
TDGVRPSTW of Fresh Agricultural Products Distribution: Considering Both Economic Cost and Environmental Cost


Abstract
:1. Introduction
- The first category takes carbon emission or fuel consumption as the optimization target. Aiming to minimize fuel consumption, Suzuki [5] established the pollution routing problem (PRP) model with capacity and vehicle number constraints. Li et al. [6] established a multi-depot vehicle routing problem (MDVRP) model that can share depot resources. Considering that the speed of vehicles on various sections depends on the time of departure and the time period in which the vehicles are travelling, Alinaghian and Naderipour [7] established the time-dependent vehicle routing problems (TDVRP) model and allowed multiple paths to be selected between nodes; aiming to minimize carbon emissions, Manerba et al. [8] used the emission factor model to convert the mileage of vehicles into carbon emissions. Yu et al. [9] constructed the heterogeneous fleet green vehicle routing problem with time windows (HFGVRPTW). Ehmke et al. [10] considered that vehicle speed changed with different time periods and road sections. The vehicle speed was defined as a random variable, and the influence of speed and load on the path to carbon emission minimization was analyzed. A TDVRP model with vehicle numbers constraint was constructed.
- The second type takes environmental cost and economic cost as the optimization target. Micale et al. [11] built models including maximum vehicle capacity, speed, carbon emissions, asymmetric paths, and time windows constraints, and applied the technique for order performance by similarity to ideal solution (TOPSIS) technology to integrate economic and environmental factors. TOPSIS is a criterion for selecting the most suitable solution. Fukasawa et al. [12] took the speed as a continuous decision variable, adopted the road section speed optimization strategy to make vehicles run at the optimal speed in each road section, and took the minimization of the total cost composed of fuel consumption cost and driver’s salary as the optimization objective, respectively, and constructed a PRP model and open green vehicle routing problem with time windows (GVRPTW) model with vehicle numbers and time window constraints. Aiming at the one-to-one pickup and delivery problem, Soysal et al. [13] constructed a heterogeneous VRPTW model with the optimization objective of minimizing the total cost composed of fuel consumption cost, driver wage cost, and penalty cost for violating the time windows, considering that vehicle speed varies with urban and non-urban sections.
- The third category takes two or more conflicting optimization objectives as objective functions. Giallanza and Puma [14] assumed that customer demand was a fuzzy number simulated by a time-dependent algorithm and established a multi-objective fuzzy chance-constrained programming model. Ghannadpour and Zarrabi [K] established a multi-objective heterogeneous VRPTW model with fuel consumption, minimizing vehicle use and maximizing customer satisfaction as optimization objectives. Zulvia et al. [15] constructed a multi-objective GVRPTW model of perishable products, with operating cost, deterioration cost, carbon emission minimization, and customer satisfaction maximization as optimization objectives. Bravo et al. [16] constructed a multi-objective PRPTW model for heterogeneous VRPPD with the optimization objectives of minimizing total fuel consumption and total driving time and maximizing the number of customers served.
- The precise algorithm is one that can find an optimal solution to a problem. Yu et al. [9] proposed an improved branch price algorithm (BAP) to solve HFGVRPTW, and the results showed that the improved BAP algorithm greatly reduces the branch and calculation time. The model established by Xiao and Konak [22] took into account capacity and mileage constraints, time windows constraints, heterogeneous fleets, and time-varying road network conditions and proposed a hybrid algorithm of mixed integer linear programming (MIP) and iterative neighborhood search.
- The basic idea of the traditional heuristic algorithm is to start from the current solution, search for a better solution in the neighborhood of the current solution and continue to search until there is no better solution. Li et al. [23] improved the local search stage of the Clarke and Wright heuristic algorithms to solve the two-echelon position path problem (2E-LRP). In the hybrid heuristic algorithm designed by Wang et al. [24], the Clarke and Wright savings heuristic algorithm (CWSHA) and the sweep algorithm were used to generate the initial population continuously.
- Metaheuristic algorithm is an improvement of the heuristic algorithm, which is the combination of the random algorithm and local search algorithm. Demir et al. [25] proposed an adaptive large-scale neighborhood search algorithm based on simulated annealing. Eight removal operators and four insertion operators were used to search the neighborhood to generate a new solution and simulated annealing acceptance rules were used to determine whether to select the new solution as the current solution. Sadati et al. [26] developed a hybrid general variable neighborhood search and tabu search approach to solve the model effectively.
- A hybrid algorithm combining adaptive genetic algorithm and neighborhood search algorithm is designed, which considers both the search breadth and the search depth. The chromosomes in the population are disturbed by the crossover and mutation operation of the genetic algorithm, and the excellent chromosomes in the population are deeply searched by the neighborhood search algorithm.
- Different fresh agricultural products have different perishability. Does the difference in perishability of fresh agricultural products have an impact on driving routes and customer assignment schemes? This paper will clarify the problem through experiments.
- In order to improve the quality and diversity of the initial population, three different methods were used to generate the initial population in this paper. The three methods are, respectively, the CW saving algorithm, nearest neighbor insertion algorithm, and random method.
2. Problem Description and Model Formulation
2.1. Problem Description
- The vehicle is of the same type and the driving speed is different in different time periods at the same time, and you can start at different times and return to the distribution center after completing the task;
- The customer demand is less than the vehicle capacity, and there is only one vehicle for its services;
- The distribution center has a time window within which vehicles must leave and return;
- The engine is switched off while the vehicle is waiting and during customer service, and there is no fuel consumption or carbon emission.
2.2. Model Formulation
2.2.1. Calculation Method of Travel Time for the Cross Time Section
- Calculate the travel time in the initial period.. If , then , , end of calculation; If , , , turn to step 2.
- ; , if , then , , repeat step 2; otherwise, , , the calculation of the driving time of section is completed.

