1. Introduction
A control flow graph (CFG) represents all paths of a program that might be traversed during execution and is a fundamental data structure in program analysis. In a CFG, nodes represent basic blocks of instructions and directed edges represent jumps in the control flow. The CFG lays foundation for many other program analysis techniques, such as data flow analysis [
1,
2], taint analysis [
3,
4], and symbolic execution [
5,
6,
7]. The CFG is also widely applied in program verification [
8,
9], malware detection [
10,
11,
12,
13], code similarity analysis [
14,
15,
16], and software vulnerability detection [
17,
18]. Therefore, utilizing appropriate approaches to construct complete and precise CFG is necessary.
However,
indirect jumps bring challenges to constructing complete CFGs [
19]. In C/C++ programs, a program’s jump can be categorized as direct or indirect. A direct jump has a statically specified target which points to a single location in the program, whereas an indirect branch has a dynamically specified target which may point to any number of locations in the program. Indirect jumps are commonly used to realize dynamic program behaviors by implementing common programming constructs, such as virtual function calls and calls through function pointers. Although indirect jumps are common and useful, due to their dynamic nature, it is usually difficult to resolve the target of an indirect jump through static analysis. This leads to inherent challenges in constructing complete CFGs.
Current solutions for CFG construction fall into three categories: static analysis, dynamic analysis, and hybrid analysis. Static techniques [
20,
21,
22] do not need to concrete execute of target programs, and only need to analyze the code to understand the program structure. The approaches can traverse the whole program code and has the advantages of high coverage and low time cost. Therefore, static analysis tools for constructing CFGs, such as IDA Pro [
20] for binary code and LLVM [
22] for source code, are widely applied in various program analyses. However, static techniques have poor completeness because it is difficult to resolve indirect jump relations statically.
Dynamic techniques execute programs on a set of test cases and extract the control flow information from the execution traces. The approaches can resolve a certain of indirect jumps and discover precise control flow. However, the completeness of the CFG constructed by the approaches depends on the capability of the test cases to cover indirect jumps. In order to improve the coverage of test cases, Xu et al. [
23] proposed to systematically force a program’s execution to explore both branches of each conditional. However, because forced execution is a heavyweight analysis technique, the approach still has poor coverage in analysis of large-scale programs.
In recent years, hybrid techniques [
24,
25,
26,
27] have been proposed to resolve indirect jumps that cannot be handled by pure static analyses, and to improve the completeness of CFGs. Babic et al. [
24] combined dynamic and static techniques to construct CFGs. They computed an underapproximation of the transition relation by resolving indirect jumps with a set of seed tests, and augmenting the computed relation with statically computed direct jumps. In their approach, the completeness of CFGs still depends on the coverage of the seed test cases. However, in their work, they only generated test cases randomly and did not study how to generate effective test cases. Zhu et al. [
26] proposed using
coverage-based gray-box fuzzing (CGF) to generate test cases to handle indirect jumps.
Gray-box fuzzing is a scalable and practical approach to software testing. It is widely applied to vulnerability detection and test case generation. Existing gray-box fuzzers usually use an evolutionary algorithm to generate test cases based on the feedback information from the execution. CGF is the most prevalent fuzzing scheme, which guides test case generation with the coverage information and aims to generate test cases which can achieve the maximum code coverage. CGF uses lightweight instrumentation to gain coverage information during runtime. Test cases exercising new path are added to the seed pool, and new test cases are generated by mutating the inputs in the seed pool. AFL is the state-of-the-art coverage-based gray-box fuzzer. It and its extensions have shown high practicability and scalability in vulnerability detection.
Zhu et al. [
26] used CGF for the first time in CFG construction and resolved a certain of indirect jumps. Nevertheless, the purpose of CGF is to improve the coverage of the whole program, not the coverage of indirect jumps. The approach spends a lot of resources to test the code unrelated to indirect jumps. Therefore, it cannot exercise indirect jumps efficiently, which resulting in the constructed CFG is not enough completeness.
In summary, the hybrid analysis is a promising approach to construct more complete and precise CFGs. How to generate test cases that exercise more indirect jumps is the key of hybrid approaches. In the state-of-the-art approach to constructing CFGs, the test case generation still faces the following problems.
Undirected. In order to resolve indirect jumps, the existing approaches use CGF to generate test cases. CGF seeks to increase the coverage of a seed tests for entire analyzed program rather than indirect jumps. However, stressing code unrelated to indirect jumps is a waste of resources in constructing CFGs. Therefore, CGF is considered to be undirected and unable to resolve indirect jumps efficiently in CFG construction.
