
Minimizing the In-Cloud Bandwidth for On-Demand Reactive and Proactive Streaming Applications


Abstract
:1. Introduction
- to propose a new reactive protocol named Share All Slotted Stream Tapping (SASST) based on the technique Slotted Stream Tapping (SST) [11,23] for unpopular video streams. It has been shown in [11,23] to be competitive in performances and in ease of implementation than the rest of the reactive protocols,
- to propose a new proactive technique named the new optimal proactive protocol (NOPP) for popular video streams using optimal video segments to broadcast channels scheduling for known and unknown time horizon cases.
2. Related Work
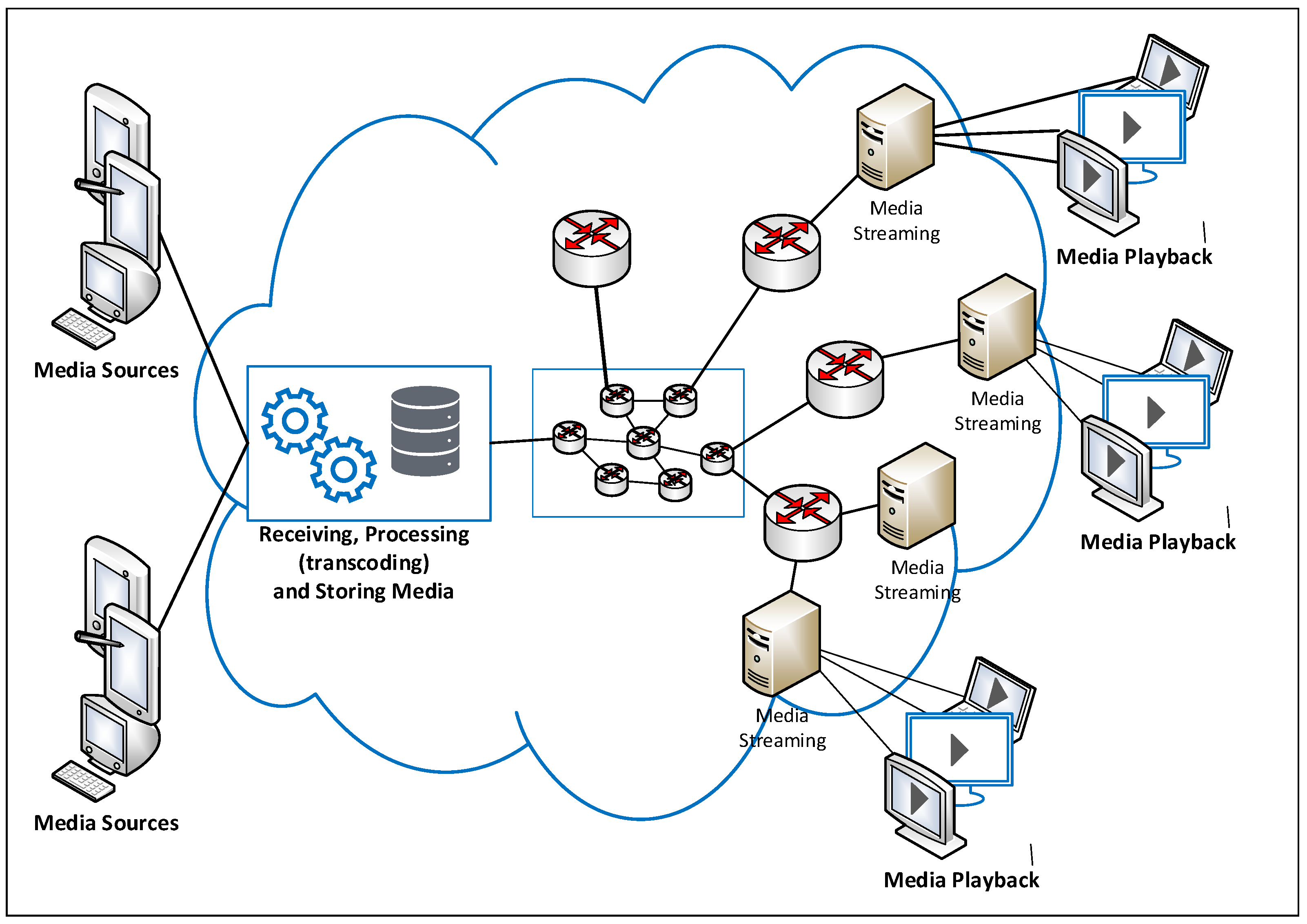
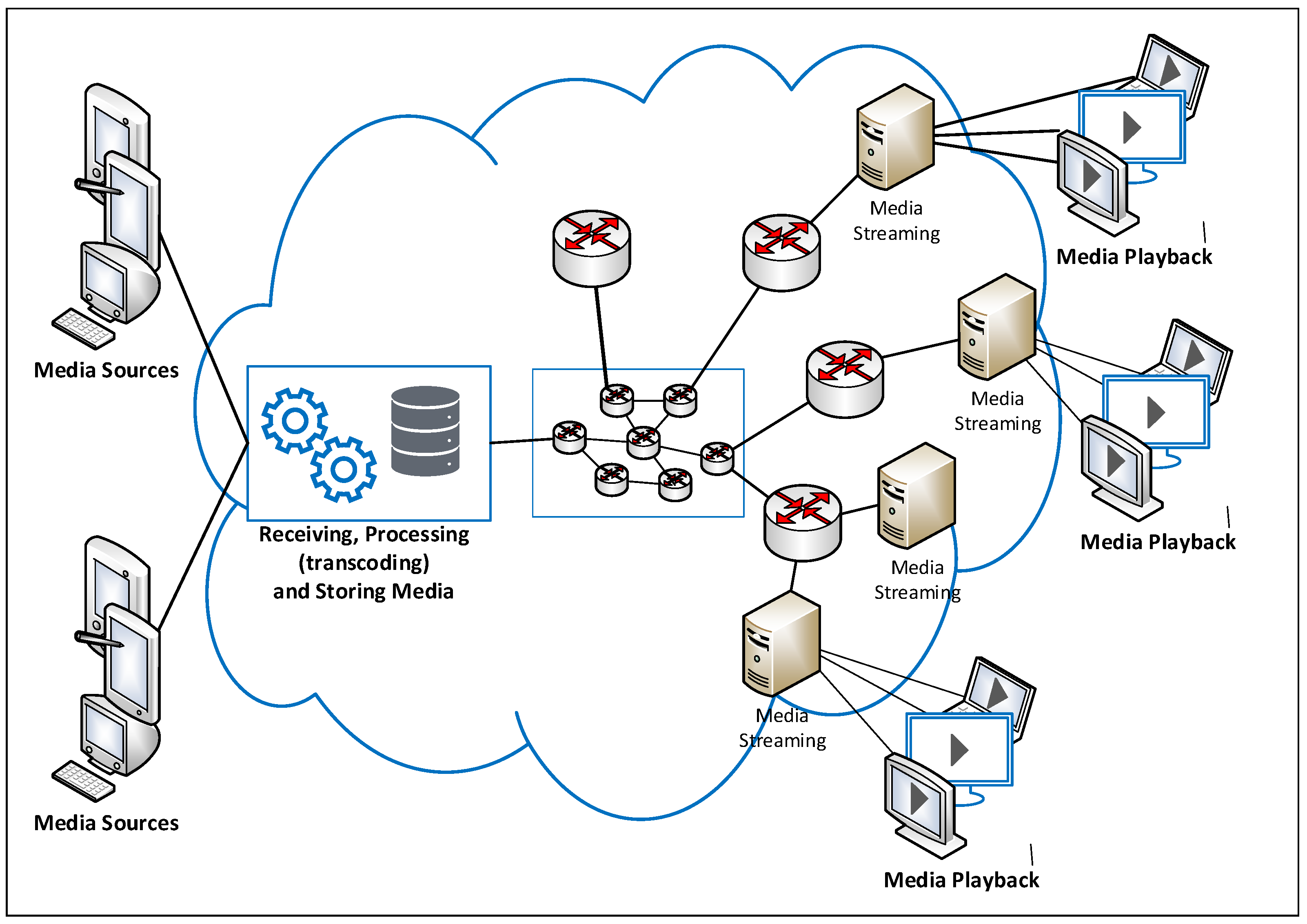
2.1. Considered Cloud-Based Streaming Architecture
2.2. Previous Work
- In reactive protocols: Dyadic is outperforming Unicast, ST and SST techniques in terms of bandwidth consumption. But, it is very hard to implement as reported in [8]. This raises the following question: Could we assure a trade off between the bandwidth consumption and the implementation level of difficulty in the reactive category?
