
Improving the Performance of Vietnamese–Korean Neural Machine Translation with Contextual Embedding

Abstract
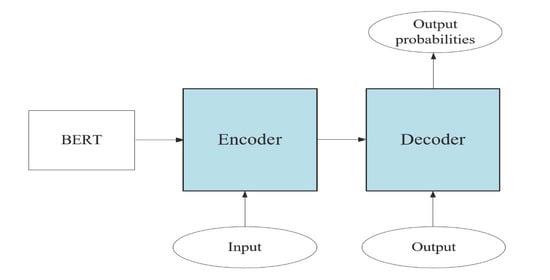
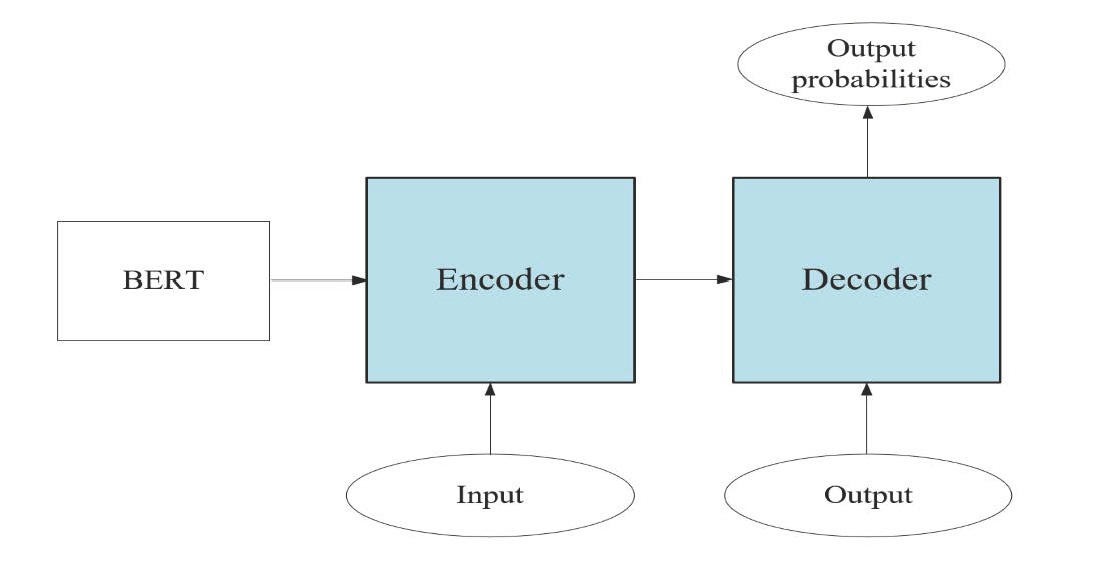
1. Introduction
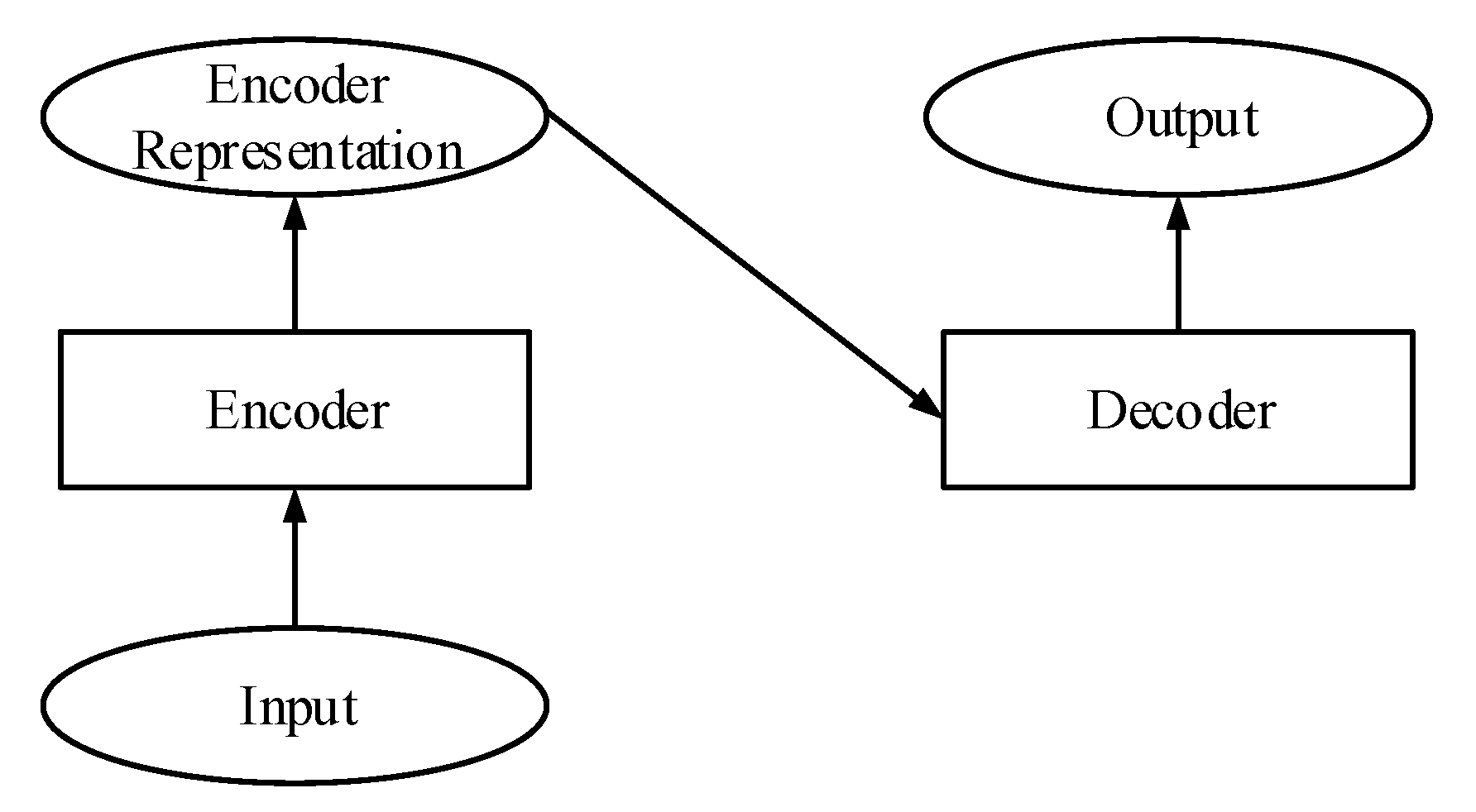
2. Transformer Model
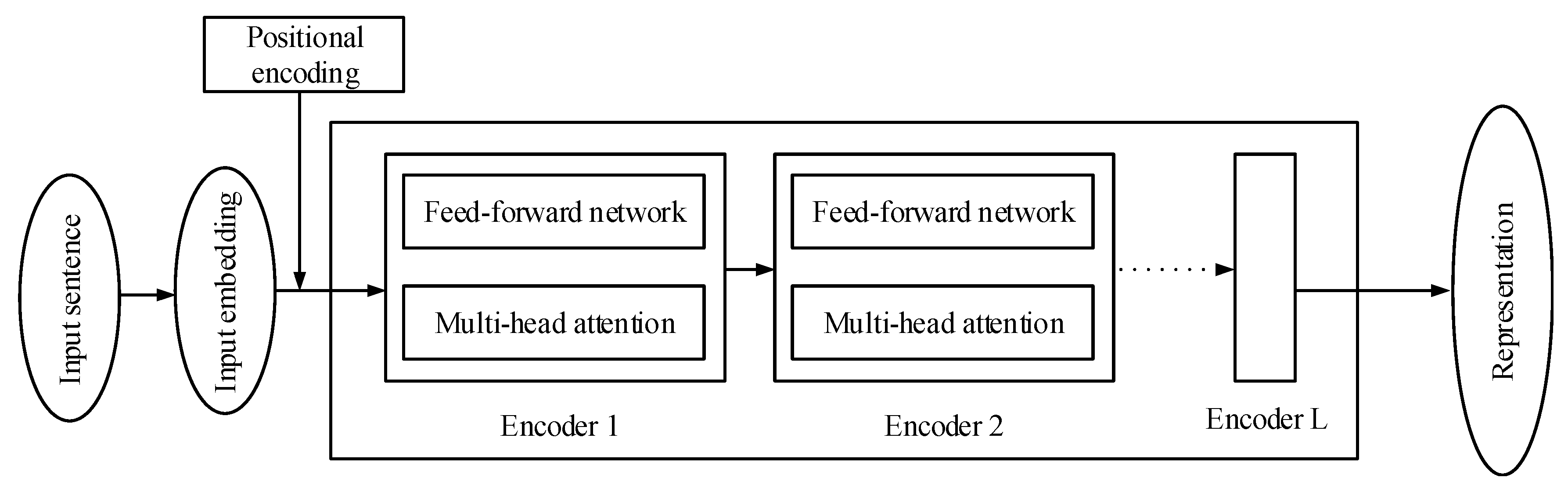
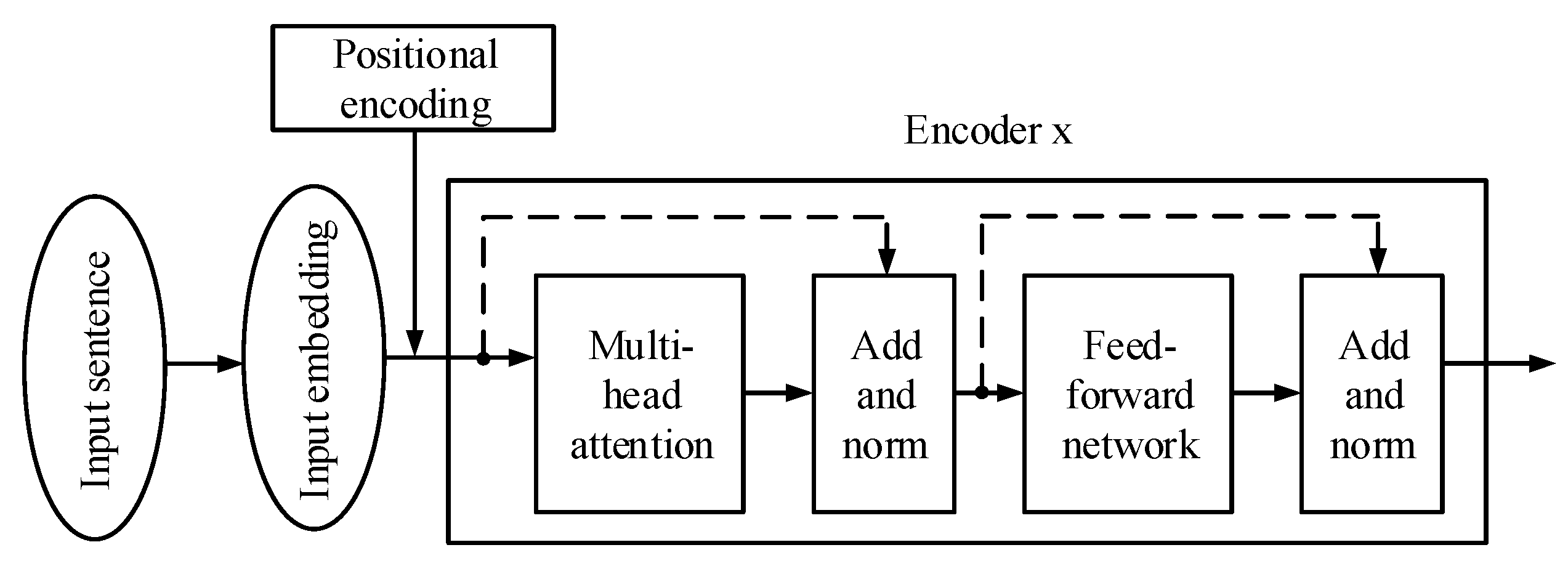
