
Deep Learning-Based Community Detection Approach on Multimedia Social Networks




Abstract
:1. Introduction
2. Related Works
2.1. Social Network Modeling
2.2. Community Detection Algorithm
3. Methodology
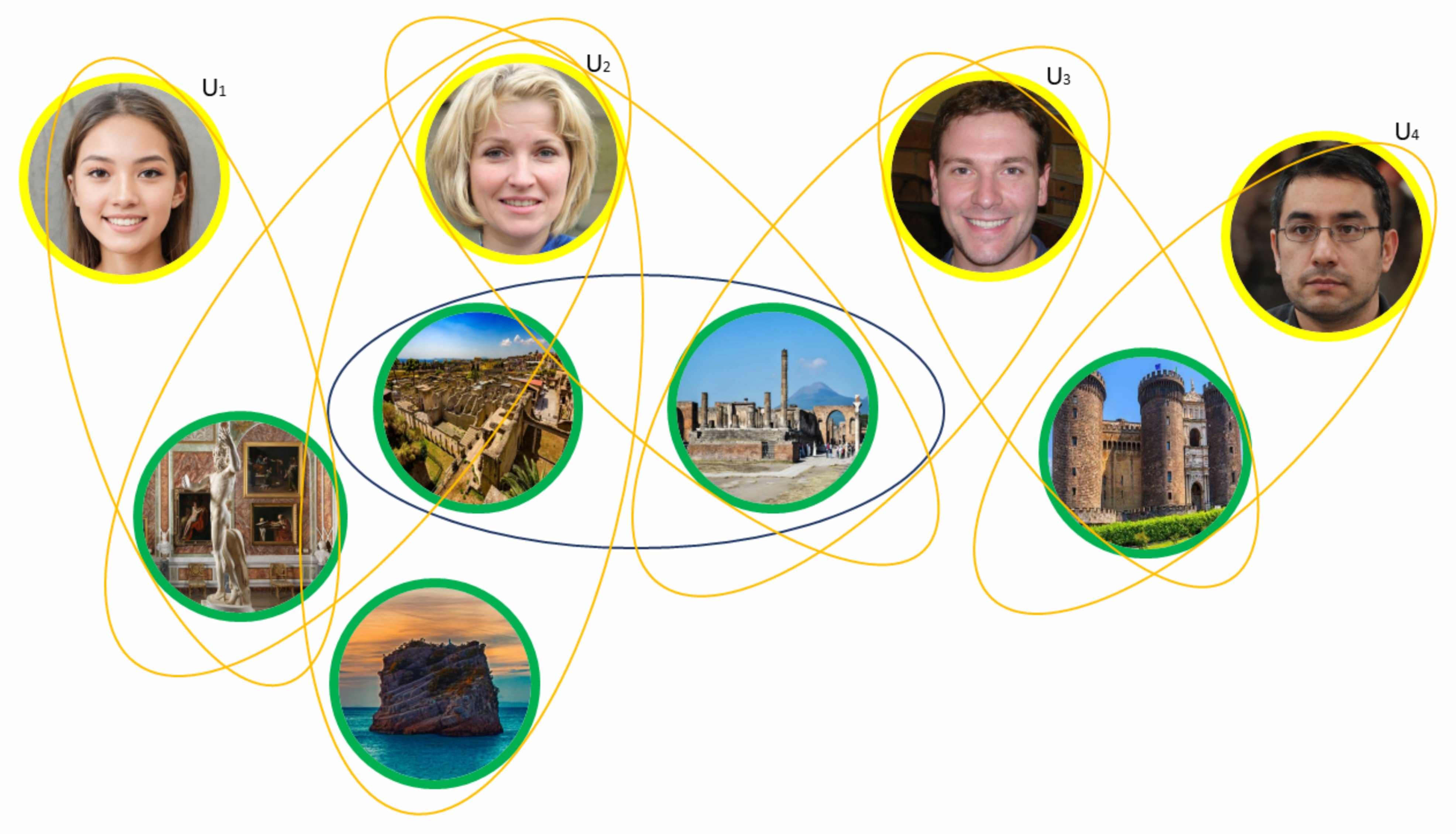
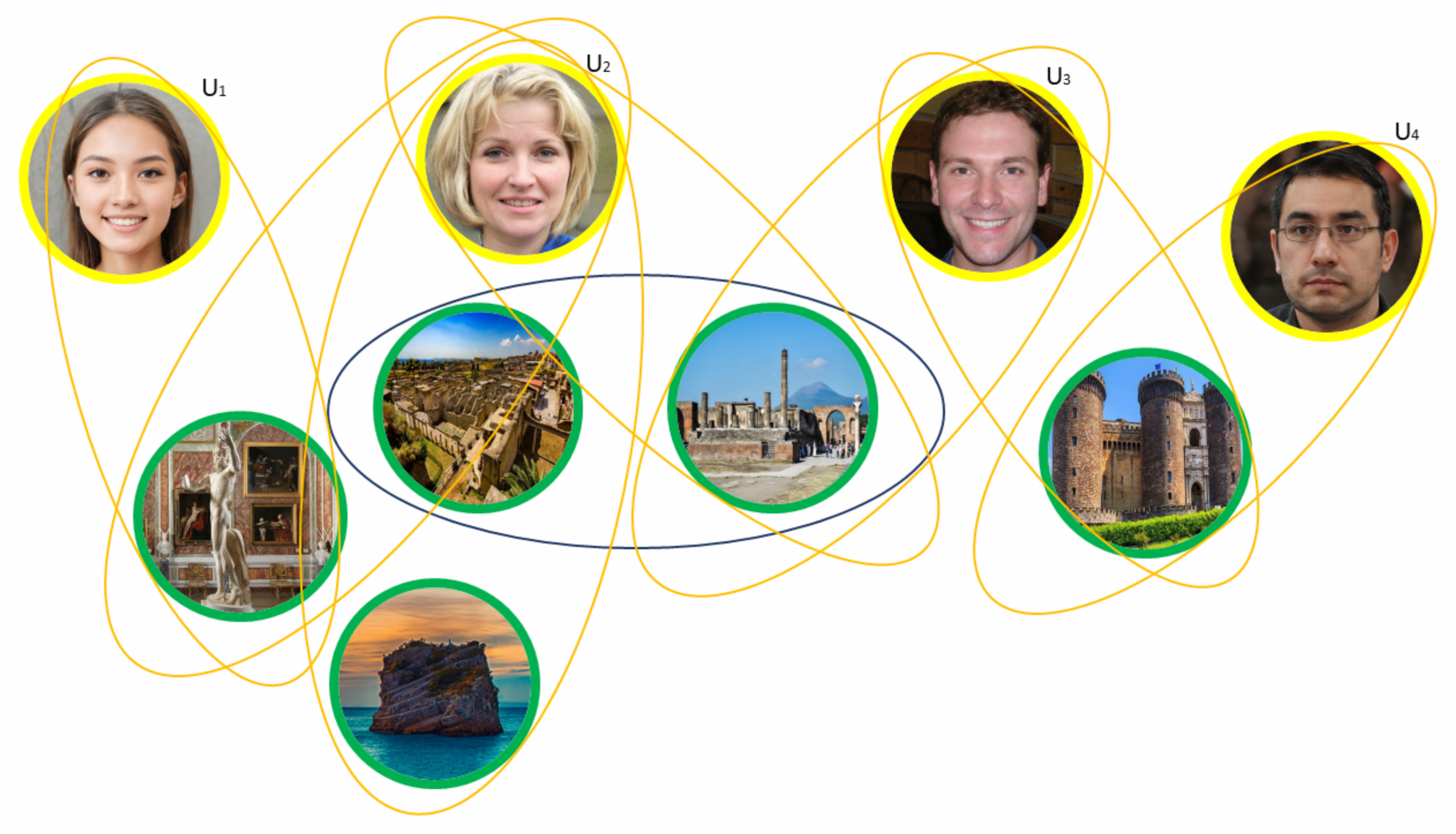
3.1. Multimedia Social Network Model
- User-to-user: representing a user’s actions with another user, which are, formally, defined as , where and , where ;
