
Forecasting the Bearing Capacity of the Driven Piles Using Advanced Machine-Learning Techniques

 ,
,  ,
, 
Abstract
:1. Introduction
2. Materials and Methods
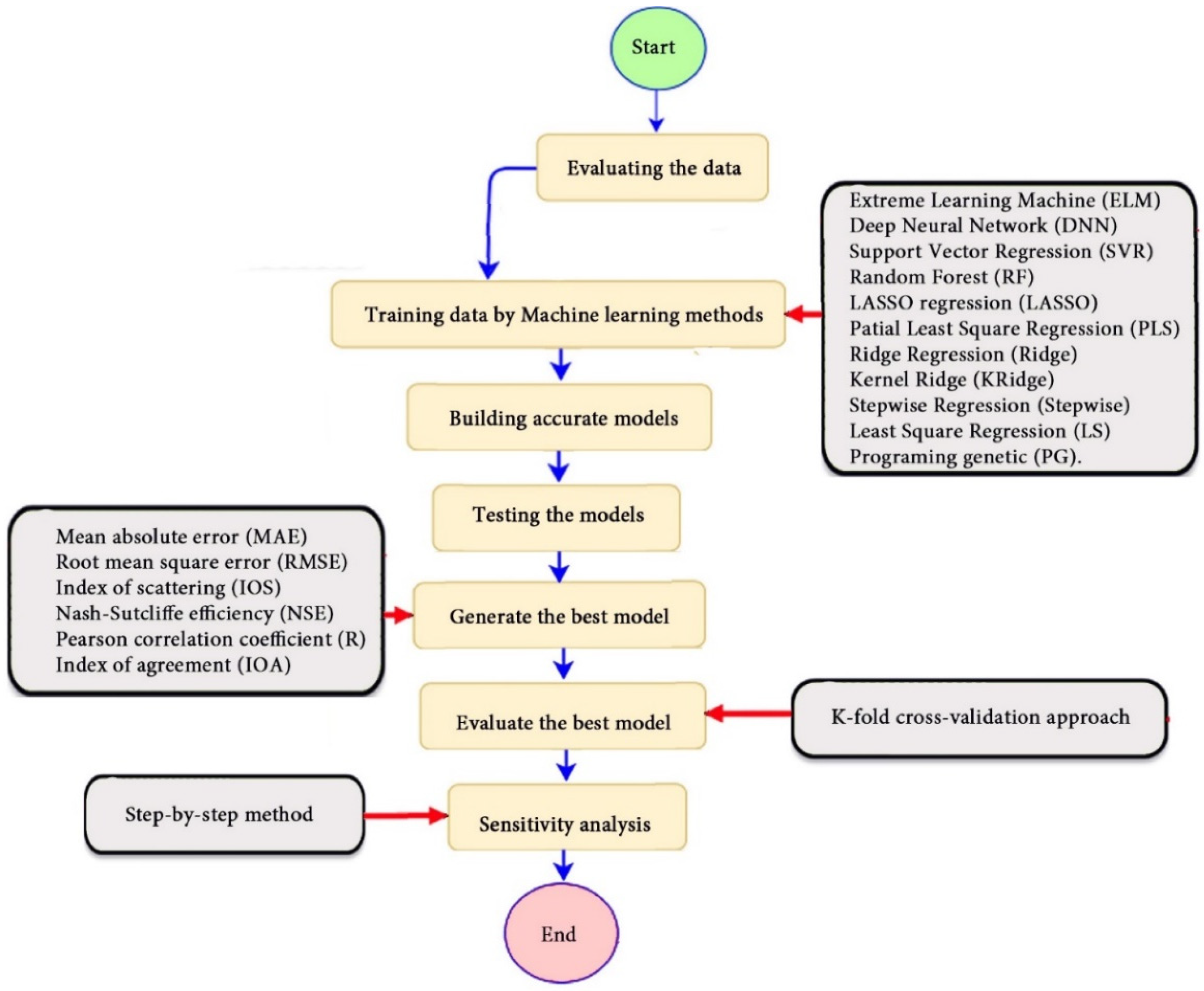
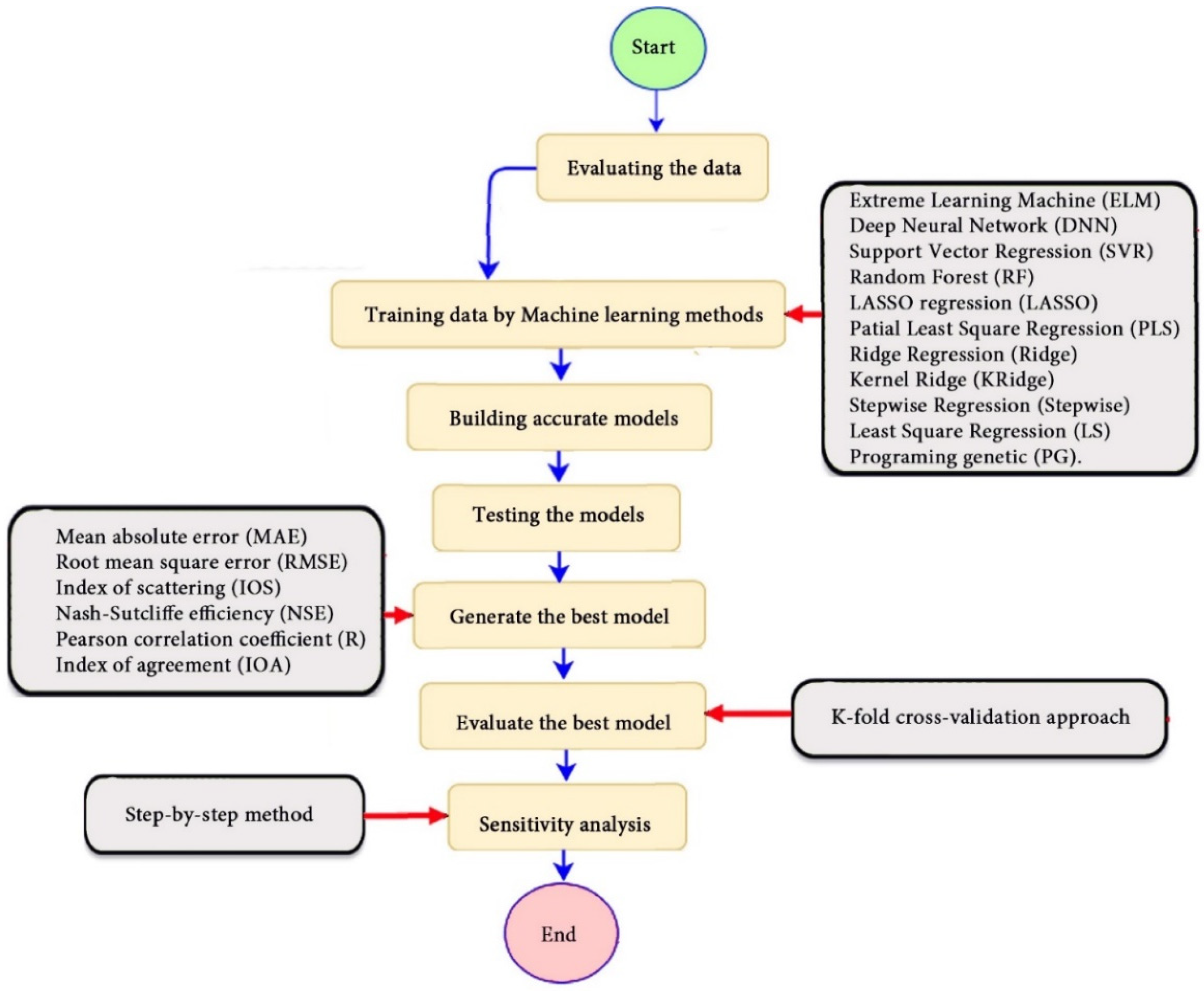
2.1. Overview of the Methodology
2.2. Database
2.3. Machine-Learning Methods
2.4. Statistical Performance Indicators
- Mean absolute error (MAE):
- 2.
- Root mean square error (RMSE):
- 3.
- Index of scattering (IOS):
- 4.
- Coefficient of determination (R2):
- 5.
- Pearson correlation coefficient (R):
- 6.
- Index of agreement (IOA):
2.5. Methodology
- Creating a geotechnical database, collected from different countries such as Iran, Mexico, and India. In this step, 100 static load-bearing tests on the UBC of steel- and concrete-driven piles were collected as datasets.
- Modeling the chosen inputs by means of numerous machine-learning methods. The ELM, DNN, SVR, RF, LASSO, PLS, Ridge, K Ridge, Stepwise, and GP methods have been employed in this step for suggesting 11 models.
- Defining the optimal model for estimating the pile-bearing capacity value using important statistical performance indicators such as MAE, RMSE, IOS, R2, R, and IOA.
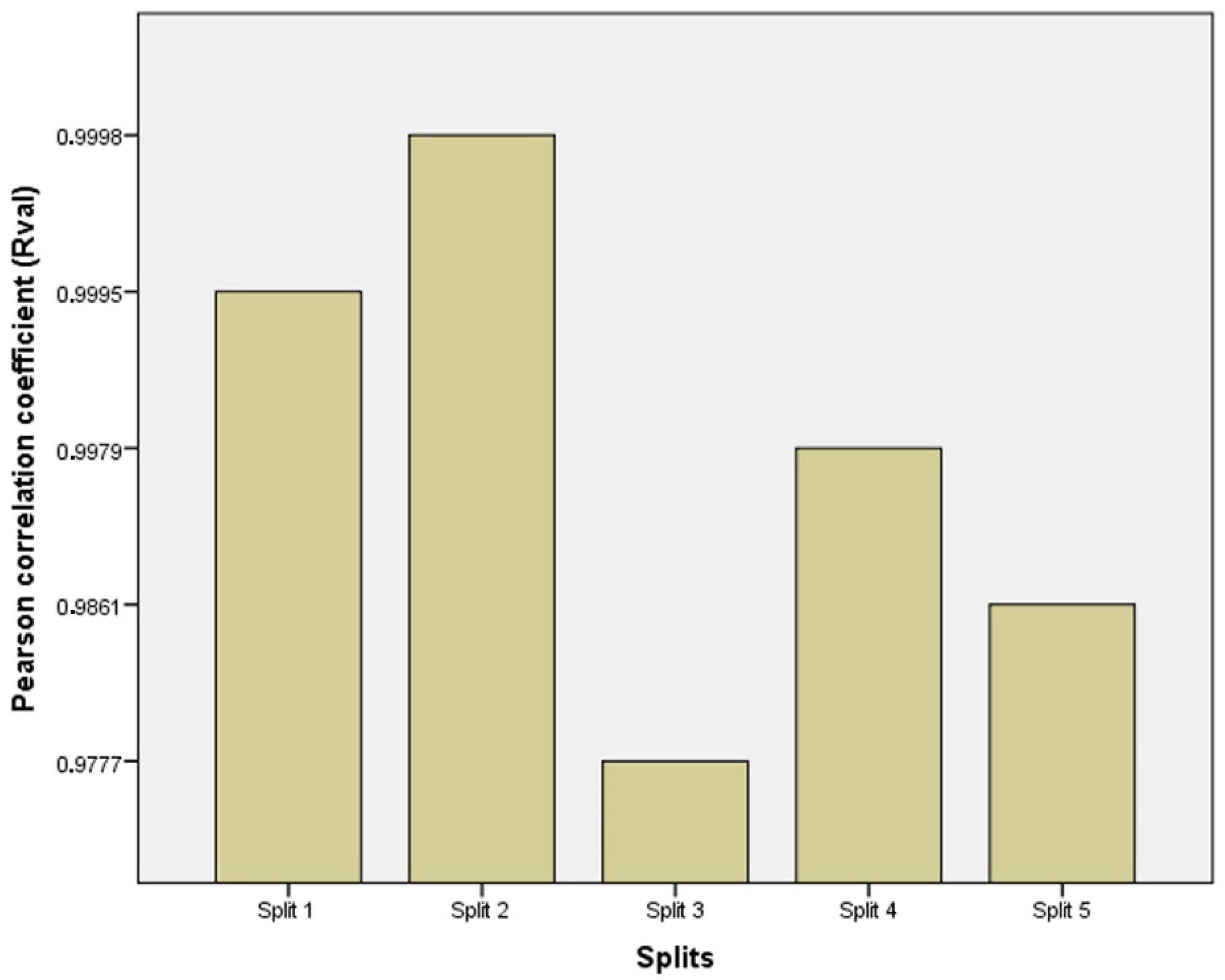
- Evaluating the predictive capability of the optimal model to overcome under-fitting and over-fitting problems by utilizing the K-fold cross-validation approach with K = 5.
