
A Mini-Survey and Feasibility Study of Deep-Learning-Based Human Activity Recognition from Slight Feature Signals Obtained Using Privacy-Aware Environmental Sensors


Abstract
:1. Introduction
1.1. Background and Scope
1.2. Sensors and Human Behavior Patterns
1.3. Contributions
- A mini-survey presents existing HAR survey papers published between January 2016 and October 2021 and representative HAR studies reported between January 2019 and June 2021.
- Recent trends and developments of ADL studies are introduced, especially for the use of privacy-aware sensors.
- A dataset obtained using a fisheye lens monocular camera is provided with the aim reducing the burden of annotations.
- A dataset obtained using five privacy-aware environmental sensors is provided for long-term human monitoring.
1.4. Outline
2. Mini Survey
2.1. Existing HAR Surveys
2.2. State-of-the-Art HAR Studies
2.3. Recent Trends and Developments of ADL Studies
3. Vision-Based Approach Using a Fisheye Lens Monocular Camera
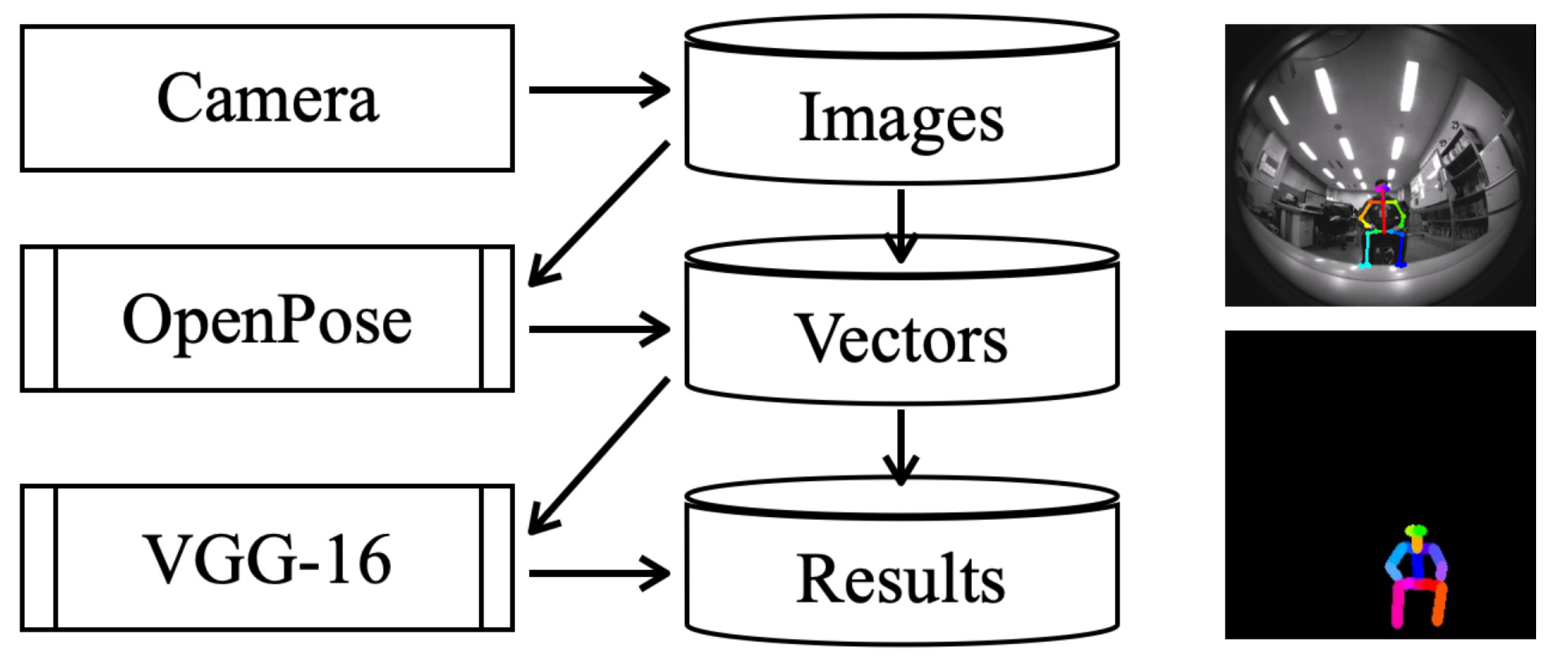
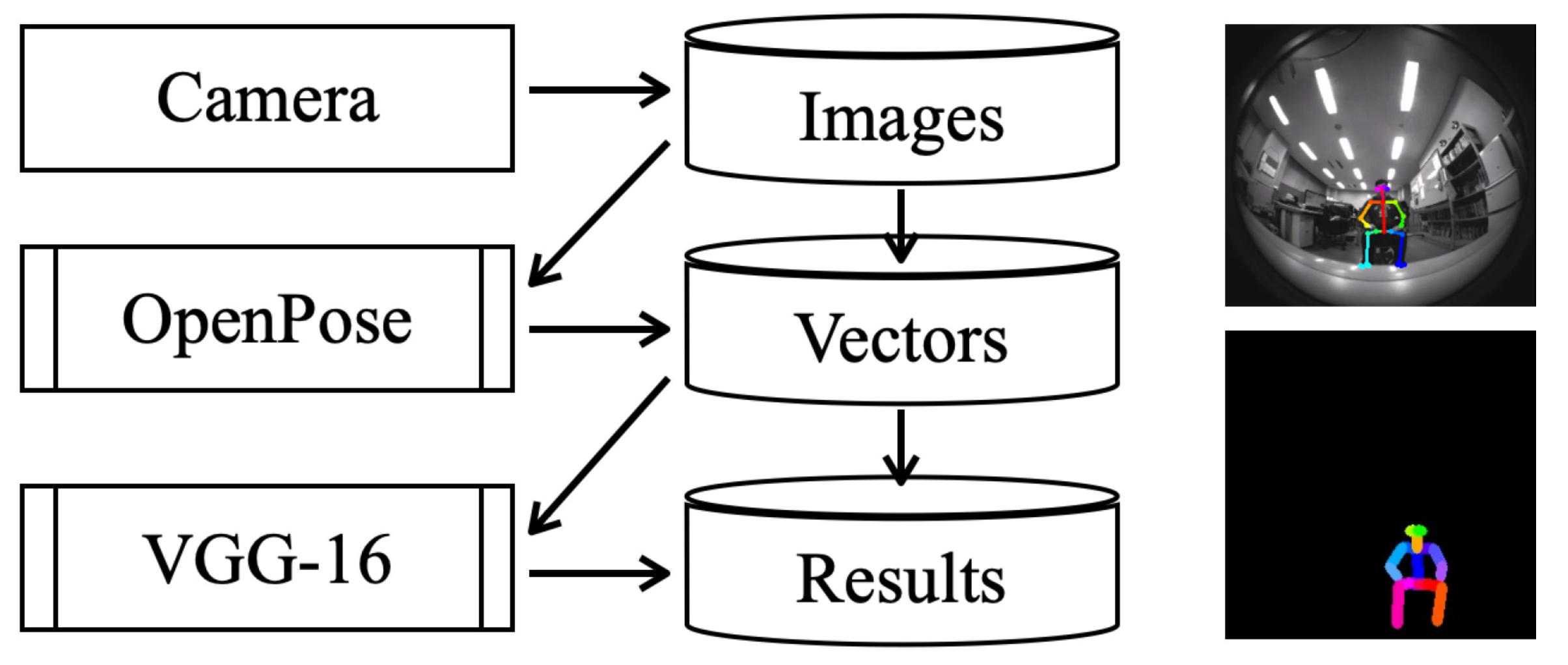
3.1. Proposed Sensor System and Recognition Method
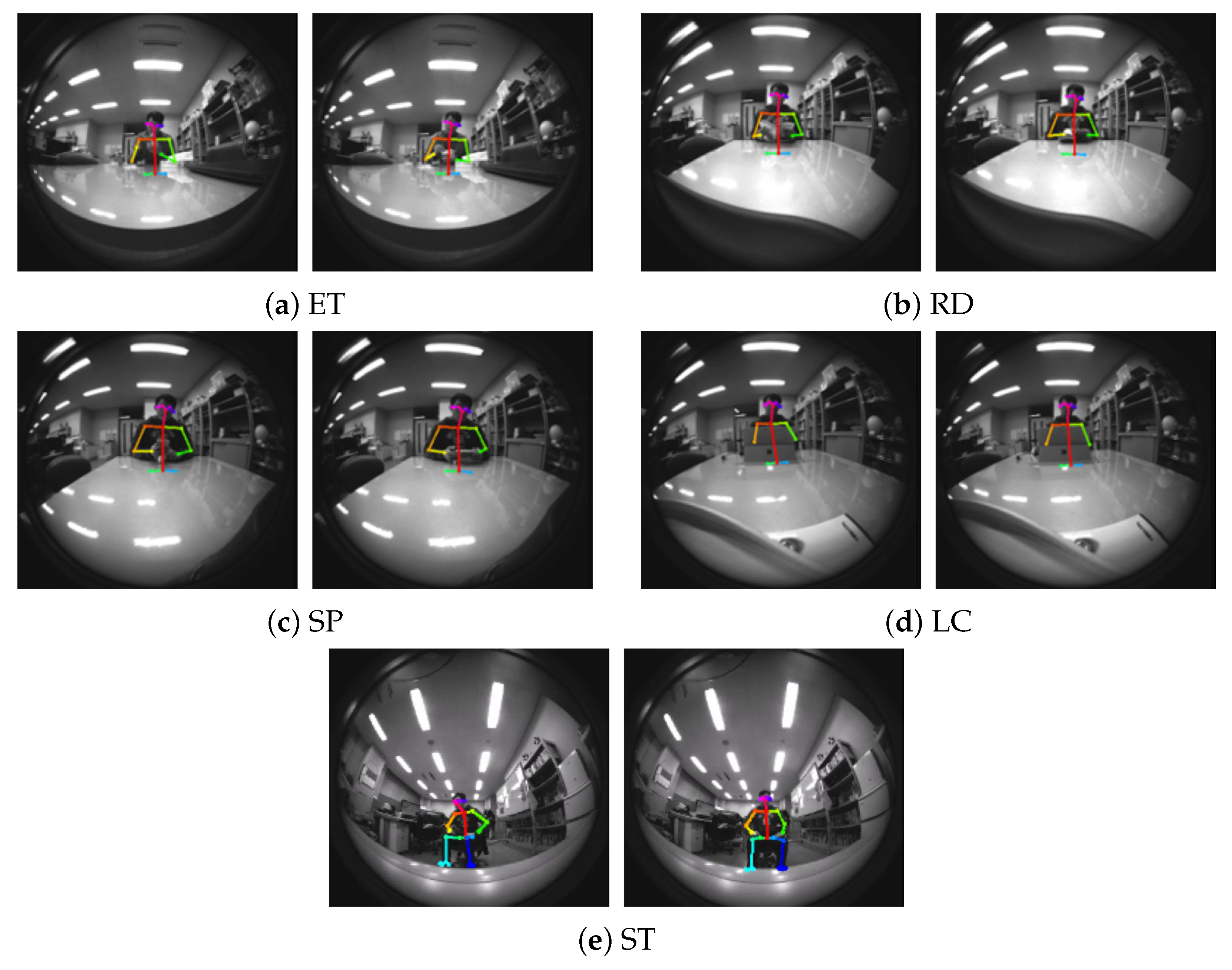
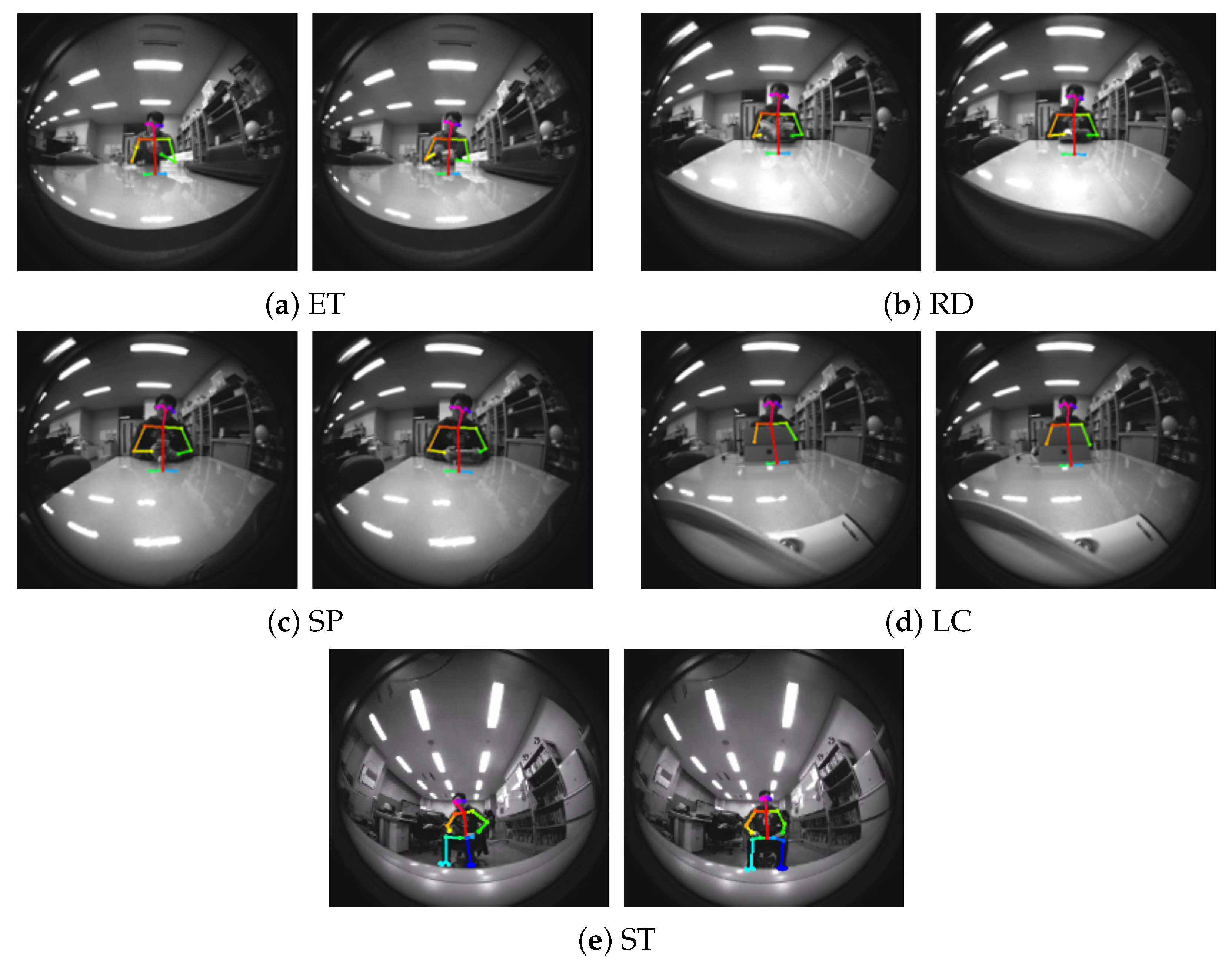
3.2. Setup and the Obtained First Dataset
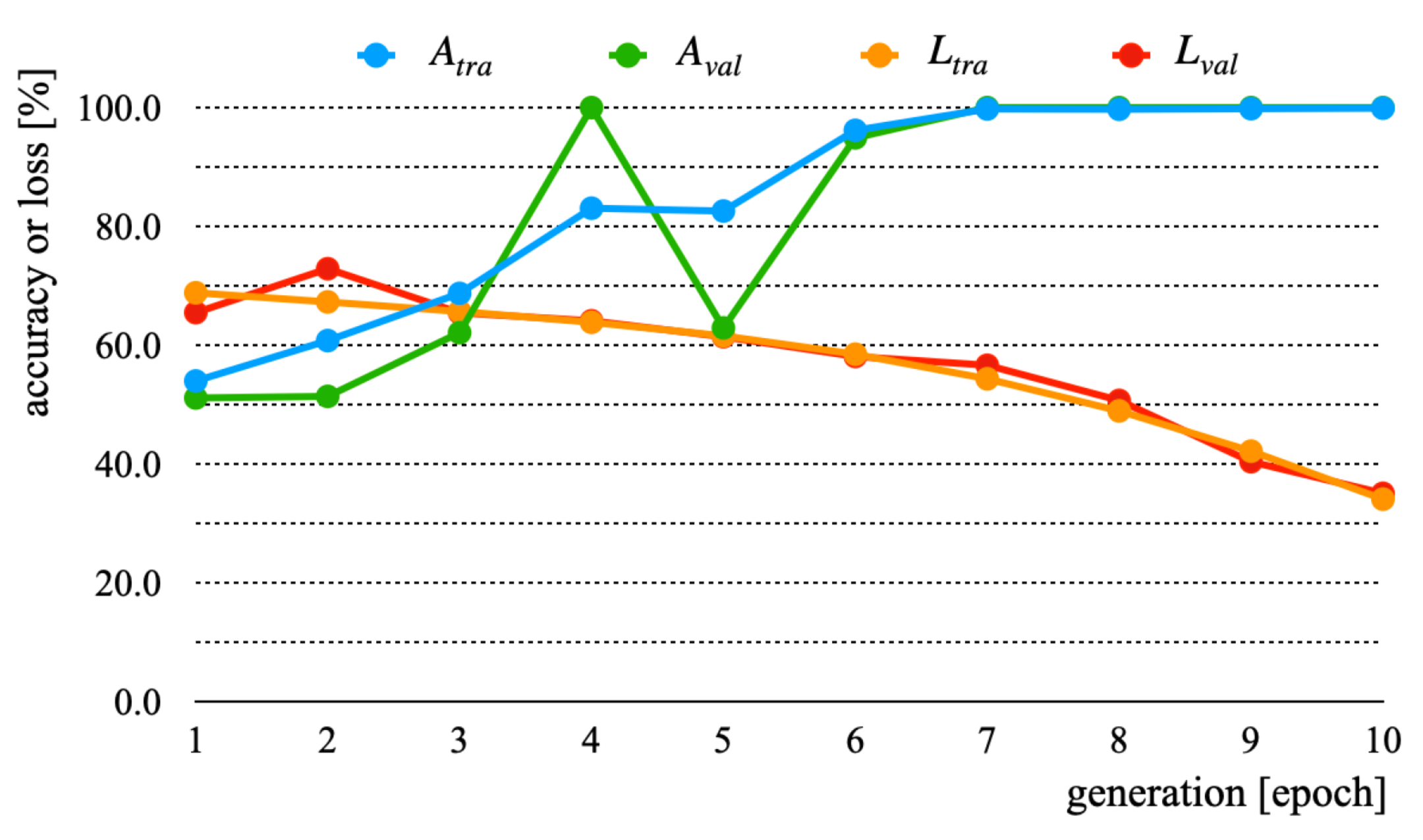
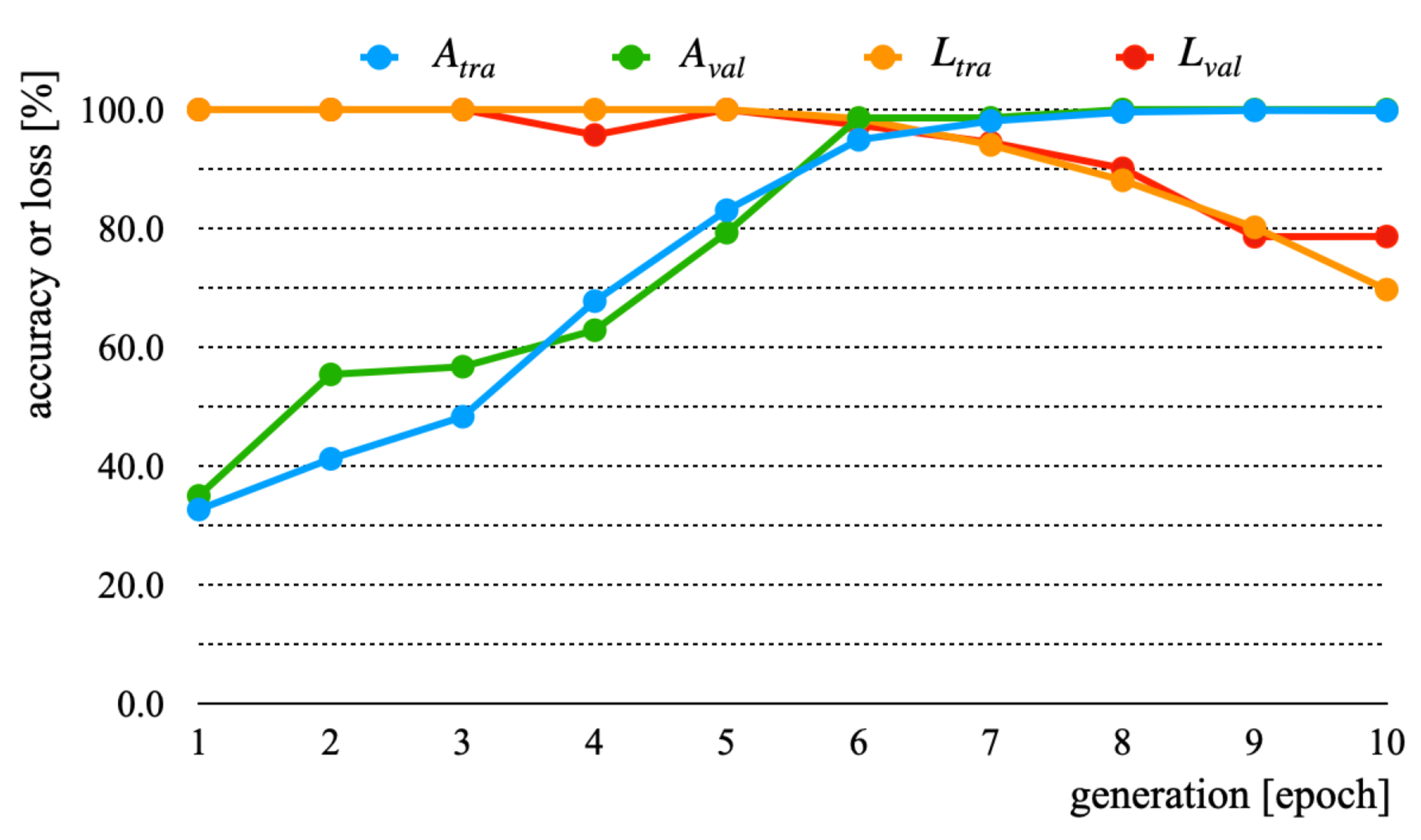
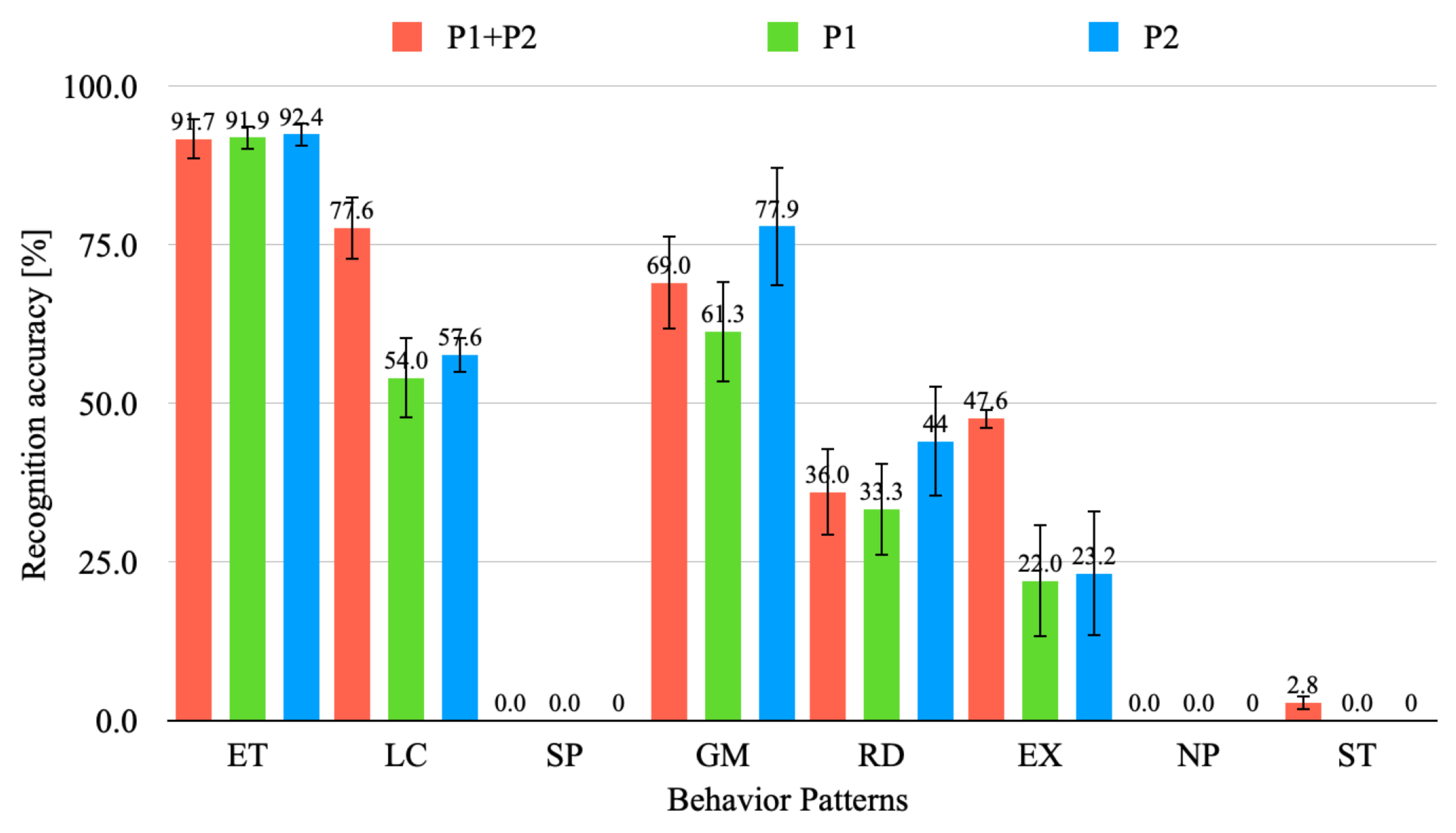
3.3. Experiment Results and Discussion
4. Environmental Approach Using Air and Thermometric Sensors
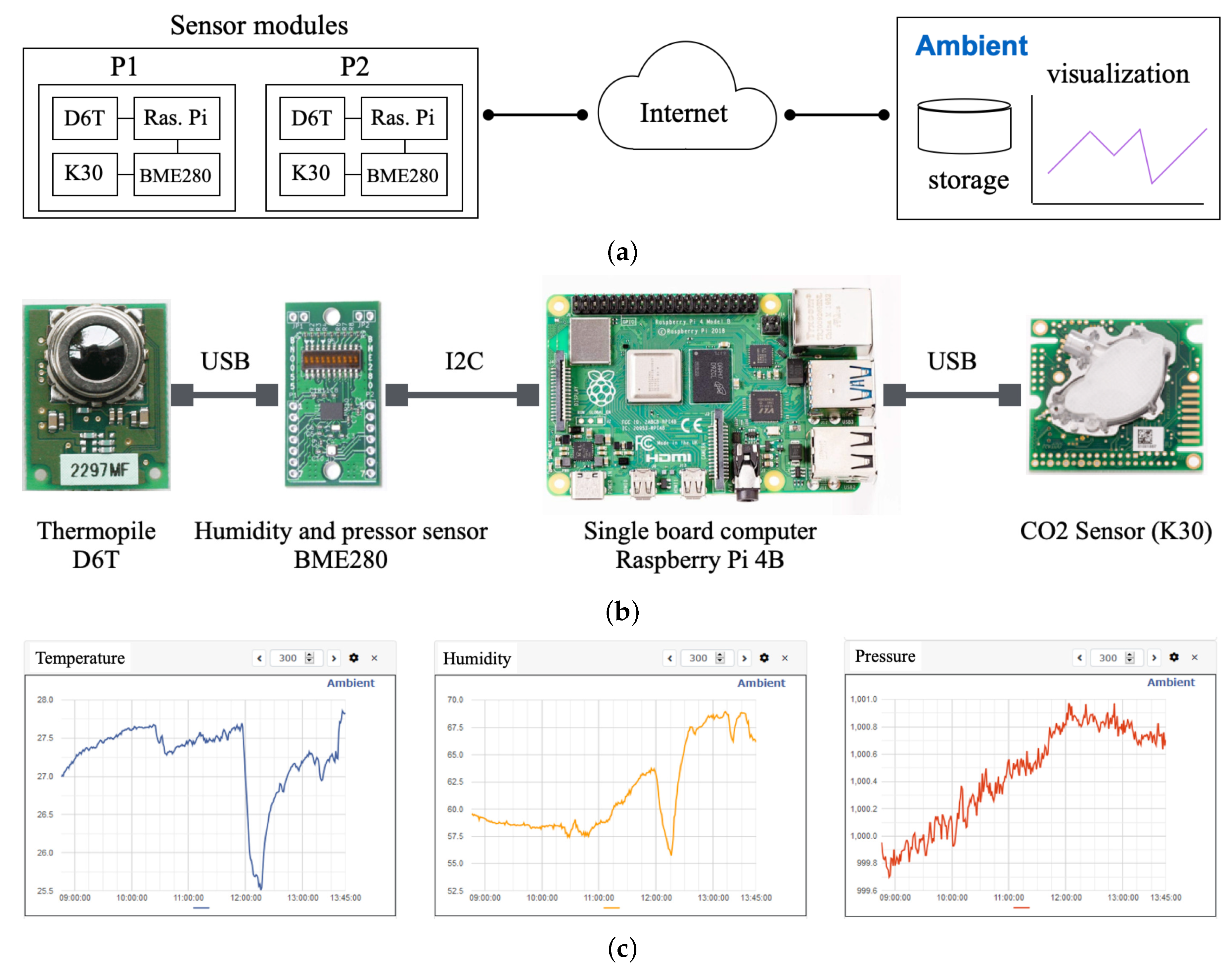
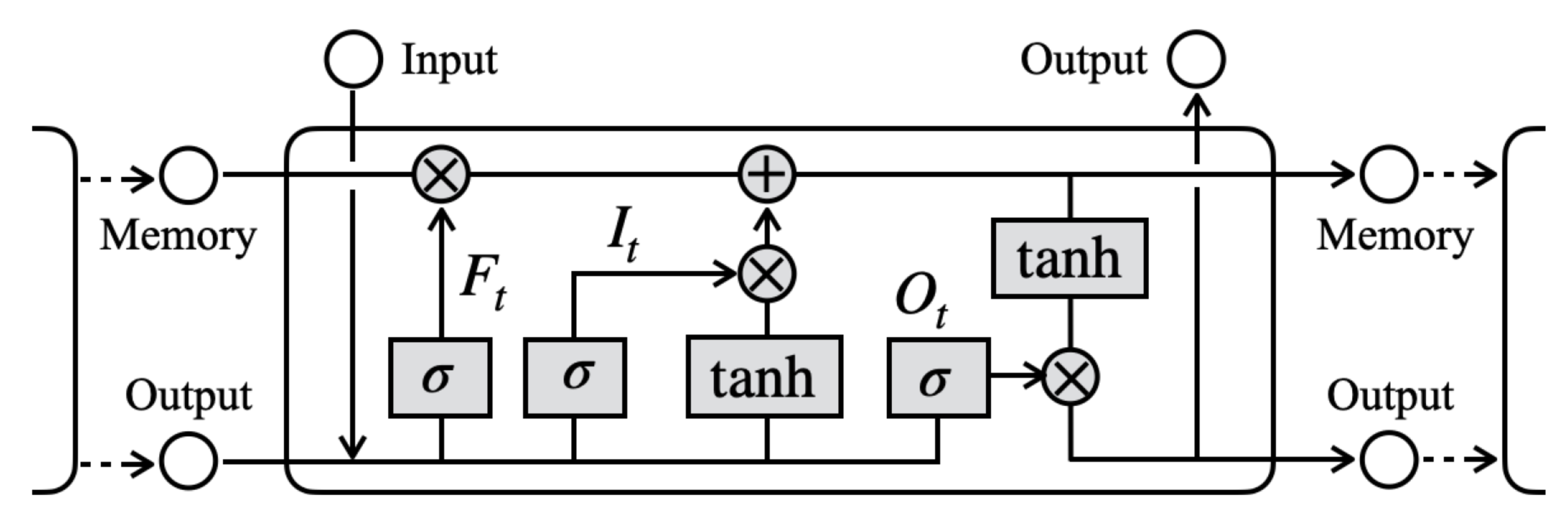
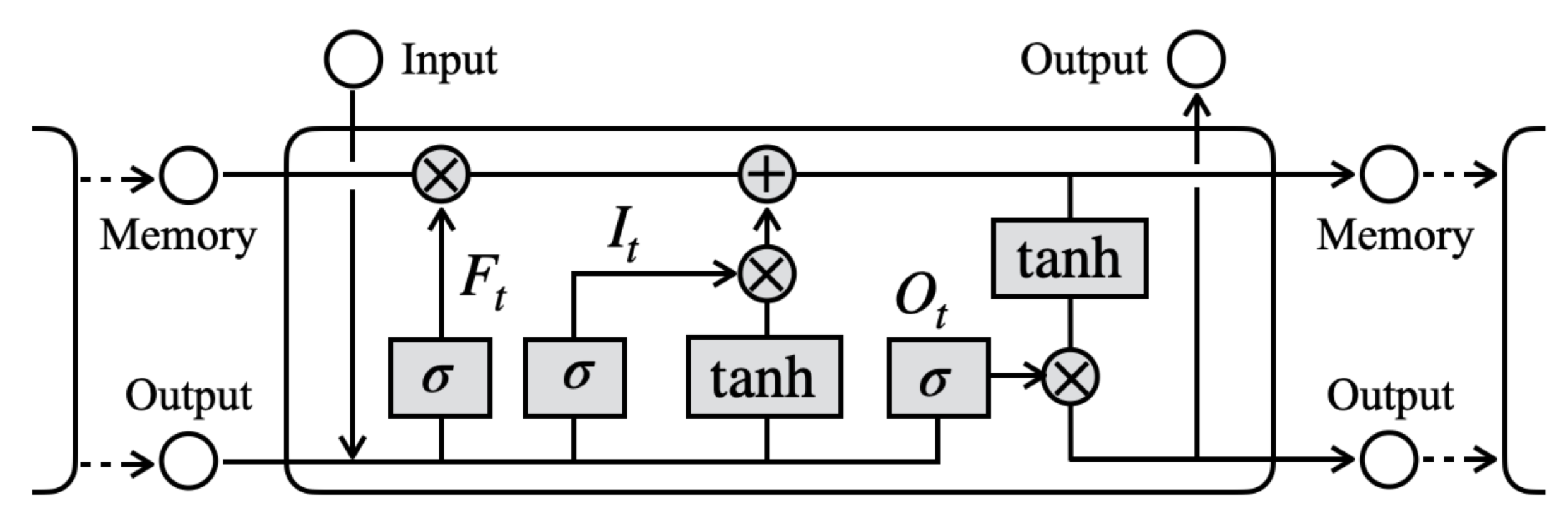
4.1. Proposed Sensor System and Recognition Method
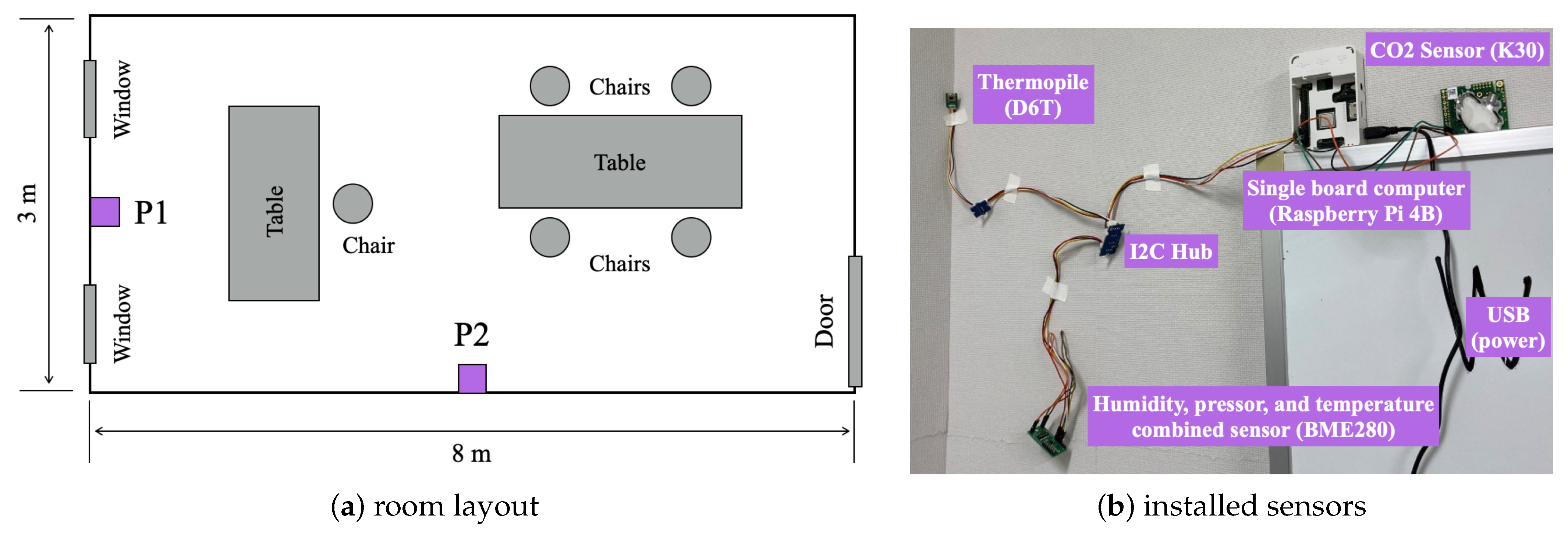
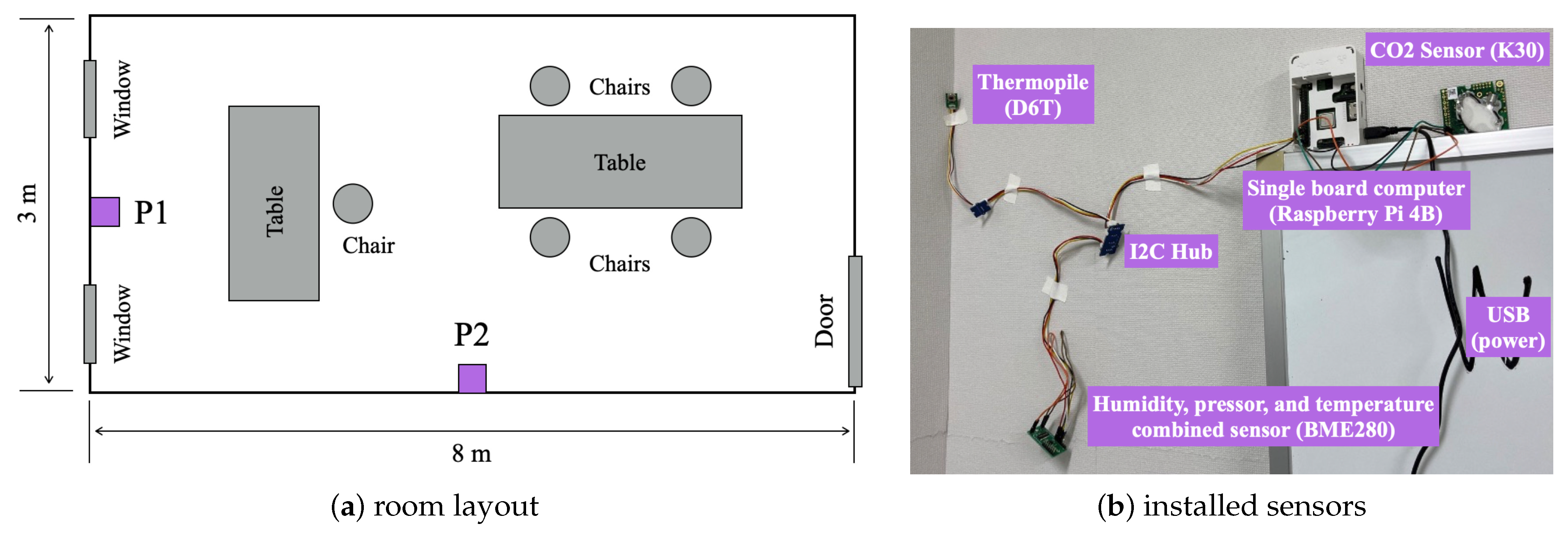
4.2. Setup and the Obtained Second Dataset
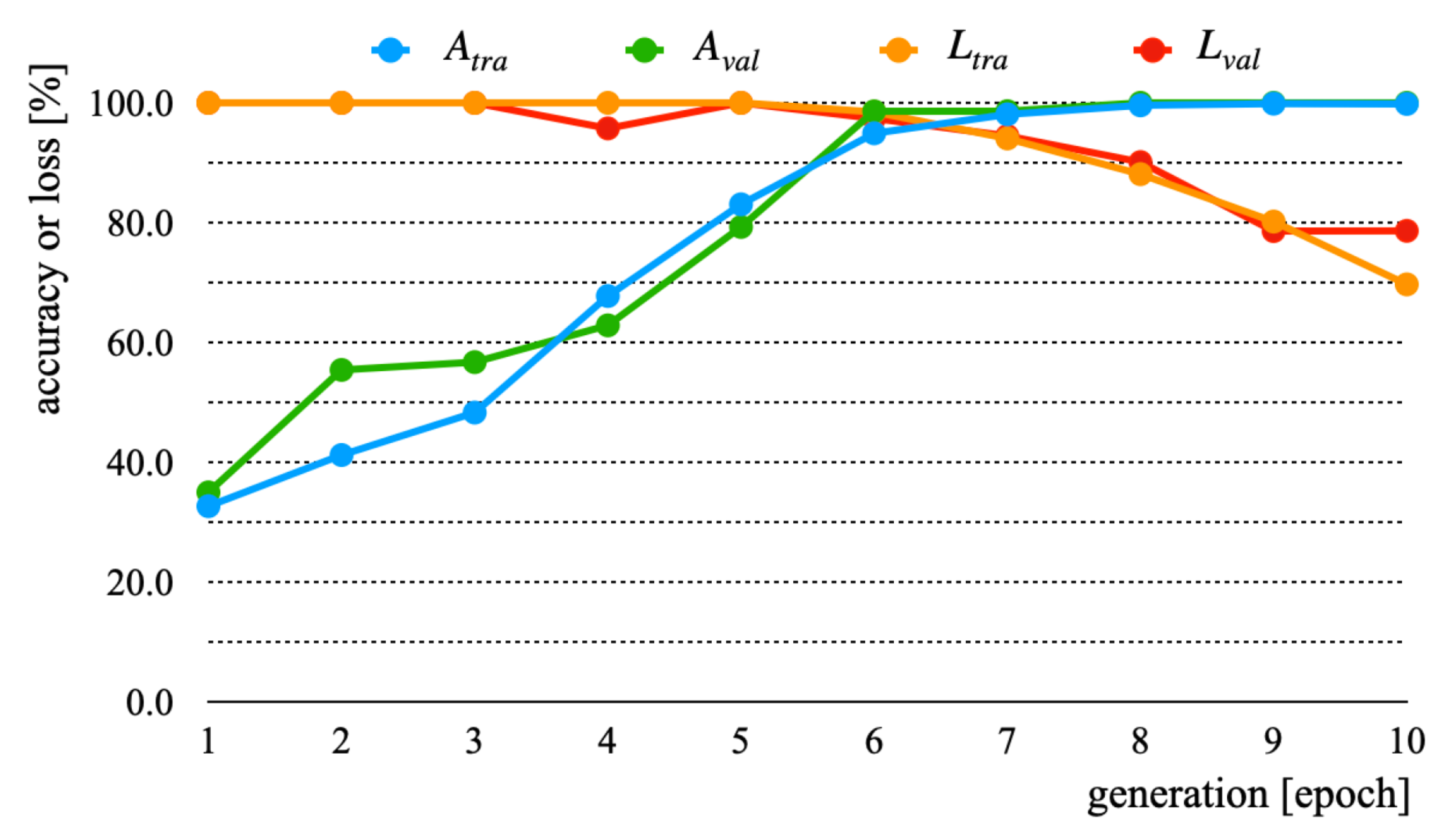
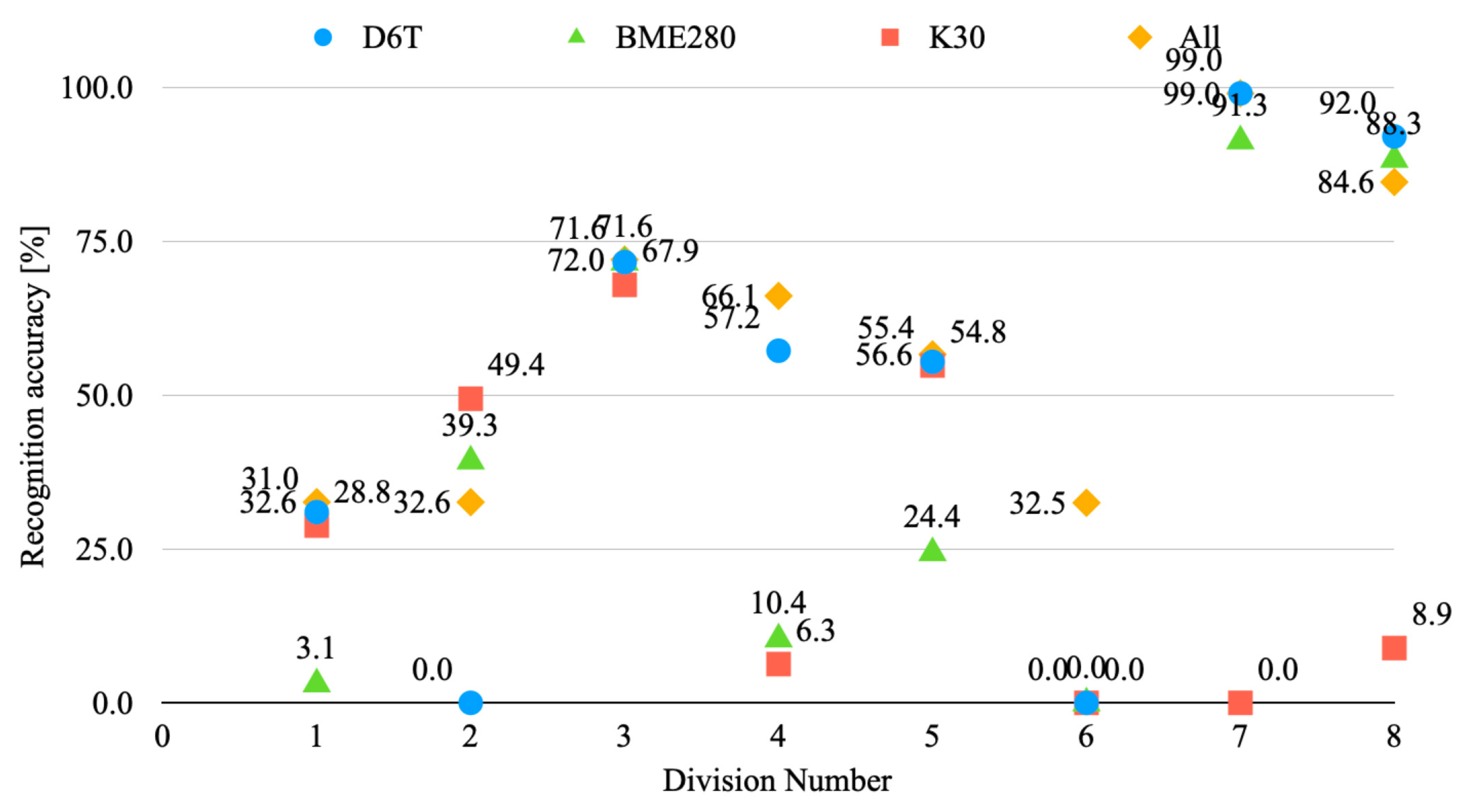
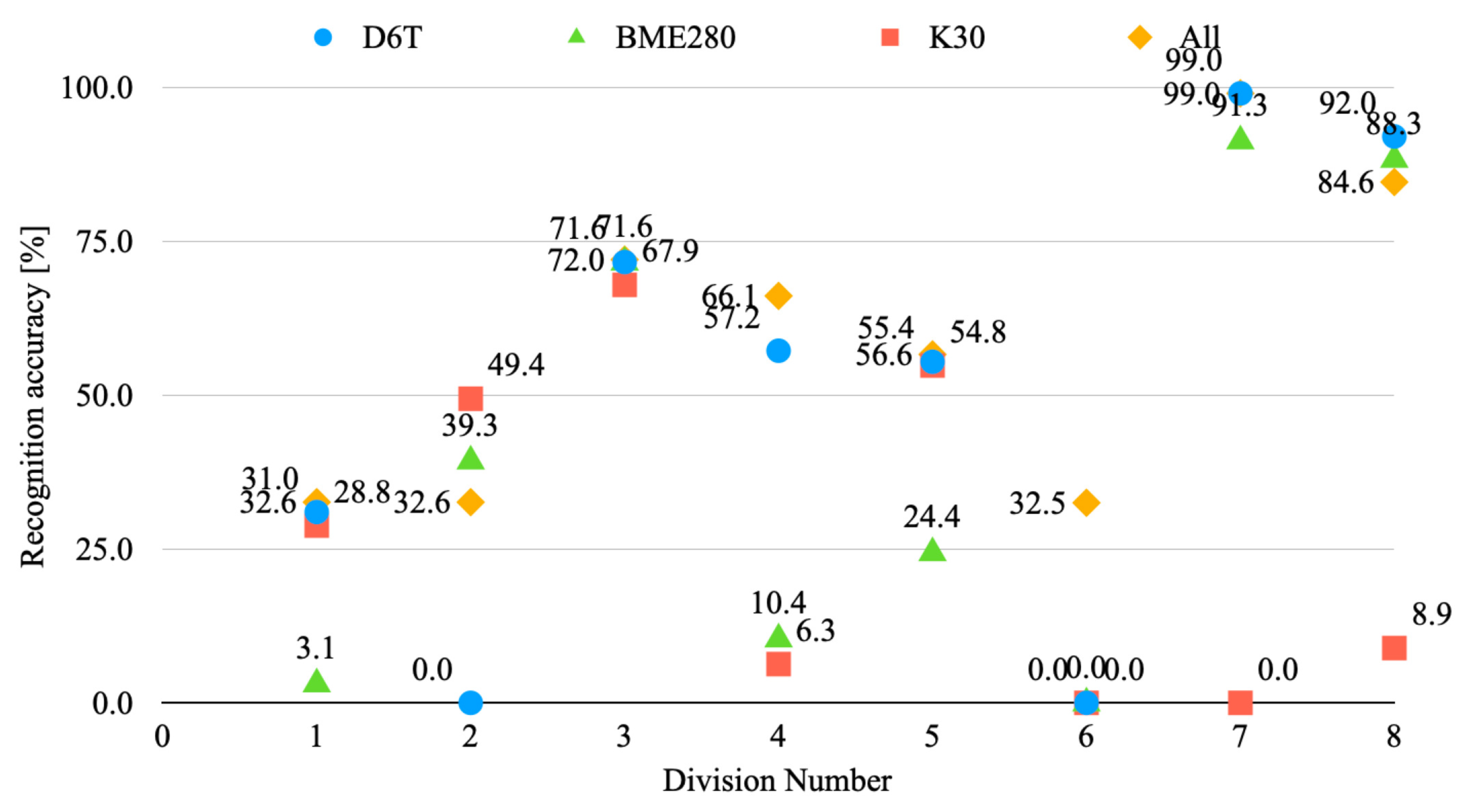
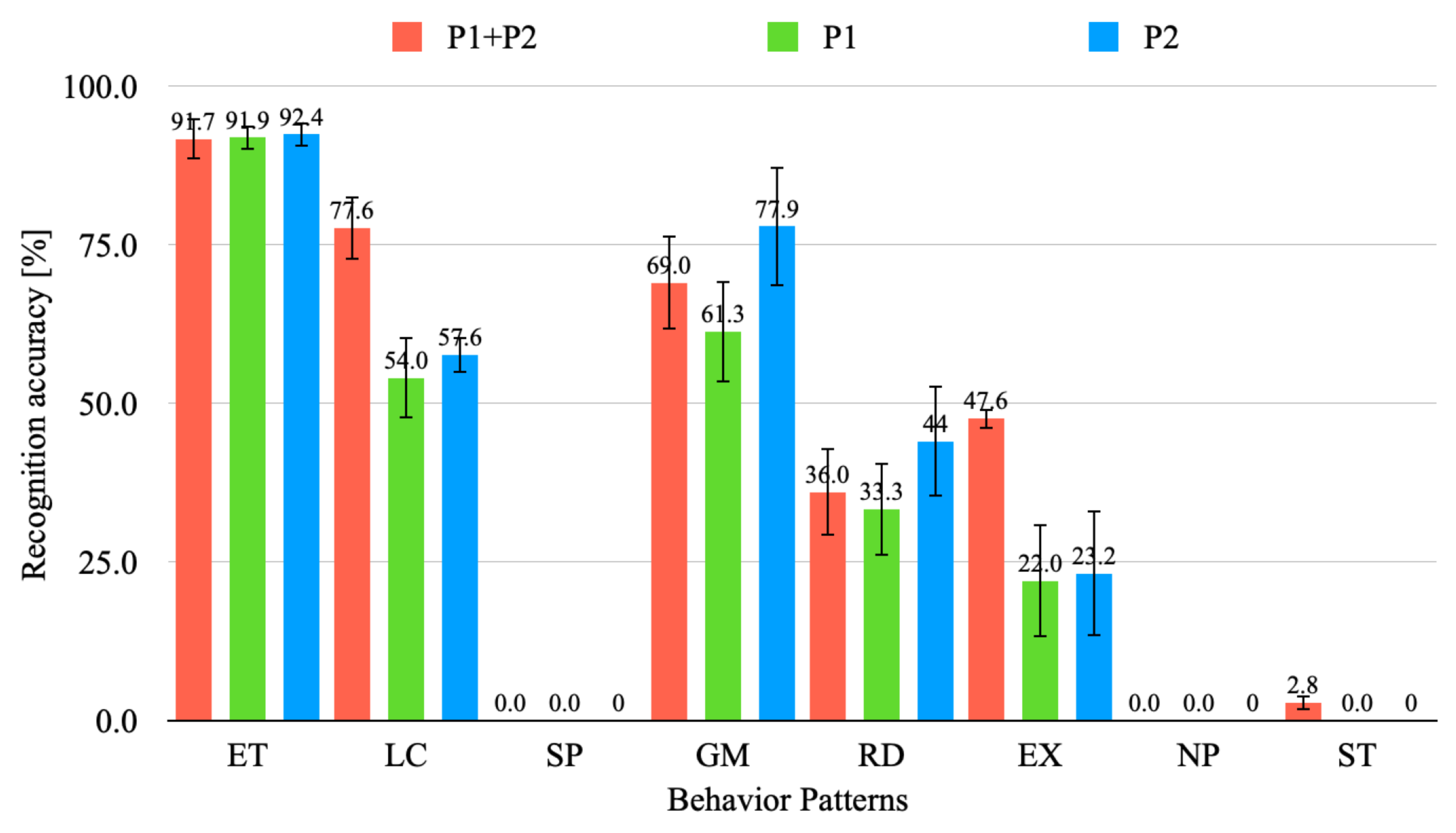
4.3. Experiment Results and Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| 1D | one-dimensional |
| 2D | two-dimensional |
| 3D | three-dimensional |
| ADL | activities of daily living |
| COCO | common objects in context |
| DL | deep learning |
| CML | conventional machine learning |
| CNN | convolutional neural network |
| DC | deep clustering |
| DT | decision tree |
| EBT | ensemble bagged trees |
| EL | ensemble learning |
| ELM | extreme learning machine |
| ES | environmental sensors |
| ET | eating |
| EX | exiting |
| FoV | field of view |
| GM | game |
| GPU | graphics processing unit |
| I2C | inter-integrated circuit |
| IEMO-CAP | interactive emotional dyadic motion capture |
| IoT | internet of things |
| IPL-JPDA | improved pseudo-labels joint probability domain adaptation |
| kNN | k nearest neighbor |
| LC | laptop computer |
| LDA | linear discriminant analysis |
| LiDAR | light detection and ranging |
| LSTM | short-term memory |
| MCB | multi-channel bidirectional |
| MEMS | microelectromechanical systems |
| MLP | multilayer perceptron |
| MPII | Max Planck Institut Informatik |
| NB | naive Bayes |
| NP | nap |
| NDIR | non-dispersive infrared sensor |
| OME | one-minute-gradual |
| PAFs | part affinity fields |
| PIR | pyroelectric infrared |
| RD | reading |
| RF | random forests |
| RGB-D | red, green, and blue–depth |
| RNN | recurrent neural network |
| I2C | inter-integrated circuit |
| SBC | single board computer |
| SP | smartphone operation |
| ST | sitting |
| SVM | support vector machines |
| TOF | time of flight |
| TSSCV | time-series split cross-validation |
| TV | television |
| UART | universal asynchronous receiver–transmitter |
| WS | wearable sensors |
| YOLO | you look only once |
| ZSL | zero-shot learning |
References
- Moeslund, T.B.; Hilton, A.; Krüger, V. A Survey of Advances in Vision-Based Human Motion Capture and Analysis. Comput. Vis. Image Underst. 2006, 104, 90–126. [Google Scholar] [CrossRef]
- Escalera, S.; Athitsos, V.; Guyon, I. Challenges in Multi-modal Gesture Recognition. Gesture Recognit. 2017, 1–60. [Google Scholar] [CrossRef] [Green Version]
- Liu, J.; Gu, Y.; Kamijo, S. Customer Behavior Classification Using Surveillance Camera for Marketing. Multimed. Tools Appl. 2017, 76, 6595–6622. [Google Scholar] [CrossRef]
- Kanda, T.; Miyashita, T.; Osada, T.; Haikawa, Y.; Ishiguro, H. Analysis of Humanoid Appearances in Human—Robot Interaction. IEEE Trans. Robot. 2008, 24, 725–735. [Google Scholar] [CrossRef]
- Shamsuddin, S.; Yussof, H.; Ismail, L.; Hanapiah, F.A.; Mohamed, S.; Piah, H.A.; Zahari, N.I. Initial Response of Autistic Children in Human–Robot Interaction Therapy with Humanoid Robot nao. In Proceedings of the IEEE Eighth International Colloquium on Signal Processing and its Applications, Malacca, Malaysia, 23–25 March 2012; pp. 188–193. [Google Scholar]
- Thomas, G.; Gade, R.; Moeslund, T.B.; Carr, P.; Hilton, A. Computer Vision for Sports: Current Applications and Research Topics. Comput. Vis. Image Underst. 2017, 159, 3–18. [Google Scholar] [CrossRef]
- Liu, J.N.K.; Wang, M.; Feng, B. iBotGuard: An Internet-based Intelligent Robot security system using Invariant Face Recognition Against Intruder. IEEE Trans. Syst. Man Cybern. Part C 2005, 35, 97–105. [Google Scholar] [CrossRef]
- Bowyer, K.W.; Hollingsworth, K.; Flynn, P.J. Image Understanding for Iris Biometrics: A Survey. Comput. Vis. Image Underst. 2008, 110, 281–307. [Google Scholar] [CrossRef]
- Pantic, M.; Rothkrantz, L.J.M. Automatic analysis of facial expressions: The state-of-the art. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 1424–1445. [Google Scholar] [CrossRef] [Green Version]
- Hu, W.; Tan, T.; Wang, L.; Maybank, S. A Survey on Visual Surveillance of Object Motion and Behaviors. IEEE Trans. Syst. Man Cybern. Part C 2004, 34, 334–352. [Google Scholar] [CrossRef]
- Inoue, M.; Taguchi, R.; Umezaki, T. Vision-based Bed Detection for Hospital Patient Monitoring System. In Proceedings of the 40th Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Honolulu, HI, USA, 17–21 July 2018; pp. 5006–5009. [Google Scholar]
- Madokoro, H.; Nakasho, K.; Shimoi, N.; Woo, H.; Sato, K. Development of Invisible Sensors and a Machine-Learning-Based Recognition System Used for Early Prediction of Discontinuous Bed-Leaving Behavior Patterns. Sensors 2020, 20, 1415. [Google Scholar] [CrossRef] [Green Version]
- Uddin, M.Z.; Khaksar, W.; Torresen, J. Ambient Sensors for Elderly Care and Independent Living: A Survey. Sensors 2018, 18, 2027. [Google Scholar] [CrossRef] [Green Version]
- Foerster, F.; Smeja, M.; Fahrenberg, J. Detection of Posture and Motion by Accelerometry: A Validation Study in Ambulatory Monitoring. Comput. Hum. Behav. 1999, 15, 571–583. [Google Scholar] [CrossRef]
- Jähne-Raden, N.; Kulau, U.; Marschollek, M.; Wolf, K.H. INBED: A Highly Specialized System for Bed-Exit-Detection and Fall Prevention on a Geriatric Ward. Sensors 2019, 19, 1017. [Google Scholar] [CrossRef] [Green Version]
- Erden, F.; Velipasalar, S.; Alkar, A.Z.; Cetin, A.E. Sensors in Assisted Living: A survey of signal and image processing methods IEEE Signal Process. Mag. 2016, 33, 36–44. [Google Scholar]
- Komatsu, Y.; Hamada, K.; Notoya, Y.; Kimura, K. Image Recognition Technology that Helps Save Energy in Room Air Conditioners. Hitachi Rev. 2015, 64, 8. [Google Scholar]
- Naslund, J.A.; Aschbrenner, K.A.; Bartels, S.J. Wearable devices and smartphones for activity tracking among people with serious mental illness Ment. Health Phys. Act. 2016, 10, 10–17. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ramos, C.; Augusto, J.C.; Shapiro, D. Ambient Intelligence—The Next Step for Artificial Intelligence. IEEE Intell. Syst. 2008, 23, 15–18. [Google Scholar] [CrossRef]