2.1. The Encoder of the Transformer
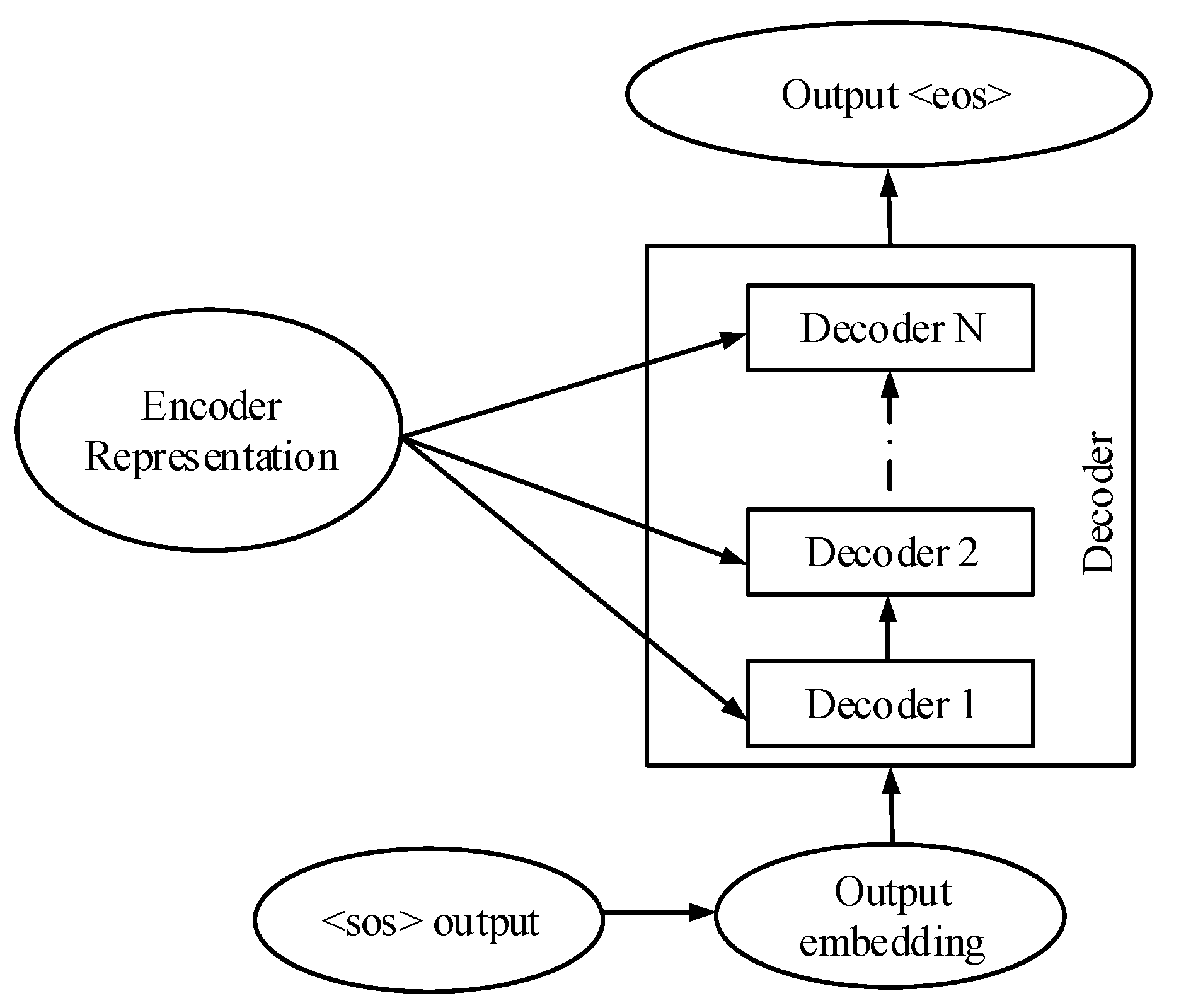
2.2. The Decoder of the Transformer
2.3. Encoder and Decoder Architecture of the Transformer
3. Linguistic Annotation
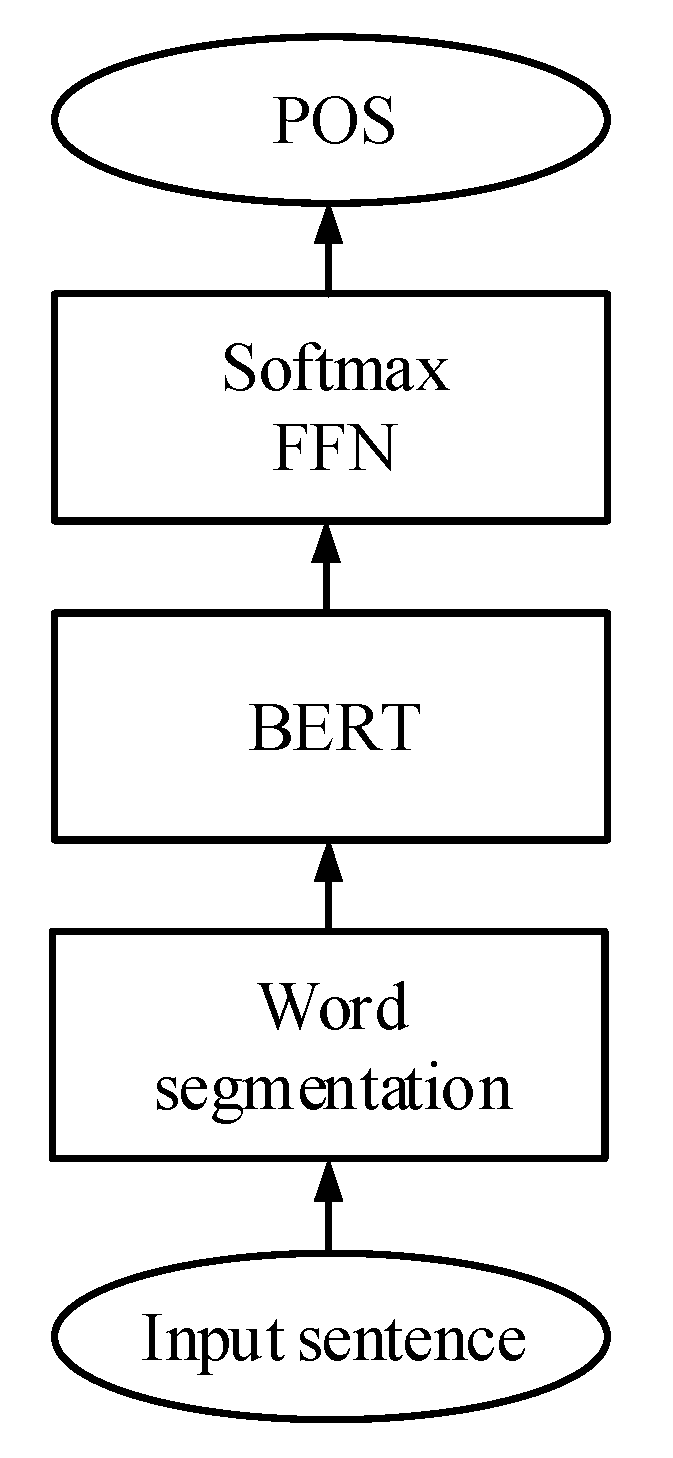
3.1. Vietnamese Parts of Speech
3.2. Korean Morphological Analysis and Word Sense Disambiguation
4. Experimentations and Results
4.1. Vietnamese–Korean Parallel Corpus
4.2. Machine Translation Experiments
- Baseline: building NMT without the BERT model, using Vietnamese sentences with word segmentation and original Korean sentences;
- KrUTagger: building NMT without the BERT model, using Vietnamese sentences with word segmentation and Korean sentences with MA and WSD;
- VnPOS: building NMT without the BERT model, using Vietnamese sentences with word segmentation and POS tagging and Korean sentences with MA and WSD; and
- VietBERT+NMT: building NMT with the Vietnamese BERT model, using Vietnamese sentences with word segmentation and POS tagging and Korean sentences with MA and WSD.
