
A Novel Heterogeneous Parallel Convolution Bi-LSTM for Speech Emotion Recognition


Abstract
:1. Introduction
2. Related Work
2.1. Emotion Feature Extraction
2.2. Speech Emotion Recognition Models
2.3. Our Contributions
- (1)
- 32D LLD features at the frame-level are extracted, and its HSF features at the sentence-level are computed. Totally, 72D acoustic features are used as the input of the model.
- (2)
- The proposed HPCB architecture can be trained with features extracted at the sentence-level (high-level descriptors), or at the frame-level (low-level descriptors) simultaneously.
- (3)
- We provide a comprehensive analysis of Heterogeneous Parallel network training for the sake of SER, demonstrate its advantages within corpus evaluations, and observe performance gains.
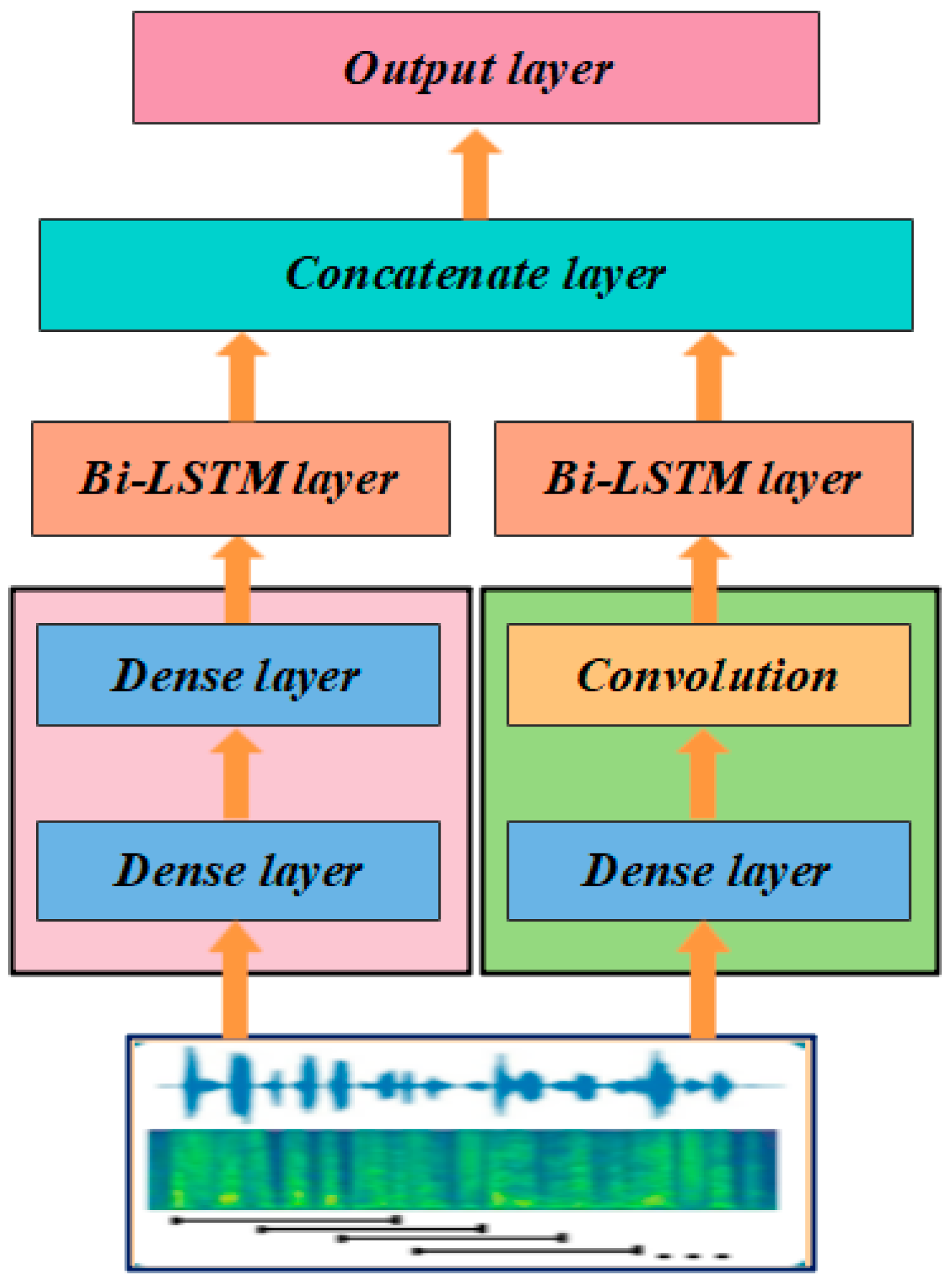
3. Methods
Heterogeneous Parallel Conv-BiLSTM (HPCB)
4. Experimental Evaluations
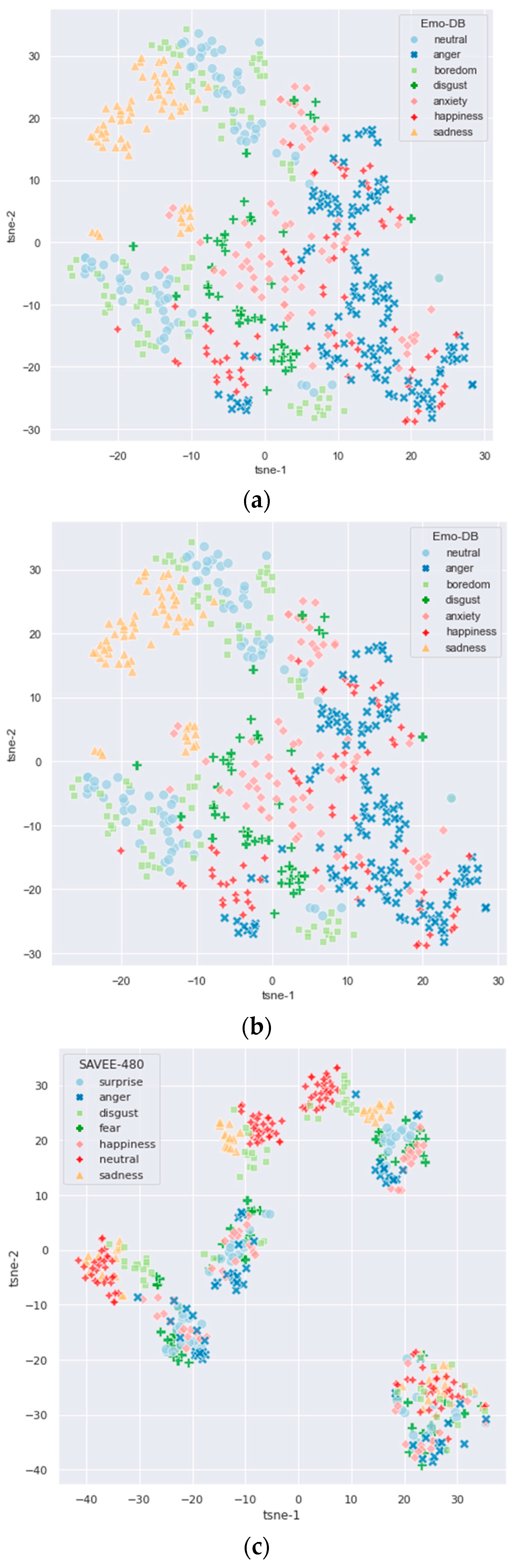
4.1. Databases
4.2. Feature Extraction
4.3. Experimental Setup
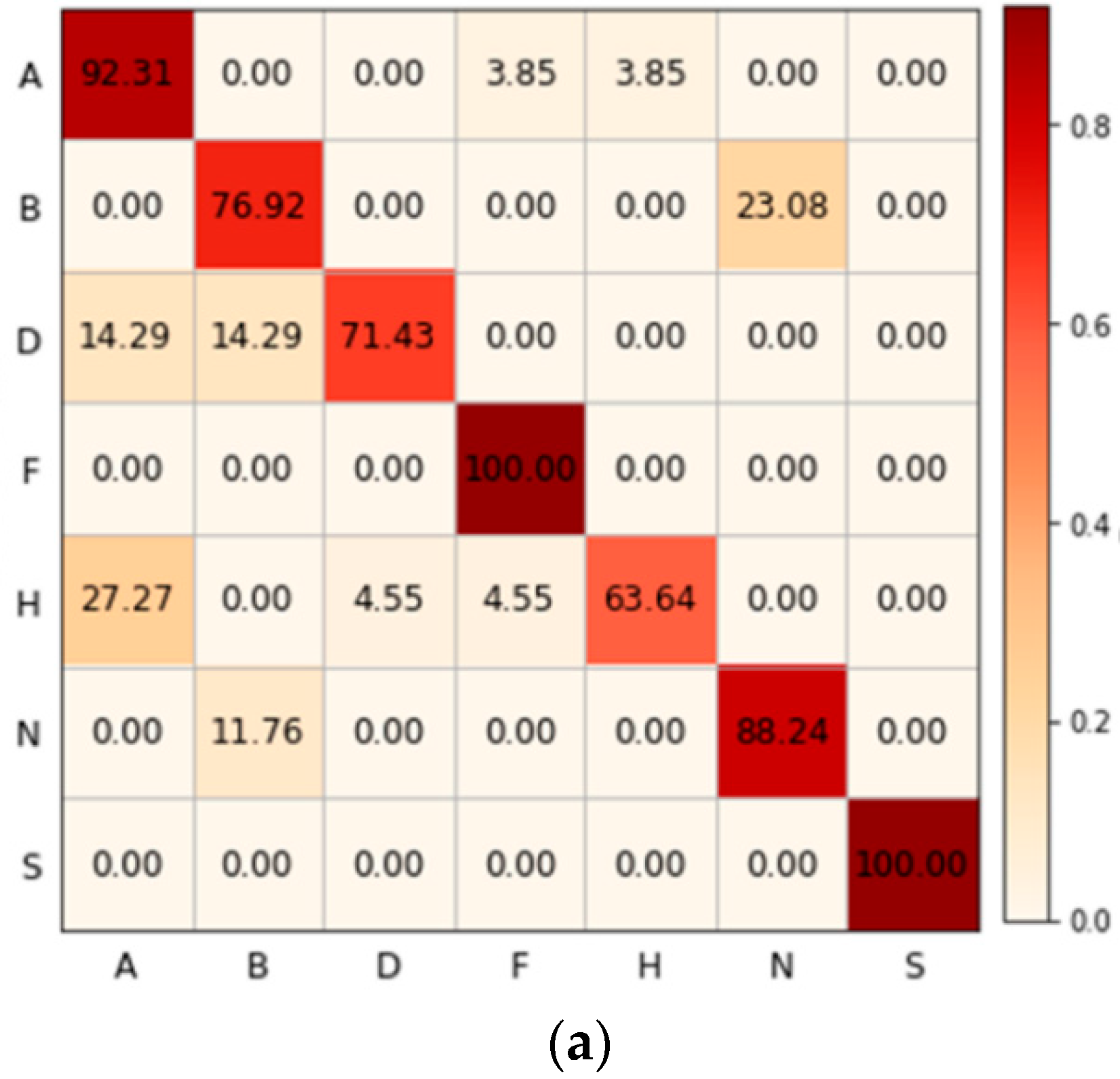
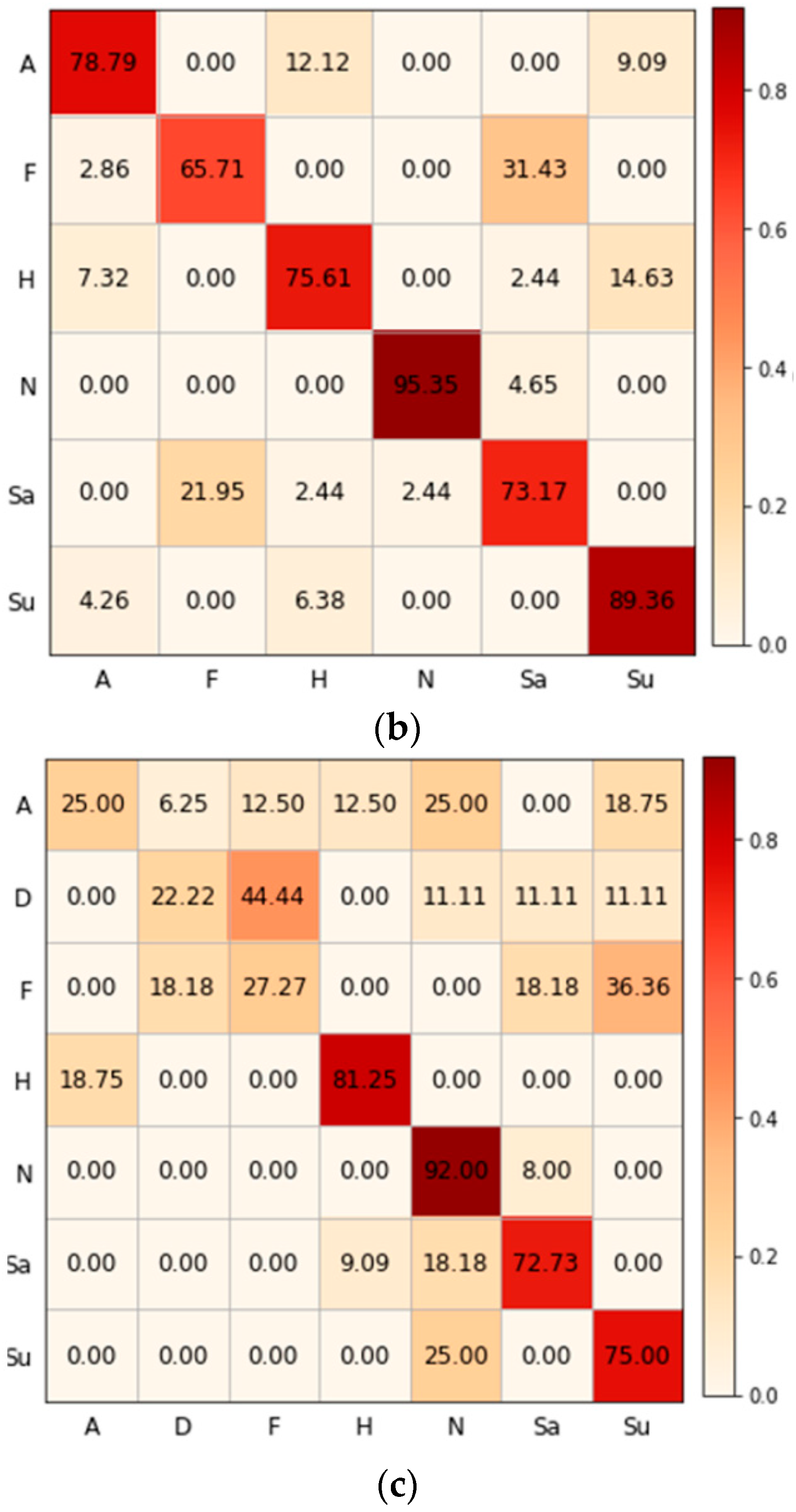
4.4. The Performance of HPCB and Its Peer Methods
5. Discussion
6. Conclusions
Author Contributions
Funding
Informed Consent Statement
Acknowledgments
Conflicts of Interest
References
- Hsu, J.H.; Su, M.H.; Wu, C.H.; Chen, Y.H. Speech emotion recognition considering nonverbal vocalization in affective conversations. IEEE/ACM Trans. Audio Speech Lang. Process. 2021, 29, 1675–1686. [Google Scholar] [CrossRef]
- Zhou, L.; Gao, J.; Li, D.; Shum, H.-Y. The design and implementation of xiaoice, an empathetic social chatbot. Comput. Linguist. 2020, 46, 1–62. [Google Scholar] [CrossRef]
- Brosch, T.; Scherer, K.R.; Grandjean, D.; Sander, D. The impact of emotion on perception, attention, memory, and decision making. Swiss. Med. Wkly. 2013, 143, w13786. [Google Scholar] [CrossRef] [PubMed]