2.2.2. Freshness Loss Coefficient Function
2.2.3. Carbon Emission Estimation Function
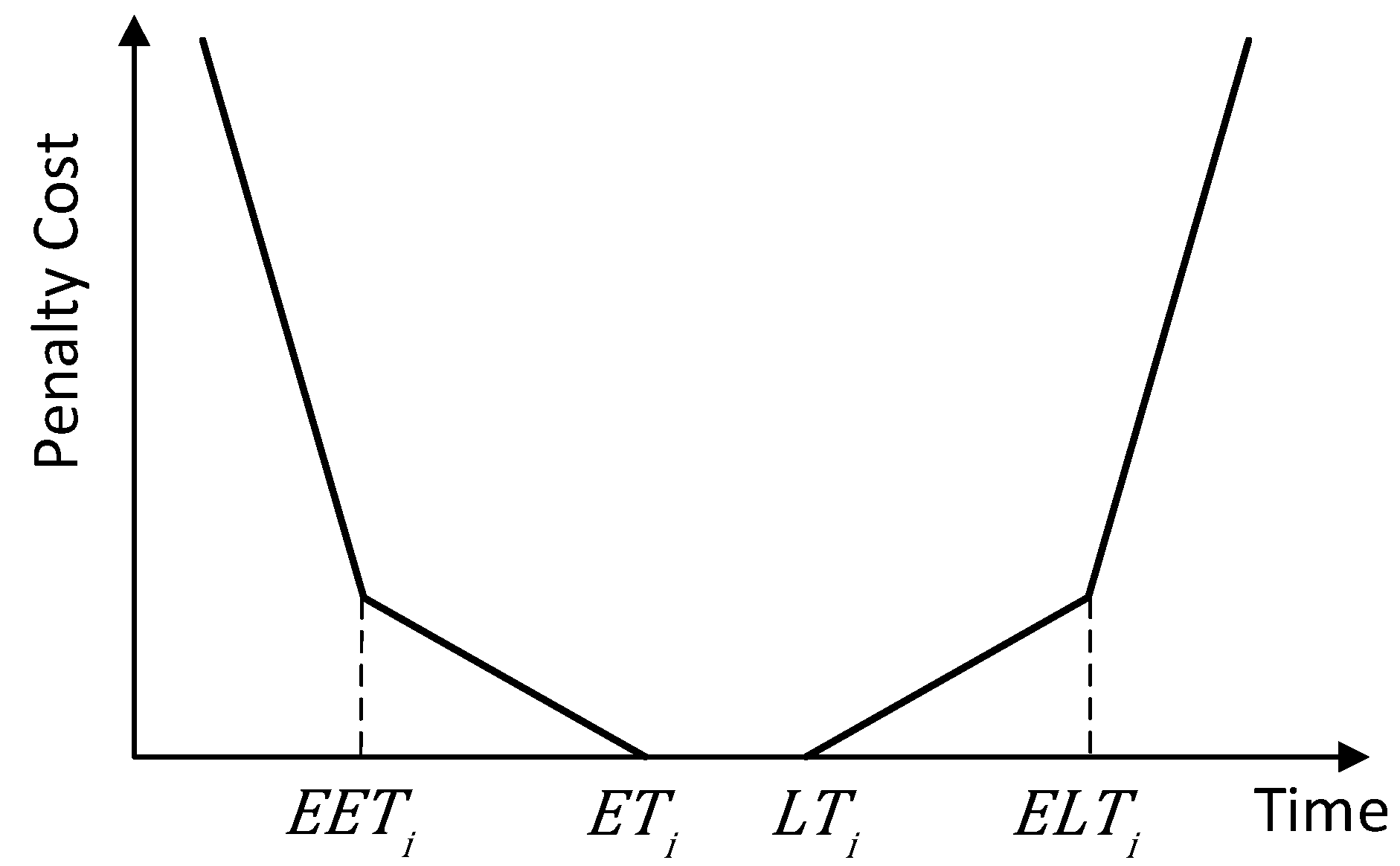
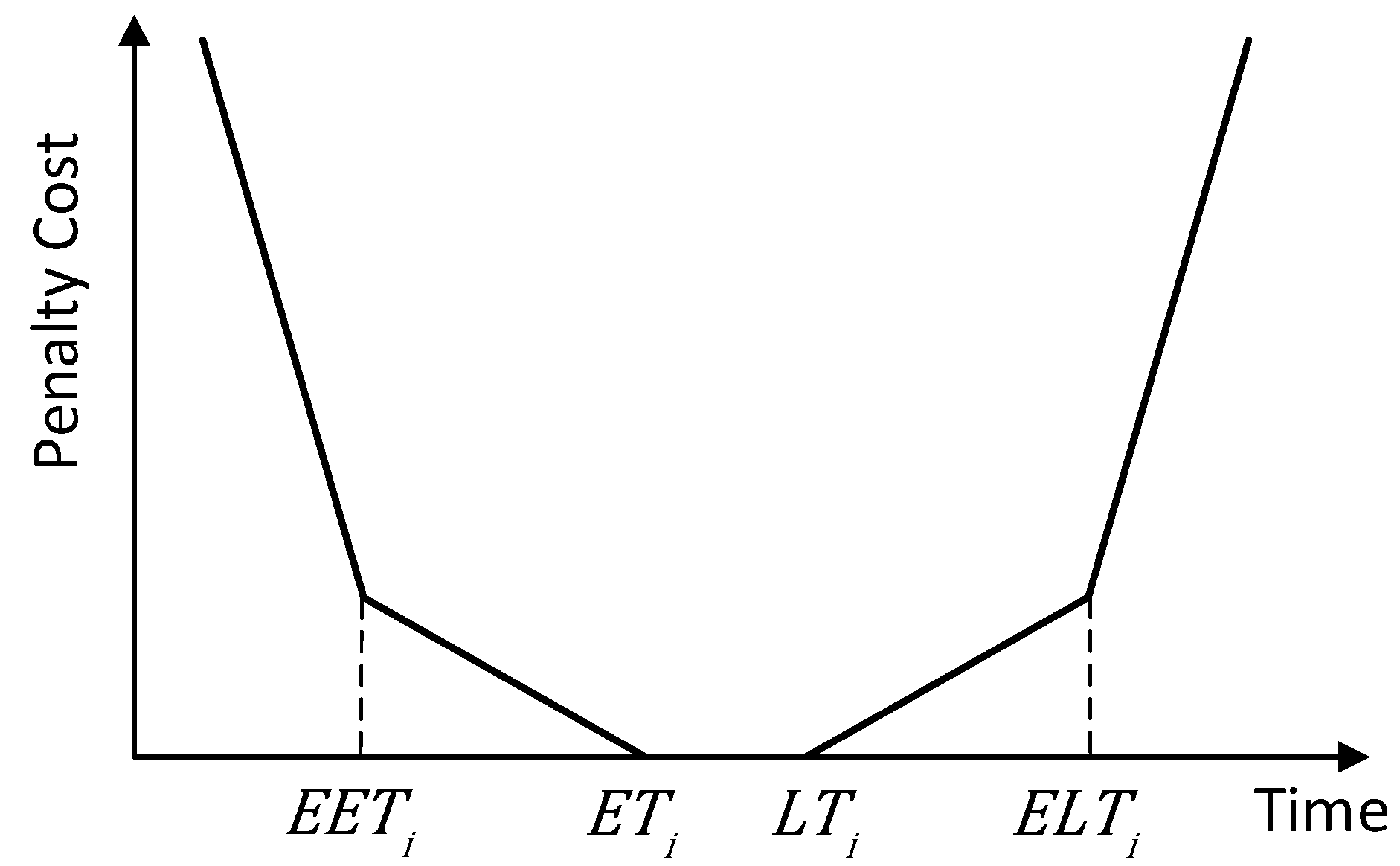
2.2.4. Soft Time Windows Model
2.2.5. Symbol and Variable Definitions
2.2.6. TDGVRPSTW Model Formulation
3. Variable Neighborhood Adaptive Genetic Algorithm
3.1. Algorithm Model
3.2. Initial Population
3.3. Fitness Function
3.4. Genetic Operators
3.4.1. Selection Operator
3.4.2. Crossover Operator
3.4.3. Mutation Operator
3.5. Variable Neighborhood Descent Operator
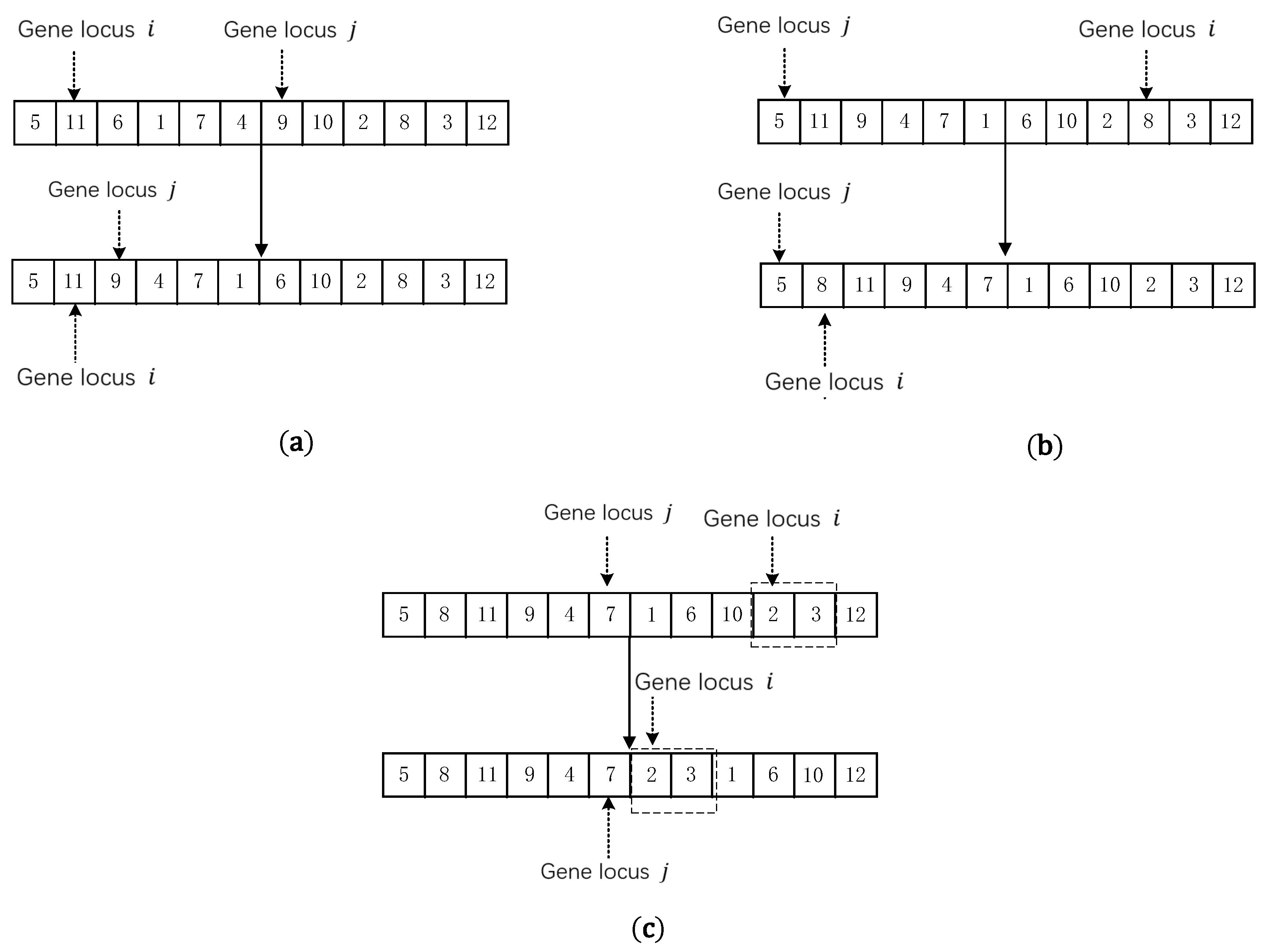
3.5.1. Gene Fragment Inversion Operator
3.5.2. Insertion Operator of Single Gene Location
3.5.3. Insertion Operator of Double Gene Location
4. Computational Experiments and Analyses
4.1. Data and Parameter Setting
4.2. Algorithm Comparison Experiment in VRPSTW Model
4.3. Algorithm Comparison Experiment in TDGVRPSTW Model
- The initial population of both algorithms is generated by random method.
- The adaptive function, crossover operator, and mutation operator in AGA are consistent with those described in Section 3.4.
- HGA is composed of GA and local search, which are called sequentially.
- The exchange method of local search is to exchange the path fragments of any two individuals in the population [40].
