1. Introduction
With the rapid development of the Internet of Things, advanced high-end computing equipment, and the popularization of communication technology, there are already many applications developed on the IoT-connected platforms, such as cloud-based vehicle routing [
1], medical and healthcare [
2], freight transportation system [
3], blockchain-based IoT [
4], etc. The automobile was hailed as the fourth C after the 3C industry. In recent years, after various technology companies have accelerated their investment in Internet of Vehicles (IoV), this industry has set off the biggest change in a century. With the increasing popularity of connected medical devices, companies from the communications technology (ICT) and financial services industries are taking the lead. Healthcare and life sciences are aspiring industries that are close behind. The emerging Internet of Medical Things (IoMT) is becoming a form of medical care. This major change not only helps to simplify the clinical workflow, which is helpful for an infected patient to identify symptoms [
5] and provides better treatment rapidly, but also helps to realize remote care.
Blockchain technology, a solution to ensure a trust relationship, has widespread applications relating to Internet of Things (IoT) and Industrial IoT (IIoT) [
6]. Blockchain and IIoT has been gaining enormous attention in areas beyond its cryptocurrency roots since more or less 2014: blockchain and cybersecurity, blockchain and finance, blockchain and anti-counterfeit labels, blockchain and smart contracts [
7], etc.
People transmit a large amount of media content on the Internet to achieve real-time interactions. At the same time, data are exposed on these public platforms and have run into unforeseen risks. It is easy to attract the attention of stakeholders and even to be maliciously attacked, causing the attacked files tampered with or even destroyed before they are spread. Therefore, how to avoid malicious tampering and misappropriation of secret information is an urgent task.
With the rapid growth of the number of the IoT applications, the amount of data that needs to be transmitted also grows rapidly in multiple activities and even about the environmental conditions that we need to monitor and control at a distance. For users, the environment of various IOT applications contains a lot of key and sensitive information. Therefore, higher requirements are put forward to protect the secure transmission of multimedia data to the destination, and information hiding was born in response to this demand. Information hiding technology, also known as steganography, is to use the content in digital media as a cover media to embed the secret message that you want to convey into the content. To protect the secret message and increase security, it is now used in various applications, for example, identity verification used to protect information content and intellectual property rights [
8,
9,
10]. These technologies hide the secret information in the multimedia content. During transmitting, it is not easy to find that there is a secret message in the content. The receiving party only needs to know how to extract the information hidden in the content so that complete information can be obtained safely. In response to different application methods, two categories are distinguished: digital watermarking and information hiding. Digital watermarking is mainly used to protect intellectual property rights and verify the integrity of information; information hiding is to hide the secret message in the embedded content, not easily discovered, and the restored content also has a considerable degree of image quality.
In the past few decades, reversible data hiding (RDH), also known as lossless data hiding, has gradually become a very active research topic in the field of data hiding. In reversible data hiding, after the confidential information is retrieved, the original images, such as medical images or military images, are not allowed to degrade at all, but its application is now extended. Through the cloud technology, IoT applications, blockchain, AI artificial intelligence technology, and algorithms [
1,
2,
3,
4,
5,
6,
7], RDH can be used as a tool to do many things with reversible image operations. After operating the image to the desired target, we can explore all the feature values to be restored to the original image from the target image. These feature values are some derived auxiliary parameters, and then these auxiliary parameters are embedded in the target image through reversible data embedding technology.
The three main methods are difference expansion (DE) [
11], histogram shifting (HS) [
12,
13,
14], and prediction error expansion (PEE) [
15,
16,
17]. The histogram shifting (HS) [
12] proposed by Ni et al. in 2006 changes the histogram of the image in hiding the embedding secret message, and the histogram is based on the count of the number of all pixel values in the gray-scale image and is drawn into a graph. The pixel value that appears most is the peak point, and the pixel value that does not appear is the zero point. The pixel values in between will move one unit to the zero point to create space. At this time, the peak point can hide the embedding secret message with secret data 1 bit. For the HS method, because the pixel value can only be adjusted at most 1 bit each time, it can have higher image quality, but the embedding capacity will be relatively low. Other scholars have successively proposed related technologies based on the HS method, including generalized histogram shifting [
18], two dimensional histogram shifting (TDHS) [
19], and adaptive embedding [
20].
Another mainstream method of RDH that Thodi and Rodriguez first proposed is the prediction error expansion (PEE) [
15], which is based on the difference between the pixel values to perform the action of embedding, so embedding capacity is twice higher compared with the general DE. Additionally, PEE has a more complex predictor than DE, so it produces a prediction error that is smaller than the pixel differences of DE. In order to reduce the excessive distortion after embedding the secret message, Hu et al. proposed an improved method [
21] to reduce the size of the location map. In 2014, Peng et al. proposed an improved PVO-based reversible data hiding (IPVO) method [
22] based on pixel-value ordering (PVO) and prediction-error expansion (PEE). The IPVO method makes full use of image redundancy to hide information at the prediction errors of 0 or 1/−1 to achieve excellent embedding performance. In 2020, Kumar and Jung successively proposed a pairwise IPVO method [
23] to hide data in a smoother block and used the bin reservation strategy [
24] to further combine PEE technology to increase the capacity embedded in the carrier. However, the method has lower image quality under low hidden payload. In 2020, Li et al. proposed an improved prediction-error expansion (I-PEE) scheme [
25] to achieve higher embedding capacity and good image quality.
In the spatial domain, exquisite pictures are usually transmitted or stored in a JPEG compression format. In view of this, in 2017, Wang et al. proposed a robust significant bit-difference expansion (SBDE) method [
26], which uses the higher significant bits (HiSB) in the pixel value as the cover image represented by (
). The reason is that general image processing or attacks will make changes in the lower significant bits (LoSB). Therefore, hiding the data in
can better maintain the integrity of the data content and increase the robustness of the hiding method. In 2020, Kumar and Jung [
27] also proposed the two-layer embedding (TLE) method that hides two secret data in the original pixels. Kumar and Jung’s TLE strategy based on the HS method of PEE uses the sorted predictors and repeatedly embedding, keeping the pixel value unchanged to increase the embedding capacity. The TLE method effectively solves the problem of low capacity of the SBDE method, but there is still room for improvement. Based on the constant pixel value, this method uses a round-trip recursive embedding strategy for the high-capacity and high-quality reversible information hiding of quotient images to hide more secret information and maintain good image quality. The following are the main contributions of our method:
- (1)
Our method is called recurrent robust reversible data hiding (triple-RDH). The secret message is embedded back and forth in a recursive round-trip way, which effectively increases the embedding capacity.
- (2)
Our method hides the secret message on the quotient images to resist malicious attacks and increase the robustness.
- (3)
In addition, our method makes full use of the similarity and correlation of adjacent quotient pixels to maintain stable image quality while increasing the embedding capacity.
- (4)
We also split the quotient image into gray pixels and white pixels, using different recursive parameters to adjust the embedding capacity and image quality.
- (5)
Therefore, the recurrent round-trip embedding strategy (double R-TES embedding strategy) achieves better performance than the TLE and SBDE methods in terms of embedding capacity and image quality.
This article reviews the Kumar and Jung’s method in
Section 2, the proposed method is described in
Section 3,
Section 4 is the experimental results, and the conclusion is summarized in
Section 5.
2. Related Work
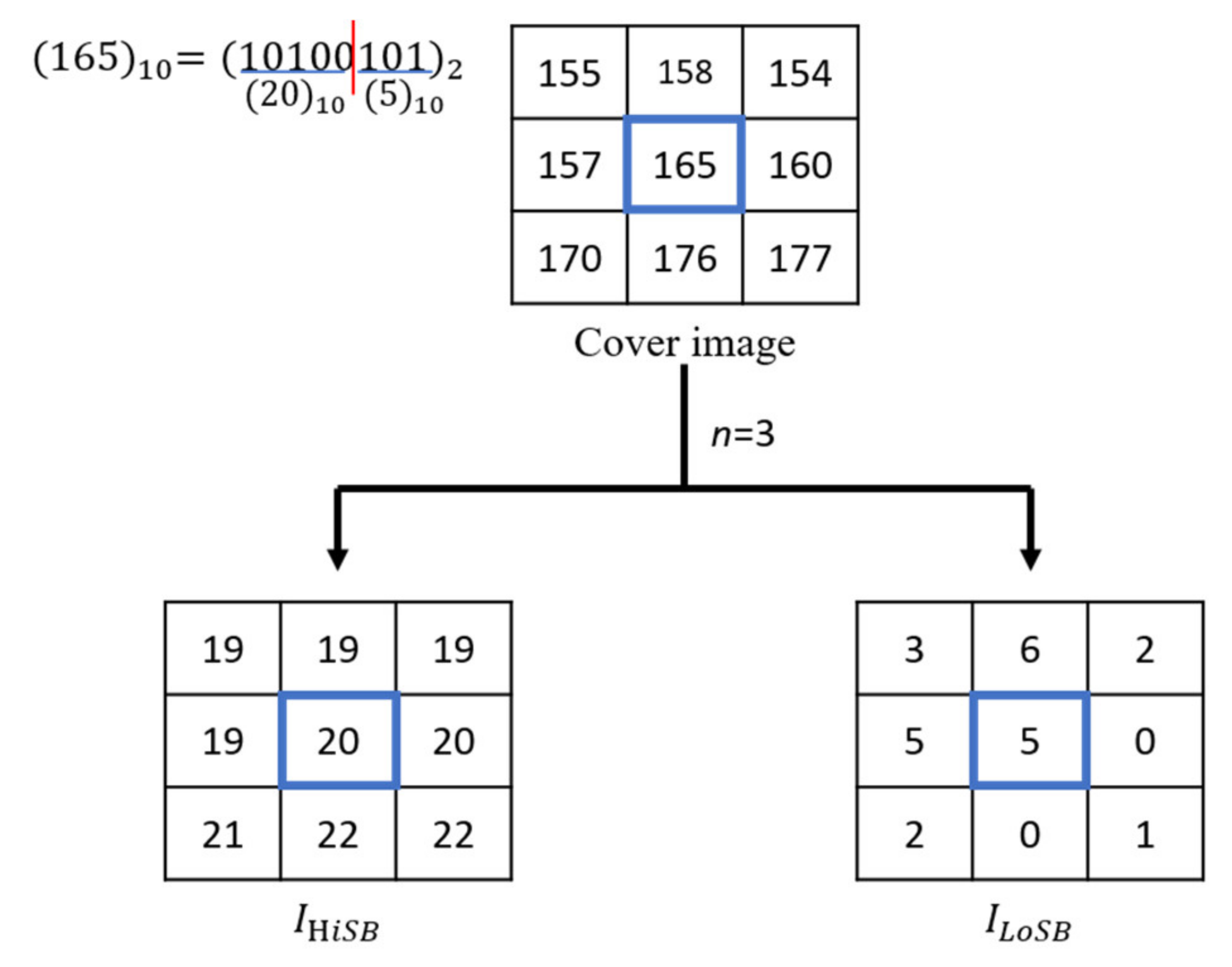
In the spatial domain, all pixels on the first layer correspond to their own corresponding values of the least significant bit (LSB); all pixels on the eighth layer correspond to their own corresponding values of the most significant bit (MSB). That is, the LoSBs contains the least significant n bits; the HiSBs contains the higher significant () bits. That is to say, in the eight-level bit plane, the original image pixel from the intensity value of level 1–127 is changed to 0, and the intensity value of the level 128–255 is changed to 1, and the resulting binary image is described below. The higher significant images of the higher layers are called higher significant bits and represented by images, and the images of the lower significant of the lower layers are called lower significant bits (LoSBs). In this article, images are represented. That is, the LoSBs contain the least significant n bits; the HiSBs contain the higher significant () bits. For example, a gray-scale pixel value is 155 = . Assuming = 3, the pixel value of the original image pixel in this image is = 3, and the pixel value in this image is = 19. Most of the information hiding techniques in spatial domain directly change the LSBs of the pixel value to achieve the embedding of secret data.