- Acampora, G.; Cook, D.J.; Rashidi, P.; Vasilakos, A.V. A Survey on Ambient Intelligence in Healthcare. Proc. IEEE Inst. Electr. Eng. 2013, 101, 2470–2494. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- LeCun, Y.; Boser, B.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.; Jackel, L.D. Backpropagation Applied to Handwritten Zip Code Recognition. Neural Comput. 1989, 1, 541–551. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Aggarwal, J.K.; Cai, Q. Human motion analysis: A review. Comput. Vis. Image Underst. 1999, 73, 428–440. [Google Scholar] [CrossRef]
- Zhang, F.; Niu, K.; Xiong, J.; Jin, B.; Gu, T.; Jiang, Y.; Zhang, D. Towards a Diffraction-based Sensing Approach on Human Activity Recognition. In Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies (IMWUT), London, UK, 11–13 September 2019; pp. 1–25. [Google Scholar]
- Turaga, P.; Chellappa, R.; Subrahmanian, V.; Udrea, O. Machine Recognition of Human Activities: A Survey. IEEE Trans. Circuits Syst. Video Technol. 2008, 18, 1473–1488. [Google Scholar] [CrossRef] [Green Version]
- Candamo, J.; Shreve, M.; Goldgof, D.; Sapper, D.; Kasturi, R. Understanding Transit Scenes: A Survey on Human Behavior-Recognition Algorithms. IEEE Trans. Intell. Transp. Syst. 2010, 11, 206–224. [Google Scholar] [CrossRef]
- Lara, O.D.; Labrador, M.A. A Survey on Human Activity Recognition using Wearable Sensors. IEEE Commun. Surv. Tutor. 2013, 15, 1192–1209. [Google Scholar] [CrossRef]
- Aggarwal, J.K.; Ryoo, M.S. Human activity analysis: A review. ACM Comput. Surv. 2011, 16, 1–43. [Google Scholar] [CrossRef]
- Ke, S.R.; Thuc, H.L.U.; Lee, Y.J.; Hwang, J.N.; Yoo, J.H.; Choi, K.H. A Review on Video-Based Human Activity Recognition. Computers 2013, 2, 88–131. [Google Scholar] [CrossRef]
- Aggarwal, J.K.; Xia, L. Human activity recognition from 3D data: A review. Pattern Recognit. Lett. 2014, 48, 70–80. [Google Scholar] [CrossRef]
- Dai, J.; Wu, J.; Saghafi, B.; Konrad, J.; Ishwar, P. Towards Privacy-Preserving Activity Recognition Using Extremely Low Temporal and Spatial Resolution Cameras. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 68–76. [Google Scholar]
- Dargan, S.; Kumar, M.; Ayyagari, M.R.; Kumar, G. A Survey of Deep Learning and Its Applications: A New Paradigm to Machine Learning. Arch. Comput. Methods Eng. 2020, 27, 1071–1092. [Google Scholar] [CrossRef]
- Chen, J.; Ran, X. Deep Learning With Edge Computing: A Review. Proc. IEEE 2019, 107, 1655–1674. [Google Scholar] [CrossRef]
- Haensch, W.; Gokmen, T.; Puri, R. The Next Generation of Deep Learning Hardware: Analog Computing. Proc. IEEE 2019, 107, 108–122. [Google Scholar] [CrossRef]
- Biswal, A.; Nanda, S.; Panigrahi, C.R.; Cowlessur, S.K.; Pati, B. Human Activity Recognition Using Machine Learning: A Review Prog. Adv. Comput. Intell. Eng. 2021, 323–333. [Google Scholar] [CrossRef]
- Bouchabou, D.; Nguyen, S.M.; Lohr, C.; LeDuc, B.; Kanellos, I. A Survey of Human Activity Recognition in Smart Homes Based on IoT Sensors Algorithms: Taxonomies, Challenges, and Opportunities with Deep Learning. Sensors 2021, 21, 6037. [Google Scholar] [CrossRef] [PubMed]
- Chen, K.; Zhang, D.; Yao, L.; Guo, B.; Yu, Z.; Liu, Y. Deep Learning for Sensor-based Human Activity Recognition: Overview, Challenges, and Opportunities. ACM Comput. Surv. 2021, 54, 1–40. [Google Scholar] [CrossRef]
- Mihoub, A. A Deep Learning-Based Framework for Human Activity Recognition in Smart Homes. Mob. Inf. Syst. 2021, 2021, 6961343. [Google Scholar] [CrossRef]
- Muralidharan, K.; Ramesh, A.; Rithvik, G.; Prem, S.; Reghunaath, A.A.; Gopinath, M.P. 1D Convolution Approach to Human Activity Recognition Using Sensor Data and Comparison with Machine Learning Algorithms. Int. J. Cogn. Comput. Eng. 2021, 2, 130–143. [Google Scholar]
- Shaikh, M.B.; Chai, D. RGB-D Data-Based Action Recognition: A Review. Sensors 2021, 21, 4246. [Google Scholar] [CrossRef]
- Straczkiewicz, M.; James, P.; Onnela, J.-P. A Systematic Review of Smartphone-Based Human Activity Recognition Methods for Health Research. Digit. Med. 2021, 4, 148. [Google Scholar] [CrossRef]
- Beddiar, D.R.; Nini, B.; Sabokrou, M. Vision-based human activity recognition: A survey. Multimed. Tools Appl. 2020, 79, 30509–30555. [Google Scholar] [CrossRef]
- Carvalho, L.I.; Sofia, R.C. A Review on Scaling Mobile Sensing Platforms for Human Activity Recognition: Challenges and Recommendations for Future Research. IoT 2020, 1, 25. [Google Scholar] [CrossRef]
- Dang, L.M.; Min, K.; Wang, H.; Piran, J.; Lee, C.H.; Moon, H. Sensor-based and vision-based human activity recognition: A comprehensive survey. Pattern Recognit. 2020, 108, 107561. [Google Scholar] [CrossRef]
- Demrozi, F.; Pravadelli, G.; Bihorac, A.; Rashidi, P. Human Activity Recognition Using Inertial, Physiological and Environmental Sensors: A Comprehensive Survey. IEEE Access 2020, 8, 210816–210836. [Google Scholar] [CrossRef]
- Fu, B.; Damer, N.; Kirchbuchner, F.; Kuijper, A. Sensing Technology for Human Activity Recognition: A Comprehensive Survey. IEEE Access 2020, 8, 83791–83820. [Google Scholar] [CrossRef]
- Hussain, Z.; Sheng, Q.Z.; Zhang, W.E. A review and categorization of techniques on device-free human activity recognition. J. Netw. Comput. Appl. 2020, 167, 102738. [Google Scholar] [CrossRef]
- Jung, I.Y. A review of privacy-preserving human and human activity recognition. Int. J. Smart Sens. Intell. Syst. 2020, 1, 13. [Google Scholar] [CrossRef]
- Sherafat, B.; Ahn, C.R.; Akhavian, R.; Behzadan, A.H.; Golparvar-Fard, M.; Kim, H.; Lee, Y.C.; Rashidi, A.; Azar, E.R. Automated Methods for Activity Recognition of Construction Workers and Equipment: State-of-the-Art Review. J. Constr. Eng. Manag. 2020, 146, 03120002. [Google Scholar] [CrossRef]
- Dang, L.M.; Piran, M.J.; Han, D.; Min, K.; Moon, H. A Survey on Internet of Things and Cloud Computing for Healthcare. Electronics 2019, 8, 768. [Google Scholar] [CrossRef] [Green Version]
- Dhiman, C.; Vishwakarma, D.K. A review of state-of-the-art techniques for abnormal human activity recognition. Eng. Appl. Artif. Intell. 2019, 77, 21–45. [Google Scholar] [CrossRef]
- Elbasiony, R.; Gomaa, W. A Survey on Human Activity Recognition Based on Temporal Signals of Portable Inertial Sensors. In Proceedings of the International Conference on Advanced Machine Learning Technologies and Applications (AMLTA2), Cairo, Egypt, 28–30 March 2019; pp. 734–745. [Google Scholar]
- Hussain, Z.; Sheng, M.; Zhang, W.E. Different Approaches for Human Activity Recognition: A Survey. arXiv 2019, arXiv:1906.05074. [Google Scholar]
- Jobanputra, C.; Bavishi, J.; Doshi, N. Human Activity Recognition: A Survey. Procedia Comput. Sci. 2019, 155, 698–703. [Google Scholar] [CrossRef]
- Li, X.; He, Y.; Jing, X. A Survey of Deep Learning-Based Human Activity Recognition in Radar. Remote Sens. 2019, 11, 1068. [Google Scholar] [CrossRef] [Green Version]
- Sousa Lima, W.; Souto, E.; El-Khatib, K.; Jalali, R.; Gama, J. Human Activity Recognition Using Inertial Sensors in a Smartphone: An Overview. Sensors 2019, 19, 3213. [Google Scholar] [CrossRef] [Green Version]
- Slim, S.O.; Atia, A.; Elfattah, M.M.A.; Mostafa, M.S.M. Survey on Human Activity Recognition based on Acceleration Data. Int. J. Adv. Comput. Sci. Appl. 2019, 10, 84–98. [Google Scholar] [CrossRef]
- Wang, J.; Chen, Y.; Hao, S.; Peng, X.; Hu, L. Deep learning for sensor-based activity recognition: A survey. Pattern Recognit. Lett. 2019, 119, 3–11. [Google Scholar] [CrossRef] [Green Version]