- In proactive protocols: modern HTTP streaming protocols are based on (1) dividing the video into equally-sized segments and (2) sending them to the client as fast as segments are ready. SB is the only protocol compliant with these two properties (of modern streaming protocols). Unfortunately, its segments to channels scheduling is not optimal in terms of the consumed bandwidth. This raises the following question: How could this scheduling problem be stated and solved?
3. Optimizing Cloud-Based Streaming Internal Bandwidth: Case of an Unpopular Video
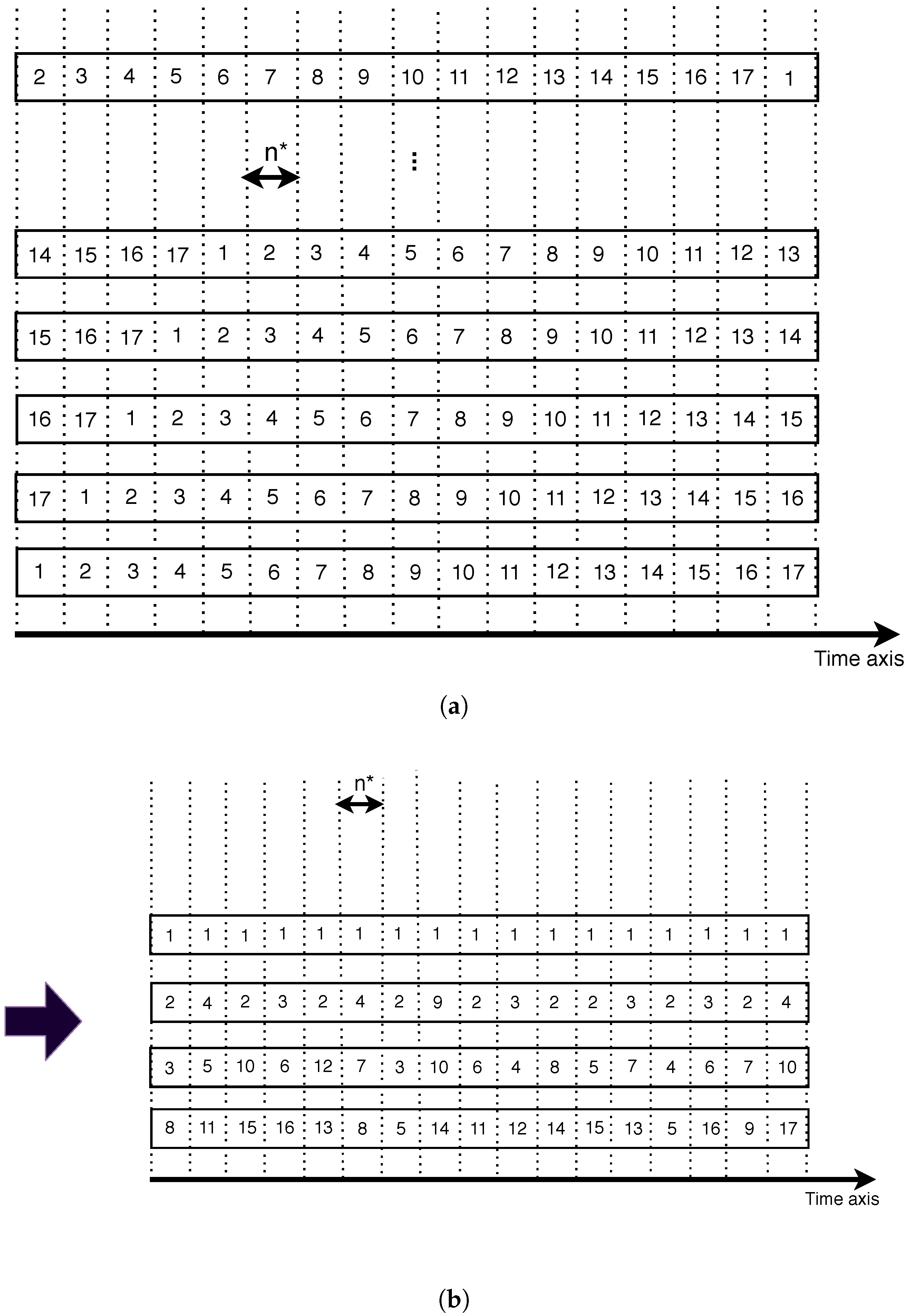
3.1. SASST Principle
3.1.1. SST Principle
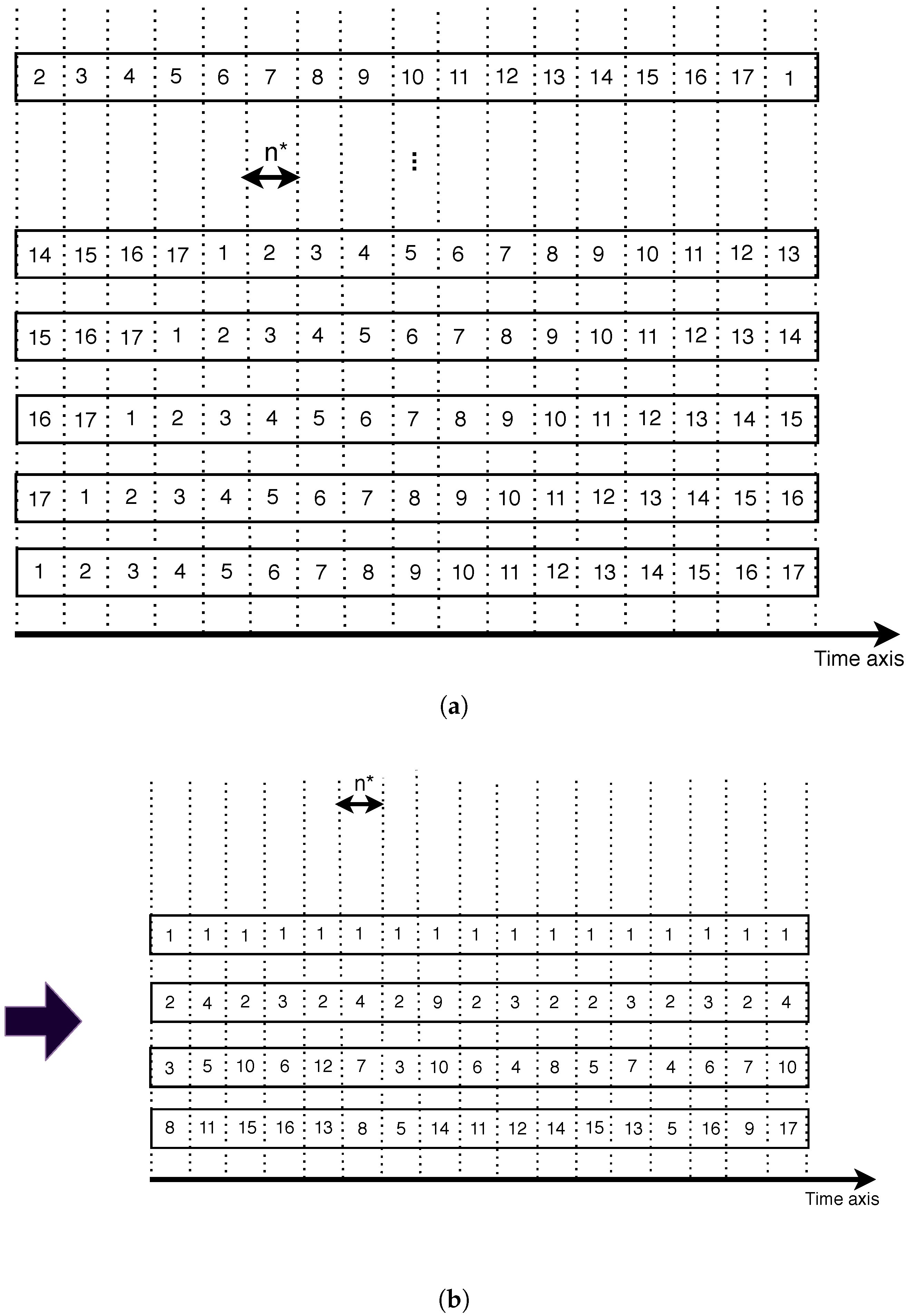
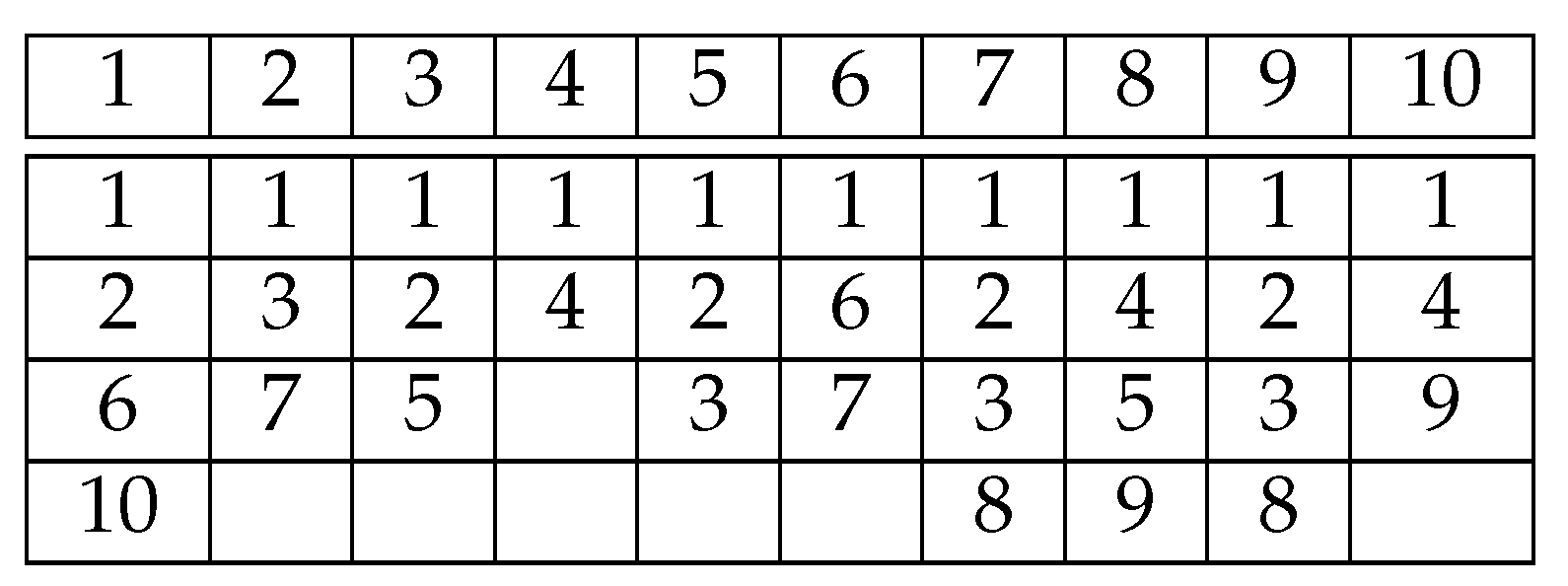
3.1.2. SASST Variant
3.2. SASST Performance Evaluation: Case of a Deterministic High Load
3.3. SASST Performance Evaluation: Case of a Probabilistic Load
