
Bituminous Mixtures Experimental Data Modeling Using a Hyperparameters-Optimized Machine Learning Approach

 ,
,  ,
,  ,
,  ,
, 

Abstract
:1. Introduction
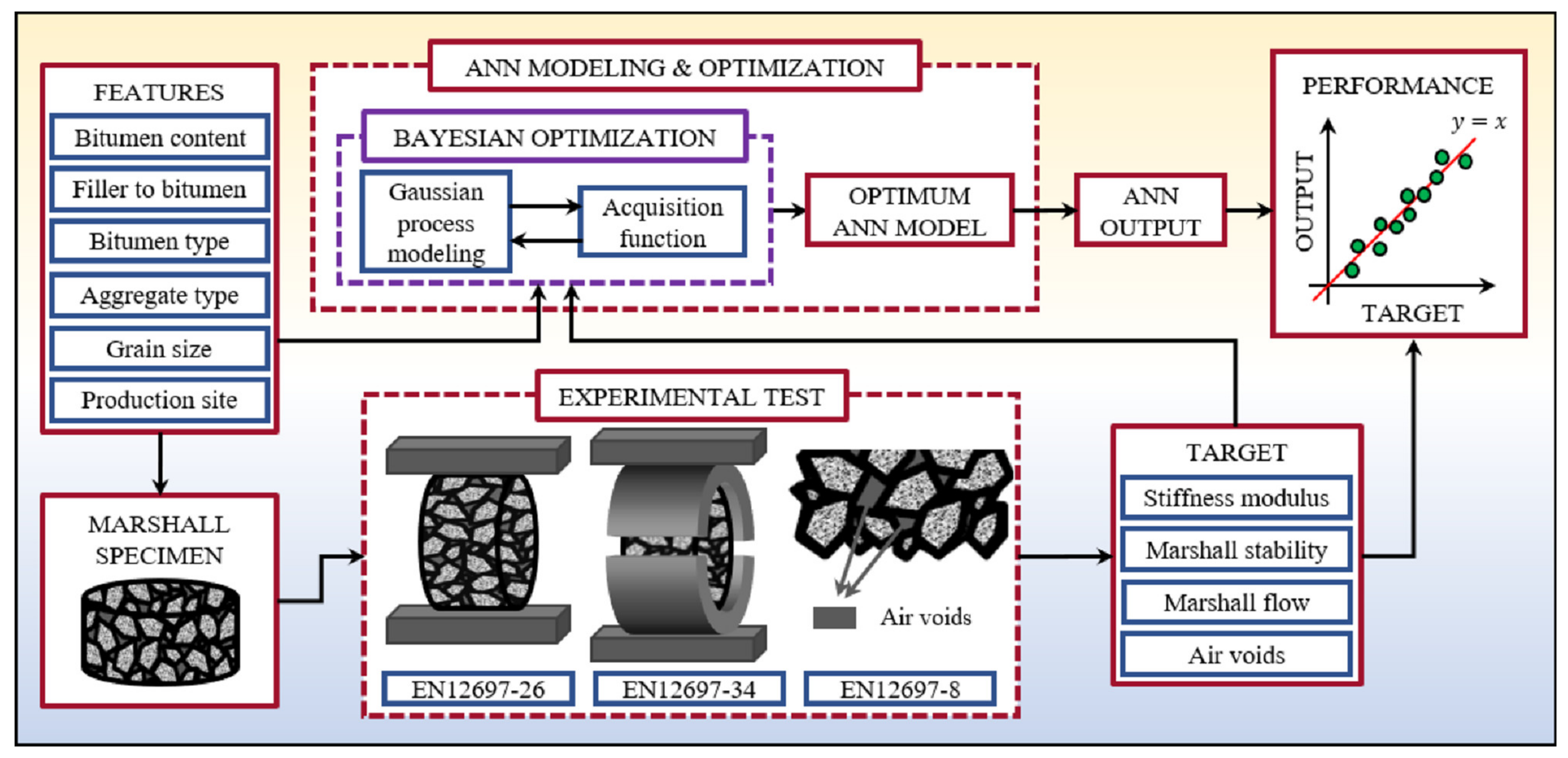
2. Materials and Experimental Design
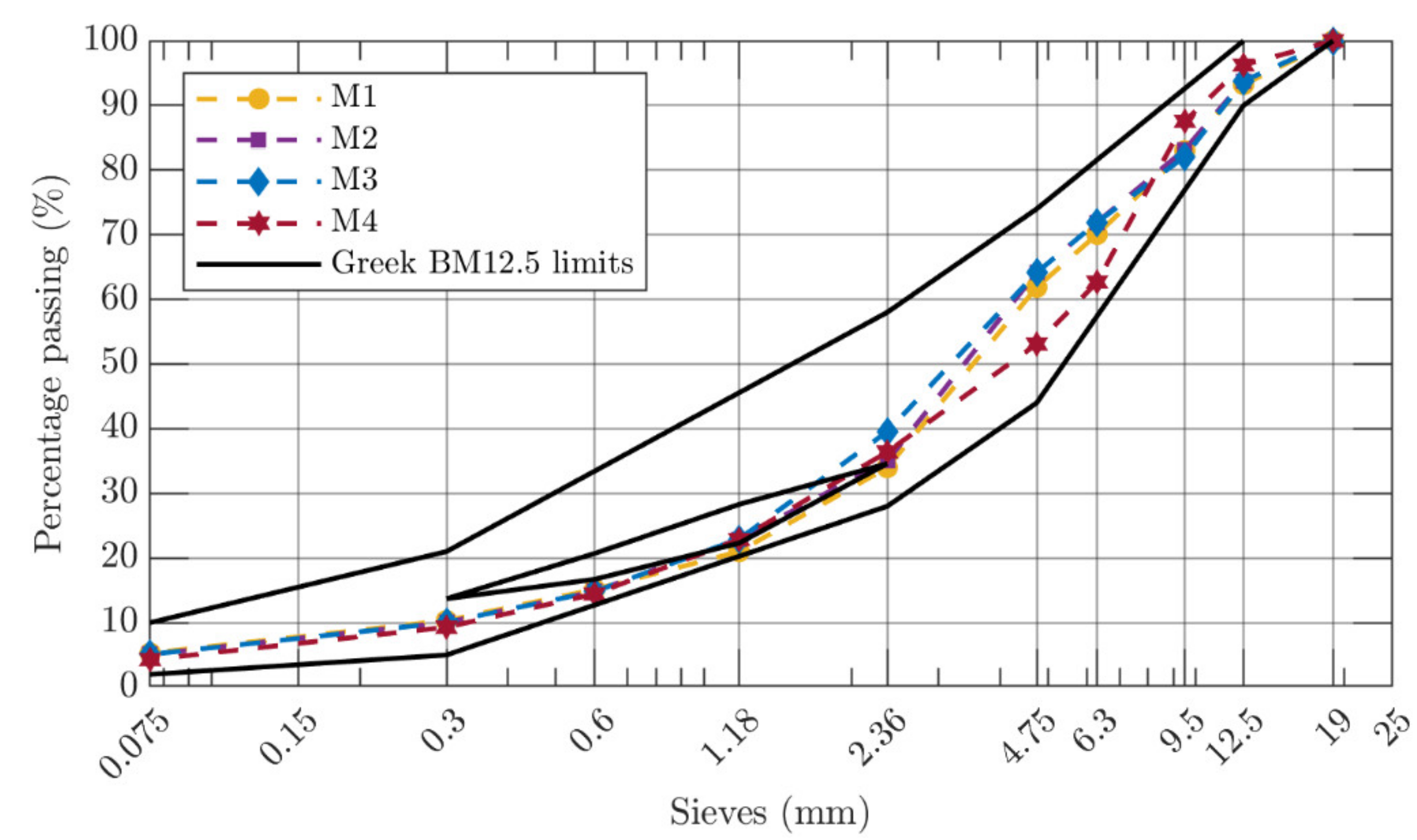
