Towards TBM Automation: On-The-Fly Characterization and Classification of Ground Conditions Ahead of a TBM Using Data-Driven Approach

 ,
,  , ,
, ,
Abstract
1. Introduction
1.1. The Japanese Highway Classification System (JH System)
2. Project Description and Geology
2.1. Project Background
2.2. Geologic Setting
3. Database and Data Collection
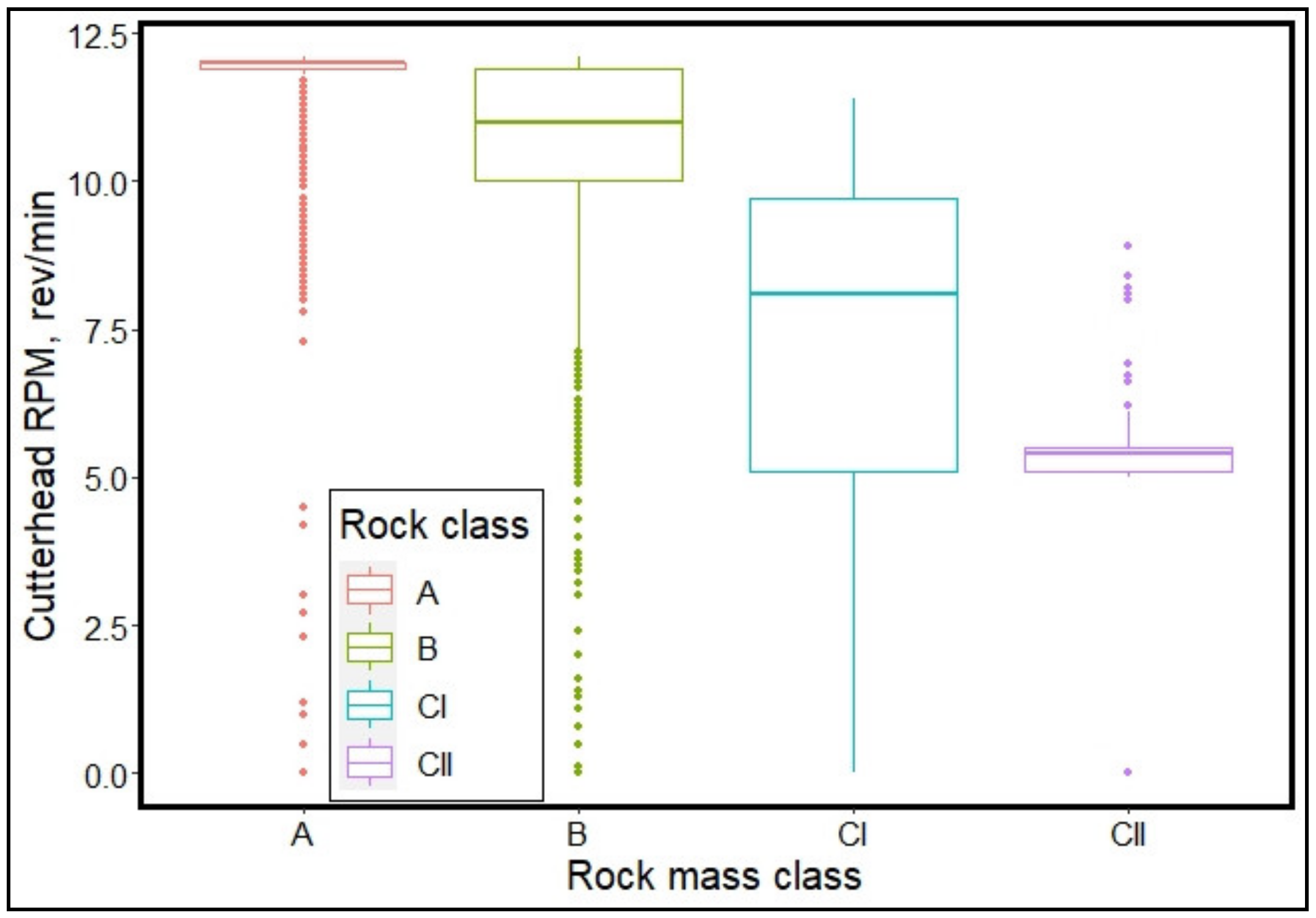
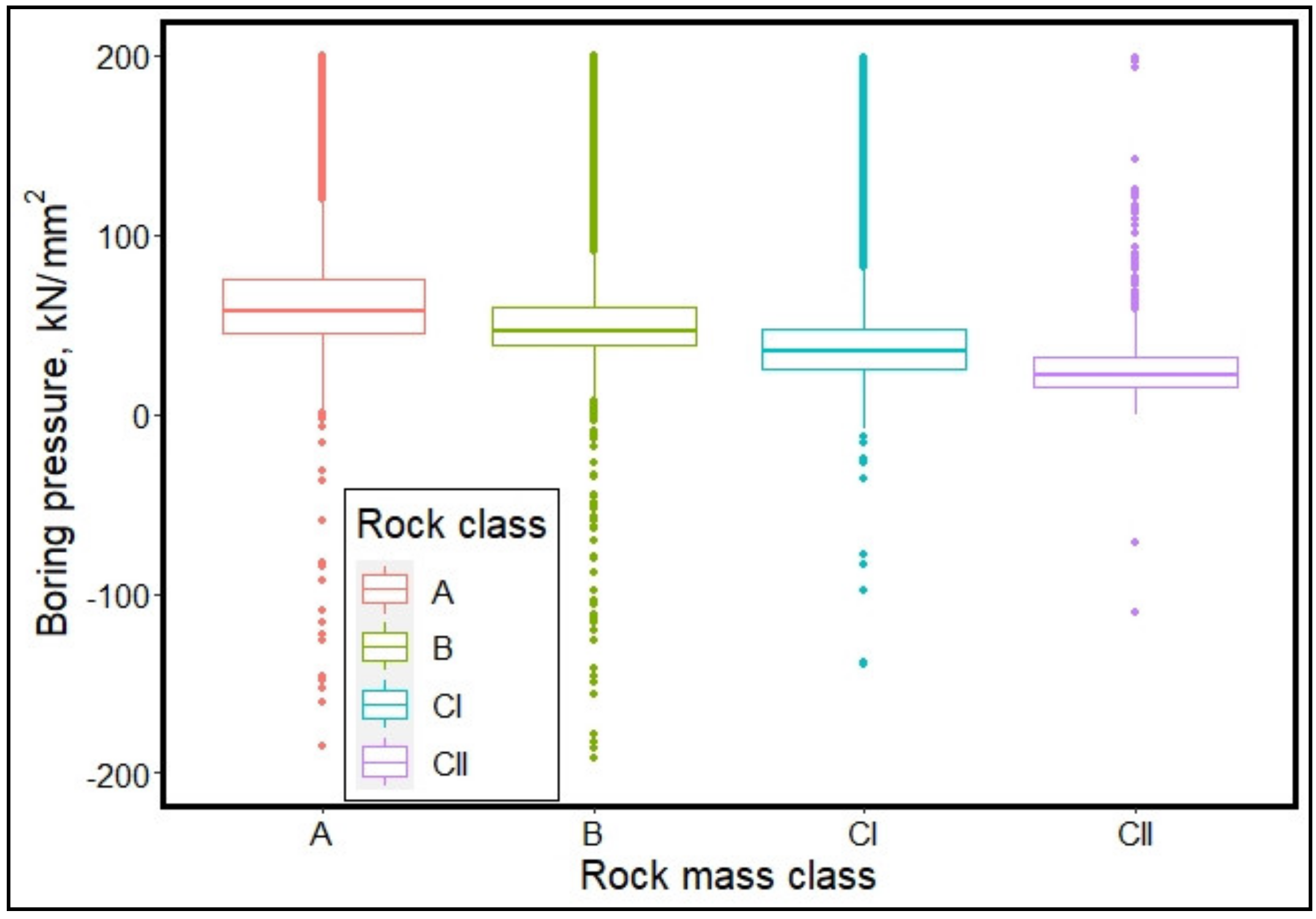
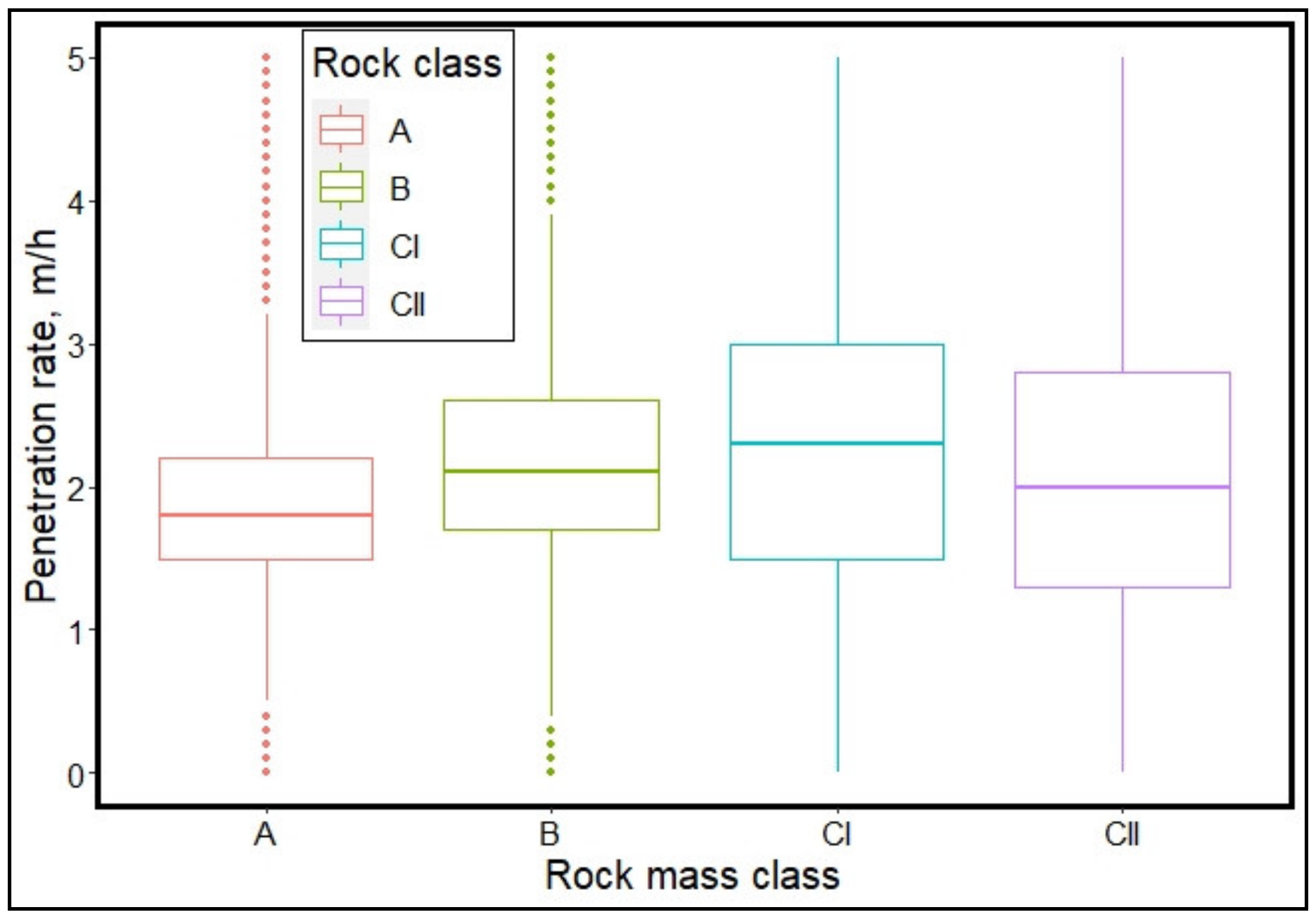
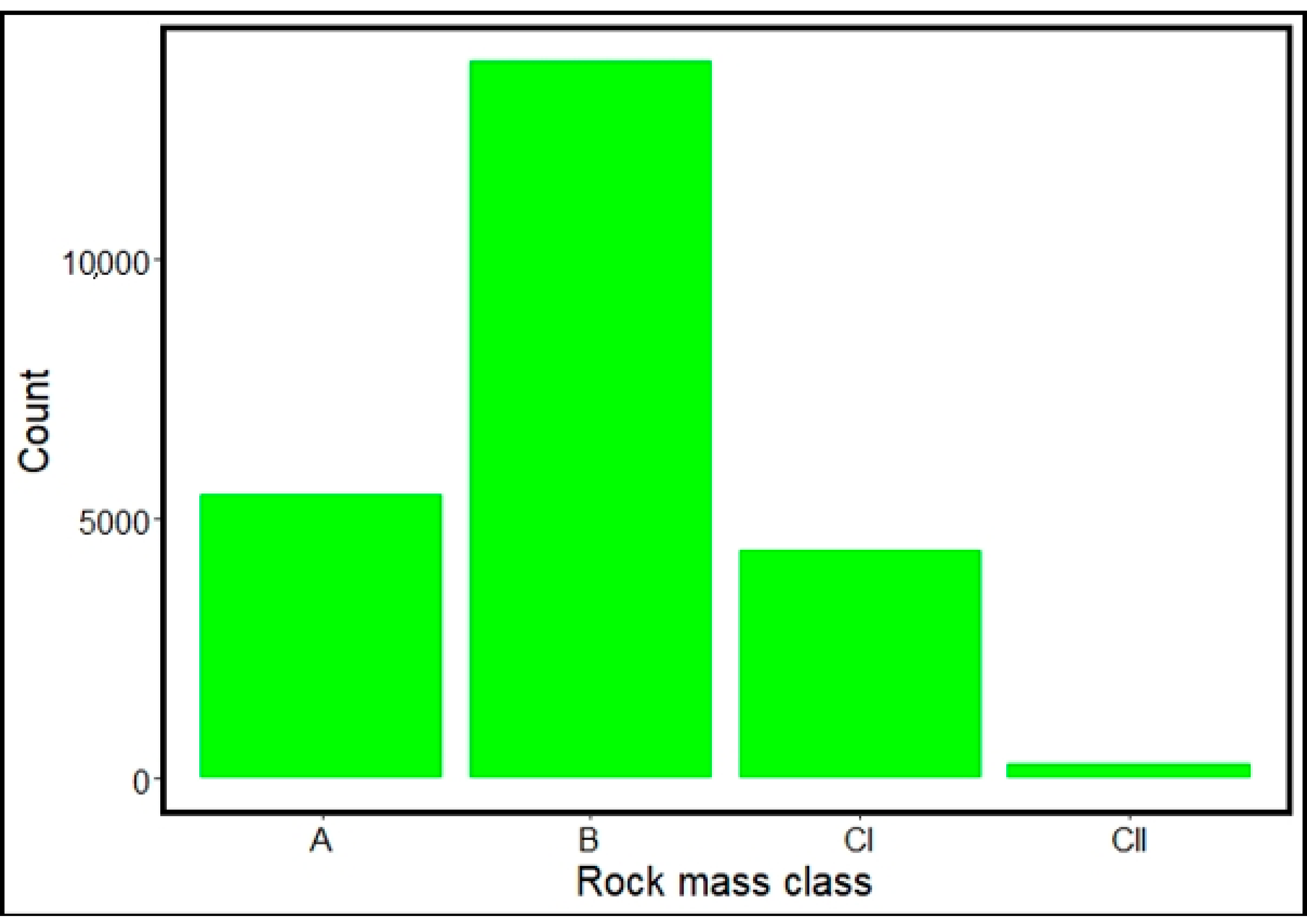
3.1. Data Exploration
3.2. Variable Importance
4. Development of Machine Learning (ML) Models
4.1. Data Preprocessing