4.2.1. NMT
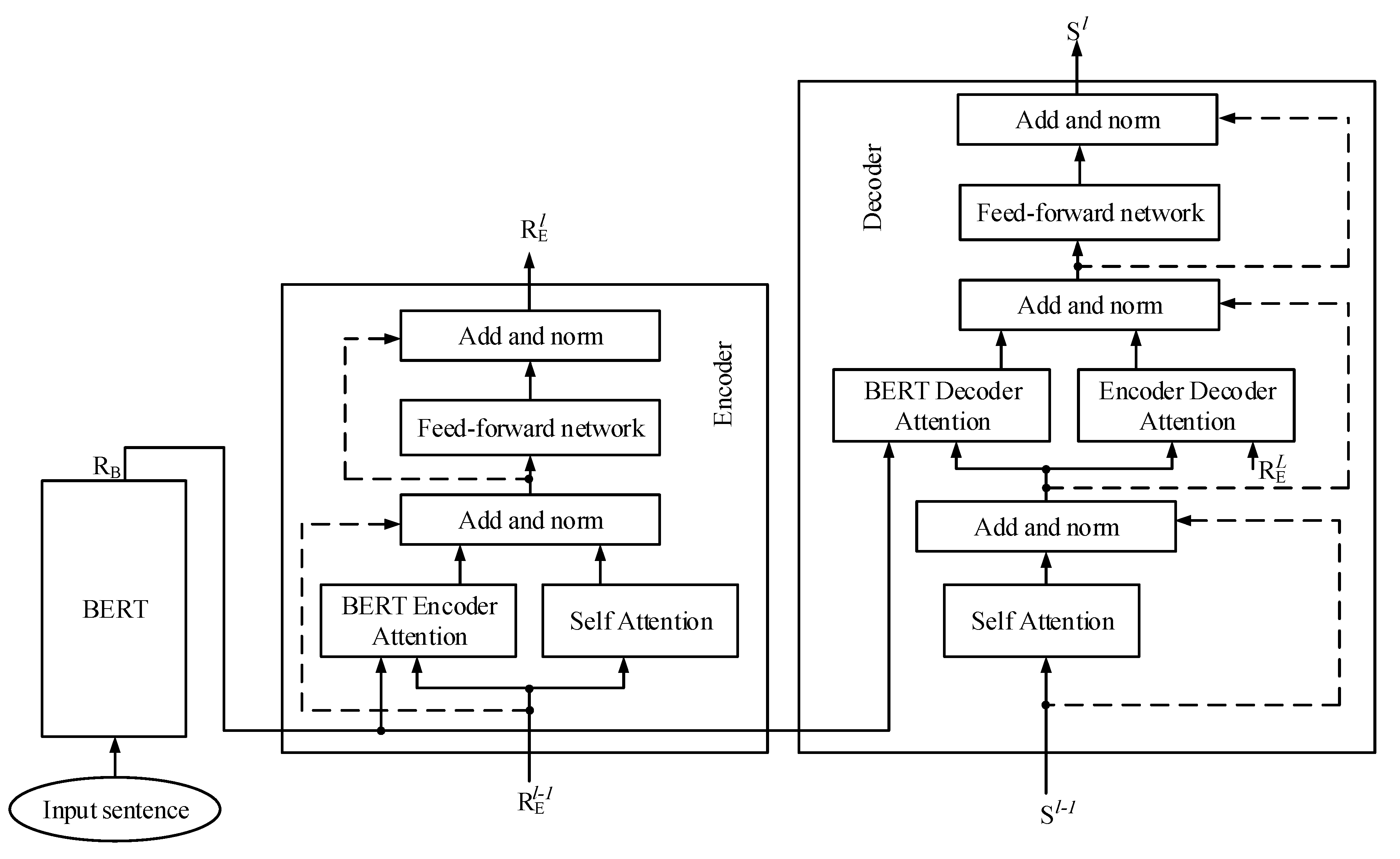
4.2.2. BERT-Fused Model
4.3. Results
4.4. Discussion
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
References
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; Association for Computational Linguistics: Minneapolis, MN, USA, 2019; pp. 4171–4186. [Google Scholar]
- Zhu, J.; Xia, Y.; Wu, L.; He, D.; Qin, T.; Zhou, W.; Li, H.; Liu, T.-Y. Incorporating BERT into Neural Machine Translation. arXiv 2020, arXiv:2002.06823. [Google Scholar]
- Nguyen, D.Q.; Tuan Nguyen, A. PhoBERT: Pre-Trained Language Models for Vietnamese. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2020, online, 16–20 November 2020; Association for Computational Linguistics: Stroudsbur, PA, USA, 2020; pp. 1037–1042. [Google Scholar]
- Lan, Z.; Chen, M.; Goodman, S.; Gimpel, K.; Sharma, P.; Soricut, R. ALBERT: A Lite BERT for Self-Supervised Learning of Language Representations. arXiv 2020, arXiv:1909.11942. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Joshi, M.; Chen, D.; Liu, Y.; Weld, D.S.; Zettlemoyer, L.; Levy, O. SpanBERT: Improving Pre-Training by Representing and Predicting Spans. Trans. Assoc. Comput. Linguist. 2020, 8, 64–77. [Google Scholar] [CrossRef]
- Le, H.; Vial, L.; Frej, J.; Segonne, V.; Coavoux, M.; Lecouteux, B.; Allauzen, A.; Crabbé, B.; Besacier, L.; Schwab, D. FlauBERT: Unsupervised Language Model Pre-Training for French. In Proceedings of the 12th Language Resources and Evaluation Conference, Marseille, France, 11–16 May 2020; European Language Resources Association: Marseille, France, 2020; pp. 2479–2490. [Google Scholar]
- Scheible, R.; Thomczyk, F.; Tippmann, P.; Jaravine, V.; Boeker, M. GottBERT: A Pure German Language Model. arXiv 2020, arXiv:2012.02110. [Google Scholar]
- Cui, Y.; Che, W.; Liu, T.; Qin, B.; Wang, S.; Hu, G. Revisiting Pre-Trained Models for Chinese Natural Language Processing. In Proceedings of the Findings of the Association for Computational Linguistics, EMNLP 2020, online, 16–20 November 2020; Association for Computational Linguistics: Stroudsbur, PA, USA, 2020; pp. 657–668. [Google Scholar]
- Lee, S.; Jang, H.; Baik, Y.; Park, S.; Shin, H. KR-BERT: A Small-Scale Korean-Specific Language Model. arXiv 2020, arXiv:2008.03979. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. arXiv 2016, arXiv:1409.0473. [Google Scholar]
- Cho, K.; van Merriënboer, B.; Bahdanau, D.; Bengio, Y. On the Properties of Neural Machine Translation: Encoder–Decoder Approaches. In Proceedings of the SSST-8, Eighth Workshop on Syntax, Semantics and Structure in Statistical Translation, Doha, Qatar, 25 October 2014; Association for Computational Linguistics: Doha, Qatar, 2014; pp. 103–111. [Google Scholar]
- Klein, G.; Kim, Y.; Deng, Y.; Senellart, J.; Rush, A. OpenNMT: Open-Source Toolkit for Neural Machine Translation. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, British Columbia, Canada, 28 July 2017; Association for Computational Linguistics: Vancouver, BC, Canada, 2017; pp. 67–72. [Google Scholar]
- Hieber, F.; Domhan, T.; Denkowski, M.; Vilar, D.; Sokolov, A.; Clifton, A.; Post, M. Sockeye: A Toolkit for Neural Machine Translation. arXiv 2018, arXiv:1712.05690. [Google Scholar]
