1. Introduction
It is believed that by employing new teaching methods or education systems, students can not only be able to obtain good grades and good jobs but also connect and combine the critical areas of their learning with meeting various needs of the 21st century. STEM is an education system based on the idea of an interdisciplinary field for Science, Technology, Engineering, and Math. Recently, there has been a significant movement from STEM to STEAM (Science, Technology, Engineering, Arts, and Math), as the inclusion of “arts” can help students to “connect the dots” in learning, which is lacking in STEM [
1]. As a prime part of arts, music is popular and interesting to many people from an early age, and many people study musical skills. One of the most popular musical instruments is the piano. Learning to play the piano may require learners to be motivated and involve mathematical and engineering processes [
2]. Much research has shown that music positively affects the human brain and the memory of the learner as both sides of the brain are employed [
3]. Playing musical instruments helps to improve listening, recognition, and voice differentiation and helps in filtering background noise. These skills can be employed in normal daily routines; for example, students have to concentrate in class despite various distractions. Additional studies also show that playing the piano can help to prevent age-related listening problems. Moreover, playing the piano can improve hand-eye and body coordination where accuracy and strength are required to play the piano. While piano players are reading the score, their left and right hands have to be coordinated and systematized simultaneously. Moreover, their feet have to control the pedals at the same time, which means that both the hands and feet are used and must be coordinated. This allows cognitive development and body balance at the same time.
As mentioned before, playing musical instruments can improve learners’ memory, and many studies have revealed that music positively affects the human body and brain in several ways. When playing the piano, the brain communicates with various body parts. Adult keyboard playing can help human growth hormone (HGH) stimulation and increase muscle mass while decreasing and delaying osteoporosis. Nowadays, there are several ways to learn the piano, such as face-to-face classes or online learning, both of which have limitations. For example, non-standard evaluation depends on teachers’ ability and experience and software limitations, and the lack of quality internet affects online learning, which can lead to communication failure and misunderstandings while learning.
Many parents are aware that learning piano-playing skills can be an important foundation for many life skills. Playing the piano helps to make connections in the brain that help in the development of other skills such as speaking skills, language skills, motivation, memory skills, and emotional expression. These skills can help children to acquire skills such as patience, diligence, cooperation, memorization, goal setting, discipline, and emotional control. The researcher strongly believes that with these skills, piano learners can achieve and develop their abilities in various ways.
This study aims to improve the playing skills of piano learners by analyzing and classifying the piano sounds into three categories: “Good”, “Normal”, and “Bad” and thereby assisting piano learners in understanding their performance levels and improving their piano skills quickly. There are four classification approaches investigated in this research, including Support Vector Machine (SVM), Naive Bayes (NB), Convolutional Neural Network (CNN), and Long Short-Term Memory (LSTM). This study will contribute to the integration of music education and computer science technology in learning. The data analysis is divided into two parts, which are “Legato” and “Staccato”, to obtain accurate results. Legato, which means smooth and gentle in Italian, involves the use of the sustain pedal, while “Staccato”, which means short and separate in Italian, does not require the use of the sustain pedal.
The remainder of this paper is organized as follows.
Section 2 explains the related works of STEAM education and automatic music assessment.
Section 3 briefs the characteristics of piano performances.
Section 4 presents our methodology, including four assessment approaches: Support Vector Machine (SVM), Naive Bayes (NB), Convolutional Neural Network (CNN), and Long Short-Term Memory (LSTM).
Section 5 discusses the experimental results. Then,
Section 6 offers conclusions and indicates future research possibilities.
2. Related Work
Children and teachers have a tremendous impact on piano lessons and piano playing, as it depends on how much children are involved in music and how well teachers understand children’s issues. Many parents’ awareness of piano and understanding piano is one of the standard bases on string instruments regarding aesthetics STEAM education in these recent years.
Several works were based on STEAM education. The reason why STEAM education is able to succeed is that it encourages students to be more innovative [
4]. The work of [
5], EarSketch, an integrated STEAM education system, showed the potential of the proposed STEAM programming environment using musical beats, samples, and effects to broaden computing participation in an authentic learning environment in both computational and musical domains.
The previous articles were focused on the integration of engineering, music, arts, education, and technology. Many kinds of research have combined the dimensions of music, arts, and engineering. With the development of media such as applications, the piano teaching system in music schools, and applications to teach young children, access to piano-related resources is easier and quicker. The research was conducted in regard to development, such as empirical research about music performance [
6] in which musical performances were compared. This research was inspired by previous research into Movement and Touch in Piano Performance Research, [
7] which describes musical behavior. Body movements in piano performances are employed to produce the desired sound with the highest precision in the parameters that include time, rhythm, dynamics, low tones, and voice. Body movements during piano performances may also be used for communication purposes to show emotion or to interact with the other participants and audience. The pianist controls the rhythm and speed of each piano hammer by pressing the touch-sensitive keys with varying degrees of pressure and by operating the three pedals with their feet.
On the other hand, several works investigate musical performance evaluation. For instance, the use of dynamic time-warping with distance for classifying violin performances is presented in [
8], which reaches an accuracy of 90%. In addition, the study in [
9] used Support Vector Machine (SVM) to assess the tone quality of trumpet performance. The author divided the experiment into two parts. The first part separated the datasets into three equivalent classes: good, medium, and bad. The second part separated the datasets into two classes of good and bad at the median rating. SVM achieves an accuracy of 54% for three-class classification and an accuracy of 72% for two-class classification with a median rating.
Thus far, there were only very limited studies about assessment for music performance, but there were several methods to explore the music teaching system such as music scoring, music measurement, music performances improvement, modeling of music performance, and music education. The work “
Musical Performance at the Millennium” [
6] compared the performance of different musical instruments from recent decades, around 1995 to 2002. The past related work [
8] that inspired me to explore musical performance evaluation used the dynamic time-warping with distance for classifying violin performances. Another work [
9] used machine learning methods such as SVM to classify trumpet performances. In addition, the study in [
10] proposed enhancing violin learning with smart technologies, including audio, image, video, and motion. The research in [
11] used augmented reality (AR) techniques to devise a self-taught instrument for beginner students on Guitar [
11]. In [
12], the authors investigated the factors for music education in primary schools between 71 music teachers and non-music specialists. The main point is that the attitudes with effective long-term training can affect teachers’ confidence to help the non-music specialists to improve music skills and knowledge. In [
13], the authors reviewed some important work for music technology from 2000 to 2011. They concluded that more substantial studies on teaching strategies in using technology are needed. In [
14], a “Lyrics2Learn” system was developed to help kindergarten students improve reading through music and technology. Research in [
15] investigated the communication for 5–6-year-old children who performed in social interactions by learning English activities classroom with music. The author found good results for children who had positive performance in social interaction to improve their communication through English activities in the classroom with music. In [
16], the authors proposed a tool for learning music with ICT (Information and Communication Technologies). It was found that learning music with ICT can induce creative-musical processes in students.
For our research on automatic assessment methods for piano performances, we examine the feasibility of classifying piano sounds to determine if the performances are good, bad, or normal. This helps piano learners quickly know if their ways of finger placing, striking, or movement are right or not. To the best of our knowledge, there is no prior research on this topic. The main contribution of this research is the development of automatic approaches for assessing piano sounds and helping both teachers and piano learners to understand how to improve piano playing.
3. The Characteristic of Piano Performance
3.1. Piano Performance
A piano can be classified as a keyboard instrument with struck strings. While a note is played, the only influence that a musician can have is to either stop it by releasing the key or play it again while it is still active. The piano also has a sustain pedal that can release the keys when a player presses it without stopping the sound of the notes. Therefore, the notes will be active until the sustain pedal is released. When a performer plays classical and traditional pieces, the sustain pedal is used during most pieces. It is immediately released and pressed again to sustain and stop all notes on a regular basis [
17]. The sustain pedals are crucial to help learners play loudly and with a smooth dynamic. There are three standard types of pedals on a piano, the left pedal is called the una corda pedal, the middle pedal is called the sostenuto pedal, and the right pedal is called the sustain pedal [
18].
3.2. The Musical Scale
The musical scale is arranged according to pitch, including notes, octaves, and symbols for sharp and flat notes [
19]. The musical scale is used to form melody and harmony, which can be major or minor in key. In Italian terms, major and minor scales were expressed “W” tone and “H” semitone.
3.2.1. Major
The sound of natural major scales is happy, bright, and uplifting. The seven notes of major scales are followed by the interval pattern: “W-W-H-W-W-W-H”. The meaning of W and H are “whole-whole-half-whole-whole-whole-half”.
3.2.2. Minor
For minor scales, the sound is sad, dark, and emotional. The seven notes of minor scales follow the interval pattern: “W-H-W-W-H-W-W”. The meaning of W and H are “whole-half-whole-whole-half-whole-whole”.
3.3. Music Articulation
Music articulation is a necessary technique in terms of music performance. Notes or groups of notes can be expressed by using common marking, such as Slur articulation, Legato articulation, and Staccato articulation.
3.3.1. Legato Articulation
Legato is a form of harmonious musical articulation when notes are performed smoothly and fluently. The audience should have the impression that the notes and sounds are connected. The critical determinant of the Legato technique is the damping of string oscillation, and the intervals between the sounds should not be noticeable. An example of a C Major Scale in Legato is shown in
Figure 1.
3.3.2. Staccato Articulation
Staccato is a description of musical articulation. An audience should have the impression that the tones of the note and sounds are separated, similar to a short-detached note. In addition, based on the Staccato technique, the sounds are visibly crushed in order to emphasize separate changes in the pitch. The pianist requires Staccato articulation skill by sudden suppression of strings vibration by fingers. This may make people happy and relaxed [
20]. The example C Major Scale in Staccato is shown in
Figure 2.
4. Methodology
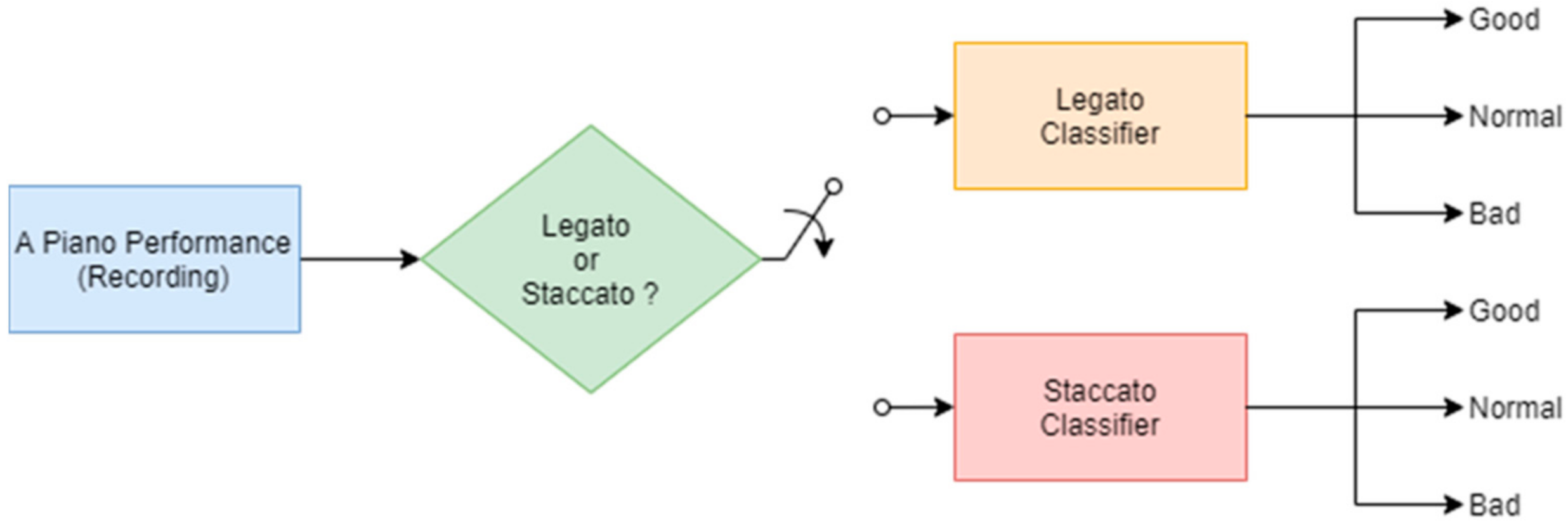
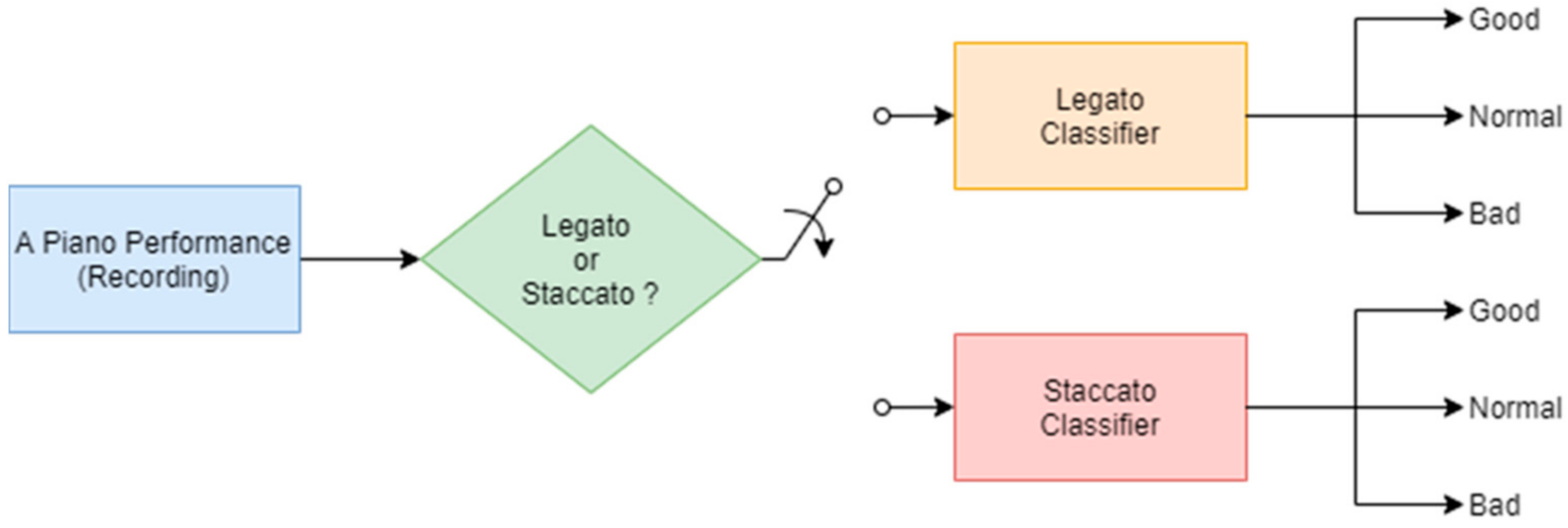
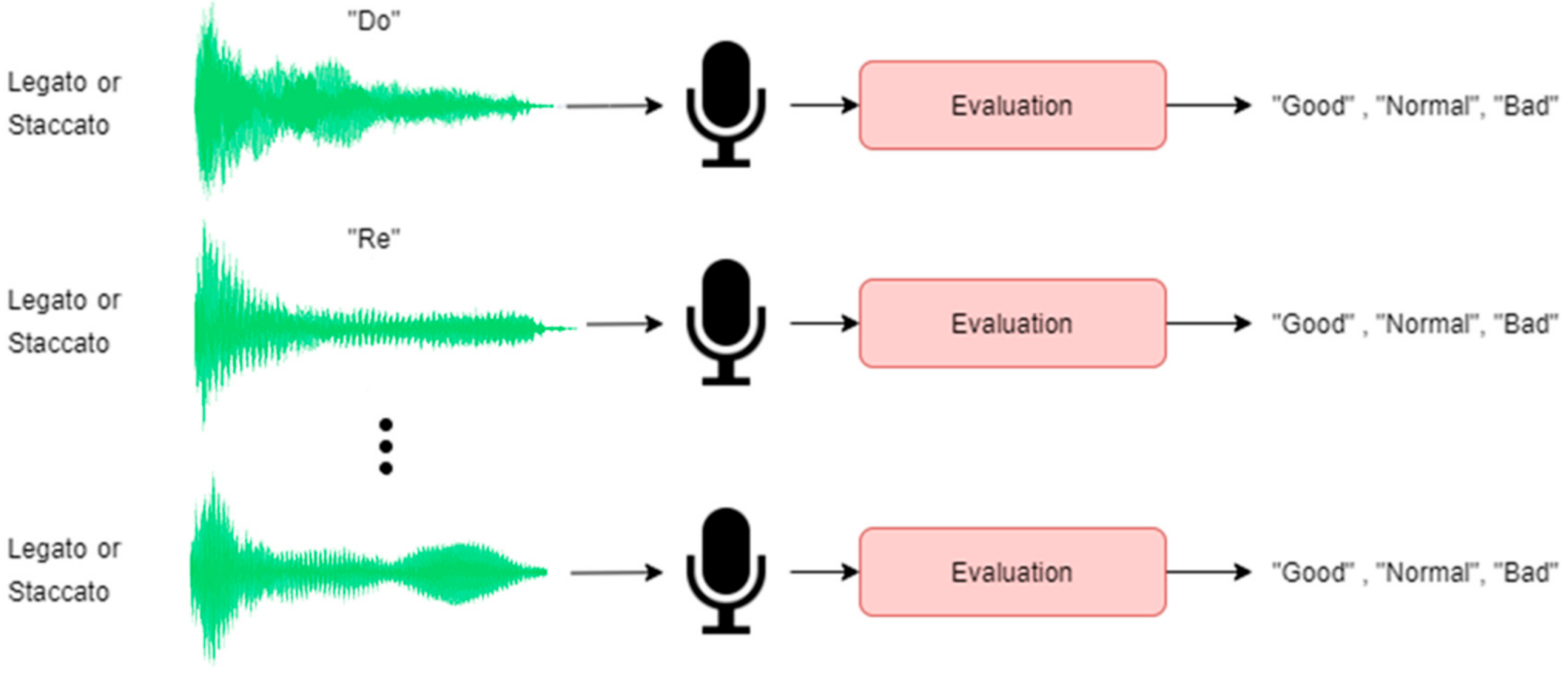
The piano performance assessment is formulated as a problem of classifying a piano sound as “good”, “normal”, or “bad”. This study applied four classifiers to identify piano sounds, namely: Support Vector Machine (SVM), Naive Bayes (NB), Convolutional Neural Network (CNN), and Long Short-Term Memory (LSTM). Each of the classifiers comes in two types, one for Legato and the other for Staccato, as shown in
Figure 3.
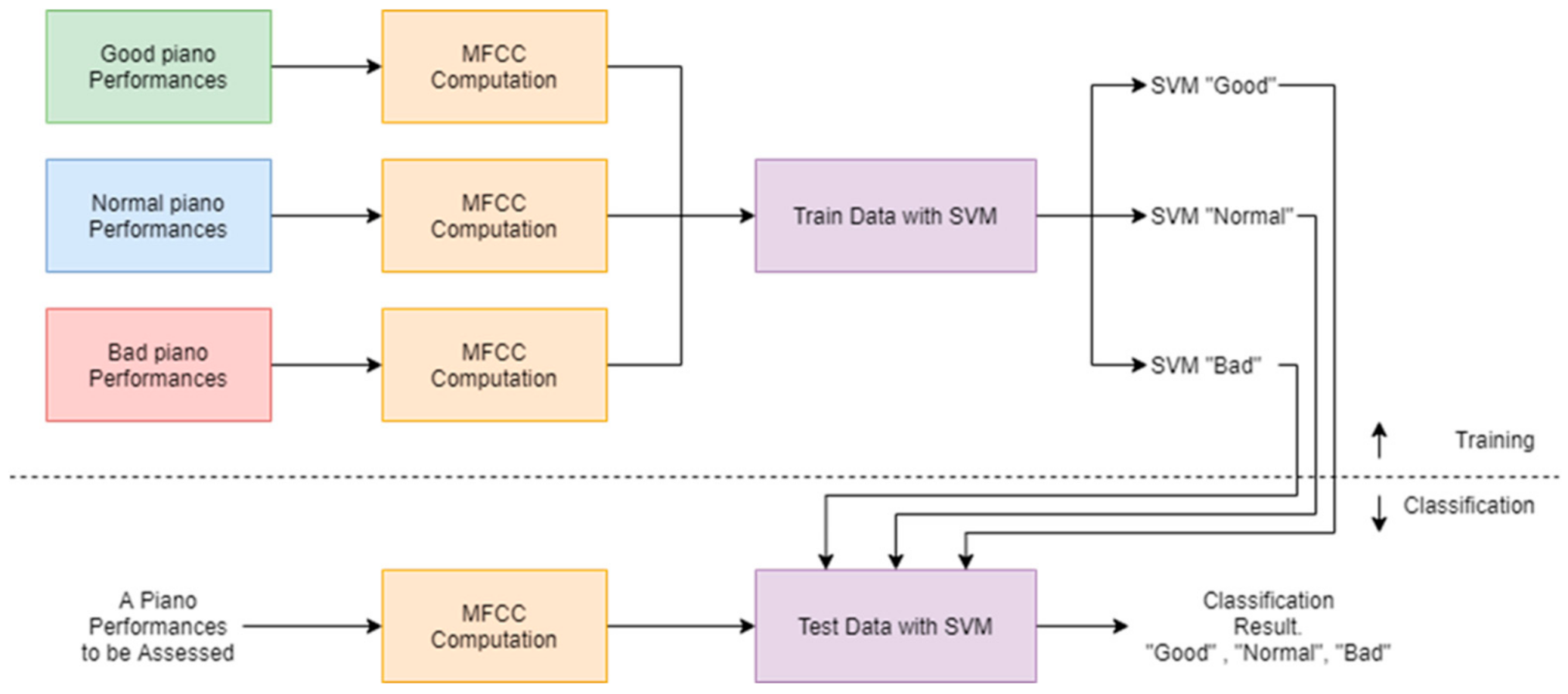
4.1. Support Vector Machine (SVM) Approach
Support Vector Machine (SVM) is one of the most powerful classifiers when applied to various classification problems, such as speaker identification and pattern recognition. The concept of SVM is to find the hyperplane to separate the groups of data from different classes, and the best hyperplane is to let the margin between classes be maximized. A hyperplane is defined as Equation (1)
where
and
x are weight, bias, and data point, respectively. By considering the distance between a point
x and a hyperplane as Equation (2)
an optimal hyperplane can be found by maximizing the distance to the closest data points from both classes.
In this study, we used the one-against-one method for SVM multi-classification [
21]. A number of binary classifiers together with one-against-one techniques can be included to extend SVM for a multi-class classification problem [
22].