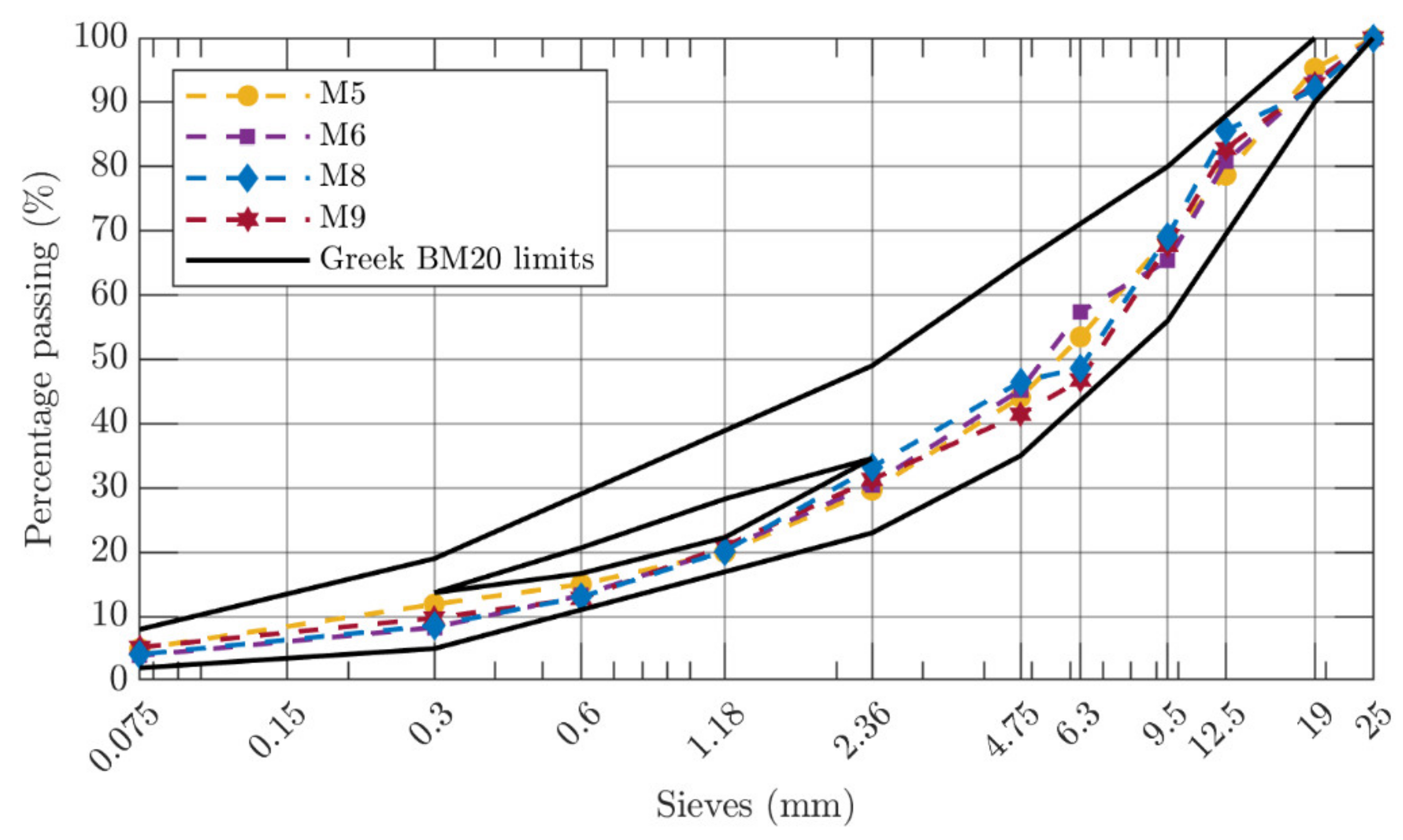
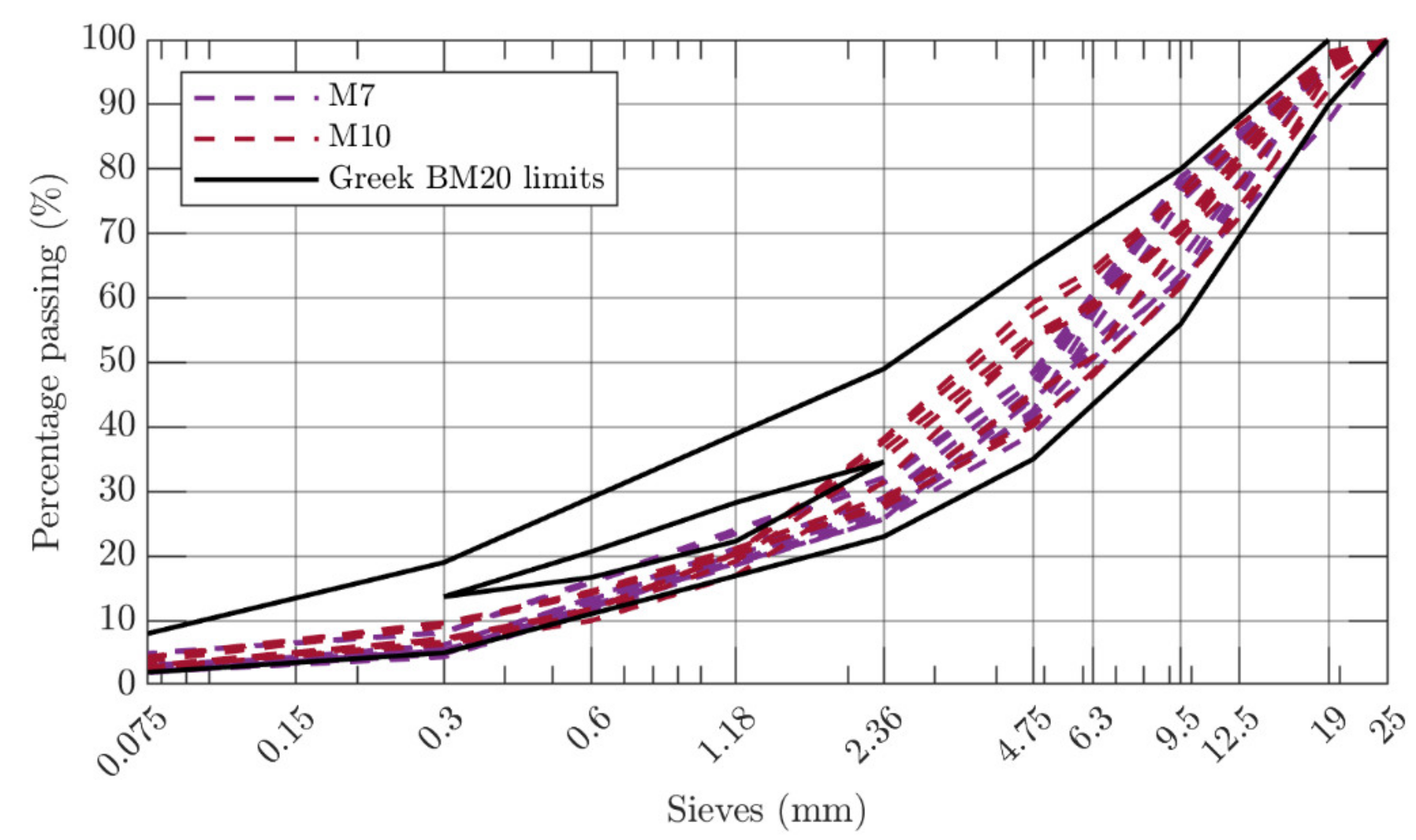
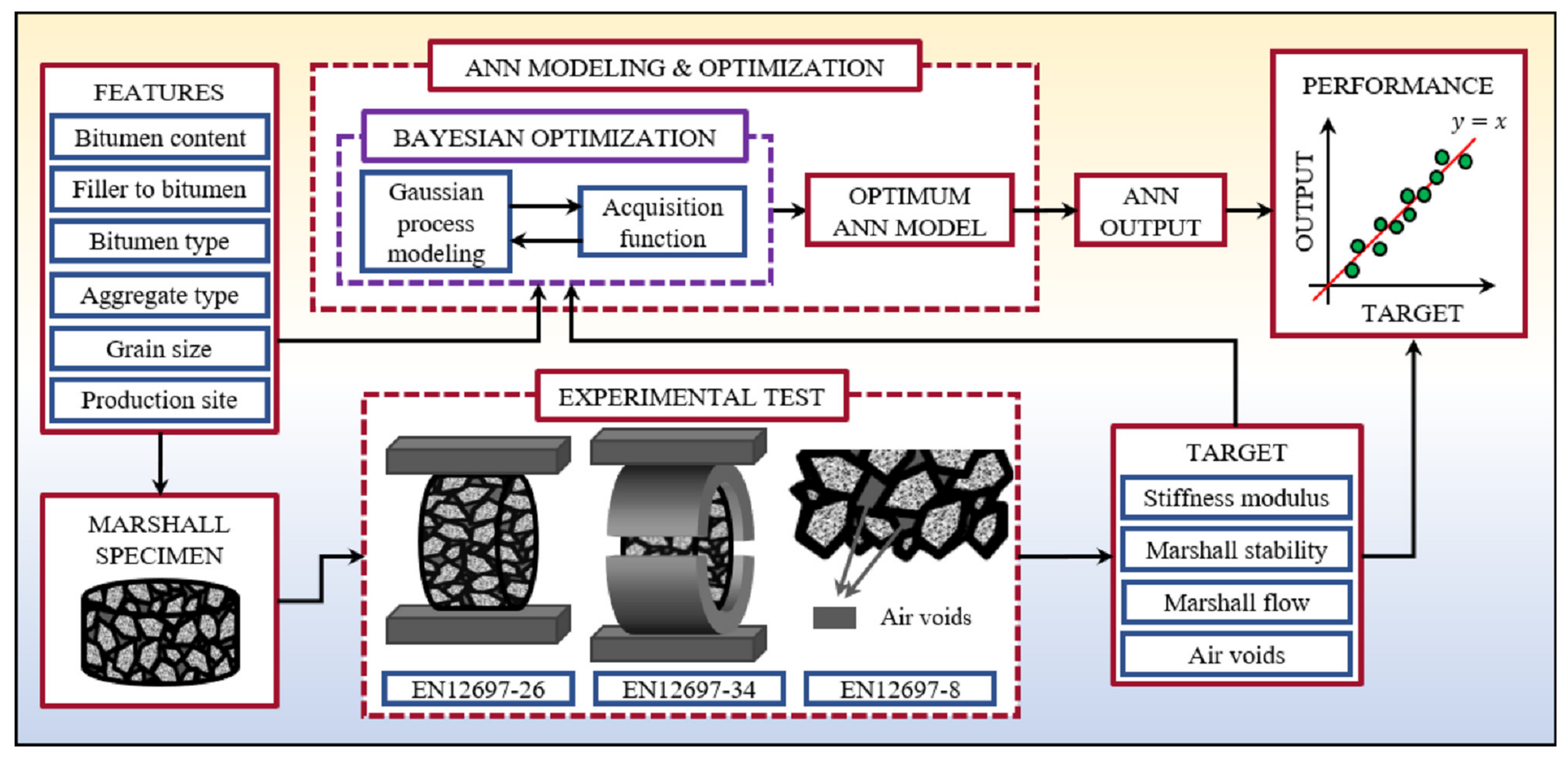
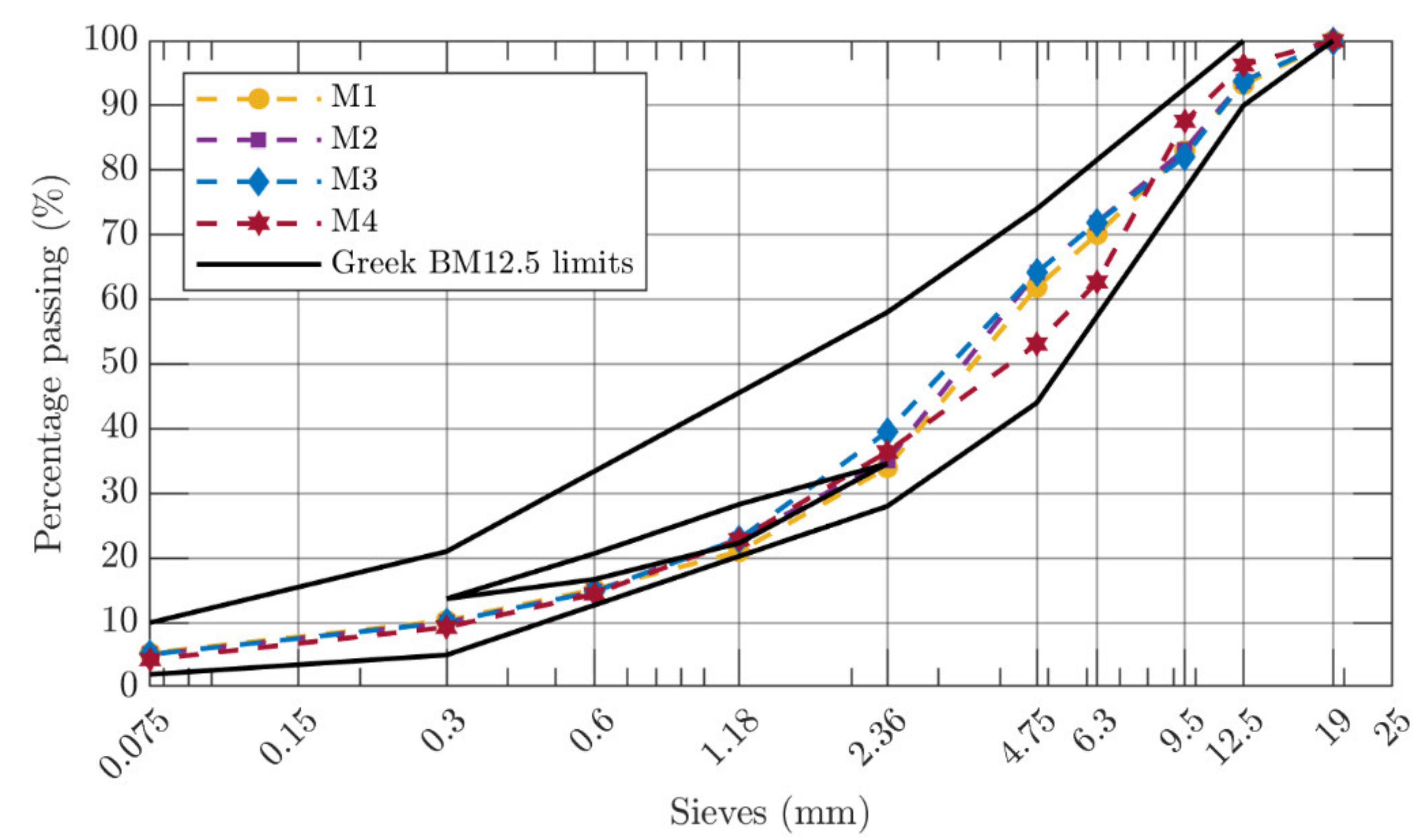
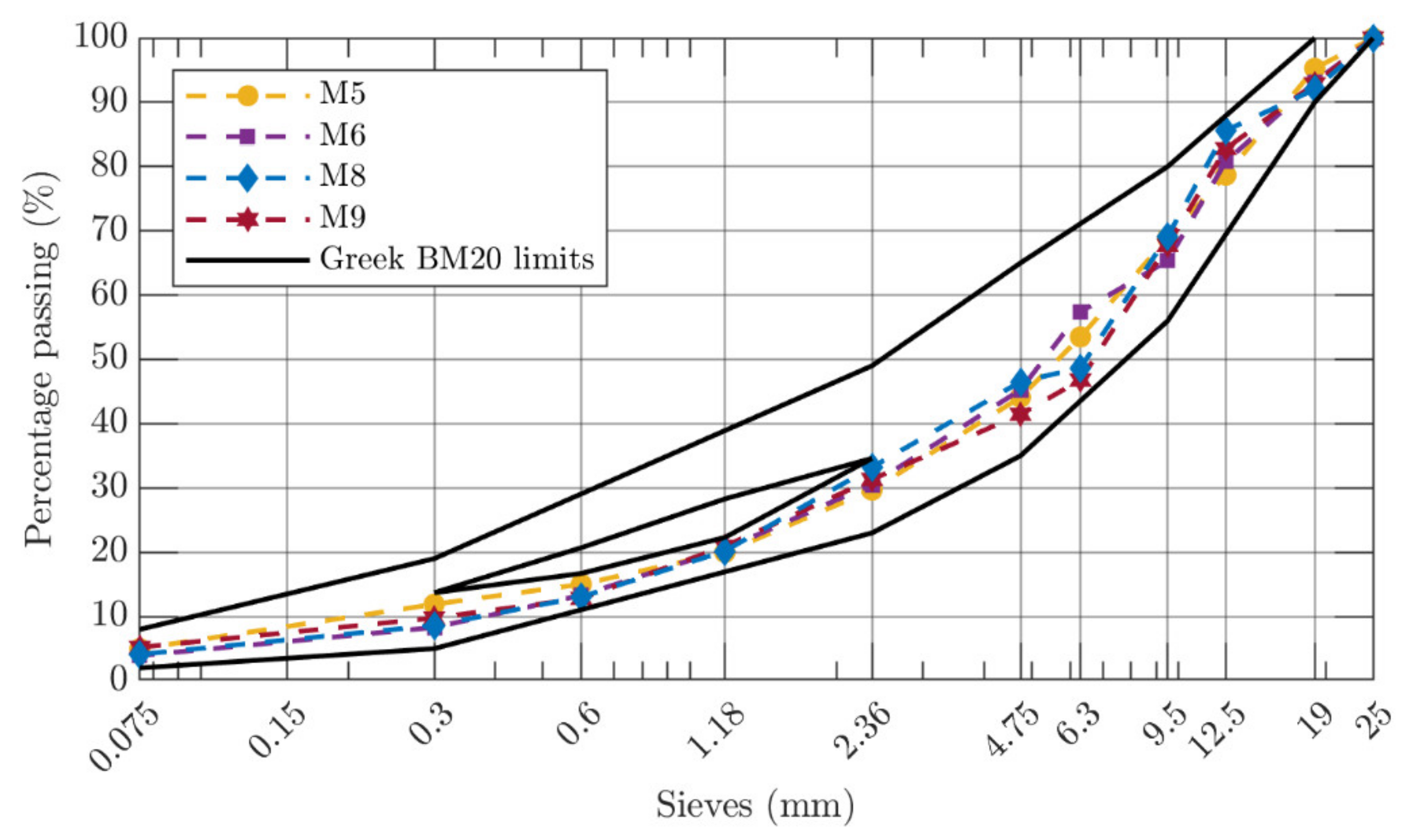
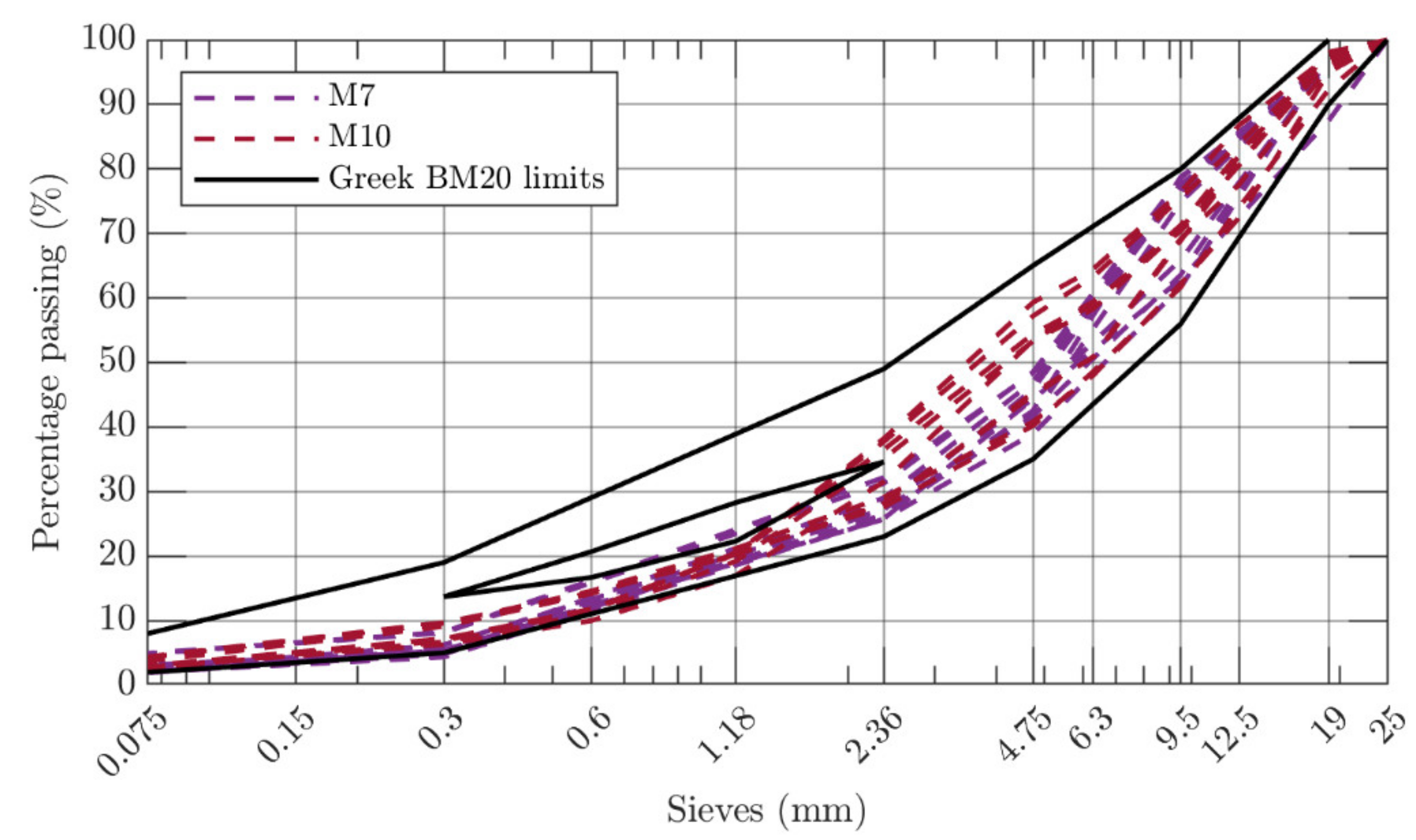
2.1. Materials
2.2. Experimental Design
3. Methodology