Unsustainable. The existing CGF uses coverage information obtained during runtime to guide test case generation. Many previous work showed that CGF always reaches a “stuck” state because it cannot obtain new information in the later stage. In the state, testing is unable to generate test cases to cover new code and to exercise new indirect jumps.
In this paper, we propose a novel hybrid approach combining dynamic and static analysis to resolve indirect jumps and construct more complete CFGs for C/C++ programs. The approach is motivated by the observation that only a few jumps in programs are indirect, and directed testing of indirect jumps code may resolve more indirect jumps than CGF used in existing approaches. Instead of CGF, our key insight is to use directed gray-box fuzzing (DGF) to efficiently generate test cases that exercise indirect jumps.
DGF is an improvement of traditional gray-box fuzzing proposed by Böhme et al. [
28]. Its main idea is to focus on interesting parts of code, rather than to spend a lot of time on undirected exploration of the whole program like coverage-based fuzzing. Previous studies [
28,
29,
30,
31,
32,
33,
34] have shown that DGF has good practicability in the vulnerability detection. When testing large-scale programs, it can generate test cases to exercise the given targets more effectively than the coverage-based fuzzing.
More specifically, we first use static analysis to resolve direct jumps and construct static inter-procedural CFGs. Then, taking indirect jump locations as targets, DGF is used to generate test cases that can exercise as many indirect jumps as possible. We run the analyzed program with the generated test cases and resolve the indirect jump targets. Finally, the results of static and dynamic analysis are combined to construct the CFG with indirect control-flow transitions.
Our other observation is that the combined CFGs contains new structure information of the program, which can be used to further optimize the DGF-based test case generation. Therefore, we propose an iterative feedback mechanism to continuously optimize the input generation. The CFG constructed through multiple iterations is taken as the final output.
In summary, the ability of our approach to construct more complete CFG mainly depends on the following improvements: (1) the DGF technique is used to generate test cases that exercise indirect jumps instead of CGF, which can resolve more indirect jumps than undirected test cases generation used in existing approaches, and (2) an iterative feedback mechanism is proposed to continuously optimize the input generation, which alleviates the unsustainability of the existing approaches and further resolve more indirect jumps.
On the basis of the techniques, we implement a prototype, dubbed by DGF-CFGConstructor, for constructing CFGs of programs and evaluate it on eight benchmarks. In the experiments, we investigate the effectiveness of our DGF-based test case generation and the iterative feedback mechanism. The results demonstrate that our approach can resolve more indirect jump relations and construct more complete CFGs than existing approaches. As a preliminary step, we also evaluate the application of our techniques in real-world program analysis. The results show that our techniques is useful in discovering vulnerabilities deeply hidden in the code.
The main contributions of this paper are summarized as follows:
We proposed a novel hybrid approach to construct more complete CFGs by utilizing the DGF technique in test case generation.
We designed an iterative feedback mechanism to make a virtuous cycle between CFG combination and test case generation. The mechanism further improves the completeness of constructed CFGs.
We implemented a prototype for constructing CGFs and evaluated the effectiveness of our techniques through comparing with the existing approaches on eight benchmarks.
The remainder of this paper is organized as follows.
Section 2 presents that indirect jumps is widely distributed in real-world programs, which brings challenges to the CFG construction. The overview of the proposed approach is described in
Section 3.
Section 4 describes the details of the four key steps in our method. The implementation details of our prototype are presented in
Section 5.
Section 6 evaluates our techniques. We summarize the related work in
Section 7 and provide our conclusions in
Section 8.
3. Overview
In order to solve the aforementioned limitations in existing approaches, we propose a DGF-based hybrid approach to constructing CFGs. The approach aims to efficiently generate test cases that exercise indirect jumps and to construct more complete CFGs.
Figure 2 shows the overview of our proposed approach. The input is a program to be analyzed, which can be either source code or binary code. The output is the constructed inter-procedural control flow graph (iCFG) with indirect jumps. Our approach consists of three major components: static iCFG construction, DGF-based test case generation, and indirect jump monitoring.
Static iCFG construction. First, we use a static analysis to obtain the call graph (CG) of the program and CFGs of each function. There are some popular static tools that can be used to construct CG and functions’ CFGs, such as LLVM [
22] for source code and IDA Pro [
20] for binary code. Then, we combine the CG and CFGs to construct the iCFG. We present more details in
Section 4.1.
