
Achieving Semantic Consistency for Multilingual Sentence Representation Using an Explainable Machine Natural Language Parser (MParser)


Abstract
:1. Introduction
- (1)
- Heterogeneous grammatical rules: The language grammars of the components in Ei and Ci have their own rules to generate a sentence and it is impossible to achieve a one-to-one mapping.
- (2)
- Synonyms and homonyms: Each term in Ei may have several synonyms or homonyms. A wrong term in meaning may cause semantic ambiguity.
- (3)
- Peculiar language phenomena: Some phenomena in Ei never appear in Ci, resulting in asymmetric mapping. For example, the particles of “を, に, で, へ, より” in Japanese do not have counterparts in Chinese.
- (1)
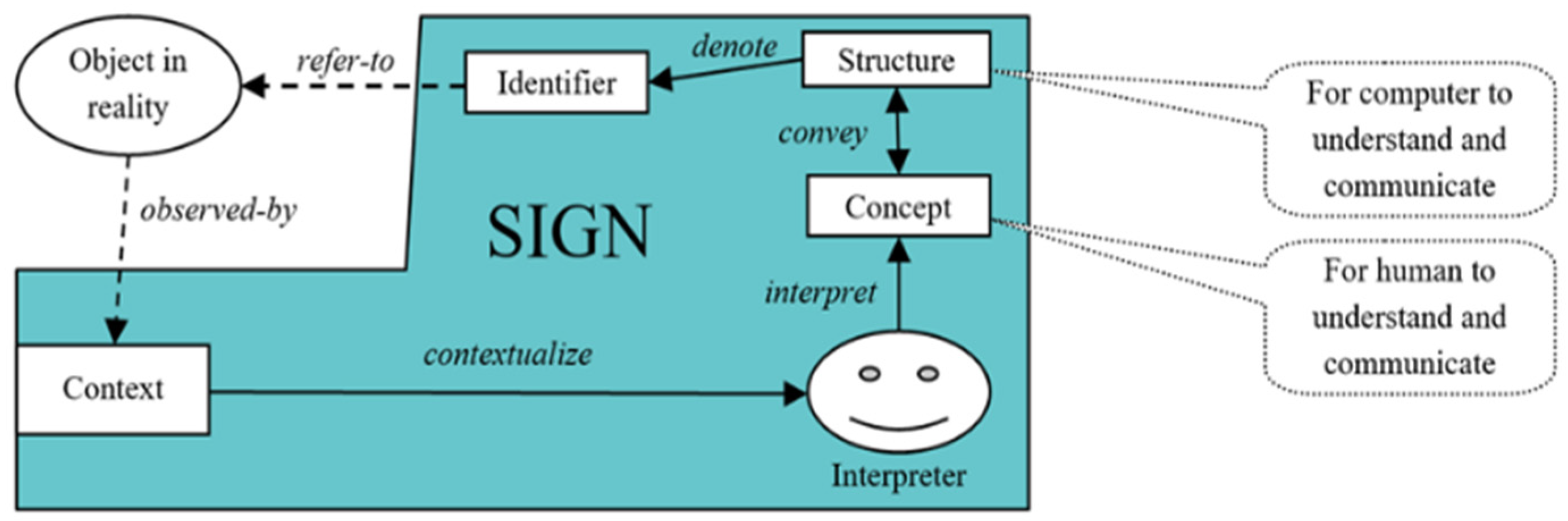
- Computer-human-understandable representation: providing information understandable by both computers and humans, realizing the accurate interpretation of sentences in the human-computer messaging cycle of humans and computers without ambiguity.
- (2)
- Accurate semantic representation among computing applications: applying computer-human-understandable information in computing applications and enabling information to be semantically interoperable.
- (3)
- Automated multilingual information processing by software agents: allowing multilingual information to be automatically processed across domains and contexts.
- (1)
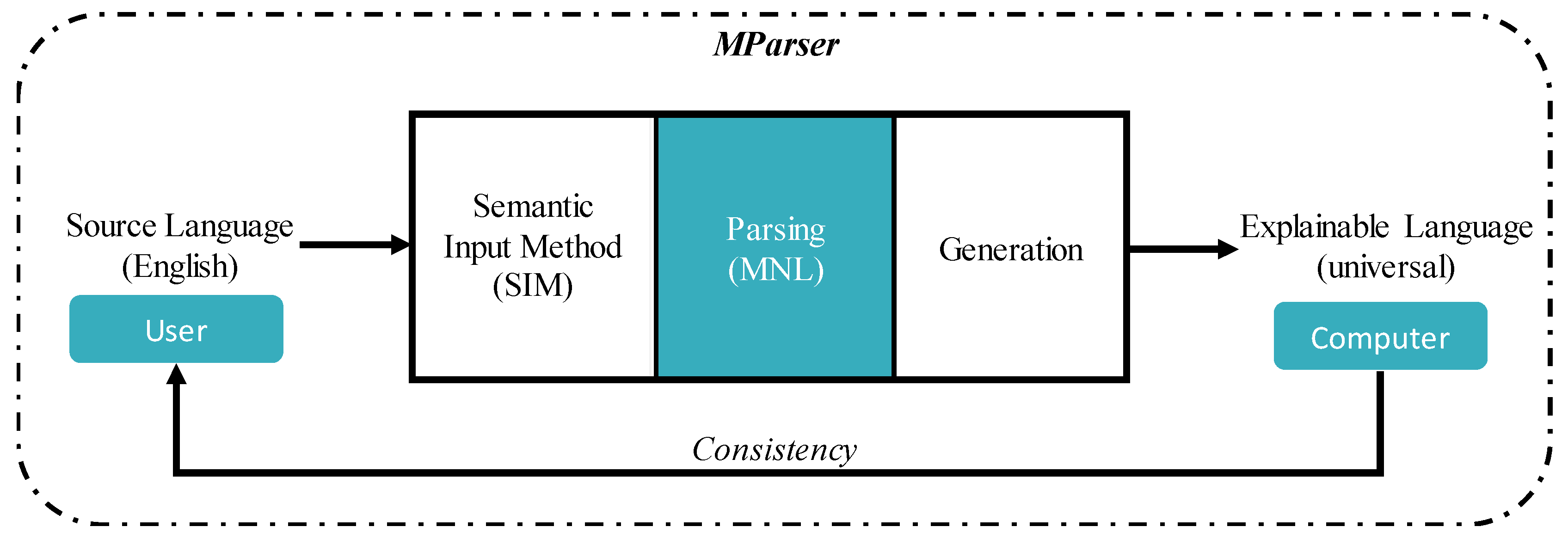
- In the human input, each unique concept is collaboratively edited with SIM [15] based on a common dictionary (CoDic) [17] for eliminating atomic concept ambiguity and morphological features. Thus, a simple English sentence can be converted to a sequence of unique concepts across conversational contexts.
- (2)
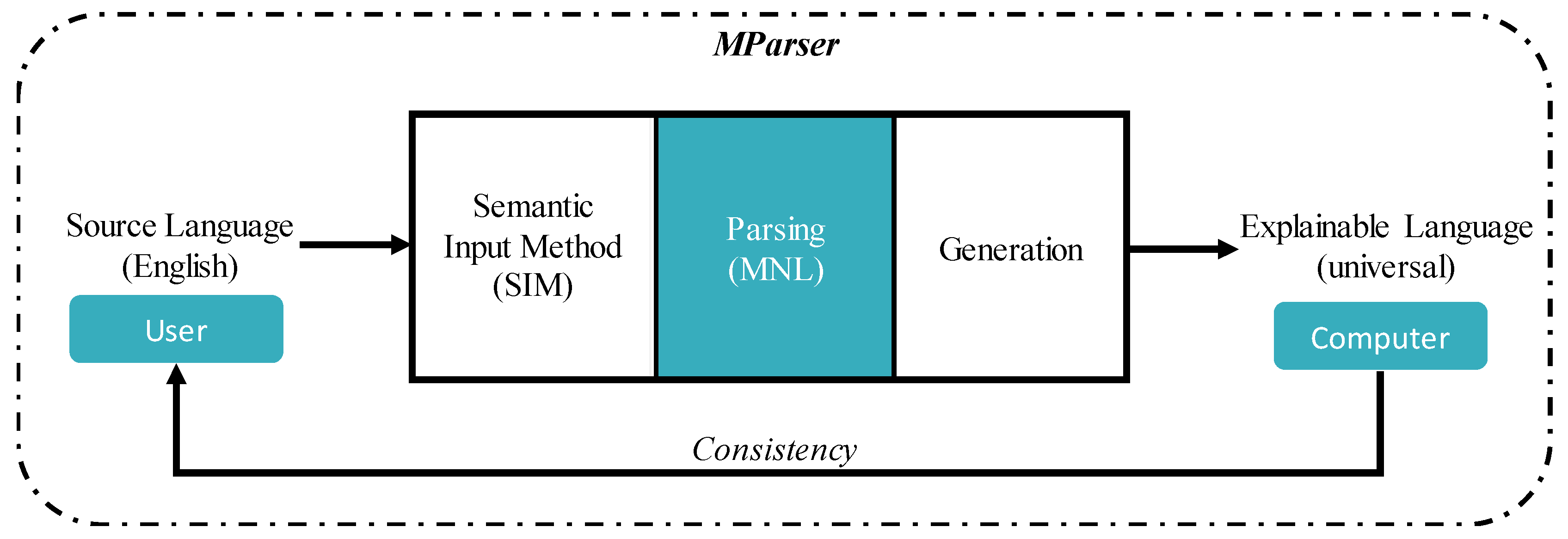
- To maintain complex semantic concept consistency between computers and users, an MParser for English sentences parses the semantic roles between English words and represents them for deriving a unique concept that can be accurately represented and understood by computers through case grammar [16]. The cases are used to label words, which are aligned from local language perspectives. The proposed parser utilizes powerful linguistic tools such as Stanford Parser and universal dependency relations.
- (3)
- Evaluate the proposed MParser through annotator agreement between the expert’s case labeling and MParser’s outputs. Additionally, 154 non-expert participants investigated judgments of semantic expressiveness.
