
Cross Domain Adaptation of Crowd Counting with Model-Agnostic Meta-Learning



Abstract
:1. Introduction
- (1)
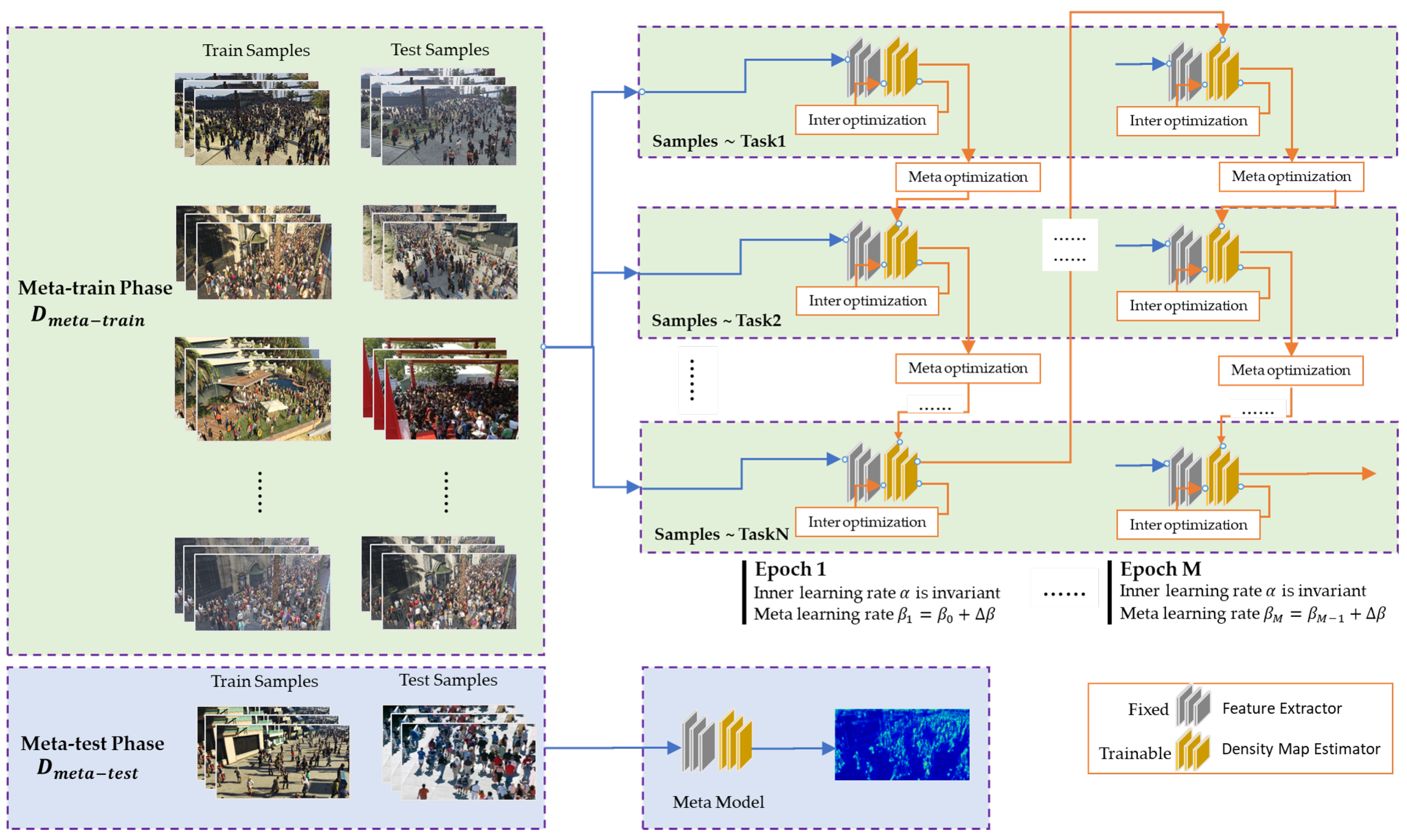
- To improve the model’s generalization ability, in the density map estimation phase, we propose a meta-learning-based method, which accelerates the model’s convergence in few-shot scenes with the dynamic meta-learning rate .