4.4. Experiments with Different Optimization Objectives
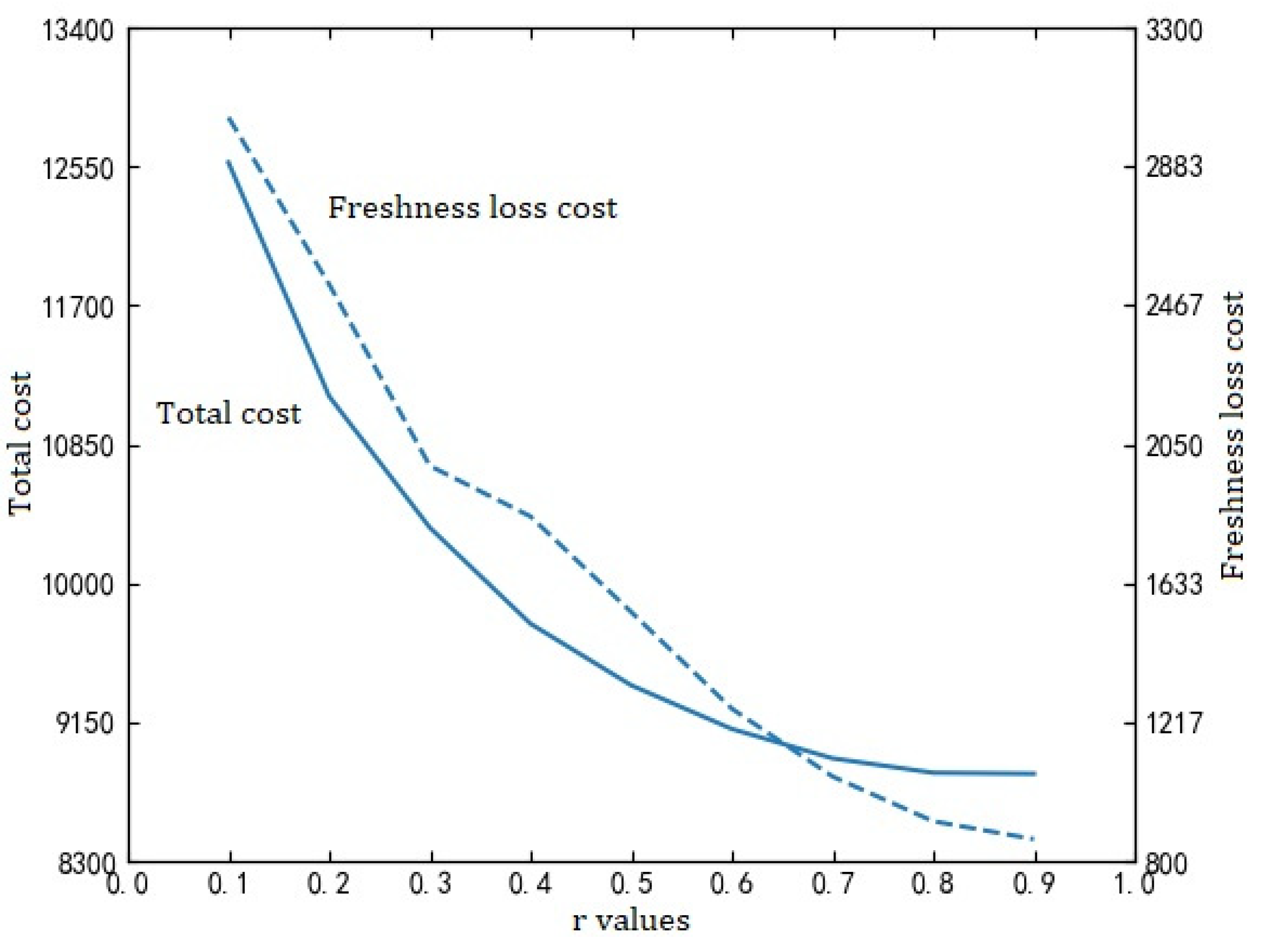
4.5. Experiments of Different Regulatory Factors
4.6. Experiments to Analyze the Relationship among Distribution Cost, Carbon Emission Cost, and Freshness Loss
5. Discussion
- According to previous studies, soft time windows have many advantages over traditional hard time windows [34]. The penalty cost setting of broken line soft time windows is closer to the actual feeling of customers [18]. This paper further verifies that the proposed approach can obtain better solutions and is more efficient compared with the hyper-heuristic genetic algorithm through the comparison experiment of the broken line soft time windows model. The proposed approach is more suitable for the broken line soft time windows model.
- In the TDGVRPSTW model, the optimal solution found by the proposed approach was better than AGA and HGA, and the number of iterations was less, so the proposed approach is more efficient in optimizing. The literature [26] has proved that a systematic change of neighborhood structure can optimize the search of the solution space. This paper experiments with the sorting of the optimal solutions of three algorithms and shows that the diversity of neighborhood structure is very important for search results and efficiency, and the more diverse the neighborhood structure, the better the results and efficiency.
- According to previous studies [6], the geographical distribution of customers will have a great impact on the distribution cost. Through experiments on standard data sets, this paper further found that the geographical distribution of customers will affect the proportion of each part of the total cost. Enterprises can design different optimization objective functions according to different geographical distribution types of customers.
- Experimental results of different regulatory factors show that the difference in time sensitivity of fresh agricultural products has a great impact on the total cost and distribution plan. With the reduction of time sensitivity of fresh agricultural products, the total cost will be greatly reduced, and the proportion of fresh loss cost to total cost will also be greatly reduced.
- The experiments on the relationship between itemized costs show that carbon emission costs account for the lowest proportion of total costs. Assign weight to each itemized cost. If the weight of carbon emission cost increases, the cost of carbon emission will decrease while the total cost will increase. If the weight of distribution cost and freshness loss cost increases, the total cost decreases. That is, when companies focus on reducing carbon emissions, the total cost increases.
- In this paper, standard calculation examples were used for the experiment. The standard calculation examples lack road slope data, which have an impact on the carbon emissions of vehicles. Future studies can be conducted on the basis of real cases with road slope, and more accurate conclusions on carbon emissions will be drawn.
6. Conclusions
- In practice, the enterprise should rationally choose the optimization goal and arrange the vehicle distribution plan according to the distribution law of customers, the time-sensitivity of fresh products, the customer time window, and the time-varying road network conditions.
