3.1. Construction of the Projection Pursuit Regression Tree
Multiple regression models are widely used, but it is difficult to interpret the final model, especially when there are many independent variables. Additionally, if there are nonlinear patterns between the dependent variable and independent variables, the multiple regression model is more difficult to interpret. Most regression trees have better interpretability than the ordinary multiple regression model. With recursive partitioning of the independent variable space, the regression tree discovers interesting features in each partitioned space of the independent variables. However, one of the main purposes of regression is to explain the dependent variable using the independent variables. In this paper, the dependent variable is focused and a new regression tree—the projection pursuit regression tree—is proposed.
The original idea of the projection pursuit regression tree comes from the projection pursuit classification tree [
24]. In the projection pursuit regression tree, a modified approach to split nodes and assign values in the final node is used.
Let be the set of observations in a specific node and be a p-dimensional vector. Then, in each node,
- step 1:
Divide into two groups: group 1 with small values and group 2 with large values (eg. Assign to group 1 if . Otherwise, assign to group 2.)
- step 2:
Find the optimal 1-dimensional projection to separate group 1 and group 2 using one of the projection pursuit indices that involves class information—the LDA, PDA, or Lr index.
- step 3:
Project the data in the node onto the optimal projection , i.e., .
If , use as the optimal projection.
- step 4:
Find the best cut-off, c, to separate group 1 and group 2.
- step 5:
Group 1 is assigned to the left node, and group 2 is assigned to the right node
In step 2, the projection pursuit index is needed to separate group 1 and group 2. The LDA index, Lr index [
25], and PDA index [
26] were developed to find the projection from a separating view of groups. The LDA index is based on linear discriminant analysis and is useful for finding the view that maximizes between-group variation relative to within-group variation. If the correlations among variables are high or the number of variables is relatively large compared with the number of observations, the PDA index is useful to escape the data piling problem [
27] in the LDA index. The amount of penalty on correlations can be controlled with the tuning parameter
. The PDA index with
is the same as the LDA index. Both the LDA and PDA indexes use all information in the variance-covariance matrix of the independent variables. On the other hand, the Lr index ignores the covariances among variables and uses only the variances of the independent variables (
, where
is the
lth variable of the projected data in
ith group
jth observation and
is the
projection matrix).
r determines how to calculate the distance between two points in each dimension. With different selections of indices and the parameters associated with indices, the interesting features of our data space can be found.
The projection pursuit regression tree is designed to provide an exploratory data analysis tool, and the tree structure is constructed to retain this feature. In each node, the observations are separated into a group with small Y values and a group with large Y values; the group with small Y values is assigned to the left node, and the group with large Y values is assigned to the right node. To retain this directional convention, the direction of the optimal projection in step 3 is modified.
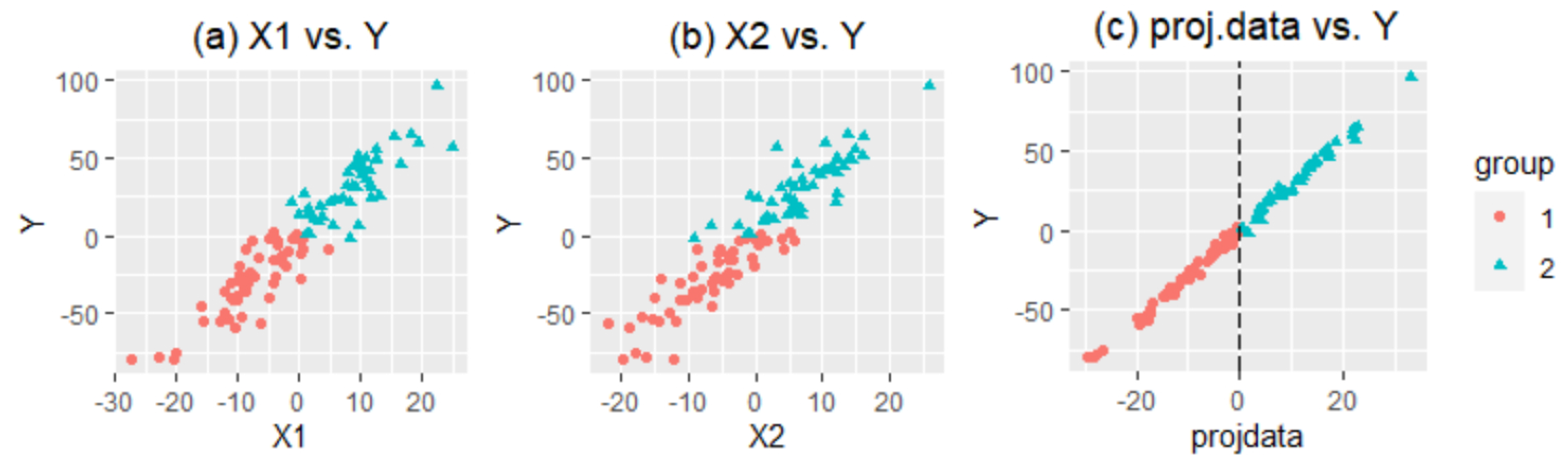
To explain how the projection pursuit regression tree works, a toy example is used. One-hundred observations with two independent variables,
and
, and one dependent variable,
Y, are randomly chosen. In this toy example data,
and
are highly correlated with
Y (
Figure 1a,b). In step 1, the data are divided into two groups: group 1 (●) and group 2 (▲). In step 2, the LDA index is used to find the optimal projection to separate group 1 and group 2.