- Nweke, H.F.; Teh, Y.W.; Al-Garadi, M.A.; Alo, U.R. Deep learning algorithms for human activity recognition using mobile and wearable sensor networks: State of the art and research challenges. Expert Syst. Appl. 2018, 105, 233–261. [Google Scholar] [CrossRef]
- Ramamurthy, S.R.; Roy, N. Recent trends in machine learning for human activity recognition—A survey. WIREs Data Min. Knowl. Discov. 2018, 8, e1254. [Google Scholar] [CrossRef]
- Shickel, B.; Tighe, P.J.; Bihorac, A.; Rashidi, P. DeepEHR: A survey of recent advances in deep learning techniques for electronic health record (EHR) analysis. IEEE J. Biomed. Health Inform. 2018, 22, 1589–1604. [Google Scholar] [CrossRef]
- Wang, P.; Li, W.; Ogunbona, P.; Wan, J.; Escalera, S. RGB-D-based human motion recognition with deep learning: A survey. arXiv 2018, arXiv:1711.08362. [Google Scholar] [CrossRef] [Green Version]
- Cornacchia, M.; Ozcan, K.; Zheng, Y.; Velipasalar, S. A survey on activity detection and classification using wearable sensors. IEEE Sens. J. 2017, 17, 386–403. [Google Scholar] [CrossRef]
- Chen, C.; Jafari, R.; Kehtarnavaz, N. A survey of depth and inertial sensor fusion for human action recognition. Multimed. Tools Appl. 2017, 76, 4405–4425. [Google Scholar] [CrossRef]
- Morales, J.; Akopian, D. Physical activity recognition by smartphones, a survey. Biocybern. Biomed. Eng. 2017, 37, 388–400. [Google Scholar] [CrossRef]
- Rault, T.; Bouabdallah, A.; Challal, Y.; Marin, F. A survey of energy-efficient context recognition systems using wearable sensors for healthcare applications. Pervasive Mob. Comput. 2017, 37, 23–44. [Google Scholar] [CrossRef] [Green Version]
- Vyas, V.V.; Walse, K.H.; Dharaskar, R.V. A Survey on Human Activity Recognition using Smartphone. Int. J. Adv. Res. Comput. Sci. Manag. Stud. 2017, 5, 118–125. [Google Scholar]
- Dawn, D.D.; Shaikh, S.H. A comprehensive survey of human action recognition with spatiotemporal interest point (STIP) detector. Vis. Comput. 2016, 32, 289–306. [Google Scholar] [CrossRef]
- Onofri, L.; Soda, P.; Pechenizkiy, M.; Iannello, G. A survey on using domain and contextual knowledge for human activity recognition in video streams. Expert Syst. Appl. 2016, 63, 97–111. [Google Scholar] [CrossRef]
- Fu, Z.; He, X.; Wang, E.; Huo, J.; Huang, J.; Wu, D. Personalized Human Activity Recognition Based on Integrated Wearable Sensor and Transfer Learning. Sensors 2021, 21, 885. [Google Scholar] [CrossRef]
- Gorji, A.; Khalid, H.U.R.; Bourdoux, A.; Sahli, H. On the Generalization and Reliability of Single Radar-Based Human Activity Recognition. IEEE Access 2021, 9, 85334–85349. [Google Scholar] [CrossRef]
- Gul, M.A.; Yousaf, M.H.; Nawaz, S.; Ur Rehman, Z.; Kim, H. Patient Monitoring by Abnormal Human Activity Recognition Based on CNN Architecture. Electronics 2020, 9, 1993. [Google Scholar] [CrossRef]
- Hussain, T.; Nugent, C.; Moore, A.; Liu, J.; Beard, A. A Risk-Based IoT Decision-Making Framework Based on Literature Review with Human Activity Recognition Case Studies. Sensors 2021, 21, 4504. [Google Scholar] [CrossRef]
- Mekruksavanich, S.; Jitpattanakul, A. LSTM Networks Using Smartphone Data for Sensor-Based Human Activity Recognition in Smart Homes. Sensors 2021, 21, 1636. [Google Scholar] [CrossRef]
- Mekruksavanich, S.; Jitpattanakul, A. Biometric User Identification Based on Human Activity Recognition Using Wearable Sensors: An Experiment Using Deep Learning Models. Electronics 2021, 10, 308. [Google Scholar] [CrossRef]
- Moreira, D.; Barandas, M.; Rocha, T.; Alves, P.; Santos, R.; Leonardo, R.; Vieira, P.; Gamboa, H. Human Activity Recognition for Indoor Localization Using Smartphone Inertial Sensors. Sensors 2021, 21, 6316. [Google Scholar] [CrossRef] [PubMed]
- Nafea, O.; Abdul, W.; Muhammad, G.; Alsulaiman, M. Sensor-Based Human Activity Recognition with Spatiotemporal Deep Learning. Sensors 2021, 21, 2141. [Google Scholar] [CrossRef]
- Xiao, J.; Chen, L.; Chen, H.; Hong, X. Baseline Model Training in Sensor-Based Human Activity Recognition: An Incremental Learning Approach. IEEE Access 2021, 9, 70261–70272. [Google Scholar] [CrossRef]
- Ahmed, N.; Rafiq, J.I.; Islam, M.R. Enhanced Human Activity Recognition Based on Smartphone Sensor Data Using Hybrid Feature Selection Model. Sensors 2020, 20, 317. [Google Scholar] [CrossRef] [Green Version]
- Ashry, S.; Ogawa, T. Gomaa, W. CHARM-Deep: Continuous Human Activity Recognition Model Based on Deep Neural Network Using IMU Sensors of Smartwatch. IEEE Sens. J. 2020, 20, 8757–8770. [Google Scholar] [CrossRef]
- Debache, I.; Jeantet, L.; Chevallier, D.; Bergouignan, A.; Sueur, C. A Lean and Performant Hierarchical Model for Human Activity Recognition Using Body-Mounted Sensors. Sensors 2020, 20, 3090. [Google Scholar] [CrossRef]
- Ehatisham-Ul-Haq, M.; Azam, M.A.; Amin, Y.; Naeem, U. C2FHAR: Coarse-to-Fine Human Activity Recognition With Behavioral Context Modeling Using Smart Inertial Sensors. IEEE Access 2020, 8, 7731–7747. [Google Scholar] [CrossRef]
- Ferrari, A.; Micucci, D.; Mobilio, M.; Napoletano, P. On the Personalization of Classification Models for Human Activity Recognition. IEEE Access 2020, 8, 32066–32079. [Google Scholar] [CrossRef]
- Hamad, R.A.; Yang, L.; Woo, W.L.; Wei, B. Joint Learning of Temporal Models to Handle Imbalanced Data for Human Activity Recognition. Appl. Sci. 2020, 10, 5293. [Google Scholar] [CrossRef]
- Ihianle, I.K.; Nwajana, A.O.; Ebenuwa, S.H.; Otuka, R.I.; Owa, K.; Orisatoki, M.O. A Deep Learning Approach for Human Activities Recognition From Multimodal Sensing Devices. IEEE Access 2020, 8, 179028–179038. [Google Scholar] [CrossRef]
- Irvine, N.; Nugent, C.; Zhang, S.; Wang, H.; Ng, W.W.Y. Neural Network Ensembles for Sensor-Based Human Activity Recognition Within Smart Environments. Sensors 2020, 20, 216. [Google Scholar] [CrossRef] [Green Version]
- Khannouz, M.; Glatard, T. A Benchmark of Data Stream Classification for Human Activity Recognition on Connected Objects. Sensors 2020, 20, 6486. [Google Scholar] [CrossRef]
- Lawal, I.A.; Bano, S. Deep Human Activity Recognition With Localisation of Wearable Sensors. IEEE Access 2020, 8, 155060–155070. [Google Scholar] [CrossRef]
- Al Machot, F.R.; Elkobaisi, M.; Kyamakya, K. Zero-Shot Human Activity Recognition Using Non-Visual Sensors. Sensors 2020, 20, 825. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mukherjee, S.; Anvitha, L.; Lahari, T.M. Human activity recognition in RGB-D videos by dynamic images. Multimed. Tools Appl. Vol. 2020, 79, 19787–19801. [Google Scholar] [CrossRef] [Green Version]
- Mutegeki, R.; Han, D.S. A CNN-LSTM Approach to Human Activity Recognition. In Proceedings of the International Conference on Artificial Intelligence in Information and Communication (ICAIIC), Fukuoka, Japan, 19–21 February 2020; pp. 362–366. [Google Scholar]
- Pham, C.; Pham, C.; Nguyen-Thai, S.; Tran-Quang, H.; Tran, S.; Vu, H.; Tran, T.H.; Le, T.L. SensCapsNet: Deep Neural Network for Non-Obtrusive Sensing Based Human Activity Recognition. IEEE Access 2020, 8, 86934–86946. [Google Scholar] [CrossRef]
- Popescu, A.C.; Mocanu, I.; Cramariuc, B. Fusion Mechanisms for Human Activity Recognition Using Automated Machine Learning. IEEE Access 2020, 8, 143996–144014. [Google Scholar] [CrossRef]
- Qin, Z.; Zhang, Y.; Meng, S.; Qin, Z.; Choo, K.K.R. Imaging and fusing time series for wearable sensor-based human activity recognition. Inf. Fusion 2020, 53, 80–87. [Google Scholar] [CrossRef]