2. Related Work
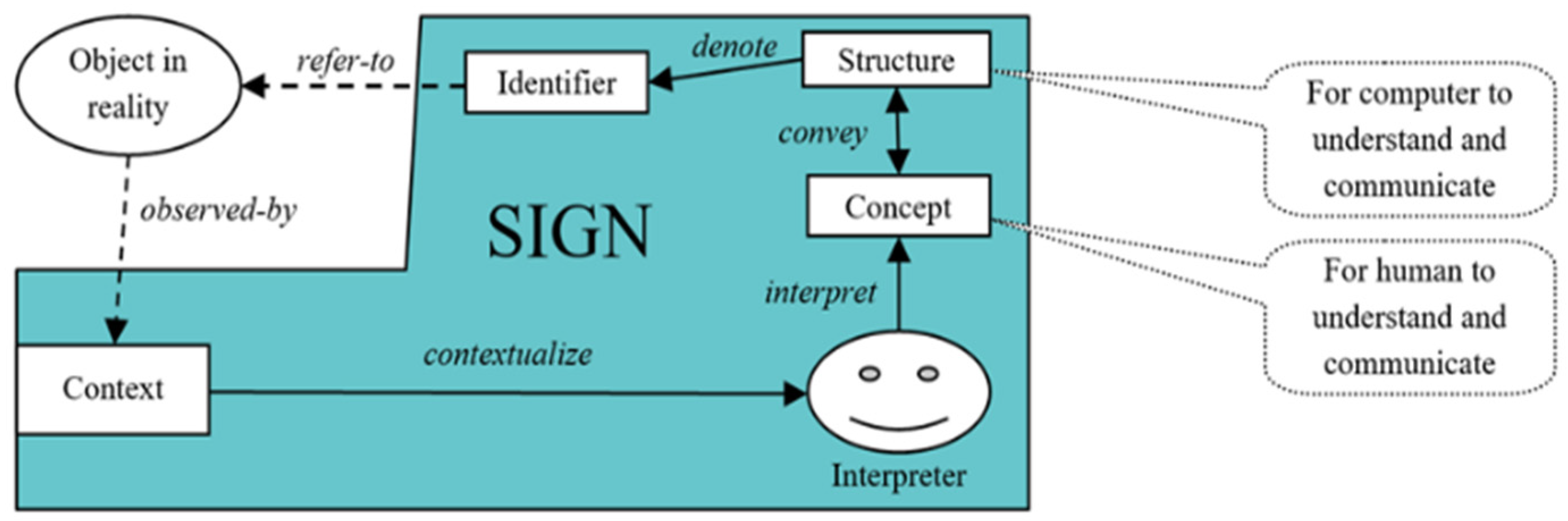
3. MParser
3.1. Overview
3.2. Methodology
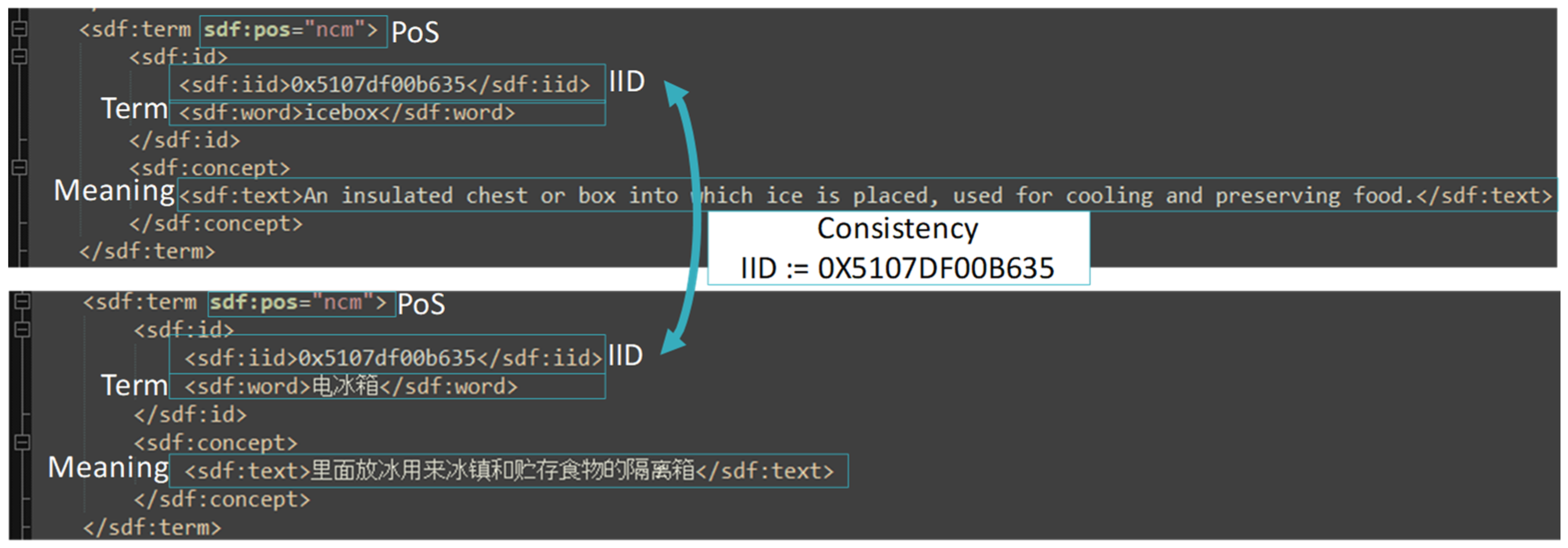
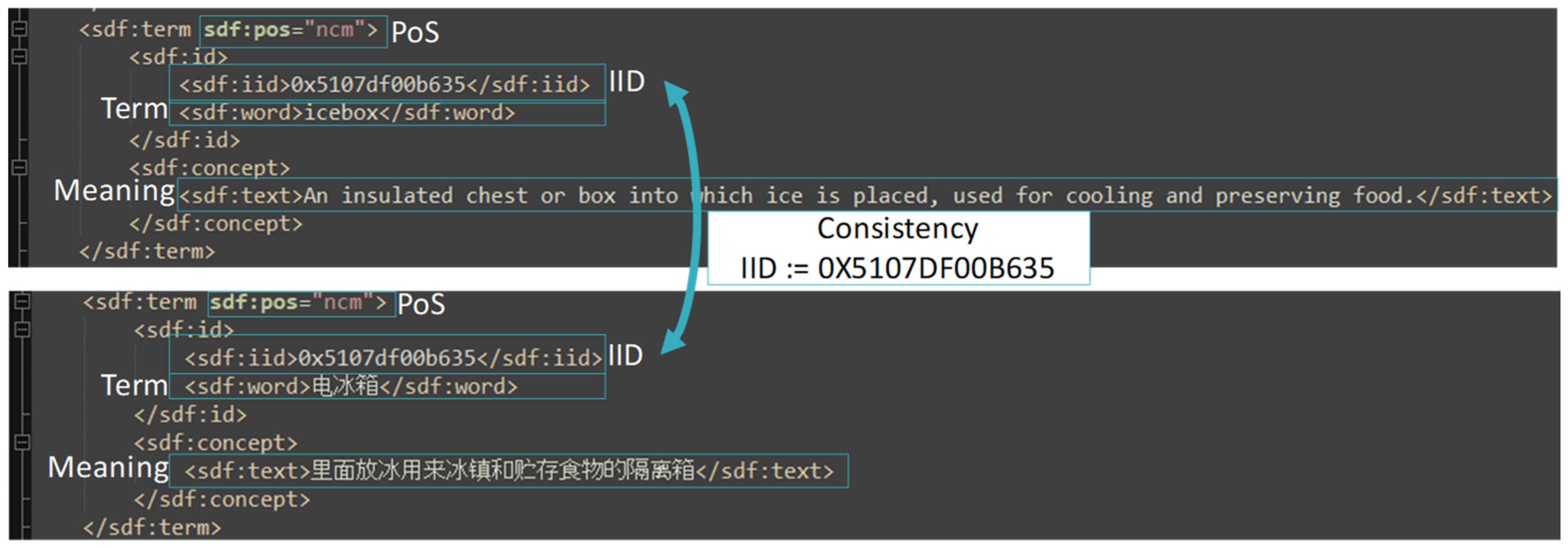
- IID: = POS+Y+ID: indicates the universal sign representational form. For instance, iid = 5107df00b635, in which 1 after 5 refers to common noun, 7df refers to year 2015, and 00b635 is ID.
- Term indicates literal representational form for a sign, e.g., “icebox” is the literal representation of the sign 5107df00b635 in English context.
- Meaning is the sense of a sign, e.g., “An insulated chest or box into which ice is placed, used for cooling and preserving food” is the sense of 5107df00b635.
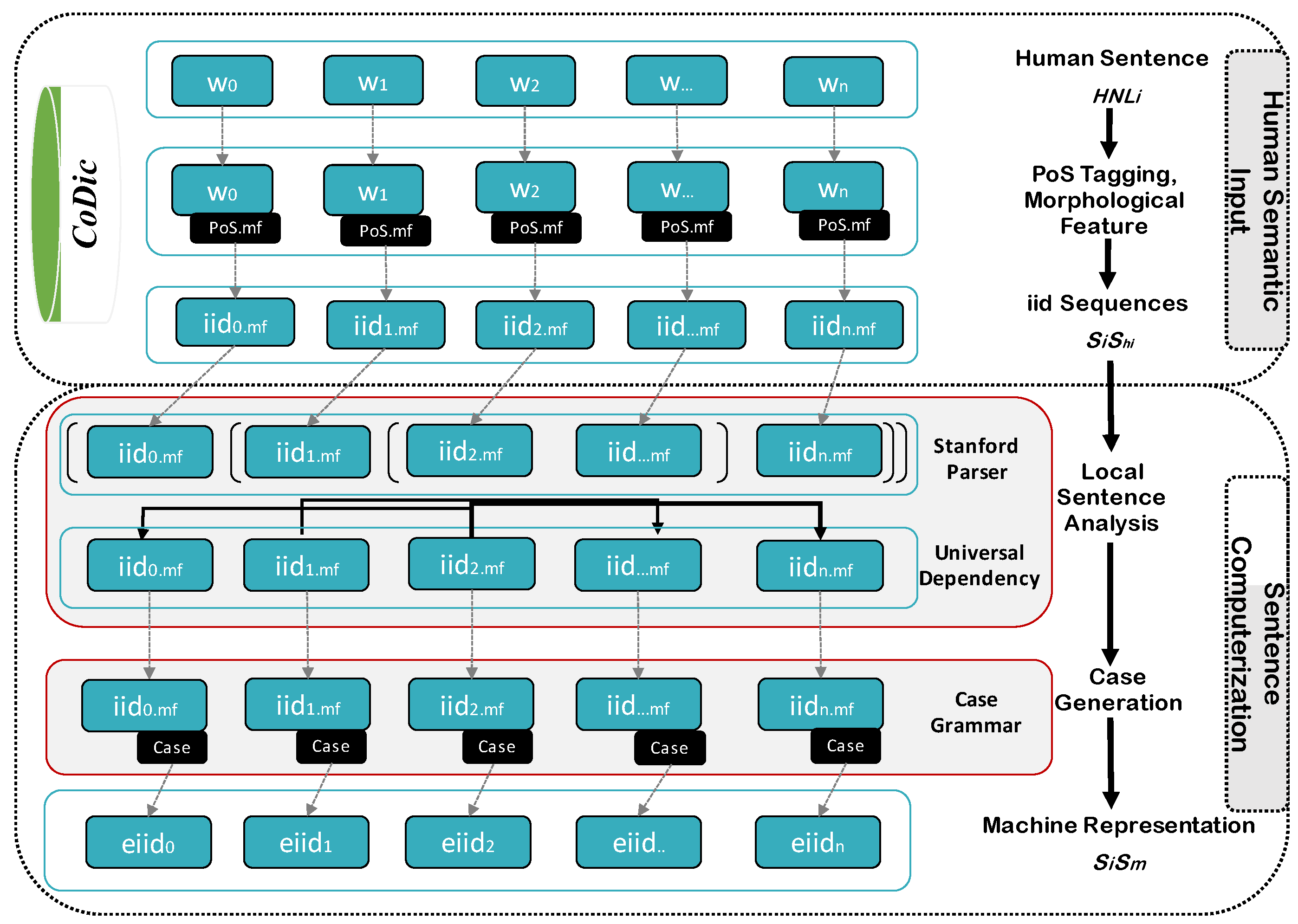
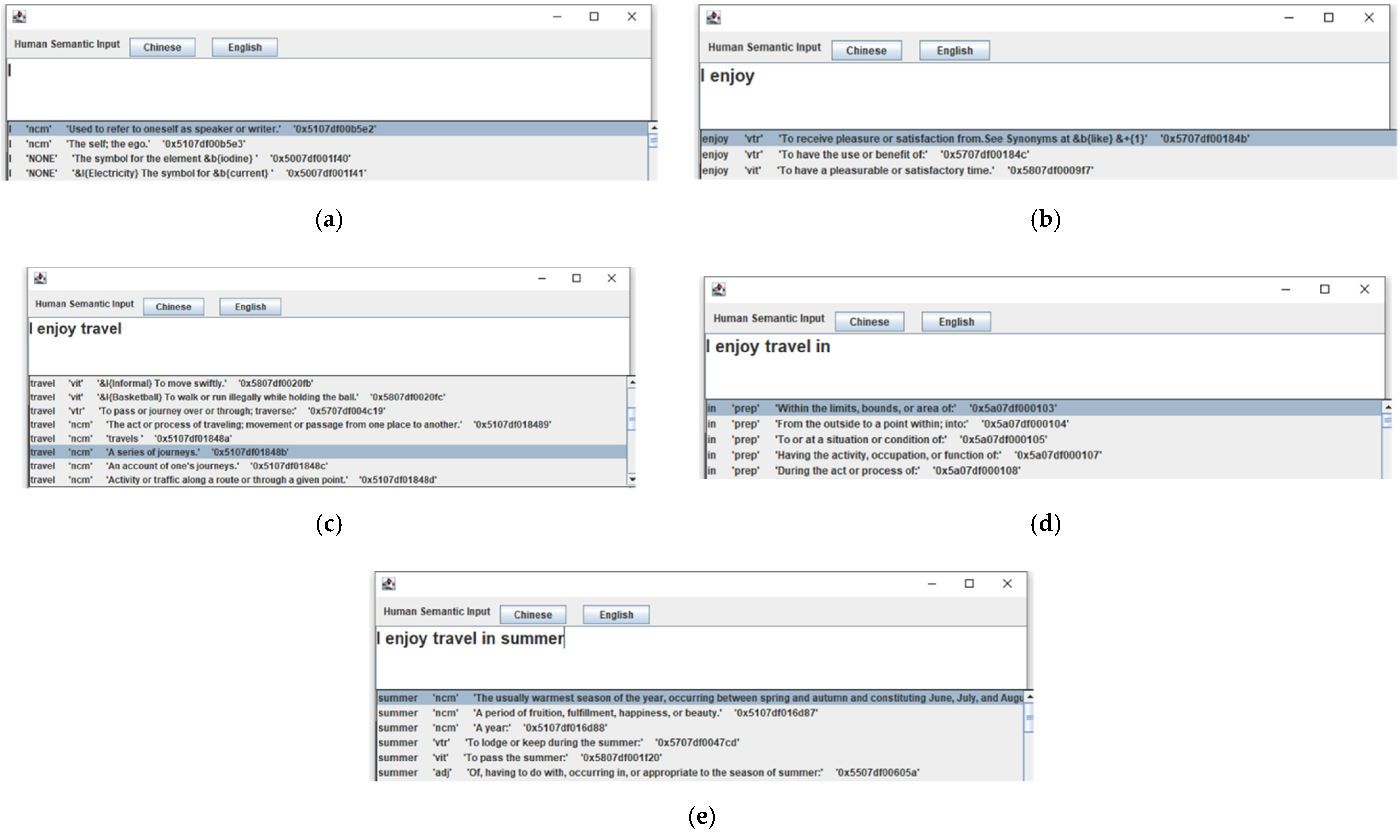
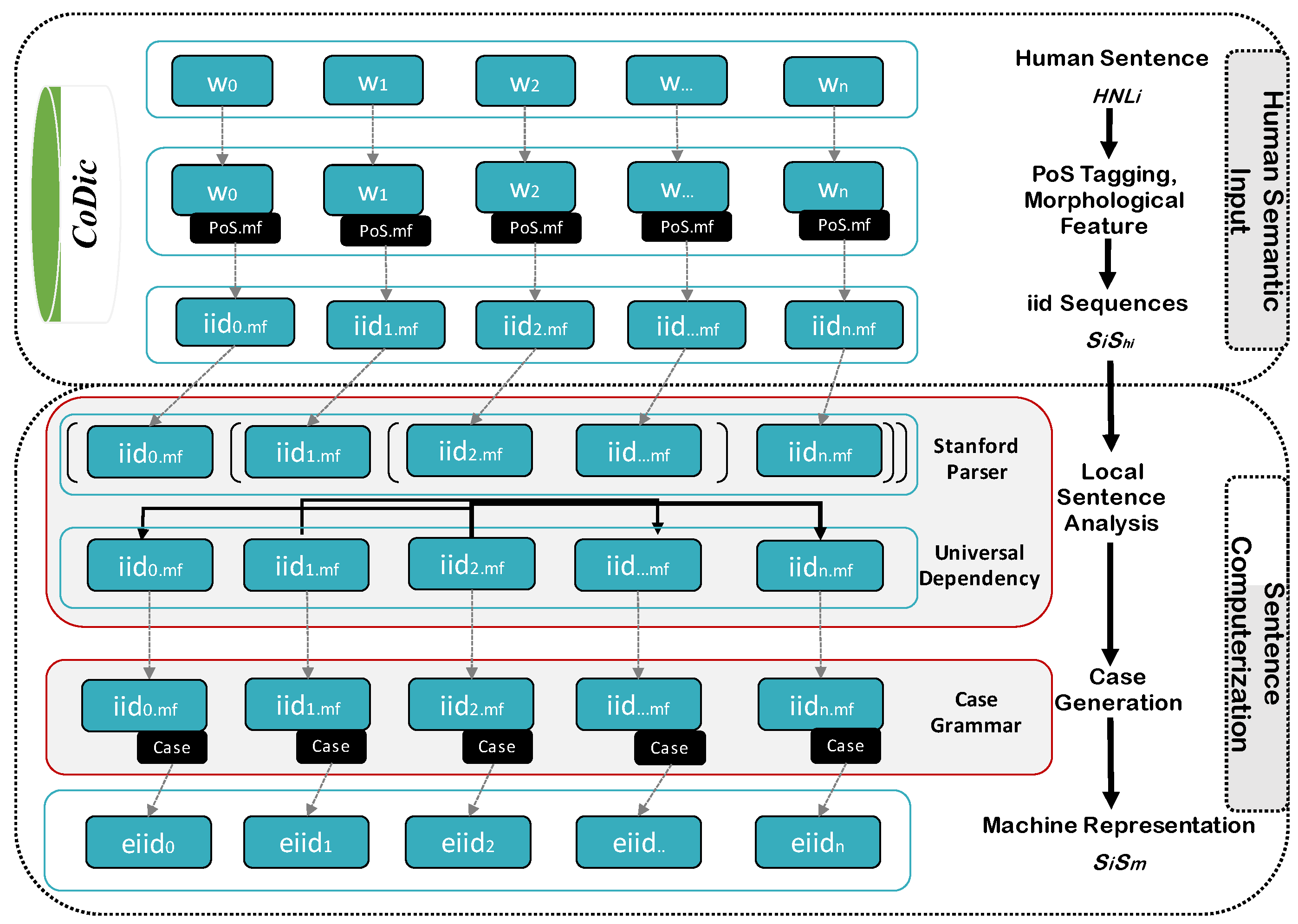
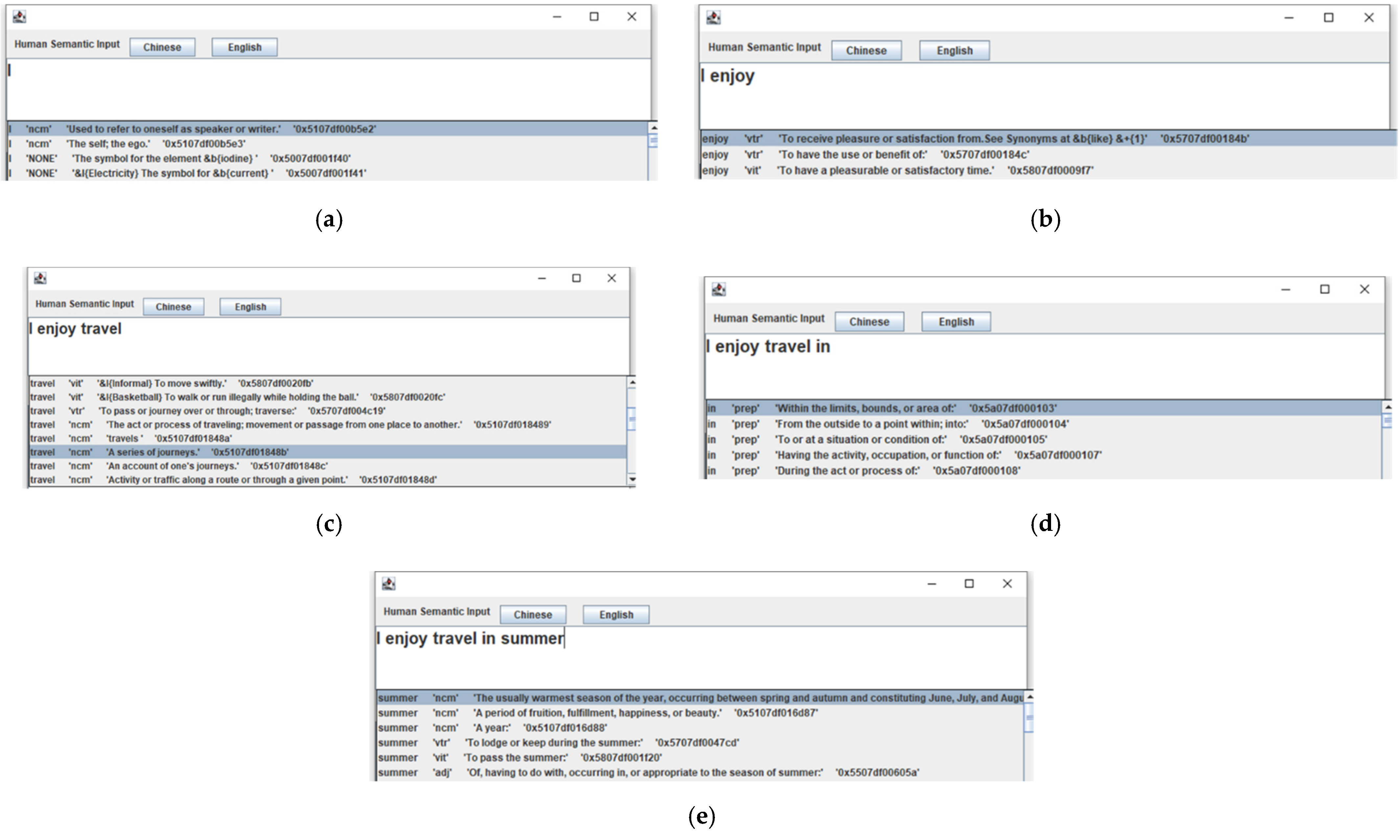
4. Human Semantic Input (HSI)
5. Sentence Computerization (SC)
5.1. Local Sentence Analysis
| [(‘ROOT’, [(‘NP’, [(‘NP’, [(‘DT’, [‘the’]), (‘JJ’, [‘quick’]), (‘JJ’, [‘brown’]), (‘NN’, [‘fox’])]), (‘NP’, [(‘NP’, [(‘NNS’, [‘jumps’])]), (‘PP’, [(‘IN’, [‘over’]), (‘NP’, [(‘DT’, [‘the’]), (‘JJ’, [‘lazy’]), (‘NN’, [‘dog’])])])])])])] |
| [[((u’jumps’, u’VBZ’), u’nsubj’, (u’fox’, u’NN’)), ((u’fox’, u’NN’), u’det’, (u’The’, u’DT’)), ((u’fox’, u’NN’), u’amod’, (u’quick’, u’JJ’)), ((u’fox’, u’NN’), u’amod’, (u’brown’, u’JJ’)), ((u’jumps’, u’VBZ’), u’nmod’, (u’dog’, u’NN’)), ((u’dog’, u’NN’), u’case’, (u’over’, u’IN’)), ((u’dog’, u’NN’), u’det’, (u’the’, u’DT’)), ((u’dog’, u’NN’), u’amod’, (u’lazy’, u’JJ’))]] |
5.2. Case Generation
- Nominative Case (NOM): denotes a semantic category of entities that initiate actions, trigger events, or give states. Nominative case often associates with the agentive properties of volition, sentience, instigation, and motion.
- Predicative case (PRE): denotes a semantic category of process in terms of action, event, or state. The process starts from a sign in the semantic category of the nominative.