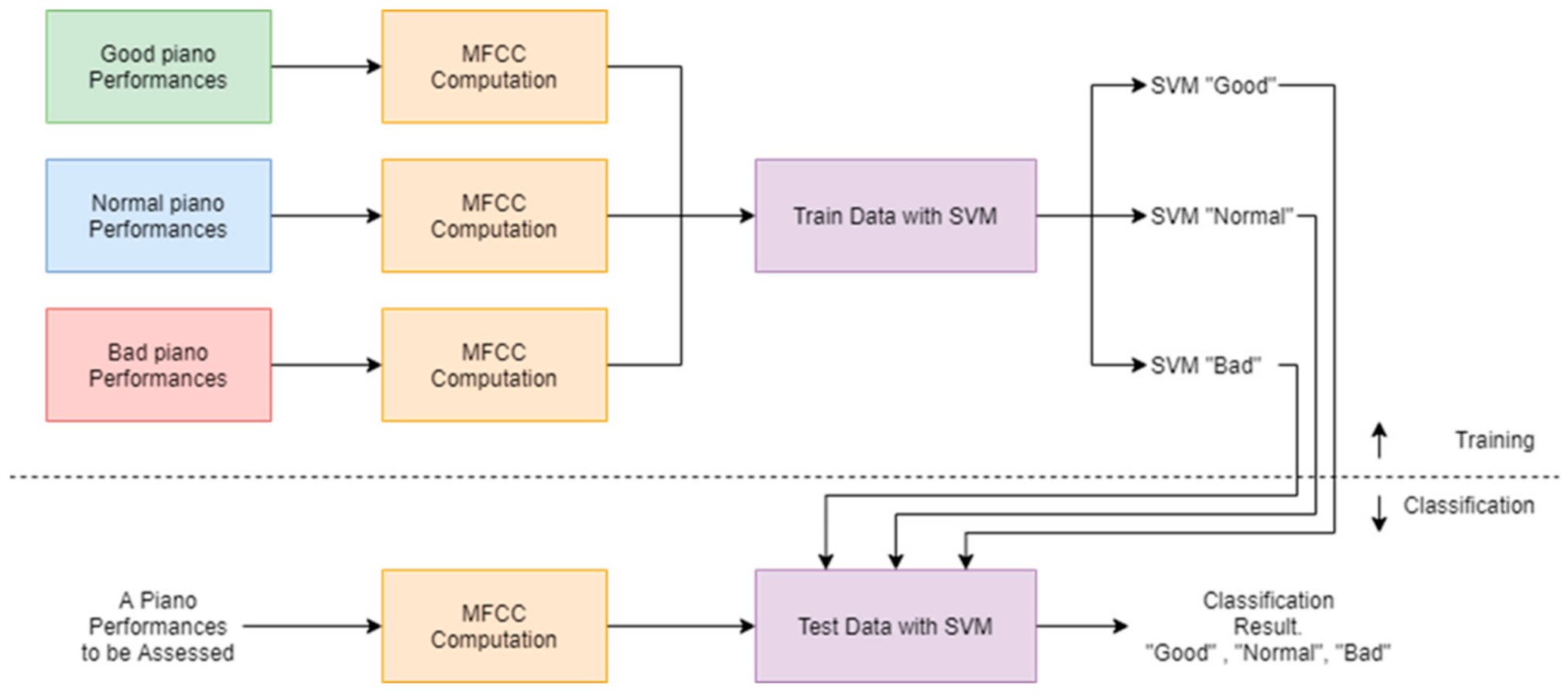
As there are three classes, Good, Normal, and Bad, in our task, we need = three SVM classifiers.
In the SVM classification, the database is split into training–test partitions: training data are used to find the optimal hyperplane. Each testing data are predicted after the predictive model is obtained, as shown in
Figure 4. The data samples are first converted from their digital waveform representation to Mel-frequency Cepstral Coefficients (MFCCs).
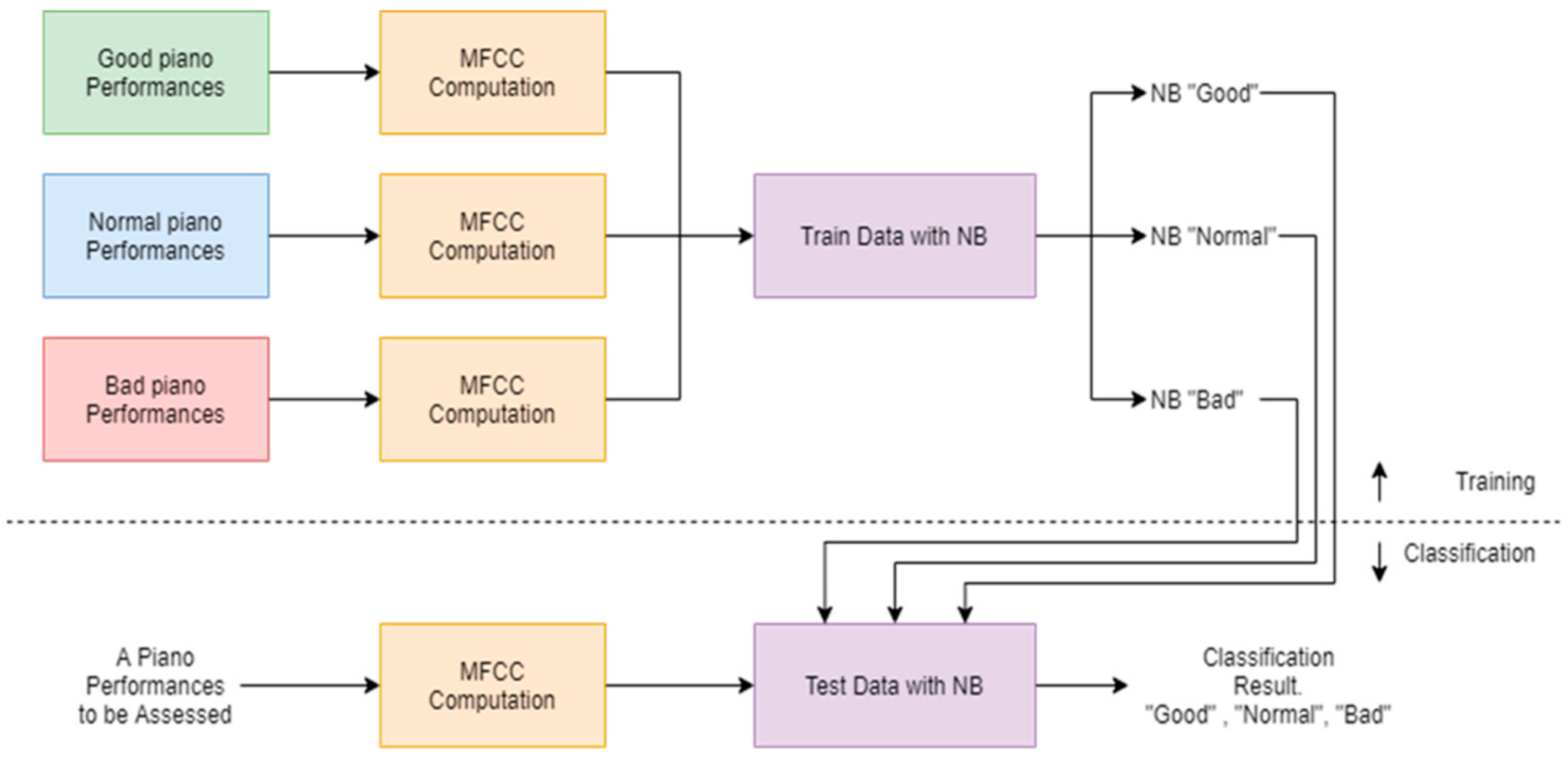
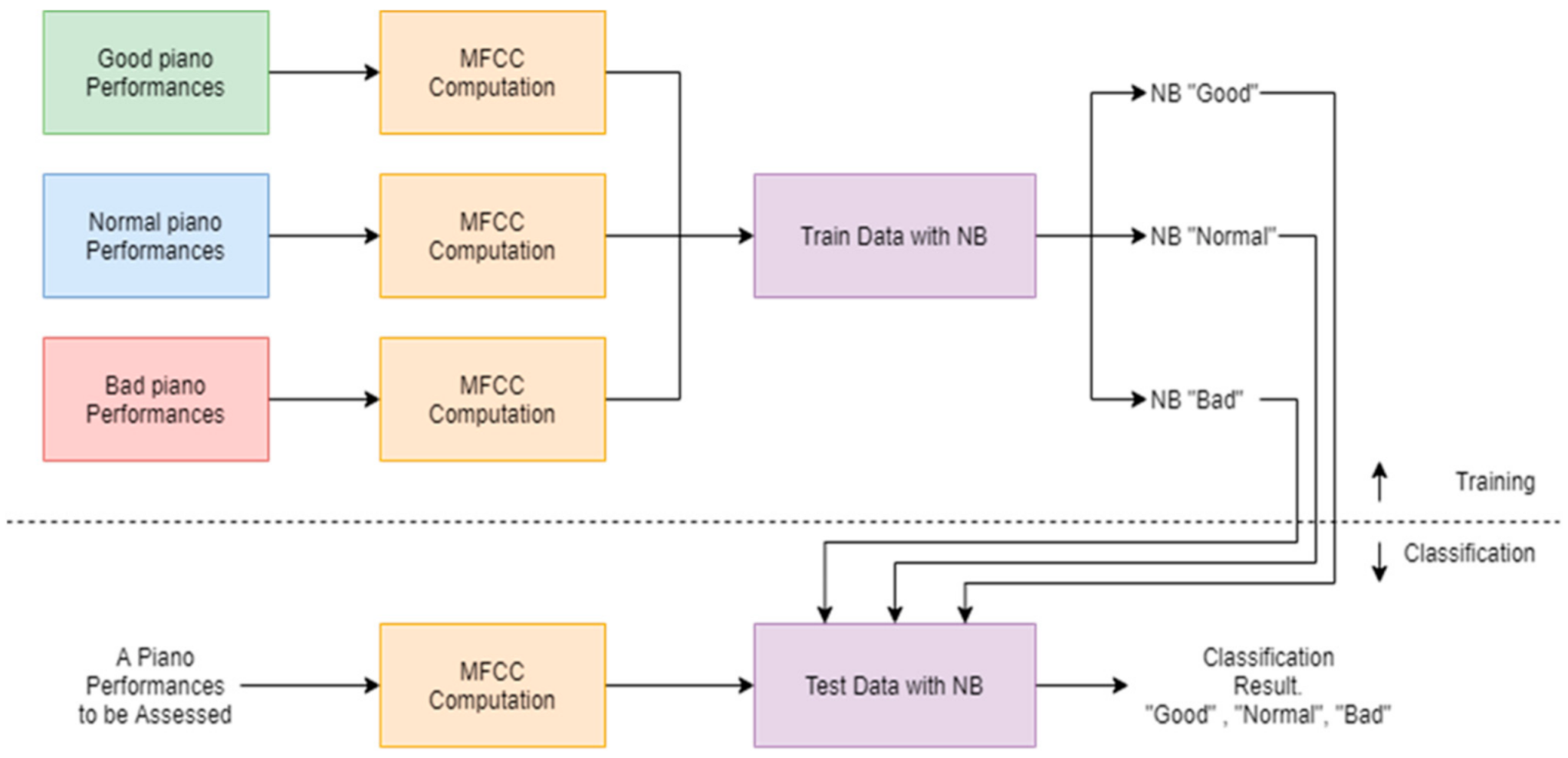
4.2. Naive Bayes (NB) Approach
Since piano sound evaluation is formulated as a multi-class classification problem, the Naive Bayes classifier (NB) can be employed to classify piano sounds in this study. In the NB framework, the feature items from one class are assumed independent of other attribute values. Our aim is to evaluate
P(
C|
M), which is the probability of class
C that a piano recording
M belongs to, where
C ∈ {Good, Normal, Bad} and
M is a stream of Mel-frequency cepstral coefficients (MFCCs) extracted from piano recording. According to the Bayes’ theorem:
and
P(
M) does not involve the classification; we have
P(
C|
M) ∝
P(
M|
C)
P(
C). Thus, a piano recording can be determined as one of the three classes by
In this study, we used the Gaussian Naive Bayes classifier, in which
is a Gaussian density function. The NB-based piano performance assessment system is shown in
Figure 5.
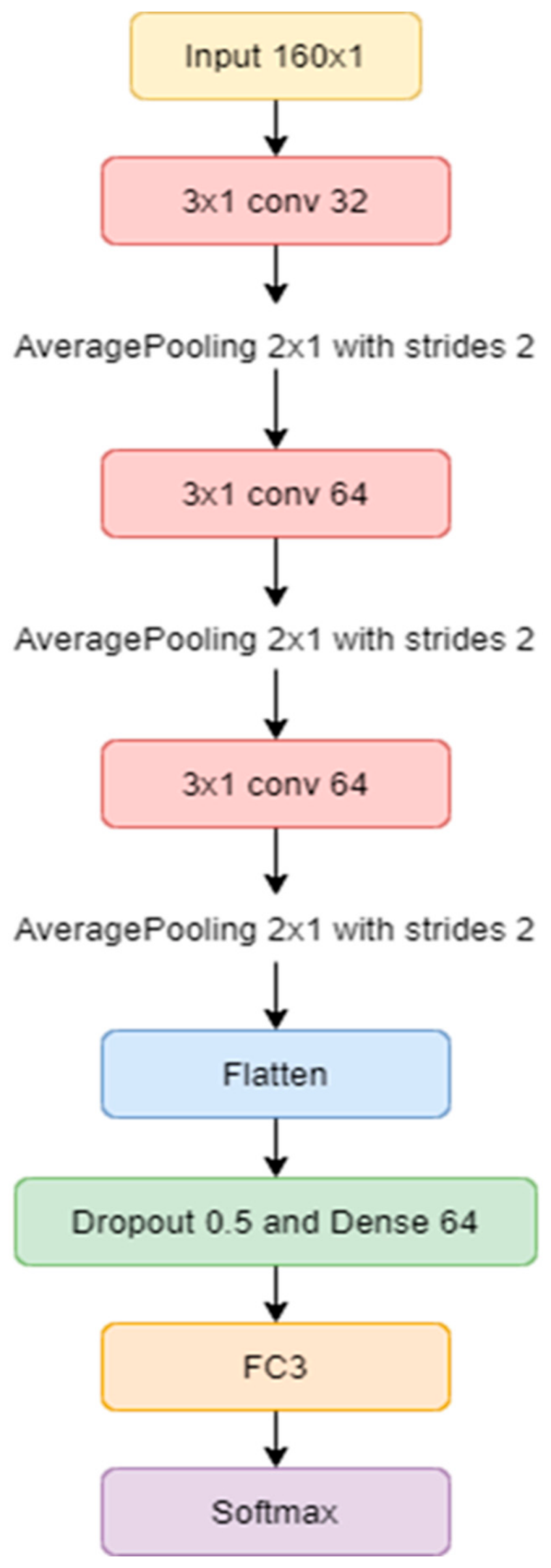
4.3. Convolutional Neural Network (CNN) Approach
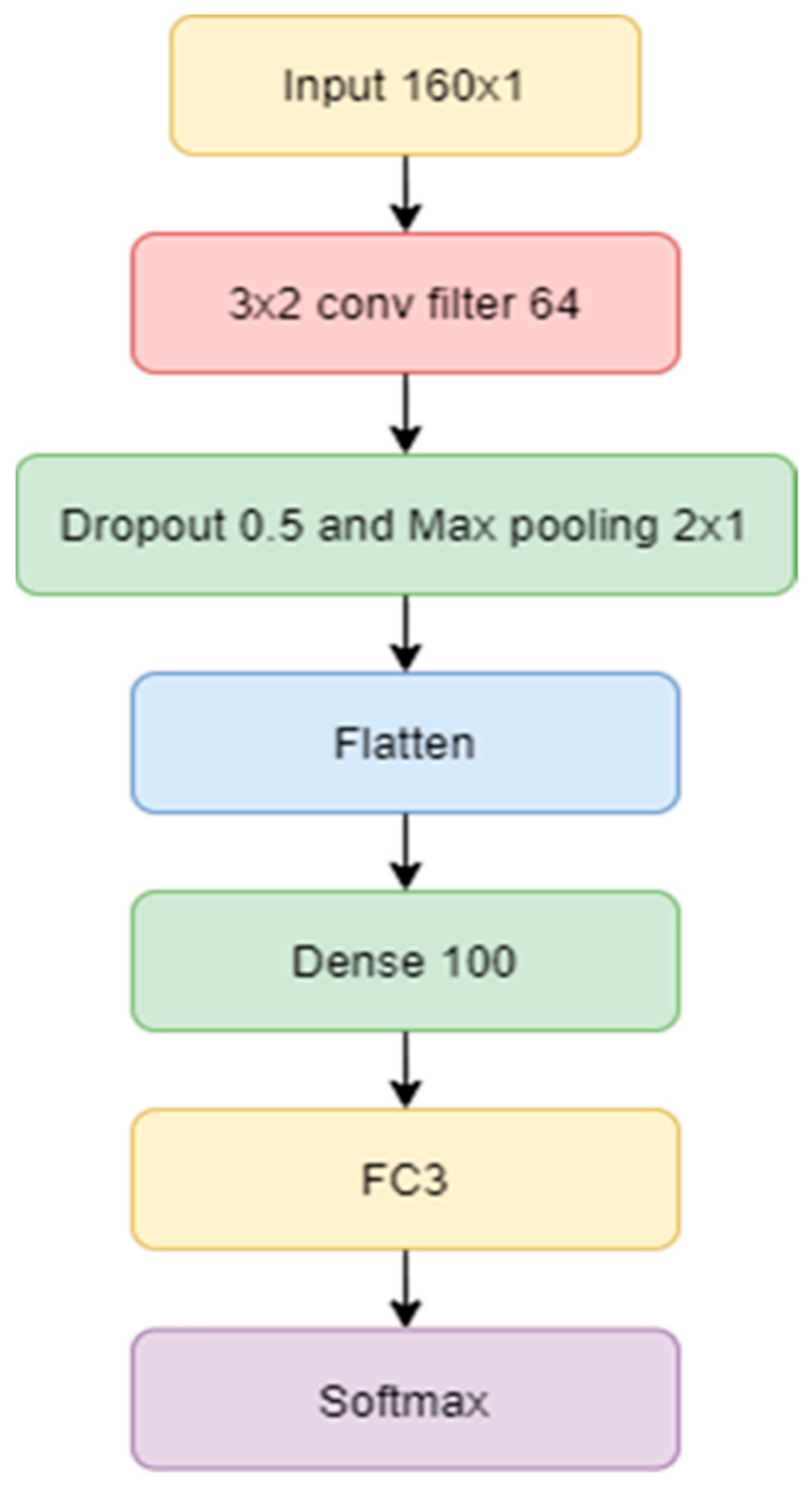
The Convolution Neural Network (CNN) is an approach that uses the feed-forward architect style, which is considered as a special format of deep artificial neural networks [
23]. This approach works similarly to basic artificial neural networks. However, the layer of convolution conducting shows effective results superior to others in deep learning artificial neural networks. For instance, in contrast to normal artificial neural networks, CNN is able to distinguish relevant variables independently and works well with complex information [
24]. When compared with shallow artificial neural networks, CNN has more advantages in terms of efficiency and memory, which has impacted usability.
The CNN commonly used the SoftMax Activation Function for multi-class classification problems [
25,
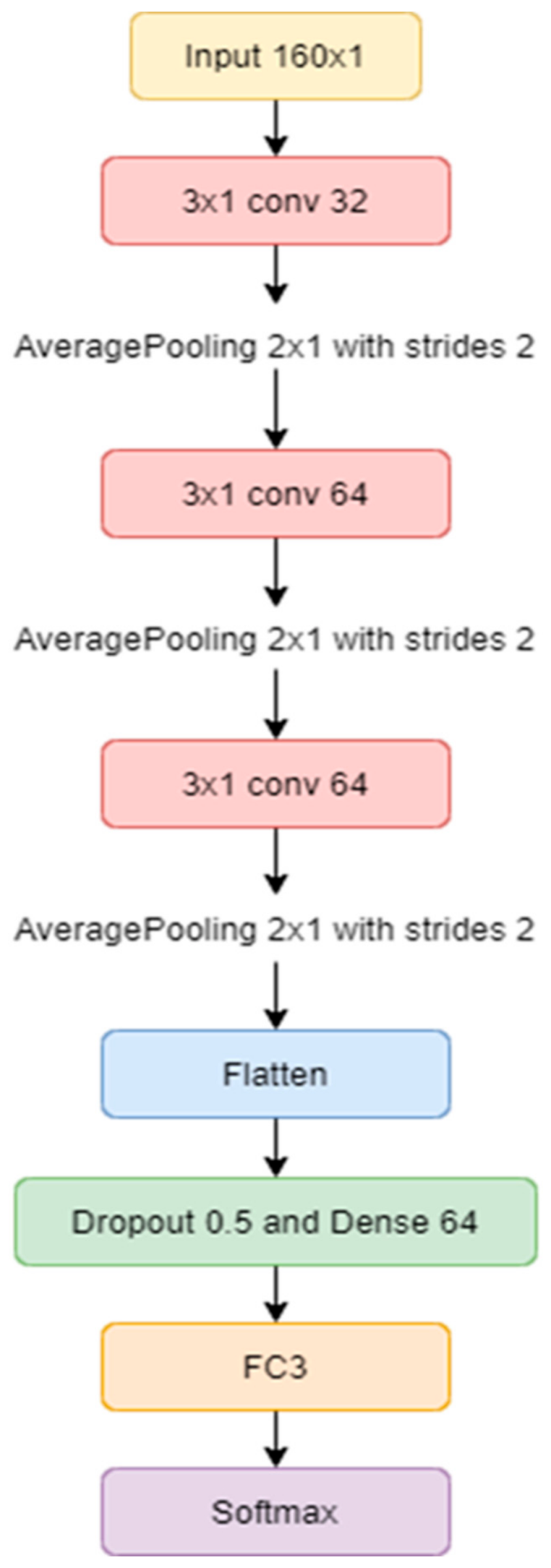
26]. Prior to the SoftMax, piano recordings were converted from their waveform representation into the Mel-frequency cepstral coefficients (MFCCs). The process can be separated into three convolution layers by CNN, as shown in
Figure 6. All of the layers are percolated by 3 × 1 filters using the Rectified Linear Unit (ReLU) activation function, defined as
where
x represents an input value. After the ReLU activation function, we use a dropout mechanism to prevent overfitting data. The dropout value is set at 0.5. Additionally, average pooling is applied at the end of each convolutional layer.
