
MMPC-RF: A Deep Multimodal Feature-Level Fusion Architecture for Hybrid Spam E-mail Detection


Abstract
:1. Introduction
2. Related Works
2.1. Text-Based Feature Extraction Techniques
2.2. Image-Based Feature Extraction Techniques
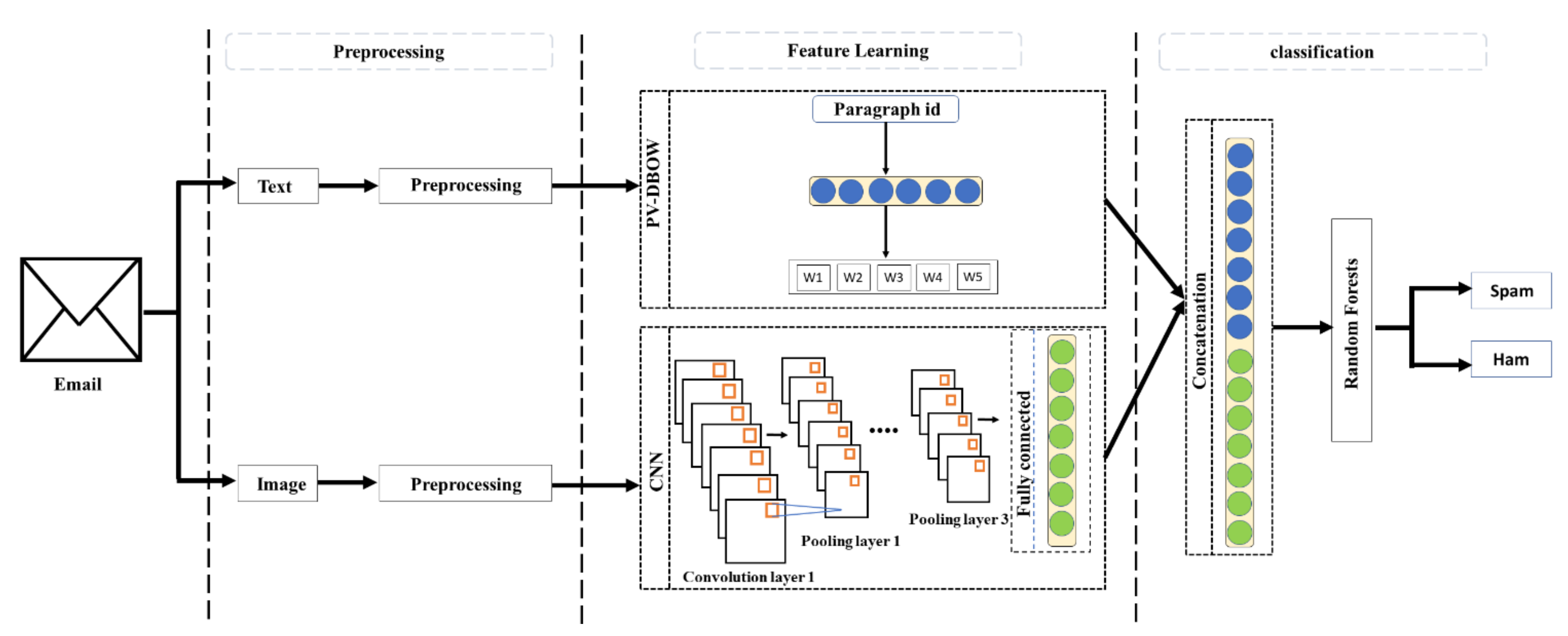
3. Methodology
3.1. The PV-DBOW Model
3.2. The CNN Model
3.3. Random Forest Classifier
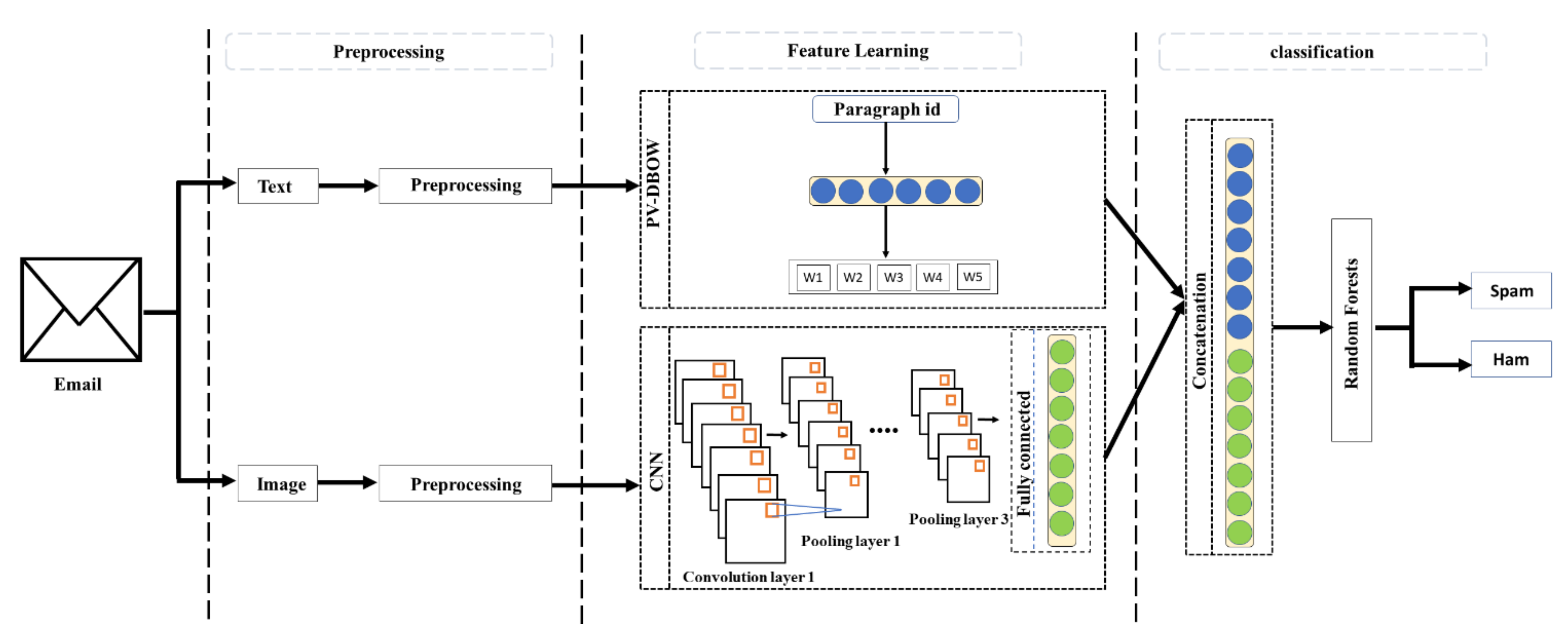
3.4. The Proposed Approach
3.4.1. Dataset
3.4.2. The MMPC-RF Architecture
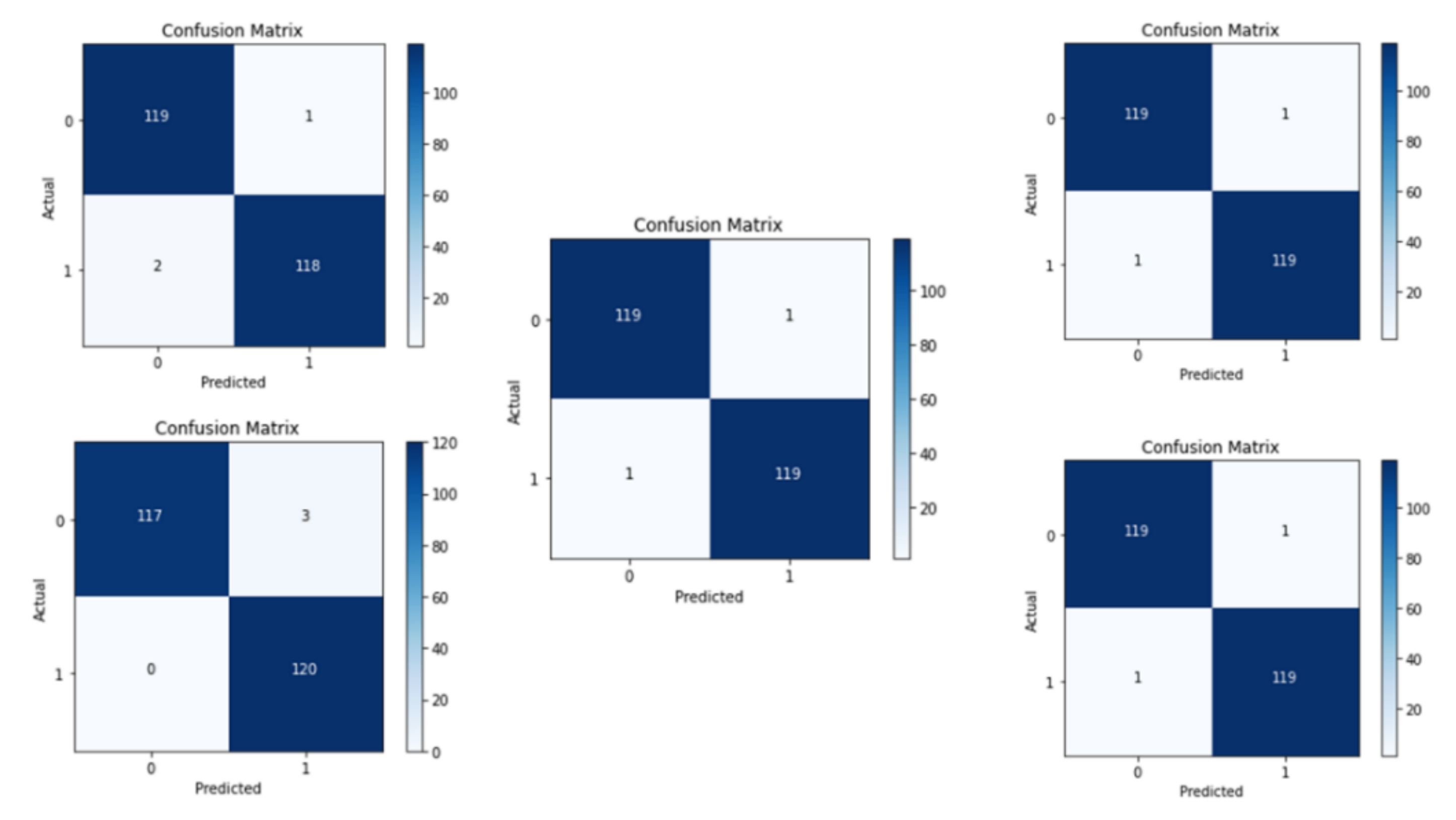
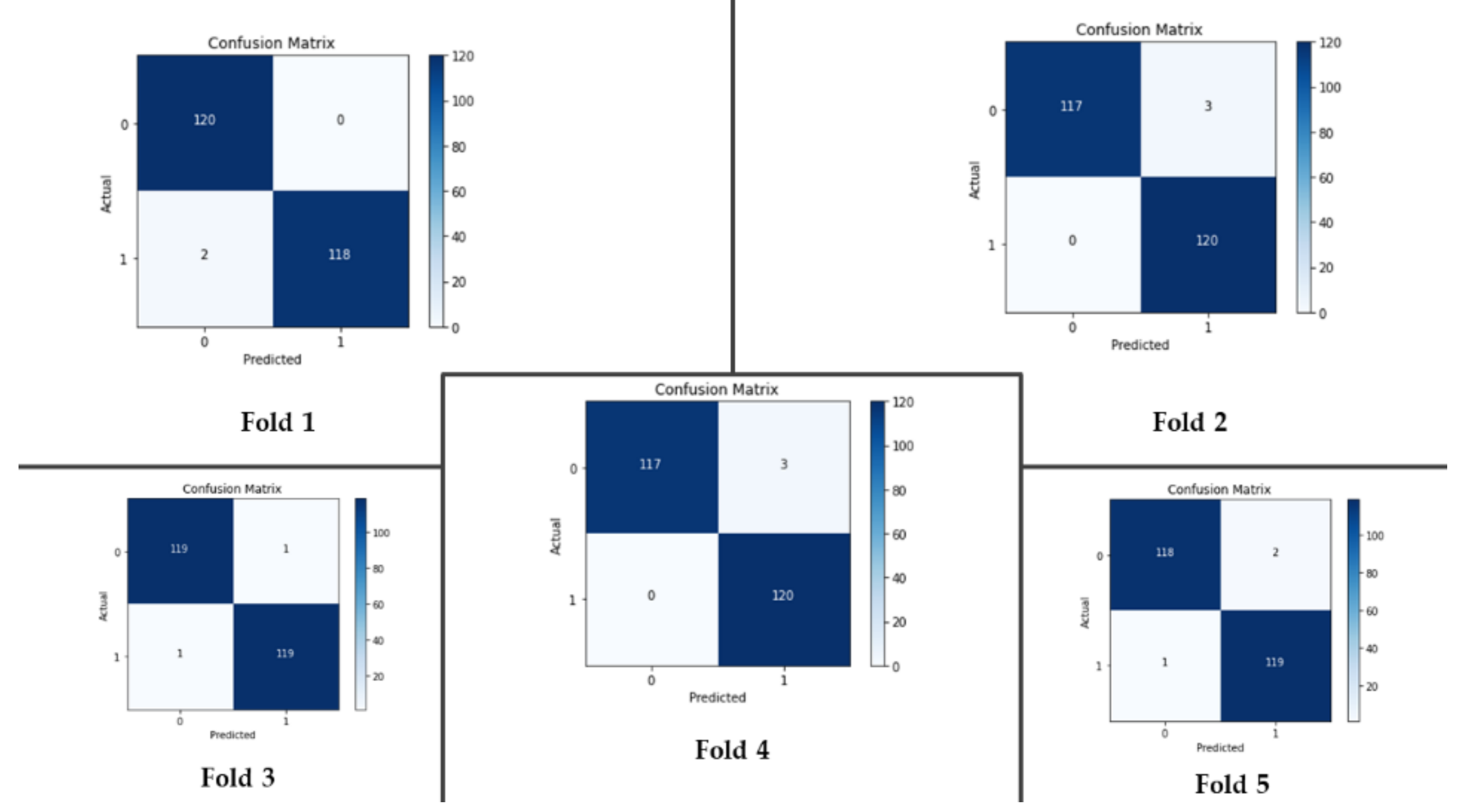
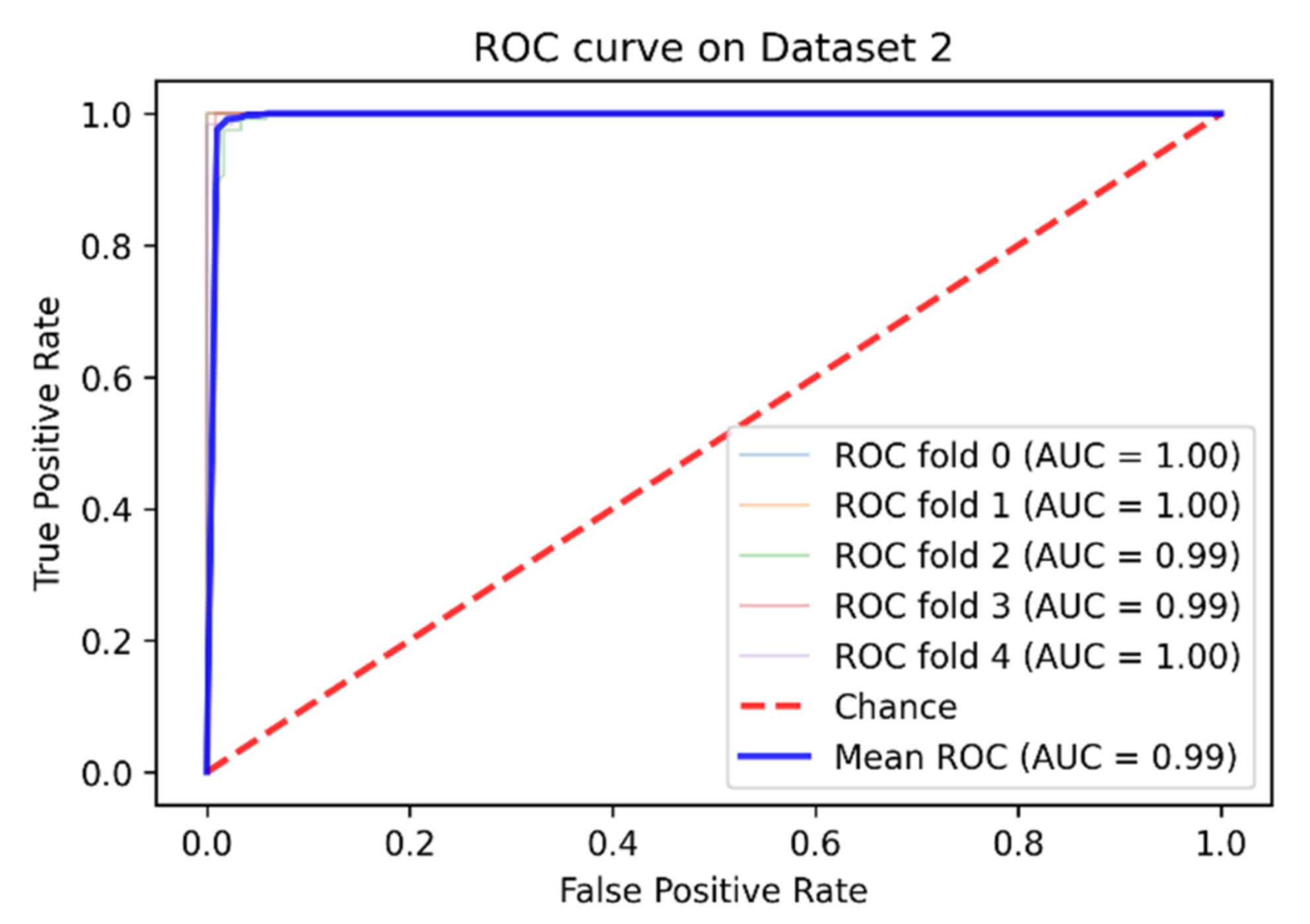
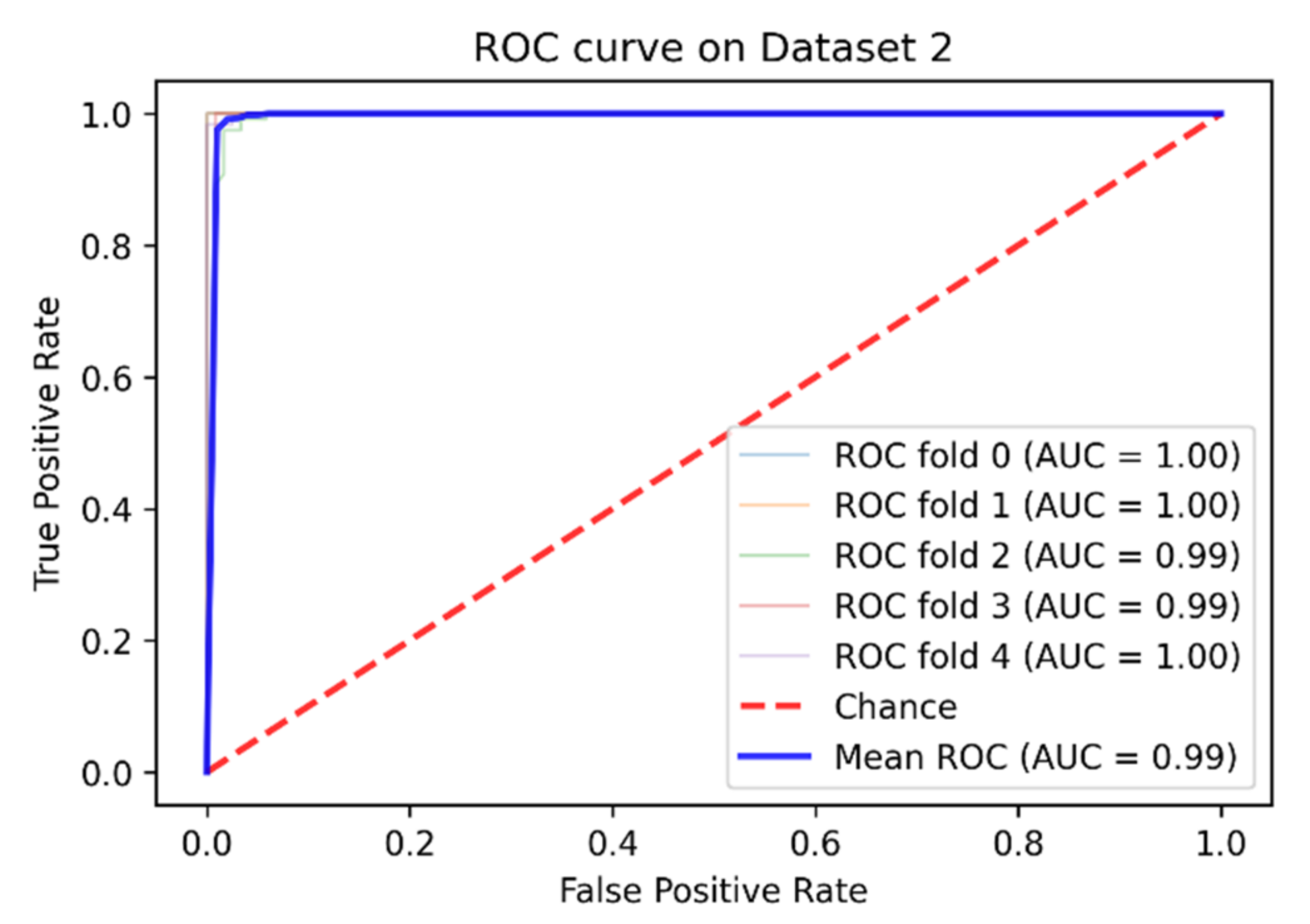
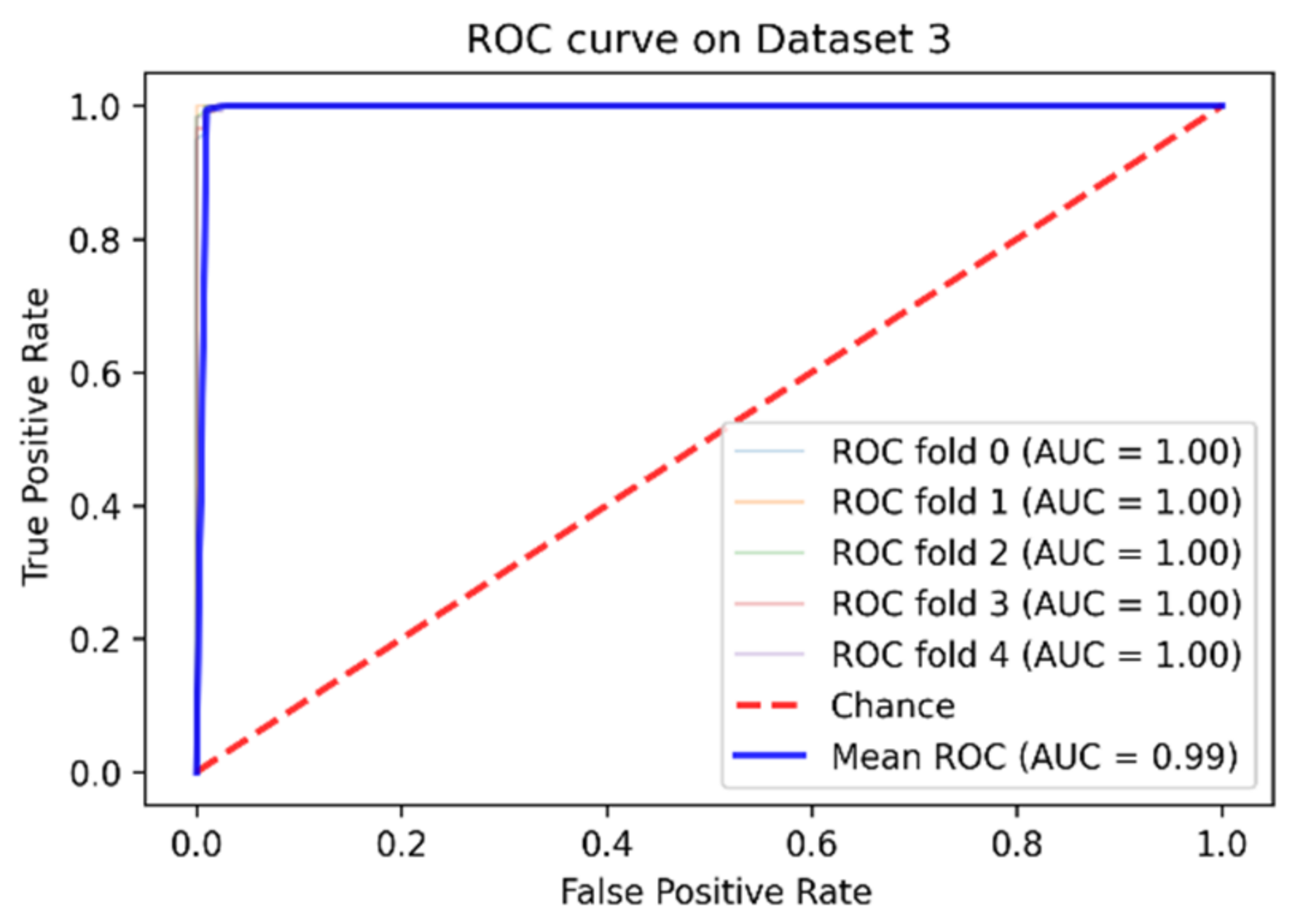
4. Experimental Results and Comparative Study
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Karim, A.; Azam, S.; Shanmugam, B.; Kannoorpatti, K.; Alazab, M. A comprehensive survey for intelligent spam email detection. IEEE Access 2019, 7, 168261–168295. [Google Scholar] [CrossRef]
- Dada, E.G.; Bassi, J.S.; Chiroma, H.; Abdulhamid, S.M.; Adetunmbi, A.O.; Ajibuwa, O.E. Machine learning for email spam filtering: Review, approaches and open research problems. Heliyon 2019, 5, e01802. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Biggio, B.; Fumera, G.; Pillai, I.; Roli, F. A survey and experimental evaluation of image spam filtering techniques. Pattern Recognit. Lett. 2011, 32, 1436–1446. [Google Scholar] [CrossRef]
- Yang, H.; Liu, Q.; Zhou, S.; Luo, Y. A spam filtering method based on multi-modal fusion. Appl. Sci. 2019, 9, 1152. [Google Scholar] [CrossRef] [Green Version]