- Accusative case (ACC): denotes a semantic class of patients who are the participants affected by the semantic class of agents marked by agentive case, which is the direct object of an agentive action.
- Dative case (DAT): denotes a semantic class of indirect participants relevant to an action or event. The objective participant marked by dative is called recipient or beneficiary of an action.
- Genitive case (GEN): denotes a semantic category of attributes that belong to things. It describes an attributive relationship of one thing to another thing.
- Linking case (LIN): denotes the thing that corresponds to the theme of thematic nominatives, such as attributes, classification, or identification of a theme.
- Adverbial case (ADV): denotes a semantic category of constraints belonging to predicative signs (i.e., a verb). It corresponds to the adverbial syntactic case.
- Complementary case (COM): denotes additional attributes of an entity, an action, an event, or a state, such as means, location, movement, time, causality, extent, and range. Under the PRE structure, COM is shown in COMv form. Under the NOM/ACC/DAT structure, COM is shown in COMn form. For other situations, it just shows COM form.
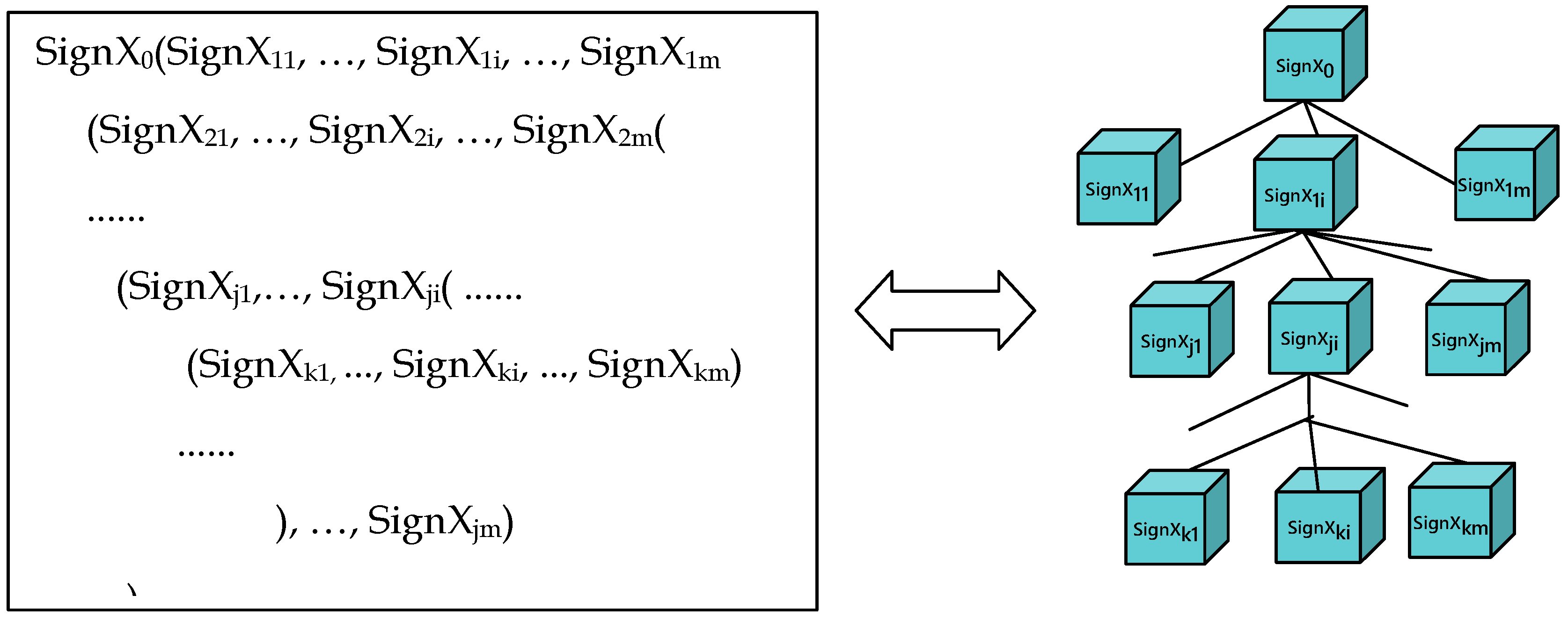
Tree Generation
- (1)
- There is a known PoS already associated with the term (HSI);
- (2)
- The term has a clear grammatical relationship with other terms in a sentence (local sentence analysis).
| [(‘NOM’, [(‘GEN’, [‘the’]), (‘GEN’, [‘quick’]), (‘GEN’, [‘brown’]), (‘NOM’, [‘fox’])]), (‘PRE’,[(‘PRE’, [‘jump’])]), (‘COMv’, [(‘COMv’, [‘over’]), (‘ACC’, [(‘GEN’, [‘the’]), (‘GEN’, [‘lazy’]), (‘ACC’, [‘dog’])])])])] |
- Linearize input to a term sequence S.
- Connect each term in S to its smallest subtree in TSignX.
- Append one case in each node of TSignX based on case grammar rules.
- Parse the universal dependency labels at each branching node N of the TSignX.
- Find the dependency relationship in the node of each word:
- If exist corresponding dependency label, then replace the current case using dependency mapping rules;
- If no dependency relationship, keep the current case.
