The importance of computer vision-related technology and research is increasing with the increasing efficiency of hardware computing. The main research areas in computer vision are object detection and classification techniques. Accurate detection and quick identification of objects has always been the most important issue in this area. Among all object detection methods, machine learning is one of the most frequently studied. In recent years, there have been many successful applications such as face detection and recognition [
1,
2], vehicle detection and tracking [
3,
4,
5], and pedestrian detection [
6,
7,
8]. There many single-class offline learning algorithms in machine learning that use massive training data and algorithms to find an approximation function closest to the unknown target function. The most common ones are Adaptive Boosting [
9] and Support Vector Machine [
10]. These single-class offline learning algorithms usually require a person to collect and classify a large number of positive and negative samples, after which different feature extraction and selection methods are used to find the distinguishable features for the dataset. Finally, these features are combined into a detection model by using a machine learning algorithm. For multiple objects, it is necessary to train several detection models in the same way. Although single-class offline learning has performed well in the field of object detection, substantial training time is necessary for multi-object detection. Thus, it is not recommended to combine several single object models together. As a result, multi-class offline learning is proposed.
Multi-class offline learning has many benefits, both in detection and classification. For example, detection speed and the discrimination of the multi-class offline learning model in classifying several objects usually perform better than the model built by multiple single-class offline learning models, as multi-class offline learning algorithms are obtained by combining or modifying single-class offline learning algorithms in a variety of ways. In addition, the algorithm, developed in this way, adapts to the multi-category classification problem. Some examples of such algorithms are Multi-class Support Vector Machine [