- (2)
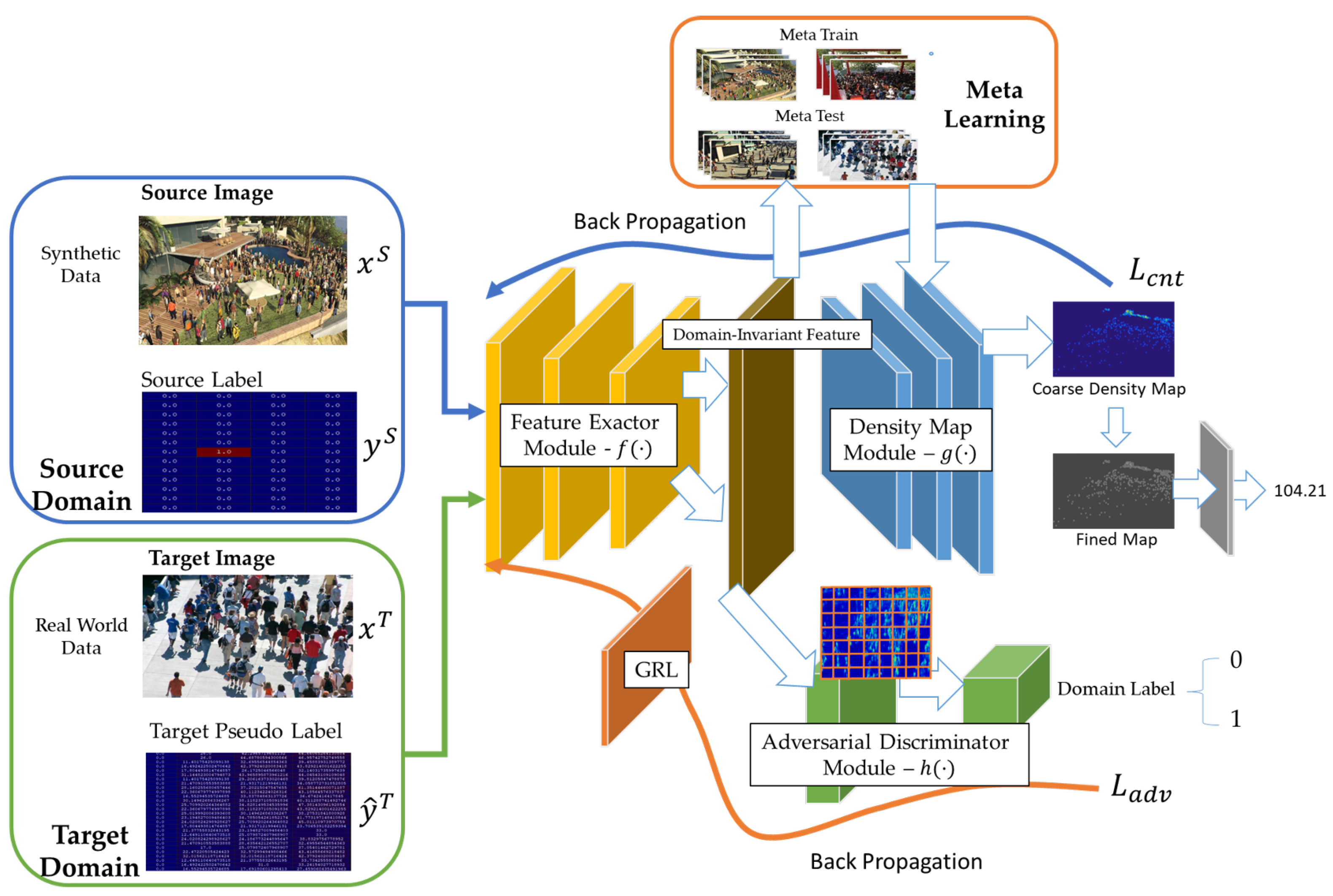
- In cross-domain scenarios, domain-invariant feature extraction is essential to align the source and target domains. We propose an adaptive domain-invariant feature extracting module based on gradient reversal layer (GRL) to perform domain adaptation.
- (3)
- To conclude, we discuss the effectiveness of domain adaptation with two critical model generalization phases in crowd-counting scenarios: feature-map extraction and density-map estimation. Experiments show that the methods we propose in this paper can improve performance over the baseline and achieve state-of-the-art performance.
2. Related Work
2.1. Crowd Counting
2.2. Domain Adaptation
2.3. Few-Shot Learning
2.4. Synthetic Dataset
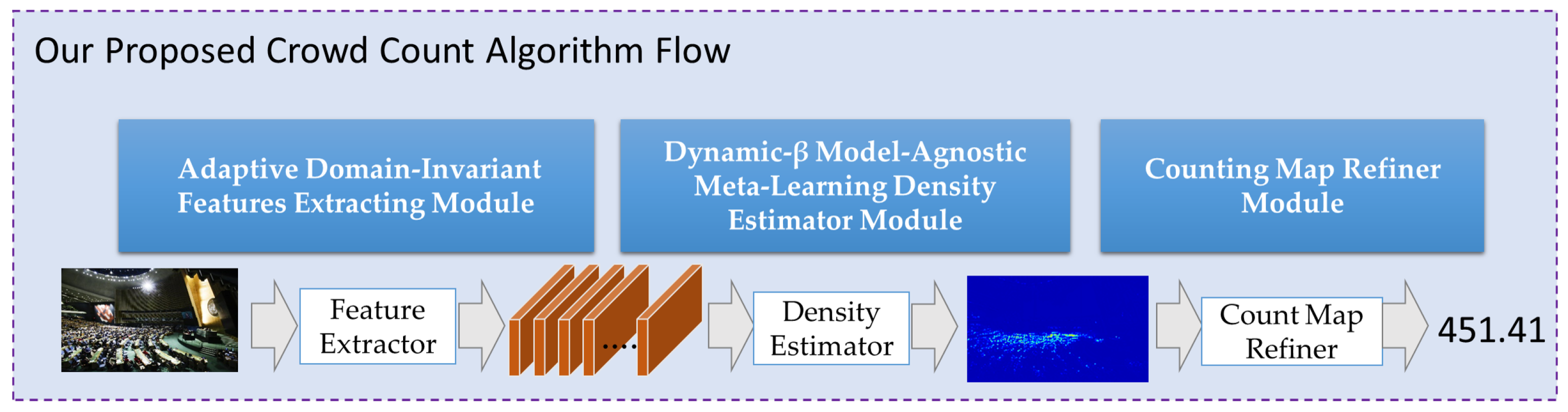
3. Methods
3.1. Density-Map Estimator Module Based on Dynamic- MAML
| Algorithm 1 Dynamic- MAML |