- Before making a distribution plan, enterprises should have a reasonable estimate of the time sensitivity of fresh agricultural products to be distributed. When agricultural products are time-sensitive, freshness loss has a great impact on the total cost, and enterprises should pay attention to reducing freshness loss. When agricultural products are time-insensitive, freshness loss has little impact on the total cost, and enterprises can give priority to other cost indicators, such as carbon emissions.
- The proportion of carbon emission cost in the total cost is relatively low, so the carbon trading price can be appropriately raised to attract enterprises to pay attention to the reducing of carbon emission.
- The preference of enterprises for different optimization objectives in the total cost will significantly affect the total cost, so the weight should be allocated according to the actual situation to achieve the purpose of enterprises.
- The research in this paper is based on the same fresh agricultural products transported by all vehicles, but in reality, the fresh agricultural products transported by each vehicle may be different, and a variety of fresh agricultural products may be mixed in one vehicle. In these cases, the relationship between freshness loss and total cost, as well as the influence of time sensitivity of agricultural products on distribution plan, need to be further explored.
- Furthermore, consider the situation of customer orders. A customer’s order may contain a variety of fresh agricultural products, and the splitting and merging of customer orders will make transportation more efficient and should be considered, as well as how to do the splitting and merging of orders. These problems require further study.
- The study in this paper is based on a static scenario, and a study of the dynamic scenario of TDGVRPSTW has not been carried out. The design of research methods in dynamic situations can become the direction of future research.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Lin, C.; Choy, K.; Ho, G.; Chung, S.; Lam, H. Survey of Green Vehicle Routing Problem: Past and future trends. Expert Syst. Appl. 2014, 41, 1118–1138. [Google Scholar] [CrossRef]
- Bektaş, T.; Laporte, G. The Pollution-Routing Problem. Transp. Res. Part B Methodol. 2011, 45, 1232–1250. [Google Scholar] [CrossRef]
- Erdoğan, S.; Miller-Hooks, E. A Green Vehicle Routing Problem. Transp. Res. Part E Logist. Transp. Rev. 2012, 48, 100–114. [Google Scholar] [CrossRef]
- Chang, D.J.; Morlok, E.K. Vehicle Speed Profiles to Minimize Work and Fuel Consumption. J. Transp. Eng. 2005, 131, 173–182. [Google Scholar] [CrossRef]
- Suzuki, Y. A dual-objective metaheuristic approach to solve practical pollution routing problem. Int. J. Prod. Econ. 2016, 176, 143–153. [Google Scholar] [CrossRef]
- Li, J.; Wang, R.; Li, T.; Lu, Z.; Pardalos, P.M. Benefit analysis of shared depot resources for multi-depot vehicle routing problem with fuel consumption. Transp. Res. Part D Transp. Environ. 2018, 59, 417–432. [Google Scholar] [CrossRef]
- Alinaghian, M.; Naderipour, M. A novel comprehensive macroscopic model for time-dependent vehicle routing problem with multi-alternative graph to reduce fuel consumption: A case study. Comput. Ind. Eng. 2016, 99, 210–222. [Google Scholar] [CrossRef]
- Manerba, D.; Mansini, R.; Zanotti, R. Attended Home Delivery: Reducing last-mile environmental impact by changing customer habits. IFAC-PapersOnLine 2018, 51, 55–60. [Google Scholar] [CrossRef]
- Yu, Y.; Wang, S.; Wang, J.; Huang, M. A branch-and-price algorithm for the heterogeneous fleet green vehicle routing problem with time windows. Transp. Res. Part B Methodol. 2019, 122, 511–527. [Google Scholar] [CrossRef]
- Ehmke, J.F.; Campbell, A.; Thomas, B.W. Vehicle routing to minimize time-dependent emissions in urban areas. Eur. J. Oper. Res. 2016, 251, 478–494. [Google Scholar] [CrossRef]
- Micale, R.; Marannano, G.; Giallanza, A.; Miglietta, P.; Agnusdei, G.; La Scalia, G. Sustainable vehicle routing based on firefly algorithm and TOPSIS methodology. Sustain. Future 2019, 1, 100001. [Google Scholar] [CrossRef]
- Fukasawa, R.; He, Q.; Song, Y. A disjunctive convex programming approach to the pollution-routing problem. Transp. Res. Part B Methodol. 2016, 94, 61–79. [Google Scholar] [CrossRef]
- Soysal, M.; Çimen, M.; Demir, E. On the mathematical modeling of green one-to-one pickup and delivery problem with road segmentation. J. Clean. Prod. 2018, 174, 1664–1678. [Google Scholar] [CrossRef] [Green Version]