11], Joint Boosting [
12], and Random Forests [
13]. Although these multi-class offline learning algorithms effectively solve the problem of multiple objects classification, people must collect and classify a large number of positive and negative samples in advance, thus requiring more memory space and training time. These problems could mean that the algorithm cannot be trained in real-time with their application in some specific situations. To solve these problems, an online learning algorithm is proposed in this paper.
The online learning algorithm does not need to collect a large number of positive and negative samples in advance; instead, providing data one by one can make it adapt to the scene gradually. As a result, it does not need to learn the classifier at one time from a large number of samples. This not only reduces the training time of the detection model, but also decreases the memory space required. Most of these online learning algorithms evolved from offline learning algorithms. However, some of them also evolved from single-class to multi-class, like offline learning.
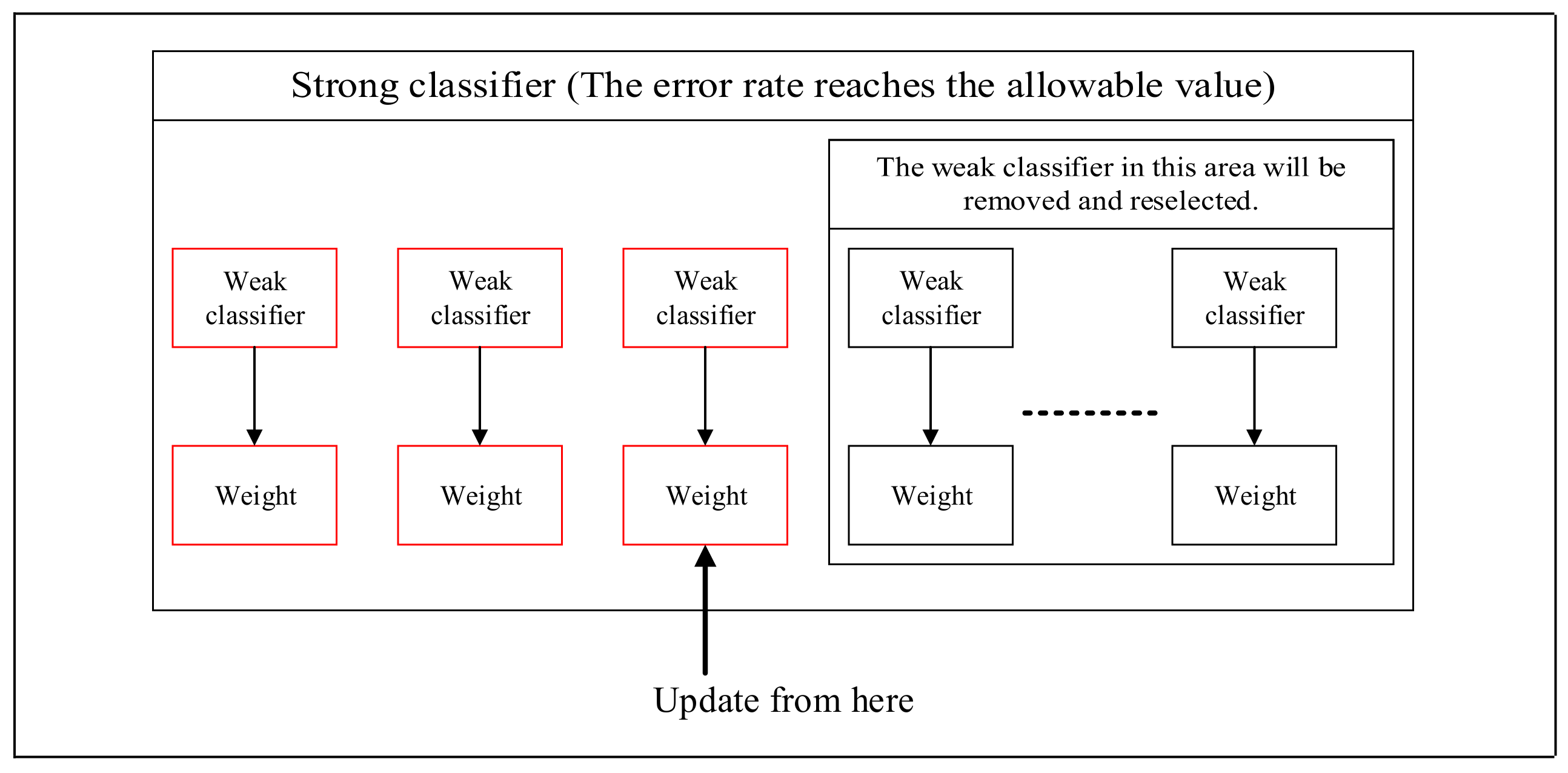
Oza and Russell proposed Online Boosting [
14], that is an improved online version of Adaptive Boosting [
9], which achieves the effect of boosting by simulating the number of times the data are sampled. Grabner and Bischof proposed another Online Boosting method [
15,
16], which simulates Adaptive Boosting [
9] but executes in a single-step method. It mainly selects the better classifier from the selector and combines these classifiers into one strong classifier. It replaces the weak classifier in the selector according to the adaption degree of samples to update the model. In addition to these improved online learning algorithms inspired by the offline learning algorithm, other algorithms were also proposed to combine with these online learning algorithms, e.g., On-line Conservative Learning, which was proposed by Roth, Peter M. [