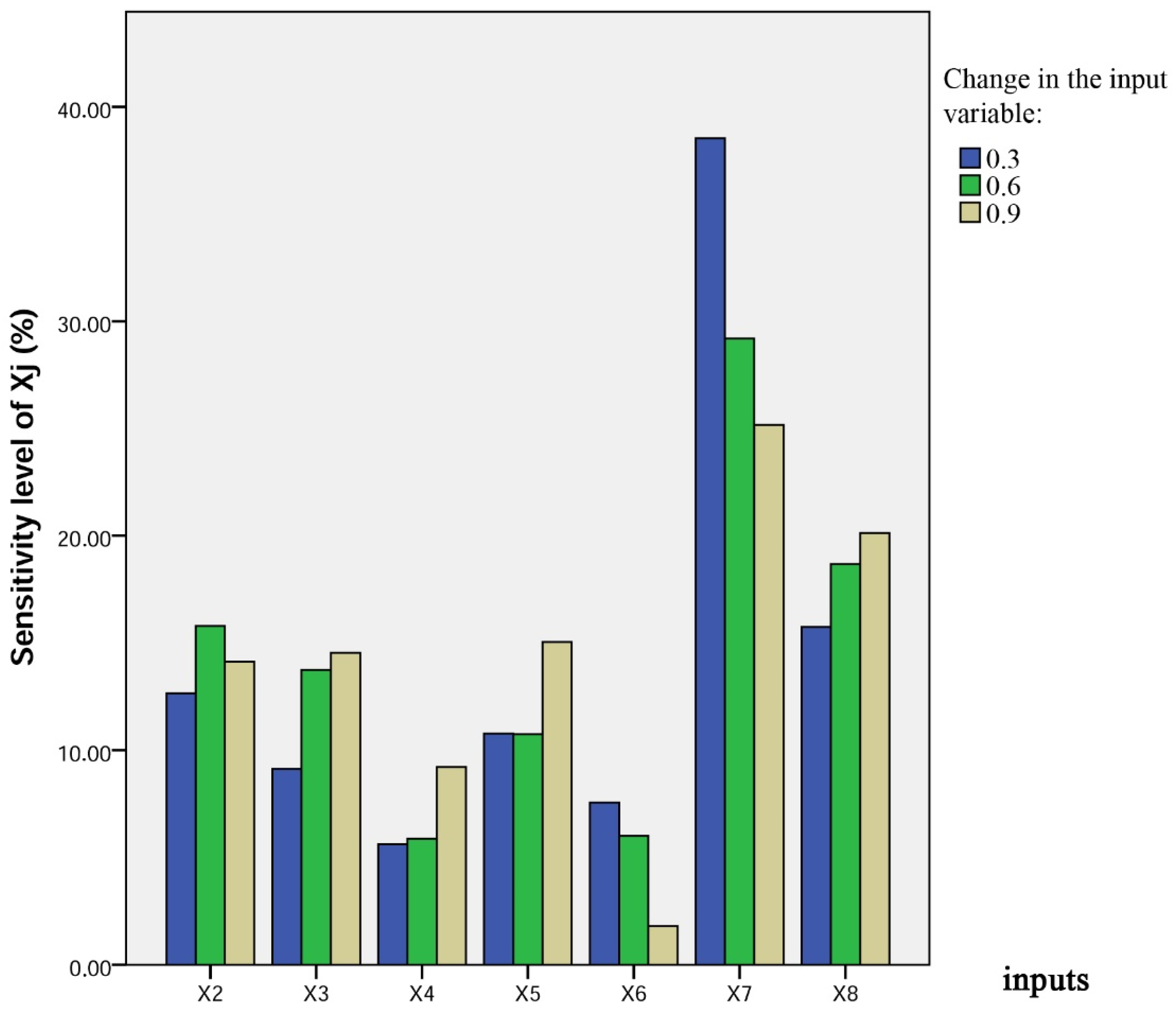
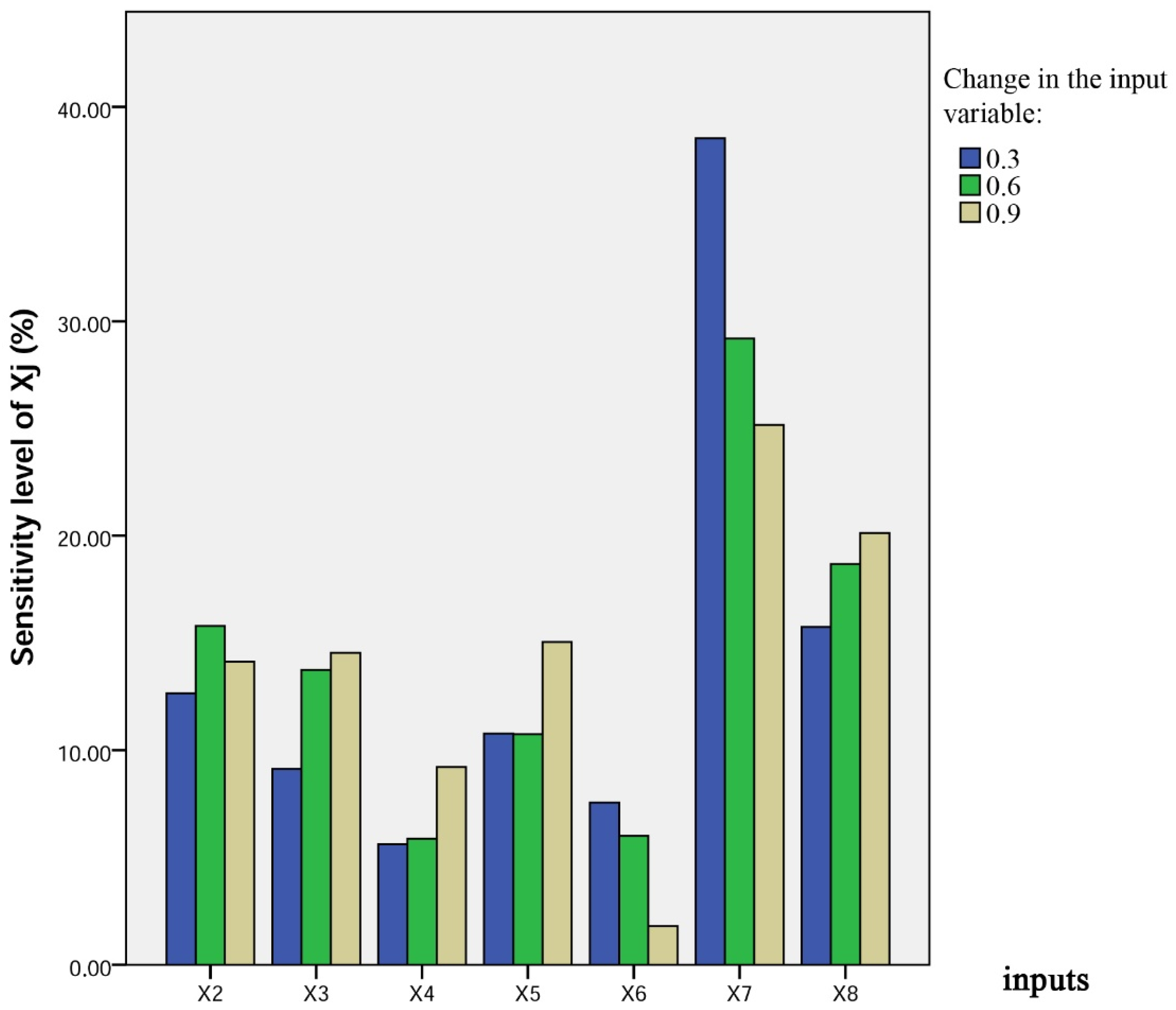
- Performing a sensitivity analysis by using the step-by-step method to define the most or least influential input on the bearing capacity via the proposed model.
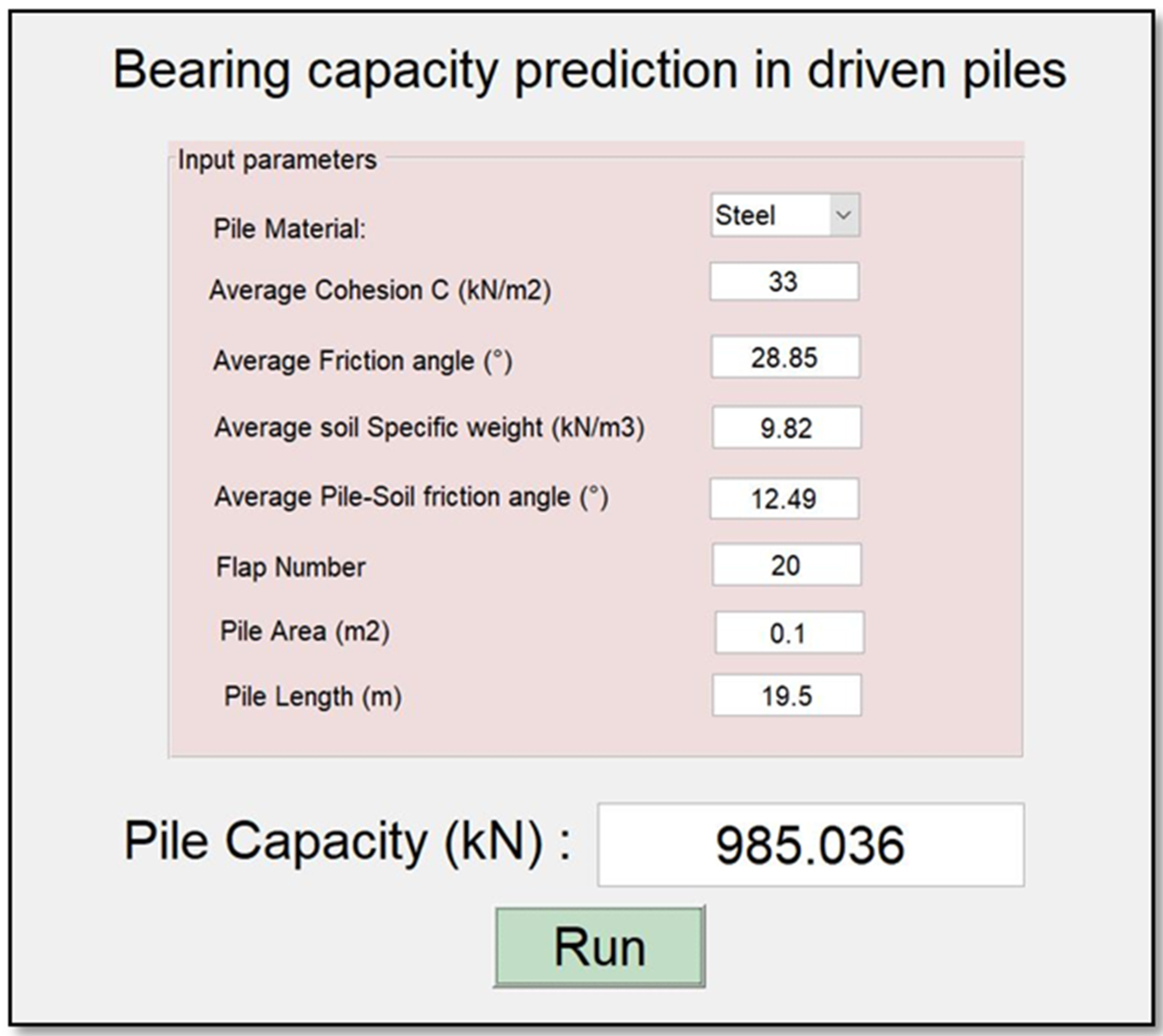
- Designing a reliable, easy-to-use, and graphical interface based on our optimal model.
3. Results
3.1. Database Compilation
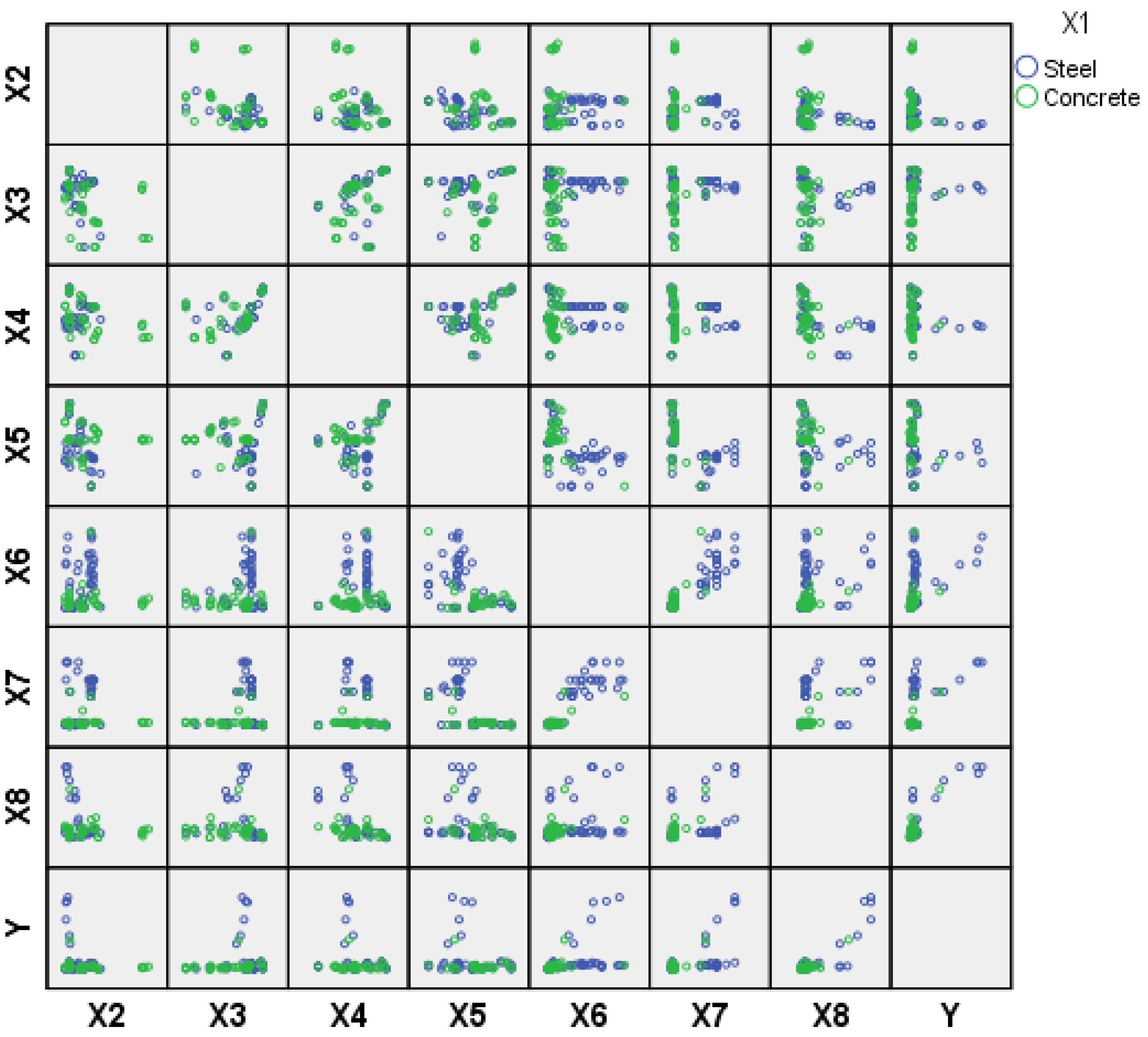
3.2. Correlation between Bearing Capacity and Input Parameters
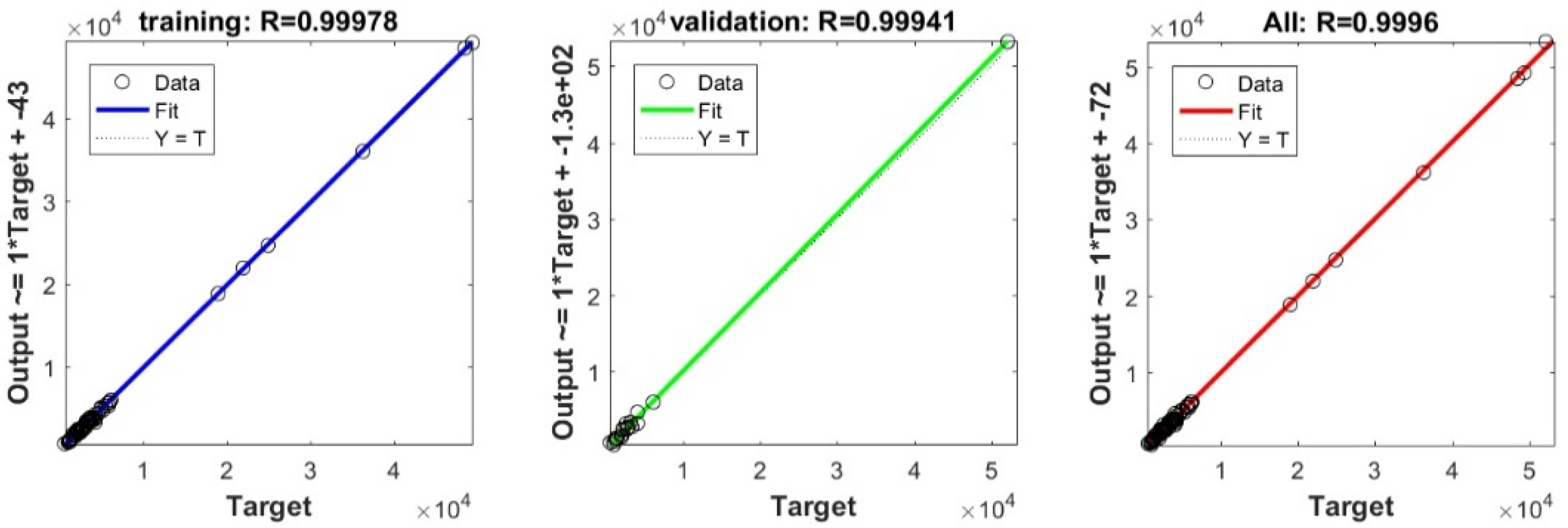
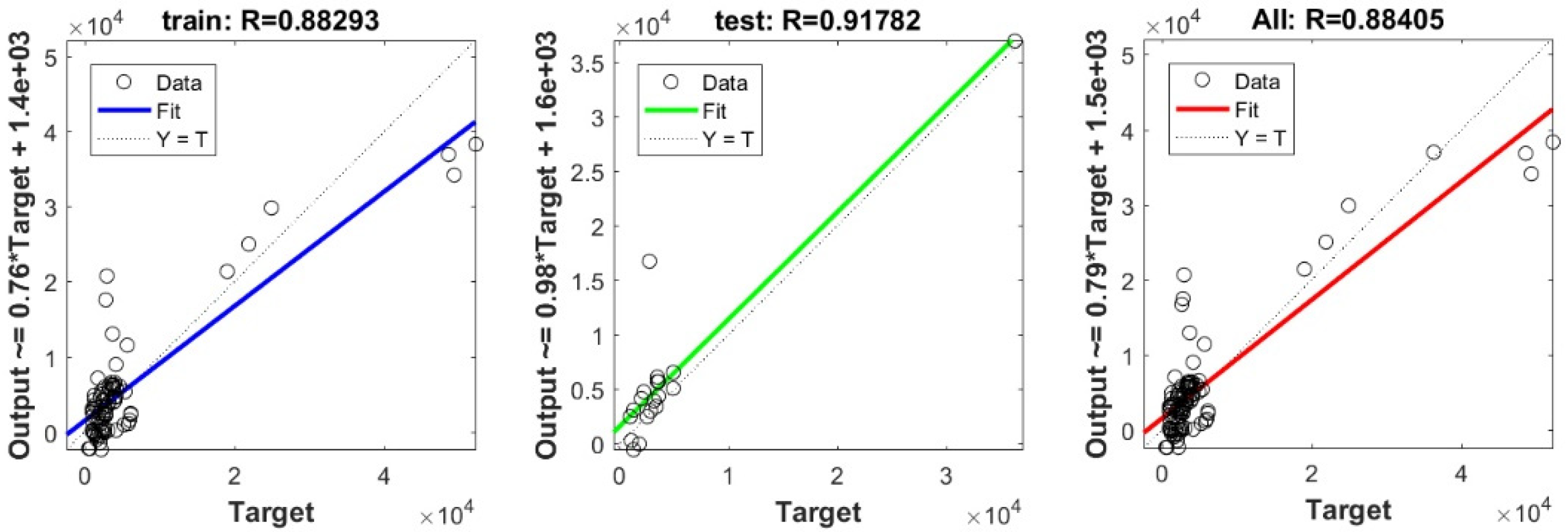
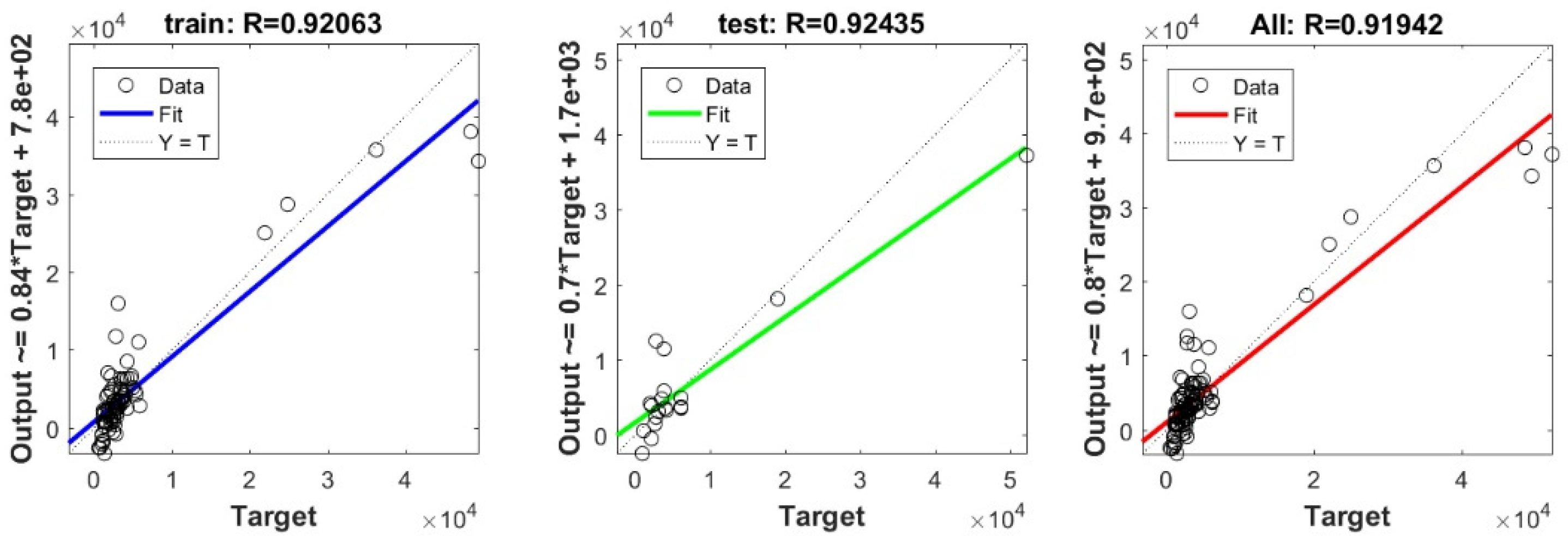
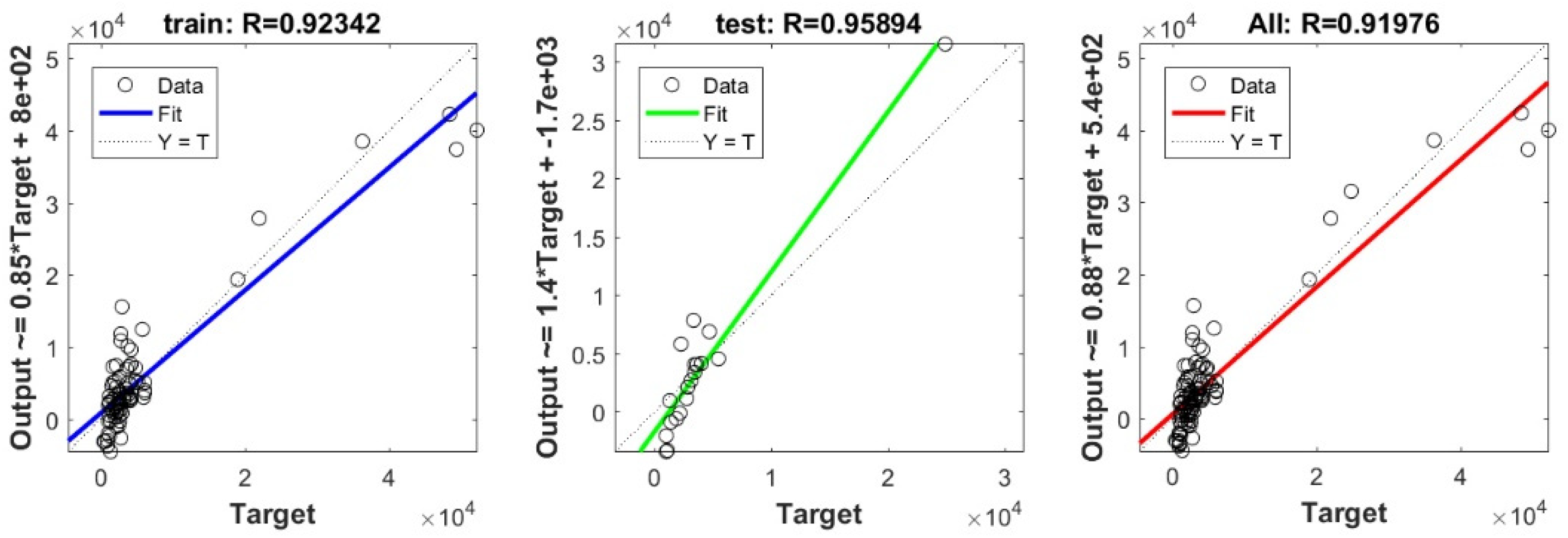
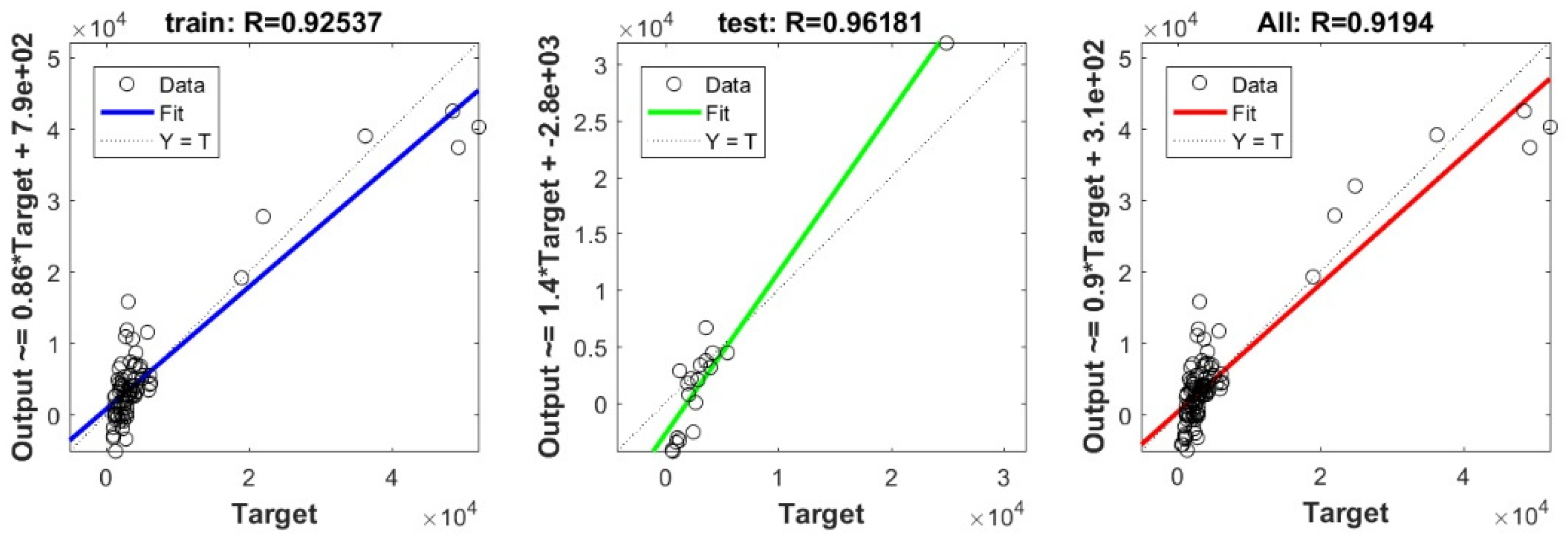
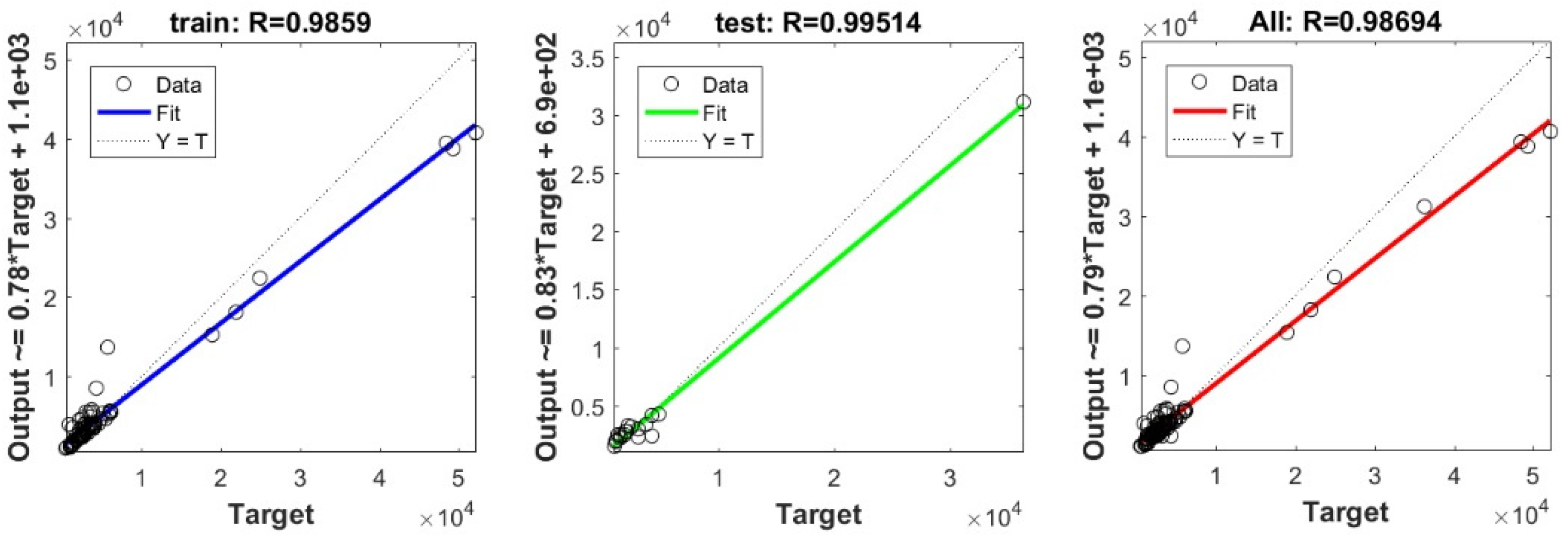
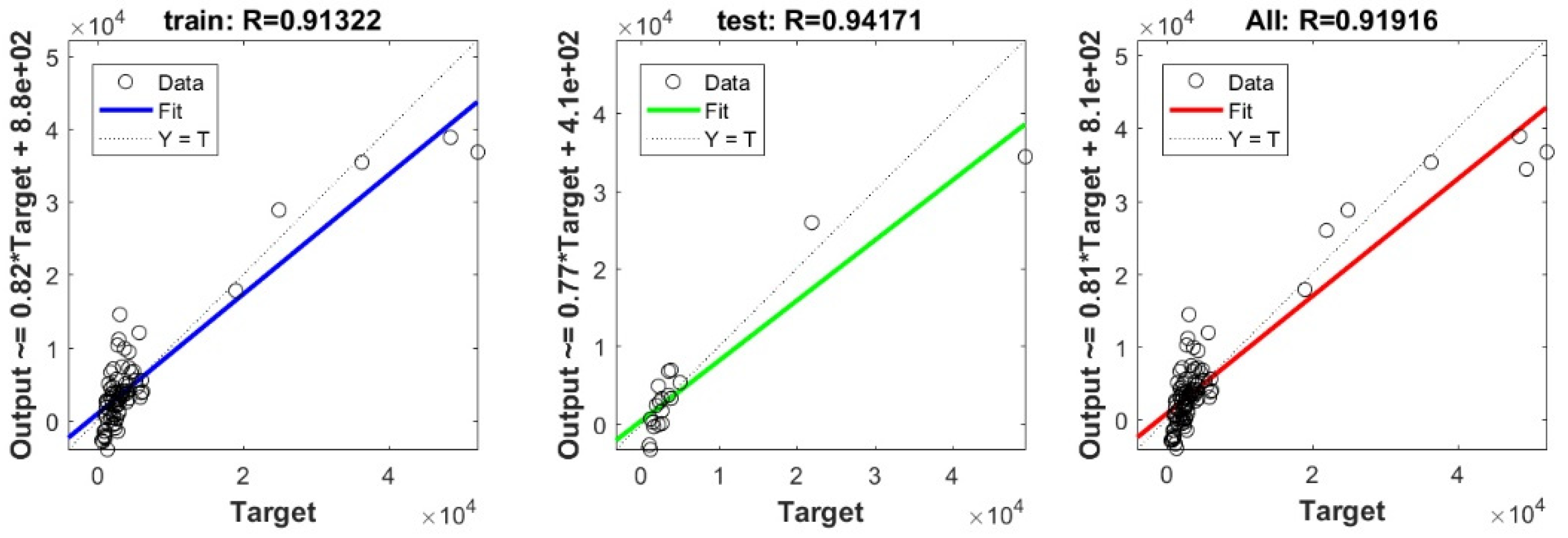
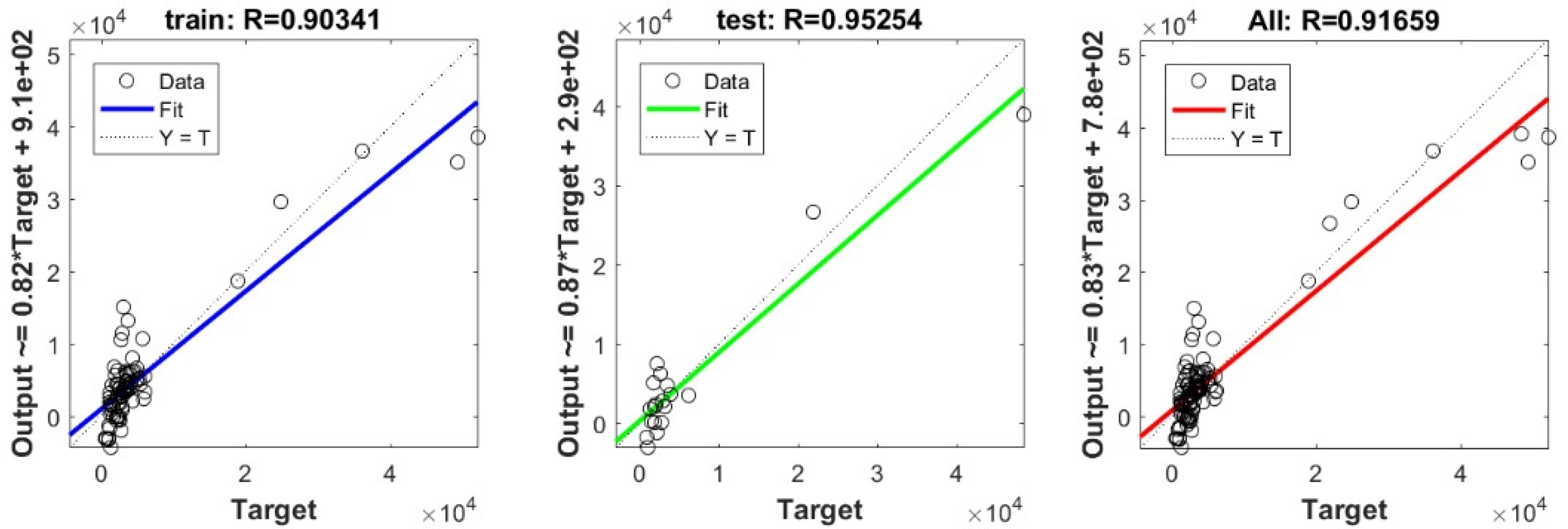
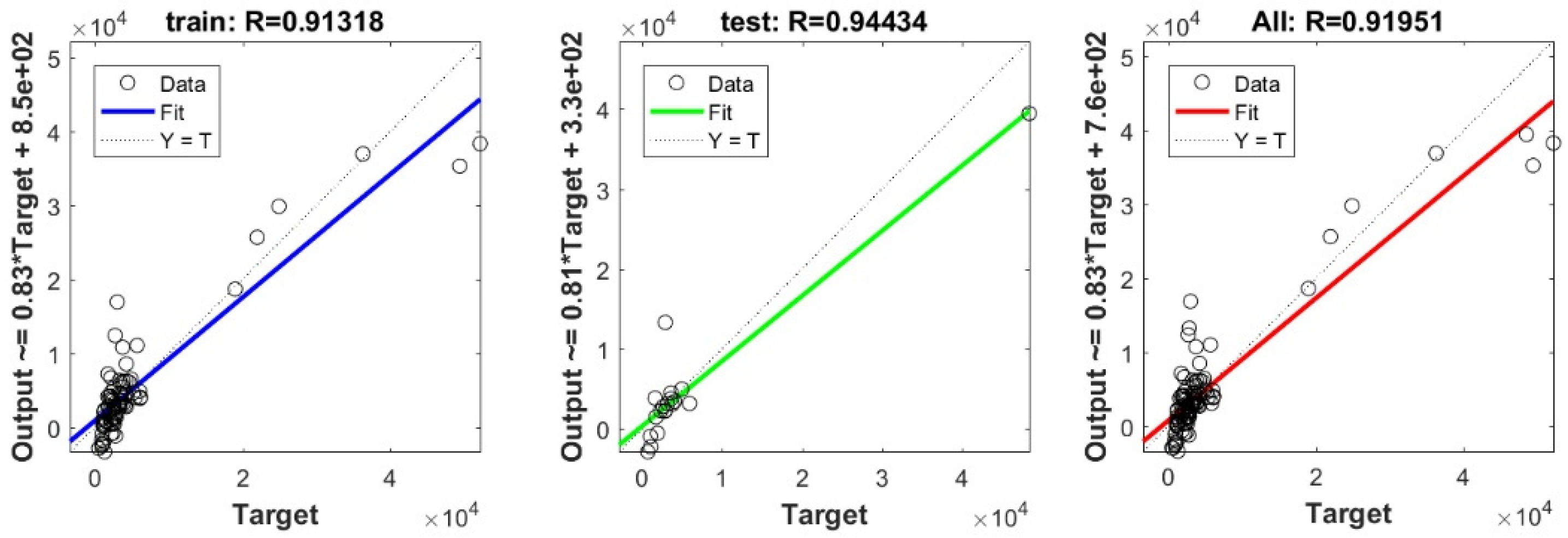
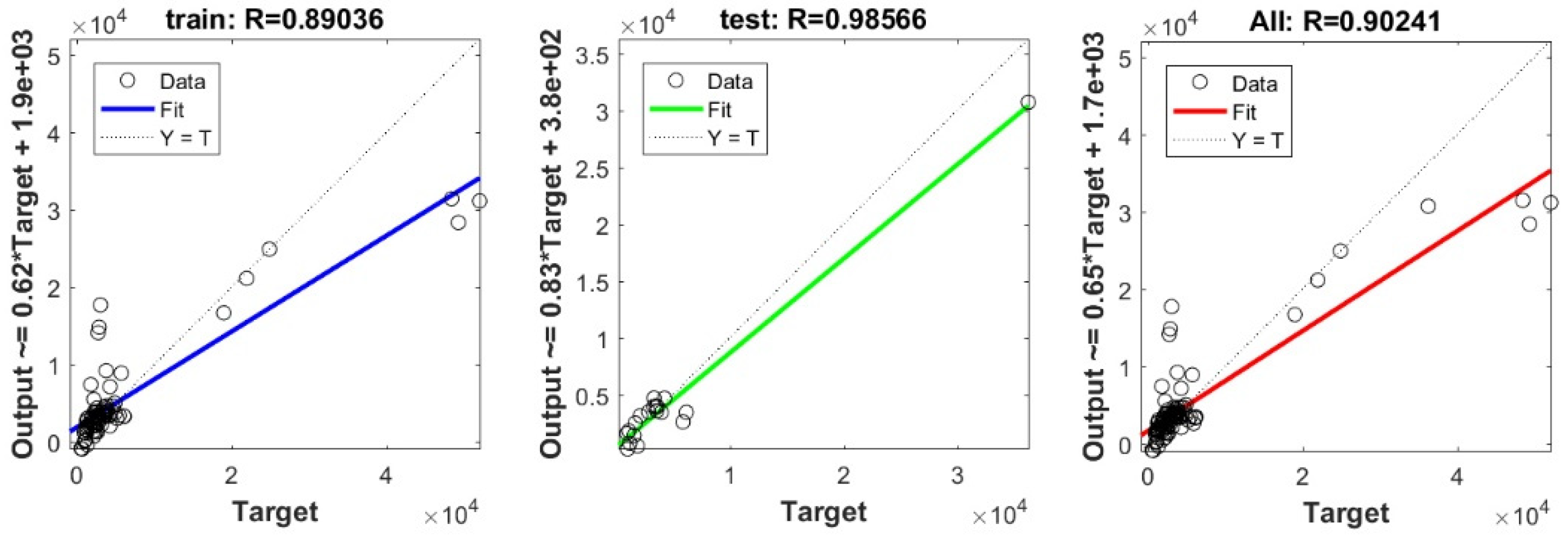
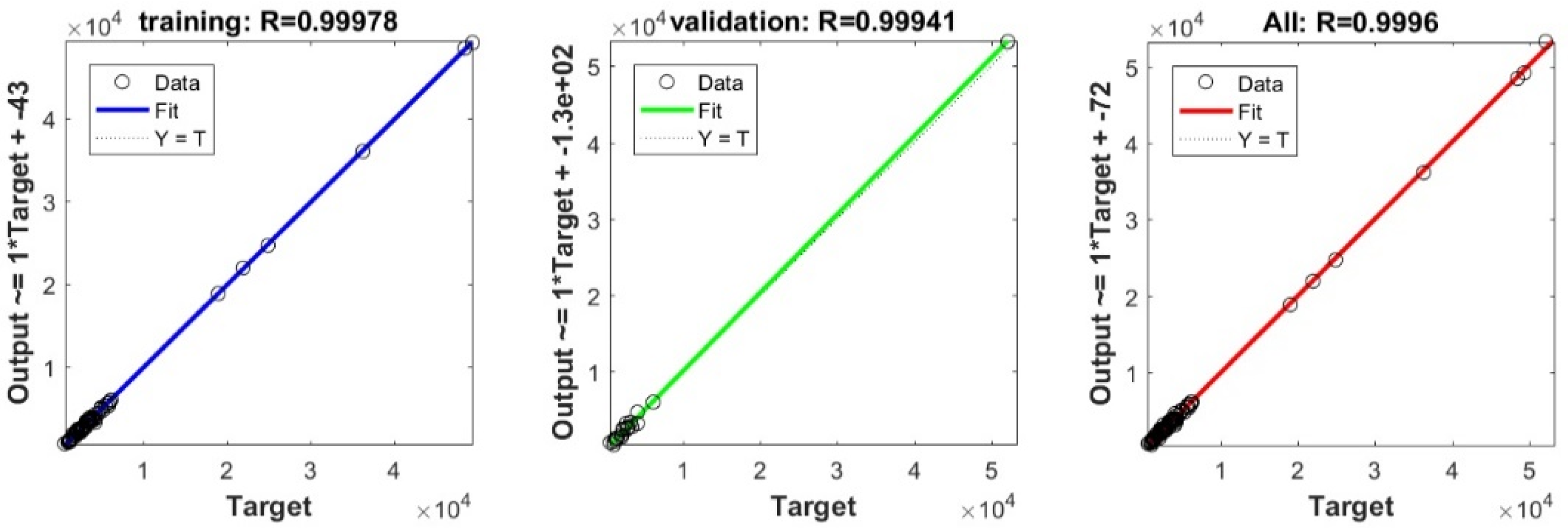
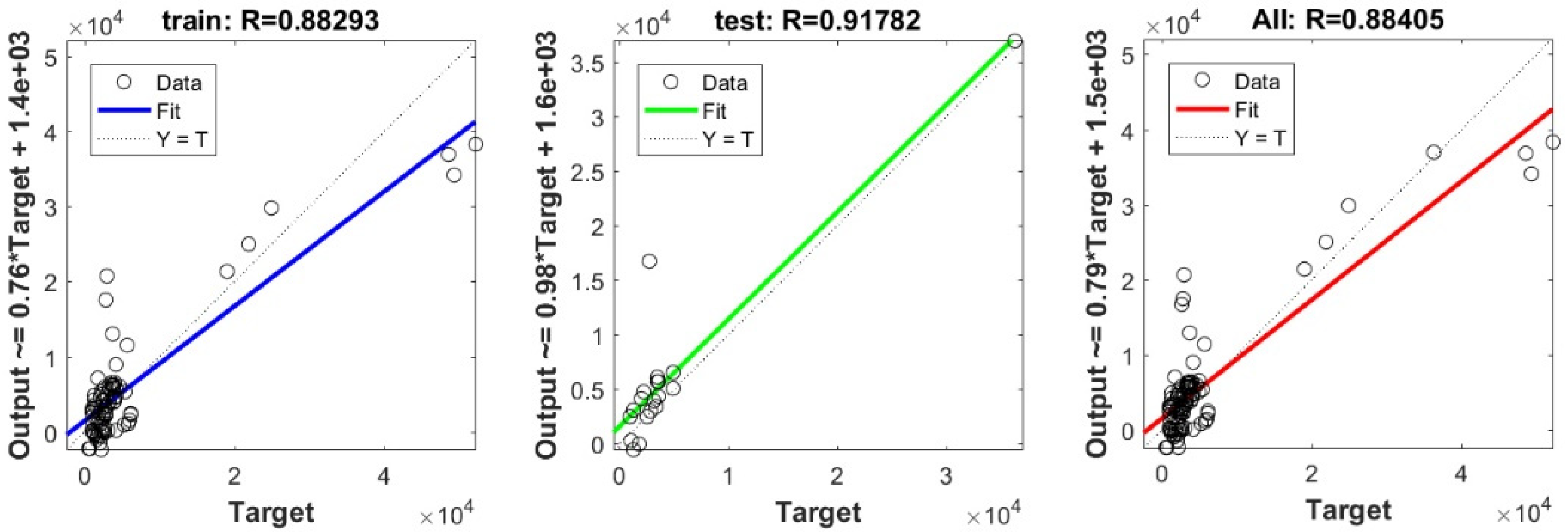
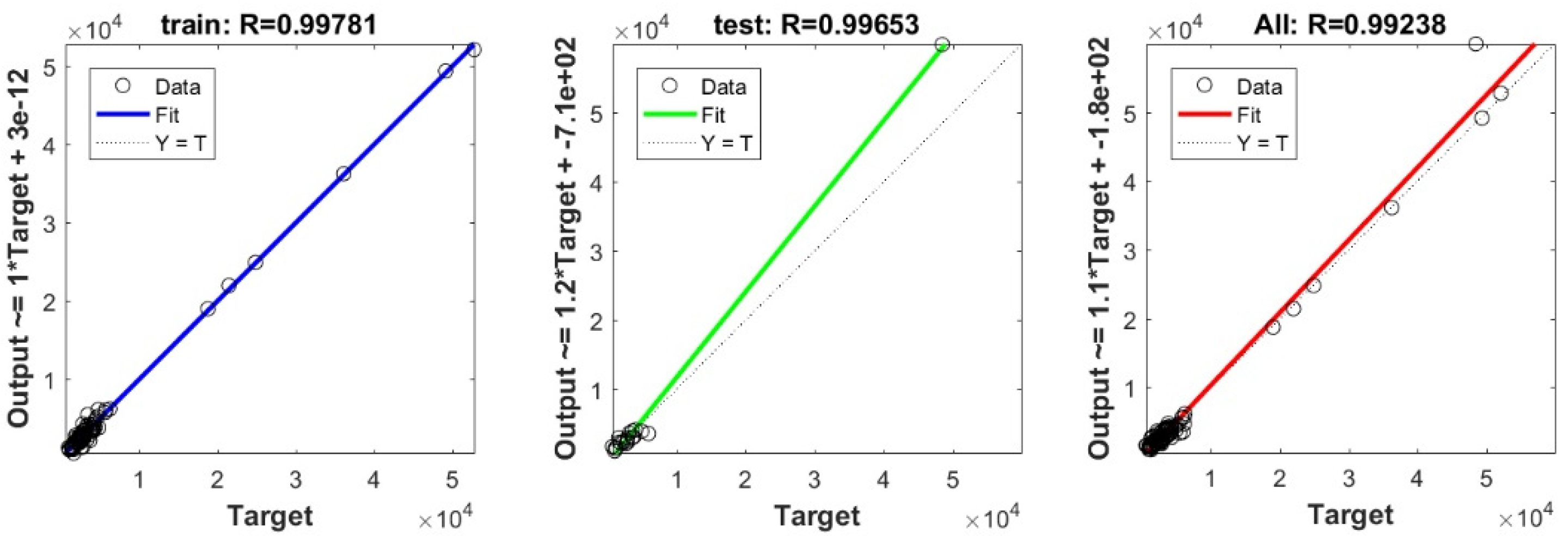
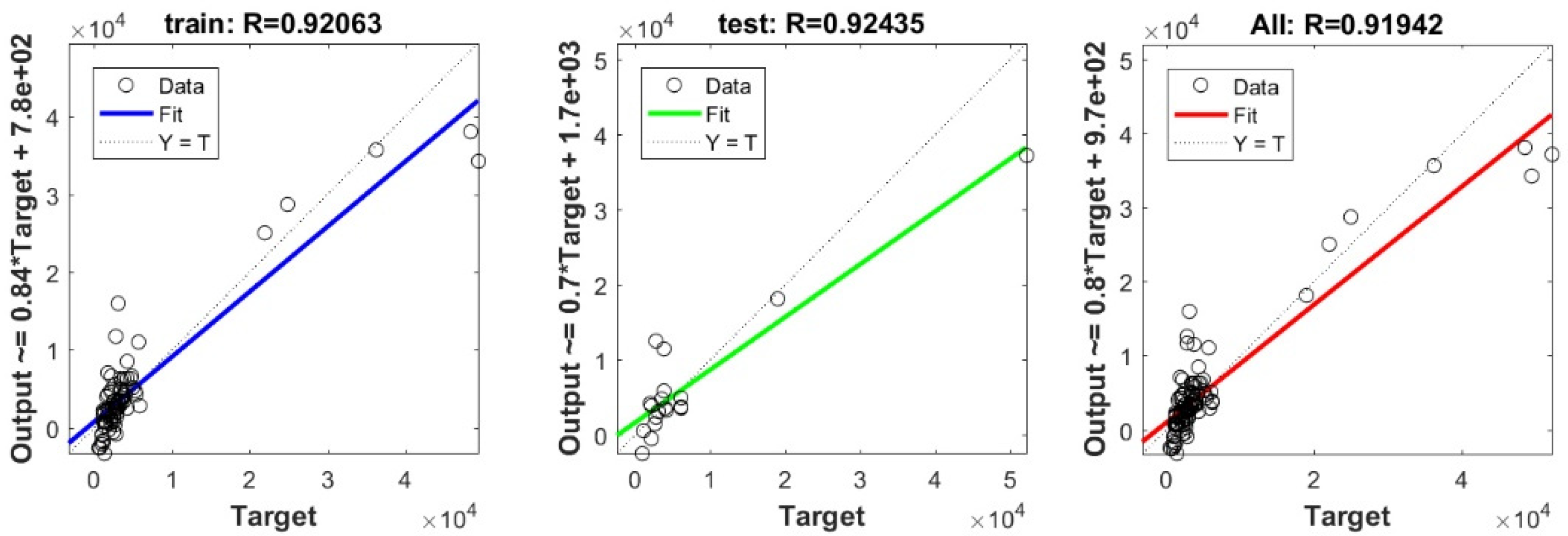
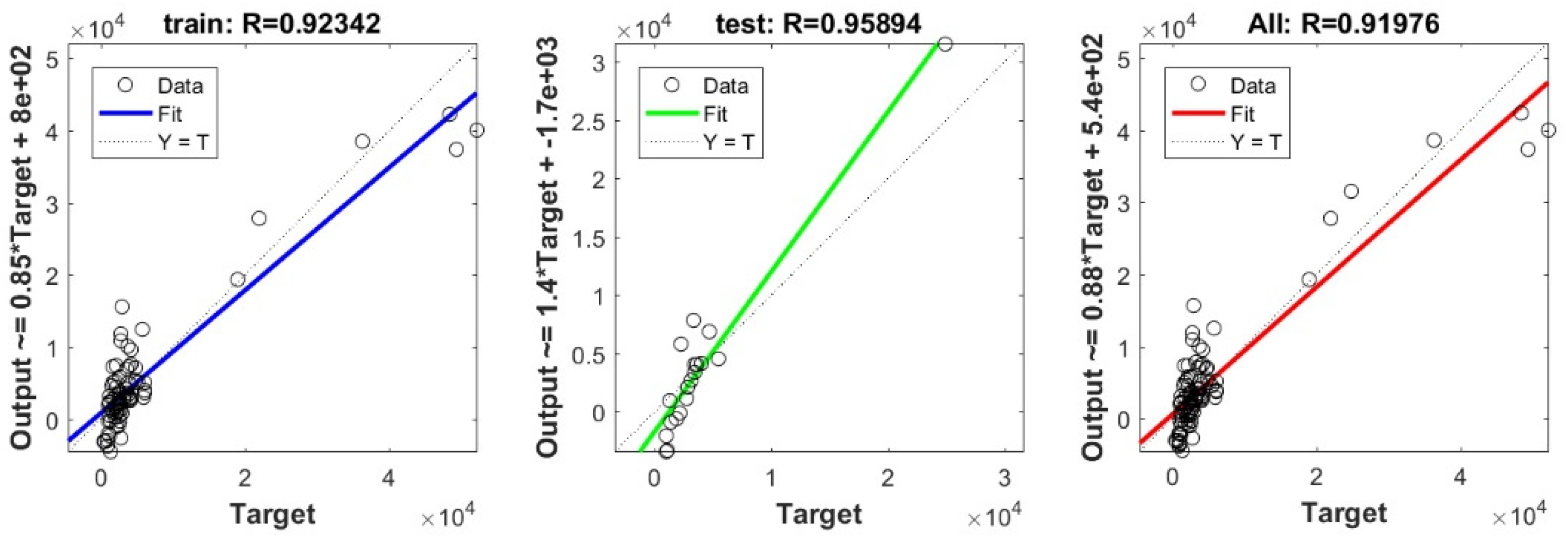
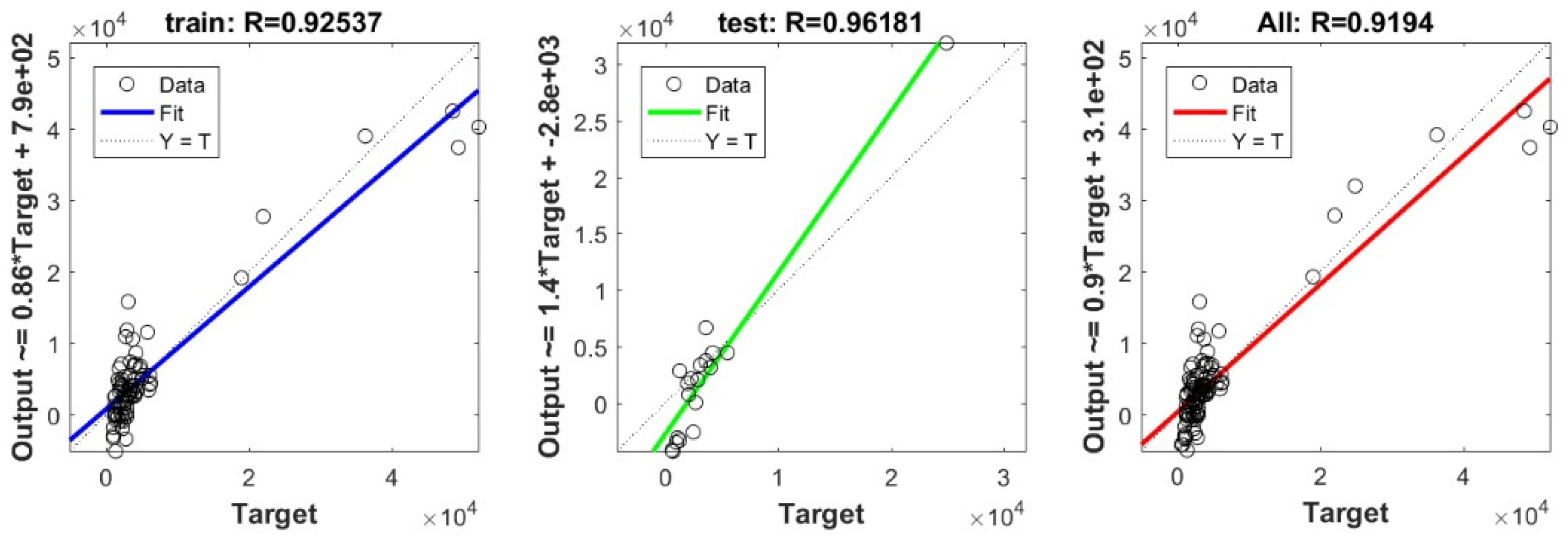
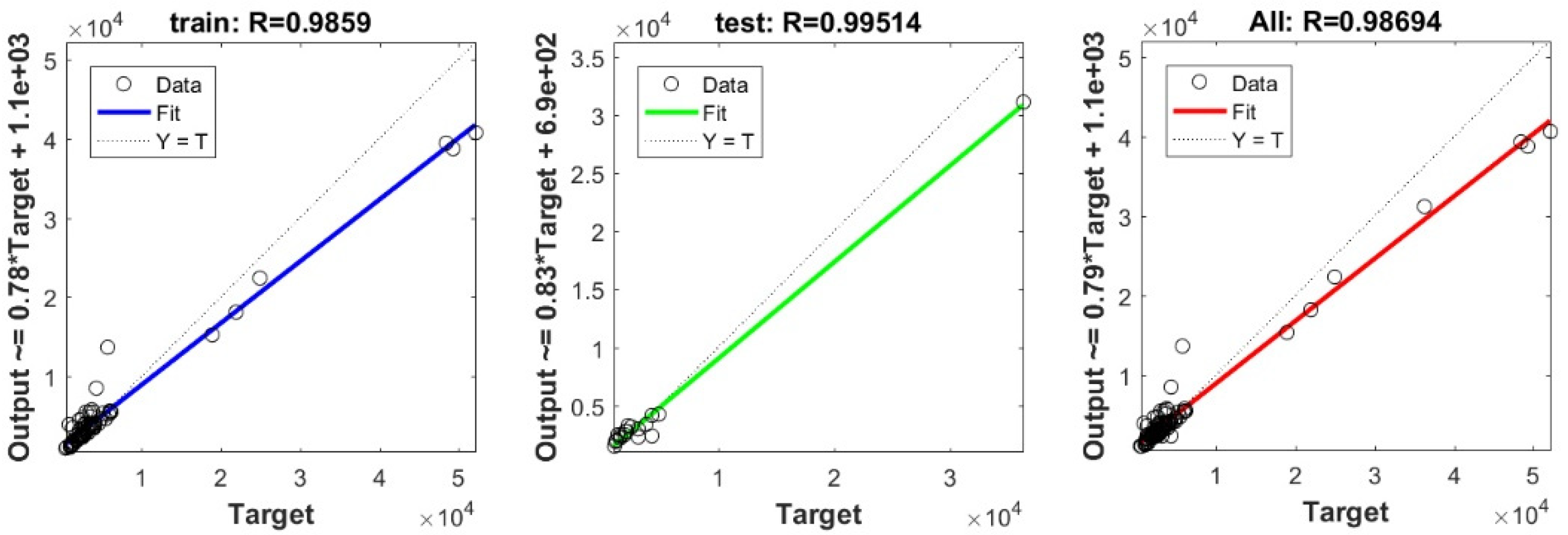
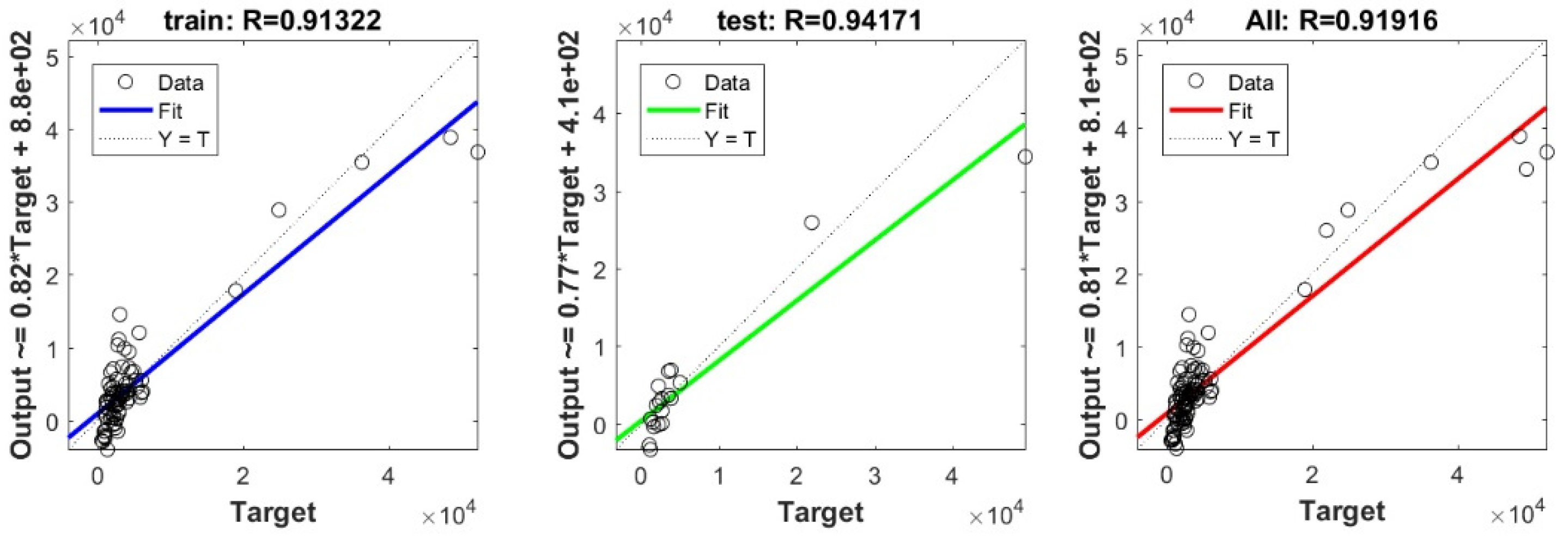
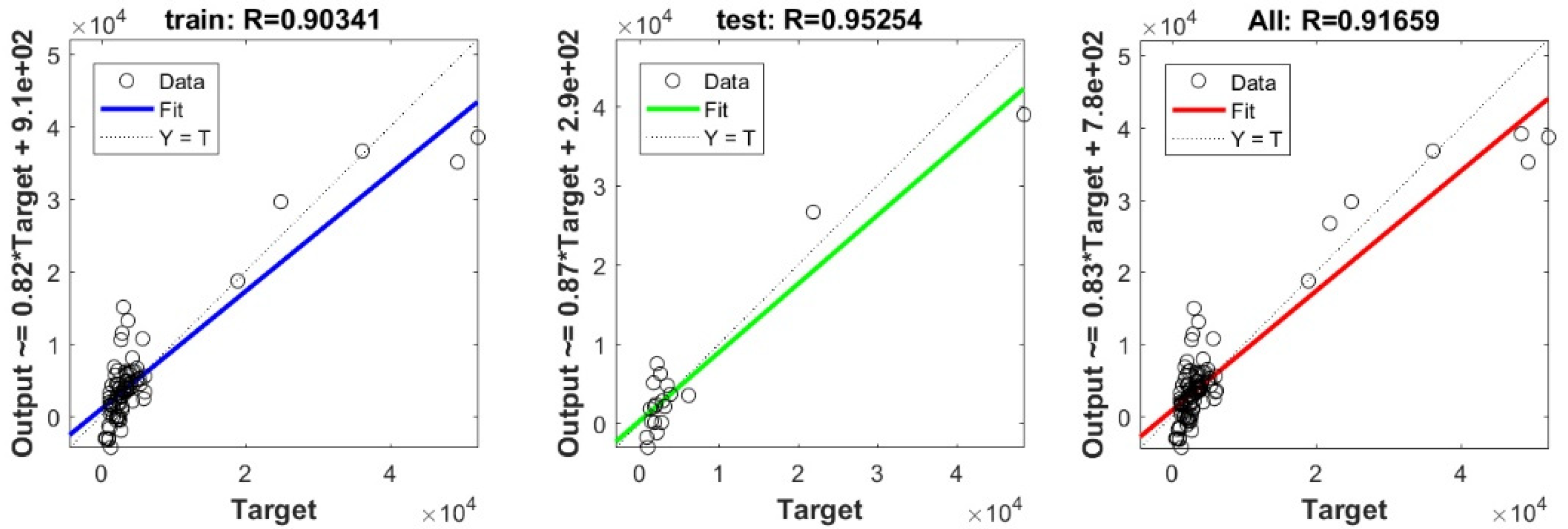
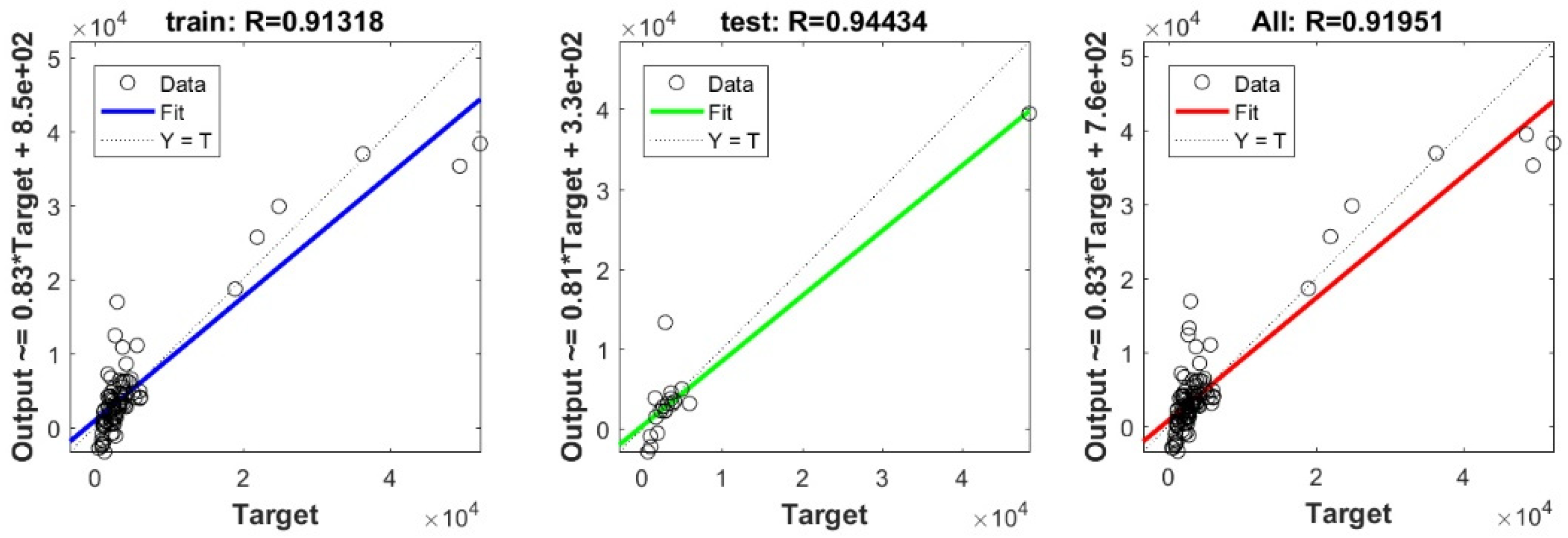
3.3. Bearing Capacity Prediction through AI Models
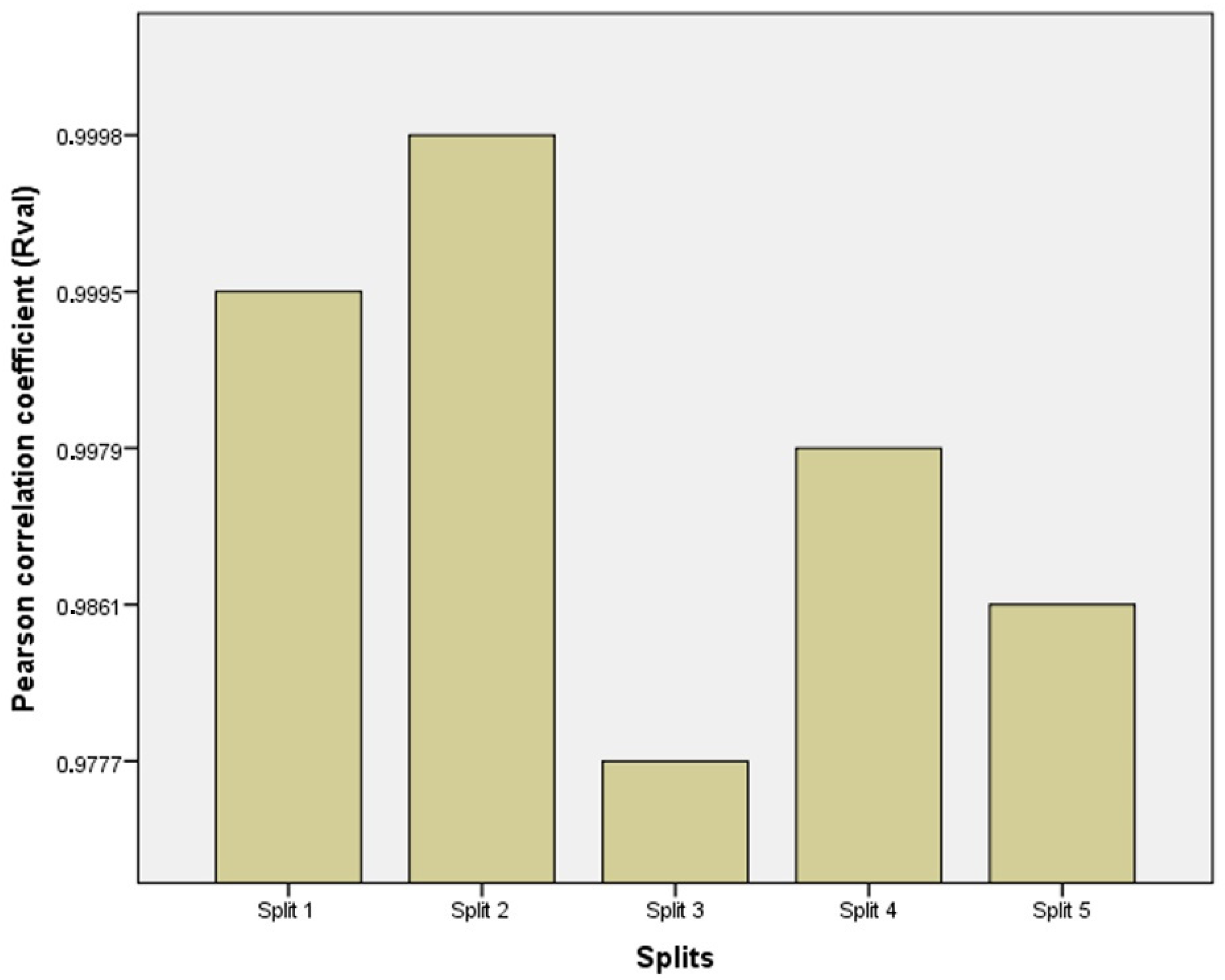
3.4. Evaluating the Best Fitted Model Using the K-Fold Cross-Validation Approach
3.5. Comparison between the Proposed Models and Empirical Formulae
3.6. Sensitivity Analysis
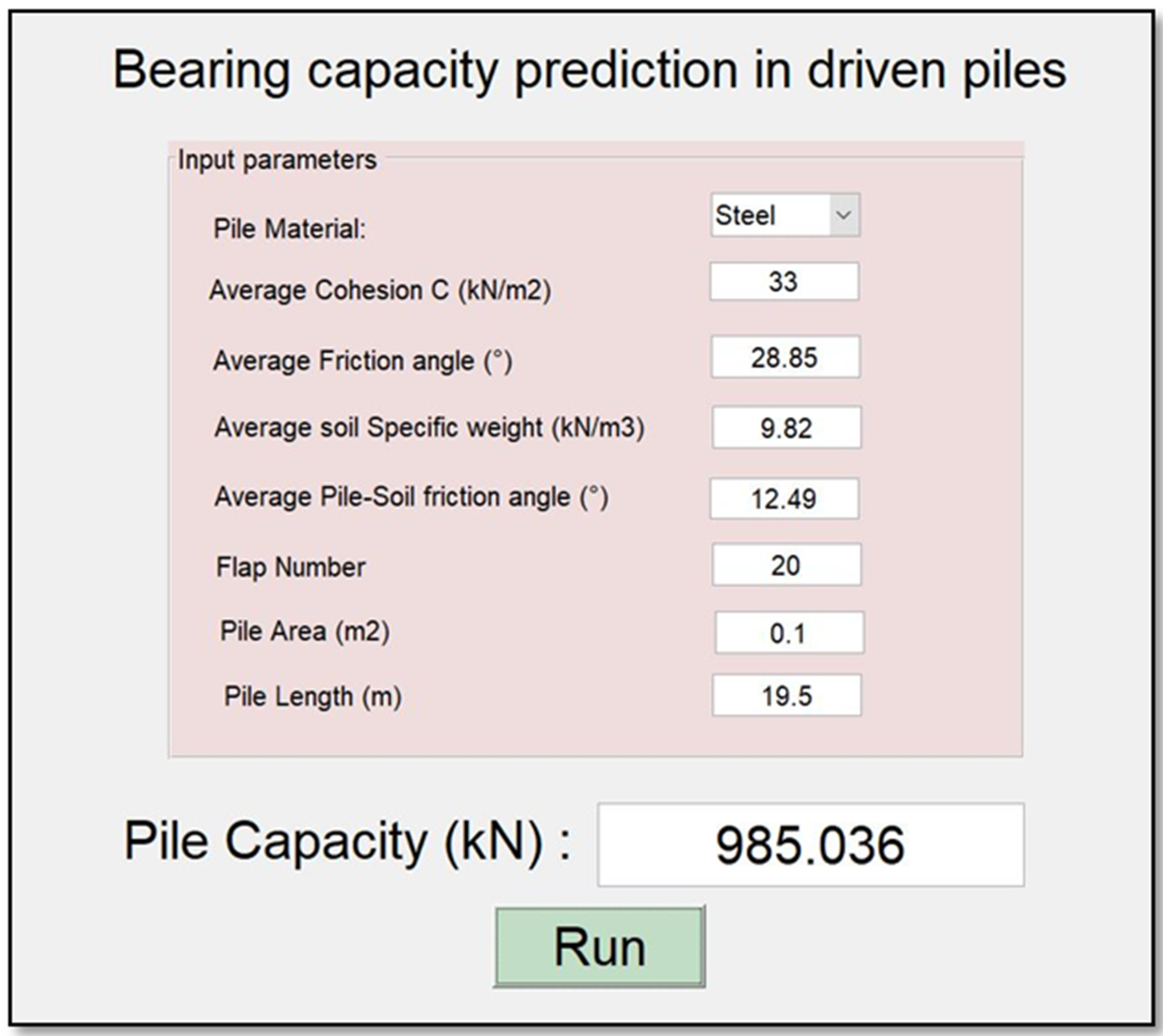
3.7. Graphical User Interface (GUI) Design “BeaCa2021”
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
Appendix A


References
- Jahed Armaghani, D.; Shoib, R.S.N.S.B.R.; Faizi, K.; Rashid, A.S.A. Developing a hybrid PSO–ANN model for estimating the ultimate bearing capacity of rock-socketed piles. Neural Comput. Appl. 2017, 28, 391–405. [Google Scholar] [CrossRef]
- Yong, W.; Zhou, J.; Jahed Armaghani, D.; Tahir, M.M.; Tarinejad, R.; Pham, B.T.; Van Huynh, V. A new hybrid simulated annealing-based genetic programming technique to predict the ultimate bearing capacity of piles. Eng. Comput. 2021, 37, 2111–2127. [Google Scholar] [CrossRef]
- Niazi, F.S.; Mayne, P.W. CPTu-based enhanced UniCone method for pile capacity. Eng. Geol. 2016, 212, 21–34. [Google Scholar] [CrossRef]
- Meyerhof, G.G. Bearing Capacity and Settlement of Pile Foundations. J. Geotech. Eng. Div. 1976, 102, 197–228. [Google Scholar] [CrossRef]
- Coyle, H.M.; Castello, R.R. New Design Correlations for Piles in Sand. J. Geotech. Eng. Div. 1981, 107, 965–986. [Google Scholar] [CrossRef]
- Shahin, M.A. Intelligent computing for modeling axial capacity of pile foundations. Can. Geotech. J. 2010, 47, 230–243. [Google Scholar] [CrossRef] [Green Version]
- Cai, G.; Liu, S.; Puppala, A.J. Reliability assessment of CPTU-based pile capacity predictions in soft clay deposits. Eng. Geol. 2012, 141–142, 84–91. [Google Scholar] [CrossRef]
- Cai, G.; Liu, S.; Tong, L.; Du, G. Assessment of direct CPT and CPTU methods for predicting the ultimate bearing capacity of single piles. Eng. Geol. 2009, 104, 211–222. [Google Scholar] [CrossRef]
- Eslami, A.; Heidarie Golafzani, S. Relevant data-based approach upon reliable safety factor for pile axial capacity. Mar. Georesour. Geotechnol. 2020, 39, 1373–1386. [Google Scholar] [CrossRef]
- Momeni, E.; Nazir, R.; Jahed Armaghani, D.; Maizir, H. Prediction of pile bearing capacity using a hybrid genetic algorithm-based ANN. Measurement 2014, 57, 122–131. [Google Scholar] [CrossRef]