- Ott, M.; Edunov, S.; Baevski, A.; Fan, A.; Gross, S.; Ng, N.; Grangier, D.; Auli, M. Fairseq: A Fast, Extensible Toolkit for Sequence Modeling. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics (Demonstrations), Minneapolis, MN, USA, 2–7 June 2019; Association for Computational Linguistics: Minneapolis, MN, USA, 2019; pp. 48–53. [Google Scholar]
- Graça, M.; Kim, Y.; Schamper, J.; Khadivi, S.; Ney, H. Generalizing Back-Translation in Neural Machine Translation. In Proceedings of the Fourth Conference on Machine Translation (Volume 1: Research Papers), Florence, Italy, 1–2 August 2019; Association for Computational Linguistics: Florence, Italy, 2019; pp. 45–52. [Google Scholar]
- Johnson, M.; Schuster, M.; Le, Q.V.; Krikun, M.; Wu, Y.; Chen, Z.; Thorat, N.; Viégas, F.; Wattenberg, M.; Corrado, G.; et al. Google’s Multilingual Neural Machine Translation System: Enabling Zero-Shot Translation. Trans. Assoc. Comput. Linguist. 2017, 5, 339–351. [Google Scholar] [CrossRef]
- Bojar, O.; Federmann, C.; Fishel, M.; Graham, Y.; Haddow, B.; Koehn, P.; Monz, C. Findings of the 2018 Conference on Machine Translation (WMT18). In Proceedings of the Third Conference on Machine Translation: Shared Task Papers, Brussels, Belgium, 31 October–1 November 2018; Association for Computational Linguistics: Brussels, Belgium, 2018; pp. 272–303. [Google Scholar]
- Östling, R.; Tiedemann, J. Neural Machine Translation for Low-Resource Languages. arXiv 2017, arXiv:1708.05729. [Google Scholar]
- Tong, A.N.; Diduch, L.L.; Fiscus, J.G.; Haghpanah, Y.; Huang, S.; Joy, D.M.; Peterson, K.; Soboroff, I.M. Overview of the NIST 2016 LoReHLT Evaluation, Machine Translation Special Issue NLP in Low Resource Language. Mach. Transl. 2018, 32, 11–30. [Google Scholar] [CrossRef]
- Wu, Y.; Schuster, M.; Chen, Z.; Le, Q.V.; Norouzi, M.; Macherey, W.; Krikun, M.; Cao, Y.; Gao, Q.; Macherey, K.; et al. Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation. arXiv 2016, arXiv:1609.08144. [Google Scholar]
- Gehring, J.; Auli, M.; Grangier, D.; Yarats, D.; Dauphin, Y.N. Convolutional Sequence to Sequence Learning. In Proceedings of the 34th International Conference on Machine Learning, Volume 70, Sydney, NSW, Australia, 6–11 August 2017; pp. 1243–1252. [Google Scholar] [CrossRef]
- Huang, J.-X.; Lee, K.-S.; Kim, Y.-K. Hybrid Translation with Classification: Revisiting Rule-Based and Neural Machine Translation. Electronics 2020, 9, 201. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. In Proceedings of the Advances in Neural Information Processing Systems 30, Long Beach, CA, USA, 4–9 December 2017; Curran Associates, Inc.: New York, NY, USA, 2017; pp. 5998–6008. [Google Scholar]
- Vu, V.-H.; Nguyen, Q.-P.; Shin, J.-C.; Ock, C.-Y. UPC: An Open Word-Sense Annotated Parallel Corpora for Machine Translation Study. Appl. Sci. 2020, 10, 3904. [Google Scholar] [CrossRef]
- Nguyen, Q.-P.; Vo, A.-D.; Shin, J.-C.; Tran, P.; Ock, C.-Y. Korean-Vietnamese Neural Machine Translation System with Korean Morphological Analysis and Word Sense Disambiguation. IEEE Access 2019, 7, 32602–32616. [Google Scholar] [CrossRef]
- Snover, M.; Dorr, B.; Schwartz, R.; Micciulla, L.; Makhoul, J. A Study of Translation Edit Rate with Targeted Human Annotation; Association for Machine Translation in the Americas: College Park, MD, USA, 2006; p. 9. [Google Scholar]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.-J. Bleu: A Method for Automatic Evaluation of Machine Translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 6–12 July 2002; Association for Computational Linguistics: Philadelphia, PA, USA, 2002; pp. 311–318. [Google Scholar]