17,
18]. In this algorithm, two models are compared, and the higher confidence sample is taken to automatically update the model. It achieves the goal of complete automatic learning and does not need people to label samples. Saffari [
19] proposed On-line Random Forests, which can be applied in multi-class object detection. It trains each Decision Tree by simulating the number of times the data are sampled, without using Pruning. This is an improved version of Random Forest [
13].
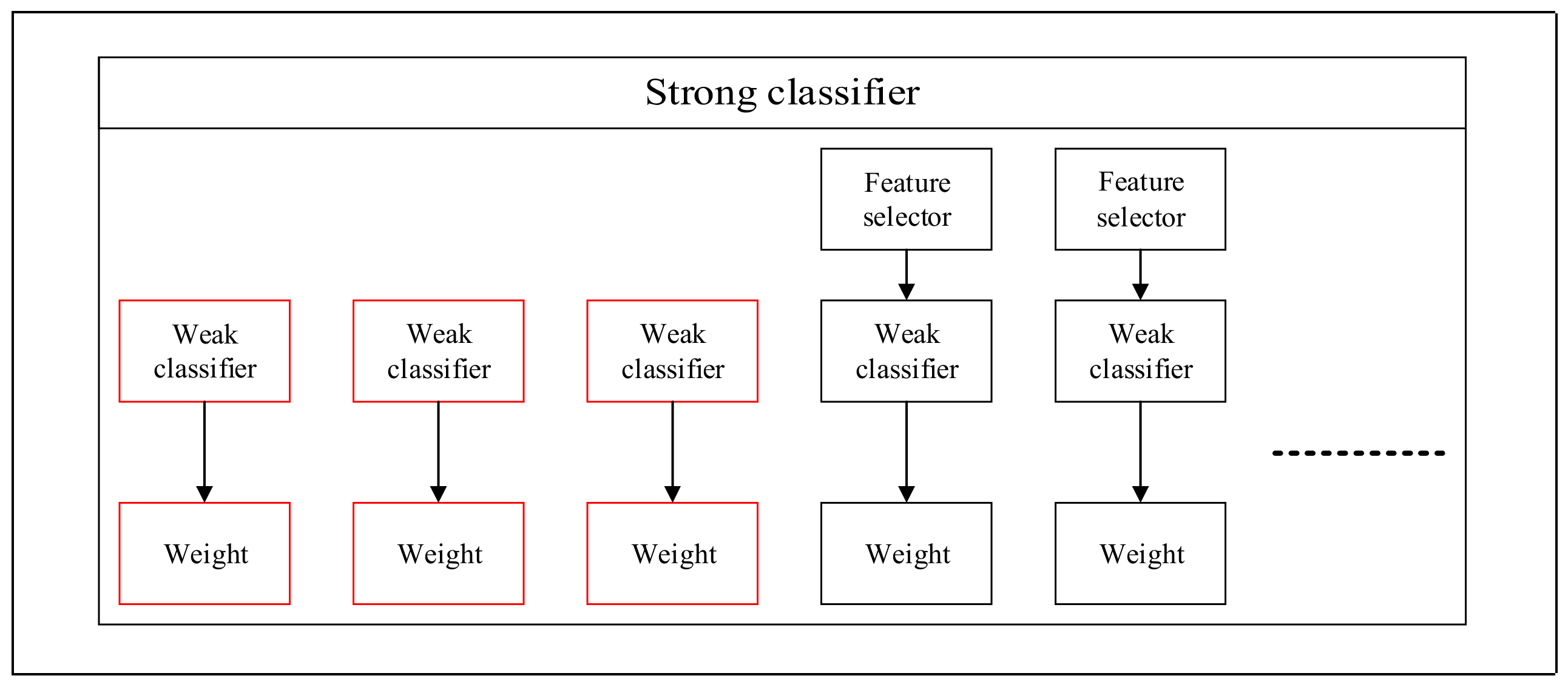
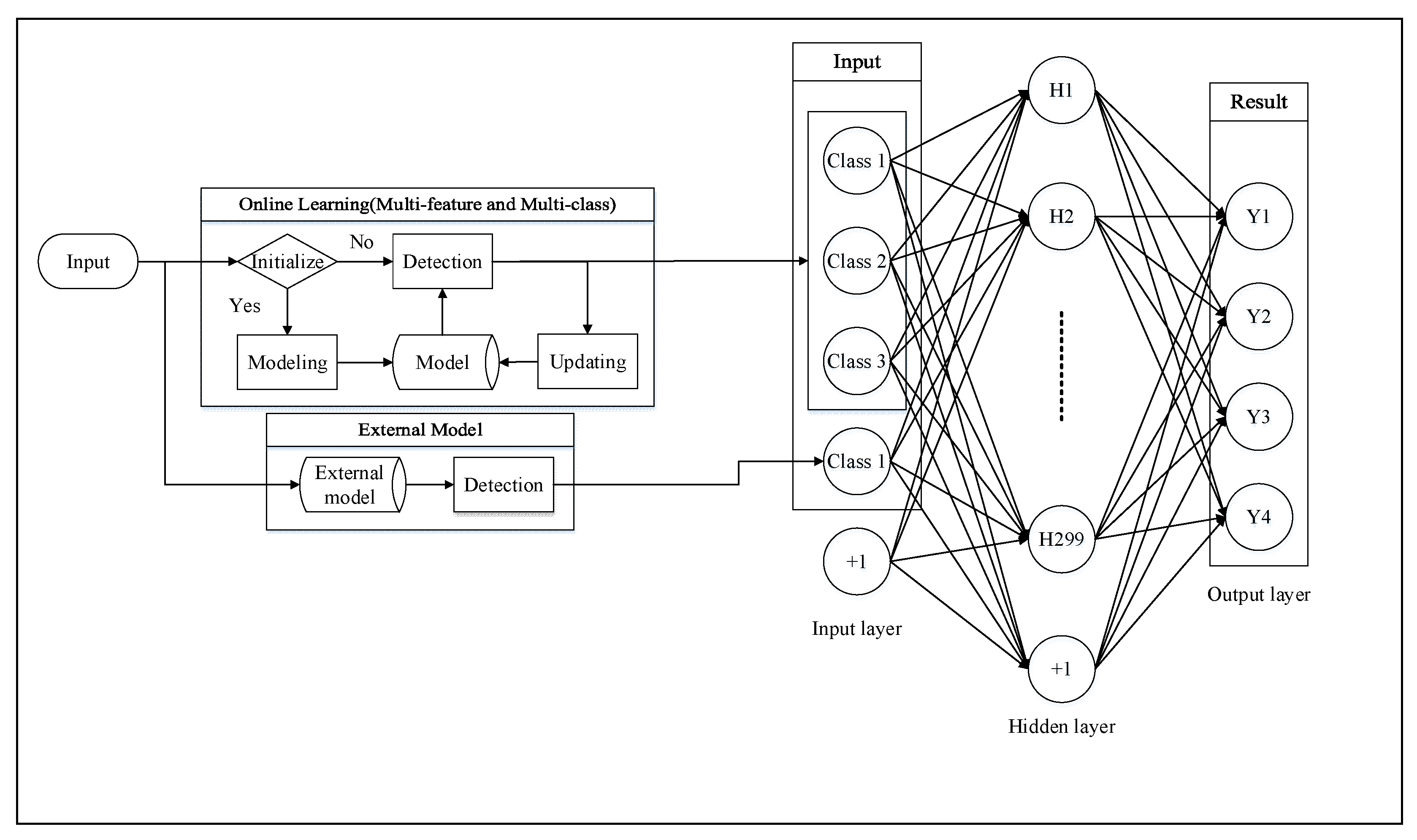
However, certain problems remain in the existing online learning algorithms. For example, online learning algorithm is an algorithm for general objects, so there is a huge influence on detection accuracy and learning speed depending on how suitable features are selected for these samples [
20,
21]. The online learning algorithms [
14,
15,
16], use a single feature during learning. If they use a feature that does not detect a certain object well, for example, using a Haar-like feature [
22] to detect a ball-shaped object or LBP [
23] to detect a smooth object, the performance suffers. In particular, multi-class classification has this problem because a single feature has insufficient distinguishing ability to distinguish several objects at the same time. Therefore, if we can dynamically allocate the type of feature according to the pattern pool, the problem would be solved. In addition, there are some online learning algorithms such as Online Random Forest [
19] whose models are irreversible as soon as the decision has been made. As a result, if the algorithm makes a false decision, the final performance of the detection model declines. At this time, if we can adjust the model thoroughly and correct the false decision, the detection model is able to perform well again. In addition, the classification result would also be bad if the feature that is used cannot effectively classify certain special samples. Most of the existing online learning algorithms, [
14,
15,