- User-to-multimedia object: representing the relationships a user has with other media objects, possibly associated with a weight (depending to the analyzed MSN). The weight assigned to such hyperarcs indicates the importance of the relationship of an MSN. Mathematically, it can be described as with , where and , where ;
- Similarity: represented by the similarity relations between two users or between two objects. Mathematically, it is described as with and with . The weight associated with this class of hyperarcs is a function of different factors, such as the metric used and the type of vertex considered.
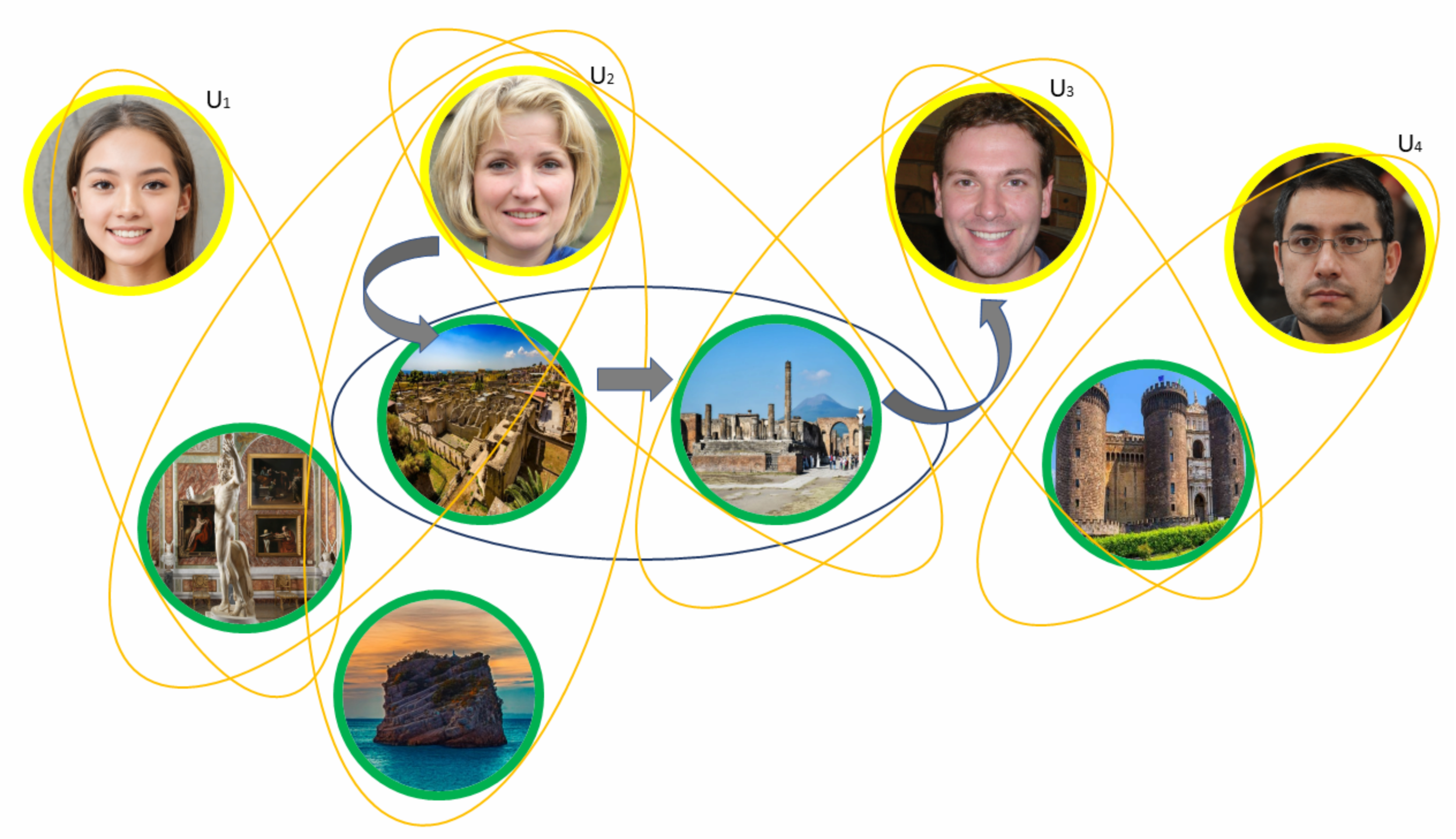
3.2. Community Detection Approach Based on Deep Learning
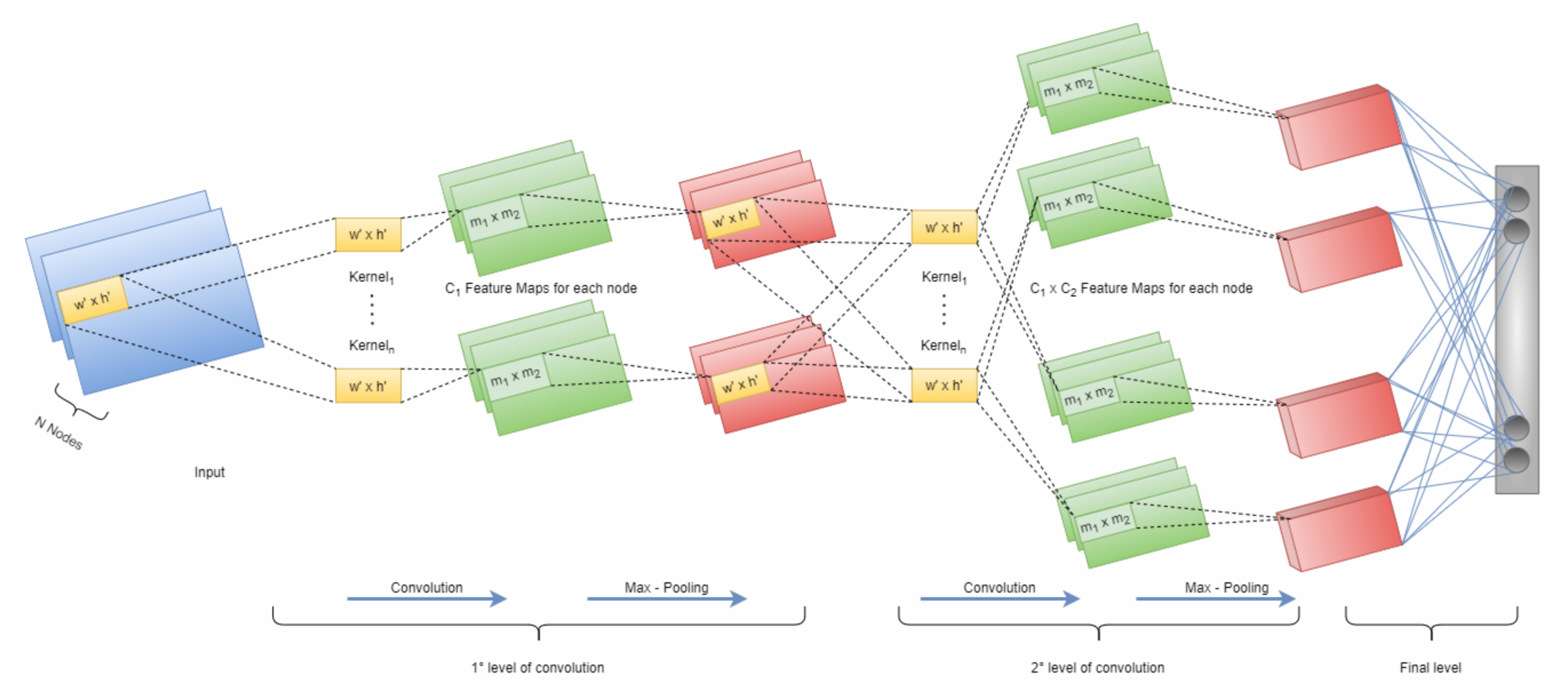