- Feng, H.; Yang, X.; Liu, B.; Chao, J. A spam filtering method based on multi-modal features fusion. In Proceedings of the 2011 7th International Conference on Computational Intelligence and Security, CIS 2011, Sanya, China, 3–4 December 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 421–426. [Google Scholar]
- Seth, S.; Biswas, S. Multimodal Spam Classification Using Deep Learning Techniques. In Proceedings of the 13th International Conference on Signal-Image Technology and Internet-Based Systems, SITIS 2017, Jaipur, India, 4–7 December 2017; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2018; pp. 346–349. [Google Scholar]
- Worring, M.; Smeulders, A.W.M.; Snoek, C.G.M. Early versus late fusion in semantic video analysis. In Proceedings of the 13th annual ACM international conference on Multimedia, Singapore, 6–11 November 2005. [Google Scholar] [CrossRef]
- Santos, I.; Laorden, C.; Sanz, B.; Bringas, P.G. Enhanced Topic-based Vector Space Model for semantics-aware spam filtering. Expert Syst. Appl. 2012, 39, 437–444. [Google Scholar] [CrossRef] [Green Version]
- Hnini, G.; Riffi, J.; Mahraz, M.A.; Yahyaouy, A.; Tairi, H. Spam filtering system based on nearest neighbor algorithms. In Proceedings of the International Conference on Artificial Intelligence & Industrial Applications, Meknes, Morocco, 19–20 March 2020; Lecture Notes in Networks and Systems; Springer: Cham, Switzerland, 2020; pp. 36–46. [Google Scholar]