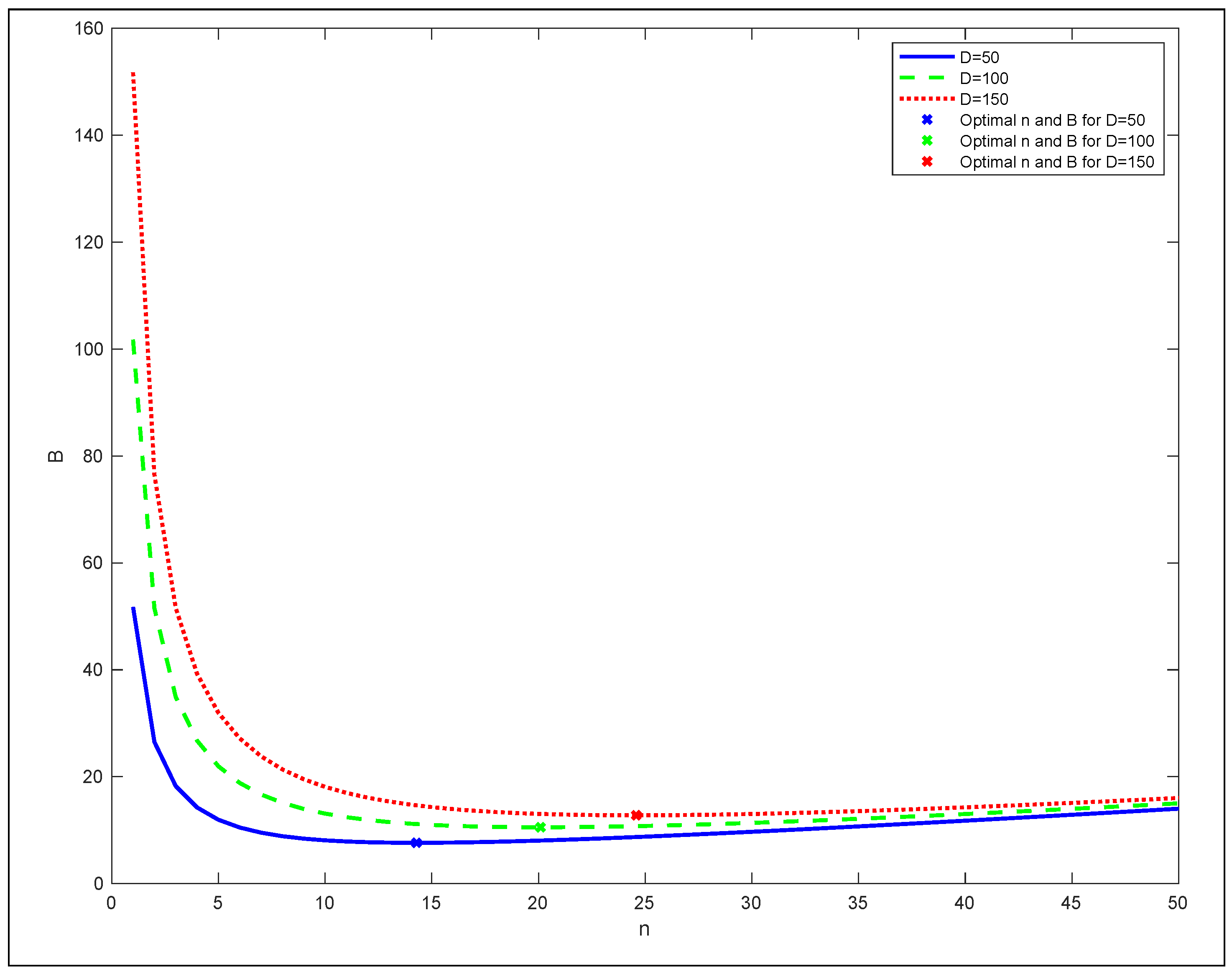
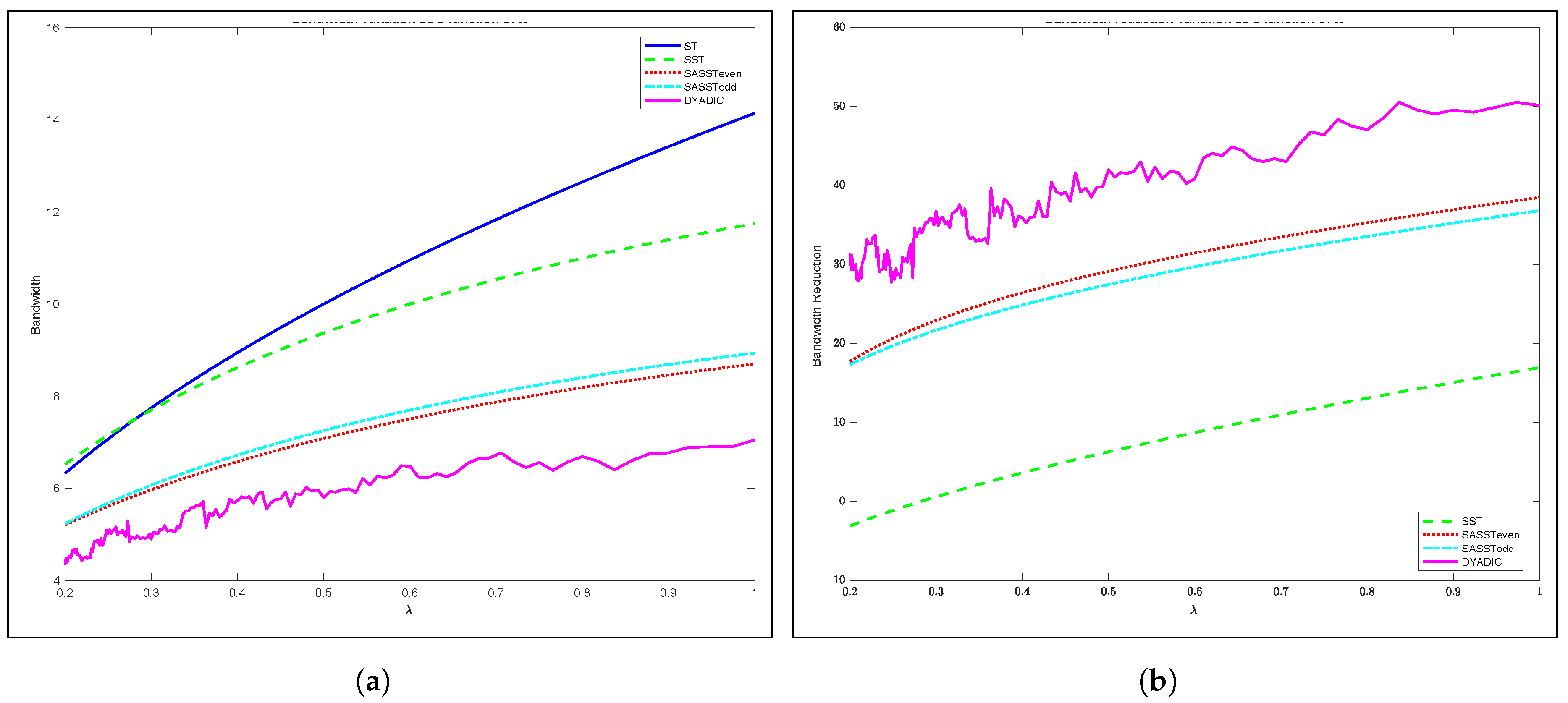
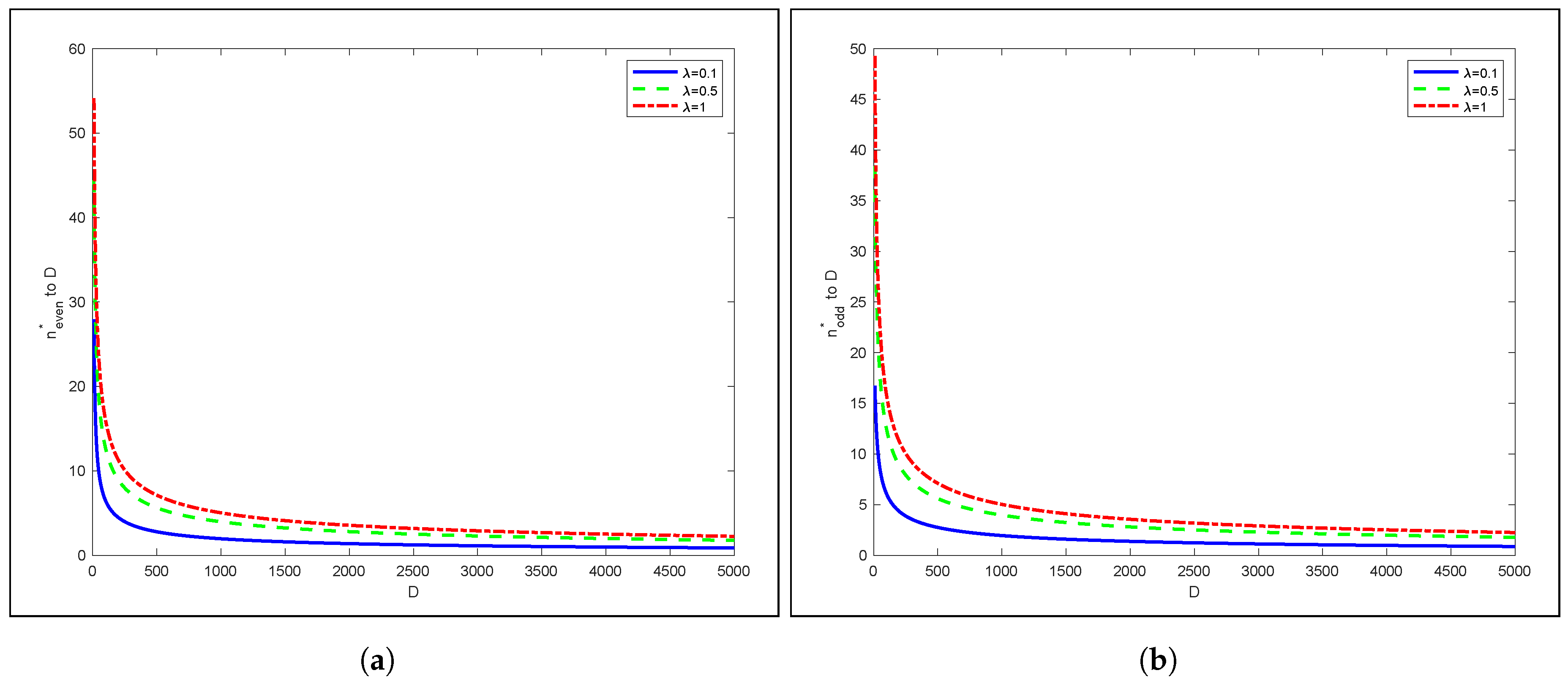
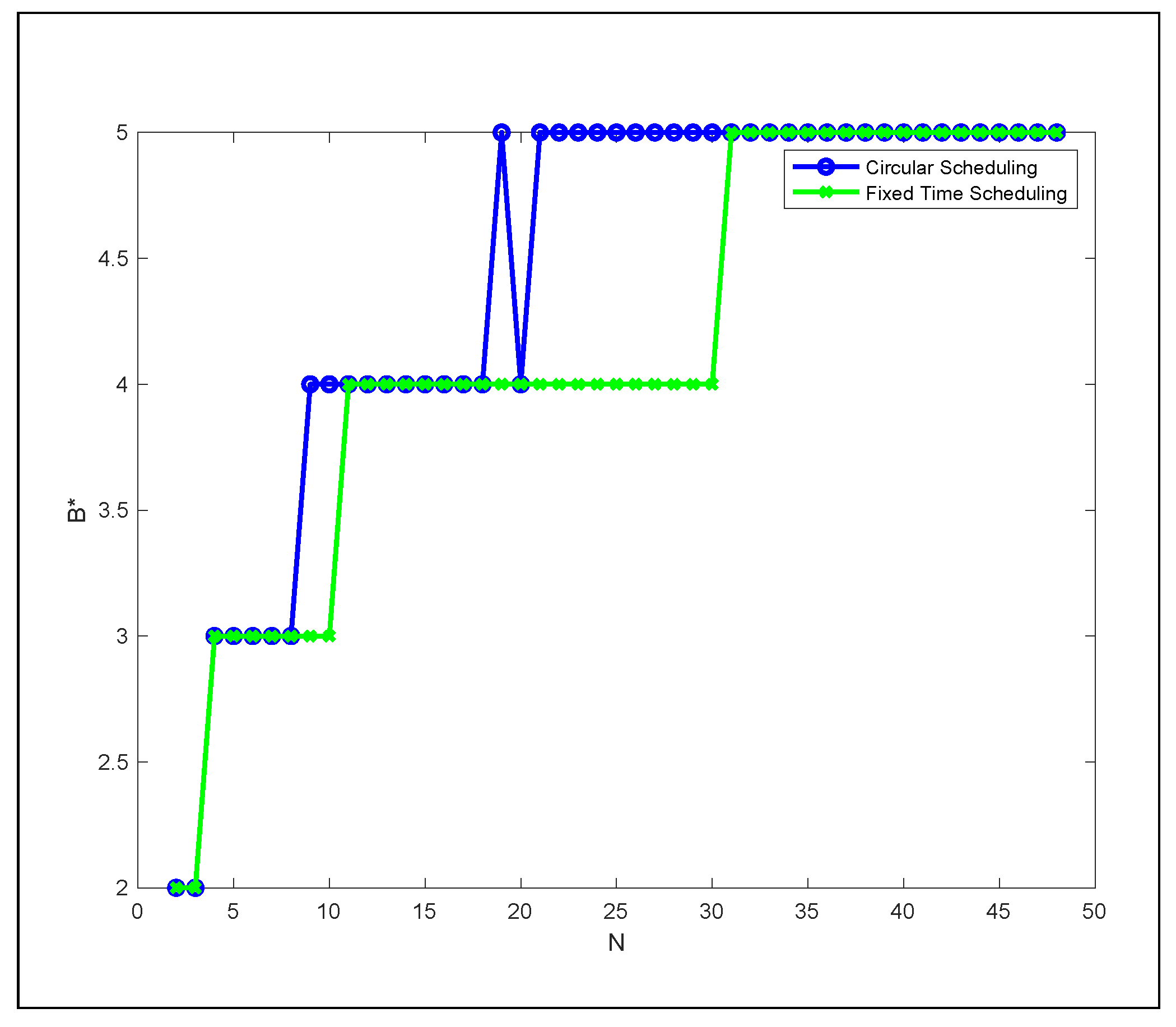
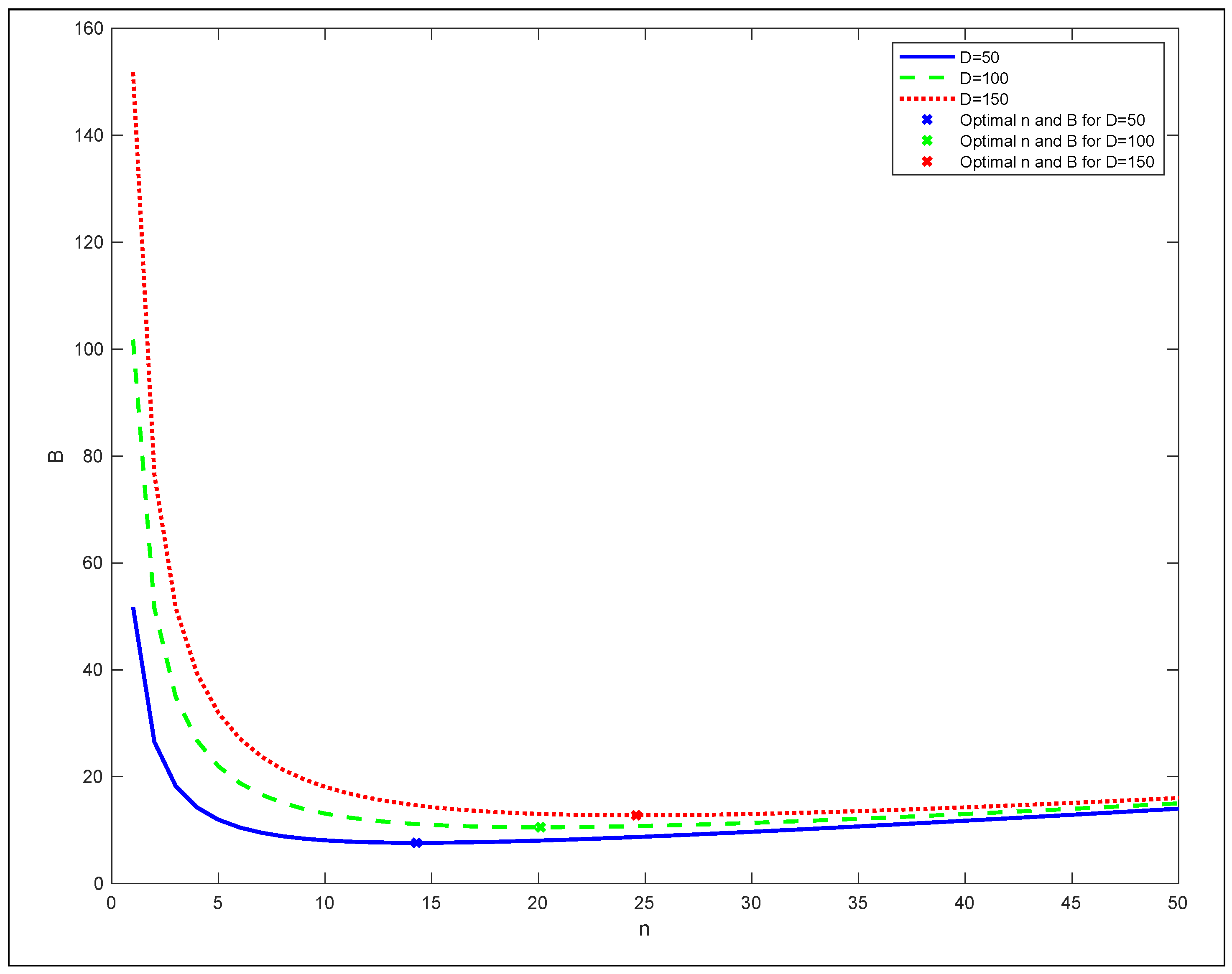
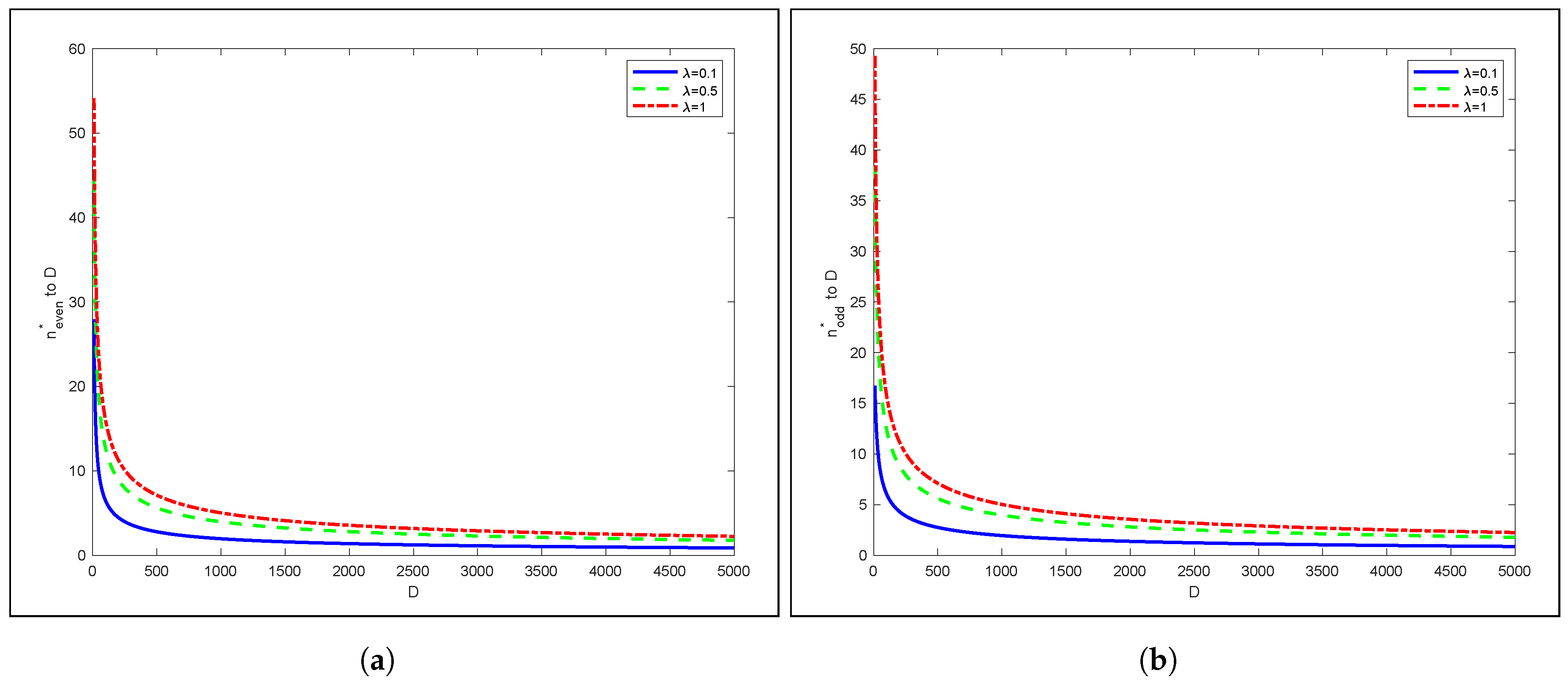
3.4. SASST Performance Evaluation: Numerical Analysis
4. Optimizing Cloud-Based Streaming Internal Bandwidth: Case of Popular Video
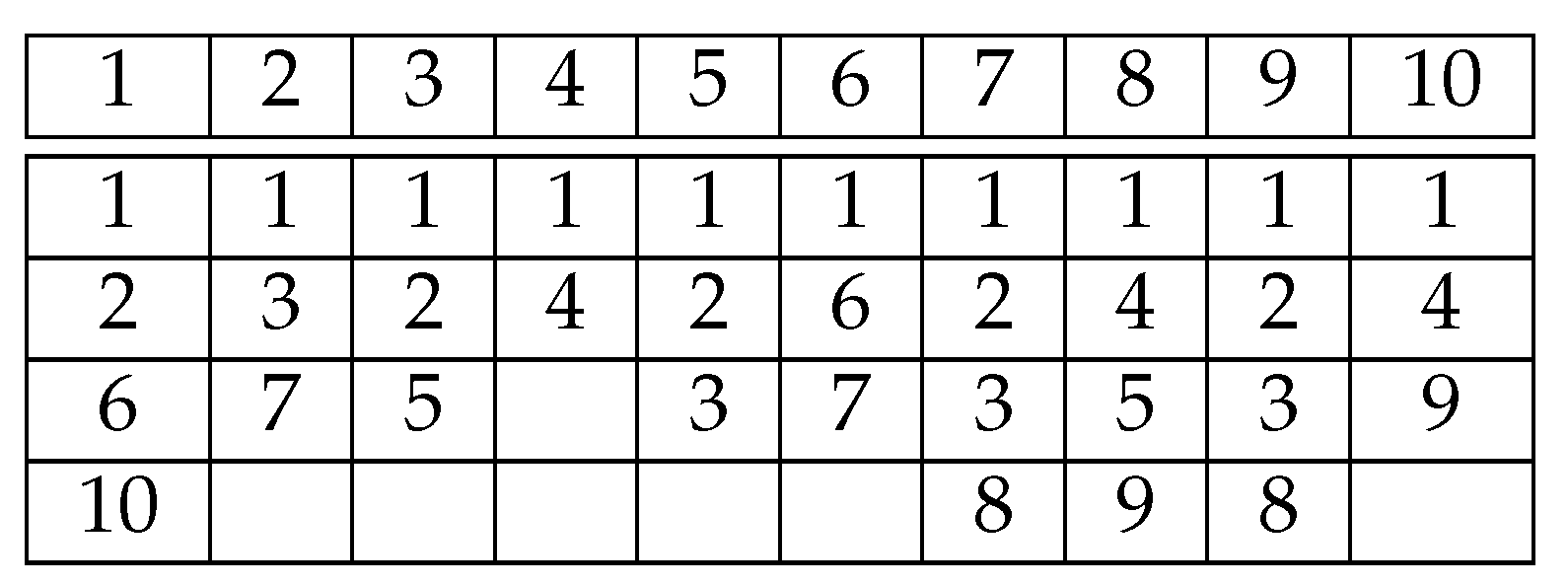
4.1. Approximating SASST by SB
4.2. Linear Program Formulation for a Fixed Time Horizon
4.3. Linear Program Formulation for an Unknown Time Horizon
4.4. NOPP Deployment
- The administrator of the streaming system should set (1) the number of segments of the video and (2) the streaming time horizon. in the system ggraphical interface If he wants to use a periodic scheduling, then he should indicate that instead of the time horizon.
