1. Introduction
Social media has become the number one channel of communication for people. Here, they share their thoughts and opinions on different topics, and share what articles they have read etc., shaping their narrow community with these activities.
These activities have intensified during the pandemic, and people spent more time online during lockdown and home office periods. Therefore, their news consumption has changed, and social media portals have become their primary communication channel. We cannot announce the end of the epidemic yet, but we can already say that this displacement to the online space will continue in the coming periods, both in terms of work and news consumption, communication and different forms of entertainment.
We definitely need to address these manifestations on different platforms (in this case, focusing on Twitter), and as machine learning becomes more popular and important, as does natural language processing (NLP). We need to address, analyze, and research emotions related to these platforms.
There are many options for executing sentiment analyses, from ‘human categorization’ to ‘dictionary based ’ and ‘deep learning’ methods. In the field of tools, we can choose from fully ready-to-use tools, development kits, and completely custom-developed models. One such tool is ‘TextBlob’ (
https://textblob.readthedocs.io/en/dev/ accessed on 1 October 2021), which is fully ready to be integrated into any analysis—just import the library, and it is ready to use. As mentioned earlier, there are also options that allow us to create our own models, and build and train them based on our own data. ‘Using Bidirectional encoder representations from transformers’ (BERT) (
https://github.com/google-research/bert accessed on 1 October 2021) for sentiment analysis is one of the most powerful tools that we can use, but we can also create a ‘Recurrent neural network’ (
https://developers.google.com/machine-learning/glossary/#recurrent_neural_network accessed on 1 October 2021) (RNN) or use the ‘Natural Language Toolkit’ (
https://www.nltk.org/ accessed on 1 October 2021) (NLTK) with the VADER lexicon and SentimentIntensityAnalyzer.
The main goal is to train a model to sentiment prediction by looking at correlations between words and tagging it to positive or negative sentiments.
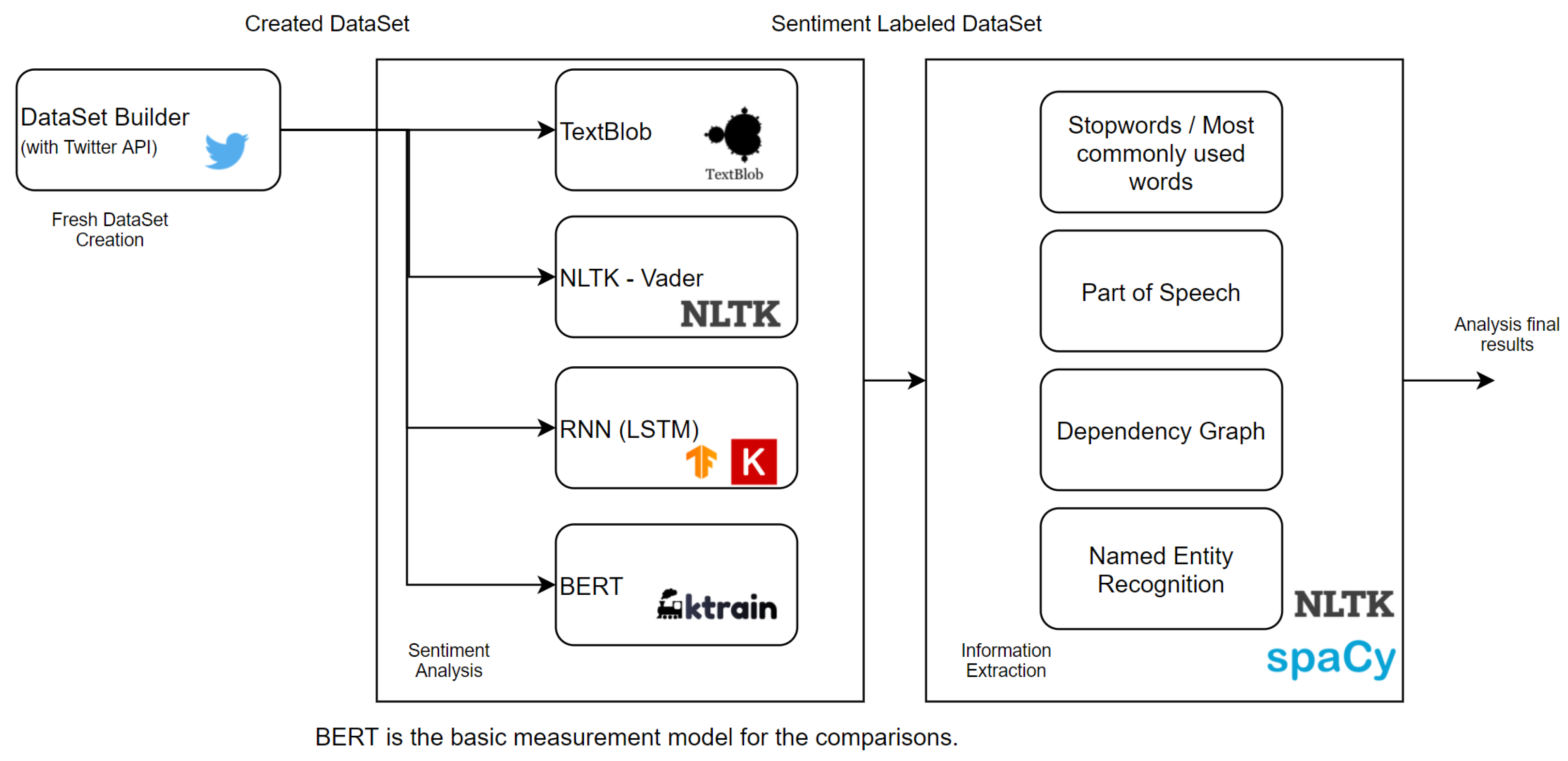
Thus, we created the RNN, BERT, NLTK–Vader lexicon models and imported the TextBlob tool into our analysis. We compared these primarily with the results of BERT. For the sentiment analyses, we also expanded the usual ‘positive’, ‘negative’, and ‘neutral’ categories with ‘strongly positive or negative’ and ‘weakly positive or negative’ options for deeper analysis, and to explore differences between models.
By performing further analysis on the data labelled by the RNN model obtained in this way, it is possible to determine, even more precisely, what emotions that the given topic evoked from people in a given time period, in the ‘COVID’ theme, in this case. For these results, we used ‘Information extraction’ (IE) and ‘Named entity recognition’ (NER) analyses.
Today is an age of information overload; the way in which we read has changed. Most of us tend to skip the entire text, whether that is an article or a book, and just read the ‘relevant’ bits of text. Journalists are also increasingly striving to highlight the most relevant information in their articles, so by only reading these highlights and headlines, we can have a ‘frame or the knowledge of the most valuable information parts’ about this subject. The task of information extraction involves extracting meaningful information from unstructured text data and presenting it in a structured format. Simplified ‘Named entity recognition’ provides a solution for understanding text and highlighting categorized data from it, where we can define different methods of the named entity recognition extraction, like ‘Lexicon approach’ or ‘Rule-based systems’, or even ‘Machine learning based system’. By performing these analyses, we can obtain deeper, information-supported sentiment results that can provide the foundation for many other research studies.
In the IE area, ‘Part of Speech’ (POS) tagging-based analyses and ‘Dependency Graph’ generation were performed, followed by NER analysis. With POS tagging, we determined which words that people use most often in positive and negative tweets, and we also examined what ‘stopwords’ occur in these cases. With the help of the ‘Dependency Graph’, we looked at what was the most positive tweet in the given analysis, and how this tweet was structured. Then, in the NER analysis, we expanded all of this, and tried to get a picture of what the differences were in the case of positive and negative tweets. What people, places, and more were mentioned in their tweets related to that topic.
The ‘spacy’ (
https://spacy.io/ accessed on 1 October 2021) library provided the basics for the analyses. Like the NER analysis, it was based on default trained pipelines from ‘spacy’, which can identify a variety of named and numerical entities, including companies, locations, organizations, and products.
The RNN model was built and taught using the libraries and capabilities provided by ‘Tensorflow’ (
https://www.tensorflow.org/ accessed on 1 October 2021) and ‘Keras’ (
https://keras.io/ accessed on 1 October 2021). The DataSet is created and cleaned by our written scraper script, which uses the Twitter API. This script always provides the most up-to-date data, and is possible in a given time period in a given topic (COVID-19).
5. Sentiment Analysis Results
The analyses were run in late August and early September. Accordingly, we defined time intervals (29 August 2021 and 31 August 2021, 2 September 2021 and 4 September 2021), and defined the topic keyword, which was ‘COVID’, and set the dataset size to 500 tweets to build the datasets of 500 tweets from both September and August time intervals, using the Twitter API Standard option.
We would like to present the methods of this analysis flow in the first place; we expect similar results with a larger amount of data as well. The reason for this period is that it is the period of starting school in many countries. School may have already started, or will start soon. It is a particularly important period in the knowledge of the next, fourth wave of COVID-19.
5.1. Prolog
The classification of the tweets was based on the polarity and compound values, which were obtained from the different models. The models were used here as described in the methodology section. In the case of TextBlob and NLTK-VADER, the appropriate methods of the library were parameterized and used; in the case of RNN and BERT, it was taught and used according to their previous descriptions.
The basic result is determined using the BERT transformer mechanism. We do not aim to compare all models with all other models; we would like to present and explain the methodological differences of the TextBlob, NLTK-VADER and RNN models, and then analyze the results of the model that best approached the results of BERT in more depth.
We expect the results of the RNN to be the closest to the results provided by BERT, due to its methodological sophistication.
The interval for each category was properly defined, including the extended (‘strongly’, ‘weakly’) categories as well. Based on the values, the tweets were categorized and labeled in the appropriate category. In the case of BERT, the positive and negative categories were not further subdivided, due to the role.
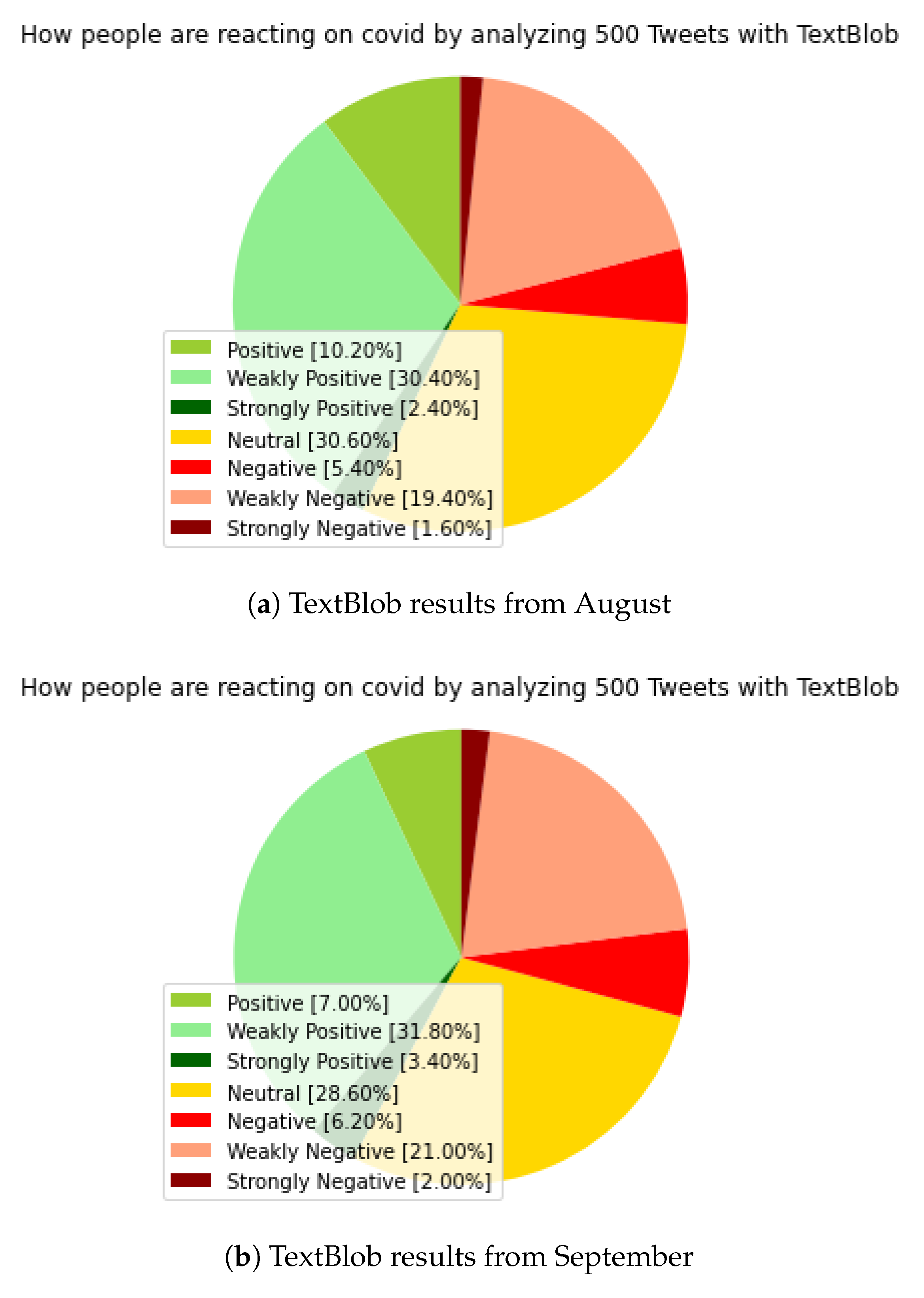
5.2. TextBlob
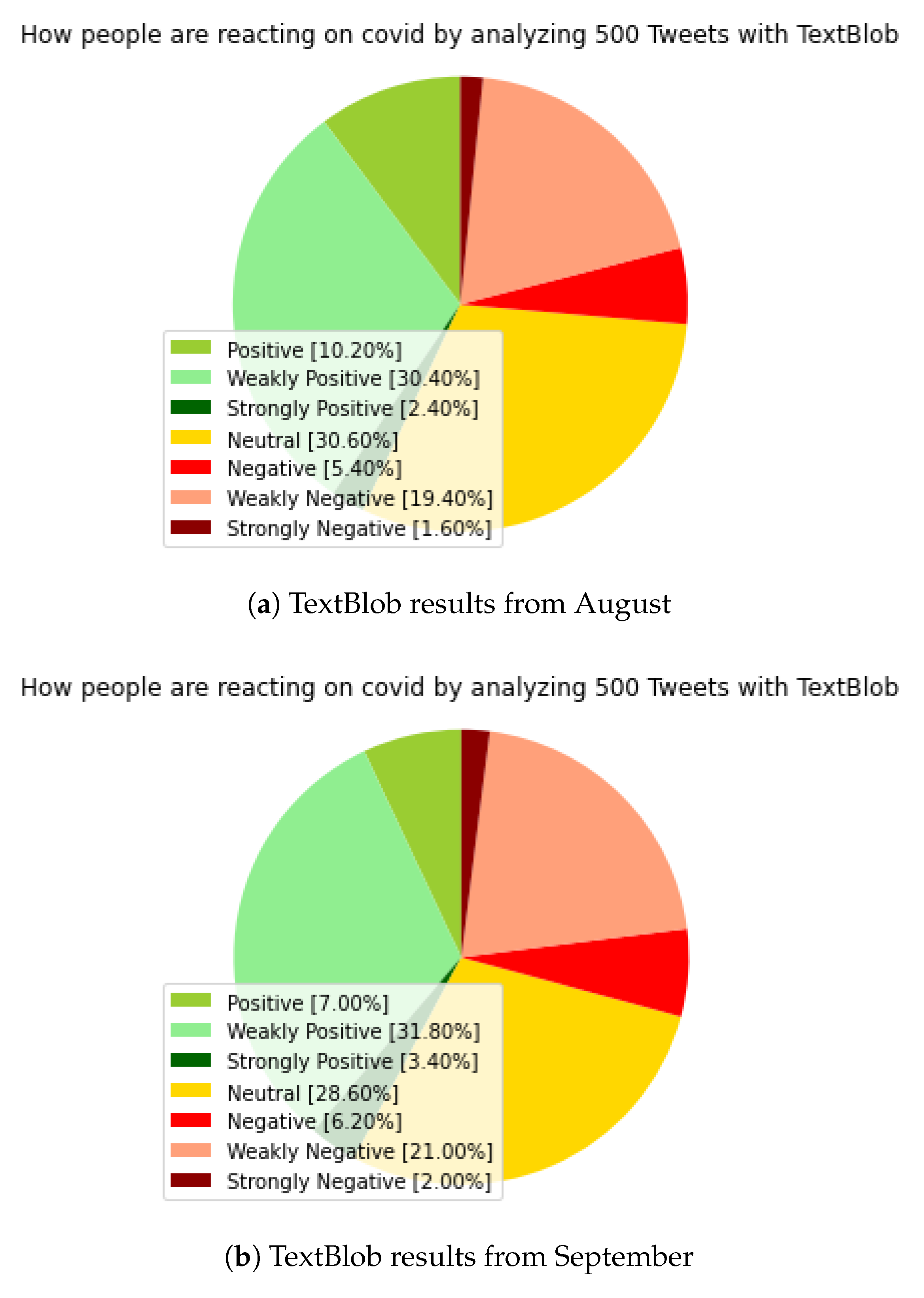
In
Figure 2, the neutral value dominates in both examined periods, which significantly distorts the result. The August results in
Figure 2a show a 30.60 percent neutral value, which is significant. The results from September in
Figure 2b also show that the neutral value is 28.60 percent. A small shift can be seen in the case of the neutral values of the two studied periods, which was in a negative direction.
In both August and September, ‘weakly positive’ values dominated their category, with 30.40 and 31.80 percentages. In the negative section, we can see a similar ‘weakly negative’ dominance. Due to the significant neutral values, the results are not exactly the most favorable for further analysis.