16] and so on, have this problem. A good solution would be to combine these learning algorithms with an external model according to the status of the model after learning to increase the detection performance of the model. Finally, since the sample of online learning is a one-by-one input, it would also be a challenge to preserve the better distinguished sample. Online Conservative Learning [
17,
18] chooses the sample which confidence as the updating sample is higher to solve this problem. With this approach, however, we cannot determine the more representative sample. Therefore, On-line Learning with Adaptive Model [
24] proposes a solution to sample storage and replacement. This method derives the more representative samples by calculating the importance and combining similar samples. For these reasons, this paper proposes an online multi-class learning and detection system that can dynamically allocate features based on samples and can combine with external models based on the learning effect to increase the performance of the model. Therefore, the proposed model not only uses the concept of the sharing feature in Joint Boosting classifier [
12] to build the model, but also uses the feature selector in Online Boosting algorithm [
15,
16] to update and select features that are distinguished better. Then, we used Back Propagation Neural Network [
25] to combine it with the external model. In the pattern pool, the proposed model adopts the same method in On-line Learning with Adaptive Model [
24] to make an update. In the feature part, the proposed model uses Haar-like [
22], Histogram of Oriented Gradient (HOG) [
26], and Local Binary Patterns (LBP) [
23]. Except for simplifying the last two features so that it can use Integral image [
27] to speed up the model, we also proposed an algorithm to dynamically allocate and replace features according to the learning samples. Finally, we proposed a new updating method by combining the Joint Boosting Classifier [
12] with the Online Boosting [
15,
16]. The system is able to adjust the model according to all pattern pools so that it is not affected by previous false decisions.