- The system solves either the first version (with fixed time horizon) or the second version (periodic) of the LP. A manifest file containing the optimal scheduling is then generated and stored in the storage node with video segments.
- The SN starts by requesting the manifest (of the session description) file from the storage node to know how to reorder the arriving segments. Then, it starts the download of video segments, the reordering and the streaming to the Internet users’ devices. The storage node could use RTP or HTTP/3 to push the video segments.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Cisico: Cisco Annual Internet Report (2018–2023) White Paper. 2018. Available online: https://www.cisco.com/c/en/us/solutions/collateral/executive-perspectives/annual-internet-report/white-paper-c11-741490.html (accessed on 1 July 2021).
- Adobe. 2015. Available online: http://www.adobe.com/products/hds-dynamic-streaming.html (accessed on 6 January 2021).
- Apple: HTTP Live Streaming. 2015. Available online: http://tools.ietf.org/html/draft-pantos-http-live-streaming-12 (accessed on 6 January 2021).
- Microsoft. 2015. Available online: http://www.iis.net/downloads/microsoft/smooth-streaming (accessed on 6 January 2020).
- Stockhammer, T. Dynamic adaptive streaming over http–: Standards and design principles. In Proceedings of the Second Annual ACM Conference on Multimedia Systems, San Jose, CA, USA, 23–25 February 2011; pp. 133–144. [Google Scholar]
- Carter, S.W.; Long, D.D.E.; Pâris, J.F. Video-on-Demand Broadcasting Protocols. 2000. Available online: citeseer.ist.psu.edu/carter00videodemand.html (accessed on 6 January 2020).
- Pardue, L.; Bradbury, R.; Hurst, S. Hypertext Transfer Protocol (HTTP) over Multicast QUIC Internet Engineering Task Force. Draft-Pardue-Quic-http-Mcast-09. August 2021. Available online: https://www.ietf.org/id/draft-pardue-quic-http-mcast-09.html (accessed on 20 November 2021).
- Bar-Noy, A.; Goshi, J.; Ladner, R.E.; Tam, K. Comparison of stream merging algorithms for media-on-demand. Multimed. Syst. 2004, 9, 115–129. [Google Scholar] [CrossRef]
- Carter, S.R.; Paris, J.F.; Mohan, S.; Long, D.D.E. A dynamic heuristic broadcasting protocol for video-on-demand. In Proceedings of the IEEE 21st International Conference on Distributed Computing Systems (ICDCS ’01), Washington, DC, USA, 7–10 July 2001; p. 657. [Google Scholar]
- Eager, D.; Vernon, M.; Zahorjan, J. Optimal and Efficient Merging Schedules for Video-on-Demand Servers. In Proceedings of the Seventh ACM International Conference on Multimedia (Part 1), Orlando, FL, USA, 30 October–5 November 1999; Available online: http://www.cs.usask.ca/faculty/eager (accessed on 20 January 2021).