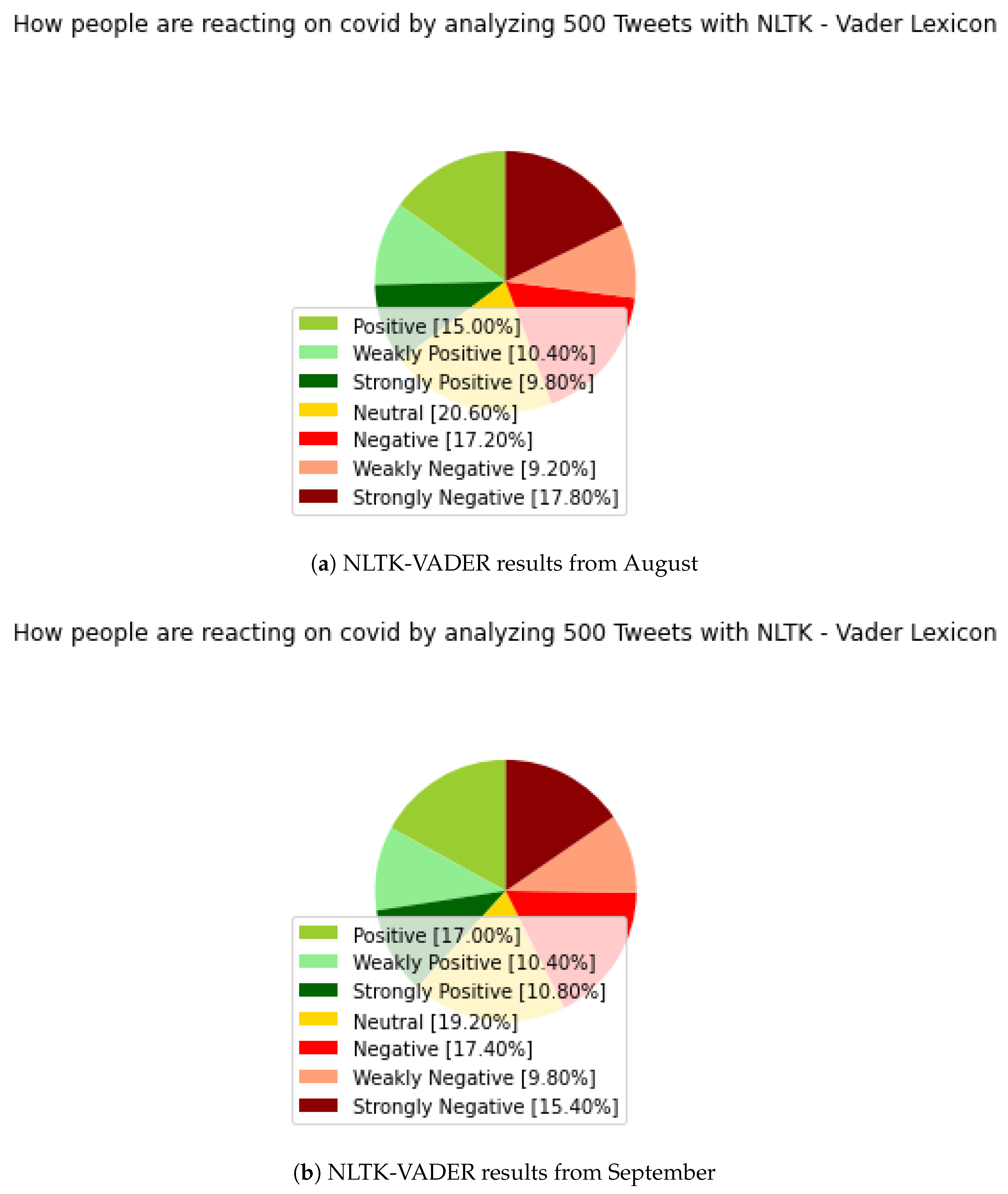
5.3. Natural Language Toolkit (NLTK)—Valence Aware Dictionary and Sentiment Reasoner (VADER)
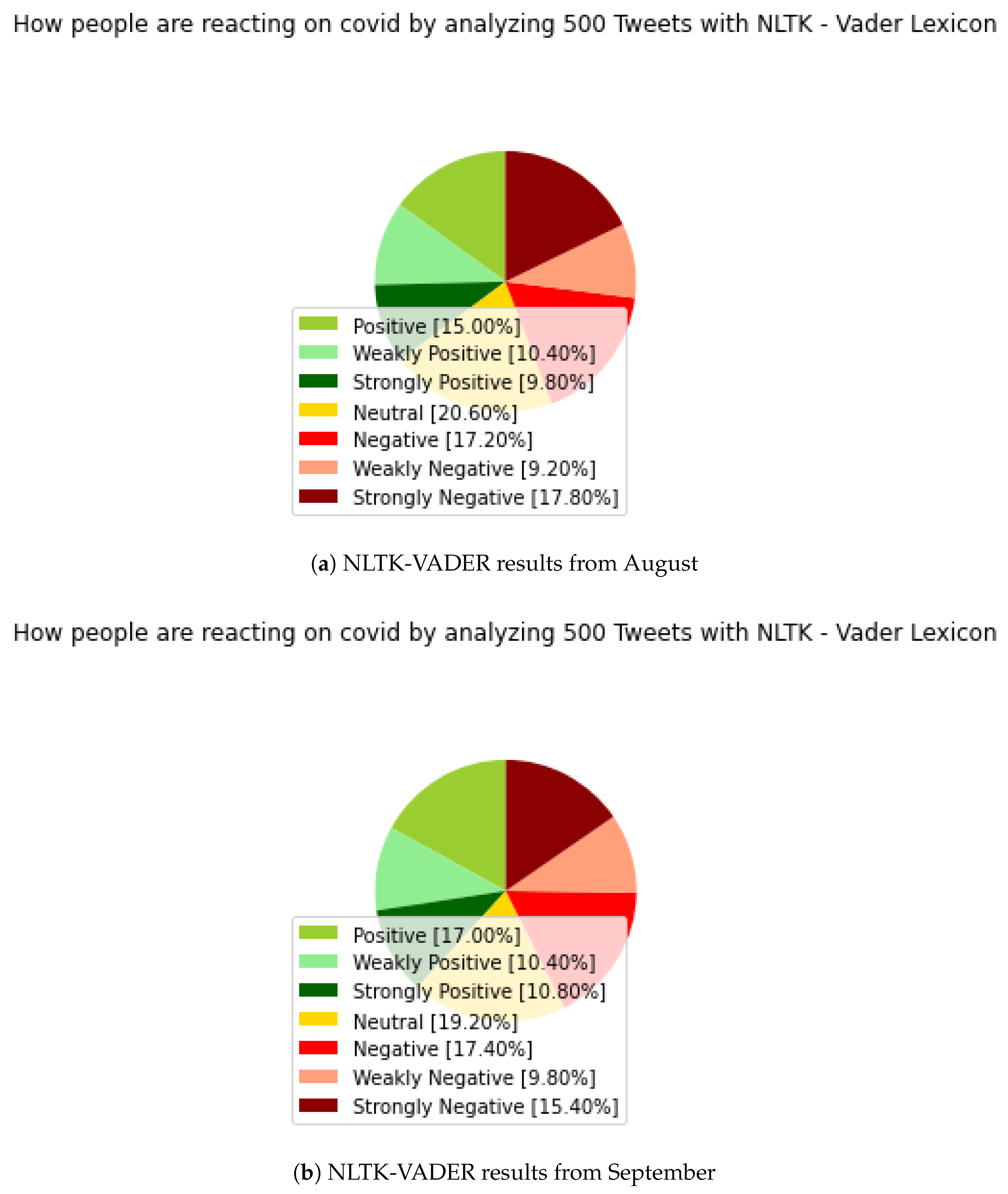
In
Figure 3, the results of NLTK—VADER show a significant improvement over the results of the previous TextBlob. It is enough to look only at the values of the neutral categories and see significant differences in the stages of the positive and negative parts.
In the case of the August result, which can be seen in
Figure 3a, the neutral value decreased significantly, and now it is only 20.60 percent. Similarly, in
Figure 3b, the neutral value is 19.20 percent, compared to previous results, which reached 30 percent, or it was very close to this value.
In the case of the August results, there are also significant differences within the positive parts, and there is no longer such a ‘weakly positive’ dominance; due to the technological changes, we can assume a more accurate result on the same datasets as we used in the case of TextBlob. Here, we can see 15 percent ‘positive’, 10.40 percent ‘weakly positive’ and 9.80 percent ‘strongly positive’ sentiment values. In September, 17 percent ‘positive’, 10.40 percent ‘weakly positive’ and 10.80 percent ’strongly positive’ sentiment values were observed.
Similar movements can be observed in the negative sections, with 9.2 percent ‘weakly negative’, 17.2 percent ‘negative’ and 17.8 percent ‘strongly negative’ in August. In September, 9.8 percent were ‘weakly negative’, 17.4 percent were ‘negative’, and 15.4 percent were ‘strongly negative’ sentiment values. Despite a significant decrease in the neutral section, there are still too much data in this category, although we can definitely report an improvement on previous TextBlob results. The goal is to eliminate or considerably minimize the neutral values, in order to confirm the results with subsequent analyses. A neutral value still makes the result a little bit uncertain.
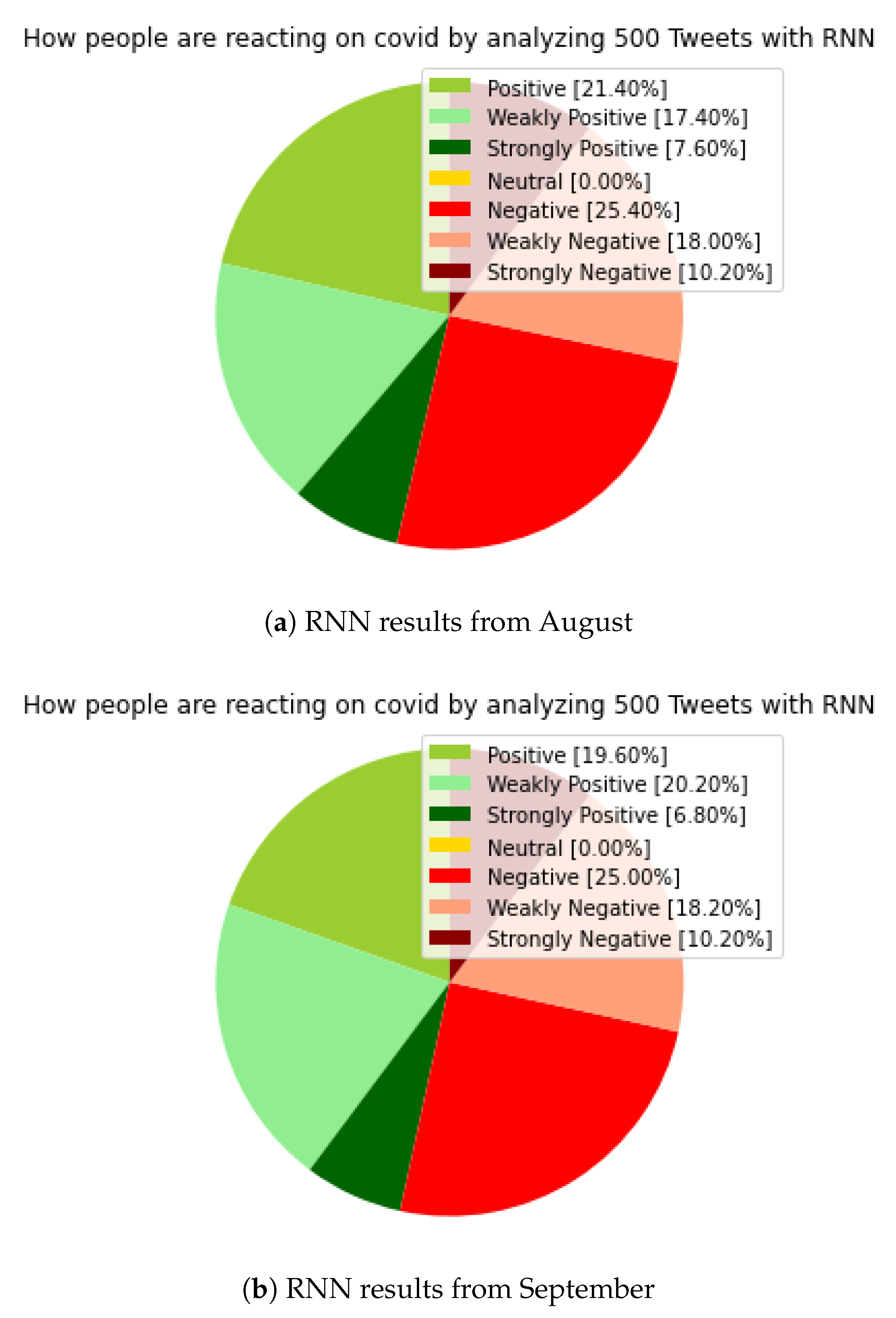
5.4. Recurrent Neural Network (RNN)
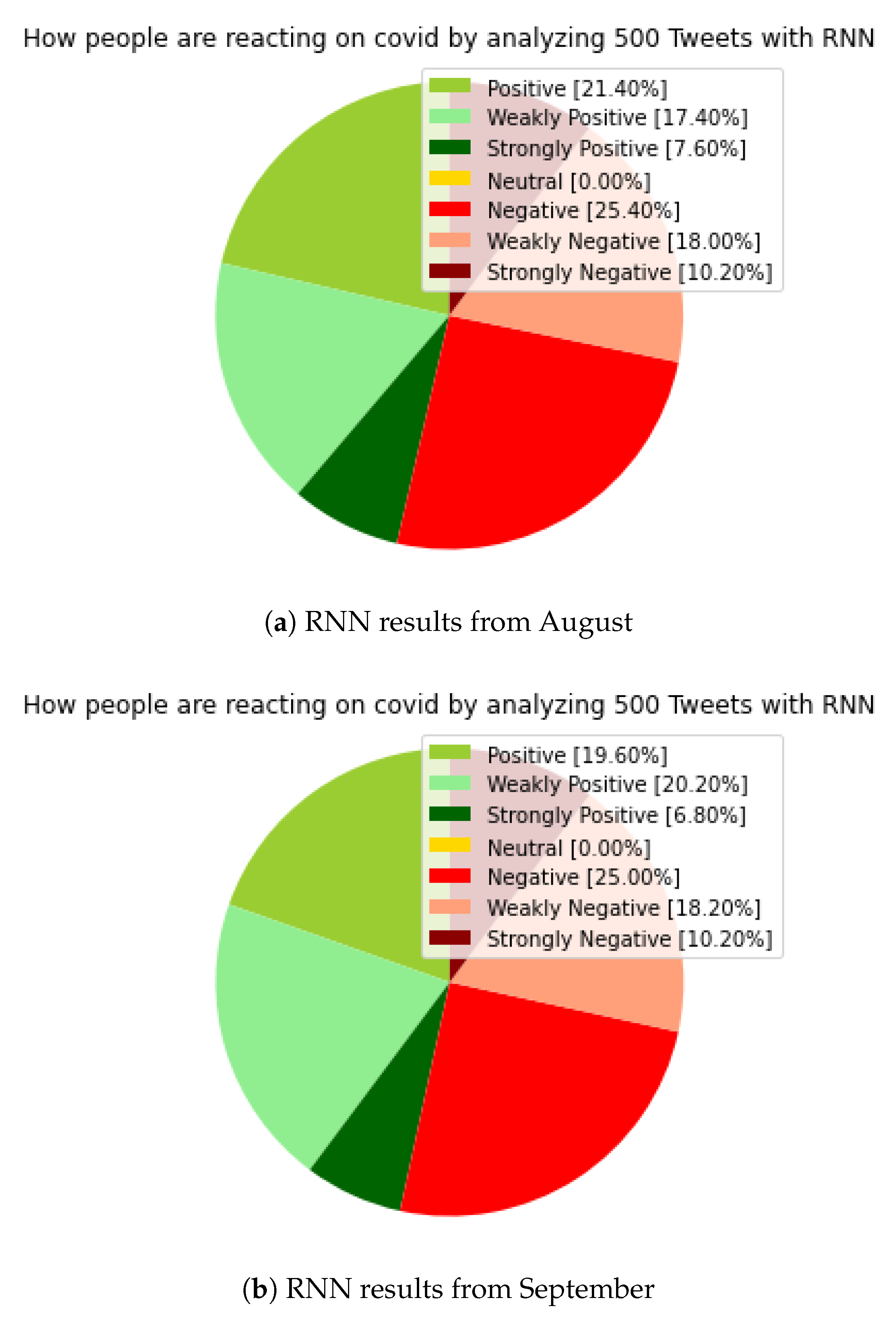
In
Figure 4, the results of RNN, when compared to the previous two (TextBlob and NLTK-VADER), has a neutral section of 0 percent in both August and September results, which is a significant improvement. In addition, small changes in distribution were observed in both the positive and negative sections compared to the previous models. In the case of the previous models, especially in the case of the NLTK-VADER results, there is a similarity in the result categories, both in positive and negative sections, the huge difference, and of course the neutral category. Our model was able to place all tweets in a category, as we expected, which significantly increases the establishment of a clearer picture of these specific periods.
The value of ‘strongly positive’ was 7.60 percent in August, down from 6.80 percent in September. The ‘positive’ section was 21.40 percent in August, but it was 19.60 percent in September; the ‘weakly positive’ values rising from 17.40 percent in August to 20.20 percent in September. Overall, in addition to the changes in ratios, the positive section increased by 0.2 percent overall, but there was a shift toward the ‘weakly positive’ section.
For the negative sections, the ‘strongly negative’ value was unchanged at 10.20 percent in both August and September. The ‘negative’ value fell from 25.4 percent in August to 25 percent in September. The ‘weakly negative’ value rose from 18 percent in August to 18.2 percent. Despite a small 0.2 percentage increase in positive values, and even in the case of minimal movements inside of the negative section, the negative sections still represent a larger overall section, plus in the case of positive values, a shift toward a ‘weakly’ value should be highlighted.
In summary, the results of the RNN model and the results of previous models show a strong division; there is some kind of “boundary line” based on the studied periods, which is very difficult to move. People have their own opinions about the pandemic, which has lasted for almost two years. Due to the significant neutral result seen in the TextBlob result, it is difficult to write a conclusion, but the results of the subsequent NLTK-VADER and then the RNN results, where the neutral values decreased significantly and then disappeared, already give some picture. They show a shift in the negative direction; during the period under review, the negative sections provided a higher percentage value overall, and in the case of the RNN model, the shift to the already mentioned ‘weakly positive’ section can be highlighted again.
Vaccinations, and the relatively ‘free summer’, also provide a basis for the positive parts in the studies, and the uncertainties of starting school and the fourth wave continue to maintain a more negative attitude.
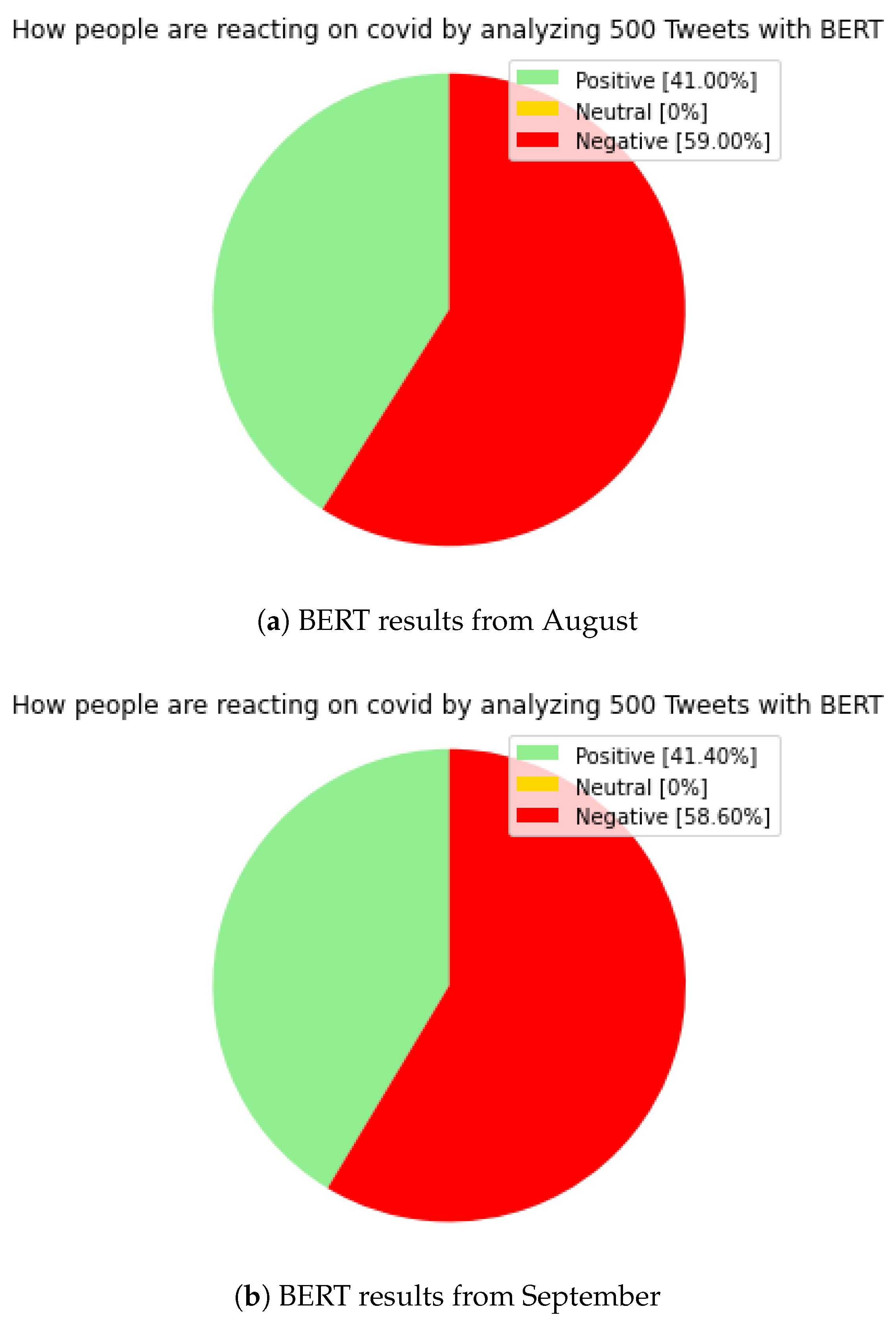
5.5. Bidirectional Encoder Representations from Transformers (BERT)
As we mentioned earlier, BERT was used as a kind of comparative result.