- Tzirakis, P.; Zhang, J.H.; Schuller, B.W. End-to-end speech emotion recognition using deep neural networks. In Proceedings of the International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 5089–5093. [Google Scholar]
- Tahon, M.; Devillers, L. Towards a small set of robust acoustic features for emotion recognition: Challenges. IEEE/ACM Trans. Audio Speech Lang. Process. 2016, 24, 16–28. [Google Scholar] [CrossRef] [Green Version]
- Reeves, B.; Nass, C.I. The Media Equation: How People Treat Computers, Television, and New Media Like Real People and Places; Cambridge University Press: Cambridge, UK, 1996. [Google Scholar]
- Koolagudi, S.G.; Rao, K.S. Emotion recognition from speech: A review. Int. J. Speech Technol. 2012, 15, 99–117. [Google Scholar] [CrossRef]
- Vogt, T.; Andre, E.; Wagner, J. Automatic recognition of emotions from speech: A review of the literature and recommendations for practical realization. Affect Emot. Hum. Comput. Interact. 2008, 48, 75–91. [Google Scholar]
- Jiang, P.; Fu, H.; Tao, H.; Lei, P.; Zhao, L. Parallelized convolutional recurrent neural network with spectral features for speech emotion recognition. IEEE Access 2019, 9, 90368–90376. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, Y.; Weninger, F.; Schuller, B. Multi-task deep neural network with shared hidden layers: Breaking down the wall between emotion representations. In Proceedings of the International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 4490–4494. [Google Scholar]
- Lotfian, R.; Busso, C. Formulating emotion perception as a probabilistic model with application to categorical emotion classification. In Proceedings of the International Conference on Affective Computing and Intelligent Interaction (ACII), San Antonio, TX, USA, 23–26 October 2017; pp. 415–420. [Google Scholar]
- Schuller, B.; Batliner, A.; Steidl, S.; Seppi, D. Recognizing realistic emotions and affect in speech: State of the art and lessons learnt from the first challenge. Speech Commun. 2011, 53, 1062–1087. [Google Scholar] [CrossRef] [Green Version]