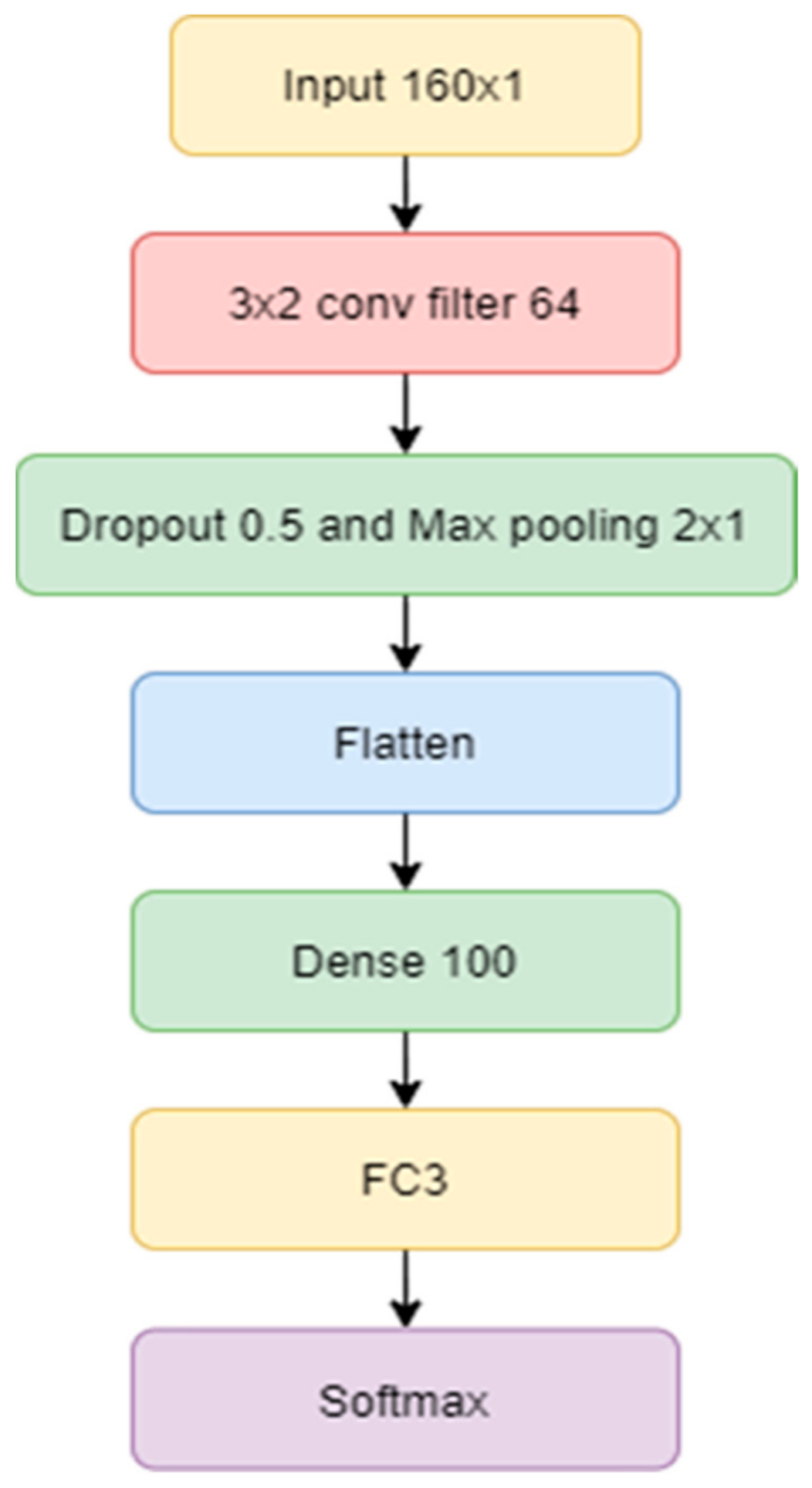
In
Figure 6, the architecture of the 3-layer CNN shows that the feature maps have three phases of convolutional layers. As previously mentioned, in the first convolutional phase, the current input size is 160 × 1 on 3 sets of convolutional layers with a kernel size of 3 × 1; the kernel is used to deal with detailed local features. Therefrom, the process transfers the operation into Flatten and Dropout. After the final convolutional layer, the dropout parameter value was set at 0.5, followed by Dense layers of 64 neurons. The process finally ended with a Fully Connected layer, transferring vector to the SoftMax Activation.
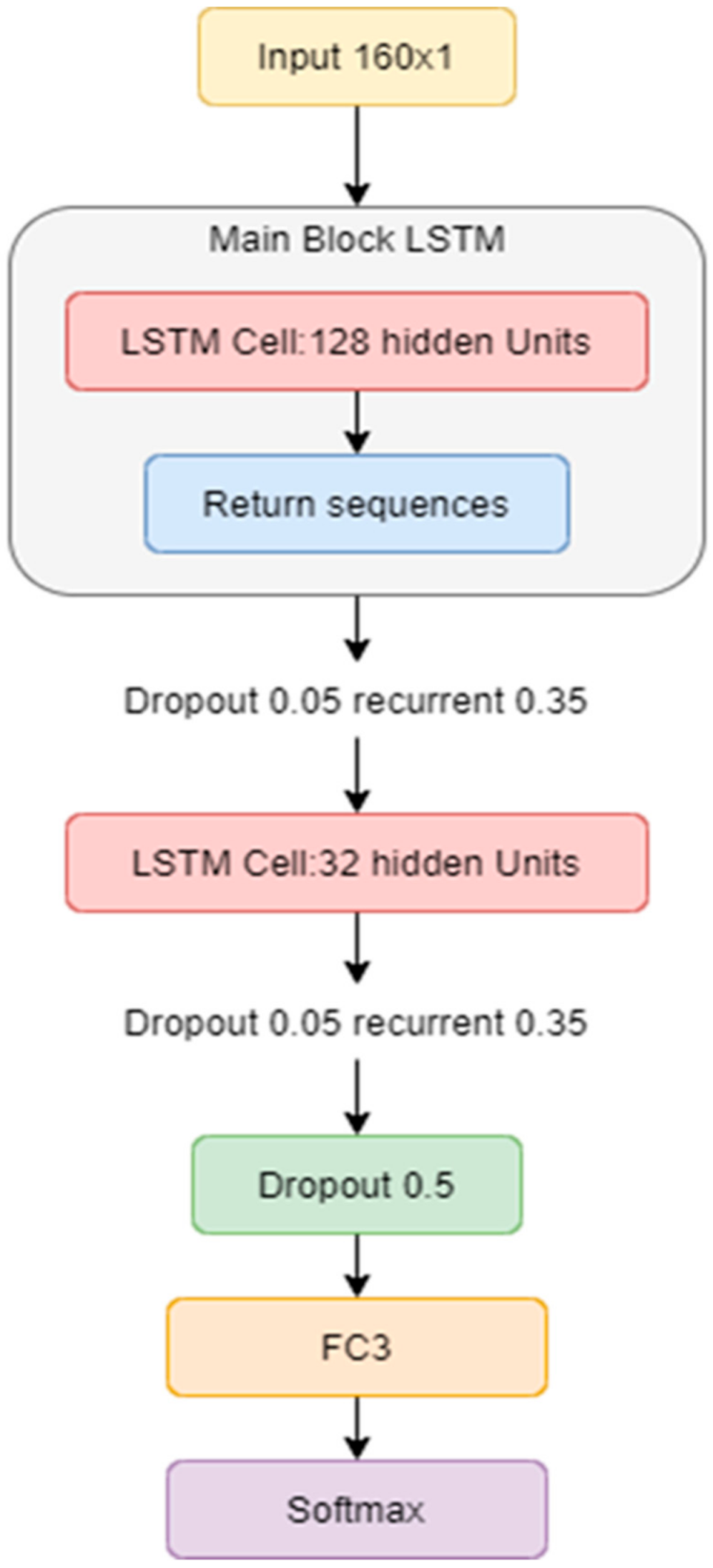
4.4. Long Short-Term Memory (LSTM) Approach
LSTM (Long-Short Term Memory) is a type of recurrent neural network (RNN) consisting of an input, an output, and a forget gate [
27]. This network addresses the problem of vanishing gradients of RNN by splitting into three inner-cell gates and building the so-called memory cells to store information in a long range [
28]. This network is used for processing, making predictions, and classifying based on time series data; LSTM was first introduced in 1997 and was further developed as a successful architecture by Ilya et al. in 2014 [
29].
For LSTM classification, we use the “Librosa python library for audio signal processing” [
30]. Piano recordings are converted from their waveform representation into the Mel-frequency cepstral coefficients (MFCCs), the same as the CNN approach from the previous. The proposed LSTM approach is shown in
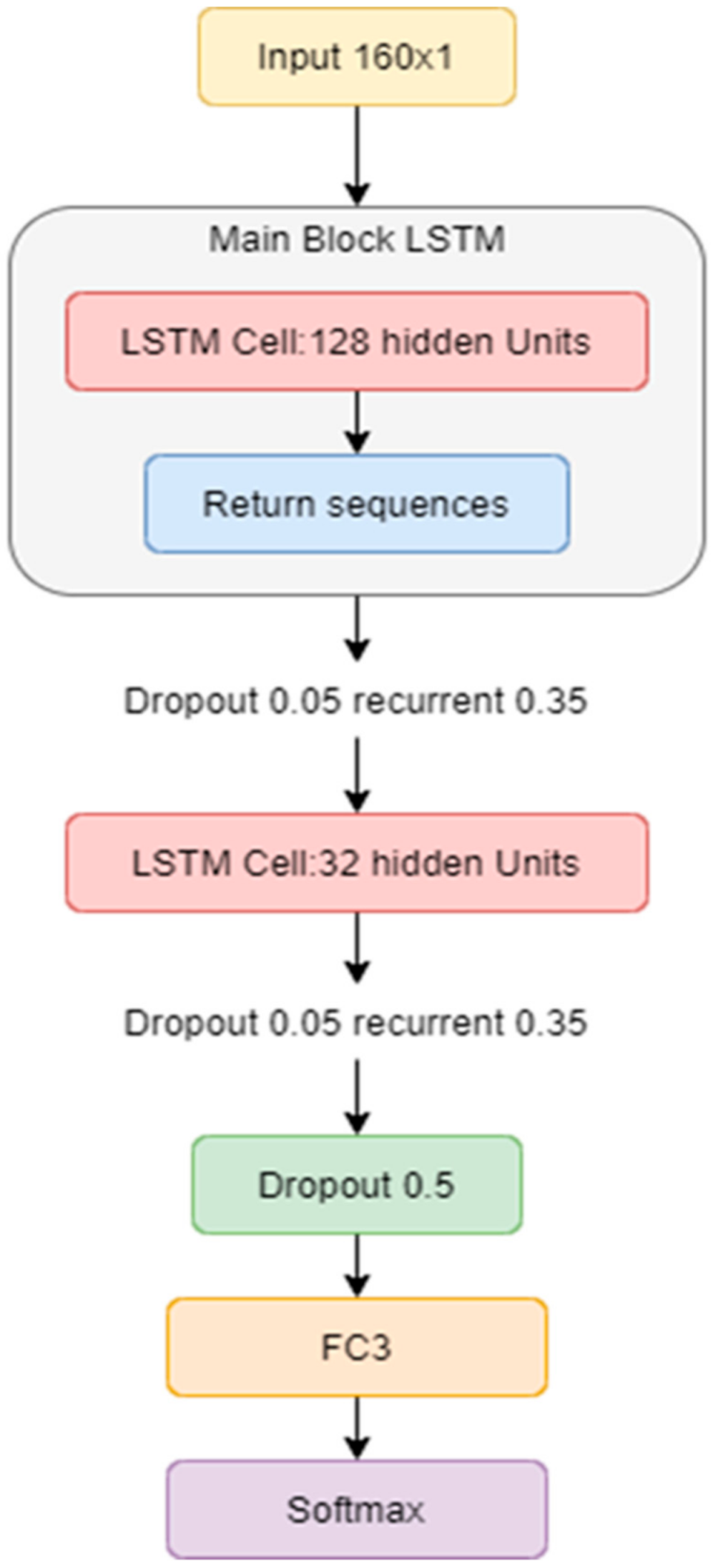
Figure 7. Here, we used MFCCs as the LSTM model input. We used 2-layers LSTM architecture, in which we used the dropout value for preventing the overfitting data. In this case, the dropout value was set at 0.5. Then, we used Dense layers of 64 neurons. Finally, we used a Fully Connected layer, transferring vector to SoftMax Activation.
Figure 7 shows the two LSTM blocks. The current input size is 160 × 1, which is the same as the CNN approach. The first LSTM block has 128 hidden units. Regarding the main LSTM block, the return sequences parameter is used in each input time step with hidden state output. The dropout and recurrent rates are 0.05 and 0.35, respectively. Furthermore, the second LSTM block with 32 hidden units is used without return sequences. The dropout and recurrent rates are set to 0.05 and 0.35, respectively. Next, the dropout value is set at 0.5. The process ends with a Fully Connected layer, transferring vector to the SoftMax Activation.
The four classification methods used in this study represent the prevalent techniques in machine learning applications. To be specific, the former two methods, SVM and NB, could be the representatives for the so-called shallow learning, and the latter two methods, CNN and LSTM, could be the representatives for the deep learning strategy. In addition, SVM, NB, and CNN could be regarded as static classifiers, which do not depend on time or sequential relationships, while LSTM could be regarded as a dynamic classifier, which captures the sequential information carried by data. Because each of the methods has its own pros and cons, we made a comparison for the performances of the four methods and indicated a suggested direction for the implementation of a piano performance assessment system.
5. Experiments and Results
Experiments were conducted to evaluate the proposed piano performance assessment approaches with respect to two types of music articulation. The first is Legato with soft and gentle notes using the sustain pedal, and the second is Staccato with detached notes and no use of the sustain pedal. Four assessment approaches: Support Vector Machines (SVM), Naive Bayes classifier (NB), Convolutional Neural Network (CNN), and Long Short-Term Memory (LSTM) were compared in this work and also used in analyzing piano performances for kids’ songs.
5.1. Recording Configurations
The piano sounds were recorded using a microphone connected to audio-technical serial no. AT9931PC with the configuration shown in
Table 1. Our experiments were run using Dell T430 Workstation Tower Type 710, an Intel Xeon E5 2470 × 2 (Dual CPU) 2.30 Ghz (16 Cores 32 Threads) with Memory DDR3 ECC 24 GB Bus 1600 Quad Channel Config, SAS Raid 0 1TB × 2 SSHD Seagate FirePro 2TB, Server Grade with 80 Plus platinum label, and 990 w Redundant Power Supply in this experiment.
5.2. The Category of Scales and Accidentals
This study focused on the category of scales and accidentals to help piano learners play the most basic scale correctly. The major and minor scales that the piano learners played are shown in
Table 2.
5.3. Performance Dataset Description
Piano performers in our dataset are played by piano teachers and learners ranging from the beginning level to the middle level. There are nine piano learners containing three groups: (i) kindergarten (4–5 years old), (ii) elementary school (7–10 years old), and (iii) junior high school (12–15 years old) for two consecutive years (2018–2020). In addition, there are four piano teachers participating in the data recording, and most of the piano teachers graduated and passed the piano exam of the Associated Board of the Royal Schools of Music (ABRSM) or Trinity’s Piano certificate exams in grade 8 piano advanced level. The certifications are accepted worldwide. Currently, piano teachers teach piano at Yamaha Music School and KPN Music Academy in Thailand.
We guaranteed that every participant was competent enough to provide beginner, intermediate, and advanced piano performances. By listening to the recordings repeatedly in terms of Legato scale, Staccato scale, and kids’ song by referring to the song or scale to be the same as the original masterpieces, four experts’ annotations were combined through a voting scheme to labels of Good, Normal, and Bad performance.
In the musical performance, a “good” performance must consist of sharp sounds and straight notes. This could be generated by pressing the keypad with accurate hand weight and not missing the keypad. Moreover, when the performer plays a “good” performance, it is essential that they transmit the emotion by capturing the right style, mood, and tone of the song. They must as well scale the correct notes and play with accurate performance techniques such as dynamic articulation (Staccato, Legato, Tie, Slur, and etc.) and expression timing (measures or bars as whole note, half note, quarter note, and eight-note, respectively.) From the “good” performance listed above, it is highly required for piano performers to achieve the criteria while playing on stage or in piano competitions.
As for “normal” performances, there may be some errors when pressing the piano keypad. For example, when piano performers play the scale, they may make mistakes such that one or two keypads are pressed simultaneously. Furthermore, in terms of the playing style and technique in “normal” performance, there might be issues in transmitting emotion and expression, resulting in the performer unintentionally playing with unclear articulation and some note errors.
5.4. Experimental Setup
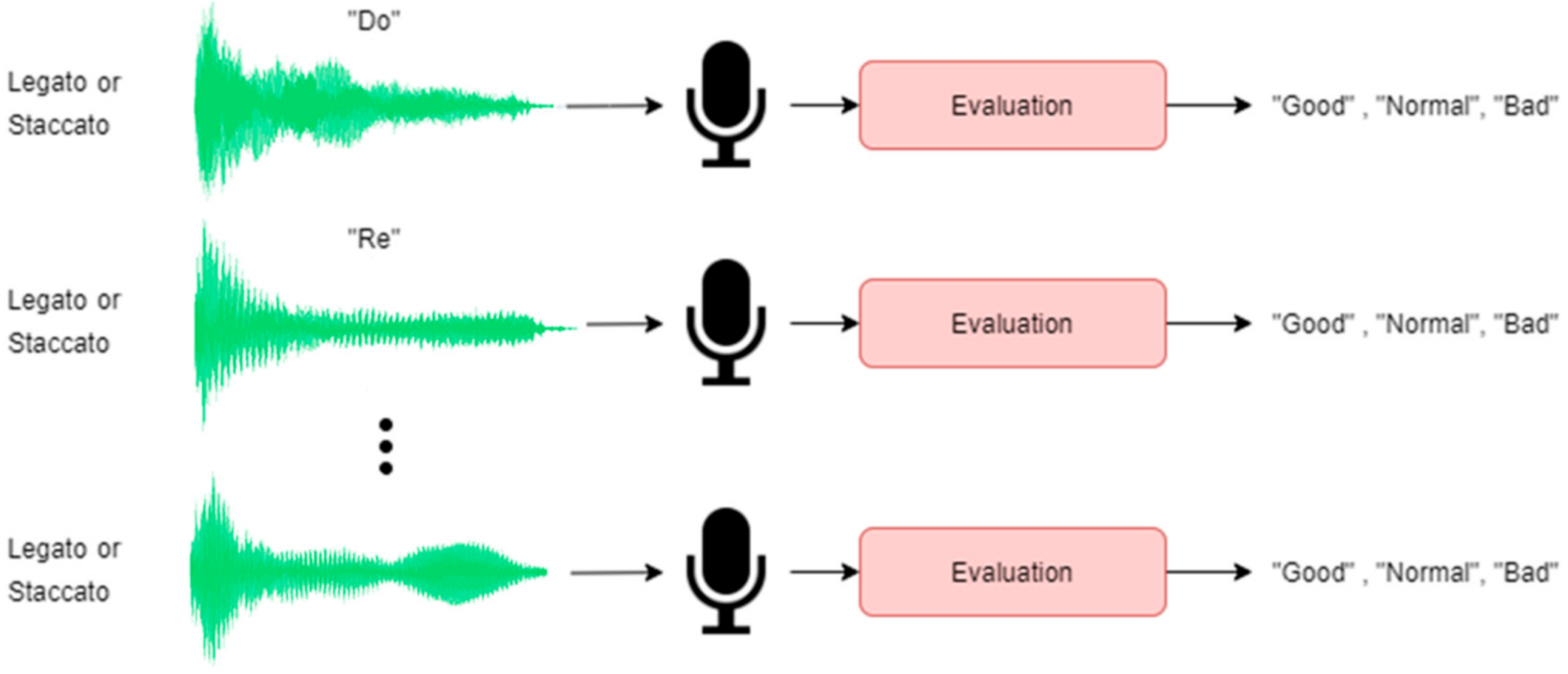
The experiment settings were divided into two parts, which were Legato and Staccato types of musical articulation. The performances of the piano sounds were analyzed and classified into three categories: “Good”, “Normal”, and “Bad”, as shown in
Figure 8.
The performers played each scale note by note with pedals (C = Do, D = Re, E = Mi, F = Fa, G = Sol, A = La, B = Ti). There were 180 note files collected from each performer in total, and there were 2340 note files from 13 performers. Data for training were from six performers. We used the data from teacher 1 and teacher 2 to represent good performance; student 2 and student 5 to represent normal performance, and student 3 and student 8 to represent bad performance. A total of 1080 datasets were collected for training in total. Data for testing were from seven performers. We used the data from teacher 3 and teacher 4 to represent good performance; student 4, student 6, and student 7 to represent normal performance, and student 1 and student 9 to represent bad performance. There were 1260 datasets were collected for testing in total. MFCC features were computed for the Legato/Staccato notes are shown in
Table 3.