- Shrestha, A.; Li, H.; Le Kernec, J.; Fioranelli, F. Continuous Human Activity Classification From FMCW Radar With Bi-LSTM Networks. IEEE Sens. J. 2020, 20, 13607–13619. [Google Scholar] [CrossRef]
- Taylor, W.; Shah, S.A.; Dashtipour, K.; Zahid, A.; Abbasi, Q.H.; Imran, M.A. An Intelligent Non-Invasive Real-Time Human Activity Recognition System for Next-Generation Healthcare. Sensors 2020, 20, 2653. [Google Scholar] [CrossRef] [PubMed]
- Tanberk, S.; Kilimci, Z.H.; Tükel, D.B.; Uysal, M.; Akyokuş, S. A Hybrid Deep Model Using Deep Learning and Dense Optical Flow Approaches for Human Activity Recognition. IEEE Access 2020, 8, 19799–19809. [Google Scholar] [CrossRef]
- Wan, S.; Qi, L.; Xu, X.; Tong, C.; Gu, Z. Deep Learning Models for Real-time Human Activity Recognition with Smartphones. Mob. Netw. Appl. 2020, 25, 743–755. [Google Scholar] [CrossRef]
- Wang, L.; Liu, R. Human Activity Recognition Based on Wearable Sensor Using Hierarchical Deep LSTM Networks. Circuits Syst. Signal Process. 2020, 39, 837–856. [Google Scholar] [CrossRef]
- Xia, K.; Huang, J.; Wang, H. LSTM-CNN Architecture for Human Activity Recognition. IEEE Access 2020, 8, 56855–56866. [Google Scholar] [CrossRef]
- Xu, H.; Li, J.; Yuan, H.; Liu, Q.; Fan, S.; Li, T.; Sun, X. Human Activity Recognition Based on Gramian Angular Field and Deep Convolutional Neural Network. IEEE Access 2020, 8, 199393–199405. [Google Scholar] [CrossRef]
- Chung, S.; Lim, J.; Noh, K.J.; Kim, G.; Jeong, H. Sensor Data Acquisition and Multimodal Sensor Fusion for Human Activity Recognition Using Deep Learning. Sensors 2019, 19, 1716. [Google Scholar] [CrossRef] [Green Version]
- Concone, F.; Re, G.L.; Morana, M. A Fog-Based Application for Human Activity Recognition Using Personal Smart Devices. ACM Trans. Internet Technol. 2019, 19, 1–20. [Google Scholar] [CrossRef]
- Ding, R.; Li, X.; Nie, L.; Li, J.; Si, X.; Chu, D.; Liu, G.; Zhan, D. Empirical Study and Improvement on Deep Transfer Learning for Human Activity Recognition. Sensors 2019, 19, 57. [Google Scholar] [CrossRef] [Green Version]
- Ding, J.; Wang, Y. WiFi CSI-Based Human Activity Recognition Using Deep Recurrent Neural Network. IEEE Access 2019, 7, 174257–174269. [Google Scholar] [CrossRef]
- Gumaei, A.; Hassan, M.M.; Alelaiwi, A.; Alsalman, H. A Hybrid Deep Learning Model for Human Activity Recognition Using Multimodal Body Sensing Data. IEEE Access 2019, 7, 99152–99160. [Google Scholar] [CrossRef]
- Ehatisham-Ul-Haq, M.; Javed, A.; Azam, M.A.; Malik, H.M.A.; Irtaza, A.; Lee, I.H.; Mahmood, M.T. Robust Human Activity Recognition Using Multimodal Feature-Level Fusion. IEEE Access 2019, 7, 60736–60751. [Google Scholar] [CrossRef]
- Gani, M.O.; Richard, T.F.; Roger, J.P.; Muhammad, O.S.; Ahmed, A.; Sheikh, J.K.; Ahamed, I. A lightweight smartphone based human activity recognition system with high accuracy. J. Netw. Comput. Appl. 2019, 141, 59–72. [Google Scholar] [CrossRef]
- Li, H.; Shrestha, A.; Heidari, H.; Le Kernec, J.; Fioranelli, F. Bi-LSTM Network for Multimodal Continuous Human Activity Recognition and Fall Detection. IEEE Sens. J. 2019, 20, 1191–1201. [Google Scholar] [CrossRef] [Green Version]
- Kim, K.; Jalal, A.; Mahmood, M. Vision-Based Human Activity Recognition System Using Depth Silhouettes: A Smart Home System for Monitoring the Residents. J. Electr. Eng. Technol. 2019, 14, 2567–2573. [Google Scholar] [CrossRef]
- Naveed, H.; Khan, G.; Khan, A.U. Asad Ullah Khan, Aiman Siddiqi; Muhammad Usman Ghani Khan Human activity recognition using mixture of heterogeneous features and sequential minimal optimization. Int. J. Mach. Learn. Cybern. 2019, 10, 2329–2340. [Google Scholar] [CrossRef]
- Qi, W.; Su, H.; Yang, C.; Ferrigno, G.; De Momi, E.; Aliverti, A. A Fast and Robust Deep Convolutional Neural Networks for Complex Human Activity Recognition Using Smartphone. Sensors 2019, 19, 3731. [Google Scholar] [CrossRef] [Green Version]
- Siirtola, P.; Röning, J. Incremental Learning to Personalize Human Activity Recognition Models: The Importance of Human AI Collaboration. Sensors 2019, 19, 5151. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tian, Y.; Zhang, J.; Chen, L.; Geng, Y.; Wang, X. Single Wearable Accelerometer-Based Human Activity Recognition via Kernel Discriminant Analysis and QPSO-KELM Classifier. IEEE Access 2019, 7, 109216–109227. [Google Scholar] [CrossRef]
- Voicu, R.A.; Dobre, C.; Bajenaru, L.; Ciobanu, R.I. Human Physical Activity Recognition Using Smartphone Sensors. Sensors 2019, 19, 458. [Google Scholar] [CrossRef] [Green Version]
- Xu, S.; Tang, Q.; Jin, L.; Pan, Z. A Cascade Ensemble Learning Model for Human Activity Recognition with Smartphones. Sensors 2019, 19, 2307. [Google Scholar] [CrossRef] [Green Version]
- Xu, C.; Chai, D.; He, J.; Zhang, X.; Duan, S. InnoHAR: A Deep Neural Network for Complex Human Activity Recognition. IEEE Access 2019, 7, 9893–9902. [Google Scholar] [CrossRef]
- Yang, Y.; Hou, C.; Lang, Y.; Guan, D.; Huang, D.; Xu, J. Open-set human activity recognition based on micro-Doppler signatures. Pattern Recognit. 2019, 85, 60–69. [Google Scholar] [CrossRef]
- Zebin, T.; Scully, P.J.; Peek, N.; Casson, A.J.; Ozanyan, K.B. Design and Implementation of a Convolutional Neural Network on an Edge Computing Smartphone for Human Activity Recognition. IEEE Access 2019, 7, 133509–133520. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhang, Z.; Zhang, Y.; Bao, J.; Zhang, Y.; Deng, H. Human Activity Recognition Based on Motion Sensor Using U-Net. IEEE Access 2019, 7, 75213–75226. [Google Scholar] [CrossRef]
- Zhu, R.; Xiao, Z.; Li, Y.; Yang, M.; Tan, Y.; Zhou, L.; Lin, S.; Wen, H. Efficient Human Activity Recognition Solving the Confusing Activities Via Deep Ensemble Learning. IEEE Access 2019, 7, 75490–75499. [Google Scholar] [CrossRef]
- Espinilla, M.; Medina, J.; Nugent, C. UCAmI Cup. Analyzing the UJA Human Activity Recognition Dataset of Activities of Daily Living. Proceedings 2018, 2, 1267. [Google Scholar] [CrossRef] [Green Version]
- Anguita, D.; Ghio, A.; Oneto, L.; Parra, X.; Reyes-Ortiz, J. Energy efficient smartphone-based activity recognition using fixed-point arithmetic. Int. J. Univers. Comput. Sci. 2013, 19, 1295–1314. [Google Scholar]
- Zhang, M.; Sawchuk, A. USC-HAD: A daily activity dataset for ubiquitous activity recognition using wearable sensors. In Proceedings of the ACM Conference on Ubiquitous Computing (UbiComp) Workshop on Situation, Activity and Goal Awareness (SAGAware), Pittsburgh, PA, USA, 5–8 September 2012. [Google Scholar]
- Kwapisz, J.R.; Weiss, G.M.; Moore, S.A. Activity recognition using cell phone accelerometers. ACM SigKDD Explor. Newsl. 2011, 12, 74–82. [Google Scholar] [CrossRef]
- Reyes-Ortiz, J.L.; Oneto, L.; Samá, A.; Parra, X.; Anguita, D. Transition-Aware Human Activity Recognition Using Smartphones. Neurocomputing; Springer: Berlin/Heidelberg, Germany, 2015. [Google Scholar]
- Vaizman, Y.; Ellis, K.; Lanckriet, G.; Weibel, N. ExtraSensory app: Data collection in-the-wild with rich user interface to self-report behavior. In Proceedings of the CHI Conference on Human Factors in Computing Systems, Montréal, QC, Canada, 21–26 April 2018; pp. 1–12. [Google Scholar]
- Vavoulas, G.; Chatzaki, C.; Malliotakis, T.; Pediaditis, M.; Tsiknakis, M. The MobiAct dataset: Recognition of activities of daily living using smartphones. In Proceedings of the Information and Communication Technologies for Ageing Well and e-Health (ICT4AWE), Rome, Italy, 21–22 April 2016; pp. 143–151. [Google Scholar]