3.2.1. Ingestion Layer
3.2.2. Convolutional Layer
3.2.3. Max-Pooling Layer
3.2.4. Fully Connected Layer
4. Experimental Evaluation
4.1. Experimental Protocol
- Time efficiency analysis of our approach on the artificial dataset, varying the matrix sparsity and number of nodes;
- Performance analysis during the training phase considering the loss value and different optimization metrics;
4.2. Metrics
4.3. Architecture
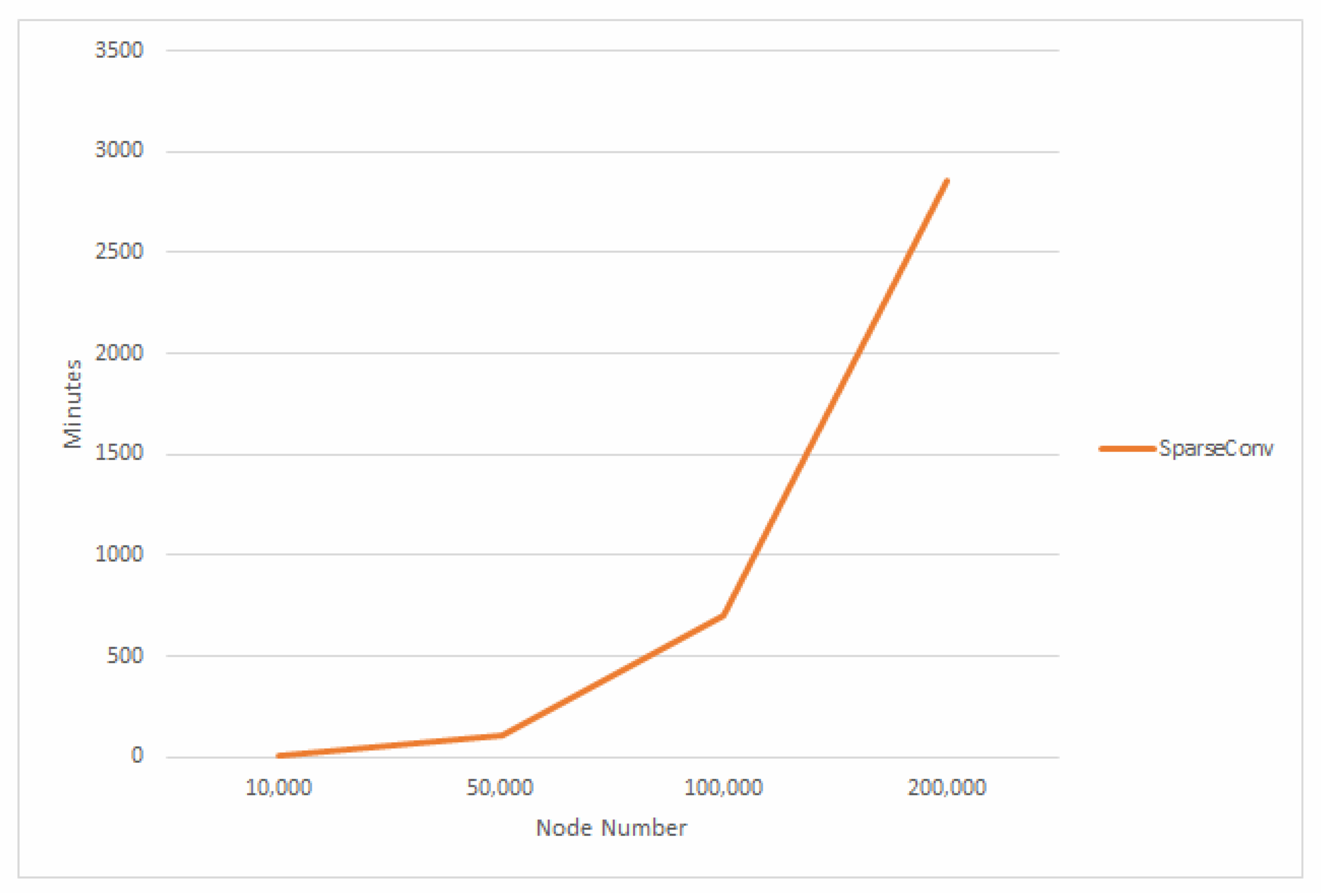
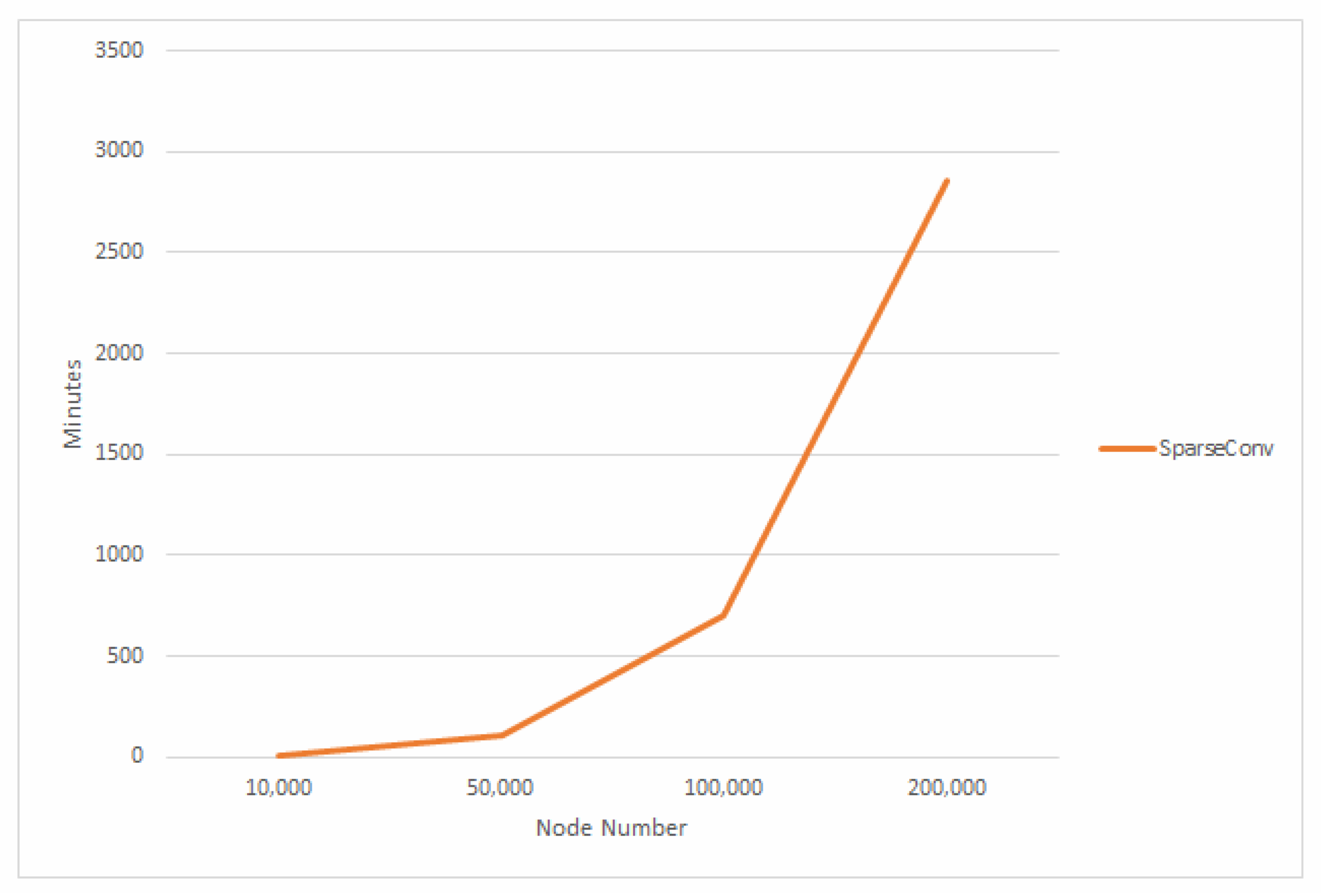
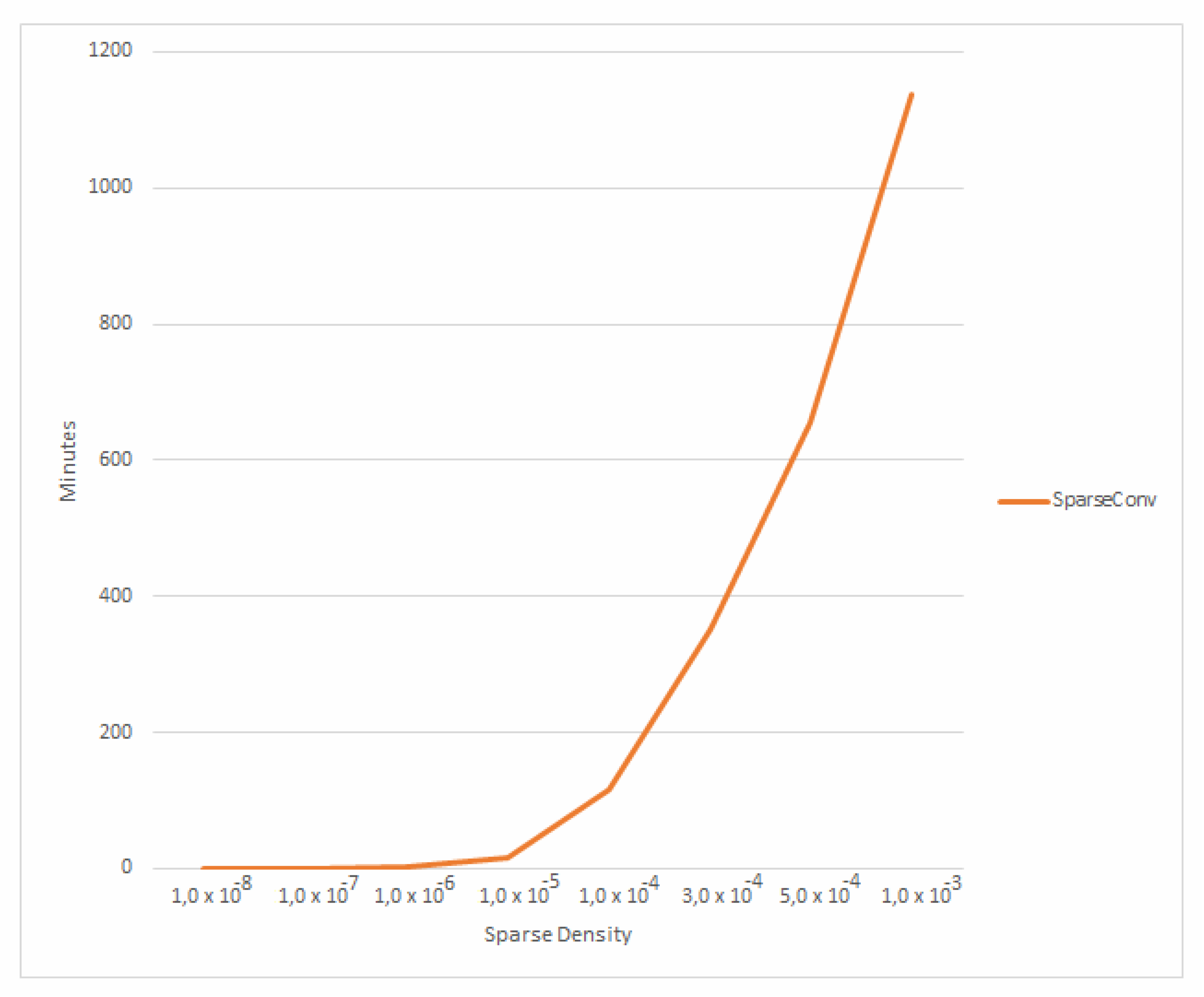
4.4. Running Time Analysis
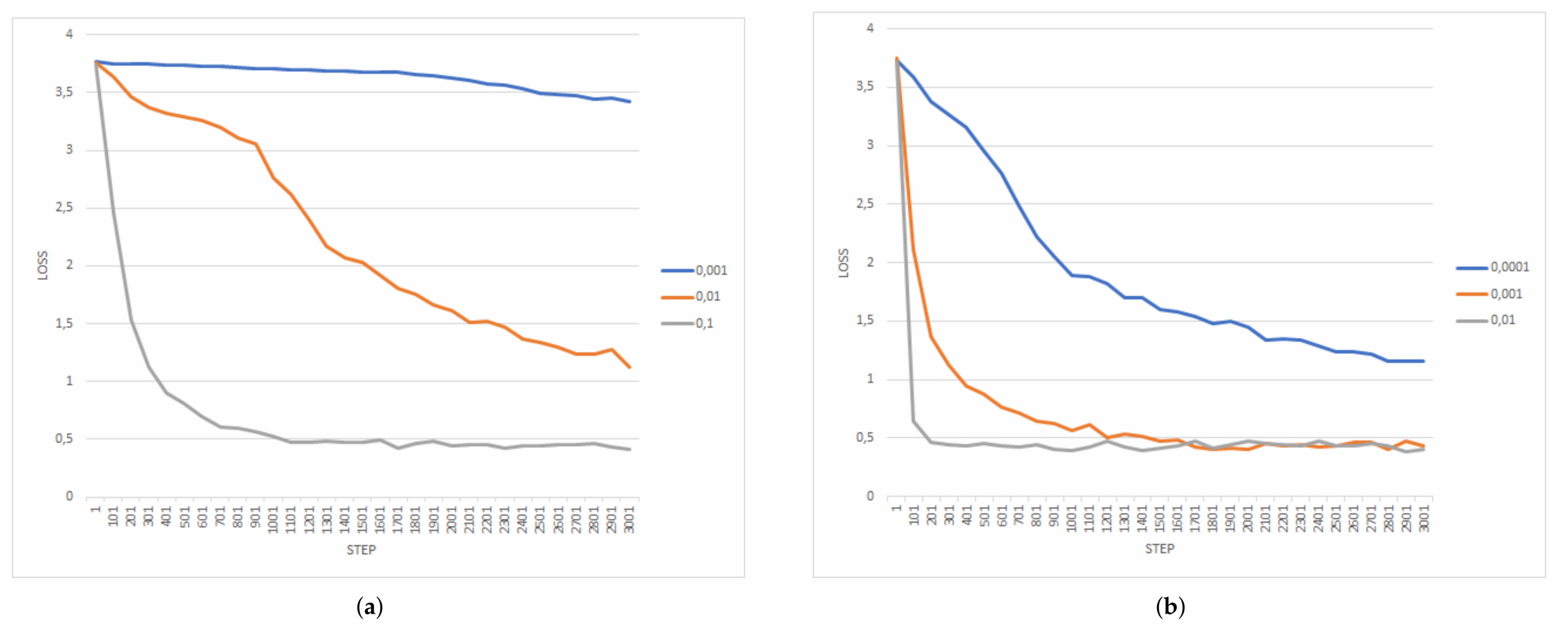
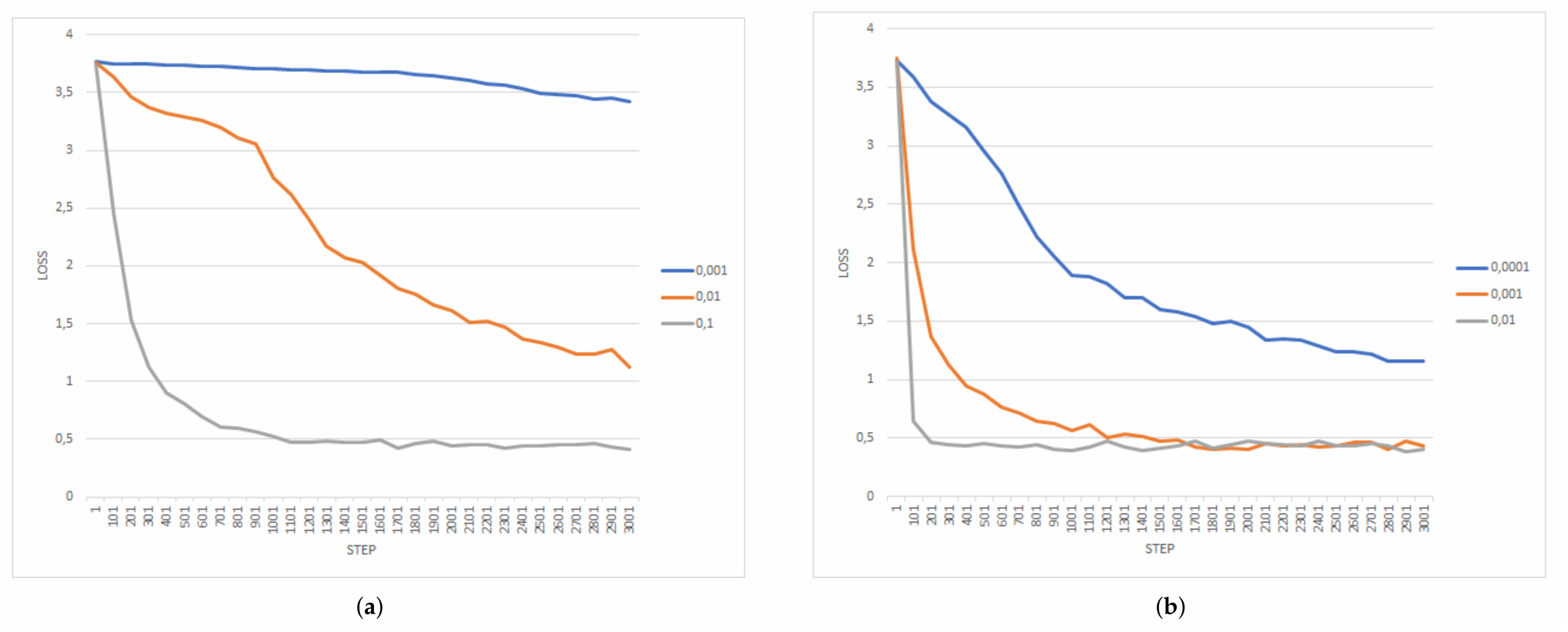
4.5. Training Performance Analysis
- Learning rate (0.1, 0.01, 0.001);
- Kernel number (three and ten);
- Optimizer (gradient descent and Adam);
- Decaying rate.