4.2. ML Models Description
4.2.1. Random Forest (RF)
4.2.2. Extremely Randomized Tree (ERT)
4.3. Machine Learning Process
4.4. ML Model Performance Metrics
4.4.1. Accuracy and Balanced Accuracy
4.4.2. F1 Score
4.4.3. Cohen’s Kappa Coefficient (k)
5. Results and Discussion
5.1. Classification Performance the ML Models
5.2. Comparison of the ML Models
6. Conclusions
- The proposed approach was applied to a dataset from the Pahang-Selangor Raw Water tunnel (PSRWT) project in Malaysia. A comparison between the ML model classification results and the measured rock mass classes shows that the proposed approach is effective. The identification and classification accuracies were 95% and 94% for ERT and RF, respectively with kappa values of at least 0.90.
- A bootstrap comparison of the performance of the two ML models, RF and ERT, indicated no model outperformed the other. Due to the randomized nature of node splitting, ERT is more computationally expensive than RF. Therefore, if the performance of ERT is not significantly better than that of RF, it is recommendable to adopt RF.
- The most influential TBM operating parameter in classifying the rock mass is the cutterhead RPM followed by cutterhead thrust. The two least influential parameters are stroke speed and rate of penetration. Therefore, TBM thrust and RPM can be adjusted in real-time by determining the rock mass class being excavated using the ML models developed in this paper.
- From a practical standpoint, the overall results obtained in this study show that the data-oriented approach is a useful tool for on-the-fly rock mass conditions identification, characterization and classification of ground conditions along tunnel alignment. It can be a tool for on-site decision making such as selecting support systems or refining preliminary support systems based on ground condition encountered.
