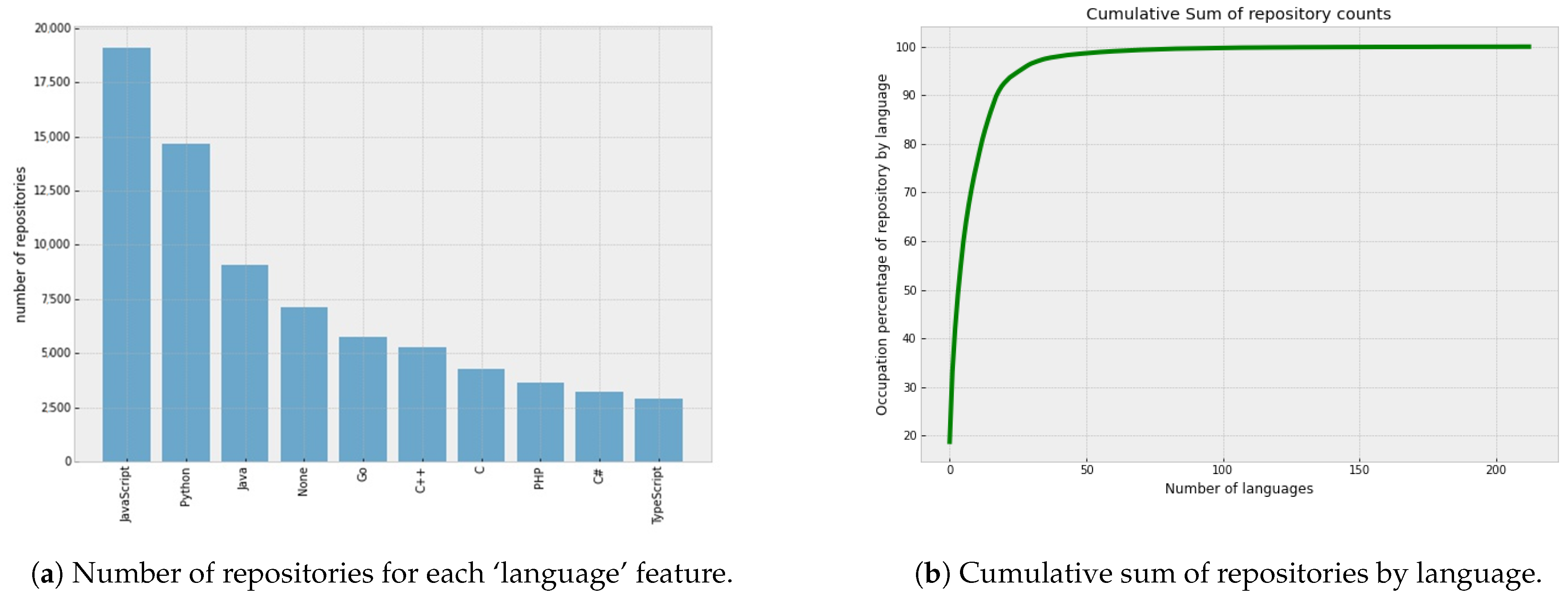
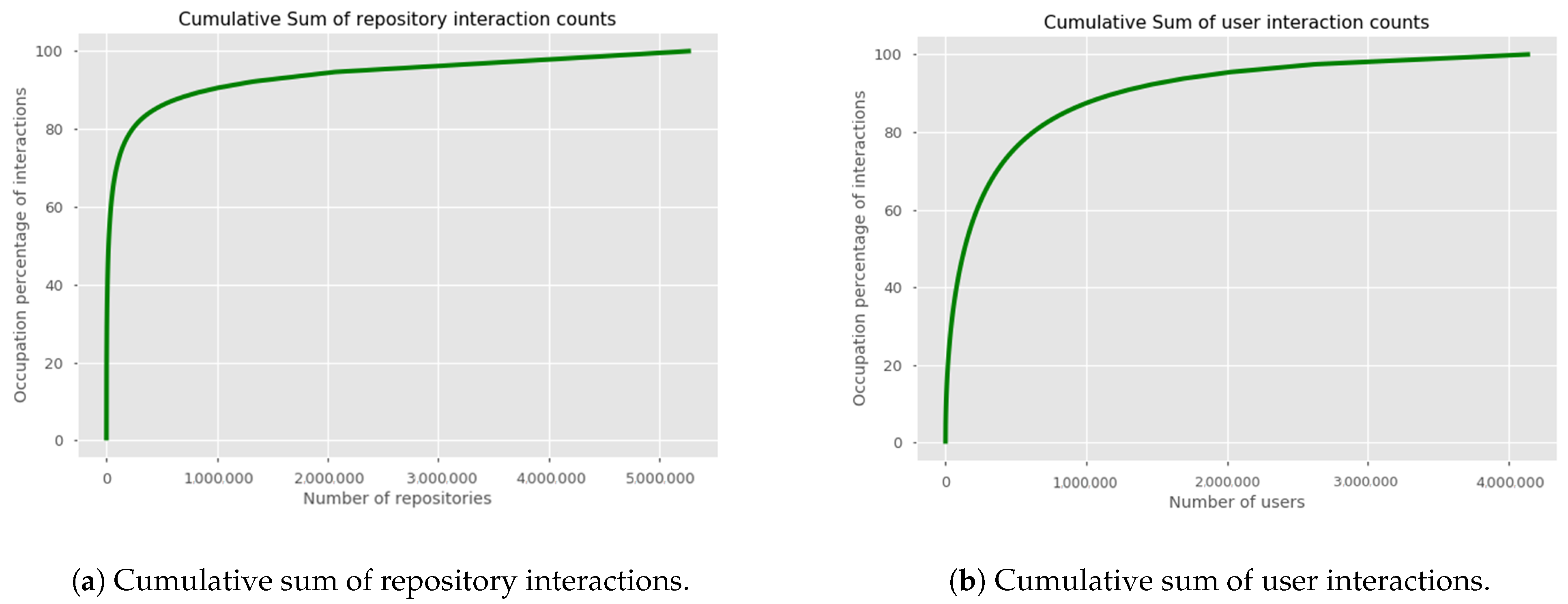
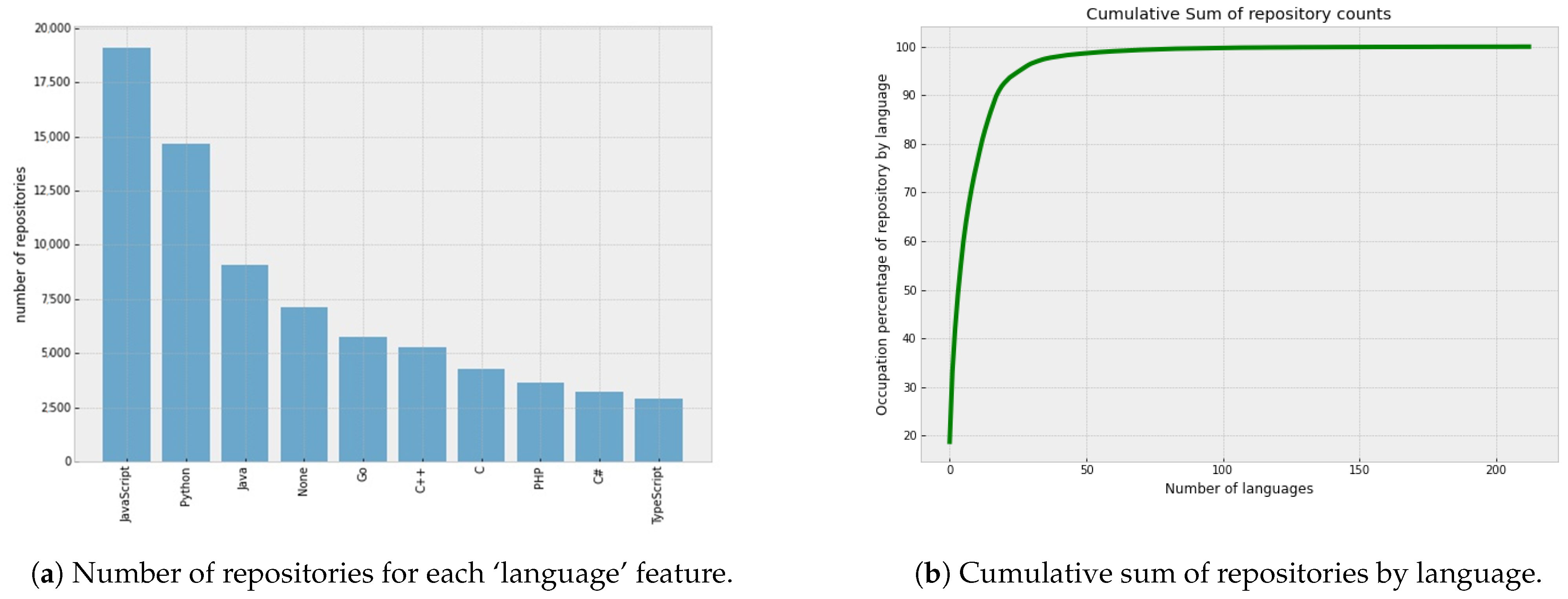
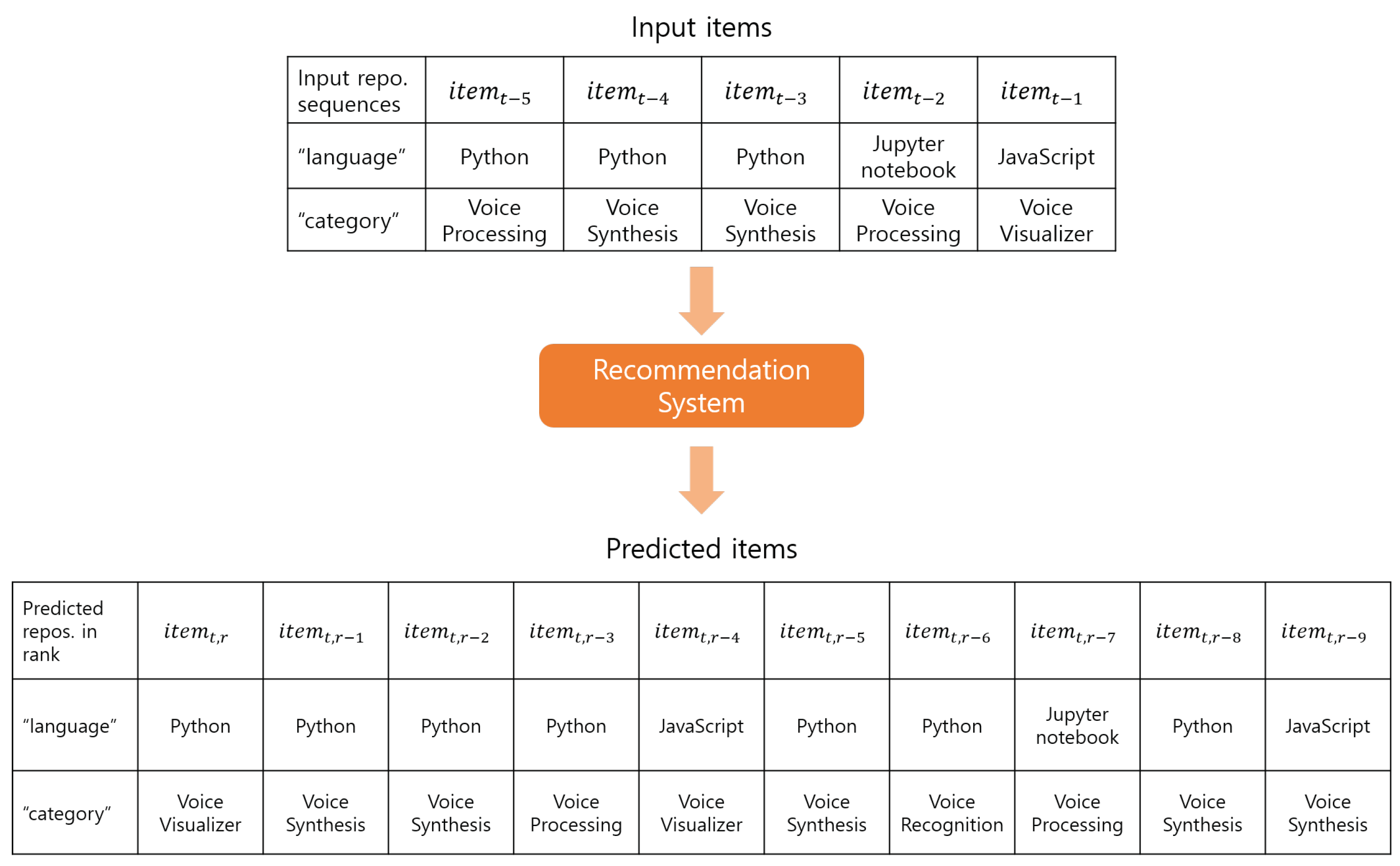
3.1. GitHub Dataset
3.2. Baseline Recommendation Models
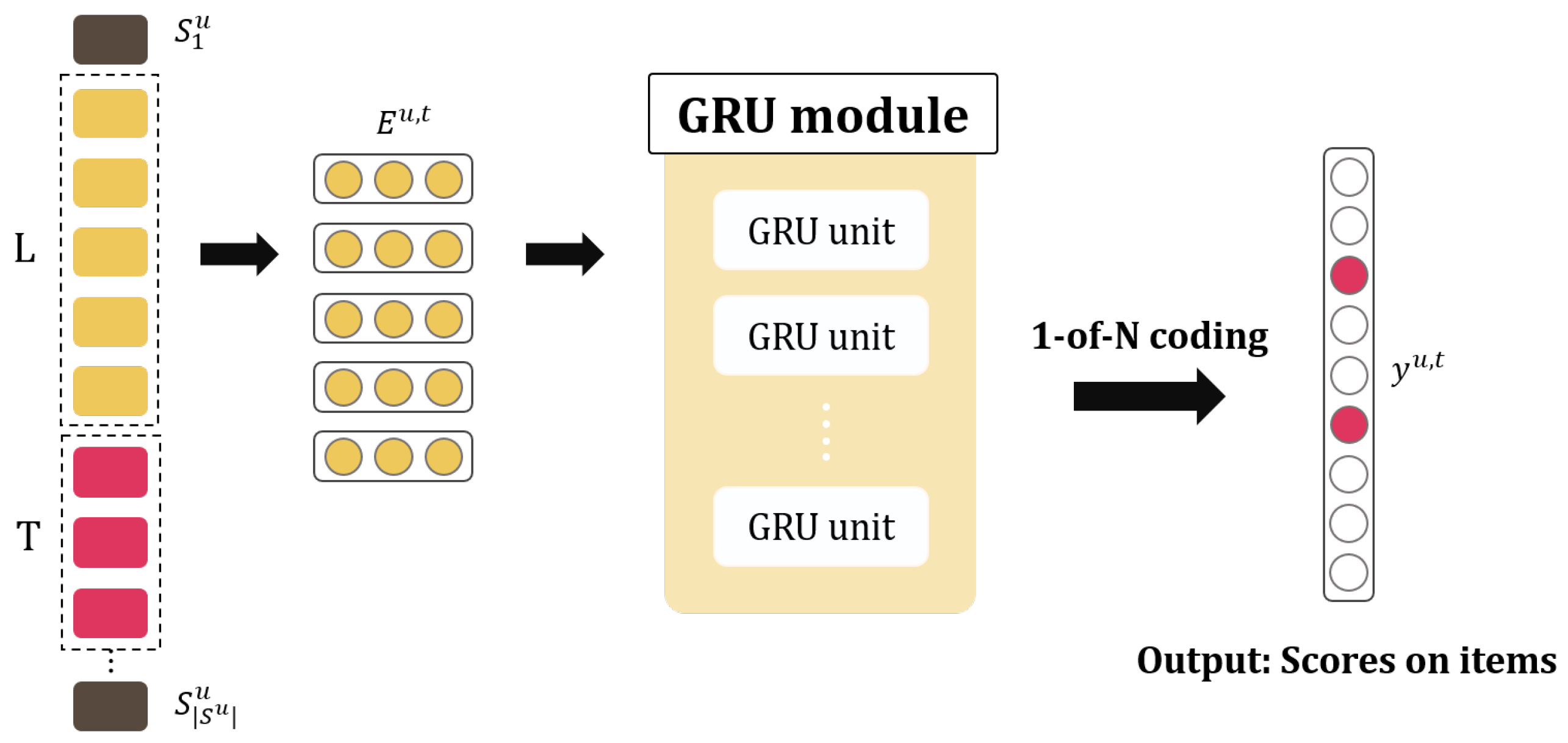
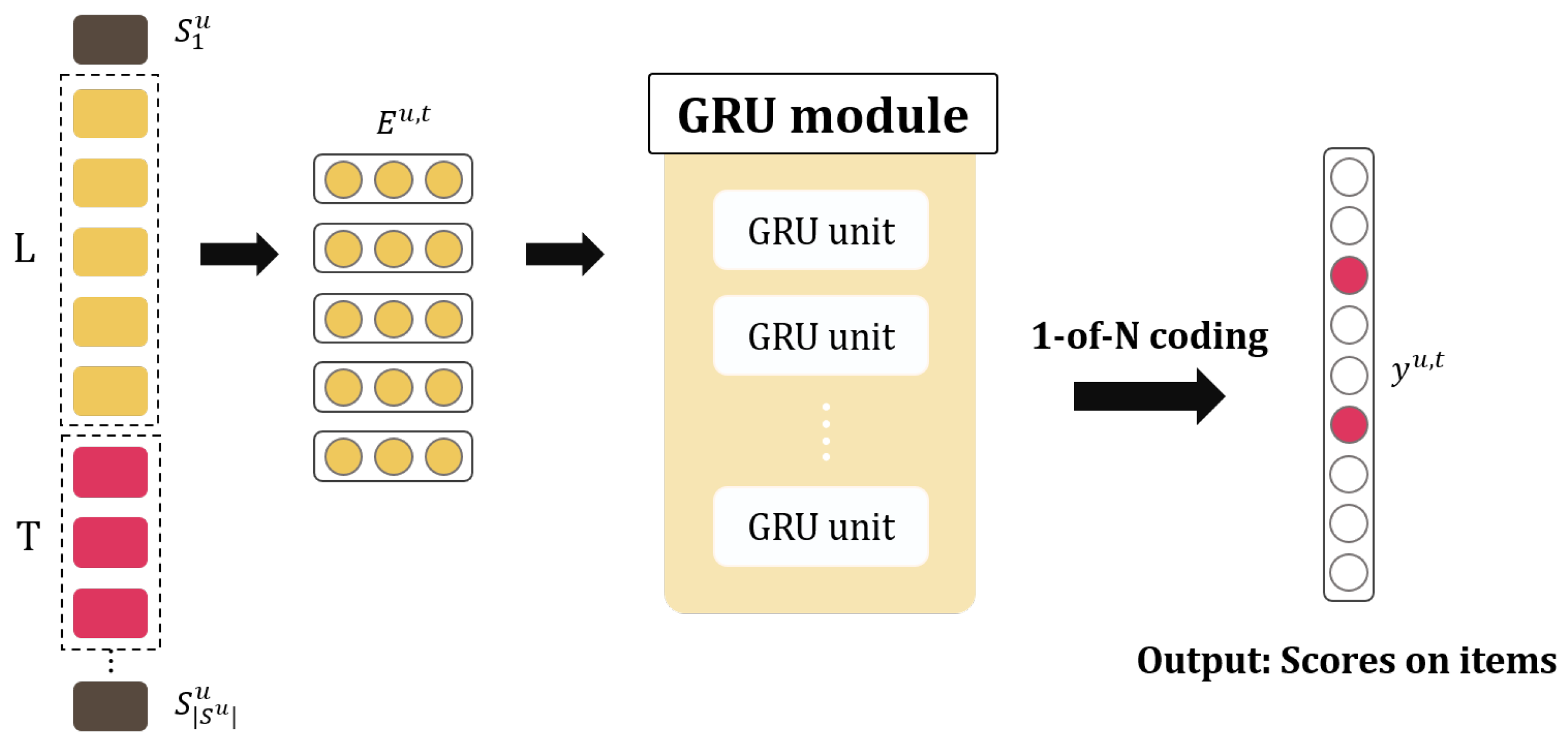
3.2.1. GRU4Rec
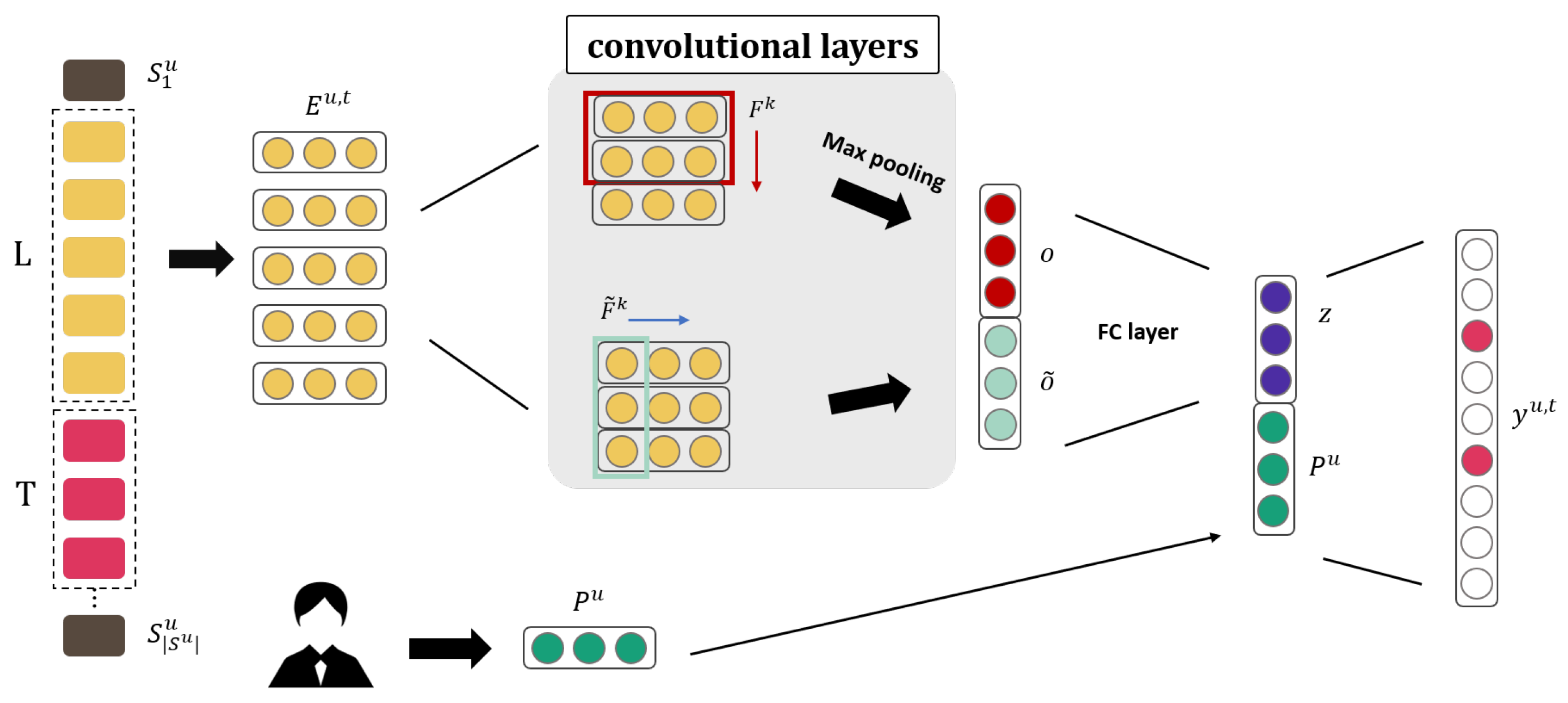
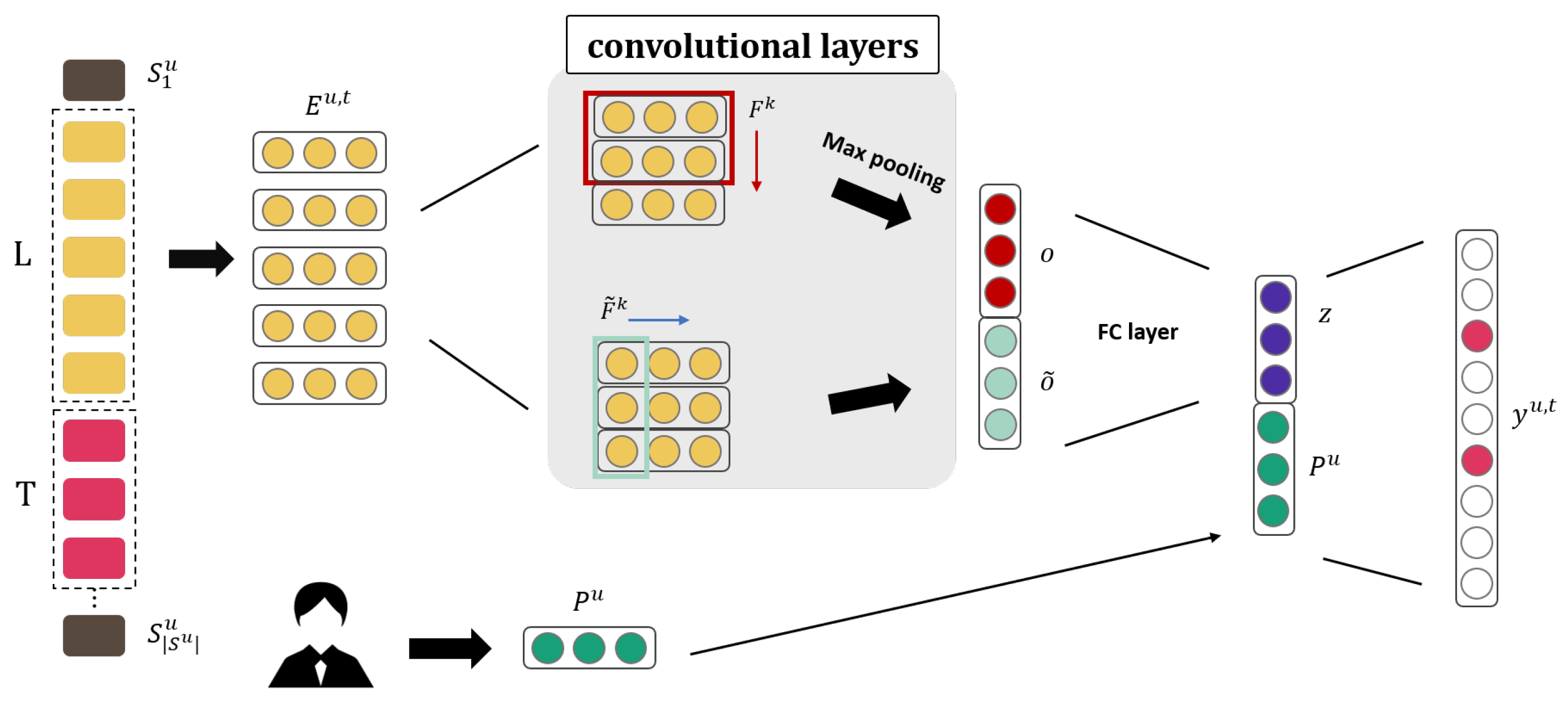
3.2.2. Caser
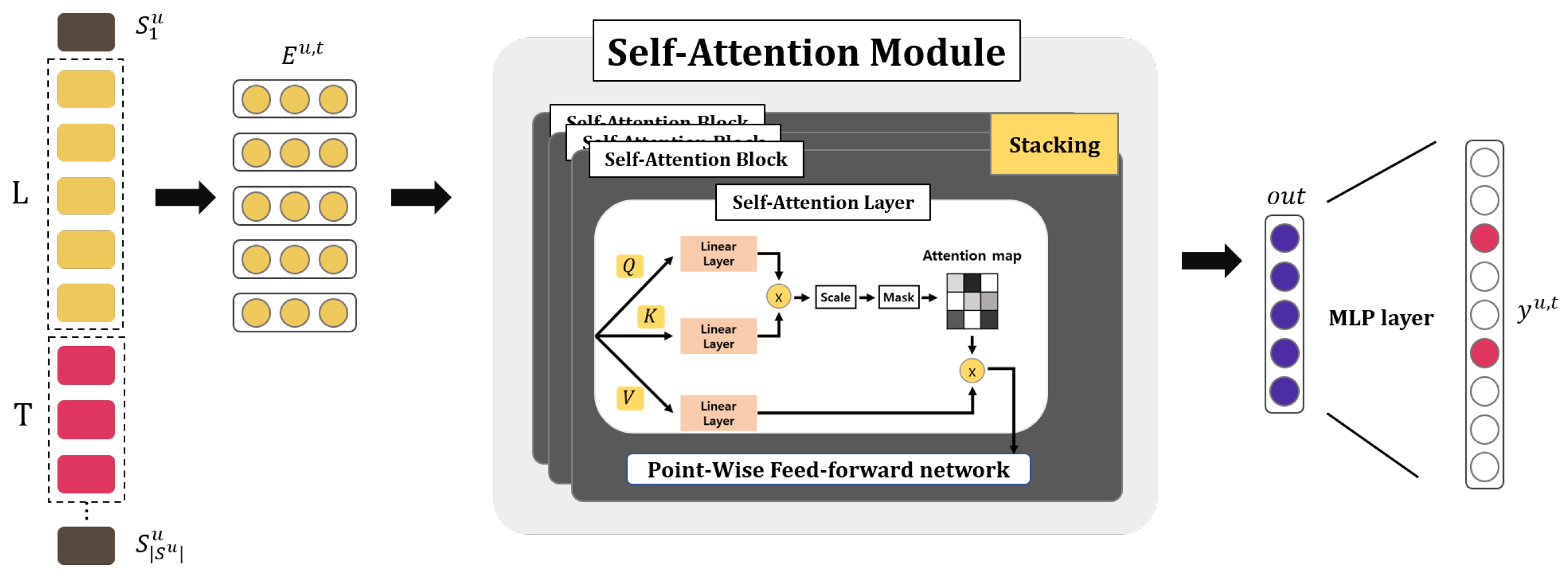
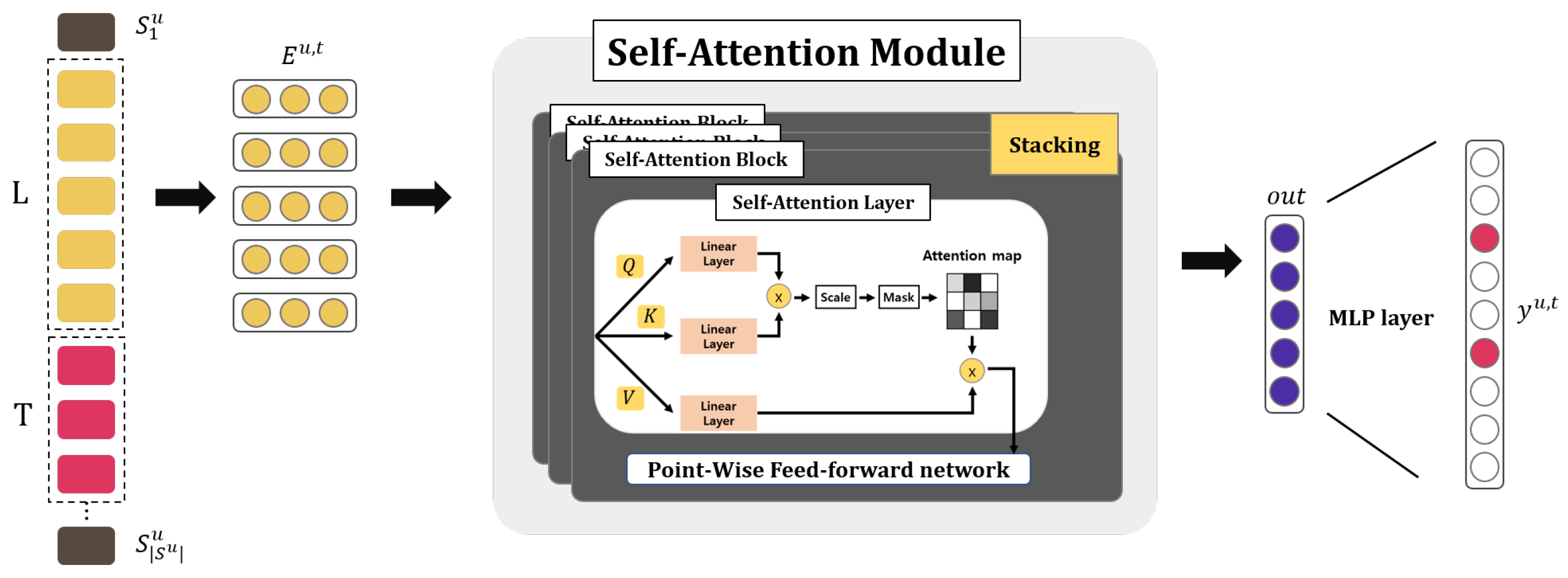
3.2.3. SASRec
4. Experiments
4.1. Experimental Setup
4.1.1. Dataset
4.1.2. Evaluation Metrics
4.2. Performance Analysis
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- He, X.; Liao, L.; Zhang, H.; Nie, L.; Hu, X.; Chua, T.S. Neural collaborative filtering. In Proceedings of the 26th International Conference on World Wide Web, Parth, Australia, 3–7 April 2017; pp. 173–182. [Google Scholar]
- He, X.; Chua, T.S. Neural factorization machines for sparse predictive analytics. In Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval, Tokyo, Japan, 7–11 August 2017; pp. 355–364. [Google Scholar]
- Guo, H.; Tang, R.; Ye, Y.; Li, Z.; He, X. DeepFM: A factorization-machine based neural network for CTR prediction. In Proceedings of the 26th International Joint Conference on Artificial Intelligence, Melbourne, Australia, 19–25 August 2017; pp. 1725–1731. [Google Scholar]
