
A Practical and Adaptive Approach to Predicting Indoor CO2

 , ,
, ,
Abstract
:1. Introduction
- A deep learning solution for indoor CO2 prediction that can be trained with just a small amount of recent environmental data (i.e., temperature, humidity and CO2) collected over a short time frame, thereby guaranteeing a high prediction accuracy after few days from the beginning of the data collection with no model pre-training.
- An updating mechanism based on a mobile window that keeps the CO2 predictions consistent with any environmental changes. As a result, the CO2 predictions can be effectively used to regulate HVAC systems, guaranteeing IAQ comfort to occupants.
2. Related Work
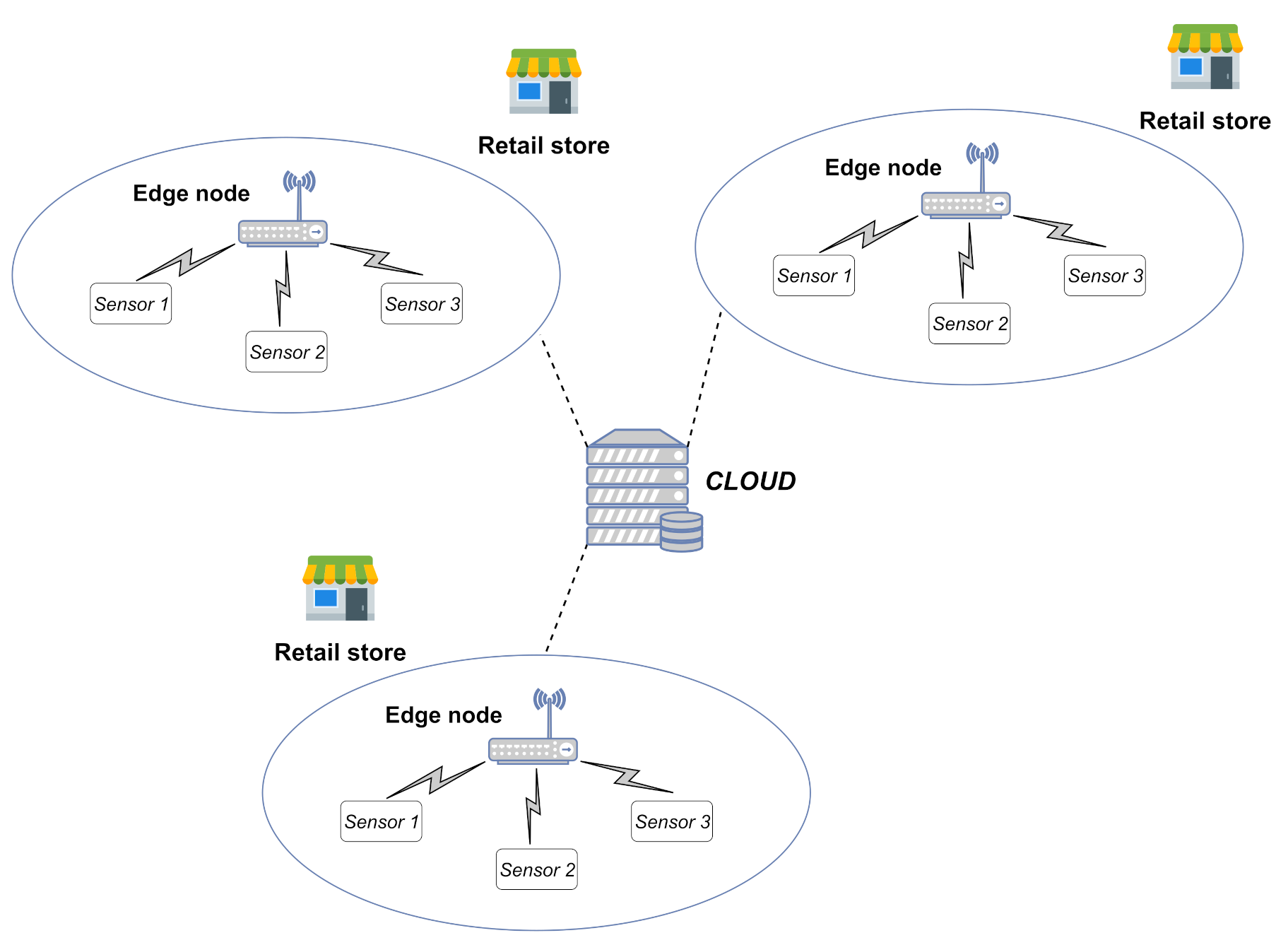
3. Dataset
- Temperature [°C];
- Relative humidity [%];
- Air pressure [hPa];
- Carbon dioxide concentration [ppm];
- Activity level.
4. Methodology
4.1. Neural Network Architecture
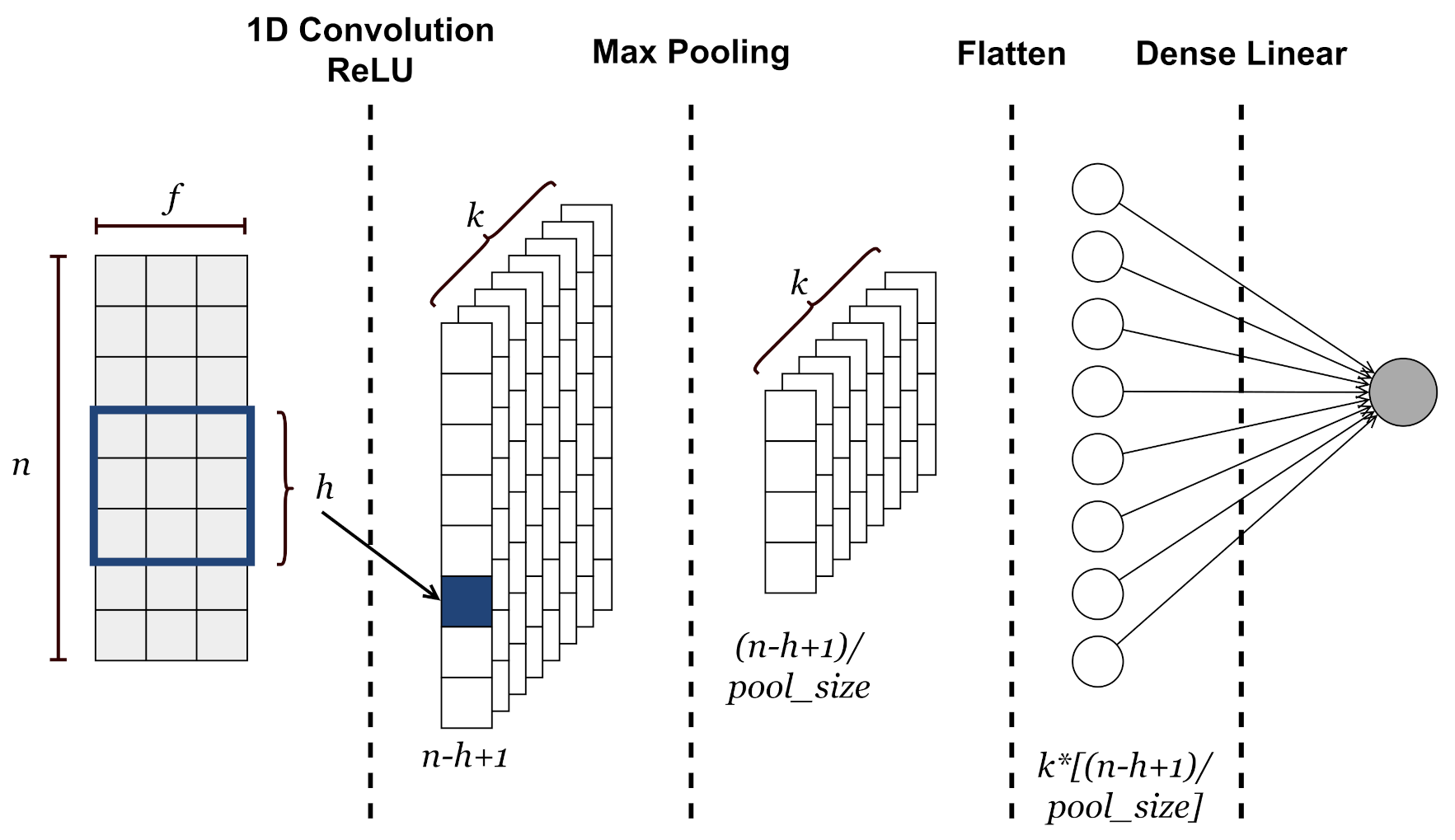
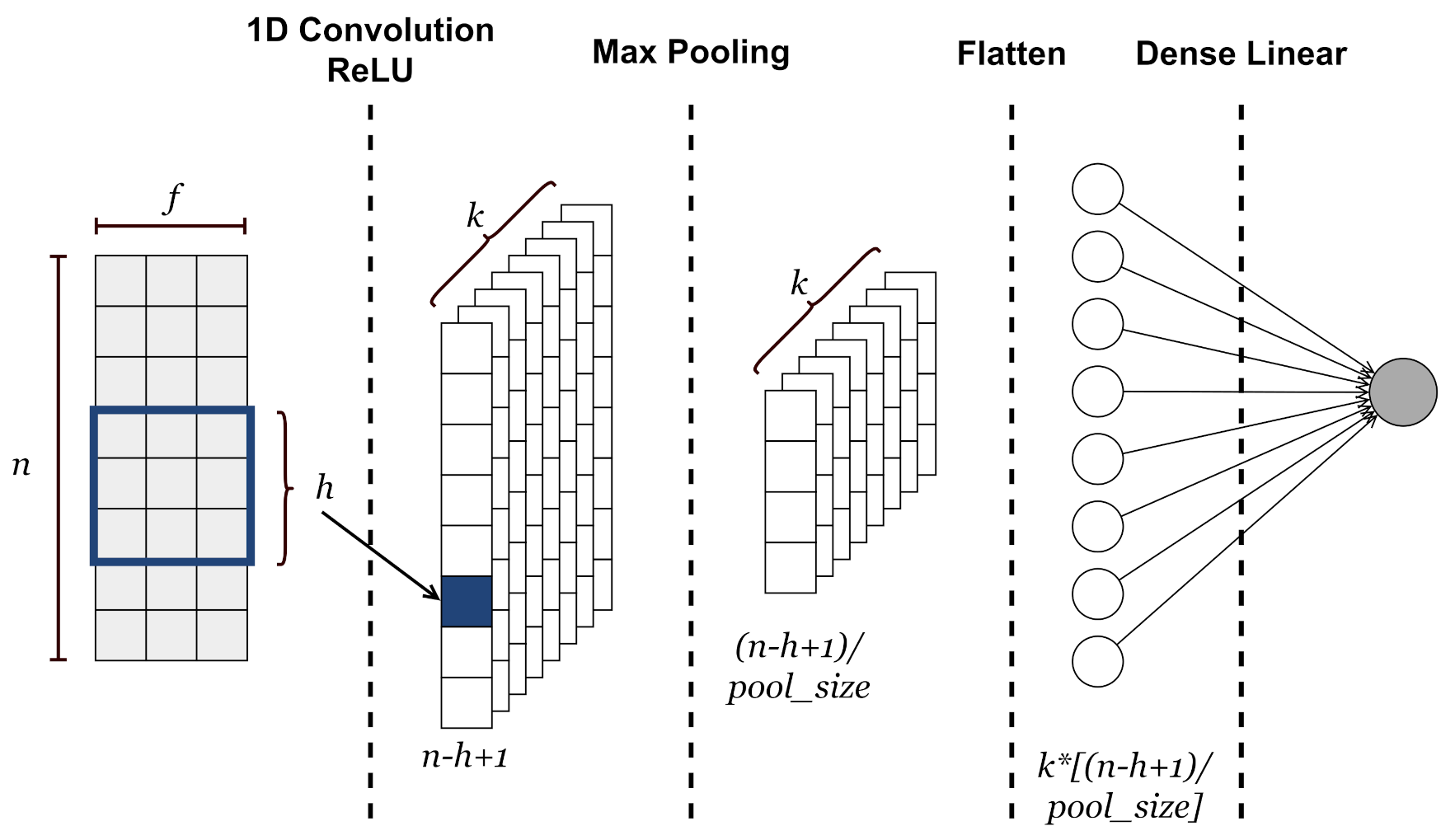
- Input layer. A sample consists of the values of the input environmental variables (i.e., temperature, humidity and CO2) covering a window of n quarters of an hour. Basically, a sample is a data matrix of size , where n is the number of quarters of an hour and f is the number of features. This kind of approach is possible due to the temporal nature of environmental variables. Indeed, the values of temperature, humidity or CO2 at close time intervals are correlated with each other. Before feeding the neural network, the input values are normalized by defining a maximum and minimum value for each variable.
- 1D Convolutional Layer. It is devoted to analyzing and extracting features along the time-dimensional axis of the input data. This layer outputs a matrix of size in which each column is a feature vector extracted through so-called convolutional filters or kernels. Each of these k kernels slides over the input matrix with a step equal to 1 and performs a convolution operation to extract the most significant local information. The common rectified linear activation function (i.e., ReLU(x) = max{0,x}) is used to extract non-linearity patterns from data.
- Max Pooling layer. It aims to learn most valuable information from extracted feature vectors by applying a subsampling operation to the output matrix from the CNN layer. This operation involves a filter that slides along each feature map according to a step given by the stride parameter and applies a maximum operation to a number of elements equal to the pool size parameter. In this case, the stride is set equal to pool size. A matrix of is obtained as output.
- Flatten layer. It reshapes the input matrix to provide a one-dimensional feature vector which can be used to make predictions by the output layer.
- Output layer. This linear fully connected layer, whose output consists of a single neuron, predicts the CO2 value for the next quarter hour.