Figure 1c is the scatter plot of the projected values of
and
vs.
Y.
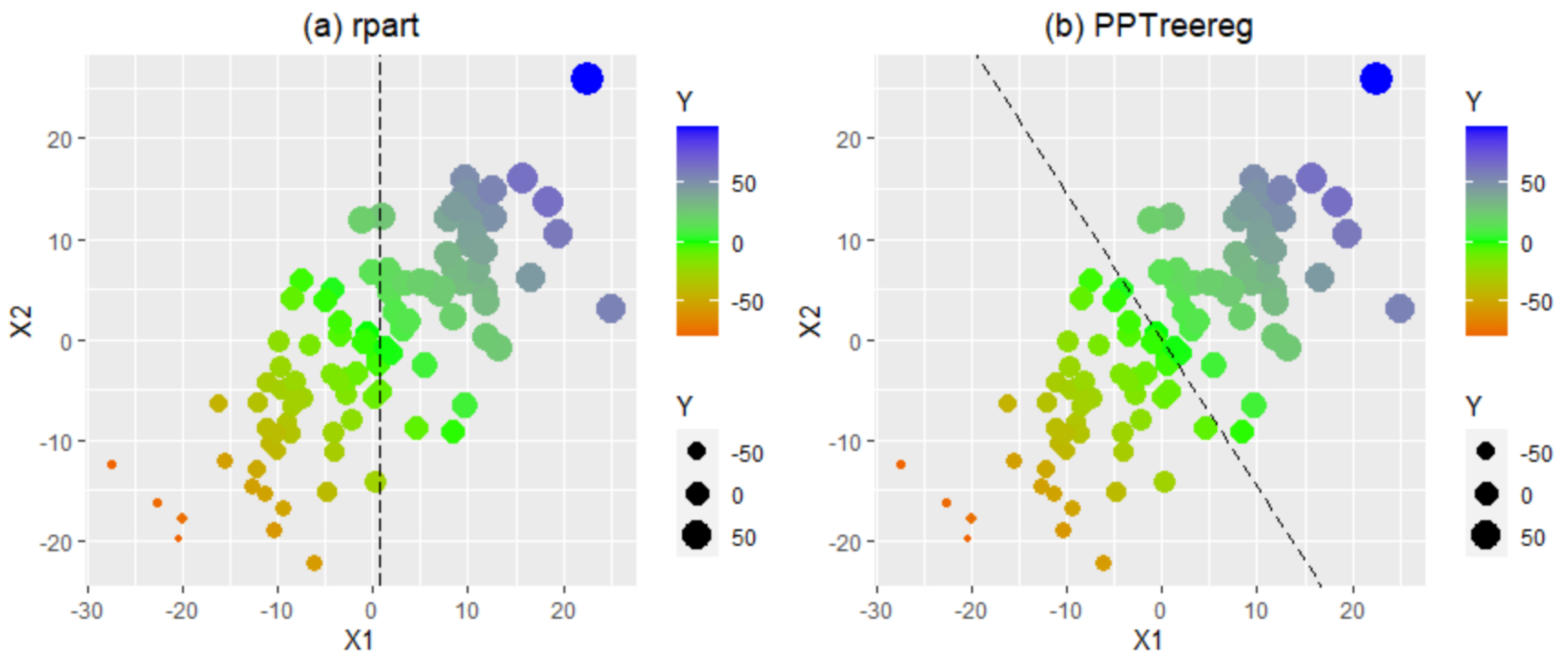
Figure 2 shows the difference between CART and the projection pursuit regression tree in dividing the space of independent variables. The dashed vertical line in the scatter plot of
and
represents the cut-off point in each method. The observations on the left/lower side of this line are assigned to the left node, and those on the right/upper side are assigned to the right node. CART uses the variable
to separate the two groups. Because CART uses one variable at a time, the separating line is parallel to the axes of the variables. In contrast, the projection pursuit regression tree uses a linear combination of the independent variables
, and this separating line can be in any direction, including the direction parallel to axes.