- Hidasi, B.; Karatzoglou, A.; Baltrunas, L.; Tikk, D. Session-based recommendations with recurrent neural networks. arXiv 2015, arXiv:1511.06939. [Google Scholar]
- Wu, C.Y.; Ahmed, A.; Beutel, A.; Smola, A.J.; Jing, H. Recurrent recommender networks. In Proceedings of the Tenth ACM International Conference on Web Search and Data Mining, Cambridge, UK, 6–10 February 2017; pp. 495–503. [Google Scholar]
- Xu, C.; Zhao, P.; Liu, Y.; Xu, J.; Sheng, V.S.S.; Cui, Z.; Zhou, X.; Xiong, H. Recurrent Convolutional Neural Network for Sequential Recommendation. In Proceedings of the World Wide Web Conference 2019, San Francisco, CA, USA, 13–17 May 2019; pp. 3398–3404. [Google Scholar]
- Chatzis, S.P.; Christodoulou, P.; Andreou, A.S. Recurrent latent variable networks for session-based recommendation. In Proceedings of the 2nd Workshop on Deep Learning for Recommender Systems, Como, Italy, 27 August 2017; pp. 38–45. [Google Scholar]
- Tang, J.; Wang, K. Personalized top-n sequential recommendation via convolutional sequence embedding. In Proceedings of the Eleventh ACM International Conference on Web Search and Data Mining, Marina Del Rey, CA, USA, 5–9 February 2018; pp. 565–573. [Google Scholar]
- Yuan, F.; Karatzoglou, A.; Arapakis, I.; Jose, J.M.; He, X. A Simple Convolutional Generative Network for Next Item Recommendation. In Proceedings of the Twelfth ACM International Conference on Web Search and Data Mining, Melbourne, Australia, 11–15 February 2019; pp. 582–590. [Google Scholar]