DGF-based test case generation. The main function of this component is to generate test cases that can exercise indirect jumps. First, a static analysis is used to search all indirect jump locations in the target program. Then, the indirect jump locations are taken as the targets to implement a distance-based DGF. DGF casts the reachability of target locations as optimization problem and minimizes the distance of the generated test cases to the targets. We collect the test cases that execute unique paths during the DGF and add them to the test case queue, which will be used in the following dynamic execution. The details of the test case generation are given in
Section 4.2.
Indirect jump monitoring. The purpose of this component is to execute the target program using the generated test cases and to resolve the target addresses of indirect jumps through runtime monitoring. First, we instrument the target program at each of indirect jump locations. When an indirect jump is triggered, the instrumented program can record its target address. Then, all test cases generated by DGF are provided to the target program in turn. We can obtain all indirect jump relations triggered during the execution. More details of the component are shown in
Section 4.3.
By combining the results of static iCFG construction and indirect jump monitoring, an iCFG with indirect jumps can be constructed.
We observe that a new iCFG is constructed with the test cases generated by DGF. However, the distance calculation in DGF in turn depends on the iCFG. The new iCFG contains the new structure information of the program, which can be used to further direct the test case generation. Therefore, we propose an
iterative feedback mechanism in CFG construction. The mechanism makes full use of the new information and further improves the completeness of CFGs. We present more details of the iterative feedback mechanism in
Section 4.4.
The workflow of our approach is shown in Algorithm 1. At the beginning of the algorithm, a static analysis is used to analyze the target program
p and to construct a static iCFG. Then, we search the locations of all indirect jump instructions in
p, and instrument each of them to obtain the instrumented program
. Next, the loop with iterative feedback starts at line 5. At the beginning of feedback loop, iCFG is set as static iCFG. Taking the locations of indirect jumps as the targets, DGF calculates the test case distance according to iCFG and generates test cases which are added to the test cases queue. Then, all instances in the test case queue are used to execute the instrumented program
, and the indirect jump relations are resolved through runtime monitoring. We update the iCFG by combining the new indirect jump edges with the original iCFG. The new iCFG are used as feedback to the DGF-based test case generation for next iteration, and lines 6–8 will be repeated. When a timeout is reached or the testing is aborted, the algorithm ends and outputs the iCFG updated in the last iteration.
| Algorithm 1: The workflow of DGF-based CFG construction. |
 |
4. Methodology
This section elaborates the three key components and the iterative feedback mechanism in our approach.
4.1. Static CFG Construction
The main function of the component is to construct the iCFG for target program using static analyses. First, we construct CG and the function’s CFGs. The CG of a program consists of the nodes representing functions and edges representing function calls. For each function, we construct a CFG in which nodes represent basic blocks and edges represent jumps among basic blocks. Some static analysis tools can provide the function to obtain CG and CFGs, such as LLVM’s built-in APIs for source code and IDA Pro for binary code.
Based on the CG and CFG, we can construct iCFG by connecting all call-sites with the first basic block of the called functions.
Figure 3 shows an example of the static iCFG construction. The gray basic blocks represent the basic blocks ending with call instructions. For call-site
a, we can resolve the called function
. Then, the edge from call-site to the first basic block of called function,
, is added to connect the CFGs of
and
. Similarly, we can connect the CFGs of all functions according to the call relations to get the iCFG. It should be noted that the indirect jump edges are not included in the constructed iCFG because static tools cannot resolve them. In the following steps, we adopt dynamic analysis to resolve indirect jumps and augment the iCFG.
4.2. DGF-Based Test Case Generation
The test case generation is the core part in our approach, and its main function is to generate test cases that can exercise as many indirect jumps as possible. Aiming at the undirectedness of CGF that is used in the test case generation of existing CFG construction approach, we propose employing the distance-based DGF technique instead of CGF to generate test cases.
We introduce the DGF technique into the test case generation of CFG construction to resolve more indirect jumps. The main idea is to take the indirect jump locations as the targets of DGF and calculate the distance of each seed to the target code. According the distance, we evaluate the priority of seed in fuzzing evolution. Seeds closer to indirect jump locations gain higher priority. Therefore, the seed set evolves closer to indirect jump locations and may trigger more indirect jumps.
Figure 4 shows the workflow of the test case generation based on DGF. The test case generation contains two phases: distance calculation and fuzzing loop.
4.2.1. Distance Calculation
The seed distance calculation is introduced from AFLGo [
28], and it can determine the importance of the seed. The calculation is based on the constructed iCFG and consists of the following three steps.
(1)
Function-level distance on CG. If a function contains indirect jump instructions, it is taken as target function. The set of all target functions is represented as
. We use
to represent the distance between any two functions on CG, i.e., the number of edges on the shortest path between the two functions. The function-level distance determines the distance between an arbitrary function to all target functions. Supposing a function
f and target functions
are given, the function-level distance of
f, represented as
, is defined as the harmonic mean of the distance between the function
f to all target functions as follows.
where
is the set of functions that are members of
and are reachable from
f.