Both the significant-bit-difference expansion (SBDE) method proposed by Wang et al. [
26] and the two-layer embedding (TLE) method proposed by Kumar and Jung at (2020) [
27] utilize the HiSBs to achieve the information embedding and make the hiding methods more robust. Both the SBDE and TLE methods consider that the distortion of the
image should not be too large. It will only embed the secret message in the embedding area with low complexity. The measure of complexity complex is the variance of the pixel value on the
image. The smaller the variance, the higher the smoothness, which means that embedding secret information in this area will cause less distortion, therefore increasing the image visual quality. However, the SBDE method hides the data in the bit difference, resulting in severe image distortion. Therefore, the TLE method enhances the hiding performance both in image quality and embedding capacity.
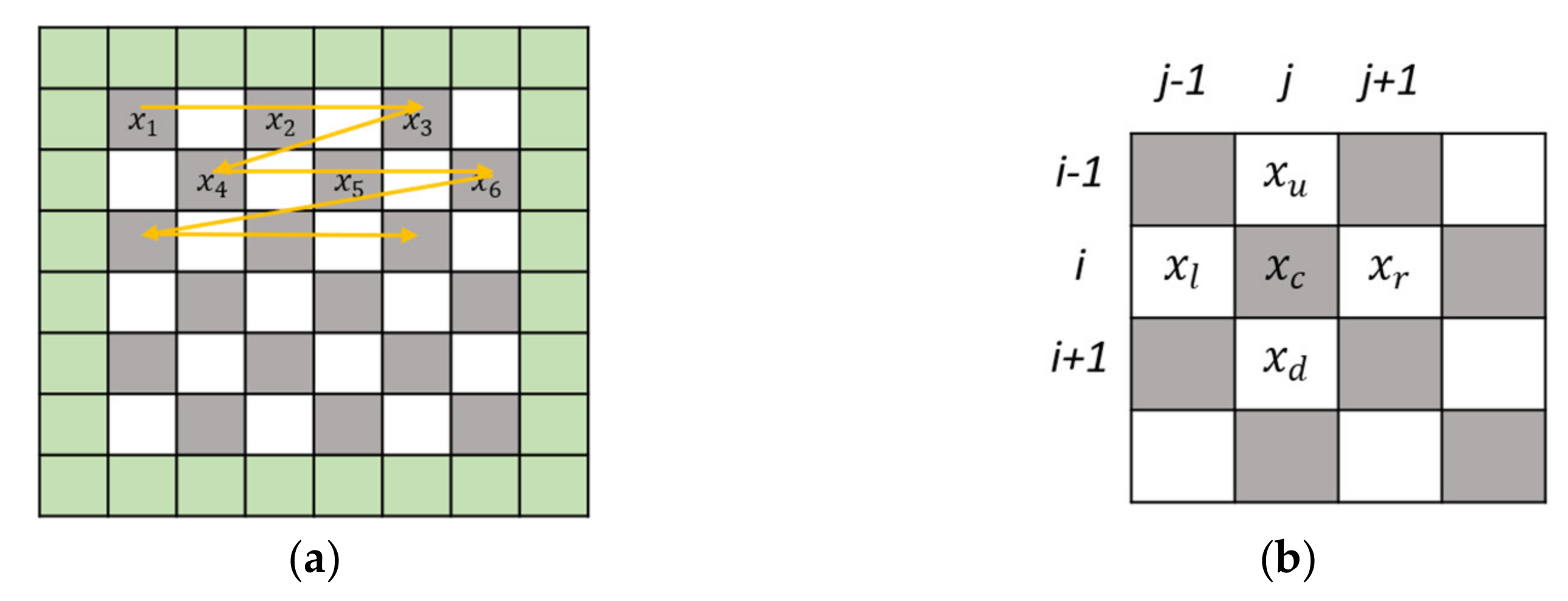
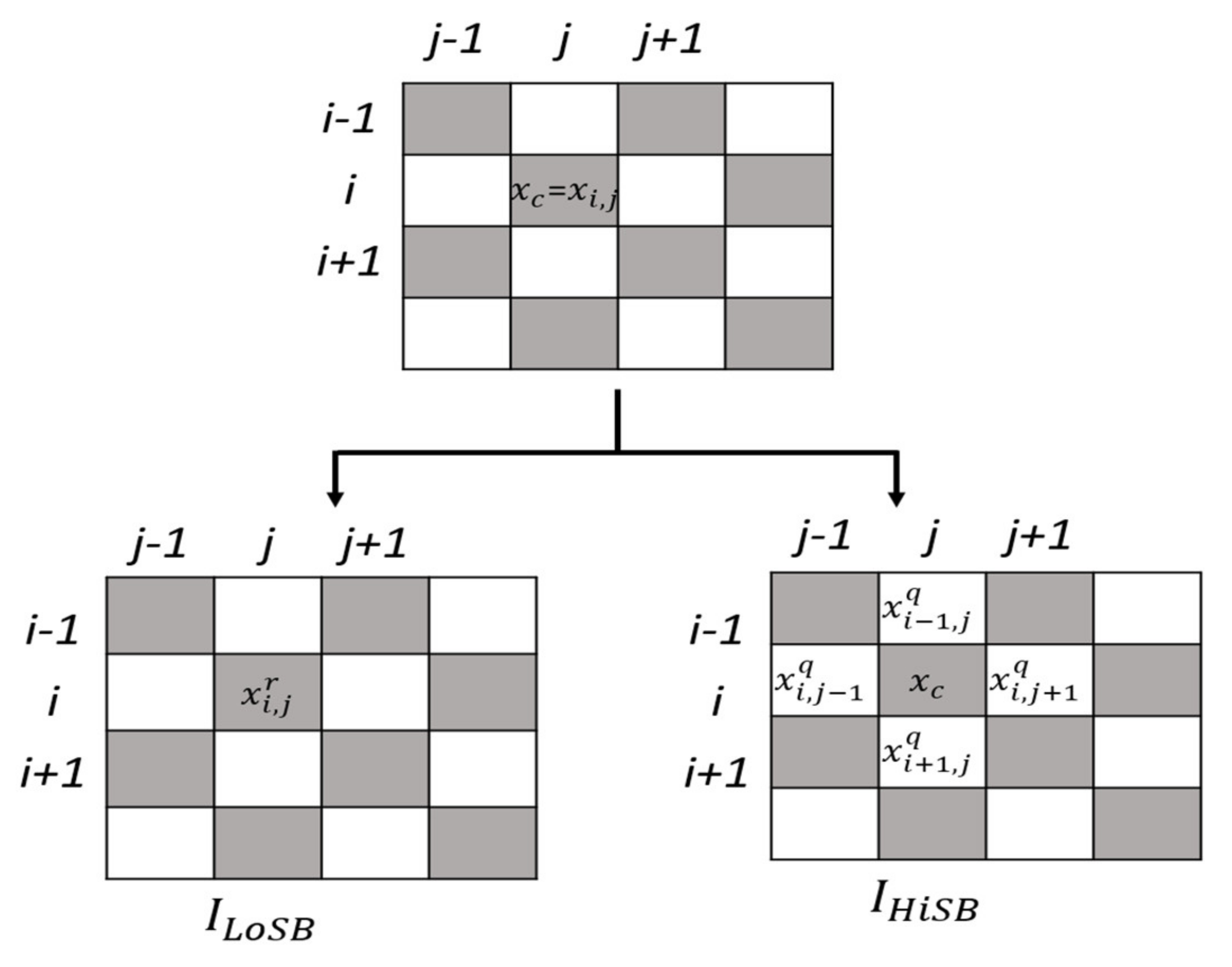
2.1. Embedding Method of TLE
The TLE method first divides the pixel value of an
image into white and gray chessboards, as shown in
Figure 1a. The secret information to be hidden is repeatedly embedded in the whole gray pixel values and then in the whole white pixel values.