- Giallanza, A.; Puma, G.L. Fuzzy green vehicle routing problem for designing a three echelons supply chain. J. Clean. Prod. 2020, 259, 120774. [Google Scholar] [CrossRef]
- Zulvia, F.E.; Kuo, R.; Nugroho, D.Y. A many-objective gradient evolution algorithm for solving a green vehicle routing problem with time windows and time dependency for perishable products. J. Clean. Prod. 2020, 242, 118428. [Google Scholar] [CrossRef]
- Bravo, M.; Rojas, L.P.; Parada, V. An evolutionary algorithm for the multi-objective pick-up and delivery pollution-routing problem. Int. Trans. Oper. Res. 2017, 26, 302–317. [Google Scholar] [CrossRef]
- Wu, D.; Liu, Y.; Zhou, K.; Li, K.; Li, J. A multi-objective particle swarm optimization algorithm based on human social behavior for environmental economics dispatch problems. Environ. Eng. Manag. J. 2019, 18, 1599–1607. [Google Scholar] [CrossRef]
- Wu, D.Q.; Dong, M.; Li, H.Y. Vehicle Routing Problem with Time Windows Using Multi-Objective Co-Evolutionary Approach. Int. J. Simul. Model. 2016, 15, 742–753. [Google Scholar] [CrossRef]
- Wu, D.; Huo, J.; Zhang, G.; Zhang, W. Minimization of Logistics Cost and Carbon Emissions Based on Quantum Particle Swarm Optimization. Sustainability 2018, 10, 3791. [Google Scholar] [CrossRef] [Green Version]
- Muñoz-Villamizar, A.; Velázquez-Martínez, J.C.; Mejía-Argueta, C.; Gámez-Pérez, K. The impact of shipment consolidation strategies for green home delivery: A case study in a Mexican retail company. Int. J. Prod. Res. 2021, 1–18. [Google Scholar] [CrossRef]
- Liu, C.; Kou, G.; Zhou, X.; Peng, Y.; Sheng, H.; Alsaadi, F.E. Time-dependent vehicle routing problem with time windows of city logistics with a congestion avoidance approach. Knowl.-Based Syst. 2020, 188, 104813. [Google Scholar] [CrossRef]
- Xiao, Y.; Konak, A. The heterogeneous green vehicle routing and scheduling problem with time-varying traffic congestion. Transp. Res. Part E Logist. Transp. Rev. 2016, 88, 146–166. [Google Scholar] [CrossRef]
- Li, H.; Zhang, L.; Lv, T.; Chang, X. The two-echelon time-constrained vehicle routing problem in linehaul-delivery systems. Transp. Res. Part B Methodol. 2016, 94, 231–245. [Google Scholar] [CrossRef]
- Wang, Y.; Assogba, K.; Fan, J.; Xu, M.; Liu, Y.; Wang, H. Multi-depot green vehicle routing problem with shared transportation resource: Integration of time-dependent speed and piecewise penalty cost. J. Clean. Prod. 2019, 232, 12–29. [Google Scholar] [CrossRef]
- Franceschetti, A.; Demir, E.; Honhon, D.; Van Woensel, T.; Laporte, G.; Stobbe, M. A metaheuristic for the time-dependent pollution-routing problem. Eur. J. Oper. Res. 2017, 259, 972–991. [Google Scholar] [CrossRef] [Green Version]
- Sadati, M.E.H.; Çatay, B. A hybrid variable neighborhood search approach for the multi-depot green vehicle routing problem. Transp. Res. Part E Logist. Transp. Rev. 2021, 149, 102293. [Google Scholar] [CrossRef]
- Deng, W.; Xu, J.; Zhao, H.; Song, Y. A Novel Gate Resource Allocation Method Using Improved PSO-Based QEA. IEEE Trans. Intell. Transp. Syst. 2020, 1–9. [Google Scholar] [CrossRef]
- Deng, W.; Xu, J.; Gao, X.-Z.; Zhao, H. An Enhanced MSIQDE Algorithm With Novel Multiple Strategies for Global Optimization Problems. IEEE Trans. Syst. Man Cybern. Syst. 2020, 1–10. [Google Scholar] [CrossRef]
- Deng, W.; Shang, S.; Cai, X.; Zhao, H.; Zhou, Y.; Chen, H.; Deng, W. Quantum differential evolution with cooperative coevolution framework and hybrid mutation strategy for large scale optimization. Knowl.-Based Syst. 2021, 224, 107080. [Google Scholar] [CrossRef]
- Rahbari, A.; Nasiri, M.M.; Werner, F.; Musavi, M.; Jolai, F. The vehicle routing and scheduling problem with cross-docking for perishable products under uncertainty: Two robust bi-objective models. Appl. Math. Model. 2019, 70, 605–625. [Google Scholar] [CrossRef]
- Alkaabneh, F.; Diabat, A.; Gao, H.O. Benders decomposition for the inventory vehicle routing problem with perishable products and environmental costs. Comput. Oper. Res. 2020, 113, 104751. [Google Scholar] [CrossRef]
- Shao, J.; Cao, Q.; Shen, M.; Sun, Y. Research on Multi-objective Optimization for Fresh products VRP Problem. Ind. Eng. Manag. Syst. 2015, 20, 122–127+134. [Google Scholar]
- Zhou, X.C.; Zhou, K.J.; Wang, L.; Liu, C.S.; Huang, X.B. Review of green vehicle routing model and its algorithm in logistics distribution. Syst. Eng. Theory Pract. 2021, 41, 213–230. [Google Scholar]