- D18 Committee. Test Method for High-Strain Dynamic Testing of Deep Foundations; ASTM International: West Conshohocken, PA, USA, 2008. [Google Scholar]
- Berezantzev, V.G. Design of deep foundations. In Proceedings of the Proc. 5th ICSMFE, Montreal, QC, Canada, 11–13 September 1965. [Google Scholar]
- Hansen, J.B. Simple statical computation of permissible pileloads. Christ. Nielsen Post 1951, 12, 14–17. [Google Scholar]
- De Beer, E.E. Etude des fondations sur pilotis et des fondations directes. Ann. Trav. Publics Belqique 1945, 46, 1–78. [Google Scholar]
- Vesic, A.S. Design of pile foundations. In NCHRP Synthesis of Highway Practice; Transportation Research Board: Washington, DC, USA, 1977. [Google Scholar]
- Abu-Farsakh, M.Y.; Titi, H.H. Assessment of Direct Cone Penetration Test Methods for Predicting the Ultimate Capacity of Friction Driven Piles. J. Geotech. Geoenvironmental Eng. 2004, 130, 935–944. [Google Scholar] [CrossRef]
- Kordjazi, A.; Pooya Nejad, F.; Jaksa, M.B. Prediction of ultimate axial load-carrying capacity of piles using a support vector machine based on CPT data. Comput. Geotech. 2014, 55, 91–102. [Google Scholar] [CrossRef]
- Maizir, H.; Suryanita, R.; Jingga, H. Estimation of pile bearing capacity of single driven pile in sandy soil using finite element and artificial neural network methods. In Proceedings of the International Conference on Engineering and Technology, Computer, Basic and Applied Sciences ECBA, Osaka, Japan, 28–29 November 2016. [Google Scholar]
- Graine, N.; Hjiaj, M.; Krabbenhoft, K. 3D failure envelope of a rigid pile embedded in a cohesive soil using finite element limit analysis. Int. J. Numer. Anal. Methods Geomech. 2021, 45, 265–290. [Google Scholar] [CrossRef]
- Conte, E.; Pugliese, L.; Troncone, A.; Vena, M. A Simple Approach for Evaluating the Bearing Capacity of Piles Subjected to Inclined Loads. Int. J. Geomech. 2021, 21, 04021224. [Google Scholar] [CrossRef]
- Debiche, F.; Kettab, R.M.; Benbouras, M.A.; Benbellil, B.; Djerbal, L.; Petrisor, A.-I. Use of GIS systems to analyze soil compressibility, swelling and bearing capacity under superficial foundations inalgiers region, ALGERIA. Urban. Arhit. Constr. 2018, 9, 357–370. [Google Scholar]
- Ikeagwuani, C.C. Estimation of modified expansive soil CBR with multivariate adaptive regression splines, random forest and gradient boosting machine. Innov. Infrastruct. Solut. 2021, 6, 199. [Google Scholar] [CrossRef]
- Shahin, M.A.; Jaksa, M.B.; Maier, H.R. State of the art of artificial neural networks in geotechnical engineering. Electron. J. Geotech. Eng. 2008, 8, 1–26. [Google Scholar]
- Benbouras, M.A.; Kettab, R.M.; Zedira, H.; Petrisor, A.-I.; Debiche, F. Dry density in relation to other geotechnical proprieties of Algiers clay. Rev. Şcolii Dr. Urban. 2017, 2, 5–14. [Google Scholar]
- Nawari, N.O.; Liang, R.; Nusairat, J. Artificial intelligence techniques for the design and analysis of deep foundations. Electron. J. Geotech. Eng. 1999, 4, 1–21. [Google Scholar]
- Mahesh, P. Modeling pile capacity using generalized regression neural network. In Proceedings of the Indian Geotechnical Conference, Kochi, India, 15–17 December 2011; No. N-027. pp. 811–814. [Google Scholar]
- Milad, F.; Kamal, T.; Nader, H.; Erman, O.E. New method for predicting the ultimate bearing capacity of driven piles by using Flap number. KSCE J. Civ. Eng. 2015, 19, 611–620. [Google Scholar] [CrossRef]
- Moayedi, H.; Raftari, M.; Sharifi, A.; Jusoh, W.A.W.; Rashid, A.S.A. Optimization of ANFIS with GA and PSO estimating α ratio in driven piles. Eng. Comput. 2020, 36, 227–238. [Google Scholar] [CrossRef]