Figure 1a also shows that during the embedding process of the TLE method, the pixel values of the first column and the first row and the last column and last row of the
image will not be changed. The TLE embedding procedure is as follows.
Input: a gray-scale image .
Output: a gray-scale stego image .
Step 1. The binary representation of each pixel value in the gray-scale image is (, ∈{0, 1}. The cover image is decomposed into an image () and an image (), where the pixel value of each pixel in the image is = ( | }.
Step 2. For the convenience of description, let the
image be represented by the gray-scale pixel (
) in
Figure 1b. In the
image, it is used as the carrier for embedding the secret message of the embedding binary. Let
; in
Figure 1b, the white pixel values of the top, bottom, left and right of the pixel (
) are (
). For the convenience of explanation, let
. The vector
is sorted according to the pixel value from small to large, and the result is
.
Step 3. The local complexity of the pixel
is defined as its surrounding four white pixel values
, and the variance (
), as shown in Equation (1).
where
, is the average value of the white pixel values around the pixel
.
Step 4. The calculation of predictor:
Table 1 lists three predictor methods suggested by Kumar and Jung. Each predictor will have a pair of predictors (
) used as a prediction error. Predictor method 1 will use the largest and smallest pixel values in the ordered vector (
), which is a pair of extreme values neighbors of pixel
. The extreme value neighbors are
and
as predictors
and
. The predictor method 2 is the most comprehensive predictor, which will use the four white neighbors of pixel
. Each predictor
or
will use the average of the three white neighbors to make predictions. The design of predictor method 3 puts the predictors between the extreme predictor method 1 and the comprehensive predictor method 2.
Step 5. Two-layer embedding (TLE) strategy: refers to the strategy that each pixel in the image (
) can embed the secret data twice. In the first layer embedding program, the TLE strategy uses Equation (2) to embed the secret bit
into the pixel
, and the method is: first calculate the first prediction error
, and then the to-be-embedded secret bit
, as in Equation (2):
where
is the intermediation value after embedding in the first layer.
Step 6. In the second embedding layer, the TLE method calculates the second prediction error
, and then uses Equation (3) to hide the secret bit
into
.
where
is the stego pixel value after embedding in the second layer.
The TLE method aims at the prediction error , and then the pixel value on the original image will add . If the prediction error , then the pixel value on the image will be the intermediation value subtracting after the first layer of the embedding procedure.
In the TLE strategy, the design predictor
is always greater than the predictor
, so the predictor (
) embedded in the second layer can be modified to
by Equation (4):
Step 7. The pixel of is converted to binary, which is the original and pixel of converted to binary, which is the original () combined into a stego pixel, until all the pixels are combined into a gray-scale stego image .
Step 8. Steps 2 to 7 are repeated to perform the TLE embedding method on the white pixel of .
Some auxiliary information is needed. The auxiliary information includes the following:
Location map (LM): To avoid the overflow/underflow problem and to lossless extract the secret message and restore the image recovery, the following Equation (5) is used to pre-process the image to generate a location map (LM). If
, the location map
is represented by 0; if not
MAX or
MIN,
is represented by 1.
2.2. Embedding Example
The following example shows the method of TLE. Assuming that a gray-scale image
has 3 × 3 pixels, its pixel value is shown in
Figure 2. First, set
is used to divide the cover image
into 2 planes, namely
image and
image. Then, the
image is used as the secret carrier. Take the pixel value (
) of the
image as a carrier, which is 20. The following example illustrates the embedding process:
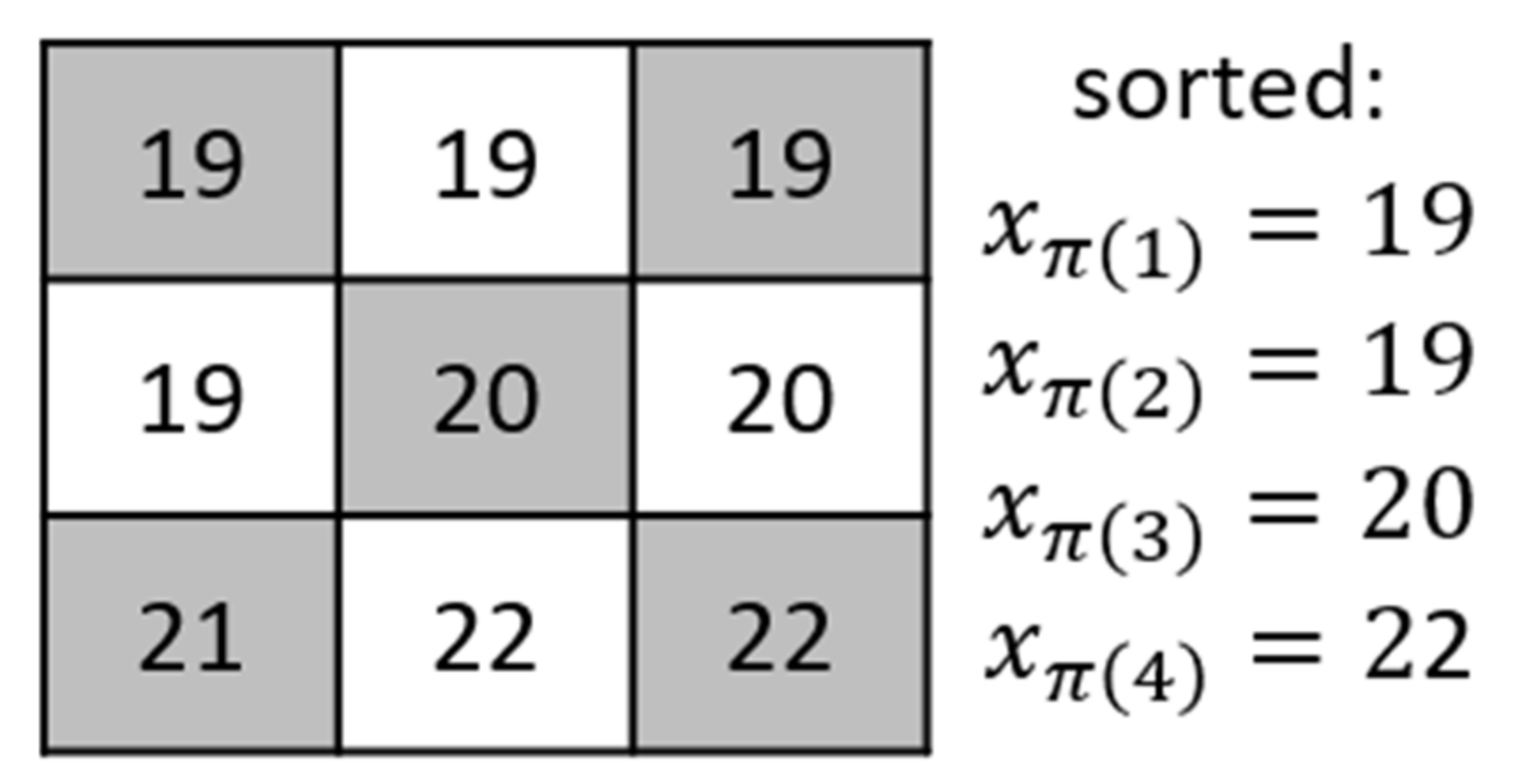
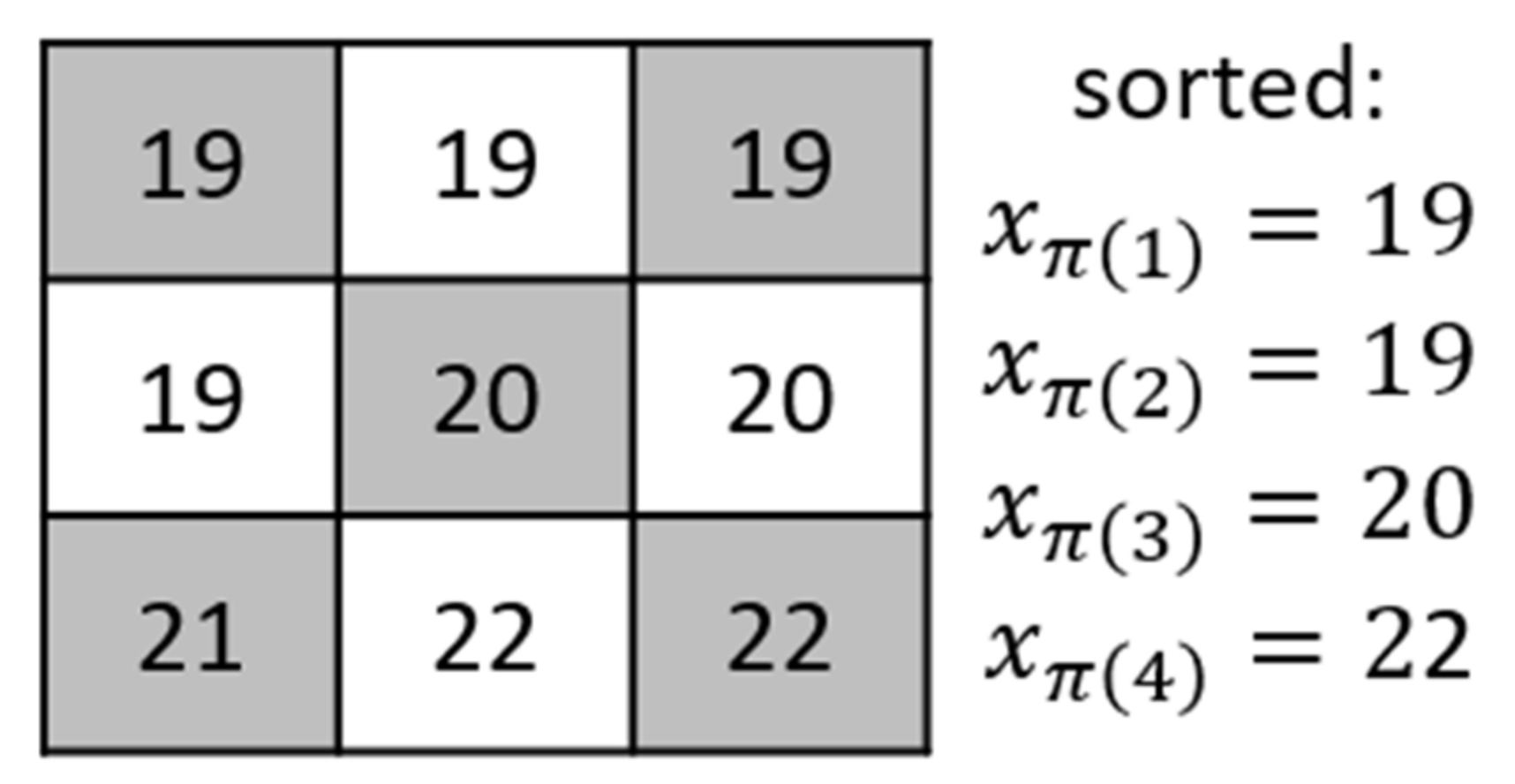
The TLE method sorts the up, down, left, and right pixel values of the pixel (
) to obtain the result: (
) = (19, 19, 20, 22), as shown in
Figure 3.