- Ayadi, M.E.; Kamel, M.; Karray, F. Survey on speech emotion recognition: Features, classification schemes, and databases. Pattern Recognit. 2011, 44, 572–587. [Google Scholar] [CrossRef]
- Mirsamadi, S.; Barsoum, E.; Zhang, C. Automatic speech emotion recognition using recurrent neural networks with local attention. In Proceedings of the International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 2227–2231. [Google Scholar]
- Schmitt, M.; Ringeval, F.; Schuller, B. At the border of acoustics and linguistics: Bag-of-audio-words for the recognition of emotions in speech. In Proceedings of the INTERSPEECH, San Francisco, CA, USA, 8–12 September 2016; pp. 495–499. [Google Scholar]
- Lee, J.; Tashev, I. High-level feature representation using recurrent neural network for speech emotion recognition. In Proceedings of the INTERSPEECH, Dresden, Germany, 6–10 September 2015; pp. 1–4. [Google Scholar]
- Han, K.; Yu, D.; Tashev, I. Speech emotion recognition using deep neural network and extreme learning machine. In Proceedings of the INTERSPEECH, Singapore, 7–10 September 2014; pp. 223–227. [Google Scholar]
- Trigeorgis, G.; Ringeval, F.; Brueckner, R.; Marchi, E.; Nicolaou, M.A.; Schuller, B.; Zafeiriou, S. Adieu features? End-to-end speech emotion recognition using a deep convolutional recurrent network. In Proceedings of the International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 5200–5204. [Google Scholar]
- Neumann, M.; Vu, N.T. Attentive convolutional neural network based speech emotion recognition: A study on the impact of input features, signal length, and acted speech. arXiv 2017, arXiv:1706.00612. [Google Scholar]
- Satt, A.; Rozenberg, S.; Hoory, R. Efficient emotion recognition from speech using deep learning on spectrograms. In Proceedings of the INTERSPEECH, Stockholm, Sweden, 24–27 August 2017; pp. 1089–1093. [Google Scholar]
- Li, P.; Song, Y.; McLoughlin, I.V.; Guo, W.; Dai, L.R. An attention pooling based representation learning method for speech emotion recognition. In Proceedings of the INTERSPEECH, Hyderabad, India, 2–6 September 2018; pp. 3087–3091. [Google Scholar]