- Shaik, S.; Krishna, K.S.R.; Abbas, M.; Ahmed, M.; Mavaluru, D. Applying several soft computing techniques for prediction of bearing capacity of driven piles. Eng. Comput. 2019, 35, 1463–1474. [Google Scholar] [CrossRef]
- Harandizadeh, H.; Jahed Armaghani, D.; Khari, M. A new development of ANFIS–GMDH optimized by PSO to predict pile bearing capacity based on experimental datasets. Eng. Comput. 2021, 37, 685–700. [Google Scholar] [CrossRef]
- Moayedi, H.; Jahed Armaghani, D. Optimizing an ANN model with ICA for estimating bearing capacity of driven pile in cohesionless soil. Eng. Comput. 2018, 34, 347–356. [Google Scholar] [CrossRef]
- Kardani, N.; Zhou, A.; Nazem, M.; Shen, S.-L. Estimation of Bearing Capacity of Piles in Cohesionless Soil Using Optimised Machine Learning Approaches. Geotech. Geol. Eng. 2020, 38, 2271–2291. [Google Scholar] [CrossRef]
- Liu, L.; Moayedi, H.; Rashid, A.S.A.; Rahman, S.S.A.; Nguyen, H. Optimizing an ANN model with genetic algorithm (GA) predicting load-settlement behaviours of eco-friendly raft-pile foundation (ERP) system. Eng. Comput. 2020, 36, 421–433. [Google Scholar] [CrossRef]
- Dehghanbanadaki, A.; Khari, M.; Amiri, S.T.; Armaghani, D.J. Estimation of ultimate bearing capacity of driven piles in c-φ soil using MLP-GWO and ANFIS-GWO models: A comparative study. Soft Comput. 2021, 25, 4103–4119. [Google Scholar] [CrossRef]
- Alavi, A.H.; Gandomi, A.H.; Mollahasani, A.; Bazaz, J.B. Linear and tree-based genetic programming for solving geotechnical engineering problems. In Metaheuristics in Water, Geotechnical and Transport Engineering; Elsevier: Amsterdam, The Netherlands, 2013; pp. 289–310. ISBN 978-0-12-398296-4. [Google Scholar]
- Narendra, B.S.; Sivapullaiah, P.V.; Suresh, S.; Omkar, S.N. Prediction of unconfined compressive strength of soft grounds using computational intelligence techniques: A comparative study. Comput. Geotech. 2006, 33, 196–208. [Google Scholar] [CrossRef]
- Rezania, M.; Javadi, A.A. A new genetic programming model for predicting settlement of shallow foundations. Can. Geotech. J. 2007, 44, 1462–1473. [Google Scholar] [CrossRef]
- Stockard, D.M. Case Histories-Pile Driving in the Gulf of Mexico; OnePetro: Houston, TX, USA, 1979. [Google Scholar]
- Stockard, D.M. Case Histories: Pile Driving Offshore India; OnePetro: Houston, TX, USA, 1986. [Google Scholar]
- Tucker, L.M.; Briaud, J.-L. Analysis of the Pile Load Test Program at the Lock and Dam 26 Replacement Project; Texas A&M University College Station Dept of Civil Engineering: College Station, TX, USA, 1988. [Google Scholar]
- Gupta, R.C. Estimating Bearing Capacity Factors and Cone Tip Resistance. J. Jpn. Geotech. Soc. 2002, 42, 117–127. [Google Scholar] [CrossRef] [Green Version]
- Fellenius, B.H.; Altaee, A. Pile dynamics in geotechnical practice—six case histories. In Deep Foundations 2002: International Perspective Theory Design, Construction Perform; American Society of Civil Engineers: Reston, VA, USA, 2012; pp. 619–631. [Google Scholar] [CrossRef] [Green Version]
- Benbouras, M.A.; Kettab Mitiche, R.; Zedira, H.; Petrisor, A.I.; Mezouar, N.; Debiche, F. A new approach to predict the Compression Index using Artificial Intelligence Methods. Mar. Georesources Geotechnol. 2019, 37, 704–720. [Google Scholar] [CrossRef]
- Benbouras, M.A.; Kettab, R.M.; Zedira, H.; Debiche, F.; Zaidi, N. Comparing Nonlinear Regression Analysis And Artificial Neural Networks To Predict Geotechnical Parameters From Standard Penetration Test. Urban. Archit. Constr. Arhit. Constr. 2018, 9, 275–288. [Google Scholar]