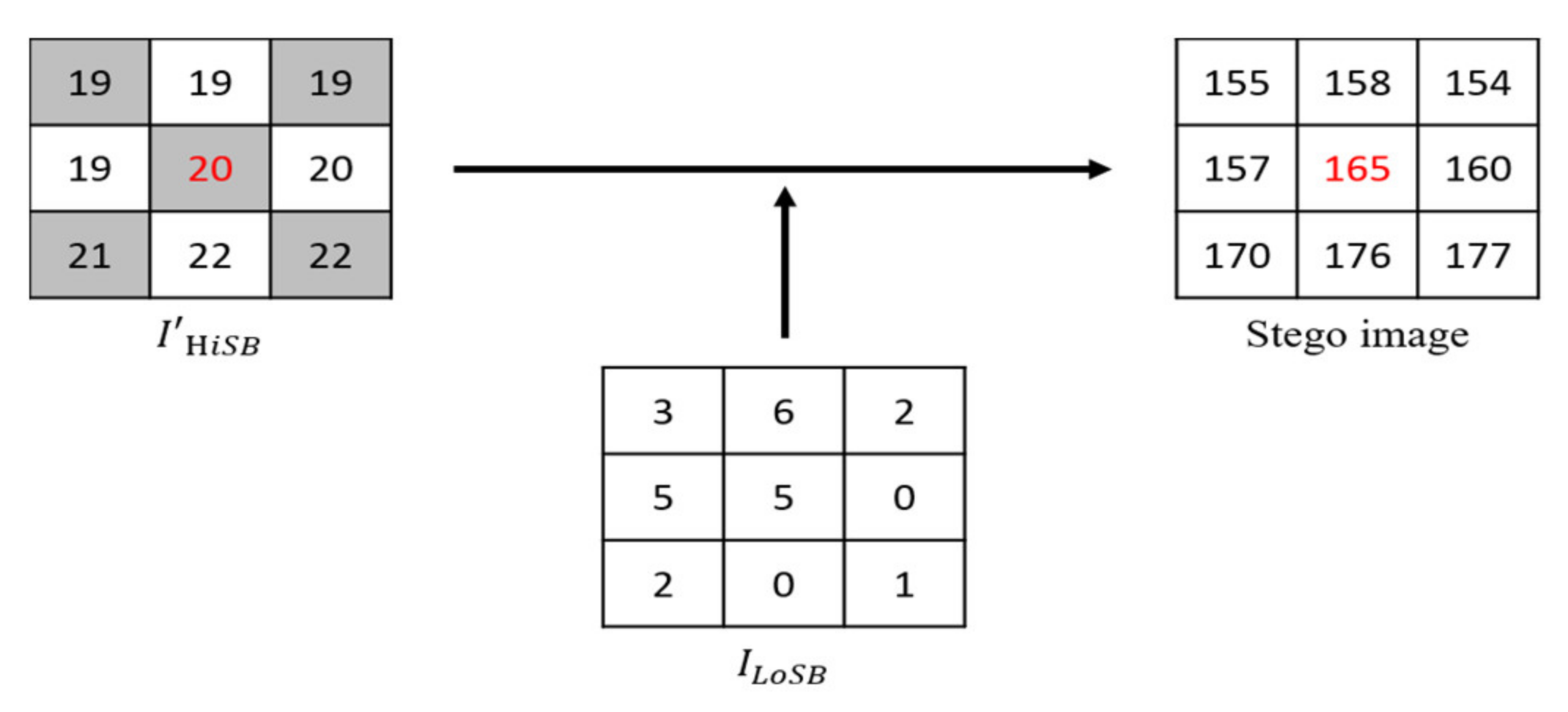
The TLE strategy first selects which predictor method to use and then judges whether embedding secret bit can be embedded in according to Equation (2). Then according to Equation (3) the TLE strategy judges whether or not the second layer of secret bit can be embedded.
Assume this example uses predictor method 1, that is,
,
) = (
. Additionally, suppose
and
, then the prediction error
is calculated according to Equation (2); therefore,
=
, and this completes the secret data embedding of the first layer. Then, the prediction error
is calculated according to Equation (3) as well as
, and this completes the second layer embedding. The embedded
is combined with the pixel value of
to complete the embedding process, as shown in
Figure 4.
The TLE method has the possibility of keeping the pixel value unchanged after embedding. It not only reduces the distortion of the image but also increases the embedding capacity and then uses the secret data algorithm to extract the secret message to achieve the purpose of information hiding.
3. Proposed Method
The pixel value of the image is prone to the strong correlation among pixels, that is, is very similar to and . Once the condition that is always smaller than is established and the pixel is squeezed between the two predictors , there is a high probability that ∈{0, 1} or ∈{−1, 0}. For , the pixel can carry one secret bit , and then if , then it again carries another secret bit Even if two secret bits are carried, because ≤ ≤ , the stego pixel value does not change much, and good image quality can be maintained. Accordingly, the embedding is somehow like a repeated oscillation effect. The effect comes from embedding 1 bit data to make the original pixel approach the predictor and then embedding another 1 bit data to make the pixel approach the predictor in the reverse direction. The proposed method utilizes the repeated oscillation effect to increase the embedding capacity without affecting the distortion of the image. This research method proposed an embedding strategy, which is called the recurrent round-trip embedding strategy (referred to as double R-TES strategy), that the pixel after embedding secret data will move back and forth between the two predictors . The R-TES strategy embeds performs ) times of outbound/backbound embedding, so the pixel can carry 2 bit data. At the same time, location map bits are also derived to record the embedding secret data such that the secret message can be completely extracted, and the pixel values of image can be exactly recovered.
In the proposed information hiding scheme, the image
is classified into two parts: un-embeddable and embeddable parts. The un-embeddable part is the pixel values of the first column and the first row and the last column and the last row. The remainder pixels of image
can be used as cover image pixels to carry the secret data bits. Like the TLE method, we also first divide the pixel value of a quotient image into white and gray chessboards, as shown in
Figure 5, and then the secret information to be hidden is repeatedly embedded in the pixel values of the gray grid first. According to the same embedding procedure, the hidden secret data are repeatedly embedded into the pixel values of the white grid.
3.1. Recurrent Robust Reversible Data Hiding (Triple-RDH) Embedding Method
Input: a gray-scale cover image .
Output: a gray-scale stego image .
Step 1. For the pixel in the embeddable area, the image
is sheared into a quotient image (i.e., higher significant bit-plane image
) and a remainder image (i.e., lower significant bit-plane image
); that is, each embeddable pixel
is divided into a quotient image pixel
and a remainder image pixel
using the quotient and remainder operands, respectively, by Equation (6).
for
, where
, and
; ‘
div’ and ‘
mod’ are the divide and modulo operations, respectively. Each quotient pixel
of the image
is labeled into two image pixels of gray and white as in a chessboard-shaped chessboard.
Step 2. For each pixel on the chessboard image , let . Then, the top, bottom, left, and right of the pixel are another-color pixel values that are different from the color of . The pixel values are, respectively, If is gray, then () is the four white neighboring pixels of ; if is white, then () is the four gray neighboring pixels of .
Step 3. The sort() function is used to sort (
) in ascending order, and the result obtained is (
).
The sort() function is the unique one-to-one mapping. In the case of equal value, pixels are ordered by , if = and k <.
Step 4. The local complexity of pixel
is defined as the variance (
) of the surrounding four color pixel values (
), as shown in Equation (8).
where
which is the average value of the four color pixel values around pixel
.
Step 5. The recurrent round-trip embedding strategy (referred to as double R-TES strategy) is expressed. For the convenience of explanation, assume that
is a gray pixel at this time:
Step 6. and are two predetermined peak points. According to the experimental statistics of this research, setting = 1 and = −1 will make the embedding capacity more effective.