These procedures continue until a node is declared as a final node. To decide whether a node is final, two different ways are provided: one is for exploring data, and the other is for predicting. For the exploratory data analysis, a tree with a predefined depth can be constructed. With this approach, the projection pursuit regression tree divides the
Y values into
groups and explores the properties of each group.
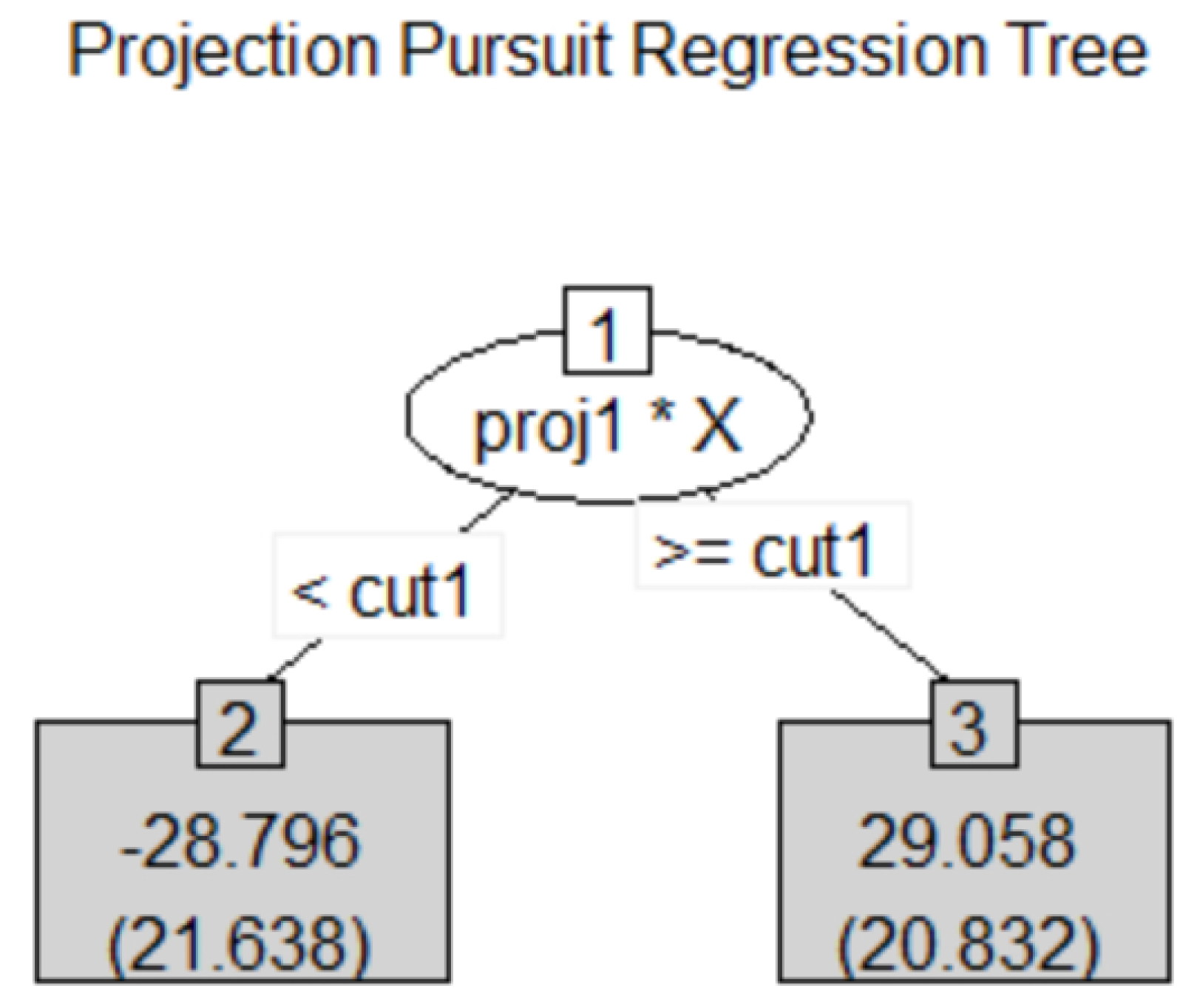
Figure 3 is a simple projection pursuit regression tree for the toy example with depth 1. The data with small
Y values have small
and
values, and the data with large
Y values have large
and
values. For the prediction purpose, the final node is declared if the number of observations in a node is small or if the between-groups sum of squares is relatively smaller than the within-groups sum of squares. The second criterion is similar to the classical Fisher’s LDA idea.