5.5. Experimental Results
In this section, the data were further divided into two subsets of experiments, which is the Legato part using the “vibrato” notes with the sustain pedal and the Staccato part using detached notes without the support pedals to investigate the distribution of the rate of accurate prediction across the three categories: “Good”, “Normal”, and “Bad”. The accuracy
of the piano evaluation system is characterized by:
5.5.1. Legato Part Experiment
Experiment results for the Legato part are presented in
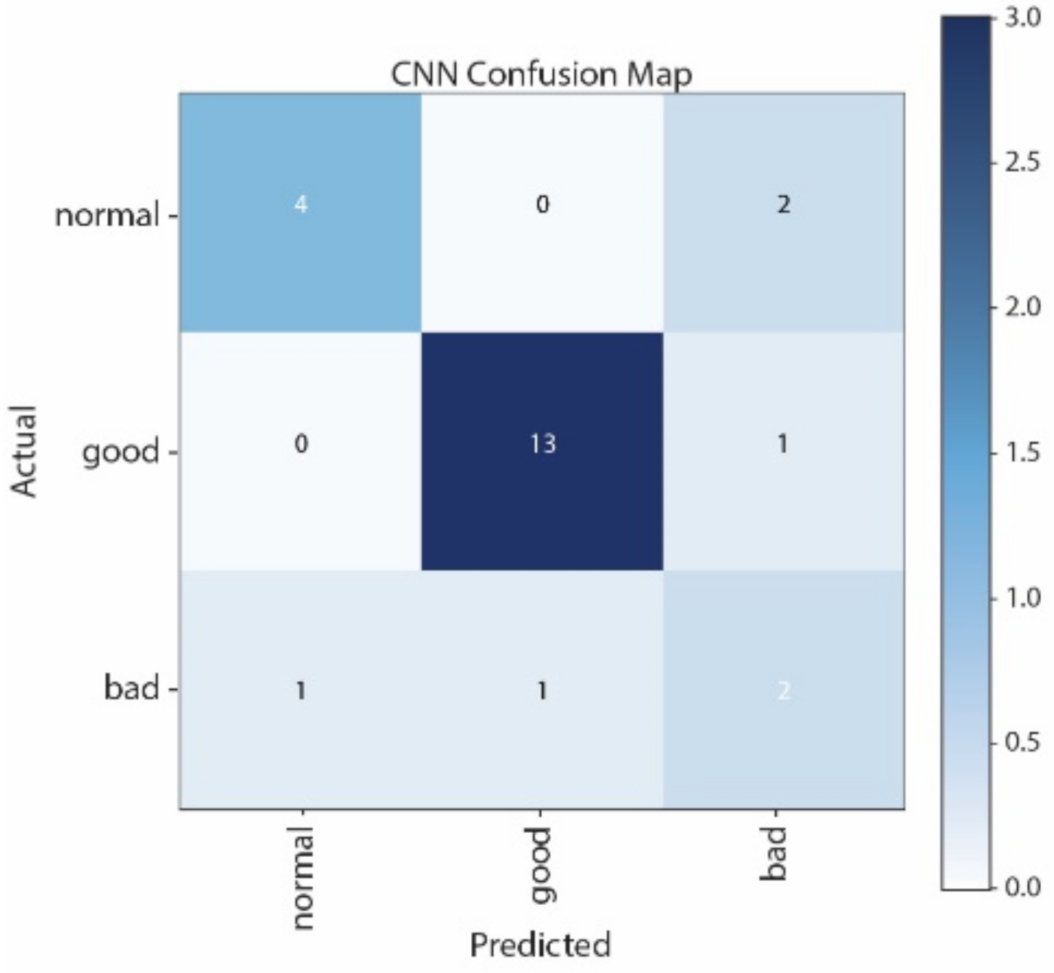
Table 4 with respect to SVM, NB, CNN, and LSTM. The system of CNN yielded an accuracy of 93.65%, which is higher than SVM’s 83.80%, LSTM’s 64.12%, and NB’s 60.87%. In this experiment, we tuned “nu, kernel, and decision function shape”, which is a hyperparameter for classification NuSVC (SVM). Then, we used the default hyperparameter for Gaussian Naive Bayes (NB). In addition, for CNN, we used 3-layers CNN, and for LSTM, we used 2-layers LSTM as hyperparameters.
Figure 9,
Figure 10,
Figure 11 and
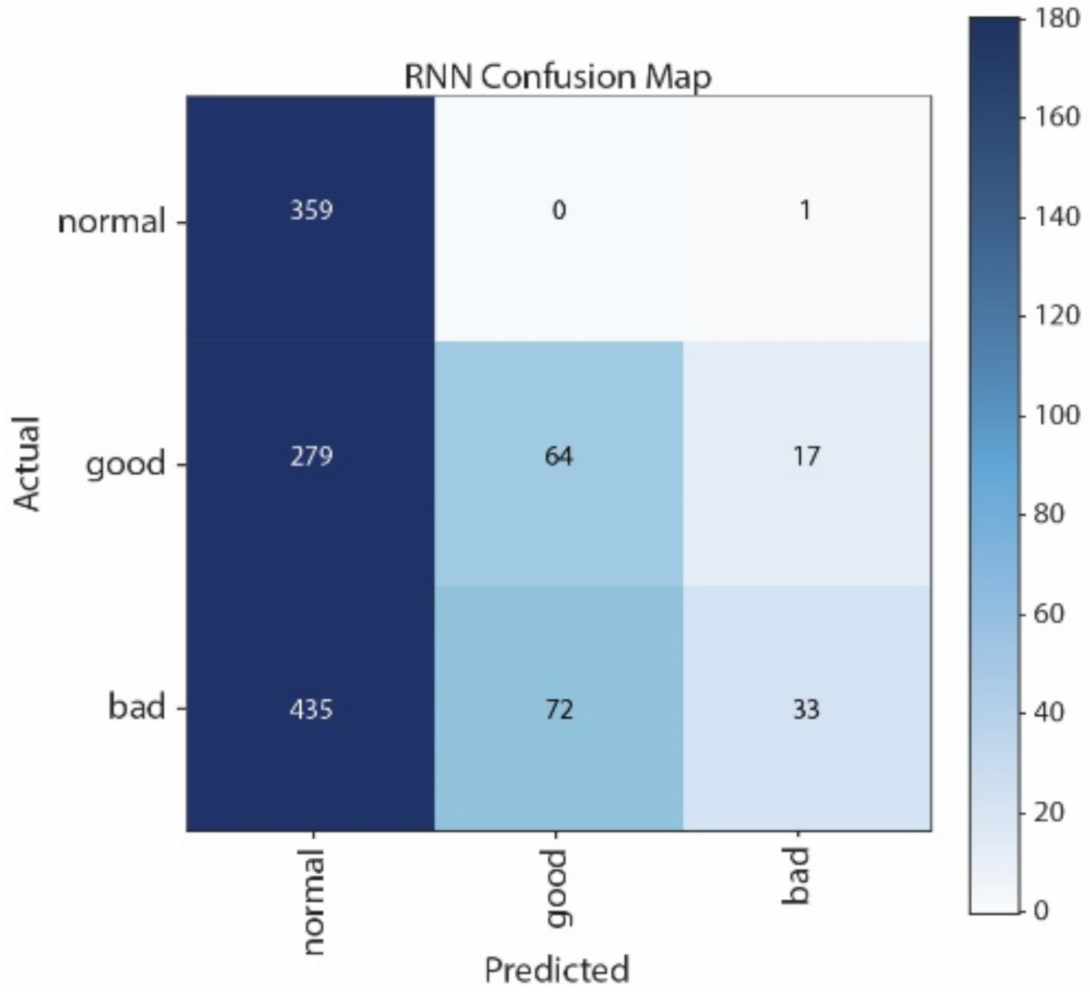
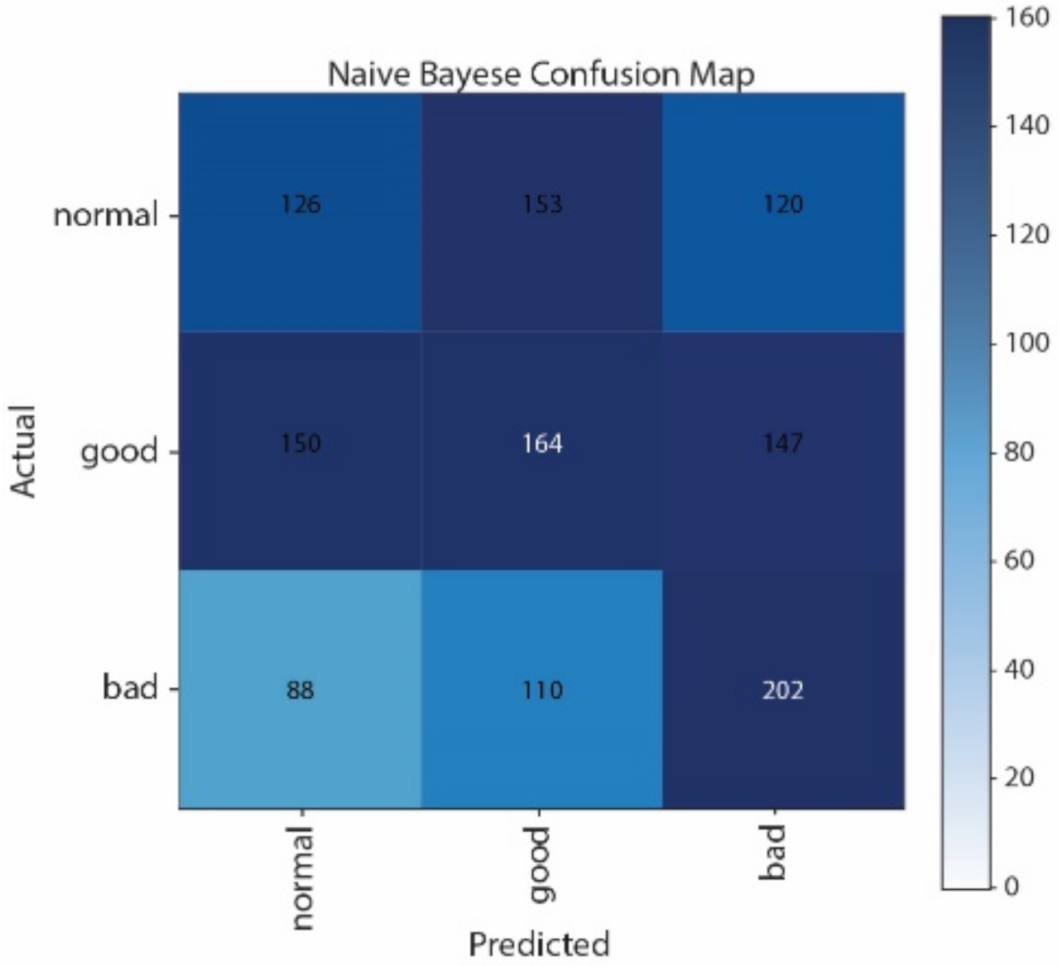
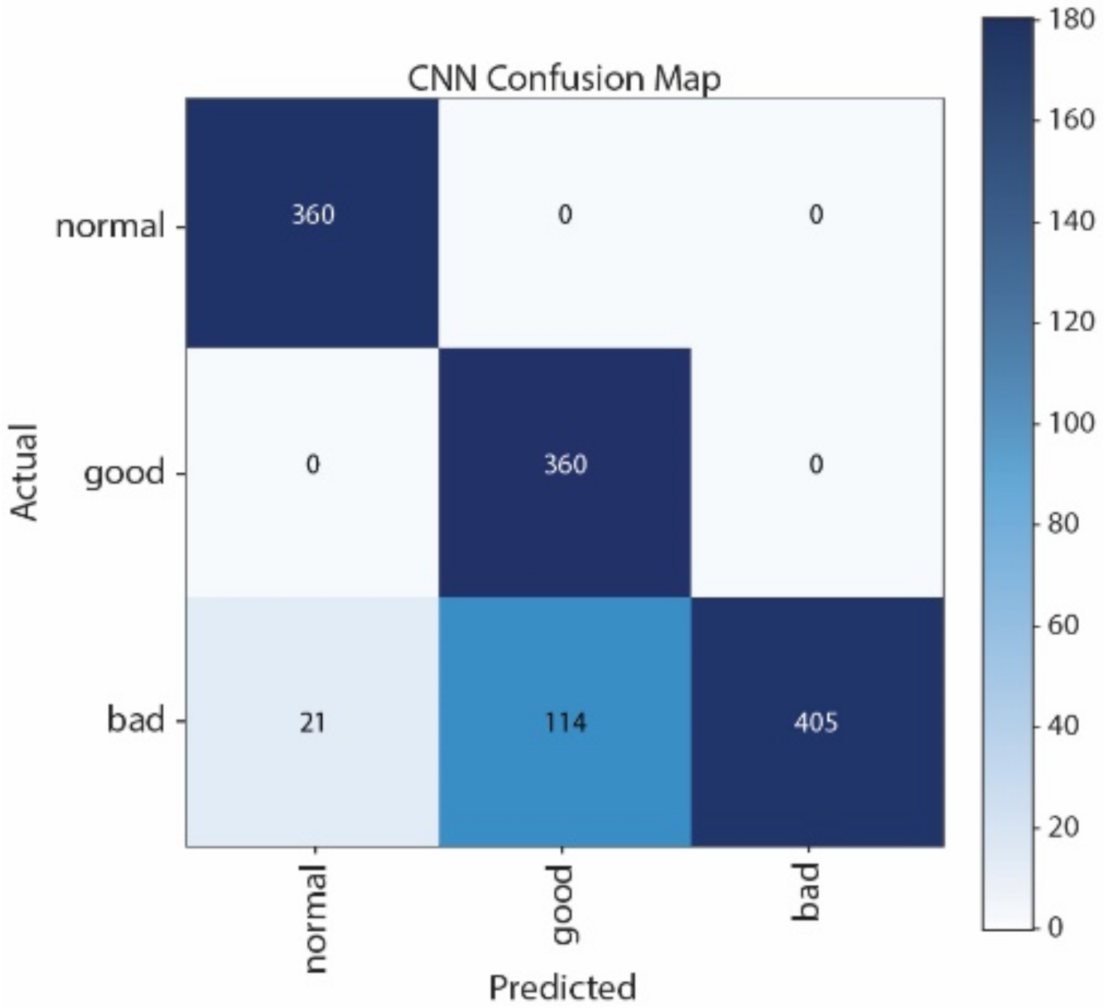
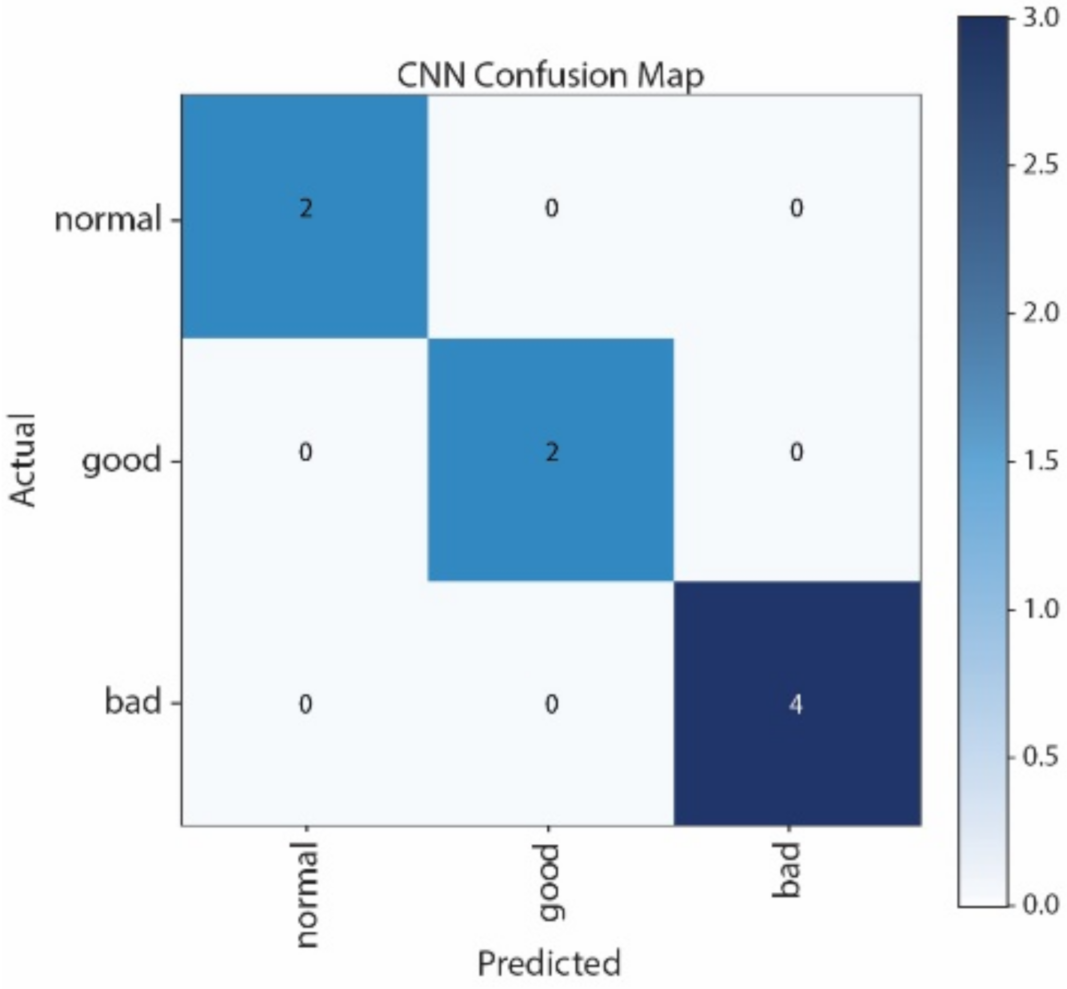
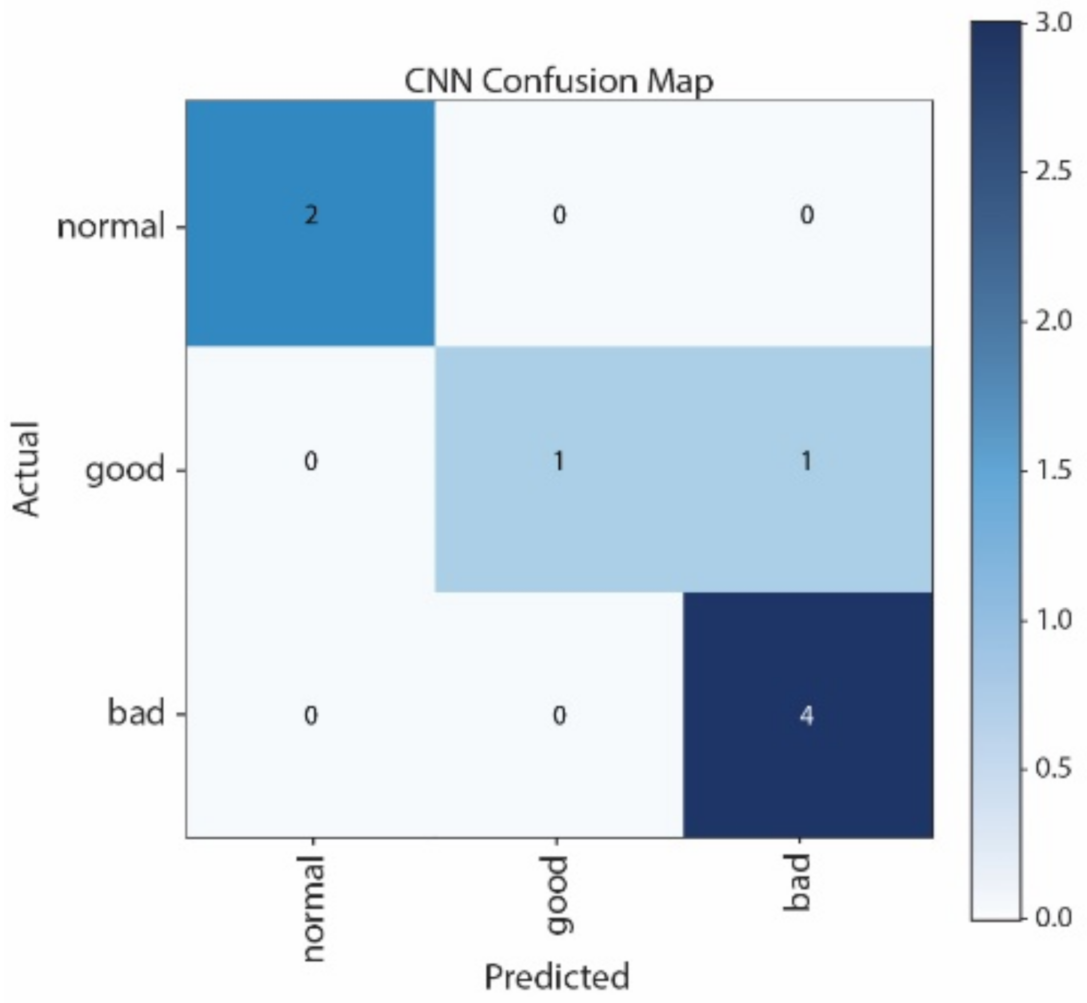
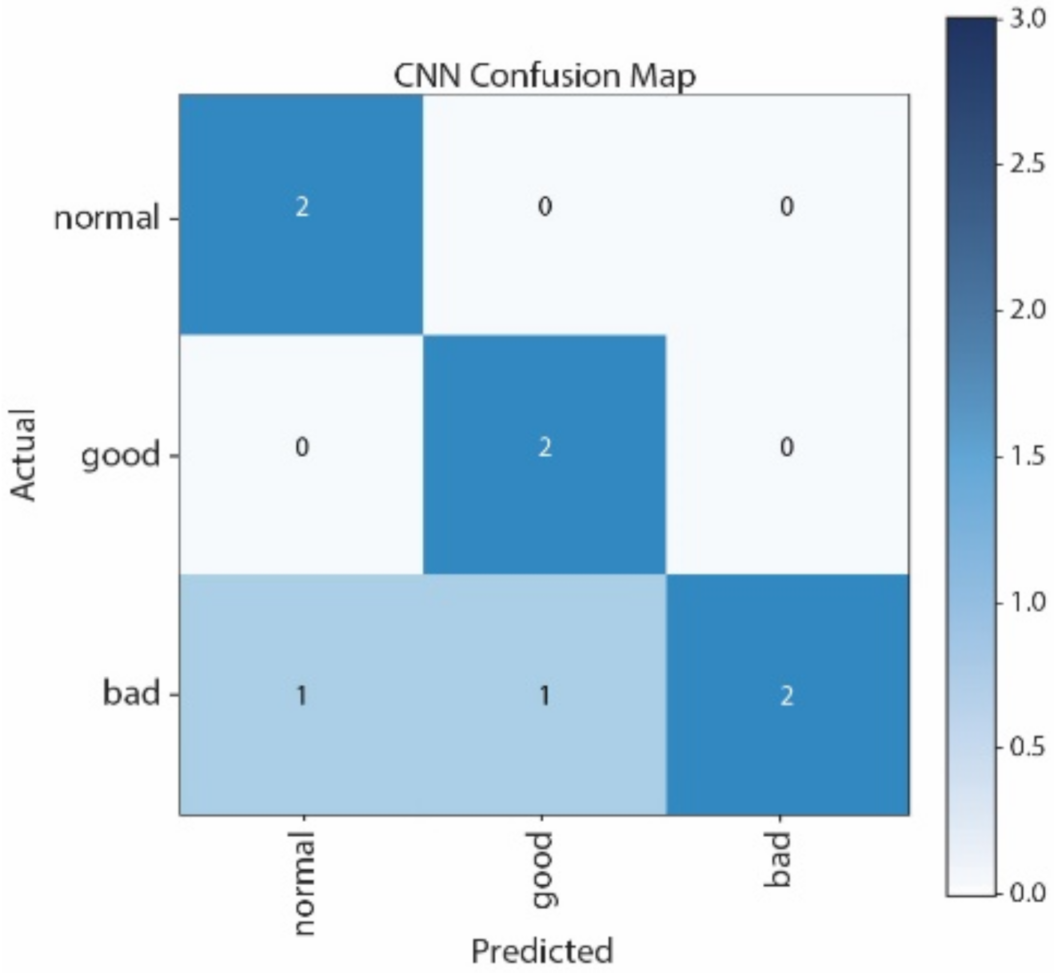
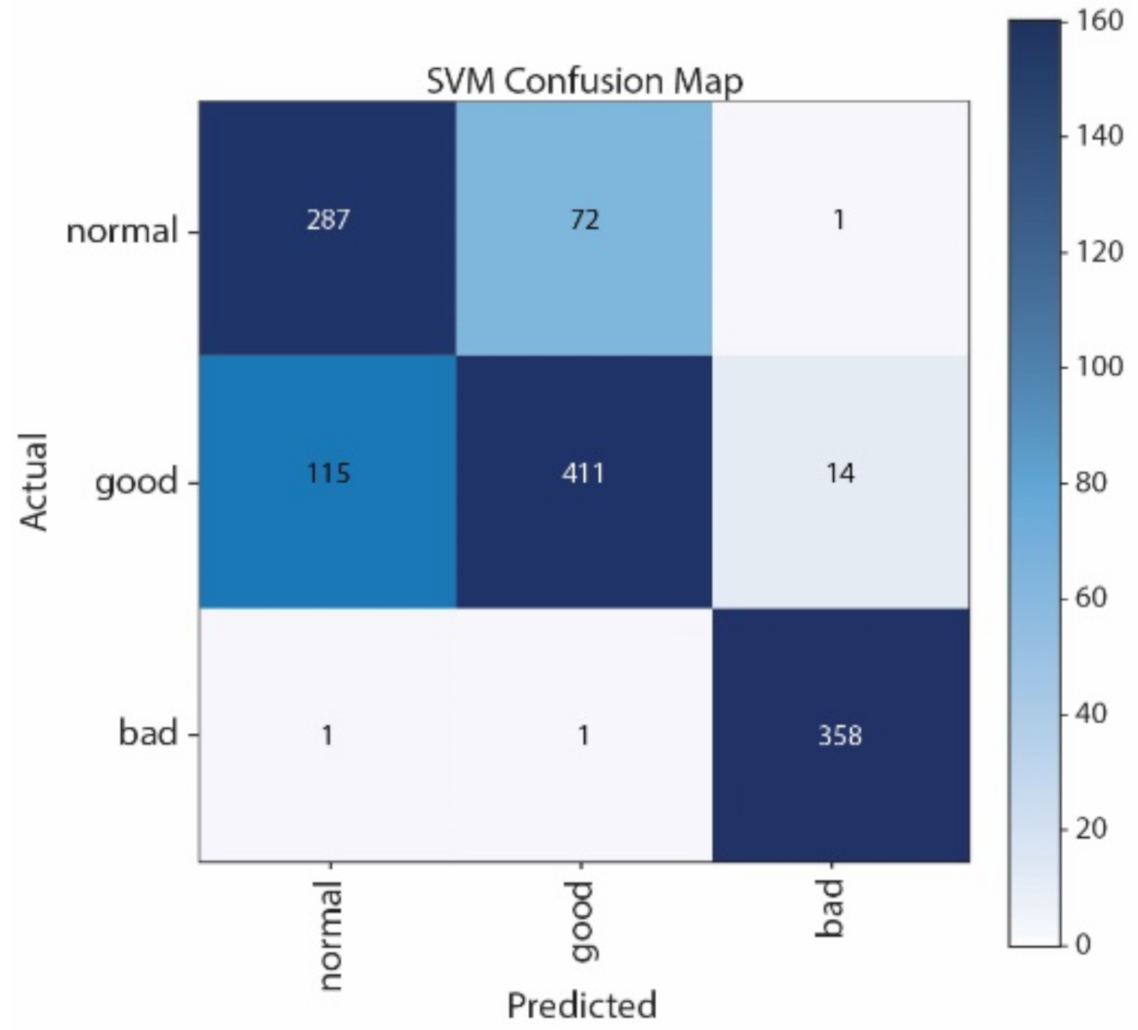
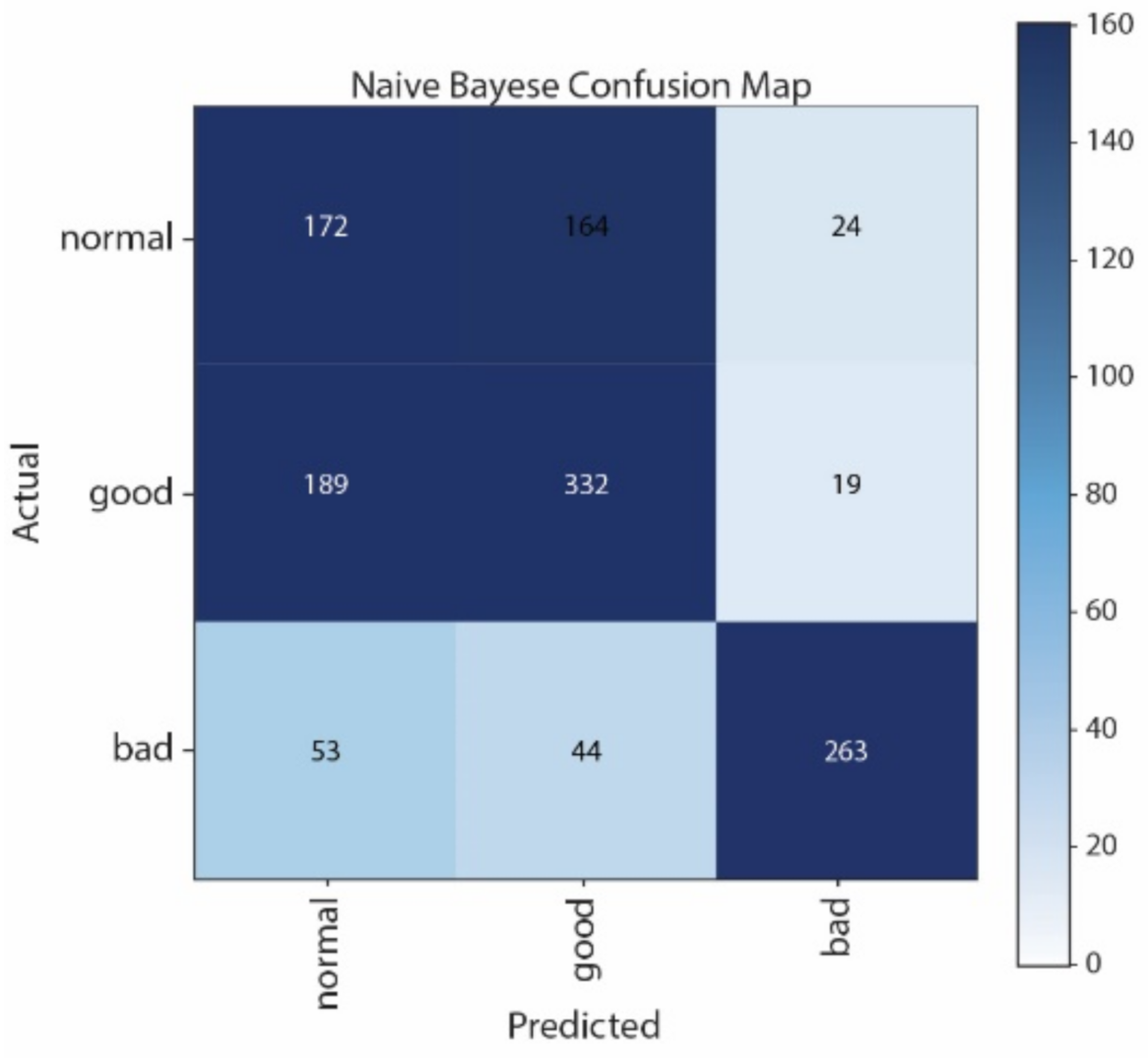
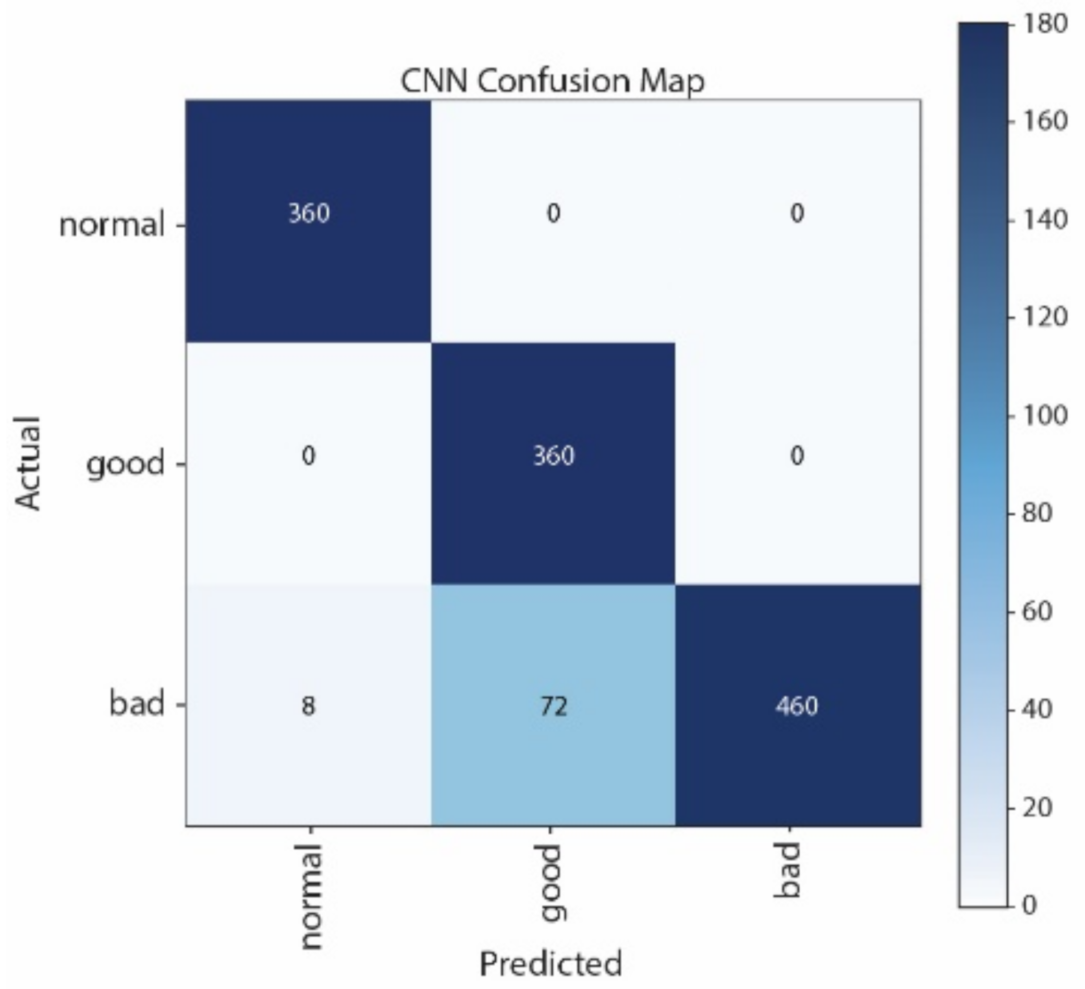
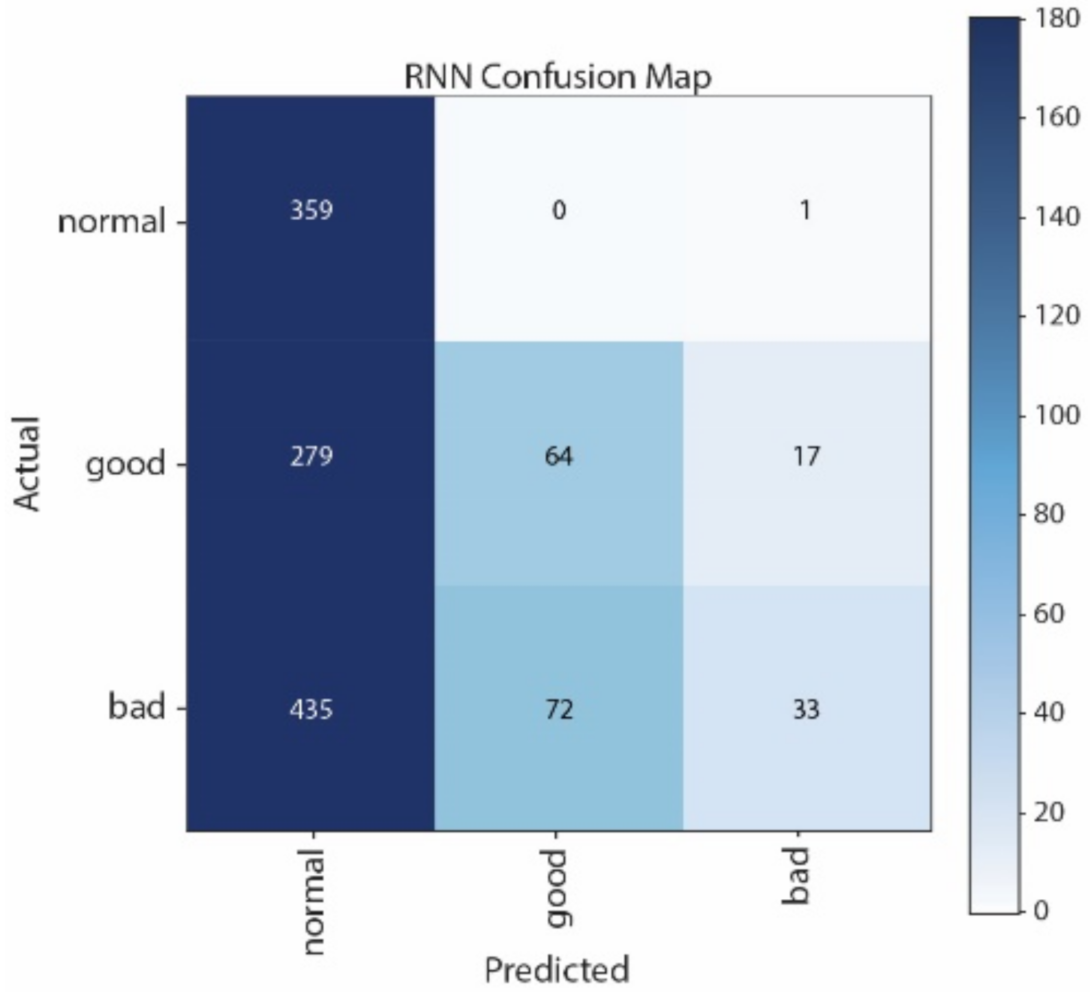
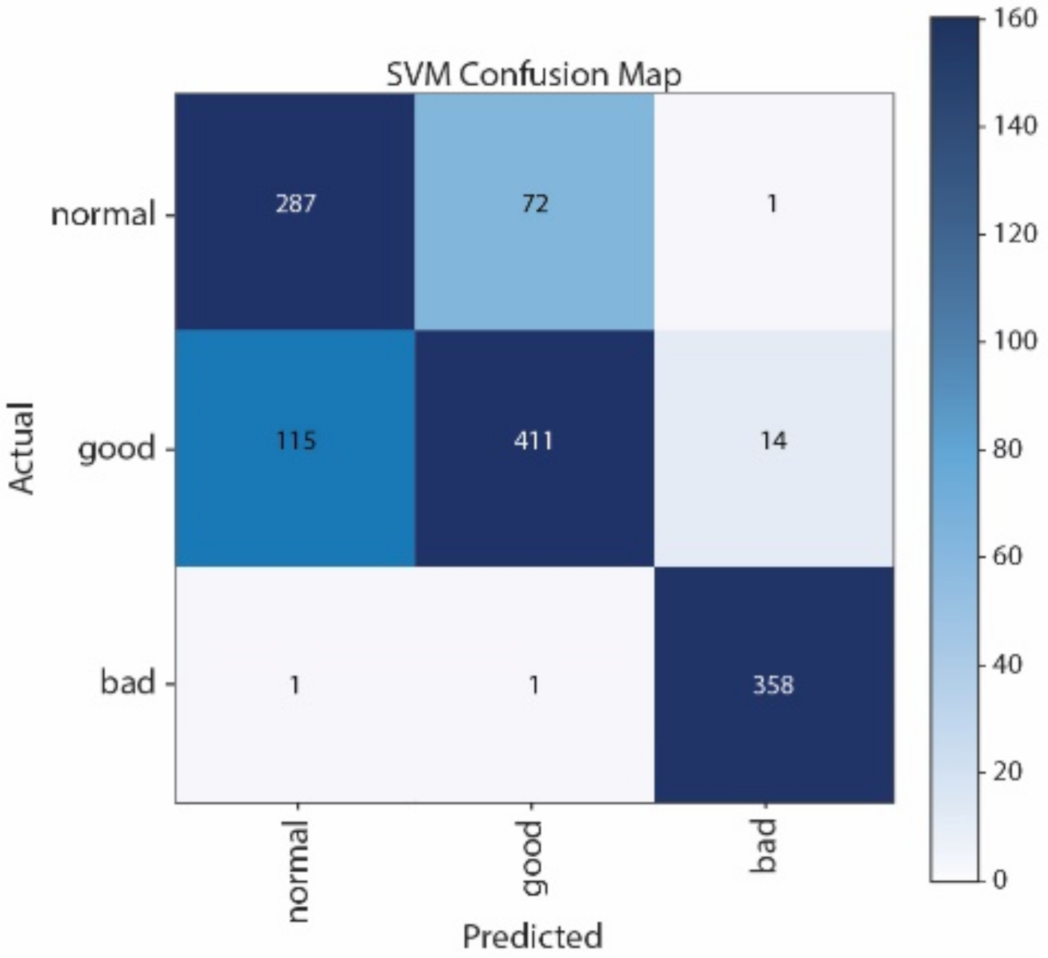
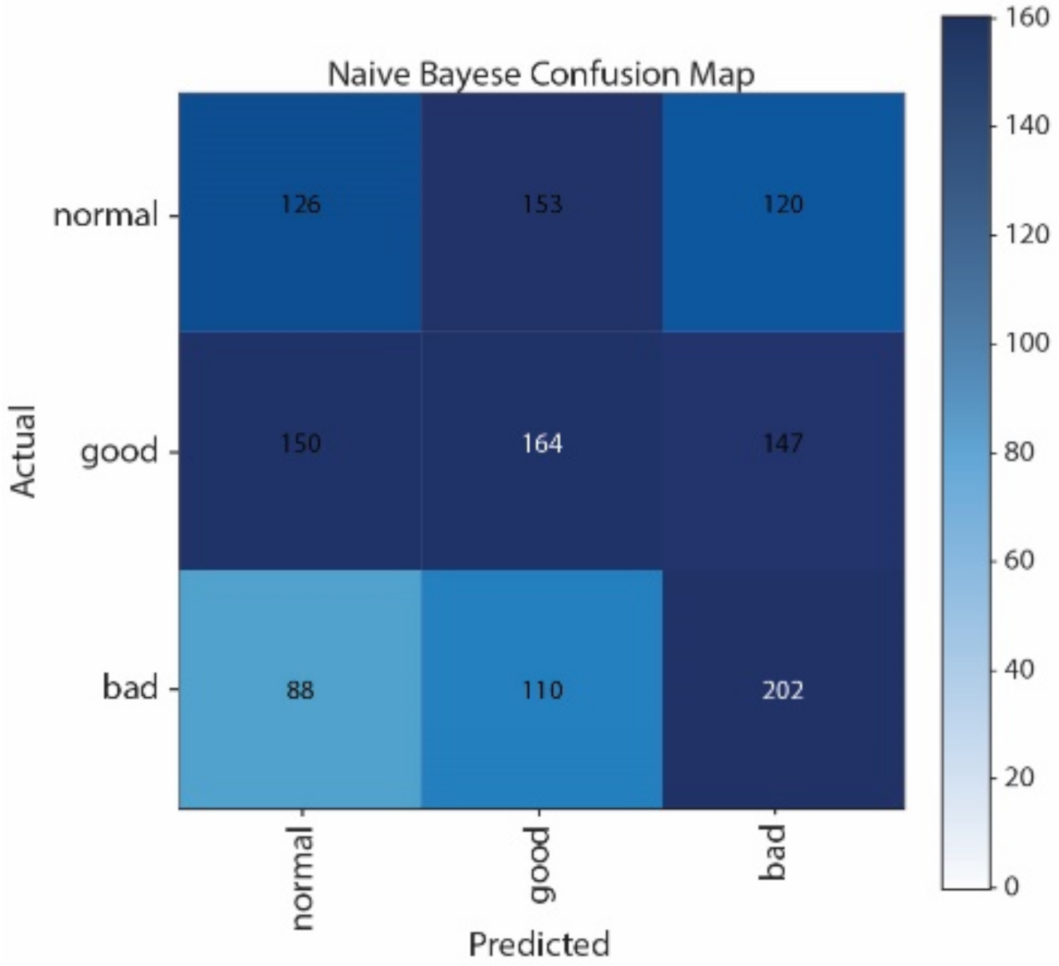
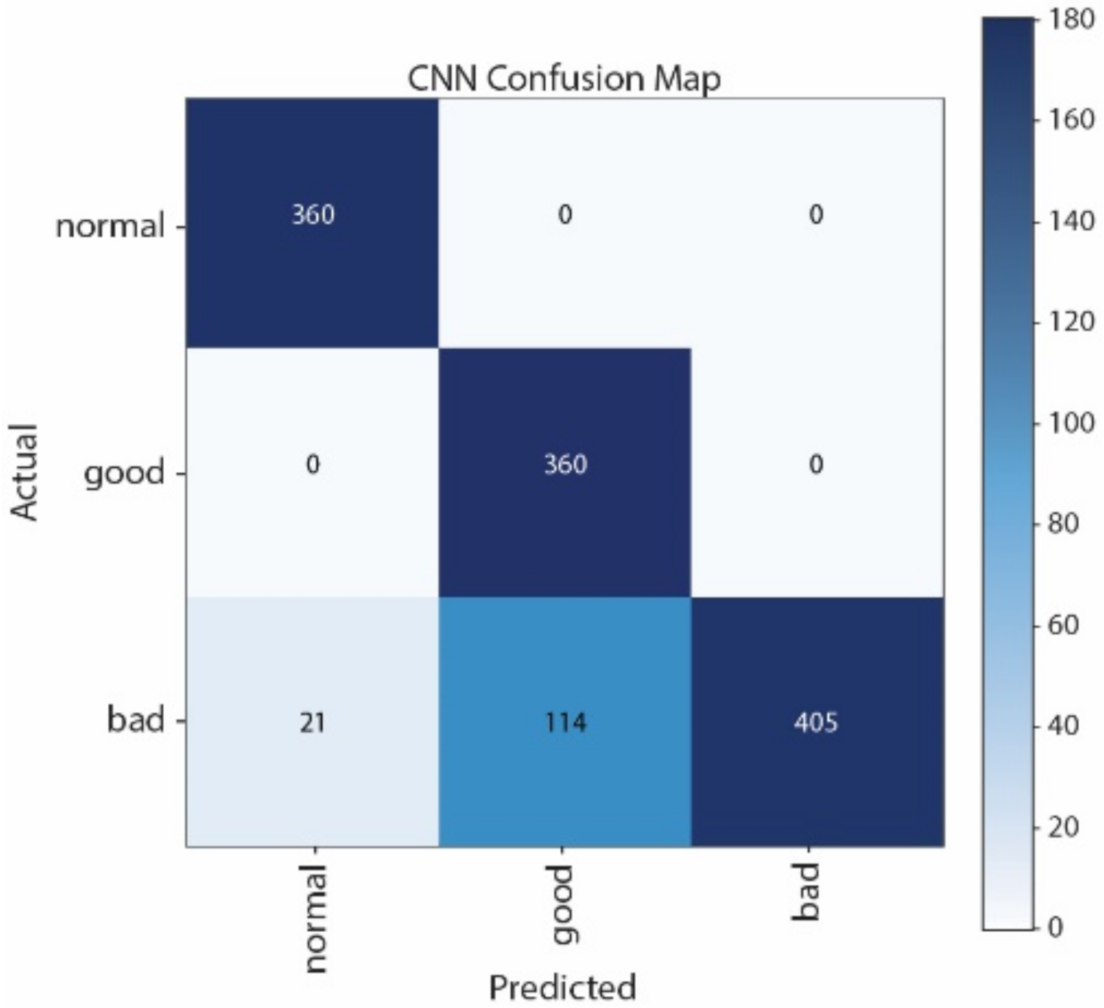