- Zheng, G.; Zhang, F.; Zheng, Z.; Xiang, Y.; Yuan, N.J.; Xie, X.; Li, Z. DRN: A deep reinforcement learning framework for news recommendation. In Proceedings of the 2018 World Wide Web Conference on Wolrd Wide Web, Lyon, France, 23–27 April 2018; pp. 167–176. [Google Scholar]
- Kang, W.C.; McAuley, J. Self-attentive sequential recommendation. In Proceedings of the 2018 IEEE International Conference on Data Mining (ICDM), Singapore, 17–20 November 2018; pp. 197–206. [Google Scholar]
- Sun, F.; Liu, J.; Wu, J.; Pei, C.; Lin, X.; Ou, W.; Jiang, P. BERT4Rec: Sequential recommendation with bidirectional encoder representations from transformer. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, Beijing, China, 19–23 October 2019; pp. 1441–1450. [Google Scholar]
- Wang, Y.; Wang, L.; Li, Y.; He, D.; Liu, T.Y. A Theoretical Analysis of NDCG Type Ranking Measures. In Proceedings of the 26th Annual Conference on Learning Theory, Princeton, NJ, USA, 12–14 June 2013; pp. 25–54. [Google Scholar]
- Portugal, R.L.Q.; Casanova, M.A.; Li, T.; do Prado Leite, J.C.S. GH4RE: Repository Recommendation on GitHub for Requirements Elicitation Reuse. In Proceedings of the 29th International Conference on Advanced Information Systems Engineering (CAiSE), Essen, Germany, 12–16 June 2017; pp. 113–120. [Google Scholar]