- Amayri, O.; Bouguila, N. A study of spam filtering using support vector machines. Artif. Intell. Rev. 2010, 34, 73–108. [Google Scholar] [CrossRef]
- Metsis, V.; Androutsopoulos, I.; Paliouras, G. Spam Filtering with Naive Bayes—Which Naive Bayes? In Proceedings of the CEAS 2006—Third Conference on Email and Anti-Spam, Mountain View, CA, USA, 27–28 July 2006. [Google Scholar]
- Diale, M.; Celik, T.; Van Der Walt, C. Unsupervised feature learning for spam email filtering. Comput. Electr. Eng. 2019, 74, 89–104. [Google Scholar] [CrossRef]
- Zareapoor, M.; Shamsolmoali, P.; Afshar Alam, M. Highly discriminative features for phishing email classification by SVD. In Advances in Intelligent Systems and Computing; Springer: Berlin/Heidelberg, Germany, 2015; pp. 649–656. [Google Scholar]
- Gomez, J.C.; Moens, M.F. PCA document reconstruction for email classification. Comput. Stat. Data Anal. 2012, 56, 741–751. [Google Scholar] [CrossRef]
- Cai, D.; Chang, L.; Ji, D. Latent semantic analysis based on space integration. In Proceedings of the 2012 IEEE 2nd International Conference on Cloud Computing and Intelligence Systems, IEEE CCIS 2012, Hangzhou, China, 30 December 2012; pp. 1430–1434. [Google Scholar]
- Ghizlane, H.; Anass, F.; Jamal, R.; Mohamed Adnane, M.; Ali, Y.; Hamid, T. Spam Filtering based on PV-DBOW model. Int. J. Data Anal. Tech. Strateg. 2021, in press. [Google Scholar]