Input: is the fixed inter learning rate is the initial meta learning rate is the hyper-gradient learning rates randomly initialize M is the count of training iterations Output: is the parameters of meta-learning model
|
3.2. Adaptive Domain-Invariant Feature-Extracting Module
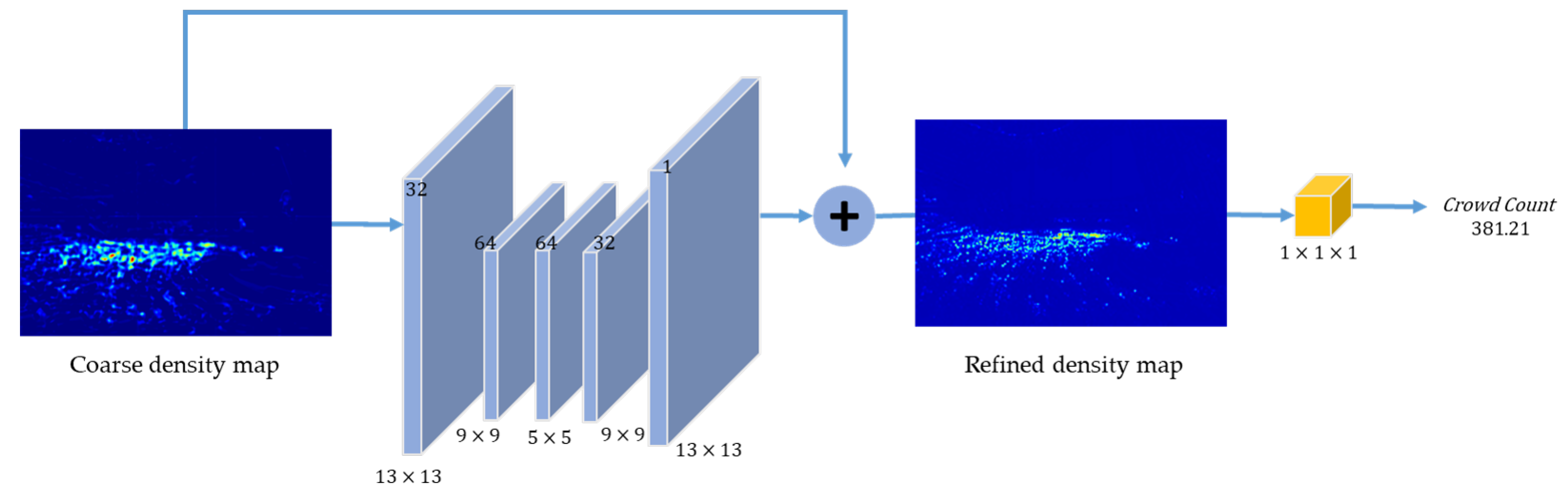
3.3. Crowd-Counting Refined-Mapper Module
4. Experiments
- Verify whether our proposed density-map estimator, based on dynamic- MAML, can accelerate convergence and improve crowd-counting performance in few-shot learning scenarios over the baseline and FSCC performances.
- Verify and evaluate the effectiveness of our proposed domain-invariant feature representation in cross-domain scenarios.
- Perform additional ablation studies on the efficacy of our proposed method, to verify the effectiveness of two key phases: feature extraction and density estimation.