- Fu, Z.; Eglese, R.W.; Li, L. A unified tabu search algorithm for vehicle routing problems with soft time windows. J. Oper. Res. Soc. 2008, 59, 663–673. [Google Scholar] [CrossRef] [Green Version]
- Han, Y.J.; Peng, Y.F.; Wei, H.; Shi, B.L. Hyper-heuristic genetic algorithm for vehicle routing problem with soft time windows. Comput. Integr. Manuf. Syst. 2019, 25, 2571–2579. [Google Scholar]
- Pamosoaji, A.K.; Dewa, P.K.; Krisnanta, J.V. Proposed Modified Clarke-Wright Saving Algorithm for Capacitated Vehicle Routing Problem. J. Ind. Eng. Manag. 2019, 1, 9–15. [Google Scholar] [CrossRef]
- Solomon, M.M. Algorithms for the Vehicle Routing and Scheduling Problems with Time Window Constraints. Oper. Res. 1987, 35, 254–265. [Google Scholar] [CrossRef] [Green Version]
- Vidal, T.; Crainic, T.G.; Gendreau, M.; Prins, C. Heuristics for multi-attribute vehicle routing problems: A survey and synthesis. Eur. J. Oper. Res. 2013, 231, 1–21. [Google Scholar] [CrossRef]
- Liu, Z.; Chen, Y.; Li, J.; Zhang, D. Spatiotemporal-Dependent Vehicle Routing Problem Considering Carbon Emissions. Discret. Dyn. Nat. Soc. 2021, 2021, 9729784. [Google Scholar] [CrossRef]
- Ghannadpour, S.F.; Zarrabi, A. Multi-objective heterogeneous vehicle routing and scheduling problem with energy minimizing. Swarm Evol. Comput. 2019, 44, 728–747. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable Neighborhood Adaptive Genetic Algorithm | Hyper-Heuristic Genetic Algorithm | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| TC | IT | VN | VR | LR/% | RT | TC | IT | VN | VR | LR/% | RT |
| 4627.1 | 14 | 4 | 0-11-19-7-10-20-9-1-0 | 42.5 | 229.41 | 4763.8 | 38 | 4 | 0-5-16-6-18-8-17-13-0 | 47.0 | 220.25 |
| 0-14-15-2-22-23-25-4-0 | 53.5 | 223.0 | 0-14-15-2-22-23-4-25-0 | 53.5 | 212.74 | ||||||
| 0-21-12-3-24-0 | 23.0 | 190.0 | 0-21-12-3-24-1-0 | 28.0 | 221.02 | ||||||
| 0-5-16-6-18-8-17-13-0 | 47.0 | 221.26 | 0-11-19-7-10-20-9-0 | 37.5 | 218.40 | ||||||
| Data set | VNAGA | AGA | HGA | Gap_a% | Gap_h% | |||
|---|---|---|---|---|---|---|---|---|
| TC | IT | TC | IT | TC | IT | |||
| C102 | 3534.94 | 34 | 3607.76 | 46 | 3586.20 | 41 | 2.06 | 1.45 |
| C104 | 3333.77 | 22 | 3397.78 | 35 | 3371.44 | 23 | 1.92 | 1.13 |
| C106 | 4291.84 | 18 | 4540.34 | 42 | 4427.89 | 16 | 5.79 | 3.17 |
| C204 | 4097.12 | 32 | 4180.29 | 59 | 4187.67 | 28 | 2.03 | 2.21 |
| R103 | 5520.32 | 65 | 5616.37 | 71 | 5623.00 | 89 | 1.74 | 1.86 |
| R109 | 5880.64 | 30 | 5968.69 | 52 | 5921.22 | 24 | 1.50 | 0.69 |
| R111 | 5423.99 | 51 | 5473.31 | 95 | 5473.84 | 53 | 0.91 | 0.92 |
| R204 | 4632.26 | 36 | 4648.47 | 34 | 4640.60 | 47 | 0.35 | 0.18 |
| RC103 | 4901.52 | 27 | 5091.85 | 45 | 5012.69 | 20 | 3.88 | 2.27 |
| RC104 | 4303.35 | 53 | 4370.36 | 64 | 4351.55 | 66 | 1.56 | 1.12 |
| RC107 | 4275.99 | 24 | 4360.23 | 58 | 4307.63 | 31 | 1.97 | 0.74 |
| RC208 | 4340.03 | 36 | 4400.36 | 47 | 4398.62 | 39 | 1.39 | 1.35 |
| Average | 4544.65 | 36 | 4637.98 | 54 | 4608.53 | 40 | 2.09 | 1.42 |
| Data Set | Minimize Total Cost | Minimize Carbon Emissions | Minimize Freshness Loss | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| TC | CE | CE/TC | FL | FL/TC | TC | CE | CE/TC | FL | FL/TC | TC | CE | CE/TC | FL | FL/TC | |
| C102 | 3534.94 | 284.01 | 8.03% | 1346.93 | 38.10% | 10,604.01 | 249.35 | 2.35% | 1373.31 | 12.95% | 10,044.25 | 617.34 | 6.15% | 1218.05 | 12.13% |
| C104 | 3333.77 | 259.51 | 7.78% | 1315.69 | 39.47% | 6547.7 | 247.36 | 3.78% | 1488.2 | 22.73% | 5543.9 | 514.49 | 9.28% | 1153.94 | 20.81% |
| C106 | 4291.84 | 358.65 | 8.36% | 1341.4 | 31.25% | 9387.17 | 250.83 | 2.67% | 1442.71 | 15.37% | 6407.58 | 496.9 | 7.75% | 1303.53 | 20.34% |
| C204 | 4097.12 | 287.82 | 7.02% | 1951.8 | 47.64% | 6479.35 | 268.39 | 4.14% | 2043.81 | 31.54% | 13,985.59 | 666.46 | 4.77% | 1642.84 | 11.75% |
| R103 | 5520.32 | 586.05 | 10.62% | 651.18 | 11.80% | 5549.46 | 585.29 | 10.55% | 662.88 | 11.94% | 9361.53 | 1198.16 | 12.80% | 570.78 | 6.10% |
| R109 | 5880.64 | 694.03 | 11.80% | 659.66 | 11.22% | 6129.95 | 642.72 | 10.48% | 698.99 | 11.40% | 10,083.33 | 1342.92 | 13.32% | 593.03 | 5.88% |
| R111 | 5423.99 | 644.57 | 11.88% | 673.69 | 12.42% | 5977.12 | 641.76 | 10.74% | 668.07 | 11.18% | 10,953.24 | 1435.94 | 13.11% | 580.6 | 5.30% |
| R204 | 4632.26 | 487.55 | 10.53% | 924.22 | 19.95% | 5385.83 | 428.65 | 7.96% | 1066.77 | 19.81% | 6476.78 | 764.25 | 11.80% | 798.24 | 12.32% |
| RC103 | 4901.52 | 509.05 | 10.39% | 1124.41 | 22.94% | 5265.35 | 507.21 | 9.63% | 1151.62 | 21.87% | 13,142.21 | 1721.63 | 13.10% | 1003.82 | 7.64% |
| RC104 | 4303.35 | 425.43 | 9.89% | 1069.99 | 24.86% | 4442.85 | 420.97 | 9.48% | 1108.2 | 24.94% | 11,768.28 | 1534.69 | 13.04% | 971.71 | 8.26% |