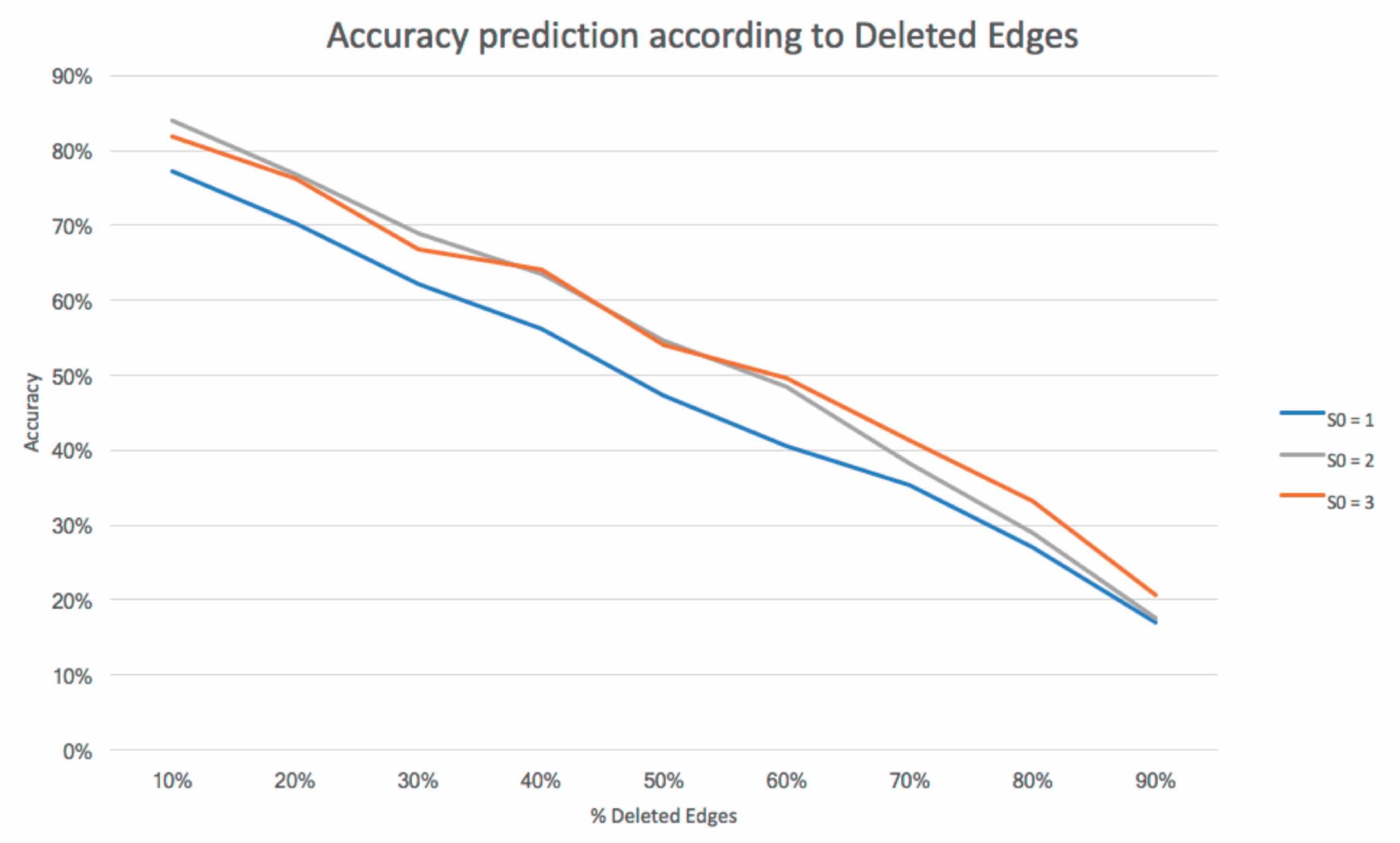
4.6. Effectiveness Evaluation
5. Conclusions
- Extending the testing phase to other datasets such as Facebook, Twitter, etc., not only with respect to Flickr;
- Optimizing the analysis of influence and recommendation algorithms;
- Reducing the impact of lurkers (a type of behavior on social media in which a user interrupts an online silence or passive thread-viewing habit to engage in a virtual conversation; the term implies that a user typically does not participate in social media or online social activities) based on communities in social networks;
- Improving the community detection also using embedding techniques directly on hypergraphs, which transform a state space with high dimensionality into a new space with low-dimensionality (e.g., vectors), having the advantages of being able to lighten the computational complexity and to apply many techniques of machine learning.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Rathore, S.; Sharma, P.K.; Loia, V.; Jeong, Y.S.; Park, J.H. Social network security: Issues, challenges, threats, and solutions. Inf. Sci. 2017, 421, 43–69. [Google Scholar] [CrossRef]
- Bayrakdar, S.; Yucedag, I.; Simsek, M.; Dogru, I.A. Semantic analysis on social networks: A survey. Int. J. Commun. Syst. 2020, 33, e4424. [Google Scholar] [CrossRef]
- Liu, F.; Xue, S.; Wu, J.; Zhou, C.; Hu, W.; Paris, C.; Nepal, S.; Yang, J.; Yu, P.S. Deep learning for community detection: Progress, challenges and opportunities. arXiv 2020, arXiv:2005.08225. [Google Scholar]
- Amato, F.; Moscato, V.; Picariello, A.; Sperlí, G. Multimedia social network modeling: A proposal. In Proceedings of the 2016 IEEE Tenth International Conference on Semantic Computing (ICSC), Laguna Hills, CA, USA, 4–6 February 2016; pp. 448–453. [Google Scholar]
- Amato, F.; Moscato, V.; Picariello, A.; Piccialli, F.; Sperlí, G. Centrality in heterogeneous social networks for lurkers detection: An approach based on hypergraphs. Concurr. Comput. Pract. Exp. 2018, 30, e4188. [Google Scholar] [CrossRef]
- Antelmi, A. Towards an Exhaustive Framework for Online Social Networks User Behaviour Modelling. In Proceedings of the 27th ACM Conference on User Modeling, Adaptation and Personalization, Larnaca, Cyprus, 9–12 June 2019; pp. 349–352. [Google Scholar]
- Amato, F.; Moscato, V.; Picariello, A.; Ponti, G.; Sperlì, G. Influence Analysis in Business Social Media. In Proceedings of the MIDAS@ PKDD/ECML, Skopje, Macedonia, 18–22 September 2017; pp. 43–54. [Google Scholar]
- Wang, F.; She, J.; Ohyama, Y.; Jiang, W.; Min, G.; Wang, G.; Wu, M. Maximizing positive influence in competitive social networks: A trust-based solution. Inf. Sci. 2021, 546, 559–572. [Google Scholar] [CrossRef]
- Li, G.; Dong, M.; Yang, F.; Zeng, J.; Yuan, J.; Jin, C.; Hung, N.Q.V.; Cong, P.T.; Zheng, B. Misinformation-oriented expert finding in social networks. World Wide Web 2020, 23, 693–714. [Google Scholar] [CrossRef]
- Wu, D.; Fan, S.; Yuan, F. Research on pathways of expert finding on academic social networking sites. Inf. Process. Manag. 2021, 58, 102475. [Google Scholar] [CrossRef]
- Qi, G.J.; Aggarwal, C.; Tian, Q.; Ji, H.; Huang, T. Exploring Context and Content Links in Social Media: A Latent Space Method. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 850–862. [Google Scholar] [CrossRef]
- Jin, X.; Luo, J.; Yu, J.; Wang, G.; Joshi, D.; Han, J. Reinforced Similarity Integration in Image-Rich Information Networks. IEEE Trans. Knowl. Data Eng. 2013, 25, 448–460. [Google Scholar] [CrossRef]