After constructing the tree structure with the observed data, the numerical values are assigned to the final nodes. Five different models are provided in our projection pursuit regression tree to assign numerical values in the final nodes. Let and be the th observations in a specific final node, , where is the number of observations in the node and is the best projection of the previous node. Then, for a new observation ,
- Model 1:
- Model 2:
= median()
- Model 3:
where and are estimated from the simple linear regression model with new variable that is generated from the optimal projection .
- Model 4:
where are estimated from the multiple linear regression model with all independent variables.
- Model 5:
where are estimated from the multiple linear regression model with the selected independent variables.
In Model 5,
is the predetermined number and the independent variables are selected using the correlations with
Y.
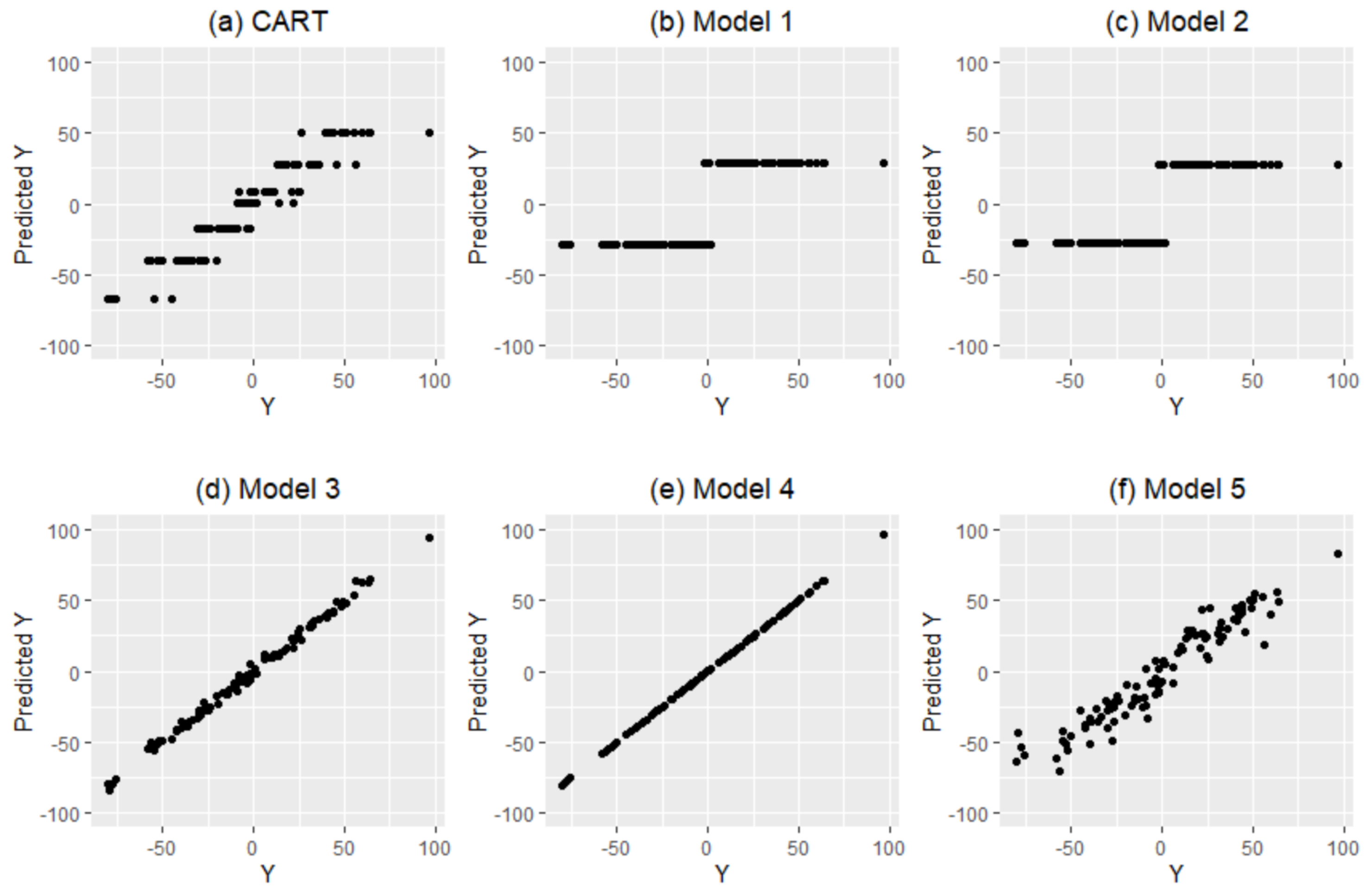
Figure 4 shows how CART and the projection pursuit regression tree with Models 1–5 assign values to the final node. For
Figure 4, the toy example data is fitted to a projection pursuit regression tree with depth 1 (
Figure 3). The result of CART has 7 final nodes, and each node is assigned to one value. In Models 1 and 2, the mean and median of the small
Y group are assigned to the left node and the mean and median of the large
Y group are assigned to the right node. For Model 3,
is used to predict the
Y values, where
is the projected data of the first node. The
model is used for Model 4, and
is used for Model 5 (
).
The MSEs of the fitted values with multiple linear regression, CART, the random forest for regression [
11], and the projection pursuit regression tree with various models for the final node are summarized in