- Micucci, D.; Mobilio, M.; Napoletano, P. UniMiB SHAR: A Dataset for Human Activity Recognition Using Acceleration Data from Smartphones. Appl. Sci. 2017, 7, 1101. [Google Scholar] [CrossRef] [Green Version]
- Malekzadeh, M.; Clegg, R.G.; Cavallaro, A.; Haddadi, H. Protecting sensory data against sensitive inferences. In Proceedings of the First Workshop on Privacy by Design in Distributed Systems (W-P2DS), Porto, Portugal, 23–26 April 2018; pp. 1–6. [Google Scholar]
- Ordonez Morales, F.J.; De Toledo, P.; Sanchis, A. Activity Recognition Using Hybrid Generative/Discriminative Models on Home Environments Using Binary Sensors. Sensors 2013, 13, 5460–5477. [Google Scholar] [CrossRef]
- Van Kasteren, T.L.; Englebienne, G.; Kröse, B.J. Human activity recognition from wireless sensor network data: Benchmark and software. In Activity Recognition in Pervasive Intelligent Environments; Springer: Berlin/Heidelberg, Germany, 2011; pp. 165–186. [Google Scholar]
- Kasteren, T.; Englebienne, G.; Kröse, B. An activity monitoring system for elderly care using generative and discriminative models. Pers. Ubiquitous Comput. 2010, 14, 489–498. [Google Scholar] [CrossRef] [Green Version]
- Banos, O.; Garcia, R.; Holgado-Terriza, J.A.; Damas, M.; Pomares, H.; Rojas, I.; Saez, A.; Villalonga, C. mHealthDroid: A novel framework for agile development of mobile health applications. In Proceedings of the Sixth International Work-Conference Ambient Assisted Living and Daily Activities (IWAAL), Belfast, UK, 2–5 December 2014; pp. 91–98. [Google Scholar]
- Weiss, G.M.; Yoneda, K.; Hayajneh, T. Smartphone and Smartwatch-Based Biometrics Using Activities of Daily Living. IEEE Access 2019, 7, 133190–133202. [Google Scholar] [CrossRef]
- Morris, D.; Saponas, T.S.; Guillory, A.; Kelner, I. RecoFit: Using a Wearable Sensor to Find, Recognize, and Count Repetitive Exercises. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Toronto, ON, Canada, 6 April 2014; pp. 3225–3234. [Google Scholar]
- Sztyler, T.; Stuckenschmidt, H.; Petrich, W. Position-aware activity recognition with wearable devices. Pervasive Mob. Comput. 2017, 38, 281–295. [Google Scholar] [CrossRef]
- Cook, D.J.; Crandall, A.S.; Thomas, B.L.; Krishnan, N.C. CASAS: A Smart Home in a Box. Computer 2013, 46, 62–69. [Google Scholar] [CrossRef] [Green Version]
- Li, W.; Zhang, Z.; Liu, Z. Action recognition based on a bag of 3D points. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, USA, 13–18 June 2010; pp. 9–14. [Google Scholar]
- Wang, J.; Liu, Z.; Wu, Y.; Yuan, J. Mining actionlet ensemble for action recognition with depth cameras. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 1290–1297. [Google Scholar]
- Chen, C.; Jafari, R.; Kehtarnavaz, N. UTD-MHAD: A multimodal dataset for human action recognition utilizing a depth camera and a wearable inertial sensor. In Proceedings of the IEEE International Conference on Image Processing (ICIP) Quebec City, QC, Canada, 27–30 September 2015; pp. 168–172. [Google Scholar]
- Shahroudy, A.; Liu, J.; Ng, T.T.; Wang, G. NTU RGB+D: A Large Scale Dataset for 3D Human Activity Analysis. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1010–1019. [Google Scholar]
- Stisen, A.; Blunck, H.; Bhattacharya, S.; Prentow, T.S.; Kjaergaard, M.B.; Dey, A.; Sonne, T.; Jensen, M.M. Smart Devices are Different: Assessing and MitigatingMobile Sensing Heterogeneities for Activity Recognition. In Proceedings of the 13th ACM Conference on Embedded Networked Sensor Systems, Seoul, Korea, 1–4 November 2015; pp. 127–140. [Google Scholar]
- Reyes-Ortiz, J.L.; Oneto, L.; Samá, A.; Parra, X.; Anguita, D. Transition-Aware Human Activity Recognition Using Smartphones. Neurocomputing 2016, 171, 754–767. [Google Scholar] [CrossRef] [Green Version]
- Chavarriaga, R.; Sagha, H.; Calatroni, A.; Digumarti, S.T.; Tröster, G.; Millán, J.D.R.; Roggen, D. The opportunity challenge: A benchmark database for on-body sensor-based activity recognition. Pattern Recognit. Lett. 2013, 34, 2033–2042. [Google Scholar] [CrossRef] [Green Version]
- Roggen, D.; Calatroni, A.; Rossi, M.; Holleczek, T.; Förster, K.; Tröster, G.; Lukowicz, P.; Bannach, D.; Pirkl, G.; Ferscha, A.; et al. Collecting complex activity datasets in highly rich networked sensor environments. In Proceedings of the Seventh International Conference on Networked Sensing Systems (INSS), Kassel, Germany, 15–18 June 2010; pp. 233–240. [Google Scholar]
- Altun, K.; Barshan, B.; Tunçel, O. Comparative study on classifying human activities with miniature inertial and magnetic sensors. Pattern Recognit. 2010, 43, 3605–3620. [Google Scholar] [CrossRef]
- Banos, O.; Villalonga, C.; Garcia, R.; Saez, A.; Damas, M.; Holgado-Terriza, J.A.; Lee, S.; Pomares, H.; Rojas, I. Design, implementation and validation of a novel open framework for agile development of mobile health applications. Biomed. Eng. Online 2015, 14, S6. [Google Scholar] [CrossRef] [Green Version]
- Gorelick, L.; Blank, M.; Shechtman, E.; Irani, M.; Basri, R. Actions as Space-Time Shapes. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 2247–2253. [Google Scholar] [CrossRef] [Green Version]
- Schuldt, C.; Laptev, I.; Caputo, B. Recognizing human actions: A local SVM approach. In Proceedings of the 17th International Conference on Pattern Recognition (ICPR), Cambridge, UK, 26–26 August 2004. [Google Scholar]
- Reiss, A.; Stricker, D. Introducing a New Benchmarked Dataset for Activity Monitoring. In Proceedings of the 16th International Symposium on Wearable Computers, Newcastle, UK, 18–22 June 2012; pp. 108–109. [Google Scholar]
- Shi, X.; Chen, Z.; Wang, H.; Yeung, D.Y.; Wong, W.K.; Woo, W.C. Convolutional LSTM network: A machine learning approach for precipitation nowcasting. In Proceedings of the Advances in Neural Information Processing Systems 28 (NIPS), Montreal, QC, Canada, 7–12 December 2015; pp. 1–9. [Google Scholar]
- Schuster, M.; Paliwal, K.K. Bidirectional recurrent neural networks. IEEE Trans. Signal Process. 1997, 45, 2673–2681. [Google Scholar] [CrossRef] [Green Version]
- Vapnik, V.N. An overview of statistical learning theory. IEEE Trans. Neural Netw. 1999, 10, 988–999. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 8–10 June 2015; pp. 1–9. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Chollet, F. Xception: Deep Learning With Depthwise Separable Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- Huang, G.B.; Zhu, Q.Y.; Siew, C.K. Extreme learning machine: Theory and applications. Neurocomputing 2006, 70, 489–501. [Google Scholar] [CrossRef]
- Xian, Y.; Lampert, C.H.; Schiele, B.; Akata, Z. Zero-Shot Learning—A Comprehensive Evaluation of the Good, the Bad and the Ugly. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 2251–2265. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI), Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Anguita, D.; Ghio, A.; Oneto, L.; Parra, X.; Reyes-Ortiz, J.L. A Public Domain Dataset for Human Activity Recognition Using Smartphones. In Proceedings of the Computational Intelligence and Machine Learning (ESANN 2013), Bruges, Belgium, 24–26 April 2013; pp. 437–442. [Google Scholar]
- Anguita, D.; Ghio, A.; Oneto, L.; Parra, X.; Reyes-Ortiz, J.L. Human activity recognition on smartphones using a multiclass hardware-friendly support vector machine. In Proceedings of the International Workshop on Ambient Assisted Living (IWAAL), Vitoria-Gasteiz, Spain, 3–5 December 2012; pp. 216–223. [Google Scholar]
- Gubbi, J.; Buyya, R.; Marusic, S.; Palaniswami, M. Internet of Things (IoT): A vision, architectural elements, and future directions. Future Gener. Comput. Syst. 2013, 29, 1645–1660. [Google Scholar] [CrossRef] [Green Version]