 ,
, 





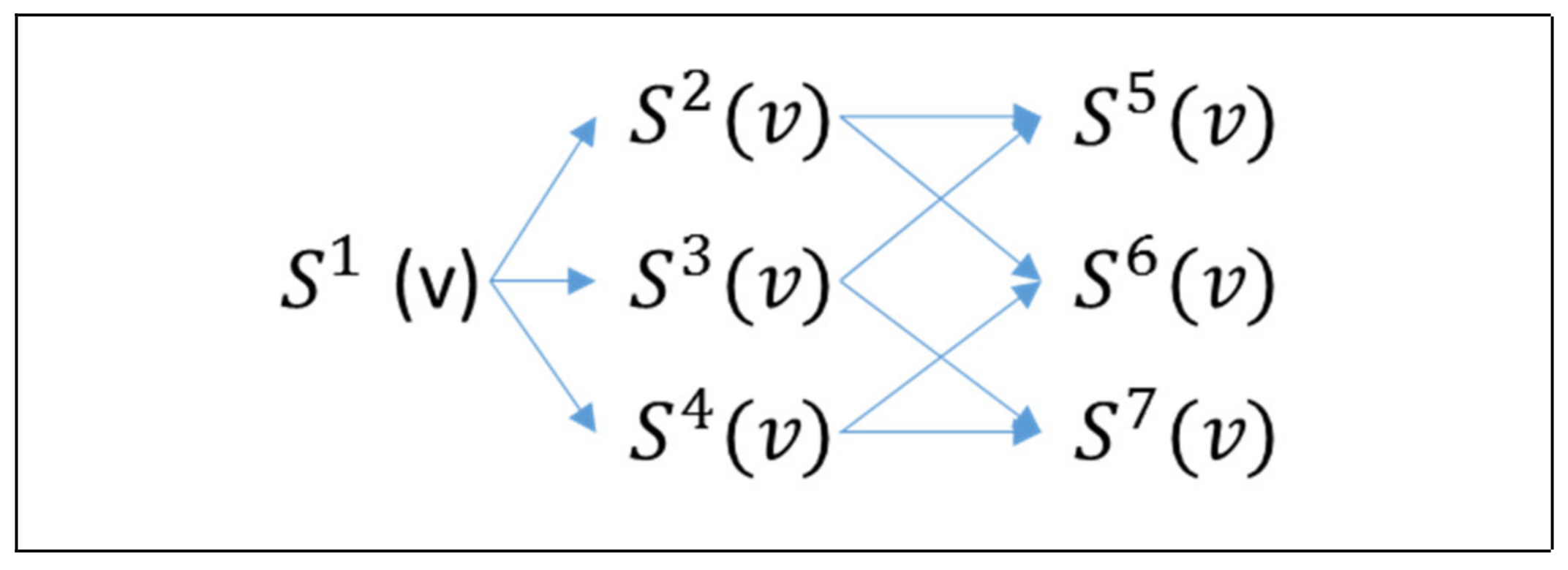
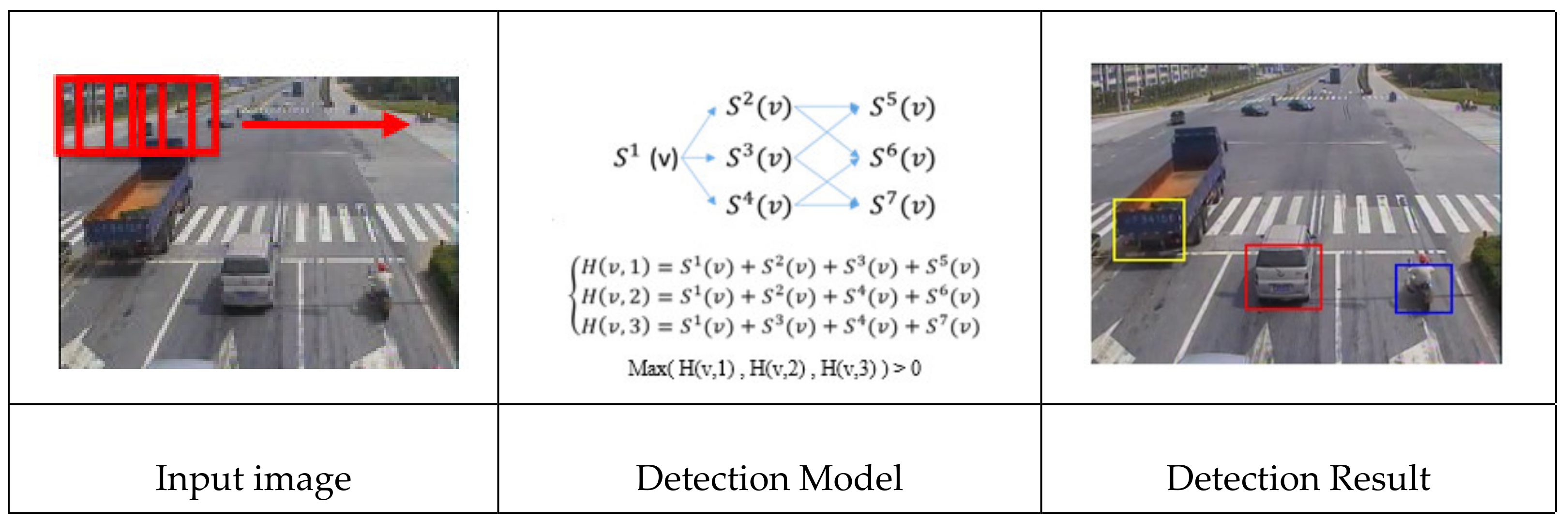