- Garg, U.; Agarwal, S.; Gupta, S.; Dutt, R.; Singh, D. Prediction of emotions from the audio speech signals using MFCC, MEL and Chroma. In Proceedings of the International Conference on Computational Intelligence and Communication Networks (CICN), Bhimtal, India, 25–26 September 2020; pp. 1–5. [Google Scholar]
- Kumbhar, H.S.; Bhandari, S.U. Speech emotion recognition using MFCC features and LSTM network. In Proceedings of the International Conference on Computing, Communication, Control and Automation (ICCUBEA), Pune, India, 19–21 September 2019; pp. 1–3. [Google Scholar]
- Cirakman, O.; Gunsel, B. Online speaker emotion tracking with a dynamic state transition model. In Proceedings of the International Conference on Pattern Recognition (ICPR), Cancún, Mexico, 4–8 December 2016; pp. 307–312. [Google Scholar]
- Wang, K.; An, N.; Li, B.N.; Zhang, Y.; Li, L. Speech emotion recognition using Fourier parameters. IEEE Trans. Affect. Comput. 2015, 25, 69–75. [Google Scholar] [CrossRef]
- Kim, Y.; Provost, E.M. ISLA: Temporal segmentation and labeling for audio-visual emotion recognition. IEEE Trans. Affect. Comput. 2019, 10, 196–208. [Google Scholar] [CrossRef]
- New, T.L.; Foo, S.W.; Silva, L. Speech emotion recognition using hidden Markov models. Speech Commun. 2003, 41, 603–623. [Google Scholar]
- Neiberg, D.; Elenius, K.; Laskowski, K. Emotion recognition in spontaneous speech using GMMs. In Proceedings of the INTERSPEECH, Pittsburgh, PA, USA, 17–21 September 2006; pp. 809–812. [Google Scholar]
- Kokane, A.; Ram Mohana Reddy, G. Multiclass SVM-based language independent emotion recognition using selective speech features. In Proceedings of the International Conference on Advances in Computing, Communications and Informatics (ICACCI), New Delhi, India, 24–27 September 2014; pp. 1069–1073. [Google Scholar]