Figure 12 show the Confusion Matrices of SVM, NB, CNN, and LSTM, respectively. The correct classification and misclassification across three sound classes can be observed. We can see from
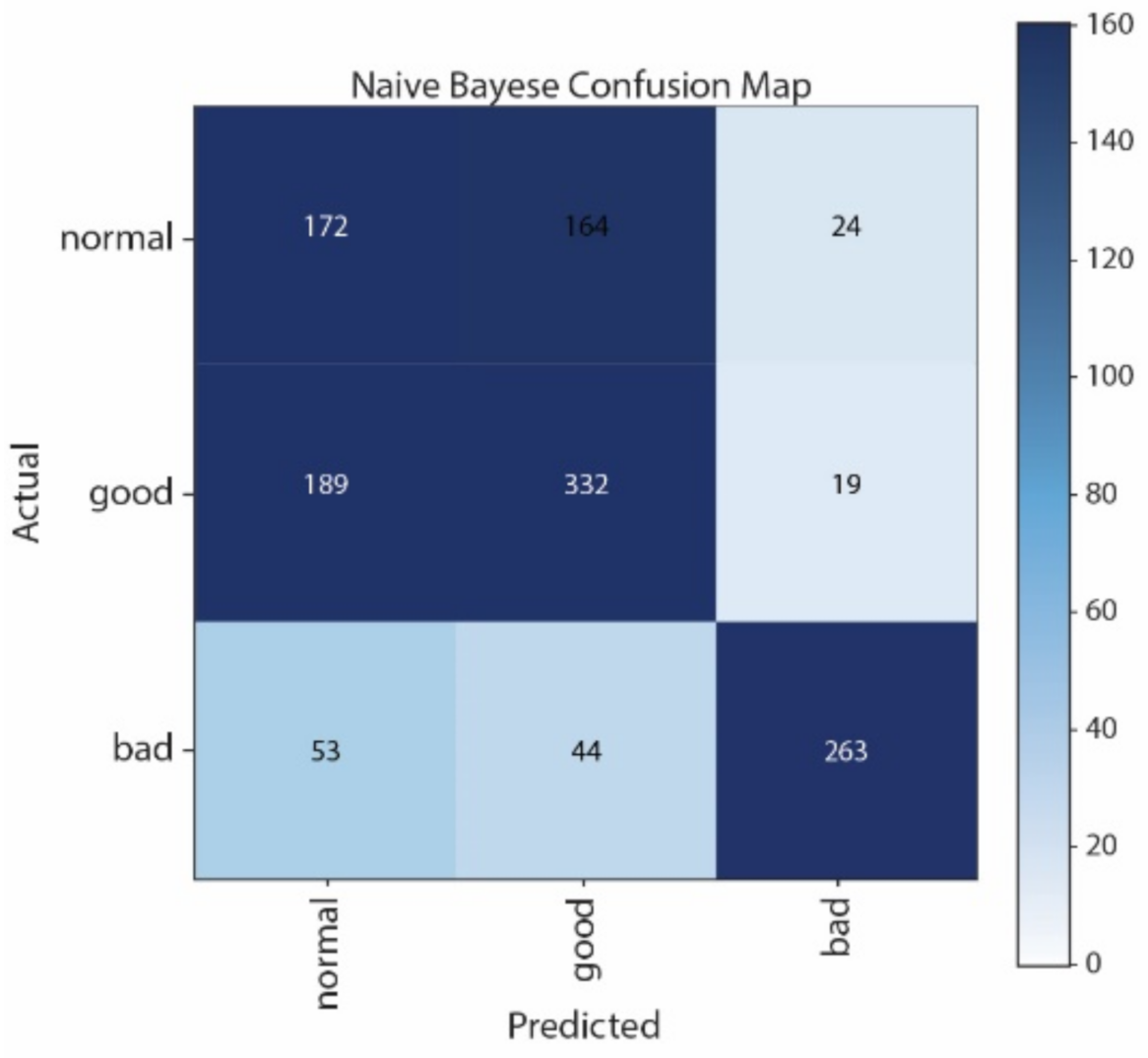
Figure 10 that normal and good classes are highly misclassified in using NB, and from
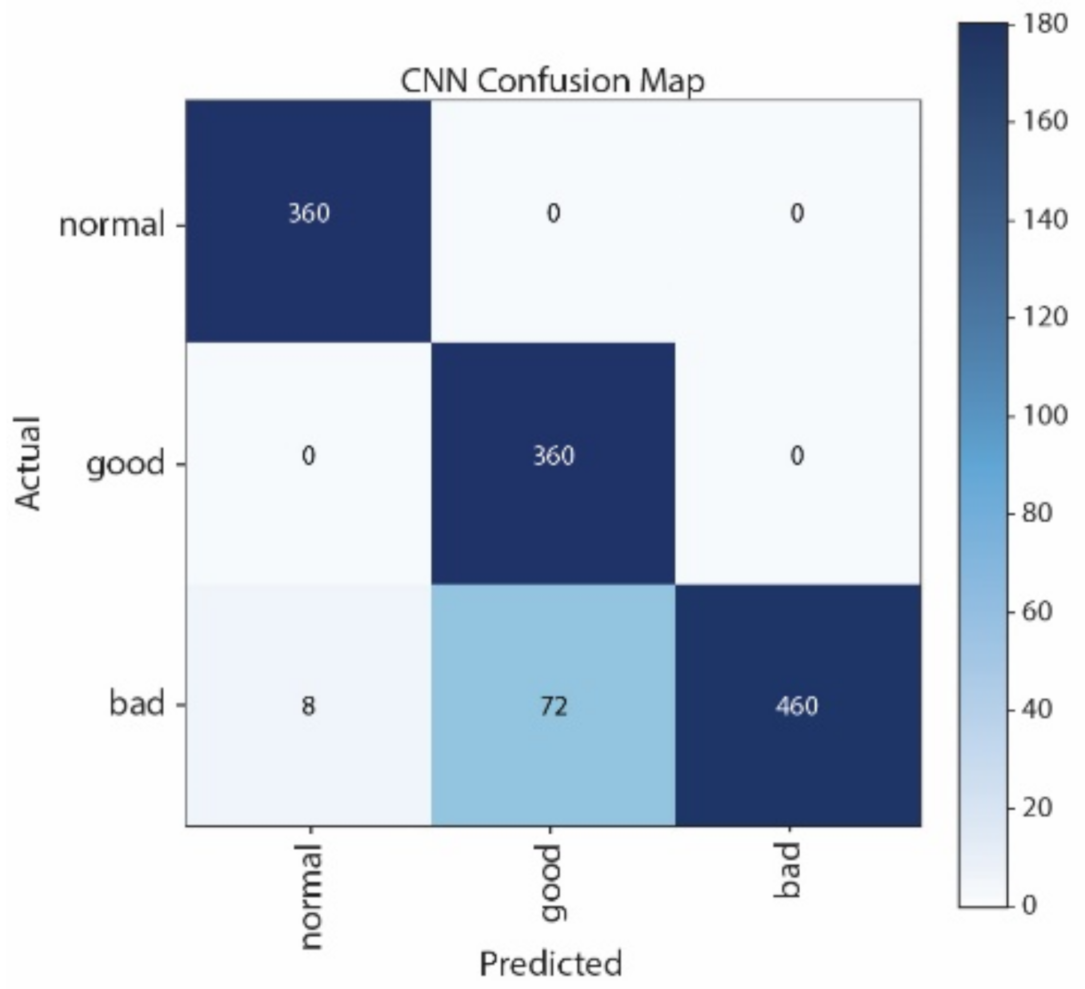
Figure 12 that most of the samples are classified as normal in using LSTM. By contrast, most of the samples can be correctly classified by using CNN. Moreover, CNN performs better than SVM, especially in distinguishing good and normal classes.
5.5.2. Staccato Part Experiment
Table 5 shows the classification results. The CNN approach achieves an accuracy of 89.36%, which is also higher than that of SVM, NB, and LSTM. Similar to the results obtained with the Legato part, CNN performs the best, compared to the other three approaches.
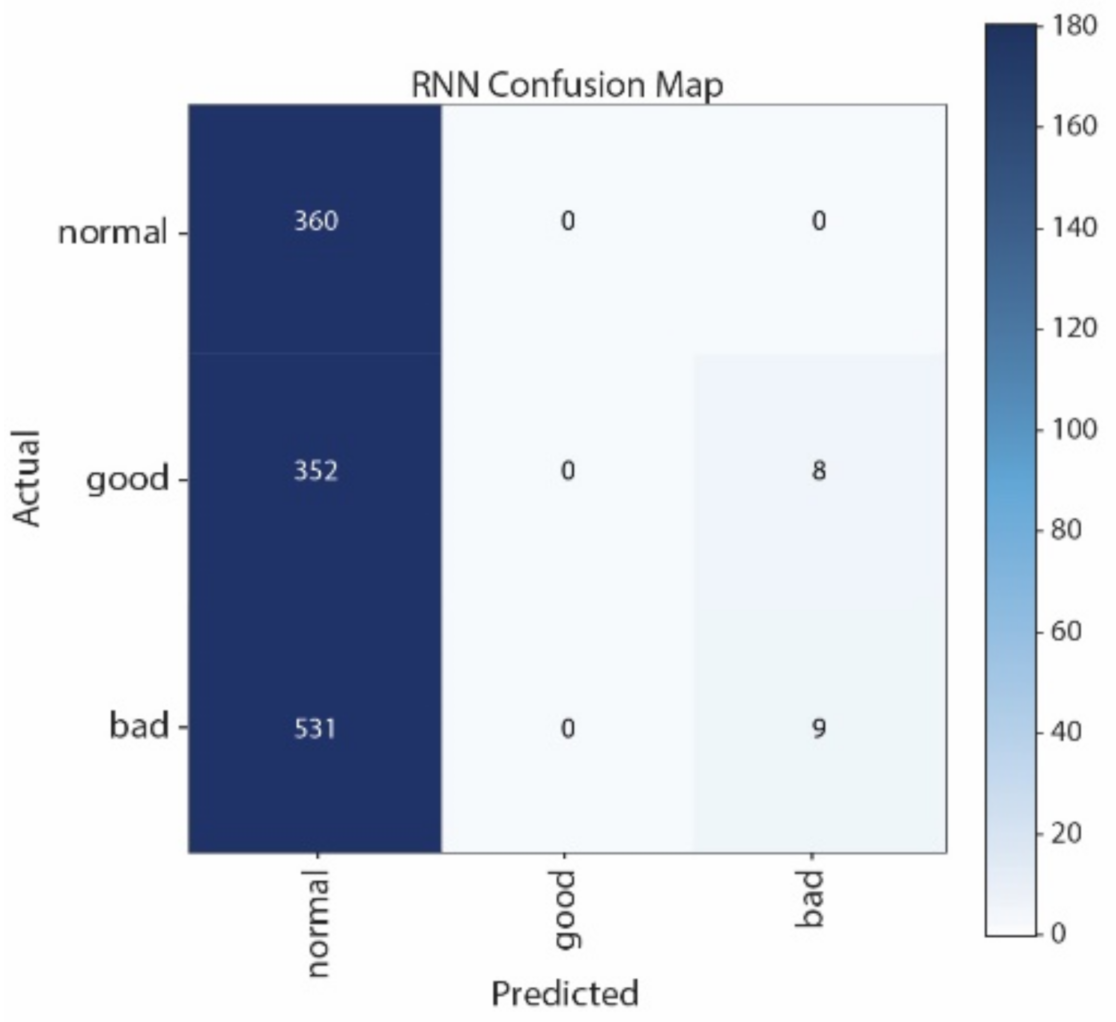
It can be seen from the Confusion Matrices in
Figure 13,
Figure 14,
Figure 15 and
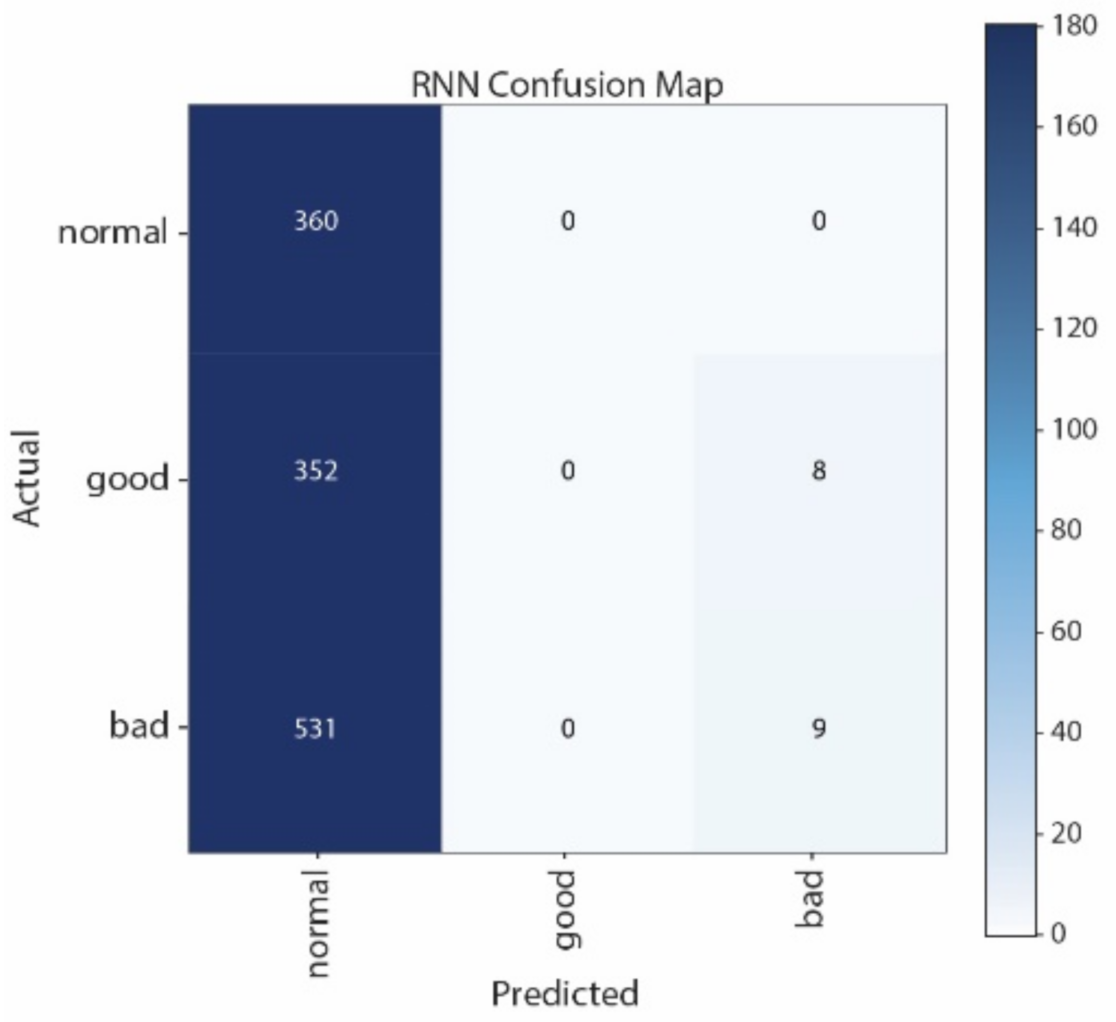
Figure 16 that the largest numbers and the second largest numbers of the wrong classification are made by LSTM, i.e., 532 “Bad” are wrongly predicted as “Normal”, and 352 “Good” are wrongly predicted as “Normal”, respectively.
5.5.3. K-Fold Cross-Validation Results
To confirm the above experiment, we used K-fold Cross-Validation to compare the Legato part and the Staccato part, where K is equal to the number of cross-validation rounds” [
31].
Table 6 shows the 10-fold Cross-Validation results. In this experiment, we found that our system performs better in the Legato part (accuracy of 89.66%) than that in the Staccato part (83.49%).
5.5.4. Song for Kids by CNN Approach