- Huang, G.-B.; Zhu, Q.-Y.; Siew, C.-K. Extreme learning machine: Theory and applications. Neurocomputing 2006, 70, 489–501. [Google Scholar] [CrossRef]
- Biau, G.; Scornet, E. A random forest guided tour. Test 2016, 25, 197–227. [Google Scholar] [CrossRef] [Green Version]
- Awad, M.; Khanna, R. Support vector regression. In Efficient Learning Machines: Theories, Concepts, and Applications for Engineers and System Designers; Awad, M., Khanna, R., Eds.; Apress: Berkeley, CA, USA, 2015; pp. 67–80. ISBN 978-1-4302-5990-9. [Google Scholar]
- Vinzi, V.E.; Chin, W.W.; Henseler, J.; Wang, H. Editorial: Perspectives on partial least squares. In Handbook of Partial Least Squares: Concepts, Methods and Applications; Springer Handbooks of Computational Statistics; Esposito Vinzi, V., Chin, W.W., Henseler, J., Wang, H., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; pp. 1–20. ISBN 978-3-540-32827-8. [Google Scholar]
- Hebiri, M.; Lederer, J. How Correlations Influence Lasso Prediction. IEEE Trans. Inf. Theory 2013, 59, 1846–1854. [Google Scholar] [CrossRef] [Green Version]
- Douak, F.; Melgani, F.; Benoudjit, N. Kernel ridge regression with active learning for wind speed prediction. Appl. Energy 2013, 103, 328–340. [Google Scholar] [CrossRef]
- Hoerl, A.E.; Kennard, R.W. Ridge Regression—1980: Advances, Algorithms, and Applications. Am. J. Math. Manag. Sci. 1981, 1, 5–83. [Google Scholar] [CrossRef]
- Jennrich, R.I.; Sampson, P.F. Application of Stepwise Regression to Non-Linear Estimation. Technometrics 1968, 10, 63–72. [Google Scholar] [CrossRef]
- Wagner, S.; Kronberger, G.; Beham, A.; Kommenda, M.; Scheibenpflug, A.; Pitzer, E.; Vonolfen, S.; Kofler, M.; Winkler, S.; Dorfer, V.; et al. Architecture and design of the HeuristicLab optimization environment. In Advanced Methods and Applications in Computational Intelligence; Topics in Intelligent Engineering and Informatics; Klempous, R., Nikodem, J., Jacak, W., Chaczko, Z., Eds.; Springer International Publishing: Berlin/Heidelberg, Germany, 2014; pp. 197–261. ISBN 978-3-319-01436-4. [Google Scholar]
- Tikhamarine, Y.; Malik, A.; Pandey, K.; Sammen, S.S.; Souag-Gamane, D.; Heddam, S.; Kisi, O. Monthly evapotranspiration estimation using optimal climatic parameters: Efficacy of hybrid support vector regression integrated with whale optimization algorithm. Environ. Monit. Assess. 2020, 192, 696. [Google Scholar] [CrossRef] [PubMed]
- Amin Benbouras, M.; Petrisor, A.-I. Prediction of Swelling Index Using Advanced Machine Learning Techniques for Cohesive Soils. Appl. Sci. 2021, 11, 536. [Google Scholar] [CrossRef]
- Breiman, L.; Spector, P. Submodel Selection and Evaluation in Regression. The X-Random Case. Int. Stat. Rev. Rev. Int. Stat. 1992, 60, 291–319. [Google Scholar] [CrossRef]
- Oommen, T.; Baise, L.G. Model development and validation for intelligent data collection for lateral spread displacements. J. Comput. Civ. Eng. 2010, 24, 467–477. [Google Scholar] [CrossRef]
- Goetz, J.N.; Brenning, A.; Petschko, H.; Leopold, P. Evaluating machine learning and statistical prediction techniques for landslide susceptibility modeling. Comput. Geosci. 2015, 81, 1–11. [Google Scholar] [CrossRef]
- Amin, B. Predicting Shear Stress Parameters in Consolidated Drained Conditions Using Artificial Intelligence Methods. Basic Appl. Sci.-Sci. J. King Faisal Univ. 2021, 22, 1–7. [Google Scholar] [CrossRef]
- Liong, S.-Y.; Lim, W.-H.; Paudyal, G.N. River Stage Forecasting in Bangladesh: Neural Network Approach. J. Comput. Civ. Eng. 2000, 14, 1–8. [Google Scholar] [CrossRef]