4.2. Proposed Approach
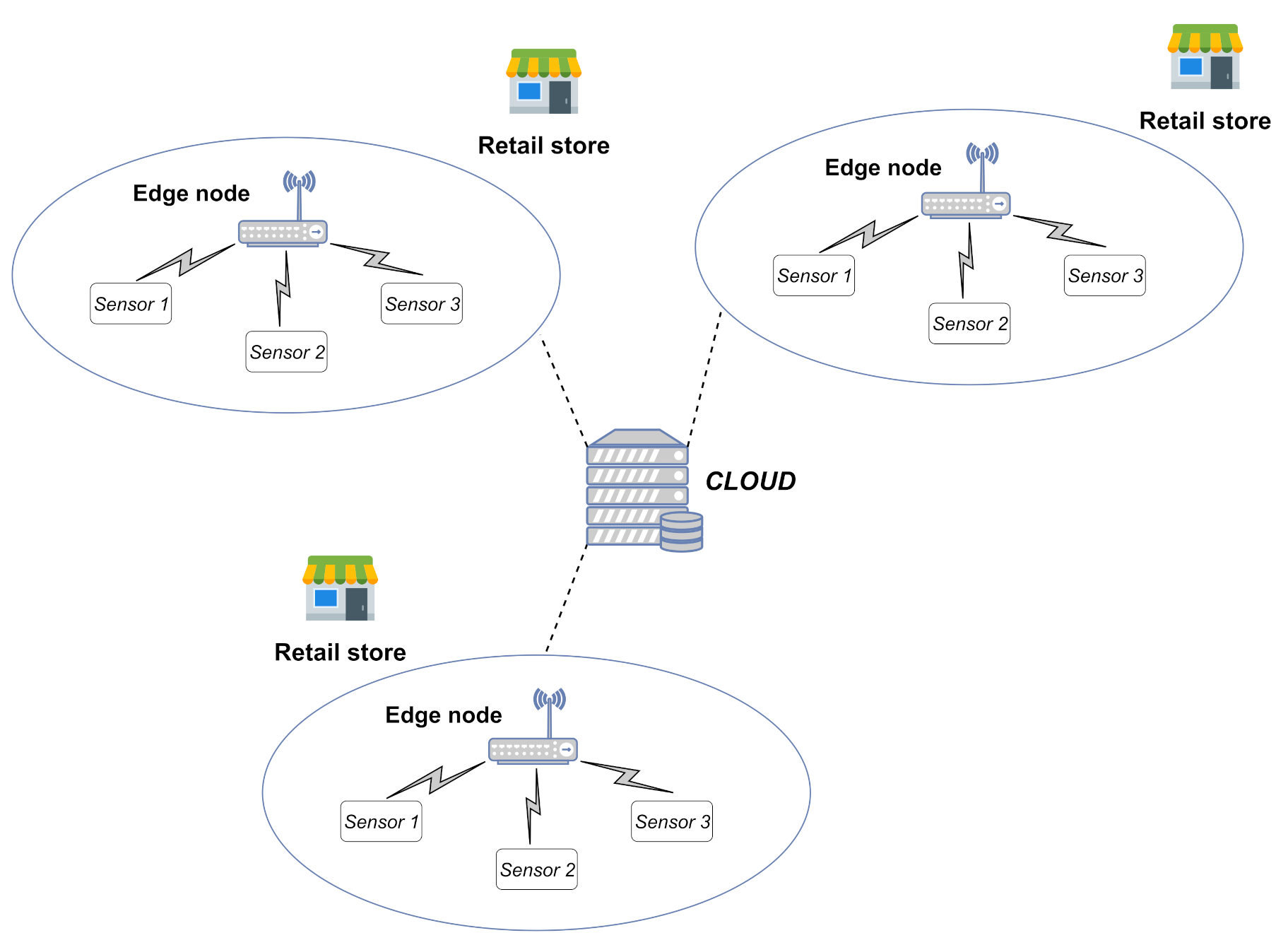
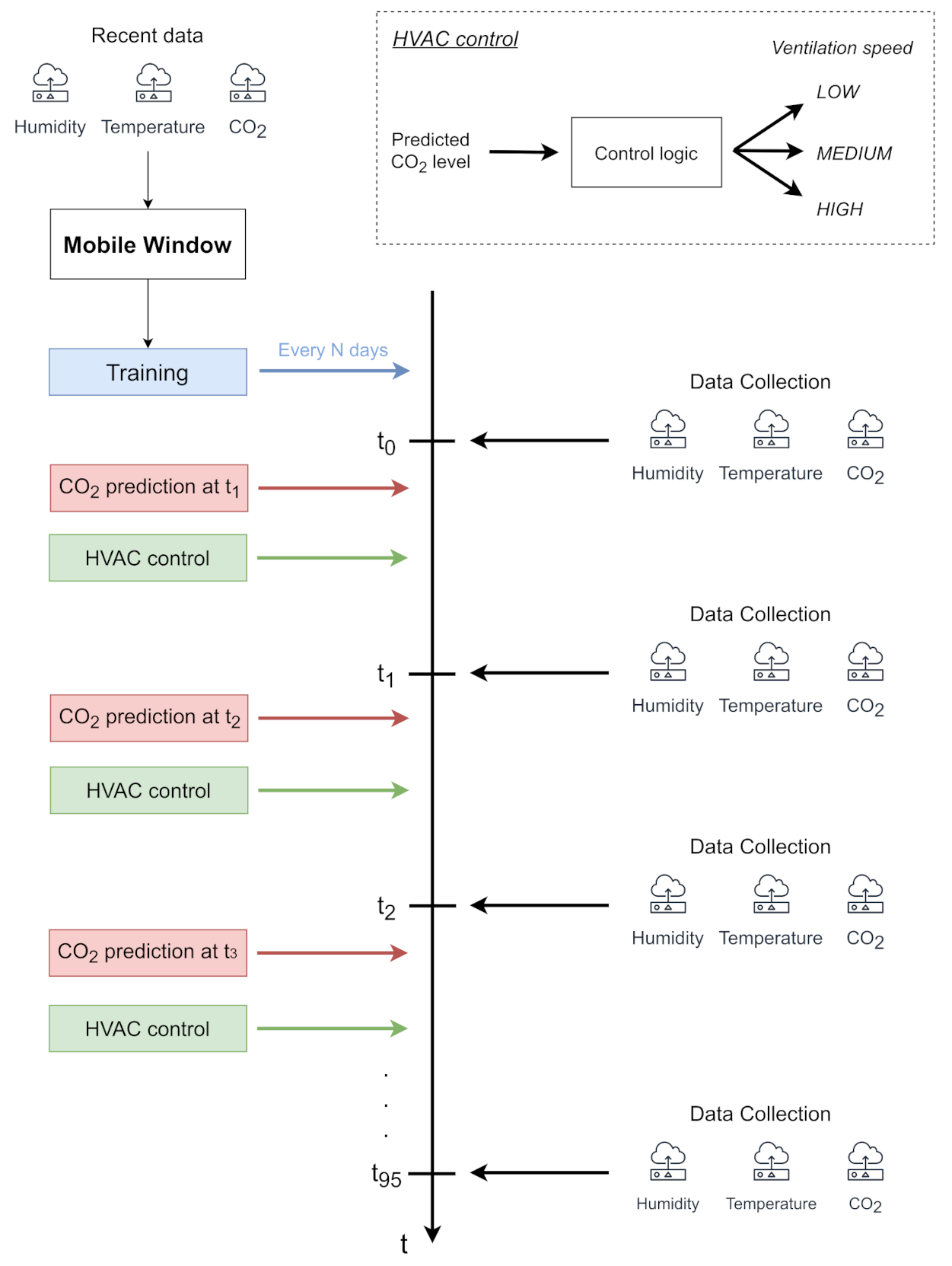
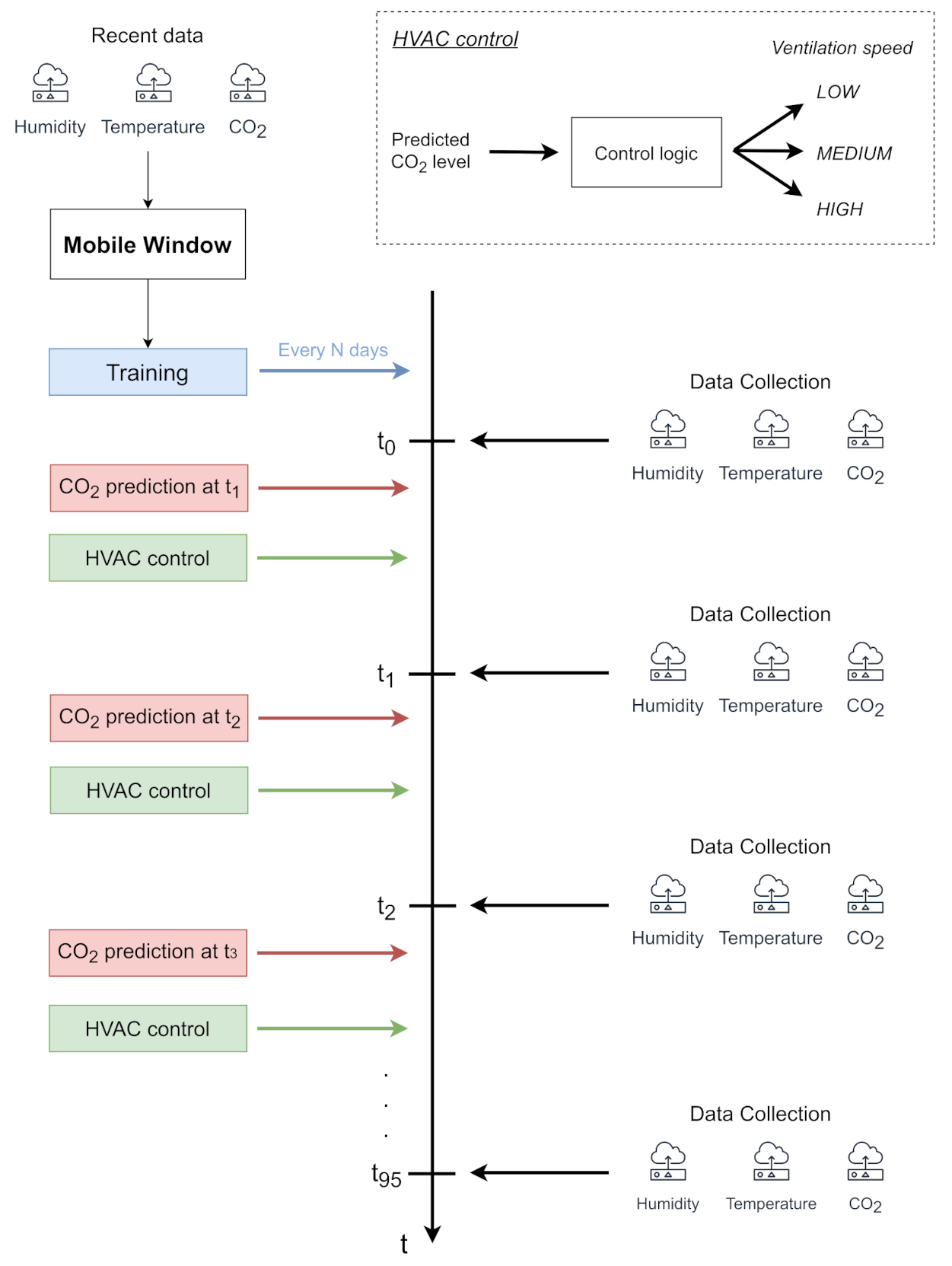
- Every quarter of an hour of the day t0, t1, …, t95, the environmental data (i.e., temperature, humidity, CO2) are collected on the edge device through smart IoT sensors. Indeed, collecting data every 15 min guarantees a good trade-off among the accuracy of analysis, battery lifetime of sensors and storage capabilities of the edge device. Moreover, some industrial protocols, such as Modbus, keep the channel busy during their reading operations. A quarter-hour granularity avoids occupying the physical channel at a high rate as well, enabling the edge device to perform other local operations (e.g., actuation and energy data monitoring) without potential interference.
- Immediately after the data collection, every quarter of an hour, t0, t1, …, t95, the system handles the collected data as samples. In particular, the sample, including the values of the environmental variables of the last n quarters of an hour, is given to the convolutional neural network to predict the CO2 level of the next quarter hour. In this way, the forecast value of CO2 for the next future is regularly provided, taking into account the behavior of the environmental variables in the last short period. The predicted value can be effectively used to regulate HVAC systems in advance in order to keep the CO2 level under control.
- Every N days, a window of data collected over the last few days is used to update the neural network model. In the first period of the deployment, this window progressively increases to account for a larger amount of information to improve the modeling of the environmental variables. As a result, the proposed approach guarantees the improvement of the performance as soon as possible. Once the window achieves its optimal size as the trade-off between the prediction accuracy and computational demand, it slides over time to update the models, effectively becoming a mobile window. From a processing point of view, the data are handled as samples, which are then used to feed the 1D convolutional neural network for training the model. This operation can be properly scheduled after the last data collection operation of the day (before t0).
