2. Literature Review
Several studies have been conducted to investigate student field specialization (student major) using ML. Past research has used different ML techniques and input features to study the relationship between student data and student majors. Alshaikh et al. [
3] built a recommendation system to suggest suitable colleges for KAU students based on the students’ grades, college specializations, and enrollment requirements. They applied this system to a dataset of 960 KAU preparatory students in 2017. Two methods were used to evaluate the accuracy of the k-nearest-neighbor algorithm. In the first method, the dataset was split into two datasets, 20% of the dataset for testing and the remaining 80% for training, which generated 70.83% accuracy. The second approach applied k-fold cross-validation, where the dataset was split into K smaller sets and the test was applied K times. Pupara et al. [
50] have proposed an accurate institutional recommender system (RS) that was developed by combining decision tree and association rule methodologies. The RS is intended to assist students in selecting acceptable colleges based on their context and educational institution information using a mobile device. Ezz and Elshenawy [
9] presented an adaptive recommendation system for predicting a suitable engineering department for students enrolled in an engineering preparatory year college using classification methods such as SVM, k-nearest neighbor (KNN), linear regression (LR), quadratic discriminant analysis (QDA), and RF. The system recommends a suitable engineering department among seven engineering departments for each student based on his academic performance and the proposed system has an average accuracy of 82.57%. In the study of Salaki et al. [
51], 3 ML algorithms, namely, naïve Bayes (NB), RF, and sequential minimal optimization (SMO), were trained on a dataset collected from three different educational colleges in Bangladesh to identify and select the best groups of educational majors to streamline the selection of a suitable direction for new students. The results showed that RF had the best performance, with 84.9% accuracy, 84.9% precision, 84.6% sensitivity, and an F-measure of 84.3%. In a study conducted by Fiarni et al. [
52], an academic decision support system was built in the IS department to classify and recommend IS sub-majors for students using a C4.5 decision tree classifier and a rule-based approach. Bautista et al. [
10] adopted 8 methods (namely, the J48 tree classifier, logistic function classifier, naïve Bayes (NB), nominal regression, decision tree CHAID, neural network multilayer perceptron, neural network radial basis function, and nearest neighbor) to recommend a suitable specialization for engineering students. The first three methods were tested in Weka and achieved accuracies of 80.5%, 64.30%, and 60.11%, respectively. The last 5 experiments conducted in SPSS, yielded accuracies of 64.00%, 68.20%, 71.30%, 61.00%, and 71.20%. Moreover, the J48 tree classifier performed the best, with the highest accuracy of 80.5%. A study conducted by Kularbphettong and Tongsiri [
53] aimed to develop a decision support system for student major selection using two ML methods, J48 and Bayesian network algorithms (BNs). Their results showed that BNs performed the best, with 92.13%, 0.93, and 0.91 accuracy, precision, and F-measure, respectively. Meng and Fu [
35] applied 8 classification methods, namely, SVM, decision tree (DT), naïve Bayes (GNB), RF, gradient boosting decision tree (GBDT), convolutional neural network (CNN), collaborative filtering (CF), and recurrent neural network (RNN), to recommend appropriate college majors. RF performed best, with an accuracy of 97.87% and an f-score of 96.60%. Wei et al. [
54] proposed an improved SVM-based prediction system model for predicting second major selection. Their experimental results indicated that the proposed method performed best, with an accuracy of 87.36%, AUC of 0.8735, the sensitivity of 85.37%, and specificity of 89.33%, Sethi et al. [
55] conducted a study to predict the appropriate study stream for students in higher secondary education. They found that the neural network (NN) outperformed the other approaches with a classification accuracy of 86.72%, the sensitivity of 0.92, specificity of 0.82, and MCC of 0.72. Abosamra et al. [
56] examined various types of ML predictions models on a dataset, which gave the best choice as a (NN) architecture that provides 6.26 an average root mean squared error, and a mean absolute error of 5.74 based on a scale of 0 to 100.
The artificial neural network (ANN) method was adopted by Latifah et al. [
57] to predict suitable student specialization in a dataset of 314 students based on student records from the iGracias Integrated Academic Information System at Telkom University in 2016, and they achieved an accuracy of 94.81%. The NB method and analytic hierarchy process (AHP) techniques were adopted by Zubaedah et al. [
58] to build a decision support system to predict suitable specialization in technical faculty in Indonesia. A rule-based classification algorithm (PART) was adopted by Tamiza et al. [
59] to propose an intelligent model for selecting and predicting suitable university specialization. The model achieved an accuracy of 73.7%. Iyer and Variawa [
60] built a system model to guide first-year undeclared/undecided engineering students to predict suitable engineering majors. They found that the RF approach outperformed the other classification algorithms, with the highest accuracy of 57%. AlAhmar [
61] developed a rule-based expert system that suggested majors for students at the undergraduate level. Kamal et al. [
62] has used RF classifiers to analyze students’ personality and intelligence across various majors and academic programs and predict suitable college majors for students based on academic results, personality, and level of intelligence with an accuracy of level one at 96.1% and 94.72% at second level respectively, moreover, they have investigated that their framework has potential to recommend a student towards future higher degree options.