| RC107 | 4275.99 | 430.91 | 10.08% | 1085.99 | 25.40% | 4298.93 | 421.15 | 9.80% | 1121.86 | 26.10% | 13,065.52 | 1723.6 | 13.19% | 982.1 | 7.52% |
| RC208 | 4340.03 | 384.51 | 8.86% | 1536.25 | 35.40% | 7334.66 | 298.59 | 4.07% | 1856.07 | 25.31% | 8149.18 | 914.84 | 11.23% | 1359.81 | 16.69% |
| Average | 4544.65 | 446.01 | 9.81% | 1140.10 | 25.09% | 6450.20 | 413.52 | 6.41% | 1223.54 | 18.97% | 9915.12 | 1077.60 | 10.87% | 1014.87 | 10.24% |
| r | TC | FL | FL/TC |
|---|---|---|---|
| 0.1 | 12,573.78 | 3030.28 | 0.241 |
| 0.2 | 11,143.33 | 2529.54 | 0.227 |
| 0.3 | 10,339.7 | 1985.22 | 0.192 |
| 0.4 | 9752.06 | 1833.39 | 0.188 |
| 0.5 | 9375.41 | 1546.94 | 0.165 |
| 0.6 | 9107.99 | 1256.90 | 0.138 |
| 0.7 | 8928.38 | 1053.55 | 0.118 |
| 0.8 | 8840.07 | 919.37 | 0.104 |
| 0.9 | 8834.48 | 865.78 | 0.098 |
| r | VR | DT | RT |
|---|---|---|---|
| 0.1 | 0-45-47-36-11-19-16-44-38-40-9-20-10-32-35-34-3-12-5-48-7-0 | 0 | 937.35 |
| 0-15-42-14-37-31-30-1-6-18-8-46-17-49-21-4-25-24-26-0 | 141.55 | 971.23 | |
| 0-27-28-50-33-29-39-23-22-41-43-2-13-0 | 89 | 730.35 | |
| 0.2 | 0-42-14-45-5-6-18-8-46-49-10-32-20-9-35-24-25-4-43-0 | 0 | 937.16 |
| 0-33-29-39-23-15-38-44-16-17-37-13-2-21-26-12-3-34-50-1-0 | 9.16 | 990.13 | |
| 0-28-27-7-48-47-36-19-11-30-31-40-22-41-0 | 95.03 | 464.66 | |
| 0.3 | 0-5-45-48-47-36-19-11-7-18-8-46-49-10-32-20-35-34-24-12-17-31-0 | 0 | 952.44 |
| 0-37-42-14-44-16-38-15-41-22-40-6-13-4-25-43-2-0 | 0 | 936.57 | |
| 0-33-50-27-28-26-21-23-39-29-3-30-9-1-0 | 9.16 | 456.48 | |
| 0.4 | 0-28-27-45-36-47-48-19-11-30-31-7-18-6-40-50-9-20-32-35-34-3-24-12-17-5-0 | 95.03 | 941.92 |
| 0-33-29-39-23-22-41-43-4-25-21-13-2-26-0 | 9.16 | 937.57 | |
| 0-37-42-15-14-38-44-16-8-46-49-10-1-0 | 0 | 648.39 | |
| 0.5 | 0-31-7-47-36-19-11-30-9-35-34-20-32-48-17-5-37-13-0 | 0 | 943.74 |
| 0-45-27-28-50-33-29-39-23-41-22-40-2-43-21-4-25-24-3-12-26-0 | 0 | 932.79 | |
| 0-14-42-15-38-44-16-6-18-8-46-49-10-1-0 | 0 | 638.53 | |
| 0.6 | 0-27-28-50-33-29-39-23-41-22-40-21-4-25-24-12-26-2-0 | 89 | 943.97 |
| 0-45-36-47-48-7-31-30-11-19-49-46-10-32-20-9-35-34-3-17-1-0 | 0 | 940.84 | |
| 0-42-15-14-38-44-16-5-8-18-6-37-43-13-0 | 0 | 728.44 | |
| 0.7 | 0-5-45-48-47-36-19-11-31-30-9-20-10-32-35-34-3-26-24-21-12-0 | 0 | 939.08 |
| 0-15-42-14-38-44-16-6-18-8-7-49-46-17-37-43-13-4-25-2-0 | 141.55 | 948.67 | |
| 0-1-27-28-50-33-29-39-23-41-22-40-0 | 0 | 458.85 | |
| 0.8 | 0-27-28-42-15-14-38-44-16-5-6-18-8-46-49-10-32-20-1-50-26-2-13-37-17-0 | 89 | 923.48 |
| 0-23-39-29-33-12-40-21-22-41-43-4-25-24-34-3-0 | 166.79 | 940.08 | |
| 0-45-48-47-36-11-19-7-31-30-9-35-0 | 0 | 755.60 | |
| 0.9 | 0-28-3-33-29-39-23-40-6-18-8-46-49-7-31-10-32-20-35-13-5-17-37-2-21-26-12-0 | 95.03 | 999.46 |
| 0-27-42-14-16-38-44-15-41-22-43-4-25-24-34-1-0 | 89 | 942.22 | |
| 0-45-36-47-48-19-11-30-9-50-0 | 0 | 459.99 |
| DC | CE | FL | TC | WV | |||
|---|---|---|---|---|---|---|---|
| 0.1 | 0.5 | 0.4 | 7188.21 | 1053.29 | 2058.83 | 10,300.33 | 2069 |
| 0.1 | 0.6 | 0.3 | 7206.43 | 1034.51 | 2070.57 | 10,311.51 | 1962.52 |
| 0.1 | 0.7 | 0.2 | 7213.84 | 1012.65 | 2100.61 | 10,327.1 | 1850.36 |
| 0.1 | 0.8 | 0.1 | 7194.61 | 998.27 | 2141.15 | 10,334.03 | 1732.19 |
| 0.2 | 0.5 | 0.3 | 7100.59 | 1061.71 | 2079.87 | 10,242.17 | 2574.93 |
| 0.2 | 0.6 | 0.2 | 7092.37 | 1048.93 | 2107.28 | 10,248.58 | 2469.29 |
| 0.2 | 0.7 | 0.1 | 7095.68 | 1019.11 | 2142.78 | 10,257.57 | 2346.79 |
| 0.3 | 0.5 | 0.2 | 6964.8 | 1073.49 | 2079.87 | 10,118.16 | 3042.16 |
| 0.3 | 0.6 | 0.1 | 6985.66 | 1034.51 | 2129.81 | 10,149.98 | 2929.39 |
| 0.4 | 0.5 | 0.1 | 6767.45 | 1030.93 | 2115.12 | 9913.5 | 3433.96 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, D.; Wu, C. TDGVRPSTW of Fresh Agricultural Products Distribution: Considering Both Economic Cost and Environmental Cost. Appl. Sci. 2021, 11, 10579. https://doi.org/10.3390/app112210579
Wu D, Wu C. TDGVRPSTW of Fresh Agricultural Products Distribution: Considering Both Economic Cost and Environmental Cost. Applied Sciences. 2021; 11(22):10579. https://doi.org/10.3390/app112210579
Chicago/Turabian StyleWu, Daqing, and Chenxiang Wu. 2021. "TDGVRPSTW of Fresh Agricultural Products Distribution: Considering Both Economic Cost and Environmental Cost" Applied Sciences 11, no. 22: 10579. https://doi.org/10.3390/app112210579
APA StyleWu, D., & Wu, C. (2021). TDGVRPSTW of Fresh Agricultural Products Distribution: Considering Both Economic Cost and Environmental Cost. Applied Sciences, 11(22), 10579. https://doi.org/10.3390/app112210579