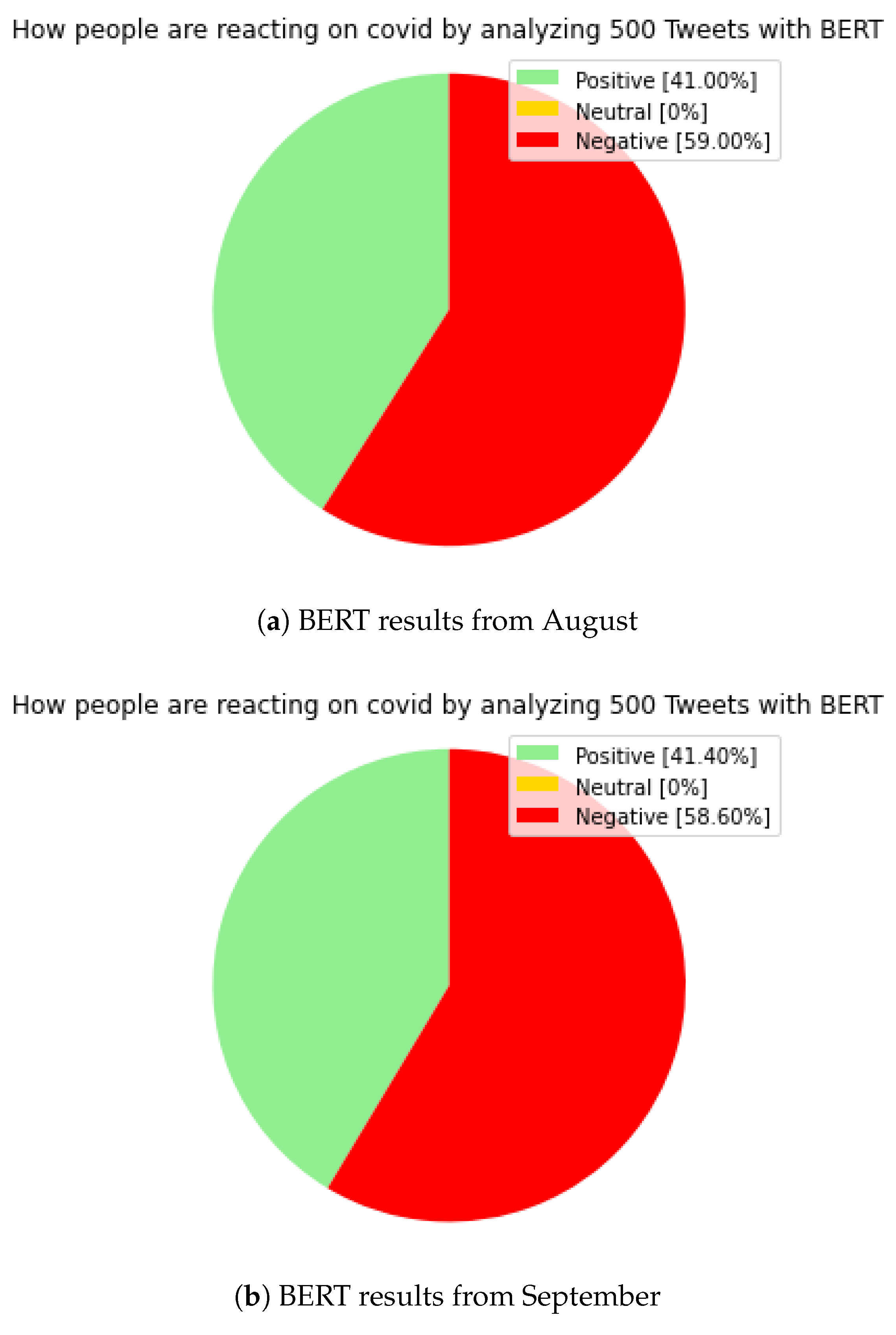
Figure 5 shows the results obtained by BERT. Of course, without the neutral category, in the case of BERT, in contrast to the previously presented models, we did not further categorize the positive and negative categories, because we only consider the results of BERT as a benchmark/comparative result for comparison to the other models, so we obtained a classic, ‘positive’, ‘neutral’, ‘negative’ result in the same time periods as in the previous models.
For the BERT model, the ‘positive’ section was 41 percent in August, which increased to 41.40 percent in September. The ‘neutral’ section was 0 percent according to our expectations. The ‘negative’ section was 59 percent in August, down from 58.60 percent in September. The results of BERT are mostly approximated by the results of the RNN model, which met our expectations.
The aggregated positive result for RNN in August was 46.40 percent, and the negative result was 53.60 percent. Similarly, in September, the aggregated positive score was 46.60 percent, and the negative was 53.40 percent. Here, we can see a slight shift in the positive direction too, but overall, the negative section dominates. This confirms the effectiveness of our RNN model, where we could also see a more detailed statement by further categorizing in positive and negative sections.
Based on the comparative results by BERT, we will perform further analyses on the results of the RNN model, to gain more insight into the sentiment results in this period. To do this, we perform information extraction (IE) and named entity recognition (NER) analyses. For the TextBlob and NLTK models, due to the significant neutral categories, we did not include a comparison with the results of BERT.
Our goal, with the help of these analyses, is to give a comprehensive picture of these periods, what sentiment states people are in, and what characterizes the tweets, which was written at that time. How the tweets were structured, what was mostly mentioned in them, and what can be said about these tweets are all important.
6. Information Extraction Results
As we have mentioned earlier, these analyses are performed on the results of the RNN model. After the sentiment analyses, we have aggregated the extended sentiment categories, so the analyses were performed on separate positive and negative datasets.
6.1. Prolog
We started the POS analysis by comparing the ‘stopwords’ (which words occur in a positive and negative attitude), and then, we followed this with the most commonly used words in the same categorization approach. The “nltk.corpus” (‘stopwords’ download and inclusion in the analysis) and “nltk.tokenize” libraries were used.
This was followed by the ‘stopwords’ removals and re-tokenization of tweets, with the entire POS analysis, which covers the positive and then the negative category. Finally, for the most followed positive tweets, we built dependency graphs. The ‘spacy’, ‘spacy—en core web sm’ pipeline and the ‘displacy’ visualization option were used for these analyses.
6.2. Stopwords and Most Commonly Used Words
Stopwords are the most common words in any natural language. For the purpose of analyzing text data and building NLP models, these stopwords might not add much value to the meaning of the document.
6.2.1. August
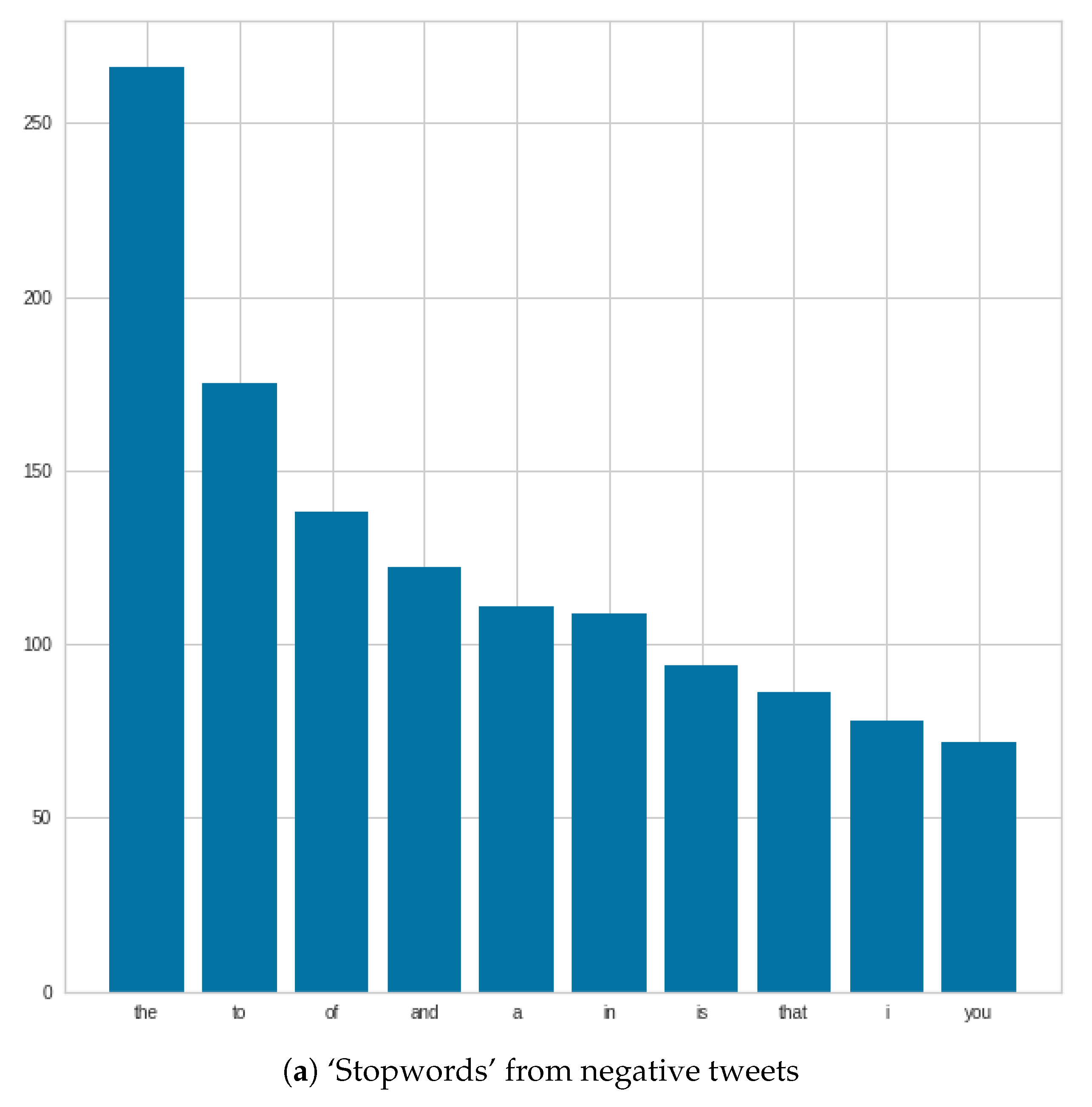
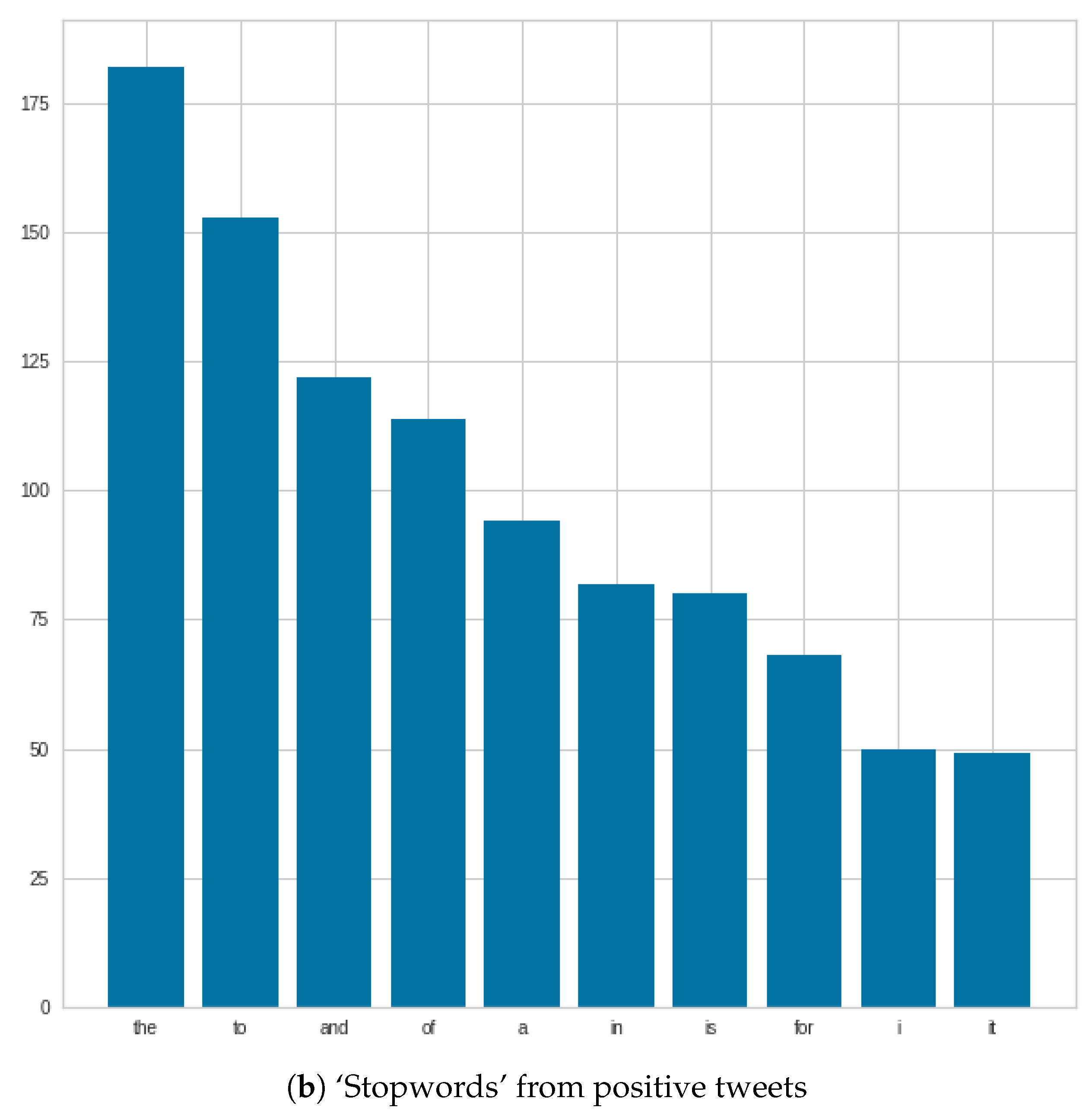
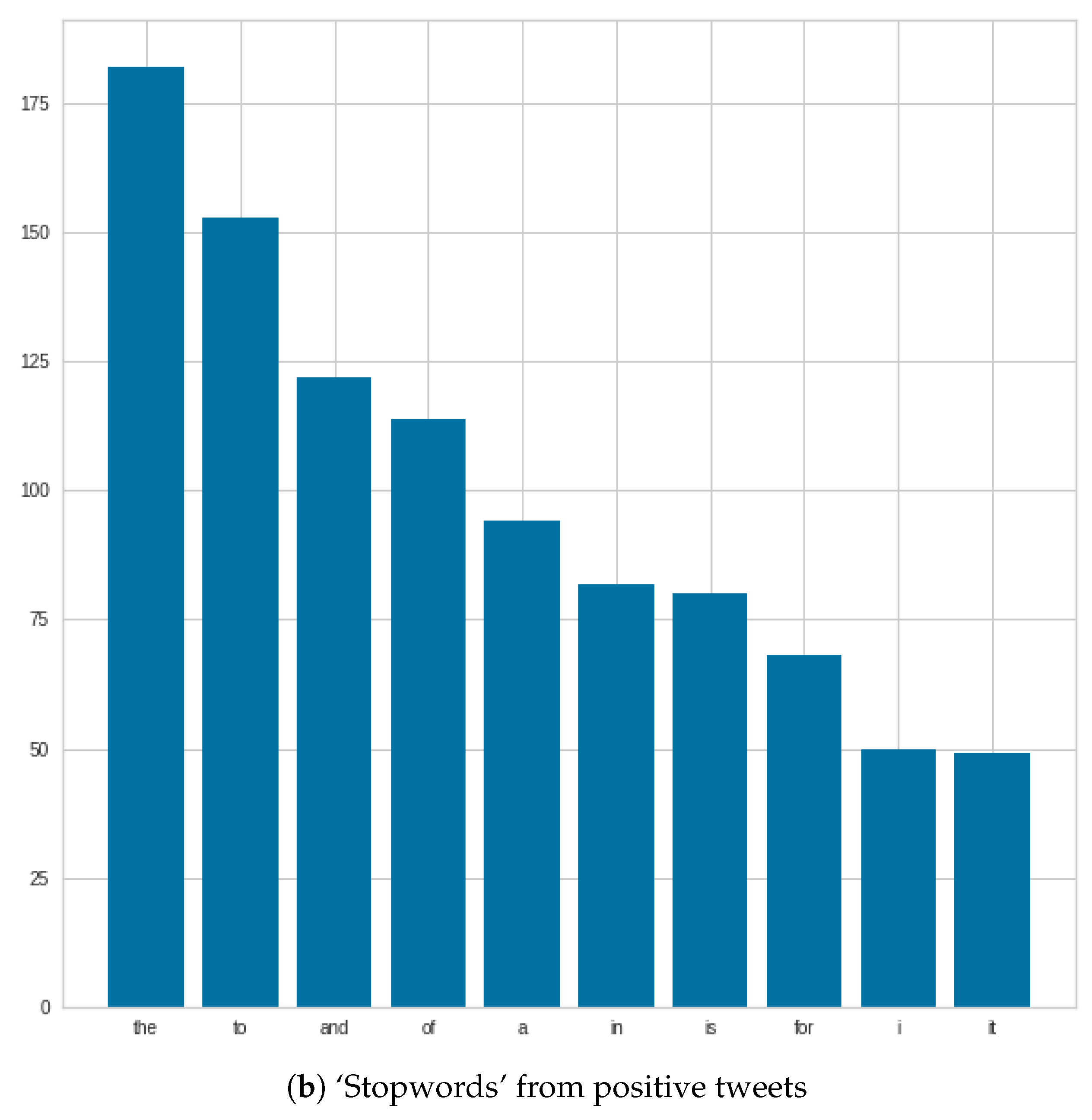
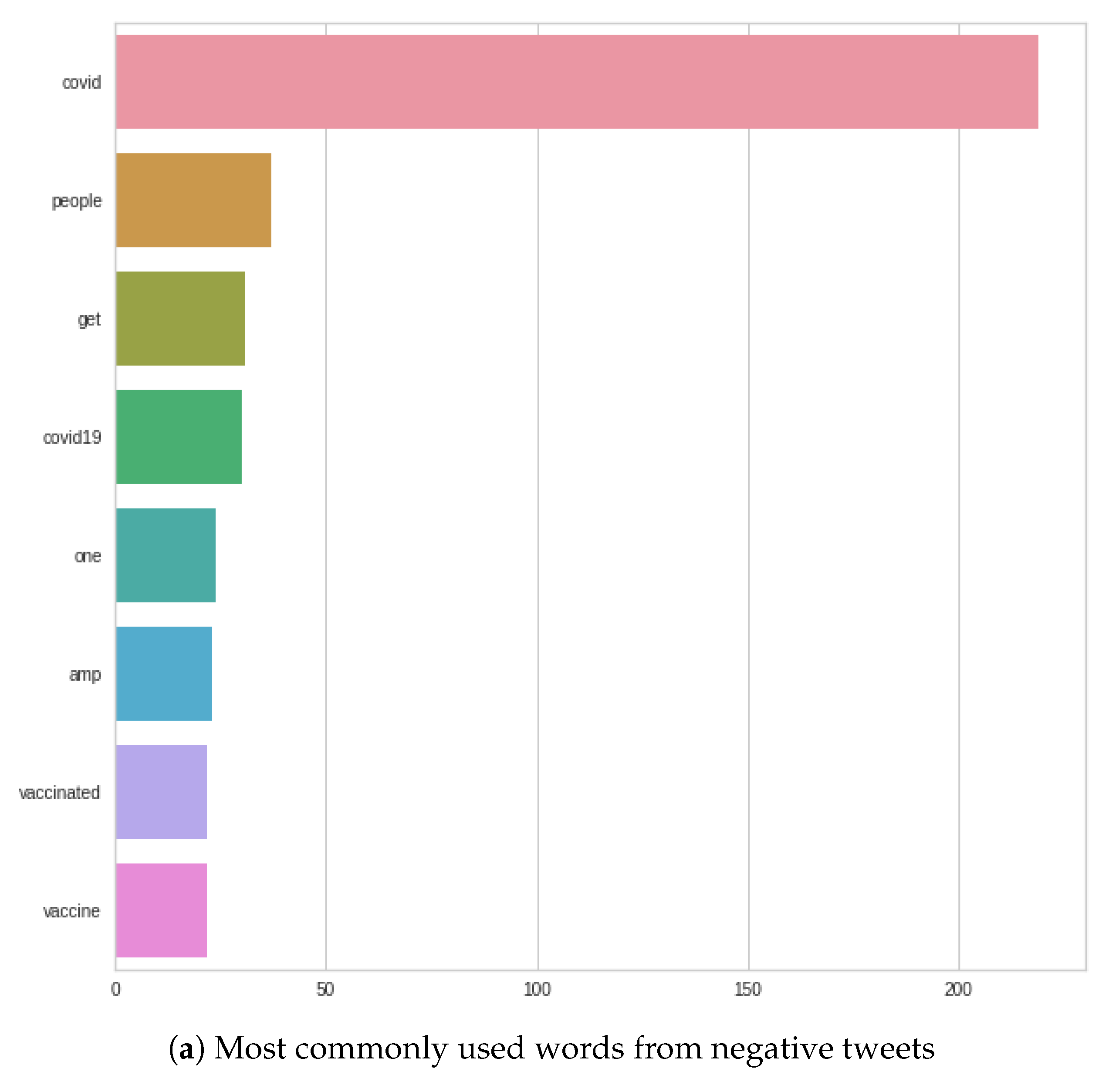
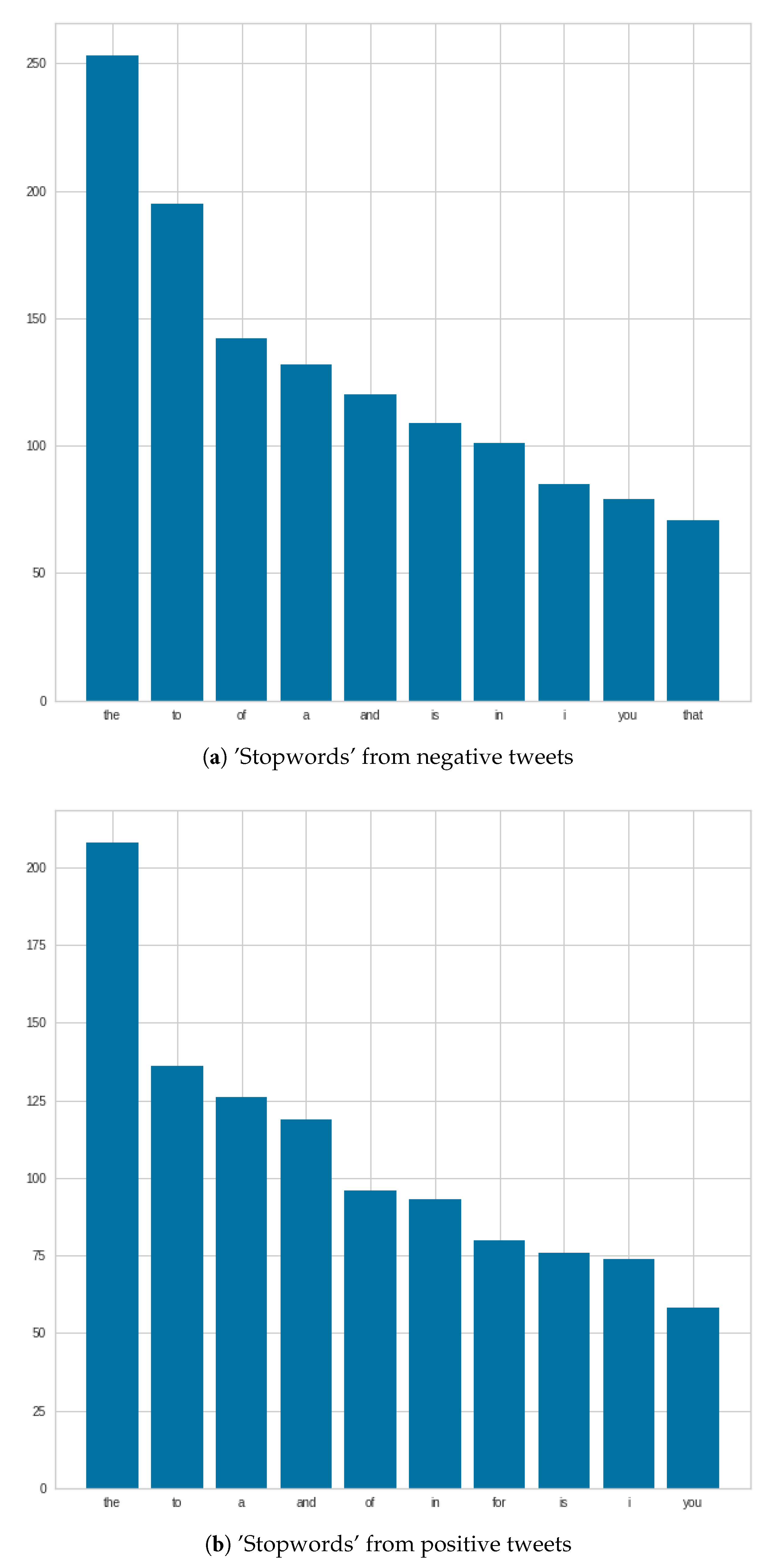
Figure 6 shows that ‘stopwords’ were very similar in both positive and negative tweets, and in some cases, we see changes in positions, such as ‘and and ’of’. In addition, in the negative case, the number of ‘the’s can be highlighted.