Although the attractiveness of higher education institutions in many areas of student field of study selection has been extensively researched, there is a paucity of evidence available for modeling the relationship between these factors and intelligent recommendation of student fields based on the job market and student history and experience. To our knowledge, no studies have been conducted on the use of any ML algorithm specifically designed for the purpose of predicting student specialization and identifying the extent to which various parameters contribute to the determination of the specialization of students. As a result of this discovery, we were inspired to conduct our current study. As a result, the current research has implications for higher education, students, and the labor market.
4. Results and Discussion
Consequently, the selection of an appropriate and suitable field of study is a paramount issue for both students and educational institutes. Therefore, in this section, we investigated the student field (student major) of specialization selection using different ML techniques based on student academic history and the current job market. We also visualized the current dataset to further understand the input variables and performed several experiments using Python to answer the research questions.
We performed data visualization using Python to further understand the experimental dataset. These visualization results show the importance of input attributes in predicting field specialization.
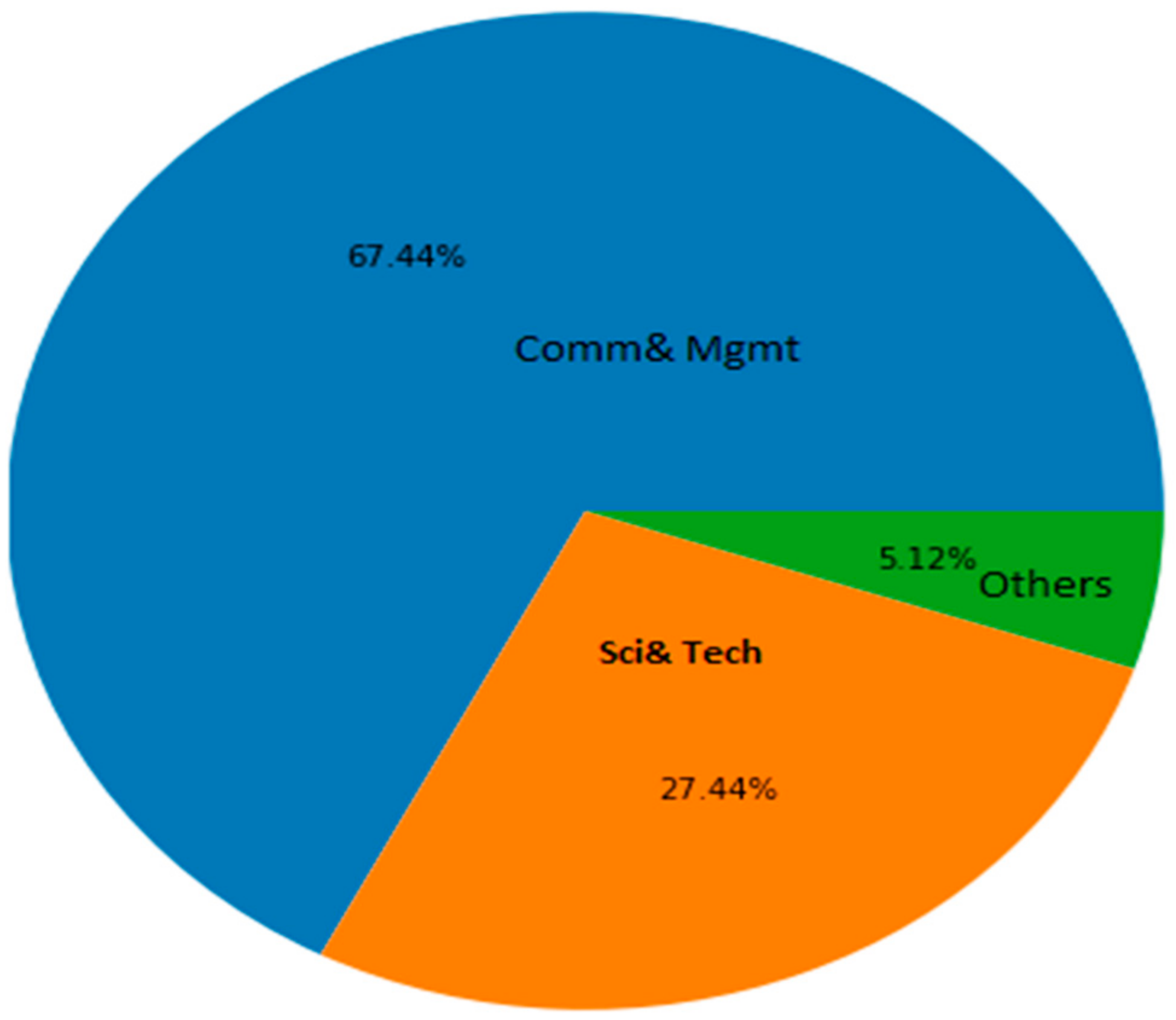
Figure 2 shows that higher secondary students who obtained jobs mostly majored in commerce and science. This result further indicates that commerce and science fields are currently in the greatest demand.