- Cho, S.W.; Lee, E.-H.; Lee, J.-H. Phrase-Level Grouping for Lexical Gap Resolution in Korean-Vietnamese SMT. In Computational Linguistics; Hasida, K., Pa, W.P., Eds.; Springer: Singapore, 2018; Volume 781, pp. 127–136. ISBN 978-981-10-8437-9. [Google Scholar]
- Koehn, P.; Hoang, H.; Birch, A.; Callison-Burch, C.; Federico, M.; Bertoldi, N.; Cowan, B.; Shen, W.; Moran, C.; Zens, R.; et al. Moses: Open Source Toolkit for Statistical Machine Translation. In Proceedings of the 45th Annual Meeting of the Association for Computational Linguistics Companion Volume Proceedings of the Demo and Poster Sessions, Prague, Czech Republic, 23–30 June 2007; Association for Computational Linguistics: Prague, Czech Republic, 2007; pp. 177–180. [Google Scholar]
- Banerjee, S.; Lavie, A. METEOR: An Automatic Metric for MT Evaluation with Improved Correlation with Human Judgments. In Proceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization, Ann Arbor, MI, USA, 29 June 2005; Association for Computational Linguistics: Philadelphia, PA, USA, 2005; pp. 65–72. [Google Scholar]
- Sudharsan, R. Getting Started with Google BERT; Packt Publishing Ltd.: Birmingham, UK, 2021; ISBN 978-1-83882-159-3. [Google Scholar]
- Nguyen, D.Q.; Vu, T.; Nguyen, D.Q.; Dras, M.; Johnson, M. From Word Segmentation to POS Tagging for Vietnamese. In Proceedings of the Australasian Language Technology Association Workshop 2017, Brisbane, Australia, 7–8 December 2017; pp. 108–113. [Google Scholar]
- Nguyen, L.T.; Nguyen, D.Q. PhoNLP: A Joint Multi-Task Learning Model for Vietnamese Part-of-Speech Tagging, Named Entity Recognition and Dependency Parsing. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies: Demonstrations, online, 6–11 June 2021; Association for Computational Linguistics: Philadelphia, PA, USA, 2021; pp. 1–7. [Google Scholar]
- Nguyen, D.Q.; Verspoor, K. An Improved Neural Network Model for Joint POS Tagging and Dependency Parsing. In Proceedings of the CoNLL 2018 Shared Task: Multilingual Parsing from Raw Text to Universal Dependencies, Brussels, Belgium, 31 October–1 November 2018; Association for Computational Linguistics: Philadelphia, PA, USA, 2018; pp. 81–91. [Google Scholar]
- Shin, J.C.; Ock, C.Y. Korean Homograph Tagging Model Based on Sub-Word Conditional Probability. KIPS Trans. Softw. Data Eng. 2014, 3, 407–420. [Google Scholar] [CrossRef][Green Version]
- Na, S.-H.; Kim, Y.-K. Phrase-Based Statistical Model for Korean Morpheme Segmentation and POS Tagging. IEICE Trans. Inf. Syst. 2018, E101.D, 512–522. [Google Scholar] [CrossRef]
- Matteson, A.; Lee, C.; Kim, Y.; Lim, H. Rich Character-Level Information for Korean Morphological Analysis and Part-of-Speech Tagging. In Proceedings of the 27th International Conference on Computational Linguistics, Santa Fe, NM, USA, 20–26 August 2018; Association for Computational Linguistics: Philadelphia, PA, USA, 2018; pp. 2482–2492. [Google Scholar]
- Min, J.; Jeon, J.-W.; Song, K.-H.; Kim, Y.-S. A Study on Word Sense Disambiguation Using Bidirectional Recurrent Neural Network for Korean Language. J. Korea Soc. Comput. Inf. 2017, 22, 41–49. [Google Scholar] [CrossRef]