(2)
Basic block-level distance on iCFG. The basic blocks containing indirect jump instructions are called target basic blocks. The set of all target basic blocks is represents as
. We use
to represent distance between any two basic block. In a function, the distance is the number of edges on the shortest path between the two basic blocks on the CFG. The basic block-level distance determines the distance from an arbitrary basic block to target basic blocks, which is represented as
. Based on the function-level distance, the basic block-level distance is calculated as follows.
where
is the set of all basic blocks in function
f.
is a constant that represents the average length of functions in distance calculation.
T represents a set of special basic blocks that we call
transfer basic blocks. A transfer basic block should satisfy the following conditions: (a) the basic block ends with a call instruction and (b) the target function called by the call instruction can reach the target functions on CG.
(3)
Seed distance. Based on the basic block-level distance, the distance from an arbitrary seed
s to the target basic blocks is calculated and represented as
. More specifically, the seed distance is defined as the average distance of all basic blocks on the seed execution trace, i.e.,
where
is the set of basic blocks on the execution trace of the seed
s.
An example is taken to describe the basic block-level distance calculation in
Figure 5. In the example,
a is the considered basic block and
f is the target block. The gray basic blocks
b and
d are transfer basic blocks. According to the iCFG, there is a reachable path from
a to
f, i.e.,
. Therefore, the basic-block-level distance from
a to the target block
f is calculated as follows.
The distances of function-level and basic-block-level (steps (1) and (2)) are calculated by static analysis. Only the seed distance calculation (step (3)) needs to be performed at runtime and instrumented into target programs.
4.2.2. Fuzzing Loop
Our fuzzing loop (the right part of
Figure 4) is modified based on the classical gray-box fuzzing loop. The difference is that the purpose of the existing fuzzing is to find program vulnerabilities, while the purpose of our fuzzing is to generate test cases that exercise more indirect jumps. The workflow of our fuzzing loop is shown in Algorithm 2.
| Algorithm 2: The fuzzing loop of test case generation. |
 |
The fuzzing loop takes an initial seed set as input. In each loop, one seed s is chosen from S and assigned energy according to the seed distance. The energy represents the priority of seeds in the fuzzing evolution. The seeds closer to the targets (indirect jump locations) can obtain more energy and have more chances to generate test cases by mutating. Therefore, the mutation may generate test cases closer to the indirect jump locations in the next loop. Then, the program instrumented with seed distance calculation executes with the test cases and evaluates each of them. The seed pool S is updated according to the results of the evaluation. By repeating the above steps, we can continuously update the seed pool to make the inputs closer to indirect jump locations. The fuzzing loop runs until a timeout or abort signal is received. Finally, all seeds in the evolved seed pool are output to the test case queue, which will be used to resolve indirect jump relations.
4.3. Indirect Jump Instrumentation and Monitoring
With the seed tests generated above, we execute the target program and monitor it at runtime to discover indirect jumps relations. First, in order to record indirect jump relations, the target program is instrumented at each indirect jump instruction and the entry of each function. We define a global value
to represent whether a function call is an indirect jump. At each indirect jump instruction, when the instruction is executed,
is assigned to
and the basic block that the indirect jump instruction belongs to is recorded as the source of the indirect jump, represented as
. At the entry of a function, we check the value of
. If it is
, the first basic block of this function is recorded as the target of the indirect jump, represented as
. A indirect jump relation is represented as a pair
. Then, we provide all seed test cases generated in the previous stage (
Section 4.2) to the instrumented program and resolve as many indirect jump relations as possible.
It is worth mentioning that we perform two different instrumentations for the original target program. One is to calculate the seed distance, while the other is to record the indirect jump relations. Theoretically, both of them can be performed in the process of fuzzing. However, inserting too many instructions in fuzzing may cause a lot of runtime overhead. Therefore, our approach separates the two instrumentations to minimize the overhead.
4.4. Iterative Feedback Mechanism
A new and more complete iCFG can be constructed by adding the discovered indirect jump edges
to the old iCFG. We observed that the combined iCFG contains new structure information of the target program and can be used to optimize the DGF-based test case generation (
Section 4.2). Therefore, we propose an iterative feedback mechanism to achieve a virtuous cycle between CFG combination and input generation and continuously improve the completeness of CFGs.