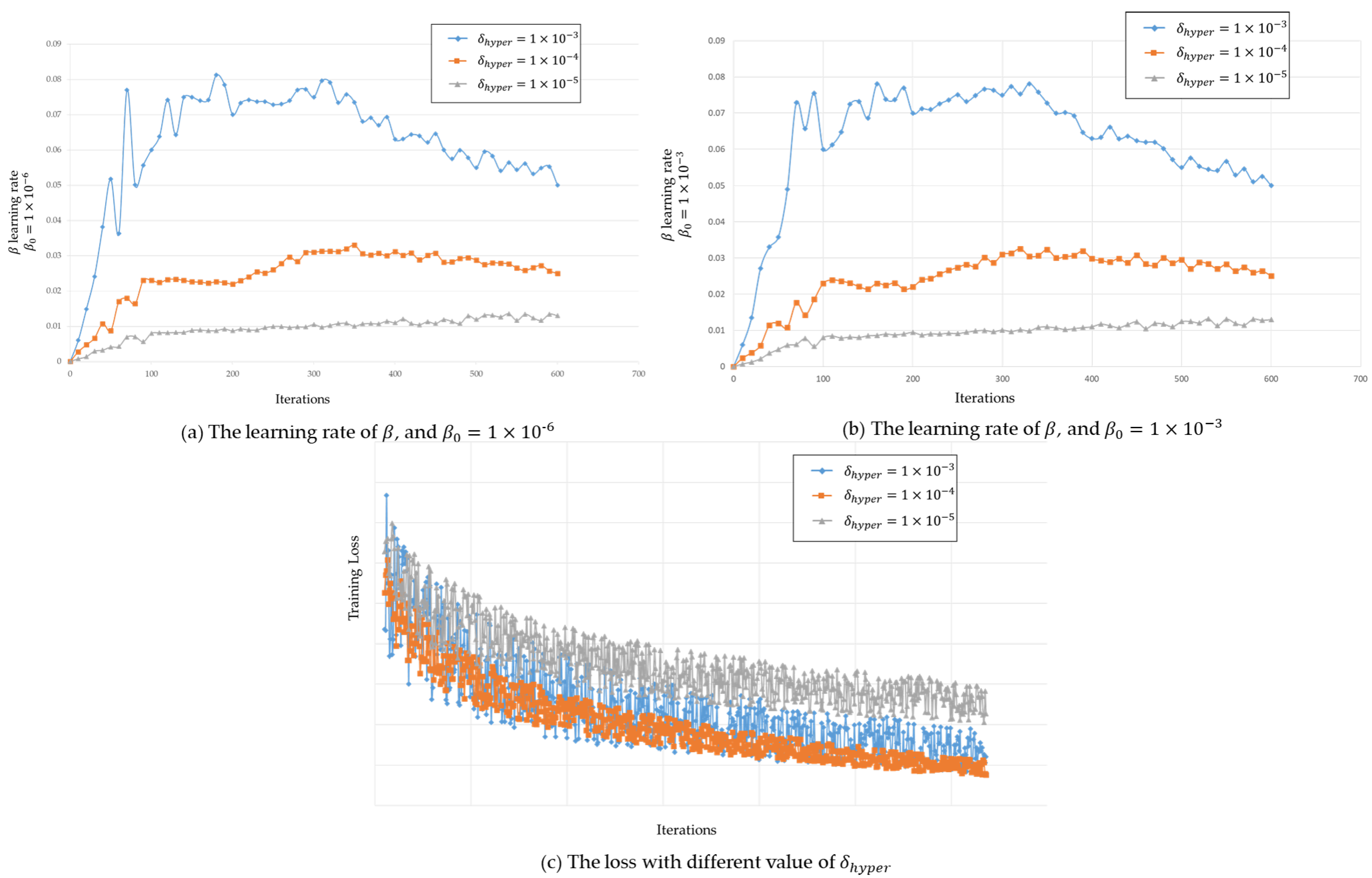
4.1. Evaluation of the Density-Map Estimator Based on Dynamic- MAML
4.2. Evaluation of Domain-Invariant Feature Representation in Cross-Domain Scenarios
4.3. Ablation Study
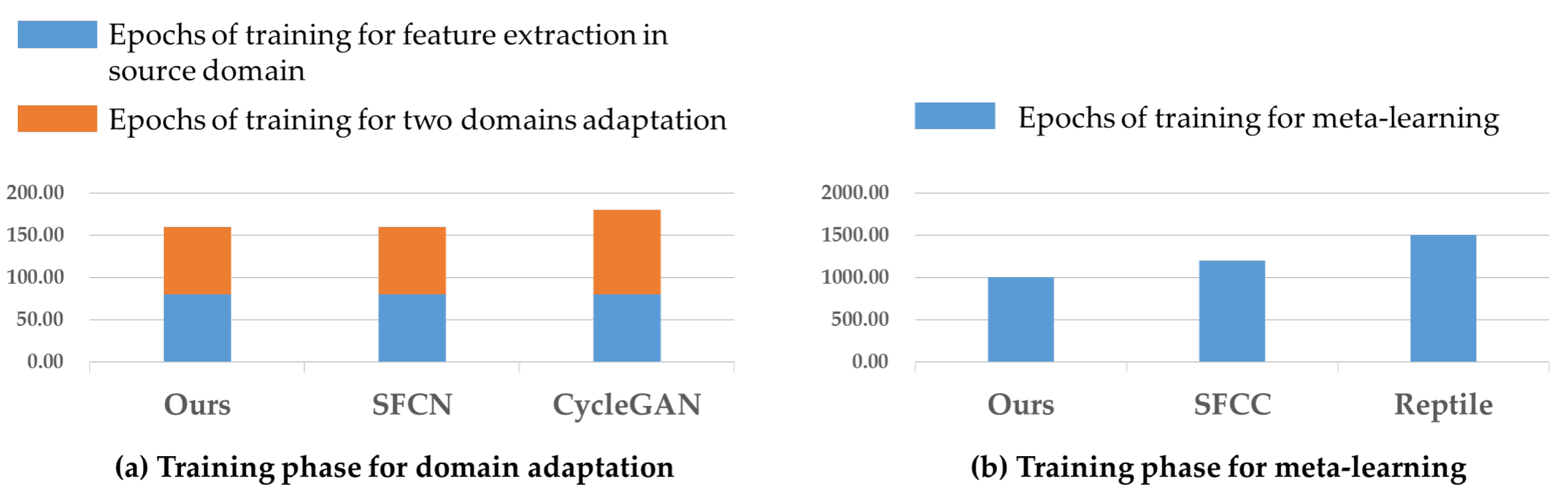
4.4. Computational Cost Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Gao, G.; Gao, J.; Liu, Q.; Wang, Q.; Wang, Y. CNN-based Density Estimation and Crowd Counting: A Survey. arXiv 2020, arXiv:2003.12783. [Google Scholar]
- Cenggoro, T.W. Deep learning for crowd counting: A survey. Eng. Math. Comput. Sci. J. 2019, 1, 17–28. [Google Scholar] [CrossRef]
- Shao, J.; Kang, K.; Change Loy, C.; Wang, X. Deeply learned attributes for crowded scene understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4657–4666. [Google Scholar]
- Gao, J.; Wang, Q.; Li, X. Pcc net: Perspective crowd counting via spatial convolutional network. IEEE Trans. Circuits Syst. Video Technol. 2019, 30, 3486–3498. [Google Scholar] [CrossRef] [Green Version]
- Gao, J.; Han, T.; Wang, Q.; Yuan, Y. Domain-adaptive crowd counting via inter-domain features segregation and gaussian-prior reconstruction. arXiv 2019, arXiv:1912.03677. [Google Scholar]
- Zhang, Y.; Zhou, D.; Chen, S.; Gao, S.; Ma, Y. Single-image crowd counting via multi-column convolutional neural network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 589–597. [Google Scholar]
- Onoro-Rubio, D.; López-Sastre, R.J. Towards perspective-free object counting with deep learning. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 615–629. [Google Scholar]
- Hossain, M.; Hosseinzadeh, M.; Chanda, O.; Wang, Y. Crowd counting using scale-aware attention networks. In Proceedings of the 2019 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 7–11 January 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1280–1288. [Google Scholar]
- Han, T.; Gao, J.; Yuan, Y.; Wang, Q. Focus on semantic consistency for cross-domain crowd understanding. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1848–1852. [Google Scholar]
- Gao, J.; Wang, Q.; Yuan, Y. Feature-aware adaptation and structured density alignment for crowd counting in video surveillance. arXiv 2019, arXiv:1912.03672. [Google Scholar]
- Idrees, H.; Saleemi, I.; Seibert, C.; Shah, M. Multi-source multi-scale counting in extremely dense crowd images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 2547–2554. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 27–29 October 2017; pp. 2223–2232. [Google Scholar]
- Reddy, M.K.K.; Hossain, M.; Rochan, M.; Wang, Y. Few-shot scene adaptive crowd counting using meta-learning. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 1–5 March 2020; pp. 2814–2823. [Google Scholar]
- Wortsman, M.; Ehsani, K.; Rastegari, M.; Farhadi, A.; Mottaghi, R. Learning to learn how to learn: Self-adaptive visual navigation using meta-learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 6750–6759. [Google Scholar]
- Gall, J.; Yao, A.; Razavi, N.; Van Gool, L.; Lempitsky, V. Hough forests for object detection, tracking, and action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 2188–2202. [Google Scholar] [CrossRef]
- Wu, B.; Nevatia, R. Detection and tracking of multiple, partially occluded humans by bayesian combination of edgelet based part detectors. Int. J. Comput. Vis. 2007, 75, 247–266. [Google Scholar] [CrossRef]