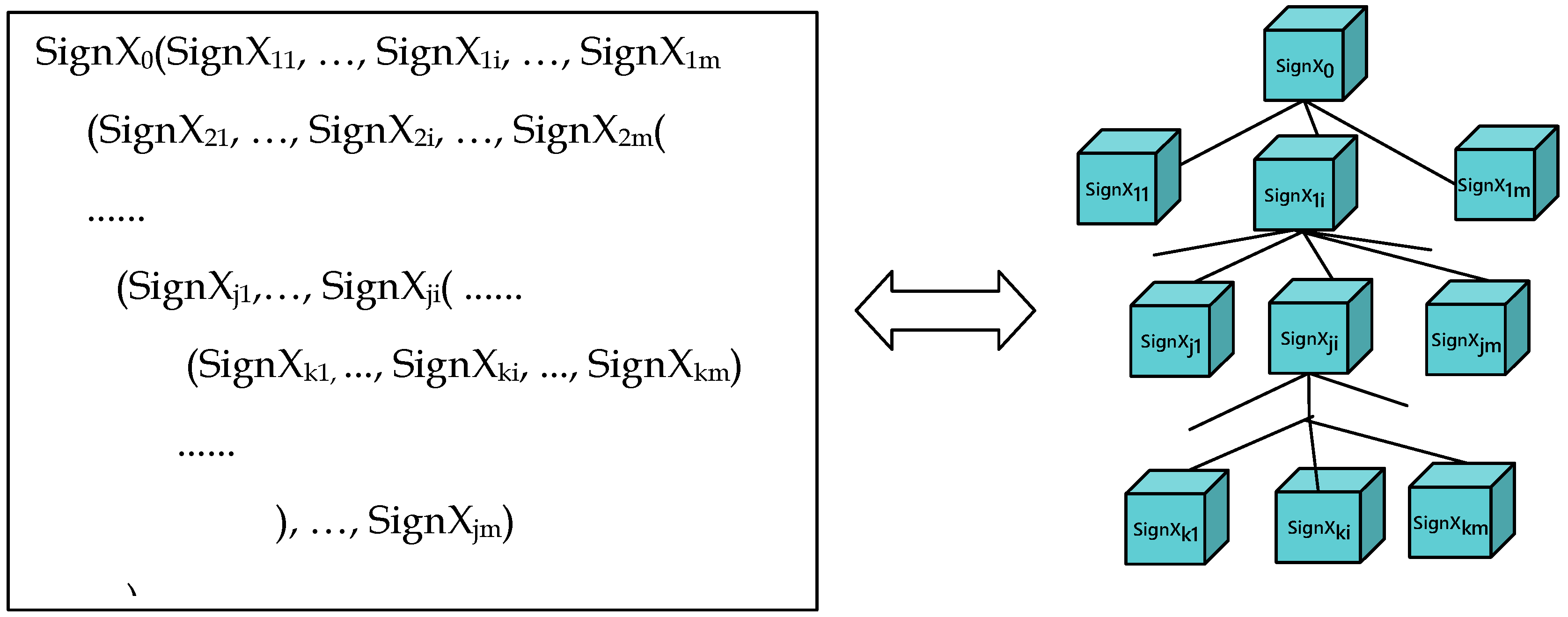
5.3. Machine Representation
|
6. Implementation
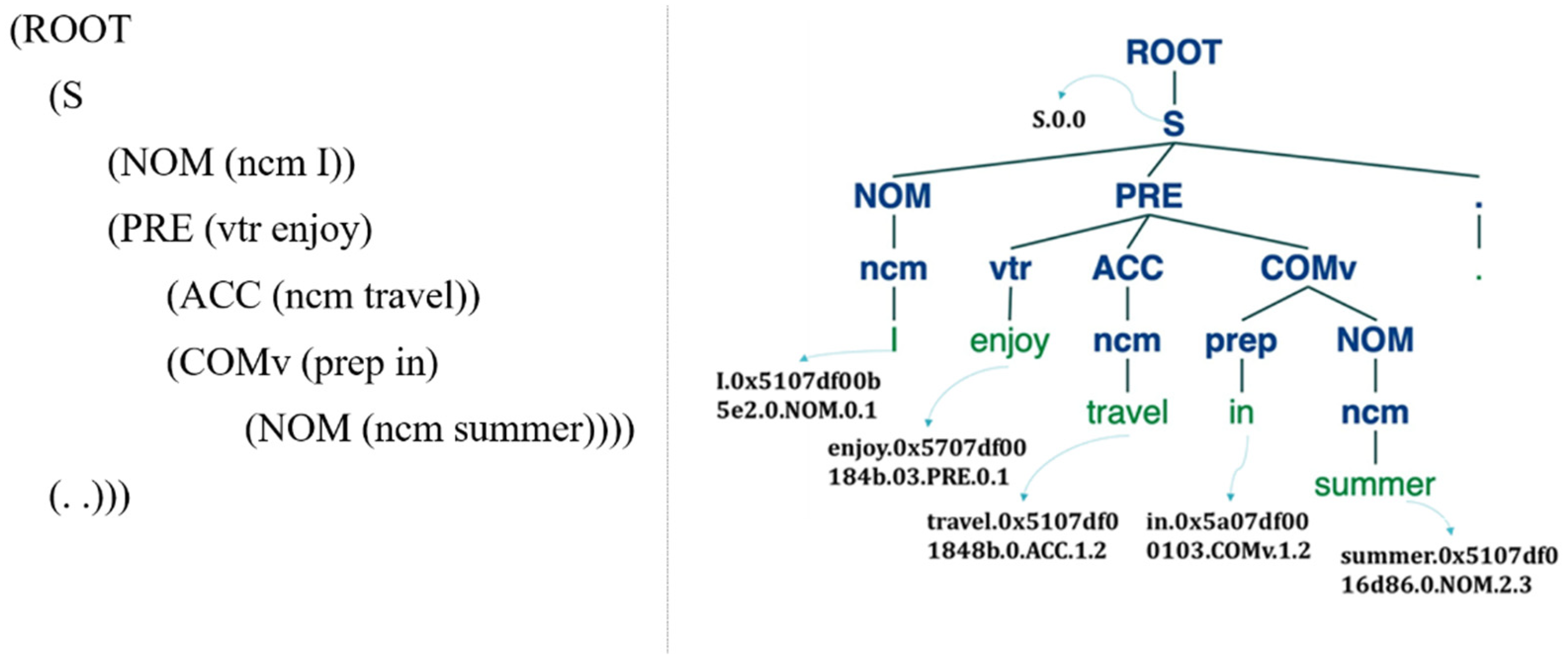
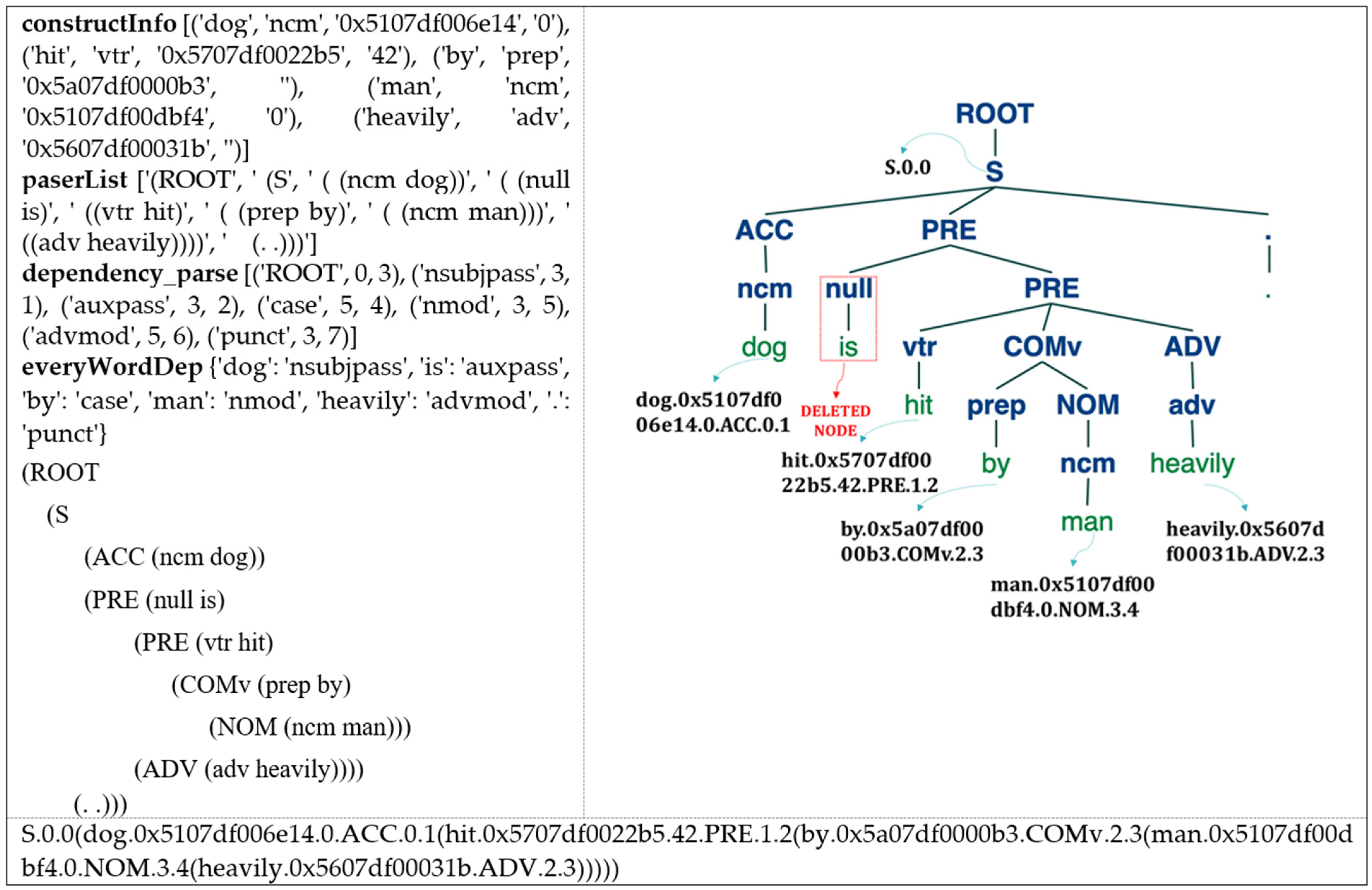
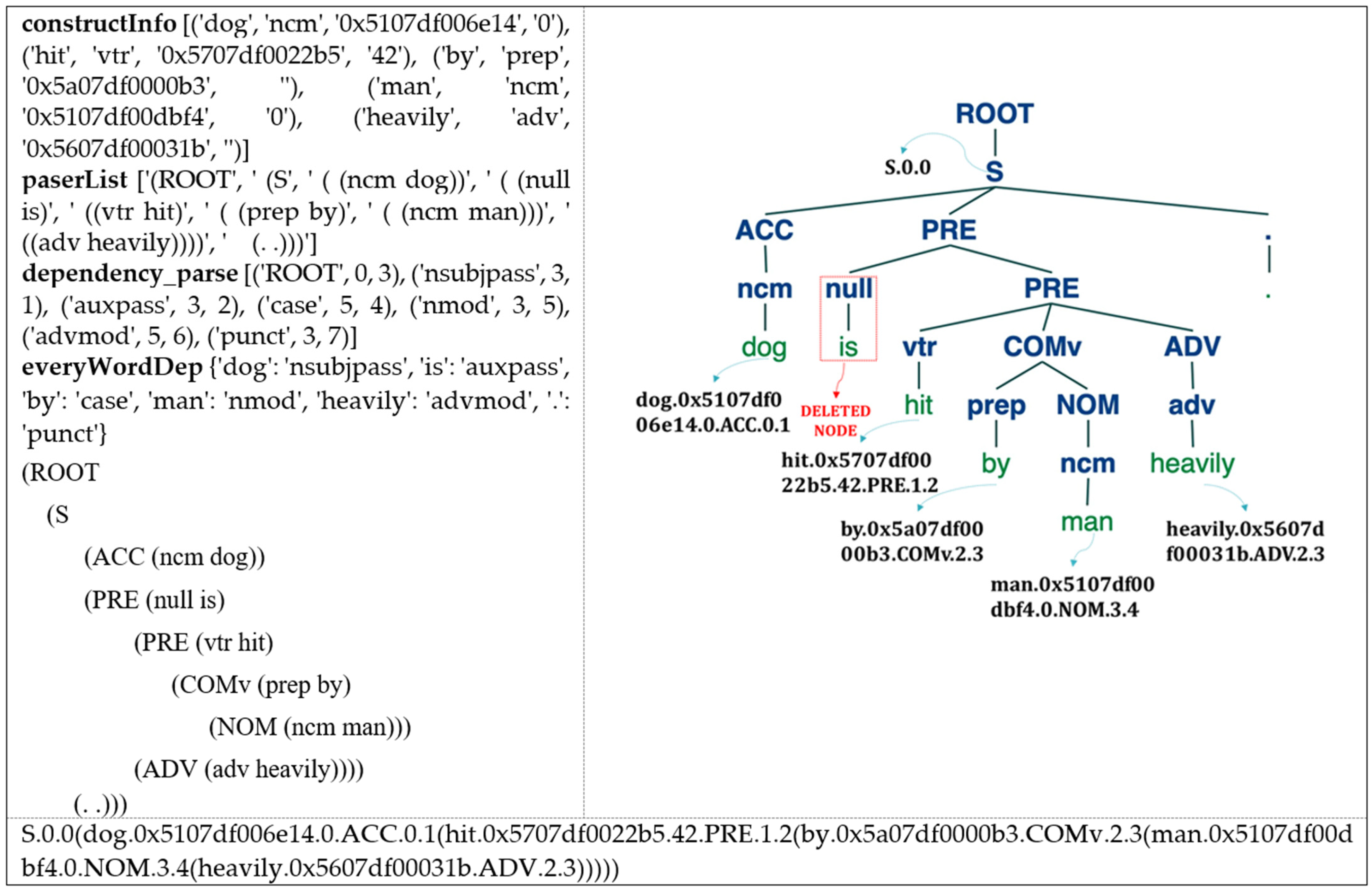
| constructInfo [(‘I’, ‘ncm’, ‘0x5107df00b5e2′, ‘0′), (‘enjoy’, ‘vtr’, ‘0x5707df00184b’, ‘03′), (‘travel’, ‘ncm’, ‘0x5107df032b53′, ‘0′), (‘in’, ‘prep’, ‘0x5a07df000103′, ‘‘), (‘summer’, ‘ncm’, ‘0x5107df016d86′, ‘0′)] |
| paserList [‘(ROOT’, ‘ (S’, ‘ ((ncm I))’, ‘ ( (vtr enjoy)’, ‘ ((ncm travel))’, ‘ ((prep in)’, ‘ ( (ncm summer))))’, ‘ (. .)))’] |
| dependency_parse [(‘ROOT’, 0, 2), (‘nsubj’, 2, 1), (‘dobj’, 2, 3), (‘case’, 5, 4), (‘nmod’, 2, 5), (‘punct’, 2, 6)] everyWordDep {‘I’: ‘nsubj’, ‘travel’: ‘dobj’, ‘in’: ‘case’, ‘summer’: ‘nmod’, ‘.’: ‘punct’} |
- (1)
- This sentence begins from an S, which is a declarative sentence.