The key problem of iterative feedback mechanism is how to recalculate the seed distance on the new iCFG. If we simply use the approach in
Section 4.2.1 to recalculate the distance, it will bring redundant time overhead. To minimize the overhead, we develop an incremental calculation to update the distance.
Figure 6 shows an example of updating the distance adopting the incremental calculation. The node
t is the target basic block. The solid lines represent the jump edges in the old iCFG and the dash line
represents the newly discovered indirect jump edge. Because the new edge changes the structure of the iCFG, the basic block-level distance needs to be updated.
Through observation, it can be found that the new edge only affects the distance of the basic blocks before the edge on iCFG, but not the distance of the basic blocks after the edge. Therefore, we only need to calculate the distance of the precursors of the source basic block of the edge. In the example, the distances of
a and
b need to be recalculated, while the distances of
c and
d do not. The updated results of the example are shown in
Table 2.
4.5. Illustrating with Examples
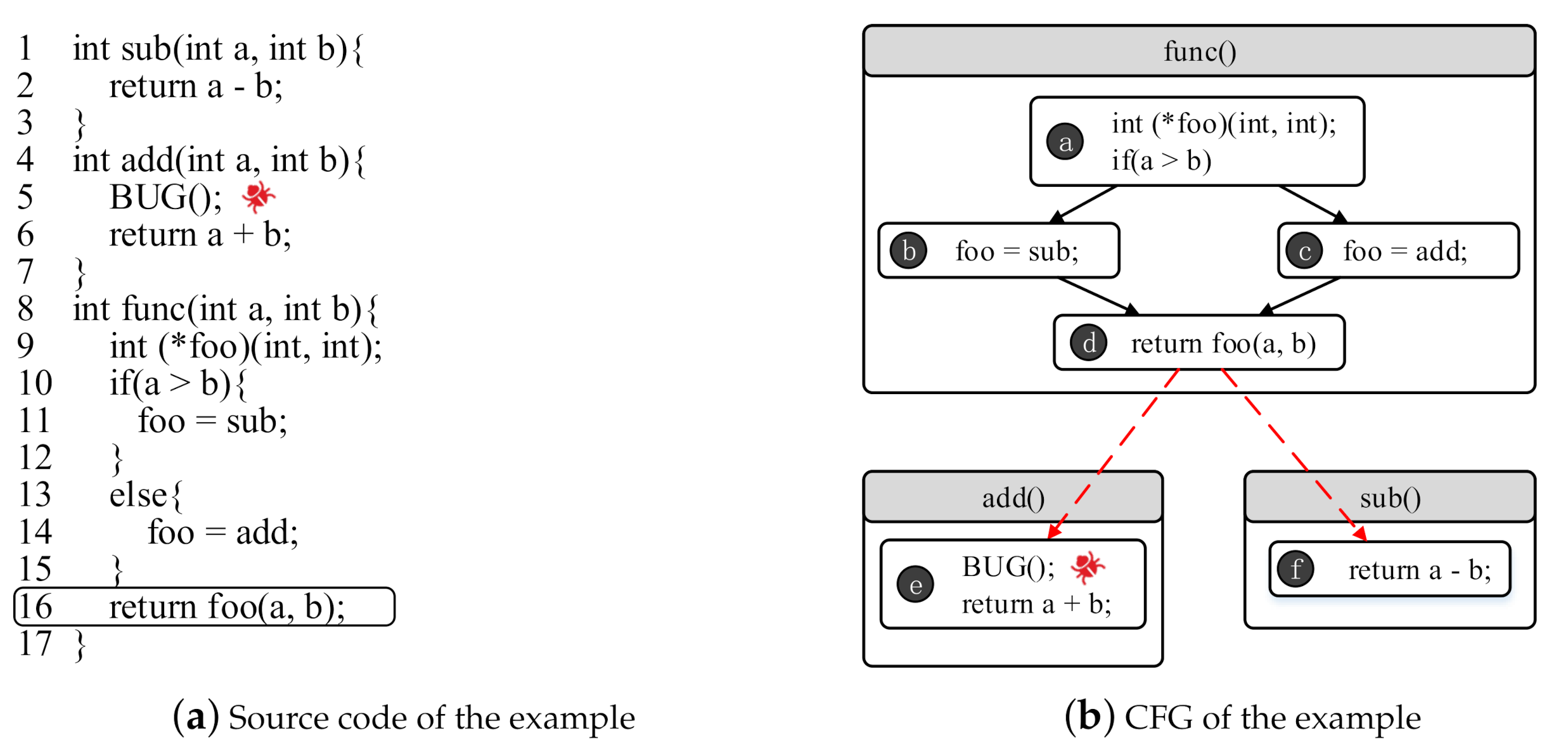
In this section, let us discuss the motivating example in
Figure 1 again. As we noted above, the edges
and
are indirect jumps, and
determine whether the vulnerability in function
can be discovered successfully. If we use LLVM’s APIs to construct the CFG for this example, the constructed CFG will not contain the two indirect jump edges, which leads to the failure to discover the vulnerability.