- Srinivasan, S.; Ravi, V.; Alazab, M.; Ketha, S.; Al-Zoubi, A.M.; Kotti Padannayil, S. Spam Emails Detection Based on Distributed Word Embedding with Deep Learning. Stud. Comput. Intell. 2021, 919, 161–189. [Google Scholar] [CrossRef]
- Gibson, S.; Issac, B.; Zhang, L.; Jacob, S.M. Detecting spam email with machine learning optimized with bio-inspired metaheuristic algorithms. IEEE Access 2020, 8, 187914–187932. [Google Scholar] [CrossRef]
- AbdulNabi, I.; Yaseen, Q. ScienceDirect The 2nd International Workshop on Data-Driven Security (DDSW 2021) Spam Email Detection Using Deep Learning Techniques. Procedia Comput. Sci. 2021, 184, 853–858. [Google Scholar] [CrossRef]
- Wu, C.T.; Cheng, K.T.; Zhu, Q.; Wu, Y.L. Using visual features for anti-spam filtering. In Proceedings of the International Conference on Image Processing, ICIP, Genoa, Italy, 11–14 September 2005; IEEE: Piscataway, NJ, USA, 2005; pp. 509–512. [Google Scholar]
- Aradhye, H.B.; Myers, G.K.; Herson, J.A. Image analysis for efficient categorization of image-based spam E-mail. In Proceedings of the International Conference on Document Analysis and Recognition, ICDAR, Seoul, South Korea, 31 August–1 September 2005; IEEE: Piscataway, NJ, USA, 2005; pp. 914–918. [Google Scholar]
- Liu, Q.; Qin, Z.; Cheng, H.; Wan, M. Efficient modeling of Spam Images. In Proceedings of the Third International Symposium on Intelligent Information Technology and Security Informatics, Jian, China, 2–4 April 2010. [Google Scholar] [CrossRef]