Table 1. For the comparison, the
lm,
randomForest, and
rpart functions in R are used. In this toy example,
lm and the projection pursuit regression tree with Model 4 show the best performance.
randomForest shows poor performance on these data. The MSE of
randomForest is much higher than that of the
lm method. The result of
rpart is worse than that of
randomForest. In the projection pursuit regression tree, the performances of various models are quite different. The MSEs of the Model 1 and 2 are much higher than that of
rpart. This result is mainly due to the simple tree with depth 1 (the depth of the
rpart model is 3). If a more complex tree with a greater depth is used, the performance of Models 1 and 2 can be improved. Model 5 shows similar performance to
rpart, and Model 3 shows better performance than
randomForest. The performance of Model 4 is similar to that of
lm. From this result, it is confirmed that the predictability with various models of assigning final values can be improved.
3.2. Features of the Projection Pursuit Regression Tree
The projection pursuit regression tree is developed to explore data in each partitioned data space instead of the whole data space by focusing on the value of the dependent variable (Y). This tree always divides the data by Y values; the observations with smaller Y values are assigned to the left node and the observations with larger Y values are assigned to the right node. After fitting the projection pursuit regression tree, all final nodes are sorted by their estimated values—the node that is furthest to the left has the smallest estimated value, and the rightmost node has the largest estimated value. Therefore, with this tree structure, the most important variables for large or small Y values can be determined.