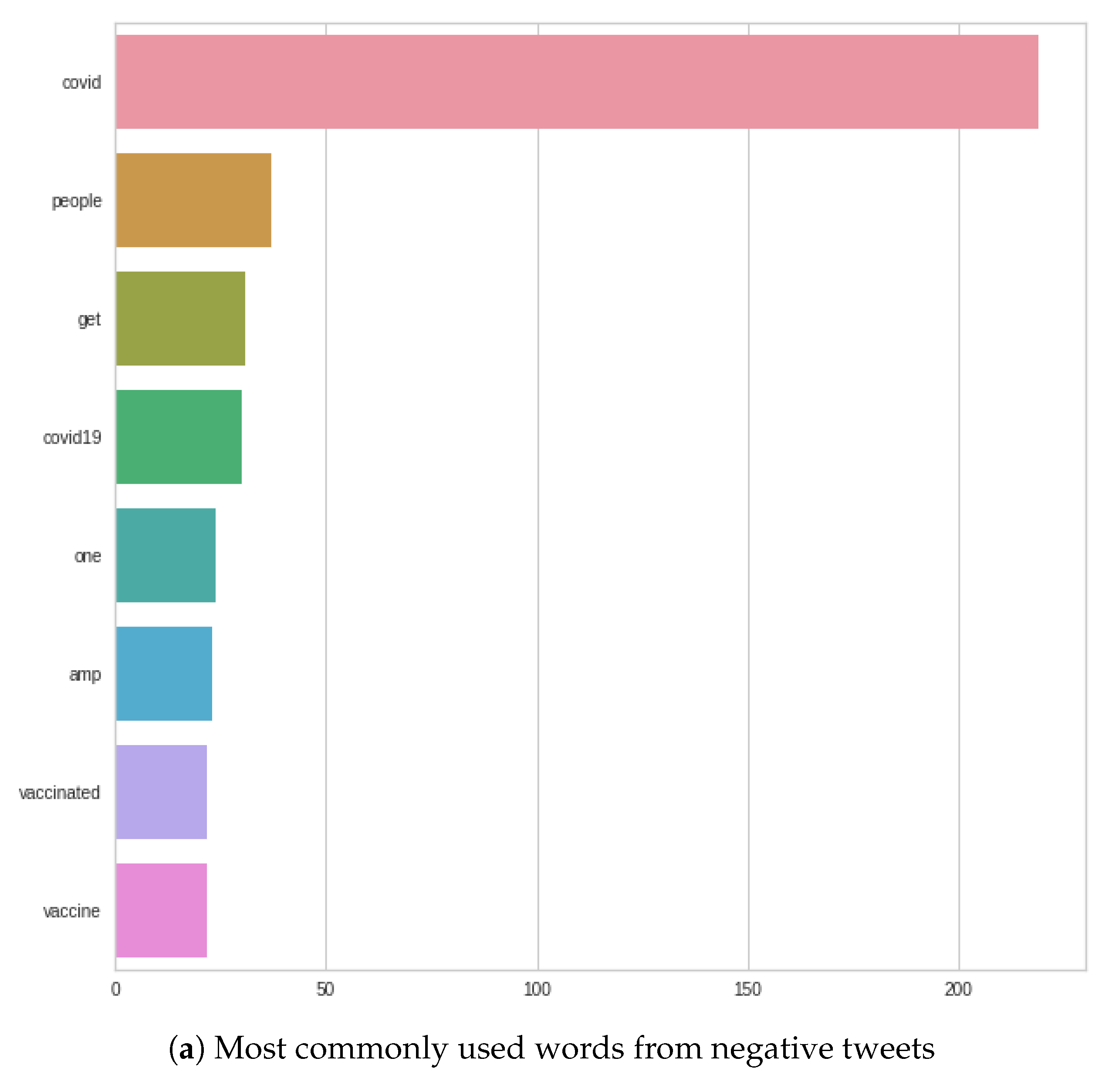
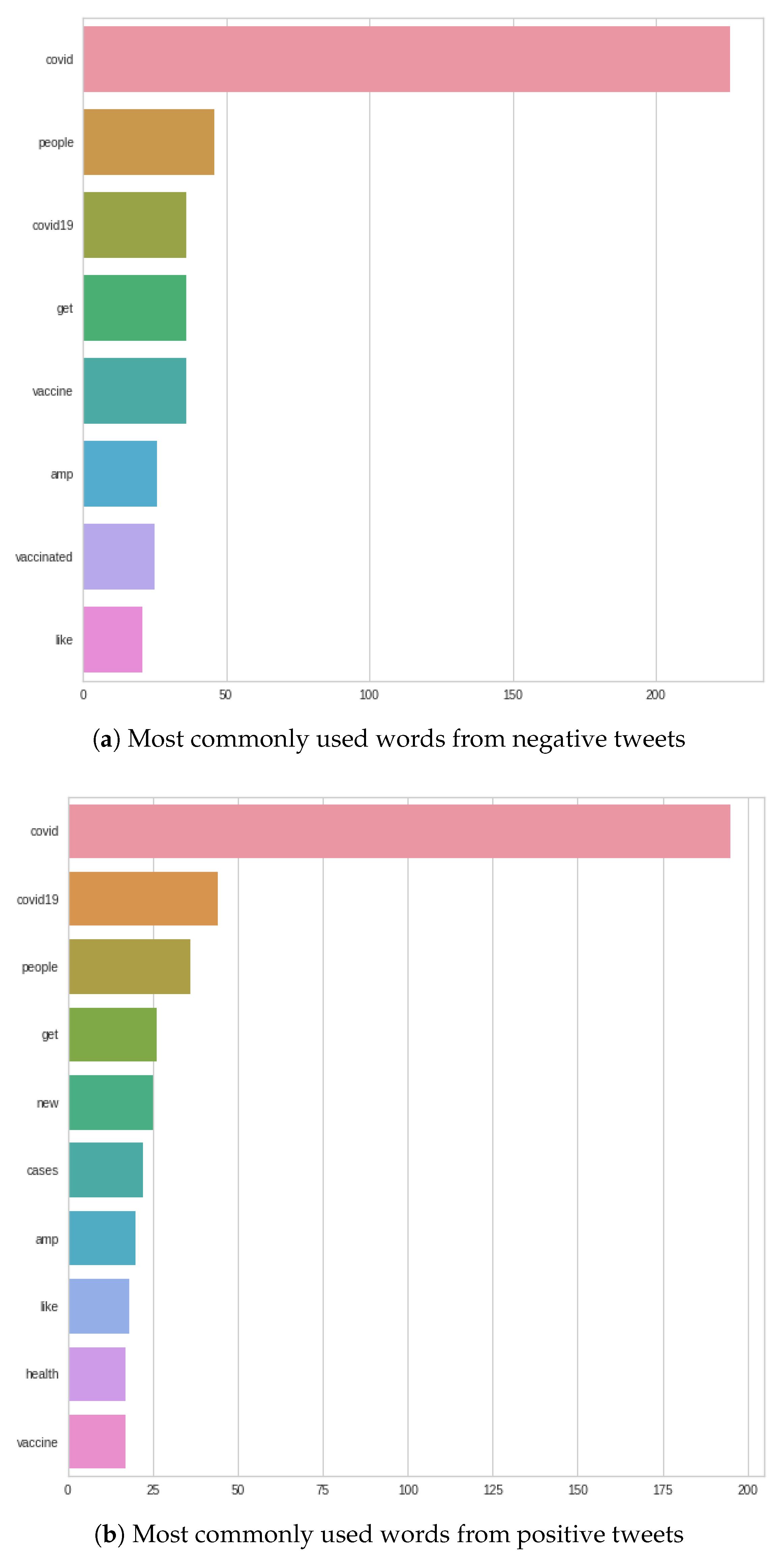
Figure 7 shows that, for the most commonly used words, the word ‘COVID’ completely dominates in both negative and positive tweets. After that, there are differences, such as in the negative case, where the word ‘COVID’ is followed by the following words: ‘people’, ‘get’, ‘COVID-19’; as opposed to the positive case, where the next three words are: ‘COVID-19’, ‘people’, ‘vaccine’. In the negative case, ‘vaccine’ or ‘vaccinated’ appear only at the very end of the figure, in contrast to positive tweets, where ‘vaccine’ is the fourth most common word.
6.2.2. September
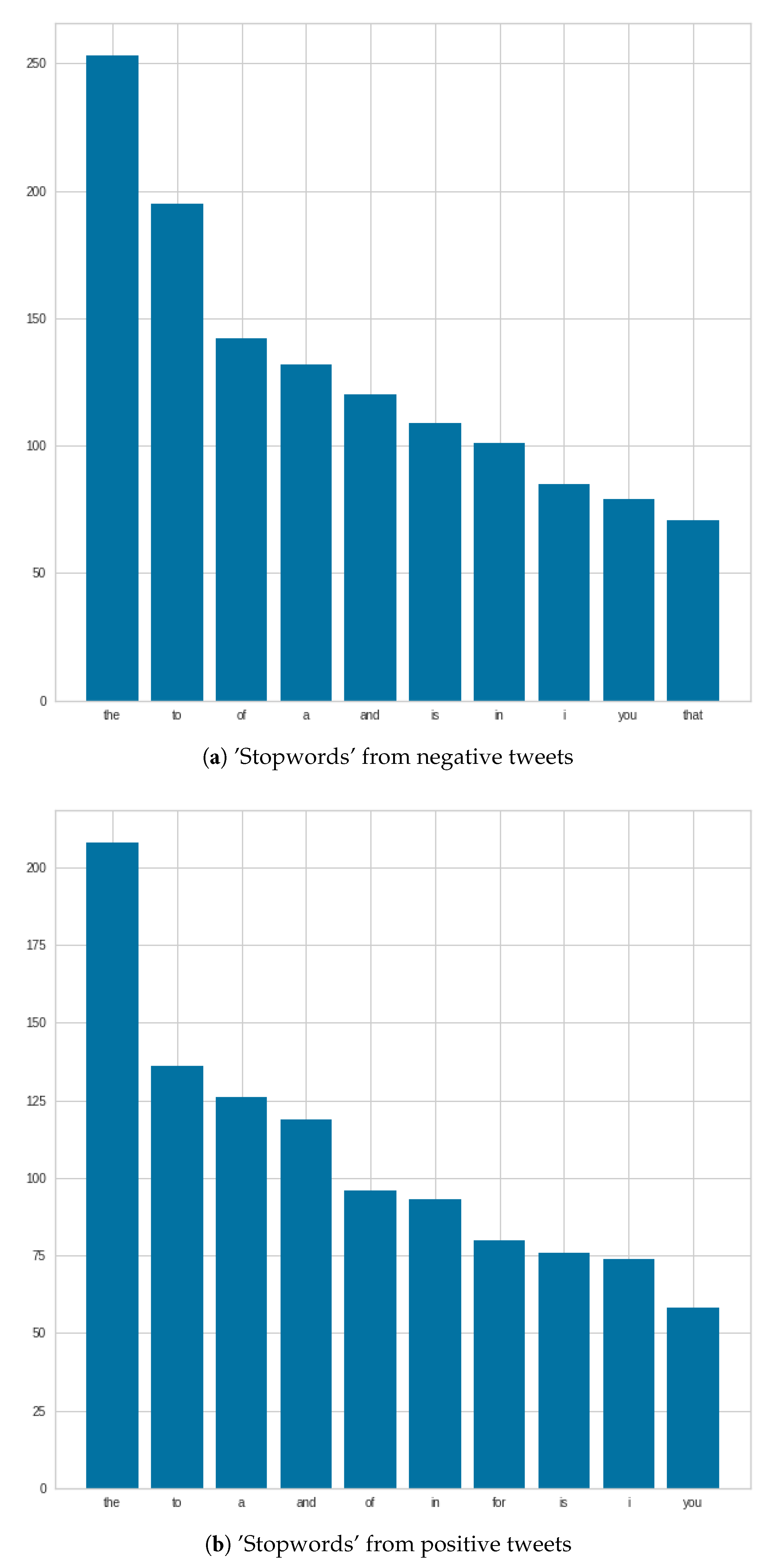
Figure 8 shows what ‘stopwords’ occurred in September for negative and positive tweets. In the case of negative tweets, the first three ‘stopwords’ are the same as in August. In the case of positive tweets, the number of ‘the’ ‘stopwords’ are increased, compared to the number of August. The third place of “a” can be mentioned, which was at fifth place in August.
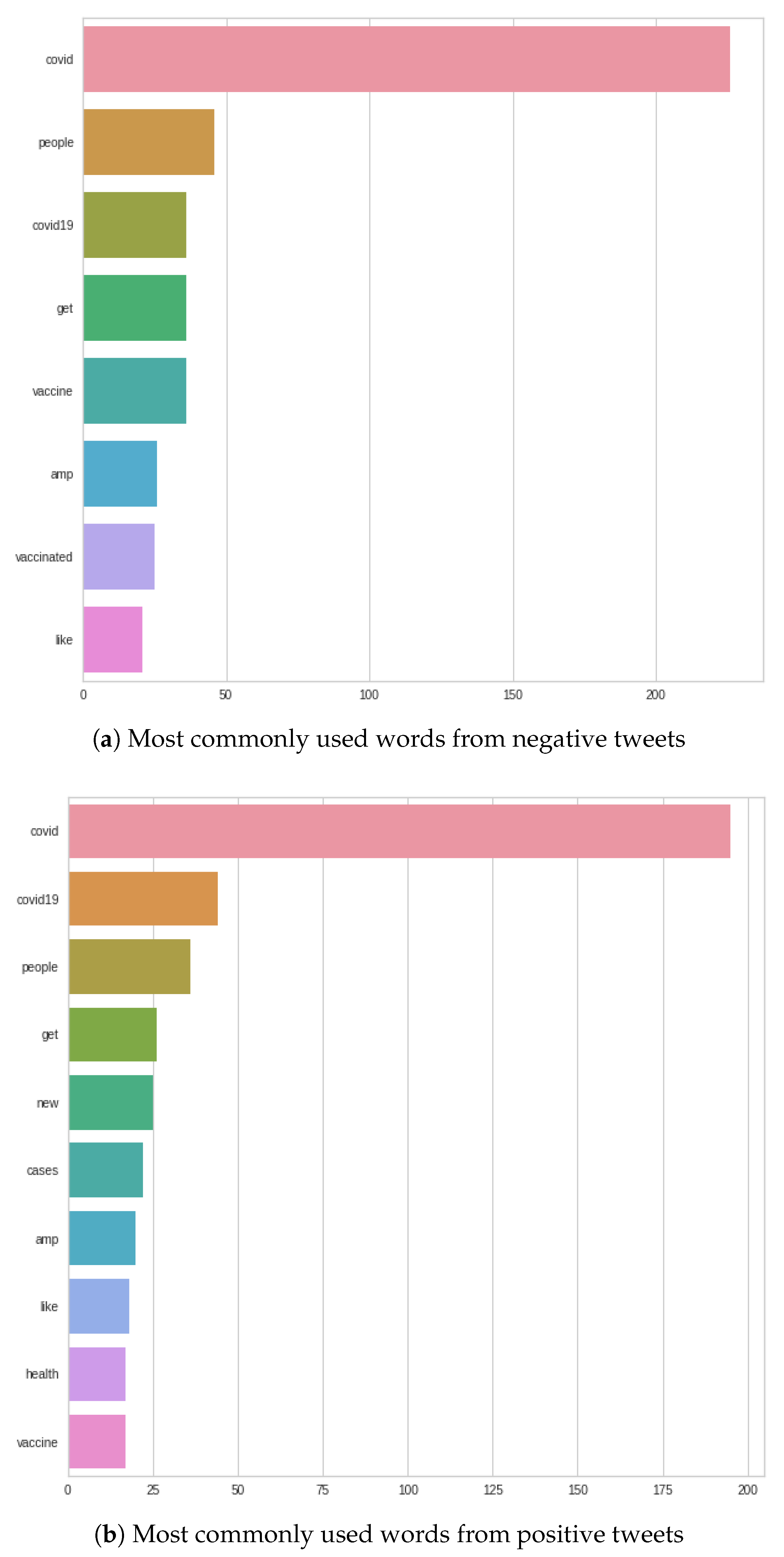
Figure 9 shows that even in September, the word ‘COVID’ completely dominated the tweets as well. In the case of negative tweets, ‘COVID’ is followed by the following three words: ‘people’, ‘COVID-19’, and ‘get’. In positive tweets, after ‘COVID’, these three words feature: ‘COVID-19’, ‘people’ and ‘get’. For both negative and positive words, the three most common words following the word ‘COVID’ are the same. There is a difference in the order—for negative tweets, the word ‘people’ is the first after ‘COVID’, and in positive words, ‘people’ is second in the queue after ‘COVID’; the first is ‘COVID-19’.