5. Simulation Setup
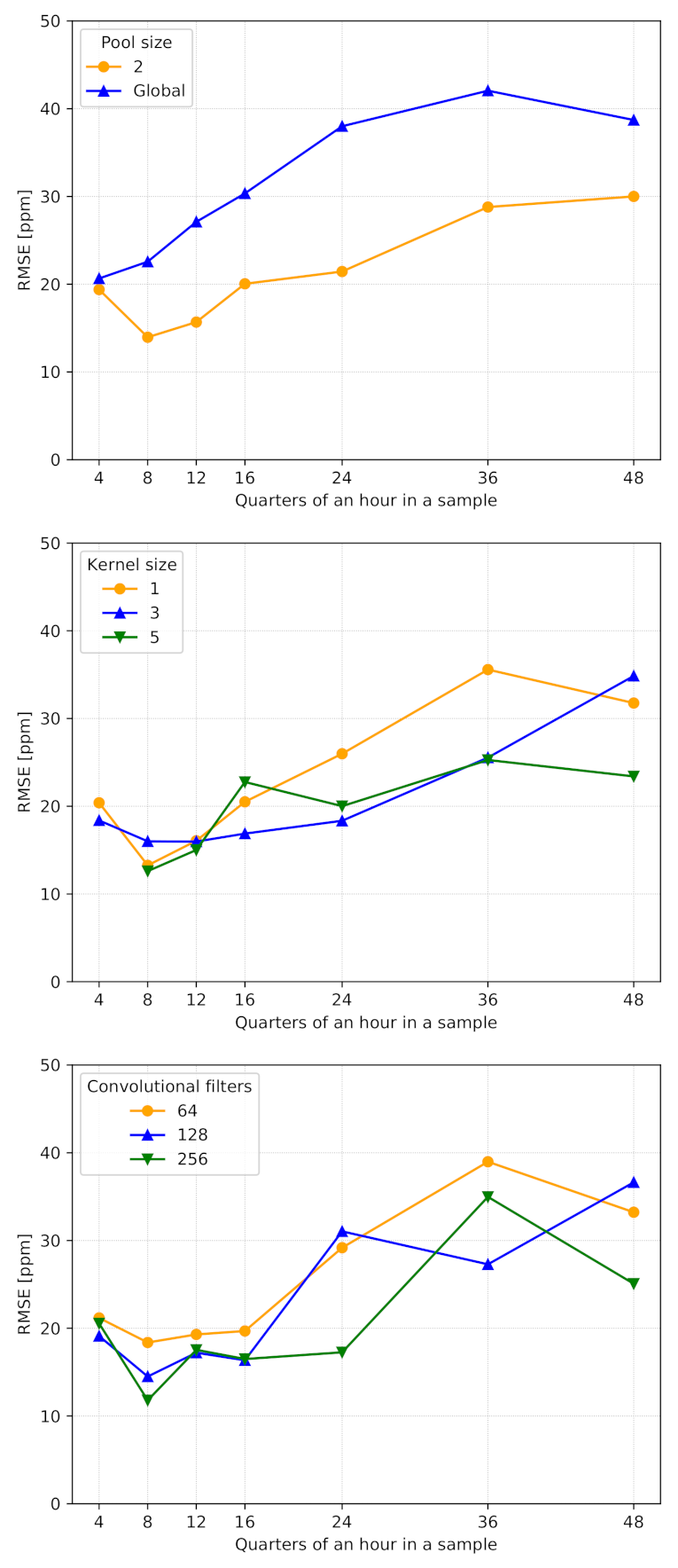
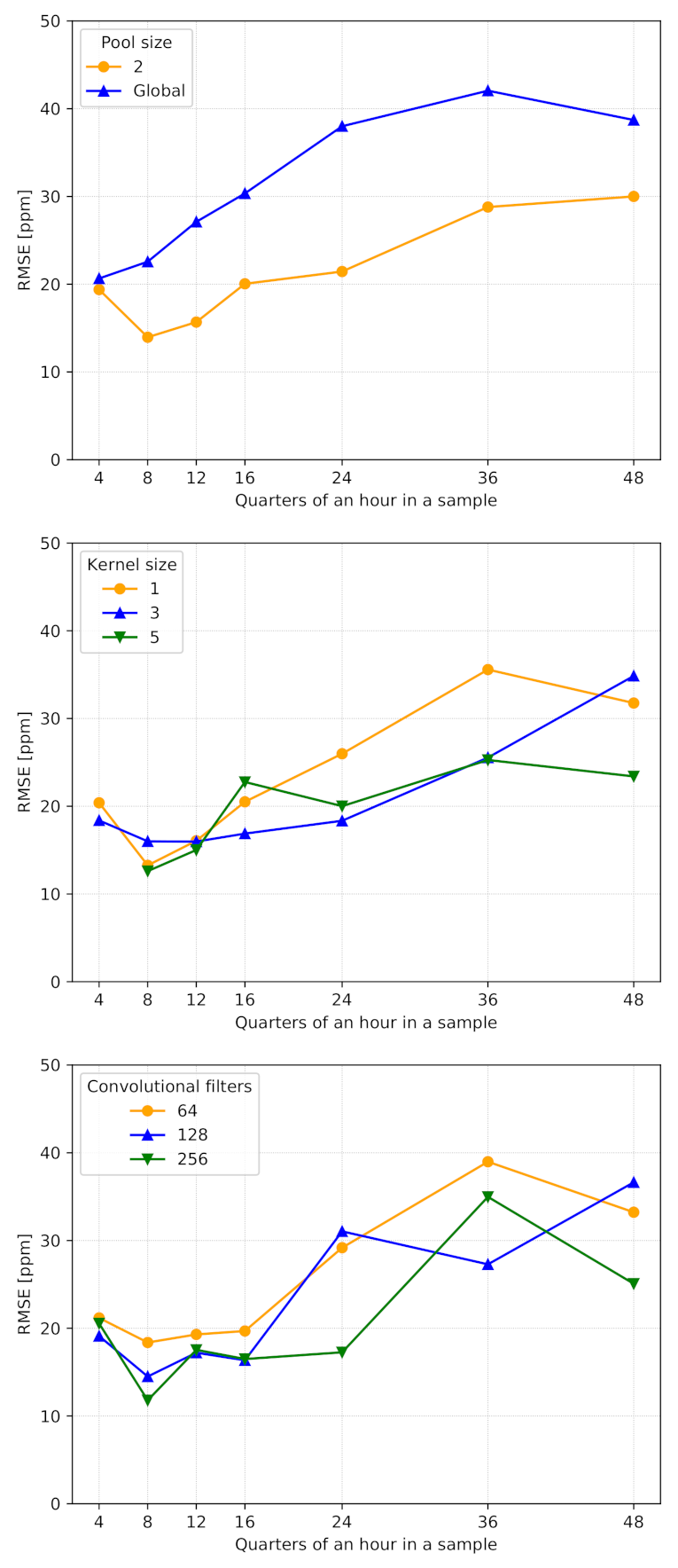
- Pool size is important to extract the most relevant information from the feature vectors provided by the convolutional layer. According to Figure 4, we set it equal to 2, as global max pooling impacted the accuracy significantly.
- Kernel size has a central role in extracting valuable information along the time dimension. The simulation results reported in Figure 4 show similar performances between different kernel sizes. Thus, we set it equal to 3, which is one of the standard values for CNNs.