Next, we examined our piano performance assessment system for whole song performances. There were five kids’ songs used in this experiment, including Beautiful Brown Eyes, Hot Cross Buns, Jingle Bells, The Cuckoo, and Twinkle Twinkle. For each song, we collected 117 piano performances from four teachers and nine students, including 39 performances played with left hands, 39 performances played with right hands, and 39 performances played with both left and right hands. Here, we only tested the CNN-based approach since it performs better than the other three approaches. Furthermore, we modified the configuration of CNN from
Figure 6,
Figure 7,
Figure 8,
Figure 9,
Figure 10,
Figure 11,
Figure 12,
Figure 13,
Figure 14,
Figure 15,
Figure 16 and
Figure 17 in order to better handle the long duration of the whole song performance.
Figure 17 shows the architecture of the 2-layer CNN with Filters. In the three phases of the CNN feature maps, the current input size is 160 × 1 on three sets of convolutional layers with kernel size 3 × 1. The kernel was used to deal with local features in the first convolutional phase. We used a dropout parameter value of 0.5 and Max pooling 2 × 1. Finally, the process transfers the operation into Flatten, Dense, Fully Connected layer, and SoftMax Activation. We determined the new hyperparameters appropriate for the evaluation of kids’ songs performances by using the training data of 54 samples and then tested the other 63 data samples. Other parameters in this experiment follow the best parameters obtained from both the Legato and Staccato scale experiments. The resulting classification accuracies are shown in
Table 7.