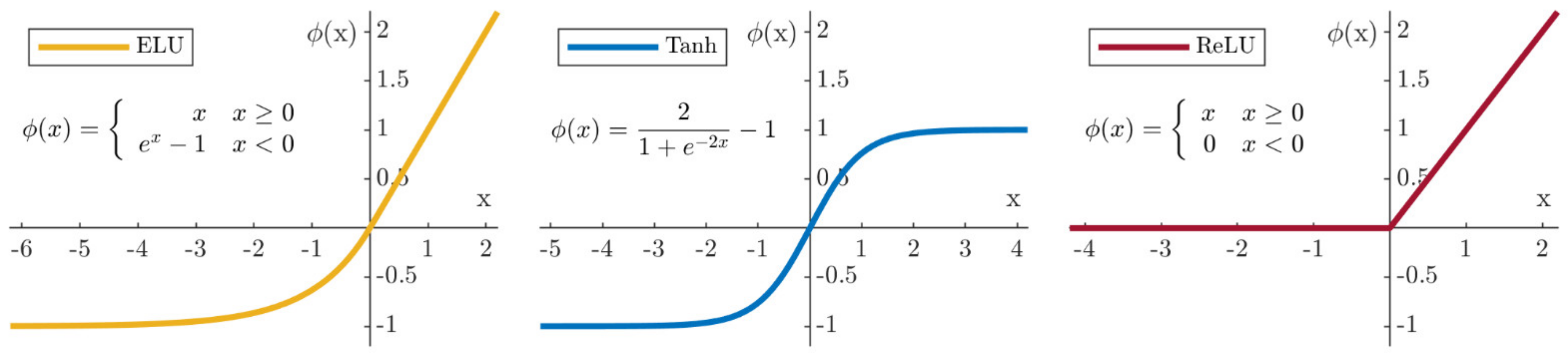
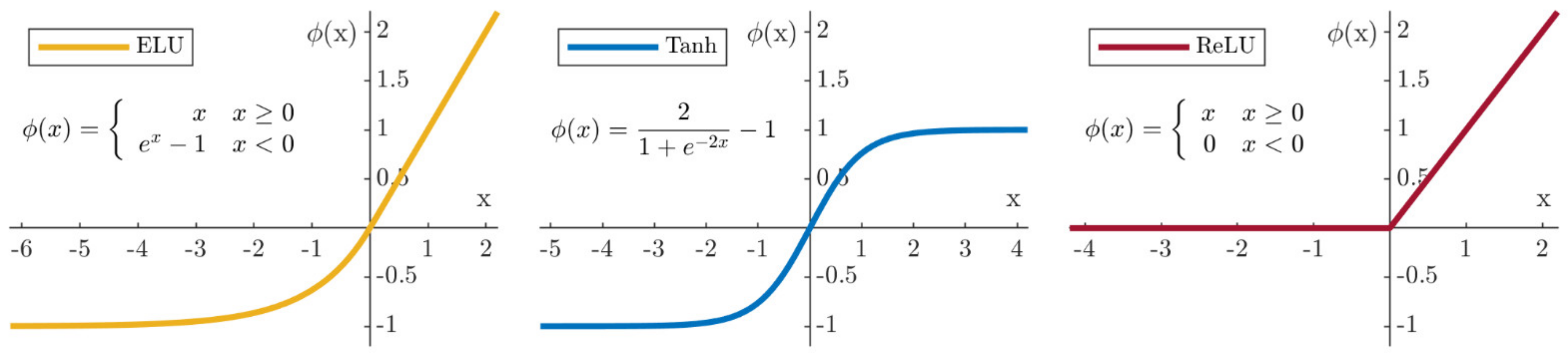
3.1. Artificial Neural Networks
3.2. ANN Optimization
3.3. ANN Regularization
3.4. k-Fold Cross Validation
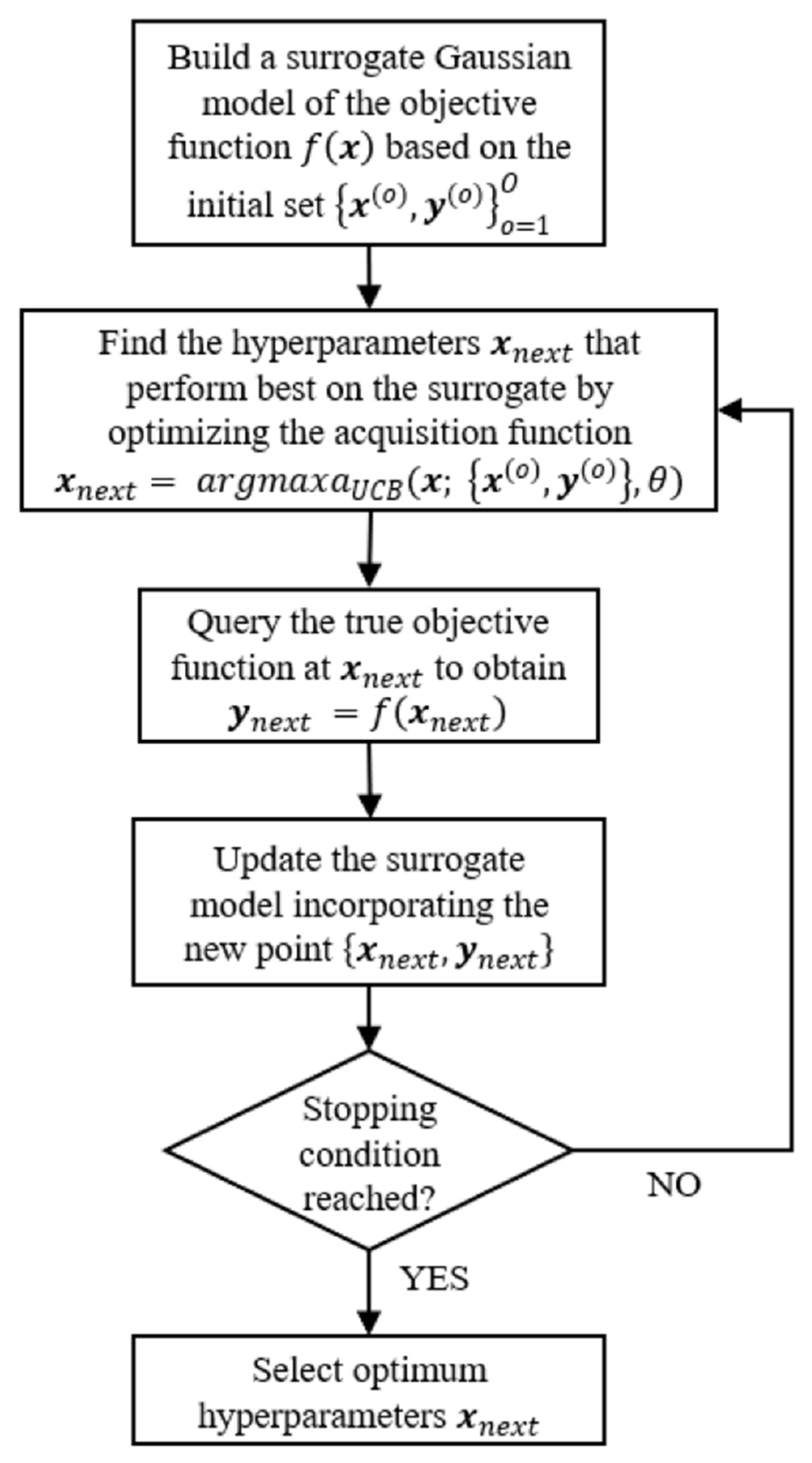
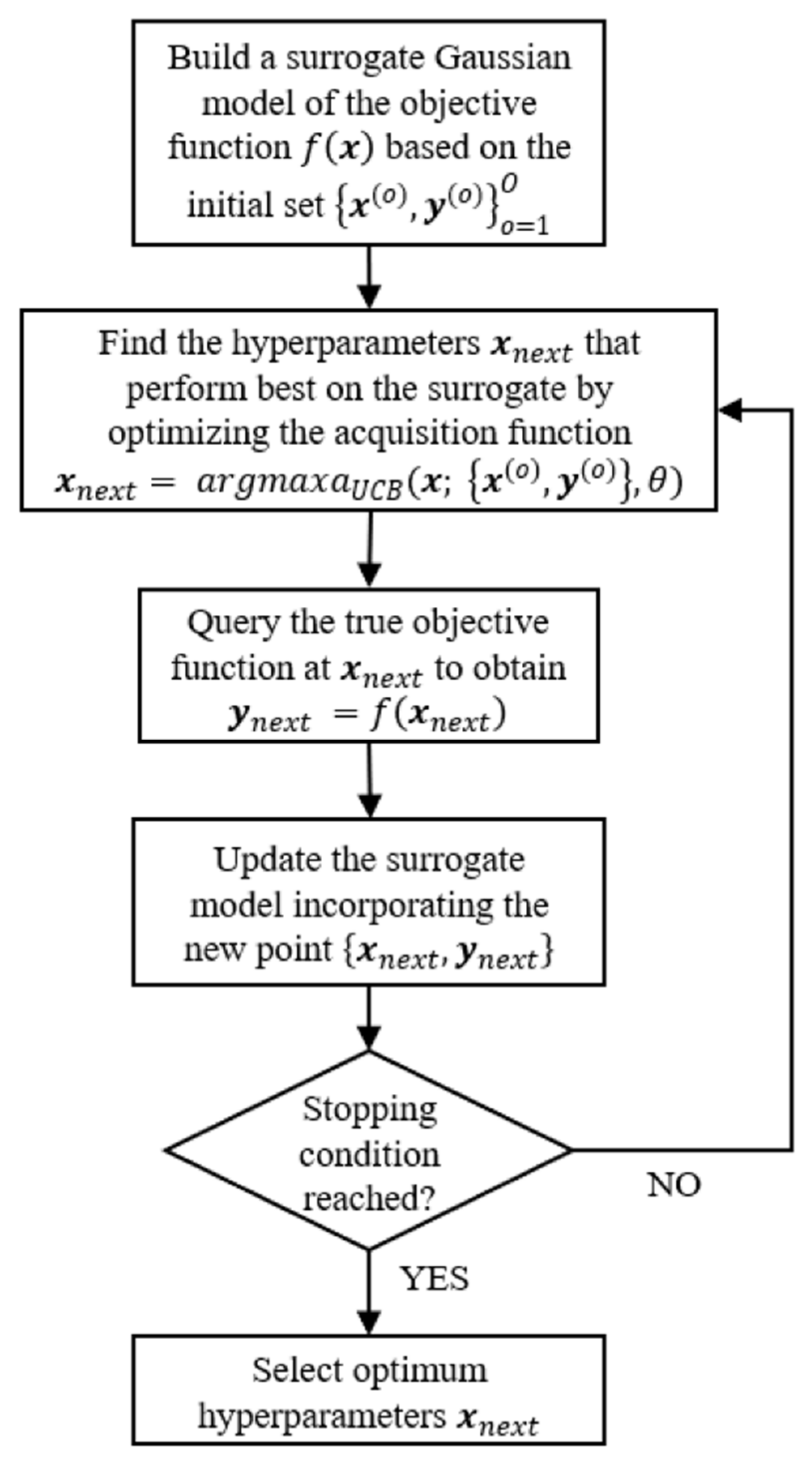
3.5. Bayesian Hyperparameters Optimization
- , for the number of hidden network layers L;
- , for the number of neurons for each hidden layer;
- for the set of activation functions to be applied after each hidden layer;
- for the learning rate ;
- for the weight decay parameter ;
- for the number of learning process iterations.