- Li, M.; Zhang, Z.; Huang, K.; Tan, T. Estimating the number of people in crowded scenes by mid based foreground segmentation and head-shoulder detection. In Proceedings of the 2008 19th International Conference on Pattern Recognition, Tampa, FL, USA, 8–11 December 2008; IEEE: Piscataway, NJ, USA, 2008; pp. 1–4. [Google Scholar]
- Wan, J.; Luo, W.; Wu, B.; Chan, A.B.; Liu, W. Residual regression with semantic prior for crowd counting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 4036–4045. [Google Scholar]
- Pham, V.Q.; Kozakaya, T.; Yamaguchi, O.; Okada, R. Count forest: Co-voting uncertain number of targets using random forest for crowd density estimation. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3253–3261. [Google Scholar]
- Boominathan, L.; Kruthiventi, S.S.; Babu, R.V. Crowdnet: A deep convolutional network for dense crowd counting. In Proceedings of the 24th ACM International Conference on Multimedia, Amsterdam, The Netherlands, 15–19 October 2016; pp. 640–644. [Google Scholar]
- Wang, Y.; Hu, S.; Wang, G.; Chen, C.; Pan, Z. Multi-scale dilated convolution of convolutional neural network for crowd counting. Multimed. Tools Appl. 2020, 79, 1057–1073. [Google Scholar] [CrossRef]
- Ma, Z.; Hong, X.; Wei, X.; Qiu, Y.; Gong, Y. Towards a Universal Model for Cross-Dataset Crowd Counting. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 3205–3214. [Google Scholar]
- Varol, G.; Romero, J.; Martin, X.; Mahmood, N.; Black, M.J.; Laptev, I.; Schmid, C. Learning from synthetic humans. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 109–117. [Google Scholar]
- Nam, H.; Lee, H.; Park, J.; Yoon, W.; Yoo, D. Reducing domain gap via style-agnostic networks. arXiv 2019, arXiv:1910.11645. [Google Scholar]
- Pan, S.J.; Ni, X.; Sun, J.T.; Yang, Q.; Chen, Z. Cross-domain sentiment classification via spectral feature alignment. In Proceedings of the 19th International Conference on World Wide Web, Raleigh, NC, USA, 26–30 April 2010; pp. 751–760. [Google Scholar]
- Pan, F.; Shin, I.; Rameau, F.; Lee, S.; Kweon, I.S. Unsupervised intra-domain adaptation for semantic segmentation through self-supervision. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 3764–3773. [Google Scholar]
- Sohn, K.; Liu, S.; Zhong, G.; Yu, X.; Yang, M.H.; Chandraker, M. Unsupervised domain adaptation for face recognition in unlabeled videos. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 27–29 October 2017; pp. 3210–3218. [Google Scholar]
- Ganin, Y.; Lempitsky, V. Unsupervised domain adaptation by backpropagation. arXiv 2014, arXiv:1409.7495. [Google Scholar]
- Hoffman, J.; Wang, D.; Yu, F.; Darrell, T. Fcns in the wild: Pixel-level adversarial and constraint-based adaptation. arXiv 2016, arXiv:1612.02649. [Google Scholar]
- Sankaranarayanan, S.; Balaji, Y.; Jain, A.; Lim, S.N.; Chellappa, R. Learning from synthetic data: Addressing domain shift for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3752–3761. [Google Scholar]
- Hoffman, J.; Tzeng, E.; Park, T.; Zhu, J.Y.; Isola, P.; Saenko, K.; Efros, A.; Darrell, T. Cycada: Cycle-consistent adversarial domain adaptation. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 1989–1998. [Google Scholar]