As shown in
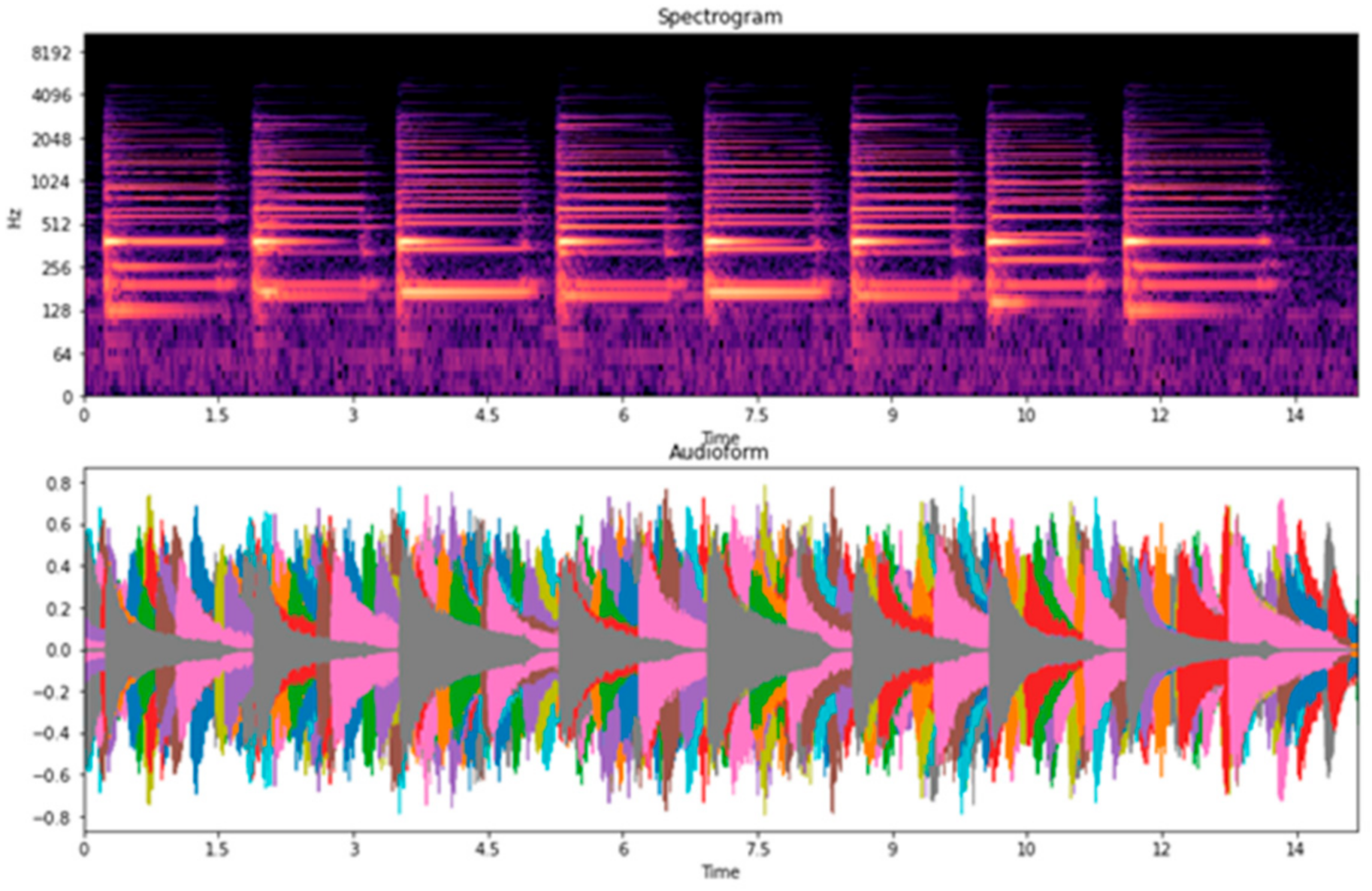
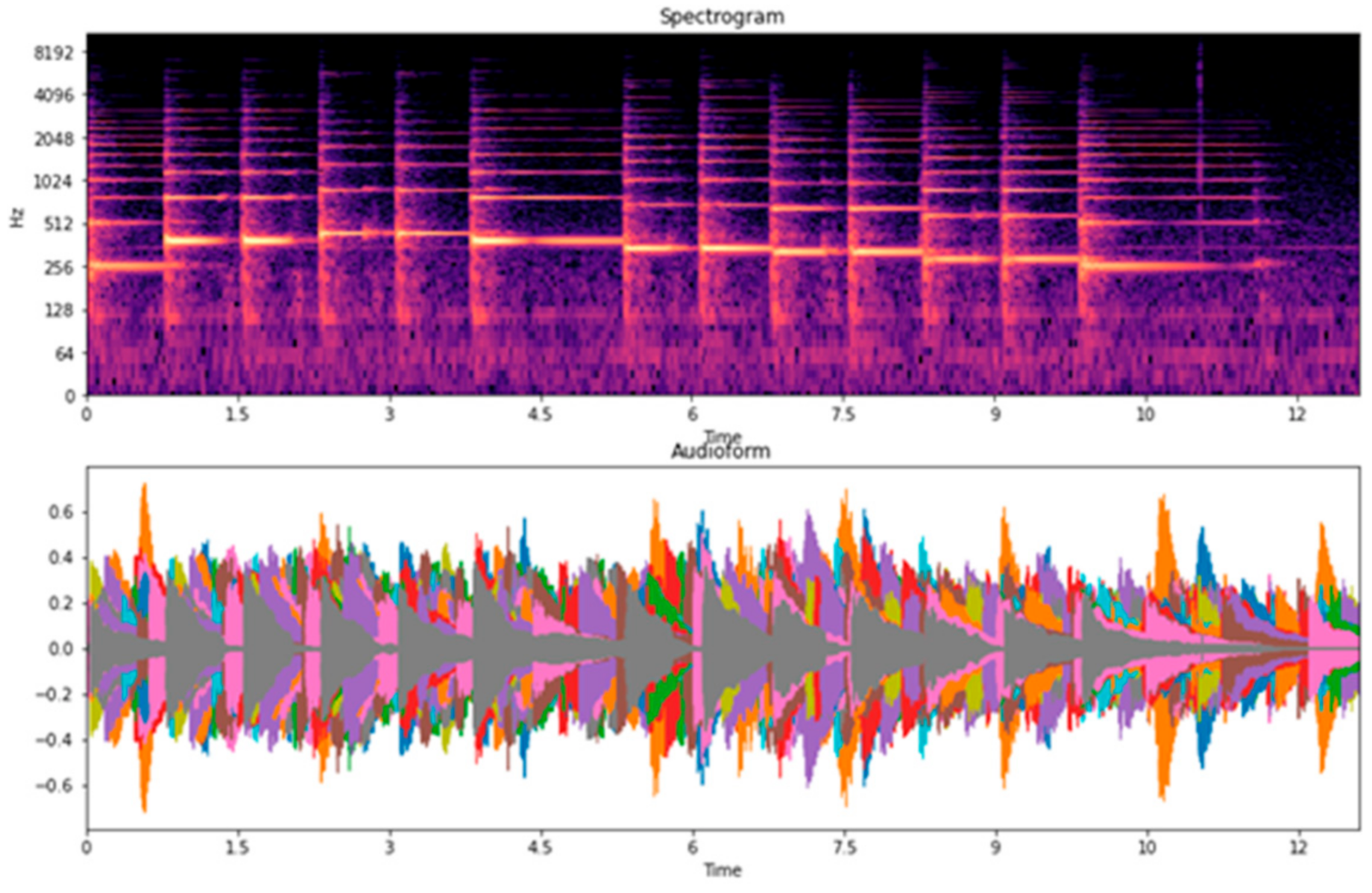
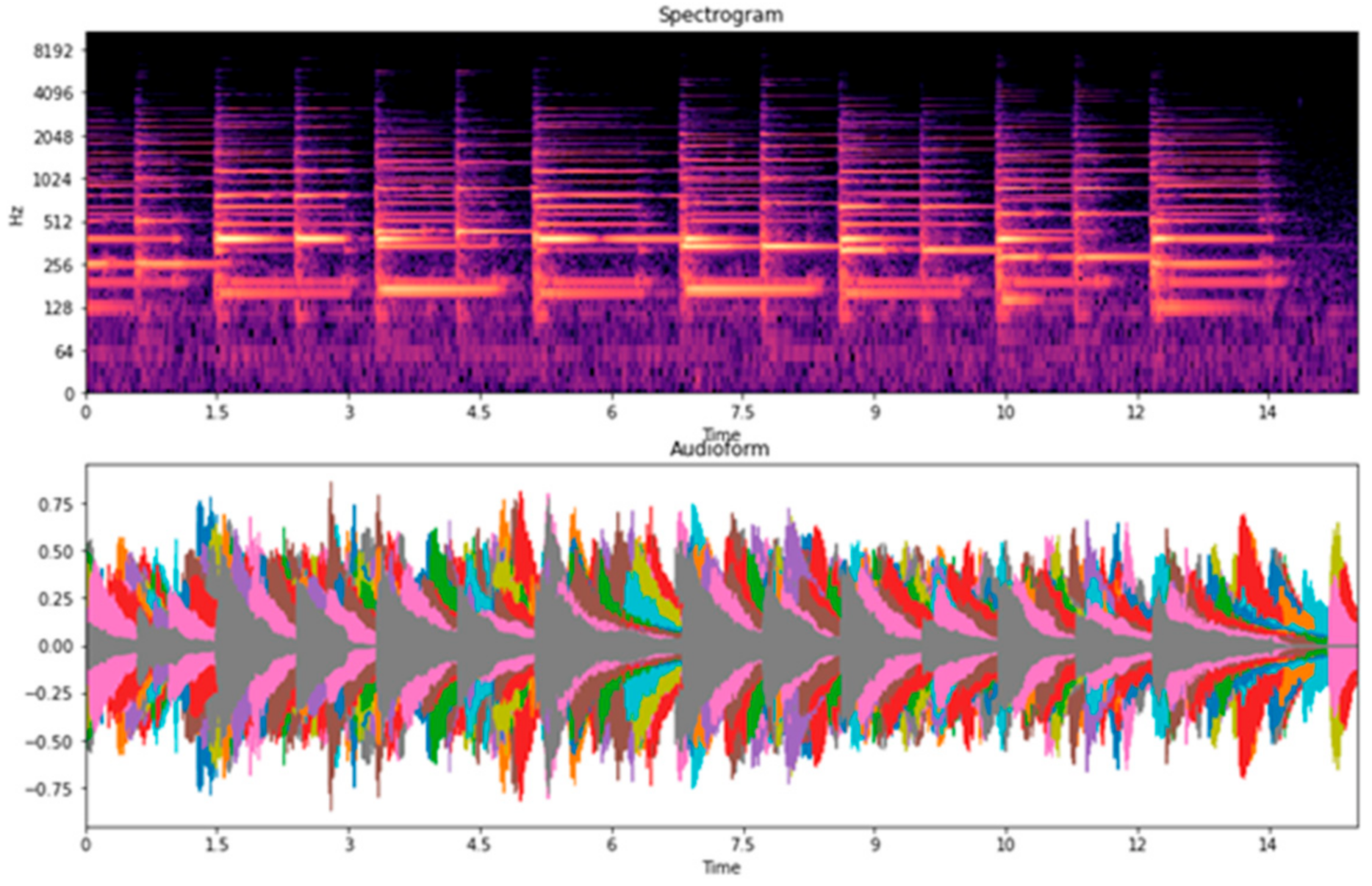
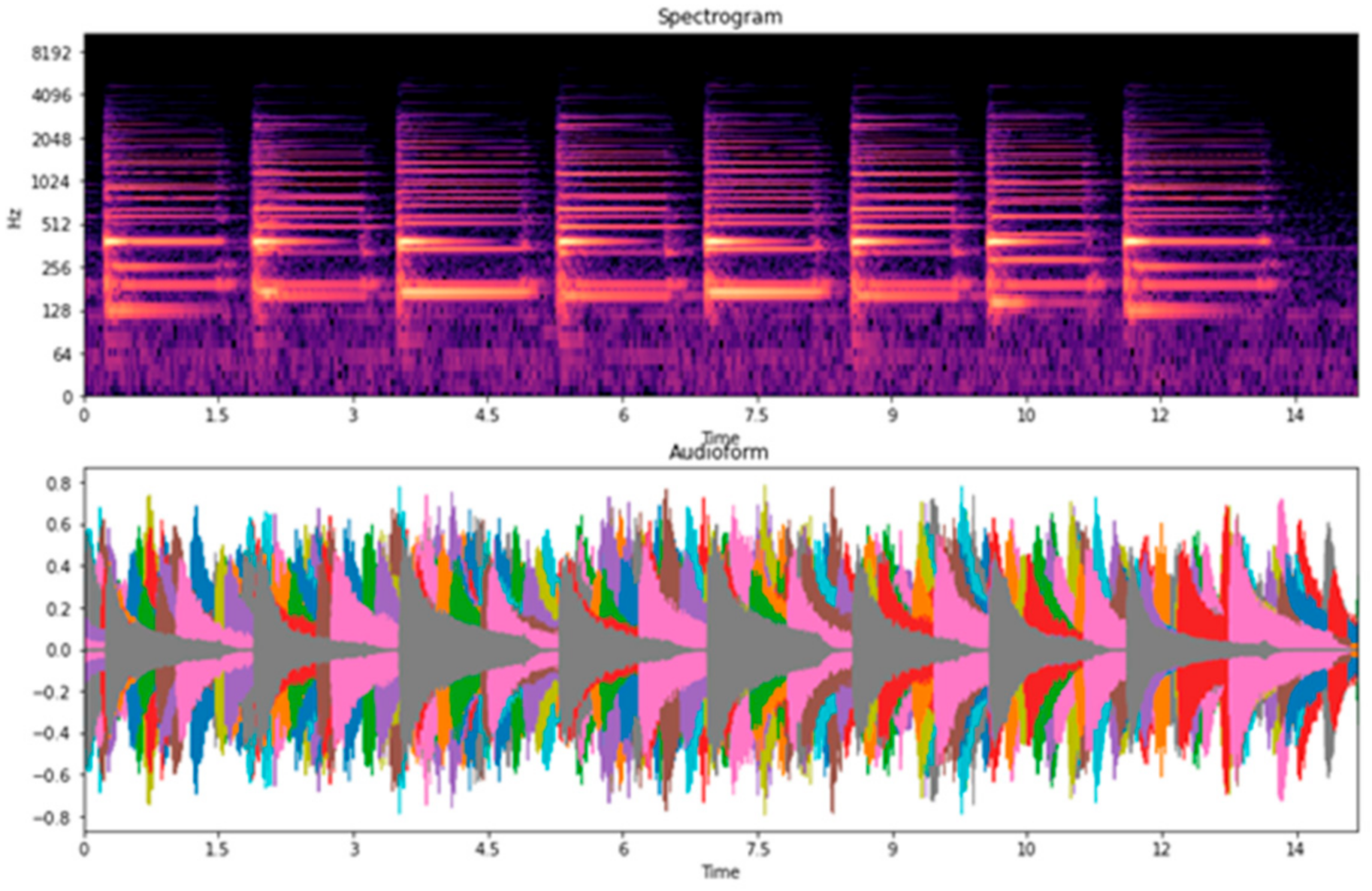
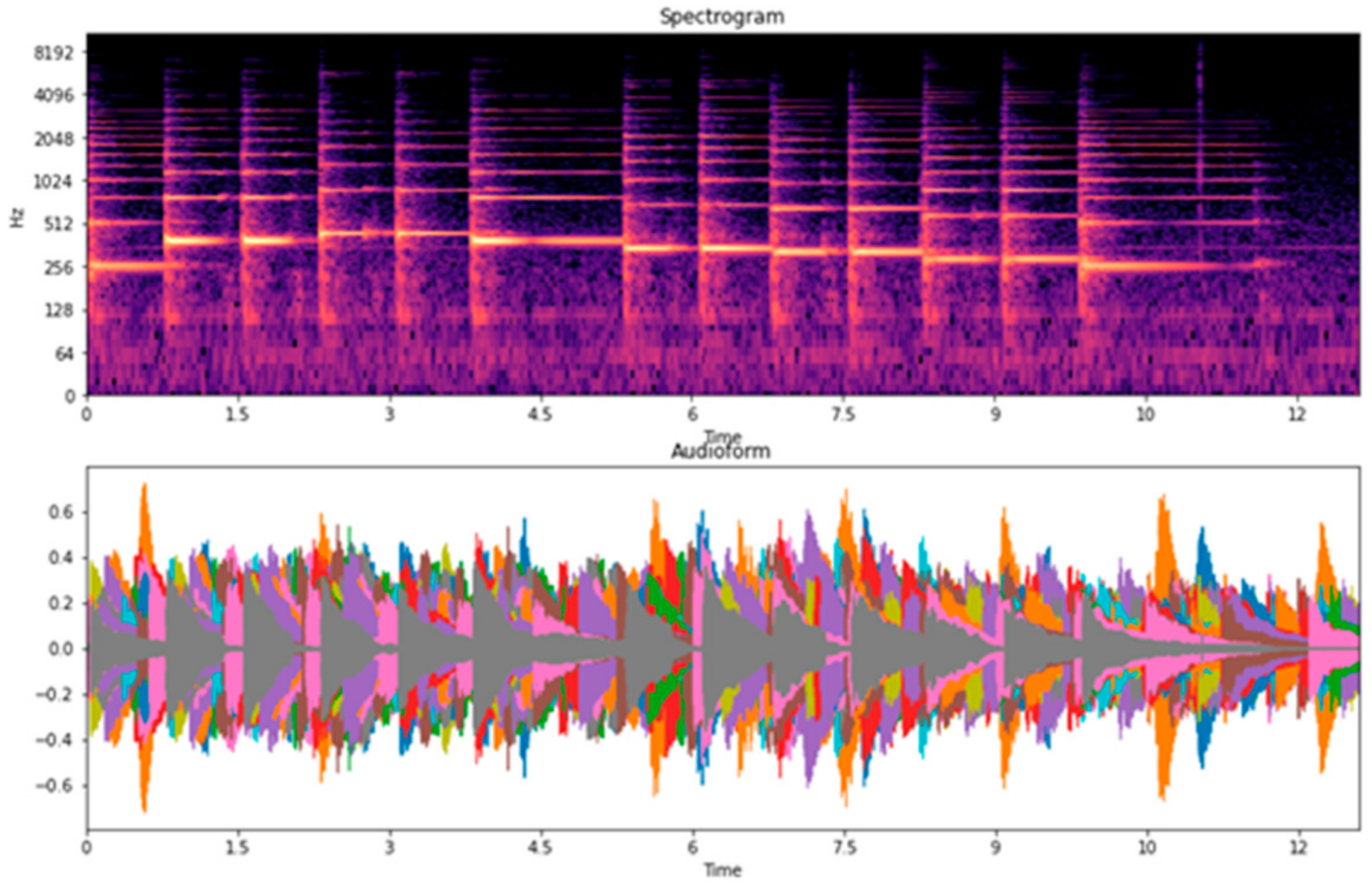
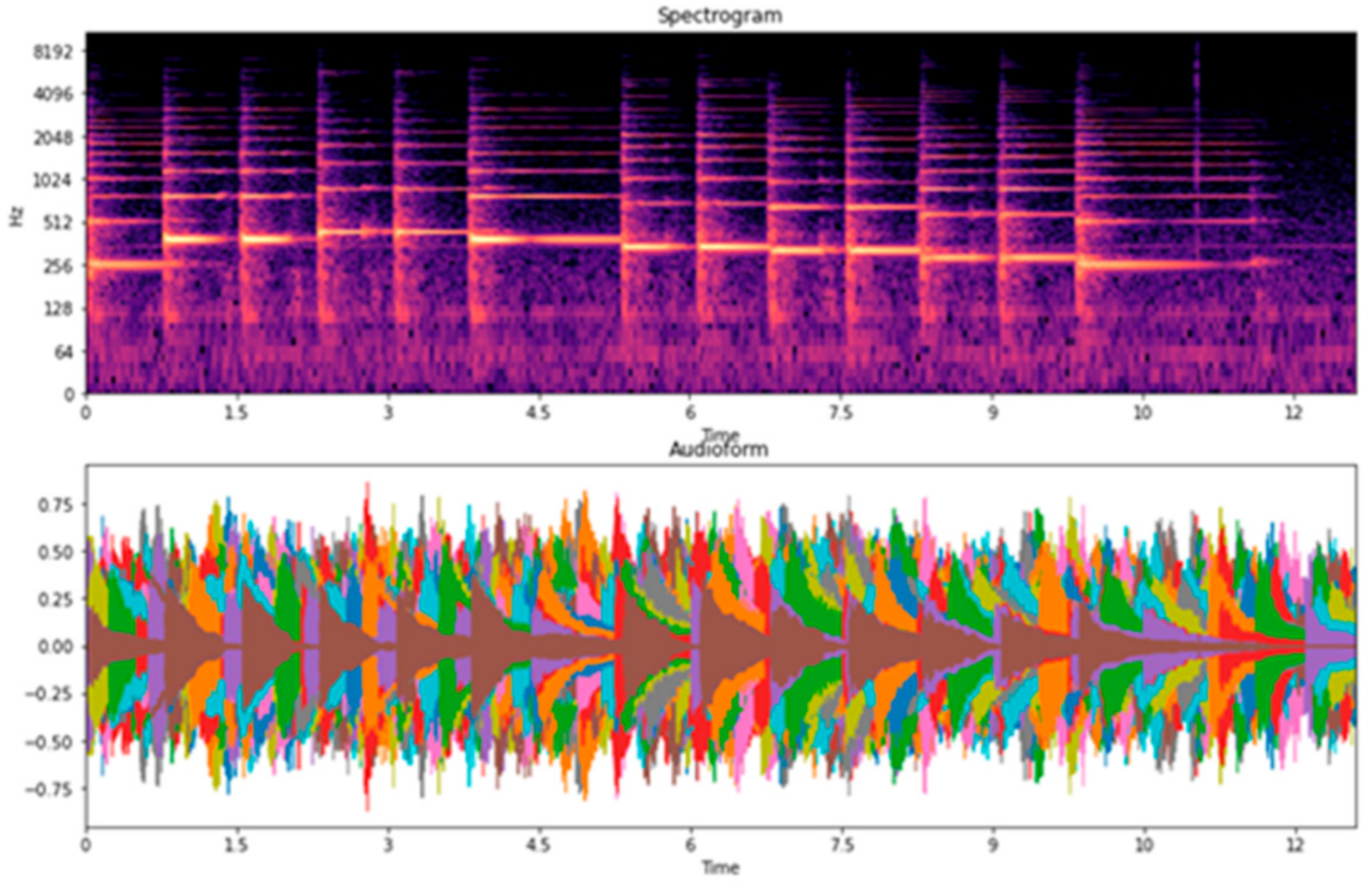
Table 7, we examined four types of piano performance, including playing with the left hand, playing with the right hand, playing with both left and right hands, and the overall playing (overall is the datasets combination of the left hand, right hand, and both left and right hands). For the overall classification, accuracies are higher than 80%. Among them, we found that the song “Twinkle Twinkle” had the lowest accuracy when compared to the other songs. Thus, we focused on the recordings of the song “Twinkle Twinkle”, associated with the spectrograms, waveforms, and confusion matrices. We observed the main problem of Twinkle Twinkle in terms of beat and tempo in the spectrograms, and waveforms are shown in
Figure 18,
Figure 19,
Figure 20 and
Figure 21. The beat is used as the placement of sounds in time, with repeated or regular patterns, while the tempo is the rate of speed for a piece of music [
32,
33]. In this case, the classification accuracy for the piano performances is lower when played with both left and right hands and is higher when played with separate hands. When we divided the dataset for each hand, the overlapping of the beat and tempo in the spectrograms and waveforms was reduced. Hence, we speculate that this might be due to the changeable characteristics of beat and tempo in both left and right hands, making it difficult to classify.