- Hsia, J.H.; Chen, M.S. Language-model-based detection cascade for efficient classification of image-based spam e-mail. In Proceedings of the 2009 IEEE International Conference on Multimedia and Expo, ICME 2009, New York, NY, USA, 28 June–3 July 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 1182–1185. [Google Scholar]
- Gao, Y.; Yang, M.; Zhao, X.; Pardo, B.; Wu, Y.; Pappas, T.N.; Choudhary, A. Image spam hunter. In ICASSP, Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing—Proceedings, Las Vegas, NV, USA, 31 March–4 April 2008; IEEE: Piscataway, NJ, USA, 2008; pp. 1765–1768. [Google Scholar]
- Zuo, H.; Li, X.; Wu, O.; Hu, W.; Luo, G. Image Spam Filtering Using Fourier-Mellin Invariant Features. In Proceedings of the 2009 IEEE International Conference on Acoustics, Speech and Signal Processing, Taipei, Taiwan, 19–24 April 2009. [Google Scholar]
- Dredze, M.; Gevaryahu, R.; Elias-Bachrach, A. Learning Fast Classifiers for Image Spam. In Proceedings of the Fourth Conference on Email and Anti-Spam, Mountain View, CA, USA, 2–3 August 2007. [Google Scholar]
- Annapurna, A.; Mark, S. Image spam analysis and detection. Artic. J. Comput. Virol. Hacking Tech. 2018, 14, 39–52. [Google Scholar] [CrossRef]
- Chavda, A.; Potika, K.; Di Troia, F.; Stamp, M. Support Vector Machines for Image Spam Analysis. In Proceedings of the 15th International Joint Conference on e-Business and Telecommunications (ICETE 2018)—Volume 1: DCNET, ICE-B, OPTICS, SIGMAP and WINSYS, Porto, Portugal, 26–28 July 2018; SciTePress: Setúbal, Portugal, 2018; Volume 1. [Google Scholar] [CrossRef]