- Number of convolutional filters was set to 64. Indeed, as reported in Figure 4, we noticed that higher values (e.g., 128 and 256) guaranteed similar performances, especially when samples included a few quarter-hour measurements. In this way, we provide more compact and lightweight models, reducing their memory footprints and guaranteeing faster computation, especially on limited-power and resource-constrained devices.
- The learning rate was set to 0.001, a value used in many complex and non-linear problems, which guarantees a good trade-off between convergence and computational time.
- The batch size was set to 32 to guarantee stability, and to limit the memory footprints of the models.
- Adam optimizer [22] was used as the optimization algorithm.
- RMSE was used as the loss function during the training.
- The validation split was set to 0.3, as per common practice in studies on CO2 prediction. Before the split, we shuffled the samples so that both training and validation sets contained samples which were spread across the whole time window. Please note that we did not shuffle the time series within a single sample, as we wanted to preserve the chronological order of the consecutive quarters of hour.
- The maximum number of epochs was set to 5000, alongside an early stopping patience parameter set to 25 epochs.
6. Results and Discussion
- 1.
- The first experiment aimed to understand the impact of the mobile window, aiming to highlight the practical and adaptive features of the proposed approach;
- 2.
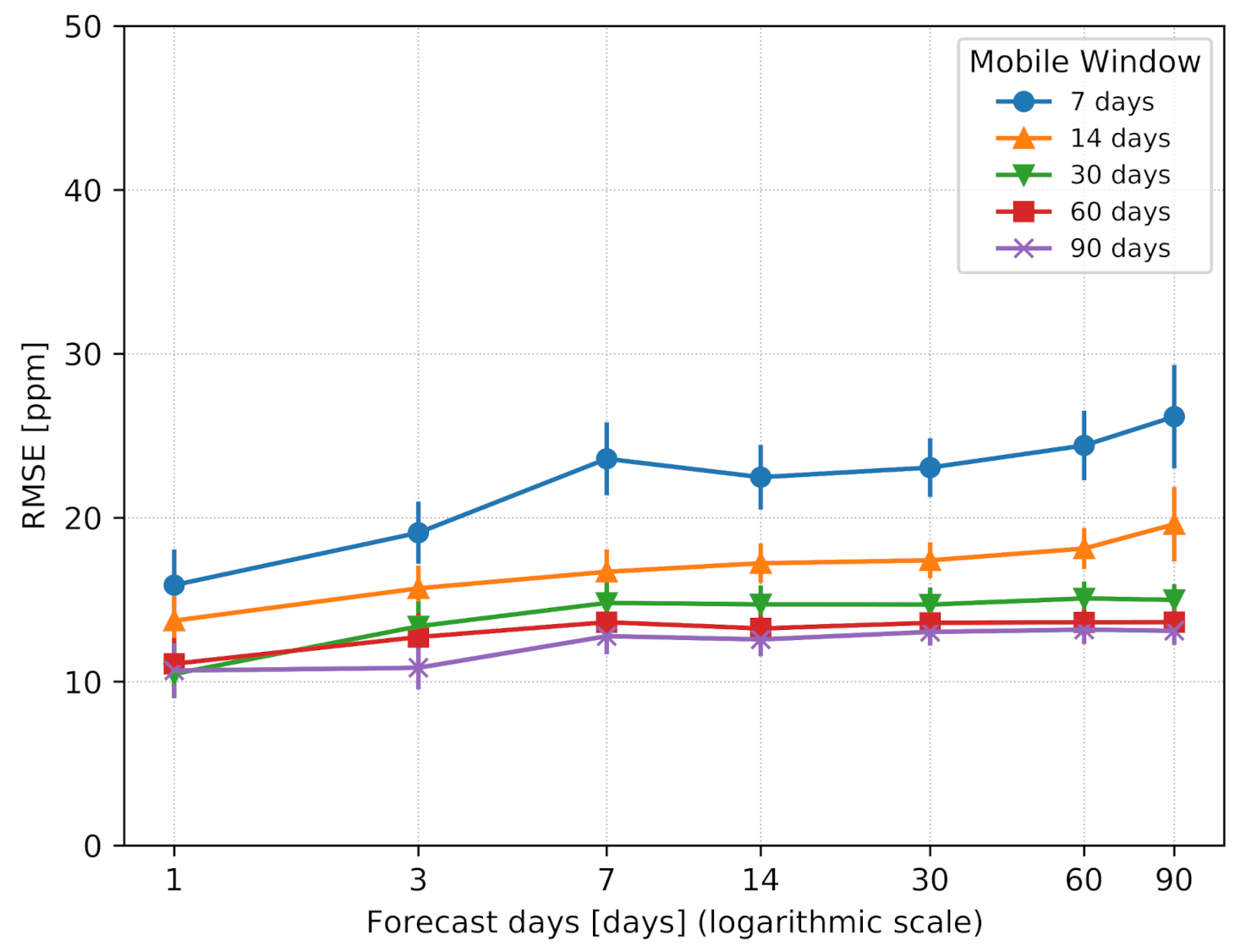
- The second test evaluated the performance when more days in the future were predicted in order to simulate a model update after N days.