Figure 3 shows that commerce and management students in higher secondary schools mostly take science and technology fields as postgraduates.
In
Figure 4, the blue portion (1) represents Mkt and finance, and the yellow portion (0) represents the Mkt and HR.
Figure 4 indicates that 55.81% of students take the MKT& Finance program in postgraduate education, and others take the MKT & HR field.
At this step, we have obtained considerable knowledge about the data and can easily build models. Although there are lots of studies related to the selection of majors by students and its influential factors [
1,
2,
3,
4,
5,
6,
7,
68], studies with a machine learning approach in this domain are limited [
7]. In this study, we investigate the student study field based on student job markets, student academic history, and job experience. As the number of factors, size of the datasets, methods applied varied in different studies, it is impractical to compare these studies. Some of these studies were listed in
Table 2. To find an appropriate ML model and student factors for our proposed recommendation system, this study conducts two experiments on datasets using the Python Sklearn library. Sklearn is a Python library that is used to train and deploy ML models. In this section, we investigate the following research question:
Question 1: Can we model the student undergraduate major path choice according to the job market and student academic history by applying different ML algorithms, and if so, which ML classifier offers optimal performance in predicting student undergraduate major selection?
The first experiment was conducted to explore this question. In the first experiment, we applied several Tree based ML models (DT algorithm, RF algorithm, extra tree classifier, and XGBoost) and SVM to our dataset by using their default parameters. Decision-tree has been widely implemented in various domains, such as in medical fields [
75], marketing prediction tasks [
76], and education [
77,
78], due to its various well-known attractive features [
79]. Features such as simplicity, comprehensive calculations, no required parameters, and the capability of handling mixed types of data, encouraged us to select DT in this study. Random forests are used in this study due to being easy and stable with many interesting properties. One of these interesting properties is that they provide a powerful computation of variables [
80]. The extra tree classifier is one of the learning algorithms that can aggregate the results of multiple de-correlated decision trees collected in a “forest” to output its classification result. It has been applied in this study because it is similar to RF; however, it is faster, and its method in the construction of the decision tree in the forest is optimal. The tree-based algorithm is simple and requires less data; additionally, it is easy to understand and easily implemented [
81,
82]. Conversely, deep learning (artificial neural network) is complex, computationally expensive, and requires more data [
83]. Additionally, we did not use the naive Bayes algorithm, which is a very commonly used algorithm to solve real-life problems because it overlooked how to calculate probabilities [
84]. We used SVM because the performance is good using small datasets [
85,
86]. Moreover, it does not apply a strict requirement on the number of samples and sample points; additionally, it can process error distributions and can be easily promoted. XGBoost was used in this study because it has higher predictive accuracy than other ML algorithms, such as SVM and DT [
87,
88]. Our dataset contains both numeric and categorical attributes. Therefore, the selected model must perform well on categorical data. For the first experimental dataset, we used 19 input features, which are shown in
Table 1, and the target variable was
specialization. First, we converted the target variable (specialization) into a binary form (0,1) by using python, wherein “0” denotes marketing and finance (Mk&Fin) and “1” represents the Market and Human resources Field (Mk&HR). As ML algorithms cannot directly work on categorical data, and to convert input features in digital form, we used a hot encoding technique. Hot encoding is a technique that can map categorical data into integers; as a result, the Ml algorithm can produce better results. Hot encoding is useful when there is no relationship between the variables. The 10-fold cross-validation method was used to increase the generalization ability of the models and to ensure that the model behavior was optimal. Furthermore, accuracy, true positive rate (TPR), false-positive rate (FPR), and receiver operating characteristic (ROC) curve were used as evaluation metrics. The accuracy represents the percentage of correct predictions of the model given unseen data. In ML, the TPR is also known as recall or sensitivity and indicates the percentage of actual positive values that are correctly predicted by the model. Finally, the ROC curve plots the TPR of the model [
89]. The current study performance metrics are shown below.