- Subasi, A.; Radhwan, M.; Kurdi, R.; Khateeb, K. IoT based mobile healthcare system for human activity recognition. In Proceedings of the 15th Learning and Technology Conference (L&T), Jeddah, Saudi Arabia, 25–26 February 2018; pp. 29–34. [Google Scholar]
- Jourdan, T.; Boutet, A.; Frindel, C. Toward privacy in IoT mobile devices for activity recognition. In Proceedings of the 15th EAI International Conference on Mobile and Ubiquitous Systems: Computing, Networking and Services (MobiQuitous’18), New York, NY, USA, 5–7 November 2018; pp. 155–165. [Google Scholar]
- Zhang, H.; Xiao, Z.; Wang, J.; Li, F.; Szczerbicki, E. A Novel IoT-Perceptive Human Activity Recognition (HAR) Approach Using Multihead Convolutional Attention. IEEE Internet Things J. 2020, 7, 1072–1080. [Google Scholar] [CrossRef]
- Hendry, D.; Chai, K.; Campbell, A.; Hopper, L.; O’Sullivan, P.; Straker, L. Development of a Human Activity Recognition System for Ballet Tasks. Sports Med. Open 2020, 6, 10. [Google Scholar] [CrossRef]
- Ekman, P.; Davidson, R.J. The Nature of Emotion: Fundamental Questions; Oxford University Press: Oxford, UK, 1994. [Google Scholar]
- Nguyen, T.H.C.; Nebel, J.C.; Florez-Revuelta, F. Recognition of Activities of Daily Living with Egocentric Vision: A Review. Sensors 2016, 16, 72. [Google Scholar] [CrossRef] [PubMed]
- Wiener, J.M.; Hanley, R.J.; Clark, R.; Van Nostrand, J.F. Measuring the Activities of Daily Living: Comparisons Across National Surveys. J. Gerontol. 1990, 45, 229–237. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pirsiavash, H.; Ramanan, D. Detecting activities of daily living in first-person camera views. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 2847–2854. [Google Scholar]
- Chelli, A.; Pátzold, M. A Machine Learning Approach for Fall Detection and Daily Living Activity Recognition. IEEE Access 2019, 7, 38670–38687. [Google Scholar] [CrossRef]
- Diraco, G.; Leone, A.; Sicilia, P. AI-Based Early Change Detection in Smart Living Environments. Sensors 2019, 19, 3549. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Busso, C.; Bulut, M.; Lee, C.C.; Kazemzadeh, A.; Mower, E.; Kim, S.; Chang, J.N.; Lee, S.; Narayanan, S.S. IEMOCAP: Interactive Emotional Dyadic Motion Capture Database. Lang. Resour. Eval. 2008, 42, 335. [Google Scholar] [CrossRef]
- Zadeh, A.; Zellers, R.; Pincus, E.; Morency, L.P. Mosi: Multimodal Corpus of Sentiment Intensity and Subjectivity Analysis in Online Opinion Videos. IEEE Intell. Syst. 2016, 31, 82–88. [Google Scholar] [CrossRef]
- Dhall, A.; Goecke, R.; Ghosh, S.; Joshi, J.; Hoey, J.; Gedeon, T. From individual to group-level emotion recognition: Emotiw 5.0. In Proceedings of the 19th ACM International Conference on Multimodal Interaction (ICMI), Glasgow, Scotland, UK, 13–17 November 2017; pp. 524–528. [Google Scholar]
- Mollahosseini, A.; Hasani, B.; Mahoor, M.H. AffectNet: A Database for Facial Expression, Valence, and Arousal Computing in the Wild. IEEE Trans. Affect. Comput. 2019, 10, 18–31. [Google Scholar] [CrossRef] [Green Version]
- Ekman, P.; Friesen, W.V. Constants across cultures in the face and emotion. J. Personal. Soc. Psychol. 1971, 17, 124. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Nojavanasghari, B.; Baltrusáitis, T.; Hughes, C.E.; Morency, L.P. EmoReact: A Multimodal Approach and Dataset for Recognizing Emotional Responses in Children. In Proceedings of the 18th ACM International Conference on Multimodal Interaction, Tokyo, Japan, 12–16 November 2016; pp. 137–144. [Google Scholar]
- Chen, O.O.R.W.; Picard, R.W. Gifgif+: Collecting emotional animated gifs with clustered multi-task learning. In Proceedings of the Seventh International Conference on Affective Computing and Intelligent Interaction, San Antonio, TX, USA, 23–26 October 2017; pp. 510–517. [Google Scholar]
- Kim, Y.; Soyata, T.; Behnagh, R.F. Towards Emotionally Aware AI Smart Classroom: Current Issues and Directions for Engineering and Education. IEEE Access 2018, 6, 5308–5331. [Google Scholar] [CrossRef]
- Marinoiu, E.; Zanfir, M.; Olaru, V.; Sminchisescu, C. 3D Human Sensing, Action and Emotion Recognition in Robot-Assisted Therapy of Children With Autism. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 2158–2167. [Google Scholar]
- Ahmed, F.; Bari, A.S.M.H.; Gavrilova, M.L. Emotion Recognition from Body Motion. IEEE Access 2020, 8, 11761–11781. [Google Scholar] [CrossRef]
- Ma, Y.; Paterson, H.M.; Pollick, F.E. A Motion Capture Library for the Study of Identity, Gender, and Emotion Perception from Biological Motion. Behav. Res. Methods 2006, 38, 134–141. [Google Scholar] [CrossRef] [Green Version]
- Cao, Z.; Hidalgo, G.; Simon, T.; Wei, S.-E.; Sheikh, Y. OpenPose: Realtime Multi-Person 2D Pose Estimation Using Part Affinity Fields. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 172–186. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Nibali, A.; He, Z.; Morgan, S.; Prendergast, L. 3D Human Pose Estimation With 2D Marginal Heatmaps. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Long Beach, CA, USA, 16–20 June 2019; pp. 1477–1485. [Google Scholar]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep High-Resolution Representation Learning for Human Pose Estimation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 5693–5703. [Google Scholar]
- Belagiannis, V.; Zisserman, A. Recurrent Human Pose Estimation. In Proceedings of the 12th IEEE International Conference on Automatic Face and Gesture Recognition (FG), Washington, DC, USA, 30 May–3 June 2017; pp. 468–475. [Google Scholar]
- Papandreou, G.; Zhu, T.; Chen, L.C.; Gidaris, S.; Tompson, J.; Murphy, K. PersonLab: Person Pose Estimation and Instance Segmentation with a Bottom-Up, Part-Based, Geometric Embedding Model. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 269–286. [Google Scholar]
- Fang, H.S.; Xie, S.; Tai, Y.W.; Lu, C. RMPE: Regional Multi-Person Pose Estimation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2334–2343. [Google Scholar]
- Insafutdinov, E.; Pishchulin, L.; Andres, B.; Andriluka, M.; Schiele, B. Deepercut: A Deeper, Stronger, and Faster Multi-Person Pose Estimation Model. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016; pp. 34–50. [Google Scholar]
- Pishchulin, L.; Insafutdinov, E.; Tang, S.; Andres, B.; Andriluka, M.; Gehler, P.; Schiele, B. Deepcut: Joint Subset Partition and Labeling for Multi-Person Pose Estimation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 4929–4937. [Google Scholar]
- Wei, S.E.; Ramakrishna, V.; Kanade, T.; Sheikh, Y. Convolutional Pose Machines. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 4724–4732. [Google Scholar]
- Carreira, J.; Agrawal, P.; Fragkiadaki, K.; Malik, J. Human Pose Estimation with Iterative Error Feedback. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 4733–4742. [Google Scholar]
- Noori, F.M.; Wallace, B.; Uddin, M.Z.; Torresen, J. A Robust Human Activity Recognition Approach Using OpenPose, Motion Features, and Deep Recurrent Neural Network. In Proceedings of the Scandinavian Conference on Image Analysis (SCIA), Norrköping, Sweden, 11–13 June 2019; pp. 299–310. [Google Scholar]
- Kim, W.; Sung, J.; Saakes, D.; Huang, C.; Xiong, S. Ergonomic postural assessment using a new open-source human pose estimation technology (OpenPose). Int. J. Ind. Ergon. 2021, 84, 103164. [Google Scholar] [CrossRef]
- Cao, Z.; Simon, T.; Wei, S.-E.; Sheikh, Y. Realtime multi-person 2d pose estimation using part affinity fields. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 7291–7299. [Google Scholar]