- Fu, L.Q.; Mao, X.; Chen, L.J. Relative speech emotion recognition based artificial neural network. In Proceedings of the Pacific Asia Conference on Language, Information and Computing (PACLIC), Wuhan, China, 19–20 December 2018; pp. 140–144. [Google Scholar]
- Xu, H.H.; Gao, J.; Yuan, J. Application of speech emotion recognition in intelligent household robot. In Proceedings of the International Conference on Artificial Intelligence and Computational Intelligence (AICI), Sanya, China, 23–24 October 2010; pp. 537–541. [Google Scholar]
- Schuller, B.W. Speech emotion recognition: Two decades in a nutshell, benchmarks, and ongoing trends. Commun. ACM 2018, 61, 90–99. [Google Scholar] [CrossRef]
- Khaki, H.; Erzin, E. Use of affect based interaction classification for continuous emotion tracking. In Proceedings of the International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 2881–2885. [Google Scholar]
- Xie, Y.; Liang, R.; Liang, Z.; Huang, C.; Zou, C.; Schuller, B. Speech emotion classification using attention-based LSTM. IEEE/ACM Trans. Audio Speech Lang. Process. 2019, 27, 1675–1685. [Google Scholar] [CrossRef]
- Mao, Q.; Dong, M.; Huang, Z.; Zhan, Y. Learning salient features for speech emotion recognition using convolutional neural networks. IEEE Trans. Multimed. 2014, 16, 2203–2213. [Google Scholar] [CrossRef]
- Chen, M.; He, X.; Yang, J.; Zhang, H. 3-D convolutional recurrent neural networks with attention model for speech emotion recognition. IEEE Signal Process. Lett. 2018, 25, 1440–1444. [Google Scholar] [CrossRef]
- Zhao, Z.; Zheng, Y.; Zhang, Z.; Wang, H.; Zhao, Y.; Li, C. Exploring spatio-temporal representations by integrating attention-based Bidirectional-LSTM-RNNs and FCNs for speech emotion recognition. In Proceedings of the INTERSPEECH, Hyderabad, India, 2–6 September 2018; pp. 272–276. [Google Scholar]
- Sainath, T.N.; Vinyals, O.; Senior, A.; Sak, H. Convolutional, long short-term memory, fully connected deep neural networks. In Proceedings of the International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brisbane, Australia, 19–24 April 2015; pp. 4580–4584. [Google Scholar]