3.6. Implementation Details
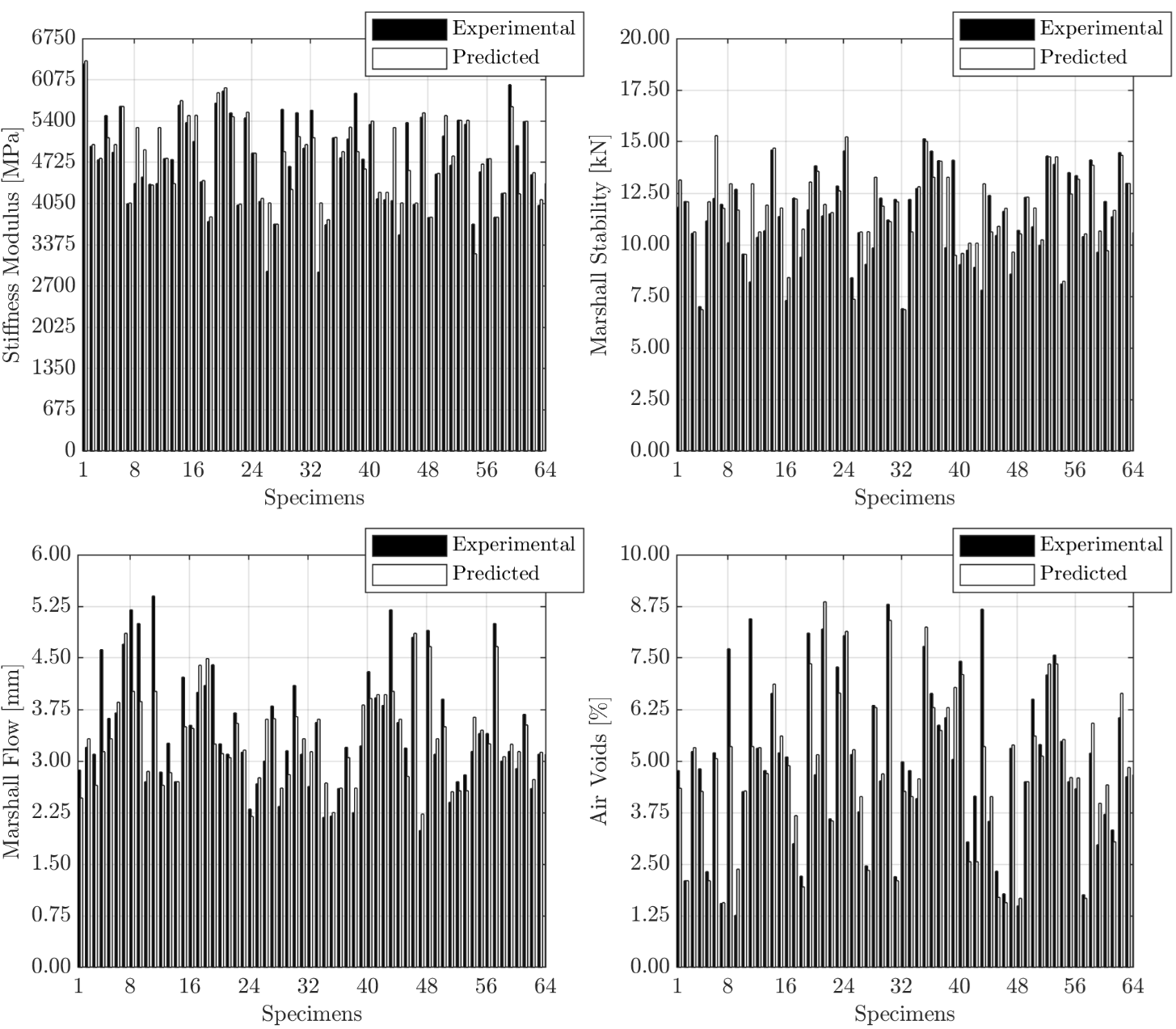
4. Results and Discussion
5. Conclusions
- To perform proper neural modeling, the evaluation of the several network structures resulting from the selection of different model hyperparameters values is required. The procedure developed in this article allowed the limitations of the most widely used ANN toolbox to be overcome.
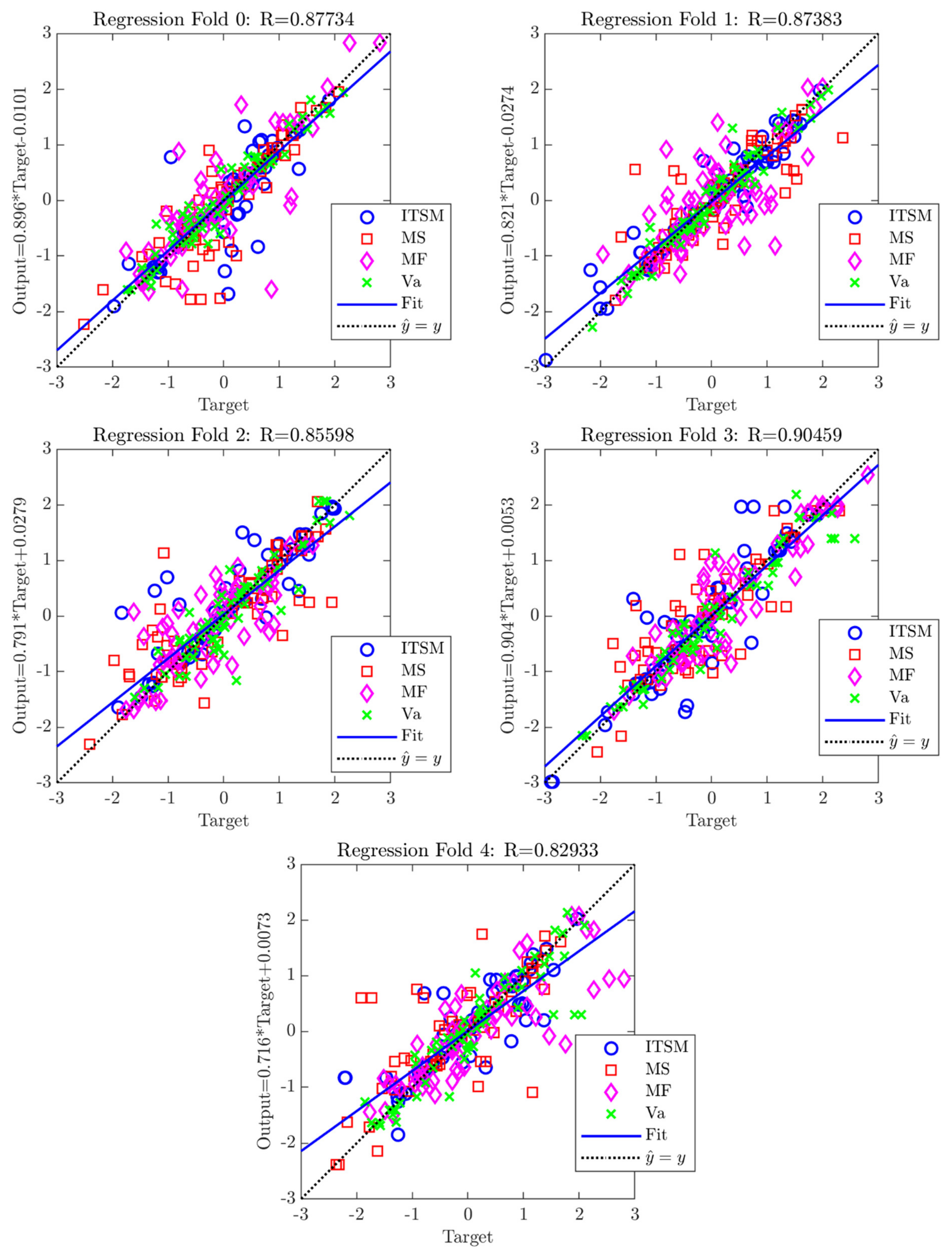
- The proposed approach with the k-fold CV produces more reliable results in terms of model validation error, with respect to the standard grid search based on a random data set partition: in fact, if the procedure were based on a fixed random split of the available data set, different results are possible, worse (R4 = 0.829) or better (R3 = 0.906) than the most likely situation represented by the k-fold CV (RCV = 0.868), due to the different distribution of the training and validation data.
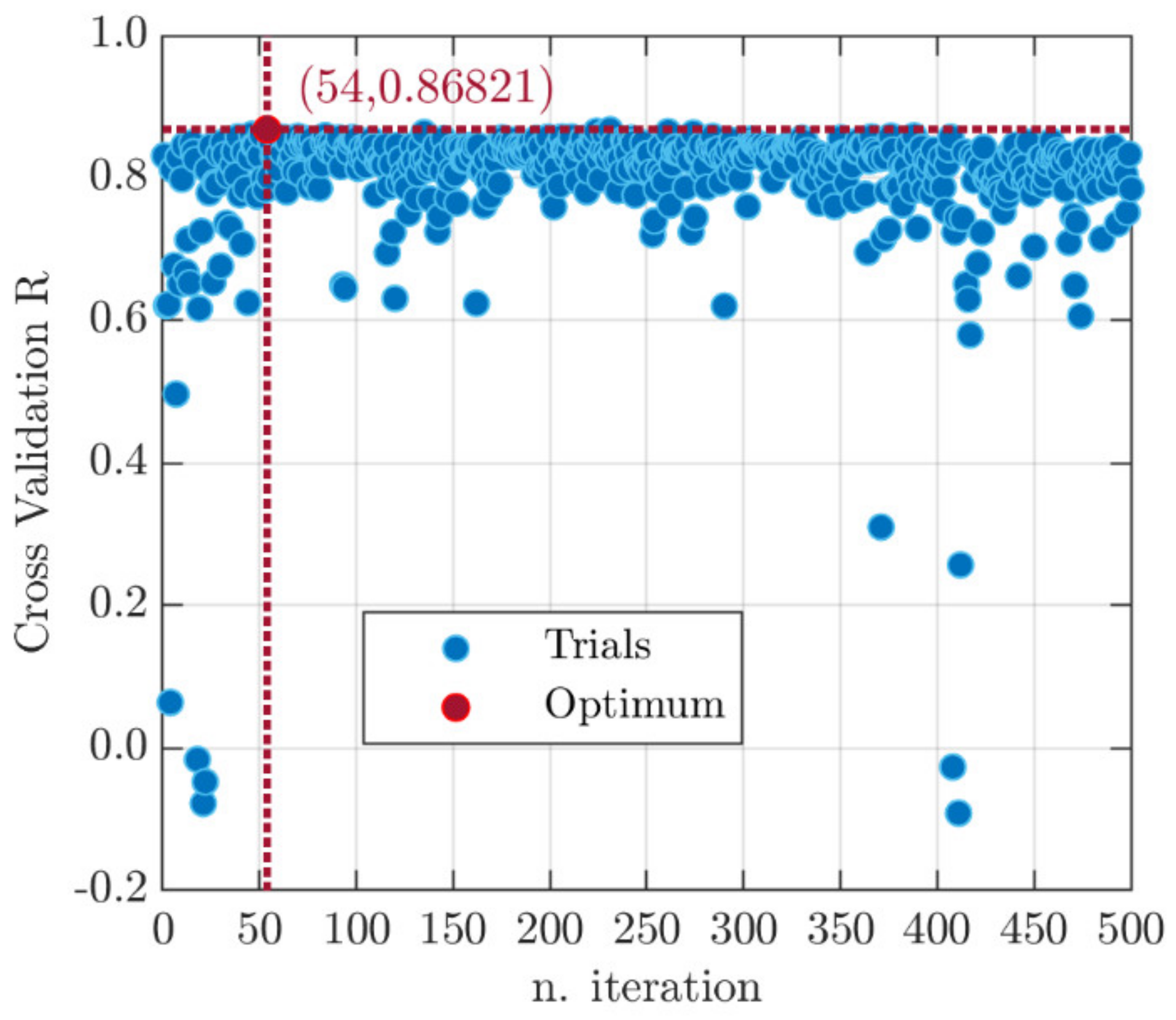
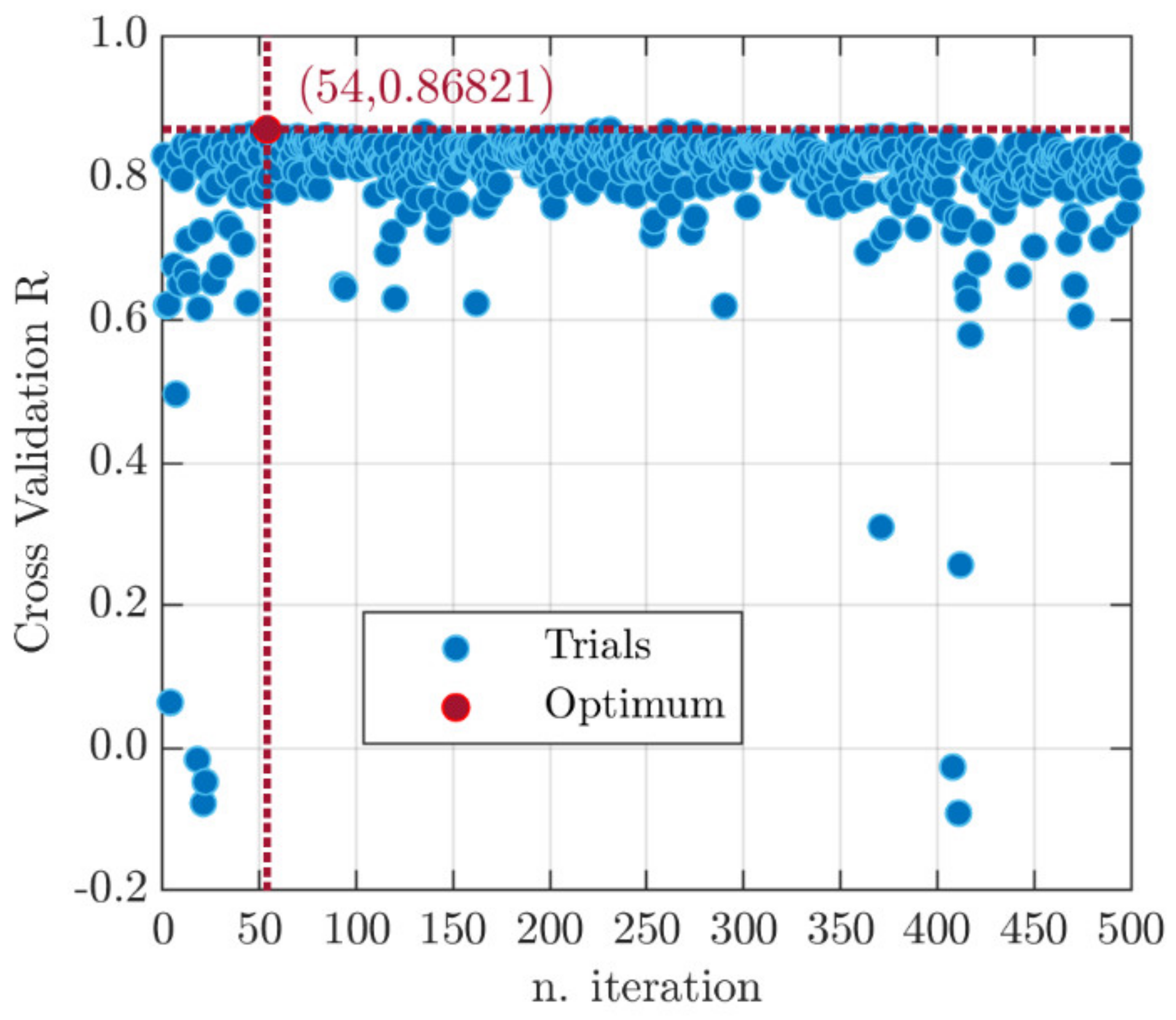
- The BO algorithm has shown to be successful in solving the challenging problem of properly setting the model hyperparameters: it has identified the optimal solution, in terms of algorithmic and structural configuration of the ANN, in only 54 iterations. The hallmark of such a technique lies in the ability