- Andriluka, M.; Pishchulin, L.; Gehler, P.; Schiele, B. 2D Human Pose Estimation: New Benchmark and State of the Art Analysis. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 24–27 June 2014; pp. 3686–3693. [Google Scholar]
- Iqbaland, U.; Gall, J. Multi-Person Pose Estimation with Local Joint-to-Person Associations. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016; pp. 627–642. [Google Scholar]
- Pan, S.J.; Yang, Q. A Survey on Transfer Learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.; Li, K.; Fei-Fei, L. ImageNet: A Large-Scale Hierarchical Image Database. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Miami Beach, FL, USA, 22–24 June 2009; pp. 248–255. [Google Scholar]
- Zagoruyko, S.; Komodaki, N. Wide residual networks. arXiv 2016, arXiv:1605.07146. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1492–1500. [Google Scholar]
- Gao, S.; Cheng, M.M.; Zhao, K.; Zhang, X.Y.; Yang, M.H.; Torr, P.H. Res2Net: A New Multi-scale Backbone Architecture. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 652–662. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, inception-resnet and the impact of residual connections on learning. arXiv 2016, arXiv:1602.07261. [Google Scholar]
- Huang, J.; Rathod, V.; Sun, C.; Zhu, M.; Korattikara, A.; Fathi, A.; Fischer, I.; Wojna, Z.; Song, Y.; Guadarrama, S.; et al. Speed/Accuracy Trade-Offs for Modern Convolutional Object Detectors. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3296–3297. [Google Scholar]
- Madokoro, H.; Yamamoto, S.; Nishimura, Y.; Nix, S.; Woo, H.; Sato, K. Prototype Development of Small Mobile Robots for Mallard Navigation in Paddy Fields: Toward Realizing Remote Farming. Robotics 2021, 10, 63. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980v9. [Google Scholar]
- Qian, N. On the momentum term in gradient descent learning algorithms. Neural Netw. 1999, 12, 145–151. [Google Scholar] [CrossRef]
- Tieleman, T.; Hinton, G. Lecture 6.5–RMSProp: Divide the Gradient by a Running Average of its Recent Magnitude. COURSERA Neural Netw. Mach. Learn. 2012, 4, 26–31. [Google Scholar]
- Gross, J.J.; John, O.P. Individual Differences in Two Emotion Regulation Processes: Implications for Affect, Relationships, and Well-Being. J. Personal. Soc. Psychol. 2003, 85, 348–362. [Google Scholar] [CrossRef] [PubMed]
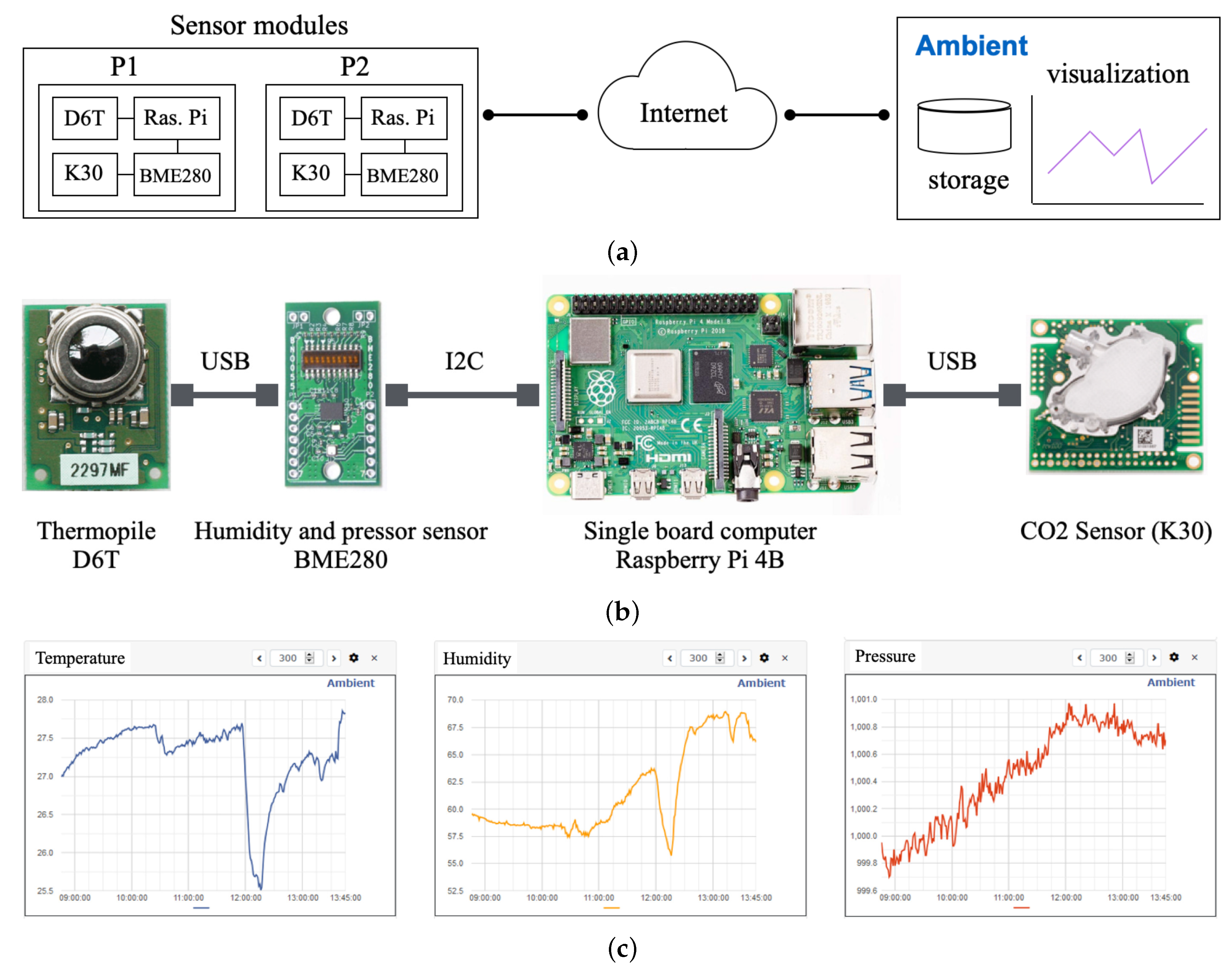
- Saari, M.; bin Baharudin, A.M.; Hyrynsalmi, S. Survey of prototyping solutions utilizing Raspberry Pi. In Proceedings of the 40th International Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO), Opatija, Croatia, 22–26 May 2017; pp. 991–994. [Google Scholar]
- Yang, D.Q.B.; Gu, N. Indoor multiple human targets localization and tracking using thermopile sensor. Infrared Phys. Technol. 2019, 97, 349–359. [Google Scholar]
- Madokoro, H.; Kiguchi, O.; Nagayoshi, T.; Chiba, T.; Inoue, M.; Chiyonobu, S.; Nix, S.; Woo, H.; Sato, K. Development of Drone-Mounted Multiple Sensing System with Advanced Mobility for In Situ Atmospheric Measurement: A Case Study Focusing on PM2.5 Local Distribution. Sensors 2021, 21, 4881. [Google Scholar] [CrossRef] [PubMed]
- Hochreiter, S. The Vanishing Gradient Problem During Learning Recurrent Neural Nets and Problem Solutions. Int. J. Uncertain. Fuzziness Knowl.-Based Syst. 1998, 6, 107–116. [Google Scholar] [CrossRef] [Green Version]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Pub. | Authors | Sensing Modality | Approach | Num. | ||||
|---|---|---|---|---|---|---|---|---|
| Year | (A–Z) | Camera | SM | WS | ES | CML | DL | Ref. |
| 2021 | Biswal et al. [36] | √ | √ | √ | 48 | |||
| 2021 | Bouchabou et al. [37] | √ | √ | √ | 113 | |||
| 2021 | Chen et al. [38] | √ | √ | √ | √ | 191 | ||
| 2021 | Mihoub et al. [39] | √ | √ | 64 | ||||
| 2021 | Muralidharan et al. [40] | √ | √ | √ | √ | 115 | ||
| 2021 | Shaikh et al. [41] | √ | √ | 150 | ||||
| 2021 | Straczkiewicz et al. [42] | √ | √ | √ | √ | 140 | ||
| 2020 | Beddiar et al. [43] | √ | √ | √ | 237 | |||
| 2020 | Carvalho et al. [44] | √ | √ | √ | 136 | |||
| 2020 | Dang et al. [45] | √ | √ | √ | √ | √ | √ | 236 |
| 2020 | Demrozi et al. [46] | √ | √ | √ | √ | 219 | ||
| 2020 | Fu et al. [47] | √ | √ | 183 | ||||
| 2020 | Hussain et al. [48] | √ | √ | √ | 165 | |||
| 2020 | Jung [49] | √ | √ | 60 | ||||
| 2020 | Sherafat [50] | √ | √ | √ | √ | √ | 132 | |
| Year | (A–Z) | Camera | SM | WS | ES | CML | DL | Ref. |
| 2019 | Dang et al. [51] | √ | √ | 187 | ||||
| 2019 | Dhiman et al. [52] | √ | √ | √ | 208 | |||
| 2019 | Elbasiony et al. [53] | √ | √ | 48 | ||||
| 2019 | Hussain et al. [54] | √ | 141 | |||||
| 2019 | Jobanputra et al. [55] | √ | 9 | |||||
| 2019 | Li et al. [56] | √ | √ | 106 | ||||
| 2019 | Lima et al. [57] | √ | √ | √ | 149 | |||
| 2019 | Slim et al. [58] | √ | √ | √ | √ | 119 | ||
| 2019 | Wang et al. [59] | √ | √ | √ | 77 | |||
| 2018 | Nweke et al. [60] | √ | √ | 275 | ||||
| 2018 | Ramamurthy et al. [61] | √ | √ | √ | √ | 83 | ||
| 2018 | Shickel et al. [62] | √ | √ | √ | 63 | |||
| 2018 | Wang et al. [63] | √ | √ | 182 | ||||
| 2017 | Cornacchia et al. [64] | √ | √ | √ | 225 | |||
| 2017 | Chen et al. [65] | √ | √ | 78 | ||||
| 2017 | Morales et al. [66] | √ | √ | 65 | ||||
| 2017 | Rault et al. [67] | √ | √ | 88 | ||||
| 2017 | Vyas et al. [68] | √ | 39 | |||||
| 2016 | Dawn et al. [69] | √ | √ | 66 | ||||
| 2016 | Onofri et al. [70] | √ | 90 | |||||
| Year | Authors | Methods | Datasets |
|---|---|---|---|
| 2021 | Fu et al. [71] | IPL-JPDA | original |
| 2021 | Gorji et al. [72] | CML (RF) | original |
| 2021 | Gul et al. [73] | YOLO+CNN | original |
| 2021 | Hussain et al. [74] | CML (RF) | [123] |
| 2021 | Mekruksavanich et al. [75] | 4-CNN-LSTM | [124] |
| 2021 | Mekruksavanich et al. [76] | CNN-LSTM | [124,125] |
| 2021 | Moreira et al. [77] | ConvLSTM | original |
| 2021 | Nafea et al. [78] | CNN-BiLSTM | [124,126] |
| 2021 | Xiao et al. [79] | DIM-BLS | [124,126] |
| 2020 | Ahmed et al. [80] | CML (SVM) | [127] |
| 2020 | Ashry et al. [81] | BLSTM | original |
| 2020 | Debache et al. [82] | CML and CNN | original |
| 2020 | Ehatisham-Ul-Haq et al. [83] | CML | [128] |
| 2020 | Ferrari et al. [84] | Adaboost+CNN | [129,130,131] |
| 2020 | Hamad et al. [85] | CNN-LSTM | [132,133,134] |
| 2020 | Ihianle et al. [86] | MCBLSTM | [135,136] |
| 2020 | Irvine et al. [87] | EL | [123] |
| 2020 | Khannouz et al. [88] | CML | [135,137] |
| 2020 | Lawal et al. [89] | CNN | [138] |
| 2020 | Machot et al. [90] | ZSL | [139] |
| 2020 | Mukherjee et al. [91] | CNN (ResNet-101) | [140]+original |
| 2020 | Mutegeki et al. [92] | CNN-LSTM | [124] |
| 2020 | Pham et al. [93] | CNN-LSTM | [141,142,143] |
| 2020 | Popescu et al. [94] | CNN | [141,142,143] |
| 2020 | Qin et al. [95] | CNN (Fusion-ResNet) | [135,144] |
| 2020 | Shrestha et al. [96] | BLSTM | original |
| 2020 | Taylor et al. [97] | CML | original |
| 2020 | Tanberk et al. [98] | 3D-CNN-LSTM | original |
| 2020 | Wan et al. [99] | CNN | [124] |
| 2020 | Wang et al. [100] | H-LSTM | [124] |
| 2020 | Xia et al. [101] | LSTM-CNN | [126,145,146] |
| 2020 | Xu et al. [102] | CNN (Fusion-Mdk-ResNet) | [124,126,147] |
| 2019 | Chung et al. [103] | LSTM | original |
| 2019 | Concone et al. [104] | HMM | original |
| 2019 | Ding et al. [105] | CNN+TL | [125,148] |
| 2019 | Ding et al. [106] | RNN (LSTM) | original |
| 2019 | Gumaei et al. [107] | RNN | [149] |
| 2019 | Ehatisham-Ul-Haq et al. [108] | CML (kNN, SVM) | [142] |
| 2019 | Gani et al. [109] | GMM | original |