- Sun, X.; Xu, W.; Xia, X.; Chen, X.; Li, B. Personalized project recommendation on GitHub. Sci. China Inf. Sci. 2018, 61, 050106. [Google Scholar] [CrossRef] [Green Version]
- Shao, H.; Sun, D.; Wu, J.; Zhang, Z.; Zhang, A.; Yao, S.; Liu, S.; Wang, T.; Zhang, C.; Abdelzaher, T. paper2repo: GitHub Repository Recommendation for Academic Papers. In Proceedings of the Web Conference 2020, Taipei, Taiwan, 20–24 April 2020; pp. 629–639. [Google Scholar]
- Zhang, L.; Zou, Y.; Xie, B.; Zhu, Z. Recommending Relevant Projects via User Behaviour: An Exploratory Study on Github. In Proceedings of the 1st International Workshop on Crowd-Based Software Development Methods and Technologies, Hong Kong, China, 17 November 2014; pp. 25–30. [Google Scholar]
- Matek, T.; Zebec, S.T. GitHub open source project recommendation system. arXiv 2016, arXiv:1602.02594. [Google Scholar]
- Xu, W.; Sun, X.; Hu, J.; Bin, L. REPERSP: Recommending Personalized Software Projects on GitHub. In Proceedings of the International Conference on Software Maintenance and Evolution (ICSME), Shanghai, China, 17–24 September 2017; pp. 648–652. [Google Scholar]
- Xu, W.; Sun, X.; Xia, X.; Chen, X. Scalable Relevant Project Recommendation on GitHub. In Proceedings of the 9th Asia-Pacific Symposium on Internetware, Shanghai, China, 23 September 2017; pp. 1–10. [Google Scholar]