to take past evaluations into account so as to limit the loss function recalls. Nonetheless, the reader should be aware that the BO procedure results may be linked to the constraints set by the research engineer in terms of hyperparameters’ variability.
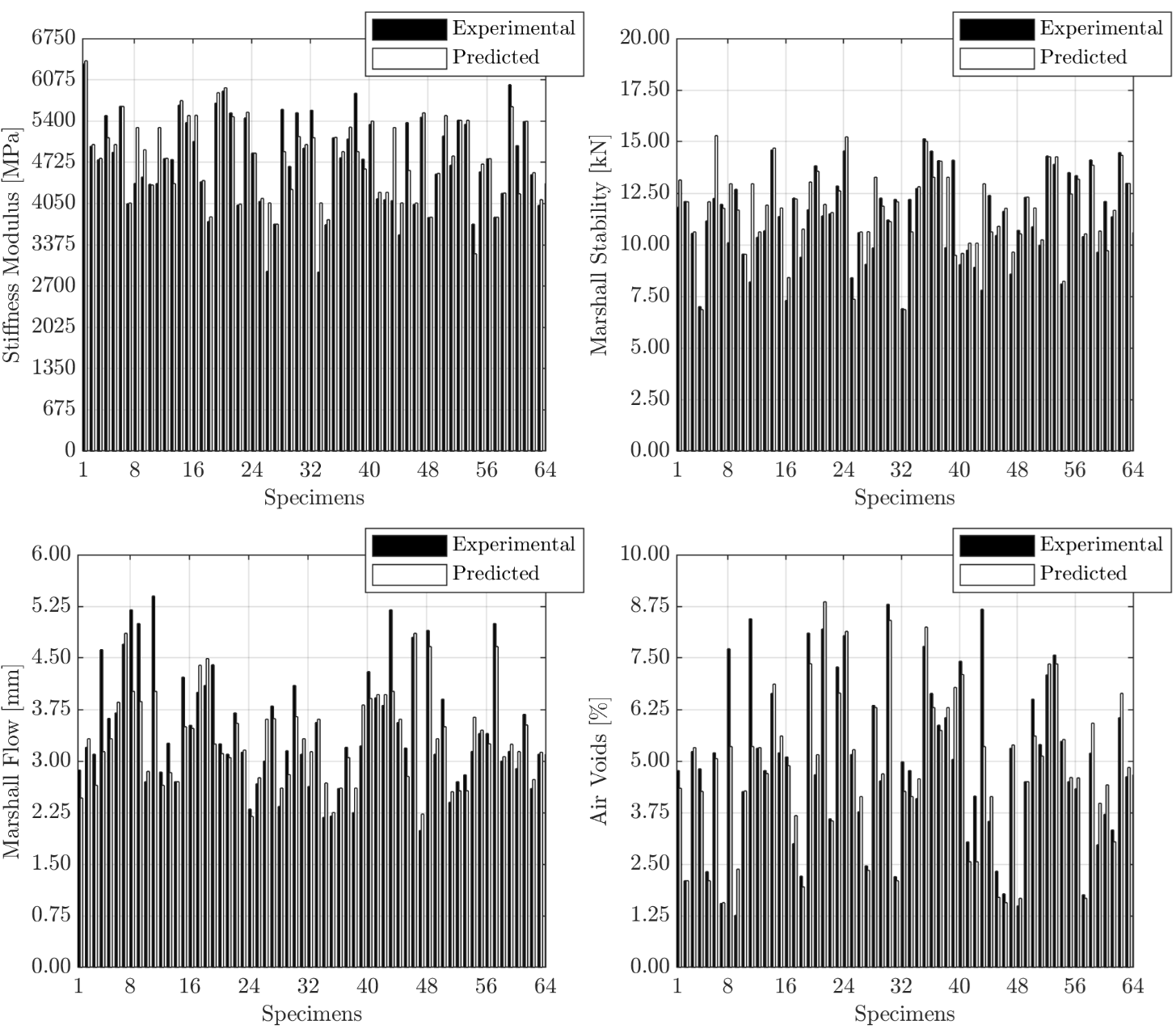
- In the current paper, Marshall parameters, ITSM, as well as AV content have been determined simultaneously by a single multi-output ANN, unlike previous studies; therefore, such approach represents an integrated predictive model of the selected mechanical and volumetric properties.
- The neural network structure best suited (MSECV = 0.249, RCV = 0.868) to model experimental mixtures data is defined by 5 layers, 37 neurons in each hidden layer and transfer function. A learning step size equal to 0.01 and weight decay equal to are implemented in the Ranger training algorithm.
- The algorithms applied and the analytical steps taken by the artificial networks have been illustrated in detail to make the procedure followed replicable to the reader. If it is desired to put the proposed model into service for the designed application (e.g., use in a laboratory or plant for estimates of mechanical parameters and volumetric properties of bituminous mixtures), then the optimized ANN must be trained with all available data.