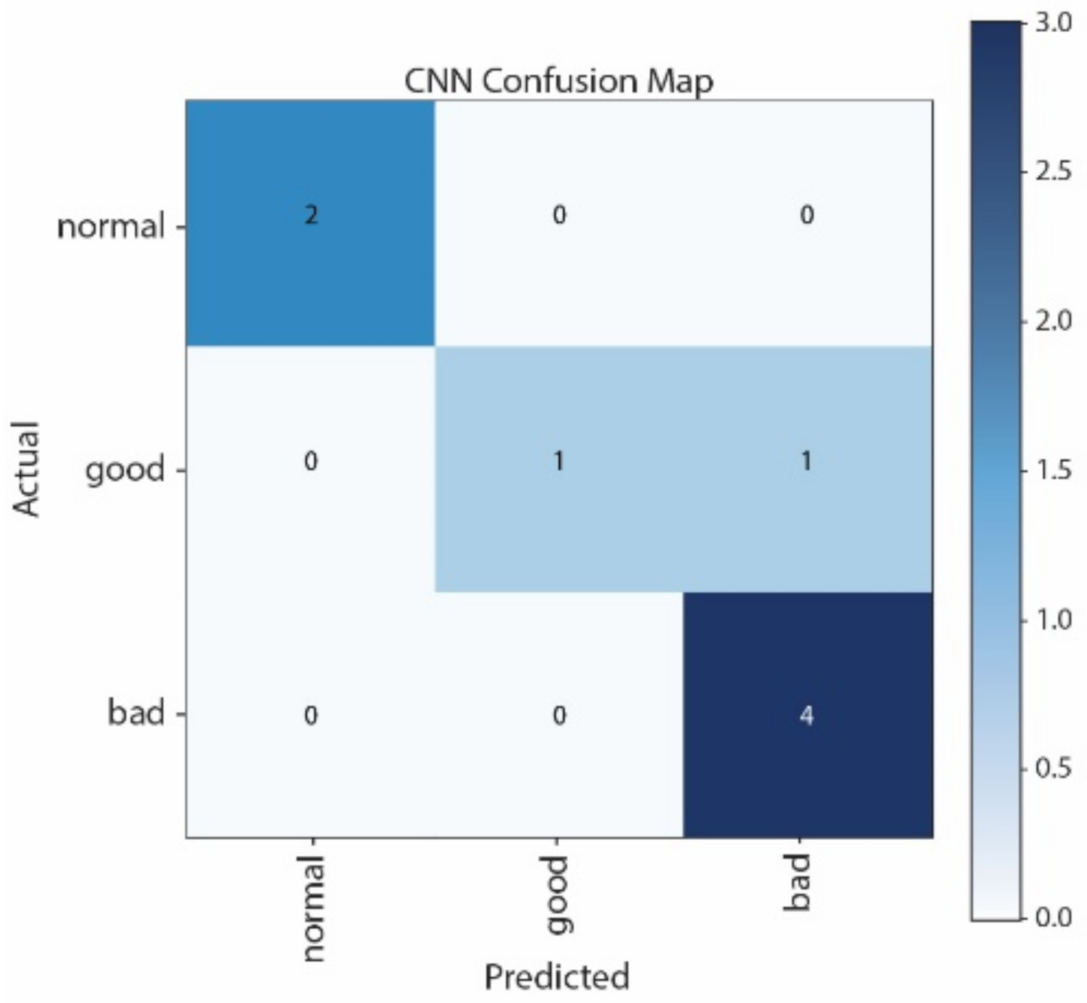
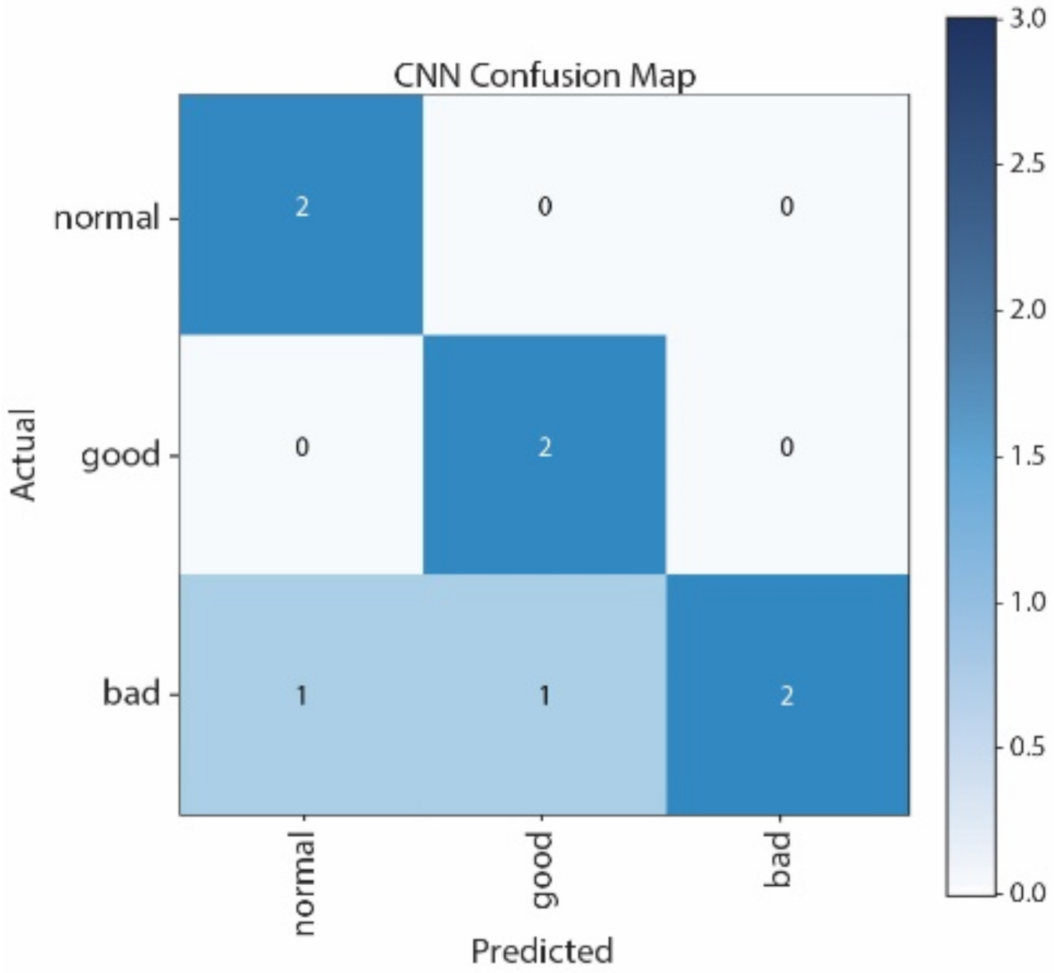
To summarize, the left hand in the song “Twinkle Twinkle” achieves 100% accuracy using the CNN classifier. The confusion matrices, shown in
Figure 22,
Figure 23,
Figure 24 and
Figure 25, indicate the correct classification and misclassification into three categories: “Good”, “Normal”, and “Bad”. From these matrices, the prediction of the left hand shows no classification error. The Confusion Matrices of Twinkle Twinkle shows that the number of correct classification in the left hand is made by CNN, i.e., four “Normal” are correctly predicted as “Normal”, two “Good” are correctly predicted as “Good”, and two “Bad” are correctly predicted as “Bad”.
Finally, kids’ songs, including Beautiful Brown Eyes, Hot Cross Buns, Jingle Bells, The Cuckoo, and Twinkle Twinkle, were assessed in this experiment. Here, the CNN-based approach is used to support the results, similarly to the previous experiment on the scale parts of Legato and Staccato. The approach performed accurately even in songs with long duration and different beats and rhythms. The song “Hot Cross Bun” achieved the best result, with an accuracy of 90.47%, Beautiful Brown Eyes 90.32%, Jingle bell 80.70%, The Cuckoo 83.87%, and Twinkle Twinkle 80.46%, respectively.
6. Conclusions
One of the reasons that piano learners play the piano is for technical skill practice, for instance, Legato, Staccato, and other articulations. However, learners do not know which techniques and skills are the best for their piano performance improvement. Hence this research aims to explain and compare results for the accurate identification of piano sounds. The performers are four piano teachers and nine students, a total of thirteen people, for training and assessing processes with four different methods: Support Vector Machine (SVM), Naive Bayes (NB), Convolutional Neural Network (CNN), and Long Short-Term Memory (LSTM) to evaluate the sounds. Datasets were recorded for all performers.
In this study, model technique analysis was used to explain the model prediction to create an automatic assessment process for piano performance. The results show that the CNN approach outperformed other approaches in all assessment criteria. Furthermore, this study obtained identification accuracy results for CNN performance in two ways: piano sounds in Legato using the sustain pedal at 93.65% accuracy, and piano sounds in Staccato with detached notes and no use of the sustain pedal at 89.36%. In addition, to evaluate the accuracy, kids’ songs were performed to collect data. The results reveal that the accuracy rates were higher than eighty percent.
However, there are some limitations. The data were collected using scales and songs in the evaluation process. The experimental dataset could be expanded by including performances with other musical instruments and different types of music to include, for instance, Classical, Jazz, Pop, Blues, Punk, Disco, Rock, or Heavy Metal. In addition, our current experiment tool is the piano; future studies could include other instruments such as strings, woodwind, brass, or percussion to test accuracy for different tones, rhythms, and musical styles. Furthermore, we achieved robust correctness accuracy for piano sound data with each method which used six scales, major and minor keys, and various key signatures together with two major types of musical articulation (Staccato and Legato), which helps to validate this approach. Moreover, this research can be of benefit to the music industry and could be used to enhance music teaching, study, and testing in the future.
Author Contributions
Conceptualization, V.P. and W.-H.T.; methodology, V.P. and W.-H.T.; soft-ware, V.P.; formal analysis, V.P.; investigation, V.P.; resources, V.P.; data curation, V.P.; writing—original draft preparation, V.P.; writing—review and editing, V.P. and W.-H.T.; visualization, V.P.; supervision, W.-H.T.; project administration, V.P. and W.-H.T. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Ministry of Science and Technology, Taiwan, under grant MOST-106-2221-E-027-125-MY2.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data indicated in this research are available from students and piano teachers at Yamaha Music School and KPN Music Academy in Thailand.
Acknowledgments
The authors express their gratitude to the National Taipei University of Technology for supporting this research.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Perignat, E.; Katz-Buonincontro, J. STEAM in practice and research: An integrative literature review. Think. Ski. Creat. 2019, 31, 31–43. [Google Scholar] [CrossRef]
- Allina, B. The development of STEAM educational policy to promote student creativity and social empowerment. Arts Educ. Policy Rev. 2018, 119, 77–87. [Google Scholar] [CrossRef]
- Chandrasekaran, B.; Kraus, N. Music, Noise-Exclusion, and Learning. Music Percept. 2010, 27, 297–306. [Google Scholar] [CrossRef]
- Herro, D.; Quigley, C. Exploring teachers’ perceptions of STEAM teaching through professional development: Implications for teacher educators. Prof. Dev. Educ. 2017, 43, 416–438. [Google Scholar] [CrossRef]
- Engelman, S.; Magerko, B.; McKlin, T.; Miller, M.; Edwards, D.; Freeman, J. Creativity in Authentic STEAM Education with EarSketch. In Proceedings of the 2017 ACM SIGCSE Technical Symposium on Computer Science Education, Seattle, WA, USA, 8–11 March 2017; pp. 183–188. [Google Scholar] [CrossRef]
- Gabrielsson, A. Music Performance Research at the Millennium. Psychol. Music 2003, 31, 221–272. [Google Scholar] [CrossRef]
- Goebl, W. Movement and Touch in Piano Performance. In Handbook of Human Motion; Muller, B., Wolf, S.I., Eds.; Springer: Berlin, Germany, 2017; pp. 1–18. [Google Scholar] [CrossRef]
- Giraldo, S.; Ortega, A.; Perez, A.; Ramirez, R.; Waddell, G.; Williamon, A. Automatic Assessment of Violin Performance Using Dynamic Time Warping Classification. In Proceedings of the 26th Signal Processing and Communications Applications Conference (SIU 2018), Izmir, Turkey, 2–5 May 2018. [Google Scholar] [CrossRef] [Green Version]
- Knight, T.; Upham, F.; Fujinaga, I. The potential for automatic assessment of trumpet tone quality. In Proceedings of the 12th International Society for Music Information Retrieval Conference (ISMIR 2011), Miami, FL, USA, 24–28 October 2011; pp. 573–578. [Google Scholar]
- Ramirez, R.; Canepa, C.; Ghisio, S.; Kolykhalova, K.; Mancini, M.; Volta, E.; Volpe, G.; Giraldo, S.; Mayor, O.; Perez, A.; et al. Enhancing Music Learning with Smart Technologies. In Proceedings of the 5th International Conference on Movement and Computing, Genoa, Italy, 28–30 June 2018; pp. 1–4. [Google Scholar] [CrossRef] [Green Version]
- Del Rio-Guerra, M.S.; Martin-Gutierrez, J.; Lopez-Chao, V.A.; Flores Parra, R.; Ramirez Sosa, M.A. AR Graphic Representation of Musical Notes for Self-Learning on Guitar. Appl. Sci. 2019, 9, 4527. [Google Scholar] [CrossRef] [Green Version]
- Holden, H.; Button, S. The teaching of music in the primary school by the non-music specialist. Br. J. Music Educ. 2006, 23, 23–38. [Google Scholar] [CrossRef] [Green Version]
- Webster, P.R. Key research in music technology and music teaching and learning. J. Music Technol. Educ. 2012, 4, 115–130. [Google Scholar] [CrossRef]
- Germeroth, C.; Kelleman, B.; Spartz, J. Lyrics2Learn: Teaching Fluency through Music and Technology. Educ. Sci. 2018, 8, 91. [Google Scholar] [CrossRef] [Green Version]
- Lee, L.; Chang, H.-Y. Music Technology as a Means for Fostering Young Children’s Social Interactions in an Inclusive Class. Appl. Syst. Innov. 2021, 4, 93. [Google Scholar] [CrossRef]
- Bolívar-Chávez, O.-E.; Paredes-Labra, J.; Palma-García, Y.-V.; Mendieta-Torres, Y.-A. Educational Technologies and Their Application to Music Education: An Action-Research Study in an Ecuadorian University. Mathematics 2021, 9, 412. [Google Scholar] [CrossRef]
- Karioun, M.; Tihon, S.; De Vleeschouwer, C.; Ganseman, J.; Jacques, L. Deep learning in Automatic Piano Transcription. Master’s Thesis, École polytechnique de Louvain, Louvain-la-Neuve, Belgium, 2018. [Google Scholar]
- Askenfelt, A.; Jansson, E. From touch to string vibrations the initial course of the piano tone. J. Acoust. Soc. Am. 1987, 81, S61. [Google Scholar] [CrossRef] [Green Version]
- Honingh, A.; Bod, R. In search of universal properties of musical scales. J. New Music Res. 2011, 40, 81–89. [Google Scholar] [CrossRef]
- Nielzen, S.; Cesarec, Z. Emotional Experience of Music as a Function of Musical Structure. Psychol. Music 1982, 10, 7–17. [Google Scholar] [CrossRef]
- Wu, H.; Wang, L.; Zhao, Z.; Shu, C.; Lu, C. Support Vector Machine Based Differential Pulse-Width Pair Brillouin Optical Time Domain Analyzer. IEEE Photonics J. 2018, 10, 1–11. [Google Scholar] [CrossRef]
- Wu, H.; Wang, L.; Guo, N.; Shu, C.; Lu, C. Brillouin Optical Time-Domain Analyzer Assisted by Support Vector Machine for Ultrafast Temperature Extraction. J. Light. Technol. 2017, 35, 4159–4167. [Google Scholar] [CrossRef]
- Jadhav, M.; Sharma, Y.K.; Bhandari, G.M. Currency Identification and Forged Banknote Detection Using Deep Learning. In Proceedings of the International Conference on Innovative Trends and Advances in Engineering and Technology (ICITAET 2019), Shegaon, India, 27–28 December 2019. [Google Scholar] [CrossRef]
- Tran, V.T.; Tsai, W.H. Acoustic-Based Emergency Vehicle Detection Using Convolutional Neural Networks. IEEE Access 2020, 8, 75702–75713. [Google Scholar] [CrossRef]
- Siripibal, N.; Supratid, S.; Sudprasert, C. A Comparative Study of Object Recognition Techniques: Softmax, Linear and Quadratic Discriminant Analysis Based on Convolutional Neural Network Feature Extraction. In Proceedings of the 2019 International Conference on Management Science and Industrial Engineering, Phuket, Thailand, 24–26 May 2019; pp. 209–214. [Google Scholar] [CrossRef]
- Zhao, Z.Q.; Zheng, P.; Xu, S.T.; Wu, X. Object Detection with Deep Learning: A Review. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, Y.; Cao, H. Prediction for Tourism Flow Based on LSTM Neural Network. Procedia Comput. Sci. 2018, 129, 277–283. [Google Scholar] [CrossRef]
- Gers, F.A.; Schmidhuber, J.; Cummins, F. Learning to Forget: Continual Prediction with LSTM. Neural Comput. 2000, 12, 2451–2471. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- McFee, B.; Raffel, C.; Liang, D.; Ellis, D.P.; McVicar, M.; Battenberg, E.; Nieto, O. librosa: Audio and music signal analysis in python. In Proceedings of the 14th python in science conference, Austin, TX, USA, 6–12 July 2015; pp. 18–25. [Google Scholar] [CrossRef] [Green Version]
- Raschka, S. Model Evaluation, Model Selection, and Algorithm Selection in Machine Learning. arXiv 2018, arXiv:1811.12808. [Google Scholar]
- Scheirer, E.D. Tempo and Beat Analysis of Acoustic Musical Signals. J. Acoust. Soc. Am. 1998, 103, 588–601. [Google Scholar] [CrossRef] [Green Version]
- Dixon, S. Automatic extraction of tempo and beat from expressive performances. J. New Music Res. 2001, 30, 39–58. [Google Scholar] [CrossRef] [Green Version]
Figure 1.
An example C Major Scale in Legato.
Figure 1.
An example C Major Scale in Legato.
Figure 2.
An example C Major Scale in Staccato.
Figure 2.
An example C Major Scale in Staccato.
Figure 3.
Overview of the system.
Figure 3.
Overview of the system.
Figure 4.
The piano performance assessment system using SVM approach.
Figure 4.
The piano performance assessment system using SVM approach.
Figure 5.
The piano performance assessment system using NB Approach.
Figure 5.
The piano performance assessment system using NB Approach.
Figure 6.
Architecture of the 3-layers CNN.
Figure 6.
Architecture of the 3-layers CNN.
Figure 7.
Architecture of the 2-layers LSTM.
Figure 7.
Architecture of the 2-layers LSTM.
Figure 8.
The process of performance assessment for Legato/Staccato notes.
Figure 8.
The process of performance assessment for Legato/Staccato notes.
Figure 9.
Confusion Matrix obtained with SVM for Legato performance.
Figure 9.
Confusion Matrix obtained with SVM for Legato performance.
Figure 10.
Confusion Matrix obtained with NB for Legato performance.
Figure 10.
Confusion Matrix obtained with NB for Legato performance.
Figure 11.
Confusion Matrix obtained with CNN for Legato performance.
Figure 11.
Confusion Matrix obtained with CNN for Legato performance.
Figure 12.
Confusion Matrix obtained with LSTM for Legato performance.
Figure 12.
Confusion Matrix obtained with LSTM for Legato performance.
Figure 13.
Confusion Matrix obtained with SVM for Staccato performance.
Figure 13.
Confusion Matrix obtained with SVM for Staccato performance.
Figure 14.
Confusion Matrix obtained with NB for Staccato performance.
Figure 14.
Confusion Matrix obtained with NB for Staccato performance.
Figure 15.
Confusion Matrix obtained with CNN for Staccato performance.
Figure 15.
Confusion Matrix obtained with CNN for Staccato performance.
Figure 16.
Confusion Matrix obtained with LSTM for Staccato performance.
Figure 16.
Confusion Matrix obtained with LSTM for Staccato performance.
Figure 17.
Architecture of the 2-layers CNN with Filters.
Figure 17.
Architecture of the 2-layers CNN with Filters.
Figure 18.
Waveforms and Spectrograms of piano performances played with left hand.
Figure 18.
Waveforms and Spectrograms of piano performances played with left hand.
Figure 19.
Waveforms and Spectrograms of piano performances played with right hand.
Figure 19.
Waveforms and Spectrograms of piano performances played with right hand.
Figure 20.
Waveforms and Spectrograms of piano performances played with both left and right hands.
Figure 20.
Waveforms and Spectrograms of piano performances played with both left and right hands.
Figure 21.
Waveforms and Spectrograms of piano performances with the overall played.
Figure 21.
Waveforms and Spectrograms of piano performances with the overall played.
Figure 22.
Confusion Matrix of classifying piano performance of Twinkle Twinkle played with left hand.
Figure 22.
Confusion Matrix of classifying piano performance of Twinkle Twinkle played with left hand.
Figure 23.
Confusion Matrix of classifying piano performance of Twinkle Twinkle played with right hand.
Figure 23.
Confusion Matrix of classifying piano performance of Twinkle Twinkle played with right hand.
Figure 24.
Confusion Matrix of classifying piano performance of Twinkle Twinkle played with both left and right hands.
Figure 24.
Confusion Matrix of classifying piano performance of Twinkle Twinkle played with both left and right hands.
Figure 25.
Confusion Matrix of classifying piano performance of Twinkle Twinkle with the overall played.
Figure 25.
Confusion Matrix of classifying piano performance of Twinkle Twinkle with the overall played.
Table 1.
Recording equipment and specifications.
Table 1.
Recording equipment and specifications.
| Descriptions |
|---|
| Sampling rate | 22,050 Hz |
| Channel | monophonic |
| Resolution | 16 bits |
| Microphone model | Audio-technical serial no. AT9931PC |
Table 2.
The Category of Scales and Accidentals.
Table 2.
The Category of Scales and Accidentals.
| Major Scales | Number of Accidentals | Minor Scales | Number of Key Signatures |
|---|
| C Major | No | D Minor | 1 Flat |
| F Major | 1 Flat | E Minor | 1 Sharp |
| G Major | 1 Sharp | A Minor | No |
Table 3.
Our databases.
| DB-1 | Scales | Legato | #Training = 1080 |
| #Testing = 1260 |
| Staccato | #Training = 1080 |
| #Testing = 1260 |
| DB-2 | Songs for Kids | Hot Cross Bun | #Training = 54 |
| #Testing = 63 |
| Beautiful Brown Eyes | #Training = 54 |
| #Testing = 63 |
| Jingle Bell | #Training = 54 |
| #Testing = 63 |
| The Cuckoo | #Training = 54 |
| #Testing = 63 |
| Twinkle Twinkle | #Training = 54 |
| #Testing = 63 |
Table 4.
Experiment results for Legato part.
Table 4.
Experiment results for Legato part.
| Classifiers | Accuracy (%) |
|---|
| SVM | 83.80% |
| NB | 60.87% |
| CNN | 93.65% |
| LSTM | 64.12% |
Table 5.
Staccato part results.
Table 5.
Staccato part results.
| Classifiers | Accuracy (%) |
|---|
| SVM | 82.03% |
| NB | 54.12% |
| CNN | 89.36% |
| LSTM | 49.44% |
Table 6.
K-fold Cross-Validation results.
Table 6.
K-fold Cross-Validation results.
| Round | Legato | Staccato |
|---|
| Accuracy (%) | Accuracy (%) |
|---|
| 1 | 91.03% | 85.51% |
| 2 | 85.41% | 79.86% |
| 3 | 87.50% | 84.02% |
| 4 | 93.05% | 81.25% |
| 5 | 90.97% | 81.94% |
| 6 | 88.19% | 80.55% |
| 7 | 95.83% | 85.41% |
| 8 | 85.41% | 82.63% |
| 9 | 89.58% | 88.88% |
| 10 | 89.58% | 84.82% |
| Average | 89.66% | 83.49% |
Table 7.
CNN Classification results for kids’ songs.
Table 7.
CNN Classification results for kids’ songs.
| Song | Left Hand
Accuracy (%) | Right Hand
Accuracy (%) | Both Left and Right Hands
Accuracy (%) | Overall
Accuracy (%) |
|---|
| Hot Cross Buns | 82.33% | 73.22% | 75.91% | 90.47% |
| Beautiful Brown Eyes | 69.34% | 68.22% | 90.81% | 90.32% |
| Jingle Bell | 85.77% | 61.17% | 87.76% | 88.70% |
| The Cuckoo | 83.86% | 61.46% | 74.46% | 83.87% |
| Twinkle Twinkle | 100% | 87.50% | 75.00% | 80.64% |
| Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}