- Extension of this research should also focus on exploring other ML techniques including deep learning methods as well as developing a framework for operationalizing this approach in TBMs.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Barton, N.; Lien, R.; Lunde, J. Engineering classification of rock masses for the design of tunnel support. Rock Mech. Rock Eng. 1974, 6, 189–236. [Google Scholar] [CrossRef]
- Bieniawski, Z.T. Geomechanics classification of rock masses and its application in tunneling. In Proceedings of the 3rd International Congress on Rock Mechanics, Denver, CO, USA, 1 September 1974; p. II-A. [Google Scholar]
- Palmstrøm, A. Characterizing rock masses by the RMi for use in practical rock engineering. Tunn. Undergr. Space Technol. 1996, 11, 175–188. [Google Scholar] [CrossRef]
- Hoek, E.; Brown, E.T. Practical estimates of rock mass strength. Int. J. Rock Mech. Min. Sci. 1997, 34, 1165–1186. [Google Scholar] [CrossRef]
- Jalalifar, H.; Mojedifar, S.; Sahebi, A. Prediction of rock mass rating using fuzzy logic and multi-variable RMR regression model. Int. J. Min. Sci. Technol. 2014, 24, 237–244. [Google Scholar] [CrossRef]
- Shi, S.-S.; Li, S.-C.; Li, L.-P.; Zhou, Z.-Q.; Wang, J. Advance optimized classification and application of surrounding rock based on fuzzy analytic hierarchy process and Tunnel Seismic Prediction. Autom. Constr. 2014, 37, 217–222. [Google Scholar] [CrossRef]
- Lee, K.H.; Park, J.H.; Park, J.; Lee, I.M.; Lee, S.W. Electrical resistivity tomography survey for prediction of anomaly inmechanized tunneling. Geomech. Eng. 2019, 19, 93–104. [Google Scholar]
- Zhang, Q.; Liu, Z.; Tan, J. Prediction of geological conditions for a tunnel boring machine using big operational data. Autom. Constr. 2019, 100, 73–83. [Google Scholar] [CrossRef]
- Liu, Q.; Wang, X.; Huang, X.; Yin, X. Prediction model of rock mass class using classification and regression tree integrated AdaBoost algorithm based on TBM driving data. Tunn. Undergr. Space Technol. 2020, 106, 103595. [Google Scholar] [CrossRef]
- Shahriar, K.; Sargheini, J.; Hedayatzadeh, M.; Hamidi, J.K. Performance Prediction of Hard Rock TBM Using Rock Mass Classification. In Rock Mechanics in Civil and Environmental Engineering—Proceedings of the European Rock Mechanics Symposium EUROCK; Taylor & Francis Group: London, UK, 2010; ISBN 978-0-415-58654-2. [Google Scholar]
- Mahdevari, S.; Torabi, S.R. Prediction of tunnel convergence using Artificial Neural Networks. Tunn. Undergr. Space Technol. 2012, 28, 218–228. [Google Scholar] [CrossRef]
- Mahdevari, S.; Torabi, S.R.; Monjezi, M. Application of artificial intelligence algorithms in predicting tunnel convergence to avoid TBM jamming phenomenon. Int. J. Rock Mech. Min. Sci. 2012, 55, 33–44. [Google Scholar] [CrossRef]
- Mahdevari, S.; Shahriar, K.; Yagiz, S.; Shirazi, M.A. A support vector regression model for predicting tunnel boring machine penetration rates. Int. J. Rock Mech. Min. Sci. 2014, 72, 214–229. [Google Scholar] [CrossRef]
- Ren, Q.; Wang, G.; Li, M.; Han, S. Prediction of Rock Compressive Strength Using Machine Learning Algorithms Based on Spectrum Analysis of Geological Hammer. Geotech. Geol. Eng. 2018, 37, 475–489. [Google Scholar] [CrossRef]