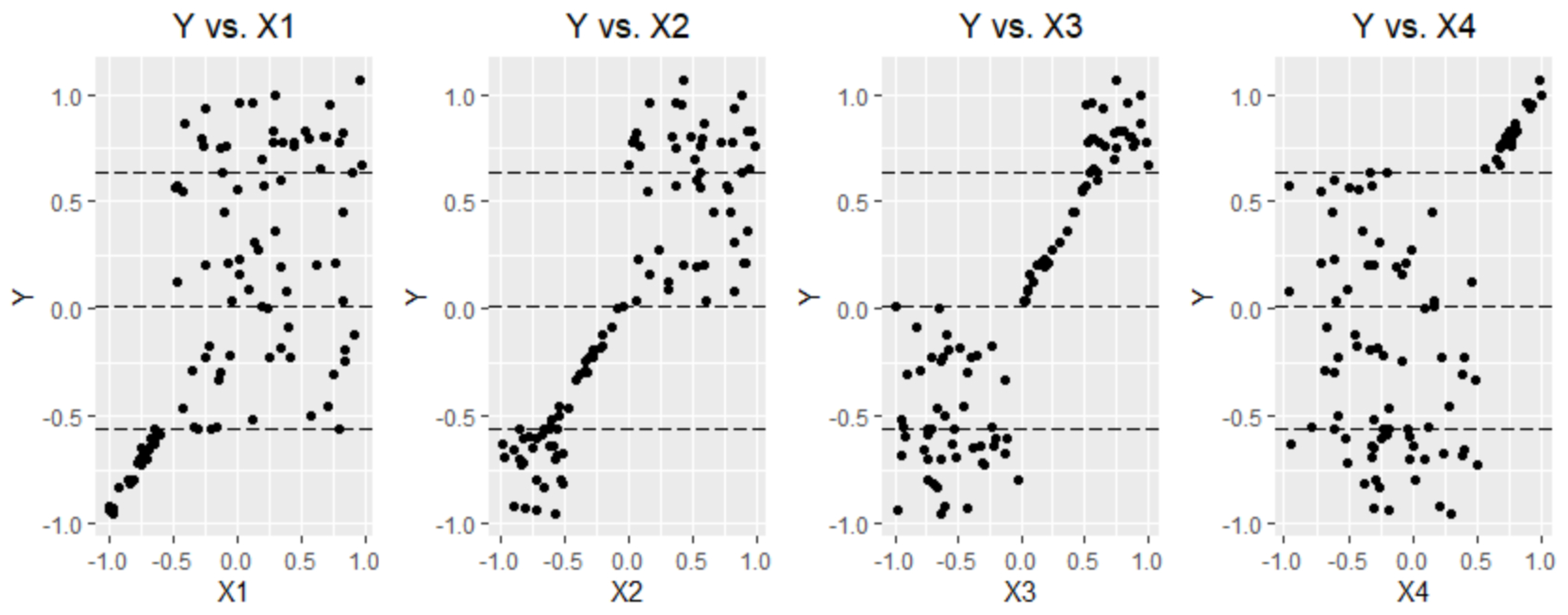
To examine this feature of the projection pursuit regression tree more deeply, 100 bservations with one dependent variable and four independent variables are simulated. Let Q1, Q2, and Q3 be the 25%, 50%, and 75% quartiles of Y. The
Y values are divided into four groups—G1, G2, G3 and G4—with these quartiles.
is linearly associated with
Y in G1 and does not have any relation with
Y in the other groups. Similarly,
shows a linear relationship with
Y only in G2, X3 shows an association with
Y only in G3, and X4 shows an association with
Y only in G4. The structures of the data are presented in
Figure 5. The relationships between
Y and the Xs depend on the range of
Y values.