Step 7. Then, determine whether can be used a carrier to embed information: compare the gray pixel of the original cover image with the gray pixel that has been embedded back and forth . times (that is, at most bits of information have been hidden). If , this means that the process goes back to Step 6, and the recurrent round-trip embedding strategy can be used again and again to let be the carrier and have the opportunity to embed more than two secret data bits. If , then go to Step 8.
Step 8. When the last embeddable gray pixel of , i.e., and , has been processed, the procedure in a zig-zag canning manner starts to proceed to the first embeddable white pixel , i.e., 2 and 3 of , until all white pixels are processed to embed secret data.
Step 9. The final process is to merge the quotient image pixels (
HiSBs) and the remainder image pixels
LoSBs) back to the gray-scale stego image pixels by Equation (11) and return the stego image
where ‘
mul’ stands for the multiplier operator.
This research will generate some extra information: the location map and the parameters for hiding data bits. The lossless compression technology “Arithmetic Coding” is used to compress the location map to a length of () << , and the least significant bit (LSB) substitution method is used with other additional information to hide the end of the image. The function of location map has the following two situations:
CASE 1: When the recursive parameter
= 1, the location map
is used to avoid overflow/underflow problems and lossless extraction of secret message to restore the image.
CASE 2: When the recursive parameter > 1, the location map is used to allow the receiving end to recover smoothly in the process of extracting the information, and every pixel must be recorded how many times the triple-RDH embedding method have been carried out on the pixel; every time it is carried out, it hides a 2-bit data with = 1, otherwise = 0.
In addition to the location map, the parameters are required as additional information, where using two bits to encode the value and using four bits to encode the () values. The index value is recorded to distinguish the boundary of extra information and the secret message . The position of the last embedded pixel value is found out when extracting the extra information.
The extra information items and the required bit sizes are shown in
Table 2. It is required to embed the overhead information at the end of the cover image by exploiting the LSB method. The size of extra information is
bits, and the LSB, which has been replaced by the extra information, is represented as
.
3.2. Embedding Example
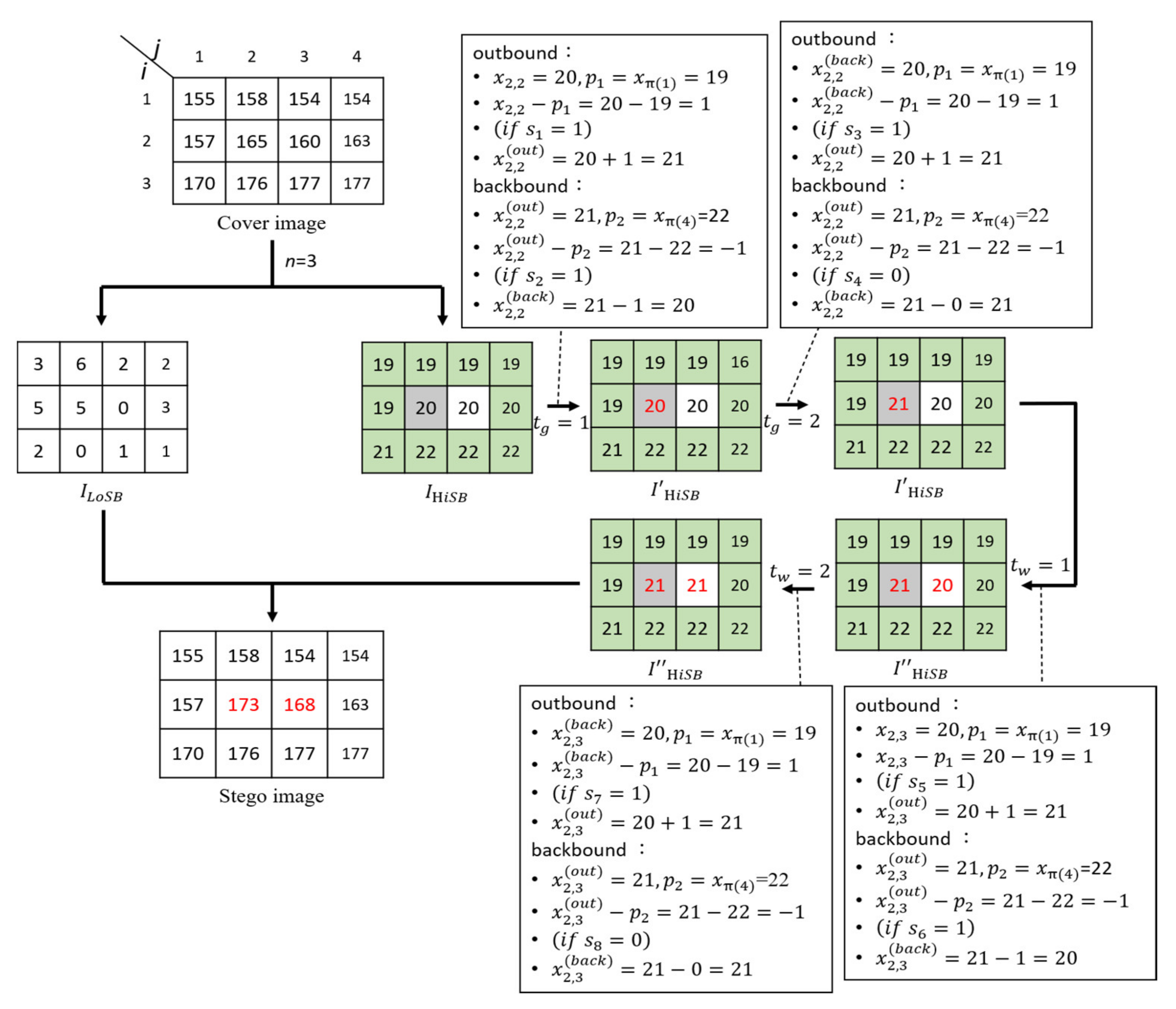
We take a cover image with 12 pixels as shown in
Figure 6 to illustrate the data embedding procedure. The cover image is split into two images,
and
through Equation (6). The quotient pixels in the
image are divided into gray pixels and white pixels in a chessboard manner. Let us suppose there is a secret bitstream
= “1110 1110” and the predictor method 1 is used in this example.
First, the recurrent round-trip embedding strategy (double R-TES) for the gray pixel is used to calculate the prediction error . According to Equation (9), the first secret bit is taken out from the secret message 𝑆, and then is calculated. This completes the embedding of the outbound value and then calculates the backbound value . According to Equation (10), the secret bit is embedded to obtain the backbound value . It is observed that . According to the double R-TES embedding strategy, the gray pixel can continue embedding more secret data bits. At this time, the recursive parameter . According to Equation (6), the prediction error , and is taken from the message S again to make . According to Equation (7) again, . After is embedded into , the result is obtained, and the embedding of the backbound is completed.
Since
, in this example, only two pixels
are embeddable, so Step 8 is executed to start embedding the message in another embeddable white pixel
.
Table 3 shows the embedding process in which the proposed triple-RDH is applied to embed the remainder data
into the white pixels.
3.3. Extracting the Message and Restoring the Original Image
At this stage, the receiver uses the instructions of the additional information to extract the secret message embedded in the stego image according to the reverse operation method of the embedding procedure to recover the original image .
Like the recurrent robust reversible data hiding (triple-RDH) method in this study, we distinguish the stego image () into embeddable and un-embeddable areas: the pixel values of the first column, first row, last column, and last row of the stego image are the un-embeddable part. For each embeddable stego pixel , the quotient operation is = div .
As mentioned above, since we need to reverse the hidden method to extract the secret message and recover the original pixel value, we need to extract the message bits from the white pixels with the recursive parameter first until all the secret messages hidden in the white pixels are retrieved and the white pixel value is recovered, then the recursive parameter is used to start message extraction and recovery of gray pixel value. In the following extraction equation, we take the recursive parameters and as an illustration.
The receiver will use the following Equations (13) and (14) in the information extraction and recovery procedure of the pixel value. When
, the white pixel value will be processed first.
Then, when
, the message extraction and recovery procedure of pixel value use the following Equations (15) and (16) to recovery white pixel value and extract the secret message until all the white pixel values are restored and the secret message is extracted.
After completing the extraction of the white pixel value and the recovery of white pixel value, the information extraction and the recovery program procedure of the pixel value again use Equations (13) and (14) (at this time ), and Equations (15) and (16) (at this time ) are used to restore the gray pixel value and take out the secret message in sequence.
After extracting the hidden information, the location map (
LM) is separated and decompressed into the original form, and the obtained image is reprocessed using Equation (17) to obtain the cover image.