- Sharmin, T.; Di Troia, F.; Potika, K.; Stamp, M. Convolutional neural networks for image spam detection. Inf. Secur. J. 2020, 29, 103–117. [Google Scholar] [CrossRef]
- Shang, E.X.; Zhang, H.G. Image spam classification based on convolutional neural network. In Proceedings of the International Conference on Machine Learning and Cybernetics, Jeju, Korea, 10–13 July 2016; IEEE Computer Society: Washington, DC, USA, 2016; pp. 398–403. [Google Scholar]
- Kim, B.; Abuadbba, S.; Kim, H. DeepCapture: Image Spam Detection Using Deep Learning and Data Augmentation. In Proceedings of the Australasian Conference on Information Security and Privacy, Perth, WA, Australia, 30 November–2 December 2020; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2020; Volume 12248, pp. 461–475. [Google Scholar] [CrossRef]
- Srinivasan, S.; Ravi, V.; Sowmya, V.; Krichen, M.; Ben Noureddine, D.; Anivilla, S.; Soman, K.P. Deep Convolutional Neural Network Based Image Spam Classification. In Proceedings of the 2020 6th Conference on Data Science and Machine Learning Applications, CDMA 2020, Riyadh, Saudi Arabia, 4–5 March 2020; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2020; pp. 112–117. [Google Scholar]
- Le, Q.; Mikolov, T. Distributed Representations of Sentences and Documents. In Proceedings of the 31st International Conference on Machine Learning, PMLR, Beijing, China, 21–26 June 2014; Volume 32. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.; Dean, J. Distributed Representations of Words and Phrases and their Compositionality. In Advances in Neural Information Processing Systems; Curran Associates Inc.: Red Hook, NY, USA, 2013; pp. 3111–3119. [Google Scholar]