Notes: TP (true positive), FN (false negative), TN (true negative), FP (false positive).
DT algorithms belong to the supervised category of ML algorithms. A DT is simple and easily understandable. We selected this technique because it is widely used by researchers due to its simplicity. In addition, a DT has some great advantages, such as representing rules that could be easily understood and interpreted by users [
81]. This type of algorithm performs well for categorical and numerical attributes and does not require complex data preparation. In short, ML classifiers and their outputs are easy to understand for individuals with a non-analytical background [
90]. The default parameters (ccp_alpha = 0.0, criterion = ‘gini’, min_samples_split = 2) are used to train the DT model, and an accuracy of 55% was obtained by DT using 10-fold cross-validation.
Table 3 shows that the DT correctly classifies student specialization with a TPR of 0.87 and an FPR of 0.71.
In the second step of the first experiment, RF classifiers were used to predict student specialization given a student placement dataset. The RF classifier is a supervised learning algorithm that applies to both classification and regression problems [
80]. RF creates multiple DTs from random sample data and then gives predictions on high-accuracy trees [
91,
92]. The RF classifier predicts the student field specialization with the following default parameters (bootstrap = True, ccp_alpha = 0.0, criterion = ‘gini’, max_depth = 15, max_features = ‘auto’,max_leaf_nodes = 10). The TPR of RF is 0.70, and the FPR is 0.20, as shown in
Table 4.
Extra tree classifiers (ETC) are used in the third step to predict the student’s field of specialization. ETC is an ensemble learning technique that collects the result of multiple trees. The approach is similar to an RF classifier, but the tree construction method differs. The accuracy of the ETC classifier on the student dataset is 0.52. During training, the ETC Classifier used the default parameters (n_estimators = 100, random_state = 0) to predict student specialization with high accuracy. The TPR and FPR of the ETC classifier were 0.53 and 0.49, respectively, as shown in
Table 5.
In the fourth step of the first experiment, we used the SVM classifier. SVM is a supervised learning algorithm that is mostly used for classification problems. SVM finds the hyperplane that divides a dataset into two classes [
93]. SVM classifiers perform well on clean and small datasets. Furthermore, SVM is faster than other machine learning techniques [
93]. The best accuracy (52%) of SVM was achieved with the following default parameters (random_state = 0, tol = 1 × 10
−5), as shown in
Table 6. The TPR and FPR of SVM are 0.53 and 0.49, respectively, as shown in
Table 7.
Finally, we used the XGBoost classifier to predict student specializations by using default parameters (base_score = 0.5, booster = ‘gbtree’, colsample_bylevel = 1, learning_rate = 0.1). XGBoost is a popular boosting technique in ensemble ML, and its performance is good on structured and tabular data. XGBoost is also called GBC. XGBoost uses parallel tree boosting to solve real-life data science problems. We used this technique because its impact has been widely recognized in many machine learning and data mining challenges, where it has become a commonly used and popular tool among Kaggle’s competitors and data scientists [
87]. XGBoost predicts the student’s specialization with an accuracy of 61%, and the TPR and FPR of the XGBoost classifier are 0.57 and 0.35, respectively, as shown in
Table 8.
In the first experiment, the TPR and accuracy of the RF and GBC classifiers were higher than DT, SVM, and ETC, and the FPR was lower than that of DT, SVM, and ETC, as shown in
Figure 5, which indicates that the performance of these classifiers in predicting field specializations is good, compared to that of the alternatives. Sometimes, accuracy is misleading when the dataset is imbalanced [
94,
95,
96]. In other words, if the ratio of some classes is less than that of others in the dataset, we used the ROC curve and TPR, which is also called recall. We used ROC to further understand the performance of the models. The ROC is an evaluation metric that represents the performance of an ML model in the form graph [
97] by plotting the TPR and FPR of the model.
Figure 5 shows that the TPR of the RF and GBC classifiers was high, compared to that of the DT, SVM, and ETC. The results also showed that RF and GBC classifiers are appropriate classifiers to build student field recommendation systems because they can handle ordinal, non-ordinal, and categorical data and are also good choices for skewed and multimodal data [
98]. Moreover, the RF and GBC classifier ensemble method outperforms simple DT classifiers. The previous study showed that the performance of SVM in small data is good and faster [
93]. Furthermore, DT and ETC are unstable and have high sensitivities for overfitting classifiers [
15].