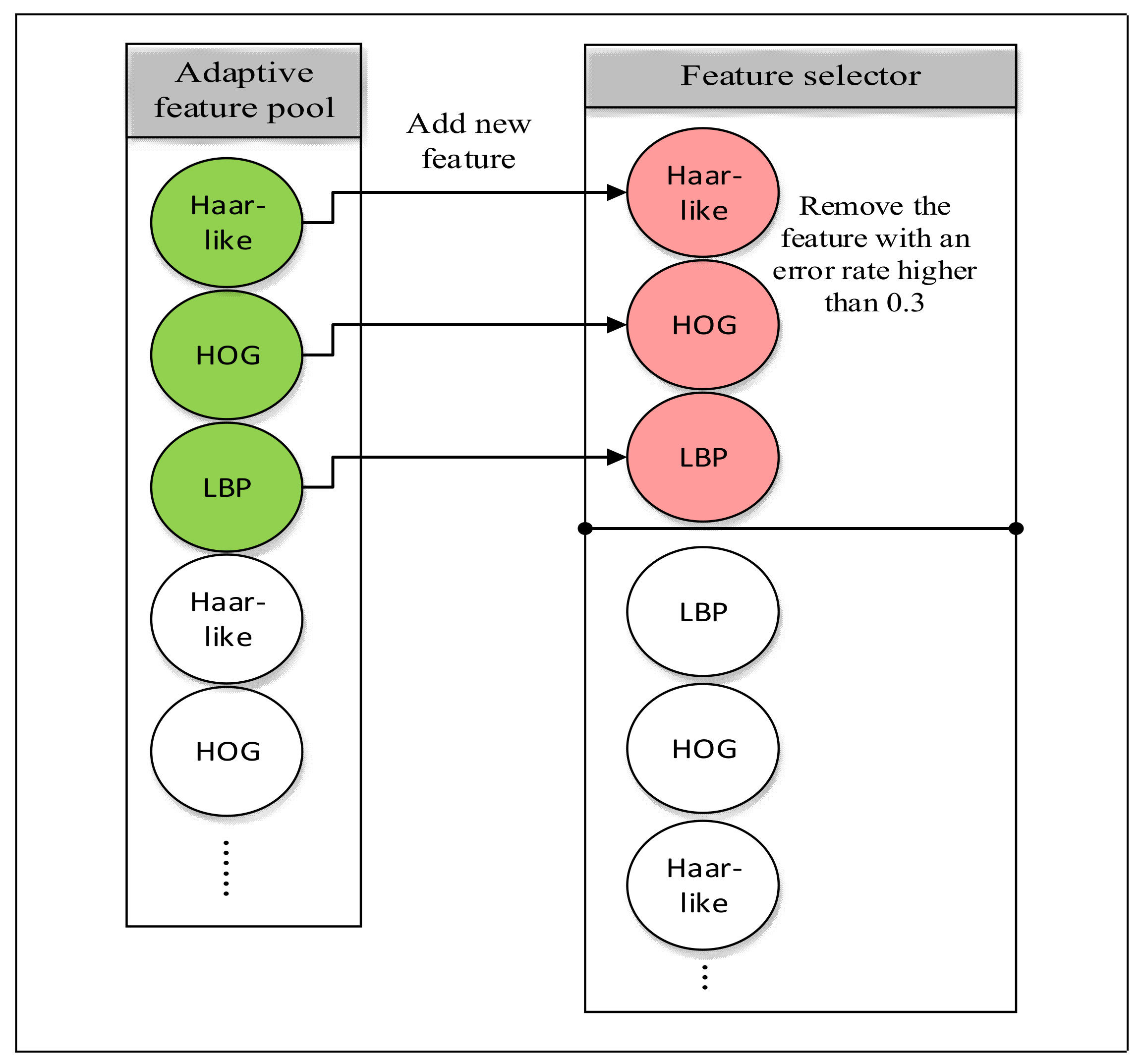






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}