- Kang, M.Y.; Kim, B. Word Sense Disambiguation Using Embedded Word Space. J. Comput. Sci. Eng. 2017, 11, 32–38. [Google Scholar] [CrossRef][Green Version]
- Luong, T.; Pham, H.; Manning, C.D. Effective Approaches to Attention-Based Neural Machine Translation. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; Association for Computational Linguistics: Philadelphia, PA, USA, 2015; pp. 1412–1421. [Google Scholar]
- Sennrich, R.; Haddow, B.; Birch, A. Neural Machine Translation of Rare Words with Subword Units. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Berlin, Germany, 7–12 August 2016; Association for Computational Linguistics: Philadelphia, PA, USA, 2016; pp. 1715–1725. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| POS Tagging Systems | Accuracy (%) |
|---|---|
| BiLSTM-CNN-CRF [34] | 95.4 |
| VnCoreNLP-POS [33] | 95.9 |
| JPTDP-v2 [33] | 95.7 |
| JointWPD [35] | 96.0 |
| PhoBERTbase | 96.8 |
| Form | Meaning |
|---|---|
| Initial | anh ấy làm việc tại trường đại học FPT (he works at the University of FPT) |
| Word Seg. | anh_ấy làm_việc tại trường đại_học FPT |
| Word Seg. and POS | anh_ấy|N làm_việc|V tại|E trường|N đại_học|N FPT|Ny |
| Form | Meaning |
|---|---|
| Initial | 배를 너무 많이 먹어서 배가 아프다. bae-leul neo-mu man-hi meog-eo-seo bae-ga a-peu-da. (I have a stomachache because I ate too many pears.) |
| UTagger applied form | 배__03/NNG + 를/JKO 너무__01/MAG 많이/MAG 먹__02/VV + 어서/EC 배__01/NNG + 가/JKS아프__02/VA + 다/EF + ./SF bae__03/NNG + leul/JKO neo + mu__01/MAG man-hi/MAG meog__02/VV + eo-seo/EC bae__01/NNG + ga/JKS a-peu__02/VA + da__02/VA |
| Research | MA (%) | WSD (%) |
|---|---|---|
| Phrase-based statistical model [37] | 96.35 | |
| Bi-long short-term memory [38] | 96.20 | |
| Bidirectional recurrent neural network [39] | 96.20 | |
| Statistical-based [40] | 96.42 | |
| UTagger | 98.20 | 96.52 |
| Sentences | Average Length | Tokens | Vocabularies | ||
|---|---|---|---|---|---|
| Korean | Initial | 412,317 | 11.6 | 4,782,063 | 389,752 |
| MA and WSD | 20.1 | 8,287,635 | 68,719 | ||
| Vietnamese | 14.5 | 5,958,096 | 39,748 | ||
| Systems | BLEU | METEOR | TER |
|---|---|---|---|
| Baseline | 13.52 | 0.115 | 71.46 |
| KrUTagger | 25.10 | 0.189 | 64.03 |
| VnPOS | 26.81 | 0.197 | 61.07 |
| VietBERT+NMT | 28.22 | 0.209 | 58.53 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vu, V.-H.; Nguyen, Q.-P.; Tunyan, E.V.; Ock, C.-Y. Improving the Performance of Vietnamese–Korean Neural Machine Translation with Contextual Embedding. Appl. Sci. 2021, 11, 11119. https://doi.org/10.3390/app112311119
Vu V-H, Nguyen Q-P, Tunyan EV, Ock C-Y. Improving the Performance of Vietnamese–Korean Neural Machine Translation with Contextual Embedding. Applied Sciences. 2021; 11(23):11119. https://doi.org/10.3390/app112311119
Chicago/Turabian StyleVu, Van-Hai, Quang-Phuoc Nguyen, Ebipatei Victoria Tunyan, and Cheol-Young Ock. 2021. "Improving the Performance of Vietnamese–Korean Neural Machine Translation with Contextual Embedding" Applied Sciences 11, no. 23: 11119. https://doi.org/10.3390/app112311119
APA StyleVu, V.-H., Nguyen, Q.-P., Tunyan, E. V., & Ock, C.-Y. (2021). Improving the Performance of Vietnamese–Korean Neural Machine Translation with Contextual Embedding. Applied Sciences, 11(23), 11119. https://doi.org/10.3390/app112311119