- (2)
- The noun (ncm) we is case NOM [I-ncm-NOM] if it is before a verb such at ncm-NOM ← vtr-PRE (except GEN, ADV and others).
- (3)
- The verb (v) enjoy is case PRE [enjoy-vtr-P] where transitive verb (vtr) follows only one noun structure, such that vtr-PRE → vtr-PRE noun [supplementary: vit-PRE; vdi-PRE → vdi-PRE noun1 noun2.]
- (4)
- The noun (ncm) travel is case ACC [travel-ncm-ACC] if it is before a vtr verb such at vtr-PRE ← ncm-ACC.
- (5)
- The preposition (prep) in is case COMv [in-prep-COMv] under PRE structure.
- (6)
- The noun (ncm) summer is case NOM [summer-ncm-NOM], such that in-prep-COMv← summer-ncm-NOM.
| S.0.0(I.0x5107df00b5e2.0.NOM.0.1(enjoy.0x5707df00184b.03.PRE.0.1(travel.0x5107df01848b.0.ACC.1.2(in.0x5a07df000103.COMv.1.2(summer.0x5107df016d86.0.NOM.2.3))))) |
7. Evaluation
7.1. Dataset
7.2. Experiment Settings
| 1. Very unclear 2. Unclear 3. Acceptable 4. Clear 5. Perfectly clear |
7.3. Results
7.4. Discussion
7.4.1. Case Labeling
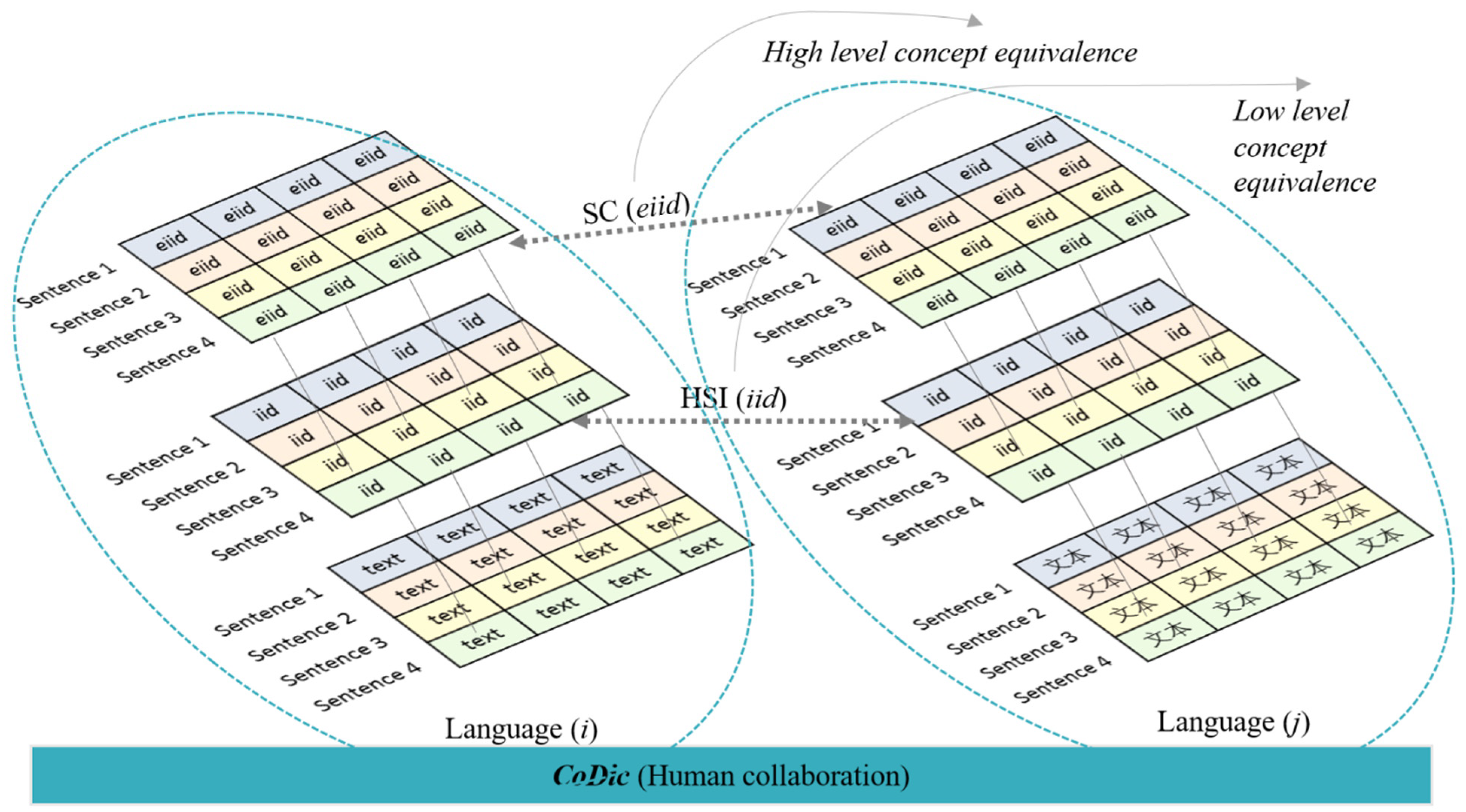
7.4.2. Semantic Consistency
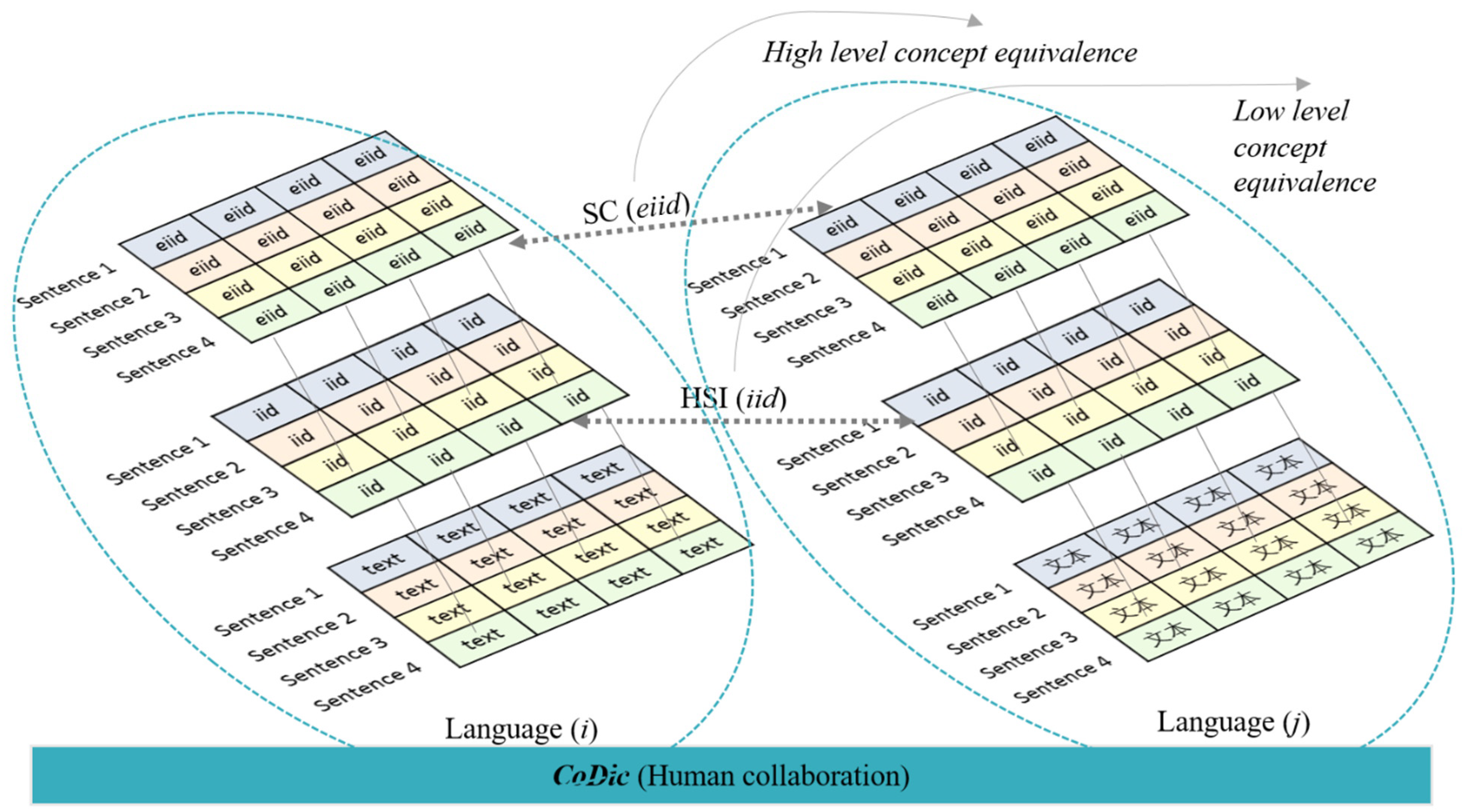
- (1)
- ∀ LLCi ⊂ IIDi⊂ CoDic
- (2)
- ∀ LLCj ⊂ IIDj ⊂ CoDic
- (3)
- Mapping relationship: LLCi ↔ LLCj
- (1)
- ∀ HLCi ⊂ EIIDi
- (2)
- ∀ HLCj ⊂ EIIDj
- (3)
- Mapping relationship: HLCi ↔ HLCj
- (1)
- Mapping relationship: IID ↔ EIID, which is iid in Def. 4 mapped to eiid in Def. 5
8. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Parts of Speech (PoS)

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| PoS | Abbr. | Definition | |
|---|---|---|---|
| Noun (n) | Common | Ncm | A term class denoting a common entity. |
| Proper Person | npp | A term class denoting a proper person entity. | |
| Proper Organization | nop | A term class denoting a proper organizational entity. | |
| Proper Geography | ngp | A term class denoting a proper geographical entity. | |
| Pronoun | npr | A term class substituting a noun or a noun phrase. | |
| Verb (v) | Intransitive | vit | A term class denoting an action, an event, or a state without following any entity. |
| Transitive | vtr | A term class denoting an action, an event, or a state following only one entity. | |
| Ditransitive | vdi | A term class denoting an action, an event, or a state without following only two entities. | |
| Copulative | cop | A term class denoting a linkage between an entity and a copulated component (coc) that expresses a state of being. Adopting “coc” is to avoid the confusion of current use of “predicative expression”. | |
| Adjective | adj | A term class describing the attributes of an entity. | |
| Adverb | adv | A term class describing the attributes of an action, an event, or a state. | |
| Preposition | prep | A term class denoting a relation to other noun-formed term(s) before, in the middle, or after. | |
| Conjunction | conj | A term class connecting terms, phrases and clauses, such as and, or, and if. | |
| Interjection | int | A term class expressing a spontaneous feeling or reaction. | |
| Onomatopoeia | ono | A term class imitating, resembling, or suggesting a sound. | |
| Particle | par | A term class indicating a case encompassed by it. | |
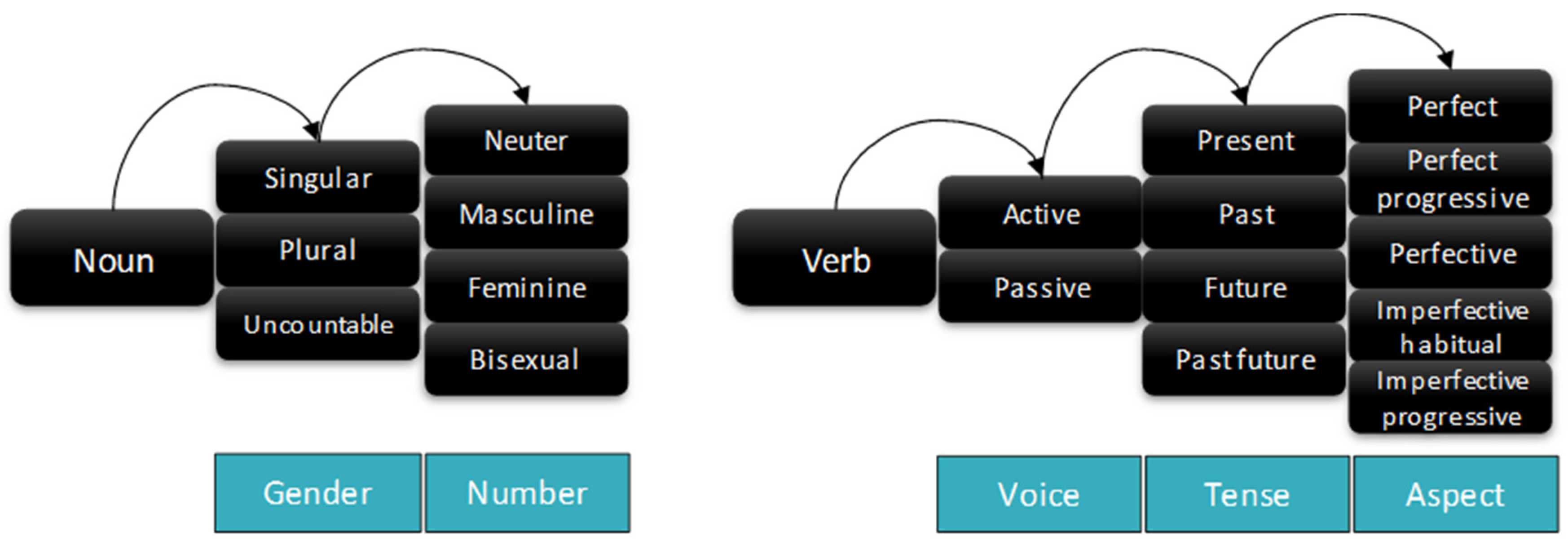
Appendix B. Grammatical Features
- -
- Perfect (prf): a verb form that indicates that an action or circumstance occurred earlier than the time under consideration, often focusing attention on the resulting state rather than on the occurrence itself. E.g., “I have made dinner”.