- El Amin Bourouis, M.; Zadjaoui, A.; Djedid, A. Contribution of two artificial intelligence techniques in predicting the secondary compression index of fine-grained soils. Innov. Infrastruct. Solut. 2020, 5, 96. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Authors | Inputs | Methods | Database | References |
|---|---|---|---|---|
| Nawari et al. (1999) | SPT-N values and geometrical properties | Neural Network | 25 | [25] |
| Mahnesh (2011) | Dynamic stress-wave data | Support Vector Machines and Generalized Regression Neural Network | 105 | [26] |
| Milad et al. (2015) | Flap number, basic properties of the surrounding soil, pile geometry, and pile-soil friction angle | Artificial Neural Network, Genetic Programming and Linear Regression | 100 | [27] |
| Jahed et al. (2017) | Soil length to socket length ratio, total length to diameter ratio, uniaxial compressive strength, and standard penetration test | hybrid PSO–ANN | 132 | [1] |
| Moayedi and Jahed (2018) | Internal friction angle of soil located in shaft and tip, pile length, effective vertical stress at pile toe and pile area | ICA-ANN | 59 | [31] |
| Yong et al. (2021) | Pile length, pile cross-sectional area, hammer weight, pile set, and drop height | ANFIS, GP, and SA–GP | 50 | [2] |
| Shaik et al. (2019) | Internal friction angle of soil located in shaft and tip, effective vertical stress at pile toe, pile area, and pile length | ICA-ANN and ANFIS | 59 | [29] |
| Kardani et al. (2020) | Shear resistance angle at the shaft of the pile, soil shear resistance angle at the tip of the pile, length of pile, cross-sectional area of the pile, and effective stress at the tip of the pile | Decision tree, k-nearest neighbor, Multilayer Perceptron Artificial Neural Network, Random Forest, Support Vector Regressor, and Extreme Gradient Boosting | 59 | [32] |
| Harandizadeh et al. (2021) | CPT and pile loading test results | ANFIS and ANFIS–GMDH–PSO | 72 | [30] |
| Moayedi et al. (2020) | Pile diameter, pile length, relative density, embedment ratio, and both the pile end resistance and base resistance | GA-ANFIS and PSO-ANFIS | 20 | [28] |
| Liu et al. (2020) | Laboratory and in situ testing results | ANFIS, ANN, and GA-ANN | 43 | [33] |
| Dehghanbanadaki et al. (2021) | Pile area, pile length, flap number, average cohesion and friction angle, average soil-specific weight, and average pile-soil friction angle | MLP–GWO and ANFIS–GWO | 100 | [34] |
| Code | Parameter Type | Type of Variable | Subdivision | Variable |
|---|---|---|---|---|
| X1 | Input | Qualitative | X1 = 1 (Steel) | Pile material |
| X1 = 2 (Concrete) | ||||
| X2 | Input | Quantitative | Average cohesion (kN/m2) | |
| X3 | Input | Quantitative | Average friction angle (°) | |
| X4 | Input | Quantitative | Average soil-specific weight (kN/m3) | |
| X5 | Input | Quantitative | Average pile-soil friction angle (°) | |
| X6 | Input | Quantitative | Flap number | |
| X7 | Input | Quantitative | Pile area (m2) | |
| X8 | Input | Quantitative | Pile length (m) | |
| Y | Output | Quantitative | Pile capacity (kN) |
| Algorithms | Algorithm Parameters | Value |
|---|---|---|
| ELM | Hidden layers | H = 1 |
| Hidden neurons | N = 12 | |
| Activation function | ‘linear’ | |
| Regulation parameter | C = 0.02 | |
| DNN | Hidden layers | H = 2 |
| Hidden neurons in the first layer | N1 = [1–20] | |
| Hidden neurons in the second layer | N2 = [1–20] | |
| Activation function in the first layer | ‘Tansig’ | |
| Activation function in the second layer | ‘Tansig’ | |
| SVR | Regulation parameter C | Series of C |