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhou, F.; Scullion, T.; Sun, L. Verification and modeling of three-stage permanent deformation behavior of asphalt mixes. J. Transp. Eng. 2004, 130, 486–494. [Google Scholar] [CrossRef]
- Gandomi, A.H.; Alavi, A.H.; Mirzahosseini, M.R.; Nejad, F.M. Nonlinear genetic-based models for prediction of flow number of asphalt mixtures. J. Mater. Civ. Eng. 2011, 23, 248–263. [Google Scholar] [CrossRef]
- Alavi, A.H.; Ameri, M.; Gandomi, A.H.; Mirzahosseini, M.R. Formulation of flow number of asphalt mixes using a hybrid computational method. Constr. Build. Mater. 2011, 25, 1338–1355. [Google Scholar] [CrossRef]
- Dias, J.L.F.; Picado-Santos, L.; Capitão, S. Mechanical performance of dry process fine crumb rubber asphalt mixtures placed on the Portuguese road network. Constr. Build. Mater. 2014, 73, 247–254. [Google Scholar] [CrossRef]
- Liu, Q.T.; Wu, S.P. Effects of steel wool distribution on properties of porous asphalt concrete. Key engineering materials. Trans. Tech Publ. 2014, 599, 150–154. [Google Scholar] [CrossRef]
- Garcia, A.; Norambuena-Contreras, J.; Bueno, M.; Partl, M.N. Influence of steel wool fibers on the mechanical, termal, and healing properties of dense asphalt concrete. J. Test. Eval. 2014, 42, 1107–1118. [Google Scholar] [CrossRef]
- Pasandín, A.; Pérez, I. Overview of bituminous mixtures made with recycled concrete aggregates. Constr. Build. Mater. 2015, 74, 151–161. [Google Scholar] [CrossRef] [Green Version]
- Zaumanis, M.; Mallick, R.B.; Frank, R. 100% hot mix asphalt recycling: Challenges and benefits. Transp. Res. Procedia 2016, 14, 3493–3502. [Google Scholar] [CrossRef] [Green Version]
- Wang, L.; Gong, H.; Hou, Y.; Shu, X.; Huang, B. Advances in pavement materials, design, characterisation, and simulation. Road Mater. Pavement Des. 2017, 18, 1–11. [Google Scholar] [CrossRef]
- Erkens, S.; Liu, X.; Scarpas, A. 3D finite element model for asphalt concrete response simulation. Int. J. Geomech. 2002, 2, 305–330. [Google Scholar] [CrossRef]
- Giunta, M.; Pisano, A.A. One-dimensional visco-elastoplastic constitutive model for asphalt concrete. Multidiscip. Modeling Mater. Struct. 2006, 2, 247–264. [Google Scholar] [CrossRef]
- Underwood, S.B.; Kim, R.Y. Viscoelastoplastic continuum damage model for asphalt concrete in tension. J. Eng. Mech. 2011, 137, 732–739. [Google Scholar] [CrossRef]
- Yun, T.; Kim, Y.R. Viscoelastoplastic modeling of the behavior of hot mix asphalt in compression. KSCE J. Civ. Eng. 2013, 17, 1323–1332. [Google Scholar] [CrossRef]
- Pasetto, M.; Baldo, N. Computational analysis of the creep behaviour of bituminous mixtures. Constr. Build. Mater. 2015, 94, 784–790. [Google Scholar] [CrossRef]
- Di Benedetto, H.; Sauzéat, C.; Clec’h, P. Anisotropy of bituminous mixture in the linear viscoelastic domain. Mech. Time Depend. Mater. 2016, 20, 281–297. [Google Scholar] [CrossRef]
- Pasetto, M.; Baldo, N. Numerical visco-elastoplastic constitutive modelization of creep recovery tests on hot mix asphalt. J. Traffic Transp. Eng. 2016, 3, 390–397. [Google Scholar] [CrossRef]
- Darabi, M.K.; Huang, C.W.; Bazzaz, M.; Masad, E.A.; Little, D.N. Characterization and validation of the nonlinear viscoelastic- viscoplastic with hardening-relaxation constitutive relationship for asphalt mixtures. Constr. Build. Mater. 2019, 216, 648–660. [Google Scholar] [CrossRef]
- Kim, S.H.; Kim, N. Development of performance prediction models in flexible pavement using regression analysis method. KSCE J. Civ. Eng. 2006, 10, 91–96. [Google Scholar] [CrossRef]
- Laurinavičius, A.; Oginskas, R. Experimental research on the development of rutting in asphalt concrete pavements reinforced with geosynthetic materials. J. Civ. Eng. Manag. 2006, 12, 311–317. [Google Scholar] [CrossRef]
- Shukla, P.K.; Das, A. A re-visit to the development of fatigue and rutting equations used for asphalt pavement design. Int. J. Pavement Eng. 2008, 9, 355–364. [Google Scholar] [CrossRef]
- Rahman, A.A.; Mendez Larrain, M.M.; Tarefder, R.A. Development of a nonlinear rutting model for asphalt concrete based on Weibull parameters. Int. J. Pavement Eng. 2019, 20, 1055–1064. [Google Scholar] [CrossRef]
- Specht, L.P.; Khatchatourian, O.; Brito, L.A.T.; Ceratti, J.A.P. Modeling of asphalt-rubber rotational viscosity by statistical analysis and neural networks. Mater. Res. 2007, 10, 69–74. [Google Scholar] [CrossRef]
- Mirzahosseini, M.R.; Aghaeifar, A.; Alavi, A.H.; Gandomi, A.H.; Seyednour, R. Permanent deformation analysis of asphalt mixtures using soft computing techniques. Expert Syst. Appl. 2011, 38, 6081–6100. [Google Scholar] [CrossRef]
- Androjić, I.; Marović, I. Development of artificial neural network and multiple linear regression models in the prediction process of the hot mix asphalt properties. Can. J. Civ. Eng. 2017, 44, 994–1004. [Google Scholar] [CrossRef]
- Alrashydah, E.I.; Abo-Qudais, S.A. Modeling of creep compliance behavior in asphalt mixes using multiple regression and artificial neural networks. Constr. Build. Mater. 2018, 159, 635–641. [Google Scholar] [CrossRef]
- Ziari, H.; Amini, A.; Goli, A.; Mirzaiyan, D. Predicting rutting performance of carbon nano tube (CNT) asphalt binders using regression models and neural networks. Constr. Build. Mater. 2018, 160, 415–426. [Google Scholar] [CrossRef]
- Montoya, M.A.; Haddock, J.E. Estimating asphalt mixture volumetric properties using seemingly unrelated regression equations approaches. Constr. Build. Mater. 2019, 225, 829–837. [Google Scholar] [CrossRef]
- Lam, N.-T.-M.; Nguyen, D.-L.; Le, D.-H. Predicting compressive strength of roller-compacted concrete pavement containing steel slag aggregate and fly ash. Int. J. Pavement Eng. 2020, 2020, 1–14. [Google Scholar] [CrossRef]
- Baldo, N.; Manthos, E.; Pasetto, M. Analysis of the mechanical behaviour of asphalt concretes using artificial neural networks. Adv. Civ. Eng. 2018, 2018, 1650945. [Google Scholar] [CrossRef] [Green Version]
- Tarefder, R.A.; White, L.; Zaman, M. Neural network model for asphalt concrete permeability. J. Mater. Civ. Eng. 2005, 17, 19–27. [Google Scholar] [CrossRef]
- Ozsahin, T.S.; Oruc, S. Neural network model for resilient modulus of emulsified asphalt mixtures. Constr. Build. Mater. 2008, 22, 1436–1445. [Google Scholar] [CrossRef]
- Tapkın, S.; Çevik, A.; Uşar, Ü. Accumulated strain prediction of polypropylene modified marshall specimens in repeated creep test using artificial neural networks. Expert Syst. Appl. 2009, 36, 11186–11197. [Google Scholar] [CrossRef]
- Xiao, F.; Amirkhanian, S.; Juang, C.H. Prediction of fatigue life of rubberized asphalt concrete mixtures containing reclaimed asphalt pavement using artificial neural networks. J. Mater. Civ. Eng. 2009, 21, 253–261. [Google Scholar] [CrossRef]
- Ahmed, T.M.; Green, P.L.; Khalid, H.A. Predicting fatigue performance of hot mix asphalt using artificial neural networks. Road Mater. Pavement Des. 2017, 18, 141–154. [Google Scholar] [CrossRef]
- Ceylan, H.; Schwartz, C.W.; Kim, S.; Gopalakrishnan, K. Accuracy of predictive models for dynamic modulus of hot-mix asphalt. J. Mater. Civ. Eng. 2009, 21, 286–293. [Google Scholar] [CrossRef] [Green Version]
- Le, T.-H.; Nguyen, H.-L.; Pham, B.T.; Nguyen, M.H.; Pham, C.-T.; Nguyen, N.-L.; Le, T.-T.; Ly, H.-B. Artificial intelligence-based model for the prediction of dynamic modulus of stone mastic asphalt. Appl. Sci. 2020, 10, 5242. [Google Scholar] [CrossRef]
- Ghorbani, B.; Arulrajah, A.; Narsilio, G.; Horpibulsuk, S.; Bo, M.-W. Thermal and mechanical properties of demolition wastes in geothermal pavements by experimental and machine learning techniques. Constr. Build. Mater. 2021, 280, 122499. [Google Scholar] [CrossRef]
- Aksoy, A.; Iskender, E.; Kahraman, H.T. Application of the intuitive k-NN Estimator for prediction of the Marshall Test (ASTM D1559) results for asphalt mixtures. Constr. Build. Mater. 2012, 34, 561–569. [Google Scholar] [CrossRef]
- Van Thanh, D.; Feng, C.P. Study on marshall and rutting test of SMA at abnormally high temperature. Constr. Build. Mater. 2013, 47, 1337–1341. [Google Scholar] [CrossRef]
- Abdoli, M.; Fathollahi, A.; Babaei, R. The application of recycled aggregates of construction debris in asphalt concrete mix design. Int. J. Environ. Res. 2015, 9, 489–494. [Google Scholar] [CrossRef]
- Sarkar, D.; Pal, M.; Sarkar, A.K.; Mishra, U. Evaluation of the properties of bituminous concrete prepared from brick-stone mix aggregate. Adv. Mater. Sci. Eng. 2016, 2016, 2761038. [Google Scholar] [CrossRef] [Green Version]
- Xu, B.; Chen, J.; Zhou, C.; Wang, W. Study on Marshall design parameters of porous asphalt mixture using limestone as coarse aggregate. Constr. Build. Mater. 2016, 124, 846–854. [Google Scholar] [CrossRef]
- Zumrawi, M.M.; Khalill, F.O. Experimental study of steel slag used as aggregate in asphalt mixture. Am. J. Constr. Build. Mater. 2017, 2, 26–32. [Google Scholar] [CrossRef]
- Al-Ammari, M.A.S.; Jakarni, F.M.; Muniandy, R.; Hassim, S. The effect of aggregate and compaction method on the physical properties of hot mix asphalt. IOP Conf. Ser. Mater. Sci. Eng. 2019, 512, 012003. [Google Scholar] [CrossRef]
- Tapkın, S.; Çevik, A.; Uşar, Ü. Prediction of Marshall test results for polypropylene modified dense bituminous mixtures using neural networks. Expert Syst. Appl. 2010, 37, 4660–4670. [Google Scholar] [CrossRef]
- Ozgan, E. Artificial neural network based modelling of the Marshall Stability of asphalt concrete. Expert Syst. Appl. 2011, 38, 6025–6030. [Google Scholar] [CrossRef]