- Zhang, Y.; Lo, D.; Kochhar, P.S.; Xia, X.; Li, Q.; Sun, J. Detecting similar repositories on GitHub. In Proceedings of the 2017 IEEE 24th International Conference on Software Analysis, Evolution and Reengineering (SANER), Klagenfurt, Austria, 20–24 February 2017; pp. 13–23. [Google Scholar] [CrossRef]
- Zhang, P.; Xiong, F.; Leung, H.; Song, W. FunkR-pDAE: Personalized Project Recommendation Using Deep Learning. IEEE Trans. Emerg. Top. Comput. 2018, 1. [Google Scholar] [CrossRef]
- Rajaraman, A.; Ullman, J.D. Mining of Massive Datasets; Cambridge University Press: Cambridge, MA, USA, 2011. [Google Scholar]
- Defferrard, M.; Bresson, X.; Vandergheynst, P. Convolutional neural networks on graphs with fast localized spectral filtering. In Proceedings of the 30th International Conference on Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 3844–3852. [Google Scholar]
- Davidson, J.; Liebald, B.; Liu, J.; Nandy, P.; Van Vleet, T.; Gargi, U.; Gupta, S.; He, Y.; Lambert, M.; Livingston, B.; et al. The YouTube video recommendation system. In Proceedings of the Fourth ACM Conference on Recommender Systems, Barcelona, Spain, 26–30 September 2010; pp. 293–296. [Google Scholar]
- Koren, Y.; Bell, R. Advances in collaborative filtering. Recomm. Syst. Handb. 2015, 77–118. Available online: https://link.springer.com/chapter/10.1007/978-1-4899-7637-6_3 (accessed on 10 February 2021).
- Guo, Y.; Wang, M.; Li, X. An interactive personalized recommendation system using the hybrid algorithm model. Symmetry 2017, 9, 216. [Google Scholar] [CrossRef] [Green Version]