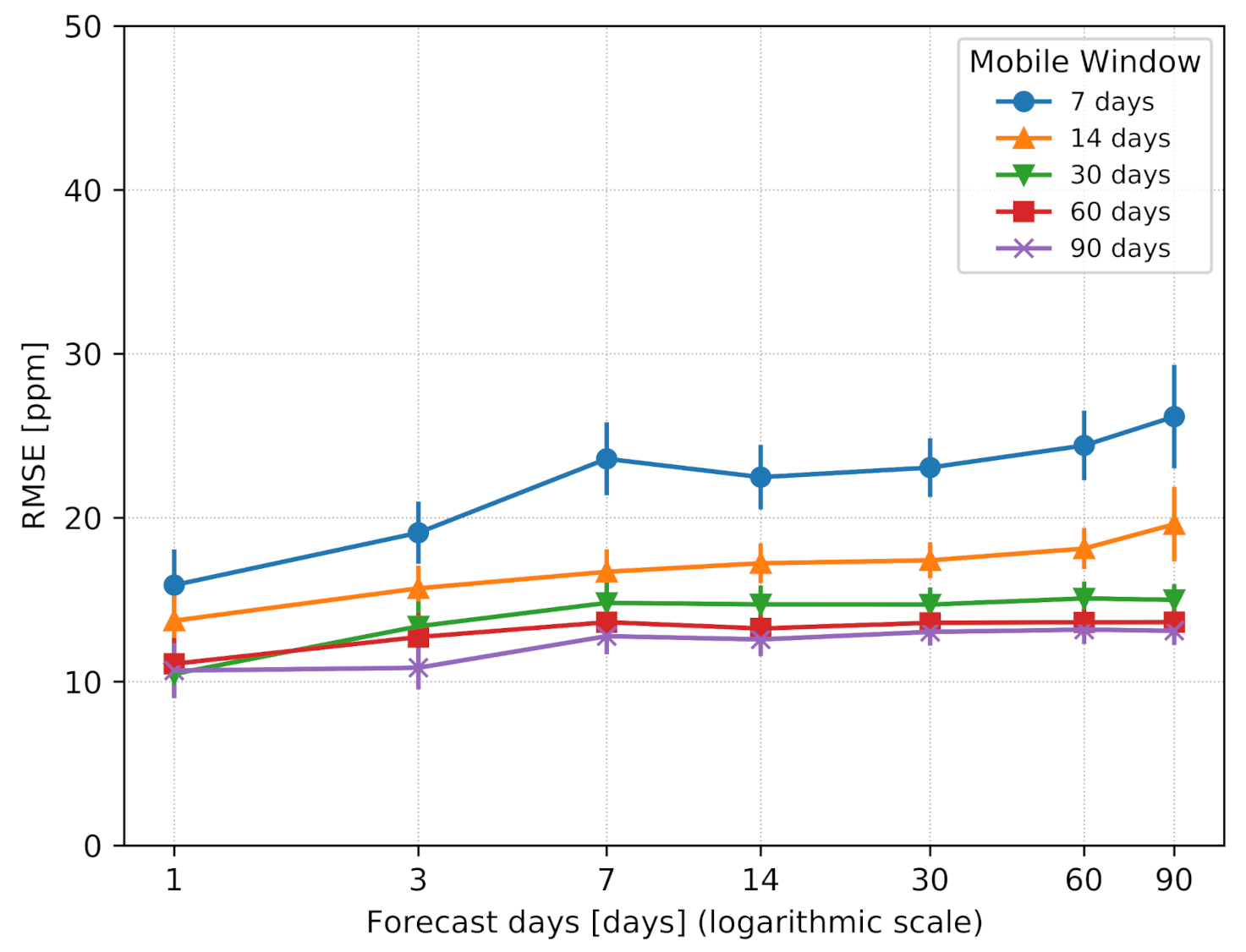
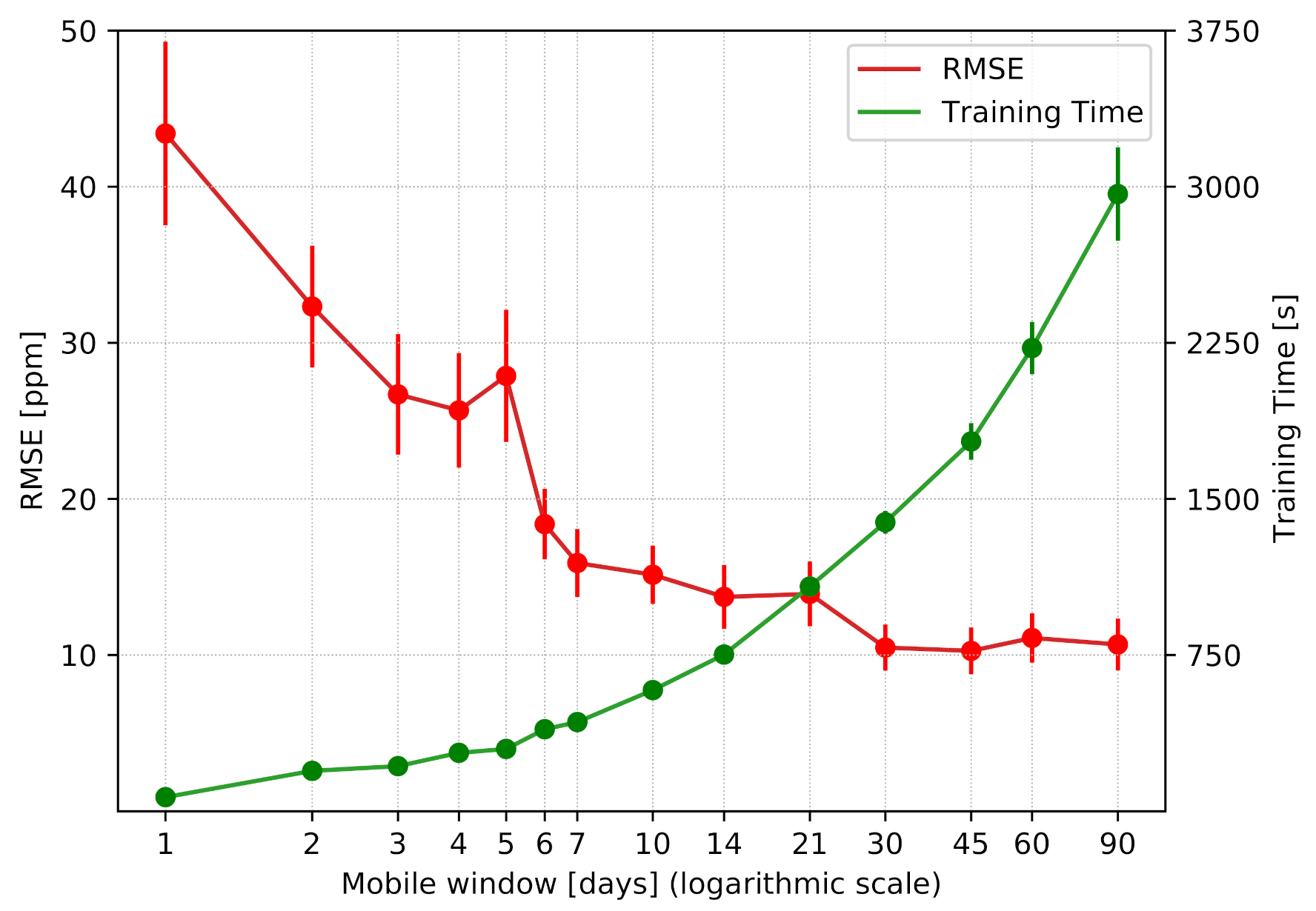
6.1. Mobile Window
- 1.
- In the first period of the system deployment, the performance can be progressively improved by introducing more data in the mobile window.
- 2.
- After only a month of data collection, the proposed approach guarantees the best performance in terms of prediction accuracy.
- 3.
- A window of data including the last 30 days can be effectively moved over time to freshen the model at a certain rate, effectively becoming a mobile window.
6.2. Model Update Rate
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Satish, U.; Mendell, M.J.; Shekhar, K. Is CO2 an indoor pollutant? Direct effects of low-to-moderate CO2 concentrations on human decision-making performance. Environ. Health Perspect 2012, 120, 1671–1677. [Google Scholar] [CrossRef] [Green Version]
- Peng, Z.; Jimenez, J.L. Exhaled CO2 as a COVID-19 Infection Risk Proxy for Different Indoor Environments and Activities. Environ. Sci. Technol. Lett. 2021, 8, 392–397. [Google Scholar] [CrossRef]
- Join Research Center (JRC) of the European Commission. Available online: https://susproc.jrc.ec.europa.eu/ (accessed on 16 May 2021).
- The Modbus Organization. Available online: https://modbus.org/ (accessed on 13 July 2021).
- Wi-Fi Alliance. Available online: https://www.wi-fi.org/ (accessed on 13 July 2021).