- Gazdar, A.; Belghith, A. Slotted stream tapping. In Proceedings of the 2004 ACM Workshop on Next-Generation Residential Broadband Challenges (NRBC ’04), New York, NY, USA, 15 October 2004; ACM Press: New York, NY, USA, 2004; pp. 50–56. [Google Scholar] [CrossRef]
- Liao, W.; Li, V.O.K. The split and merge protocol for interactive video-on-demand. IEEE MultiMedia 1997, 4, 51–62. [Google Scholar] [CrossRef] [Green Version]
- Pâris, J.F.; Carter, S.W.; Long, D.D.E. A universal distribution protocol for video-on-demand. In Proceedings of the IEEE International Conference on Multimedia and Expo 2000, New York, NY, USA, 30 July–2 August 2000. [Google Scholar]
- Pâris, J.F.; Long, D.D.E. An analytic study of stream tapping protocols. In Proceedings of the IEEE International Conference on Multimedia and Expo (ICME 2006), Toronto, ON, Canada, 9–12 July 2006; pp. 1237–1240. [Google Scholar]
- Carter, S.W.; Long, D.D.E. Improving video-on-demand server effeciency through stream tapping. In Proceedings of the 6th International Conference on Computer Communications and Netrworks (ICCCN’97), Las Vegas, NV, USA, 22–25 September 1997; pp. 200–207. [Google Scholar]
- Aggarwal, C.C.; Wolf, J.L.; Yu, P.S. A permutation-based pyramid broadcasting scheme for video-on-demand systems. In Proceedings of the IEEE International Conference on Multimedia and Computing Systems, Hiroshima, Japan, 17–23 July 1996; pp. 118–126. [Google Scholar]
- Belghith, A.; Gazdar, A. Generalization of fixed delay broadcasting protocols. In Proceedings of the Third International Conference on Intelligent Computing and Information Systems, Cairo, Egypt, 15–18 March 2007. [Google Scholar]
- Hu, A. Video-on-Demand broadcasting protocols: A comprehensive study. In Proceedings of the Twentieth Annual Joint Conference of the IEEE Computer and Communications Society (Infocom’01), Anchorage, AK, USA, 22–26 April 2001. [Google Scholar]
- Hua, K.A.; Sheu, S. Skyscraper broadcasting: A new broadcasting scheme for metropolitan video-on-demand systems. ACM SIGCOMM Comput. Commun. Rev. 1997, 27, 89–100. [Google Scholar] [CrossRef]
- Juhn, L.S.; Tseng, L.M. Fast broadcasting for hot video access. In Proceedings of the Internantional Workshop on Real-Time Computing Systems and Application, Taipel, Taiwan, 27–29 October 1997; pp. 237–243. [Google Scholar]
- Juhn, L.S.; Tseng, L.M. Harmonic broadcasting for video-on-demand service. IEEE Trans. Broadcast. 1997, 43, 268–271. [Google Scholar] [CrossRef] [Green Version]
- Viswanathan, S.; Imielinski, T. Pyramid broadcasting for video-on-demand service. Int. Soc. Opt. Eng. SPIE 1995, 24, 66–77. [Google Scholar]
- Gazdar, A.; Belghith, A. Hybrid broadcasting protocols: A comparative study. In Proceedings of the 2004 IEEE Symposium on Signal Processing and Information Technology (ISSPIT ’04), Rome, Italy, 18–21 December 2004. [Google Scholar]
- Amazon. Amazon Cloudfront Media Streaming Tutorials. Available online: https://aws.amazon.com/cloudfront/streaming/ (accessed on 5 July 2021).
- IBM. IBM Video Streaming Developers. Available online: https://developers.video.ibm.com (accessed on 10 January 2021).
- Microsoft. Azure Documentation. Available online: https://docs.microsoft.com/en-us/azure/?product=media (accessed on 10 January 2021).
- Google. Video AI. Available online: https://cloud.google.com/video-intelligence (accessed on 10 January 2021).
- Cao, G. Topology-aware multi-objective virtual machine dynamic consolidation for cloud datacenter. Sustain. Comput. Inform. Syst. 2019, 21, 179–188. [Google Scholar] [CrossRef]
- Farzai, S.; Shirvani, M.H.; Rabbani, M. Multi-objective communication-aware optimization for virtual machine placement in cloud datacenters. Sustain. Comput. Inform. Syst. 2020, 28, 100374. [Google Scholar] [CrossRef]
- Gopu, A.; Venkataraman, N. Optimal vm placement in distributed cloudenvironment using moea/d. Soft Comput. 2019, 23, 11277–11296. [Google Scholar] [CrossRef]
- Tian, H.; Wu, J.; Shen, H. Efficient algorithms for vm placement in cloud data centers. In Proceedings of the 2017 18th International Conference on Parallel and Distributed Computing, Applications and Technologies (PDCAT), Taipei, Taiwan, 18–20 December 2017; pp. 75–80. [Google Scholar] [CrossRef]
- Zhao, C.; Parhami, B. Virtual network embedding on massive substrate networks. Trans. Emerg. Telecommun. Technol. 2020, 31, e3849. [Google Scholar] [CrossRef] [Green Version]
- Rizvandi, N.B.; Taheri, J.; Zomaya, A.Y. Some observations on optimal requency selection in dvfs-based energy consumption minimization. J. Parallel Distrib. Comput. 2011, 71, 1154–1164. [Google Scholar] [CrossRef] [Green Version]
- Safari, M.; Khorsand, R. Energy-aware scheduling algorithm for time-constrained workflow tasks in dvfs-enabled cloud environment. Simul. Model. Pract. Theory 2018, 87, 311–326. [Google Scholar] [CrossRef]
- Stavrinides, G.L.; Karatza, H.D. An energy-efficient, qos-aware and cost-effective scheduling approach for real-time workflow applications in cloud computing systems utilizing dvfs and approximate computations. Future Gener. Comput. Syst. 2019, 96, 216–226. [Google Scholar] [CrossRef]
- Wu, T.; Gu, H.; Zhou, J.; Wei, T.; Liu, X.; Chen, M. Soft error-aware energy-efficient task scheduling for workflow applications in dvfs-enabled cloud. J. Syst. Archit. 2018, 84, 12–27. [Google Scholar] [CrossRef]
- Caggiani Luizelli, M.; Richter Bays, L.; Salete Buriol, L.; Pilla Barcellos, M.; Paschoal Gaspary, L. How physical network topologies affect virtual network embedding quality: A characterization study based on isp and datacenter networks. J. Netw. Comput. Appl. 2016, 70, 1–16. [Google Scholar] [CrossRef]
- Cheng, X.; Su, S.; Zhang, Z.; Wang, H.; Yang, F.; Luo, Y.; Wang, J. Virtual network embedding through topology-aware node ranking. SIGCOMM Comput. Commun. Rev. 2011, 41, 38–47. [Google Scholar] [CrossRef]
- Chowdhury, M.; Rahman, M.R.; Boutaba, R. Vineyard: Virtual network embedding algorithms with coordinated node and link mapping. IEEE/ACM Trans. Netw. 2012, 20, 206–219. [Google Scholar] [CrossRef]
- Fischer, A.; Botero, J.F.; Beck, M.T.; de Meer, H.; Hesselbach, X. Virtual network embedding: A survey. IEEE Commun. Surv. Tutor. 2013, 15, 1888–1906. [Google Scholar] [CrossRef]
- Li, J.; Zhang, N.; Ye, Q.; Shi, W.; Zhuang, W.; Shen, X. Joint resource allocation and online virtual network embedding for 5g networks. In Proceedings of the GLOBECOM 2017—2017 IEEE Global Communications Conference, Singapore, 4–8 December 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Afolabi, I.; Taleb, T.; Samdanis, K.; Ksentini, A.; Flinck, A. Network Slicing and Softwarization: A Survey on Principles, Enabling Technologies, and Solutions. IEEE Commun. Surv. Tutor. 2018, 20, 2429–2453. [Google Scholar] [CrossRef]