3.4. Extraction Example
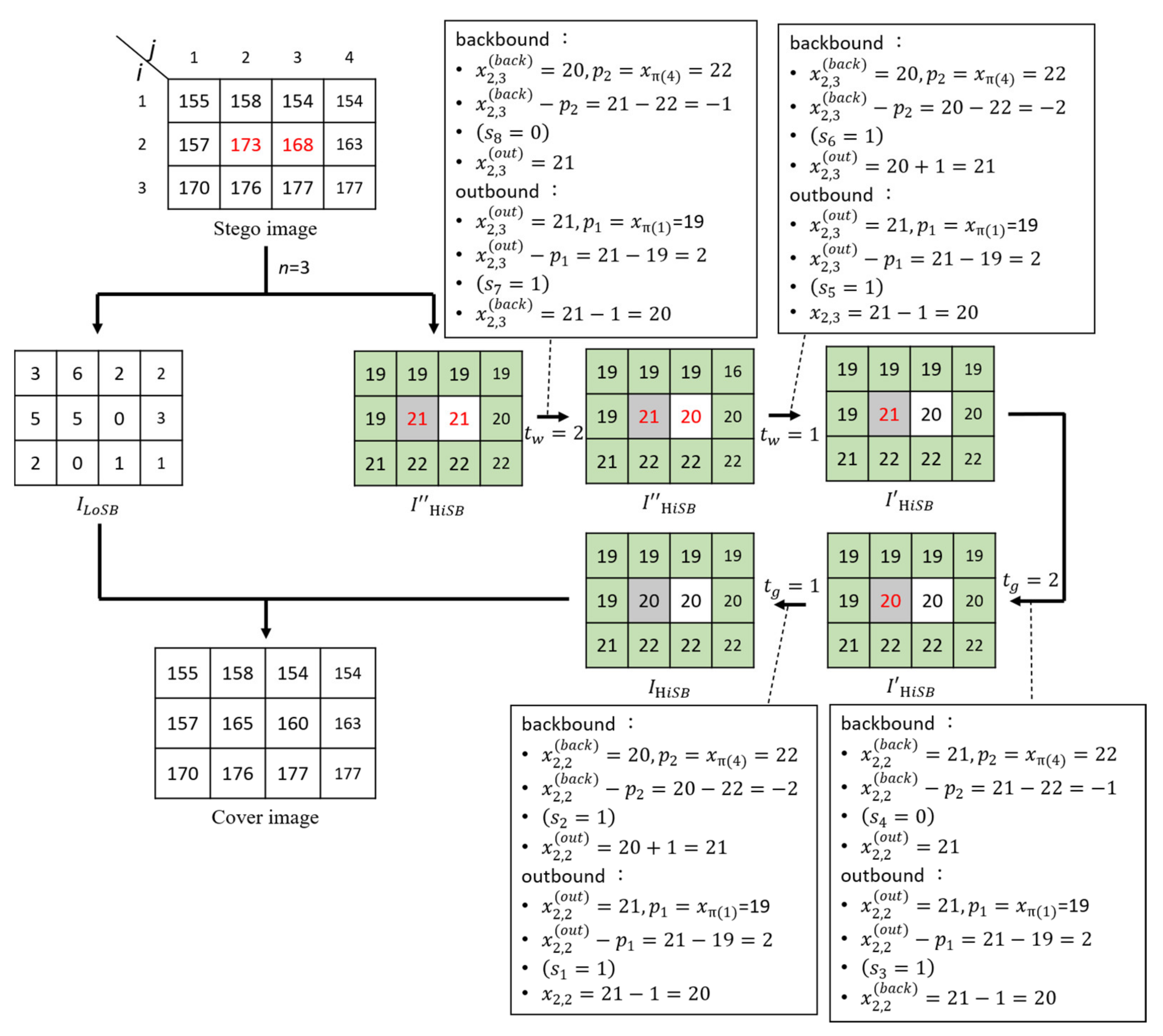
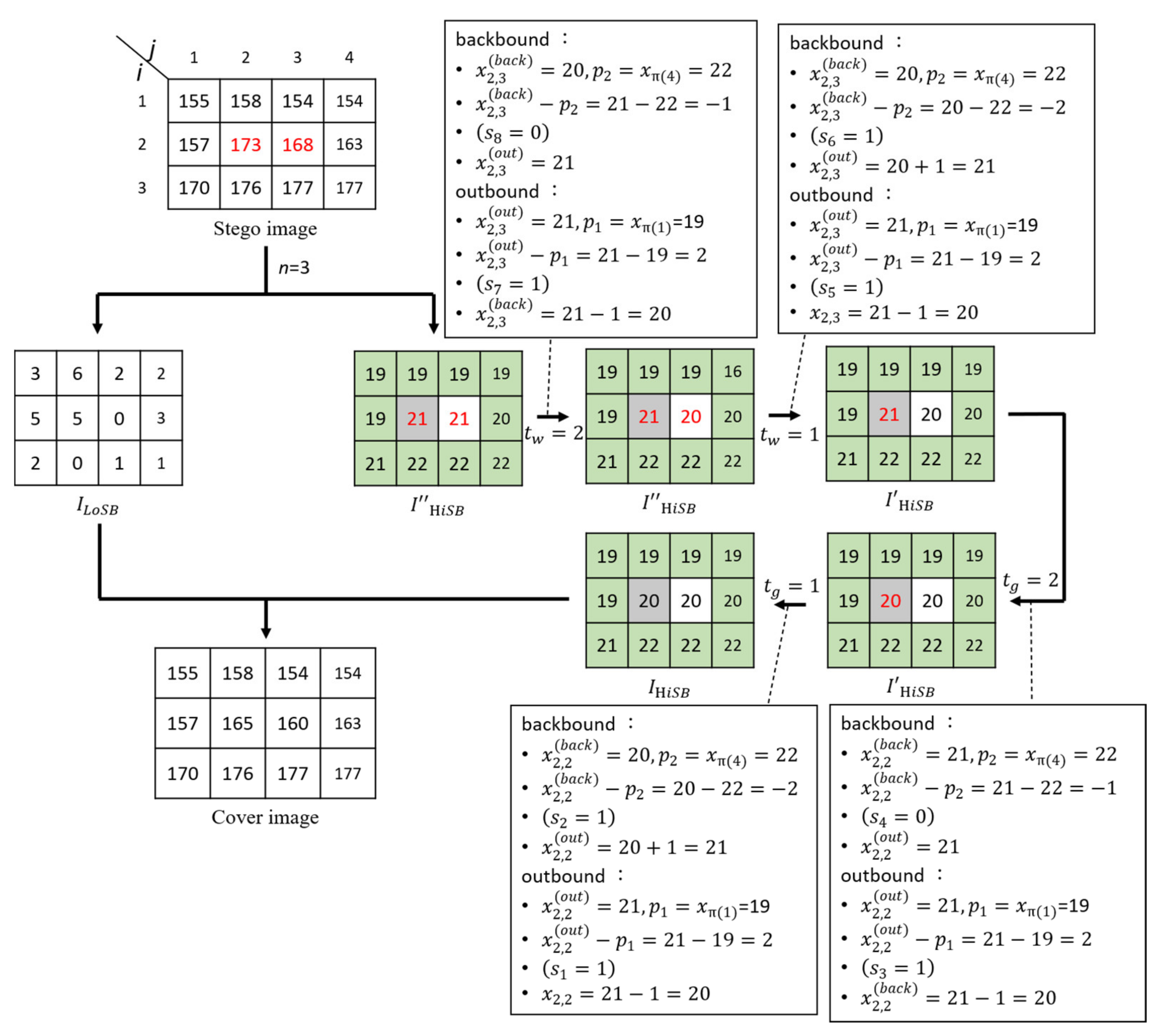
The extraction process is exactly the reserve of the embedding process, so the message extraction and recovery procedures of the pixel value only need to be reversed. The following is an example of the extraction process:
First, take a stego image in
Figure 7 and use Equation (6) to split it into two images
and
. The embeddable pixel in the image
is divided into a gray pixel and a white pixel in a chessboard manner. First, the extract extraction for the white pixel and calculate the backbound prediction error
, and according Equation (13),
, and
is unchanged; therefore,
. Next, calculate the outbound prediction error so that
. According to Equation (14),
, and
subtract 1 to restore the pixel value, so
. This completes the extraction of the outbound journey. Then, when the recursive parameter
, the backbound prediction error is also calculated, so that
, which is expressed according to Equation (15);
, and add 1 to
to restore the pixel value, so
. Finally, calculate the outbound prediction error so that
. According to Equation (16),
, and
subtract 1 to restore the pixel value, so
. Finally, the secret bitstream extracted from the white pixels is as
“1110”, and the pixel values are also restored.
In this example, there are only two pixels
so the next step is to extract the information from the gray pixel
when the recursive parameter
. In order to simply express the extraction process,
Table 4 is used to show the changes in the values of the gray pixel during the extraction process to extract the secret bitstream
“1110”.
Figure 7 illustrates the whole extraction and recovery processes.
4. Experimental Results
The hardware device used by our proposed recurrent robust reversible data hiding (triple-RDH) method is i7 with a solid-state disk with 16GB of memory. The operating system is Win10, and the tool developed is MATLAB. Ten 512 × 512 gray-scale images (“Lena”, “Baboon”, “Barbara”, “Boat”, “Elaine”, “F16”, “House”, “Pepper”, “Sailboat”, and “Tiffany”) are used as the test images, as shown in
Figure 8. The secret data are binary string generated by a random function.
The following two evaluation metrics are used in our experiment: embedding capacity (EC) and peak signal-to-noise ratio (PSNR). EC represents the amount of secret data that can be embedded in the image, usually calculated in bits. The maximum embedding capacity refers to the maximum amount of data that can be embedded in an image. The PSNR computes the peak signal-to-noise ratio, in decibels, between two images. The higher the PSNR, the better, indicating that the stego image is highly undetectable. The calculation method of PSNR is , where MAX is the maximum possible pixel value of the image. The method in this article is mainly based on the gray-scale image, so MAX is 255, and MSE is the mean square error, calculated by , where H is the length of the picture, W is the width of the picture, are the pixel value positions, is the cover image, and is the stego image.