- Suen, H.Y.; Hung, K.E.; Lin, C.L. TensorFlow-based automatic personality recognition used in asynchronous video interviews. IEEE Access 2019, 7, 61018–61023. [Google Scholar] [CrossRef]
- Zou, F.; Shen, L.; Jie, Z.; Zhang, W.; Liu, W. A sufficient condition for convergences of Adam and RMSProp. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 11119–11127. [Google Scholar]
- Liu, Z.-T.; Xie, Q.; Wu, M.; Cao, W.-H.; Mei, Y.; Mao, J.-W. Speech emotion recognition based on an improved brain emotion learning model. Neurocomputing 2018, 309, 145–156. [Google Scholar] [CrossRef]
- Sun, Y.; Wen, G.; Wang, J. Weighted spectral features based on local Hu moments for speech emotion recognition. Biomed. Signal Process. Control 2015, 18, 80–90. [Google Scholar] [CrossRef]
- Wen, G.; Li, H.; Huang, J.; Li, D.; Xun, E. Random deep belief networks for recognizing emotions from speech signals. Comput. Intell. Neurosci. 2017, 5, 1–9. [Google Scholar] [CrossRef]
- Tao, H.; Liang, R.; Zha, C.; Zhang, X.; Zhao, L. Spectral features based on local Hu moments of Gabor spectrograms for speech emotion recognition. IEICE Trans. Inf. Syst. 2016, 99, 2186–2189. [Google Scholar] [CrossRef] [Green Version]
- Sainath, T.N.; Weiss, R.J.; Senior, A.; Wilson, K.W.; Vinyals, O. Learning the speech front-end with raw waveform CLDNNs. In Proceedings of the INTERSPEECH, Dresden, Germany, 6–10 September 2015; pp. 1–5. [Google Scholar]
- Dai, T.; Zhu, L.; Wang, Y.; Carley, K.M. Attentive stacked denoising autoencoder with Bi-LSTM for personalized context-aware citation recommendation. IEEE/ACM Trans. Audio Speech Lang. Process. 2020, 28, 553–568. [Google Scholar] [CrossRef]
- Wang, H.; Zhao, D.Q. Emotion analysis of Microblog based on emotion dictionary and Bi-GRU. In Proceedings of the Asia-Pacific Conference on Image Processing, Electronics and Computers (IPEC), Dalian, China, 14–16 April 2020; pp. 197–200. [Google Scholar]