In the case of negative tweets, it should be noted that the word ‘vaccine’ was significantly ahead compared to the August results. In contrast to the positive words, the word ‘vaccine’ slid significantly backwards, and the word ‘cases’ moved forward; plus, the word of ‘health’ appeared in the plot, which was not displayed previously.
Compared to August, only small changes are seen, and the plots describe what words occur in tweets on the topic of COVID-19, and we can get an idea about the topics people are interested in, and how they describe their opinions about it.
6.3. Part of Speech Tags and Dependency Graph
After analyzing the different words, for both negative and positive tweets, it is definitely worth conducting a full part of speech analysis of which elements build up the negative and positive tweets.
As we have mentioned earlier, in some cases, a dependency graph can be used to see the actual relationships between words and to draw conclusions from them. Therefore, for the tweets with the most followers, we created a dependency graph from the datasets.
6.3.1. August
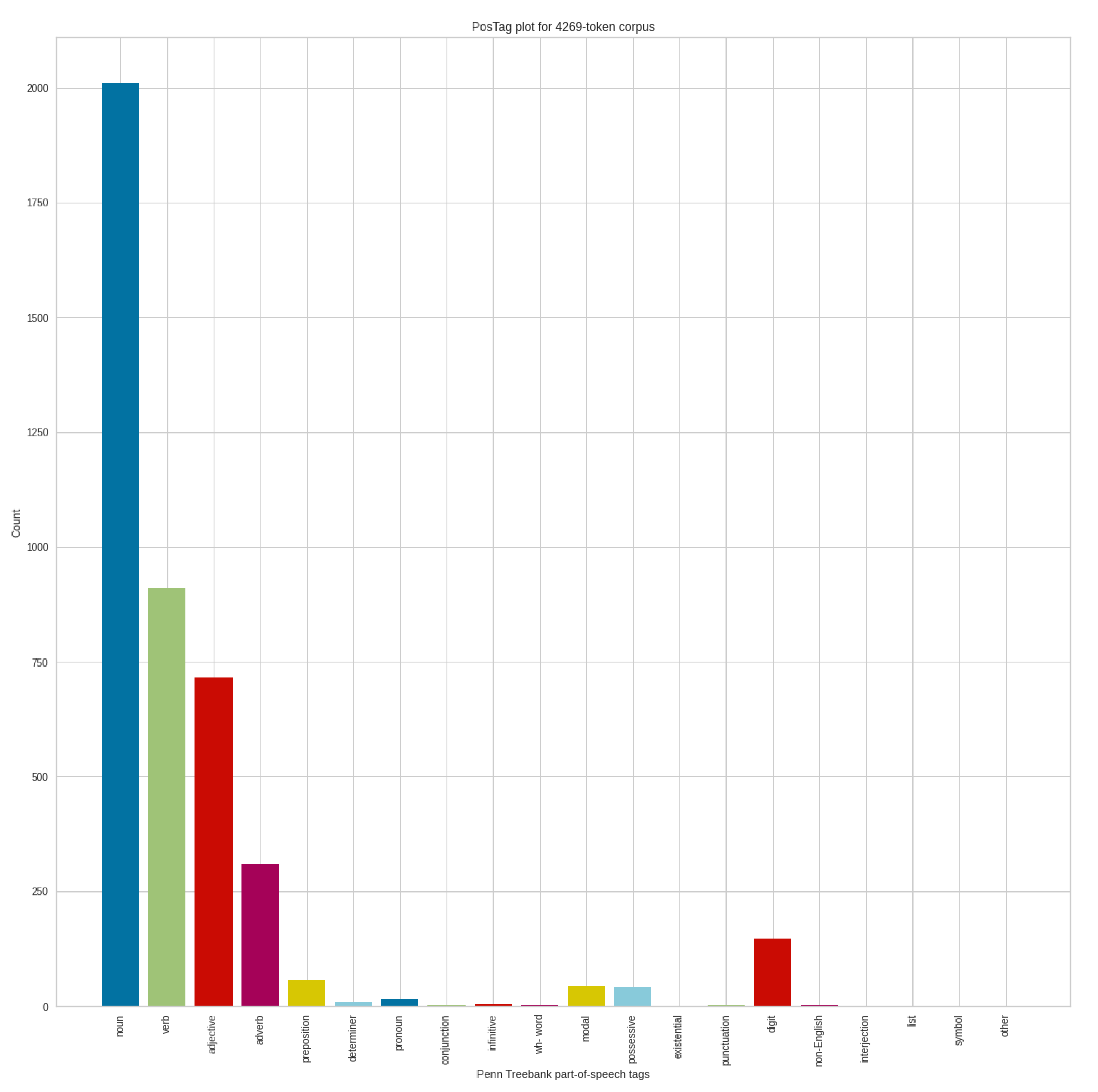
Figure 10 shows that the analysis was done with 4269 token corpus in the case of negative tweets, where the number of nouns exceeds two thousand. This is followed by verbs, adjectives and adverbs. The number of digits can also be highlighted.
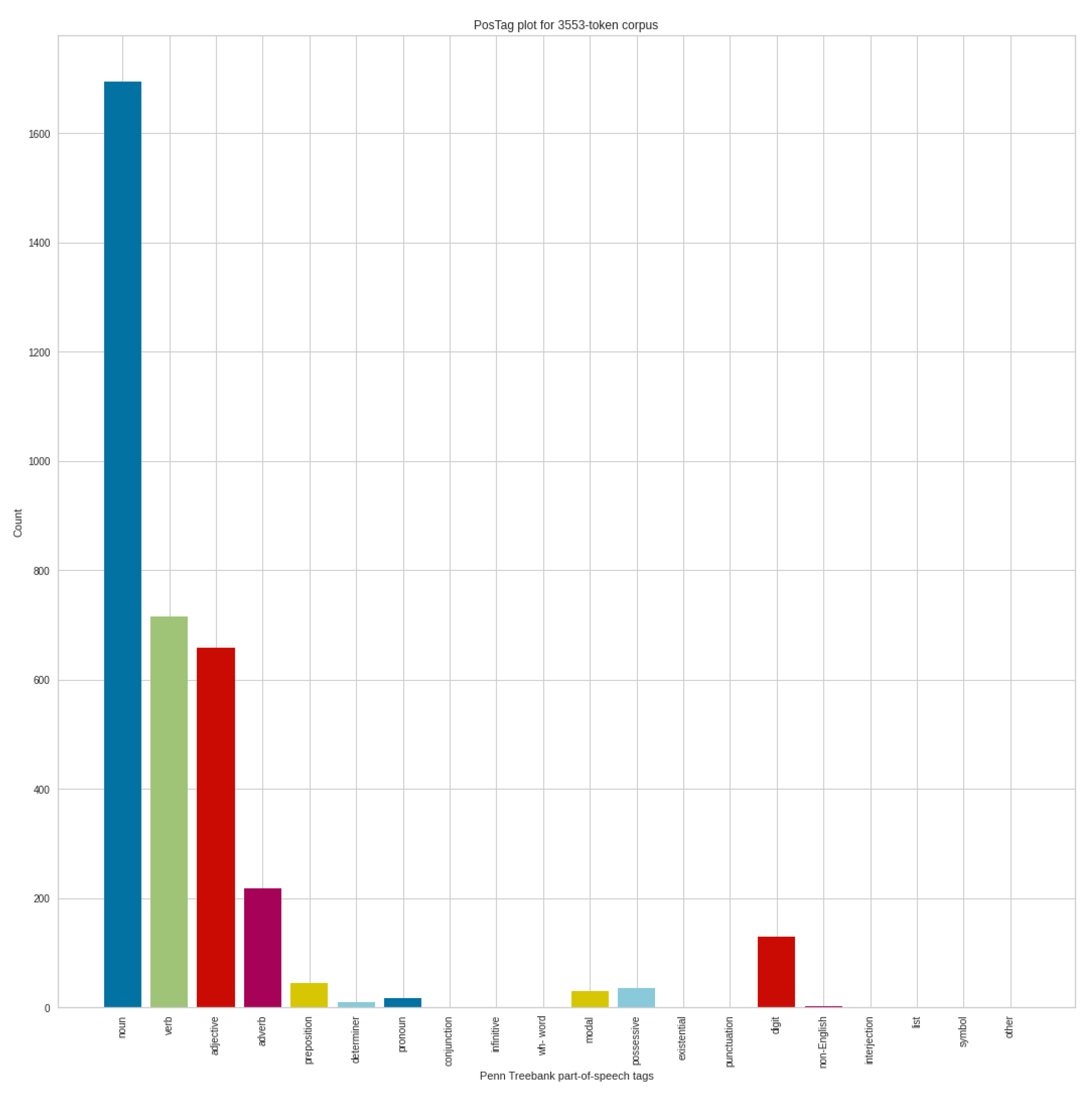
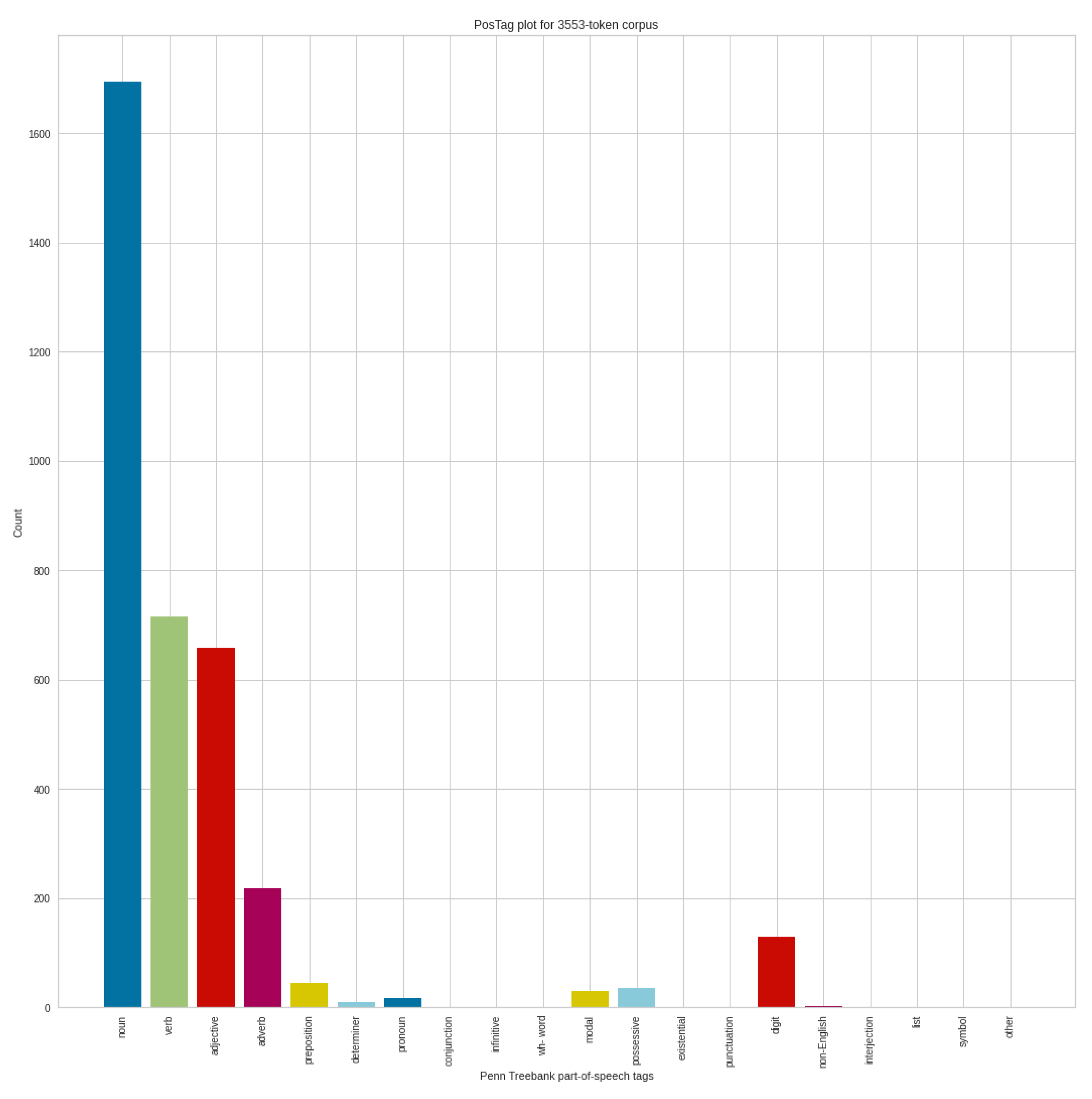
Figure 11 shows the part of speech analysis results from August on the positive tweets, which contain 3553 token corpus. Of course, the number of nouns is the most prominent here as well, followed by verbs, adjectives, and adverbs. We cannot see unusual results here either. Comparing the negative and positive POS analyses in August, we can mainly see the differences in the proportions, both in each POS group, and in the number of tokens that can be analyzed.
Following the POS analyses, let’s look at the results of the dependency graph (
Figure 12 shows the structure of the tweet), using the positive twitter post with the most followers from the August dataset. There are two links at the end of the tweet; this is covered in the figure.
6.3.2. September
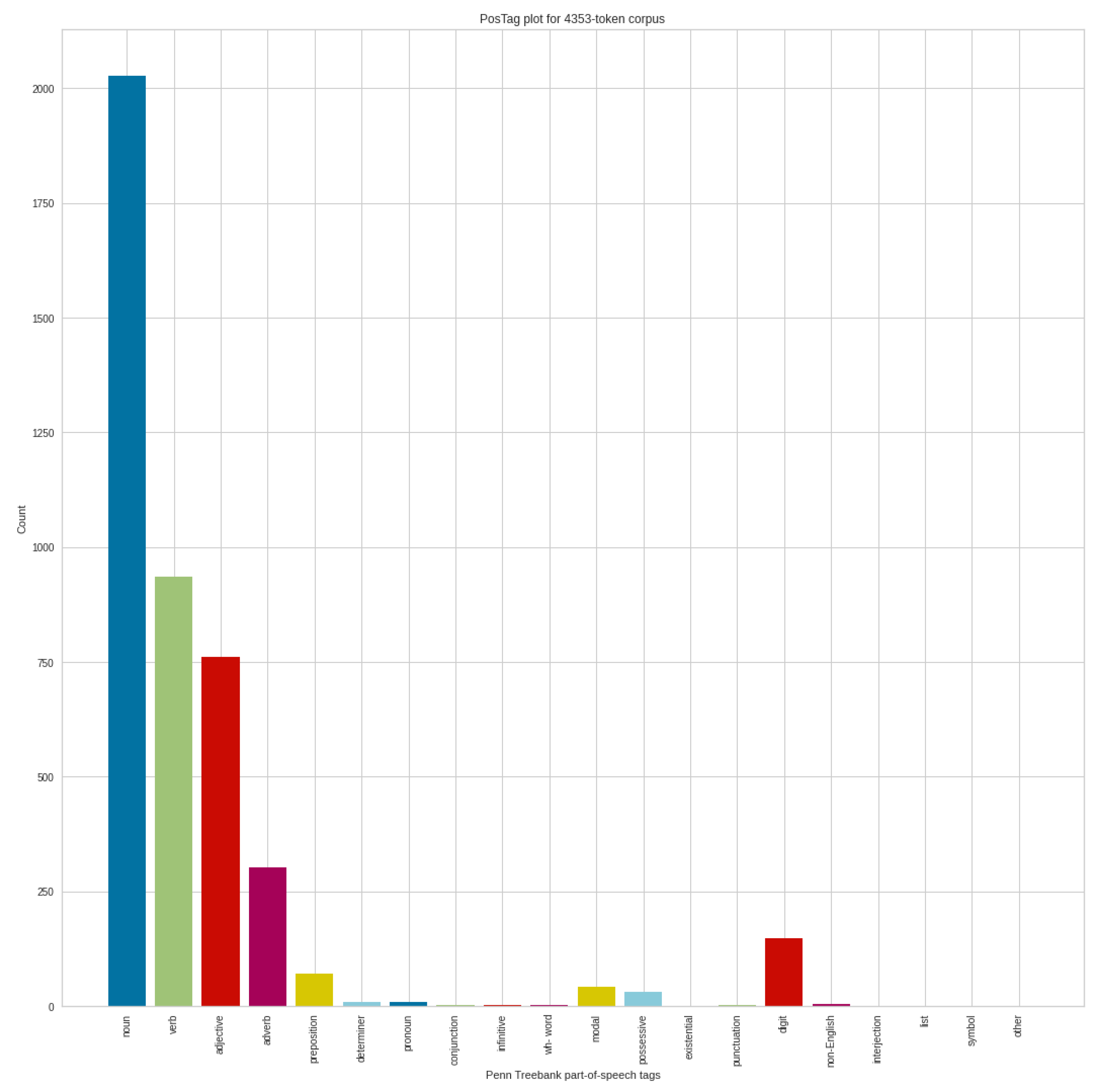
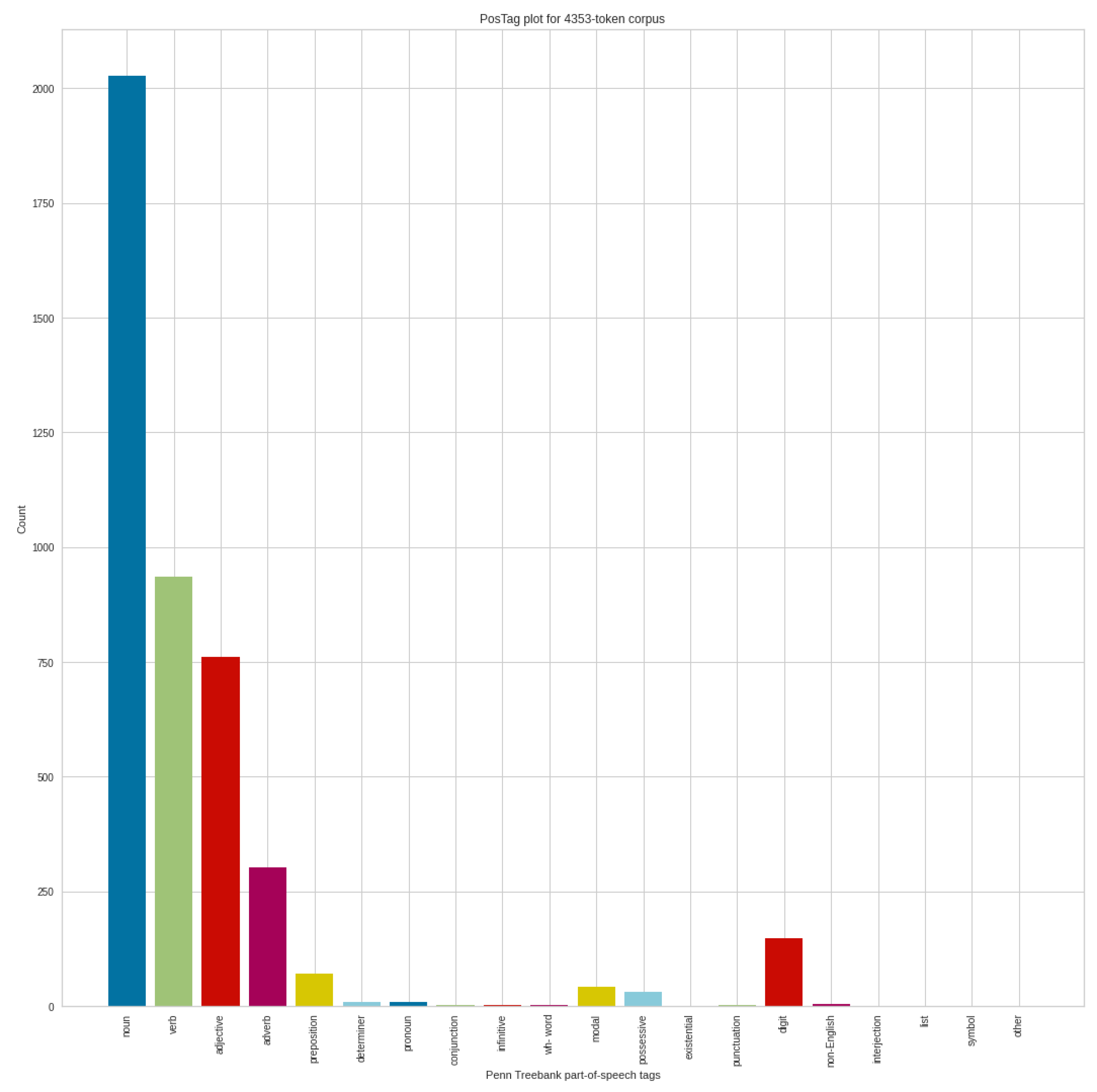
Figure 13 shows the POS analysis of the negative tweets in the September dataset, which includes 4353 token corpus. The structure of the analysis, of course, is similar to previous analyses, in the same way that the noun dominates, followed by verbs, adjectives and adverbs. If we compare the August negative POS results with the POS analysis results of the September negative tweets, we can see shifts. In addition to the increase in the number of nouns, the number of adjectives produced a more serious increase. In addition, minimal movements are noticeable in the other POS categories as well.