- Salakhutdinov, R.; Mnih, A.; Hinton, G. Restricted Boltzmann machines for collaborative filtering. In Proceedings of the 24th International Conference on Machine Learning, Corvalis, OR, USA, 20–24 June 2007; pp. 791–798. [Google Scholar]
- Sedhain, S.; Menon, A.K.; Sanner, S.; Xie, L. Autorec: Autoencoders meet collaborative filtering. In Proceedings of the 24th International Conference on World Wide Web, Florence, Italy, 18–22 May 2015; pp. 111–112. [Google Scholar]
- Wu, Y.; DuBois, C.; Zheng, A.X.; Ester, M. Collaborative denoising auto-encoders for top-n recommender systems. In Proceedings of the Ninth ACM International Conference on Web Search and Data Mining, San Francisco, CA, USA, 22–25 February 2016; pp. 153–162. [Google Scholar]
- Rendle, S.; Freudenthaler, C.; Schmidt-Thieme, L. Factorizing personalized markov chains for next-basket recommendation. In Proceedings of the 19th International Conference on World Wide Web, Raleigh, NC, USA, 26–30 April 2010; pp. 811–820. [Google Scholar]
- He, R.; McAuley, J. Fusing similarity models with markov chains for sparse sequential recommendation. In Proceedings of the IEEE 16th International Conference on Data Mining (ICDM), Barcelona, Spain, 12–15 December 2016; pp. 191–200. [Google Scholar]