- Lee, K.H.; Kim, D.H. Design of a convolutional neural network for speech emotion recognition. In Proceedings of the International Conference on Information and Communication Technology Convergence (ICTC), Jeju, Korea, 21–23 October 2020; pp. 1332–1335. [Google Scholar]
- Sara, S.; Nicholas, F.; Geoffrey, E.H. Dynamic routing between capsules. In Proceedings of the Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017; pp. 1–11. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | WAR | UAR |
|---|---|---|
| GA-BEL [41] | 38.55 | 38.55 |
| HuWSF [42] | 43.50 | 43.50 |
| RDBN [44] | 48.50 | 48.50 |
| PCRN [9] | 58.25 | 58.25 |
| Bi-LSTM [46] | / | 75.00 |
| Bi-GRU [47] | / | 72.50 |
| CNN [48] | / | 76.67 |
| CLDNN [45] | / | 61.67 |
| CapsNet [49] | / | 63.33 |
| HPCB (Ours) | / | 79.67 |
| Model | WAR | UAR |
|---|---|---|
| HuWSF [42] | 81.74 | / |
| RDBN [43] | 82.32 | / |
| LNCMSF [44] | / | 74.46 |
| ACRNN [36] | / | 82.82 |
| PCRN [9] | 86.44 | 84.53 |
| Bi-LSTM [46] | / | 71.03 |
| Bi-GRU [47] | / | 70.09 |
| CNN [48] | / | 78.50 |
| CLDNN [45] | / | 56.07 |
| CapsNet [49] | / | 77.57 |
| HPCB (Ours) | / | 84.65 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, H.; Huang, H.; Han, H. A Novel Heterogeneous Parallel Convolution Bi-LSTM for Speech Emotion Recognition. Appl. Sci. 2021, 11, 9897. https://doi.org/10.3390/app11219897
Zhang H, Huang H, Han H. A Novel Heterogeneous Parallel Convolution Bi-LSTM for Speech Emotion Recognition. Applied Sciences. 2021; 11(21):9897. https://doi.org/10.3390/app11219897
Chicago/Turabian StyleZhang, Huiyun, Heming Huang, and Henry Han. 2021. "A Novel Heterogeneous Parallel Convolution Bi-LSTM for Speech Emotion Recognition" Applied Sciences 11, no. 21: 9897. https://doi.org/10.3390/app11219897
APA StyleZhang, H., Huang, H., & Han, H. (2021). A Novel Heterogeneous Parallel Convolution Bi-LSTM for Speech Emotion Recognition. Applied Sciences, 11(21), 9897. https://doi.org/10.3390/app11219897