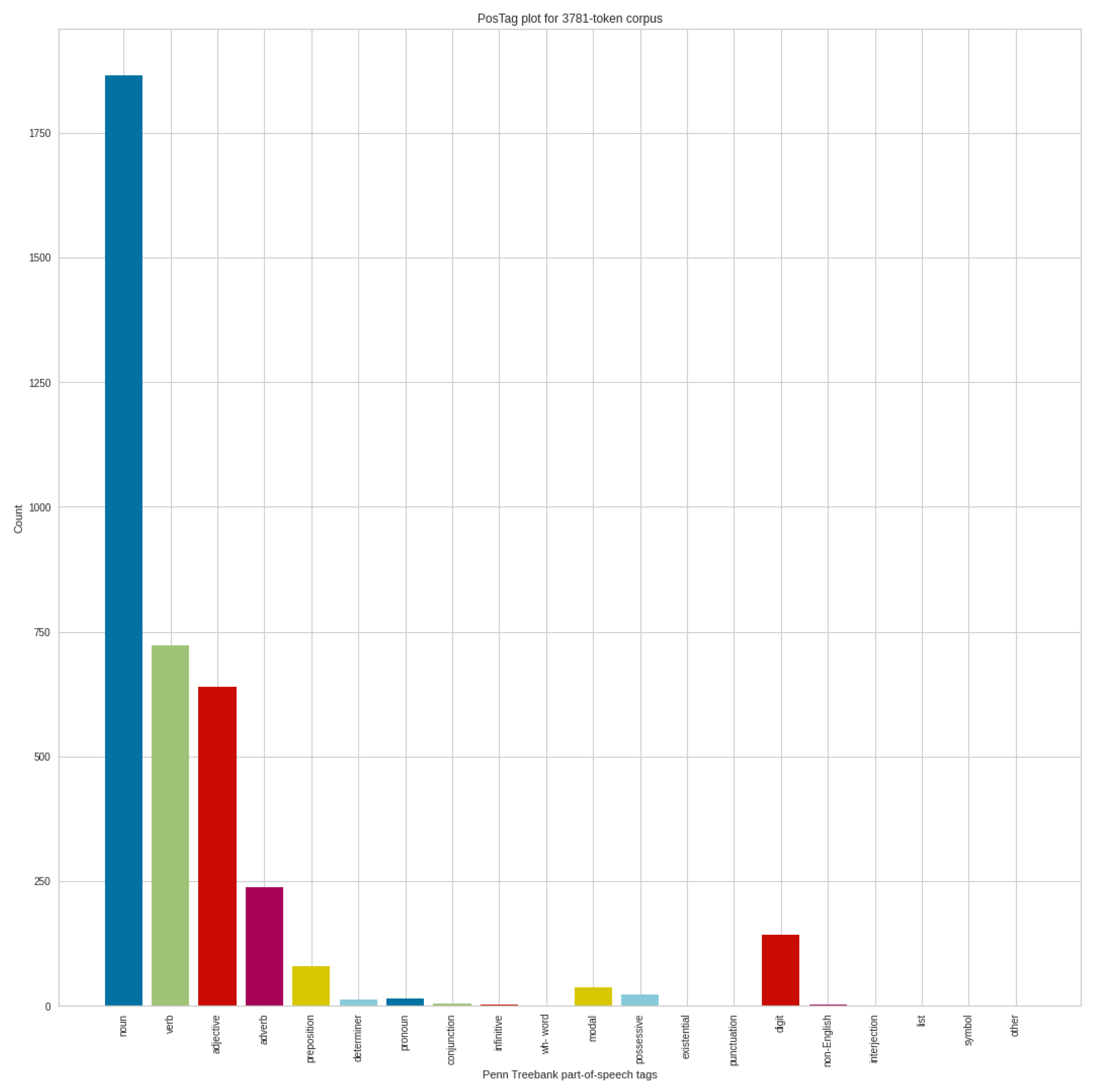
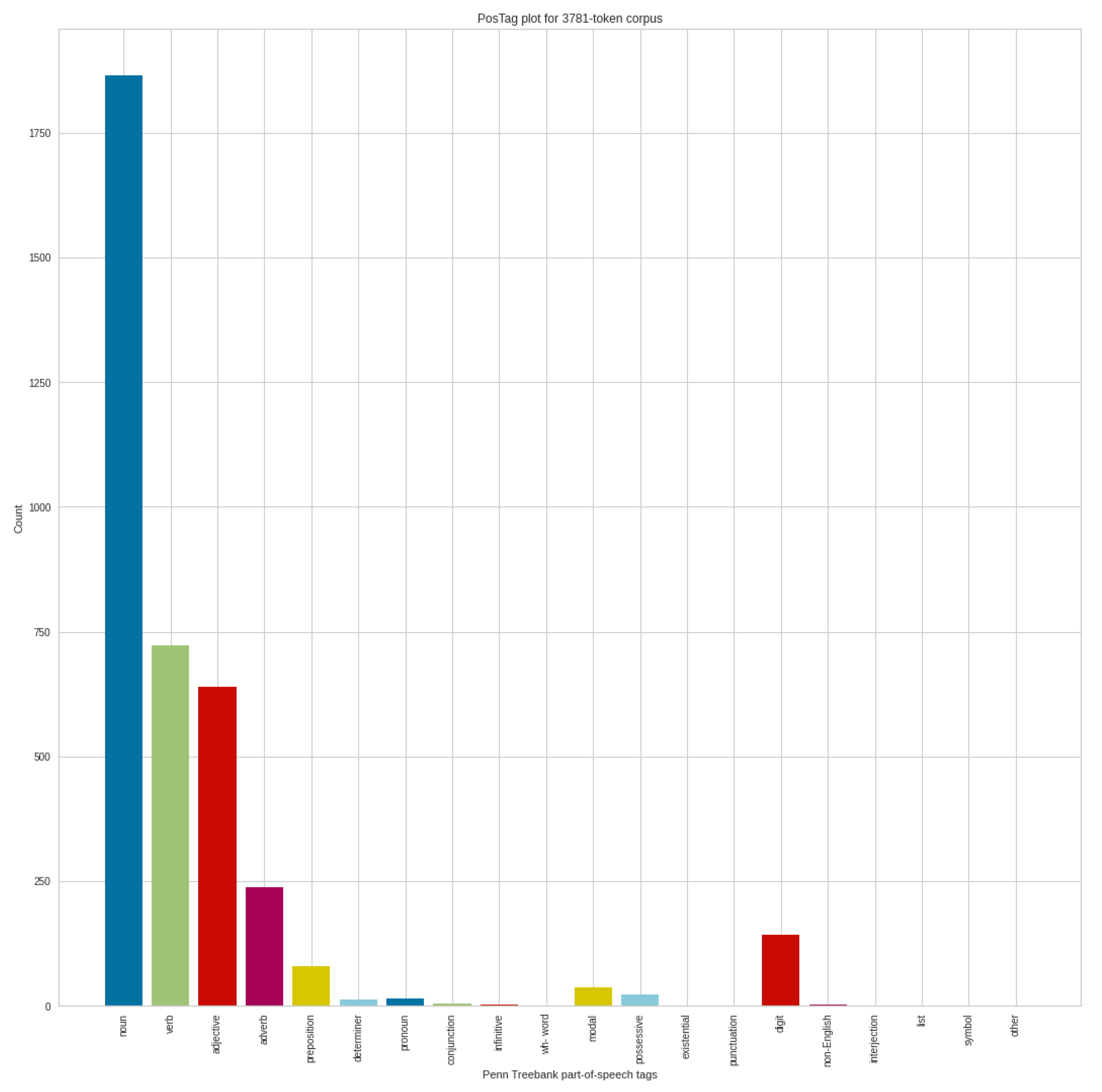
Figure 14 shows the POS analysis of the positive tweets in September, where 3781 token corpus were identified. Compared to the POS results of negative tweets, the order of the POS categories is the same. In addition to the decrease in the number of nouns, we can also see a significant decrease in the case of verbs, adjectives and adverbs. Of course, the smaller number from the tokenization process also plays a role in this, which is again a change or difference in the structure of tweets.
Comparing the positive POS results in August and the positive POS results in September, it can be seen that the number of tokens were similarly reduced compared to the results obtained in the negative cases. This already draws attention to significant differences in the words of the texts of negative and positive tweets. Comparing the POS categories for the positive tweets in August and September, we can see decreases again in verbs, and an increase in the number of nouns and adjectives.
Following the POS analyses, let’s look at the results of the dependency graph. (
Figure 15) In this case, a fairly long tweet has reached the most people directly, so here, we would like to illustrate that the method can be used for a large and aggregate sentence, or sentences. There are two links at the end of the tweet; this is covered in the figure.
With the help of part of speech and word analyses, which examine a deeper structure following the sentiment analysis, we already have a picture of the tweets, which were written during the given periods. What characterizes the negative and positive tweets, are what differences appear between positive and negative tweets in a given period. We could see what words occurred most often in the periods for both positive and negative tweets, and what differences appear in the tweets written on the same topic in the two periods. The POS analysis even showed the structure of the tweets, and how many differences there are between the texts of the positive and negative tweets, which occurred in the case of tokenization first, and the number of tokens in positive cases is significantly lower.
Based on the information extraction analyses and results, it may be worthwhile to include other disciplines, such as psychology or linguistics in future work, and expand the analyses purposefully.
In the next section, we explore the results with Named Entity Recognition to gain more detailed information.
6.4. Named Entity Recognition Results
We continue to use the RNN results, continuing the analyses what we started in the information extraction section. Thus, the RNN results still aggregate to the positive and negative parts.
6.4.1. August
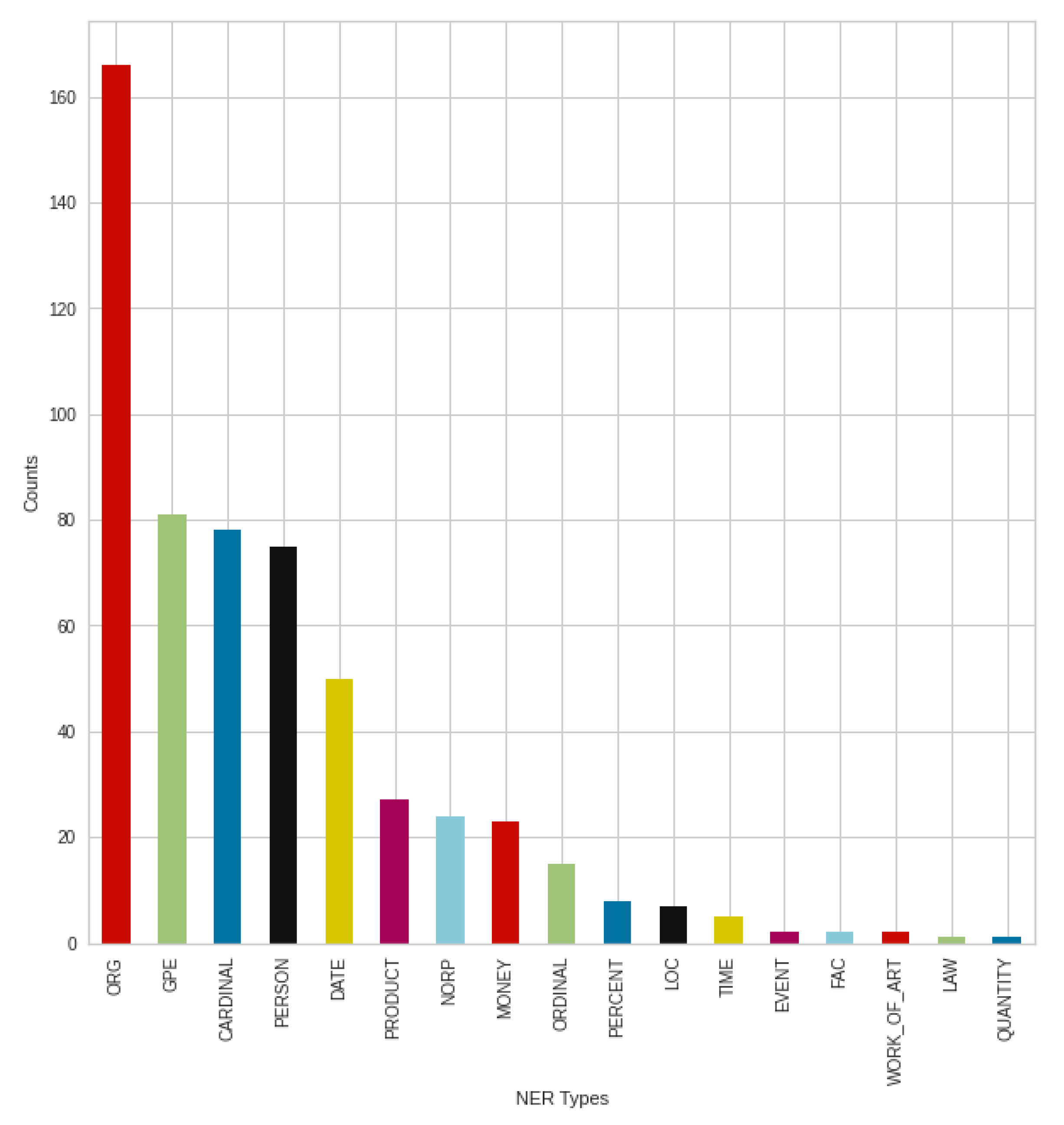
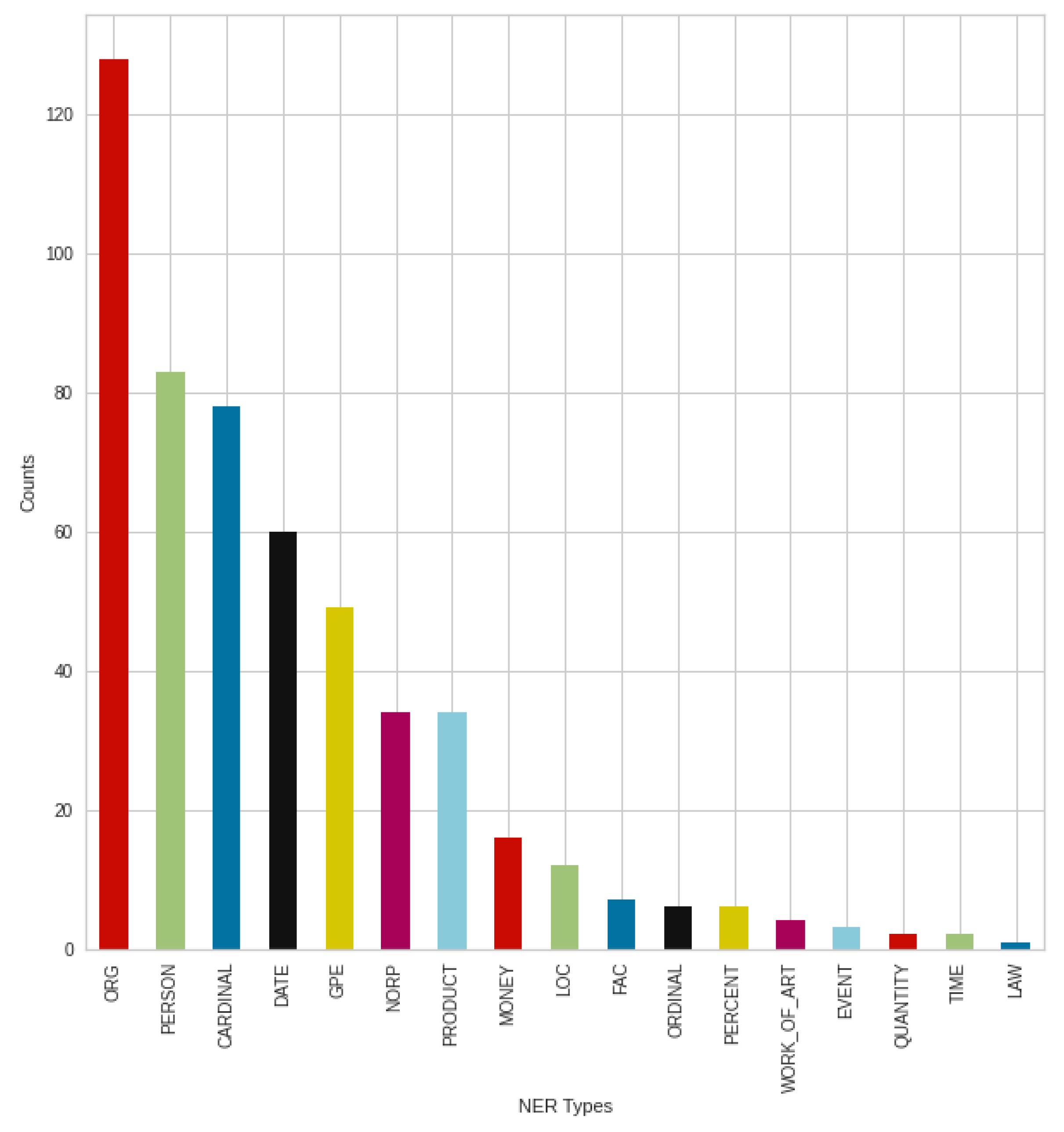
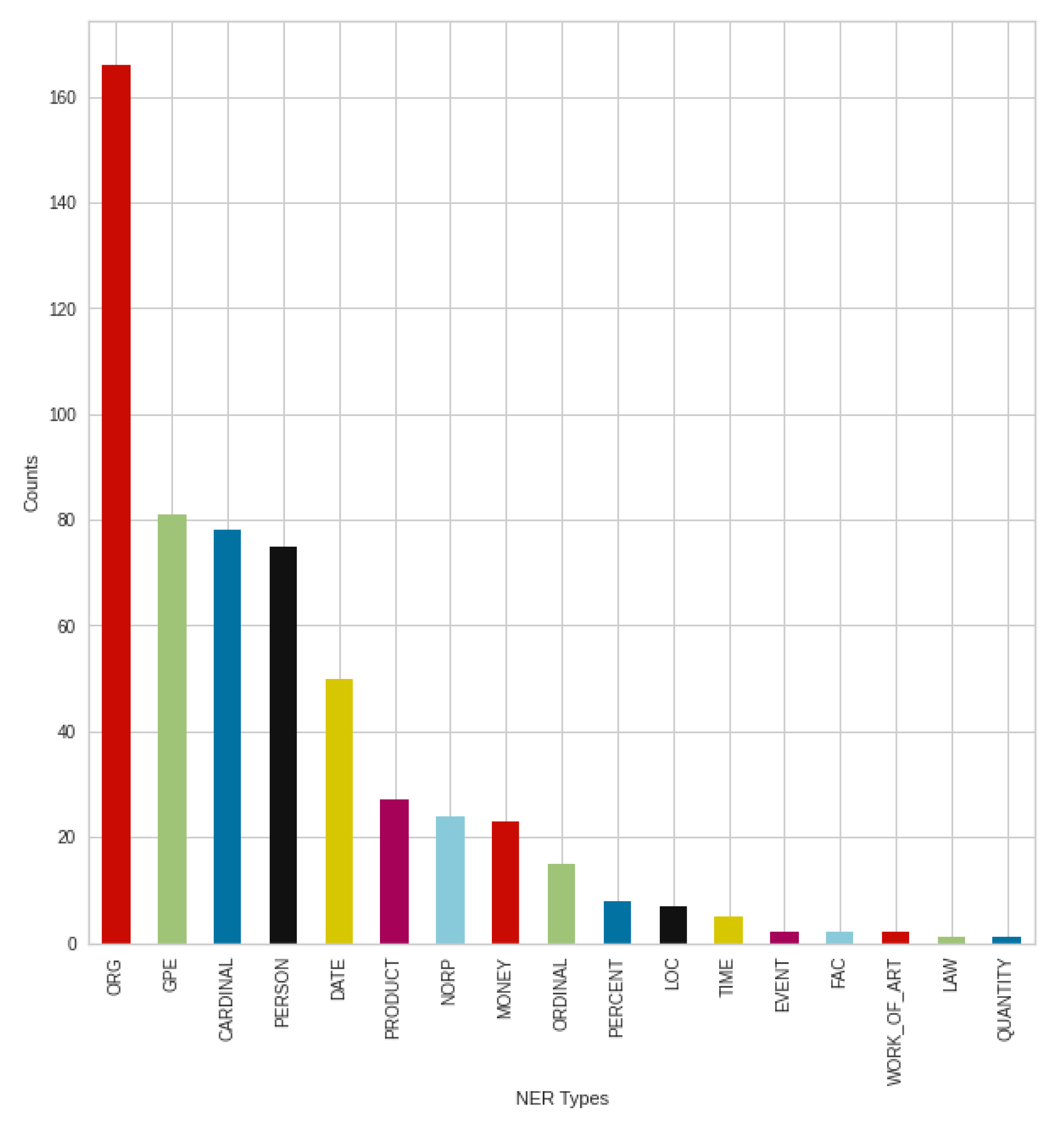
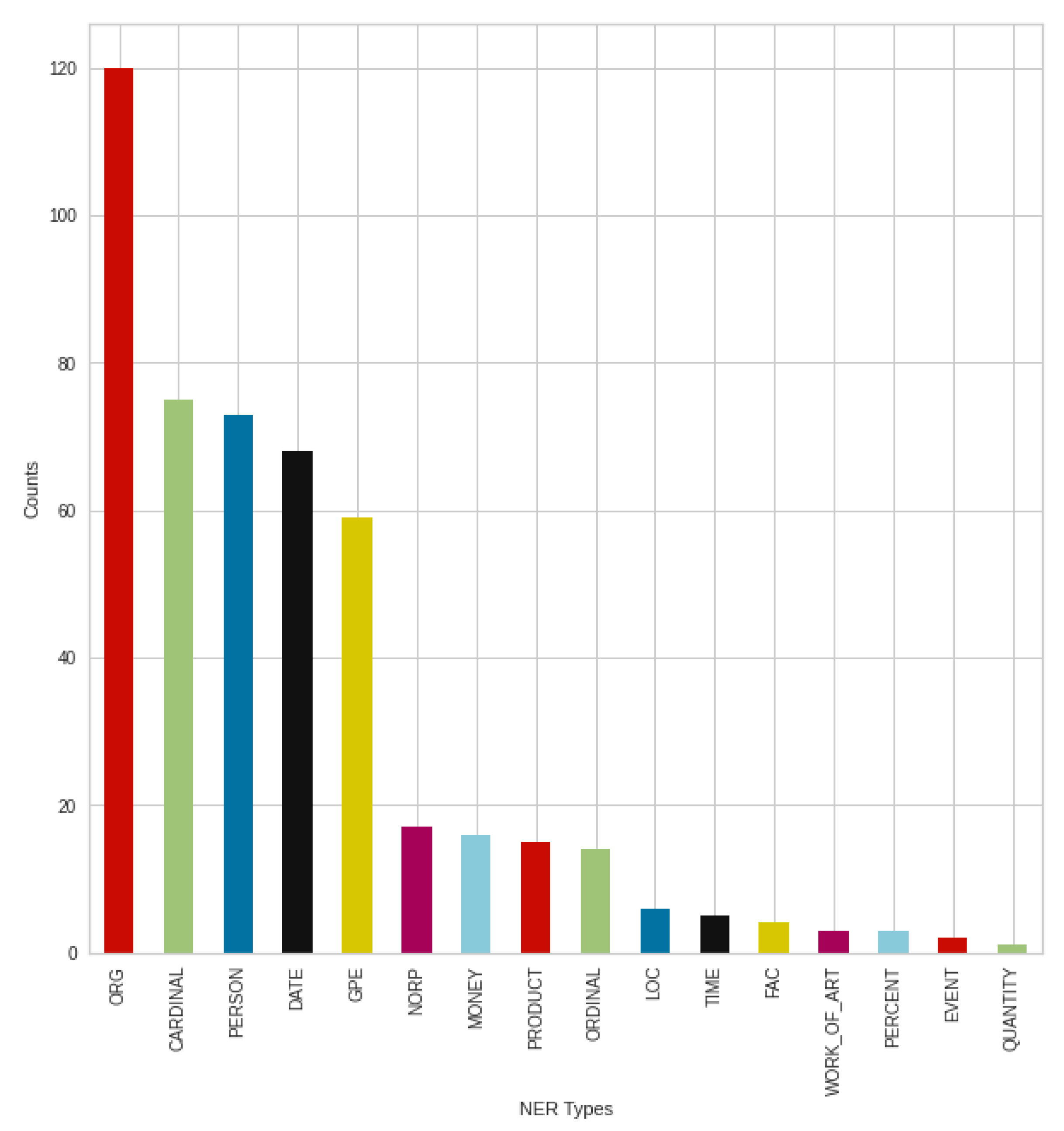
Figure 16 shows the negative tweets posted in August broken down into NER types, to see how these posts are structured, and what people mention primarily on the topic of COVID-19. In most cases, various organizations, agencies, and institutions were mentioned (‘ORG’). This is followed by countries, states, and cities (‘GPE’). In addition, numbers (’CARDINAL’—Numerals that do not fall under another type) and people/persons (‘PERSON’) followed these types before dates (‘DATE’). After different organizations, which is an outstanding result, the types that follow are very close results. Based on the results, money (‘MONEY’) and various products (‘PRODUCT’) were mentioned less at the time.