- -
- Perfect Progressive (pfg): a verb form that indicates that an action was progressive and finished at a time. E.g., “I had been doing homework until 6 PM yesterday”.
- -
- Perfective (pfv): a grammatical aspect that describes an action viewed as a simple whole, i.e., a unit without interior composition. Sometimes called the aoristic aspect, which is a verb form to usually refer to past events. For example, “I came”.
- -
- Imperfective (ipfv): a grammatical aspect used to describe a situation viewed with interior composition. The imperfective is used to describe ongoing, habitual, repeated, or similar semantic roles, whether that situation occurs in the past, present, or future. Although many languages have a general imperfective, others have distinct aspects for one or more of its various roles, such as progressive, habitual, and iterative aspects.
- -
- Imperfective habitual (iph): describes habitual and repeated actions. For example, “I read”. “The rain beat down continuously through the night”.
- -
- Imperfective progressive (ipp): describes ongoing actions or events. For example, “The rain was beating down”.
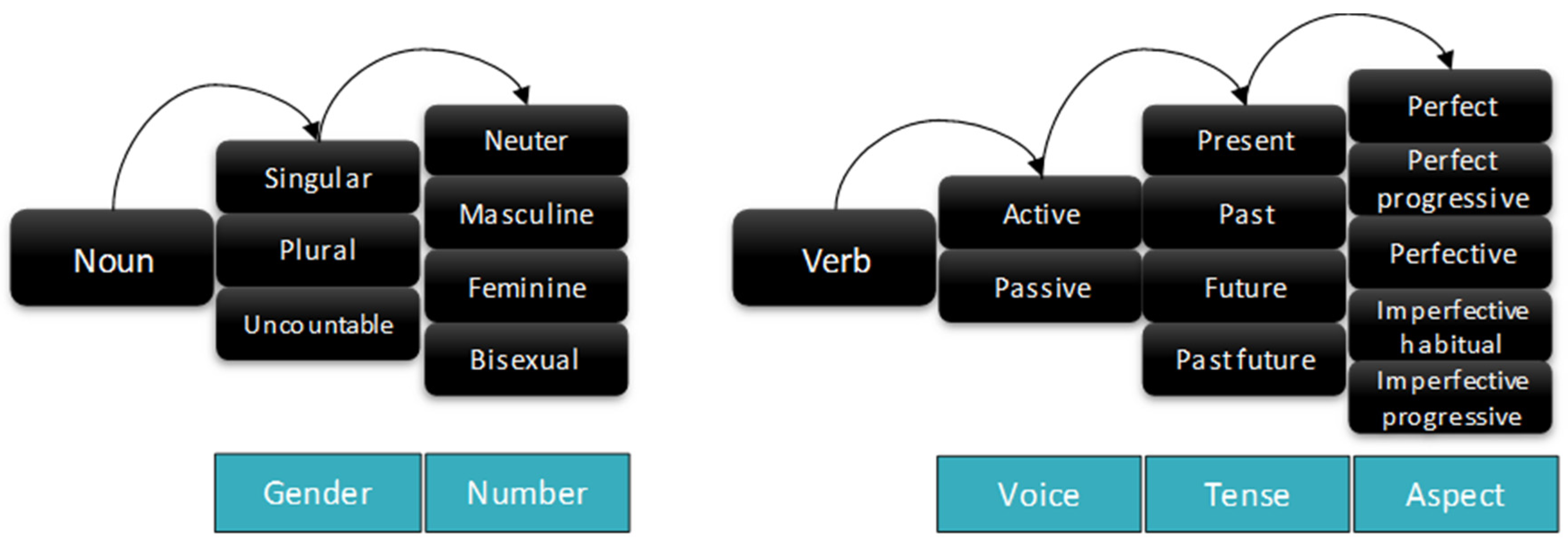
| Number | Gender | Binary Postfix | Hex Postfix |
|---|---|---|---|
| Countable singular | Neuter | 0000 | 0 |
| Masculine | 0001 | 1 | |
| Feminine | 0010 | 2 | |
| Bisexual | 0011 | 3 | |
| Countable plural | Neuter | 0100 | 4 |
| Masculine | 0101 | 5 | |
| Feminine | 0110 | 6 | |
| Bisexual | 0111 | 7 | |
| Uncountable | Neuter | 1000 | 8 |
| Masculine | 1001 | 9 | |
| Feminine | 1010 | A | |
| Bisexual | 1011 | B |
| Voice | Tense | Aspect | Binary Postfix | Hex Postfix |
|---|---|---|---|---|
| active | Present | Perfect | 0000 0000 | 00 |
| Perfect progressive | 0000 0001 | 01 | ||
| Perfective | 0000 0010 | 02 | ||
| Imperfective habitual | 0000 0011 | 03 | ||
| Imperfective progressive | 0000 0100 | 04 | ||
| Past | Perfect | 0001 0000 | 10 | |
| Perfect progressive | 0001 0001 | 11 | ||
| Perfective | 0001 0010 | 12 | ||
| Imperfective habitual | 0001 0011 | 13 | ||
| Imperfective progressive | 0001 0100 | 14 | ||
| Future | Perfect | 0010 0000 | 20 | |
| Perfect progressive | 0010 0001 | 21 | ||
| Perfective | 0010 0010 | 22 | ||
| Imperfective habitual | 0010 0011 | 23 | ||
| Imperfective progressive | 0010 0100 | 24 | ||
| Past future | Perfect | 0011 0000 | 30 | |
| Perfect progressive | 0011 0001 | 31 | ||
| Perfective | 0011 0010 | 32 | ||
| Imperfective habitual | 0011 0011 | 33 |
Appendix C. MParser Output—75 Sentences
| 1. | I like apples. (I.NOM like.PRE apple.ACC) |
| 2. | I miss those times and cherish them often. (I.NOM miss.PRE those.GEN time.ACC cherish.PRE them.ACC often.ADV) |
| 3. | She has been found. (She.NOM find.PRE) |
| 4. | Nobody can understand. (Nobody.NOM can.PRE understand.PRE) |
| 5. | His method was strange but impressive. (His.GEN method.NOM was.PRE strange.LIN impressive.LIN) |
| 6. | She said she is waiting until night. (she.NOM said.PRE she.NOM. wait.PRE. until.COMv night.NOM) |
| 7. | We need to speed into perspective. (we.NOM. need.PRE speed.PRE into.COMv perspective.NOM) |
| 8. | The size of sample will change user behavior. (size.NOM of sample.NOM change.PRE user.ACC behavior.ACC) |
| 9. | The car was sold with a three warranty. (Car.ACC sell.PRE with.COMv three.NOM warranty.NOM) |
| 10. | The crash occurred in our province. (Crash.NOM occurr.PRE in.COMv our.GEN province.NOM) |
| 11. | Russia remains hostage oil and gas prices. (Russia.NOM remain.PRE hostage.ACC oil.ACC gas.ACC price.ACC) |
| 12. | Previous appointees stayed the role until their deaths. (Previous.GEN appointee.NOM stay.PRE role.ACC until.COMv their.GEN death.NOM) |
| 13. | Everyone has been for their particular skill. (Everyone.NOM is.PRE for.LIN their.GEN particular.GEN skill.NOM) |
| 14. | They have their cake and eat it too. (They.NOM have.PRE their.GEN cake.ACC eat.PRE it.ACC too.ADV) |
| 15. | It was experiencing some hard moments. (It.NOM experience.PRE some.GEN hard.GEN moment.ACC) |
| 16. | I ‘m going to join the club. (I.NOM go.PRE join.PRE club.ACC) |
| 17. | This dispute with the legal is just beginning. (This.GEN dispute.NOM with.COMn legal.NOM is.LIN just.ADV beginning.COMn) |
| 18. | She said the outage started in the afternoon. (She.NOM said.PRE outage.NOM started.PRE in.COMv afternoon.NOM) |
| 19. | Our teacher’s appearance looks bad and dirty. (Our.GEN teacher.NOM appearance.NOM look.LIN bad.COM dirty.COM) |
| 20. | The quick brown fox jumped over the lazy dog. (Quick.GEN brown.GEN fox.NOM jump.PRE over.COMv lazy.GEN dog.NOM) |
| 21. | I wish you are lucky too. (I.NOM wish.PRE you.NOM are.PRE lucky.LIN too.ADV) |
| 22. | I spoke to my mum at last night. (I.NOM spoke.PRE my.GEN mum.ACC at.COMv last.GEN night.NOM) |
| 23. | Everybody wants to their mark. (Everybody.NOM want.PRE their.GEN mark.ACC) |
| 24. | The dog is hit by the man heavily. (Dog.ACC hit.PRE by.COMv man.NOM heavily.ADV) |
| 25. | The day finally dawned. (Day.NOM finally.ADV dawn.PRE) |
| 26. | They are just excited about the honor. (They.NOM are.PRE just.ADV excited.LIN about.COMv honor.NOM) |
| 27. | She detailed the highs and lows. (She.NOM detail.PRE high.ACC low.ACC) |
| 28. | Two of the soldiers were catching ride. (Two.NOM soldier.NOM catch.PRE ride.ACC) |
| 29. | The students also track the men’s progress. (Student.NOM also.ADV track.PRE man. ACC progress.ACC) |
| 30. | He is popular in all of the House. (He.NOM is.PRE popular.LIN in.COMv all.GEN House.NOM) |
| 31. | Fame released in UK cinemas. (Fame.NOM release.PRE in.COMv UK.NOM cinema.NOM) |
| 32. | I enjoy travel in summer. (I.NOM enjoy.PRE travel.ACC in.COMv summer.NOM) |
| 33. | We relied on the integrity of truth. (We.NOM rely.PRE integrity.ACC truth.ACC) |
| 34. | His sense of taste is returning. (His.GEN sense.NOM taste.NOM return.PRE) |
| 35. | Home builders also jumped most financials. (Home.NOM builder.NOM also.ADV jump.PRE most.GEN financial.ACC) |
| 36. | They were taxed income when we earned them. (They.NOM tax.PRE income.ACC we.NOM earn.PRE them.ACC) |
| 37. | She joined a sport during primary school. (She.NOM join.PRE sport.ACC during.COMv primary.NOM school.NOM) |
| 38. | Your friends are good men. (Your.GEN friend.NOM are.LIN good.GEN man.ACC) |
| 39. | You will find links to this news. (You.NOM find.PRE link.ACC to.COMv this.GEN news.NOM) |
| 40. | Some radio channels will move new position. (Some.GEN radio.NOM channel.NOM move.PRE new.GEN position.ACC) |
| 41. | She has also worked with battery hens. (She.NOM also.ADV work.PRE with.COMv battery.NOM hen.NOM) |
| 42. | The group now owns venues across the country. (Group.NOM now.NOM own.PRE venue.ACC across.COMv country.NOM) |
| 43. | The student finished their season in one hour. (Student.NOM finish.PRE their.GEN season.ACC in.COMv one.NOM hour.NOM) |
| 44. | It sets the two on collision courses. (It.NOM set.PRE two.ACC on.COMv collision.NOM course.NOM) |
| 45. | The two people were taking in the class. (Two.GEN people.NOM talk.PRE in.COMv class.NOM) |
| 46. | The financial crisis has many of those bets. (Financial.GEN crisis.NOM has.PRE many.GEN those.GEN bet.ACC) |
| 47. | The party is at a new location. (Party.NOM is.PRE at.LIN new.GEN location.NOM) |
| 48. | This is great place to start the trip. (This.NOM is.PRE great.COM place.LIN start.PRE trip.ACC) |
| 49. | I want to pick something else really. (I.NOM want.PRE pick.PRE something.ACC else.GEN really.ADV) |
| 50. | You should find a similar thing like sport. (You.NOM should.ADV find.PRE similar.GEN thing.ACC like.COMv sport.NOM) |
| 51. | The violence was some of the worst ethnic in China for decades. (Violence.NOM is.PRE some.GEN worst.GEN ethnic.ACC in.COMn China.NOM for.COMv decade.NOM) |
| 52. | The market is mired in scandals and has not recovered good. (Market.NOM mired.PRE in.COMv scandals.NOM not.ADV recover.PRE good.COM) |
| 53. | The insurgents often attack police and sometimes city officials at night. (Insurgent.NOM often.ADV attack.PRE police.ACC sometimes.ADV city.ACC official.ACC at.COMv night.NOM.) |
| 54. | The cake is made by the shop after months slowly. (Cake.ACC made.PRE by.COMv shop.NOM after.COMv month.NOM slowly.ADV) |
| 55. | His detention began in this week when he was trying to leave the city on a false passport. (His.GEN detention.NOM begin.PRE in.COMv this.GEN week.NOM he.NOM try.PRE leave.PRE city.ACC on.COMv false.GEN passport.NOM) |
| 56. | I want to thank every member of congress who stood tonight with courage. (I.NOM want.PRE thank.PRE every.GEN member.ACC congress.ACC stand.PRE tonight.ADV with.COMv courage.NOM) |
| 57. | It was his job to fight the war and make an assessment when the time came. (It.NOM is.PRE his.GEN job.ACC fight.PRE war.ACC make.PRE assessment.ACC time.NOM come.PRE) |
| 58. | The Justice Department scheduled a news conference Tuesday afternoon to announce the indictment. (Justice.NOM Department.NOM schedule.PRE news.ACC conference.ACC in.COMv afternoon.NOM announce.PRE indictment.ACC) |
| 59. | The president had been scheduled to leave for the trip on Sunday. (President.NOM schedule.PRE leave.PRE for.COMv trip.NOM on.COM Sunday.NOM) |
| 60. | A sale has been hit after a robbery in a store. (Sale.ACC hit.PRE after.COMv robbery.NOM in.COMv store.NOM) |
| 61. | I have won this race twice and it would be great to win it again. (I.NOM win.PRE this.GEN race.ACC twice.ADV it.NOM is.LIN great.COM win.PRE it.ACC again.ADV) |
| 62. | We ‘ve got great commanders on the ground in leadership. (We.NOM get.PRE great.GEN commander.ACC on.COMv ground.NOM in.COMv leadership.NOM) |