- Energy Harvesting Wireless Sensor Solutions and Networks from EnOcean. Available online: https://www.enocean.com/ (accessed on 13 July 2021).
- Vanus, J.; Martinek, R.; Bilik, P.; Zidek, J.; Dohnalek, P.; Gajdos, P. New method for accurate prediction of CO2 in the smart home. In Proceedings of the 2016 IEEE International Instrumentation and Measurement Technology Conference Proceedings, Taipei, Taiwan, 23–26 May 2016; pp. 1–5. [Google Scholar]
- Khorram, M.; Faria, P.; Abrishambaf, O.; Vale, Z.; Soares, J. CO2 Concentration Forecasting in an Office Using Artificial Neural Network. In Proceedings of the 2019 20th International Conference on Intelligent System Application to Power Systems (ISAP), New Delhi, India, 10–14 December 2019; pp. 1–6. [Google Scholar]
- Ahn, J.; Shin, D.; Kim, K.; Yang, J. Indoor Air Quality Analysis Using Deep Learning with Sensor Data. Sensors 2017, 17, 2476. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kallio, J.; Tervonen, J.; Räsänen, P.; Mäkynen, R.; Koivusaari, J.; Peltola, J. Forecasting office indoor CO2 concentration using machine learning with a one-year dataset. Build. Environ. 2021, 187, 107409. [Google Scholar] [CrossRef]
- Sharma, P.K.; Mondal, A.; Jaiswal, S.; Saha, M.; Nandi, S.; De, T.; Saha, S. IndoAirSense: A framework for indoor air quality estimation and forecasting. Atmos. Pollut. Res. 2020, 12, 10–22. [Google Scholar] [CrossRef]
- Putra, J.C.; Safrilah, S.; Ihsan, M. The prediction of indoor air quality in office room using artificial neural network. AIP Conf. Proc. 2018, 1977, 020040. [Google Scholar]
- Khazaei, B.; Shiehbeigi, A.; Kani, A.H.M.A. Modeling indoor air carbon dioxide concentration using artificial neural network. Int. J. Environ. Sci. Technol. 2019, 16, 729–736. [Google Scholar] [CrossRef]
- Skön, J.; Johansson, M.; Raatikainen, M.; Leiviskä, K.; Kolehmainen, M. Modelling indoor air carbon dioxide (CO2) concentration using neural network. Int. J. Environ. Chem. Ecol. Geol. Geophys. Eng. World Acad. Sci. Eng. Technol. 2012, 61, 37–41. [Google Scholar]
- Kim, Y. Convolutional Neural Networks for Sentence Classification. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 21 October 2014; pp. 1746–1751. [Google Scholar]
- Doriguzzi-Corin, R.; Millar, S.; Scott-Hayward, S.; Martinez-del-Rincon, J.; Siracusa, D. LUCID: A Practical, Lightweight Deep Learning Solution for DDoS Attack Detection. IEEE Trans. Netw. Serv. Manag. 2020, 17, 876–889. [Google Scholar] [CrossRef] [Green Version]
- Albawi, S.; Mohammed, T.A.; Al-Zawi, S. Understanding of a convolutional neural network. In Proceedings of the 2017 International Conference on Engineering and Technology (ICET), Antalya, Turkey, 21–23 August 2017; pp. 1–6. [Google Scholar]
- Kiranyaz, S.; Ince, T.; Abdeljaber, O.; Avci, O.; Gabbouj, M. 1-D Convolutional Neural Networks for Signal Processing Applications. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 8360–8364. [Google Scholar]
- Lara-Benítez, P.; Carranza-García, M.; Riquelme, J. An Experimental Review on Deep Learning Architectures for Time Series Forecasting. Int. J. Neural Syst. 2020, 31. [Google Scholar] [CrossRef] [PubMed]
- Keras: The Python Deep Learning API. Available online: https://keras.io/ (accessed on 11 July 2021).
- How to Develop Convolutional Neural Network Models for Time Series Forecasting. Available online: https://machinelearningmastery.com/how-to-develop-convolutional-neural-network-models-for-time-series-forecasting/ (accessed on 11 July 2021).
- Kingma, D.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Related Work | Dataset Size | Input Variables | AI Architecture | Automated Model Update |
|---|---|---|---|---|
| This Work | Adaptive (Max 30 days) | Temperature, Humidity, CO2 | 1D CNN | Yes |
| Vanus et al. [7] | One year | Temperature, humidity, time, date | Random Forest | No |
| Khorram et al. [8] | 242 days | CO2, weekday, hour, minute | ANN | No |
| Ahn et al. [9] | Six months | Fine dust, light amount, VOC, CO2, temperature and humidity | GRU | No |
| Kallio et al. [10] | One year | CO2, PIR, temperature and humidity | Ridge, Decision Tree, Random Forest, MLP | No |
| Sharma et al. [11] | One week | Indoor NO2, wind speed, wind direction, number of student | LSTM | No |
| Putra et al. [12] | One week | CO2 | ANN | No |
| Khazaei et al. [13] | One week | CO2, humidity, temperature | MLP | No |
| Skön et al. [14] | Six months | Temperature, humidity | MLP | No |
| Parameter | Value |
|---|---|
| Environmental variables in input | Temperature, humidity, CO2 |
| Time granularity of data | 15 min |
| Quarters of an hour in a sample | 8 |
| Number of kernel filters—Convolutional layer | 64 |
| Kernel size—Convolutional layer | 3 |
| Pool size—Max Pooling layer | 2 |
| Learning rate | 0.001 |
| Batch size | 32 |
| Optimizer | Adam |
| Loss function | Mean squared error |
| Validation split | 0.3 |
| Maximum number of epochs | 5000 |
| Patience | 25 |
| Parameter | Range |
|---|---|
| Temperature | 0–40 °C |
| Humidity | 0–80 % |
| CO2 | 350–5000 ppm |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Segala, G.; Doriguzzi-Corin, R.; Peroni, C.; Gazzini, T.; Siracusa, D. A Practical and Adaptive Approach to Predicting Indoor CO2. Appl. Sci. 2021, 11, 10771. https://doi.org/10.3390/app112210771
Segala G, Doriguzzi-Corin R, Peroni C, Gazzini T, Siracusa D. A Practical and Adaptive Approach to Predicting Indoor CO2. Applied Sciences. 2021; 11(22):10771. https://doi.org/10.3390/app112210771
Chicago/Turabian StyleSegala, Giacomo, Roberto Doriguzzi-Corin, Claudio Peroni, Tommaso Gazzini, and Domenico Siracusa. 2021. "A Practical and Adaptive Approach to Predicting Indoor CO2" Applied Sciences 11, no. 22: 10771. https://doi.org/10.3390/app112210771
APA StyleSegala, G., Doriguzzi-Corin, R., Peroni, C., Gazzini, T., & Siracusa, D. (2021). A Practical and Adaptive Approach to Predicting Indoor CO2. Applied Sciences, 11(22), 10771. https://doi.org/10.3390/app112210771