Figure 17 shows the breakdown of August positive tweets into NER types. In this case, the organizations, companies, institutions, etc. (‘ORG’) produced an outstanding result, just like in negative tweets. This is followed by a more significant rearrangement. Meanwhile, in the case of negative tweets, the type of countries, states, cities (‘GPE’) was the second strongest NER type; in positive cases, the numbers type (‘CARDINAL’) was the second strongest NER type, and the countries, states, cities were only the fifth, which is a significant difference. Furthermore, for positive tweets, the third strongest was the ‘PERSON’ type, followed by the dates (‘DATE’).
These results suggest that people are actively talking about news, events, sharing what they have read about the topic and arguing for their opinions, which they are also trying to support, to confirm their information.
6.4.2. September
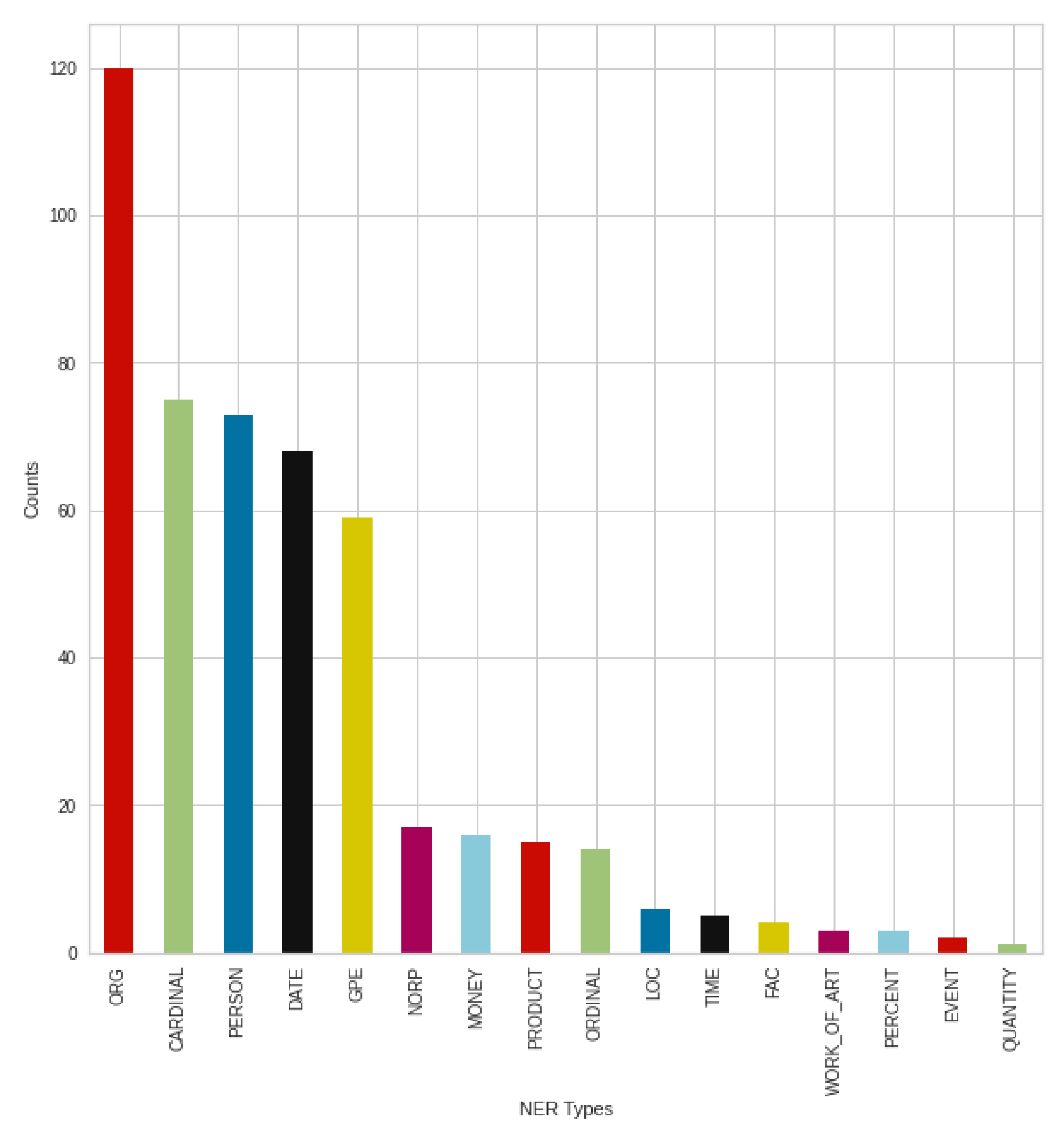
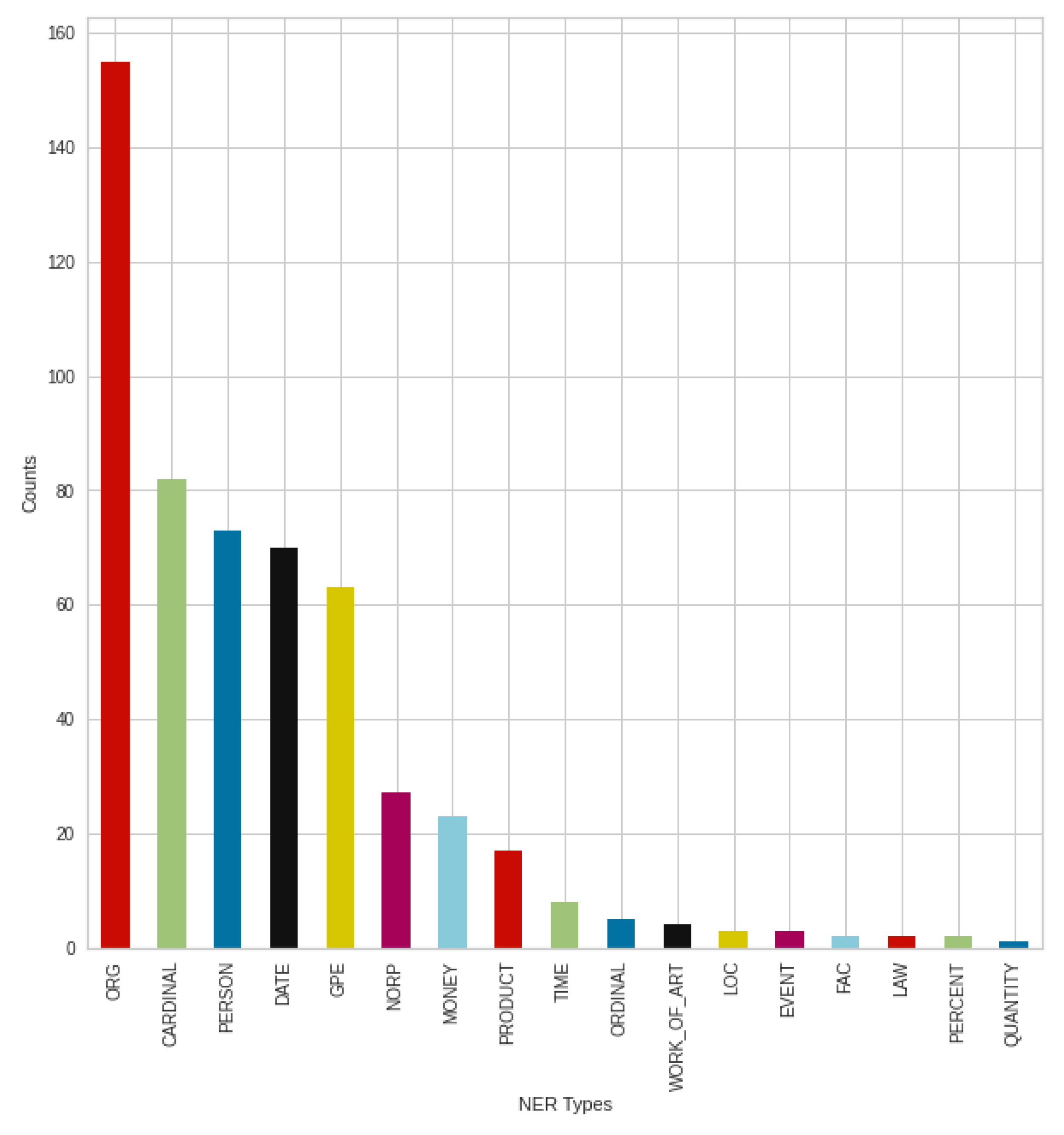
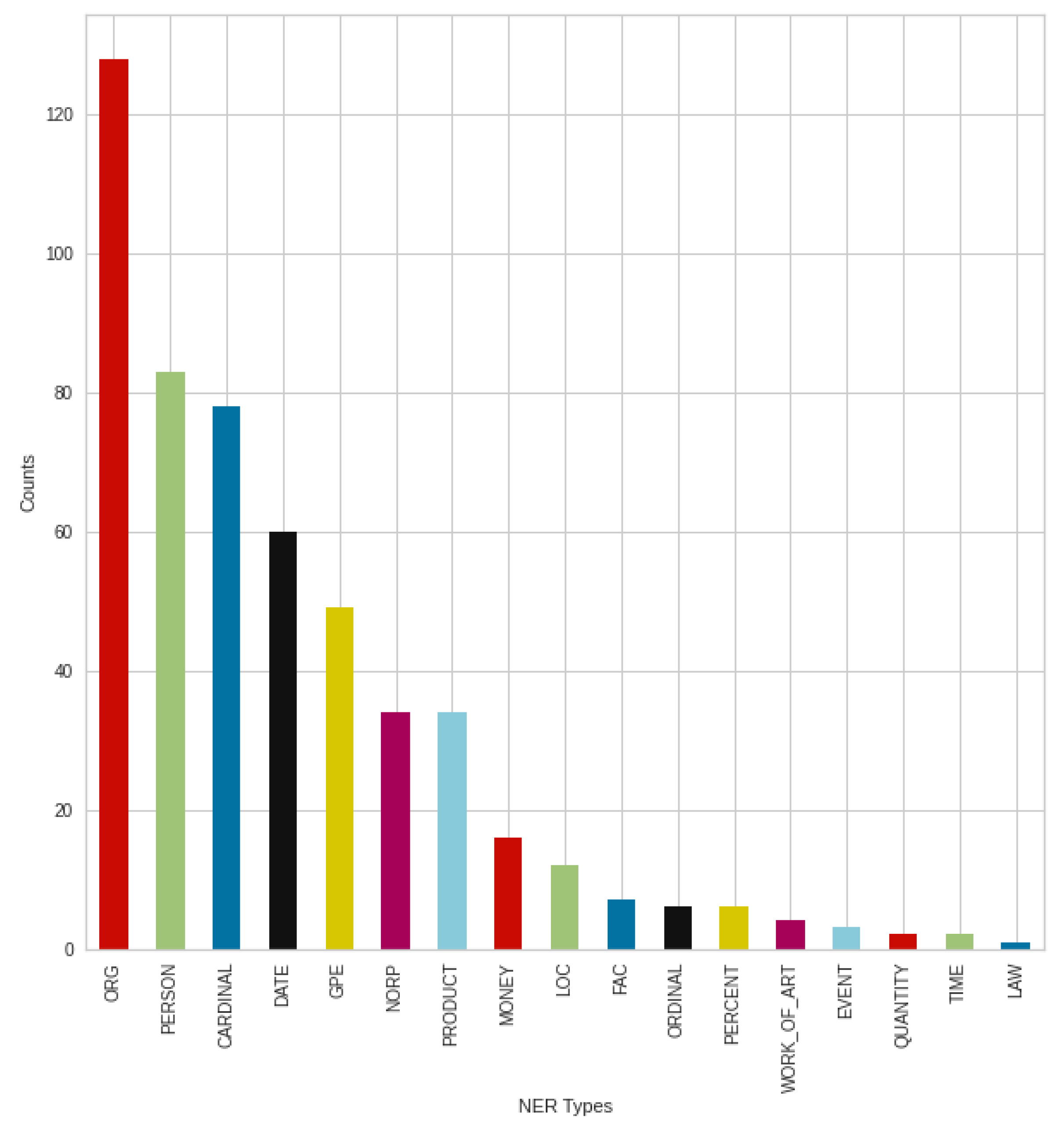
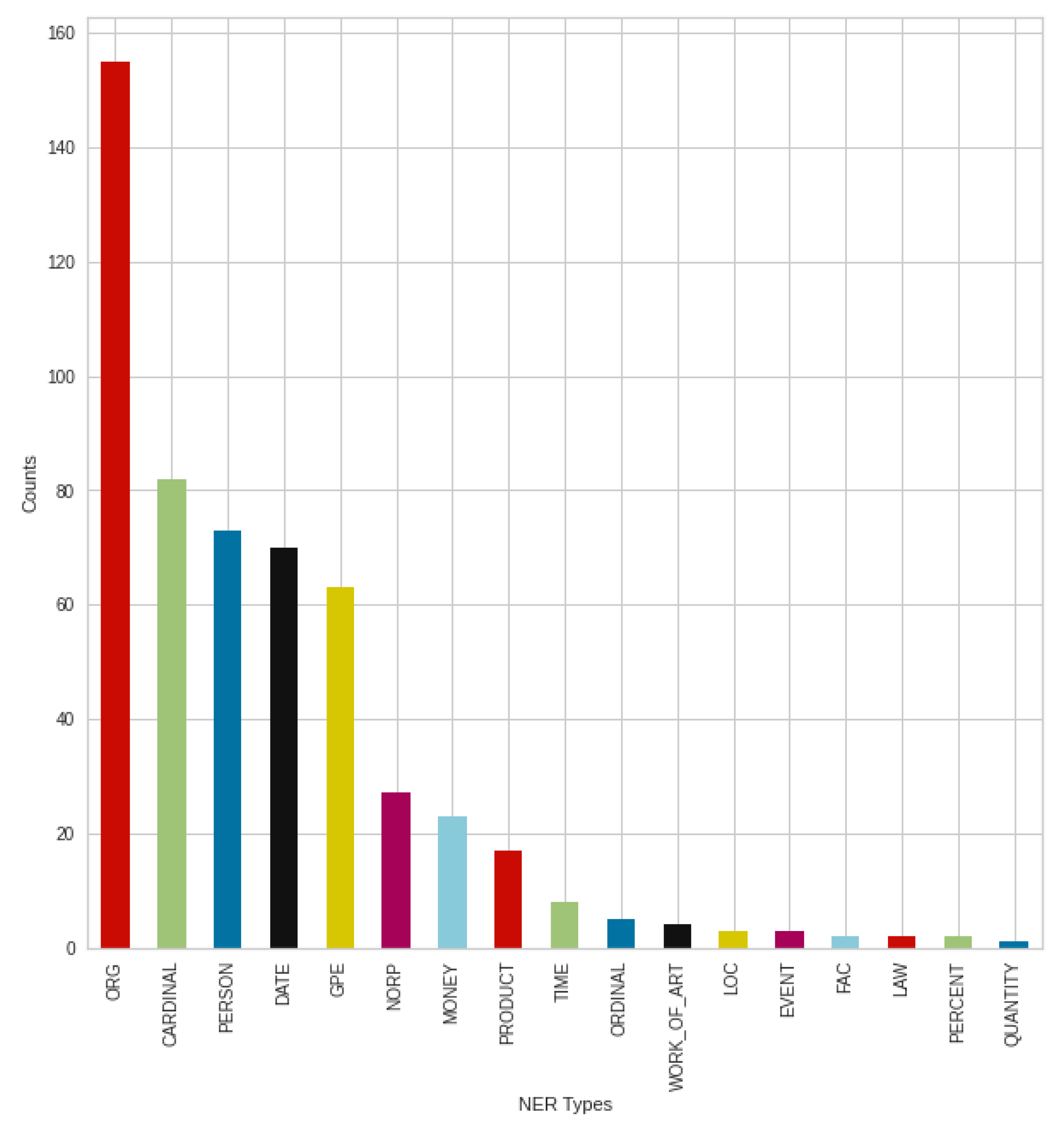
Figure 18 shows the result of the negative tweets posted in September, broken down into NER types, where once again an outstanding result from organizations, companies, institutions (‘ORG’) can be seen. This is followed by the types of persons (‘PERSON’) and numbers (‘CARDINAL’). Contrary to previous August results, there was an increase in the type of nationalities or religious or political groups (‘NORP’), similar to the type of products (‘PRODUCT’). However, the trend from August can still be seen, with minimal changes in the strongest types.