- Zhu, Z.; Su, J.; Kong, L. Measuring influence in online social network based on the user-content bipartite graph. Comput. Hum. Behav. 2015, 52, 184–189. [Google Scholar] [CrossRef]
- Chen, H.; Yin, H.; Chen, T.; Wang, W.; Li, X.; Hu, X. Social Boosted Recommendation with Folded Bipartite Network Embedding. IEEE Trans. Knowl. Data Eng. 2020. online ahead of print. [Google Scholar] [CrossRef]
- Zhang, J.; Yang, Y.; Tian, Q.; Zhuo, L.; Liu, X. Personalized Social Image Recommendation Method Based on User-Image-Tag Model. IEEE Trans. Multimed. 2017, 19, 2439–2449. [Google Scholar] [CrossRef]
- Hu, Q.; Han, Z.; Lin, X.; Huang, Q.; Zhang, X. Learning peer recommendation using attention-driven CNN with interaction tripartite graph. Inf. Sci. 2019, 479, 231–249. [Google Scholar] [CrossRef]
- Liao, X.; Zheng, D.; Cao, X. Coronavirus pandemic analysis through tripartite graph clustering in online social networks. Big Data Min. Anal. 2021, 4, 242–251. [Google Scholar] [CrossRef]
- Anandkumar, A.; Sedghi, H. Learning mixed membership community models in social tagging networks through tensor methods. arXiv 2015, arXiv:1503.04567. [Google Scholar]
- Yang, D.; Qu, B.; Yang, J.; Cudre-Mauroux, P. LBSN2Vec++: Heterogeneous Hypergraph Embedding for Location-Based Social Networks. IEEE Trans. Knowl. Data Eng. 2020. online ahead of print. [Google Scholar] [CrossRef]
- Zheng, X.; Luo, Y.; Sun, L.; Ding, X.; Zhang, J. A novel social network hybrid recommender system based on hypergraph topologic structure. World Wide Web 2018, 21, 985–1013. [Google Scholar] [CrossRef]
- Chakraborty, T.; Dalmia, A.; Mukherjee, A.; Ganguly, N. Metrics for community analysis: A survey. ACM Comput. Surv. (CSUR) 2017, 50, 54. [Google Scholar] [CrossRef]
- Cavallari, S.; Cambria, E.; Cai, H.; Chang, K.; Zheng, V. Embedding both finite and infinite communities on graph. IEEE Comput. Intell. Mag. 2019, 14, 39–50. [Google Scholar] [CrossRef]
- Danon, L.; Diaz-Guilera, A.; Duch, J.; Arenas, A. Comparing community structure identification. J. Stat. Mech. Theory Exp. 2005, 2005, P09008. [Google Scholar] [CrossRef]
- Lancichinetti, A.; Fortunato, S. Consensus clustering in complex networks. Sci. Rep. 2012, 2, 336. [Google Scholar] [CrossRef]
- Kovács, I.A.; Palotai, R.; Szalay, M.S.; Csermely, P. Community landscapes: An integrative approach to determine overlapping network module hierarchy, identify key nodes and predict network dynamics. PLoS ONE 2010, 5, e12528. [Google Scholar] [CrossRef] [Green Version]
- Vilcek, A. Deep Learning with K-Means Applied to Community Detection in Networks; CS224W Project Report; Golden Gate University: Stanford, CA, USA, 2014. [Google Scholar]
- Yang, L.; Cao, X.; He, D.; Wang, C.; Wang, X.; Zhang, W. Modularity Based Community Detection with Deep Learning. IJCAI 2016, 16, 2252–2258. [Google Scholar]
- Perozzi, B.; Al-Rfou, R.; Skiena, S. DeepWalk: Online Learning of Social Representations. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; Association for Computing Machinery: New York, NY, USA, 2014; pp. 701–710. [Google Scholar] [CrossRef] [Green Version]
- Wang, H.; Wang, J.; Wang, J.; Zhao, M.; Zhang, W.; Zhang, F.; Xie, X.; Guo, M. Graphgan: Graph representation learning with generative adversarial nets. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Wang, J.; Cao, J.; Li, W.; Wang, S. CANE: Community-aware network embedding via adversarial training. Knowl. Inf. Syst. 2021, 63, 411–438. [Google Scholar] [CrossRef]
- Li, B.; Pi, D. Learning deep neural networks for node classification. Expert Syst. Appl. 2019, 137, 324–334. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; Available online: http://www.deeplearningbook.org (accessed on 10 October 2021).