| 2019 | Li et al. [110] | BLSTM | original |
| 2019 | Kim et al. [111] | HMM | original |
| 2019 | Naveed et al. [112] | CML (SVM) | [150,151] |
| 2019 | Qi et al. [113] | CNN | original |
| 2019 | Siirtola et al. [114] | EL | original |
| 2019 | Tian et al. [115] | CML (SVM+ELM) | original |
| 2019 | Voicu et al. [116] | CML (SVM) | original |
| 2019 | Xu et al. [117] | EL | [124] |
| 2019 | Xu et al. [118] | EL | [147] |
| 2019 | Yang et al. [119] | CNN (Inception) | [124,147,152] |
| 2019 | Zebin et al. [120] | CNN (LeNet) | original |
| 2019 | Zhang et al. [121] | U-Net | [126,145,146]+original |
| 2019 | Zhu et al. [122] | EL | original |
| Parameters | Setting Values |
|---|---|
| Learning iteration | 50 epochs |
| Batch size | 4 |
| Validation split | 0.2 |
| Num. input layer | 224 × 224 × 3 units |
| Num. output layer | 2, 3, or 5 units |
| Optimization algorithms | Adam [213] |
| Parameters | Specifications |
|---|---|
| Imaging sensor | OV9282 |
| Lens size | 14 inch |
| Pixel size | 3 × 3 m |
| FoV | 163 ± 5 deg |
| Resolution | W1280 × H800 pixels |
| Frame rate | 120 fps |
| IMU | BMI055 |
| Body dimensions | L12.5 × W108.0 × H24.5 mm |
| Weight | 55 g |
| Mean power consumption | 1.5 W |
| Behavior Pattern | Subset Name | Capture Time (s) | Total Images (Frames) | Valid Images (Frames) | Conversion Ratio |
|---|---|---|---|---|---|
| ET | ET1 | 21 | 218 | 218 | 1.00 |
| ET2 | 20 | 209 | 209 | 1.00 | |
| RD | RD1 | 20 | 200 | 200 | 1.00 |
| RD2 | 20 | 200 | 200 | 1.00 | |
| SP | SP1 | 20 | 202 | 202 | 1.00 |
| SP2 | 20 | 202 | 202 | 1.00 | |
| LC | LC1 | 20 | 202 | 202 | 1.00 |
| LC2 | 20 | 204 | 172 | 0.84 | |
| ST | ST1 | 18 | 181 | 138 | 0.76 |
| ST2 | 16 | 160 | 100 | 0.63 | |
| Total | 199 | 1978 | 1843 | 0.93 | |
| Items | Specifications |
|---|---|
| OS | Windows 10 Professional 64 bit; Microsoft Corp. |
| CPU | Core i5-6200 (2.30 GHz); Intel Corp. |
| Memory | 8192 MB |
| GPU | HD Graphics 520; Intel Corp. |
| VRAM | 128 MB |
| Behavior Pattern | Subset Name | Processing Time (s) | Total Images (Frame) | Second per Frame (s) |
|---|---|---|---|---|
| ET | ET1 | 20,949 | 218 | 96.10 |
| ET2 | 21,659 | 209 | 103.63 | |
| RD | RD1 | 22,992 | 200 | 114.96 |
| RD2 | 12,056 | 200 | 60.28 | |
| SP | SP1 | 11,711 | 202 | 57.98 |
| SP2 | 11,757 | 202 | 58.20 | |
| LC | LC1 | 11,982 | 202 | 59.32 |
| LC2 | 11,750 | 172 | 68.31 | |
| ST | ST1 | 18,409 | 138 | 133.40 |
| ST2 | 13,599 | 100 | 135.99 | |
| Total | 156,864 | 1843 | 85.11 | |
| Experiment | ET | RD | SP | LC | ST |
|---|---|---|---|---|---|
| A | √ | √ | |||
| B | √ | √ | √ | ||
| C | √ | √ | √ | √ | √ |
| Category | ET | RD | SP | LC | ST |
|---|---|---|---|---|---|
| ET | 209 | 0 | 0 | 0 | 0 |
| RD | 1 | 199 | 0 | 0 | 0 |
| SP | 0 | 0 | 202 | 0 | 0 |
| LC | 0 | 0 | 1 | 171 | 0 |
| ST | 0 | 0 | 0 | 0 | 100 |
| Experiment | ||||
|---|---|---|---|---|
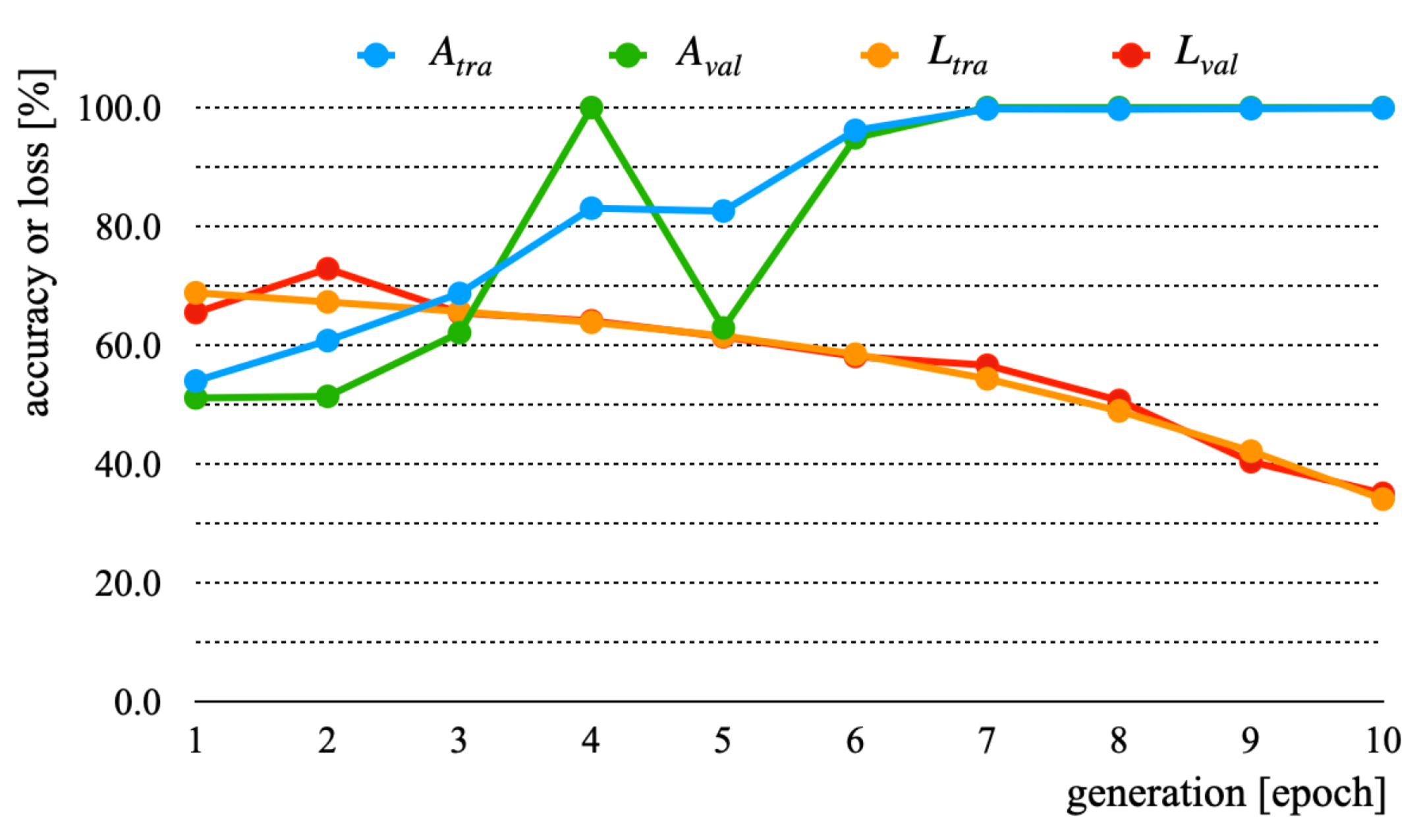
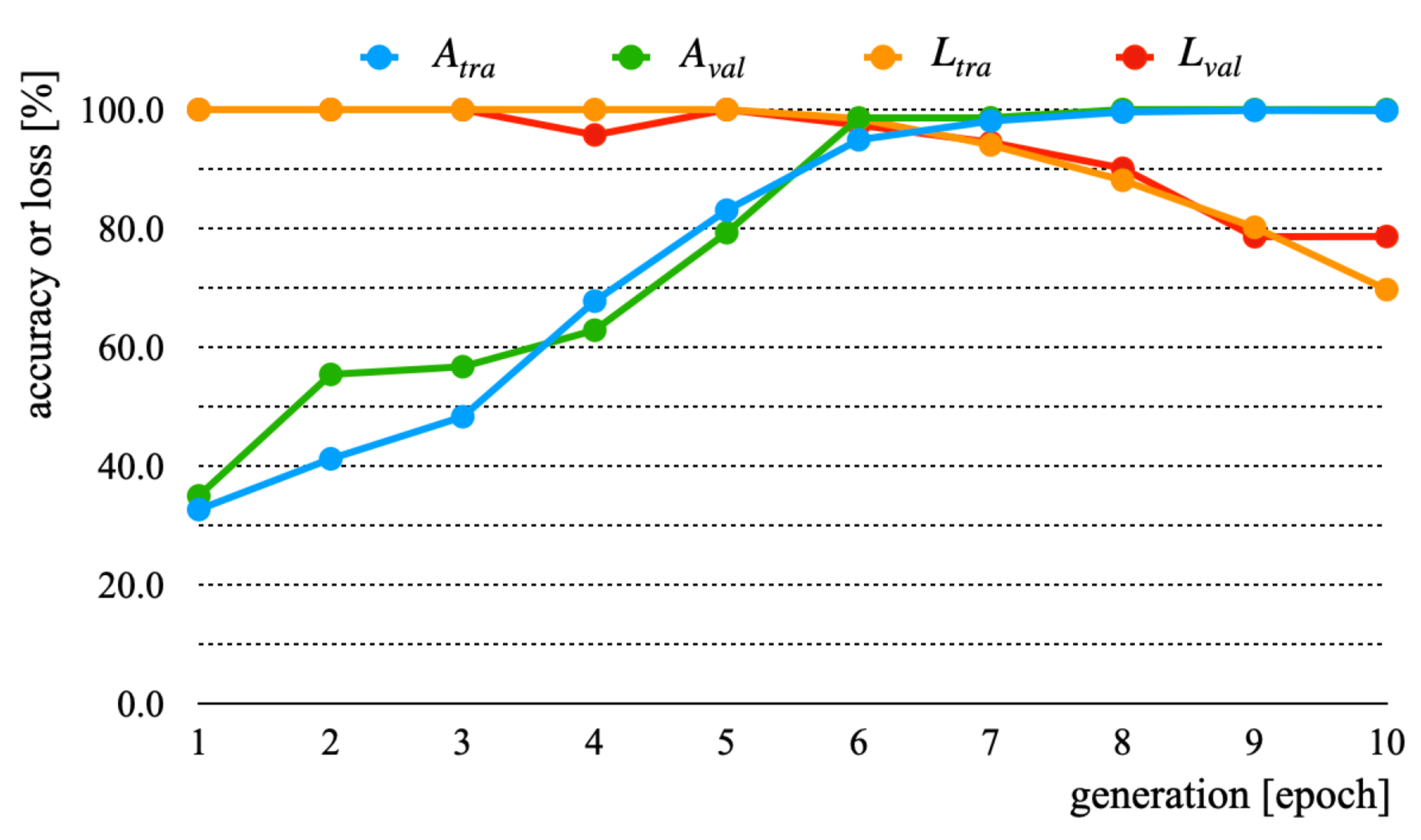
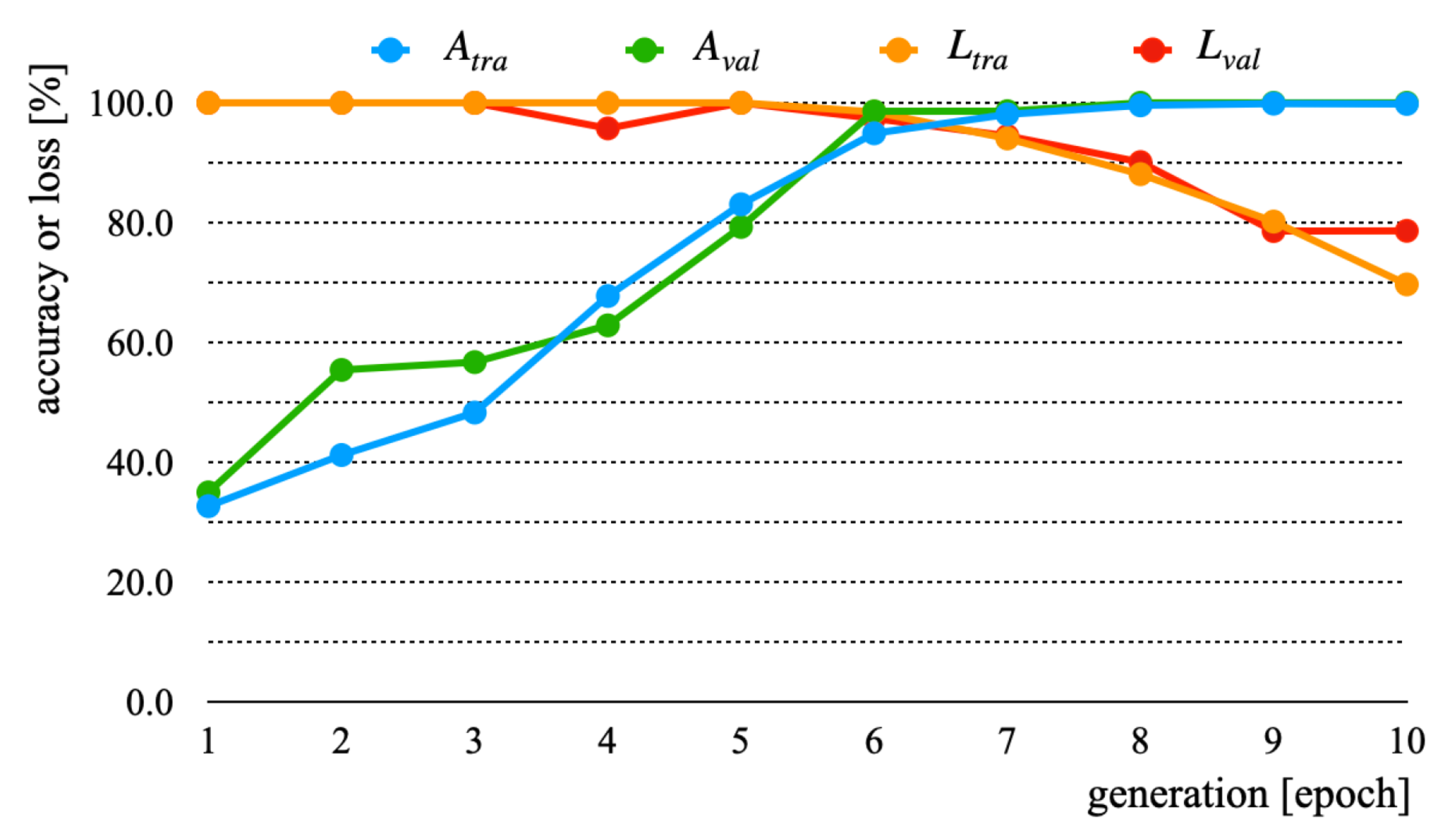
| A | 100.0 | 100.0 | 34.1 | 35.1 |
| B | 100.0 | 100.0 | 69.7 | 78.6 |
| C | 99.3 | 99.7 | 55.0 | 53.9 |
| Item | Specifications |
|---|---|
| Number of elements | 16 () |
| Horizontal view angle | 44.2 |
| Vertical view angle | 45.7 |
| Object temperature detection range | 5–50 |
| Ambient temperature detection range | 5–45 |
| Object temperature output accuracy | (maximum) |
| Temperature resolution | 0.06 C |
| Operating temperature | 0–50 C |
| Operating humidity | 20–95% |
| Sensor board dimensions | L11.6 × W12.0 × H10.7 mm |
| Item | Specifications |
|---|---|
| Target gas | CO |
| Operating principle | NDIR |
| Measurement range | 0–5000 ppm |
| Accuracy | ppm % of reading at 101.3 kPa |
| Response time | 20 s diffusion time |
| Rate of measurement | 0.5 Hz |
| Operating temperature | 0–50 C |
| Operating humidity | 0–95% |
| Sensor board dimensions | L51 × W58 × H12 mm |
| Item | Target | Specifications |
|---|---|---|
| Measurement range | Air pressure | 300–1100 hPa |
| Temperature | −40–85 C | |
| Humidity | 0–100% | |
| Resolution | Air pressure | 0.18 hPa |
| Temperature | 0.01 C | |
| Humidity | 0.008% | |
| Accuracy tolerance | Air pressure | hPa |
| Temperature | % | |
| Humidity | % | |
| Sampling intervals | 1 s | |
| Sensor dimensions | L2.5 × W2.5 × H0.93 mm |
| Parameters | Setting Values |
|---|---|
| Learning iteration | 50 epochs |
| Batch size | 2 |
| Validation split | 0.2 |
| Num. input layer | 20 or 40 units |
| Num. hidden layer | 50 units |
| Num. output layer | 8 units |
| Optimization algorithms | Adam [213] |
| Look-back | 10 |
| ET | LC | SP | GM | RD | EX | NP | ST | Total | |
|---|---|---|---|---|---|---|---|---|---|
| No. Signals | 655 | 3142 | 1139 | 3951 | 1444 | 408 | 414 | 368 | 11,521 |
| Ratio (%) | 5.69 | 27.27 | 9.89 | 34.29 | 12.53 | 3.54 | 3.59 | 3.19 | 100.00 |
| Sensor Installed Position | All Sensors | D6T | BME280 | K30 |
|---|---|---|---|---|
| P1+P2 | 60.8 (12.0) | 50.6 (17.7) | 44.6 (17.7) | 27.0 (12.7) |
| P1 | 49.8 (16.8) | 41.6 (17.7) | 30.8 (16.3) | 18.2 (9.7) |
| P2 | 58.9 (13.1) | 49.0 (16.2) | 46.5 (15.6) | 46.1 (18.5) |
| P1+P2 | EX | LC | SP | GM | RD | EX | NP | ST |
|---|---|---|---|---|---|---|---|---|
| EX | 408 | 23 | 4 | 0 | 0 | 10 | 0 | 0 |
| LC | 0 | 2437 | 0 | 62 | 552 | 73 | 0 | 17 |
| SP | 8 | 51 | 0 | 11 | 23 | 0 | 22 | 0 |
| GM | 0 | 439 | 1 | 2725 | 486 | 28 | 270 | 2 |
| RD | 536 | 0 | 468 | 0 | 627 | 0 | 0 | 113 |
| EX | 0 | 217 | 0 | 0 | 0 | 197 | 0 | 0 |
| NP | 0 | 0 | 0 | 0 | 408 | 0 | 0 | 0 |
| ST | 42 | 214 | 0 | 28 | 13 | 16 | 0 | 9 |
| P1 | EX | LC | SP | GM | RD | EX | NP | ST |
| EX | 409 | 23 | 3 | 0 | 0 | 10 | 0 | 0 |
| LC | 0 | 1696 | 0 | 114 | 1324 | 7 | 0 | 0 |
| SP | 8 | 62 | 0 | 13 | 32 | 0 | 0 | 0 |
| GM | 0 | 889 | 0 | 2420 | 642 | 0 | 0 | 0 |
| RD | 463 | 0 | 471 | 0 | 481 | 0 | 0 | 29 |
| EX | 0 | 323 | 0 | 0 | 0 | 91 | 0 | 0 |
| NP | 0 | 0 | 0 | 0 | 408 | 0 | 0 | 0 |
| ST | 42 | 222 | 9 | 28 | 13 | 8 | 0 | 0 |
| P2 | EX | LC | SP | GM | RD | EX | NP | ST |
| EX | 411 | 23 | 1 | 0 | 0 | 10 | 0 | 0 |
| LC | 42 | 1809 | 849 | 81 | 349 | 7 | 0 | 4 |
| SP | 8 | 51 | 0 | 25 | 31 | 0 | 0 | 0 |
| GM | 0 | 390 | 0 | 3078 | 483 | 0 | 0 | 0 |
| RD | 458 | 0 | 351 | 0 | 635 | 0 | 0 | 0 |
| EX | 0 | 318 | 0 | 0 | 0 | 96 | 0 | 0 |
| NP | 0 | 0 | 0 | 0 | 408 | 0 | 0 | 0 |
| ST | 42 | 80 | 9 | 28 | 155 | 8 | 0 | 0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Madokoro, H.; Nix, S.; Woo, H.; Sato, K. A Mini-Survey and Feasibility Study of Deep-Learning-Based Human Activity Recognition from Slight Feature Signals Obtained Using Privacy-Aware Environmental Sensors. Appl. Sci. 2021, 11, 11807. https://doi.org/10.3390/app112411807
Madokoro H, Nix S, Woo H, Sato K. A Mini-Survey and Feasibility Study of Deep-Learning-Based Human Activity Recognition from Slight Feature Signals Obtained Using Privacy-Aware Environmental Sensors. Applied Sciences. 2021; 11(24):11807. https://doi.org/10.3390/app112411807
Chicago/Turabian StyleMadokoro, Hirokazu, Stephanie Nix, Hanwool Woo, and Kazuhito Sato. 2021. "A Mini-Survey and Feasibility Study of Deep-Learning-Based Human Activity Recognition from Slight Feature Signals Obtained Using Privacy-Aware Environmental Sensors" Applied Sciences 11, no. 24: 11807. https://doi.org/10.3390/app112411807
APA StyleMadokoro, H., Nix, S., Woo, H., & Sato, K. (2021). A Mini-Survey and Feasibility Study of Deep-Learning-Based Human Activity Recognition from Slight Feature Signals Obtained Using Privacy-Aware Environmental Sensors. Applied Sciences, 11(24), 11807. https://doi.org/10.3390/app112411807