- Xu, H.; Zhou, J.; Asteris, P.G.; Armaghani, D.J.; Tahir, M.M. Supervised Machine Learning Techniques to the Prediction of Tunnel Boring Machine Penetration Rate. Appl. Sci. 2019, 9, 3715. [Google Scholar] [CrossRef]
- Zhang, Q.; Hu, W.; Liu, Z.; Tan, J. TBM performance prediction with Bayesian optimization and automated machine learning. Tunn. Undergr. Space Technol. 2020, 103, 103493. [Google Scholar] [CrossRef]
- Salimi, A.; Rostami, J.; Moormann, C. Application of rock mass classification systems for performance estimation of rock TBMs using regression tree and artificial intelligence algorithms. Tunn. Undergr. Space Technol. 2019, 92, 103046. [Google Scholar] [CrossRef]
- Liu, B.; Wang, R.; Zhao, G.; Guo, X.; Wang, Y.; Li, J.; Wang, S. Prediction of rock mass parameters in the TBM tunnel based on BP neural network integrated simulated annealing algorithm. Tunn. Undergr. Space Technol. 2020, 95, 103103. [Google Scholar] [CrossRef]
- Liu, K.; Liu, B.; Fang, Y. An intelligent model based on statistical learning theory for engineering rock mass classification. Bull. Int. Assoc. Eng. Geol. 2018, 78, 4533–4548. [Google Scholar] [CrossRef]
- Jung, J.-H.; Chung, H.; Kwon, Y.-S.; Lee, I.-M. An ANN to Predict Ground Condition ahead of Tunnel Face using TBM Operational Data. KSCE J. Civ. Eng. 2019, 23, 3200–3206. [Google Scholar] [CrossRef]
- Zhang, Q.; Yang, K.; Wang, L.; Zhou, S. Geological Type Recognition by Machine Learning on In-Situ Data of EPB Tunnel Boring Machines. Math. Probl. Eng. 2020, 2020, 1–10. [Google Scholar] [CrossRef]
- Erharter, G.H.; Marcher, T. MSAC: Towards data driven system behavior classification for TBM tunneling. Tunn. Undergr. Space Technol. 2020, 103, 103466. [Google Scholar] [CrossRef]
- Zhang, C.; Ma, Y. Ensemble Machine Learning: Methods and Applications; Springer: Berlin, Germany, 2012. [Google Scholar]
- Shinji, M.; Akagi, W.; Shiroma, H.; Yamada, A.; Nakagawa, K. JH Method of Rock Mass Classification for Tunnelling. In ISRM International Symposium - EUROCK 2002, 25-27 November, Madeira, Portugal; International Society for Rock Mechanics and Rock Engineering: Lisbon, Portugal, 2002; pp. 375–383. [Google Scholar]
- Abad, S.A.N.K.; Mohamad, E.; Komoo, I. Dominant weathering profiles of granite in southern Peninsular Malaysia. Eng. Geol. 2014, 183, 208–215. [Google Scholar] [CrossRef]
- Jayalakshmi, T.; Santhakumaran, A. Statistical Normalization and Back Propagationfor Classification. Int. J. Comput. Theory Eng. 2011, 89–93. [Google Scholar] [CrossRef]
- James, G.; Witten, D.; Hastie, T.; Tibishirani, R. An Introduction to Statistical Learning with Applications in R (Older Version); Springer US: New York, NY, USA, 2013. [Google Scholar]
- Geurts, P.; Ernst, D.; Wehenkel, L. Extremely randomized trees. Mach. Learn. 2006, 63, 3–42. [Google Scholar] [CrossRef]
- Seker, S.E.; Ocak, I. Performance prediction of roadheaders using ensemble machine learning techniques. Neural Comput. Appl. 2019, 31, 1103–1116. [Google Scholar] [CrossRef]
- Fürnkranz, J.; Chan, P.K.; Craw, S.; Sammut, C.; Uther, W.; Ratnaparkhi, A.; Jin, X.; Han, J.; Yang, Y.; Morik, K.; et al. Mean Absolute Error. In Encyclopedia of Machine Learning; Springer Science and Business Media LLC: Berlin, Germany, 2011; p. 652. [Google Scholar]
- Glen, S. Cohen’s Kappa Statistic. Statistics How To. 2014. Available online: https://www.statisticshowto.com/cohens-kappa-statistic/ (accessed on 4 November 2020).