- Tsai, Y.H.; Hung, W.C.; Schulter, S.; Sohn, K.; Yang, M.H.; Chandraker, M. Learning to adapt structured output space for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7472–7481. [Google Scholar]
- Wang, B.; Li, G.; Wu, C.; Zhang, W.; Zhou, J.; Wei, Y. A Framework for Self-Supervised Federated Domain Adaptation. Eurasip J. Wirel. Commun. Netw. 2021. [Google Scholar] [CrossRef]
- Wen, J.; Liu, R.; Zheng, N.; Zheng, Q.; Gong, Z.; Yuan, J. Exploiting local feature patterns for unsupervised domain adaptation. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 5401–5408. [Google Scholar]
- Caruana, R. Multitask learning. Mach. Learn. 1997, 28, 41–75. [Google Scholar] [CrossRef]
- Zhang, Y.; Yang, Q. A survey on multi-task learning. arXiv 2017, arXiv:1707.08114. [Google Scholar] [CrossRef]
- Jia, Y.; Shelhamer, E.; Donahue, J.; Karayev, S.; Long, J.; Girshick, R.; Guadarrama, S.; Darrell, T. Caffe: Convolutional architecture for fast feature embedding. In Proceedings of the 22nd ACM International Conference on Multimedia, Orlando, FL, USA, 3–7 November 2014; pp. 675–678. [Google Scholar]
- Oreshkin, B.N.; Rodriguez, P.; Lacoste, A. Tadam: Task dependent adaptive metric for improved few-shot learning. arXiv 2018, arXiv:1805.10123. [Google Scholar]
- Zhao, F.; Zhao, J.; Yan, S.; Feng, J. Dynamic conditional networks for few-shot learning. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 19–35. [Google Scholar]
- Edwards, H.; Storkey, A. Towards a neural statistician. arXiv 2016, arXiv:1606.02185. [Google Scholar]
- Rezende, D.; Danihelka, I.; Gregor, K.; Wierstra, D. One-shot generalization in deep generative models. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 20–22 June 2016; pp. 1521–1529. [Google Scholar]
- Zhang, R.; Che, T.; Ghahramani, Z.; Bengio, Y.; Song, Y. MetaGAN: An Adversarial Approach to Few-Shot Learning. In Proceedings of the 32nd Conference on Neural Information Processing Systems (NIPS 2018), Montreal, QC, Canada, 2–8 December 2018; Volume 2, p. 1. [Google Scholar]
- Zhang, Y.; Tang, H.; Jia, K. Fine-grained visual categorization using meta-learning optimization with sample selection of auxiliary data. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 233–248. [Google Scholar]
- Luo, Z.; Zou, Y.; Hoffman, J.; Fei-Fei, L. Label efficient learning of transferable representations across domains and tasks. arXiv 2017, arXiv:1712.00123. [Google Scholar]
- Fink, M. Object classification from a single example utilizing class relevance metrics. Adv. Neural Inf. Process. Syst. 2005, 17, 449–456. [Google Scholar]
- Reed, S.; Chen, Y.; Paine, T.; Oord, A.v.d.; Eslami, S.; Rezende, D.; Vinyals, O.; de Freitas, N. Few-shot autoregressive density estimation: Towards learning to learn distributions. arXiv 2017, arXiv:1710.10304. [Google Scholar]
- Koch, G.; Zemel, R.; Salakhutdinov, R. Siamese neural networks for one-shot image recognition. In Proceedings of the ICML Deep Learning Workshop, Lille, France, 10–11 July 2015; Volume 2. [Google Scholar]
- Vinyals, O.; Blundell, C.; Lillicrap, T.; Wierstra, D. Matching networks for one shot learning. Adv. Neural Inf. Process. Syst. 2016, 29, 3630–3638. [Google Scholar]
- Ganin, Y.; Kulkarni, T.; Babuschkin, I.; Eslami, S.A.; Vinyals, O. Synthesizing programs for images using reinforced adversarial learning. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 1666–1675. [Google Scholar]