| Regulation parameter lambda | Series of lambda | |
| Kernel function | ‘rbf’ | |
| RF | nTrees | nTrees = 100 |
| mTrees | mTrees = 26 | |
| LASSO | Lambda | series of lambda |
| PLS | PLS components | NumComp = 3 for PSO NumComp = 4 for GT and FS |
| Ridge | Regularization parameter lambda | lambda = 1 |
| KRidge | Regularization parameter lambda | lambda = 1 |
| Kernel function | ‘linear’ | |
| Parameter for kernel | sigma = 2 × 10−7 | |
| GP | Function set | +, −, ×, ÷, power, ln, sqrt, sin, cos, tan |
| Population size | 100 up to 500 | |
| Number of generations | 1000 | |
| Genetic operators | Reproduction, crossover, mutation |
| Range | Minimum | Maximum | Mean | SD | Variance | Skewness | Kurtosis | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Statistic | Statistic | Statistic | Statistic | Std. Error | Statistic | Statistic | Statistic | Std. Error | Statistic | Std. Error | |
| X2 | 148.00 | 0.00 | 148.00 | 32.3741 | 3.28447 | 32.84 | 1078.77 | 2.011 | 0.241 | 4.570 | 0.478 |
| X3 | 36.62 | 0.00 | 36.62 | 25.5803 | 0.96535 | 9.653 | 93.191 | −1.310 | 0.241 | 0.855 | 0.478 |
| X4 | 8.11 | 5.38 | 13.49 | 10.2029 | 0.18409 | 1.840 | 3.389 | −0.406 | 0.241 | 0.262 | 0.478 |
| X5 | 6.86 | 10.14 | 17.00 | 13.6823 | 0.16987 | 1.698 | 2.885 | 0.073 | 0.241 | −0.076 | 0.478 |
| X6 | 2277.00 | 14.00 | 2291.00 | 494.99 | 60.23 | 602.32 | 362,794.16 | 1.502 | 0.241 | 1.286 | 0.478 |
| X7 | 1.52 | 0.07 | 1.59 | 0.4327 | 0.04656 | 0.46562 | 0.217 | 1.128 | 0.241 | −0.233 | 0.478 |
| X8 | 83.80 | 14.20 | 98.00 | 27.1120 | 1.86024 | 18.60 | 346.048 | 2.761 | 0.241 | 6.962 | 0.478 |
| Y | 51,560.00 | 540.00 | 52,100.00 | 5133.12 | 929.01 | 9290.14 | 86,306,843.19 | 4.043 | 0.241 | 16.258 | 0.478 |
| X2 | X3 | X4 | X5 | X6 | X7 | X8 | Y | ||
|---|---|---|---|---|---|---|---|---|---|
| X2 | Pearson Correlation | 1 | −0.370 ** | −0.234 * | −0.221 * | 0.086 | 0.038 | −0.229 * | −0.229 * |
| Significance | 0.000 | 0.019 | 0.027 | 0.396 | 0.707 | 0.022 | 0.022 | ||
| N | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | |
| X3 | Pearson Correlation | −0.370 ** | 1 | 0.463 ** | 0.011 | 0.206 * | 0.259 ** | −0.063 | 0.099 |
| Significance | 0.000 | 0.000 | 0.916 | 0.040 | 0.009 | 0.531 | 0.326 | ||
| N | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | |
| X4 | Pearson Correlation | −0.234 * | 0.463 ** | 1 | 0.270 ** | 0.124 | 0.051 | −0.433 ** | −0.138 |
| Significance | 0.019 | 0.000 | 0.007 | 0.218 | 0.612 | 0.000 | 0.172 | ||
| N | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | |
| X5 | Pearson Correlation | −0.221 * | 0.011 | 0.270 ** | 1 | −0.489 ** | −0.555 ** | −0.189 | −0.142 |
| Significance | 0.027 | 0.916 | 0.007 | 0.000 | 0.000 | 0.059 | 0.159 | ||
| N | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | |
| X6 | Pearson Correlation | 0.086 | 0.206 * | 0.124 | −0.489 ** | 1 | 0.876 ** | 0.335 ** | 0.449 ** |
| Significance | 0.396 | 0.040 | 0.218 | 0.000 | 0.000 | 0.001 | 0.000 | ||
| N | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | |
| X7 | Pearson Correlation | 0.038 | 0.259 ** | 0.051 | −0.555 ** | 0.876 ** | 1 | 0.446 ** | 0.563 ** |
| Significance | 0.707 | 0.009 | 0.612 | 0.000 | 0.000 | 0.000 | 0.000 | ||
| N | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | |
| X8 | Pearson Correlation | −0.229 * | −0.063 | −0.433 ** | −0.189 | 0.335 ** | 0.446 ** | 1 | 0.866 ** |
| Significance | 0.022 | 0.531 | 0.000 | 0.059 | 0.001 | 0.000 | 0.000 | ||
| N | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | |
| Y | Pearson Correlation | −0.229 * | 0.099 | −0.138 | −0.142 | 0.449 ** | 0.563 ** | 0.866 ** | 1 |