The breakdown into NER types of the positive tweets shown in
Figure 19. In the case of the formation of types, this is the same as the previous August trend, especially in the case of the strongest types. If we compare the negative and positive results in September, we can see a rearrangement in the case of the less mentioned types, and a setback of the nationalities or religious or political groups (‘NORP’) type. However, this is mainly the setback of products type (‘PRODUCT’) in the positive case, which can be highlighted.
6.4.3. NER Type ‘GPE’—Deep Analysis
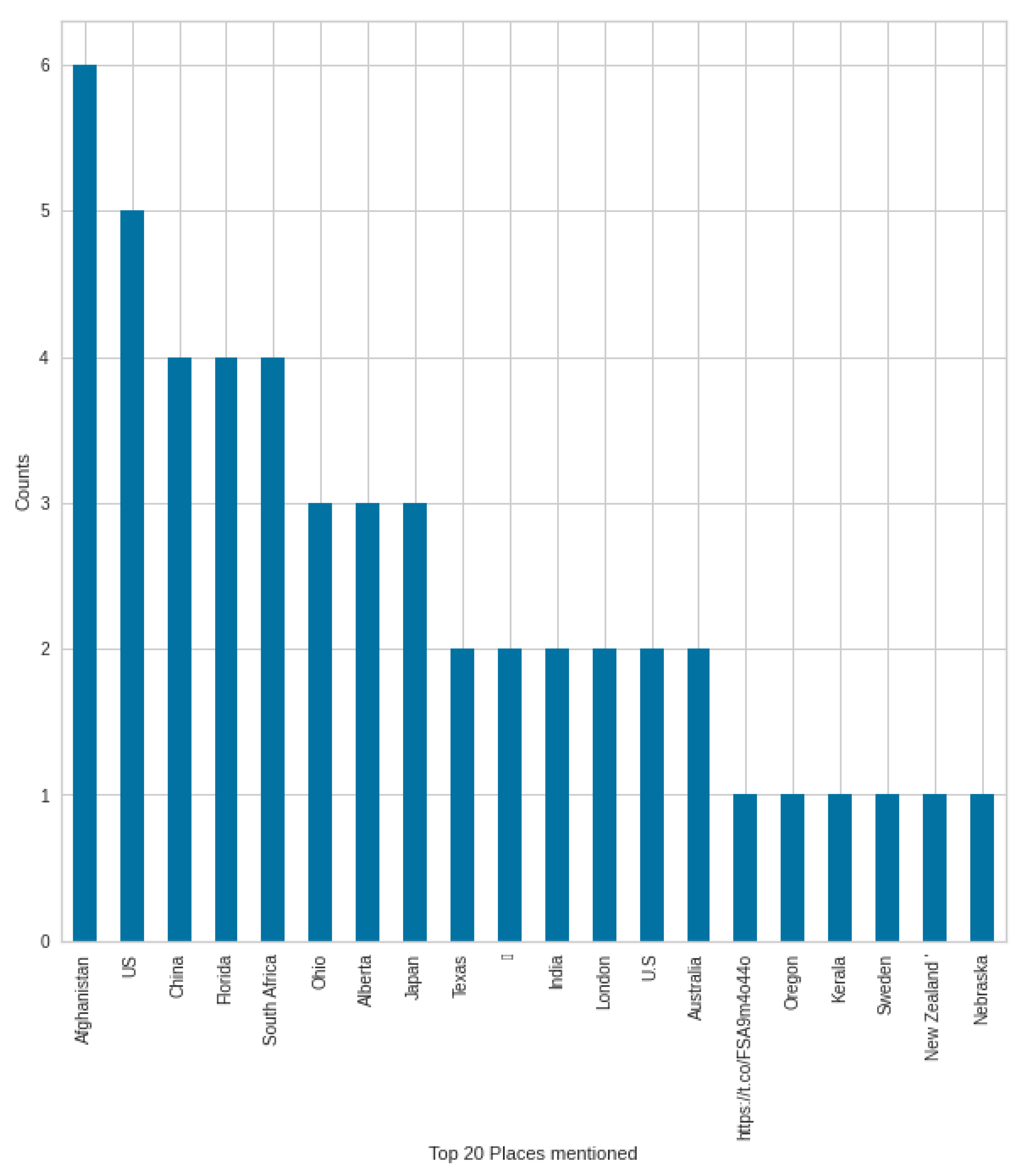
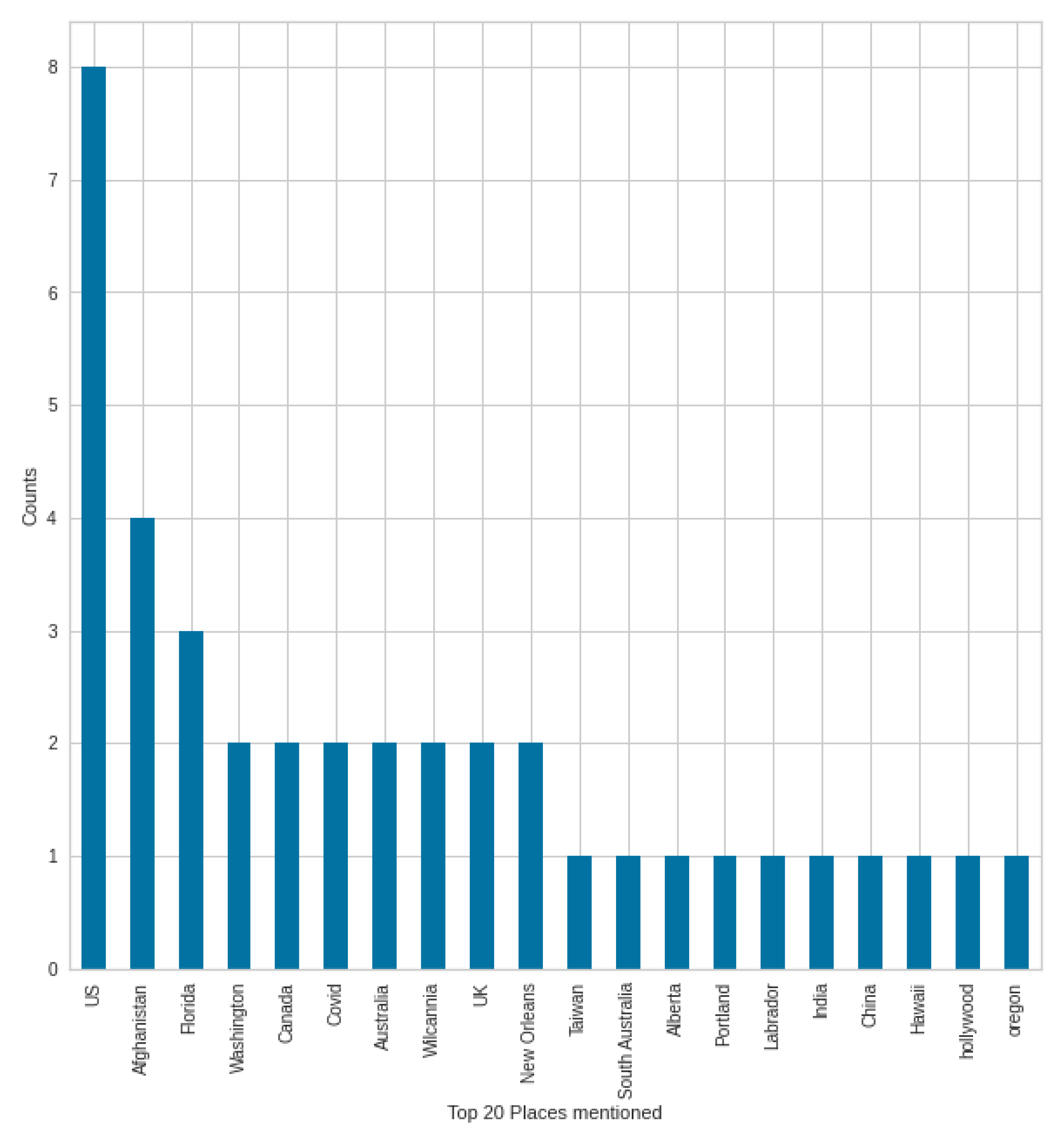
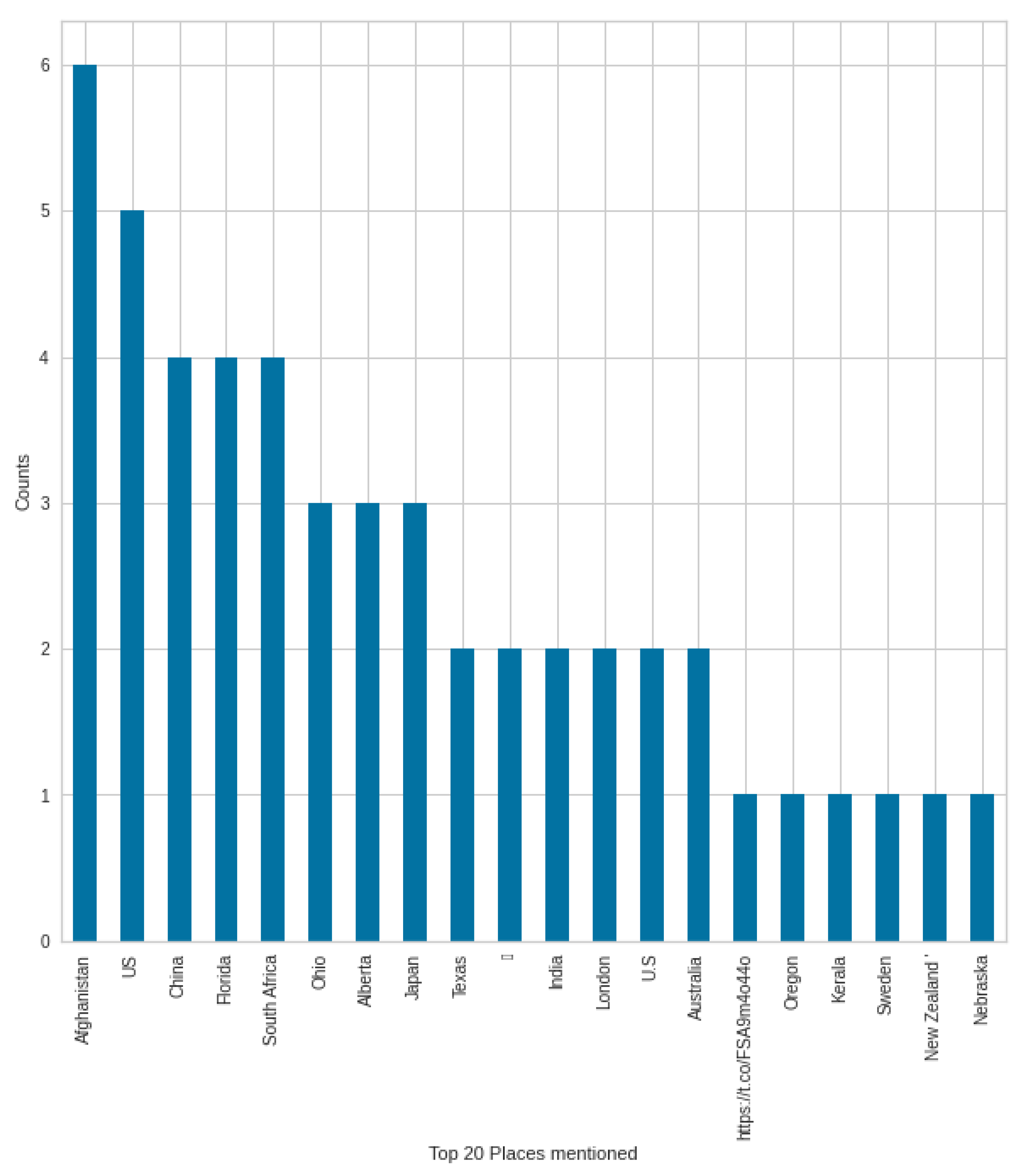
In the case of NER types, the elements of the GPE (countries, states, cities) type were mentioned the second most often in the case of negative tweets in August, which was only the fifth most often mentioned in the case of positive tweets. Therefore, we supplement the analysis with the words mentioned in the GPE type in August, in both negative and positive tweets, to see what might have resulted in this. It is possible to extend any type shown in the figure.
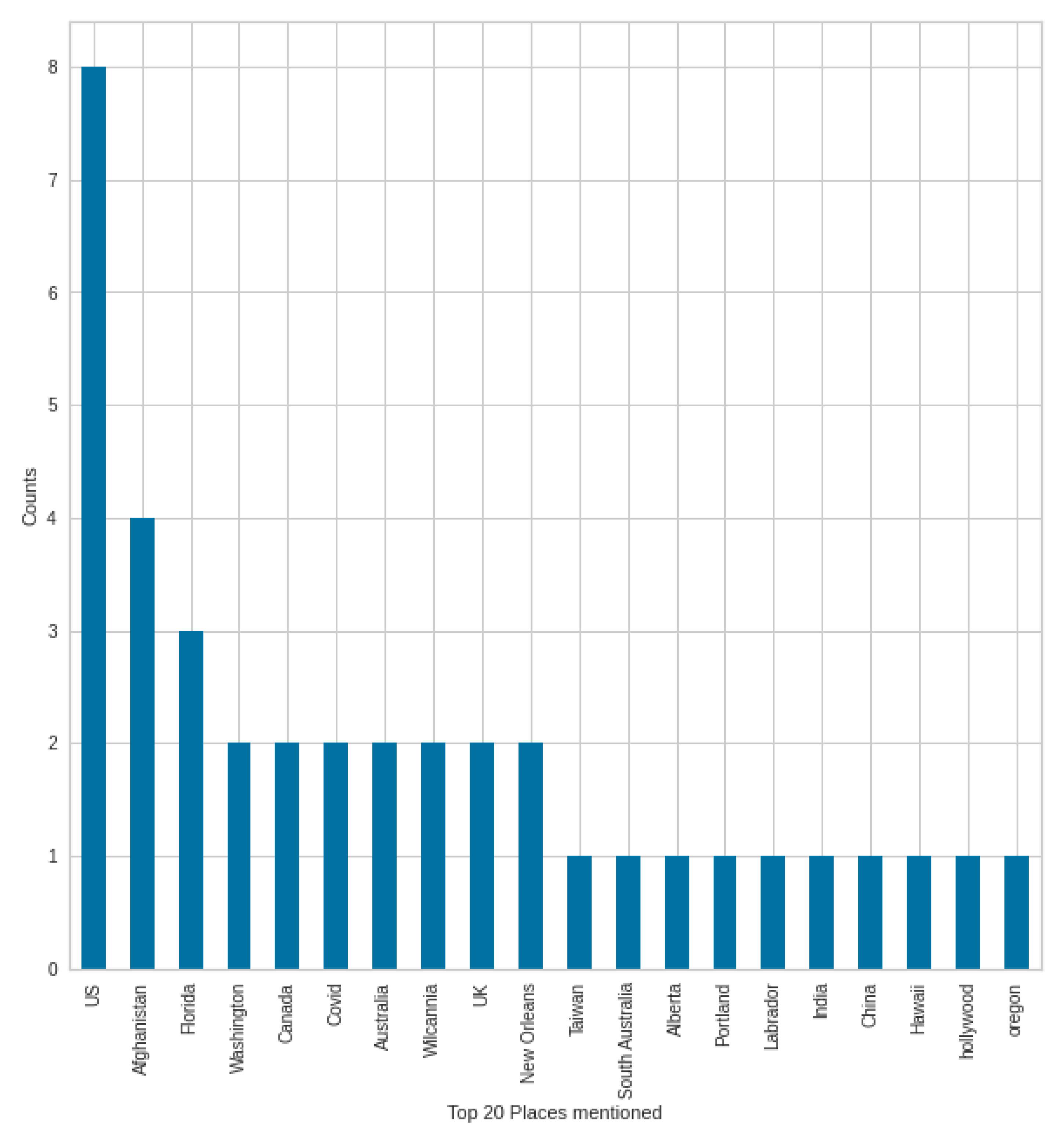
Figure 20 shows the top 20 GPE for negative tweets. In the other
Figure 21, we can see the GPEs mentioned in the case of positive tweets. In a negative case, the most mentioned country was Afghanistan, which may come as a surprise at first, but at the time, all media platforms were dealing with the Afghan withdrawal and the consequences, which also had an impact on COVID-19-themed tweets. Afghanistan was followed by the United States, China, and the state of Florida. In positive tweets, Afghanistan was the second after the United States; the third was Florida state. COVID-19 is different in countries and states, and this creates a different situation. Not surprisingly, these are mentioned in the tweets, and the unique situation is given by the situation in Afghanistan in this case—which was a unique situation at the end of the summer.
With further analyses, it was possible to explore explanations, details and information in addition to the sentiment analysis, which gives a much deeper picture of the real sentiment results of the given period, and what shaped these sentiment results.
7. Discussion and Conclusions
7.1. Conclusion
In this work, we used different models for sentiment analysis to determine how people relate to the topic of COVID-19 on social media, primarily Twitter. We have created several models: BERT, RNN, NLTK—VADER and TextBlob, to analyze “fresh” datasets. The primary goal was to work with the latest data for the period under study, so we always created the datasets according to a given limit number with the ’COVID’ keyword, and the given time period of the analyses.
The sentiment analysis was extended. In addition to the usual ‘positive’, ‘neutral’, and ‘negative’ categories, we extended that with ‘strongly positive and negative’ and ’weakly positive and negative’ categories, to detect smaller sentiment movements within the positive and negative categories when comparing the sentiment results of different time intervals.
BERT provided a comparison result for our other models, where the results of the RNN model were the most approximated to the results of BERT. Thus, we performed additional information extraction and named entity recognition analyses on the sentiment categorized and labeled results by RNN, to get a deeper picture of sentiment analysis. How people write/build their tweets, what is characteristic of their writing, what is the word usage of positive and negative tweets, what places, people and more were mentioned, as well as which events may affect their tweets. Thus, we obtained a detailed analytical result on how the result of the emotional analysis developed.
The sentiment outcomes of the late August and early September period that we examined and extended by information extraction and named entity recognition analyses, explained some of the sentiment changes between the two study periods, and examined and provided a detailed picture of tweets. These analyses also give a whole new picture to traditional sentiment analysis.
7.2. Future Work
As future work, very interesting and valuable results could be achieved by involving additional disciplines such as linguistics or psychology, and expanding the research with further targeted analyses.
By introducing new classifications, analyses, and keeping the current analyses up to date, a new extended sentiment analysis library or wrapper could be created. This could extend and simplify sentiment analysis using multiple models, and it could also provide additional analyses to interpret and manage the data. This can even provide specialized analyses for different areas as well.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}