- Prakash, A.; Boochoon, S.; Brophy, M.; Acuna, D.; Cameracci, E.; State, G.; Shapira, O.; Birchfield, S. Structured domain randomization: Bridging the reality gap by context-aware synthetic data. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 7249–7255. [Google Scholar]
- Richter, S.R.; Vineet, V.; Roth, S.; Koltun, V. Playing for data: Ground truth from computer games. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 102–118. [Google Scholar]
- Beery, S.; Liu, Y.; Morris, D.; Piavis, J.; Kapoor, A.; Joshi, N.; Meister, M.; Perona, P. Synthetic examples improve generalization for rare classes. In Proceedings of the Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 1–5 March 2020; pp. 863–873. [Google Scholar]
- Wang, Q.; Gao, J.; Lin, W.; Yuan, Y. Learning from synthetic data for crowd counting in the wild. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 8198–8207. [Google Scholar]
- Krähenbühl, P. Free supervision from video games. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2955–2964. [Google Scholar]
- Ros, G.; Sellart, L.; Materzynska, J.; Vazquez, D.; Lopez, A.M. The synthia dataset: A large collection of synthetic images for semantic segmentation of urban scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3234–3243. [Google Scholar]
- Zhang, C.; Kang, K.; Li, H.; Wang, X.; Xie, R.; Yang, X. Data-driven crowd understanding: A baseline for a large-scale crowd dataset. IEEE Trans. Multimed. 2016, 18, 1048–1061. [Google Scholar] [CrossRef]
- Berga, D.; Fdez-Vidal, X.R.; Otazu, X.; Pardo, X.M. Sid4vam: A benchmark dataset with synthetic images for visual attention modeling. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 8789–8798. [Google Scholar]
- Zheng, Y.; Huang, D.; Liu, S.; Wang, Y. Cross-domain object detection through coarse-to-fine feature adaptation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 13766–13775. [Google Scholar]
- Loy, C.C.; Chen, K.; Gong, S.; Xiang, T. Crowd counting and profiling: Methodology and evaluation. In Modeling, Simulation and Visual Analysis of Crowds; Springer: Berlin/Heidelberg, Germany, 2013; pp. 347–382. [Google Scholar]
- Li, Y.; Zhang, X.; Chen, D. CSRNet: Dilated Convolutional Neural Networks for Understanding the Highly Congested Scenes. arXiv 2018, arXiv:1802.10062. [Google Scholar]
- Liu, W.; Salzmann, M.; Fua, P. Context-Aware Crowd Counting. arXiv 2019, arXiv:1811.10452. [Google Scholar]
- Finn, C.; Abbeel, P.; Levine, S. Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks. arXiv 2017, arXiv:1703.03400. [Google Scholar]
- Behl, H.S.; Baydin, A.G.; Torr, P.H. Alpha maml: Adaptive model-agnostic meta-learning. arXiv 2019, arXiv:1905.07435. [Google Scholar]
- Jordan, M.I.; Mitchell, T.M. Machine learning: Trends, perspectives, and prospects. Science 2015, 349, 255–260. [Google Scholar] [CrossRef]
- Vanschoren, J. Meta-learning: A survey. arXiv 2018, arXiv:1810.03548. [Google Scholar]
- Nixon, M.; Aguado, A. Feature Extraction and Image Processing for Computer Vision; Academic Press: Cambridge, MA, USA, 2019. [Google Scholar]
- Ganin, Y.; Lempitsky, V. Unsupervised domain adaptation by backpropagation. In Proceedings of the International Conference on Machine Learning, Lille, France, 7–9 July 2015; pp. 1180–1189. [Google Scholar]