| Significance | 0.022 | 0.326 | 0.172 | 0.159 | 0.000 | 0.000 | 0.000 | ||
| N | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | |
| MAE × 103 | RMSE × 103 | IOS | R | R2 | IOA | |
|---|---|---|---|---|---|---|
| Concrete piles | ||||||
| DNN | 0.1650 | 0.2140 | 0.0755 | 0.9977 | 0.9954 | 0.9988 |
| ELM | 3.0424 | 4.2390 | 0.7737 | 0.9320 | 0.8686 | 0.9610 |
| Lasso | 2.4324 | 3.5390 | 0.6637 | 0.9620 | 0.9254 | 0.9700 |
| PLS | 2.5524 | 3.6390 | 0.6837 | 0.9688 | 0.9386 | 0.9700 |
| RF | 1.1024 | 2.1690 | 0.3837 | 0.9880 | 0.9761 | 0.9912 |
| Kridge | 2.2930 | 3.5917 | 0.6816 | 0.9433 | 0.8899 | 0.9641 |
| Ridge | 2.4268 | 3.6145 | 0.6876 | 0.9409 | 0.8853 | 0.9636 |
| LS | 2.3093 | 3.5867 | 0.6824 | 0.9414 | 0.8863 | 0.9656 |
| Step | 2.4738 | 3.6421 | 0.6970 | 0.9352 | 0.8746 | 0.9626 |
| SVR | 1.9787 | 4.0984 | 0.7734 | 0.9315 | 0.8676 | 0.9360 |
| GP | 0.5966 | 0.9612 | 0.1731 | 0.9975 | 0.9951 | 0.9961 |
| Steel piles | ||||||
| DNN | 0.1870 | 0.3100 | 0.0448 | 0.9997 | 0.9994 | 0.9998 |
| ELM | 3.1064 | 4.3966 | 0.9081 | 0.8478 | 0.7187 | 0.9118 |
| Lasso | 2.7149 | 3.6962 | 0.7527 | 0.8990 | 0.8082 | 0.9437 |
| PLS | 2.6329 | 3.6973 | 0.7763 | 0.8966 | 0.8038 | 0.9398 |
| RF | 1.1213 | 2.3475 | 0.4893 | 0.9875 | 0.9751 | 0.9712 |
| Kridge | 2.2482 | 3.6937 | 0.7342 | 0.8993 | 0.8088 | 0.9441 |
| Ridge | 2.3820 | 3.7165 | 0.7402 | 0.8969 | 0.8044 | 0.9436 |
| LS | 2.2646 | 3.6887 | 0.7350 | 0.8974 | 0.8054 | 0.9456 |
| Step | 2.4291 | 3.7441 | 0.7496 | 0.8912 | 0.7943 | 0.9426 |
| SVR | 1.9340 | 4.2004 | 0.8260 | 0.8875 | 0.7876 | 0.9160 |
| GP | 0.5518 | 1.0632 | 0.2257 | 0.9975 | 0.9951 | 0.9965 |
| Authors | Sample Size | Best Methods | Correlation Coefficient | References |
|---|---|---|---|---|
| Nawari et al. (1999) | 25 | ANN | 0.91 | [25] |
| Mahnesh (2011) | 105 | Generalized Regression Neural Network | 0.977 | [26] |
| Milad et al. (2015) | 100 | Neural Network | 0.9995 | [27] |
| Jahed et al. (2017) | 132 | PSO–ANN | 0.9685 | [1] |
| Moayedi and Jahed (2018) | 59 | ICA-ANN | 0.96369 | [31] |
| Yong et al. (2021) | 50 | GP | 0.997 | [28] |
| Shaik et al. (2019) | 59 | ANFIS | 0.967 | [33] |
| Kardani et al. (2020) | 59 | Extreme Gradient Boosting | 0.975 | [2] |
| Harandizadeh et al. (2021) | 72 | ANFIS–GMDH–PSO | 0.94 | [29] |
| Moayedi et al. (2020) | 20 | GA–ANFIS | 0.9935 | [34] |
| Liu et al. (2020) | 43 | GA-ANN | 0.998 | [32] |
| Dehghanbanadaki et al. (2021) | 100 | MLP–GWO | 0.991 | [30] |
| Our study | 100 | Deep Neural Network | 0.9996 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Benbouras, M.A.; Petrişor, A.-I.; Zedira, H.; Ghelani, L.; Lefilef, L. Forecasting the Bearing Capacity of the Driven Piles Using Advanced Machine-Learning Techniques. Appl. Sci. 2021, 11, 10908. https://doi.org/10.3390/app112210908
Benbouras MA, Petrişor A-I, Zedira H, Ghelani L, Lefilef L. Forecasting the Bearing Capacity of the Driven Piles Using Advanced Machine-Learning Techniques. Applied Sciences. 2021; 11(22):10908. https://doi.org/10.3390/app112210908
Chicago/Turabian StyleBenbouras, Mohammed Amin, Alexandru-Ionuţ Petrişor, Hamma Zedira, Laala Ghelani, and Lina Lefilef. 2021. "Forecasting the Bearing Capacity of the Driven Piles Using Advanced Machine-Learning Techniques" Applied Sciences 11, no. 22: 10908. https://doi.org/10.3390/app112210908
APA StyleBenbouras, M. A., Petrişor, A.-I., Zedira, H., Ghelani, L., & Lefilef, L. (2021). Forecasting the Bearing Capacity of the Driven Piles Using Advanced Machine-Learning Techniques. Applied Sciences, 11(22), 10908. https://doi.org/10.3390/app112210908