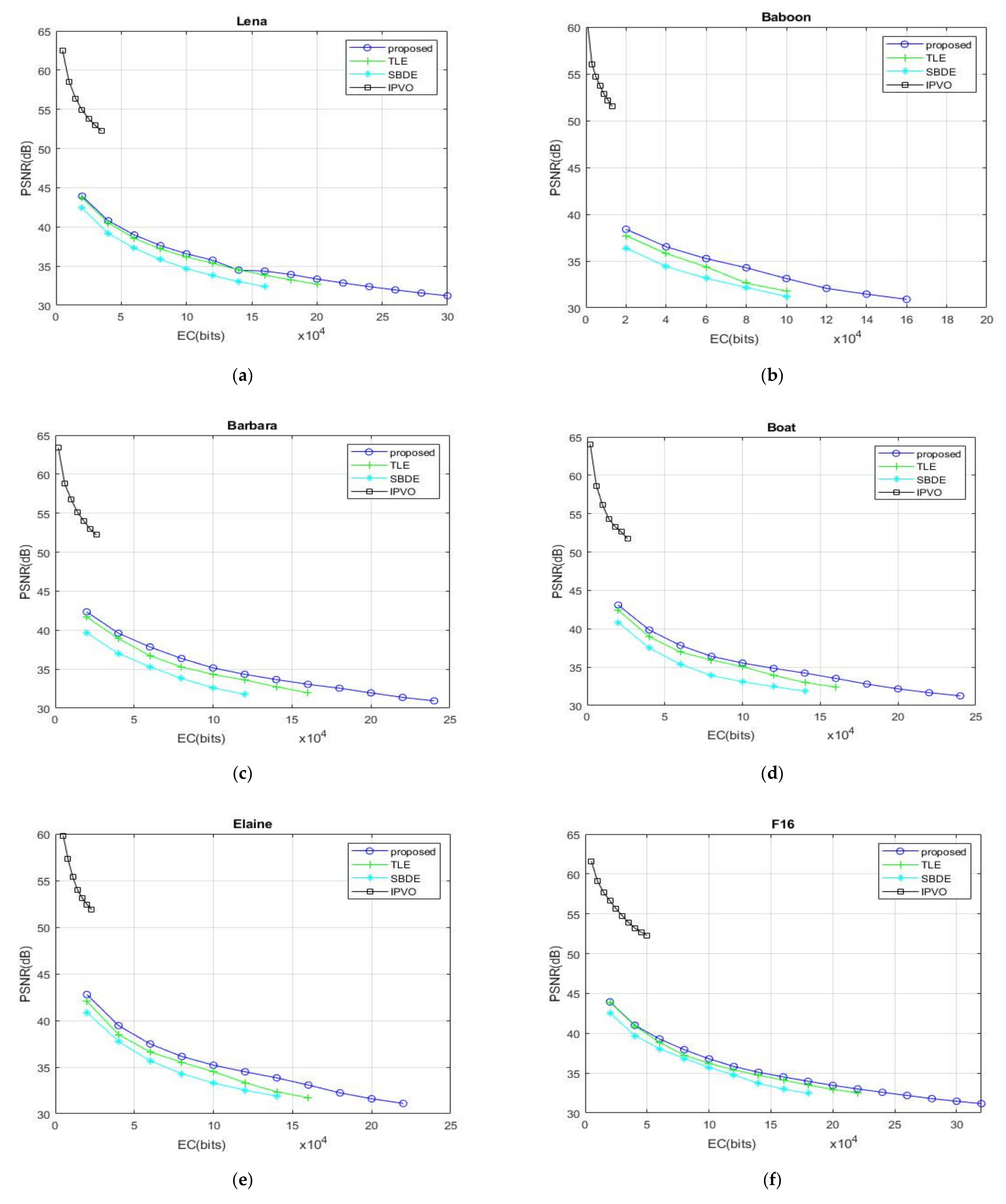
Figure 9 presents the experimental results of our proposed recurrent robust reversible data hiding (triple-RDH) method. Among the predictor methods used, predictor method 2 shows better experimental results than other predictor methods, so the proposed triple-RDH method chooses the predictor method 2 in all experiments. Additionally, we choose to compare with SBDE (significant-bit-difference expansion) [
26], TLE (two-layer embedding) [
27], and IPVO (improved pixel-value ordering) [
22], because the TLE method, SBDE method, IPVO method, and proposed triple-RDH method are all based on prediction error expansion (PEE) technique.
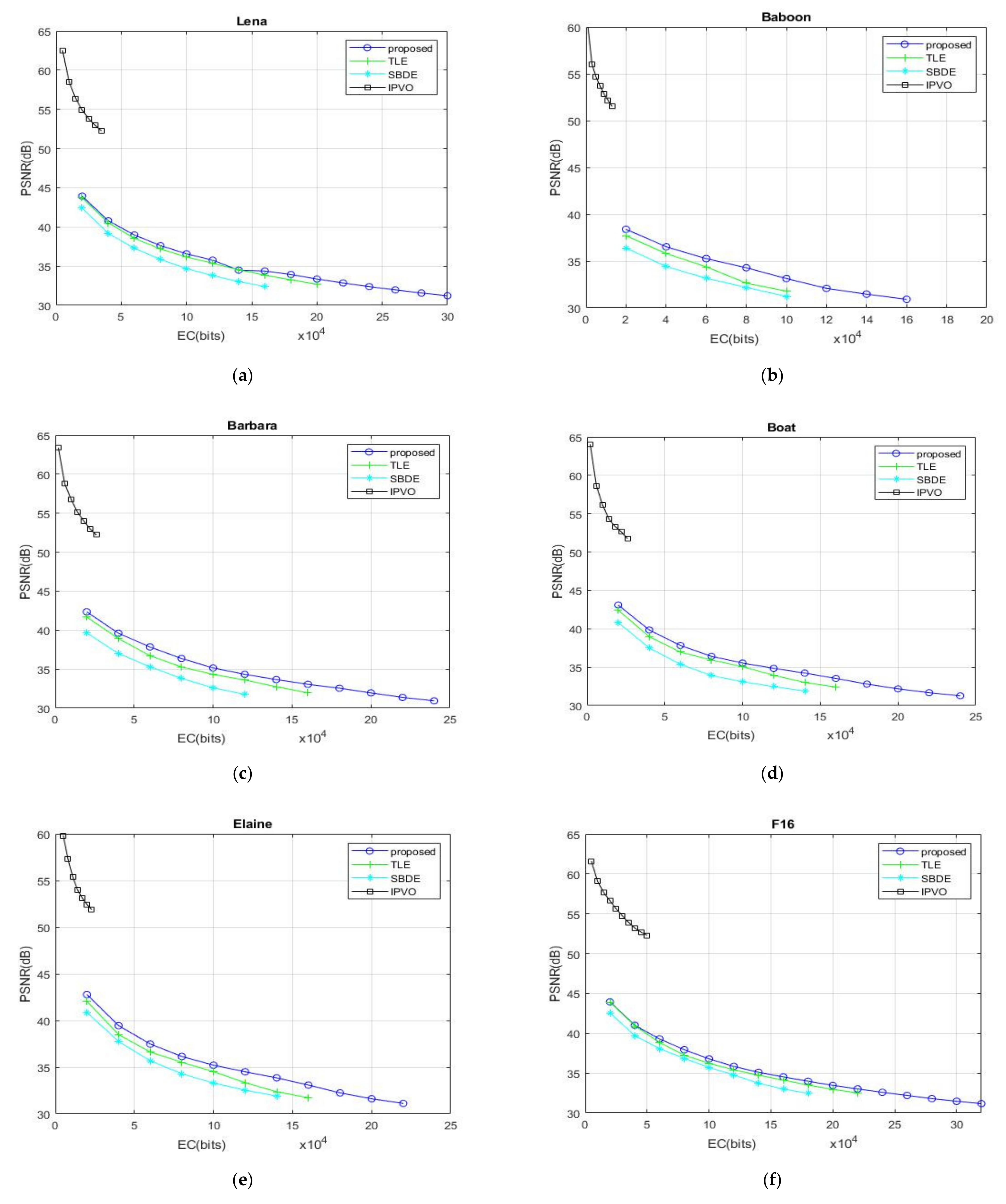
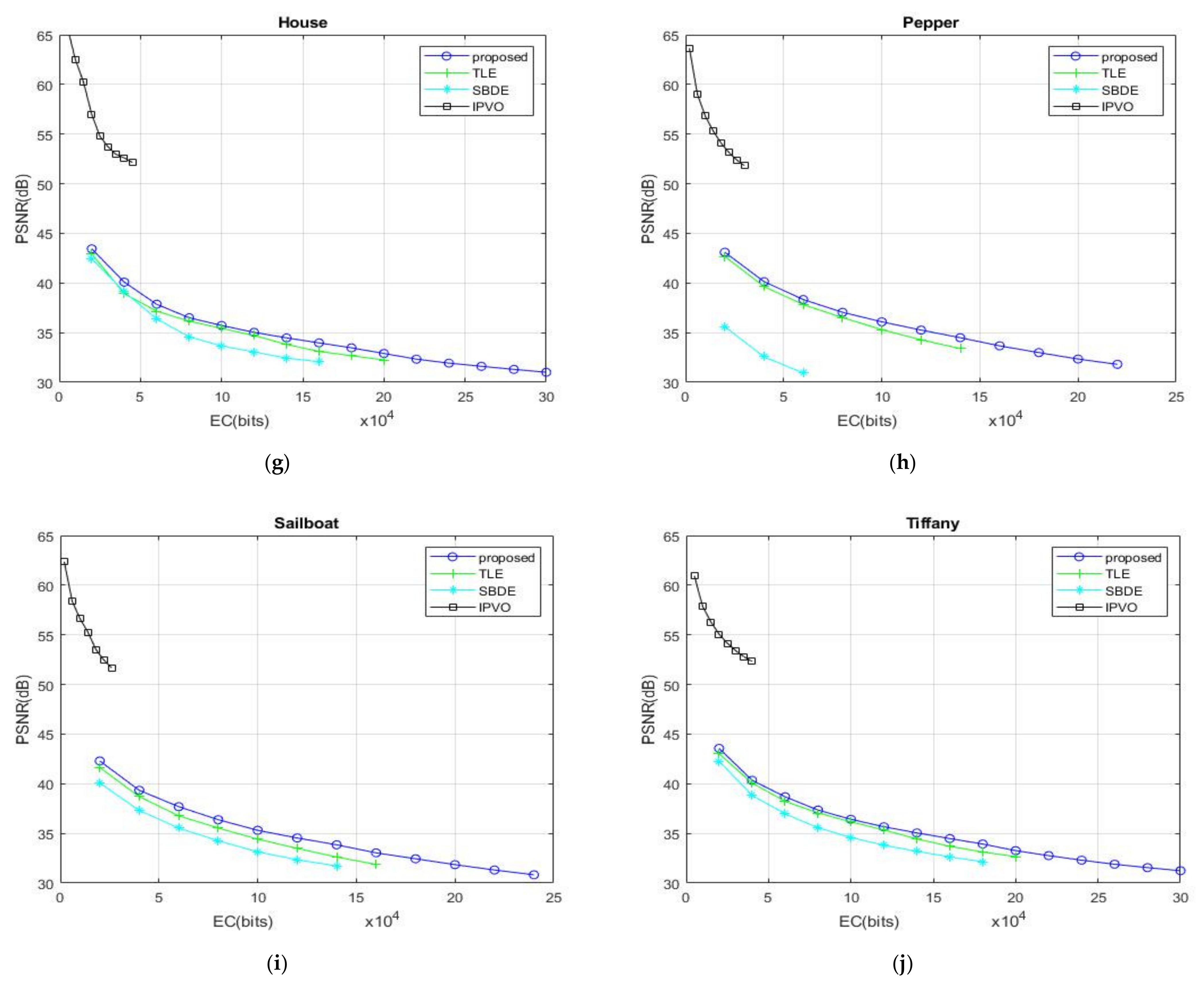
In
Figure 9, compared with the other three methods, it can be clearly seen that the EC of our proposed method is significantly larger than the other methods. In terms of PSNR, in addition to the IPVO method, the triple-RDH method we proposed is also slightly higher than that of TLE method and SBDE method.