- Yamashita, R.; Nishio, M.; Do, R.K.G.; Togashi, K. Convolutional neural networks: An overview and application in radiology. Insights Imaging 2018, 9, 611–629. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Klimt, B.; Yang, Y. The Enron Corpus: A New Dataset for Email Classification Research. In Proceedings of the European Conference on Machine Learning, Pisa, Italy, 20–24 September 2004; Springer: Berlin/Heidelberg, Germany, 2004; pp. 217–226. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Title 1 | Dataset 1 | Dataset 2 | Dataset 3 |
|---|---|---|---|
| Original dataset | [4] | [4] | [5] |
| Total e-mails | 1200 | 1200 | 2792 |
| Total spam e-mails | 600 | 600 | 2378 |
| Total ham e-mails | 600 | 600 | 414 |
| Optimizer | Adam |
|---|---|
| Learning rate | 0.001 |
| Epochs | 100 |
| Batch size | 20 |
| Dataset | Accuracy | F1-Score | Recall | Precision | ROC |
|---|---|---|---|---|---|
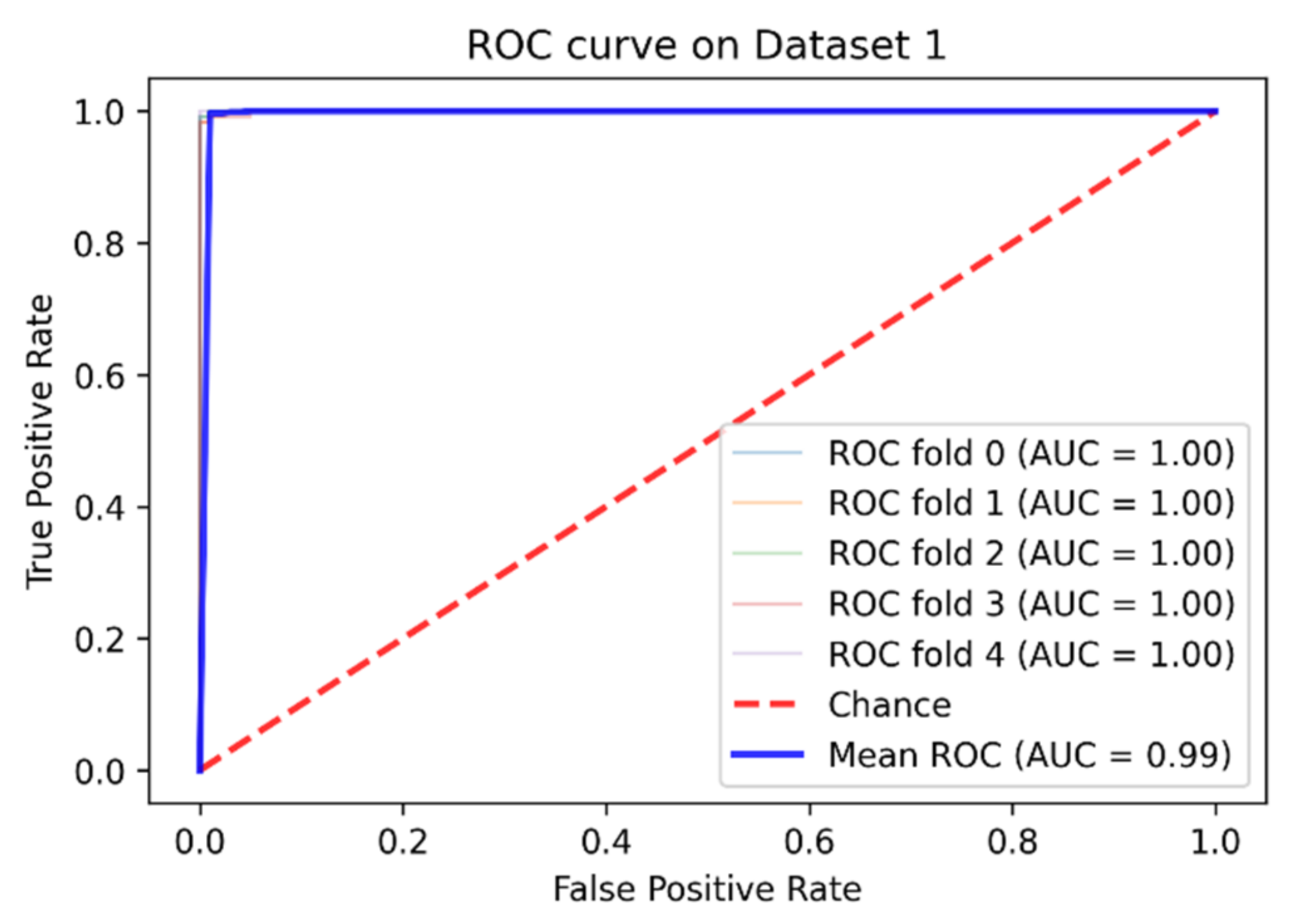
| Dataset 1 | 99.16% | 99% | 99.83% | 98.52% | 99.97% |
| Dataset 2 | 98.91% | 98.92% | 99.49% | 98.20% | 99.96% |
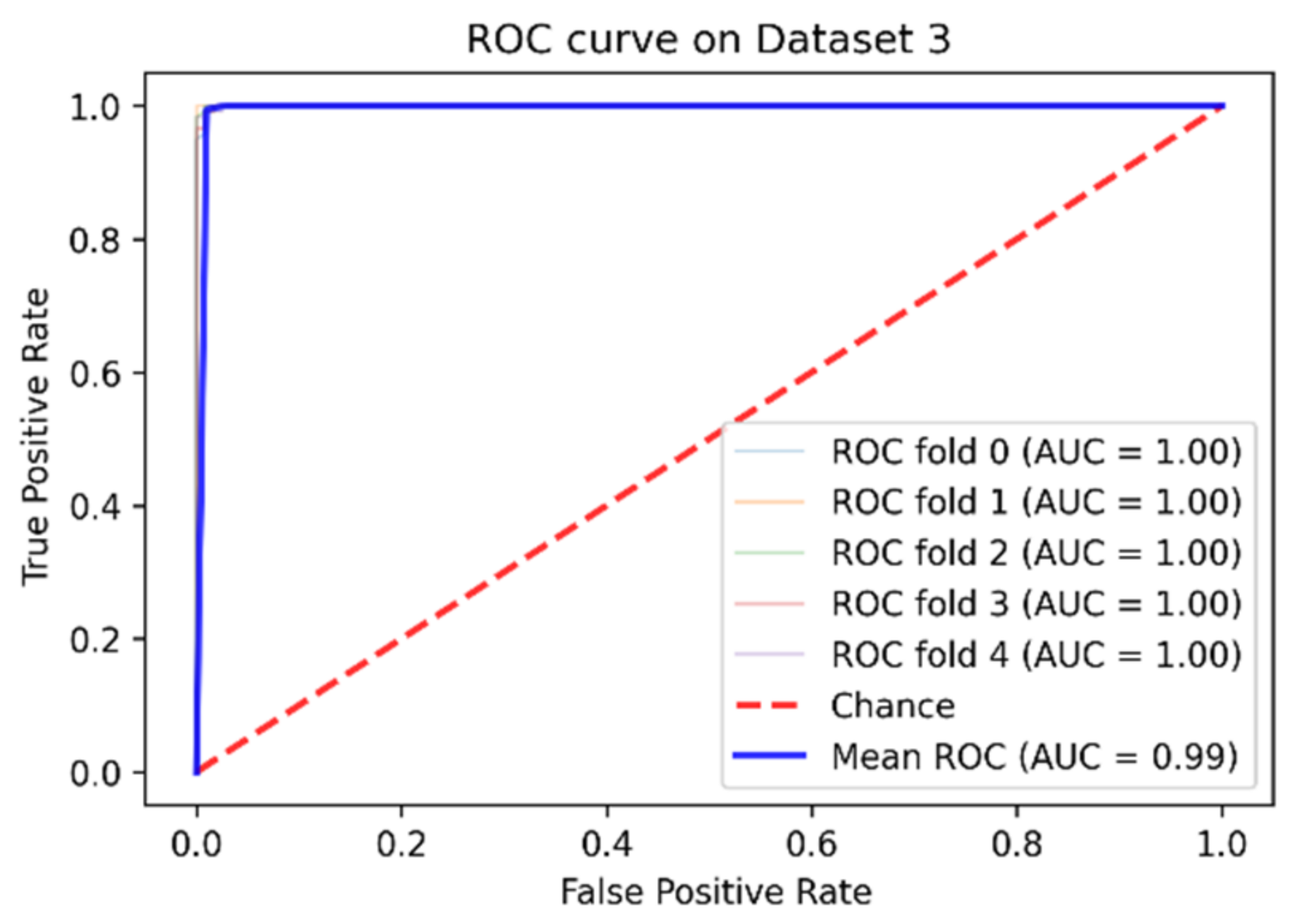
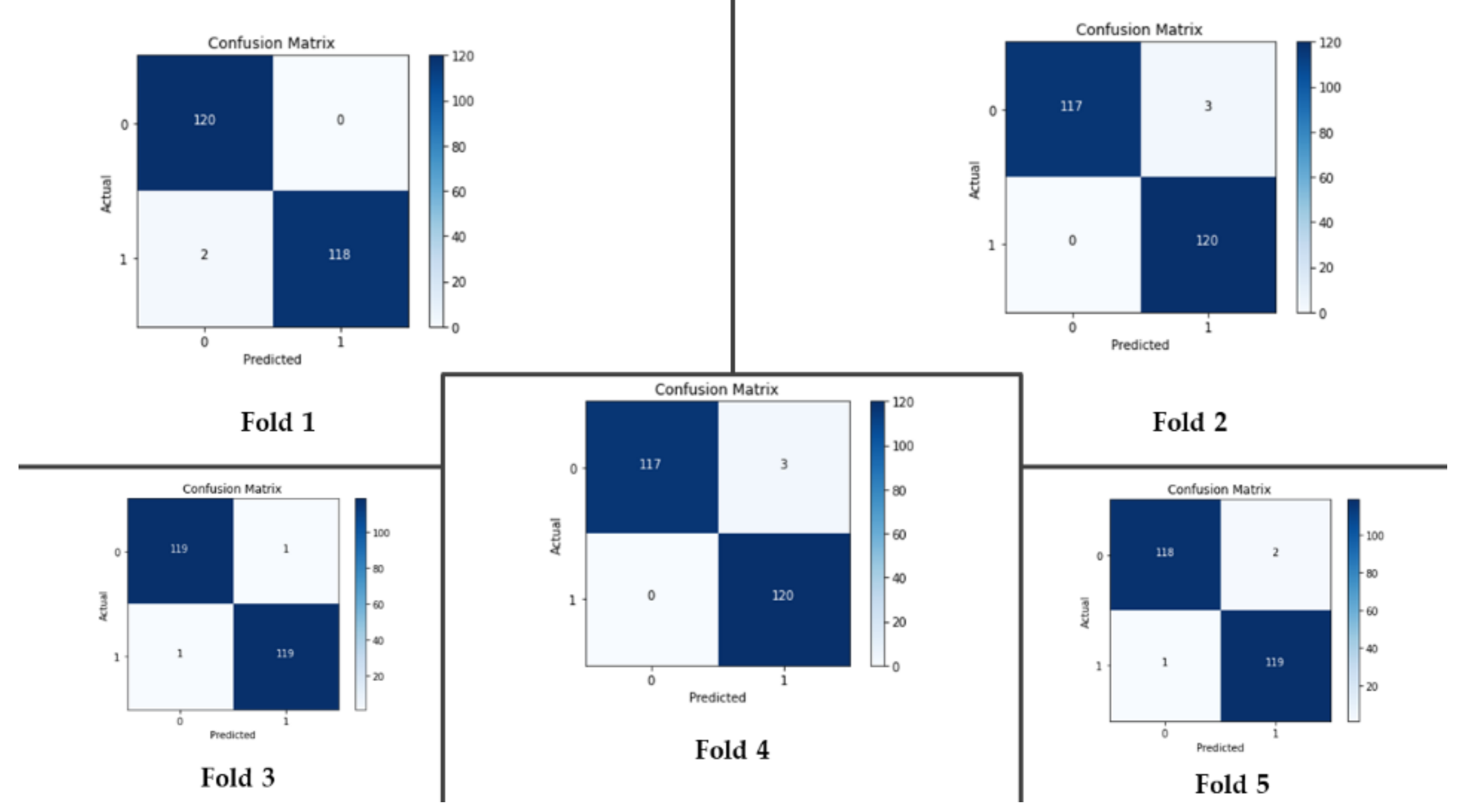
| Dataset 3 | 99% | 99.08% | 99.33% | 98.84% | 99.95% |
| Dataset | Model | Accuracy | F1-Score | Recall | Precision |
|---|---|---|---|---|---|
| Dataset 1 | SVM (Yang et al., 2019) | 98.25% | 98.25% | 98.25% | 98.10% |