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Geological Observation | Rating | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| 1. Strength of the intact rock material | Uniaxial Comp. strength. | >100 MPa | 100–50 MPa | 50–25 MPa | 25–10 MPa | 10–3 MPa | <3 MPa | ||
| Point-load Strength. | >3 MPa | 4–2 MPa | 2–1 MPa | 1–0.4 MPa | <0.4 MPa | -- | |||
| Strength judged by blow of hammer | Not broken by strong blow of hammer | Broken by strong blow of hammer | Broken by normal blow of hammer | Broken by striking rocks against each other | Broken easily by hand | Deformed by finger | |||
| Grade Point | 36 | 29 | 22 | 14 | 7 | 0 | |||
| 2. Weathering/Alteration | Degree of weathering | Fresh | Weathered along discontinuities | Weathered to the rock mass core | Sedimentary Unconsolidated | ||||
| Hydrothermal alteration | No Alteration | Partially altered and infilled with clay | Altered and weakened to the rock core | heavily altered and become clayey or sedimentary | |||||
| Grade Point | 19 | 12 | 6 | 0 | |||||
| 3. Spacing of discontinuities, mm | Spacing of Discontinuity. | D = 1 m | 1 m > d = 50 cm | 50 > d = 20 cm | 20 > d = 5 cm | 5 cm > d | |||
| R.Q.D | >80 | 80–50 | 60–30 | 40–10 | <20 | ||||
| Grade Point | 19 | 14 | 9 | 5 | 0 | ||||
| 4. Condition of discontinuities | Degree of opening | Fracture Totally-attached | Fracture Partly opened | Fracture mostly opened | Fracture opened –5 mm width | Fracture opened >5 mm | |||
| Infilled width | Nil | Nil | Nil | Clay(<5mm) | Clay (>5mm) | ||||
| Degree of Roughness | Coarse | Flat and Smooth | Partly Slickenside | Well-sharpened slickenside | |||||
| Grade Point | 26 | 20 | 13 | 7 | 0 | ||||
| 5. Effect of discontinuity strike and dip orientation declination | Strike perpendicular to Tunnel Axis | 1. Drive with dip-Dip 45–90 | 2. Drive with dip-Dip 20–45 | 3. Drive with/against dip-Dip 0–20 | 4. Drive against dip-Dip 20–45 | 4. Drive against dip-Dip 45–90 | |||
| Evaluation | Very favorable | Favorable | Normal | Unfavorable | Fair | ||||
| Strike parallel to Tunnel Axis | -- | -- | 1. Dip 0–20 | 2. Dip 20–45 | 3. Dip 45–90 | ||||
| Evaluation | -- | -- | Normal | Unfavorable | Fair | ||||
| Evaluation on Ground water and Degradation (including the possibility in the future) at the length of 10 m from face | |||||||||
| 6. Groundwater | Amount of inflow per 10m tunnel length | <1 L/min | 1–20 L/min | 20–100 L/min | >100 L/min | ||||
| General conditions | Dry/Moist | Wet | Dripping water | Flowing water | |||||
| Classification | 1 | 2 | 3 | 4 | |||||
| 7. Degradation by water | Degradation by water | Nil | Partially weakened | Loosened | Washed out | ||||
| Classification | 1 | 2 | 3 | 4 | |||||
| Rock Class | Range of Total Grade Points (%) | Description | Support Requirement |
|---|---|---|---|
| A | 100–90 | Very good rock, hard and fresh | No support |
| B | 89–70 | Good rock, hard and fresh but affected by weathering | Spot bolting, shotcrete to crown/wall |
| CI | 69–51 | Fair rock, rock is weathered, some clay in joints | Pattern bolting to crown, shotcrete to crown/wall |
| CII | 50–40 | Fair to poor rock weathered, loosed rock mass | Pattern bolting to crown/wall, shotcrete to crown/wall |
| D | 39–20 | Very poor to extremely poor rocks: considerably weathered rock mass, soft zones, partially soil properties | Pattern bolting to crown/wall, shotcrete to crown/wall, steel rib |
| E | <20 | Faults and crushed rock zone, squeezing zones | Pattern bolting to crown/wall, shotcrete to crown/wall, steel rib, steel lagging |
| TBM Parameter | Mean | Median | Minimum | Maximum |