Take the “Lena” image in
Figure 9a and
Table 5 as an example; you can see that the maximum EC of the TLE method has 214,116 bits, the maximum EC of the SBDE method has 179,793 bits, the maximum EC of IPVO method is 38,755 bits, and the maximum EC of our proposed triple-RDH method can be as high as 310,732 bits, which is 1.45 times and 1.73 times more than that of the TLE method and the SBDE method, respectively; the maximum EC of our proposed method is eight times that of the IPVO method.
When the “Lena” image in
Figure 9a has the EC = 20,000 bits, the PSNR values of the TLE method, the SBDE method, the IPVO method, and the proposed triple-RDH methods are 43.72, 42.41, 54.91, and 43.94 dB, respectively. When the embedded information is added up to 40,000 bits, the PSNR values of the TLE method, the SBDE method, and our proposed triple-RDH method are 40.52, 39.19, and 40.81 dB, respectively. At this time, the IPVO method is not capable of hiding 40,000 bits into the “Lena” image. Let us observe again if the EC is increased to 60,000 bits in the “Lena” image, the PSNR values of the TLE method, the SBDE method, and our proposed triple-RDH method are 38.55, 37.28, and 38.98 dB, respectively. It can be seen that our triple-RDH method is higher than the TLE method and the SBDE method in terms of PSNR value. The EC of the IPVO method cannot reach 40,000 bits, but we can easily embed more than 60,000 bits, and our advantage in the embedding capacity is great.
Let us observe more complicated images, such as the “Baboon” image in
Figure 9b and
Table 5 as an example. It can be seen that the maximum EC of the TLE method is 117,025 bits, the maximum EC of the SBDE method is 105,149 bits, the maximum EC of the IPVO method is 13,736 bits, and the maximum EC of our proposed triple-RDH method is 171,742 bits, which is much higher than the other three methods, which are 1.46 times and 1.63 times the TLE method and the SBDE method, respectively. The maximum EC of the proposed method is 12 times that of the IPVO method.
When the “Baboon” image in
Figure 9b is embedded in 20,000 bits, the PSNR value of the TLE method is 39.1 dB, the PSNR value of the SBDE method is 36.39 dB, and the PSNR value of the triple-RDH method we proposed has 39.8 dB, but the IPVO method is incapable of carrying 20,000 bits. When the EC is increased to 40,000 bits, the PSNR values of the TLE method, the SBDE method, and the proposed triple-RDH method are 36.73, 34.42, and 37.6 dB, respectively. When the EC is increased up to 60,000 bits, the PSNR values of the TLE method, the SBDE method, and the proposed triple-RDH method are 35.01, 33.16, and 36.08 dB, respectively. It can also be seen that the PSNR value of our proposed method is higher than those of the TLE and SBDE methods. In the image of the “Baboon”, the EC of the IPVO method is less than 20,000, so the PSNR cannot be compared.
Let us observe the average maximum EC and image quality PSNR of the ten test images in
Figure 9a–j and
Table 5. It can be seen that the average maximum EC of the TLE method is 179,587 bits, the average maximum EC of the SBDE is 149,298 bits, and the average maximum EC of IPVO is 33,465 bits. The average maximum EC of the triple-RDH method we proposed is 261,466 bits. Even in any image in
Figure 9, there is an obvious difference in the embedding capacity. We have a great advantage in the embedding capacity, and the PSNR value tends to be flat when the embedding capacity is higher. Compared with other methods, especially the PSNR of IPVO presents a steeper downward trend.
In
Figure 9a–j, when the EC is 20,000 bits, the PSNR values of TLE, SBDE, IPVO, and the proposed triple-RDH method are 42.39, 40.31, 54.34 B, and 42.89 dB on average, respectively. When the EC is 40,000 bits, the average PSNR values of TLE, SBDE, IPVO, and the proposed triple-RDH method are 39.24, 37.34, 52.71, and 39.89 dB, respectively. When the EC is 60,000 bits, the average PSNR values of TLE, SBDE, IPVO, and the proposed triple-RDH method are 37.35, 35.47, and 38.04 dB, respectively; However, the IPVO method is incapable of hiding anything at this time. The PSNR value of the proposed triple RDH method is slightly higher than those of the average PSNR values of the TLE and SBDE methods.
From
Table 5, our proposed triple-RDH method using predictor method 2 has a higher EC than Predictor methods 1 and 3. In the “Lena” image, the EC of our triple-RDH method is 4931 bits higher than that of the method using Predictor method 1, and also 7714 bits higher than that of the method using predictor method 3.
Table 5 is also a comparison table of our proposed triple-RDH method and TLE on the different predictor methods in terms of EC and PSNR metrics. It can be found that the maximum EC of all predictor methods of our proposed method is higher than that of the TLE method. At the maximum EC, the PSNR value of our proposed triple RDH method with predictor Method 2 is only slightly lower than that of the TLE method by 1.31 dB; the PSNR value of our proposed triple RDH method using predictor Method 3 is slightly lower by 1.12 dB; the PSNR value of our proposed triple RDH method using predictor method 1 is slightly lower by 1.1 dB.
Table 6 shows the results in terms of EC and PSNR using our triple-RDH method for different
and different peak points. It can be observed from the experiment results that the PSNR can reach 46.51 dB when
= 1. When
= 4, the EC can be as high as 378,971 bits, but the PSNR drops to 24.85 dB. Accordingly, we do not recommend setting
to be 4. The EC with
can reach 324,055 bits and the PSNR is maintained at 31.11 dB, achieving high capacity while maintaining good image quality PSNR, so we recommend setting
as 3. At different peak points, we find that the EC with (1, −1) is higher than those of (0, −1) and (1, 0) in most cases, so we recommend setting the peak point to (1, −1) as the best choice. The peak points (0, −1) and (1, 0) have some differences in the performance of the complex image and the smooth image. For a smooth image “F16”, when using the second predictor method and
is set as 3, the difference between peak points (1, −1) and (0, −1) in terms of EC is 6644 bits, and the difference in EC between peak points (1, −1) and (1, 0) is 58,464 bits. As for the complex image “Baboon”, the difference in terms of EC between the peak points at (1, −1) and at (0, −1) is 25,045 bits; the difference in EC between peak points at (1, −1) and at (1, 0) is 20,092 bits.
From the results, we find that using (1, 0) as the peak point in a complex image is more advantageous than using (0, −1); however, in a smooth image, using (0, −1) as the peak point will obtain good benefits in embedding capacity. Therefore, different peak points can be set according to whether the carrier is a complex image or a smooth image, and actual application requirements to achieve a balance between embedding capacity and image quality.
We observe the results in
Table 6 and find that when
n = 3,
= 1, and
= −1, the results are the best, so we set
n as 3 and peak point to (1, −1) used as the experimental parameter in
Table 7.
Table 7 shows the performance comparison of our triple-RDH method when setting
from 1 to 5 for both the complex image “Baboon” and the smooth image “F16”. When the recursive parameters are between
and
the embedding capacity EC has increased by 0.46 times; between
and
, the EC has increased by 0.15 times; between
, the EC has increased by 0.06 times; between
and
, the EC has increased by 0.02 times. The higher the
values, the lower the increased EC will be, so the benefit is not high. Accordingly, we recommend the parameters as
.
The recursive parameters
and
can also be adjusted for help embedding in different ways. We experimented with
and
, and after observing the experiment results, we found that the triple-RDH method we proposed is stable in terms of image quality PSNR and can maintain the image quality PSNR above 30 dB. Different combinations of
and
can help us make changes in different situations.
Table 8 shows the performance results of our triple-RDH method in
and
. We have observed that changing
can help us make finer adjustments to the embedding capacity and image quality, so that they can have more different embedding possibilities for various application needs.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}