On the contrary, we can find the vulnerability by using our proposed approach. First, we construct the static CFG which is the same as the CFG constructed by existing tools, and still does not contain the indirect jumps. Then, with the indirect jump location (line 16) as the target, a DGF is conducted to attempt to generate test cases that exercise the indirect jump instruction. Through using different test cases to execute and monitor the target program, the indirect jump relations can be resolved. If a test case that satisfies the constraint in line 10 is generated, such as , the edge will be discovered. On the other hand, the edge can be discovered when a test case that violates the constraint is generated, such as . Thus, we can construct a CFG that contains indirect jumps and discover the vulnerability based on the CFG.
For the simple example, it is easy to generate a test case that satisfies the constraint to exercise the indirect jump. In such case, DGF-based and CGF-based test case generations have similar performance. However, in real-world programs, constraints may be so complex that it is difficult to generate test cases that satisfy the constraints through undirected approach. Our DGF-based test case generation can show advantages in handling complex programs, which will be presented in
Section 6.
5. Implementation
Based on the proposed approaches, we develop a prototype, dubbed DGF-CFGConstructor. The implementation details of each component are as follows.
Static CFG Construction: We build up the CG and CFG based on LLVM’s IR. In the CG, functions are taken as the nodes of the graph and identified by functions’ signatures. We discover the CG’s edges through analyzing all call instructions. Specifically, if the jump address of a call instruction can be determined by the LLVM’s API
, the jump relation should be added to the CG as an edge. Otherwise, the call instruction is considered as an indirect jump location. In addition, we can obtain the CFG of each function by another LLVM’s API
. Then, the static iCFG is constructed by combining the CG and CFGs according to the method in
Section 4.1.
DGF-based Test Case Generation: The DGF-based test case generation is established on AFLGo. The indirect jump locations are considered as the target sites. We calculate the basic block-level distance calculation in a Python script and instrument the seed distance calculation in a LLVM’s . In order to balance the exploration and exploitation, we retain the annealing-based power schedules in AFLGo.
Indirect Jump Instrumentation and Monitoring: The DGF-Constructor records the executed indirect jump relations by instrumenting at the indirect jump locations and the entry of each function. The instrumentation is implemented in another LLVM’s . When a indirect jump is triggered, the relevant jump relation is recorded to a file. After all test cases are executed, we can obtain all indirect jump relations discovered at runtime in the result file.
It should be noted that although the prototype is implemented to analyze the source code at present, in principle, our techniques are also suitable for binary code. We will extend it to binary analysis by replacing the corresponding tools in the further work.
6. Evaluation
In this section, we evaluate our approach on various real-world programs and compare it with related approaches.
6.1. Evaluation Setup
We designed the experiments to answer the following four research questions:
RQ1: Does the DGF-based test cases generation work as expected to generate more test cases that exercise indirect jumps than existing approaches?
RQ2: How effective is the iterative feedback mechanism in resolving indirect jumps?
RQ3: How complete is the CFG constructed by our approach?
RQ4: What are the benefits of applying our approach to program analysis?
Evaluation Benchmarks. We evaluated DGF-CFGConstructor with 8 real-world programs; the relevant information is shown in
Table 3. These benchmarks are selected according to the evaluations in the related works [
28,
29,
35,
36].
Experimental Infrastructure. All experiments were conducted on a machine equipped with Intel(R) Core(TM) i7-6700 CPU @ 3.40 GHz with 8 cores and 64 GB RAM, running 64-bit Ubuntu LTS 16.04.
6.2. Evaluation of DGF in CFG Construction (RQ1)
In order to evaluate the effectiveness of DGF in discovering indirect jumps, we implement and compare two CFG constructors.
DGF-CFGConstructor (ours). It is our prototype that is implemented based on our proposed approaches, i.e., the DGF-based test case generation and iterative feedback mechanism. In the DGF-based test case generation, we adopt the annealing-based power schedules and set time-to-exploitation to one hour.
CGF-CFGConstructor. It is identical to our prototype except for the test case generation approach. The CFG constructor employs the CFG-based approach proposed in [
26].
We use the two CFG constructors to analyze the eight benchmarks for 20 h.
Figure 7 shows the trend of the number of indirect jumps discovered by the two approaches in the experiment.