| 63. | He intends to return to the company within next year. (He.NOM intend.PRE return.PRE company.ACC within.COMv next.GEN year.NOM) |
| 64. | Providing sensitive information to strangers by phone is dangerous. (Providing.PRE sensitive.GEN information.ACC to.COMv stranger.NOM by.COMn phone.NOM is.LIN dangerous.COM) |
| 65. | She heard the noise and thought someone must have been making it for the event. (She.NOM hear.PRE noise.ACC think.PRE someone.NOM must.ADV make.PRE it.ACC for.COMv event.NOM) |
| 66. | He had been banned over fears that raised the chances of contamination. (He.ACC ban.PRE over.COMv fear.NOM raise.PRE chance.NOM contamination.NOM) |
| 67. | Readers who want local color in their mysteries usually seek exotic foreign. (Reader.NOM want.PRE local.GEN color.ACC in.COMv their.GEN mystery.NOM usually.ADV seek.PRE exotic.GEN foreign.ACC) |
| 68. | He said he will develop a new investment strategy for several months. (He.NOM said.PRE he.NOM develop.PRE new.GEN investment.NOM strategy.NOM for.COMv several.GEN month.NOM) |
| 69. | The emerging legislation is at his economic recovery program for further years. (Emerging.GEN legislation.NOM is.PRE at.LIN his.GEN economic.NOM recovery.NOM program.NOM for.COMv further.GEN year.NOM) |
| 70. | All the records were always at hand if we must call about something. (All.GEN record.NOM are.LIN always.ADV at.COM hand.NOM we.NOM must.ADV call.PRE about.COMv something.NOM) |
| 71. | The TV series has become a big hit among viewers who find empathy with characters in the drama. (TV.NOM series.NOM become.PRE big.GEN hit.NOM among.COMv viewer.NOM find.PRE empathy.ACC with.COMv character.NOM in.COMv drama.NOM) |
| 72. | The chain of workers involved in real estate deals has grown over the years. (Chain.NOM worker.NOM involved.PRE in.COMv real.GEN estate.NOM deal.NOM grow.PRE over.COMv year.NOM) |
| 73. | Rival studios have come together to push consumers to rent more movies on their cable boxes. (Rival.NOM studio.NOM come.PRE together.ADV push.PRE consumer.ACC rent.PRE more.GEN movie.ACC on.COMv their.GEN cable.NOM boxe.NOM) |
| 74. | He fled to a neighboring town where he took a family hostage. (he.NOM fled.PRE neighbour.GEN town.ACC he.NOM take.PRE family.NOM hostage.NOM) |
| 75. | Everyone was expecting France teams to make the finals competition. (Everyone.NOM expect.PRE France.ACC team.ACC make.PRE final.GEN competition.ACC) |
References
- Zou, Y.; Lu, W. Learning Cross-lingual Distributed Logical Representations for Semantic Parsing. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Melbourne, Australia, 15–20 July 2018. [Google Scholar]
- Balahur, A.; Perea-Ortega, J.M. Sentiment analysis system adaptation for multilingual processing: The case of tweets. Inf. Process. Manag. 2015, 51, 547–556. [Google Scholar] [CrossRef]
- Noraset, T.; Lowphansirikul, L.; Tuarob, S. WabiQA: A Wikipedia-Based Thai Question-Answering System. Inf. Process. Manag. 2021, 58, 102431. [Google Scholar] [CrossRef]
- Zheng, J.; Li, Q.; Liao, J. Heterogeneous type-specific entity representation learning for recommendations in e-commerce network. Inf. Process. Manag. 2021, 58, 102629. [Google Scholar] [CrossRef]
- Etaiwi, W.; Awajan, A. Graph-based Arabic text semantic representation. Inf. Process. Manag. 2020, 57, 102183. [Google Scholar] [CrossRef]
- Liang, P. Learning executable semantic parsers for natural language understanding. Commun. ACM 2016, 59, 68–76. [Google Scholar] [CrossRef] [Green Version]
- Liang, P.; Potts, C. Bringing Machine Learning and Compositional Semantics Together. Annu. Rev. Linguistics 2015, 1, 355–376. [Google Scholar] [CrossRef] [Green Version]
- Bos, J.; Basile, V.; Evang, K.; Venhuizen, N.J.; Bjerva, J. The Groningen Meaning Bank. In Handbook of Linguistic Annotation; Springer: Berlin/Heidelberg, Germany, 2017; pp. 463–496. [Google Scholar]
- Banarescu, L.; Bonial, C.; Cai, S.; Georgescu, M.; Griffitt, K.; Hermjakob, U.; Knight, K.; Koehn, P.; Palmer, M.; Schneider, N. Abstract meaning representation for sembanking. In Proceedings of the LAW, Sofia, Bulgaria, 8–9 August 2013; pp. 178–186. [Google Scholar]
- Abend, O.; Dvir, D.; Hershcovich, D.; Prange, J.; Schneider, N. Cross-lingual Semantic Representation for NLP with UCCA. In Proceedings of the 28th International Conference on Computational Linguistics: Tutorial Abstracts, Barcelona, Spain, 8–13 December 2020; pp. 1–9. [Google Scholar]
- Boguslavsky, I.; Frid, N.; Iomdin, L.; Kreidlin, L.; Sagalova, I.; Sizov, V. Creating a Universal Networking Language module within an advanced NLP system. In Proceedings of the 18th Conference on Computational Linguistics, Saarbrücken, Germany, 31 July–4 August 2000; Volume 1, pp. 83–89. [Google Scholar]
- Nivre, J.; Marneffe, M.-C.D.; Ginter, F.; Goldberg, Y.; Hajic, J.; Manning, C.D.; McDonald, R.; Petrov, S.; Pyysalo, S.; Silveira, N.; et al. Universal dependencies v1: A multi-lingual treebank collection. In Proceedings of the of LREC, Portorož, Slovenia, 23–28 May 2016; pp. 1659–1666. [Google Scholar]
- Xiao, G.; Guo, J.; Da Xu, L.; Gong, Z. User Interoperability with Heterogeneous IoT Devices Through Transformation. IEEE Trans. Ind. Inform. 2014, 10, 1486–1496. [Google Scholar] [CrossRef]
- Nikiforov, D.; Korchagin, A.B.; Sivakov, R.L. An Ontology-Driven Approach to Electronic Document Structure Design. In Communications in Computer and Information Science; Springer: Berlin/Heidelberg, Germany, 2017; pp. 3–16. [Google Scholar]
- Xiao, G.; Guo, J.; Gong, Z.; Li, R. Semantic input method of Chinese word senses for semantic document exchange in e-business. J. Ind. Inf. Integr. 2016, 3, 31–36. [Google Scholar] [CrossRef]
- Qin, P.; Guo, J. A novel machine natural language mediation for semantic document exchange in smart city. Futur. Gener. Comput. Syst. 2020, 102, 810–826. [Google Scholar] [CrossRef]
- Guo, J. Collaborative conceptualisation: Towards a conceptual foundation of interoperable electronic product catalogue system design. Enterp. Inf. Syst. 2009, 3, 59–94. [Google Scholar] [CrossRef]
- Li, W.; Suzuki, E. Adaptive and hybrid context-aware fine-grained word sense disambiguation in topic modeling based document representation. Inf. Process. Manag. 2021, 58, 102592. [Google Scholar] [CrossRef]
- Medjahed, B.; Benatallah, B.; Bouguettaya, A.; Ngu, A.H.; Elmagarmid, A.K. Busi-ness-to-business interactions: Issues and enabling technologies. VLDB J. 2003, 12, 59–85. [Google Scholar] [CrossRef]
- Bing, L.; Jiang, S.; Lam, W.; Zhang, Y.; Jameel, S. Adaptive concept resolution for document repre-sentation and its applications in text mining. Knowl.-Based Syst. 2015, 74, 1–13. [Google Scholar] [CrossRef]
- Tekli, J. An Overview on XML Semantic Disambiguation from Unstructured Text to Semi-Structured Data: Background, Applications, and Ongoing Challenges. IEEE Trans. Knowl. Data Eng. 2016, 28, 1383–1407. [Google Scholar] [CrossRef]
- Decker, S.; Melnik, S.; Van Harmelen, F.; Fensel, D.; Klein, M.; Broekstra, J.; Erdmann, M.; Horrocks, I. The Semantic Web: The roles of XML and RDF. IEEE Internet Comput. 2000, 4, 63–73. [Google Scholar] [CrossRef]
- Wang, T.D.; Parsia, B.; Hendler, J. A survey of the web ontology landscape. In Proceedings of the International Semantic Web Conference, Athens, GA, USA, 5–9 November 2006. [Google Scholar]
- Rico, M.; Taverna, M.L.; Caliusco, M.L.; Chiotti, O.; Galli, M.R. Adding Semantics to Electronic Business Documents Exchanged in Collaborative Commerce Relations. J. Theor. Appl. Electron. Commer. Res. 2009, 4, 72–90. [Google Scholar] [CrossRef] [Green Version]
- Governatori, G. REPRESENTING BUSINESS CONTRACTS IN RuleML. Int. J. Cooperative Inf. Syst. 2005, 14, 181–216. [Google Scholar] [CrossRef] [Green Version]
- Tsadiras, A.; Bassiliades, N. RuleML representation and simulation of Fuzzy Cognitive Maps. Expert Syst. Appl. 2013, 40, 1413–1426. [Google Scholar] [CrossRef]
- Marneffe, M.; Maccartney, B.; Manning, C. Generating Typed Dependency Parses from Phrase Structure Parses. In Proceedings of the LREC’06, Genoa, Italy, 22–28 May 2006; pp. 449–454. [Google Scholar]
- Guo, J. SDF: A Sign Description Framework for Cross-context Information Resource Representation and Inter-change. In Proceedings of the 2nd Int’l Conference on Enterprise Systems (ICES 2014), Shanghai, China, 2–3 August 2014. [Google Scholar]
- Ruppenhofer, J.; Ellsworth, M.; Schwarzer-Petruck, M.; Johnson, C.R.; Baker, C.F.; Scheffczyk, J. FrameNet II: Extended Theory and Practice; International Computer Science Institute: Berkeley, CA, USA, 2006. [Google Scholar]
- Loper, E.; Yi, S.-T.; Palmer, M. Combining lexical resources: Mapping between PropBank and VerbNet. In Proceedings of the 7th International Workshop on Computational Linguistics, Syktyvkar, Russia, 23–25 September 2007. [Google Scholar]
- Palmer, M.; Gildea, D.; Kingsbury, P. The Proposition Bank: An Annotated Corpus of Semantic Roles. Comput. Linguist. 2005, 31, 71–106. [Google Scholar] [CrossRef]
- Xue, N.; Bojar, O.; Hajic, J.; Palmer, M.; Uresova, Z.; Zhang, X. Not an intelingua, but close: Comparison of English AMRs to Chinese and Czech. In Proceedings of the Ninth International Conference on Language Resources and Evaluation (LREC’14), Reykjavik, Iceland, 26–31 May 2014; pp. 1765–1772. [Google Scholar]
- White, A.S.; Reisinger, D.; Sakaguchi, K.; Vieira, T.; Zhang, S.; Rudinger, R.; Rawlins, K.; Van Durme, B. Universal Decompositional Semantics on Universal Dependencies. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing (EMNLP), Austin, TX, USA, 1–5 November 2016; pp. 1713–1723. [Google Scholar]