- Zhang, C.; Wang, K.; Yu, H.; Sun, J.; Lim, E.P. Latent factor transition for dynamic collaborative filtering. In Proceedings of the 2014 SIAM International Conference on Data Mining, Philadelphia, PA, USA, 24–26 April 2014; pp. 452–460. [Google Scholar]
- Mikolov, T.; Karafiát, M.; Burget, L.; Černockỳ, J.; Khudanpur, S. Recurrent neural network based language model. In Proceedings of the Eleventh Annual Conference of the International Speech Communication Association, Makuhari, Japan, 26–30 September 2010; pp. 1045–1048. [Google Scholar]
- Liu, Q.; Zeng, Y.; Mokhosi, R.; Zhang, H. STAMP: Short-term attention/memory priority model for session-based recommendation. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 1831–1839. [Google Scholar]
- Li, J.; Ren, P.; Chen, Z.; Ren, Z.; Lian, T.; Ma, J. Neural attentive session-based recommendation. In Proceedings of the 2017 ACM on Conference on Information and Knowledge Management, Singapore, 6–10 November 2017; pp. 1419–1428. [Google Scholar]
- Kim, J.; Wi, J.; Jang, S.; Kim, Y. Sequential Recommendations on Board-Game Platforms. Symmetry 2020, 12, 210. [Google Scholar] [CrossRef] [Green Version]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CO, USA, 4–9 December 2017; pp. 5998–6008.
- Zhang, S.; Tay, Y.; Yao, L.; Sun, A. Next Item Recommendation with Self-Attention. arXiv 2018, arXiv:1808.06414. [Google Scholar]
- Kula, M. Spotlight. 2017. Available online: https://github.com/maciejkula/spotlight (accessed on 20 December 2020).