Figure 8 shows the statistical results after 20 h. Based on the results, we observe the following cases.
In the early phase of the analysis (about the first 2 h), the number of indirect jump relations discovered by DGF-CFGConstructor (the red line) is similar to that discovered by CGF-CFGConstructor (the blue line). The reason is that DGF-CFGConstructor adopts the annealing-based power schedules. The weight of the seed distance in energy assignment is zero at the beginning and increases with the testing time. Therefore, the two implementations have similar performance in the early phase.
After the early phase, the number of indirect jump relations discovered by DGF-CFGConstructor on 7 out of 8 benchmarks (except libpng) shows a better increase than that discovered by CFG-CFGConstructor.
The statistical results in
Figure 8 shows that DGF-Constructor (the red bar) discovers more indirect jump relations than CFG-Constructor (the blue bar). For example, in the analysis of libxml2, CGF-CFGConstructor discovers 821 indirect jump relations. DGF-CFGConstructor is able to discover 1480 indirect jump relations, 80.3% more than CGF-CFGConstructor. On average, DGF-CFGConstructor discovers 61.9% more indirect jump relations than CGF-CFGConstructor on the eight benchmarks.
In the analysis of libpng, DGF-CFGConstructor and CGF-CFGConstructor discover similar number of indirect jump relations, which is not as expected. The reason may be that there are too few indirect jumps in libpng. The newly discovered indirect jumps cannot provide more feedback to DGF-based test case generation. Therefore, the two approaches show similar performance on this benchmark.
The main reason for the poor performance of CGF-CFGConstructor in discovering indirect jumps is that CGF aims to generate test cases covering the whole program. The approach assumes that all paths have the same priority and performs a undirected path exploration. This wastes a lot of time to test the code unrelated to indirect jumps. We introduce DGF-based test cases generation to mitigate this problem. The result shows that our approach discovers more indirect jump relations than the existing approach on most benchmarks.
Overall, the analysis indicates that the answer to RQ1 is definite: the DGF-based approach is able to resolve more indirect jump relations than the existing approach.
6.3. Evaluation of the Iterative Feedback Mechanism (RQ2)
In this section, we make an investigation about the effectiveness of our proposed iterative feedback mechanism. Another CFG constructor is implemented as a comparison.
NFB-CFGConstructor. It is identical to our prototype DGF-CFGConstructor, except that the iterative feedback mechanism is removed.
In the experiment, two appraisal indexes are used to evaluate the iterative feedback mechanism. The number of indirect jumps discovered is still one of them. In order to quantify the sustainable performance of the approaches, we present
stuck time as another appraisal index. “Stuck” indicates a state in the process of program testing, in which it is difficult to discover new paths. This concept is mentioned in previous works [
7,
37], but not defined accurately. We attempt to give a quantitative definition about “stuck” state in discovering indirect jumps.
is used to represent the number of indirect jump relations discovered from time
to
. If there is a time
, for any time
t, the condition
is always satisfied, then the testing is considered to get “stuck” at
. In the condition,
and
p are given constants, representing the time interval and the threshold, respectively.
Stuck time is defined as the minimum of the time satisfying the above condition and denoted as
. Intuitively,
stuck time represents the start time after which the test can hardly discover indirect jump relations.
Figure 9 shows the analysis results of CGF-CFGConstructor and NFB-CFGConstructor on the eight benchmarks. In the experiment,
is set five hours and the threshold
p is set 5%.
In the early phase of the test, DGF-CFGConstructor (the red line) and NFB-CFGConstructor (the green line) have the similar performance. After the early phase, DGF-CFGConstructor has a more obvious increase than NFB-CFGConstructor. On the all benchmarks, NFB-CFGConstructor gets stuck earlier than CGF-CFGConstructor. When the approach without iterative feedback mechanism gets stuck, our approach can still resolve new indirect jumps continuously. This is because that the iterative feedback updates the seed distance with new structure information and allows our approach to continuously generate test cases that exercise indirect jumps.
Figure 10 shows the statistical results of the two approaches after 20 h. On the all eight benchmarks, DGF-CFGConstructor (the red bar) can resolve more indirect jumps than NFB-CFGConstructor (the green bar). More specifically, our approach discovers 37.1% more indirect jump relations than the approach without the iterative feedback mechanism.
Overall, the analysis indicates that the answer to RQ2 is definite; our iterative feedback mechanism can improve the sustainability of test case generation and the ability of resolving indirect jumps.