Question 2: How is a student’s undergraduate major path choice associated with that student’s academic performance and the job market?
We performed a second experiment to investigate the second research question. The second experiment investigated how a student’s field of specialization was associated with that student’s previous academic history, salary, and experience. First, we observed the baseline characteristics of different selected variables, such as secondary education percentage, higher secondary education percentage, degree percentage, MBA percentage, and employability test percentage. Then, we performed statistical analysis (Spearman correlation) to assess the relationship between a student’s major and other input variables. The Spearman correlation shows how closely two variables are related.
Table 9 shows the Spearman correlation between student field specialization and other input variables of the current study. The statistical results show that higher student marks in higher secondary (hsc_p), university degree (Degree_p), and entry test (etest_p) play a significant role in student field of specialization, and we can easily suggest study fields according to these features. Furthermore, student work experience (work_exp) and job placement (status) also impact student field specialization. Several interesting observations are obtained from the above statistical analysis. First, students at the high secondary stage are very excited about their field in university (undergraduate level) or undergraduate major path choice. At this level, every student wants to go into a good study field. In other words, students place high importance on student field specialization decisions. Second, students who get admitted to their favorite field graduate with higher grades. Third, the student field of specialization also affects student work experience and market salary. Fourth, students who applied for their favorite field may receive high marks on their university entry test. Fifth, students who graduate in their favorite field have a high chance of getting a job. In addition, the student marks percentage in a higher secondary, university degree, and entry test is useful criteria for study field suggestion. The result also demonstrates that student marks percentage in higher secondary, university degree, entry test assignment, and other factors are beneficial to the intelligent recommendation system. Using these variables, the proposed recommender system correctly predicts student field specialization according to their marks and preferences.
The current study results show that we can design a recommendation system for predicting the field of specialization using RF, GBC, and SVM classifiers. The proposed recommendation system will offer a variety of functions to students and college/university staff, such as recommending appropriate fields of study for students, ranking highly demanding fields in the coming and current years, and predicting the future salary of recommended fields. The results also show that higher secondary education is an appropriate stage to enter a good study field. Moreover, having a suitable specialization might affect students’ academic performance and job salary, which could assist in lessening their anxiety and confusion and could lead to significantly better study program completion and increase graduation rates in the future. Having early awareness of the estimated number of incoming freshmen per study specialization program could also be of high value to the college administration. With this great insight, they would be able to allocate required resources per specialization field and better prepare schedules.
5. Conclusions
Unsuitable field of specialization selection for new graduate students has serious consequences for students and universities. Choosing an appropriate field of specialization is a critical determinant of a student’s future academic and work progression. The current study used a machine learning and statistical approach to investigate the student study field. In this study, we extracted data from the Kaggle repository, which is publicly available for research purposes, and then converted these data into a form that is acceptable for ML models. We then applied several supervised learning techniques (DT, RF, ETC, and GBC) to our dataset and evaluated them using a 10-fold cross-validation method. The findings showed that RF and, GBC predict student study fields with accuracy 0.75% and 0.61 respectively. The results indicate that RF and GBC are the most appropriate, classifiers to integrate into the intelligent field recommender system for predicting suitable fields for students according to the job market because the performance of these classifiers is good on less training data Additionally, the intelligent field recommender system will help educational institutions to suggest study fields according to the current job market and demand. Using this recommendation system, students can select a field that is according to the job market. The study also demonstrated that the student field of specialization selection is mostly dependent on the percentage of marks in higher secondary, university, and entry tests. Student work experience and student job placement also affect the student’s field of study. Furthermore, student mark percentage in higher secondary, university, and entry tests are appropriate criteria for all higher education institution admission departments to select the right undergraduate major path choice.
This experiment aims to investigate whether these data could be used to suggest an appropriate study field for students. This study used student academic data and job market data from the Kaggle repository. The student’s field of specialization is a complex problem that also depends on other factors, such as country and student family background. Therefore, these factors must be further investigated.
The Current study limitations: There are some limitations, for example, the current study has limited specializations, records, and input features. In the future, we will use design surveys to assess other factors or input features related to the student field of specialization. Additionally, the accuracy of RF, GBC, and SVM models will be further improved by increasing the number of observations and hyperparameter tuning. Then, we will build an intelligent field recommendation system using collaborative filtering to recommend suitable fields to students according to their preferences and the job market. This proposed system will help the university admission system make quick decisions about student field recommendations.


 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}