- Khuntia, S.; Das, A.K.; Mohanty, M.; Panda, M. Prediction of marshall parameters of modified bituminous mixtures using artificial intelligence techniques. Int. J. Transp. Sci. Technol. 2014, 3, 211–227. [Google Scholar] [CrossRef] [Green Version]
- Zavrtanik, N.; Prosen, J.; Tušar, M.; Turk, G. The use of artificial neural networks for modeling air void content in aggregate mixture. Autom. Constr. 2016, 63, 155–161. [Google Scholar] [CrossRef]
- James, G.; Witten, D.; Hastie, T.; Tibshirani, R. Resampling methods. In An Introduction to Statistical Learning; Springer: Berlin/Heidelberg, Germany, 2013; Volume 112, Chapter 5; pp. 176–186. [Google Scholar]
- Baldo, N.; Manthos, E.; Miani, M. Stiffness modulus and marshall parameters of hot mix asphalts: Laboratory data modeling by artificial neural networks characterized by cross-validation. Appl. Sci. 2019, 9, 3502. [Google Scholar] [CrossRef] [Green Version]
- Baldo, N.; Miani, M.; Rondinella, F.; Celauro, C. A machine learning approach to determine airport asphalt concrete layer moduli using heavy weight deflectometer data. Sustainability 2021, 13, 8831. [Google Scholar] [CrossRef]
- Shahriari, B.; Swersky, K.; Wang, Z.; Adams, R.P.; de Freitas, N. Taking the human out of the loop: A review of Bayesian optimization. Proc. IEEE 2015, 104, 148–175. [Google Scholar] [CrossRef] [Green Version]
- Bergstra, J.; Bardenet, R.; Bengio, Y.; Kégl, B. Algorithms for hyper-parameter optimization. Proceeding of the 24th Advances in Neural Information Processing Systems (NIPS 2011), Granada, Spain, 12–17 December 2011; Shawe-Taylor, J., Zemel, R., Bartlett, P., Pereira, F., Weinberger, K.Q., Eds.; Curran Associates, Inc.: New York, NY, USA, 2011. [Google Scholar]
- Bergstra, J.; Yamins, D.; Cox, D. Making a science of model search: Hyperparameter optimization in hundreds of dimensions for vision architectures. Int. Conf. Mach. Learn. PMLR 2013, 28, 115–123. [Google Scholar]
- Xiao, F.; Amirkhanian, S.N. Artificial neural network approach to estimating stiffness behavior of rubberized asphalt concrete containing reclaimed asphalt pavement. J. Transp. Eng. 2009, 135, 580–589. [Google Scholar] [CrossRef]
- Widrow, B.; Hoff, M.E. Adaptive Switching Circuits; Technical Report; Stanford University, Ca Stanford Electronics Labs: Stanford, CA, USA, 1960. [Google Scholar]
- Rosenblatt, F. Principles of Neurodynamics: Perceptrons and the Theory of Brain Mechanisms; Technical Report; Cornell Aeronautical Lab Inc.: Buffalo, NY, USA, 1961. [Google Scholar]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- McCulloch, W.S.; Pitts, W. A logical calculus of the ideas immanent in nervous activity. Bull. Math. Biophys. 1943, 5, 115–133. [Google Scholar] [CrossRef]
- Demuth, H.B.; Beale, M.H.; de Jess, O.; Hagan, M.T. Neural Network Design; Martin Hagan: Stillwater, OK, USA, 2014. [Google Scholar]
- Hagan, M.T.; Menhaj, M.B. Training feedforward networks with the Marquardt algorithm. IEEE Trans. Neural Netw. 1994, 5, 989–993. [Google Scholar] [CrossRef] [PubMed]
- Liu, L.; Jiang, H.; He, P.; Chen, W.; Liu, X.; Gao, J.; Han, J. On the variance of the adaptive learning rate and beyond. arXiv 2019, arXiv:1908.03265. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Zhang, M.R.; Lucas, J.; Hinton, G.; Ba, J. Lookahead optimizer: K steps forward, 1 step back. arXiv 2019, arXiv:1907.08610. [Google Scholar]
- Ng, A.Y. Feature selection, L 1 vs. L 2 regularization, and rotational invariance. In Proceedings of the 21th International Conference on Machine learning, Banff, AB, Canada, 4–8 July 2004; pp. 615–622. [Google Scholar] [CrossRef] [Green Version]
- Snoek, J.; Larochelle, H.; Adams, R.P. Practical bayesian optimization of machine learning algorithms. arXiv 2012, arXiv:1206.2944. [Google Scholar]
- Rasmussen, C.E. Gaussian Processes in Machine Learning. Summer School on Machine Learning; Springer: Berlin/Heidelberg, Germany, 2003; pp. 63–71. [Google Scholar]
- Kushner, H.J. A New Method of locating the maximum point of an arbitrary multipeak curve in the presence of noise. J. Basic Eng. 1964, 86, 97–106. [Google Scholar] [CrossRef]
- Mockus, J.; Tiesis, V.; Zilinskas, A. The application of Bayesian methods for seeking the extremum. In Towards Global Optimization, 2nd ed.; Dixon, L.C.W., Szego, G.P., Eds.; North Holland Publishing Co.: Amsterdam, The Netherlands, 1978; pp. 117–129. [Google Scholar]
- Srinivas, N.; Krause, A.; Kakade, S.M.; Seeger, M. Gaussian process optimization in the bandit setting: No regret and experimental design. arXiv 2009, arXiv:0912.3995. [Google Scholar]
- Nogueira, F. Bayesian Optimization: Open Source Constrained Global Optimization Tool for Python. Available online: https://github.com/fmfn/BayesianOptimization (accessed on 25 November 2021).



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Property | Aggregate Type | |
|---|---|---|
| Limestone | Diabase | |
| Los Angeles coeff. (%), EN 1097-2 | 29 | 25 |
| Polished stone value (%), EN 1097-8 | - | 55 to 60 |
| Flakiness index (%), EN 933-3 | 23 | 18 |
| Sand equivalent (%), EN 933-8 | 79 | 59 |
| Methylene blue v. (mg/g), EN 933-9 | 3.3 | 8.3 |
| Property | Bitumen Type | |
|---|---|---|
| 50/70 | Modified | |
| Penetration (0.1 × mm), EN1426 | 64 | 45 |
| Softening point (°C), EN1427 | 45.6 | 78.8 |
| Elastic recovery (%), EN 13398 | - | 97.5 |
| Fraas breaking point (°C), EN 12593 | −7.0 | −15.0 |
| Maximum Size (mm) | Aggregate Type | Bitumen Type | Production Site | Mixture ID | Specimens |
|---|---|---|---|---|---|
| 12.5 | Limestone | 50/70 | Laboratory | M1 | 30 |
| 12.5 | Limestone | Modified | Laboratory | M2 | 30 |
| 12.5 | Diabase | 50/70 | Laboratory | M3 | 30 |
| 12.5 | Diabase | Modified | Laboratory | M4 | 30 |
| 20 | Limestone | 50/70 | Laboratory | M5 | 39 |
| 20 | Limestone | Modified | Laboratory | M6 | 30 |
| 20 | Limestone | Modified | Plant | M7 | 41 |
| 20 | Diabase | 50/70 | Laboratory | M8 | 30 |
| 20 | Diabase | Modified | Laboratory | M9 | 30 |
| 20 | Diabase | Modified | Plant | M10 | 30 |
| Mixture ID | Parameter | Minimum Value | Maximum Value | Mean Value | Standard Deviation |
|---|---|---|---|---|---|
| M1 | ITSM (MPa) | 3756 | 5554 | 4556.43 | 567.93 |
| MS (kN) | 7.71 | 12.17 | 9.93 | 1.09 | |
| MF (mm) | 1.99 | 4.70 | 3.18 | 0.84 | |
| AV (%) | 1.77 | 6.37 | 3.99 | 1.37 | |
| M2 | ITSM (MPa) | 3628 | 5142 | 4345.50 | 486.50 |
| MS (kN) | 8.74 | 14.00 | 11.35 | 1.73 | |
| MF (mm) | 2.00 | 4.20 | 3.20 | 0.57 | |
| AV (%) | 2.20 | 6.29 | 4.18 | 1.23 | |
| M3 | ITSM (MPa) | 3812 | 5942 | 4804.10 | 725.03 |
| MS (kN) | 10.30 | 15.20 | 12.88 | 1.53 | |
| MF (mm) | 2.00 | 5.00 | 3.35 | 0.95 | |
| AV (%) | 1.49 | 8.91 | 5.22 | 2.38 | |
| M4 | ITSM (MPa) | 4035 | 6293 | 5076.17 | 759.06 |
| MS (kN) | 11.60 | 16.43 | 13.62 | 1.42 | |
| MF (mm) | 2.20 | 5.00 | 3.40 | 0.92 | |
| AV (%) | 1.33 | 8.36 | 5.05 | 2.18 | |
| M5 | ITSM (MPa) | 3215 | 4919 | 4252.26 | 502.24 |
| MS (kN) | 8.91 | 14.86 | 11.37 | 1.51 | |
| MF (mm) | 2.18 | 4.60 | 3.15 | 0.50 | |
| AV (%) | 2.17 | 6.75 | 4.28 | 1.16 | |
| M6 | ITSM (MPa) | 3907 | 6043 | 5243.10 | 538.97 |
| MS (kN) | 10.40 | 13.99 | 11.81 | 1.21 | |
| MF (mm) | 2.24 | 4.16 | 3.24 | 0.40 | |
| AV (%) | 1.68 | 5.21 | 3.49 | 1.08 | |
| M7 | ITSM (MPa) | 3103 | 6399 | 5065.34 | 906.93 |
| MS (kN) | 6.60 | 14.75 | 9.86 | 2.20 | |
| MF (mm) | 2.10 | 9.86 | 3.22 | 0.62 | |
| AV (%) | 3.03 | 2.20 | 5.22 | 1.19 | |
| M8 | ITSM (MPa) | 2304 | 4900 | 3829.63 | 783.23 |
| MS (kN) | 10.45 | 15.48 | 13.05 | 1.36 | |
| MF (mm) | 2.20 | 5.00 | 3.37 | 0.83 | |
| AV (%) | 0.35 | 8.44 | 4.37 | 2.43 | |
| M9 | ITSM (MPa) | 2930 | 5994 | 4911.30 | 851.15 |
| MS (kN) | 8.92 | 15.48 | 12.22 | 2.03 | |
| MF (mm) | 1.85 | 5.00 | 3.10 | 0.72 | |
| AV (%) | 1.26 | 8.44 | 4.97 | 1.86 | |
| M10 | ITSM (MPa) | 4049 | 5968 | 5309.27 | 565.88 |
| MS (kN) | 7.80 | 16.55 | 11.98 | 2.15 | |
| MF (mm) | 2.70 | 5.40 | 3.95 | 0.76 | |
| AV (%) | 4.60 | 9.70 | 7.12 | 1.59 |
| Fold | MSEmean | R—Pearson Correlation Coefficient | Rmean | |||
|---|---|---|---|---|---|---|
| ITSM | MS | MF | AV | |||
| 0 | 0.219 | 0.837 | 0.866 | 0.842 | 0.964 | 0.877 |
| 1 | 0.203 | 0.963 | 0.835 | 0.725 | 0.973 | 0.874 |
| 2 | 0.254 | 0.872 | 0.836 | 0.799 | 0.917 | 0.856 |
| 3 | 0.223 | 0.918 | 0.826 | 0.917 | 0.956 | 0.905 |
| 4 | 0.346 | 0.841 | 0.731 | 0.834 | 0.912 | 0.829 |
| CVresult | 0.249 | 0.886 | 0.819 | 0.824 | 0.944 | 0.868 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Miani, M.; Dunnhofer, M.; Rondinella, F.; Manthos, E.; Valentin, J.; Micheloni, C.; Baldo, N. Bituminous Mixtures Experimental Data Modeling Using a Hyperparameters-Optimized Machine Learning Approach. Appl. Sci. 2021, 11, 11710. https://doi.org/10.3390/app112411710
Miani M, Dunnhofer M, Rondinella F, Manthos E, Valentin J, Micheloni C, Baldo N. Bituminous Mixtures Experimental Data Modeling Using a Hyperparameters-Optimized Machine Learning Approach. Applied Sciences. 2021; 11(24):11710. https://doi.org/10.3390/app112411710
Chicago/Turabian StyleMiani, Matteo, Matteo Dunnhofer, Fabio Rondinella, Evangelos Manthos, Jan Valentin, Christian Micheloni, and Nicola Baldo. 2021. "Bituminous Mixtures Experimental Data Modeling Using a Hyperparameters-Optimized Machine Learning Approach" Applied Sciences 11, no. 24: 11710. https://doi.org/10.3390/app112411710
APA StyleMiani, M., Dunnhofer, M., Rondinella, F., Manthos, E., Valentin, J., Micheloni, C., & Baldo, N. (2021). Bituminous Mixtures Experimental Data Modeling Using a Hyperparameters-Optimized Machine Learning Approach. Applied Sciences, 11(24), 11710. https://doi.org/10.3390/app112411710