6.4. Completeness of the CFGs (RQ3)
In the above experiments, we evaluate the effectiveness of two key techniques in our approach. In this section, we further evaluate our prototype against existing approaches and attempt to answer the research question: how complete is the CFG constructed by our approach?
We compare DGF-Constructor with the following tools:
Static-CFGConstructor. It is a pure static tool implemented according to LLVM’s builtin APIs.
CGF-CFGConstructor. It is a hybrid tool based on the approach proposed in [
26]. The tool has been used in evaluating the test case generation in
Section 6.2.
There is not appraisal index to evaluate the completeness of CFGs in the previous work. In many practical program analyses, such as taint analysis and symbolic execution, analysts usually pay more attention to the code that is reachable from the entry of program on the CFG. Therefore, we adopt reachable code scale as an important factor to measure the completeness of CFGs.
More specifically, we present two appraisal indexes to quantify the scale of the reachable code. The first index is the number of functions that can be reachable from the program entry on the iCFG. The second index is the number of reachable basic blocks. On the same eight benchmarks, we use three approaches to conduct the experiment: the static analysis (Static-CFGConstructor), the CGF-based approach (CGF-CFGConstructor), and our DGF-based approach (DGF-CFGConstructor). The experiment lasted for 20 h.
Figure 11 shows the reachable code scale of the CFGs constructed by the three approaches. On most benchmarks, DGF-CFGConstructor can discover more reachable functions and basic blocks than the other two tools. Precisely, our approach discovers 62.9% more reachable functions and 94% more reachable basic blocks than Static-CFGConstructor. Compared with CGF-CFGConstructor, our approach discovers 23.9% more reachable functions and 34.9% more reachable basic blocks.
Overall, the analysis indicates that the answer to RQ3 is definite. Our approach is able to construct more complete CFGs than other approaches.
6.5. Application: Security Analysis (RQ4)
In this paper, we focus on how to construct more complete CFGs, which is a prerequisite for many program analyses. There are many applications that may benefit from our work, such as program verification, vulnerability detection, and code similarity analysis. At present, except vulnerability detection, we have not sufficiently evaluated our approach in specific applications, as it will take a lot of effort and knowledge to evaluate various applications. Therefore, in this section, we take the vulnerability detection as an example to illustrate the practical significance of our work.
Figure 12 shows a real vulnerability (CVE-2015-5221) [
38] hidden in the image processing library JasPer. The vulnerability is located deep in the program and may be triggered only when the specific call sequence is executed, i.e.,
.
Unfortunately, in the call sequence is an indirect jumps. If analysts conduct the security analysis based on the CFGs constructed by the traditional static tool, they may not be able to resolve these indirect jumps and miss the vulnerability. On the contrary, our approach can construct more complete CFGs containing this indirect jump relation and help analysts discover this vulnerability.
Although DGF-CFGConstructor is still a prototype, it has been able to analyze the real-world programs and been applied to vulnerability detection. In the future, we will improve the prototype and make it suitable for more usage scenarios.
6.6. Discussion
In this section, we will discuss the limitations of DGF-CFGConstructor and future directions of research to further improve the completeness of CFGs.
Although our DGF-based approach resolves more indirect jumps than traditional approaches, it still cannot guarantee that all indirect jumps can be exercised. Many factors affect the coverage of DGF, such as the initial seeds and the complexity of the target programs. In future work, we can try to improve the coverage of indirect jumps by improving the seed selection and further analyzing the structure of the target programs. In addition, our approach might benefit from other improvements of DGF.
The scalability of our approach depends on the two techniques, i.e., static CFG construction and dynamic directed gray-box fuzzing (DGF). The two techniques have been proved to be scalable in analyzing large-scale programs in previous researches. Therefore, our approach is also scalable. Specifically, in the static part, LLVM can construct the static CFG for any real-world program in the benchmark in a few minutes, which is trivial compared to dynamic part. On the dynamic part, directed gray-box fuzzing continues to generate test cases until it is aborted manually. Like existing fuzzing works, we cannot give an exact end time. However, intuitively, our algorithm can be aborted when the DGF-based test case generation gets stuck, i.e., the stuck time is reached. In our evaluation on eight real-world programs, the average stuck time’ is about 9.7 h.
At present, DGF-CFGConstructor is still a prototype. It is implemented to analyze source code. However, our proposed DGF-based test cases generation and iterative feedback mechanism can also be applied for binary code. We are extending DGF-CFGConstructor to the binaries.
In addition, the CFG is applied in many practical analyses. However, in this paper, we only preliminarily evaluate the application of our approach in vulnerability detection. In the future, we will extend the approach to other applications, such as malware analysis, code similarity analysis, and so on.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}