- Aldulaimy, A.; Itani, W.; Taheri, J.; Shamseddine, M. bwSlicer: A bandwidth slicing framework for cloud data centers. Future Gener. Comput. Syst. 2020, 112, 767–784. [Google Scholar] [CrossRef]
- Gazdar, A.; Belghith, A. Etude et implémentation d’une solution interactive pour la diffusion de la vidéo dans les systèmes de vidéo à la demande. In Proceedings of the 2003 Sciences of Electronic, Technologies of Information and Telecommunications (SETIT ’03), Sousse, Tunisia, 17–21 March 2003. [Google Scholar]
- Gazdar, A.; Belghith, A. Discrete interactive staggered broadcasting. In Proceedings of the 2004 IEEE Consumer Communications and Networking Conference (CCNC ’04), Las Vegas, NV, USA, 5–8 January 2004. [Google Scholar]
- Gazdar, A.; Belghith, A. Une solution vod interactive continue. In Proceedings of the 2004 Colloque Africain sur la Recherche en Informatique (CARI ’04), Hammamet, Tunisia, 27–29 November 2004. [Google Scholar]
- Pâris, J.F.; Carter, S.W.; Long, D.D.E. Efficient broadcasting protocols for video-on-demand. In Proceedings of the the International Symposium on Modelling, Analysis, and Simulation of Computing and Telecom Systems, Montreal, QC, Canada, 19–24 July 1998; pp. 127–132. [Google Scholar]
- Pâris, J.F.; Carter, S.W.; Long, D.D.E. Combining pay-per-view and video-on-demand services. In Proceedings of the Modeling, Analysis and Simulation of Computer and Telecommunication Systems, College Park, MD, USA, 24–28 October 1999. [Google Scholar]
- Bar-Noy, A.; Ladner, R.E. Windows scheduling problems for broadcast systems. In Proceedings of the 13th ACM-SIAM Symposium on Discrete Algorithms (SODA), San Francisco, CA, USA, 6–8 January 2002. [Google Scholar]
- Bar-Noy, A.; Ladner, R.E.; Tamir, T. Scheduling techniques for media-on-demand. Algorithmica 2008, 52, 413–439. [Google Scholar] [CrossRef] [Green Version]
- Pâris, J.F.; Carter, S.W.; Long, D.D.E. A low bandwidth broadcasting protocol for video-on-demand. In Proceedings of the the 7th International Conference on Computer Communication and Networks, Lafayette, LA, USA, 12–15 October 1998; pp. 609–616. [Google Scholar]
- Yan, E.M.; Kameda, T. An efficient vod broadcasting scheme with user bandwidth limit. In Proceedings of the SPIE/ACM MMCN 2003, Santa Carla, CA, USA, 23 February 2003. [Google Scholar]
- Gurobi Optimization, LLC. Gurobi Optimizer Reference Manual. 2021. Available online: https://www.gurobi.com (accessed on 5 July 2021).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Principle | Bandwidth | Implementation | |
|---|---|---|---|
| Reactive | |||
| Unicast | Opens a stream for each client request. | is the request rate, D is the video duration. | Easy. |
| ST [15] | Makes clients sharing one main stream (TS) and provides the missed part by an additional unicast stream (FTS). | Medium. | |
| SST [11,23] | In addition to what ST does, SST groups client request per slots to be served through the same streams. | Medium. | |
| Dyadic [8] | Allows clients to share all opened streams in a pseudo-optimal way. The arrival sequence should be known in advance to be optimal. | No analytical expression. | Hard. |
| Proactive | |||
| SB [6,18,44,45,46] | Divides the movie into n equally-sized segment and broadcasts each segment repeatedly in a channel. | Easy. | |
| Pyramid [6,16,20,22] | Divides the movie into n segments with size growing geometrically. Each segment is broadcast repeatedly in a channel. | , D is the video duration, w is the client waiting time. | Hard. |
| Harmonic [21,51] | Divides the movie into n equally-sized segment , , … and broadcast them such as is broadcast in channel 1 with rate b, in channel 2 with rate ,… in channel n with rate . | Hard. It is rather used as lower bound benchmark. |
| N | t (s) | N | t (s) | N | t (s) | N | t (s) | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 2 | 2 | 0.00040 | 15 | 4 | 0.00462 | 28 | 4 | 0.03661 | 41 | 5 | 0.05058 |
| 3 | 2 | 0.00348 | 16 | 4 | 0.00535 | 29 | 4 | 0.05818 | 42 | 5 | 0.05389 |
| 4 | 3 | 0.00021 | 17 | 4 | 0.00585 | 30 | 4 | 0.04598 | 43 | 5 | 0.05724 |
| 5 | 3 | 0.00118 | 18 | 4 | 0.00658 | 31 | 5 | 0.02178 | 44 | 5 | 0.06411 |
| 6 | 3 | 0.00139 | 19 | 4 | 0.00706 | 32 | 5 | 0.02313 | 45 | 5 | 0.08320 |
| 7 | 3 | 0.00134 | 20 | 4 | 0.00836 | 33 | 5 | 0.02594 | 46 | 5 | 0.06859 |
| 8 | 3 | 0.00157 | 21 | 4 | 0.00883 | 34 | 5 | 0.02769 | 47 | 5 | 0.07418 |
| 9 | 3 | 0.00189 | 22 | 4 | 0.01036 | 35 | 5 | 0.03048 | 48 | 5 | 0.07737 |
| 10 | 3 | 0.00308 | 23 | 4 | 0.01498 | 36 | 5 | 0.03213 | 49 | 5 | 0.09644 |
| 11 | 4 | 0.00229 | 24 | 4 | 0.01350 | 37 | 5 | 0.03544 | 50 | 5 | 0.11897 |
| 12 | 4 | 0.00255 | 25 | 4 | 0.02127 | 38 | 5 | 0.03567 | |||
| 13 | 4 | 0.00396 | 26 | 4 | 0.01838 | 39 | 5 | 0.04350 | |||
| 14 | 4 | 0.00393 | 27 | 4 | 0.03915 | 40 | 5 | 0.04664 |
| N | t (s) | N | t (s) | N | t (s) | N | t (s) | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 2 | 2 | 0.00024 | 14 | 4 | 0.00671 | 26 | 5 | 0.54185 | 38 | 5 | 0.17875 |
| 3 | 2 | 0.00260 | 15 | 4 | 0.00784 | 27 | 5 | 0.57136 | 39 | 5 | 0.12900 |
| 4 | 3 | 0.00023 | 16 | 4 | 0.01246 | 28 | 5 | 0.51263 | 40 | 5 | 0.22479 |
| 5 | 3 | 0.00128 | 17 | 4 | 0.01099 | 29 | 5 | 0.44969 | 41 | 5 | 0.62120 |
| 6 | 3 | 0.00144 | 18 | 4 | 0.01755 | 30 | 5 | 0.72769 | 42 | 5 | 0.20406 |
| 7 | 3 | 0.00214 | 19 | 5 | 149.31110 | 31 | 5 | 0.04119 | 43 | 5 | 0.96535 |
| 8 | 3 | 0.00242 | 20 | 4 | 0.07884 | 32 | 5 | 0.04682 | 44 | 5 | 0.90229 |
| 9 | 4 | 0.03365 | 21 | 5 | 0.81072 | 33 | 5 | 0.05502 | 45 | 5 | 1.16545 |
| 10 | 4 | 0.02758 | 22 | 5 | 0.92566 | 34 | 5 | 0.05346 | 46 | 5 | 1.16282 |
| 11 | 4 | 0.00388 | 23 | 5 | 0.92439 | 35 | 5 | 0.06545 | 47 | 5 | 1.46099 |
| 12 | 4 | 0.00496 | 24 | 5 | 1.01415 | 36 | 5 | 0.08506 | 48 | 5 | 1.68586 |
| 13 | 4 | 0.00744 | 25 | 5 | 0.38786 | 37 | 5 | 0.09712 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gazdar, A.; Hidri, L.; Ben Youssef, B.; Kefi, M. Minimizing the In-Cloud Bandwidth for On-Demand Reactive and Proactive Streaming Applications. Appl. Sci. 2021, 11, 11267. https://doi.org/10.3390/app112311267
Gazdar A, Hidri L, Ben Youssef B, Kefi M. Minimizing the In-Cloud Bandwidth for On-Demand Reactive and Proactive Streaming Applications. Applied Sciences. 2021; 11(23):11267. https://doi.org/10.3390/app112311267
Chicago/Turabian StyleGazdar, Achraf, Lotfi Hidri, Belgacem Ben Youssef, and Meriam Kefi. 2021. "Minimizing the In-Cloud Bandwidth for On-Demand Reactive and Proactive Streaming Applications" Applied Sciences 11, no. 23: 11267. https://doi.org/10.3390/app112311267
APA StyleGazdar, A., Hidri, L., Ben Youssef, B., & Kefi, M. (2021). Minimizing the In-Cloud Bandwidth for On-Demand Reactive and Proactive Streaming Applications. Applied Sciences, 11(23), 11267. https://doi.org/10.3390/app112311267