- Ehrmann, M.; Cecconi, F.; Vannella, D.; McCrae, J.P.; Cimiano, P.; Navigli, R. Representing multilingual data as linked data: The case of babelnet 2.0. In Proceedings of the LREC, Reykjavik, Iceland, 26–31 May 2014; pp. 401–408. [Google Scholar]
- Klein, D.; Manning, C.D. Accurate unlexicalized parsing. In Proceedings of the Proceedings of the 41st Annual Meeting on Association for Computational Linguistics—ACL ’03, Sapporo, Japan, 7–12 July 2003; pp. 423–430. [Google Scholar]
- Cook, V.J. Chomsky’s universal grammar and second language learning. Appl. Linguist. 1985, 6, 2–18. [Google Scholar] [CrossRef]
- Starosta, S.; Anderson, J.M. On Case Grammar: Prolegomena to a Theory of Grammatical Relations; Routledge: Abingdon, UK, 2018. [Google Scholar]
- Gkatzia, D.; Mahamood, S. A Snapshot of NLG Evaluation Practices 2005–2014. In Proceedings of the Proceedings of the 15th European Workshop on Natural Language Generation (ENLG), Brighton, UK, 10–11 September 2015; pp. 57–60. [Google Scholar]
- Chelba, C.; Mikolov, T.; Schuster, M.; Ge, Q.; Brants, T.; Koehn, P.; Robinson, T. One billion word benchmark for measuring progress in statistical language modeling. arXiv 2013, arXiv:1312.3005. [Google Scholar]
- Brysbaert, M. How Many Participants Do We Have to Include in Properly Powered Experiments? A Tutorial of Power Analysis with Reference Tables. J. Cogn. 2019, 2, 16. [Google Scholar] [CrossRef] [PubMed]
- Shrotryia, V.K.; Dhanda, U. Content Validity of Assessment Instrument for Employee Engagement. SAGE Open 2019, 9, 2158244018821751. [Google Scholar] [CrossRef] [Green Version]
- Carletta, J. Assessing agreement on classification tasks: The kappa statistic. Comput. Linguist. 1996, 22, 249–254. [Google Scholar]
- Landis, J.R.; Koch, G.G. The Measurement of Observer Agreement for Categorical Data. Biometrics 1977, 33, 159–174. [Google Scholar] [CrossRef] [Green Version]
- Shen, B.; Tan, W.; Guo, J.; Zhao, L.; Qin, P. How to Promote User Purchase in Metaverse? A Systematic Literature Review on Consumer Behavior Research and Virtual Commerce Application Design. Appl. Sci. 2021, 11, 11087. [Google Scholar] [CrossRef]
- Shen, B.; Guo, J.; Yang, Y. MedChain: Efficient Healthcare Data Sharing via Blockchain. Appl. Sci. 2019, 9, 1207. [Google Scholar] [CrossRef] [Green Version]
- Qin, P.; Tan, W.; Guo, J.; Shen, B. Intelligible Description Language Contract (IDLC)—A Novel Smart Contract Model. Inf. Syst. Front. 2021, 1–18. [Google Scholar] [CrossRef]



| 1. | Function (Input words) |
| 2. | Input |
| 3. | String ← Input word |
| 4. | if (String.pos= “ncm” or “npp” or “ntp”) then |
| 5. | Gender(G): = n | m | f | b /* Select noun’s gender */ |
| 6. | Number(N): = s | p | u /* Select noun’s number */ |
| 7. | return ← noun morphological feature (mf) |
| 8. | if (String.pos= “vtr” or “vid” or “vit”) then |
| 9. | Tense(T) = present | past | future | past future /* Select a verb’s tense */ |
| 10. | Aspect(A) = f | g | w | h | p /* Select verb’s aspect */ |
| 11. | Voice(V): = active | passive /* Select verb’s voice */ |
| 12. | return ← verb morphological feature (mf) |
| Tense of Sentence | English Sentence | HSI |
|---|---|---|
| Past perfect | She had gone home. | She.mf go.mf home. (mf refers to defined Hex) |
| Future perfect | She will have gone home. | |
| Present perfect continuous | She has been going home. | |
| Past perfect continuous | She had been going home. | |
| Future perfect continuous | She will have been going home. | |
| Simple present | She goes home. | |
| Simple past | She went home. | |
| Simple future | She will go home. | |
| Present continuous | She is going home. | |
| Past continuous | She was going home. | |
| Future continuous | She will be going home. |
| 1. | if (isCoDicPos) |
| 2. | if (CoDicpos =par and iid= “xxx”) { |
| 3. | Stanfordpos = “xxx”; |
| 4. | } else if (CoDicpos = noun or verb and mf= “xxx”) { |
| 5. | Stanfordpos = “xxx” or insert words and Stanfordpos = “xxx”; |
| 6. | } else if (CoDicpos = other PoS) { |
| 7. | Stanfordpos = “xxx”; |
| 8. | } else |
| 9. | print =”error” |
| 10. | end if; } |
| I | Enjoy | Travel | In | Summer | English(HNLi) |
|---|---|---|---|---|---|
| 0x5107df00b5e2 | 0x5707df00184b | 0x5107df01848b | 0x5a07df000103 | 0x5107df016d86 | iid |
| 0x5107df00b5e2.0.NOM.0.1 | 0x5707df00184b.03.PRE.0.1 | 0x5107df01848b.0.ACC.1.2 | 0x5a07df000103.COMv.1.2 | 0x5107df016d86.0.NOM.2.3 | eiid |
| 我 | 享受 | 旅程 | 在 | 夏天 | Chinese (HNLj) |
| HSI | English Sentence Analysis | Machine Representation |
|---|---|---|
| I.0 go.00 home.0 (I have gone home.) | I/NN (have/VBP) go/VBN home/NN. | S.0.0(I.0x5107df00b5e2.0.NOM.0.1(go.0x5707df00203d.00.PRE.1.2(home.0x5107df00afcc.0.ACC.2.3))) |
| I.0 go.40 home.0. (I have been going home.) | I/NN (have/VBP been/VBN) go/VBN home/NN. | S.0.0(I.0x5107df00b5e2.0.NOM.0.1(go.0x5707df00203d.40.PRE.1.2(home.0x5107df00afcc.0.ACC.2.3))) |
| I.0 go.04 home.0 (I am going home.) | I/NN (is/VBP) go/VBG home/NN. | S.0.0(I.0x5107df00b5e2.0.NOM.0.1(go.0x5707df00203d.04.PRE.1.2(home.0x5107df00afcc.0.ACC.2.3))) |
| Sentence Type | Number of Words | |||||
|---|---|---|---|---|---|---|
| Group A (N = 15) | Group B (N = 15) | Group C (N = 15) | Group D (N = 15) | Group E (N = 15) | Total | |
| Short Sentence (length <= 8, N = 50) | 46 (N = 10) | 59 (N = 10) | 50 (N = 10) | 54 (N = 10) | 60 (N = 10) | 269 |
| Long Sentence (length > 8, N = 25) | 45 (N = 5) | 44 (N = 5) | 45 (N = 5) | 51 (N = 5) | 51 (N = 5) | 236 |
| Total | 91 | 103 | 95 | 105 | 111 | 505 |
| Perfectly Clear | Clear | Acceptable | Unclear | Very Unclear | Total | |
|---|---|---|---|---|---|---|
| Group A | 119 | 152 | 128 | 21 | 15 | 435 |
| Group B | 130 | 192 | 98 | 9 | 6 | 435 |
| Group C | 143 | 223 | 109 | 4 | 1 | 480 |
| Group D | 127 | 166 | 90 | 3 | 4 | 390 |
| Group E | 139 | 226 | 101 | 11 | 3 | 480 |
| 30% | 43% | 24% | 2% | 1% | 2220 |
| Group | Inter-Annotator (Expert, Expert) | κ * | κavg. | Intra-Annotator (Expert, MParser) | κ * | κavg. |
|---|---|---|---|---|---|---|
| Group A (N = 15) | (Expert 1, Expert 2) | 0.688 | 0.741 | (Expert 1, MParser) | 0.637 | 0.753 |
| (Expert 2, Expert 3) | 0.831 | (Expert 2, MParser) | 0.853 | |||
| (Expert 1, Expert 3) | 0.703 | (Expert 3, MParser) | 0.768 | |||
| Group B (N = 15) | (Expert 1, Expert 2) | 0.597 | 0.663 | (Expert 1, MParser) | 0.537 | 0.668 |
| (Expert 2, Expert 3) | 0.766 | (Expert 2, MParser) | 0.685 | |||
| (Expert 1, Expert 3) | 0.627 | (Expert 3, MParser) | 0.781 | |||
| Group C (N = 15) | (Expert 1, Expert 2) | 0.648 | 0.642 | (Expert 1, MParser) | 0.603 | 0.734 |
| (Expert 2, Expert 3) | 0.673 | (Expert 2, MParser) | 0.779 | |||
| (Expert 1, Expert 3) | 0.605 | (Expert 3, MParser) | 0.821 | |||
| Group D (N = 15) | (Expert 1, Expert 2) | 0.694 | 0.687 | (Expert 1, MParser) | 0.613 | 0.724 |
| (Expert 2, Expert 3) | 0.775 | (Expert 2, MParser) | 0.835 | |||
| (Expert 1, Expert 3) | 0.593 | (Expert 3, MParser) | 0.724 | |||
| Group E (N = 15) | (Expert 1, Expert 2) | 0.686 | 0.730 | (Expert 1, MParser) | 0.616 | 0.706 |
| (Expert 2, Expert 3) | 0.837 | (Expert 2, MParser) | 0.749 | |||
| (Expert 1, Expert 3) | 0.668 | (Expert 3, MParser) | 0.753 | |||
| Avg. | Substantial | 0.693 | Substantial | 0.717 | ||
| Sentence Type | Inter-Annotator (Expert, MParser) | κavg. |
|---|---|---|
| All Sentences (N = 75) | (Expert 1, MParser) | 0.601 |
| (Expert 2, MParser) | 0.780 | |
| (Expert 3, MParser) | 0.769 | |
| Short Sentence (length <= 8) (N = 50) | (Expert 1, MParser) | 0.728 |
| (Expert 2, MParser) | 0.834 | |
| (Expert 3, MParser) | 0.819 | |
| Long Sentence (length > 8) (N = 25) | (Expert 1, MParser) | 0.505 |
| (Expert 2, MParser) | 0.726 | |
| (Expert 3, MParser) | 0.719 |
| Intra-Annotator (Expert, MParser) | MR (N = 505) | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| NOM | PRE | ACC | DAT | GEN | LIN | ADV | COM | COMv | COMn | COMall | Avg. | |
| (Expert 1, MParser) | 0.684 | 0.979 | 0.804 | 0.647 | 0.958 | 0.756 | 0.840 | 0.682 | 0.649 | 0.690 | 0.916 | 0.782 |
| (Expert 2, MParser) | 0.706 | 1 | 0.847 | 0.684 | 0.973 | 0.807 | 0.891 | 0.639 | 0.711 | 0.687 | 0.907 | 0.805 |
| (Expert 3, MParser) | 0.715 | 0.979 | 0.828 | 0.749 | 0.947 | 0.784 | 0.874 | 0.662 | 0.684 | 0.648 | 0.938 | 0.801 |
| Avg. | 0.702 | 0.986 | 0.826 | 0.693 | 0.959 | 0.782 | 0.868 | 0.661 | 0.681 | 0.675 | 0.920 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qin, P.; Tan, W.; Guo, J.; Shen, B.; Tang, Q. Achieving Semantic Consistency for Multilingual Sentence Representation Using an Explainable Machine Natural Language Parser (MParser). Appl. Sci. 2021, 11, 11699. https://doi.org/10.3390/app112411699
Qin P, Tan W, Guo J, Shen B, Tang Q. Achieving Semantic Consistency for Multilingual Sentence Representation Using an Explainable Machine Natural Language Parser (MParser). Applied Sciences. 2021; 11(24):11699. https://doi.org/10.3390/app112411699
Chicago/Turabian StyleQin, Peng, Weiming Tan, Jingzhi Guo, Bingqing Shen, and Qian Tang. 2021. "Achieving Semantic Consistency for Multilingual Sentence Representation Using an Explainable Machine Natural Language Parser (MParser)" Applied Sciences 11, no. 24: 11699. https://doi.org/10.3390/app112411699
APA StyleQin, P., Tan, W., Guo, J., Shen, B., & Tang, Q. (2021). Achieving Semantic Consistency for Multilingual Sentence Representation Using an Explainable Machine Natural Language Parser (MParser). Applied Sciences, 11(24), 11699. https://doi.org/10.3390/app112411699