| Classical k-NN [4] | 97.83% | 97.83% | 97.81% | 97.70% | |
| MMA-MF [4] | 98.42% | 98.41% | 98.45% | 98.40% | |
| Our method | 99.16% | 99% | 99.83% | 98.52% | |
| Dataset 2 | SVM [4] | 98.42% | 98.41% | 98.44% | 98.30% |
| Classical k-NN [4] | 98.08% | 98.08% | 98.13% | 97.90% | |
| MMA-MF [4] | 98.46% | 98.45% | 98.52% | 98.30% | |
| Our method | 98.91% | 98.92% | 99.49% | 98.20% | |
| Dataset 3 | P-SVM [5] | 90% | - | - | - |
| Our method | 99% | 99.08% | 99.33% | 98.84% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hnini, G.; Riffi, J.; Mahraz, M.A.; Yahyaouy, A.; Tairi, H. MMPC-RF: A Deep Multimodal Feature-Level Fusion Architecture for Hybrid Spam E-mail Detection. Appl. Sci. 2021, 11, 11968. https://doi.org/10.3390/app112411968
Hnini G, Riffi J, Mahraz MA, Yahyaouy A, Tairi H. MMPC-RF: A Deep Multimodal Feature-Level Fusion Architecture for Hybrid Spam E-mail Detection. Applied Sciences. 2021; 11(24):11968. https://doi.org/10.3390/app112411968
Chicago/Turabian StyleHnini, Ghizlane, Jamal Riffi, Mohamed Adnane Mahraz, Ali Yahyaouy, and Hamid Tairi. 2021. "MMPC-RF: A Deep Multimodal Feature-Level Fusion Architecture for Hybrid Spam E-mail Detection" Applied Sciences 11, no. 24: 11968. https://doi.org/10.3390/app112411968
APA StyleHnini, G., Riffi, J., Mahraz, M. A., Yahyaouy, A., & Tairi, H. (2021). MMPC-RF: A Deep Multimodal Feature-Level Fusion Architecture for Hybrid Spam E-mail Detection. Applied Sciences, 11(24), 11968. https://doi.org/10.3390/app112411968