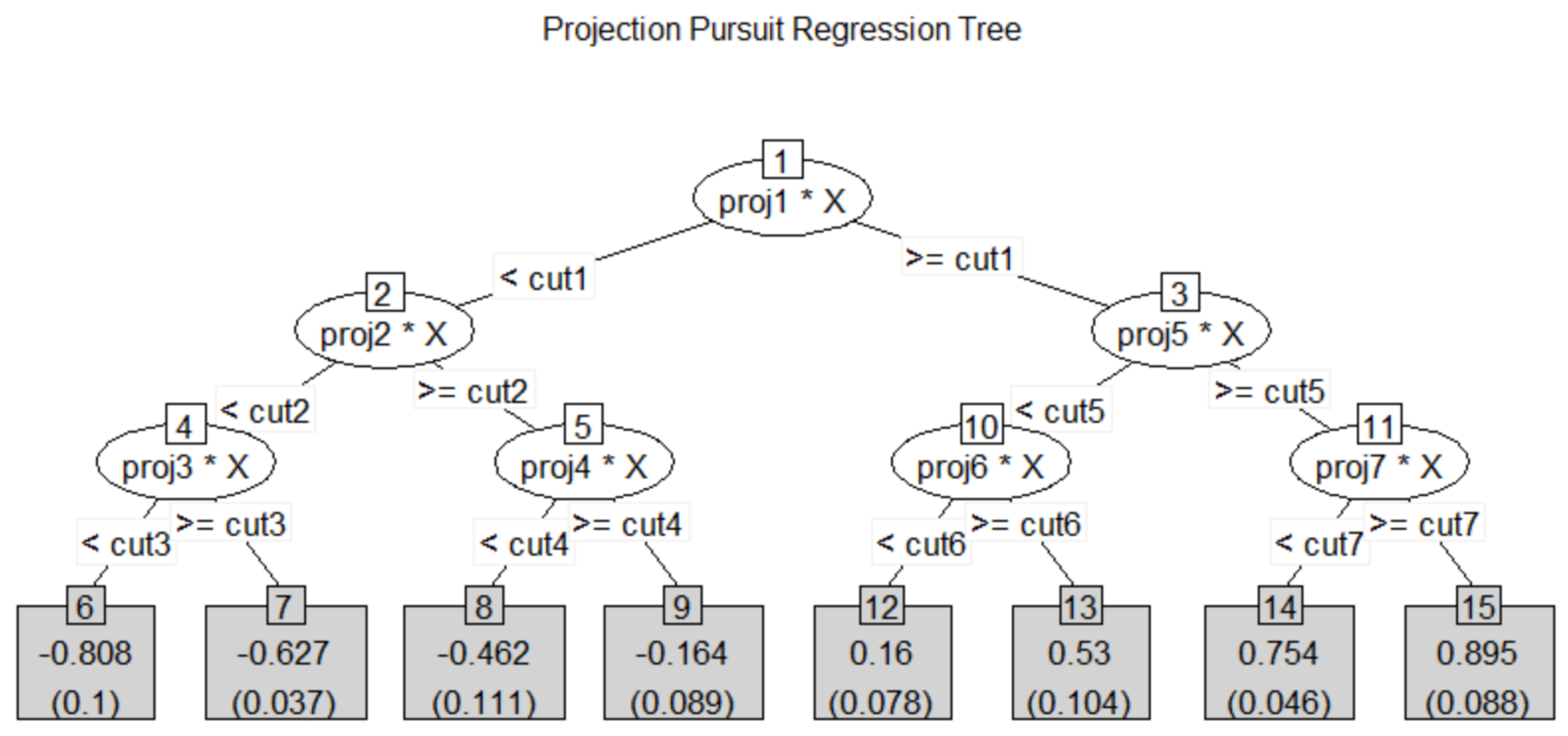
Figure 6 shows the result of the projection pursuit regression tree with depth 3, and
Table 2 shows the coefficients of projection in each node and the overall importance measure of the projection pursuit regression tree as well as the importance measure of the random forest for regression. The length of the projection is stick to one and the value of the projection coefficient depends on the number of variables. For consistent decision, the number of variables in each coefficient is multiplied for comparison. The projection coefficients of projection pursuit in each node show the role of each variable in separating the left and the right nodes. If the absolute value of a coefficient is large (great than 1), the corresponding variable plays an important role in this separation.
In node 1, all
Y values are divided into two groups—(G1, G2) and (G3, G4). To separate the smaller
Y groups (G1, G2) from the larger
Y groups (G3, G4),
and X3 should play an important role, as indicated by the coefficients of node 1. Additionally,
and
are important for separating G1 and G2. This separation occurs in node 2 and the coefficients of node 2 are large in
and
. In separating G3 and G4 in node 3,
and
are important. To separate G1 into smaller and larger groups (node 4),
should primarily be used. Additionally,
should be used for G2 (node 5),
should be used for G3 (node 10), and
should be used for G4 (node 11). All these features can be found in
Table 2 by the corresponding coefficients of each node in the projection pursuit regression tree.
Table 2 show the importance measure of the random forest for regression. The order of importance is
,
,
, and
. It shows the same result of the overall importance of the projection pursuit regression tree.
Table 3 shows MSE of multiple regression line (
lm),
randomForest,
rpart and 5 models of the projection pursuit regression tree. According to
Table 3, all methods in the projection regression tree show better performance than the other three methods,
lm,
randomForest, and
rpart.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}