- Wang, D.; Cui, P.; Zhu, W. Structural deep network embedding. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1225–1234. [Google Scholar] [CrossRef]
- Tang, J.; Qu, M.; Wang, M.; Zhang, M.; Yan, J.; Mei, Q. Line: Large-scale information network embedding. In Proceedings of the 24th International Conference on World Wide Web, Florence, Italy, 18–22 May 2015; pp. 1067–1077. [Google Scholar] [CrossRef] [Green Version]
- Thomee, B.; Shamma, D.A.; Friedland, G.; Elizalde, B.; Ni, K.; Poland, D.; Borth, D.; Li, L.J. YFCC100M: The new data in multimedia research. Commun. ACM 2016, 59, 64–73. [Google Scholar] [CrossRef]
- Tang, L.; Liu, H. Relational learning via latent social dimensions. In Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Paris, France, 28 June–1 July 2009; pp. 817–826. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Ref. | Entities | Application |
|---|---|---|---|
| Graph | [11] | Multimedia objects, concepts | Multimedia annotation |
| [12] | Images, users, and tags | Link-based similarity | |
| Bipartite | [13] | Users and contents | Influence diffusion |
| [14] | Users and contents | Social recommendation | |
| Tripartite | [15] | Users, tags, and images | Recommendation |
| [16] | Users, interaction behavior, and tags | Recommendation | |
| [17] | Users, Tweets, and topics | Coronavirus analysis | |
| Hypergraph | [18] | Users, tags, and resources | Consensus maximization |
| [19] | Users, time, and POIs | Location prediction | |
| [20] | Users and items | Recommendation |
| Model | Dataset | |
|---|---|---|
| Blogcatalog3 | Flickr | |
| CNN | 41 min | 315 min |
| DeepWalk | 21 min | 159 min |
| SDNE | 47 min | 366 min |
| LINE | 42 min | 326 min |
| GraphGAN | 49 min | 382 min |
| CANE | 55 min | 432 min |
| DNNNC | 39 min | 298 min |
| % Labeled Nodes | 10% | 30% | 60% | 90% | |
|---|---|---|---|---|---|
| Micro-F1 (%) | CNN | 30.51 | 39.67 | 44.70 | 47.92 |
| DeepWalk | 36.00 | 39.60 | 41.30 | 42.00 | |
| SDNE | 31.11 | 36.70 | 41.88 | 44.88 | |
| LINE | 30.43 | 35.99 | 41.41 | 43.46 | |
| GraphGAN | 28.78 | 39.01 | 42.71 | 44.76 | |
| CANE | 28.99 | 39.21 | 42.98 | 45.01 | |
| DNNNC | 28.15 | 38.91 | 41.89 | 44.59 | |
| Macro-F1 (%) | CNN | 14.72 | 24.98 | 31.92 | 35.12 |
| DeepWalk | 21.30 | 25.30 | 27.60 | 28.90 | |
| SDNE | 19.88 | 24.94 | 28.11 | 31.22 | |
| LINE | 18.67 | 24.81 | 27.91 | 30.64 | |
| GraphGAN | 17.88 | 23.54 | 29.87 | 33.01 | |
| CANE | 18.12 | 23.85 | 30.04 | 33.42 | |
| DNNNC | 17.55 | 23.21 | 29.45 | 32.83 |
| % Labeled Nodes | 1% | 3% | 6% | 9% | |
|---|---|---|---|---|---|
| Micro-F1 (%) | CNN | 25.94 | 35.88 | 39.43 | 44.51 |
| DeepWalk | 32.40 | 35.90 | 37.70 | 38.50 | |
| SDNE | 23.74 | 34.76 | 37.83 | 41.14 | |
| LINE | 23.01 | 34.44 | 37.75 | 40.65 | |
| GraphGAN | 23.01 | 33.10 | 37.77 | 42.32 | |
| CANE | 23.47 | 33.49 | 37.89 | 42.54 | |
| DNNNC | 22.79 | 32.99 | 37.14 | 42.16 | |
| Macro-F1 (%) | CNN | 12.15 | 20.91 | 26.46 | 29.74 |
| DeepWalk | 14.00 | 19.60 | 22.90 | 24.60 | |
| SDNE | 11.69 | 19.87 | 23.29 | 26.13 | |
| LINE | 11.52 | 19.76 | 23.01 | 25.78 | |
| GraphGAN | 13.92 | 19.91 | 25.63 | 27.39 | |
| CANE | 14.08 | 19.97 | 25.73 | 27.56 | |
| DNNNC | 13.78 | 19.66 | 25.21 | 27.01 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ferraro, A.; Moscato, V.; Sperlì, G. Deep Learning-Based Community Detection Approach on Multimedia Social Networks. Appl. Sci. 2021, 11, 11447. https://doi.org/10.3390/app112311447
Ferraro A, Moscato V, Sperlì G. Deep Learning-Based Community Detection Approach on Multimedia Social Networks. Applied Sciences. 2021; 11(23):11447. https://doi.org/10.3390/app112311447
Chicago/Turabian StyleFerraro, Antonino, Vincenzo Moscato, and Giancarlo Sperlì. 2021. "Deep Learning-Based Community Detection Approach on Multimedia Social Networks" Applied Sciences 11, no. 23: 11447. https://doi.org/10.3390/app112311447
APA StyleFerraro, A., Moscato, V., & Sperlì, G. (2021). Deep Learning-Based Community Detection Approach on Multimedia Social Networks. Applied Sciences, 11(23), 11447. https://doi.org/10.3390/app112311447