|---|---|---|---|---|
| Boring pressure (N/mm2) | 56.35 | 47.10 | −5448.20 | 1155.80 |
| Cutterhead torque (kN-m) | 562.57 | 622.00 | −31,962 | 22,523.00 |
| Cutterhead thrust force (kN) | 9910.15 | 10,619.00 | 0.00 | 11,424.00 |
| Cutterhead RPM (rev/min) | 10.29 | 11.00 | 0.00 | 12.10 |
| Rate of penetration (m/h) | 2.30 | 2.10 | 0.00 | 107.80 |
| Stroke speed (mm/min) | 38.18 | 35.00 | 0.00 | 1797.00 |
| Gripper cylinder pressure (bar) | 301.67 | 306.00 | 0.00 | 691.00 |
| Pitching (°) | −0.06 | −0.09 | −0.52 | 1.26 |
| Average motor amps (A) | 138.79 | 138.00 | 0.00 | 427.00 |
| TBM Parameter | Boring Pressure | Cutterhead Torque | Cutterhead Thrust Force | Cutterhead RPM | Rate of Penetration | Stroke Speed | Gripper Cylinder Pressure | Pitching | Average Motor Amps |
|---|---|---|---|---|---|---|---|---|---|
| Boring Pressure | 1.00 | ||||||||
| Cutterhead torque | 0.21 | 1.00 | |||||||
| Cutterhead thrust force | 0.26 | 0.28 | 1.00 | ||||||
| Cutterhead RPM | 0.14 | −0.03 | 0.45 | 1.00 | |||||
| Rate of Penetration | −0.10 | 0.05 | 0.07 | −0.02 | 1.00 | ||||
| Stroke speed | −0.10 | 0.05 | 0.07 | −0.01 | 0.98 | 1.00 | |||
| Gripper Cylinder pressure | 0.07 | 0.08 | 0.38 | 0.40 | 0.09 | 0.07 | 1.00 | ||
| Pitching | 0.04 | −0.04 | −0.06 | 0.14 | 0.00 | −0.01 | −0.09 | 1.00 | |
| Average motor amps | 0.11 | 0.23 | 0.41 | −0.07 | 0.21 | 0.22 | 0.24 | −0.02 | 1.00 |
| Rock Class | Count | |
|---|---|---|
| Unbalanced | Balanced | |
| A | 5460 | 13,817 |
| B | 13,817 | 13,817 |
| CI | 4382 | 13,817 |
| CII | 288 | 13,817 |
| Random Forest | Extremely Randomized Trees | |||
|---|---|---|---|---|
| Rock Class | F1 Score | Balanced Accuracy | F1 Score | Balanced Accuracy |
| Class: A | 0.92 | 0.95 | 0.93 | 0.95 |
| Class: B | 0.95 | 0.94 | 0.96 | 0.95 |
| Class: CI | 0.95 | 0.97 | 0.96 | 0.97 |
| Class: CII | 0.96 | 0.99 | 0.97 | 0.99 |
| Model | Accuracy | Kappa |
|---|---|---|
| Random forest | 0.942 | 0.901 |
| Extremely randomized trees | 0.950 | 0.914 |
| Model | Metric | Lower (2.5%) | 50.0% | Upper (97.5%) |
|---|---|---|---|---|
| Random forest | Kappa | 0.889 | 0.901 | 0.912 |
| Extremely randomized trees | 0.902 | 0.913 | 0.924 | |
| Random forest | Accuracy | 0.935 | 0.942 | 0.949 |
| Extremely randomized trees | 0.944 | 0.950 | 0.956 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sebbeh-Newton, S.; Ayawah, P.E.A.; Azure, J.W.A.; Kaba, A.G.A.; Ahmad, F.; Zainol, Z.; Zabidi, H. Towards TBM Automation: On-The-Fly Characterization and Classification of Ground Conditions Ahead of a TBM Using Data-Driven Approach. Appl. Sci. 2021, 11, 1060. https://doi.org/10.3390/app11031060
Sebbeh-Newton S, Ayawah PEA, Azure JWA, Kaba AGA, Ahmad F, Zainol Z, Zabidi H. Towards TBM Automation: On-The-Fly Characterization and Classification of Ground Conditions Ahead of a TBM Using Data-Driven Approach. Applied Sciences. 2021; 11(3):1060. https://doi.org/10.3390/app11031060
Chicago/Turabian StyleSebbeh-Newton, Sylvanus, Prosper E.A. Ayawah, Jessica W.A. Azure, Azupuri G.A. Kaba, Fauziah Ahmad, Zurinahni Zainol, and Hareyani Zabidi. 2021. "Towards TBM Automation: On-The-Fly Characterization and Classification of Ground Conditions Ahead of a TBM Using Data-Driven Approach" Applied Sciences 11, no. 3: 1060. https://doi.org/10.3390/app11031060
APA StyleSebbeh-Newton, S., Ayawah, P. E. A., Azure, J. W. A., Kaba, A. G. A., Ahmad, F., Zainol, Z., & Zabidi, H. (2021). Towards TBM Automation: On-The-Fly Characterization and Classification of Ground Conditions Ahead of a TBM Using Data-Driven Approach. Applied Sciences, 11(3), 1060. https://doi.org/10.3390/app11031060