- Wang, M.; Deng, W. Deep visual domain adaptation: A survey. Neurocomputing 2018, 312, 135–153. [Google Scholar] [CrossRef] [Green Version]
- Hoffman, J.; Rodner, E.; Donahue, J.; Darrell, T.; Saenko, K. Efficient learning of domain-invariant image representations. arXiv 2013, arXiv:1301.3224. [Google Scholar]
- Inoue, N.; Furuta, R.; Yamasaki, T.; Aizawa, K. Cross-Domain Weakly-Supervised Object Detection Through Progressive Domain Adaptation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Tasks | Method | 1-Shot () | 5-Shot () | ||
|---|---|---|---|---|---|
| MAE | MSE | MAE | MSE | ||
| Scene1: Clear | Baseline | 23.11 | 34.16 | 22.54 | 33.24 |
| FSCC | 19.33 | 28.08 | 19.33 | 28.08 | |
| Ours | 18.34 | 26.48 | 18.34 | 26.48 | |
| Scene2: Clouds | Baseline | 21.99 | 32.35 | 21.81 | 32.06 |
| FSCC | 17.12 | 24.52 | 17.37 | 24.92 | |
| Ours | 17.18 | 24.62 | 17.39 | 24.96 | |
| Scene3: Rain | Baseline | 14.87 | 20.89 | 14.88 | 20.91 |
| FSCC | 11.31 | 15.16 | 11.87 | 16.06 | |
| Ours | 11.32 | 15.17 | 11.91 | 16.12 | |
| Scene4: Foggy | Baseline | 32.00 | 48.45 | 32.13 | 48.66 |
| FSCC | 15.99 | 22.70 | 15.78 | 22.36 | |
| Ours | 15.71 | 22.25 | 15.99 | 22.70 | |
| Scene5: Thunder | Baseline | 39.56 | 60.59 | 39.13 | 59.90 |
| FSCC | 20.44 | 29.86 | 20.31 | 29.65 | |
| Ours | 19.23 | 27.91 | 20.01 | 29.17 | |
| Scene6: Overcast | Baseline | 19.44 | 28.25 | 19.72 | 28.70 |
| FSCC | 14.30 | 19.97 | 14.28 | 19.94 | |
| Ours | 14.22 | 19.85 | 14.65 | 20.54 | |
| Scene7: Extra Sunny | Baseline | 24.52 | 36.43 | 24.37 | 36.19 |
| FSCC | 17.49 | 25.11 | 17.47 | 25.08 | |
| Ours | 16.94 | 24.23 | 17.03 | 24.37 | |
| Average | Baseline | 25.07 | 37.30 | 24.94 | 37.10 |
| FSCC | 16.57 | 23.63 | 16.63 | 23.73 | |
| Ours | 16.13 | 22.93 | 16.47 | 23.48 | |
| Method | SH-B | MALL | UCSD | |||
|---|---|---|---|---|---|---|
| MAE | MSE | MAE | MSE | MAE | MSE | |
| NoAdapt | 22.4 | 31.3 | 5.11 | 5.98 | 16.23 | 18.22 |
| SFCN [10] | 17.1 | 26.1 | 2.56 | 3.88 | 2.09 | 2.42 |
| Ours | 17.4 | 26.8 | 2.55 | 3.81 | 2.03 | 2.41 |
| Method | GCC - > NWPU-Crowd | |
|---|---|---|
| MAE | MSE | |
| CSRNet w/o Adapt | 86.12 | 148.32 |
| CSRNet w/Adapt | 45.84 | 91.12 |
| Ours w/FE | 41.72 | 80.97 |
| Ours w/DE | 40.97 | 78.85 |
| Ours w/FE + CM | 40.83 | 79.13 |
| Ours w/FE + DE + CM | 39.18 | 77.29 |
| Method | Frames per Second |
|---|---|
| CSRnet | 8∼10 |
| SFCC | 3∼5 |
| Ours | 1∼2 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hou, X.; Xu, J.; Wu, J.; Xu, H. Cross Domain Adaptation of Crowd Counting with Model-Agnostic Meta-Learning. Appl. Sci. 2021, 11, 12037. https://doi.org/10.3390/app112412037
Hou X, Xu J, Wu J, Xu H. Cross Domain Adaptation of Crowd Counting with Model-Agnostic Meta-Learning. Applied Sciences. 2021; 11(24):12037. https://doi.org/10.3390/app112412037
Chicago/Turabian StyleHou, Xiaoyu, Jihui Xu, Jinming Wu, and Huaiyu Xu. 2021. "Cross Domain Adaptation of Crowd Counting with Model-Agnostic Meta-Learning" Applied Sciences 11, no. 24: 12037. https://doi.org/10.3390/app112412037
APA StyleHou, X., Xu, J., Wu, J., & Xu, H. (2021). Cross Domain Adaptation of Crowd Counting with Model-Agnostic Meta-Learning. Applied Sciences, 11(24), 12037. https://doi.org/10.3390/app112412037