- Koren, Y. Collaborative filtering with temporal dynamics. In Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Paris, France, 28 June–1 July 2009; pp. 447–456. [Google Scholar]
- Bharadhwaj, H.; Joshi, S. Explanations for temporal recommendations. KI-Künstliche Intell. 2018, 32, 267–272. [Google Scholar] [CrossRef] [Green Version]
- Ying, H.; Zhuang, F.; Zhang, F.; Liu, Y.; Xu, G.; Xie, X.; Xiong, H.; Wu, J. Sequential recommender system based on hierarchical attention networks. In Proceedings of the 27th International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; pp. 3926–3932. [Google Scholar]
- Hidasi, B.; Karatzoglou, A. Recurrent neural networks with top-k gains for session-based recommendations. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management, Torino, Italy, 22–26 October 2018; pp. 843–852. [Google Scholar]
- Rendle, S.; Freudenthaler, C.; Gantner, Z.; Schmidt-Thieme, L. BPR: Bayesian personalized ranking from implicit feedback. arXiv 2012, arXiv:1205.2618. [Google Scholar]
- Marung, U.; Theera-Umpon, N.; Auephanwiriyakul, S. Top-N recommender systems using genetic algorithm-based visual-clustering methods. Symmetry 2016, 8, 54. [Google Scholar] [CrossRef] [Green Version]
- Pan, R.; Zhou, Y.; Cao, B.; Liu, N.N.; Lukose, R.; Scholz, M.; Yang, Q. One-class collaborative filtering. In Proceedings of the Eighth IEEE International Conference on Data Mining, Pisa, Italy, 15–19 December 2008; pp. 502–511. [Google Scholar]
- Tseng, P. Convergence of a block coordinate descent method for nondifferentiable minimization. J. Optim. Theory Appl. 2001, 109, 475–494. [Google Scholar] [CrossRef]
- Christodoulou, P.; Chatzis, S.P.; Andreou, A.S. A variational latent variable model with recurrent temporal dependencies for session-based recommendation (VLaReT). In Proceedings of the 27th International Conference on Information Systems Development, Lund, Sweden, 22–24 August 2018; pp. 51–64. [Google Scholar]
- Ferrari Dacrema, M.; Parroni, F.; Cremonesi, P.; Jannach, D. Critically Examining the Claimed Value of Convolutions over User-Item Embedding Maps for Recommender Systems. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management, online. 19–23 October 2020; pp. 355–363. [Google Scholar]
- Yu, J.; Yin, H.; Li, J.; Wang, Q.; Hung, N.Q.V.; Zhang, X. Self-Supervised Multi-Channel Hypergraph Convolutional Network for Social Recommendation. arXiv 2021, arXiv:2101.06448. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| GitHub Dataset | ||
|---|---|---|
| Feature | Type | Description |
| train | Interactions dataset | Note to refer to a custom spotlight file to explore each sequence of train dataset |
| valid | Interactions dataset | Note to refer to a custom spotlight file to explore each sequence of valid dataset |
| test | Interactions dataset | Note to refer to a custom spotlight file to explore each sequence of test dataset |
| repo_index2id | list | Even though it is in a list format it is used to retrieve unique ids within a custom spotlight file |
| user_index2id | list | Even though it is in a list format it is used to retrieve unique ids within a custom spotlight file |
| languages | list | A unique set of computer program languages list in all repositories |
| lang2id | dict | A python dictionary format with each language and its id |
| id2lang | dict | A python dictionary format with each repository id and its language id |
| descriptions | dict | A python dictionary format with each repository id and its text description |
| descriptions_parsed | dict | A python dictionary format with each repository id and list of its parse description ids |
| voca | list | A list of parsed vocabulary from repository descriptions |
| voca2id | dict | A python dictionary formation with parsed vocabulary and its unique id |
| Datasets | #Users | #Items | #Interactions | Avg.inter./User | Avg.inter./Item | Sparsity |
|---|---|---|---|---|---|---|
| ML 1M | 6022 | 3043 | 999,154 | 165.25 | 327.03 | 94.57% |
| ML 20M | 138,493 | 18,345 | 19,984,024 | 144.30 | 1089.34 | 99.21% |
| Beauty | 22,363 | 12,101 | 198,502 | 8.88 | 16.40 | 99.93% |
| Video Games | 108,063 | 31,390 | 21,105,584 | 9.54 | 21.72 | 99.38% |
| BGG [37] | 388,413 | 87,208 | 47,351,708 | 121.91 | 542.97 | 99.86% |
| GitHub | 4,135,902 | 5,264,307 | 59,765,590 | 14.45 | 11.35 | 99.99% |
| Descriptive Statistics | ||
|---|---|---|
| minimum number of interactions | 40 | 160 |
| number of interactions | 19,064,945 | 2,968,165 |
| number of unique users | 230,469 | 14,213 |
| number of unique repository | 102,004 | 8645 |
| data sparsity | 99.92% | 97.58% |
| average interactions per user | 82.72 | 208.83 |
| average interactions per repository | 196.9 | 343.34 |
| Models | n = 40 | n = 160 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Prec@10 | Recall@10 | MAP | MRR | NDCG@10 | Prec@10 | Recall@10 | MAP | MRR | NDCG@10 | |
| GRU4Rec | 0.0005 | 0.0004 | 0.0005 | 0.0003 | 0.0021 | 0.0102 | 0.0037 | 0.0069 | 0.0023 | 0.0391 |
| Caser | 0.018 | 0.019 | 0.014 | 0.010 | 0.067 | 0.043 | 0.017 | 0.020 | 0.009 | 0.145 |
| SASRec | 0.013 | 0.013 | 0.010 | 0.007 | 0.046 | 0.018 | 0.007 | 0.011 | 0.004 | 0.069 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, J.; Wi, J.; Kim, Y. Sequential Recommendations on GitHub Repository. Appl. Sci. 2021, 11, 1585. https://doi.org/10.3390/app11041585
Kim J, Wi J, Kim Y. Sequential Recommendations on GitHub Repository. Applied Sciences. 2021; 11(4):1585. https://doi.org/10.3390/app11041585
Chicago/Turabian StyleKim, JaeWon, JeongA Wi, and YoungBin Kim. 2021. "Sequential Recommendations on GitHub Repository" Applied Sciences 11, no. 4: 1585. https://doi.org/10.3390/app11041585
APA StyleKim, J., Wi, J., & Kim, Y. (2021). Sequential Recommendations on GitHub Repository. Applied Sciences, 11(4), 1585. https://doi.org/10.3390/app11041585